Road-Aware Trajectory Prediction for Autonomous Driving on Highways



Abstract
1. Introduction
- We have developed a practical data-efficient method for trajectory prediction on highways using the curvilinear coordinate system and lane assignment. It is inevitable to collect a real dataset by driving along a roadway. However, it is also impossible to collect all the necessary data that can cover the whole range of the sensor. To mitigate this practical problem, we have proposed a data-efficient learning method to make the dataset compact. In addition, this approach enables the prediction network to learn efficiently and maintain a consistent performance even in different road segments. The details of this problem are discussed in Section 3.1.
- We have proposed a road-aware, sequence-to-sequence trajectory prediction network. Using the fact that a vehicle naturally runs along the shape of the road, we have developed an output constrained prediction network. By combining a deep learning network with the prior knowledge of the roadway, the structural limitations of the roadway have been incorporated in the network. Consequently, the proposed trajectory prediction network is able to predict a feasible and realistic intention of a driver and trajectory of the surrounding vehicles.
2. Related Work
3. Problem Statement and Methodology
3.1. Practical Problem Statement of Trajectory Prediction
3.2. Extracted Road Information from HD Maps
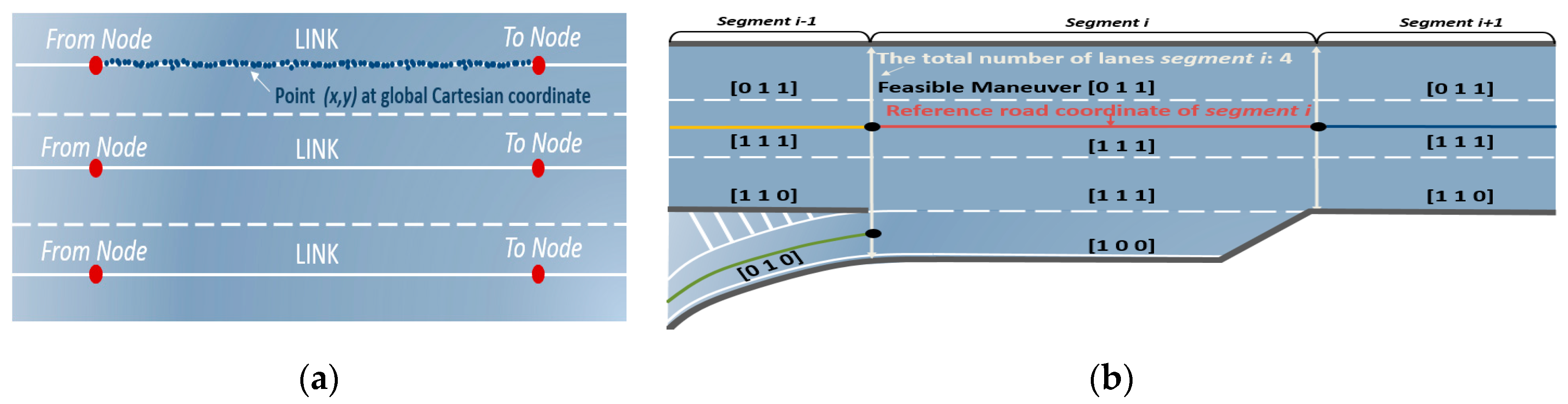
- Reference curvilinear coordinates: B-spline parameters approximating the corresponding line;
- Additional information about the segment: the total number of lanes, the reference lane, and the length of the segment;
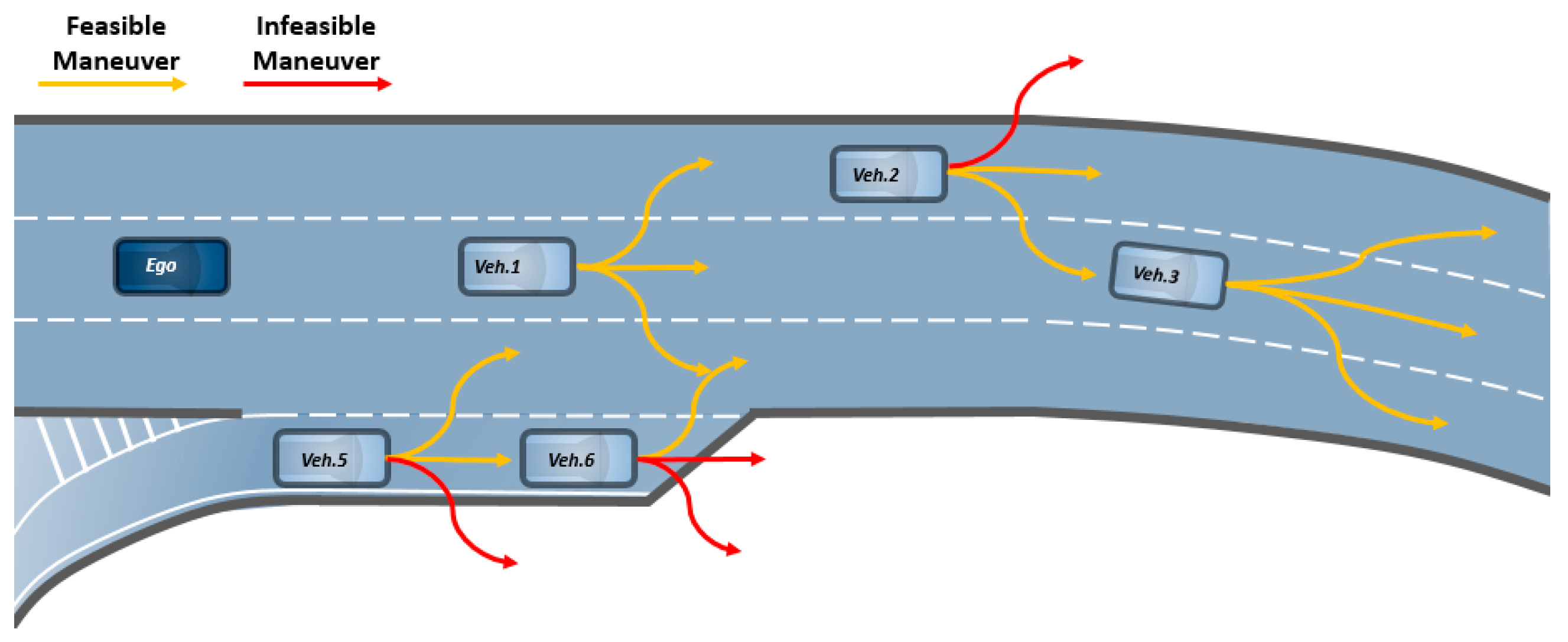
- Feasible maneuver vector for each lane: the simplest way to generate a feasible maneuver vector is the one-hot vector representing the possible maneuvers among LCL, LK, and LCR. For example, in the case of the first lane in Figure 3b, it is [0 1 1] because a vehicle can only execute LK and LCR owing to the road shape. However, it should be noted that any real values between 0 and 1 can be inputted.
3.3. Data Processing
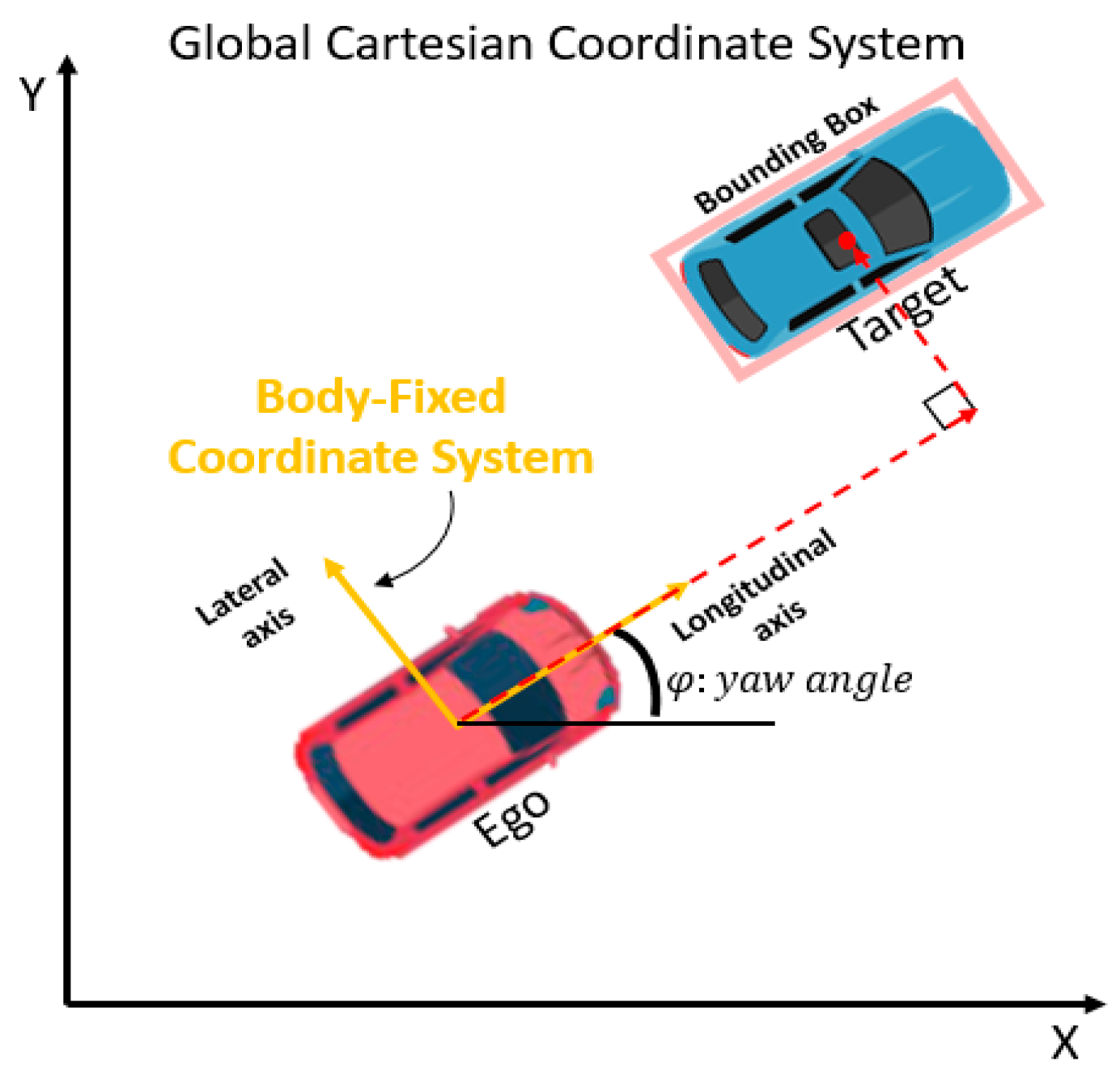
- Ego-vehicle states: global position, yaw angle, longitudinal velocity and lateral velocity;
- Target vehicle states: longitudinal relative displacement, lateral relative displacement, longitudinal relative velocity and lateral relative velocity of centroid of 2D bounding box.
- Step 1: We assume the global position of an ego vehicle to be and obtain the relative states of the surrounding vehicles using GNSS-INS and LIDAR, respectively. Then, we obtain the global position of the surrounding vehicles. Next, we find the corresponding segment on which the surrounding vehicle is located by using the position values of the “From” and the “To” nodes. Here, we can search for it first within a range which spans from the back to the front of the segment of the ego vehicle;
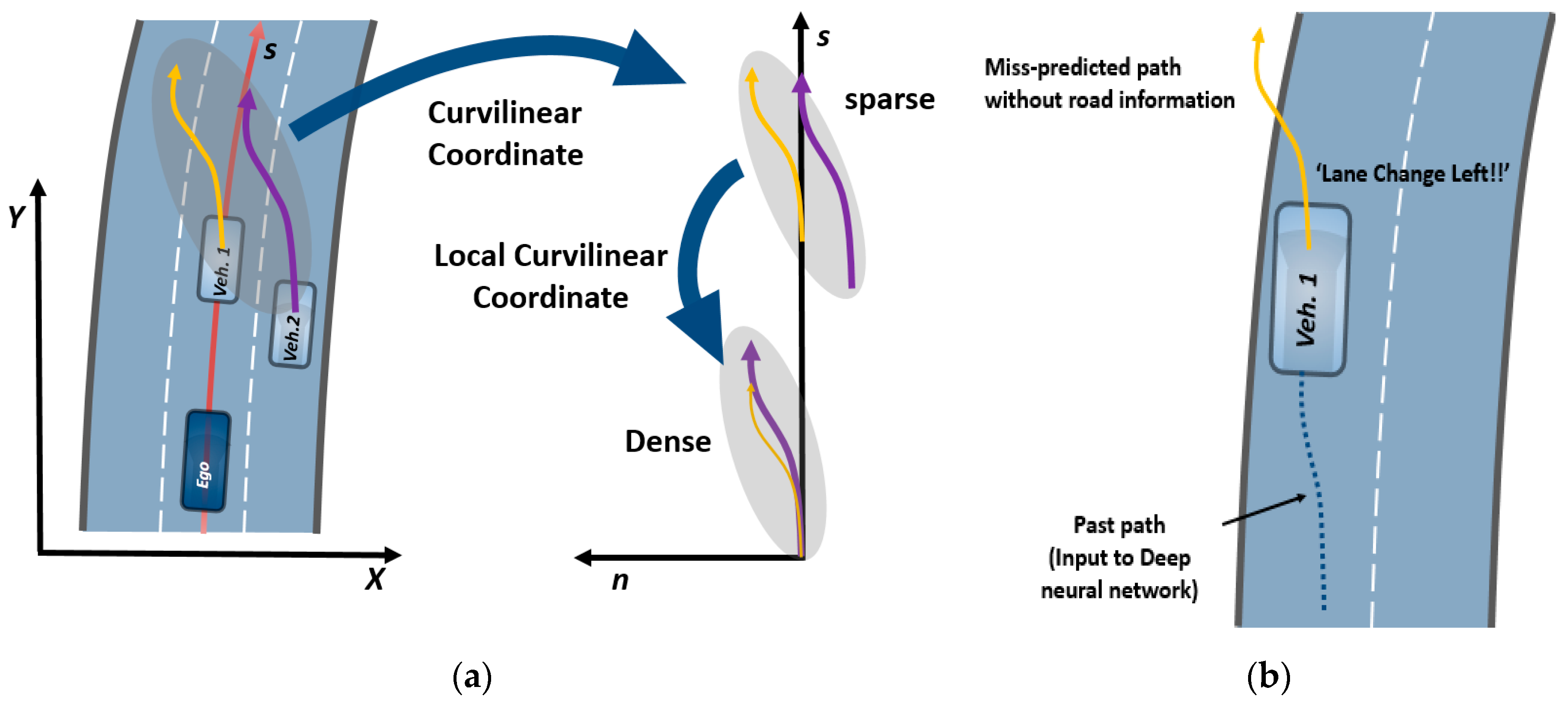
- Step 2: Once the segment is found, it indicates that the B-spline parameters, which approximate the reference roadway, have been obtained. Then, we can find the point which is the orthogonal and the nearest point to the segment (refer to the enlarged drawing in Step 1 of Figure 5.) The detailed algorithm to find this point is omitted here, since it not part of our study’s contribution. However, readers can refer to Ref. [25] for further details. After obtaining the curvilinear coordinates, we can assign the lane number to which the surrounding vehicle belongs to. Lane assignment does not require real-time determination, however, it is sufficient to use a simple threshold and a count algorithm with lateral displacement in this step. The converted curvilinear coordinates are stored in chronological order;
- Step 3: All the sequential coordinates are transformed to the local curvilinear coordinate system in which the curvilinear coordinates are translated by . In this way, the trajectories of all the surrounding vehicles are represented on the same frame of reference even though their positions are different. We define this as the local curvilinear coordinates. After transforming the position values, the velocities in the local curvilinear coordinates are obtained by simply projecting the velocities in the global Cartesian coordinates to the local curvilinear coordinates. In this way, we can generate a compact dataset by carrying out the above-mentioned procedure. Subsequently, the transformed sequential trajectory points are directly fed to the trajectory prediction network as an input sequence. The detailed trajectory prediction network architecture is described in Section 3.4;
- Step 4: Step 4 follows the trajectory prediction network. Here, we simply reposition the predicted trajectory to the curvilinear coordinate system. Following this, depending on the user’s purpose, such as a collision assessment or trajectory planning, the predicted trajectory can be used as is or translated to the Cartesian coordinates.
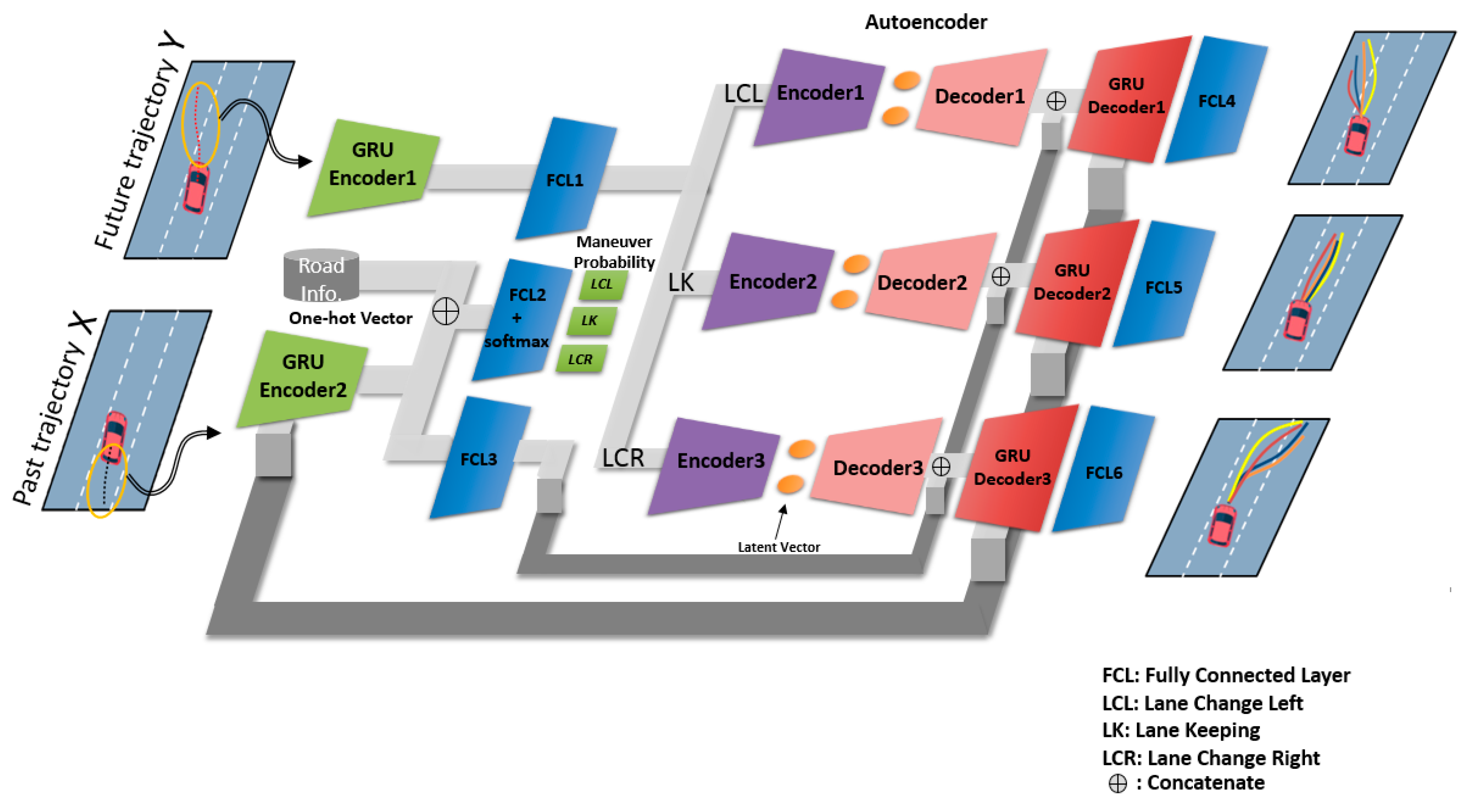
3.4. Road-aware Trajectory Prediction Network
3.4.1. Maneuver Recognition Network
3.4.2. Trajectory Prediction Network
4. Experimental Results and Analysis
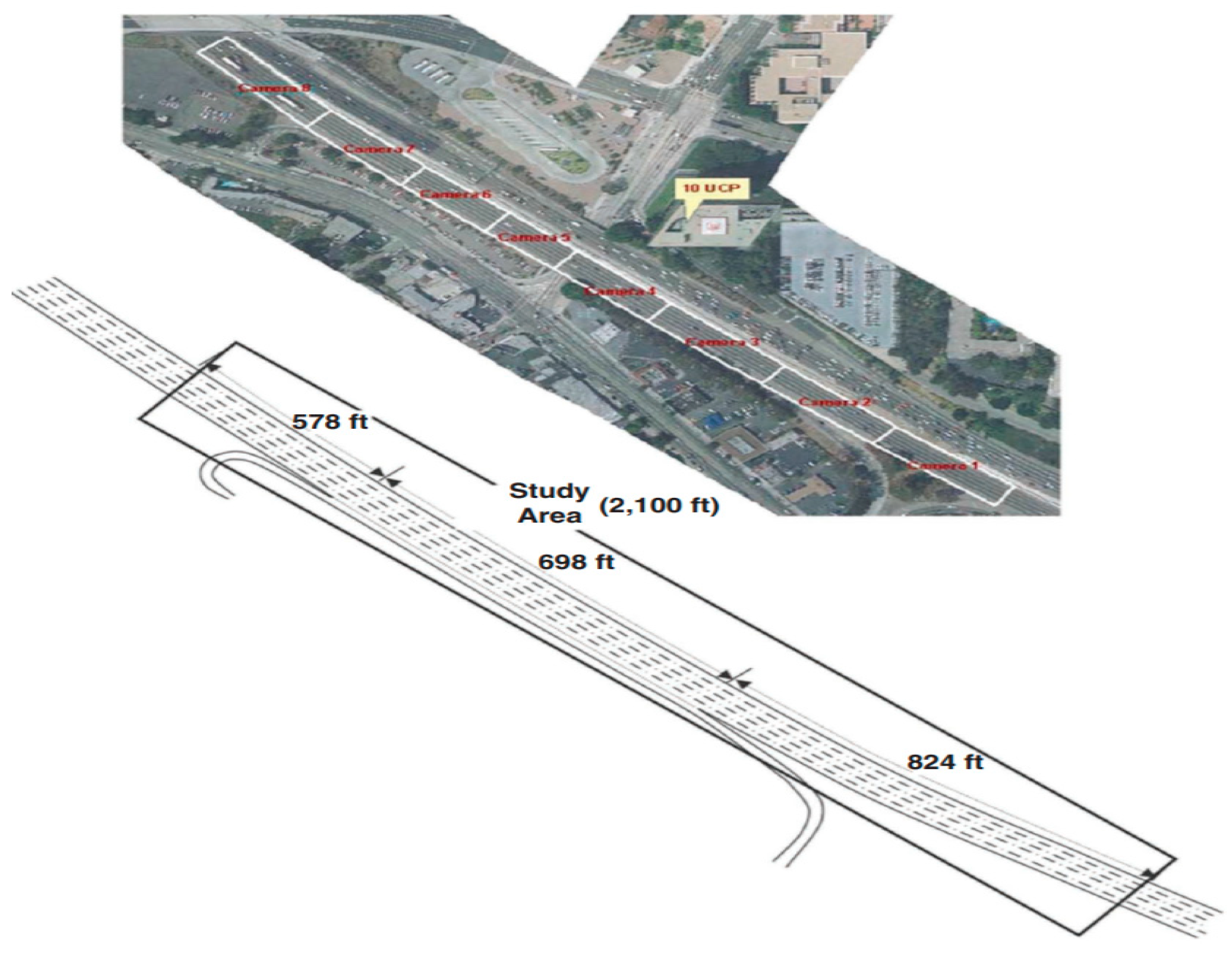
4.1. Dataset
4.2. Results and Analysis
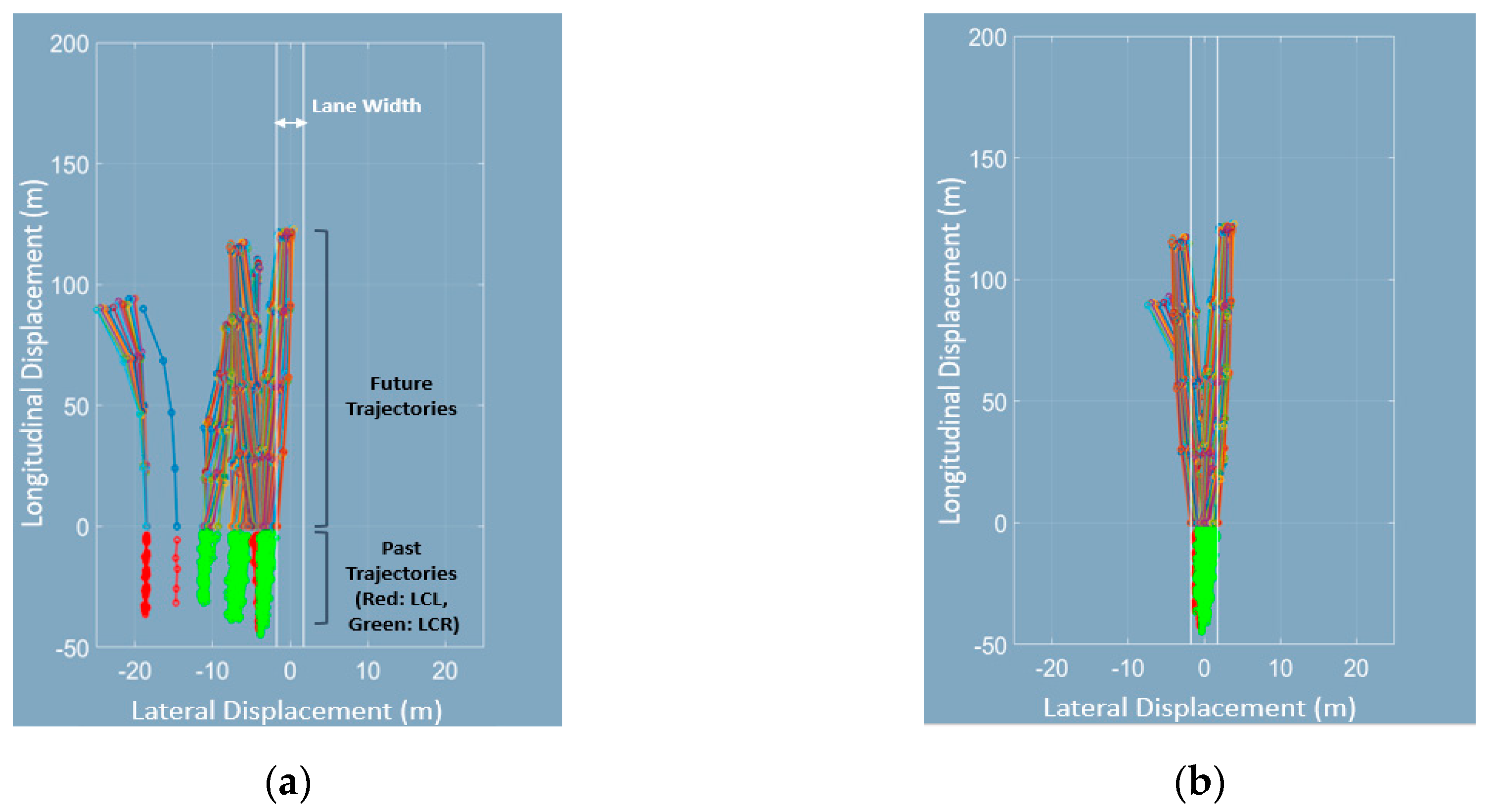
4.2.1. Effectiveness of The Local Curvilinear Coordinates
- NLS-LSTM [34]: This model is an encoder–decoder architecture that has local and non-local operation to capture interaction;
- M-LSTM [18]: This model is an encoder–decoder architecture that considers adjacent six vehicles of target vehicle and encode vehicle’s maneuver. This maneuver encoding vector is used to predict multi-modal trajectory prediction;
- MATF [35]: This model is an encoder–decoder architecture that uses multi-agent tensor to capture interaction.
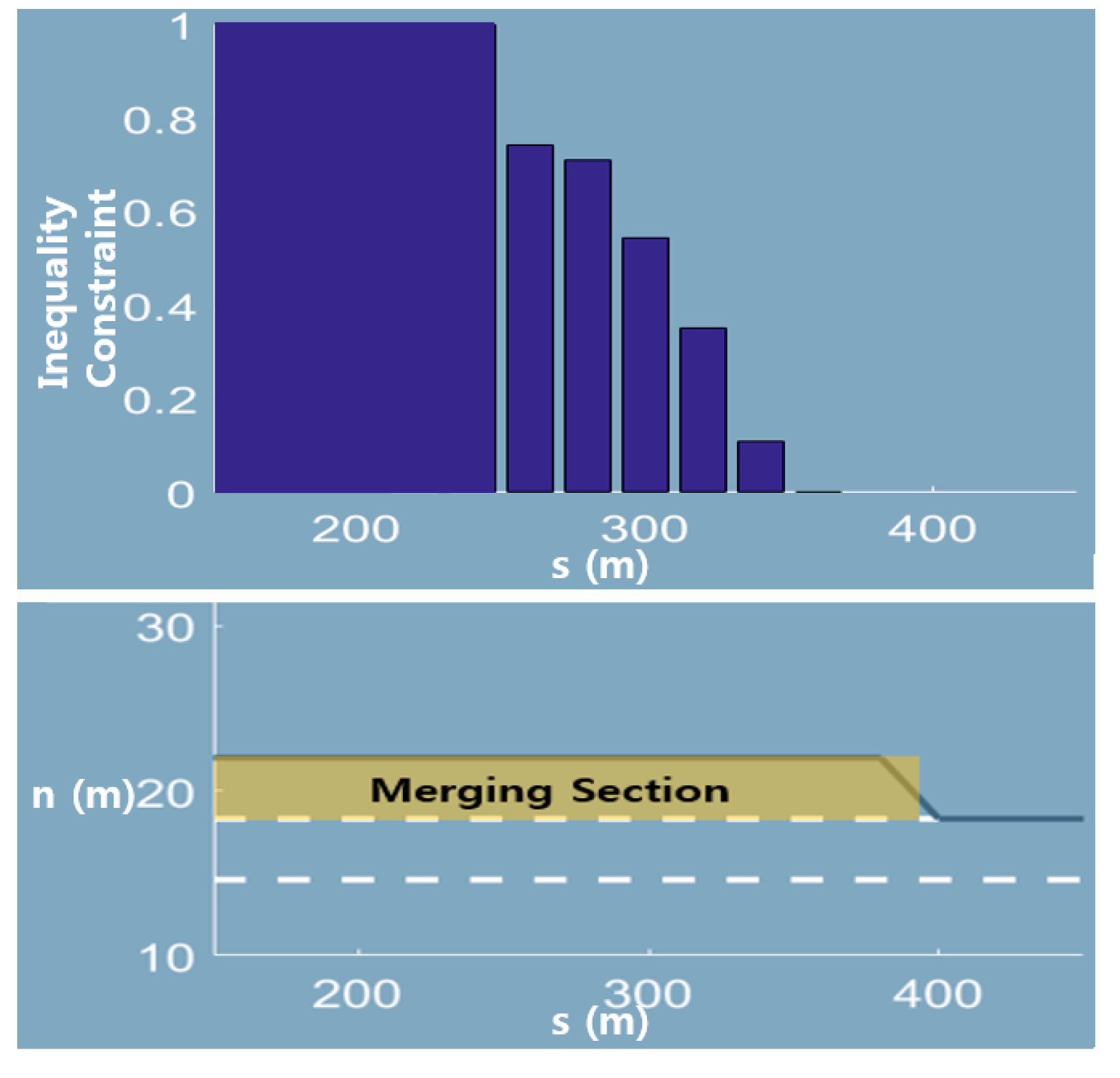
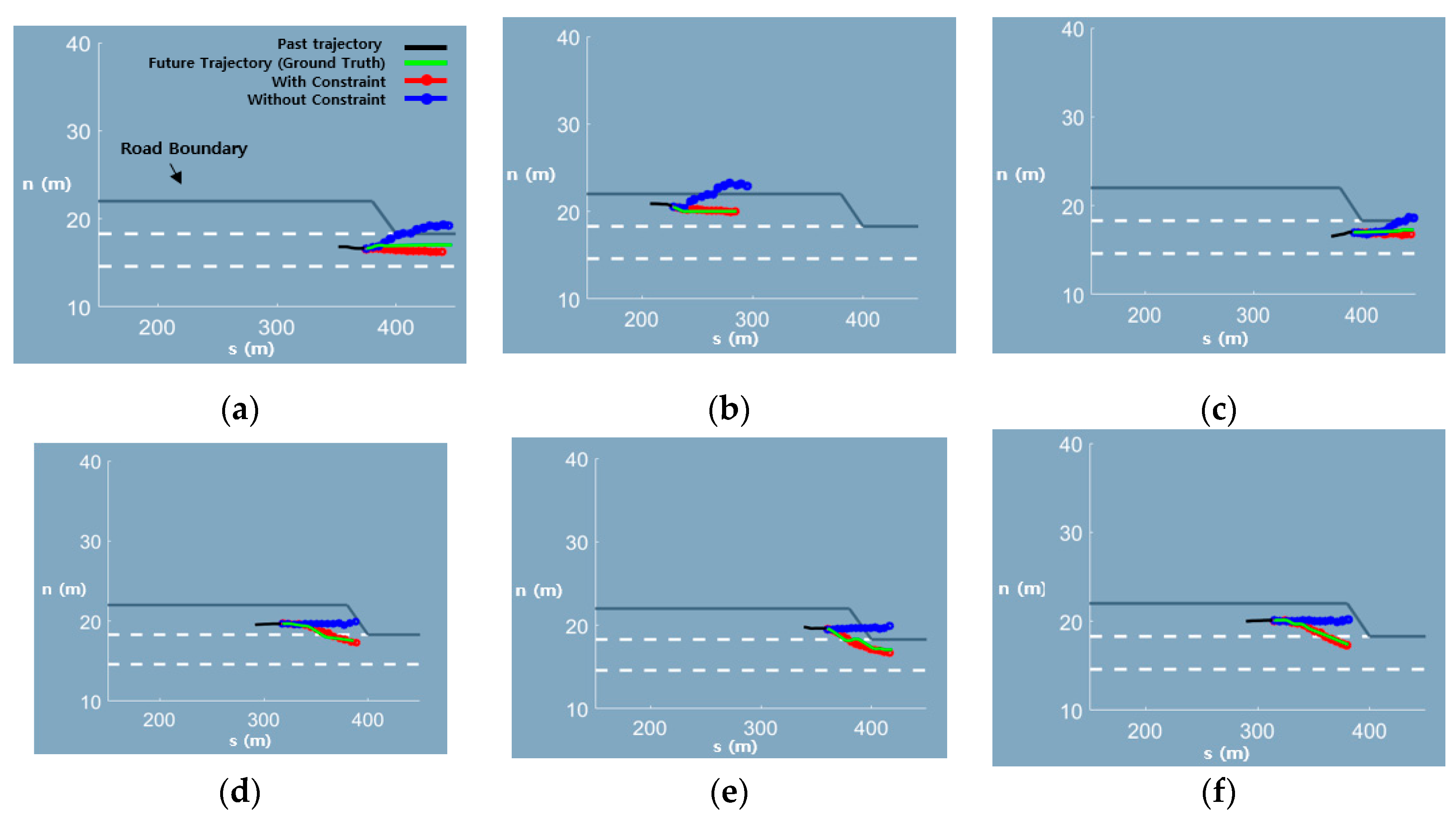
4.2.2. Feasible Trajectory Prediction at a Merging Section
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
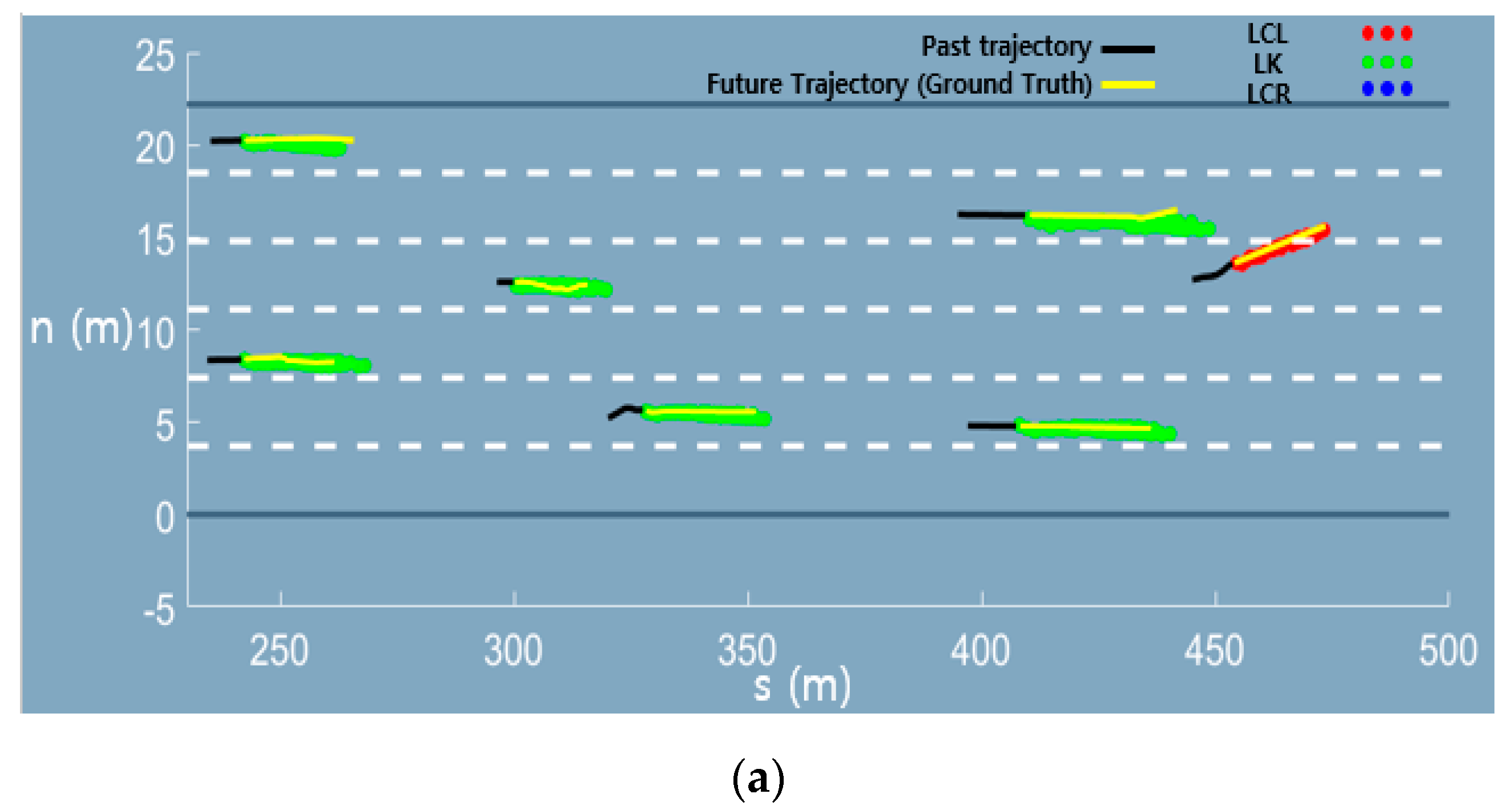
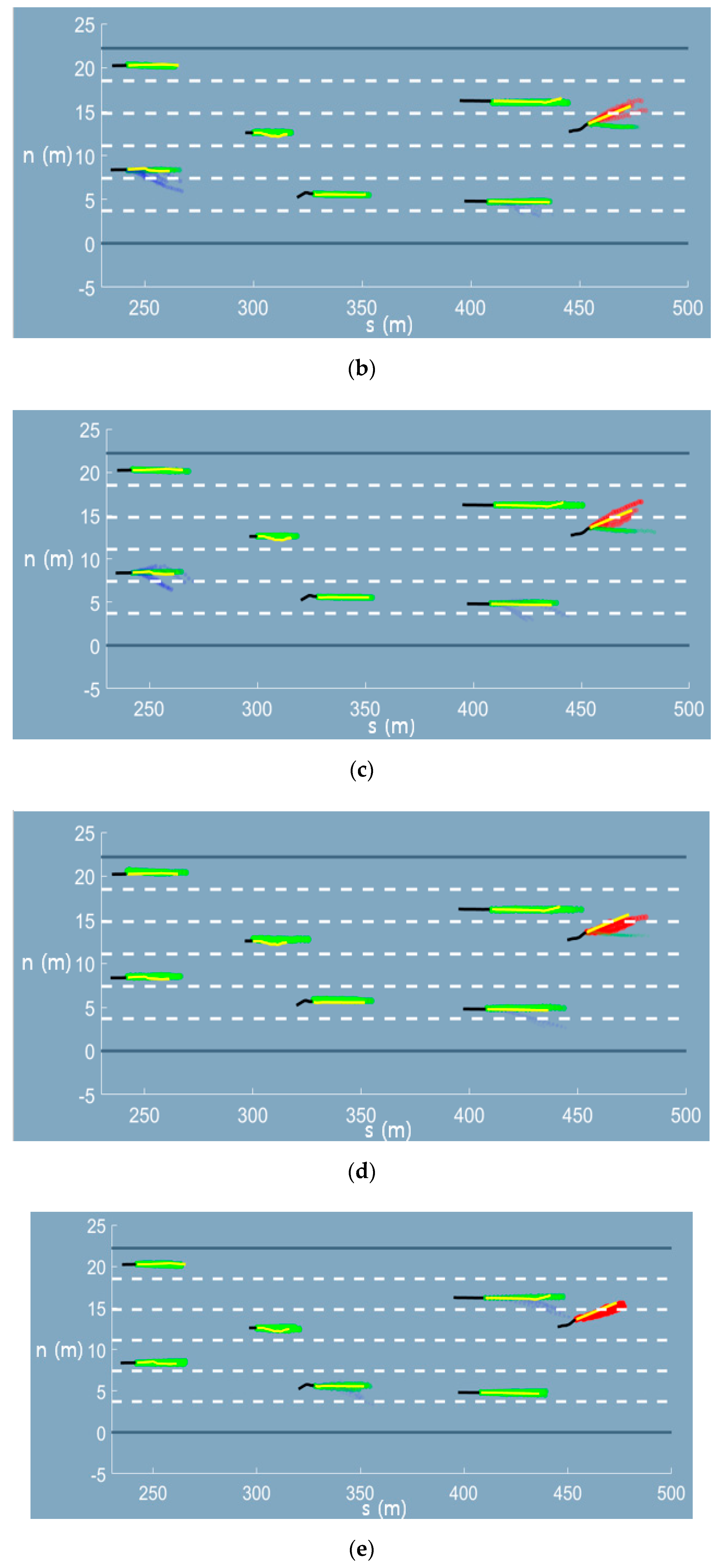
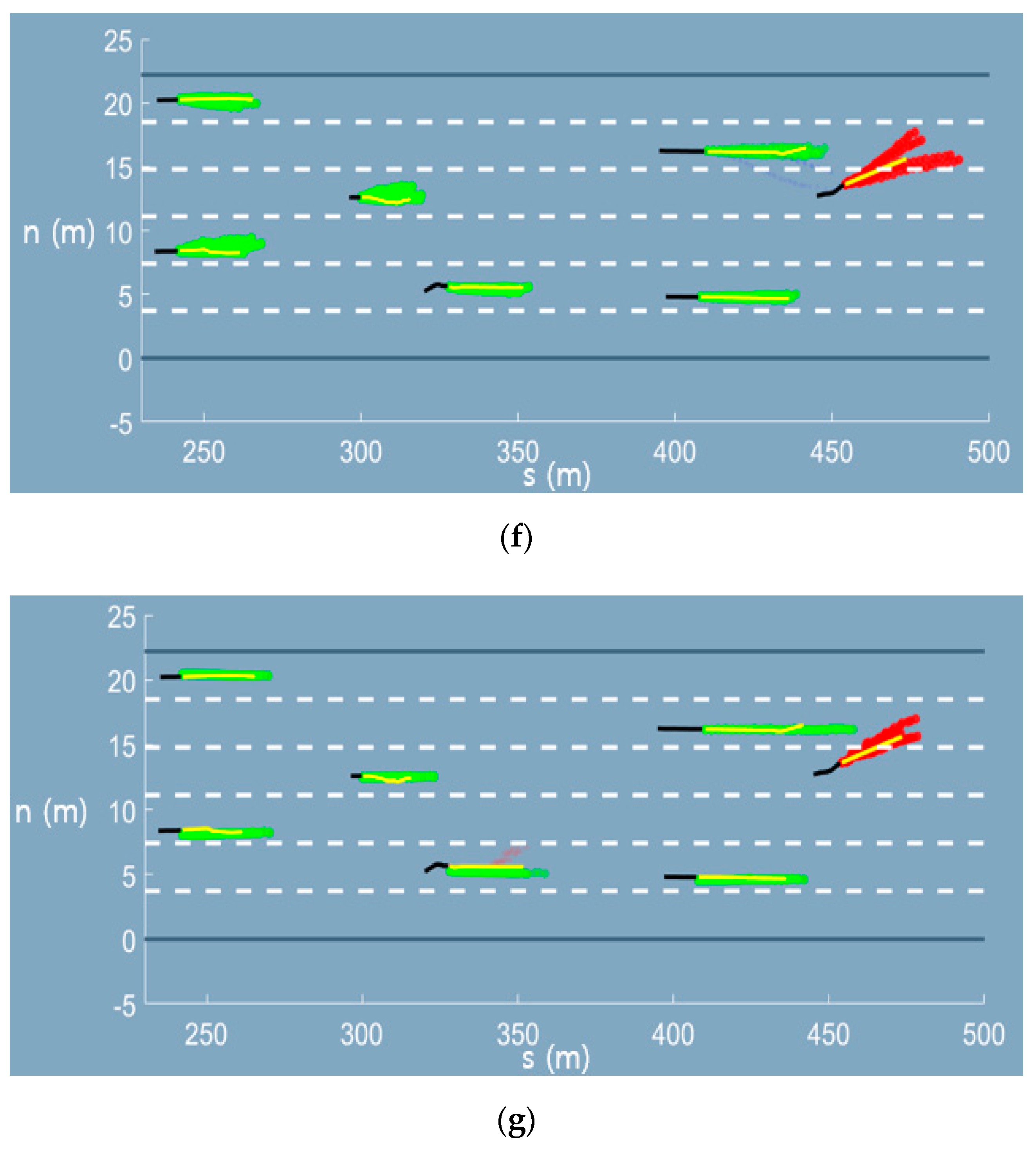
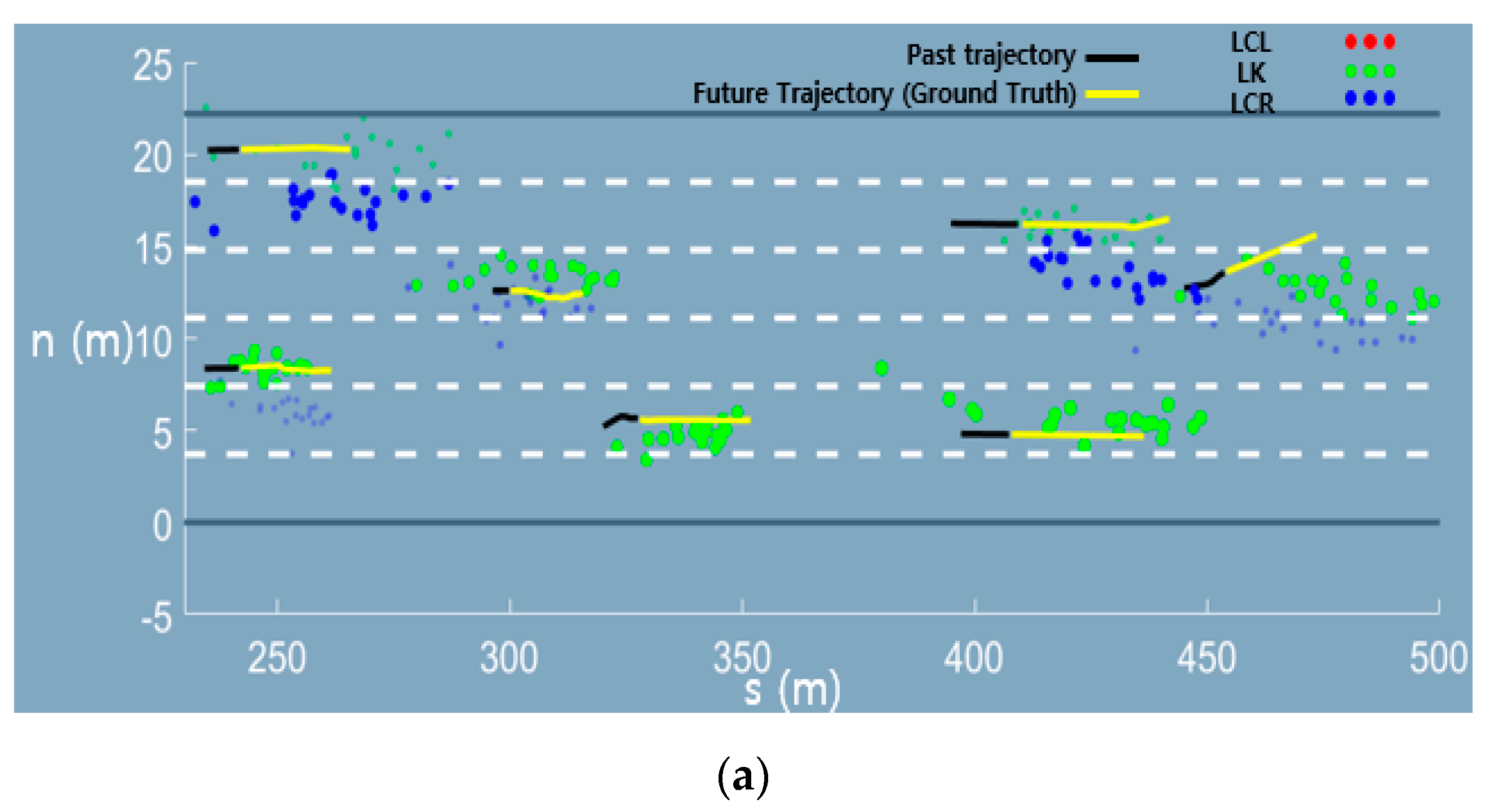
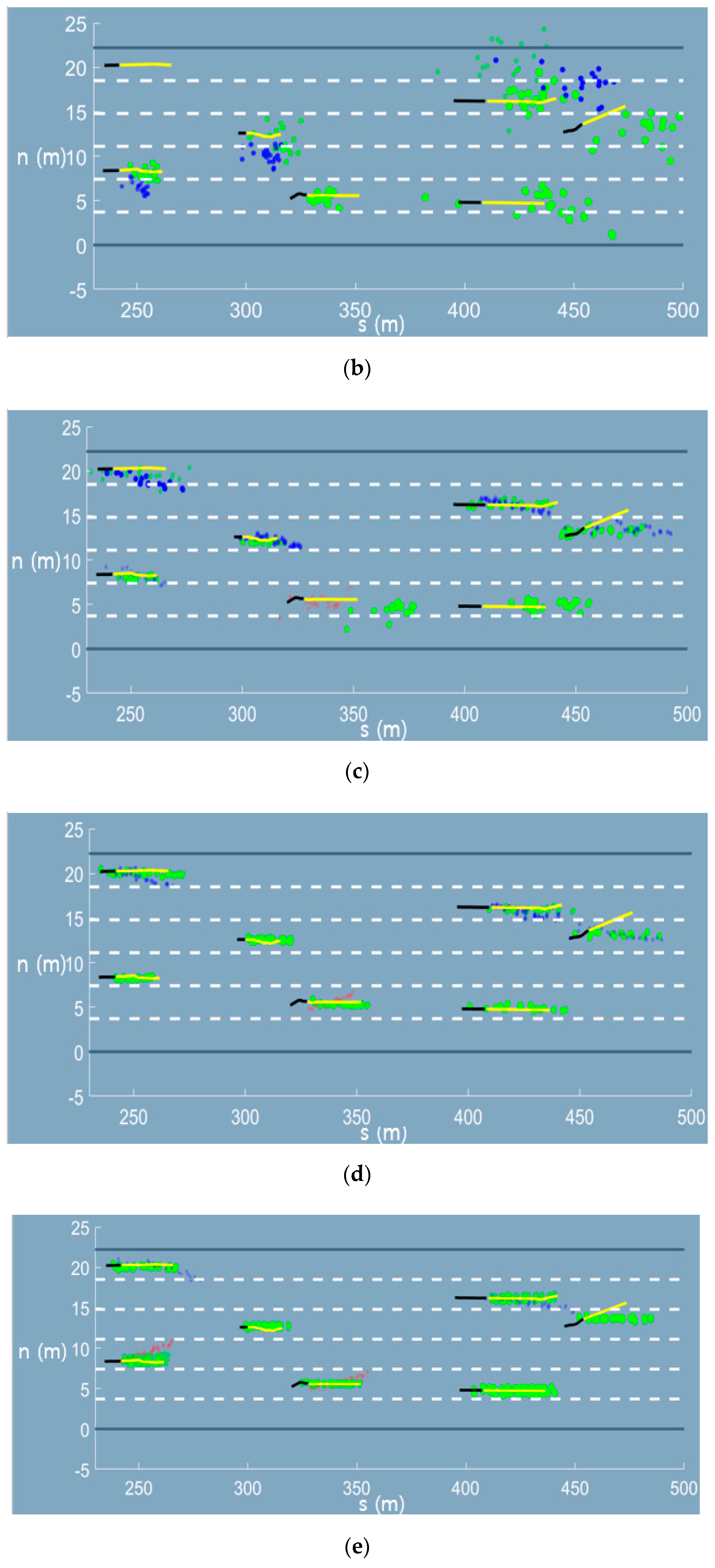
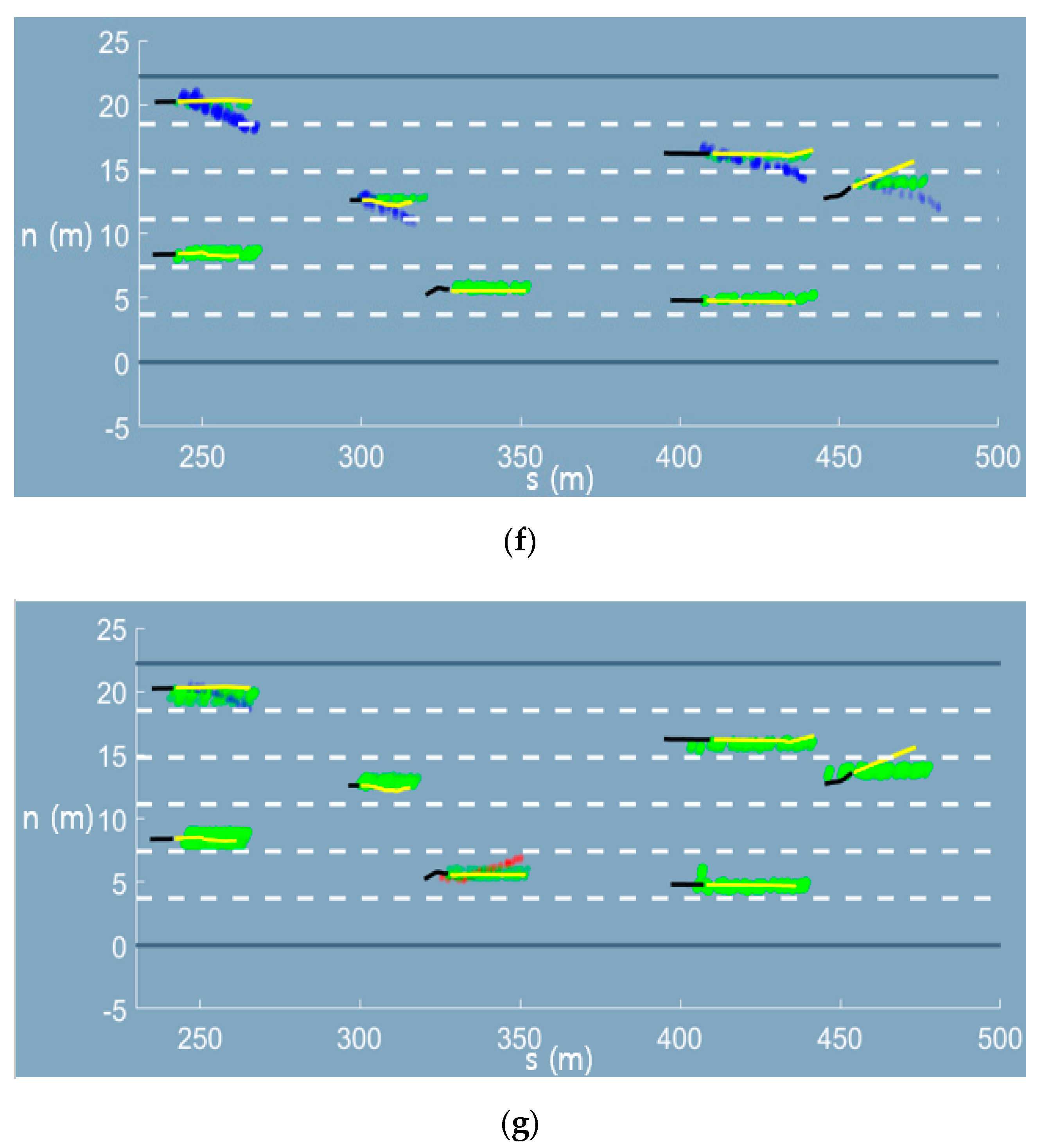
Appendix A. Graphical Results of the Trajectory Prediction Network






References
- Jeong, Y.; Yi, K. Target Vehicle Motion Prediction-Based Motion Planning Framework for Autonomous Driving in Uncontrolled Intersections. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Kim, J.; Kum, D. Collision risk assessment algorithm via lane-based probabilistic motion prediction of surrounding vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2965–2976. [Google Scholar] [CrossRef]
- Lefèvre, S.; Vasquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. Robomech. J. 2014, 1, 1–14. [Google Scholar] [CrossRef]
- Hubmann, C.; Becker, M.; Althoff, D.; Lenz, D.; Stiller, C. Decision making for autonomous driving considering interaction and uncertain prediction of surrounding vehicles. In 2017 IEEE Intelligent Vehicles Symposium (IV); IEEE: Los Angeles, CA, USA, 2017; pp. 1671–1678. [Google Scholar] [CrossRef]
- Kim, B.; Yi, K. Probabilistic states prediction algorithm using multi-sensor fusion and application to Smart Cruise Control systems. In 2013 IEEE Intelligent Vehicles Symposium (IV); IEEE: Gold Coast, Australia, 2013; pp. 888–895. [Google Scholar] [CrossRef]
- Kim, B.; Yi, K. Probabilistic and holistic prediction of vehicle states using sensor fusion for application to integrated vehicle safety systems. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2178–2190. [Google Scholar] [CrossRef]
- Zyner, A.; Worrall, S.; Nebot, E. Naturalistic Driver Intention and Path Prediction Using Recurrent Neural Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1584–1594. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In 2018 IEEE Intelligent Vehicles Symposium (IV); IEEE: Changshu, China, 2018; pp. 1672–1678. [Google Scholar] [CrossRef]
- Min, K.; Kim, D.; Park, J.; Huh, K. RNN-Based Path Prediction of Obstacle Vehicles with Deep Ensemble. IEEE Trans. Veh. Technol. 2019, 68, 10252–10256. [Google Scholar] [CrossRef]
- Feng, X.; Cen, Z.; Hu, J.; Zhang, Y. Vehicle Trajectory Prediction Using Intention-based Conditional Variational Autoencoder. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC); IEEE: Auckland, New Zealand, 2019; pp. 3514–3519. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Cheng, H.; Liao, W.; Yang, M.Y.; Sester, M.; Rosenhahn, B. MCENET: Multi-Context Encoder Network for Homogeneous Agent Trajectory Prediction in Mixed Traffic. arXiv 2002, arXiv:2002.05966. [Google Scholar]
- Meng, X.; Wang, H.; Liu, B. A robust vehicle localization approach based on gnss/imu/dmi/lidar sensor fusion for autonomous vehicles. Sensors 2017, 17, 2140. [Google Scholar] [CrossRef] [PubMed]
- Verma, S.; Eng, Y.H.; Kong, H.X.; Andersen, H.; Meghjani, M.; Leong, W.K.; Shen, X.; Zhang, C.; Ang, M.H.; Rus, D. Vehicle detection, tracking and behavior analysis in urban driving environments using road context. In 2018 IEEE International Conference on Robotics and Automation (ICRA); IEEE: Brisbane, Australia, 2018; pp. 1413–1420. [Google Scholar] [CrossRef]
- Caveney, D. Vehicular path prediction for cooperative driving applications through digital map and dynamic vehicle model fusion. In 2009 IEEE 70th Vehicular Technology Conference Fall; IEEE: Anchorage, AK, USA, 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, P.; Kurt, A.; Özgüner, Ü. Trajectory prediction of a lane changing vehicle based on driver behavior estimation and classification. In 17th International IEEE Conference on Intelligent Transportation Systems (ITSC); IEEE: Qingdao, China, 2014; pp. 942–947. [Google Scholar] [CrossRef]
- Schreier, M.; Willert, V.; Adamy, J. An integrated approach to maneuver-based trajectory prediction and criticality assessment in arbitrary road environments. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2751–2766. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Multi-modal trajectory prediction of surrounding vehicles with maneuver based lstms. In 2018 IEEE Intelligent Vehicles Symposium (IV); IEEE: Changshu, China, 2018; pp. 1179–1184. [Google Scholar] [CrossRef]
- Deo, N.; Rangesh, A.; Trivedi, M.M. How would surround vehicles move? A unified framework for maneuver classification and motion prediction. IEEE Trans. Intell. Veh. 2018, 3, 129–140. [Google Scholar] [CrossRef]
- Djuric, N.; Radosavljevic, V.; Cui, H.; Nguyen, T.; Chou, F.-C.; Lin, T.-H.; Singh, N.; Schneider, J. Uncertainty-aware short-term motion prediction of traffic actors for autonomous driving. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2084–2093. [Google Scholar] [CrossRef]
- Casas, S.; Gulino, C.; Liao, R.; Urtasun, R. Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data. arXiv 2019, arXiv:1910.08233v1. [Google Scholar]
- Wang, Z.; Zhou, S.; Huang, Y.; Tian, W. DsMCL: Dual-Level Stochastic Multiple Choice Learning for Multi-Modal Trajectory Prediction. arXiv 2020, arXiv:2003.08638. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1549–15498. [Google Scholar] [CrossRef]
- Colyar, J.; Halkias, J. US Highway 101 Dataset; Tech. Rep. Fhwa-Hrt-07-030; Federal Highway Administration (FHWA): Washington, DC, USA, 2007. [Google Scholar]
- Kim, J.; Jo, K.; Lim, W.; Lee, M.; Sunwoo, M. Curvilinear-coordinate-based object and situation assessment for highly automated vehicles. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1559–1575. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. Available online: http://proceedings.mlr.press/v15/glorot11a.html (accessed on 18 August 2020).
- Kervadec, H.; Dolz, J.; Tang, M.; Granger, E.; Boykov, Y.; Ayed, I.B. Constrained-CNN losses for weakly supervised segmentation. Med. Image Anal. 2019, 54, 88–99. [Google Scholar] [CrossRef] [PubMed]
- Neal, R.M.; Hinton, G.E. A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in Graphical Models; Springer: Berlin/Heidelberg, Germany, 1998; pp. 355–368. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Kang, K.; Rakha, H.A. Game theoretical approach to model decision making for merging maneuvers at freeway on-ramps. Transp. Res. Rec. 2017, 2623, 19–28. [Google Scholar] [CrossRef]
- Buhet, T.; Wirbel, E.; Perrotton, X. PLOP: Probabilistic poLynomial Objects trajectory Planning for autonomous driving. arXiv 2020, arXiv:2003.08744. [Google Scholar]
- Fang, L.; Jiang, Q.; Shi, J.; Zhou, B. TPNet: Trajectory Proposal Network for Motion Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6797–6806. [Google Scholar]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Non-local social pooling for vehicle trajectory prediction. In 2019 IEEE Intelligent Vehicles Symposium (IV); IEEE: Los Angeles, CA, USA, 2019; pp. 975–980. [Google Scholar] [CrossRef]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12126–12134. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part | Name | Layer Type (Depth) | Input Size | Activation | Output Size | |
|---|---|---|---|---|---|---|
| MRN (Classification) | GRU-encoder1 | GRU (2) | 4 | ReLU | ||
| FCL2 | Fully Connected (2) | 35 16 | ReLU ReLU | 16 3 | ||
| Trajectory (Regression) | GRU-encoder2 | Same as GRU-encoder1 | ||||
| FCL1,3 | Fully Connected (1) | 32 | ReLU | 16 | ||
| VAE | VAE-encoder1,2,3, | Fully Connected (2) | 16 8 | ReLU ReLU | 8 2 | |
| VAE-decoder4,5,6 | Fully Connected (2) | 2 8 | ReLU ReLU | 8 16 | ||
| GRU-decoder | GRU (2) | 32 | ReLU | 16 | ||
| FCL4,5,6 | Fully Connected (2) | 16 8 | ReLU ReLU | 8 2 | ||
| Weighted ADE (m) (Local Curvilinear Coordinate/Curvilinear Coordinate) | |||||
|---|---|---|---|---|---|
| Percentage (%) | Total | 1 s | 2 s | 3 s | 4 s |
| 5 | 1.53/9.52 | 0.61/8.34 | 1.39/8.05 | 2.29/9.44 | 3.21/12.29 |
| 10 | 1.26/7.26 | 0.57/5.72 | 1.20/6.57 | 1.80/8.06 | 2.43/10.54 |
| 15 | 1.24/5.49 | 0.58/4.22 | 1.18/4.73 | 1.75/6.15 | 2.40/7.39 |
| 20 | 1.17/5.25 | 0.49/4.70 | 1.10/4.33 | 1.68/5.45 | 2.36/6.69 |
| 40 | 1.15/3.56 | 0.49/3.07 | 1.11/3.18 | 1.64/3.85 | 2.28/4.67 |
| 60 | 1.14/3.70 | 0.52/3.24 | 1.08/3.28 | 1.64/3.81 | 2.23/4.68 |
| 80 | 1.13/3.30 | 0.49/3.00 | 1.05/2.90 | 1.63/3.41 | 2.22/4.23 |
| RMSE (m) | ||||
|---|---|---|---|---|
| Method | 1 s | 2 s | 3 s | 4 s |
| M-LSTM | 0.58 | 1.26 | 2.12 | 3.24 |
| MATF | 0.67 | 1.51 | 2.51 | 3.71 |
| MLS-LSTM | 0.56 | 1.22 | 2.02 | 3.03 |
| Ours | 0.65 | 1.36 | 2.12 | 2.94 |
| Top1 ADE (m) | |||||
|---|---|---|---|---|---|
| Total | 1.0 s | 2.0 s | 3.0 s | 4.0 s | |
| w/constraint | 1.09 | 0.49 | 0.98 | 1.60 | 2.44 |
| w/o constraint | 1.20 | 0.52 | 1.07 | 1.77 | 2.69 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, Y.; Kim, T.; Lee, H.; Park, J. Road-Aware Trajectory Prediction for Autonomous Driving on Highways. Sensors 2020, 20, 4703. https://doi.org/10.3390/s20174703
Yoon Y, Kim T, Lee H, Park J. Road-Aware Trajectory Prediction for Autonomous Driving on Highways. Sensors. 2020; 20(17):4703. https://doi.org/10.3390/s20174703
Chicago/Turabian StyleYoon, Yookhyun, Taeyeon Kim, Ho Lee, and Jahnghyon Park. 2020. "Road-Aware Trajectory Prediction for Autonomous Driving on Highways" Sensors 20, no. 17: 4703. https://doi.org/10.3390/s20174703
APA StyleYoon, Y., Kim, T., Lee, H., & Park, J. (2020). Road-Aware Trajectory Prediction for Autonomous Driving on Highways. Sensors, 20(17), 4703. https://doi.org/10.3390/s20174703