Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by IABC-BPNN in Dry Milling Operations



Abstract
1. Introduction
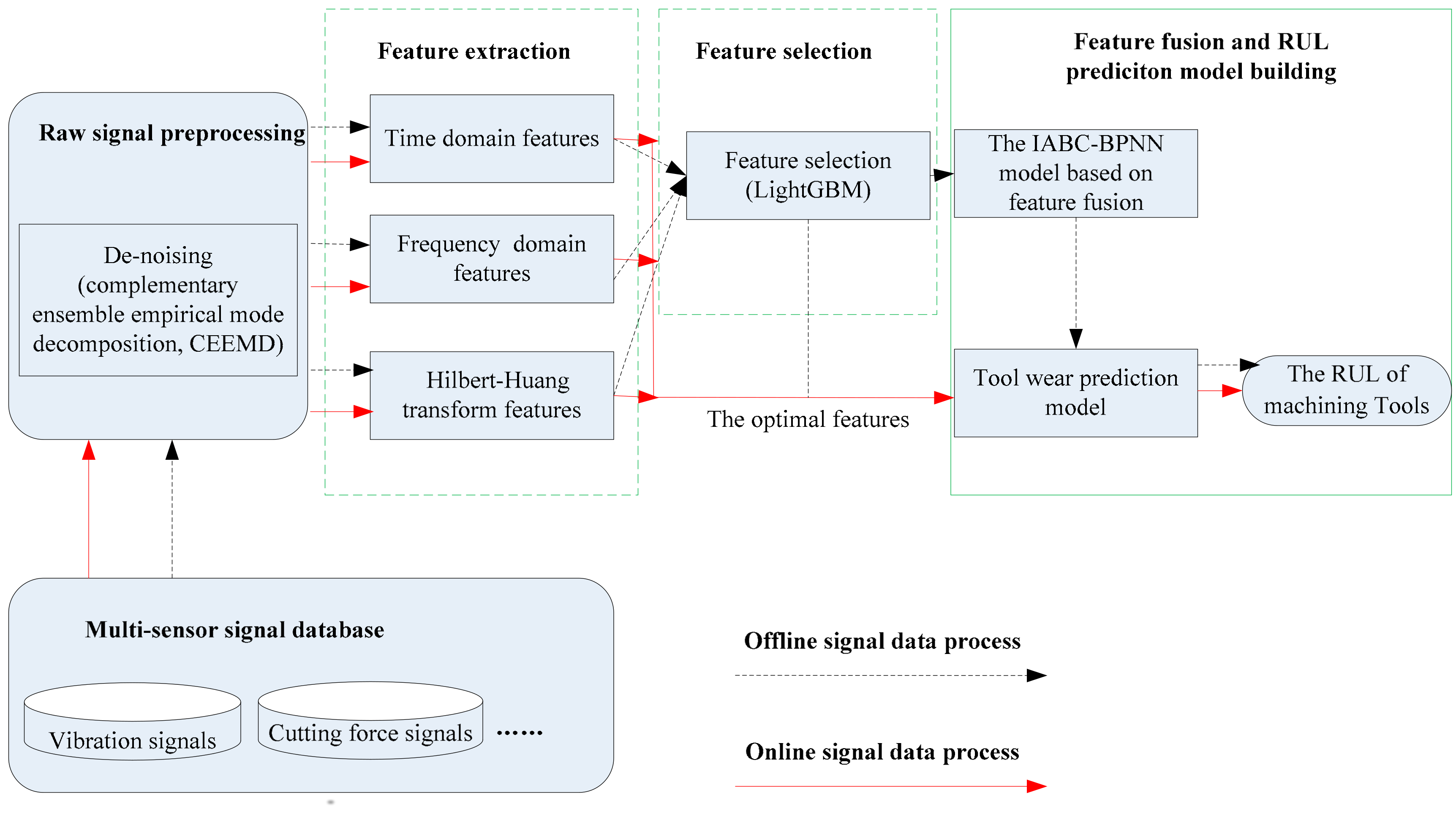
2. RUL Prediction System of Machining Tools Based on Multi-Sensor Data Fusion
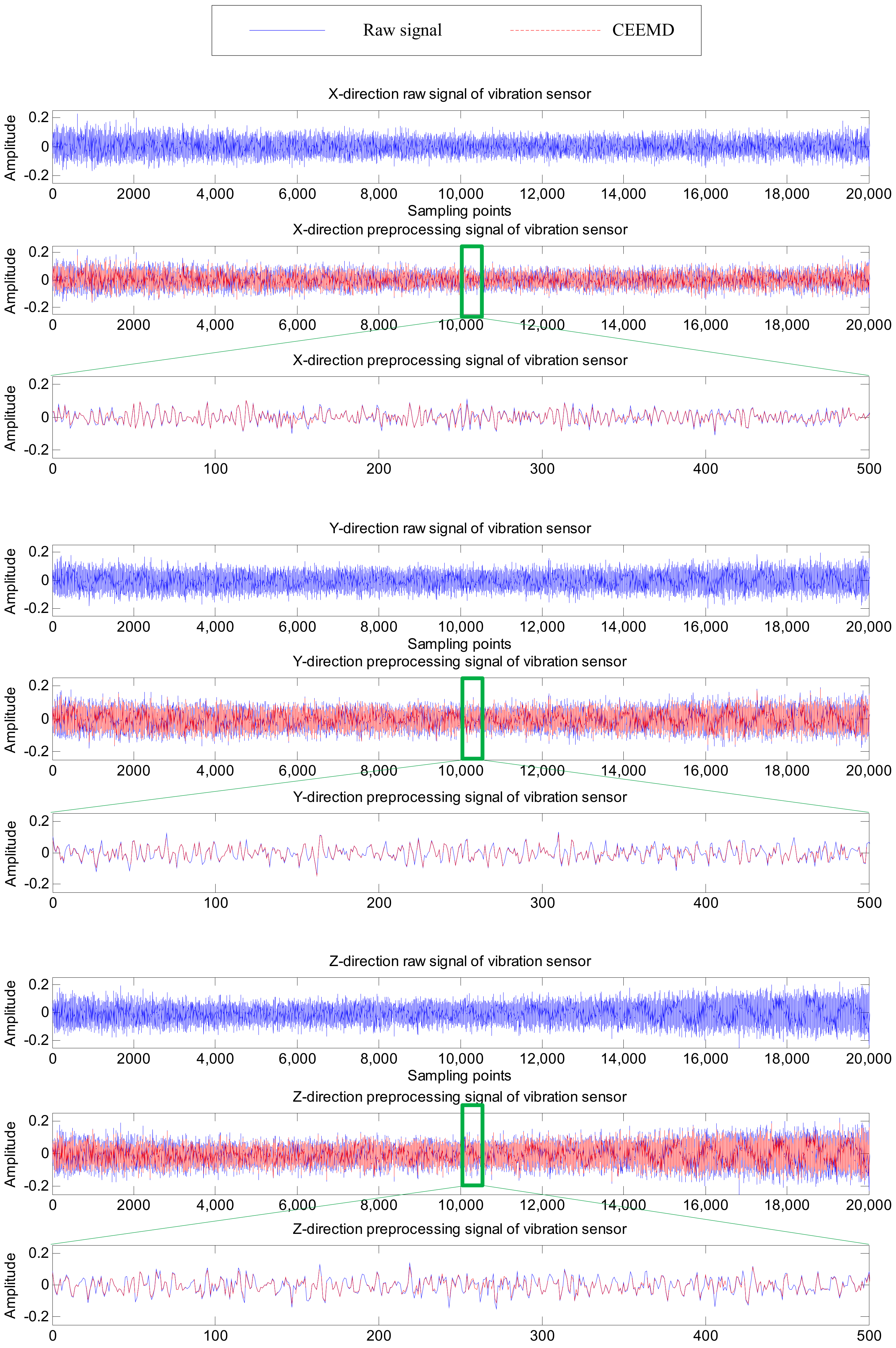
3. Signal Preprocess
- (1)
- The opposite white noise time series , whose variance is unity and mean value is zero, are added to the raw signal respectively and two new noise-added signal and are produced and expressed aswhere is the number of ensemble and set to 80, and is the signal to noise ratio coefficient and set to [0.1, 0.2].
- (2)
- The two new noised-added signal and are discomposed into the first IMF and using EMD method, then can be described asThe first residue can be calculated asIf is monotonic, the decomposition will stop. Otherwise, two new noise-added signal and are produced by adding the opposite white noise time series into and expressed asaccording to the above decomposition process, the second IMF and the second residue are calculated asThe above decomposition is repeated until the residue is monotonic, and the final IMF and residue can be given aswhere M represents the number of signal decompositions and IMFs, and can be thought of as .
- (3)
- Repeating the above two steps for N trials and adding the opposite white noise time series into the signal very trial, we will obtain the final IMFs and residual of the signals, which are expressed as:Finally, the effective IMFs are selected to eliminate the noise in sensor signals, and the reconstruction of the raw signal can be expressed as
4. Feature Extraction and Selection
4.1. Feature Extraction of the Multi-Sensor Signals
4.2. Feature Selection of the Multi-Sensor Signals
5. Feature Extraction and Selection
5.1. Feature Fusion and Tool Wear Prediction Model Based on Back Propagation Neural Network Optimized by Improved Artificial Bee Colony (Iabc-Bpnn) Algorithm
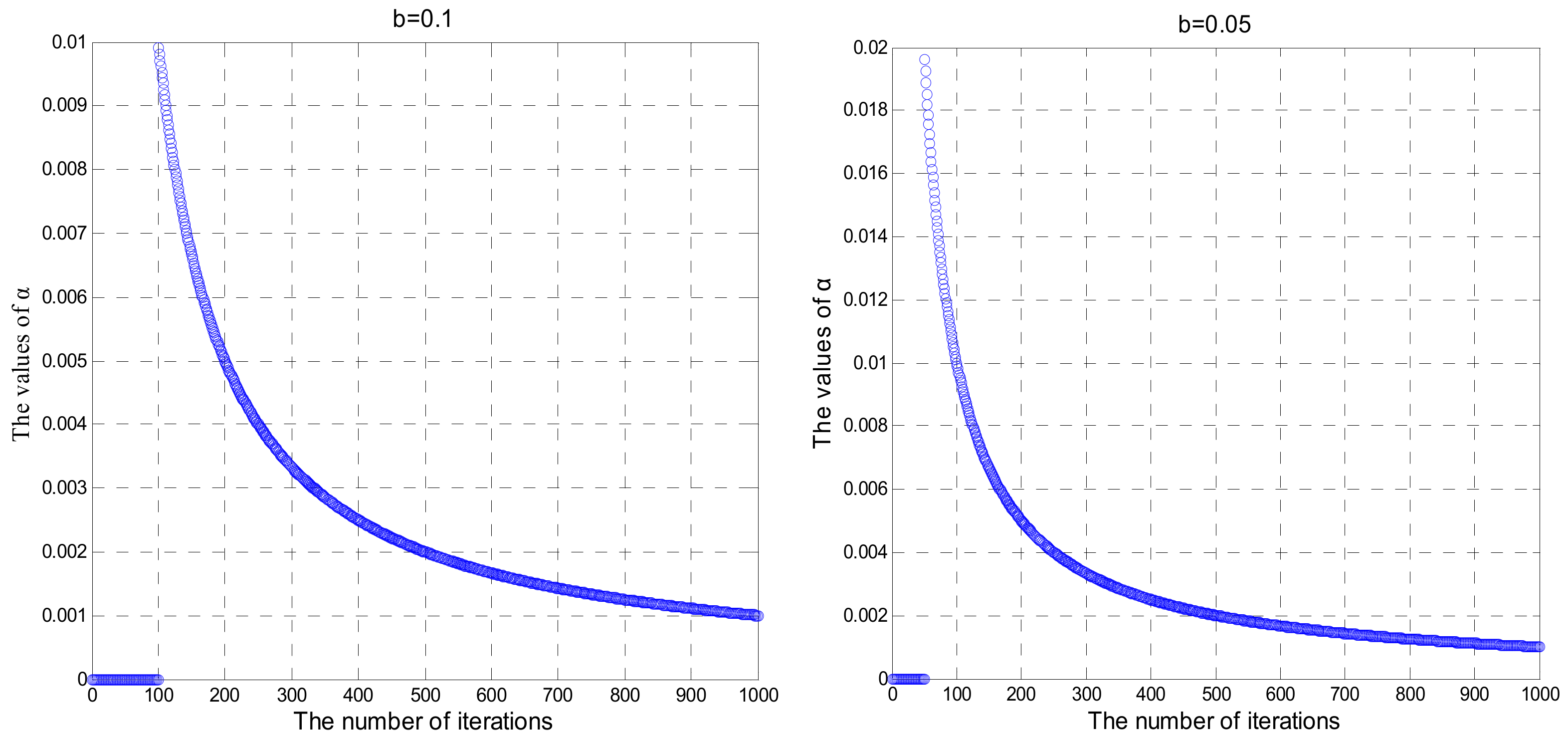
5.1.1. Improved Artificial Bee Colony (IABC) Algorithm
| Algorithm 1. The pseudo code of ABC |
| 1. Intialization stage: Initialize the population Repeat 2. Employed bee stage: Each employed bee to search new food sources in neighborhood. 3. Onlooker bee stage: Each onlooker bee to search new food sources by the probability . 4. Scout bee stage: Each scout bee to search new food sources randomly. 5. Record the best solution: Record the best solution found by all current bees. |
| Until (stop conditions are met) |
| Algorithm 2. The pseudo code of IABC |
| 1. Intialization stage: Initialize the population Repeat 2. Employed bee stage: Each employed bee to search new food sources in neighborhood. New food sources are generated by Equation (27) 3. Onlooker bee stage: Each onlooker bee to search new food sources by the probability . New food sources are generated by Equation (27). 4. Scout bee stage: Each scout bee to search new food sources randomly. 5. Record the best solution: Record the best solution found by all current bees. |
| Until (stop conditions are met) |
5.1.2. Back Propagation Neural Network (BPNN)
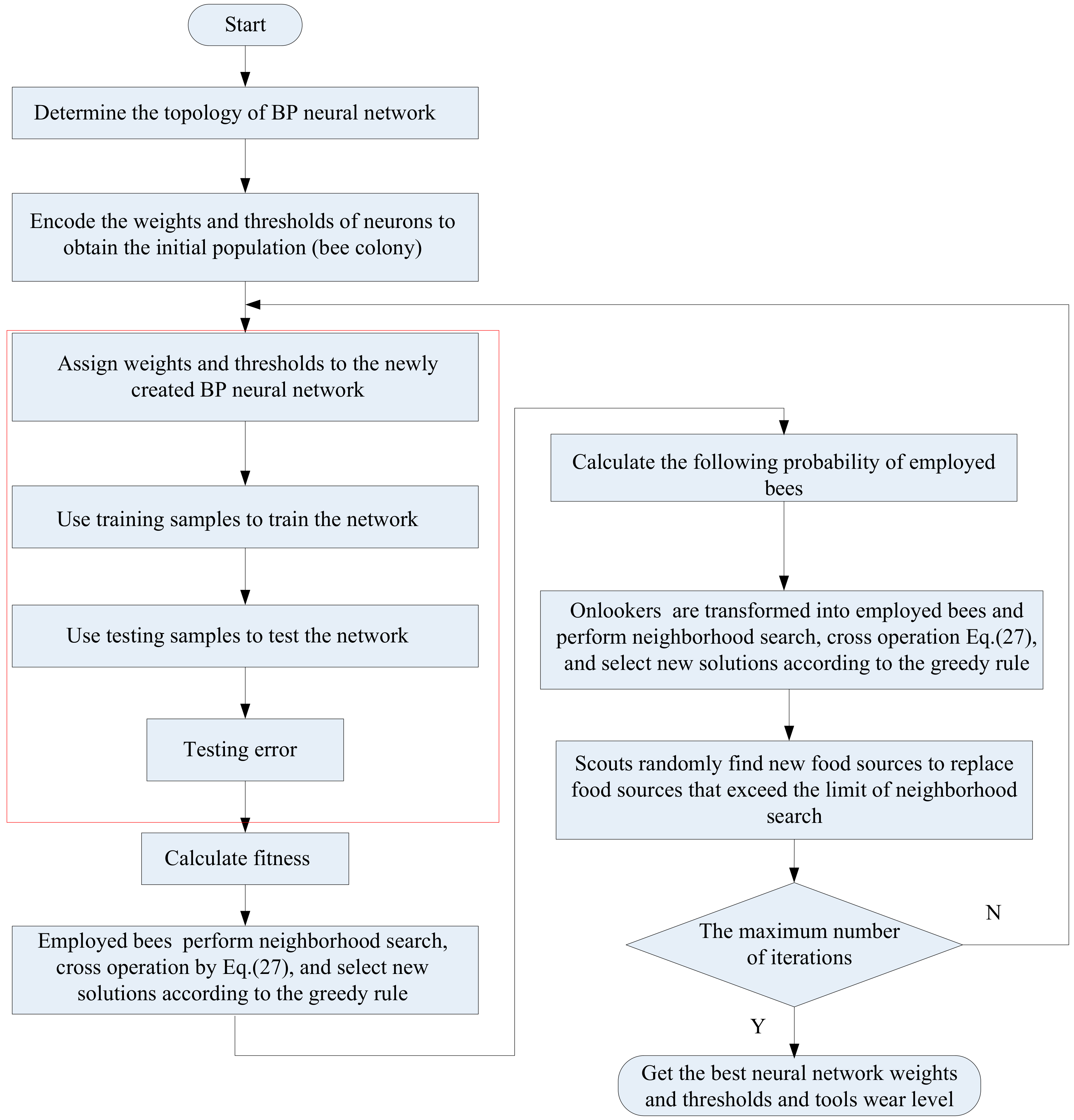
5.1.3. BPNN Optimized by Improved Artificial Bee Colony Algorithm (IABC-BPNN)
5.2. The Rul Prediction of Machining Tools Base on A Polynomial Curve Fitting
6. Experiments and Analysis
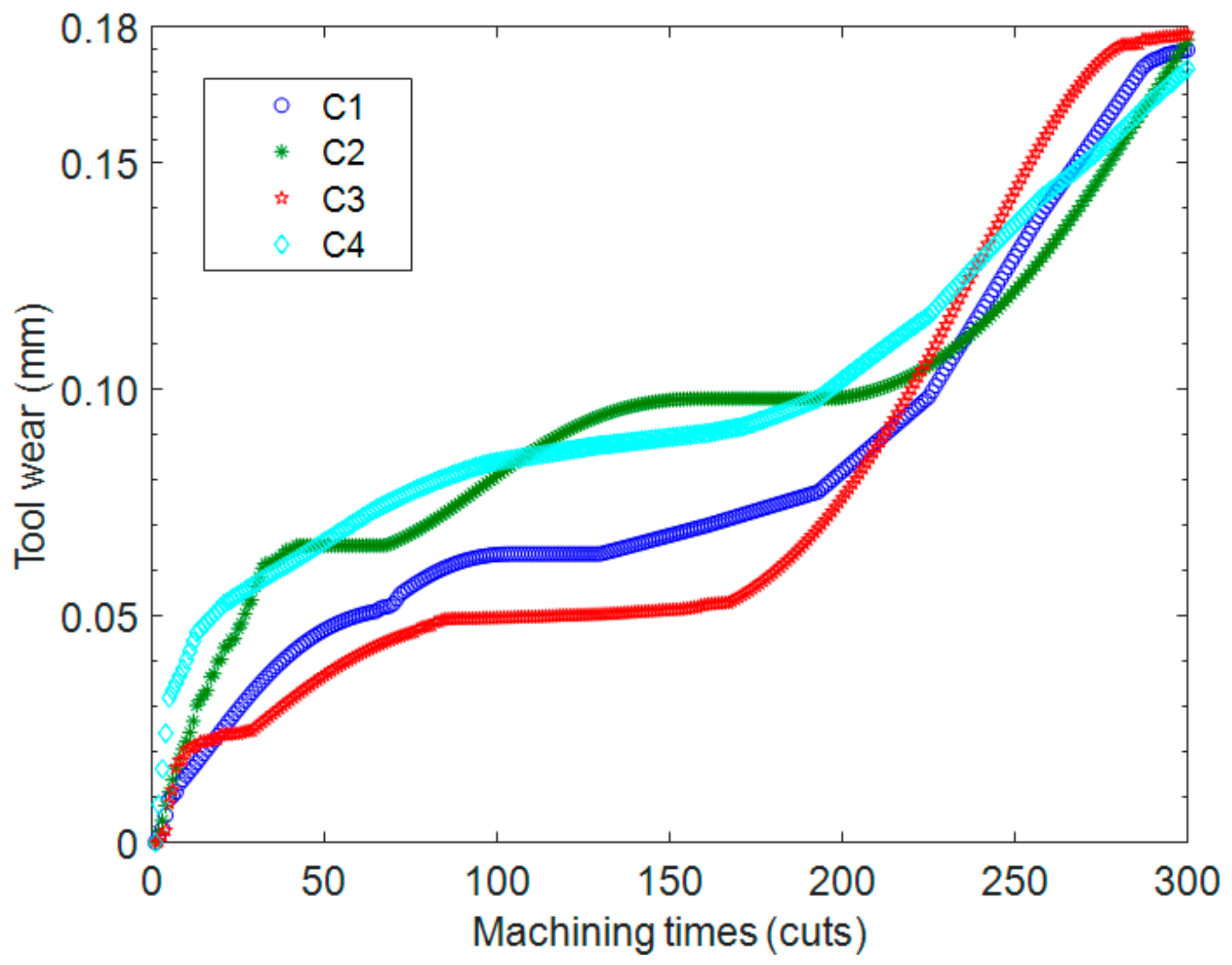
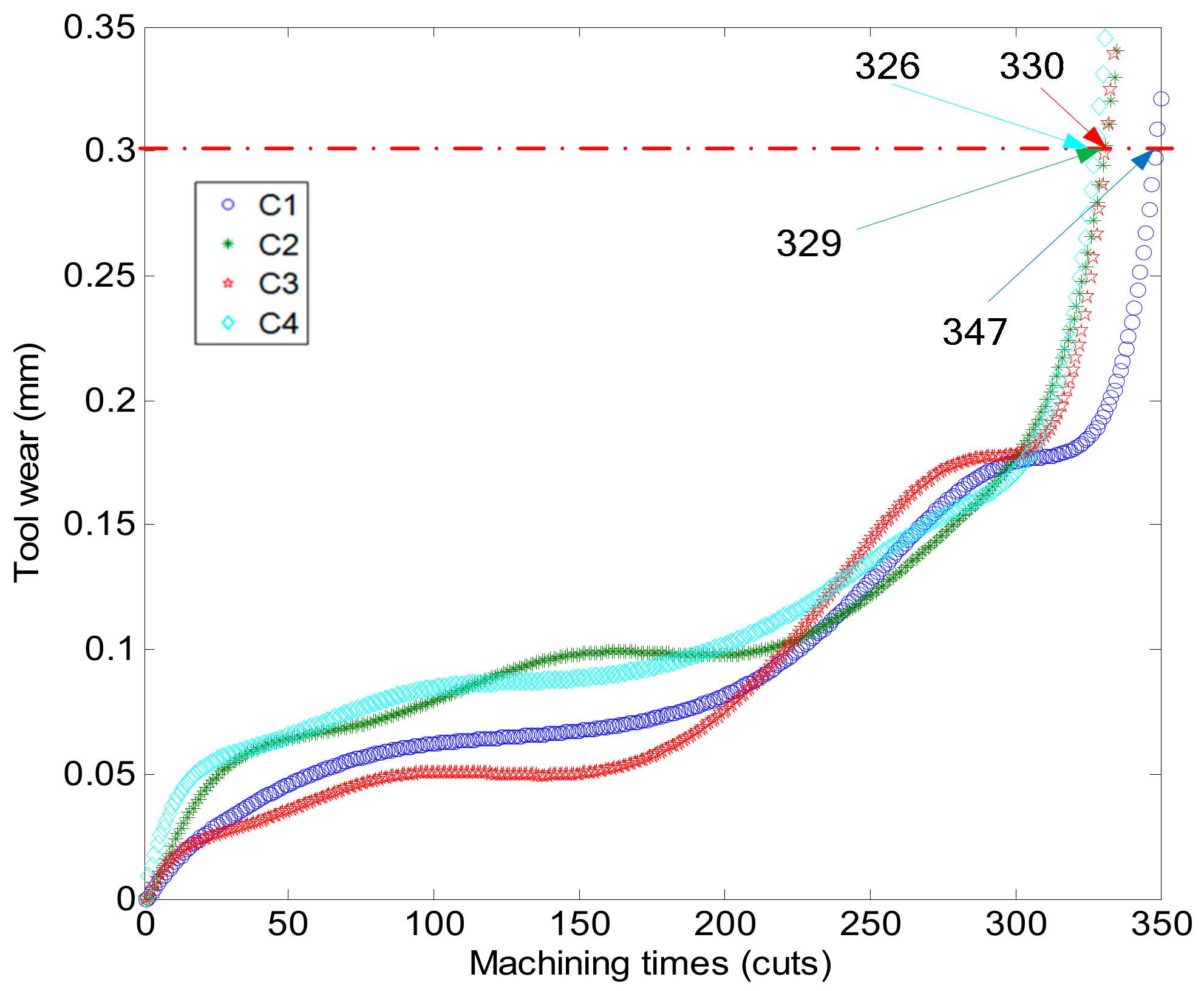
6.1. Experimental Equipment and Data Description
6.2. Results and Analysis
7. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Liao, L.; Köttig, F. A hybrid framework combining data-driven and model-based methods for system remaining useful life prediction. Appl. Soft. Comput. 2016, 44, 191–199. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, X.; Zhang, W. Remaining useful life prediction based on health index similarity. Reliab. Eng. Syst. Safe. 2019, 185, 502–510. [Google Scholar] [CrossRef]
- Chen, S.-L.; Jen, Y. Data fusion neural network for tool condition monitoring in CNC milling machining. Int. J. Mach. Tool. Manu. 2000, 40, 381–400. [Google Scholar] [CrossRef]
- Liao, L.; Köttig, F. Review of Hybrid Prognostics Approaches for Remaining Useful Life Prediction of Engineered Systems, and an Application to Battery Life Prediction. IEEE Trans. Reliab. 2014, 63, 191–207. [Google Scholar] [CrossRef]
- Sun, H.; Cao, D.; Zhao, Z.; Kang, X. A Hybrid Approach to Cutting Tool Remaining Useful Life Prediction Based on the Wiener Process. IEEE Trans. Reliab. 2018, 67, 1294–1303. [Google Scholar] [CrossRef]
- Khelif, R.; Chebel–Morello, B.; Zerhouni, N. Experience Based Approach for Li–ion Batteries RUL Prediction. IFAC Pap. Online 2015, 48, 761–766. [Google Scholar] [CrossRef]
- Yan, J.H.; Isobe, N.; Lee, J. Fuzzy Logic Combined Logistic Regression Methodology for Gas Turbine First-Stage Nozzle Life Prediction. Appl. Mech. Mater. 2007, 10–12, 583–587. [Google Scholar] [CrossRef]
- Baraldi, P.; Cadini, F.; Mangili, F.; Zio, E. Model-based and data-driven prognostics under different available information. Probab. Eng. Mech. 2013, 32, 66–79. [Google Scholar] [CrossRef]
- Pálmai, Z. Proposal for a new theoretical model of the cutting tool’s flank wear. Wear 2013, 303, 437–445. [Google Scholar] [CrossRef]
- Mosallam, A.; Medjaher, K.; Zerhouni, N. Data-driven prognostic method based on Bayesian approaches for direct remaining useful life prediction. J. Intell. Manuf. 2014, 27, 1037–1048. [Google Scholar] [CrossRef]
- Li, W.; Liu, T. Time varying and condition adaptive hidden Markov model for tool wear state estimation and remaining useful life prediction in micro-milling. Mech. Syst. Signal. Process. 2019, 131, 689–702. [Google Scholar] [CrossRef]
- Rohani Bastami, A.; Aasi, A.; Arghand, H.A. Estimation of Remaining Useful Life of Rolling Element Bearings Using Wavelet Packet Decomposition and Artificial Neural Network. Iran. J. Sci. Technol. Trans. Electr. Eng. 2019, 43, 233–245. [Google Scholar] [CrossRef]
- Patil, M.A.; Tagade, P.; Hariharan, K.S.; Kolake, S.M.; Song, T.; Yeo, T.; Doo, S. A novel multistage Support Vector Machine based approach for Li ion battery remaining useful life estimation. Appl. Energy 2015, 159, 285–297. [Google Scholar] [CrossRef]
- Razavi, S.A.; Najafabadi, T.A.; Mahmoodian, A. Remaining Useful Life Estimation Using ANFIS Algorithm: A Data-Driven Approcah for Prognostics. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 522–526. [Google Scholar]
- Kundu, P.; Darpe, A.K.; Kulkarni, M.S. Weibull accelerated failure time regression model for remaining useful life prediction of bearing working under multiple operating conditions. Mech. Syst. Sig. Process. 2019, 134, 106302. [Google Scholar] [CrossRef]
- Wu, J.; Su, Y.; Cheng, Y.; Shao, X.; Deng, C.; Liu, C. Multi-sensor information fusion for remaining useful life prediction of machining tools by adaptive network based fuzzy inference system. Appl. Soft Comput. 2018, 68, 13–23. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, H.; Hu, K.; Wu, J.; Shao, X.; Wang, Y. Multisensory data-driven health degradation monitoring of machining tools by generalized multiclass support vector machine. IEEE Access 2019, 7, 47102–47113. [Google Scholar] [CrossRef]
- Tobon-Mejia, D.A.; Medjaher, K.; Zerhouni, N. CNC machine tool’s wear diagnostic and prognostic by using dynamic Bayesian networks. Mech. Syst. Sig. Process. 2012, 28, 167–182. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Health assessment and life prediction of cutting tools based on support vector regression. J. Intell. Manuf. 2013, 26, 213–223. [Google Scholar] [CrossRef]
- Gokulachandran, J.; Mohandas, K. Comparative study of two soft computing techniques for the prediction of remaining useful life of cutting tools. J. Intell. Manuf. 2013, 26, 255–268. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, X.; Niu, W. In-process cutting tool remaining useful life evaluation based on operational reliability assessment. Int. J. Adv. Manuf. Tech. 2015, 86, 841–851. [Google Scholar] [CrossRef]
- Yu, J.; Liang, S.; Tang, D.; Liu, H. A weighted hidden Markov model approach for continuous-state tool wear monitoring and tool life prediction. Int. J. Adv. Manuf. Tech. 2016, 91, 201–211. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, X.; Zhang, J.; Jin, H. Tool Condition Monitoring and Remaining Useful Life Prognostic Based on a Wireless Sensor in Dry Milling Operations. Sensors 2016, 16, 795. [Google Scholar] [CrossRef] [PubMed]
- Yeh, J.-R.; Shieh, J.-S.; Huang, N.E. Complementary ensemble empirical mode decomposition: A novel noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, J.; Lei, J.; Li, X.; Tian, F. Tool wear predicting based on multi-domain feature fusion by deep convolutional neural network in milling operations. J. Intell. Manuf. 2019, 31, 953–966. [Google Scholar] [CrossRef]
- Zhou, Y.; Xue, W. A Multisensor Fusion Method for Tool Condition Monitoring in Milling. Sensors 2018, 18, 3866. [Google Scholar] [CrossRef]
- Yan, R.; Gao, R.X. Hilbert-Huang transform-based vibration signal analysis for machine health monitoring. IEEE Trans. Instrum. Meas. 2006, 55, 2320–2329. [Google Scholar] [CrossRef]
- Susanto, A.; Liu, C.-H.; Yamada, K.; Hwang, Y.-R.; Tanaka, R.; Sekiya, K. Application of Hilbert–Huang transform for vibration signal analysis in end-milling. Precis. Eng. 2018, 53, 263–277. [Google Scholar] [CrossRef]
- Hoseinzadeh, M.S.; Khadem, S.E.; Sadooghi, M.S. Modifying the Hilbert-Huang transform using the nonlinear entropy-based features for early fault detection of ball bearings. Appl. Acoust. 2019, 150, 313–324. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, M.L.; Qu, W.D.; Long, S.R.; Shen, S.S.P. Applications of Hilbert-Huang transform to non-stationary financial time series analysis. Appl. Stoch. Model. Bus. 2003, 19, 245–268. [Google Scholar] [CrossRef]
- Li, F.; Zhang, L.; Chen, B.; Gao, D.Z.; Cheng, Y.J.; Zhang, X.Y.; Yang, Y.Z.; Gao, K.; Huang, Z.W.; Peng, J.; et al. A Light Gradient Boosting Machine for Remainning Useful Life Estimation of Aircraft Engines. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018; pp. 3562–3567. [Google Scholar]
- Chen, C.; Zhang, Q.; Ma, Q.; Yu, B. LightGBM-PPI: Predicting protein-protein interactions through LightGBM with multi-information fusion. Chemometr. Intell. Lab. 2019, 191, 54–64. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report-tr06; Erciyes University: Kayseri, Türkiye, 2005; pp. 1–10. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Global. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Tang, K.S.; Man, K.F.; Kwong, S.; He, Q. Genetic algorithms and their applications. IEEE Signal. Proc. Mag. 1996, 13, 22–37. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Liu, M.; Yao, X.; Li, Y. Hybrid whale optimization algorithm enhanced with Lévy flight and differential evolution for job shop scheduling problems. Appl. Soft Comput. 2020, 87, 105954. [Google Scholar] [CrossRef]
- Jain, M.; Singh, V.; Rani, A. A novel nature-inspired algorithm for optimization: Squirrel search algorithm. Swarm Evol. Comput. 2019, 44, 148–175. [Google Scholar] [CrossRef]
- Zhu, G.; Kwong, S. Gbest-guided artificial bee colony algorithm for numerical function optimization. Appl. Math. Comput. 2010, 217, 3166–3173. [Google Scholar]
- Gao, W.-F.; Huang, L.-L.; Wang, J.; Liu, S.-Y.; Qin, C.-D. Enhanced artificial bee colony algorithm through differential evolution. Appl. Soft Comput. 2016, 48, 137–150. [Google Scholar] [CrossRef]
- Xue, Y.; Jiang, J.; Zhao, B.; Ma, T. A self-adaptive artificial bee colony algorithm based on global best for global optimization. Soft Comput. 2017, 22, 2935–2952. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y.; Guo, H. Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Appl. Energy 2017, 190, 390–407. [Google Scholar] [CrossRef]
- Qu, Z.; Mao, W.; Zhang, K.; Zhang, W.; Li, Z. Multi-step wind speed forecasting based on a hybrid decomposition technique and an improved back-propagation neural network. Renew. Energ. 2019, 133, 919–929. [Google Scholar] [CrossRef]
- Jian, B.-L.; Chang-Jian, C.-W.; Guo, Y.-S.; Yu, K.-T.; Yau, H.-T. Optimizing Back Propagation Neural Network Parameters to Judge Fault Types of Ball Bearings. Sens. Mater. 2020, 32, 417. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Feature | Formula |
|---|---|---|
| Time | Mean value (Tmv) | |
| Maximum (Tmax) | ||
| Root mean square (Trms) | ||
| Variance (Tvr) | ||
| Standard Deviation (Tsd) | ||
| Peak-to-peak (Tp2p) | ||
| Waveform Factor (Twf) | ||
| Skewness Factor (Tsf) | ||
| Kurtosis Factor (Tkf) | ||
| Crest Factor (Tcf) | ||
| Frequency | Mean of power spectrum (Fmv) | |
| Maximum of power spectrum (Fmax) | ||
| Root mean square of power spectrum (Frms) | ||
| Variance of power spectrum (Fvr) | ||
| Skewness of power spectrum (Fsf) | ||
| Kurtosis of power spectrum (Fkf) | ||
| Relative spectral peak per band (Frs) |
| Measured Value (mm) | Predicted Value (mm) | Predicted Value STD | Error Percentage (%) | Confidence Interval (95%) |
|---|---|---|---|---|
| 0.013 | 0.01298 | 3.97911 × 10−5 | 0.15 | [0.012967, 0.013023] |
| 0.049 | 0.04899 | 8.49575 × 10−5 | 0.02 | [0.048987, 0.049109] |
| 0.063 | 0.06301 | 4.3729 × 10−5 | 0.02 | [0.062962, 0.063024] |
| 0.068 | 0.06799 | 4.8074 × 10−5 | 0.01 | [0.067966, 0.068034] |
| 0.075 | 0.07495 | 6.1101 × 10−5 | 0.07 | [0.074926, 0.075014] |
| 0.083 | 0.08296 | 4.54606 × 10−5 | 0.05 | [0.082947, 0.083013] |
| 0.097 | 0.09698 | 4.13656 × 10−5 | 0.02 | [0.096950, 0.097010] |
| 0.131 | 0.13100 | 5.25885 × 10−5 | 0 | [0.130943, 0.131019] |
| 0.152 | 0.15201 | 2.83039 × 10−5 | 0.01 | [0.151987, 0.152027] |
| 0.175 | 0.17497 | 4.08792 × 10−5 | 0.02 | [0.174957, 0.175015] |
| Parameters | RBFN | BPNN | IABC-BPNN | NFIS |
|---|---|---|---|---|
| Learning rate | 0.1 | 0.1 | 0.1 | 0.1 |
| Network layers | 3 | 3 | 3 | 5 |
| Network structure | 16,250,1 | 16,33,1 | 16,33,1 | 16,64,128,128,1 |
| Data set | 9600 | 9600 | 9600 | 9600 |
| Error | RBFN | BPNN | IABC-BPNN | NFIS |
|---|---|---|---|---|
| RMSE | 0.1246 | 0.0679 | 0.0024 | 0.0063 |
| MAPE | 0.1563 | 0.0917 | 0.0032 | 0.0055 |
| R2 | 0.6326 | 0.8405 | 0.9953 | 0.9152 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Yao, X.; Zhang, J.; Chen, W.; Jing, X.; Wang, K. Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by IABC-BPNN in Dry Milling Operations. Sensors 2020, 20, 4657. https://doi.org/10.3390/s20174657
Liu M, Yao X, Zhang J, Chen W, Jing X, Wang K. Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by IABC-BPNN in Dry Milling Operations. Sensors. 2020; 20(17):4657. https://doi.org/10.3390/s20174657
Chicago/Turabian StyleLiu, Min, Xifan Yao, Jianming Zhang, Wocheng Chen, Xuan Jing, and Kesai Wang. 2020. "Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by IABC-BPNN in Dry Milling Operations" Sensors 20, no. 17: 4657. https://doi.org/10.3390/s20174657
APA StyleLiu, M., Yao, X., Zhang, J., Chen, W., Jing, X., & Wang, K. (2020). Multi-Sensor Data Fusion for Remaining Useful Life Prediction of Machining Tools by IABC-BPNN in Dry Milling Operations. Sensors, 20(17), 4657. https://doi.org/10.3390/s20174657