Front Vehicle Detection Algorithm for Smart Car Based on Improved SSD Model

 , and
, and 
Abstract
1. Introduction
2. SSD Network Model
2.1. Brief Introduction of SSD
2.2. Shortcomings of SSD in Vehicle Detection
- (1)
- In the front view of a smart car, the long-distance vehicle object only accounts for a small proportion of the image area in the collected detection image, and the vehicle object scale is small. Although the SSD network model has a multi-scale feature extraction network, the SSD adopts a nondiscriminatory method for different scale features, and simply selects a few feature layers for prediction without considering that the shallow and deep convolutional layers contain different local details and textural and semantic features. Therefore, the SSD network model has insufficient ability to extract features of small-scale vehicle objects and has yet achieved a satisfactory detection effect.
- (2)
- In the actual road scenes, different vehicle objects have obvious differences in characteristics, such as color, shape, and taillights, and are easily affected by changes in lighting conditions, severe weather interference, and road object occlusion. These conditions bring many challenges to the accurate detection of front vehicles. The original SSD network model has poor vehicle detection performance in complicated environments, and its robustness and environmental adaptability are poor.
- (3)
- In the network training process, the regression task is only for matching the correct detection box. Accordingly, the corresponding loss will be directly set to zero when no vehicle object is present in some pictures of the dataset; thus, the other pictures are not fully utilized. In the ranking of confidence scores, the number of negative detection boxes is much larger than that of positive detection boxes. Accordingly, the training network pays great attention to the proportion of negative samples, thereby resulting in the slow training speed of the network model.
- (4)
- When the smart car passes through intersections, urban arterial roads, and traffic jam areas, a single detection image collected may include multiple vehicle objects, thereby inevitably resulting in mutual occlusion between vehicle objects. However, the original SSD network model has poor detection performance for overlapping objects, and it is prone to miss detection in multi-object scenes.
3. Improved SSD Network Model
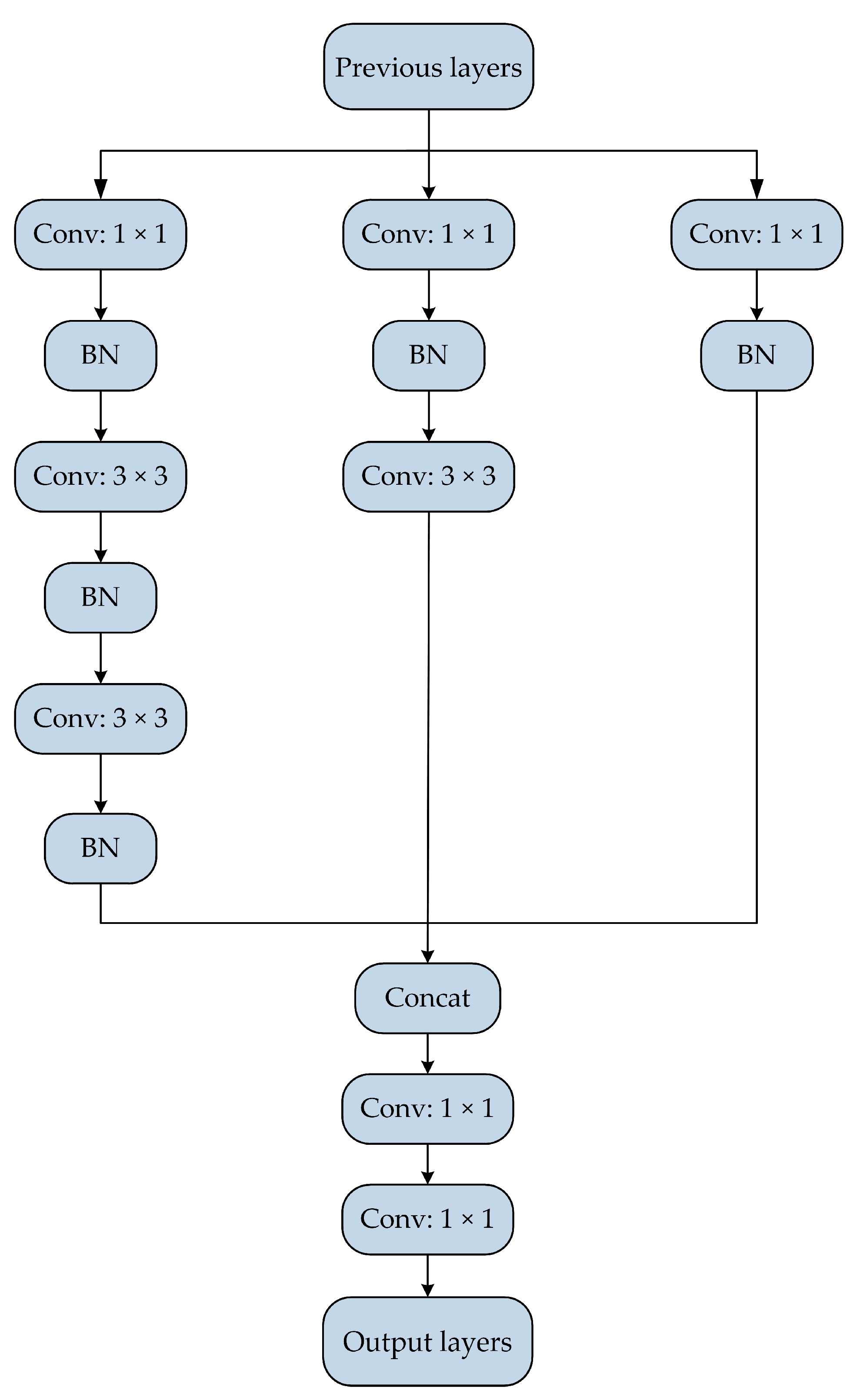
3.1. Improved Basic Structure of SSD
3.2. Weighted Mask
- (1)
- When detection boxes are present, the number of positive samples is , the number of negative samples is , , and the classification label is set.
- (2)
- When the weighted mask for positive sample classification is set to .
- (3)
- When and the ratio of positive and negative samples is controlled to 1:3, the weighted mask for negative sample classification is set to .
- (4)
- The weighted mask used for classification task is
- (5)
- Assuming that the weight coefficient of regression task is the weighted mask used for regression task is .
3.3. Improved Loss Function
4. Vehicle Detection Experiments and Discussion
4.1. Experimental Environment
4.2. Vehicle Detection Experiment Based on KITTI Dataset
4.2.1. KITTI Dataset
4.2.2. Network Training and Evaluation Indexes
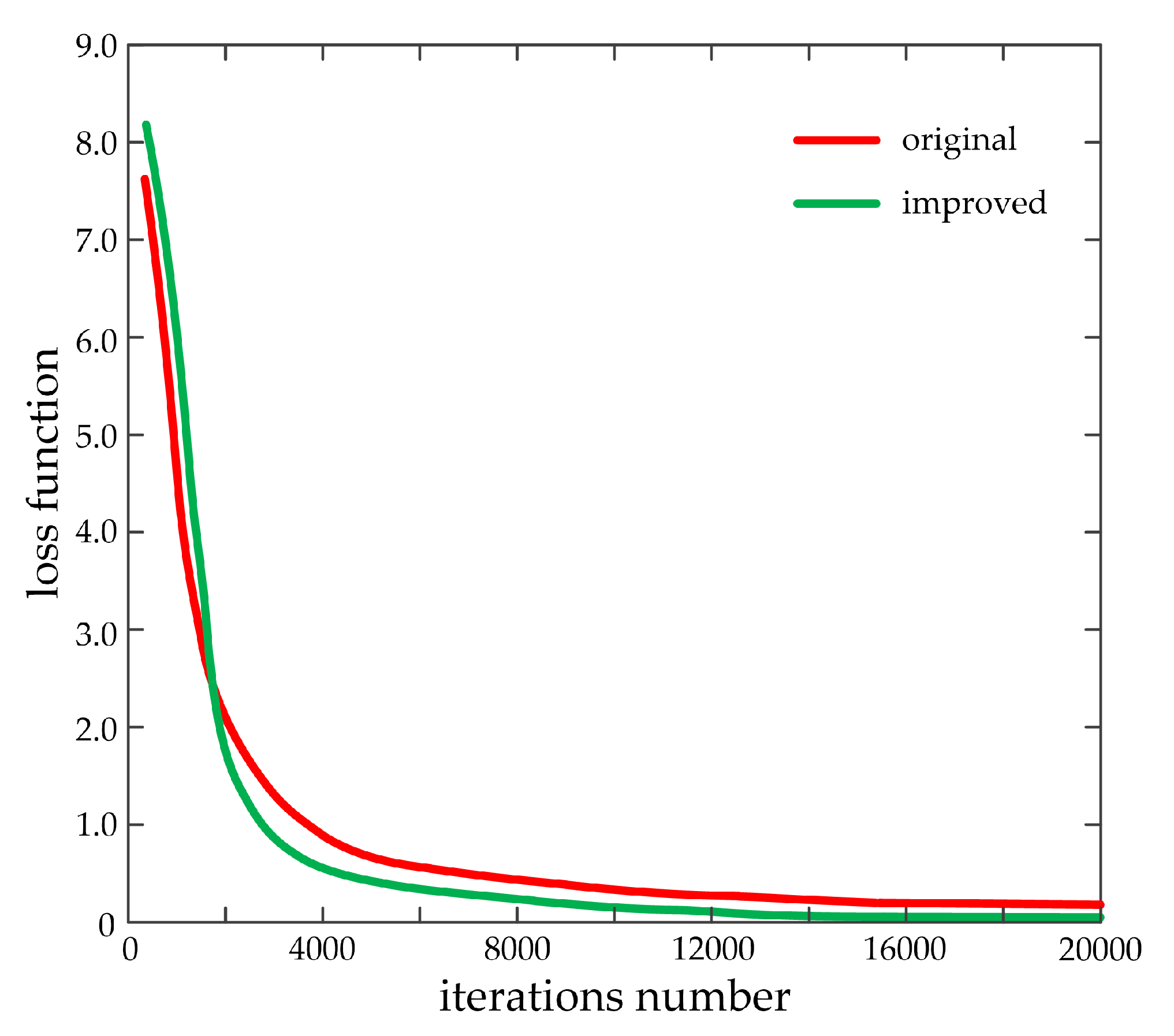
4.2.3. Experimental Test Results and Analysis
4.3. Vehicle Detection Based on Self-Made Vehicle Dataset
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, Y. Car ownership growth pattern of county-level regions in Jiangsu, China. In Proceedings of the 19th COTA International Conference of Transportation Professionals: Transportation in China—Connecting the World (CICTP), Nanjing, China, 6–8 July 2019; pp. 4461–4470. [Google Scholar]
- Wang, X.S.; Zhou, Q.Y.; Yang, J.G.; You, S.K.; Song, Y.; Xue, M.G. Macro-Level Traffic Safety Analysis in Shanghai, China. Accid. Anal. Prev. 2019, 125, 249–256. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.Y.; Liu, Q.Y.; Ma, L.; Zhang, Y.J.; Cong, H.Z. Road traffic accident severity analysis: A census-based study in China. J. Saf. Res. 2019, 70, 135–147. [Google Scholar] [CrossRef] [PubMed]
- Alrawi, F.; Ali, A. Analysis of the relationship between traffic accidents with human and physical factors in iraq. In Proceedings of the 16th Scientific and Technical Conference on Transport Systems Theory and Practice (TSTP), Katowice, Poland, 16–18 September 2019; pp. 190–201. [Google Scholar]
- Ye, L.; Yamamoto, T. Evaluating the impact of connected and autonomous vehicles on traffic safety. Phys. A Stat. Mech. Appl. 2019, 526, 121009. [Google Scholar] [CrossRef]
- Bimbraw, K. Autonomous cars: Past, present and future: A review of the developments in the last century, the present scenario and the expected future of autonomous vehicle technology. In Proceedings of the 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO), Alsace, France, 21–23 July 2015; pp. 191–198. [Google Scholar]
- Zhu, H.; Yuen, K.V.; Mihaylova, L.; Leung, H. Overview of environment perception for autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2584–2601. [Google Scholar] [CrossRef]
- Kim, J.; Hong, S.; Baek, J.; Kim, E.; Lee, H. Autonomous vehicle detection system using visible and infrared camera. In Proceedings of the 2012 12th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 17–21 October 2012; pp. 630–634. [Google Scholar]
- Zhang, S.; Zhao, X.; Lei, W.B.; Yu, Q.; Wang, Y.B. Front vehicle detection based on multi-sensor fusion for autonomous vehicle. J. Intell. Fuzzy Syst. 2020, 38, 365–377. [Google Scholar] [CrossRef]
- Dai, X.R.; Yuan, X.; Zhang, J.; Zhang, L.P. Improving the performance of vehicle detection system in bad weathers. In Proceedings of the 4th 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2016; pp. 812–816. [Google Scholar]
- Li, B.X.; Fang, L. Laser radar application in vehicle detection under traffic environment. In Proceedings of the 4th International Conference on Intelligent Computing, Communication and Devices (ICCD), Guangzhou, China, 7–9 December 2018; pp. 1077–1082. [Google Scholar]
- Aswin, M.; Suganthi Brindha, G. A novel approach for night-time vehicle detection in real-time scenario. In Proceedings of the International Conference on NextGen Electronic Technologies-Silicon to Software (ICNETS2), Chennai, India, 23–25 March 2017; pp. 99–105. [Google Scholar]
- Teoh, S.S.; Bräunl, T.; Liang, Y.X.; Xia, J.Z. Symmetry-Based monocular vehicle detection system. Mach. Vis. Appl. 2012, 23, 831–842. [Google Scholar] [CrossRef]
- Wang, X.Y.; Wang, B.; Song, l. Real-Time on-road vehicle detection algorithm based on monocular vision. In Proceedings of the 2nd International Conference on Computer Science and Network Technology (ICCSNT), Changchun, China, 29–31 December 2012; pp. 772–776. [Google Scholar]
- He, P.; Gao, F. Study on detection of preceding vehicles based on computer vision. In Proceedings of the 2013 2nd International Conference on Measurement, Instrumentation and Automation (ICMIA), Guilin, China, 23–24 April 2013; pp. 912–915. [Google Scholar]
- Li, X.; Guo, X.S.; Guo, J.B. A multi-feature fusion method for forward vehicle detection with single camera. In Proceedings of the 2013 International Conference on Mechatronics and Industrial Informatics (ICMII), Guangzhou, China, 13–14 March 2013; pp. 998–1004. [Google Scholar]
- Wu, T.Q.; Zhang, Y.; Wang, B.B.; Yu, J.H.; Zhu, D.W. A fast forward vehicle detection method by multiple vision clues fusion. In Proceedings of the International Conference on Vehicle and Mechanical Engineering and Information Technology (VMEIT), Beijing, China, 19–20 February 2014; pp. 2647–2651. [Google Scholar]
- Qu, S.R.; Xu, L. Research on multi-feature front vehicle detection algorithm based on video image. In Proceedings of the 28th Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 3831–3835. [Google Scholar]
- Zhang, Y.Z.; Sun, P.F.; Li, J.F.; Lei, M. Real-Time vehicle detection in highway based on improved Adaboost and image segmentation. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control and Intelligent Systems (CYBER), Shenyang, China, 9–12 June 2015; pp. 2006–2011. [Google Scholar]
- Kim, J.; Baek, J.; Kim, E. A novel on-road vehicle detection method using π HOG. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3414–3429. [Google Scholar] [CrossRef]
- Neumann, D.; Langner, T.; Ulbrich, F.; Spitta, D.; Goehring, D. Online vehicle detection using Haar-like, LBP and HOG feature based image classifiers with stereo vision preselection. In Proceedings of the 28th IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017; pp. 773–778. [Google Scholar]
- Deng, Y.; Liang, H.W.; Wang, Z.L.; Huang, J.J. Novel approach for vehicle detection in dynamic environment based on monocular vision. In Proceedings of the 11th IEEE International Conference on Mechatronics and Automation (IEEE ICMA), Tianjin, China, 3–6 August 2014; pp. 1176–1181. [Google Scholar]
- Arunmozhi, A.; Park, J. Comparison of HOG, LBP and Haar-like features for on-road vehicle detection. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 362–367. [Google Scholar]
- Jabri, S.; Saidallah, M.; Elalaoui, A.E.; El Fergougui, A. Moving vehicle detection using Haar-like, LBP and a machine learning Adaboost algorithm. In Proceedings of the 3rd IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018; pp. 121–124. [Google Scholar]
- Lange, S.; Ulbrich, F.; Goehring, D. Online vehicle detection using deep neural networks and lidar based preselected image patches. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 954–959. [Google Scholar]
- Qu, T.; Zhang, Q.Y.; Sun, S.L. Vehicle detection from high-resolution aerial images using spatial pyramid pooling-based deep convolutional neural networks. Multimedia Tools Appl. 2017, 76, 21651–21663. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.C.; Hu, W.D. Towards accurate tiny vehicle detection in complex scenes. Neurocomputing 2019, 347, 24–33. [Google Scholar] [CrossRef]
- Hsu, S.C.; Huang, C.L.; Chuang, C.H. Vehicle detection using simplified fast R-CNN. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–3. [Google Scholar]
- Nguyen, H. Improving Faster R-CNN framework for fast vehicle detection. Math. Probl. Eng. 2019, 2019, 1–11. [Google Scholar] [CrossRef]
- Lou, L.; Zhang, Q.; Liu, C.F.; Sheng, M.L.; Liu, J.; Song, H.M. Detecting and counting the moving vehicles using mask R-CNN. In Proceedings of the 8th IEEE Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 987–992. [Google Scholar]
- Chen, S.B.; Lin, W. Embedded system real-time vehicle detection based on improved YOLO network. In Proceedings of the 3rd IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 1400–1403. [Google Scholar]
- Sang, J.; Wu, Z.Y.; Guo, P.; Hu, H.B.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef] [PubMed]
- Raj, M.; Chandan, S. Real-Time vehicle and pedestrian detection through SSD in Indian Traffic conditions. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 439–444. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Liang, Q.K.; Zhu, W.; Long, J.Y.; Wang, Y.N.; Sun, W.; Wu, W.N. A real-time detection framework for on-tree mango based on SSD network. In Proceedings of the 11th International Conference on Intelligent Robotics and Applications (ICIRA), Newcastle, Australia, 9–11 August 2018; pp. 423–436. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Liu, S.T.; Huang, D.; Wang, Y.H. Receptive Field Block Net for accurate and fast object detection. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 404–419. [Google Scholar]
- Wei, J.; He, J.H.; Zhou, Y.; Chen, K.; Tang, Z.Y.; Xiong, Z.L. Enhanced object detection with deep convolutional neural networks for advanced driving assistance. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1572–1583. [Google Scholar] [CrossRef]
- Hong, F.; Lu, C.H.; Liu, C.; Liu, R.R.; Wei, J. A traffic surveillance multi-scale vehicle detection object method base on encoder-decoder. IEEE Access 2020, 8, 47664–47674. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.B.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12689–12697. [Google Scholar]
- Cai, Z.W.; Fan, Q.F.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the 21st ACM Conference on Computer and Communications Security (CCS), Scottsdale, AZ, USA, 3–7 November 2014; pp. 354–370. [Google Scholar]
- Dai, X.R. HybridNet: A fast vehicle detection system for autonomous driving. Signal Process. Image Commun. 2019, 70, 79–88. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Convolutional Kernel Size | Convolutional Kernel Number | Step Size | Filling | Feature Map Size |
|---|---|---|---|---|---|
| Conv1_1 | 3 × 3 | 64 | 1 | 1 | 300 × 300 |
| Conv1_2 | 3 × 3 | 64 | 1 | 1 | 300 × 300 |
| Maxpool1 | 2 × 2 | 1 | 2 | 0 | 150 × 150 |
| Conv2_1 | 3 × 3 | 128 | 1 | 1 | 150 × 150 |
| Conv2_2 | 3 × 3 | 128 | 1 | 1 | 150 × 150 |
| Maxpool2 | 2 × 2 | 1 | 2 | 0 | 75 × 75 |
| Conv3_1 | 3 × 3 | 256 | 1 | 1 | 75 × 75 |
| Conv3_2 | 3 × 3 | 256 | 1 | 1 | 75 × 75 |
| Conv3_3 | 3 × 3 | 256 | 1 | 1 | 75 × 75 |
| Maxpool3 | 2 × 2 | 1 | 2 | 0 | 38 × 38 |
| Conv4_1 | 3 × 3 | 512 | 1 | 1 | 38 × 38 |
| Conv4_2 | 3 × 3 | 512 | 1 | 1 | 38 × 38 |
| Conv4_3 | 3 × 3 | 512 | 1 | 1 | 38 × 38 |
| Maxpool4 | 2 × 2 | 1 | 2 | 0 | 19 × 19 |
| Conv5_1 | 3 × 3 | 512 | 1 | 1 | 19 × 19 |
| Conv5_2 | 3 × 3 | 512 | 1 | 1 | 19 × 19 |
| Conv5_3 | 3 × 3 | 512 | 1 | 1 | 19 × 19 |
| Maxpool5 | 3 × 3 | 1 | 1 | 1 | 19 × 19 |
| Conv6 | 3 × 3 | 1024 | 1 | 1 | 19 × 19 |
| Conv7 | 1 × 1 | 1024 | 1 | 0 | 19 × 19 |
| Conv8_1 | 1 × 1 | 256 | 1 | 0 | 19 × 19 |
| Conv8_2 | 3 × 3 | 512 | 2 | 1 | 10 × 10 |
| Conv9_1 | 1 × 1 | 128 | 1 | 0 | 10 × 10 |
| Conv9_2 | 3 × 3 | 256 | 2 | 1 | 5 × 5 |
| Conv10_1 | 1 × 1 | 128 | 1 | 0 | 5 × 5 |
| Conv10_2 | 3 × 3 | 256 | 1 | 0 | 3 × 3 |
| Conv11_1 | 1 × 1 | 128 | 1 | 0 | 3 × 3 |
| Conv11_2 | 3 × 3 | 256 | 1 | 0 | 1 × 1 |
| Sequence Number | Weather Condition | Original mAP (%) | Improved mAP (%) |
|---|---|---|---|
| 1 | Sunny | 91.56 | 95.78 |
| 2 | Cloudy | 88.72 | 93.66 |
| 3 | Rainy | 86.65 | 92.25 |
| 4 | Snowy | 86.34 | 92.02 |
| 5 | Mild Smoggy | 80.21 | 85.10 |
| Total | - | 86.70 | 91.76 |
| Sequence Number | Method | Easy | Moderate | Hard | mAP (%) | Average Processing Time (ms)/Frame | System Environment |
|---|---|---|---|---|---|---|---|
| 1 | Pointpillars [40] | 88.35 | 86.10 | 79.83 | 84.76 | 16 | Intel i7 CPU and 1080Ti GPU |
| 2 | MS-CNN [41] | 90.03 | 89.02 | 76.11 | 85.05 | 400 | Intel Xeon E5-2630 CPU@2.40 GHz; NVIDIA Titan GPU |
| 3 | HybridNet [42] | 88.68 | 87.91 | 79.07 | 85.22 | 45 | NVIDIA GTX 1080Ti GPU |
| 4 | Original SSD | 90.67 | 89.56 | 82.39 | 87.54 | 28 | Intel(R) Core(TM) i7-7700 CPU@3.60GHz; NVIDIA GeForce GTX 1080Ti GPU |
| Ours | Improved SSD | 95.76 | 94.55 | 86.23 | 92.18 | 15 | Intel(R) Core(TM) i7-7700 CPU@3.60GHz; NVIDIA GeForce GTX 1080Ti GPU |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Song, C.; Song, S.; Peng, S.; Wang, D.; Shao, Y.; Xiao, F. Front Vehicle Detection Algorithm for Smart Car Based on Improved SSD Model. Sensors 2020, 20, 4646. https://doi.org/10.3390/s20164646
Cao J, Song C, Song S, Peng S, Wang D, Shao Y, Xiao F. Front Vehicle Detection Algorithm for Smart Car Based on Improved SSD Model. Sensors. 2020; 20(16):4646. https://doi.org/10.3390/s20164646
Chicago/Turabian StyleCao, Jingwei, Chuanxue Song, Shixin Song, Silun Peng, Da Wang, Yulong Shao, and Feng Xiao. 2020. "Front Vehicle Detection Algorithm for Smart Car Based on Improved SSD Model" Sensors 20, no. 16: 4646. https://doi.org/10.3390/s20164646
APA StyleCao, J., Song, C., Song, S., Peng, S., Wang, D., Shao, Y., & Xiao, F. (2020). Front Vehicle Detection Algorithm for Smart Car Based on Improved SSD Model. Sensors, 20(16), 4646. https://doi.org/10.3390/s20164646