A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose



Abstract
1. Introduction
2. Materials and Methods
2.1. Materials and Preparation
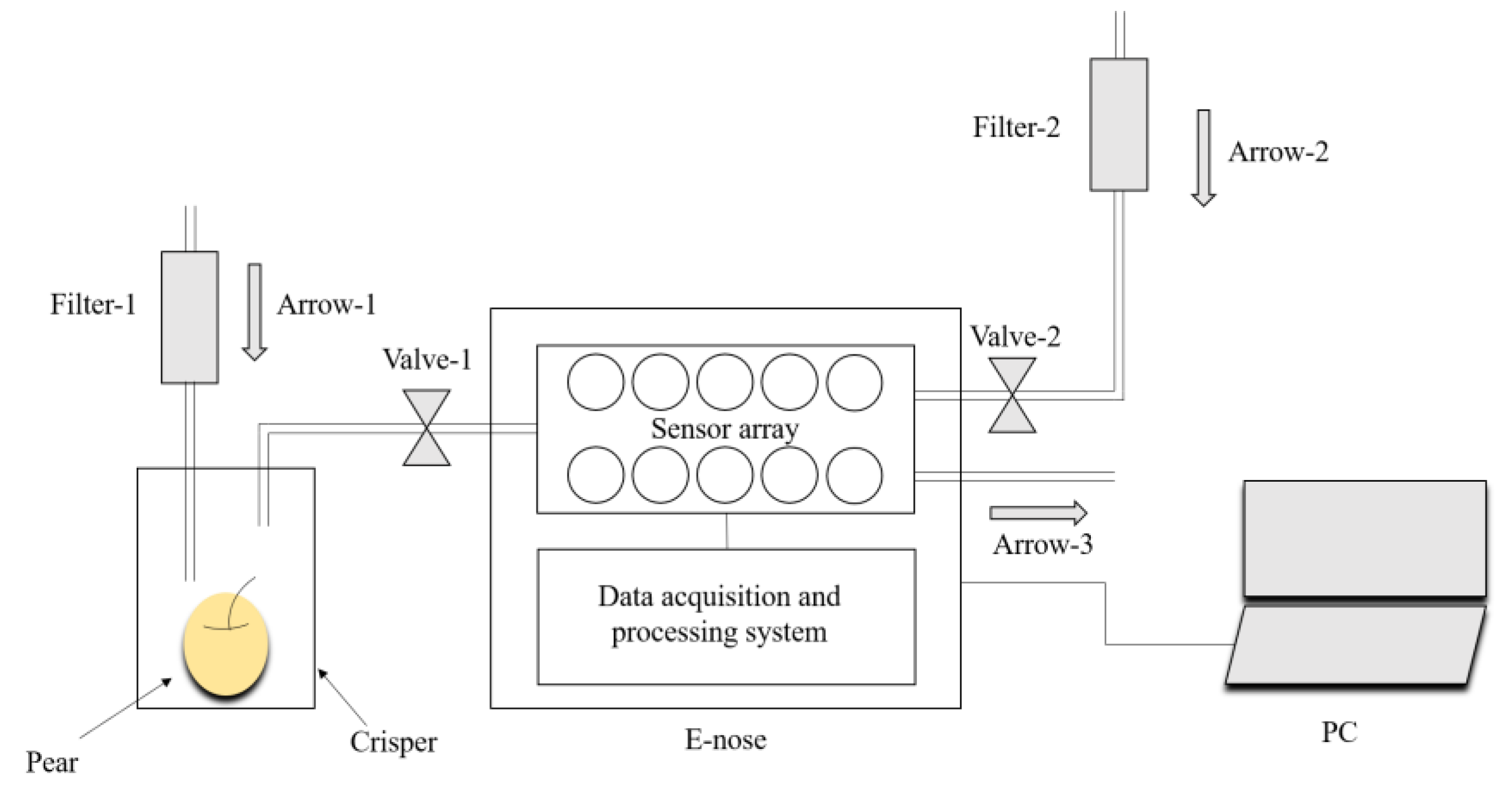
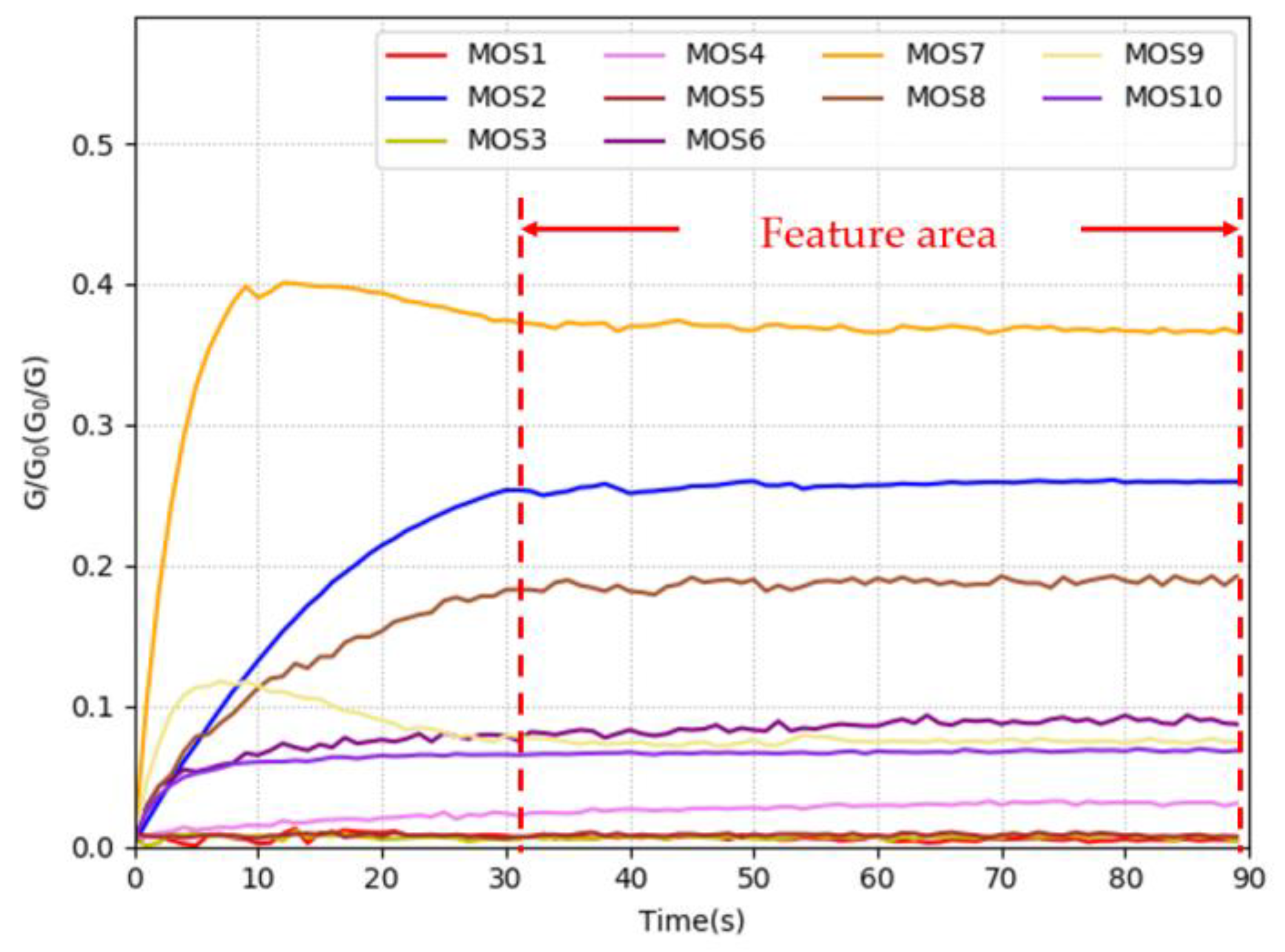
2.2. E-nose Analysis and Data Acquisition
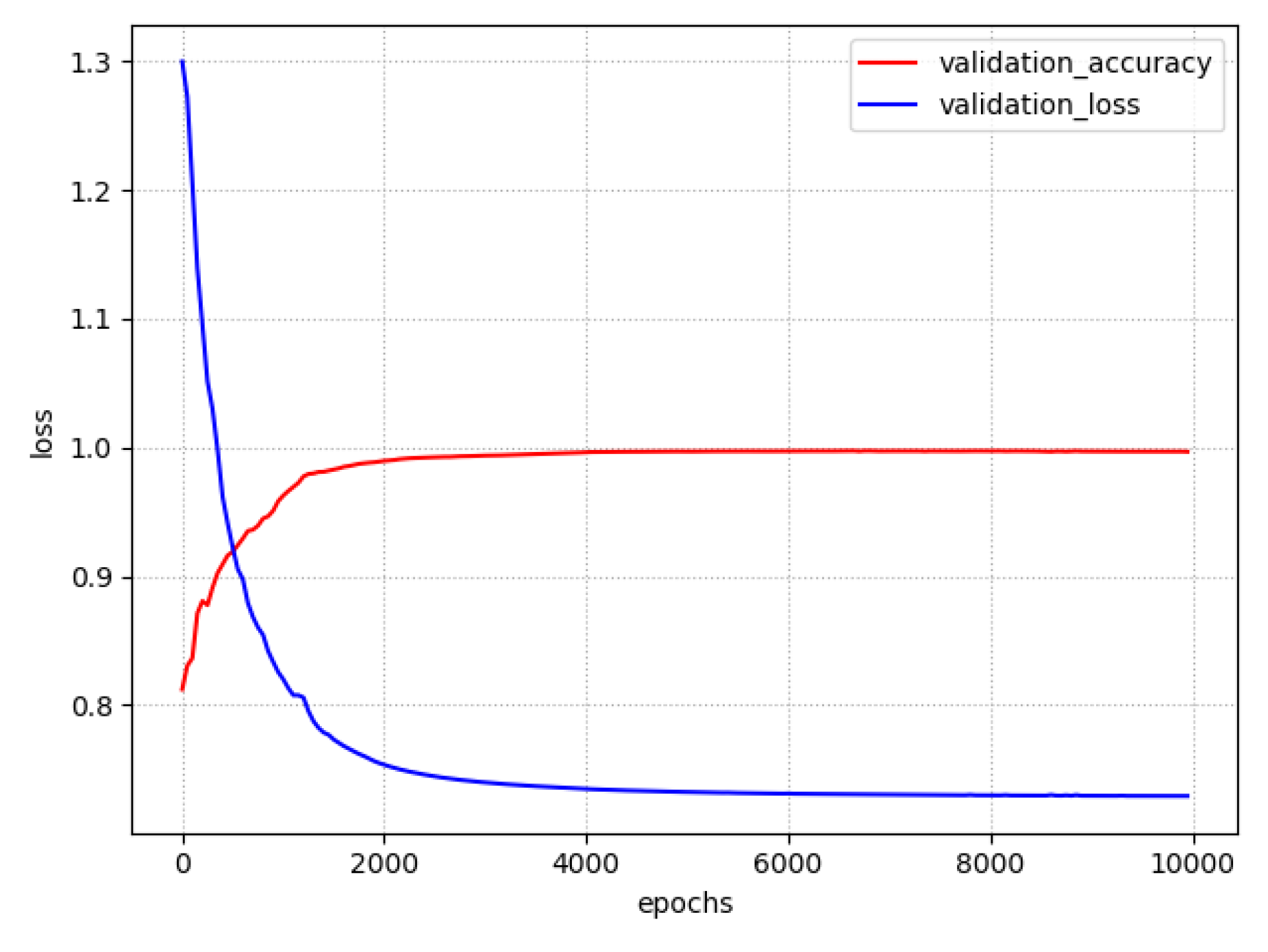
2.3. Adaptive Moment Estimation Algorithm
2.4. Synthetic Minority Oversampling Technique
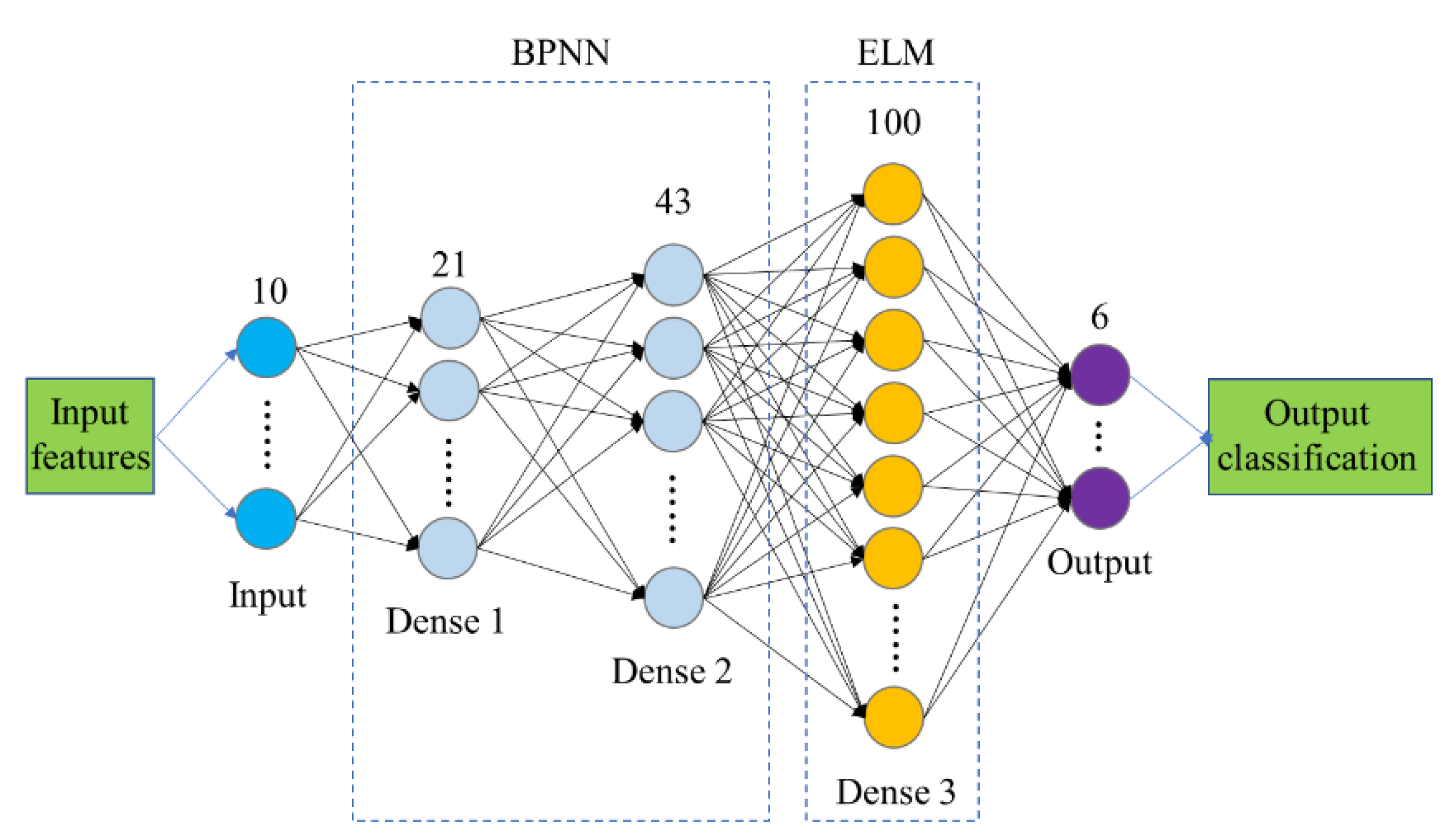
2.5. Back-Propagation Neural Network
2.6. Extreme Learning Machine
2.7. Radial Basis Function Neural Network
3. Proposed Method
| Algorithm 1. BP-ELMNN |
| Input: training data. |
| Output: predicted category. |
| Begin |
| Step 1: train the BPNN part on the training data using the Adam algorithm. |
| Step 2: randomly select the input weights and thresholds of the Dense 3 layer. |
| Step 3: calculate the input weight of the output layer using Equation (7). |
| Step 4: test the BP-ELMNN model on the test data. |
| Step 5: output the classification results. |
| End |
4. Result and Discussion
4.1. Data Analysis and Sample Supplementation
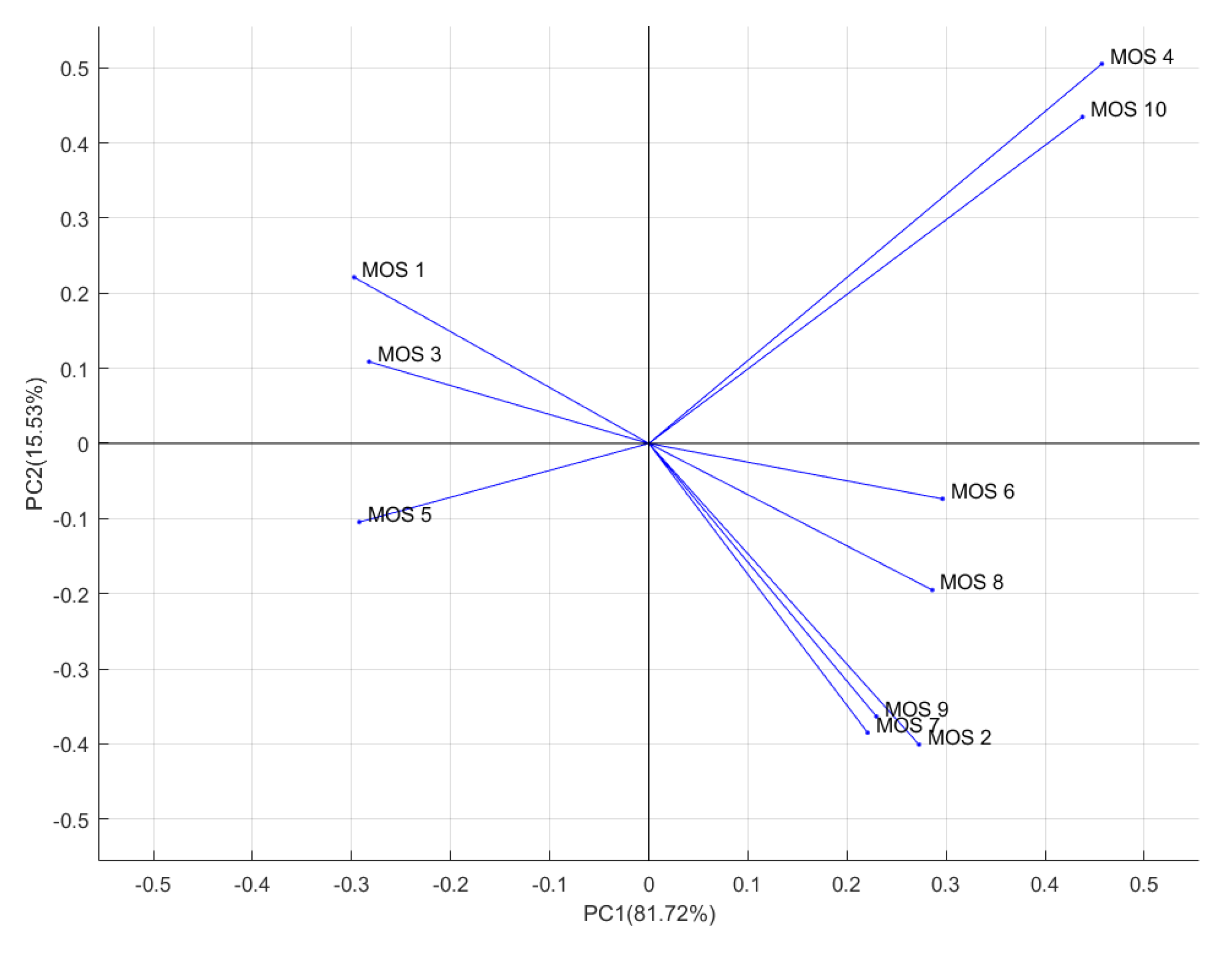
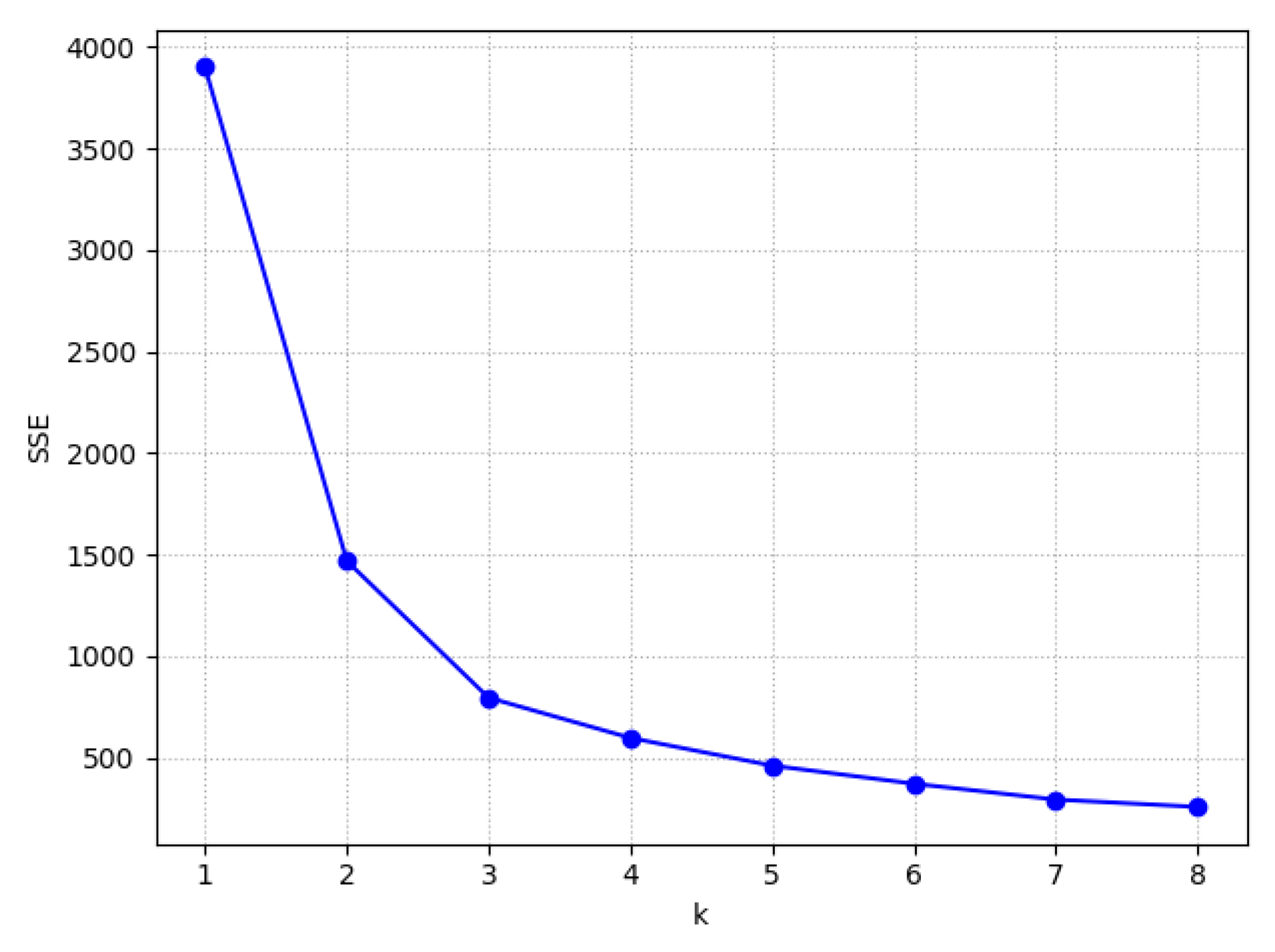
4.2. Principal Component Analysis
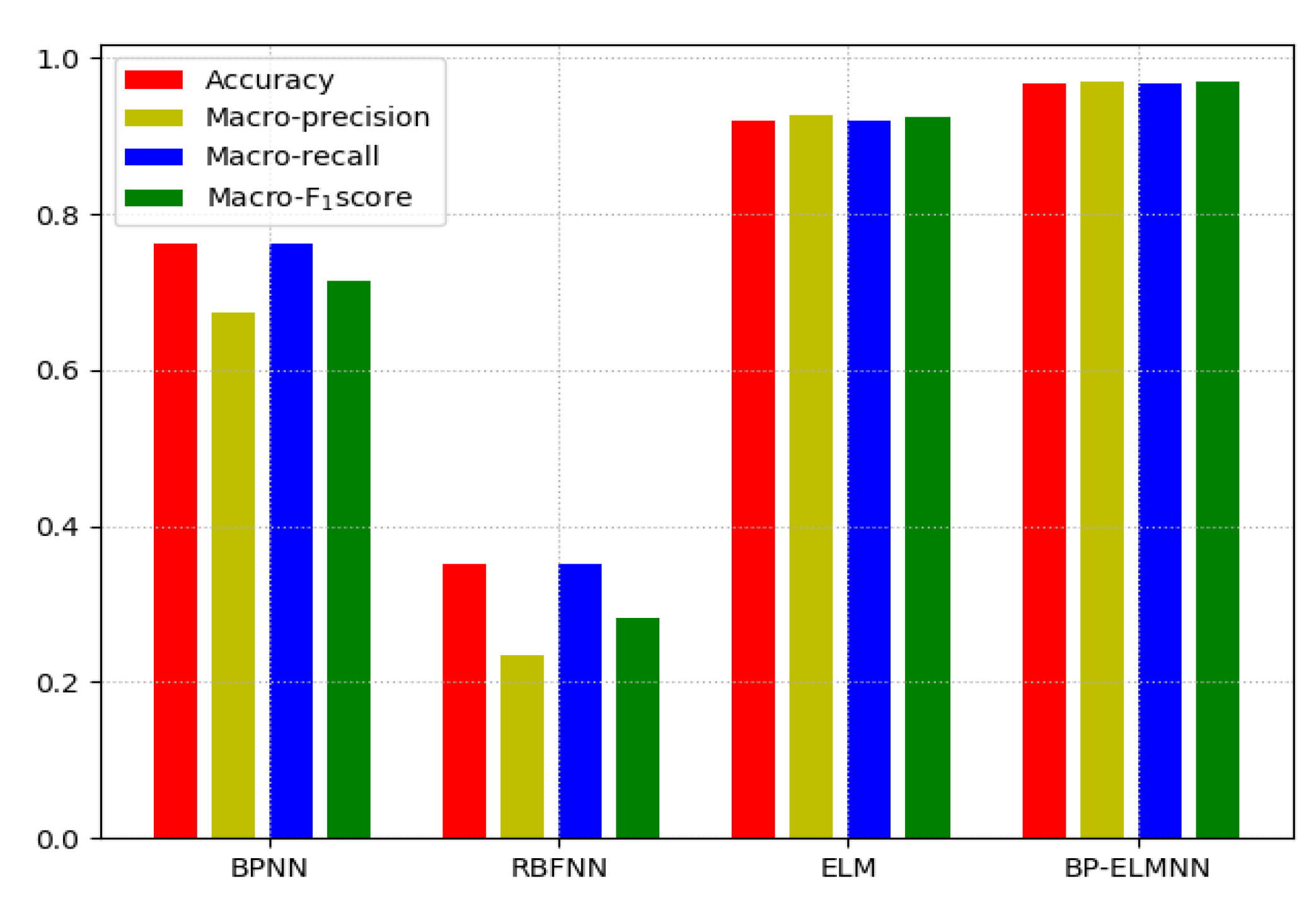
4.3. Comparison of the Classification Results of the Four Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Saquet, A. Storage of pears. Sci. Hortic. 2019, 246, 1009–1016. [Google Scholar] [CrossRef]
- EFSA. The EFSA Comprehensive European Food Consumption Database; EFSA: Parma, Italy, 2011. [Google Scholar]
- Li, X.; Wang, T.; Zhou, B.; Gao, W.-Y.; Cao, J.; Huang, L.-Q. Chemical composition and antioxidant and anti-inflammatory potential of peels and flesh from 10 different pear varieties (Pyrus spp.). Food Chem. 2014, 152, 531–538. [Google Scholar] [CrossRef] [PubMed]
- Ulaszewska, M.; Vázquez-Manjarrez, N.; Garcia-Aloy, M.; Llorach, R.; Mattivi, F.; Dragsted, L.O.; Praticò, G.; Manach, C. Food intake biomarkers for apple, pear, and stone fruit. Genes Nutr. 2018, 13, 29. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Guan, J.; Ma, S.-J.; Liu, L.-L.; Feng, Y.-X.; Cheng, Y. Calcium content and its correlated distribution with skin browning spot in bagged Huangguan pear. Protoplasma 2015, 252, 165–171. [Google Scholar] [CrossRef]
- Wei, C.; Ma, L.; Cheng, Y.; Guan, Y.; Guan, J. Exogenous ethylene alleviates chilling injury of ‘Huangguan’ pear by enhancing the proline content and antioxidant activity. Sci. Hortic. 2019, 257, 108671. [Google Scholar] [CrossRef]
- Xu, F.; Dong, S.; Xu, Q.; Liu, S. Control of brown heart in Huangguan pears with 1-methylcyclopropene microbubbles treatment. Sci. Hortic. 2020, 259, 108820. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, K.; Liu, S. Evaluation of 1-methylcyclopropene (1-MCP) and low temperature conditioning (LTC) to control brown of Huangguan pears. Sci. Hortic. 2020, 259, 108738. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, L.; Zhao, G.; Shen, C.; Yan, H.; Guan, J.; Yang, K. The effects of modified atmosphere packaging on core browning and the expression patterns of PPO and PAL genes in ‘Yali’ pears during cold storage. LWT Food Sci. Technol. 2015, 60, 1243–1248. [Google Scholar] [CrossRef]
- Lin, Y.; Lin, Y.; Lin, H.; Chen, Y.; Wang, H.; Shi, J. Application of propyl gallate alleviates pericarp browning in harvested longan fruit by modulating metabolisms of respiration and energy. Food Chem. 2018, 240, 863–869. [Google Scholar] [CrossRef]
- Xu, F.; Liu, S.; Liu, Y.; Xu, Q.; Wang, S. The combined effect of ultraviolet-C irradiation and lysozyme coatings treatment on control of brown heart in Huangguan pears. Sci. Hortic. 2019, 256, 108634. [Google Scholar] [CrossRef]
- Li, J.; Bao, X.; Xu, Y.; Zhang, M.; Cai, Q.; Li, L.; Wang, Y. Hypobaric storage reduced core browning of Yali pear fruits. Sci. Hortic. 2017, 225, 547–552. [Google Scholar] [CrossRef]
- Gliszczyńska-Świgło, A.; Chmielewski, J. Electronic Nose as a Tool for Monitoring the Authenticity of Food. A Review. Food Anal. Methods 2017, 10, 1800–1816. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, J. The prediction of food additives in the fruit juice based on electronic nose with chemometrics. Food Chem. 2017, 230, 208–214. [Google Scholar] [CrossRef] [PubMed]
- Ezhilan, M.; Nesakumar, N.; Babu, K.J.; Srinandan, C.S.; Rayappan, J.B.B. An Electronic Nose for Royal Delicious Apple Quality Assessment—A Tri-layer Approach. Food Res. Int. 2018, 109, 44–51. [Google Scholar] [CrossRef]
- Li, Q.; Yu, X.; Xu, L.; Gao, J.-M. Novel method for the producing area identification of Zhongning Goji berries by electronic nose. Food Chem. 2017, 221, 1113–1119. [Google Scholar] [CrossRef]
- Voss, H.G.J.; Stevan, S.L., Jr.; Ayub, R.A. Peach growth cycle monitoring using an electronic nose. Comput. Electron. Agric. 2019, 163, 104858. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, M.; Bhandari, B.; Guo, Z. A novel method using MOS electronic nose and ELM for predicting postharvest quality of cherry tomato fruit treated with high pressure argon. Comput. Electron. Agric. 2018, 154, 411–419. [Google Scholar] [CrossRef]
- Chen, Q.; Song, J.; Bi, J.; Meng, X.; Wu, X. Characterization of volatile profile from ten different varieties of Chinese jujubes by HS-SPME/GC–MS coupled with E-nose. Food Res. Int. 2018, 105, 605–615. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Qu, K.; Guo, F.; Liu, X.; Lin, Y.; Zou, Q. Application of Machine Learning in Microbiology. Front. Microbiol. 2019, 10, 827. [Google Scholar] [CrossRef]
- Zhong, H.; Miao, C.; Shen, Z.; Feng, Y. Comparing the learning effectiveness of BP, ELM, I-ELM, and SVM for corporate credit ratings. Neurocomputing 2014, 128, 285–295. [Google Scholar] [CrossRef]
- Marini, F. Artificial neural networks in foodstuff analyses: Trends and perspectives A review. Anal. Chim. Acta 2009, 635, 121–131. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Sander, A.; Faulstich, L.; Denecke, K. Towards automatic encoding of medical procedures using convolutional neural networks and autoencoders. Artif. Intell. Med. 2018, 93, 29–42. [Google Scholar] [CrossRef]
- Hotel, O.; Poli, J.-P.; Mer-Calfati, C.; Scorsone, E.; Saada, S. A review of algorithms for SAW sensors e-nose based volatile compound identification. Sens. Actuators B Chem. 2018, 255, 2472–2482. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chawla, N.; Bowyer, K.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Portable Electronic Nose. Available online: https://airsense.com/en/products/portable-electronic-nose (accessed on 28 June 2020).
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-RMSProp, COURSERA: Neural Networks for Machine Learning 2012. Available online: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 30 June 2020).
- Yu, Y.; Liu, F. Effective Neural Network Training with a New Weighting Mechanism-Based Optimization Algorithm. IEEE Access 2019, 7, 72403–72410. [Google Scholar] [CrossRef]
- Yang, Y.; Duan, J.; Yu, H.; Gao, Z.; Qiu, X. An Image Classification Method Based on Deep Neural Network with Energy Model. CMES-Comput. Model. Eng. Sci. 2018, 117, 555–575. [Google Scholar] [CrossRef]
- An, Y.; Wang, X.; Chu, R.; Yue, B.; Wu, L.; Cui, J.; Qu, Z. Event classification for natural gas pipeline safety monitoring based on long short-term memory network and Adam algorithm. Struct. Health Monit. 2019. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. SMOTE based class-specific extreme learning machine for imbalanced learning. Knowl.-Based Syst. 2020, 187, 104814. [Google Scholar] [CrossRef]
- Yu, D.; Wang, X.; Liu, H.; Gu, Y. A Multitask Learning Framework for Multi-Property Detection of Wine. IEEE Access 2019, 7, 123151–123157. [Google Scholar] [CrossRef]
- Sun, X.; Wan, Y.; Guo, R. Chinese wine classification using BPNN through combination of micrographs’ shape and structure features. In Proceedings of the 2009 Fifth International Conference on Natural Computation, Tianjin, China, 14–16 August 2009; Volume 6, pp. 379–384. [Google Scholar]
- Cheng, S.; Zhou, X. Network traffic prediction based on BPNN optimized by self-adaptive immune genetic algorithm. In Proceedings of the 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer, Shengyang, China, 20–22 December 2013; pp. 1030–1033. [Google Scholar]
- Tang, H.; Lei, M.; Gong, Q.; Wang, J. A BP Neural Network Recommendation Algorithm Based on Cloud Model. IEEE Access 2019, 7, 35898–35907. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2011, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Ding, S.; Zhang, J. Multi layer ELM-RBF for multi-label learning. Appl. Soft Comput. 2016, 43, 535–545. [Google Scholar] [CrossRef]
- Yu, J.; Zhan, J.; Huang, W. Identification of Wine According to Grape Variety Using Near-Infrared Spectroscopy Based on Radial Basis Function Neural Networks and Least-Squares Support Vector Machines. Food Anal. Methods 2017, 75, 3311–3460. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Sun, Y.; Long, T.; Sarkar, T.K. Fast and Robust RBF Neural Network Based on Global K-Means Clustering with Adaptive Selection Radius for Sound Source Angle Estimation. IEEE Trans. Antennas Propag. 2018, 66, 3097–3107. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, H.; Huang, T.; Qian, X. An improved maximum spread algorithm with application to complex-valued RBF neural networks. Neurocomputing 2016, 216, 261–267. [Google Scholar] [CrossRef]
- Chen, S.; Hong, X.; Harris, C.J.; Hanzo, L. Fully complex-valued radial basis function networks: Orthogonal least squares regression and classification. Neurocomputing 2008, 71, 3421–3433. [Google Scholar] [CrossRef]
- Liu, H.; Li, Q.; Yan, B.; Zhang, L.; Gu, Y. Bionic Electronic Nose Based on MOS Sensors Array and Machine Learning Algorithms Used for Wine Properties Detection. Sensors 2018, 19, 45. [Google Scholar] [CrossRef]
- Azarbad, M.; Azami, H.; Sanei, S.; Ebrahimzadeh, A. New Neural Network-based Approaches for GPS GDOP Classification based on Neuro-Fuzzy Inference System, Radial Basis Function, and Improved Bee Algorithm. Appl. Soft Comput. 2014, 25, 285–292. [Google Scholar] [CrossRef]
- Rouhani, M.; Javan, D.S. Two fast and accurate heuristic RBF learning rules for data classification. Neural Netw. 2016, 75, 150–161. [Google Scholar] [CrossRef] [PubMed]
- Lei, Y.; Dogan, U.; Zhou, D.-X.; Kloft, M. Data-Dependent Generalization Bounds for Multi-Class Classification. IEEE Trans. Inf. Theory 2019, 65, 2995–3021. [Google Scholar] [CrossRef]
- Patil, T.R.; Sherekar, S.S. Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification. Int. J. Comput. Sci. Appl. 2013, 6, 256–261. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Standard | * | ||
|---|---|---|---|---|
| Appearance | Core | Flesh | ||
| 0 | Good | Good | Good | - |
| 1 | Good | Light brown | Good | No |
| 2 | Good | Brown | Good | No |
| 3 | Good | Dark brown | Good | No |
| 4 | Brown | Dark brown | Dark brown | Yes |
| 5 | Dark brown | Dark brown | Dark brown | Yes |
| Number | Sensor | Substance Sensitivity |
|---|---|---|
| MOS1 | W1C | Aroma constituent |
| MOS2 | W5S | Sensitive to nitride oxides |
| MOS3 | W3C | Ammonia, aroma constituent |
| MOS4 | W6S | Hydrogen |
| MOS5 | W5C | Alkane, aroma constituent |
| MOS6 | W1S | Sensitive to methane |
| MOS7 | W1W | Sensitive to sulfide |
| MOS8 | W2S | Sensitive to alcohol |
| MOS9 | W2W | Aroma constituent, organic sulfur compounds |
| MOS10 | W3S | Sensitive to alkane |
| Training Samples. | Test Samples | ||
|---|---|---|---|
| Class | Number | Class | Number |
| 0 | 9 | 0 | 3 |
| 1 | 21 | 1 | 8 |
| 2 | 42 | 2 | 15 |
| 3 | 77 | 3 | 38 |
| 4 | 49 | 4 | 20 |
| 5 | 42 | 5 | 18 |
| Class | TR | TE | ||||
|---|---|---|---|---|---|---|
| The Original Number of Samples | Added Number of Samples | New Number of Samples | The Original Number of Samples | Added Number of Samples | New Number of Samples | |
| 0 | 540 | 4080 | 4620 | 180 | 2100 | 2280 |
| 1 | 1260 | 3360 | 4620 | 480 | 1800 | 2280 |
| 2 | 2520 | 2100 | 4620 | 900 | 1380 | 2280 |
| 3 | 4620 | 0 | 4620 | 2280 | 0 | 2280 |
| 4 | 2940 | 1680 | 4620 | 1200 | 1080 | 2280 |
| 5 | 2520 | 2100 | 4620 | 1080 | 1200 | 2280 |
| Methods | Accuracy | Macro-Precision | Macro-Recall | Macro-F1 Score |
|---|---|---|---|---|
| BPNN | 0.7623 | 0.6732 | 0.7623 | 0.7150 |
| RBFNN | 0.3504 | 0.2347 | 0.3504 | 0.2811 |
| ELM | 0.9190 | 0.9272 | 0.9190 | 0.9231 |
| BP-ELMNN | 0.9683 | 0.9688 | 0.9683 | 0.9685 |
| Methods | Accuracy | Macro-Precision | Macro-Recall | Macro-F1score |
|---|---|---|---|---|
| BPNN | 0.7399 | 0.6398 | 0.7055 | 0.6711 |
| RBFNN | 0.3493 | 0.1255 | 0.2153 | 0.1586 |
| ELM | 0.8809 | 0.8653 | 0.8677 | 0.8665 |
| BP-ELMNN | 0.9285 | 0.9188 | 0.9017 | 0.9089 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Gu, Y. A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose. Sensors 2020, 20, 4499. https://doi.org/10.3390/s20164499
Wei H, Gu Y. A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose. Sensors. 2020; 20(16):4499. https://doi.org/10.3390/s20164499
Chicago/Turabian StyleWei, Hao, and Yu Gu. 2020. "A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose" Sensors 20, no. 16: 4499. https://doi.org/10.3390/s20164499
APA StyleWei, H., & Gu, Y. (2020). A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose. Sensors, 20(16), 4499. https://doi.org/10.3390/s20164499