A Novel Method for Objective Selection of Information Sources Using Multi-Kernel SVM and Local Scaling

 , , and
, , and
Abstract
1. Introduction
2. Methodology
2.1. Support Vector Machines (SVMs)
2.2. Kernel Bandwidth Tuning with Local Scaling
2.3. Multiple Kernel Learning (MKL)
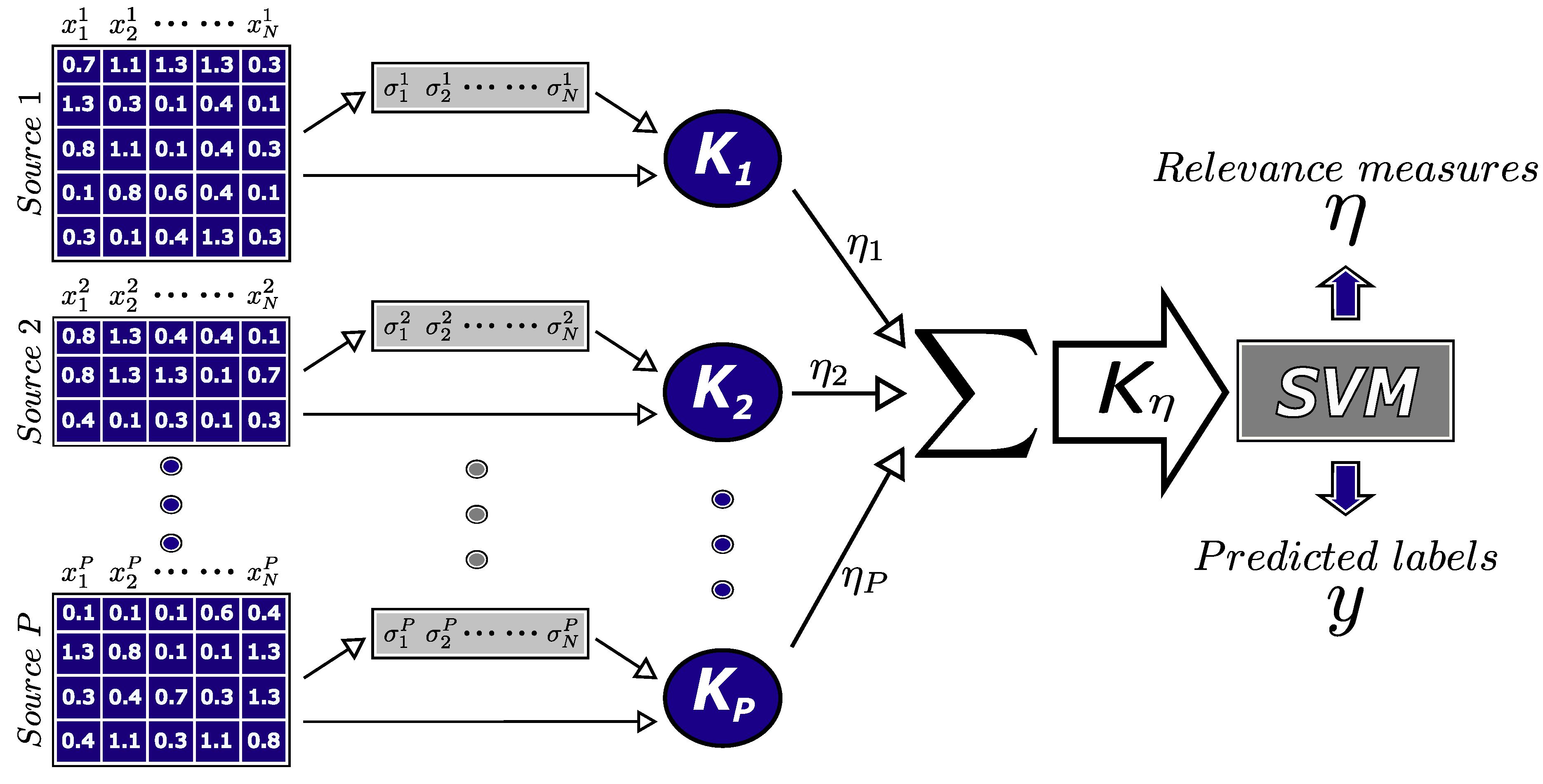
2.4. Description of the Proposed Method
2.4.1. Prediction without Data Reduction
| Algorithm 1: Algorithm without data reduction |
 |
2.4.2. Prediction with Support Vectors Only
| Algorithm 2: Algorithm with data reduction by support vectors only |
 |
2.4.3. Prediction with Mean Values of Support Vectors
| Algorithm 3: Data reduction by the mean of values related to the samples nearest to the support vectors |
 |
3. Experimental Setup
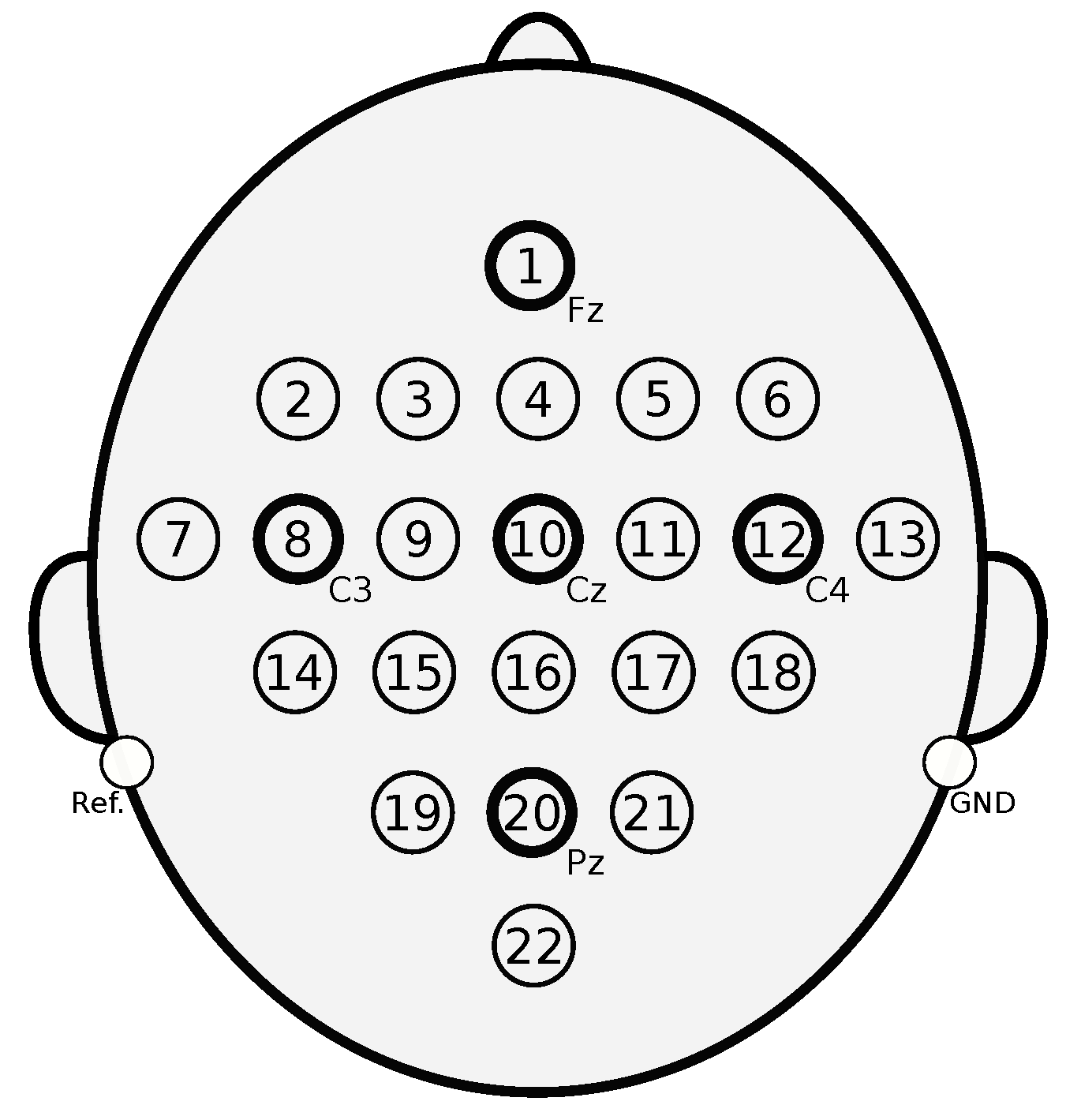
3.1. BCI Dataset
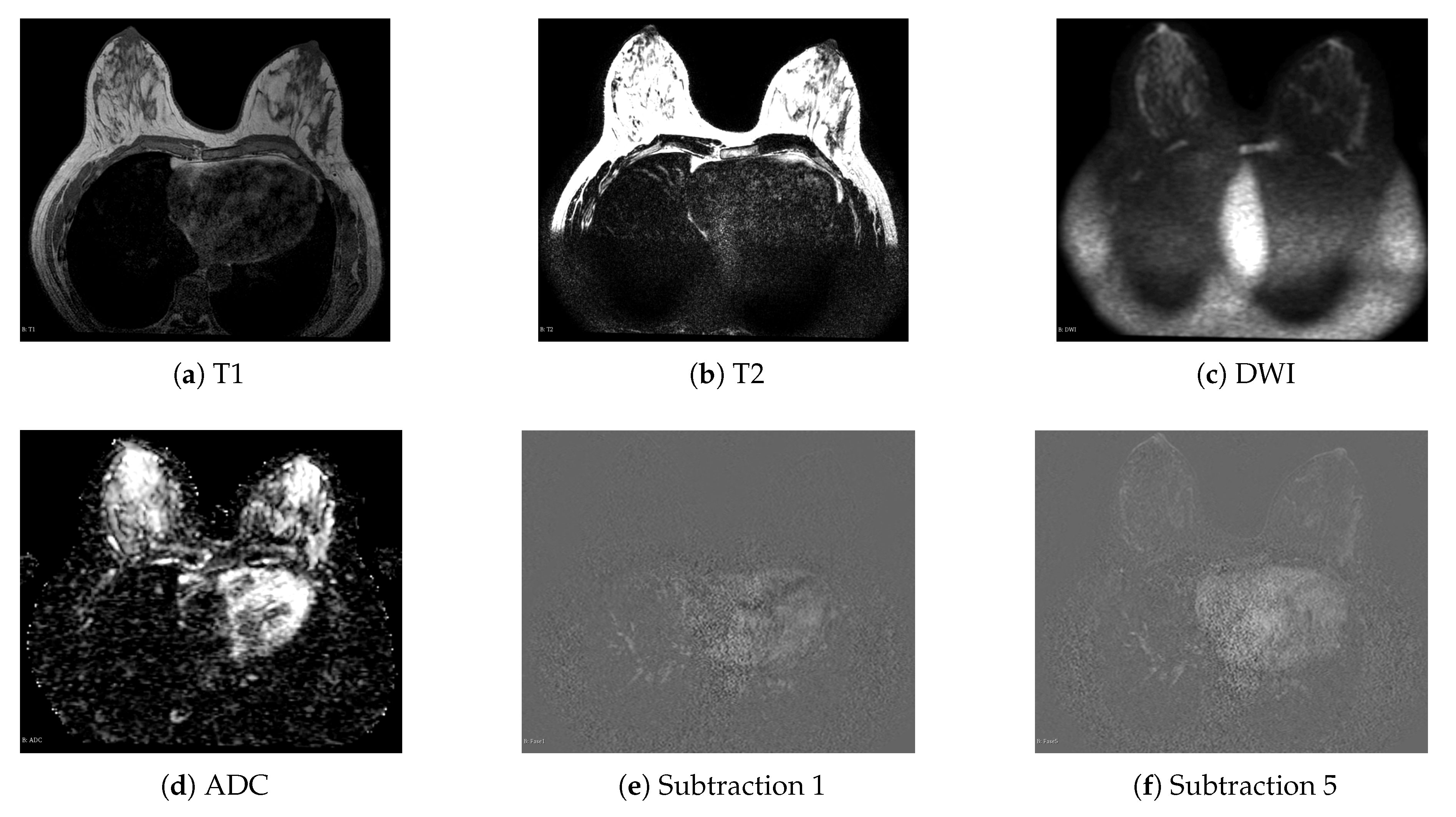
3.2. Breast Cancer Dataset
3.3. Test Settings
3.3.1. BCI Dataset Configuration
3.3.2. MRI Dataset Configuration
3.3.3. General Configuration of the Tests
4. Results and Discussion
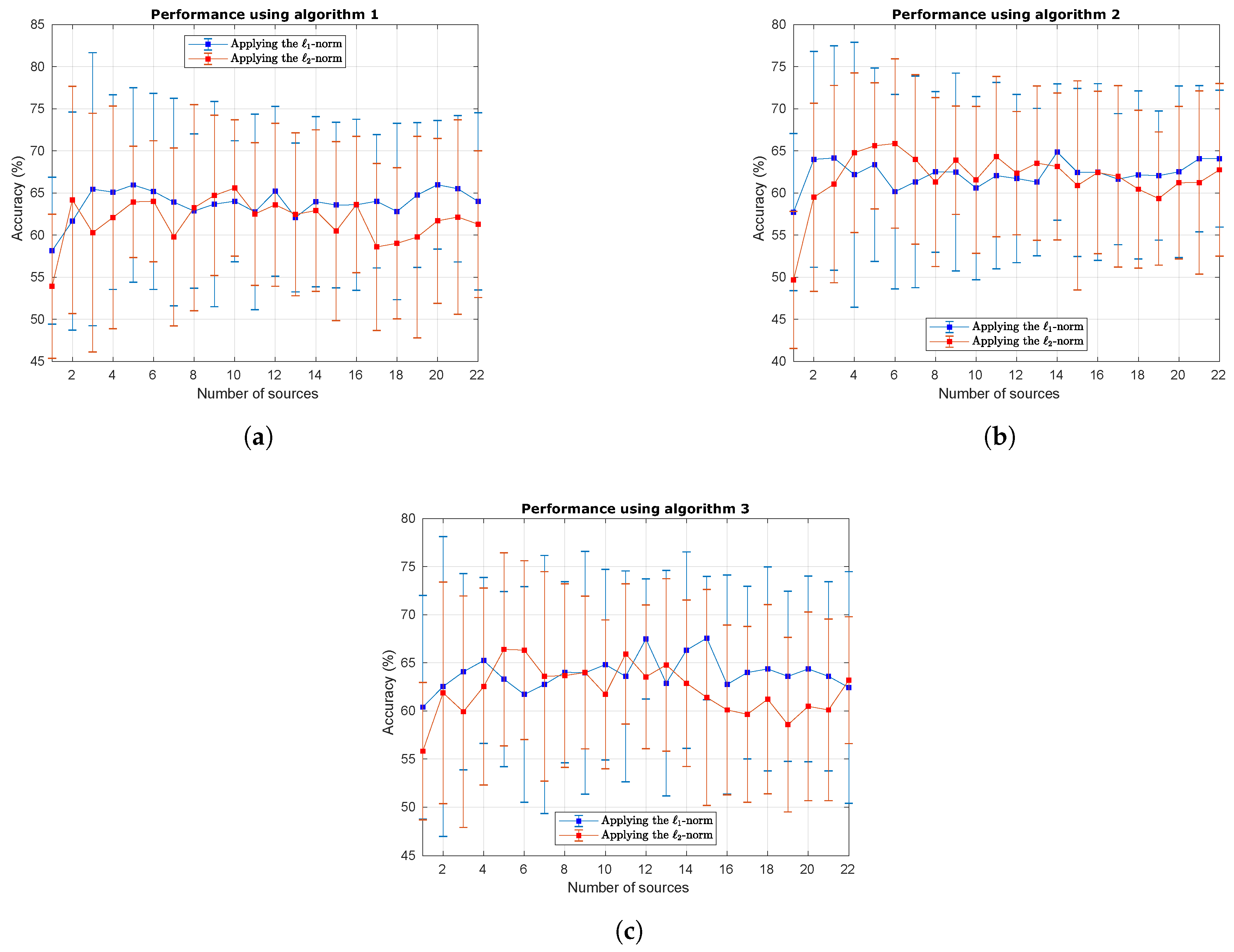
4.1. Results Obtained with the BCI Dataset
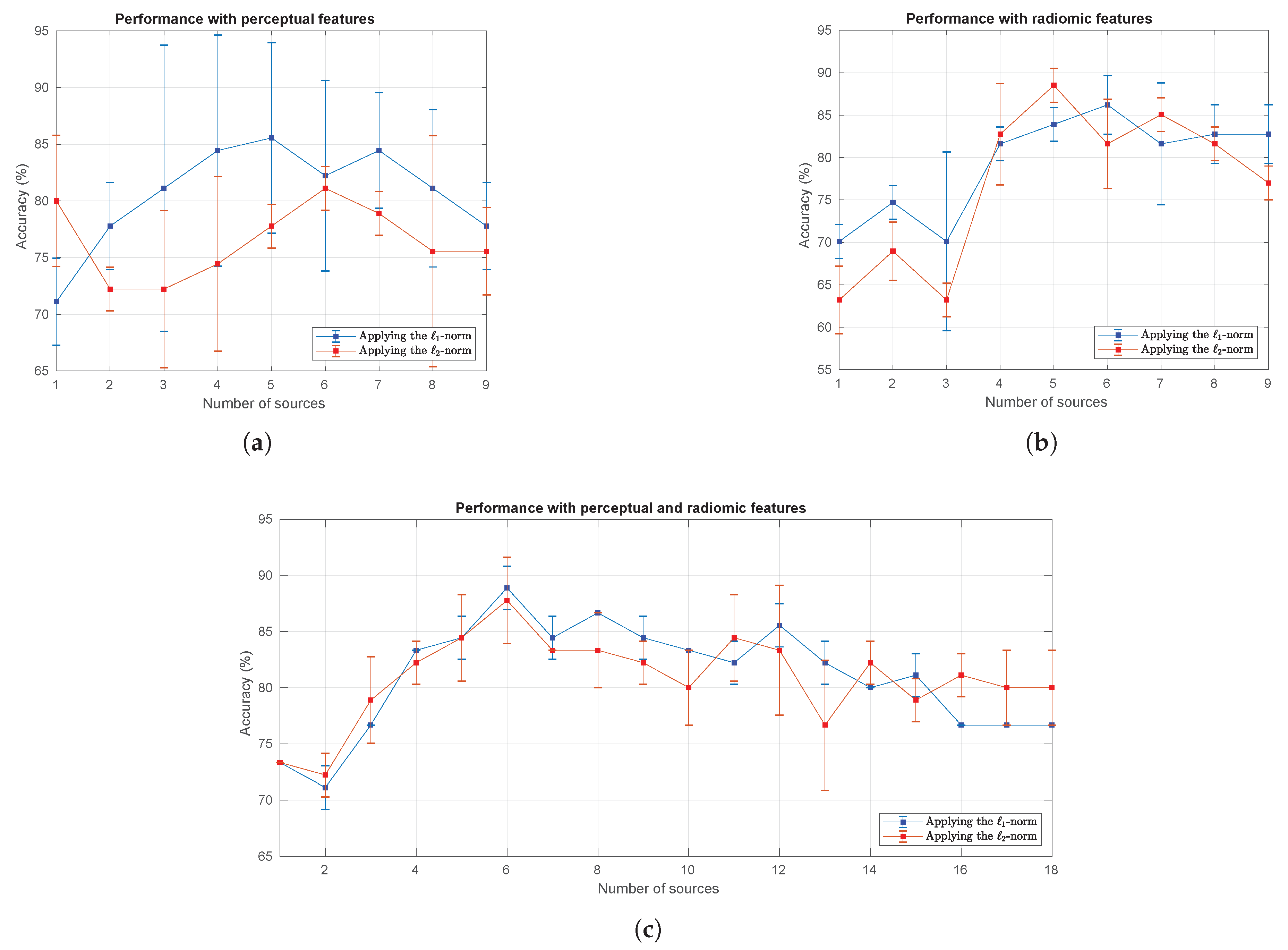
4.2. Results Obtained with the MRI Dataset
4.3. Comparison against Feature Selection Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Culache, O.; Obadă, D.R. Multimodality as a Premise for Inducing Online Flow on a Brand Website: A Social Semiotic Approach. Procedia-Soc. Behav. Sci. 2014, 149, 261–268. [Google Scholar] [CrossRef]
- Markonis, D.; Schaer, R.; Müller, H. Evaluating multimodal relevance feedback techniques for medical image retrieval. Inf. Retr. J. 2016, 19, 100–112. [Google Scholar] [CrossRef]
- Adali, T.; Levin-Schwartz, Y.; Calhoun, V.D. Multimodal data fusion using source separation: Application to medical imaging. Proc. IEEE 2015, 103, 1494–1506. [Google Scholar] [CrossRef]
- Correa, A.G.; Orosco, L.; Laciar, E. Automatic detection of drowsiness in EEG records based on multimodal analysis. Med. Eng. Phys. 2014, 36, 244–249. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yin, H.; Chai, Y.; Yang, S.X. A novel approach for multimodal medical image fusion. Expert Syst. Appl. 2014, 41, 7425–7435. [Google Scholar] [CrossRef]
- Barachant, A.; Bonnet, S. Channel selection procedure using Riemannian distance for BCI applications. In Proceedings of the 2011 5th International IEEE/EMBS Conference on Neural Engineering, Cancun, Mexico, 27 April–1 May 2011; pp. 348–351. [Google Scholar]
- Eliseyev, A.; Moro, C.; Faber, J.; Wyss, A.; Torres, N.; Mestais, C.; Benabid, A.L.; Aksenova, T. L1-penalized N-way PLS for subset of electrodes selection in BCI experiments. J. Neural Eng. 2012, 9, 045010. [Google Scholar] [CrossRef]
- Meyer, J.S.; Siegel, M.J.; Farooqui, S.O.; Jaramillo, D.; Fletcher, B.D.; Hoffer, F.A. Which MRI sequence of the spine best reveals bone-marrow metastases of neuroblastoma? Pediatr. Radiol. 2005, 35, 778–785. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 94. [Google Scholar] [CrossRef]
- Gan, G.; Ng, M.K.P. Subspace clustering with automatic feature grouping. Pattern Recognit. 2015, 48, 3703–3713. [Google Scholar] [CrossRef]
- Pir, D.; Brown, T. Acoustic Group Feature Selection Using Wrapper Method for Automatic Eating Condition Recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Lal, T.N.; Schroder, M.; Hinterberger, T.; Weston, J.; Bogdan, M.; Birbaumer, N.; Scholkopf, B. Support vector channel selection in BCI. IEEE Trans. Biomed. Eng. 2004, 51, 1003–1010. [Google Scholar] [CrossRef]
- Sotoca, J.M.; Pla, F.; Sanchez, J.S. Band selection in multispectral images by minimization of dependent information. IEEE Trans. Syst. Man Cybern. Part C 2007, 37, 258–267. [Google Scholar] [CrossRef]
- Xiang, S.; Yang, T.; Ye, J. Simultaneous feature and feature group selection through hard thresholding. In Proceedings of the 20th ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 532–541. [Google Scholar]
- Schmidt, M. Least squares optimization with L1-norm regularization. CS542B Proj. Rep. 2005, 504, 195–221. [Google Scholar]
- Subrahmanya, N.; Shin, Y.C. Automated sensor selection and fusion for monitoring and diagnostics of plunge grinding. J. Manuf. Sci. Eng. 2008, 130, 031014. [Google Scholar] [CrossRef]
- Raza, H.; Cecotti, H.; Prasad, G. Optimising frequency band selection with forward-addition and backward-elimination algorithms in EEG-based brain-computer interfaces. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar]
- Li, Y.; Wu, F.X.; Ngom, A. A review on machine learning principles for multi-view biological data integration. Briefings Bioinform. 2016, 19, 325–340. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Zhang, L.; Suganthan, P.N. Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput. Intell. Mag. 2016, 11, 41–53. [Google Scholar] [CrossRef]
- Gu, Y.; Liu, T.; Jia, X.; Benediktsson, J.A.; Chanussot, J. Nonlinear multiple kernel learning with multiple-structure-element extended morphological profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3235–3247. [Google Scholar] [CrossRef]
- Althloothi, S.; Mahoor, M.H.; Zhang, X.; Voyles, R.M. Human activity recognition using multi-features and multiple kernel learning. Pattern Recognit. 2014, 47, 1800–1812. [Google Scholar] [CrossRef]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Qiu, S.; Lane, T. A framework for multiple kernel support vector regression and its applications to siRNA efficacy prediction. IEEE/ACM Trans. Comput. Biol. Bioinform. (TCBB) 2009, 6, 190–199. [Google Scholar]
- Gönen, M.; Margolin, A.A. Localized data fusion for kernel k-means clustering with application to cancer biology. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1305–1313. [Google Scholar]
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Lanckriet, G.R.; Deng, M.; Cristianini, N.; Jordan, M.I.; Noble, W.S. Kernel-based data fusion and its application to protein function prediction in yeast. In Biocomputing 2004; World Scientific: Singapore, 2003; pp. 300–311. [Google Scholar]
- Lewis, D.P.; Jebara, T.; Noble, W.S. Support vector machine learning from heterogeneous data: An empirical analysis using protein sequence and structure. Bioinformatics 2006, 22, 2753–2760. [Google Scholar] [CrossRef] [PubMed]
- Foresti, L.; Tuia, D.; Timonin, V.; Kanevski, M.F. Time series input selection using multiple kernel learning. In Proceedings of the 18th European Symposium on Artificial Neural Networks, ESANN, Bruges, Belgium, 28–30 April 2010. [Google Scholar]
- Tuia, D.; Camps-Valls, G.; Matasci, G.; Kanevski, M. Learning relevant image features with multiple-kernel classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3780–3791. [Google Scholar] [CrossRef]
- Subrahmanya, N.; Shin, Y.C. Sparse multiple kernel learning for signal processing applications. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 788. [Google Scholar] [CrossRef] [PubMed]
- Gönen, M. Bayesian efficient multiple kernel learning. arXiv 2012, arXiv:1206.6465. [Google Scholar]
- Zelnik-Manor, L.; Perona, P. Self-tuning spectral clustering. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 1601–1608. [Google Scholar]
- Zhang, L.; Hu, X. Locally adaptive multiple kernel clustering. Neurocomputing 2014, 137, 192–197. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- Lessmann, S.; Stahlbock, R.; Crone, S.F. Genetic algorithms for support vector machine model selection. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 3063–3069. [Google Scholar]
- Gomes, T.A.; Prudêncio, R.B.; Soares, C.; Rossi, A.L.; Carvalho, A. Combining meta-learning and search techniques to select parameters for support vector machines. Neurocomputing 2012, 75, 3–13. [Google Scholar] [CrossRef]
- Liu, J.; Zio, E. SVM hyperparameters tuning for recursive multi-step-ahead prediction. Neural Comput. Appl. 2017, 28, 3749–3763. [Google Scholar] [CrossRef]
- Xu, Z.; Jin, R.; Yang, H.; King, I.; Lyu, M.R. Simple and efficient multiple kernel learning by group lasso. In Proceedings of the 27th international conference on machine learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 1175–1182. [Google Scholar]
- Areiza-Laverde, H.J.; Díaz, G.M.; Castro-Ospina, A.E. Feature Group Selection Using MKL Penalized with ℓ1-norm and SVM as Base Learner. In International Workshop on Experimental and Efficient Algorithms; Springer International Publishing: Cham, Switzerland, 2018; pp. 136–147. [Google Scholar]
- Gönen, G.B.; Gönen, M.; Gürgen, F. Probabilistic and discriminative group-wise feature selection methods for credit risk analysis. Expert Syst. Appl. 2012, 39, 11709–11717. [Google Scholar] [CrossRef]
- Kloft, M.; Brefeld, U.; Sonnenburg, S.; Zien, A. Non-sparse regularization and efficient training with multiple kernels. arXiv 2010, arXiv:1003.0079. [Google Scholar]
- Brunner, C.; Leeb, R.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set A; Institute for Knowledge Discovery (Laboratory of Brain-Computer Interfaces), Graz University of Technology: Graz, Austria, 2008; Volume 16. [Google Scholar]
- Subasi, A. Automatic recognition of alertness level from EEG by using neural network and wavelet coefficients. Expert Syst. Appl. 2005, 28, 701–711. [Google Scholar] [CrossRef]
- Li, Y.; Long, J.; Yu, T.; Yu, Z.; Wang, C.; Zhang, H.; Guan, C. An EEG-based BCI system for 2-D cursor control by combining Mu/Beta rhythm and P300 potential. IEEE Trans. Biomed. Eng. 2010, 57, 2495–2505. [Google Scholar] [CrossRef] [PubMed]
- Marın-Castrillón, D.; Restrepo-Agudelo, S.; Areiza-Laverde, H.; Castro-Ospina, A.; Duque-Munoz, L. Exploratory Analysis of Motor Imagery local database for BCI systems. In Proceedings of the I Congreso Internacional de Ciencias Básicas e Ingeniería—CICI 2016, Meta, Colombia, 19–21 October 2016. [Google Scholar]
- Amin, H.U.; Malik, A.S.; Ahmad, R.F.; Badruddin, N.; Kamel, N.; Hussain, M.; Chooi, W.T. Feature extraction and classification for EEG signals using wavelet transform and machine learning techniques. Australas. Phys. Eng. Sci. Med. 2015, 38, 139–149. [Google Scholar] [CrossRef] [PubMed]
- Ghaemi, A.; Rashedi, E.; Pourrahimi, A.M.; Kamandar, M.; Rahdari, F. Automatic channel selection in EEG signals for classification of left or right hand movement in Brain Computer Interfaces using improved binary gravitation search algorithm. Biomed. Signal Process. Control. 2017, 33, 109–118. [Google Scholar] [CrossRef]
- Haacke, E.M.; Brown, R.W.; Thompson, M.R.; Venkatesan, R. Magnetic Resonance Imaging: Physical Principles and Sequence Design; Wiley-Liss New York: New York, NY, USA, 1999; Volume 82. [Google Scholar]
- Liberman, L.; Menell, J.H. Breast imaging reporting and data system (BI-RADS). Radiol. Clin. 2002, 40, 409–430. [Google Scholar] [CrossRef]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative analysis of human-model agreement in visual saliency modeling: A comparative study. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef]
- Shaikh, F.A.; Kolowitz, B.J.; Awan, O.; Aerts, H.J.; von Reden, A.; Halabi, S.; Mohiuddin, S.A.; Malik, S.; Shrestha, R.B.; Deible, C. Technical challenges in the clinical application of radiomics. JCO Clin. Cancer Inform. 2017, 1, 1–8. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 545–552. [Google Scholar]
- Areiza-Laverde, H.J.; Duarte-Salazar, C.A.; Hernández, L.; Castro-Ospina, A.E.; Díaz, G.M. Breast Lesion Discrimination Using Saliency Features from MRI Sequences and MKL-Based Classification. In Proceedings of the Iberoamerican Congress on Pattern Recognition, Havana, Cuba, 28–31 October 2019; pp. 294–305. [Google Scholar]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Performance measures. In Learning from Imbalanced Data Sets; Springer: Cham, Switzerland, 2018; pp. 47–61. [Google Scholar]
- Areiza-Laverde, H.J.; Castro-Ospina, A.E.; Peluffo-Ordóñez, D.H. Voice Pathology Detection Using Artificial Neural Networks and Support Vector Machines Powered by a Multicriteria Optimization Algorithm. In Proceedings of the Workshop on Engineering Applications, Medellín, Colombia, 17–19 October 2018; pp. 148–159. [Google Scholar]
- Dávila-Guzmán, M.A.; Alfonso-Morales, W.; Caicedo-Bravo, E.F. Heterogeneous architecture to process swarm optimization algorithms. TecnoLógicas 2014, 17, 11–20. [Google Scholar] [CrossRef][Green Version]
- González-Pérez, J.E.; García-Gómez, D.F. Electric field relaxing electrodes design using particle swarm optimization and finite elements method. TecnoLógicas 2017, 20, 27–39. [Google Scholar] [CrossRef][Green Version]
- Clerc, M. Beyond standard particle swarm optimisation. In Innovations and Developments of Swarm Intelligence Applications; IGI Global: Hershey, PA, USA, 2012; pp. 1–19. [Google Scholar]
- Rincón, J.S.; Castro-Ospina, A.E.; Narváez, F.R.; Díaz, G.M. Machine Learning Methods for Classifying Mammographic Regions Using the Wavelet Transform and Radiomic Texture Features. In Proceedings of the International Conference on Technology Trends, Babahoyo, Ecuador, 29–31 August 2018; pp. 617–629. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Generalized fisher score for feature selection. arXiv 2012, arXiv:1202.3725. [Google Scholar]
- Vora, S.; Yang, H. A comprehensive study of eleven feature selection algorithms and their impact on text classification. In Proceedings of the 2017 Computing Conference, London, UK, 18–20 July 2017; pp. 440–449. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Number of Sources | Performance Measures (%) | Reduction Rate | Relevant Electrodes | Required Time (s) | Support Vectors | |||
|---|---|---|---|---|---|---|---|---|---|
| Acc | Geo-M | Sens | Spec | ||||||
| 1 | 22 | 64.29 | 63.89 | 71.43 | 57.14 | 0.14 | 14, 13, 18, 1, 22, 8, 7, 19, 9, 6, 4, 21, 5, 10, 17, 12, 2, 16, 15 | 0.139 | 116 (100.0 %) |
| 19 | 75.00 | 74.91 | 78.57 | 71.43 | |||||
| 2 | 22 | 53.33 | 51.64 | 40.00 | 66.67 | 0.59 | 13, 1, 12, 6, 20, 7, 3, 8, 17 | 0.090 | 116 (100.0 %) |
| 9 | 76.67 | 76.01 | 66.67 | 86.67 | |||||
| 3 | 22 | 60.71 | 59.76 | 71.43 | 50.00 | 0.91 | 8, 13 | 0.016 | 116 (100.0 %) |
| 2 | 89.29 | 88.64 | 78.57 | 100.00 | |||||
| 4 | 22 | 57.14 | 56.69 | 64.29 | 50.00 | 0.91 | 21, 22 | 0.015 | 116 (100.0 %) |
| 2 | 75.00 | 72.84 | 92.86 | 57.14 | |||||
| 5 | 22 | 60.00 | 58.50 | 73.33 | 46.67 | 0.82 | 3, 22, 1, 13 | 0.030 | 116 (100.0 %) |
| 4 | 63.33 | 62.54 | 73.33 | 53.33 | |||||
| 6 | 22 | 63.33 | 63.25 | 66.67 | 60.00 | 0.41 | 18, 7, 1, 8, 12, 10, 17, 3, 11, 9, 6, 14, 13 | 0.089 | 116 (100.0 %) |
| 13 | 70.00 | 69.92 | 66.67 | 73.33 | |||||
| 7 | 22 | 46.43 | 46.29 | 50.00 | 42.86 | 0.91 | 22, 3 | 0.016 | 116 (100.0 %) |
| 2 | 67.86 | 67.76 | 64.29 | 71.43 | |||||
| 8 | 22 | 75.00 | 74.91 | 78.57 | 71.43 | 0.82 | 18, 14, 6, 13 | 0.029 | 116 (100.0 %) |
| 4 | 85.71 | 85.42 | 92.86 | 78.57 | |||||
| 9 | 22 | 71.43 | 71.43 | 71.43 | 71.43 | 0.27 | 18, 13, 12, 7, 2, 1, 6, 3, 22, 21, 20, 19, 4, 8, 15, 14 | 0.115 | 116 (100.0 %) |
| 16 | 78.57 | 78.25 | 85.71 | 71.43 | |||||
| Average | 22 | 13, 8, 6, 1, 22, 3, 14, 18 | 116 (100.0 %) | ||||||
| 8 | |||||||||
| Subject | Number of Sources | Performance Measures (%) | Reduction Rate | Relevant Electrodes | Required Time (s) | Support Vectors | |||
|---|---|---|---|---|---|---|---|---|---|
| Acc | Geo-M | Sens | Spec | ||||||
| 1 | 22 | 67.86 | 67.76 | 71.43 | 64.29 | 0.50 | 14, 13, 18, 1, 8, 22, 19, 21, 9, 10, 4 | 0.065 | 83 (71.6 %) |
| 11 | 75.00 | 74.91 | 78.57 | 71.43 | |||||
| 2 | 22 | 66.67 | 65.32 | 53.33 | 80.00 | 0.36 | 12, 8, 13, 1, 17, 7, 16, 20, 21, 2, 6, 14, 9, 10 | 0.096 | 110 (94.8 %) |
| 14 | 66.67 | 65.32 | 53.33 | 80.00 | |||||
| 3 | 22 | 71.43 | 71.07 | 64.29 | 78.57 | 0.82 | 8, 5, 13, 14 | 0.024 | 75 (64.7 %) |
| 4 | 75.00 | 74.91 | 71.43 | 78.57 | |||||
| 4 | 22 | 46.43 | 46.29 | 50.00 | 42.86 | 0.91 | 22, 21 | 0.017 | 72 (62.1 %) |
| 2 | 78.57 | 78.57 | 78.57 | 78.57 | |||||
| 5 | 22 | 56.67 | 54.16 | 73.33 | 40.00 | 0.77 | 7, 1, 13, 3, 22 | 0.030 | 78 (67.2 %) |
| 5 | 66.67 | 65.32 | 80.00 | 53.33 | |||||
| 6 | 22 | 70.00 | 69.92 | 66.67 | 73.33 | 0.55 | 18, 8, 1, 7, 12, 17, 3, 9, 10, 14 | 0.066 | 99 (85.3 %) |
| 10 | 76.67 | 76.59 | 80.00 | 73.33 | |||||
| 7 | 22 | 46.43 | 46.29 | 50.00 | 42.86 | 0.91 | 22, 3 | 0.013 | 83 (71.6 %) |
| 2 | 67.86 | 67.76 | 64.29 | 71.43 | |||||
| 8 | 22 | 67.86 | 67.76 | 71.43 | 64.29 | 0.82 | 18, 14, 1, 13 | 0.028 | 86 (74.1 %) |
| 4 | 82.14 | 82.07 | 78.57 | 85.71 | |||||
| 9 | 22 | 71.43 | 71.43 | 71.43 | 71.43 | 0.73 | 13, 2, 12, 22, 1, 18 | 0.035 | 64 (55.2 %) |
| 6 | 78.57 | 78.25 | 85.71 | 71.43 | |||||
| Average | 22 | 1, 13, 14, 22, 18, 8 | 83 ( % %) | ||||||
| 6 | |||||||||
| Subject | Number of Sources | Performance Measures (%) | Reduction Rate | Relevant Electrodes | Required Time (s) | Support Vectors | |||
|---|---|---|---|---|---|---|---|---|---|
| Acc | Geo-M | Sens | Spec | ||||||
| 1 | 22 | 67.86 | 67.76 | 71.43 | 64.29 | 0.77 | 14, 13, 18, 9, 1 | 0.041 | 78 (67.2 %) |
| 5 | 78.57 | 78.25 | 85.71 | 71.43 | |||||
| 2 | 22 | 63.33 | 62.54 | 53.33 | 73.33 | 0.05 | 7, 1, 13, 6, 8, 9, 12, 2, 3, 14, 18, 17, 20, 10, 5, 21, 19, 15, 16, 11, 22 | 0.171 | 105 (90.5 %) |
| 21 | 63.33 | 62.54 | 53.33 | 73.33 | |||||
| 3 | 22 | 64.29 | 64.29 | 64.29 | 64.29 | 0.91 | 8, 13 | 0.017 | 78 (67.2 %) |
| 2 | 82.14 | 82.07 | 85.71 | 78.57 | |||||
| 4 | 22 | 50.00 | 50.00 | 50.00 | 50.00 | 0.91 | 22, 21 | 0.018 | 99 (85.3 %) |
| 2 | 71.43 | 71.43 | 71.43 | 71.43 | |||||
| 5 | 22 | 56.67 | 54.16 | 73.33 | 40.00 | 0.77 | 7, 1, 13, 3, 22 | 0.039 | 78 (67.2 %) |
| 5 | 66.67 | 65.32 | 80.00 | 53.33 | |||||
| 6 | 22 | 66.67 | 66.33 | 73.33 | 60.00 | 0.50 | 18, 7, 8, 12, 1, 9, 17, 10, 3, 11, 14 | 0.090 | 100 (86.2 %) |
| 11 | 73.33 | 73.33 | 73.33 | 73.33 | |||||
| 7 | 22 | 60.71 | 60.61 | 64.29 | 57.14 | 0.91 | 22, 3 | 0.017 | 83 (71.6 %) |
| 2 | 64.29 | 64.29 | 64.29 | 64.29 | |||||
| 8 | 22 | 67.86 | 67.76 | 64.29 | 71.43 | 0.77 | 18, 13, 14, 9, 1 | 0.044 | 83 (71.6 %) |
| 5 | 82.14 | 82.07 | 85.71 | 78.57 | |||||
| 9 | 22 | 71.43 | 71.43 | 71.43 | 71.43 | 0.73 | 13, 2, 12, 22, 1, 18 | 0.045 | 64 (55.2 %) |
| 6 | 71.43 | 71.43 | 71.43 | 71.43 | |||||
| Average | 22 | 13, 1, 18, 22, 9, 14, 3 | 85 ( % %) | ||||||
| 7 | |||||||||
| Using the -Norm | Using the -Norm | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm 1 | Algorithm 2 | Algorithm 3 | Algorithm 1 | Algorithm 2 | Algorithm 3 | ||||||
| Electrode | Relev | Electrode | Relev | Electrode | Relev | Electrode | Relev | Electrode | Relev | Electrode | Relev |
| 18 | 8.95 | 14 | 10.22 | 13 | 8.00 | 13 | 10.08 | 1 | 10.48 | 13 | 10.74 |
| 14 | 7.46 | 18 | 9.23 | 14 | 7.87 | 8 | 7.29 | 13 | 10.45 | 1 | 10.52 |
| 13 | 7.31 | 13 | 7.17 | 18 | 6.97 | 6 | 7.22 | 14 | 8.83 | 18 | 8.91 |
| 8 | 6.09 | 22 | 7.08 | 8 | 6.88 | 1 | 6.81 | 22 | 8.63 | 22 | 8.15 |
| 12 | 6.09 | 1 | 6.47 | 7 | 6.61 | 22 | 6.73 | 18 | 7.35 | 9 | 7.19 |
| 7 | 5.98 | 21 | 6.36 | 12 | 6.61 | 3 | 6.67 | 8 | 6.90 | 14 | 7.19 |
| 22 | 5.92 | 7 | 6.27 | 22 | 5.38 | 14 | 5.79 | 12 | 5.22 | 3 | 6.47 |
| 10 | 5.87 | 8 | 5.77 | 6 | 5.32 | 18 | 5.79 | 21 | 5.18 | 8 | 5.29 |
| 21 | 5.81 | 6 | 5.59 | 1 | 5.25 | 7 | 5.62 | 9 | 5.14 | 12 | 5.03 |
| 11 | 4.40 | 12 | 5.28 | 19 | 5.23 | 12 | 5.62 | 10 | 5.14 | 7 | 4.91 |
| 17 | 4.40 | 9 | 4.87 | 10 | 4.13 | 21 | 4.28 | 3 | 4.97 | 10 | 3.30 |
| 6 | 4.31 | 2 | 3.40 | 17 | 3.99 | 17 | 4.15 | 7 | 4.94 | 11 | 3.30 |
| 3 | 4.27 | 15 | 3.40 | 11 | 3.97 | 20 | 2.91 | 2 | 3.42 | 17 | 3.30 |
| 2 | 4.16 | 19 | 3.40 | 15 | 3.88 | 2 | 2.87 | 17 | 3.37 | 2 | 3.26 |
| 1 | 4.16 | 11 | 3.11 | 3 | 3.68 | 4 | 2.87 | 4 | 1.76 | 21 | 3.26 |
| 5 | 2.69 | 20 | 3.11 | 2 | 2.68 | 15 | 2.87 | 5 | 1.76 | 5 | 1.53 |
| 9 | 2.69 | 4 | 1.75 | 5 | 2.48 | 19 | 2.87 | 19 | 1.76 | 6 | 1.53 |
| 19 | 2.69 | 3 | 1.56 | 21 | 2.48 | 9 | 2.71 | 6 | 1.57 | 15 | 1.53 |
| 20 | 2.69 | 10 | 1.56 | 9 | 2.46 | 10 | 2.71 | 16 | 1.57 | 16 | 1.53 |
| 15 | 1.37 | 16 | 1.56 | 16 | 2.46 | 5 | 1.40 | 20 | 1.57 | 19 | 1.53 |
| 16 | 1.37 | 17 | 1.56 | 20 | 2.46 | 16 | 1.40 | 11 | 0.00 | 20 | 1.53 |
| 4 | 1.32 | 5 | 1.32 | 4 | 1.22 | 11 | 1.31 | 15 | 0.00 | 4 | 0.00 |
| Performance Measures | Using All Sources (%) | Applying Sources Reduction (%) | Reduction Rate | Relevant Sequences | Required Time (s) | Support Vectors | |
|---|---|---|---|---|---|---|---|
| Algorithm 1 | Accuracy | 73.33 | 80.00 | 0.78 | P_ADC, P_SUB4 | 0.013 | 117 (100.0 %) |
| Geo-Mean | 65.91 | 79.59 | |||||
| Sensitivity | 94.12 | 82.35 | |||||
| Specificity | 46.15 | 76.92 | |||||
| Algorithm 2 | Accuracy | 80.00 | 93.33 | 0.56 | P_SUB2, P_SUB4, P_SUB3, P_SUB5 | 0.021 | 97 (82.9 %) |
| Geo-Mean | 76.10 | 93.21 | |||||
| Sensitivity | 94.12 | 94.12 | |||||
| Specificity | 61.54 | 92.31 | |||||
| Algorithm 3 | Accuracy | 80.00 | 86.67 | 0.67 | P_SUB2, P_SUB5 P_SUB3 | 0.020 | 97 (82.9 %) |
| Geo-Mean | 76.10 | 85.09 | |||||
| Sensitivity | 94.12 | 94.12 | |||||
| Specificity | 61.54 | 76.92 |
| Performance Measures | Using All Sources (%) | Applying Sources Reduction (%) | Reduction Rate | Relevant Sequences | Required Time (s) | Support Vectors | |
|---|---|---|---|---|---|---|---|
| Algorithm 1 | Accuracy | 82.76 | 86.21 | 0.33 | R_T2, R_T1 R_DWI, R_SUB3 R_SUB5, R_SUB4 | 0.073 | 117 (100.0 %) |
| Geo-Mean | 84.02 | 87.45 | |||||
| Sensitivity | 70.59 | 76.47 | |||||
| Specificity | 100.00 | 100.00 | |||||
| Algorithm 2 | Accuracy | 79.31 | 89.66 | 0.33 | R_T1, R_DWI R_SUB3, R_T2 R_SUB4, R_SUB5 | 0.063 | 81 (69.2 %) |
| Geo-Mean | 80.44 | 90.75 | |||||
| Sensitivity | 64.71 | 82.35 | |||||
| Specificity | 100.00 | 100.00 | |||||
| Algorithm 3 | Accuracy | 86.21 | 89.66 | 0.22 | R_T1, R_DWI R_SUB3, R_T2 R_SUB5, R_SUB4 R_SUB2 | 0.113 | 92 (78.6 %) |
| Geo-Mean | 87.45 | 90.75 | |||||
| Sensitivity | 76.47 | 82.35 | |||||
| Specificity | 100.00 | 100.00 |
| Performance Measures | Using All Sources (%) | Applying Sources Reduction (%) | Reduction Rate | Relevant Sequences | Required Time (s) | Support Vectors | |
|---|---|---|---|---|---|---|---|
| Algorithm 1 | Accuracy | 76.67 | 86.67 | 0.72 | P_SUB2, P_SUB5 P_SUB4, P_SUB3 R_SUB3 | 0.033 | 117 (100.0 %) |
| Geo-Mean | 75.51 | 85.09 | |||||
| Sensitivity | 82.35 | 94.12 | |||||
| Specificity | 69.23 | 76.92 | |||||
| Algorithm 2 | Accuracy | 76.67 | 90.00 | 0.67 | P_SUB2, P_SUB5 P_SUB4, P_SUB3 R_SUB3, R_SUB5 | 0.039 | 97 (82.9 %) |
| Geo-Mean | 75.51 | 89.24 | |||||
| Sensitivity | 82.35 | 94.12 | |||||
| Specificity | 69.23 | 84.62 | |||||
| Algorithm 3 | Accuracy | 76.67 | 90.00 | 0.67 | P_SUB2, P_SUB5 P_SUB4, P_SUB3 R_SUB3, R_SUB5 | 0.051 | 97 (82.9 %) |
| Geo-Mean | 75.51 | 89.24 | |||||
| Sensitivity | 82.35 | 94.12 | |||||
| Specificity | 69.23 | 84.62 |
| Subject | Feature Selection over All Information Sources | Feature Selection After Reduce Information Sources | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Minimal Required Features | Reduction Rate (by Sources) | Accuracy | Minimal Required Features | Reduction Rate (by Sources) | |||
| With All Features | Reducing Features | With All Features | Reducing Features | |||||
| Algorithm 1 | ||||||||
| 1 | 64.29 | 85.71 | 280 | 0.00 | 75.00 | 85.71 | 362 | 0.14 |
| 2 | 53.33 | 76.67 | 667 | 0.00 | 76.67 | 73.33 | 44 | 0.59 |
| 3 | 60.71 | 92.86 | 20 | 0.68 | 89.29 | 92.86 | 22 | 0.91 |
| 4 | 57.14 | 75.00 | 207 | 0.00 | 75.00 | 89.29 | 23 | 0.91 |
| 5 | 60.00 | 70.00 | 130 | 0.00 | 63.33 | 76.67 | 69 | 0.82 |
| 6 | 63.33 | 80.00 | 3 | 0.95 | 70.00 | 80.00 | 3 | 0.95 |
| 7 | 46.43 | 67.86 | 25 | 0.50 | 67.86 | 64.29 | 1 | 0.95 |
| 8 | 75.00 | 82.14 | 52 | 0.50 | 85.71 | 85.71 | 119 | 0.82 |
| 9 | 71.43 | 78.57 | 767 | 0.00 | 78.57 | 75.00 | 83 | 0.27 |
| Average | ||||||||
| Algorithm 2 | ||||||||
| 1 | 67.86 | 85.71 | 243 | 0.00 | 75.00 | 85.71 | 300 | 0.50 |
| 2 | 66.67 | 73.33 | 166 | 0.00 | 66.67 | 70.00 | 389 | 0.36 |
| 3 | 71.43 | 96.43 | 2 | 0.91 | 75.00 | 96.43 | 2 | 0.91 |
| 4 | 46.43 | 75.00 | 201 | 0.00 | 78.57 | 85.71 | 20 | 0.91 |
| 5 | 56.67 | 70.00 | 281 | 0.00 | 66.67 | 73.33 | 163 | 0.77 |
| 6 | 70.00 | 83.33 | 420 | 0.00 | 76.67 | 80.00 | 88 | 0.55 |
| 7 | 46.43 | 67.86 | 35 | 0.41 | 67.86 | 64.29 | 32 | 0.91 |
| 8 | 67.86 | 82.14 | 62 | 0.36 | 82.14 | 85.71 | 25 | 0.86 |
| 9 | 71.43 | 78.57 | 445 | 0.00 | 78.57 | 75.00 | 26 | 0.73 |
| Average | ||||||||
| Algorithm 3 | ||||||||
| 1 | 67.86 | 85.71 | 244 | 0.00 | 78.57 | 78.57 | 97 | 0.77 |
| 2 | 63.33 | 70.00 | 167 | 0.00 | 63.33 | 70.00 | 155 | 0.05 |
| 3 | 64.29 | 89.29 | 2 | 0.91 | 82.14 | 96.43 | 58 | 0.91 |
| 4 | 50.00 | 67.86 | 2 | 0.91 | 71.43 | 82.14 | 7 | 0.91 |
| 5 | 56.67 | 73.33 | 281 | 0.00 | 66.67 | 73.33 | 163 | 0.77 |
| 6 | 66.67 | 83.33 | 420 | 0.00 | 73.33 | 80.00 | 10 | 0.82 |
| 7 | 60.71 | 71.43 | 655 | 0.00 | 64.29 | 64.29 | 32 | 0.91 |
| 8 | 67.86 | 82.14 | 5 | 0.95 | 82.14 | 82.14 | 5 | 0.95 |
| 9 | 71.43 | 78.57 | 445 | 0.00 | 71.43 | 78.57 | 184 | 0.73 |
| Average | ||||||||
| Algorithm | Feature Selection Over All Information Sources | Feature Selection after Reduce Information Sources | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Minimal Required Features | Reduction Rate (by Sources) | Accuracy | Minimal Required Features | Reduction Rate (by Sources) | |||
| With All Features | Reducing Features | With All Features | Reducing Features | |||||
| Perceptual Features | ||||||||
| 1 | 73.33 | 83.33 | 26 | 0.11 | 80.00 | 80.00 | 7 | 0.78 |
| 2 | 80.00 | 90.00 | 48 | 0.00 | 93.33 | 93.33 | 26 | 0.56 |
| 3 | 80.00 | 86.67 | 23 | 0.22 | 86.67 | 90.00 | 15 | 0.67 |
| Radiomic Features | ||||||||
| 1 | 82.76 | 96.55 | 179 | 0.00 | 86.21 | 93.10 | 171 | 0.33 |
| 2 | 79.31 | 96.55 | 173 | 0.00 | 89.66 | 93.10 | 174 | 0.33 |
| 3 | 86.21 | 96.55 | 179 | 0.00 | 89.66 | 93.10 | 269 | 0.22 |
| Perceptual and Radiomic Features | ||||||||
| 1 | 76.67 | 90.00 | 302 | 0.00 | 86.67 | 90.00 | 43 | 0.72 |
| 2 | 76.67 | 90.00 | 526 | 0.00 | 90.00 | 90.00 | 124 | 0.67 |
| 3 | 76.67 | 90.00 | 526 | 0.00 | 90.00 | 90.00 | 125 | 0.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Areiza-Laverde, H.J.; Castro-Ospina, A.E.; Hernández, M.L.; Díaz, G.M. A Novel Method for Objective Selection of Information Sources Using Multi-Kernel SVM and Local Scaling. Sensors 2020, 20, 3919. https://doi.org/10.3390/s20143919
Areiza-Laverde HJ, Castro-Ospina AE, Hernández ML, Díaz GM. A Novel Method for Objective Selection of Information Sources Using Multi-Kernel SVM and Local Scaling. Sensors. 2020; 20(14):3919. https://doi.org/10.3390/s20143919
Chicago/Turabian StyleAreiza-Laverde, Henry Jhoán, Andrés Eduardo Castro-Ospina, María Liliana Hernández, and Gloria M. Díaz. 2020. "A Novel Method for Objective Selection of Information Sources Using Multi-Kernel SVM and Local Scaling" Sensors 20, no. 14: 3919. https://doi.org/10.3390/s20143919
APA StyleAreiza-Laverde, H. J., Castro-Ospina, A. E., Hernández, M. L., & Díaz, G. M. (2020). A Novel Method for Objective Selection of Information Sources Using Multi-Kernel SVM and Local Scaling. Sensors, 20(14), 3919. https://doi.org/10.3390/s20143919