1. Introduction
Digital applications relying on information gathered by sensors and transmitted by infocommunication networks are becoming pervasive across industries. Data are continuously collected from production lines in mass-producing factories, while warehousing robots, delivery drones and driverless vehicles are ensuring the autonomous, cost efficient logistics of getting products to the end-customers. Agricultural sensors are providing unprecedented insight into the efficiency of industrial-scale food and crops production. A wide range of smart city sensors and actuators for traffic control, parking optimization, public transportation and sharing economy based urban mobility solutions make metropolitan lives more convenient and environment friendly. Autonomous video surveillance, consumer intelligence based advertisements, smart home appliances and smart phones make our lives safer, comfortable and filled with personalized user experience. Enormous amount of information and optimization opportunities lurk in this massive, hyper-connected system. The value of this huge amount of data can only be exploited if it is collected, analyzed, understood and acted upon. That is the core process to monetize information collected by various types of sensors, and that is the essence of the Internet of Things (IoT).
The high service quality requirements driven by consumer demands of the information society, pushes communication technology innovation and development forward. New applications built on top of the vast amount of process intelligence are coming out rapidly, and innovation is ongoing with a never-seen-before pace. These demands of the current world characterize the use-cases of 5G networks and their functional requirements, such as massive Machine Type Communication (mMTC), Ultra-Reliable Low-Latency Communication (URLLC) and enhanced Mobile Broadband (eMBB) [
1]. A recent surge of 5G prototype architectures and the ongoing competition for commercial 5G network deployments are academia’s and industry’s response to these challenging requirements. 5G systems utilize the paradigms of Network Function Virtualization (NFV) and Software-Defined Networking (SDN) to decouple the services’ business logic from the hardware, and realize an efficient management of computation and communication resources [
2].
A central optimization problem in realizing IoT applications using the enabling 5G technology, is allocating service components to resources, which is formalized in multiple NP-hard variants of the service placement problem. Service placement is one of the most difficult problems, as no solution exists which is scalable (i.e., do not rely on directly solving integer programs), provably meets all constraints and provides performance guarantees [
3,
4]. Due to the immediate relevance of the service placement problem, a wide range of practical heuristic algorithms have emerged, which are easy-to-deploy, highly extensible and possible to be continuously developed in an actual 5G software architecture [
5].
In parallel to algorithmic research on the service placement problem, the computation infrastructure is also evolving, becoming more dynamic and heterogeneous to contribute to meeting the challenging, service-level user requirements. In contrast, the infrastructure model of placement algorithms mostly consider only fixed substrate capacities and rarely goes beyond different capacity volumes to model heterogeneity. In addition to tackling heterogeneity and dynamicity, infrastructure modeling is an essential tool to handle the difficulty of the VNE problem by devising higher abstraction resource views for better algorithmic scalabilty.
In this paper, we contribute to 5G-enabled IoT service placement systems by proposing theoretically founded infrastructure abstractions for aggregating capacities and modeling elastic resources. We propose a service component placement heuristic algorithm design schema for meeting constraints on service path delay requirements. We show how these results can be integrated into proven prototype architectures. The focus of our paper is modeling the modern capabilities of distributed computing infrastructures, where services are deployed with respecting end-to-end requirements. More specifically, our contribution is threefold:
We propose a method to design the step-by-step delay bounds of a greedy service placement algorithm to meet end-to-end delay requirements.
We define capacity aggregation to efficiently abstract the network resources, targeting scalability and information hiding. We propose an approximation algorithm to create the aggregate infrastructure view with the desired abstraction level.
We propose an elastic resource model and admission control for the Kubernetes container management system’s Horizontal Pod Autoscaler feature [
6,
7], and show how it can be integrated with service placement algorithms.
The paper is structured as follows.
Section 2 puts our work in the context of a concrete IoT service deployment, and reviews related work on network abstraction and service placement.
Section 3 explains the base system model, and introduces the service placement problem variant solved by our earlier works.
Section 4 presents our results on end-to-end delay constraints and integrates it into our service placement framework. Our theoretical results on infrastructure modeling are presented in
Section 5 and
Section 6, which incrementally extend our base system model with capacity aggregation capability and resource elasticity modeling. Integration of our resource models to 5G-enabeld IoT orchestration systems is presented in
Section 7. Finally,
Section 8 concludes the paper.
2. Background and Related Work
2.1. Background
Meeting the Internet of Things communication requirements such as connectivity of vast number of devices with high mobility, low latency and high reliability bring grand challenges to communication networks. These are addressed by the 5G mobile technology, which enables the monetization of various sensor-aided IoT services. The enabling relationship between 5G and IoT is examined in [
1], where the state-of-the-art is extensively surveyed, gaps and research challenges are identified. The survey studies Mobile Edge Computing (MEC), data center performance optimization, edge cloud and virtualization technologies to identify their role in realizing 5G-enabled IoT applications, such as cloud robotics, industrial cyber physical systems, smart vehicles and tactile internet. Facilitating the interactions between various entities of the networking ecosystem is required to realize end-to-end IoT services. Authors of [
8] present their prototype for a functional 5G architecture for optimizing end-to-end IoT network slices, which is integrated with the Kubernetes-based Google Compute Engine.
In the following we present a remote security camera analytics and alerts use case, where the computation intensive and delay sensitive IoT services are deployed across big geographic distances by an Over-the-Top Service Provider (OTT SP).
Figure 1 shows a wide area network from the Internet Topology Zoo [
9], where a Communication Service Provider (CSP) gives network connection for an OTT SP between its service sites. The location of the security cameras is to the west (
), while the end-user location (
) is to the east. Service Access Points (SAPs) are the user locations where the service is to be consumed, possibly by another service or a person. Location of Interests (LOIs) represent location-bound points, where the sensors (i.e., security cameras) are located. These should be used as service delay reference points, because the service quality is primarily experienced here. All auxiliary functions realize the service needs to be allocated on a network path between the reference points with meeting the strict delay requirement. The CSP provides communication capabilities between the distributed cloud of a Cloud Provider (CP) having its computation nodes apart with significant geographic distance. The OTT SP is in a business relationship with a CP, reaching its data center through the CSP’s network, while also owning a private cloud proximate to site
.
If the OTT SP wishes to provide high quality IoT service over the rented infrastructure, it needs to know information about the CSPs network in significant detail to make informed decision about the IoT service component placements. On the other hand, the CSP may want to hide information from its tenants as they might be valuable or sensitive [
10], where appropriate network and computation resource abstractions are essential. In addition, the CSP might want to optimize the running services’ resource allocation to achieve higher computation resource efficiency, which should not be perceived by the OTT SP on its rented infrastructure view. The OTT SP’s orchestration system needs to work on an appropriate infrastructure view which resolves the mentioned conflicts. Aggregating servers into higher abstraction nodes (as shown in CSP Aggregate node of
Figure 1) also helps the embedding algorithm to scale up to carrier-grade network sizes. Finally, the Cloud Provider should also be able to give a descriptive view of its Kubernetes-based, optimized, dynamic data center resources.
2.2. Network Abstraction
Network infrastructure abstraction has always been important in modern network management to address the various application needs serving on top of the increasingly complex communication substrate. In a simple case, when only throughput requirements between endpoints need to be satisfied, the hose model has been proposed to describe Virtual Private Networks (VPNs) over a common substrate. The hose model has proved to be useful to efficiently provision the VPNs using a convenient tree structure [
11]. In addition to meeting the bandwidth requirements, routing costs must be considered in practical cases. Such a system has been described by an abstracted network map [
12], where the significant nodes are connected by cheapest, i.e., shortest in terms of cost metric, and highest bandwidth capacity paths, i.e., widest paths in terms of throughput. As virtual networks are the most valuable when they connect geographically distant locations, the underlying network infrastructure is likely to be managed by multiple providers. Virtual Network Embedding (VNE) is studied across multiple administrative domains in [
10], where the authors devise a distributed algorithm, segmenting the virtual networks and embedding their routes in individual steps. The presented model lacks admission control capabilities on the domain capacity resources, which is one of the main contribution of our work.
As Software Defined Networking (SDN) enabled the network-wide control from a logically centralized controller, end-to-end network management based on high abstraction policies is convenient. SDN control architecture proves to be indispensable to implement IoT networks, furthermore, their appropriate performance requires distributed SDN controller placement [
13], where abstracting the low-level management of individual devices is important. Network infrastructure abstraction is a key component to make the SDN concepts reach their full potential as studied in an SDN scalability survey [
14]. Addressing these issues, the Big Switch model has been proposed to describe a network by its transport characteristics between the endpoints [
15], which can be used to provision user traffic on top of the network, without studying its low-level details. Thanks to Network Function Virtualization (NFV), network services are decoupled from specialized hardware, packaged using virtualization technologies (such as containers and micro-services) and freely moved across computation locations [
16]. Our recent works have generalized the Big Switch model to include computation capabilities of a network and keep up infrastructure modeling with the increasingly interleaving computation and communication resources. We have defined the Big Switch-Big Software (BiS-BiS) model [
17], which has been used to build a multi-domain SDN/NFV-aware orchestration system [
18,
19]. These earlier versions of the BiS-BiS model naively sum the computation capacities and aggregate the functional capabilities of the hidden infrastructure, which ignores essential bottlenecks and lacks configuration options for the abstraction-performance trade-off. Emerging deployments of the NFV/SDN-enabled technologies in Mobile Edge Computing (MEC), Fog Computing, Industry 4.0, Internet of Things (IoT) and 5G make the networks increasingly heterogeneous. Thus, the naive BiS-BiS model’s shortcomings are crucial in real deployments. Our current work addresses mathematically founded description of abstract, highly distributed, dynamic compute and network infrastructures.
2.3. Service Placement
The central problem in SDN and NFV-based computation network architectures is the service component placement problem, which has been well-studied by both industry and academia, stated in many forms. The general problem of service placement benefits from multiple areas of network management research, such as the Virtual Network Embedding (VNE) problem [
20], Virtual Network Function (VNF) placement or Service Function Chain (SFC) resource allocation problem. Relations between these problem variants, and mutually useful results have been studied by survey papers [
21]. The core of the service component placement problem addresses how to place the service-composing VNFs and how to route their connections with various constraints on the communication and computation characteristics. The problem is notoriously NP-hard and very difficult to approximate [
3]. Moreover, modeling dynamic infrastructure capabilities such as reactive, automatic scale out of service components managed by modern container management systems is challenging. These behaviors cannot be formalized using linear constraints for integer programs, making solver-based optimization approaches hopeless [
22]. A wide range of heuristic approaches have been proposed to solve many variants of the service placement problem, which are much more promising to meet high quality service requirements scaling to the immense size of IoT networks. We target complementing heuristic placement algorithms by providing theoretically founded generalizations of the infrastructure models to describe elasticity and abstraction. Indicating the hardness of the service placement related problems, no scalable solutions have been proposed so far which have performance guarantees and provably do not violate capacity constraints [
4].
The surveys in [
20,
21] extensively study and categorize the earlier and more recent papers of VNE, defining a general optimization model, and proposing a taxonomy on the solutions based on their modeled features, algorithmic approaches and considered constraints. Focusing more on the technological aspects of VNE related problems, taking into account the modern developments in virtualization technologies, such as containerization, the survey in [
5] presents a novel classification.
Concluding from the above state-of-the-art studies, many heuristics use a greedy approach to target easy prototypization and extension capabilities. Guarantees on the deployed service’s delay are important as many emerging applications are delay sensitive. Yet, besides some exceptions [
23], delay guarantees are not well-studied in the current state-of-the-art. Other solutions propose a delay-aware model [
24], but the presented greedy heuristic does not rigorously address the delay guarantee, as the service delay is the optimization objective. Minimizing the service delay often disregards other important optimization goals, such as deployment cost. Authors of [
25] study the trade-off between load balancing the compute infrastructure and minimizing the end-to-end service delay, but the solution lacks delay guarantees, as the SFC delay is not considered as an optimization constraint. The state-of-the-art in service placement related problems lacks heuristic solutions, where delay is taken as a constraint to meet the QoS requirements, and minimize for independent objectives.
Our recent work on service placement took the approach of including delay as an optimization constraint with configurable objective function, and implementing it in an extensible heuristic algorithm framework. In our model, delay has been considered as a path-delay, i.e., end-to-end delay, constraint in the service graph. An earlier version focuses on tackling general service graph structures in the greedy VNF placement and routing algorithm [
26]. The algorithm framework has been applied to data-plane component orchestration, where the input structures are translated to the general service graph structure, and the heuristic is tuned to the domain-specific needs [
27]. Addressing the network operation scenarios, where service requests continuously arrive beyond 0-day deployments, we have extended our framework with hybrid online-offline optimization capability [
28]. Most recently, the algorithm has been integrated with our multi-operator 5G proof-of-concept architecture [
19], and its advanced features, such as path anti-affinity, has been studied by complexity theory methodologies. Our proof-of-concept implementation is conceptually similar to the previously referred IoT slice orchestration system in [
8]. In this paper, our contribution is the extension of our well-established heuristic framework with mathematically founded guarantees for the end-to-end delay constraints. Our results on end-to-end delay and infrastructure abstraction could be applied and integrated with any heuristic algorithm which uses step-by-step placement of the individual service components.
3. Base System Model and Optimization Problem
To model a wide range of the previously mentioned dynamic and heterogeneous computation resource types, we introduce four types of substrate nodes arranged in two dimensions. One dimension is the nature of the node’s capacity in terms of flexibility. Substrate nodes with fixed capacity model physical servers, legacy hardware for hosting PNFs and static virtual computation capacities, etc., while elastic substrate nodes model modern pay-as-you-use cloud platforms and auto-scaling capable Virtual Infrastructure Managers (VIMs) such as a Kubernetes host.
The other dimension of infrastructure capability modeling is the level of abstraction represented by the node. A single computation node is represented by the single types, where the placed VNF is directly instantiated, e.g., a single server or a VIM managing a few VMs running on the same or proximate server racks. Finally, aggregate node types hide information of the underlying computation capabilities and show only an abstract view of multiple (possibly distant) VNF hosting possibilities. Except the aggregate elastic category, each infrastructure type is modeled in this paper and our contributions to the domain of infrastructure modeling are summarized by the considered resource types’ abbreviations in
Table 1. The resource types are introduced one-by-one incrementally generalizing the system model, while their challenges are studied in detail. In this section we introduce the basic system model only using the single fixed, denoted by
, as this is the only type generally considered by most of the related VNE, service placement and SFC embedding literature.
3.1. System Model and Problem Formulation
We model the substrate network as an undirected, connected graph
, where substrate nodes
represent the compute resources of any type, their interconnections are the edge set
. Notations of the problem formulation and for the rest of the paper are summarized in
Table 2. The VNF repository is represented by
, which contains all VNFs supported by any parts of the system, used for building services. Keeping aligned with our primary motivation of modeling the characteristics of the infrastructure, we keep the service model simple. We formulate the problem only for the online variant of the service placement problem, restricted to path request graphs. We introduce a general capacity function
, which decides whether a set of VNFs can be placed to a substrate node due to capacity constraints. This function is incrementally extended as we introduce our proposed model for the heterogeneous substrate nodes. For now, the optimization problem is stated with only single fixed
substrate nodes, whose capacity is described by the capacity function
, while the VNF demand mapped to these substrate nodes is described with the corresponding demand function
. The service deployment’s lifetime
is considered at the time of component placement decision, as it might affect the incurring costs and the substrate network’s behavior. The placement cost of a VNF is specified by function
, taking the hosting time length and the mapping as input. Similarly, the routing cost of a request link is specified by
. If not stated otherwise, the costs
and
are regarded as input parameters. The node and link mapping functions,
and
, respectively, describe the request graph embedding solution. Link throughput capacities and requirements are not modeled in this paper as we focus on node resource abstraction. Such placement problem variants can be found in our previous work [
19,
26,
27,
28] and the literature [
20,
21].
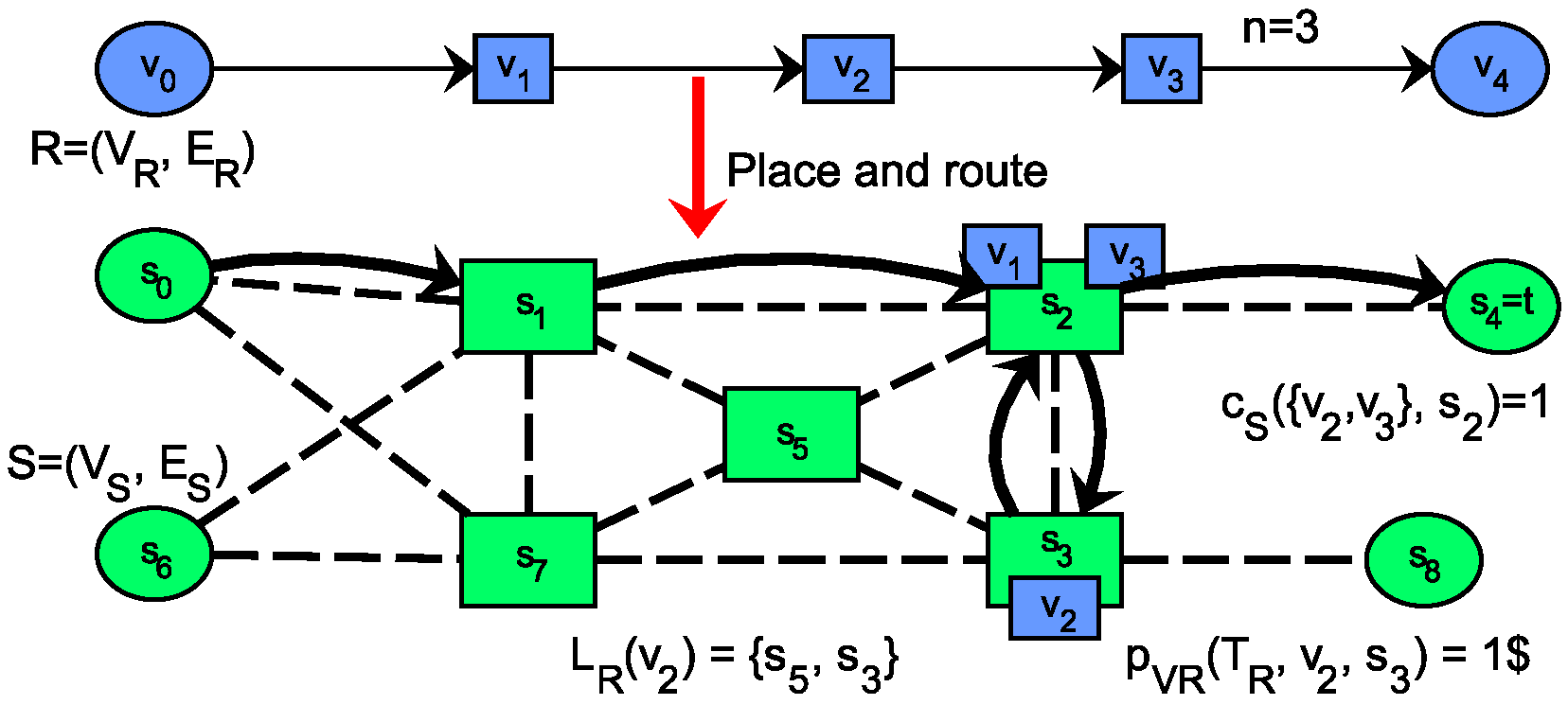
Formulation 1 shows the service placement optimization problem, where the request graph may only be a path graph, with both ends fixed to substrate nodes from
as shown in (3). A demonstrative solution for Formulation 1 and some examples for the notations of
Table 2 are shown in
Figure 2. Constraints (
1) and (2) ensure that all elements of the service are mapped. The location function
describes placement requirements for each VNF, which might come from operational policies, privacy restrictions, Service Access Point (SAP) matching rules or VNF functionality constraints. The set of feasible paths of a request edge
represents not detailed path constraints like, link capacity and routing constraints. A basic graph embedding requirement is described by (4), which ensures that the source and termination of a request link’s hosting path goes between the hosts of its ends. The general capacity function
defines for a set of VNFs whether a substrate node has enough capacity to run all functions. Prevention of overloading any substrate node (considering all resource types for extensions) is described by (5). The general capacity function is specified in (6) for single fixed
substrate node types, where the demands are integers, simply summed and upper bounded by the integer capacity. This constraint is later extended as we introduce and study the details of other substrate node types. Finally, the objective is to minimize the overall deployment cost which is the total sum of all VNF hosting cost and all routing costs, as shown in (7).
The example on
Figure 2 shows concrete values for some parameters. The service chains starting and ending nodes,
and
, respectively, have fixed locations (not subject to optimization) in the substrate graph
and
. VNF
can only be located on substrate nodes
and
, and its cost on the latter location is 1
$ for the whole service lifetime
.
| Formulation 1 Variation of the service placement problem studied in this paper. |
Input:
Output: |
3.2. Heuristic Greedy Backtrack Approach
This section briefs our greedy backtracking algorithm framework for solving service placement for various constraints in our earlier works. Here we state only the general outline of the algorithm to give sufficient background, and a previously solved service placement peculiarities are listed.
Algorithm 1 takes as input the service and substrate graph structures
and
, and returns a complete mapping structure of VNFs and their connections
and
, if any feasible is found. An ordered list of unit orchestration steps, i.e.,
legs , a pair of VNF and adjacent request link, is stored in list
and generated by function O
rderL
egsF
orM
apping(
,
). In the current case the ordering is simple, as the request graph
is a path graph between a source and a destination. In more complicated applications this function returns the legs in an order so that their source is always placed by the
function, before their own placement decisions. We note that our results on the substrate graph model are general and independent of the service graph structure. Previously published and applied versions of the greedy backtrack approach are capable of handling general service structures [
19,
26,
27,
28]. The
function generates hosting candidates and filters them according to the constraints, as shown in Formulation 1. In case such a greedy step is not successful, the functions
and
are responsible to explore other greedy mapping directions and to maintain the resource reservations, constraint states and mapping structures. When a complete mapping structure solving Formulation 1 is found, Algorithm 1 returns the solution. Our earlier work also studies tackling the runtime complexity of such a greedy mapping approach for the NP-hard service placement problem [
19,
27], these examinations are out of the scope of this paper.
In our earlier work we used this greedy heuristic service placement algorithm framework in various different settings, including general service topology structure [
26], data plane resource orchestration [
27], hybrid online-offline operational setting [
28], and integrated it into a 5G network architecture supporting advanced resource (anti)-affinity constraints [
19]. Our greedy heuristic framework has served as basis for several patents submitted by Ericsson, patenting VNF decomposition option selection, elastic substrate capacity management and VNF interconnection constraints (Patents pending).
The versatility of the greedy backtracking approach allows it to be applied in various service graph embedding scenarios, including 5G-enabled IoT prototype architectures independent of our recent work [
8]. Our algorithm framework can be easily extended, ideal for early deployment, prototype architecture integration and continuous development.
In this paper, we propose theoretical foundations to the greedy approach by providing guarantee on the embedding result’s end-to-end delay requirement. Subsequently, we present our mathematical analysis on node capacity allocation in a heterogeneous distributed computing environment by refining the substrate graph model.
| Algorithm 1 Overview of the Greedy Backtrack Metaheuristic for VNE |
| Returns a set of complete mapping structures of service graph S to resource graph R. |
| 1: | procedure Map() |
| 2: | ▹ Lists all VNFs and links to be mapped |
| 3: | while where or do |
| 4: | while not successful do |
| 5: | |
| 6: | |
| 7: | ▹ Try remapping another leg |
| 8: | end while |
| 9: | end while |
| 10: | return |
| 11: | end procedure |
4. Result on Path Delay Constraint
This section extends our system and optimization model with latency values, formalizes path delay constraint and we present our result on how to design the step-by-step delay heuristics to approximate end-to-end delay requirements. The notations related to the delay model are shown in
Table 3.
We annotate each substrate graph connection by communication delays, and calculate the distances of each substrate node pairs
, denoted by delay distance
. In our general greedy framework of Algorithm 1, the
function can allocate any path
for hosting the request edge
, which is aligned with path constraints (see
). The delay of such feasible path is denoted by
. This substrate graph path delay for hosting a request graph edge is alternatively denoted by
, to eliminate the indirection of the node mapping function
from the notation. Having the VNFs indexed in their order on the path request
R as
, we extend the original problem definition of Formulation 1 by a path delay requirement.
where
denotes the maximal allowed path delay of the used route from the beginning to the end of the service graph path.
Assume that the function OrderLegsForMapping(, ) returns the edges of the path request graph in order, starting from the fix substrate node , where the chain starts from. The algorithm updates the remaining delay budget by subtracting the used path delay after the greedy mapping of a leg leading to VNF . The termination of the request path graph R is in substrate node , which is alternatively referred to as t. We state our result on delay guarantee in the following theorem.
Theorem 1 (End-to-end delay constraint guarantee). A greedy heuristic maps a VNF in each step , where all VNFs until index i are greedily placed, i.e., , and the hosting substrate node and path of leg are being selected.
During the greedy mapping of a service graph, if for choosing the host of all VNFs ,
used delay is a fraction of the path delay requirement: ,
the used substrate node’s distance is bounded: , and
and the remaining delay requirement is bounded: ,
then the used total path delay approximates the path delay requirement:where The proof of the Theorem 1 is presented in
Appendix A.
Theorem 1 helps designing a heuristic algorithm’s step-by-step bounds on the latency values to guarantee the
-approximation of the end-to-end path delay constraint. It is important to note that the algorithm does not need to minimize for delay to comply with the constraint, i.e., shortest path calculation for each request edge might be done for the cost metric, while keeping the theorem’s bounds on the delay. The corresponding subproblem is the restricted shortest path problem, for which efficient algorithms have been proposed [
29].
Furthermore, the presented result does not utilize the previously well-studied backtracking capability of the proposed embedding framework. If substrate elements with the desired bounds can not be found, or the
-violation of the delay constraint needs to be mitigated, undoing some earlier greedy placement steps may solve the issue. Relation between the
approximation ratio and the required search space for the backtracking might be studied to design a fully polynomial-time approximation scheme (FPTAS) for the problem. A numerical example for applying Theorem 1 is shown in
Section 7.
Having demonstrated how advanced constraints, such as end-to-end delay, can be supported by the greedy backtrack framework, now we turn to refining the substrate graph model which provides powerful benefits for the embedding algorithm.
5. Result on Resource Aggregation
5.1. Revisit the BiS-BiS Model
Network abstractions of various types have proved useful in the past, such as network abstraction map [
12], hose model for VPN design [
11] and more recently the Big Switch abstraction in SDN [
15]. The Big Switch model describes network segments with their end-to-end transport characteristics. As computation and networking are increasingly interleaving thanks to softwarization and virtualization, the Big Switch approach was extended to describe both by the Big Switch-Big Software (BiS-BiS) abstraction [
17,
18]. Our work refines the BiS-BiS abstraction and provides theoretic foundation to it.
To describe an abstract view of distributed computation sites and to supply valuable information for latency sensitive applications, we propose adding internal aggregate nodes to the BiS-BiS model which describe transport and/or computation resources.
Figure 3 shows an abstract view of the lower level infrastructure view of
Figure 1. In this example, the CSP chooses to show its network aggregated into two BiS-BiS domains, describing the west and east segments of its infrastructure by CSP BiSBiS1 and CSP BiSBiS2, respectively. The CSP’s three computing locations, Server2, Server3 and Server4 of
Figure 1 are aggregated into the CSP Aggr. node of
Figure 3. The other non-aggregated nodes, Server1, DataCenter1 and Cluster1 of
Figure 1 are represented by CSP Single, DC and OTT Priv nodes, respectively. To simplify the networking structure and to hide some lower level topological information, forwarding nodes of the infrastructure are also aggregated. For instance, the two abstract forwarding nodes of CSP BiSBiS2 in
Figure 3 represent the eastern side of the forwarding topology in
Figure 1. The edges connecting the internal nodes of a BiS-BiS are annotated by delay values, describing the transport characteristics. Our embedding algorithm proposed in
Section 3 is able to operate on a substrate graph, which has such BiS-BiS domains, and is able to map service graphs with end-to-end delay constraints as described in
Section 4. The extensions required for the capacity constraints (6) to model the aggregate capacity are presented in this section.
We assume that defining the set of substrate nodes to be aggregated is out-of-scope of the underlying optimization problem, as the clustering might be more influenced by the CSP’s operational policies than rigorous mathematical measures. An extensive survey on clustering algorithms in sensor networks can be found in the literature [
30], while general graph clustering is studied in [
31].
As it was shown in previous experiments on abstract infrastructure views [
19], communicating the bottlenecks is in the interest of both the OTT SP and the CSP to avoid overbooking and under-utilization. To facilitate the effective communication of the bottlenecks, the aggregation must hold an essential property shown in Remark 1.
Remark 1 (Essential property of substrate abstraction). If a set of VNFs composing the service graph R seems to be hostable on an aggregate substrate node, then the VNF set must be able to be mapped to the underlying hidden network segment.
Given the clustering of the underlying substrate nodes which are to be aggregated, the central problem in creating the BiS-BiS view is the aggregation of the hidden nodes’ capacities into a single abstract node’s capacity. The aggregating BiS-BiS view must comply with Remark 1 and maximize the shown capabilities of the hidden network segment. In the next section we formulate this central problem as the resource contraction problem, and propose an effective solution to it.
5.2. Resource Contraction Problem
To formulate the resource abstraction problem as an optimization we first restate and generalize the capacity allocation subproblem of Formulation 1, characterized by (
1), (5) and (6).
First, the capacity allocation problem should be independent of the request graph instance
, as the aggregation view should be applicable to any service supported by the system. So we introduce a multiset of the base VNF set
including not only any set of VNFs but also their repetitions
. VNFs in an IoT service might appear multiple times, e.g., data processing and noise filtering might need to be done in multiple distributed locations, close to the sensors or end-users. Notations corresponding to this chapter are shown in
Table 4. The set of substrate nodes to be aggregated is denoted by
. Formulation 2 shows the capacity allocation problem generalized to multisets of the possible VNFs and arbitrary subsets of the substrate graph. The equations are formalized for a listing of the request multiset
, where elements with higher multiplicity are repeated accordingly. All repetitions of all VNF
must be placed somewhere, as expressed by (13). The problem only checks whether an allocation is possible, solving a subproblem of Formulation 1 with (13) and (14) relating to (
1) and (5), (6) respectively.
| Formulation 2 Capacity Allocation Problem (CAP) |
Input:
Output: True if , False otherwise
|
The resource contraction problem shown in Formulation 3 builds on the capacity allocation problem. It takes as input a subset of the substrate nodes
to be aggregated, and returns an aggregate fixed substrate node
with resource type
and aggregate capacity
. Such an example is shown in
Figure 3, where the CSP decides to aggregate its single fixed type servers in
Figure 1 into a single aggregate substrate node. This is contained in the BiS-BiS created for the western part of the CSP’s infrastructure and is connected to the other parts of the substrate graph through aggregate forwarding nodes shown in
Figure 3. The essential property of substrate abstraction of Remark 1 is formalized in (16). For all VNF sets with any multiplicity, if it seems to be placeable on the aggregate node
using the Capacity Allocation Problem (
CAP), then it must be possible to allocate it to the hidden nodes. The capacity of the aggregate node shall be maximized to show as accurate view as possible, which is formalized by the objective in (17). The capacity of the aggregate node should never exceed the sum of the hidden nodes’ capacities, formalized in (
15). Note that for evaluating the condition of (16), the Equation (14) simplifies to
.
| Formulation 3 Resource contraction problem (RCP) |
Input:
Output: |
To this end, if the RCP is solved for a set of single fixed type substrate nodes with capacity function and its accompanying demand function , then their contracted view is the aggregate fixed type substrate node with capacity A. Note that it is not necessary to define a different demand function for placing VNFs on aggregate fixed nodes, i.e., . Instead of showing the whole set of substrate nodes , the CSP can choose to publish the aggregate node, which integrates to the resource view of the OTT SPs.
Extending the substrate graph model with the aggregation node
specified by the resource contraction problem, we extend Formulation 1 to include aggregate fixed nodes in (6) as shown in (
18):
This describes a heterogeneous view of the infrastructure, while hiding some topology information as desired. The view might be periodically updated as the capacities saturate, to keep the shared information up-to-date and useful, according to the agreement among the providers.
Similar to many assignment problems, the
CAP, and thus the
RCP as well are NP-hard. The
CAP is a subproblem of the notoriously hard VNE problem, and proven to be NP-hard by reducing it to the famous 3-SAT problem [
3]. In the following we present an approximation algorithm for solving the
RCP, and we analyze its performance.
5.3. Approximating Resource Contraction
We propose a solution to efficiently approximate the NP-hard resource contraction problem (RCP) presented in Formulation 3.
The pseudo-code of aprxRCP is shown in Algorithm 2. The VNF with largest demand is selected from the input base VNF set. In lines 6 and 8 the big and small capacity substrate nodes are defined, based on being or not being able to fit , defining a 2-partition of the to-be-aggregated nodes . Note that operating on integer demands and capacities is important to achieve the approximation result. A component of the final aggregation capacity is defined by accounting for at least space in each big node in line 7. This way, the maximum amount of repetition of the biggest VNF is handled in the input multiset of CAP while solving the RCP. In addition, this approach ensures that the CAP on the hidden substrate nodes is possible, as a lower limit on the sum of such a capacity allocation is calculated. The function aprxRCP runs recursively by accounting for the highest amount of reservable capacities for the second largest VNF, by removing from the base VNF set and executing the whole function only for the small substrate nodes in line 10. As the recursively returned aggregation component cannot be higher than (otherwise the essential property of Remark 1 might be violated), a result is produced. A termination criterion for the recursion is an empty input VNF set, which results in summing the capacities of the input substrate nodes (recursively remaining nodes with small capacities) in line 3.
In each recursive call, at least one VNF, the current , is taken out of the input VNF set, so the recursion is at most deep. The algorithm performs polynomial number of steps in the input sizes in each recursive call, so the recursion always terminates and its complexity is . We state the performance guarantee of aprxRCP presented in Algorithm 2 in relation to the optimal solution of RCP.
Theorem 2 (
-approximation of the Resource Contraction Problem)
. Given any subset of the substrate graph nodes and base VNF set with capacity function and VNF demand function , Algorithm 2 -approximates the optimal solution of the Resource Contraction Problem of Formulation 3: The proof of Theorem 2 is presented in
Appendix B. A numeric example for Formulation 3 solved by
aprxRCP is presented in
Section 7.
Supported by Theorem 2, we can efficiently calculate the capacity of an aggregate fixed
type substrate node, hiding a set of single fixed
type substrate nodes. This enables a CSP to provide a heterogeneous infrastructure view to its tenant OTT SPs, hiding sensitive parts of the topology, while being able to show exact views where it is necessary, as it is demonstrated in
Figure 3. The CSP can use
aprxRCP to
-approximate the optimal aggregate capacity to be shown to its tenants’ resource orchestrators. The presented greedy heuristic framework Algorithm 1 in
Section 3.2 can be easily extended to respect the multiple types of substrate nodes, because only the capacity calculation function of Formulation 1 needs to be modified. The aggregation scheme also contributes to the scalability of the embedding algorithm executed by the OTT SP, as it decreases the number of substrate nodes in its infrastructure view. As shown in (
18), the capacity interpretation is extended for
type nodes and its implementation can be done in the
function.
| Algorithm 2 Resource contraction algorithm solving Formulation 3 |
Input:
Output: A |
| 1: | procedure aprx RCP() |
| 2: | if then |
| 3: | return (′) |
| 4: | else |
| 5: | ▹ Get the VNF with biggest demand |
| 6: | |
| 7: | |
| 8: | |
| 9: | if then |
| 10: | |
| 11: | return |
| 12: | else |
| 13: | return |
| 14: | end if |
| 15: | end if |
| 16: | end procedure |
6. Results on Elastic Resources
6.1. Modeling Resource Elasticity
To capture important characteristics of state-of-the-art computation infrastructure, we model elastic capacity and on-demand billing. Kubernetes is widely used in the industry today, thanks to its active open source community, enabling the rapid development of practical IoT deployments. As it was demonstrated earlier, Kubernetes-based virtualization architectures are a good candidate to meet the extreme requirements of IoT services [
8]. We take the widely used Horizontal Pod Autoscaler (HPA) of the Kubernetes container management system [
6] as a representative example to model resource elasticity. We propose a mathematical model of Kubernetes HPA to extend our detailed model of the heterogeneous compute and network infrastructure.
Using Kubernetes terminology, we refer to a single instance of a containerized VNF as pod, which is managed by HPA and replicated or terminated in response to changing workload. By default, HPA measures the average of all instantiated pods’ utilization of their allocated CPU capacity, and compares it to a target utilization [
7].
Definition 1 lists the HPA parameters and formalizes its operation, which is the base for describing the behavior of a single elastic substrate node .
Definition 1 (Kubernetes HPA parameters and operation)
. The following parameters are configured by the operator of HPA [7]:- 1.
and are the minimal and maximal allowed pod count,
- 2.
is the targeted scaling metric average of all running pods,
- 3.
time length of a scaling interval, when HPA evaluates metrics for scaling decisions,
- 4.
is the scaling tolerance,
- 5.
is the number of scaling intervals during the lifetime of the service R.
is the measured scaling metric average of all running pods in scaling interval . A scaling decision is made in scaling interval j, whenand the number of pods in interval recursively yields:After applying the limits, pods are terminated or instantiated to meet the count During a given scaling interval, the number of pods (i.e., VNF replicates) processing the incoming task of a VNF
is fixed. Elementary tasks of a VNF model are for example sensor data processing tasks, video processing requests, HTTP requests for a webserver VNF, flow classification requests for a firewall VNF or incoming images for an image processing VNF, etc. We extend our VNF model by assigning incoming elementary task rate
and processing rate
to VNF
. Notations for the service and substrate model extensions of this section are gathered in
Table 5.
As the default configuration of HPA uses CPU resources as scaling metric, we primarily assume the modeling characteristics based on the nature CPU utilization of computation intensive tasks. We propose to model the pod utilization states using a classic M/M/c queue, where “c” number of pods are processing the VNF’s incoming tasks in parallel. The corresponding assumptions are collected in Proposition 1.
Proposition 1 (Model scaling interval as M/M/c queue). A scaling interval of the Kubernetes HPA for a single VNF can be described by a classic M/M/c model supposing the following assumptions:
- 1.
the pods are instantiated and terminated instantly,
- 2.
the arrival process of the VNF’s task is memoryless with constant rate during the scaling interval,
- 3.
each pod has identical characteristics, including the VNF’s task processing with an identical, memoryless process with constant rate during the scaling interval,
- 4.
the task queue of VNF has infinite length and the task-to-pod assignment takes negligible time, assuming computation intensive tasks and CPU utilization scaling metrics, the pods have two distinct utilization states: busy and idle, with 100% and 0% scaling metric utilization, respectively,
- 5.
scaling metric is the average utilization of all running pods.
Note that the HPA utilization metric can be easily configured and thus the assumptions of Proposition 1 would still hold for the general scaling metric. For instance, if the application is I/O intensive, and HPA is configured to scale based on I/O resource usage, Proposition 1 remains realistic.
We state our analytical results on the M/M/c queue model in Theorem 3.
Theorem 3 (Analysis of M/M/c queue). If inequality holds for and M/M/c queue with arrival rate λ and "c" instances of servers with processing rate μ, then the expected values of the following real random variables exist and can be calculated as follows:
where and are the Laplace–Stieltjes Transform of the random variables composing the total busy time and weighted total busy time respectively. The exact definitions of the random variables and their calculations are shown in Appendix C. The proof of Theorem 3 is detailed in
Appendix C. We propose to use the expected values
and
to estimate the scaling metric of HPA.
Proposition 2 (Usage of Theorem 3 to model HPA)
. The measured scaling metric of Kubernetes HPA in any scaling interval for a single VNF can be estimated:calculated for an M/M/c queue with server count, arrival and departure rates , and , respectively. Argumentation. The momentary utilization of an M/M/c system in any given time–busy server count trajectory (i.e., a concrete realization of the random process) is calculated by the number of busy servers (pods) divided by the number of total servers "c". Thus, the average utilization in an interval t can be calculated by the area below the time–busy pod count chart until t, divided by the maximal possible (rectangular) area . As measures the area under the trajectory chart and measures the time until the idle state, their fraction gives the average utilization. Applying the assumptions of Proposition 1 this metric equals to the scaling metric which would be measured by HPA on the given pod count trajectory. This estimation neglects the dependence of the two random variables and assumes that the probability is negligible, which are realistic assumptions in a practical setting. Theorem 3 states the expected values and , which can be used to estimate the measured scaling metric .
6.2. Describing Elastic Resource Behavior
As described in Definition 1, the only non-deterministic part of HPA is the scaling metric measurement in scaling interval j. Having the estimation as shown in Proposition 2, we can model an elastic node’s behavior in response to various loads.
Algorithm 3 determines a single elastic substrate node
’s behavior (
https://github.com/nadamdb/k8s-hpa-modeling) by the trajectory of the varying pod numbers working on a single to-be-placed VNF’s task during the whole service lifetime
. Procedure
modelHPA
behavior takes as input a VNF’s intensity characteristics, and a possible elastic host node’s HPA settings. It iteratively uses the subroutine
nextHPAP
odC
ount to determine the nature of the scaling decision in each scaling interval during the lifetime of the service. The pod count trajectory function
is continuous in its first argument, which tells for each time instance the predicted number of running pods which would process the VNF
’s tasks on substrate location
. If in any scaling interval the pod count is restricted by the maximal number of pods
, the trajectory is invalidated by terminating the algorithm according to the condition in line 7. As shown in line 17, the algorithm has to handle scaling intervals when the M/M/c model’s stability criterion, i.e., a condition of Theorem 3 is not met. A cumulative overload parameter
is used between iterations, which compensates the estimated utilization metric by adding the volume of the overload. Line 21 gets the scaling metric estimation based on Proposition 2, and the overload parameter is decreased by the compensated amount. The scaling decision and the number of running pods are determined according to the HPA operation shown in Definition 1 and formalized in Algorithm 3 starting from line 24.
Note that Proposition 1 only requires the arrival and processing rates to be constant during the scaling interval. Algorithm 3 is able to handle different rates in each scaling interval, enabling it to follow dynamic changes in the request arrival or changes in the computation circumstances. The presented algorithm has been tuned to real measurements taken on a Kubernetes HPA to properly model the overloaded states, when Theorem 3 cannot be used. The overload parameter
aligns the model’s prediction with experiments. A validative comparison between the estimated pod count trajectory of Algorithm 3 and a measurement on the real pod count trajectory of a Kubernetes cluster managed by HPA is discussed in
Section 7.
| Algorithm 3 Pod count trajectory modeling of Kubernetes HPA |
Input: , parameters for defined in Definition 1
Output: |
| 1: | procedure model HPABehavior() |
| 2: | |
| 3: | ▹ Initialize output HPA trajectory function |
| 4: | ▹ Cumulative overload parameter |
| 5: | for do |
| 6: | |
| 7: | if > then |
| 8: | return⊥ ▹ Invalidate trajectory function |
| 9: | else |
| 10: | ) ▹ Use HPA pod limits in (22) |
| 11: | |
| 12: | end if |
| 13: | end for |
| 14: | return |
| 15: | end procedure |
| 16: | procedure nextHPAPodCount() |
| 17: | if then ▹ In this case the M/M/c is instable |
| 18: | |
| 19: | |
| 20: | else ▹ Use M/M/c based model |
| 21: | ▹ Get from Proposition 2 |
| 22: | |
| 23: | end if |
| 24: | if then ▹ Use (20) with |
| 25: | ▹ Use (21) with as scaling interval j |
| 26: | else |
| 27: | |
| 28: | end if |
| 29: | return |
| 30: | end procedure |
Using this model of an single elastic
substrate node, we interpret their capacities, the demands of the to-be-placed VNFs and further extend the capacity and demand functions with an additional type:
The demand function of a single VNF, to-be-placed on an elastic node is defined as the output of Algorithm 3, being either the pod count trajectory
or the invalid character ⊥. Assuming a strict QoS approach for each VNF, we allow the placement of a set of VNFs, if their sum of demand functions (i.e., their pod count trajectories) would never go above the maximal pod count
of an elastic node
. Furthermore, if a VNF alone would exceed
, the containing VNF set is considered not placeable.
The above interpretation of elastic resource capacities and demands, defines the admission control function for computation capacity managed by Kubernetes HPA. The effect of the incoming requests are modeled based on the infrastructure’s configuration, and this is used to compare the predicted dynamic demand to the allocated infrastructure capabilities. Further extending the capacity constraint (
18) (which is an extension of (6) of Formulation 1) we get:
In addition to modeling the capacity of an elastic node, the defined demand function enables us to refine the cost model of a VNF deployment on elastic substrate. If the cost of running a pod of VNF
on elastic node
for one time unit is
, then the total cost of placing the VNF here for the whole service lifetime
can be calculated:
The elastic substrate node model integrates into our heterogeneous infrastructure model, enabling the CSP to expose its detailed view of its dynamic infrastructure towards an OTT SP if necessary. The OTT SP’s orchestration algorithm can utilize this information to make VNF placement decisions and accurate cost estimations using pod count trajectory prediction. Implementing Algorithm 3 and Equations (
25) and (
26) inside the
function, enables our greedy heuristic framework to serve as the OTT SP’s orchestration algorithm over the CSP’s hybrid detailed-abstract infrastructure resources.
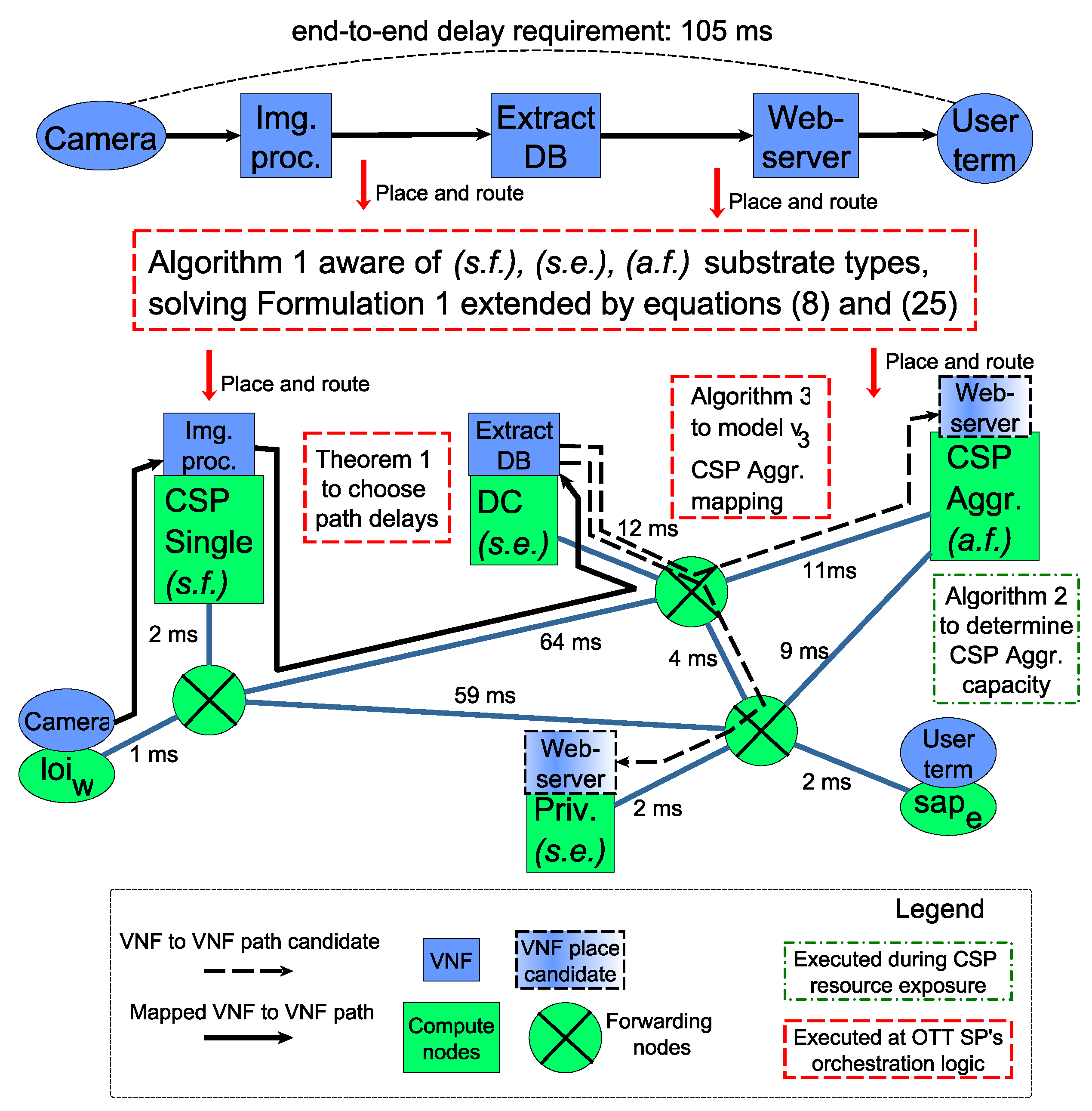
7. Practical Exploitation
In this section we summarize how our results could be integrated with the referred 5G prototype systems [
8,
19], and how they can be used for the example
remote security camera analytics and alerts IoT use case. We demonstrate the running time of Algorithm 1, and compare it to the times required by other components of our prototype system. Furthermore, we present numeric examples for applications of Theorem 1, the resource contraction problem solved by Algorithm 2 and comparing the elastic resource model of Algorithm 3 to measurement.
Figure 4 positions the presented algorithms in a general 5G-enabled IoT framework. Finally, we briefly discuss the challenges of the aggregate elastic resource type.
7.1. Result Application Examples
As shown by
Figure 4, the core service graph embedding is executed by the OTT SP’s orchestration logic, which must guarantee the end-to-end delay requirements, and be aware of the various substrate node types of the underlying heterogeneous infrastructure. As it was demonstrated, our contribution enables Algorithm 1 to solve and extended version of Formulation 1 including the delay constraint of (
8) and computation capacity constraints in (
25). Our results empower existing and future 5G architecture deployments to realize various IoT services, spanning wide geographic regions over software-controlled, abstract and dynamic infrastructures provided by multiple communication and computation entities.
7.1.1. Real-World Prototype Experiment
We have conducted experiments in a real-world sandbox environment, where the computation nodes managed by Algorithm 1 are distributed across multiple European locations [
19]. The proof-of-concept (PoC) 5G architecture prototype integrates Virtual Infrastructure Managers (VIMs), which expose their computation resources for an OTT SP’s orchestrator running Algorithm 1. Comparing our PoC to
Figure 4, the role of a CSP is played by European Internet Service Providers, while the computation infrastructure is provided by the participating institutions of the research project. We measured the deployment time of two types of Robot Control services with high reliability constraints, i.e., having the robot’s control logic provided by two independently deployed VNFs. The details of the sandbox environment, prototype implementation and the experiment scenarios are published in our earlier work [
19], here we only summarize the relevant findings.
Table 6 shows the experiment results in terms of timing, for both application types. The difference in the services is their communication underlay, which from the service placement algorithm’s perspective means different number of components. In both cases the running time of Algorithm 1 is orders of magnitudes smaller than the deployment time required by the underlying VIMs for starting and configuring the to be instantiated VNFs. In the IP routing case more components of the whole PoC architecture are involved in creating the service, this is the result of the significantly higher overall time.
We conclude that the computation requirement of Algorihtm 2 do not cause any bottlenecks in the PoC, so enriching its features with the elastic resource modeling and infrastructure aggregating of the well-scaling algorithms presented in this paper is possible. Our current paper complements this PoC with firm theoretical results to propose foundations for modeling the infrastructure resources.
7.1.2. Application of Theorem 1
Our result on greedy heuristic bound for end-to-end delay, can be used to design the step-by-step bounds for guaranteed constraint approximation performance. The OTT SP’s orchestration logic can use the conditions of Theorem 1 to make a path-delay-aware decision while choosing the routing path for individual service graph connections. Path options are illustrated by dashed arrows in
Figure 4. The following numerical example demonstrates how such bounds can be designed.
The expression for the bounds product
of Theorem 1 can be rearranged to express the estimation of
:
To numerically calculate the example, we take a 10-long service chain as the service graph, i.e.,
. Taking a permissive approach for designing the bounds (i.e.,
and
), and preserving their dependency on problem input parameters, we may take the
of their allowed intervals, as shown in
Table 7.
Substituting these bounds to Equation (
27) and making the simplifications we get actual bound for the approximation value
, shown in
Table 7. Having the bound for
we can choose the value of
from its allowed interval
. This enables us to calculate the numeric value for all other algorithm parameters, presented in the last column of
Table 7.
Note that the shown -approximation does not utilize the backtracking capability of the greedy heuristic, which drastically lowers the end-to-end delay augmentation or meets the requirement. The shown method formalizes the design process of greedy end-to-end heuristics, to tackle the trade-off between computation complexity and constraint violation. This result enables us to control the computational impact of Algorithm 1 in the whole orchestration process.
7.1.3. Resource Contraction Example Using Algorithm 2
To facilitate the VNF placement on the aggregate fixed
type substrate nodes, the CSP wishes to aggregate the capacities of its servers, and show an abstract view of the computation capacities to the OTT SP’s orchestration logic. The
CSP Aggr. compute node of
Figure 4 illustrates this scenario. The VNF placement logic uses the
case of (
25) to decide whether a VNF can be placed on the aggregate substrate node. The following numerical example shows the
-optimal solution of the NP-hard problem of Formulation 3 by our proposed approximation algorithm shown in Algorithm 2.
For simplicity we omit the capacity and demand functions from the inputs of the related problems and algorithms, and only list the substrate node capacities, VNF demands in the CAP, RCP and aprxRCP arguments. We take the base VNF set with capacity demands and to-be-aggregated substrate nodes with capacities . First, we estimate , which is obviously smaller than 20, as 5 times the VNF with demand 4 could be allocated on the aggregate node, i.e., is true, but could not be allocated on the hidden nodes, i.e., is false. Our proposed resource contraction algorithm , shown in Algorithm 2, in its first iteration with , calculates for the big capacities . In the second iteration for the small capacities, it calculates . So the aggregate capacity , which is at least -approximation of the optimal solution.
In conclusion, the CSP can efficiently show its resources meeting the essential property for abstraction, as described in Remark 1, which view can be quickly generated.
7.1.4. Comparison of Algorithm 3 to Measurement
Finally, our results on modeling Kubernetes HPA, the OTT SP, running Algorithm 1, can estimate the trajectory of VNF replication states for the IoT service’s lifetime in response to user traffic. The trajectory estimation is presented in Algorithm 3 and should be implemented in the OTT SP’s orchestration logic, making placement decisions based on (
25). This is illustrated by the placements of
Extract DB VNF and
Webserver VNF to single elastic
substrate nodes on
Figure 4.
Figure 5 shows the predicted pod count trajectory and its comparison to the behavior of a real Kubernetes cluster deployment managed by HPA. The experiment uses a webserver VNF packaged in a pod, receiving independent, identically and exponentially distributed user requests with constant arrival (
) and processing intensity (
) for an hour.
The HPA’s scaling interval is set to 1 min, with targeted scaling metric , scaling tolerance and pod limits , . The model utilizes the calculated arrival and processing rate of the webserver VNF during the current scaling interval. So that, not only a fixed pair of arrival rate and processing rate is given (as shown in Algorithm 3), but the realization of the randomized processes is used to calculate the local rates. This approach slightly generalizes the algorithm to provide a reasonable comparison to the measurement, as the Kubernetes HPA is not aware of the exact rates used for generating the arrival and processing times. These estimated rates are used as the input for the nextHPAPodCount() function to predict the utilization metric, and thus predict the number of active pods for the next scaling interval. The experiment starts with a single running pod, when both the model and the measurement initially over-provisions with very similar extent and timing. Both trajectories follow the slight oscillation around the equilibrium pod count of 11–13, resulting in at most −/+15% deviation.
Using this model the OTT SP can make a well-informed decision for deploying its IoT service over the CSP’s elastic and heterogeneous infrastructure.
7.2. Aggregate Elastic Substrate Node Type
Designing a model for aggregate elastic infrastructure node types is extremely challenging, as modeling elasticity requires various parameters describing the dynamic behavior, while aggregation abstracts the lower level infrastructure details. For instance, aggregating the view of multiple Kubernetes HPA nodes using the resource contraction problem (RCP) would require allocating a fix capacity to each of the to-be-hidden clusters. This goes against preserving the dynamic nature of the underlying nodes. On the other hand, describing the aggregate elastic node’s capabilities using well-studied queuing systems, such as the M/M/c queue, would require crude simplifications of infrastructure characteristics.
This is a possible future research direction in infrastructure modeling as dynamicity increasingly gains momentum in cloud computing, while network management of edge resources is already challenging, calling for higher computing and communication resource abstractions.
8. Conclusions
We have identified a gap between the rapid evolution of virtualization-based infrastructure technologies and the essentially unchanged substrate models of service placement algorithms. Distributed computing solutions, such as Mobile Edge Computing and 5G utilize increasingly capable infrastructure technologies for addressing quickly changing user demands, and scaling up to the immense sizes of IoT networks. On the contrary, the service component placement algorithms, managing service deployment on top of these architectures, only consider fixed substrate capacities.
Primarily, we have presented our resource aggregation model to support the scalability of network management algorithms, and help preserving sensitive infrastructure information during inter-provider control-plane communication. Secondly, we have used our classic queuing theory results to build an elastic resource model for the auto-scaling mechanism of the wide-spread container management system, Kubernetes. Our results on infrastructure modeling empower existing 5G prototype architectures to place delay-constrained IoT service components on highly dynamic and abstract resource views. In addition, we demonstrated how scalable service placement algorithms can meet path delay requirements by making greedy decisions, while optimizing for independent metrics. Our results integrate with placement algorithms using elementary service-to-resource mapping decisions, enabling their easy deployments already in the proof-of-concept phase. All of our results are complemented with rigorous mathematical theorems whose proofs have been presented in detail.
Finally, we have showcased the practical applicability of our theorems and algorithms to demonstrate what roles our results play for realizing the remote security camera analytics and alerts IoT application across wide geographic areas. The infrastructure resources provided by multiple CSPs and CPs are used by customers facing OTT SPs, who provide IoT services. All players of these complex business relations benefit from higher resource abstraction, accurate modeling of dynamic resources and efficient service placement algorithms.
The computation and communication infrastructure for realizing various IoT applications is becoming increasingly capable to keep up with the user requirements for high service quality. In emerging modern networks, the management algorithms not only have to handle communication resources, but the coordinated management of computation needs to be blended in. The contributions of this paper are believed to be essential for effective abstract resource information exchange and detailed modeling of elastic resources. We hope that our results could serve as a basis for such communication protocol definitions and standardized data models for multi-domain, heterogeneous 5G infrastructures.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}