An Efficient and Robust Deep Learning Method with 1-D Octave Convolution to Extract Fetal Electrocardiogram



Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Data
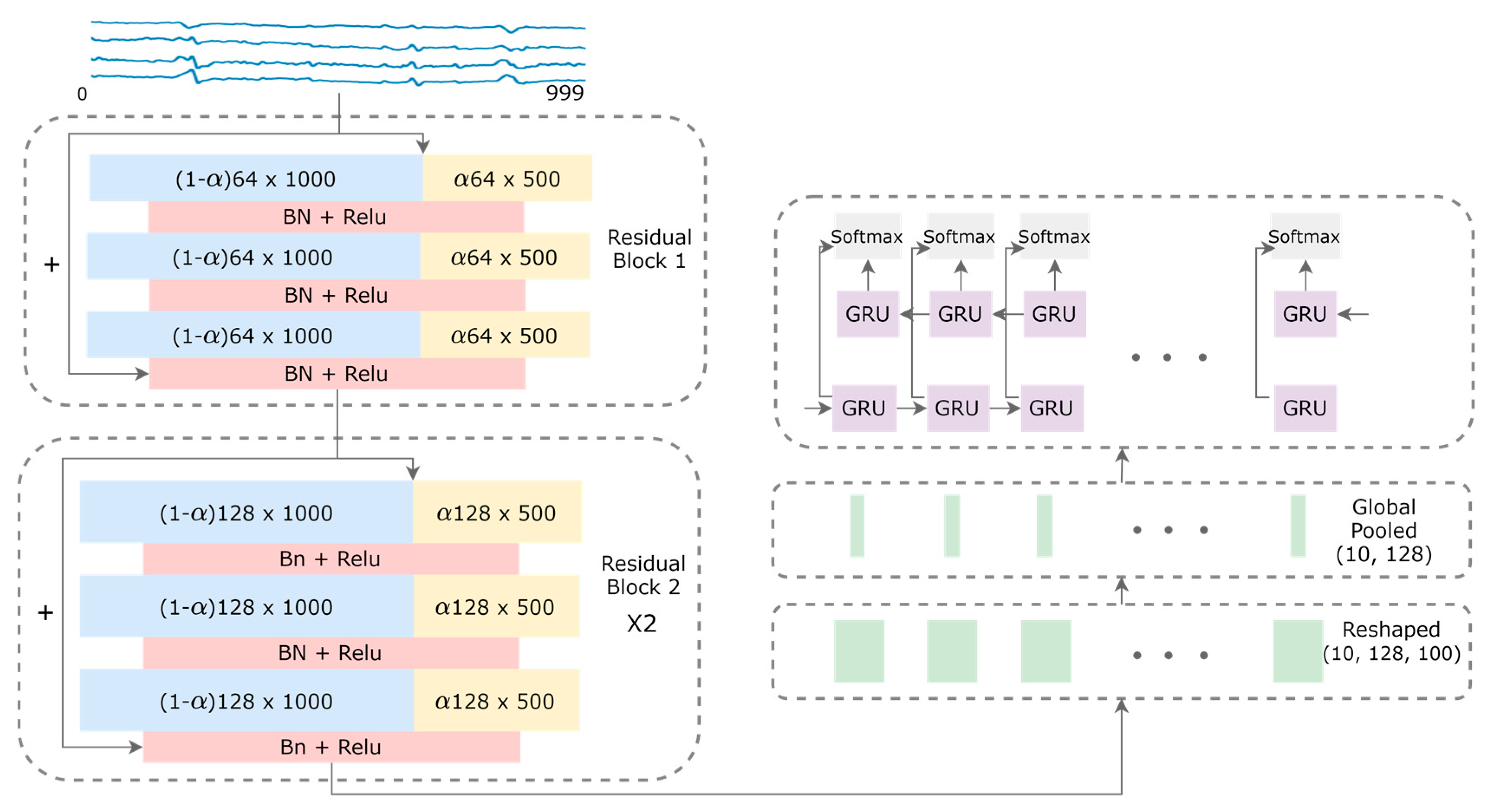
2.2. Model Architecture
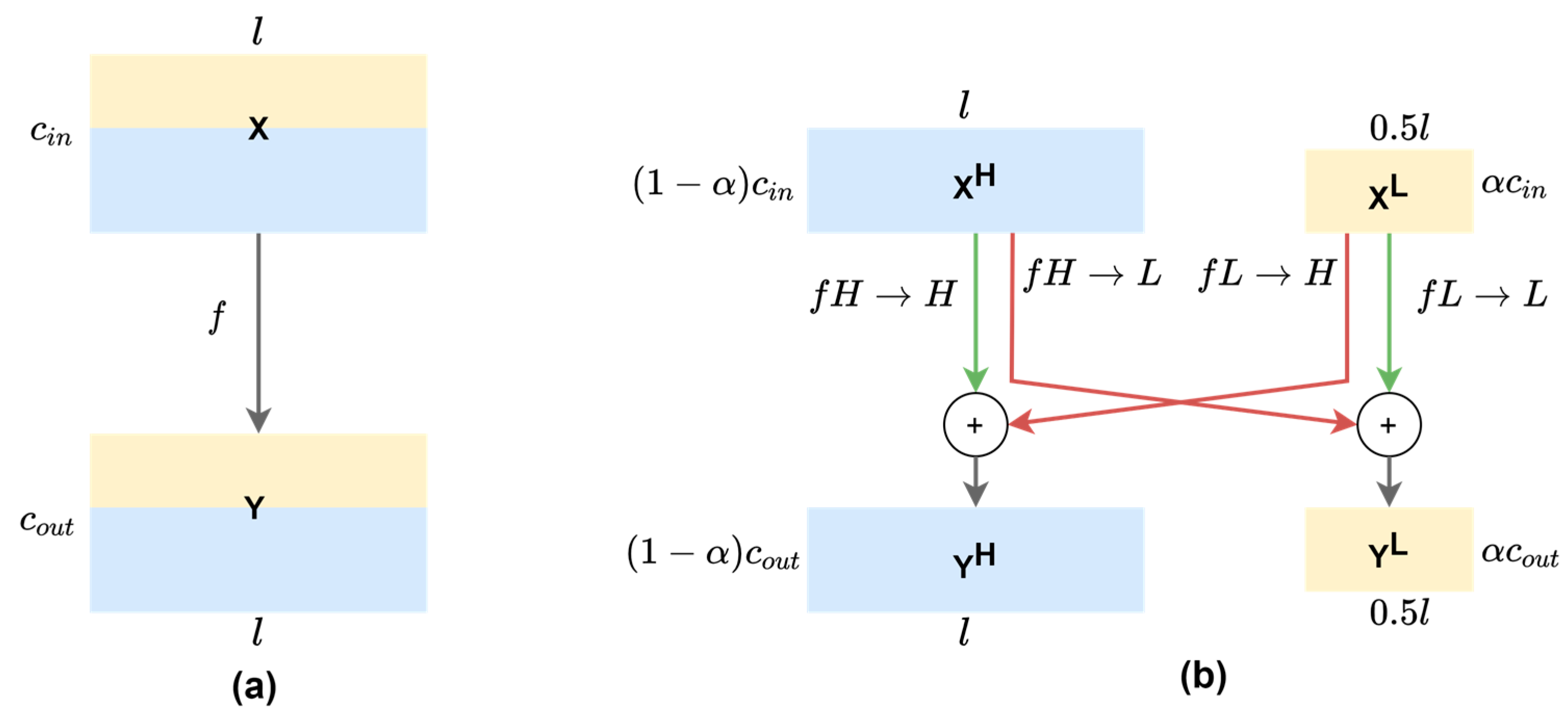
2.3. Theoretical Gains of 1-D OctConv
2.4. Visualization of Class Discriminative Regions
3. Results and Discussion
3.1. Experiment Setup
3.2. Evaluation Metrics
3.3. Results and Interpretations
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gregory, E.C.W.; MacDorman, M.F.; A Martin, J. Trends in fetal and perinatal mortality in the United States, 2006–2012. NCHS Data Brief 2014, 169, 1–8. [Google Scholar]
- Ananth, C.V.; Chauhan, S.P.; Chen, H.-Y.; D’Alton, M.E.; Vintzileos, A.M. Electronic Fetal Monitoring in the United States. Obs. Gynecol. 2013, 121, 927–933. [Google Scholar] [CrossRef]
- Le, T.; Moravec, A.; Huerta, M.; Lau, M.P.; Cao, H. Unobtrusive Continuous Monitoring of Fetal Cardiac Electrophysiology in the Home Setting. IEEE Sens. Appl. Symp. Sas. 2018, 1–4. [Google Scholar] [CrossRef]
- Slanina, Z.; Jaros, R.; Kahankova, R.; Martinek, R.; Nedoma, J.; Fajkus, M. Fetal phonocardiography signal processing from abdominal records by non-adaptive methods. Photonics Appl. Astron. Commun. Ind. High Energy Phys. Exp. 2018, 10808, 108083E. [Google Scholar] [CrossRef]
- Gilboa, S.M.; Devine, O.J.; Kucik, J.E.; Oster, M.E.; Riehle-Colarusso, T.; Nembhard, W.N.; Xu, P.; Correa, A.; Jenkins, K.; Marelli, A. Congenital Heart Defects in the United States: Estimating the Magnitude of the Affected Population in 2010. Circulation 2016, 134, 101–109. [Google Scholar] [CrossRef]
- Kahankova, R.; Martinek, R.; Jaros, R.; Behbehani, K.; Matonia, A.; Jezewski, M.; Behar, J.A. A Review of Signal Processing Techniques for Non-Invasive Fetal Electrocardiography. IEEE Rev. Biomed. Eng. 2020, 13, 51–73. [Google Scholar] [CrossRef]
- Cardoso, J.-F. Blind Signal Separation: Statistical Principles. Proc. IEEE 1998, 86, 2009–2025. [Google Scholar] [CrossRef]
- Zarzoso, V.; Nandi, A. Noninvasive fetal electrocardiogram extraction: Blind separation versus adaptive noise cancellation. IEEE Trans. Biomed. Eng. 2001, 48, 12–18. [Google Scholar] [CrossRef]
- Ungureanu, M.; Bergmans, J.W.; Oei, S.G.; Strungaru, R.; Ungureanu, G.-M. Fetal ECG extraction during labor using an adaptive maternal beat subtraction technique. Biomed. Tech. Eng. 2007, 52, 56–60. [Google Scholar] [CrossRef] [PubMed]
- Zhong, W.; Liao, L.; Guo, X.; Wang, G. A deep learning approach for fetal QRS complex detection. Physiol. Meas. 2018, 39, 045004. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.S.; Seo, M.; Kim, S.W.; Choi, M. Fetal QRS Detection Based on Convolutional Neural Networks in Noninvasive Fetal Electrocardiogram. In Proceedings of the 2018 4th International Conference on Frontiers of Signal Processing (ICFSP), Poitiers, France, 24–27 September 2018; pp. 75–78. [Google Scholar]
- La, F.-W.; Tsai, P.-Y. Deep Learning for Detection of Fetal ECG from Multi-Channel Abdominal Leads. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1397–1401. [Google Scholar]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Shuicheng, Y.; Feng, J. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks With Octave Convolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3435–3444. [Google Scholar]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Silva, I.; Behar, J.; Sameni, R.; Zhu, T.; Oster, J.; Clifford, G.D.; Moody, G.B. Noninvasive Fetal ECG: The PhysioNet/Computing in Cardiology Challenge 2013. Comput. Cardiol. 2013, 40, 149–152. [Google Scholar]
- Behar, J.; Oster, J.; Clifford, G.D. Non-invasive FECG extraction from a set of abdominal sensors. In Proceedings of the Computing in Cardiology 2013, Zaragoza, Spain, 22–25 September 2013; pp. 297–300. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078, 1724–1734. [Google Scholar]
- Ribeiro, M.; Singh, S.; Guestrin, C.; Denero, J.; Finlayson, M.; Reddy, S. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, Association for Computational Linguistics (ACL), San Diego, CA, USA, 12–17 June 2016; pp. 97–101. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Goodfellow, S.D.; Goodwin, A.; Greer, R.; Laussen, P.C.; Mazwi, M.; Eytan, D. Towards Understanding ECG Rhythm Classification Using Convolutional Neural Networks and Attention Mappings. In Proceedings of the 3rd Machine Learning for Healthcare Conference, Stanford, CA, USA, 16–18 August 2018; pp. 83–101. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tung, F.; Mori, G. CLIP-Q: Deep Network Compression Learning by In-parallel Pruning-Quantization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7873–7882. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ratio (α) | 0 | 0.25 | 0.5 | 0.75 |
|---|---|---|---|---|
| #FLOPs Cost | 100% | 78% | 63% | 53% |
| Memory Cost | 100% | 88% | 75% | 63% |
| α | F1-Test | F1-Cross | CNN-GFLOPs | GRU-FC-GFLOPs | Inference Time (s) |
|---|---|---|---|---|---|
| 0 | 0.907 | 0.872 ± 0.048 | 0.52 | 3 × 10−4 | 0.59 |
| 0.25 | 0.911 | 0.874 ± 0.054 | 0.42 | 3 × 10−4 | 0.55 |
| 0.5 | 0.901 | 0.869 ± 0.059 | 0.34 | 3 × 10−4 | 0.48 |
| 0.75 | 0.894 | 0.866 ± 0.058 | 0.29 | 3 × 10−4 | 0.45 |
| Types of Noise | SNR Level (dB) | Motion Noise | ||
|---|---|---|---|---|
| 50.6 | 36.8 | 29.12 | ||
| F1 | 0.815 | 0.739 | 0.627 | 0.844 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vo, K.; Le, T.; Rahmani, A.M.; Dutt, N.; Cao, H. An Efficient and Robust Deep Learning Method with 1-D Octave Convolution to Extract Fetal Electrocardiogram. Sensors 2020, 20, 3757. https://doi.org/10.3390/s20133757
Vo K, Le T, Rahmani AM, Dutt N, Cao H. An Efficient and Robust Deep Learning Method with 1-D Octave Convolution to Extract Fetal Electrocardiogram. Sensors. 2020; 20(13):3757. https://doi.org/10.3390/s20133757
Chicago/Turabian StyleVo, Khuong, Tai Le, Amir M. Rahmani, Nikil Dutt, and Hung Cao. 2020. "An Efficient and Robust Deep Learning Method with 1-D Octave Convolution to Extract Fetal Electrocardiogram" Sensors 20, no. 13: 3757. https://doi.org/10.3390/s20133757
APA StyleVo, K., Le, T., Rahmani, A. M., Dutt, N., & Cao, H. (2020). An Efficient and Robust Deep Learning Method with 1-D Octave Convolution to Extract Fetal Electrocardiogram. Sensors, 20(13), 3757. https://doi.org/10.3390/s20133757