Long-Term Tracking of Group-Housed Livestock Using Keypoint Detection and MAP Estimation for Individual Animal Identification


Abstract
1. Introduction
2. Background
3. Method
- Video footage is obtained from a static camera mounted above the environment of interest.
- The field of view of the camera encompasses the entire living space.
- The number of targets remains constant and each is equipped with a unique visual marker.
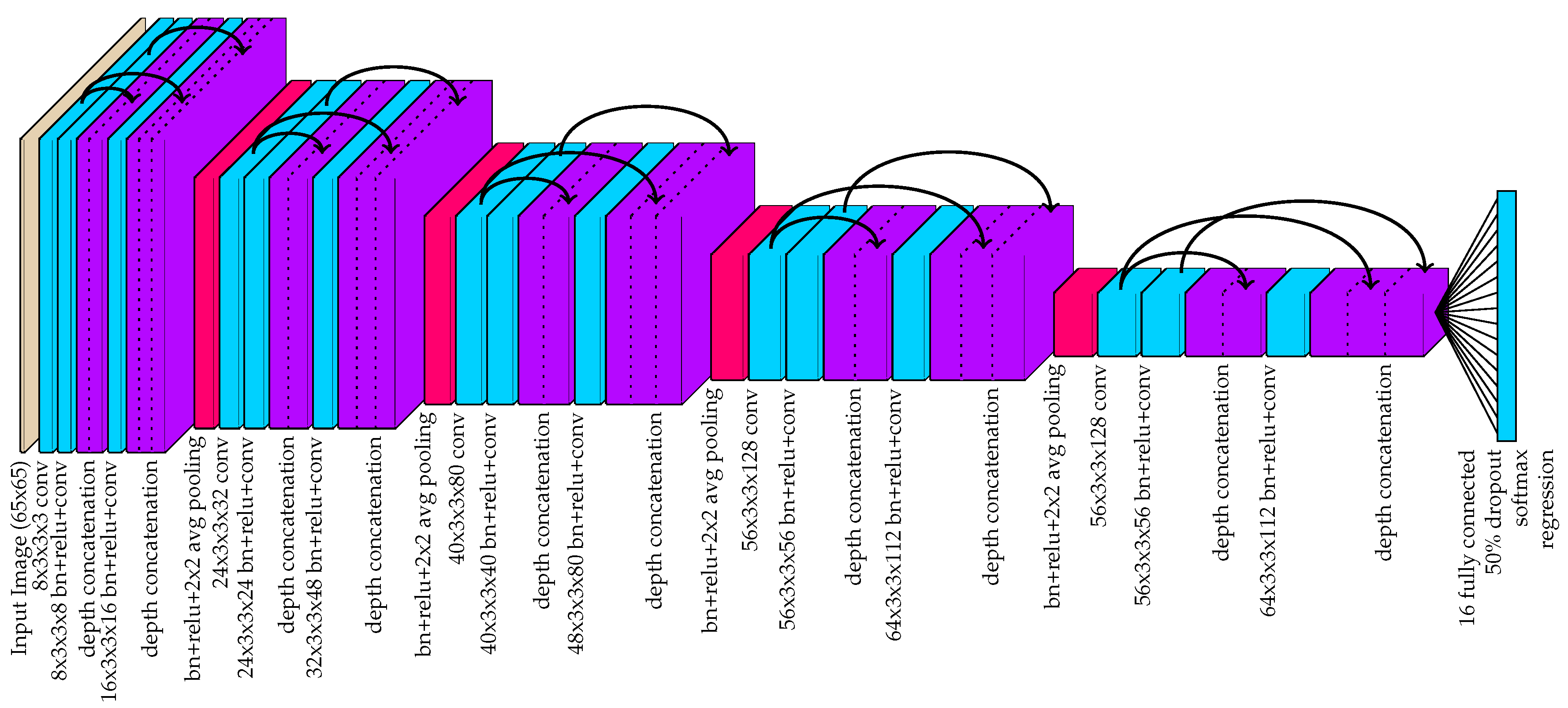
3.1. Instance Detection and Part Localization
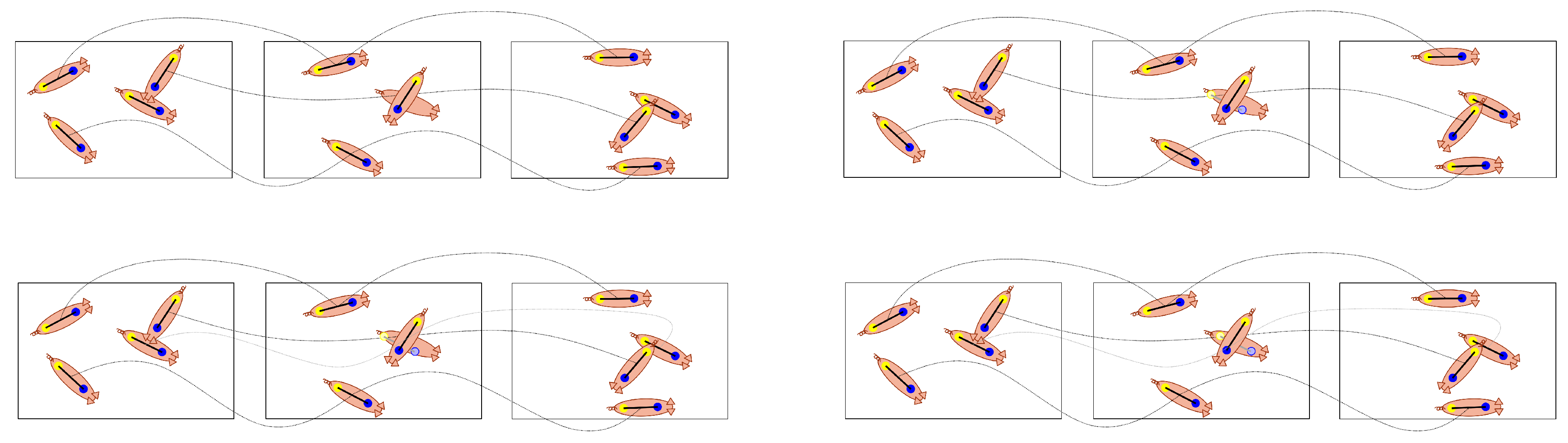
3.2. Fixed-Cardinality Track Interpolation
| Algorithm 1: Fixed-Cardinality Track Interpolation. |
 |
3.3. Visual Marker Classification
3.4. Maximum A-Posteriori (MAP) Estimation of Animal Identity
4. Training Details and Evaluation Methodology
- Location: The user is only interested in the location/orientation of each animal and the specific ID can be ignored. This scenario applies when only pen-level metrics are desired, such as average distance traveled per animal or pen space utilization.
- Location and ID (Initialized): Both the location/orientation and the ID of each animal are desired and the human annotations are provided for the first frame. This scenario assumes that several videos are being processed in sequence and that tracking results from the previous video are available. Location/orientation with ID are important for individualized metrics, such as monitoring health and identifying aggressors.
- Location and ID (Uninitialized): This scenario is the same as Location and ID (Initialized), except that human annotations are not provided for the first frame. This is the most challenging scenario because it forces the method to visually ID each animal from intermittent views of the ear tags within the time span of the video.
4.1. Ear Tag Classification
4.2. Dataset Description
4.3. Performance and Analysis
- Successful Match (Location and ID):and and
- Successful Match (Location):and and
5. Results
Hardware and Processing Times
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- PIC North America. Standard Animal Care: Daily Routines; Wean to Finish Manual; PIC North America: Hendersonville, TN, USA, 2014; pp. 23–24. [Google Scholar]
- Jack, K.M.; Lenz, B.B.; Healan, E.; Rudman, S.; Schoof, V.A.; Fedigan, L. The effects of observer presence on the behavior of Cebus capucinus in Costa Rica. Am. J. Primatol. 2008, 70, 490–494. [Google Scholar] [CrossRef] [PubMed]
- Iredale, S.K.; Nevill, C.H.; Lutz, C.K. The influence of observer presence on baboon (Papio spp.) and rhesus macaque (Macaca mulatta) behavior. Appl. Anim. Behav. Sci. 2010, 122, 53–57. [Google Scholar] [CrossRef] [PubMed]
- Leruste, H.; Bokkers, E.; Sergent, O.; Wolthuis-Fillerup, M.; Van Reenen, C.; Lensink, B. Effects of the observation method (direct v. from video) and of the presence of an observer on behavioural results in veal calves. Animal 2013, 7, 1858–1864. [Google Scholar] [CrossRef] [PubMed]
- Matthews, S.G.; Miller, A.L.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early detection of health and welfare compromises through automated detection of behavioural changes in pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef]
- Wedin, M.; Baxter, E.M.; Jack, M.; Futro, A.; D’Eath, R.B. Early indicators of tail biting outbreaks in pigs. Appl. Anim. Behav. Sci. 2018, 208, 7–13. [Google Scholar] [CrossRef]
- Burgunder, J.; Petrželková, K.J.; Modrỳ, D.; Kato, A.; MacIntosh, A.J. Fractal measures in activity patterns: Do gastrointestinal parasites affect the complexity of sheep behaviour? Appl. Anim. Behav. Sci. 2018, 205, 44–53. [Google Scholar] [CrossRef]
- Tuyttens, F.; de Graaf, S.; Heerkens, J.L.; Jacobs, L.; Nalon, E.; Ott, S.; Stadig, L.; Van Laer, E.; Ampe, B. Observer bias in animal behaviour research: Can we believe what we score, if we score what we believe? Anim. Behav. 2014, 90, 273–280. [Google Scholar] [CrossRef]
- Wathes, C.M.; Kristensen, H.H.; Aerts, J.M.; Berckmans, D. Is precision livestock farming an engineer’s daydream or nightmare, an animal’s friend or foe, and a farmer’s panacea or pitfall? Comput. Electron. Agric. 2008, 64, 2–10. [Google Scholar] [CrossRef]
- Banhazi, T.M.; Lehr, H.; Black, J.; Crabtree, H.; Schofield, P.; Tscharke, M.; Berckmans, D. Precision livestock farming: An international review of scientific and commercial aspects. Int. J. Agric. Biol. Eng. 2012, 5, 1–9. [Google Scholar]
- Tullo, E.; Fontana, I.; Guarino, M. Precision livestock farming: An overview of image and sound labelling. In Proceedings of the European Conference on Precision Livestock Farming 2013:(PLF) EC-PLF, KU Leuven, Belgium, 10–12 September 2013; pp. 30–38. [Google Scholar]
- Taylor, K. Cattle health monitoring using wireless sensor networks. In Proceedings of the Communication and Computer Networks Conference, Cambridge, MA, USA, 8–10 November 2004. [Google Scholar]
- Giancola, G.; Blazevic, L.; Bucaille, I.; De Nardis, L.; Di Benedetto, M.G.; Durand, Y.; Froc, G.; Cuezva, B.M.; Pierrot, J.B.; Pirinen, P.; et al. UWB MAC and network solutions for low data rate with location and tracking applications. In Proceedings of the 2005 IEEE International Conference on Ultra-Wideband, Zurich, Switzerland, 5–8 September 2005; pp. 758–763. [Google Scholar]
- Clark, P.E.; Johnson, D.E.; Kniep, M.A.; Jermann, P.; Huttash, B.; Wood, A.; Johnson, M.; McGillivan, C.; Titus, K. An advanced, low-cost, GPS-based animal tracking system. Rangeland Ecol. Manag. 2006, 59, 334–340. [Google Scholar] [CrossRef]
- Schwager, M.; Anderson, D.M.; Butler, Z.; Rus, D. Robust classification of animal tracking data. Comput. Electron. Agric. 2007, 56, 46–59. [Google Scholar] [CrossRef]
- Ruiz-Garcia, L.; Lunadei, L.; Barreiro, P.; Robla, I. A Review of Wireless Sensor Technologies and Applications in Agriculture and Food Industry: State of the Art and Current Trends. Sensors 2009, 9, 4728–4750. [Google Scholar] [CrossRef]
- Kim, S.H.; Kim, D.H.; Park, H.D. Animal situation tracking service using RFID, GPS, and sensors. In Proceedings of the 2010 Second International Conference on Computer and Network Technology (ICCNT), Bangkok, Thailand, 23–25 April 2010; pp. 153–156. [Google Scholar]
- Escalante, H.J.; Rodriguez, S.V.; Cordero, J.; Kristensen, A.R.; Cornou, C. Sow-activity classification from acceleration patterns: A machine learning approach. Comput. Electron. Agric. 2013, 93, 17–26. [Google Scholar] [CrossRef]
- Porto, S.; Arcidiacono, C.; Giummarra, A.; Anguzza, U.; Cascone, G. Localisation and identification performances of a real-time location system based on ultra wide band technology for monitoring and tracking dairy cow behaviour in a semi-open free-stall barn. Comput. Electron. Agric. 2014, 108, 221–229. [Google Scholar] [CrossRef]
- Alvarenga, F.A.P.; Borges, I.; Palkovič, L.; Rodina, J.; Oddy, V.H.; Dobos, R.C. Using a three-axis accelerometer to identify and classify sheep behaviour at pasture. Appl. Anim. Behav. Sci. 2016, 181, 91–99. [Google Scholar] [CrossRef]
- Voulodimos, A.S.; Patrikakis, C.Z.; Sideridis, A.B.; Ntafis, V.A.; Xylouri, E.M. A complete farm management system based on animal identification using RFID technology. Comput. Electron. Agric. 2010, 70, 380–388. [Google Scholar] [CrossRef]
- Feng, J.; Fu, Z.; Wang, Z.; Xu, M.; Zhang, X. Development and evaluation on a RFID-based traceability system for cattle/beef quality safety in China. Food Control 2013, 31, 314–325. [Google Scholar] [CrossRef]
- Floyd, R.E. RFID in animal-tracking applications. IEEE Potentials 2015, 34, 32–33. [Google Scholar] [CrossRef]
- Neethirajan, S. Recent advances in wearable sensors for animal health management. Sens. Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef]
- Schleppe, J.B.; Lachapelle, G.; Booker, C.W.; Pittman, T. Challenges in the design of a GNSS ear tag for feedlot cattle. Comput. Electron. Agric. 2010, 70, 84–95. [Google Scholar] [CrossRef]
- Ardö, H.; Guzhva, O.; Nilsson, M.; Herlin, A.H. Convolutional neural network-based cow interaction watchdog. IET Comput. Vision 2017, 12, 171–177. [Google Scholar] [CrossRef]
- Ju, M.; Choi, Y.; Seo, J.; Sa, J.; Lee, S.; Chung, Y.; Park, D. A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring. Sensors 2018, 18, 1746. [Google Scholar] [CrossRef] [PubMed]
- Psota, E.T.; Mittek, M.; Pérez, L.C.; Schmidt, T.; Mote, B. Multi-Pig Part Detection and Association with a Fully-Convolutional Network. Sensors 2019, 19, 852. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic individual pig detection and tracking in pig farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in neural information processing systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kirk, D. NVIDIA CUDA software and GPU parallel computing architecture. In Proceedings of the ISMM, New York, NY, USA, 19–25 May 2007; pp. 103–104. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia. ACM, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami Beach, FL, USA, 25–29 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vision 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, New York, NY, USA, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 3686–3693. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Dehghan, A.; Modiri Assari, S.; Shah, M. Gmmcp tracker: Globally optimal generalized maximum multi clique problem for multiple object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2016; pp. 4091–4099. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv Preprint 2016, arXiv:1603.00831. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1318–1327. [Google Scholar]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6036–6046. [Google Scholar]
- Nasirahmadi, A.; Richter, U.; Hensel, O.; Edwards, S.; Sturm, B. Using machine vision for investigation of changes in pig group lying patterns. Comput. Electron. Agric. 2015, 119, 184–190. [Google Scholar] [CrossRef]
- Kashiha, M.A.; Bahr, C.; Ott, S.; Moons, C.P.; Niewold, T.A.; Tuyttens, F.; Berckmans, D. Automatic monitoring of pig locomotion using image analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Nilsson, M.; Ardö, H.; Åström, K.; Herlin, A.; Bergsten, C.; Guzhva, O. Learning based image segmentation of pigs in a pen. In Proceedings of the Visual observation and analysis of Vertebrate And Insect Behavior –Workshop at the 22nd International Conference on Pattern Recognition (ICPR 2014), Stockholm, Sweden, 24 August 2014; pp. 24–28. [Google Scholar]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimedia 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Kongsro, J. Estimation of pig weight using a Microsoft Kinect prototype imaging system. Comput. Electron. Agric. 2014, 109, 32–35. [Google Scholar] [CrossRef]
- Zhu, Q.; Ren, J.; Barclay, D.; McCormack, S.; Thomson, W. Automatic Animal Detection from Kinect Sensed Images for Livestock Monitoring and Assessment. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology, Liverpool, UK, 26–28 October 2015; pp. 1154–1157. [Google Scholar]
- Stavrakakis, S.; Li, W.; Guy, J.H.; Morgan, G.; Ushaw, G.; Johnson, G.R.; Edwards, S.A. Validity of the Microsoft Kinect sensor for assessment of normal walking patterns in pigs. Comput. Electron. Agric. 2015, 117, 1–7. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Behavior in Pigs Using a Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed]
- Lao, F.; Brown-Brandl, T.; Stinn, J.; Liu, K.; Teng, G.; Xin, H. Automatic recognition of lactating sow behaviors through depth image processing. Comput. Electron. Agric. 2016, 125, 56–62. [Google Scholar] [CrossRef]
- Choi, J.; Lee, L.; Chung, Y.; Park, D. Individual Pig Detection Using Kinect Depth Information. KIPS Trans. Comput. Commun. Syst. 2016, 5, 319–326. [Google Scholar] [CrossRef][Green Version]
- Mittek, M.; Psota, E.T.; Pérez, L.C.; Schmidt, T.; Mote, B. Health Monitoring of Group-Housed Pigs using Depth-Enabled Multi-Object Tracking. In Proceedings of the Visual observation and analysis of Vertebrate And Insect Behavior, Cancun, Mexico, 4 December 2016; pp. 9–12. [Google Scholar]
- Kim, J.; Chung, Y.; Choi, Y.; Sa, J.; Kim, H.; Chung, Y.; Park, D.; Kim, H. Depth-Based Detection of Standing-Pigs in Moving Noise Environments. Sensors 2017, 17, 2757. [Google Scholar] [CrossRef]
- Matthews, S.G.; Miller, A.L.; PlÖtz, T.; Kyriazakis, I. Automated tracking to measure behavioural changes in pigs for health and welfare monitoring. Sci. Rep. 2017, 7, 17582. [Google Scholar] [CrossRef]
- Pezzuolo, A.; Guarino, M.; Sartori, L.; González, L.A.; Marinello, F. On-barn pig weight estimation based on body measurements by a Kinect v1 depth camera. Comput. Electron. Agric. 2018, 148, 29–36. [Google Scholar] [CrossRef]
- Fernandes, A.; Dórea, J.; Fitzgerald, R.; Herring, W.; Rosa, G. A novel automated system to acquire biometric and morphological measurements, and predict body weight of pigs via 3D computer vision. J. Anim. Sci. 2018, 97, 496–508. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Mittek, M.; Psota, E.T.; Carlson, J.D.; Pérez, L.C.; Schmidt, T.; Mote, B. Tracking of group-housed pigs using multi-ellipsoid expectation maximisation. IET Comput. Vision 2017, 12, 121–128. [Google Scholar] [CrossRef]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA; pp. 7291–7299.
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 21–37. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Venice, Italy, 22–29 October 2017; pp. 4700–4708. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, M.; Liew, S.C.; Shao, Z.; Kai, C. Markov Approximation for Combinatorial Network Optimization. IEEE Trans. Inf. Theory 2013, 59, 6301–6327. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nursery | Early Finisher | Late Finisher | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Video # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Day | X | X | X | X | X | X | X | X | X | ||||||
| Night | X | X | X | X | X | X | |||||||||
| # of Pigs | 16 | 16 | 15 | 16 | 16 | 7 | 15 | 7 | 8 | 8 | 16 | 14 | 12 | 14 | 13 |
| Activity Level | H | M | L | M | L | H | M | L | M | L | H | M | L | M | L |
| Location | |||||||
|---|---|---|---|---|---|---|---|
| Activity | High (Day) | Medium (Day) | Low (Day) | Medium (Night) | Low (Night) | Average | |
| Age | |||||||
| Nursery | 0.9267 | 0.9964 | 0.9985 | 0.9548 | 0.8405 | 0.9434 | |
| Early Finisher | 0.9961 | 0.9973 | 1 | 0.9349 | 1 | 0.9857 | |
| Late Finisher | 0.9907 | 0.989 | 0.9969 | 0.9564 | 1 | 0.9866 | |
| Average | 0.9711 | 0.9943 | 0.9984 | 0.9487 | 0.9468 | 0.9719 | |
| Location and ID (Initialized) | |||||||
| Activity | High (Day) | Medium (Day) | Low (Day) | Medium (Night) | Low (Night) | Average | |
| Age | |||||||
| Nursery | 0.8893 | 0.9941 | 0.9933 | 0.8958 | 0.6256 | 0.8796 | |
| Early Finisher | 0.9949 | 0.9847 | 1 | 0.8716 | 1 | 0.9702 | |
| Late Finisher | 0.9836 | 0.958 | 0.9897 | 0.8569 | 0.8462 | 0.9269 | |
| Average | 0.9559 | 0.9789 | 0.9943 | 0.8748 | 0.8239 | 0.9256 | |
| Location and ID (Uninitialized) | |||||||
| Activity | High (Day) | Medium (Day) | Low (Day) | Medium (Night) | Low (Night) | Average | |
| Age | |||||||
| Nursery | 0.8893 | 0.9941 | 0.694 | 0.7927 | 0.6108 | 0.7962 | |
| Early Finisher | 0.9948 | 0.9718 | 1 | 0.8946 | 0.5888 | 0.89 | |
| Late Finisher | 0.9836 | 0.8176 | 0.9897 | 0.629 | 0.5252 | 0.789 | |
| Average | 0.9559 | 0.9278 | 0.8946 | 0.7721 | 0.5749 | 0.8251 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
T. Psota, E.; Schmidt, T.; Mote, B.; C. Pérez, L. Long-Term Tracking of Group-Housed Livestock Using Keypoint Detection and MAP Estimation for Individual Animal Identification. Sensors 2020, 20, 3670. https://doi.org/10.3390/s20133670
T. Psota E, Schmidt T, Mote B, C. Pérez L. Long-Term Tracking of Group-Housed Livestock Using Keypoint Detection and MAP Estimation for Individual Animal Identification. Sensors. 2020; 20(13):3670. https://doi.org/10.3390/s20133670
Chicago/Turabian StyleT. Psota, Eric, Ty Schmidt, Benny Mote, and Lance C. Pérez. 2020. "Long-Term Tracking of Group-Housed Livestock Using Keypoint Detection and MAP Estimation for Individual Animal Identification" Sensors 20, no. 13: 3670. https://doi.org/10.3390/s20133670
APA StyleT. Psota, E., Schmidt, T., Mote, B., & C. Pérez, L. (2020). Long-Term Tracking of Group-Housed Livestock Using Keypoint Detection and MAP Estimation for Individual Animal Identification. Sensors, 20(13), 3670. https://doi.org/10.3390/s20133670