A Very High-Speed Validation Scheme Based on Template Matching for Segmented Character Expiration Codes on Beverage Cans †


 ,
,
Abstract

1. Introduction
2. Character Segmentation Prior to Validation
3. Information Extracted in Previous Stages
4. Comparing Morphologies
4.1. Expected Code
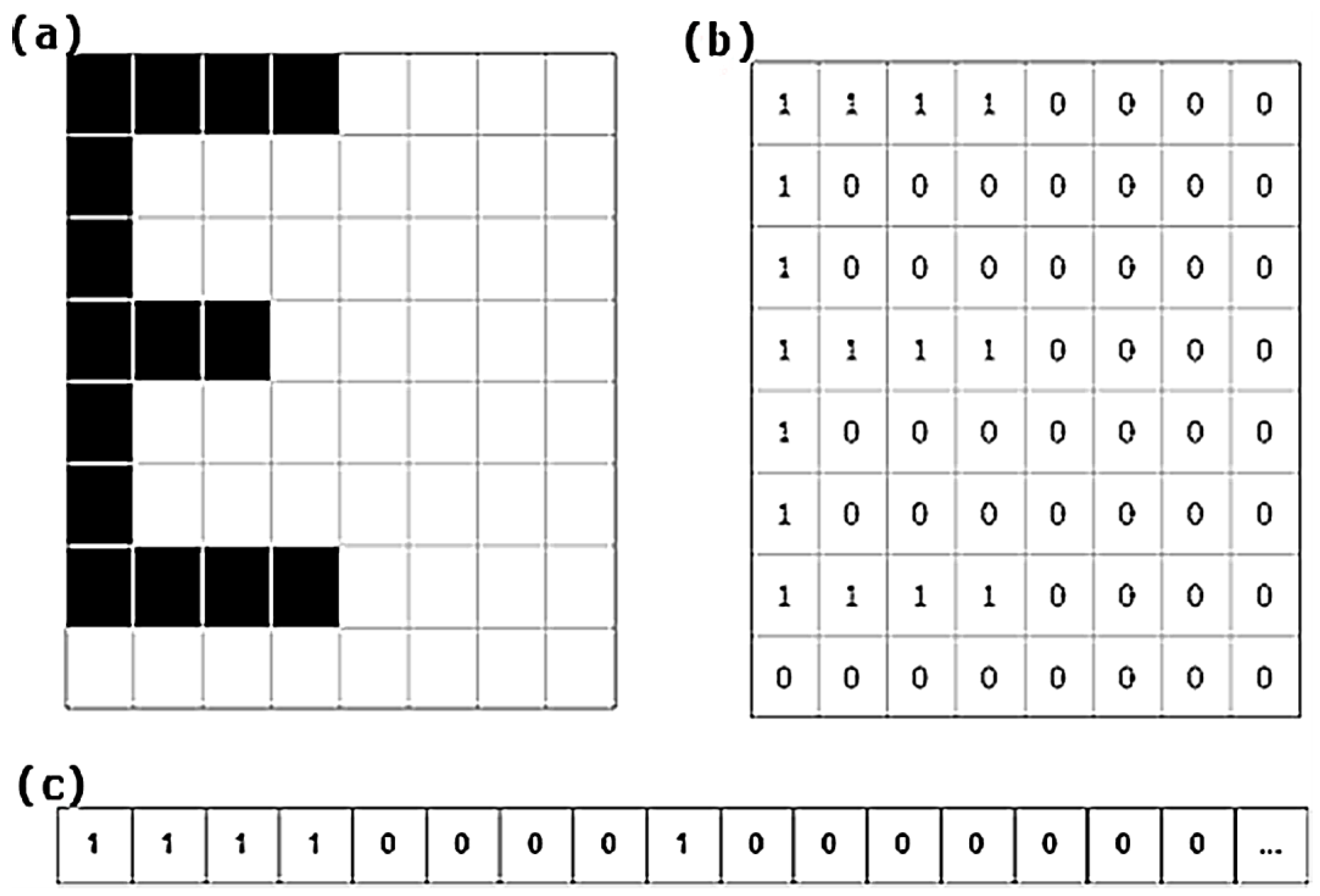
4.2. Morphologies
- If the shapes are readable and recognisable the associated morphologies will retain those qualities.
- Morphologies are extracted directly from segmentation without any analysis involving new operations such as the creation of a feature vector. There is extensive literature on how to generate a good feature vector [20,21,22,23,24,25,26,27,28], but all these techniques require valuable extra processing.
- Industrial printing standardises. It is expected that printed characters will be similar between cans and produce very similar morphologies (see Figure 7).
4.3. Distance between Two Morphologies
4.4. The Morphological Family
- Relationship: Every morphology has a greater similarity with any of the morphologies of its own family than with any other morphology belonging to another family.
- No repetition: There are never two identical morphologies within a morphological family.
4.5. The Morphological Family Database
4.6. Advantages and Disadvantages of Template Matching with MONICOD
- It is intuitive. It can be seen as a systematic matching scheme that assesses the number of ink and non-ink matches between two morphologies.
- It is simple. The only operation involved is the Boolean match and it can be further accelerated with the help of bitwise AND operations.
- It is extremely fast. Template matching involves an intensive but easily paralellisable calculation; following this scheme, the maximum number of operations involved is fixed. Moreover, in a case of validation (like this one) where there is no recognition, we do not need to reach the end of the matching process. In short, the comparison enables us to obtain a partial result as it progresses, so that once a threshold of non-matches is exceeded, we can stop the matching process, and establish that it has failed, as long as we do not need to know the magnitude of the difference.
- It is suitable for this domain. The very repetitive dynamics of can printing hints at the mechanism of template matching: text font, scale, text rotation, etc. These are all fixed properties that should not vary save for the presence of anomalies. The effects of distortion can be attenuated to an extent through the morphological family principle.
- It is very sensitive to noise.
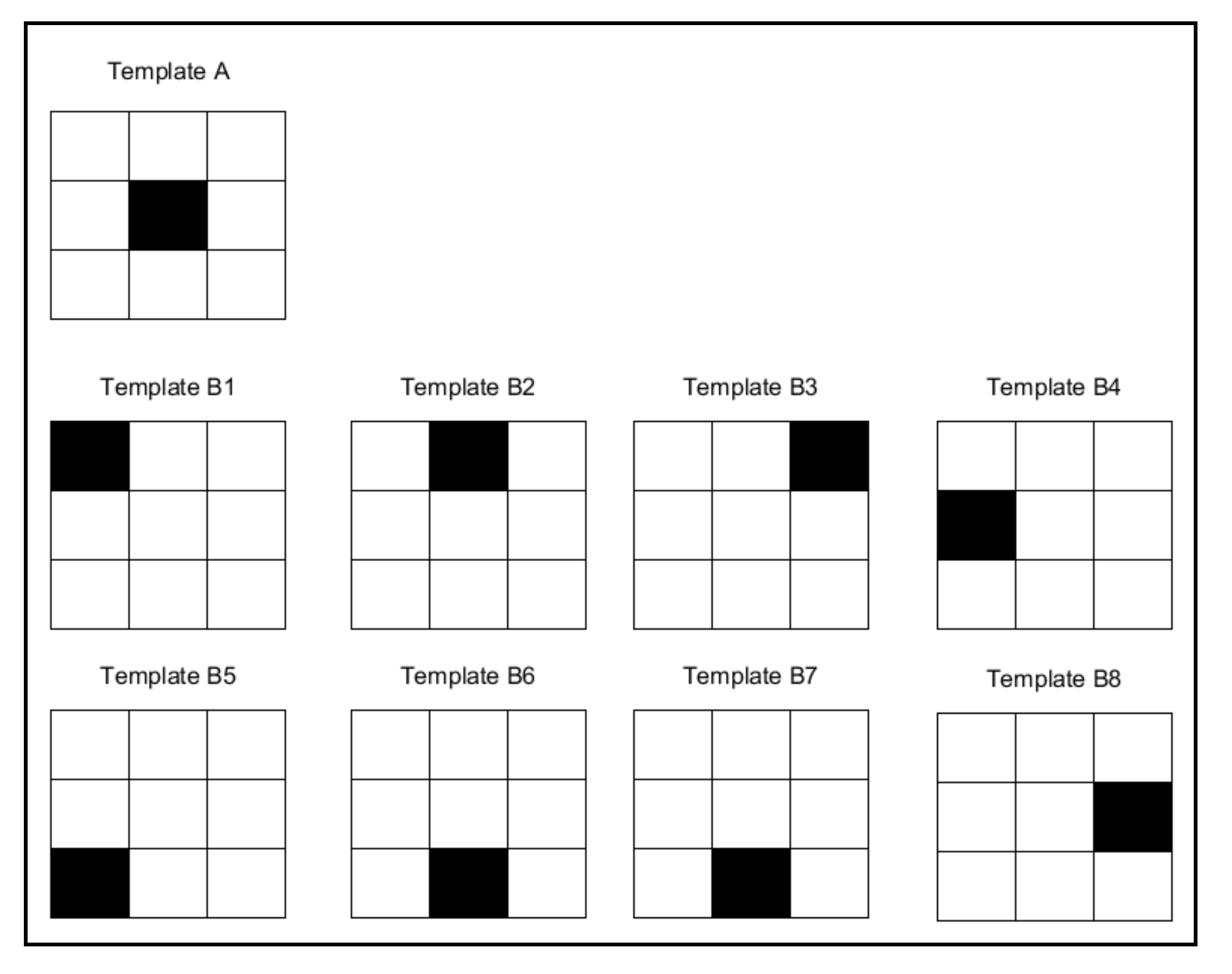
- It does not address the relative importance of where matches and discrepancies occur, only their magnitude (the number of times they occur) (see Figure 10). Conversely, a character is distinguished by where exactly the ink and background are located rather than by the quantity involved.
- Low capacity for generalisation. Consequently, it does not support common invariances. It is therefore vulnerable to translation, rotation and scale, among others. Nor does it offer native support for the different equivalent shapes that a character may have. For example, when working with different text fonts.
5. Verification
5.1. Selection
- The next expected character is not examined until the current one has been found.
- If the acquired character does not correspond to the expected one, the acquired character is assumed to be noise and the process moves on to the next acquired character (but the expected character remains the same).
- Following the matching sequence, matching is performed on a character-by-character basis. This process follows the Western reading pattern in the code to be validated: from left to right and from top to bottom.
- By reading from left to right we have useful information for refining the groupings from the previous stage: we always leave behind complete characters so that, if the current grouping does not correspond to a character, the only alternative is to consider merging it with the grouping on the right.
5.2. The Selection Algorithm
- (1)
- We select an unexamined line (expected code line index) following the top-to-bottom order.
- (2)
- The band index is Positioned on a band suitable for that expected code line following two rules (see Figure 11a):
- (a)
- The selected band is not above a band that has already been correctly recognised (or previously discarded for that character).
- (b)
- The selected band has an equal or greater number of shapes than the expected line of code as indicated by the expected line index.
- (3)
- We select the first character of the expected code (expected character index) from the band indicated by the unexamined expected line index following the order from left to right.
- (4)
- The acquired character index points to the first acquired character in the band indicated by the band index.
- (5)
- If there is no character indicated by the expected character index then the expected line is declared to have been fully validated and we return to 1.
- (6)
- If there is no shape indicated then there are missing shapes for this expected line. Another band must be selected, and we return to 2.
- (7)
- We verify the expected character with the acquired character.
- (a)
- The verification is positive. We move the shape index to the next shape to be verified staying in the same band. We select the next expected character by moving the expected character index to the next position and return to step 5 (see Figure 11d).
- (b)
- The match is negative. The shape indicated by the shape index is merged—temporarily—with the following shape and the merged shape is compared with the list of morphologies resulting from step 5 (see Figure 11b): First case; If this is a positive match, then it is considered that the two shapes are in fact fragments of the same character. We move the shape index to the following unexamined and unmerged shape. We select the next expected character by moving the expected character index to the next position and return to step 5. Second case; If it is negative, we assume that the source character is noise and move the shape index to the next shape within the current band (see Figure 11c). If the shapes remaining in this band are still sufficient for validation of the expected characters remaining on this line then we return to step 6. Otherwise we return to step 2.
5.3. Verification
- (1)
- In the first phase, the morphological family corresponding to the expected character is recovered from the MFD. The family must exist, and there must be morphologies within that family. Otherwise we are facing a critical failure in the validation and the operator should be informed immediately.
- (2)
- In the second phase, each of the morphologies of the morphological family is iterated. For each morphology the distance to the acquired “character” is obtained. Section 5.4 Distance Between Morphologies explains how this distance calculation is performed.
- (3)
- The third phase is to select the maximum similarity value (minimum distance) obtained in the previous phase when all the morphologies of the morphological family are compared with the acquired character. If it exceeds a specified threshold, verification is positive. Otherwise it is negative. This result feeds the validation resolution described in Section 5.5 Resolution.
5.4. Distance between Morphologies
- (a)
- Ink Matches (IM): counts ink matches between A and B.
- (b)
- No Ink Match (NIM): counts background matches between A and B.
- (c)
- Ink Absent (IA): counts non-matches due to ink absent in B that is present in A.
- (d)
- Unexpected Ink (UI): counts non-matches due to ink present in B that is not present in A.
5.5. Resolution
- (1)
- Expected characters verified positively (in position and line) in the acquired can image.
- (2)
- Which characters are important. The configuration of MONICOD by the user provides this information. For example, the numerical characters of time are not important. The year characters are important.
- Ignore the negative validation.
- Remove the affected can manually or mechanically.
- Stop the line to solve a critical problem. In this scenario, system recalibration may be necessary.
6. Learning
6.1. Learning During Learning Time
6.1.1. Automatic Subsystem
- (1)
- First, the conditions for incident-free validation are created. In other words, the printing system prints correctly on the cans, MONICOD has been successfully calibrated and is capable of generating the expected codes.
- (2)
- We start with an empty MFD. Since the MFD is empty, MONICOD cannot validate because it has no morphologies against which to check the input.
- (3)
- Start of the learning cycle for the current can.
- (4)
- The procedure described in [1] is applied until the true code is attained.
- (5)
- For each of the expected characters, the corresponding shape (by position) is extracted from the true code obtained and the MFD is consulted for the associated morphological family. From here, the behaviour will depend on the response of the MFD:
- (a)
- If there are no morphologies in the MFD for that expected character (morphological family), it is directly added on the basis of the shape extracted from the true code. This is the start morphological family event.
- (b)
- If morphologies already exist, all the stored morphologies are compared with the shape extracted from the true code to determine which is more similar (maximum similarity). No tied results are possible (because of the way the morphological families are populated). From here there are several possible scenarios (see flow diagram in Figure 12). Scenario 1; If the maximum similarity is above the voting threshold, the selected morphology of the MFD receives a vote. This is the assimilate morphology event (see Table 2). Scenario 2; If the similarity is below the vote threshold, but above the admission threshold, the morphology is added to the morphological family. This is the input morphology event (see Table 2). Scenario 3; If the similarity is below the admission threshold, there has been an anomaly and the candidate’s morphology is rejected. This is the reject morphology event (see Table 2).
- (6)
- Return to 3. The cycle is repeated until a sufficient number of morphologies are available for each morphological family or the supervising user stops the process. Naturally there is a maximum number of morphologies that can be supported. Other stop conditions are possible: stable MFD (no inputs), enough accumulated votes in each morphological family having completed a quota of morphologies for each morphological family, etc.
- (7)
- Once the automatic learning cycle is completed, an automatic purge of morphologies can be carried out based on the number of votes obtained. Morphologies below a given threshold are purged. This is the purge morphology event.
6.1.2. Manual Subsystem
- (1)
- View morphology
- (a)
- The supervisor views the morphology stored in the MFD catalogued by morphological family.
- (b)
- The user decides whether to delete the morphology or not.
- (2)
- If there are still morphologies to be checked, go back to 1.
6.2. Learning during Validation Time or “on-the-Fly” Learning
- Short-term morphologies are short-lived morphologies that are added and removed at validation time. They bear sufficient similarity to the set of long-term morphologies.
- Long-term morphologies are long-lived morphologies with a minimal degree of readability. Any source character must have a minimum similarity to these morphologies in order to be readable. If it has enough similarity and is sufficiently different from the short-term morphologies currently present, it can be “learned” during validation time and recorded as a short-term morphology. If the number of morphologies for that morphological family is already covered it will replace the least used short-term morphology so far.
- (1)
- The validation process is carried out.
- (2)
- One of the following actions is carried out:
- (a)
- If the code is positively validated and the morphology corresponds 100% to a stored short-term morphology, it is voted for.
- (b)
- If the code is positively validated and the quota of short-term morphologies is not complete, the morphologies of the code are added to the MFD as short-term morphologies.
- (c)
- If the code is positively validated and the quota of morphologies is complete, the short-term morphology with the fewest votes is removed and the new morphology is added. Another option is to replace the morphology that has been used the least in recent verifications.
- (d)
- If the code is NOT positively validated it is ignored for learning purposes.
7. Experimental Setup
7.1. Description and General Conditions for Obtaining the Input Samples
- The learning set (composed of 1005 frames). That is, approximately 5 s of non-continuous recording. This set was constructed by merging extracts from each of the five recordings (201 frames per recording). The frames of the set maintained the chronological order of acquisition. The set was manually verified to contain 53 cans. At 200 frames per second, this was a recording of 5.025 s in duration.
- The validation set (composed of 8884 frames). That is, approximately 45 s of non-continuous recording. The frames of the set maintained the chronological order of acquisition. The set was manually verified to contain 465 cans. At 200 frames per second, this was a recording of 44.42 s in duration.
7.2. Description of the Comparison with Other Classifiers
- (a)
- Pre-training time. The time spent on image acquisition (disk reading) and feature extraction for classification.
- (b)
- Pre-classification time. The time spent on image acquisition (disk reading) and feature extraction for classification.
- (c)
- Training time. Time spent on training.
- (d)
- Classification time. Time spent on classification.
- (1)
- A basic training set of 8000 samples (templates) is acquired with MONICOD: 1000 samples of each class.
- (2)
- A classification set of 8000 samples (templates) is acquired with MONICOD: 1000 samples of each class.
- (3)
- Repeat the experiment for percentages 0.1, 1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90 and 100.
- (a)
- Ten (10) training subsets are constructed by randomly selecting the given percentage from the basic training set. It is always guaranteed that there is the same number of representative samples from each class.
- (b)
- For each subset (in this case one) and for each classifier: For each subset (in this case one) and for each classifier: Step 1; The features of each template are extracted from the subset and matched to the classifier input. Step 2; The classifier is trained with the subset. Step 3; The features of each template are extracted from the classification set and adapted to the classifier input. Step 4; The complete classification set is classified with the classifier. Step 5; Iteration statistics (time spent in each phase, hits, misses) are recorded. Step 6; The average is calculated with the subset statistics.
8. Results and Discussion
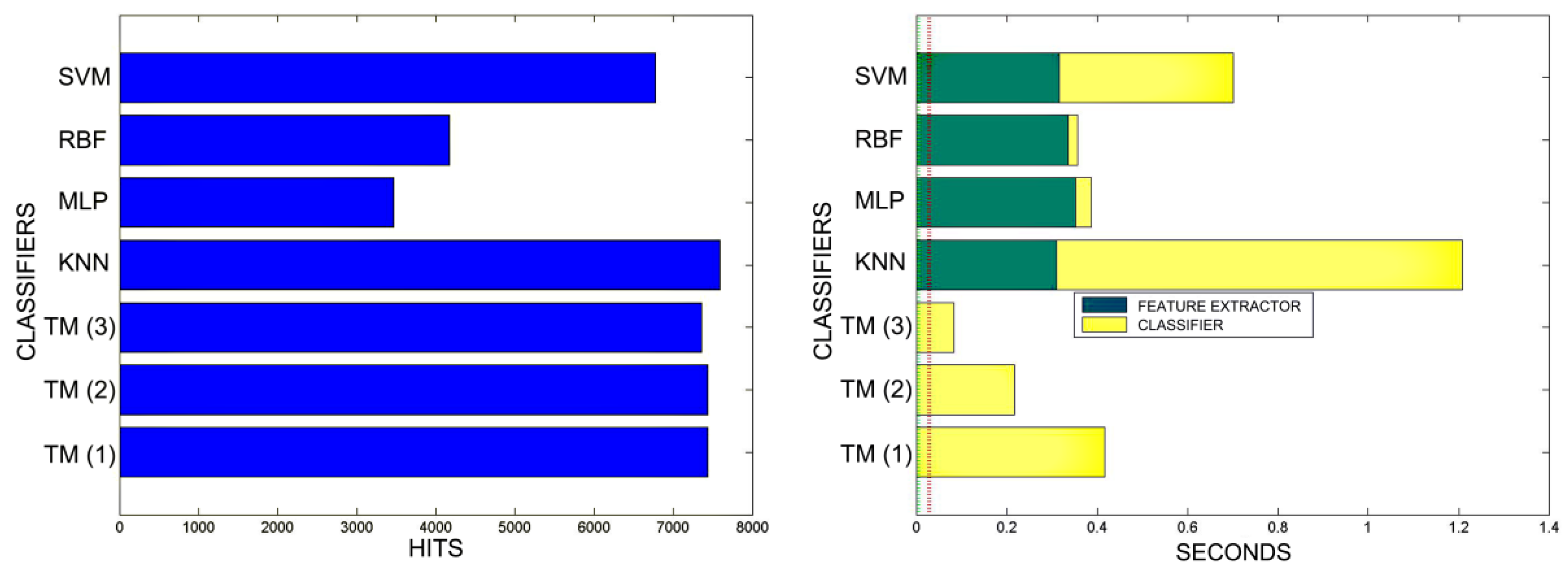
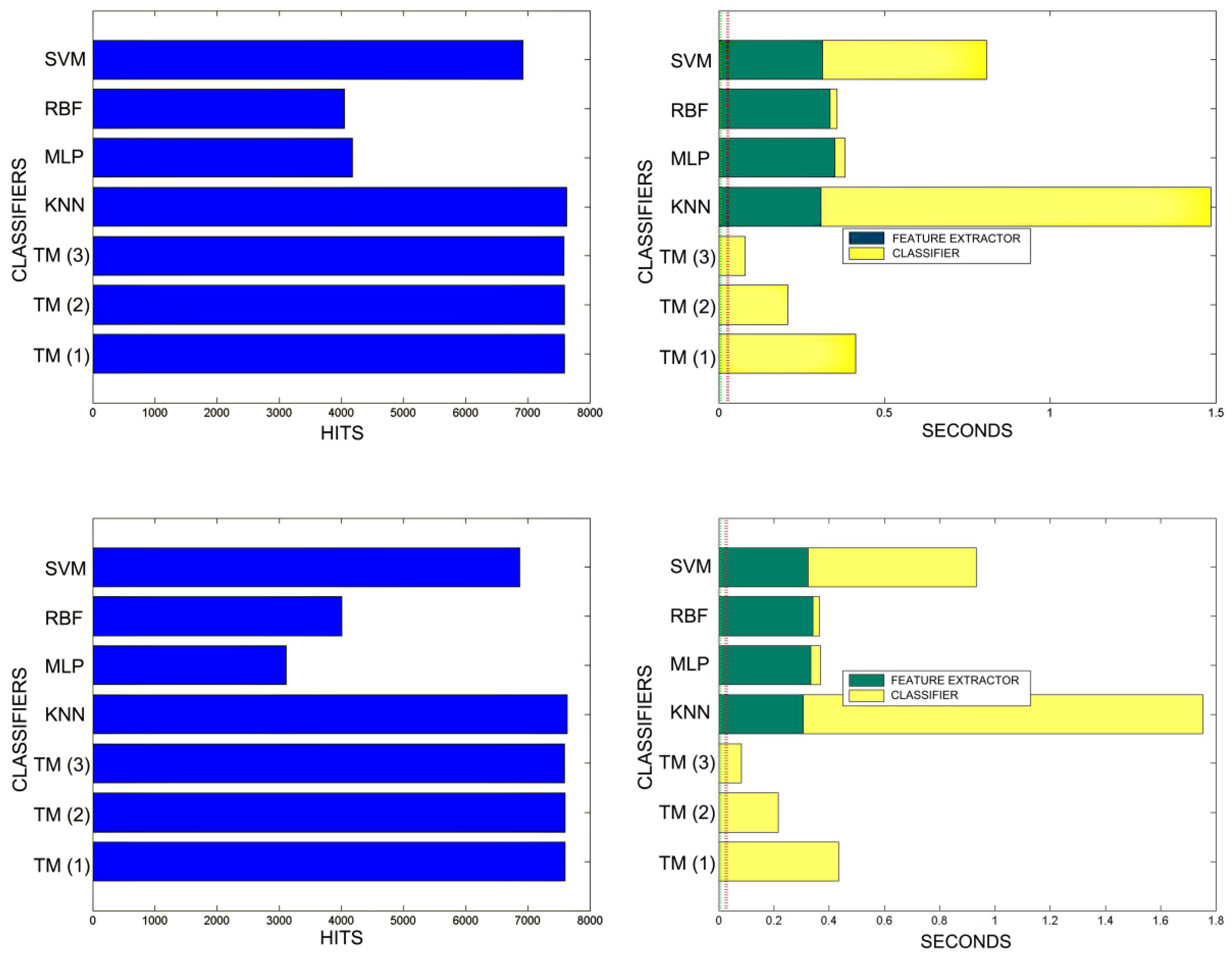
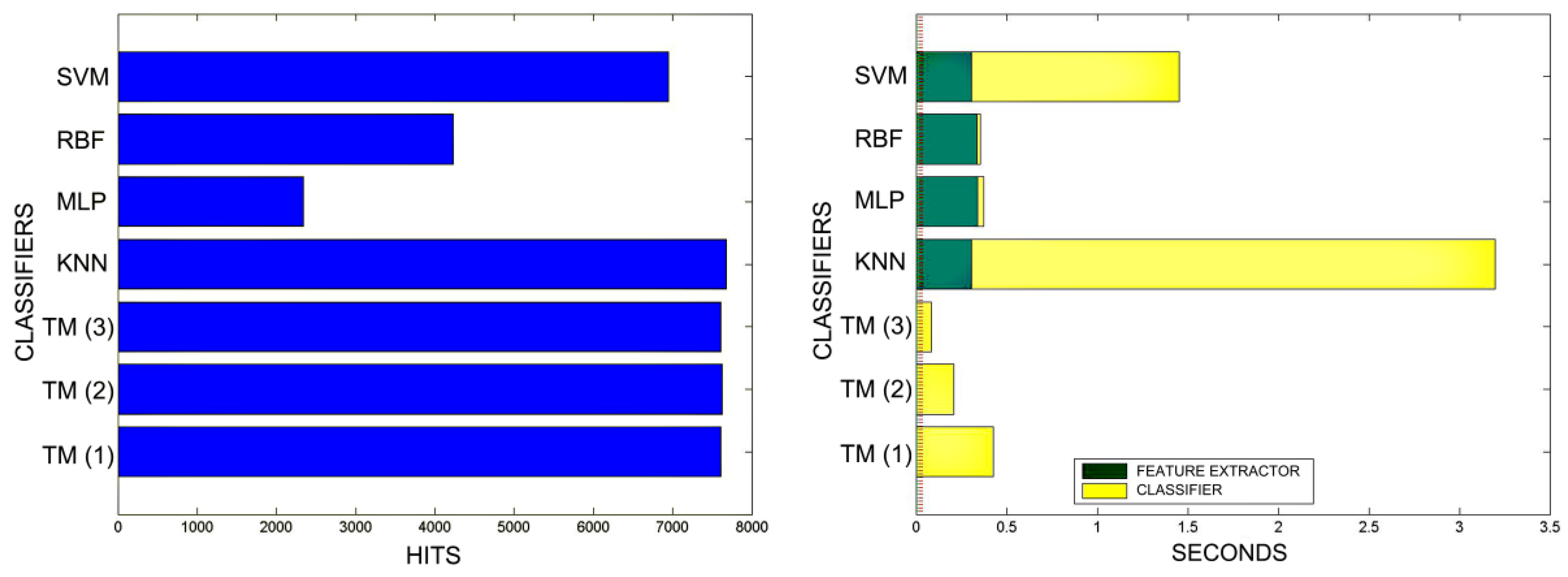
8.1. Hit Rates and Computational Performance of the Validation Algorithms Presented within MONICOD
8.2. Time and Quality Comparisons between KNN, MLP, RBF, SVM and TM (MONICOD) Classifiers
9. Conclusions and Future Work
- There is no variance due to translation. The previous methods keep the character validator ignorant of the position of the character on the can.
- There is no variance in scale. The scale specifications for the printed text are expected to be constant throughout the work day.
- The variance from rotation is an effect of the tilting of the code. However, this effect can be attenuated with simple physical approximation by bringing the camera and printing system closer together. In addition, a catalogue of code rotations could be considered during training.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rodríguez-Rodríguez, J.C.; Blasio, G.S.; García, C.R.; Quesada-Arencibia, A. A character validation proposal for high-speed visual monitoring of expiration codes on beverage cans. In Proceedings of the 13th International Conference on Ubiquitous Computing and Ambient Intelligence UCAmI 2019, Toledo, Spain, 2–5 December 2019. [Google Scholar]
- Rodríguez-Rodríguez, J.C.; Quesada-Arencibia, A.; Moreno-Díaz, R., Jr.; García, C.R. A character segmentation proposal for high-speed visual monitoring of expiration codes on beverage cans. Sensors 2016, 16, 527. [Google Scholar] [CrossRef] [PubMed]
- Cheriet, M.; Kharma, N.; Liu, C.L.; Chin, S. Character Recognition Systems: A Guide for Students and Practitioners; Wiley-Interscience: New York, NY, USA, 2007; pp. 2–4. [Google Scholar]
- Hasnat, M.A.; Habib, S.M.; Khan, M. A high-performance domain specific OCR for bangla script. In Novel Algorithms and Techniques in Telecommunications, Automation and Industrial Electronics; Sobh, T., Elleithy, K., Mahmood, A., Karim, M.A., Eds.; Springer: Dordrecht, Germany, 2007; pp. 174–178. [Google Scholar] [CrossRef]
- Sahu, N.; Sonkusare, M. A study on optical character recognition techniques. IJCSITCE 2017, 4, 1–14. [Google Scholar] [CrossRef]
- Majumder, A. Image processing algorithms for improved character recognition and components inspection. In Proceedings of the World Congress on Nature & Biologically Inspired Computing, NaBIC 2009, IEEE, Coimbatore, India, 9–11 December 2009; pp. 531–536. [Google Scholar]
- Rodriguez-Rodriguez, J.C.; Quesada-Arencibia, A.; Moreno-Diaz, R., Jr. Industrial vision systems, real time, and demanding environment: A working case for quality control. In Vision Systems: Applications; Obinata, G., Dutta, A., Eds.; I-Tech Education and Publishing: Vienna, Austria, 2007; pp. 407–422. [Google Scholar]
- Rodriguez-Rodriguez, J.C. MONICOD: Supervisión Visual a Muy Alta Velocidad de Codificación Impresa Industrial (Visual Monitoring for Ultra High Speed Printed Industrial Coding). Ph.D. Thesis, Universidad de Las Palmas de Gran Canaria, Las Palmas de Gran Canaria, Spain, 2013. [Google Scholar]
- Kalina, D.; Golovanov, R. Application of template matching for optical character recognition. In Proceedings of the IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg and Moscow, Russia, 28–31 January 2019; pp. 2213–2217. [Google Scholar] [CrossRef]
- Pechiammal, B.; Renjith, J.A. An efficient approach for automatic license plate recognition system. In Proceedings of the Third International Conference on Science Technology Engineering & Management (ICONSTEM), Chennai, India, 23–24 March 2017; pp. 121–129. [Google Scholar] [CrossRef]
- Vaishnav, A.; Mandot, M. An integrated automatic number plate recognition for recognizing multi language fonts. In Proceedings of the 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; pp. 551–556. [Google Scholar] [CrossRef]
- García-Mateos, G.; García-Meroño, A.; Vicente-Chicote, C.; Ruiz, A.; López-de-Teruel, P. Time and date OCR in CCTV video. In Image Analysis and Processing—ICIAP 2005; Roli, F., Vitulano, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3617, pp. 703–710. [Google Scholar] [CrossRef]
- Chen, D.; Odobez, J.M.; Bourlard, H. Text detection and recognition in images and video frames. Pattern Recogn. 2004, 37, 595–608. [Google Scholar] [CrossRef]
- Saradhadevi, V.; Sundaram, V. A survey on digital image enhancement techniques. IJCSIS 2010, 8, 173–178. [Google Scholar]
- Zhu, H.; Chan, F.H.Y.; Lam, F.K. Image contrast enhancement by constrained local histogram equalization. Comput. Vis. Image Und. 1999, 73, 281–290. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shapiro, L.G. Image segmentation techniques. Comput. Vis. Graph. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–168. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Syst. Man Cyb. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recogn. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Spiliotis, I.M.; Mertzios, B.G. Real-time computation of two-dimensional moments on binary images using image block representation. IEEE Trans Image Process. 1998, 7, 1609–1615. [Google Scholar] [CrossRef] [PubMed]
- Papakostas, G.A.; Karakasis, E.G.; Koulouriotis, D.E. Efficient and accurate computation of geometric moments on gray-scale images. Pattern Recogn. 2008, 41, 1895–1904. [Google Scholar] [CrossRef]
- Kotoulas, L.; Andreadis, I. Accurate calculation of image moments. IEEE T. Image Process. 2007, 16, 2028–2037. [Google Scholar] [CrossRef] [PubMed]
- Yap, P.; Paramesran, R.; Ong, S. Image analysis using hahn moments. IEEE T. Pattern Anal. 2007, 29, 2057–2062. [Google Scholar] [CrossRef] [PubMed]
- Kotoulas, L.; Andreadis, I. Image analysis using moments. In Proceedings of the 5th International Conference on Technology and Automation ICTA’05, Thessaloniki, Greece, 15–16 October 2005. [Google Scholar]
- Abdul-Hameed, M.S. High order multi-dimensional moment generating algorithm and the efficient computation of Zernike moments. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing ICASSP-97, Munich, Germany, 21–24 April 1997; Volume 4, pp. 3061–3064. [Google Scholar] [CrossRef]
- Hatamian, M. A real-time two-dimensional moment generating algorithm and its single chip implementation. IEEE T. Acoust. Speech 1986, 34, 546–553. [Google Scholar] [CrossRef]
- Dalhoum, A.L.A. A comparative survey on the fast computation of geometric moments. Eur. J. Sci. Res. 2008, 24, 104–111. [Google Scholar]
- Di Ruberto, C.; Morgera, A. A comparison of 2-d moment-based description techniques. In Image Analysis and Processing—ICIAP 2005; Roli, F., Vitulano, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3617, pp. 212–219. [Google Scholar] [CrossRef]
- Cha, S.H. Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions. Int. J. Math. Model. Meth. Appl. Sci. 2007, 1, 300–307. [Google Scholar]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silvermasn, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching in fixed dimensions. JACM 1998, 45, 891–923. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2009; pp. 268–302. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Disc. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000; pp. 93–124. [Google Scholar]
- Baum, E.B. On the capabilities of multilayer perceptrons. J. Complex. 1988, 4, 193–215. [Google Scholar] [CrossRef]
- Lee, C.C.; Chung, P.C.; Tsai, J.R.; Chang, C.I. Robust radial basis function neural networks. IEEE Syst. Man Cybern. B 1999, 29, 674–685. [Google Scholar] [CrossRef]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance | Expression |
|---|---|
| Hamming | |
| Dot product | |
| Jaccard | |
| Sørensen-Dice | |
| Tversky | |
| MONICOD |
| Event | Description | Graphic Example |
|---|---|---|
| Start morphological family | There are no morphologies in this family. Direct addition of the new morphology. |  |
| Assimilate morphology | The similarity with the most similar morphology in the family is above the voting threshold. Vote for the stored morphology. |  |
| Input morphology | The similarity with the most similar morphology in the family is above the admission threshold. The new morphology is added. |  |
| Reject morphology | The new morphology is rejected. |  |
| Purge morphology | Stored morphologies with number of votes below a given threshold are eliminated. |  |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Rodríguez, J.C.; de Blasio, G.S.; García, C.R.; Quesada-Arencibia, A. A Very High-Speed Validation Scheme Based on Template Matching for Segmented Character Expiration Codes on Beverage Cans. Sensors 2020, 20, 3157. https://doi.org/10.3390/s20113157
Rodríguez-Rodríguez JC, de Blasio GS, García CR, Quesada-Arencibia A. A Very High-Speed Validation Scheme Based on Template Matching for Segmented Character Expiration Codes on Beverage Cans. Sensors. 2020; 20(11):3157. https://doi.org/10.3390/s20113157
Chicago/Turabian StyleRodríguez-Rodríguez, José C., Gabriele S. de Blasio, Carmelo R. García, and Alexis Quesada-Arencibia. 2020. "A Very High-Speed Validation Scheme Based on Template Matching for Segmented Character Expiration Codes on Beverage Cans" Sensors 20, no. 11: 3157. https://doi.org/10.3390/s20113157
APA StyleRodríguez-Rodríguez, J. C., de Blasio, G. S., García, C. R., & Quesada-Arencibia, A. (2020). A Very High-Speed Validation Scheme Based on Template Matching for Segmented Character Expiration Codes on Beverage Cans. Sensors, 20(11), 3157. https://doi.org/10.3390/s20113157