On-Demand Channel Bonding in Heterogeneous WLANs: A Multi-Agent Deep Reinforcement Learning Approach




Abstract
1. Introduction
- The on-demand channel bonding algorithm is designed in heterogeneous WLANs to decrease transmission delay, where APs have different channel bonding capability.
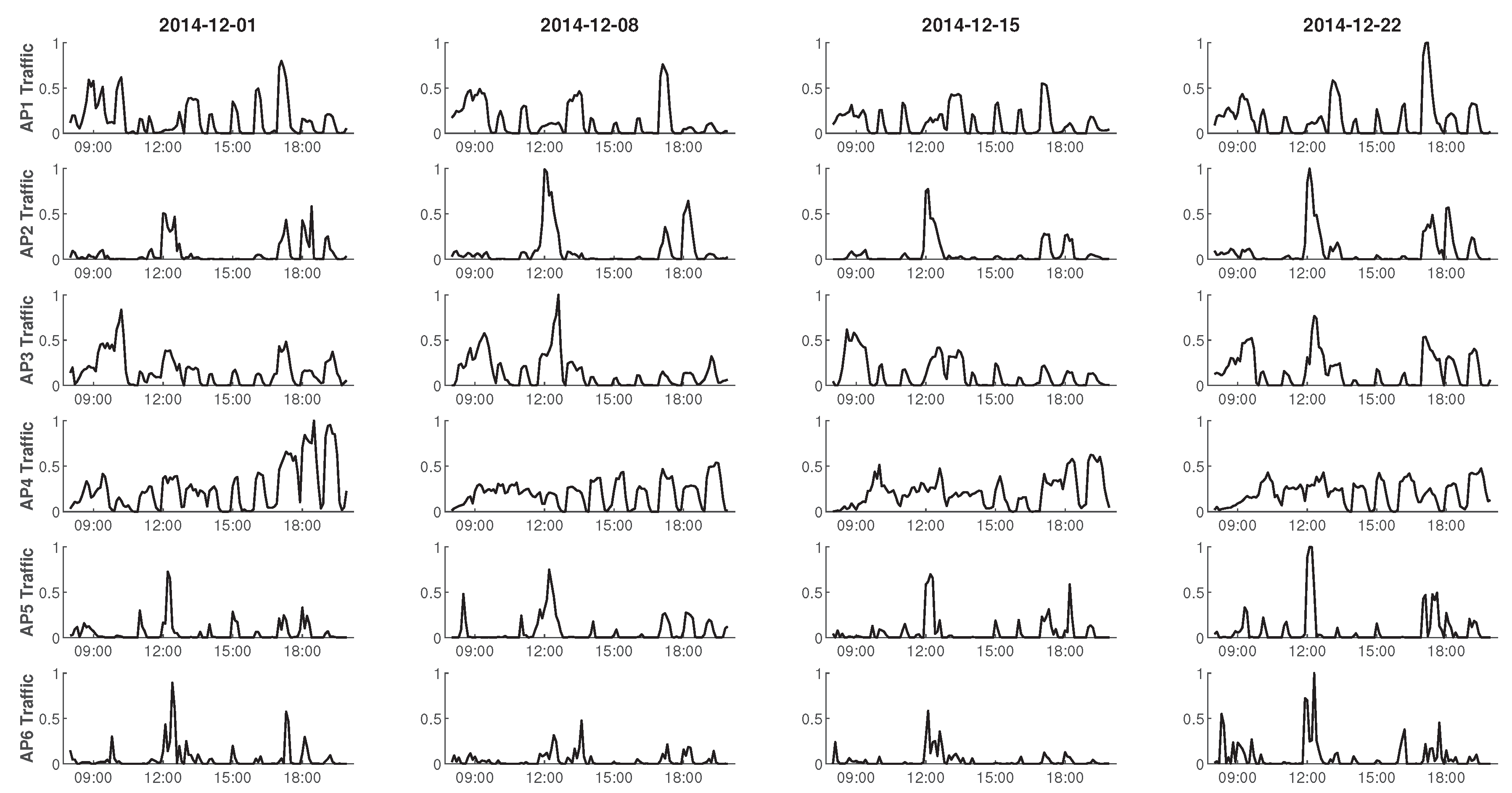
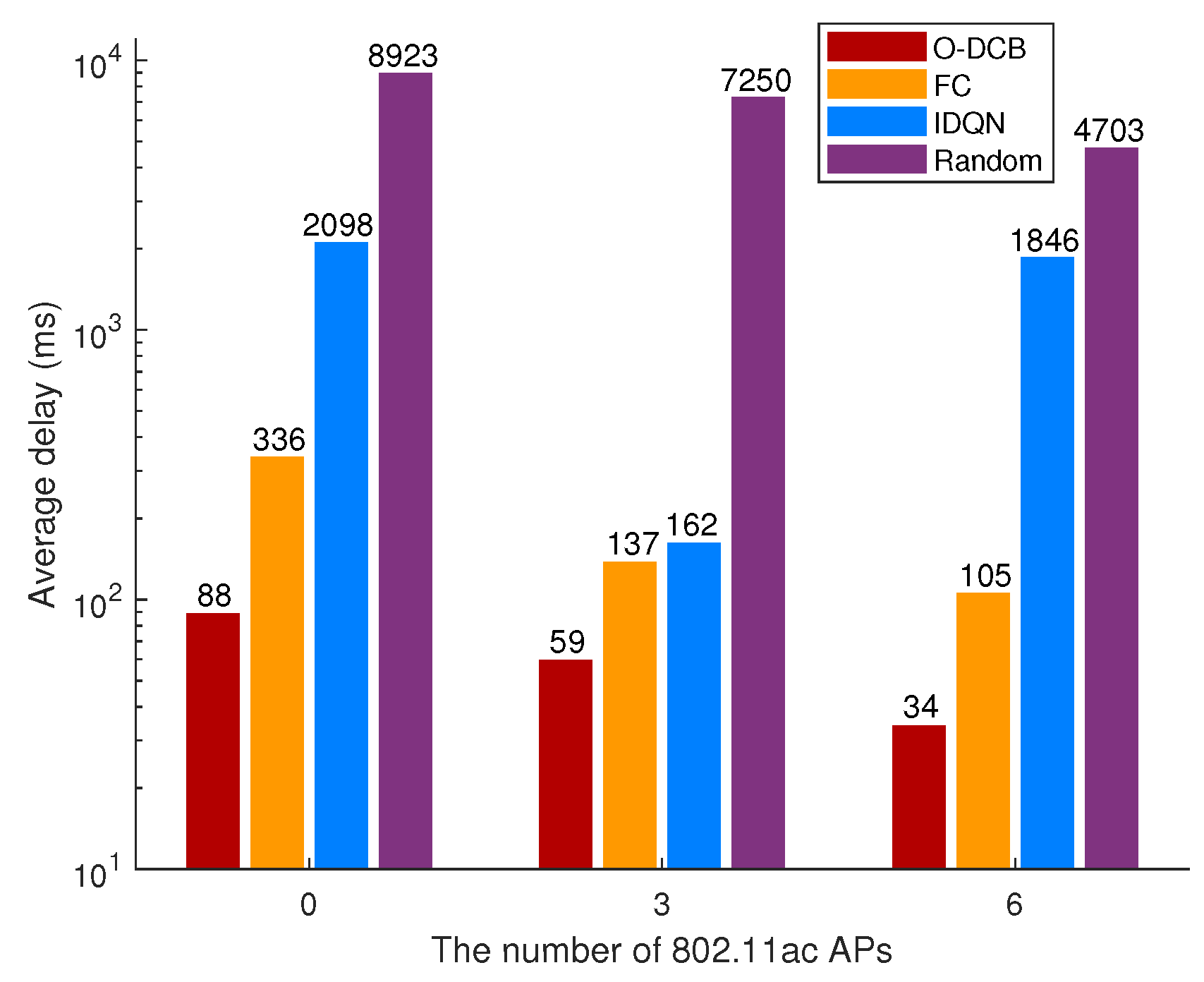
- The feasibility of DRL in channel bonding is explored in this paper. Real traffic traces collected from a campus WLAN [17] are used to train and test O-DCB, and simulation results show that O-DCB has lower delay than other channel bonding algorithms.
- In this problem, the state space is continuous and the action space is discrete. However, the size of action space increases exponentially with the number of APs by using single-agent DRL, which severely affects the learning rate. To accelerate learning, Multi-Agent Deep Deterministic Policy Gradient (MADDPG) [20] is used to train O-DCB.
2. Related Works
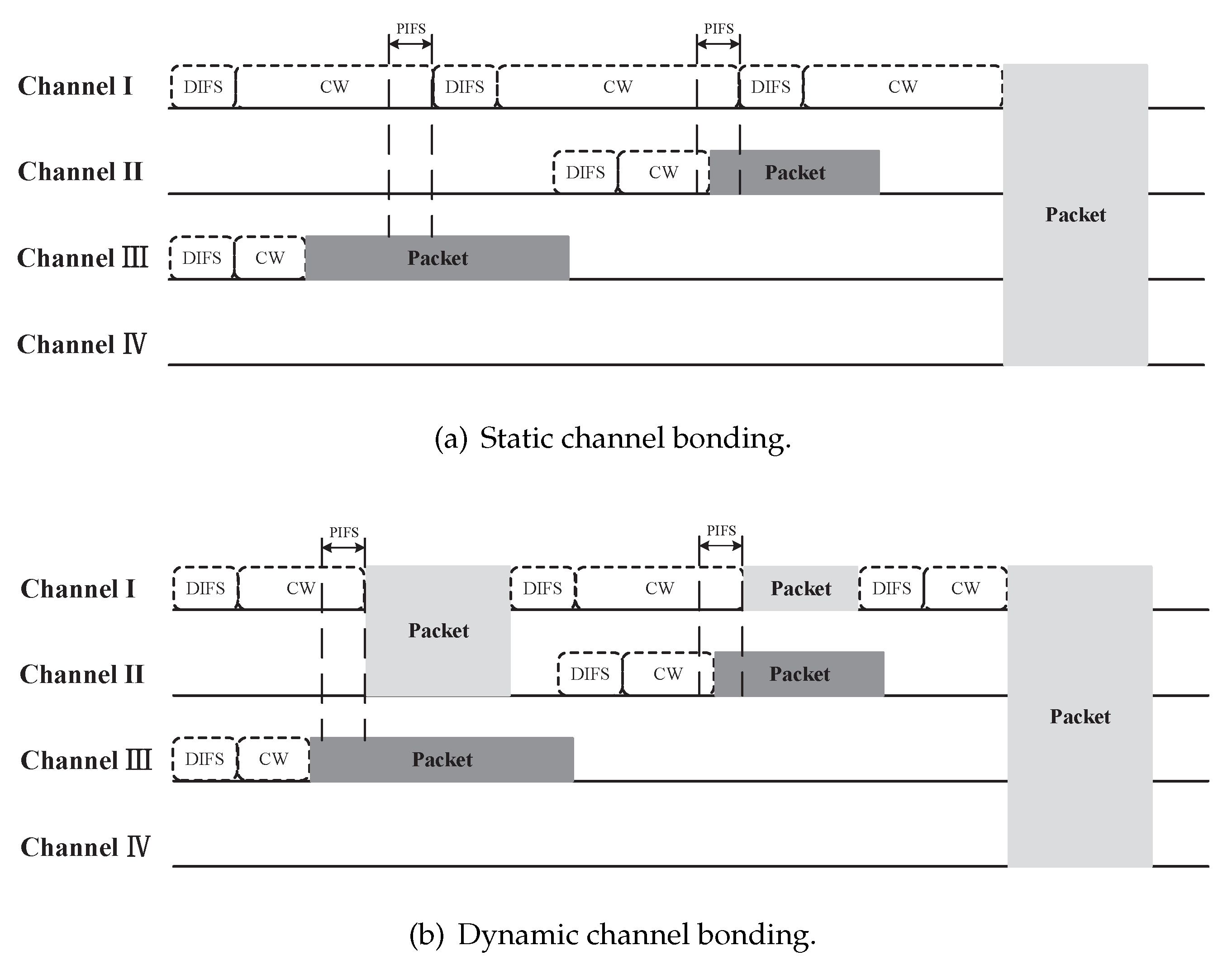
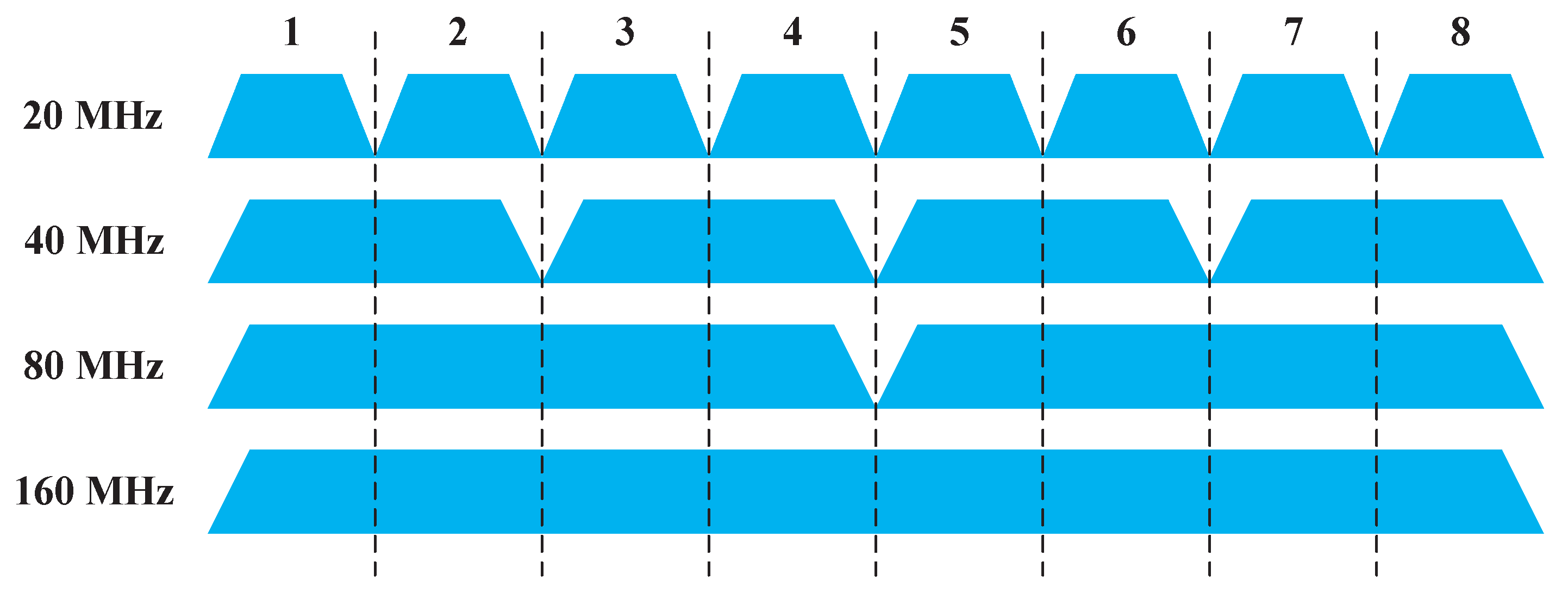
2.1. Channel Bonding
2.2. Spectrum Assignment
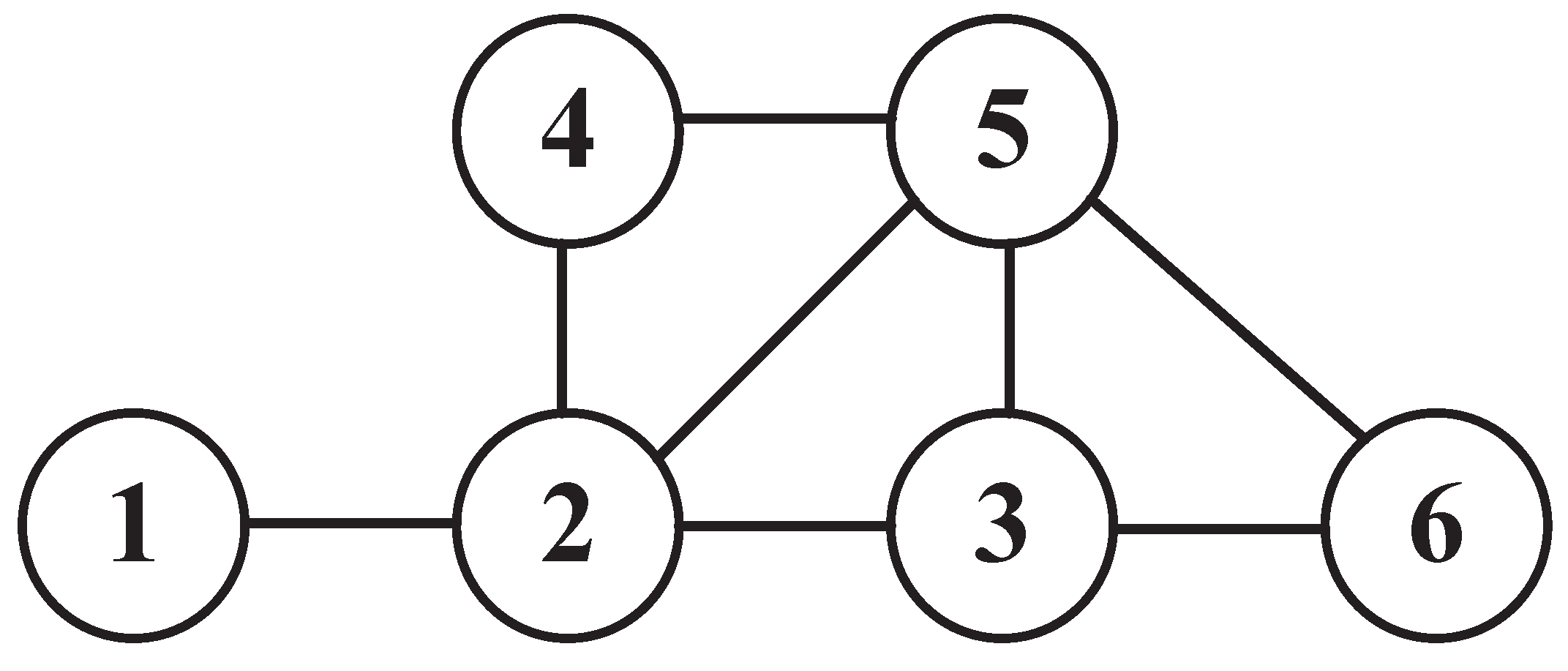
3. System Model and Problem Definition
3.1. System Model
3.2. Problem Definition
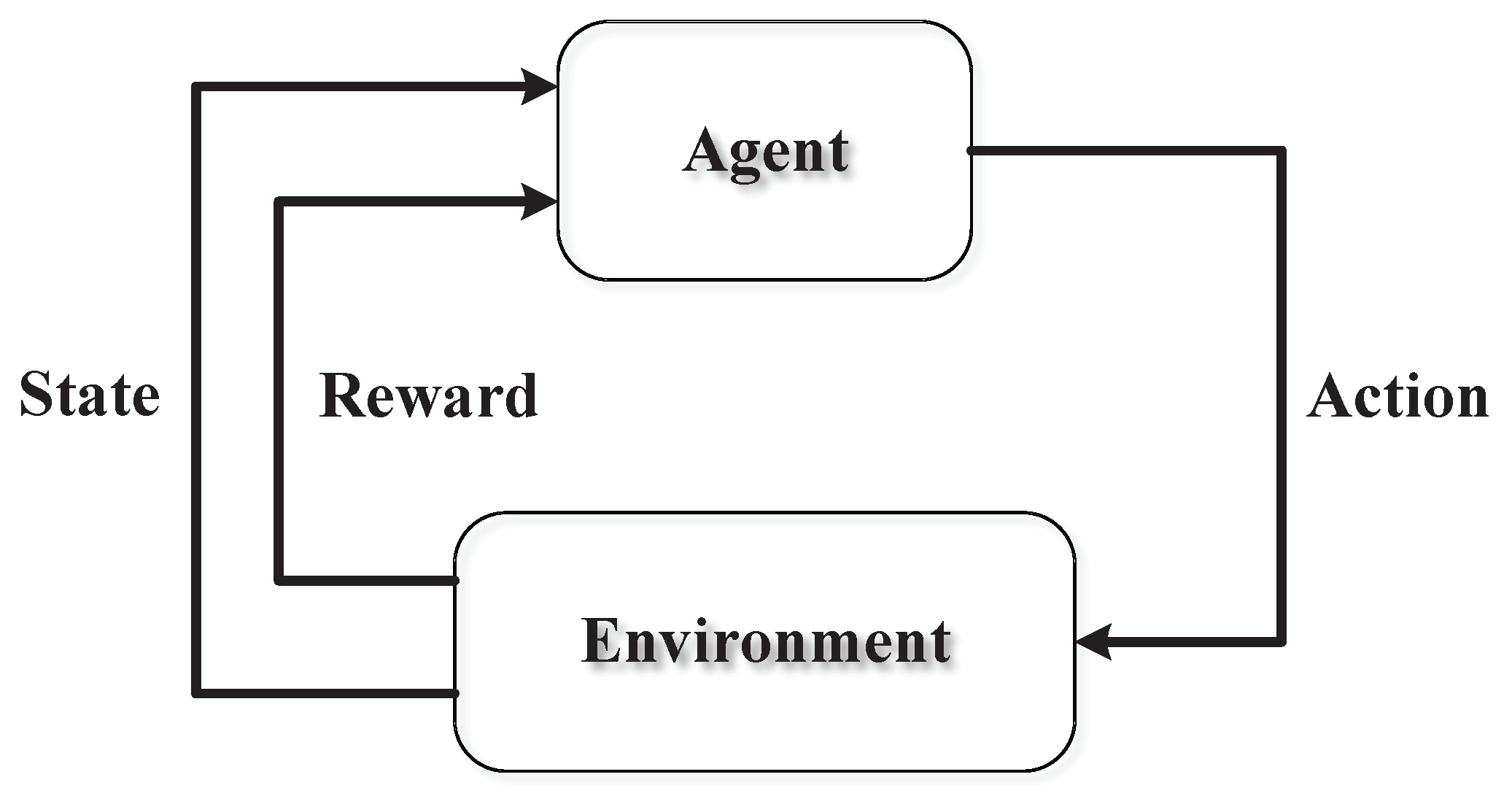
4. Preliminaries on RL
5. On-Demand Channel Bonding Algorithm
5.1. State
5.2. Action
5.3. Reward
5.4. O-DCB
| Algorithm 1:O-DCB |
| Initialization: |
| Randomly initialize actor and critic neural network and for each agent. |
| Initialize corresponding target network and with weights , . |
| Initialize replay buffer . |
| Algorithm: |
| 1: for episode in do |
| 2: Receive initial state . |
| 3: for in do |
| 4: for each agent i, select . |
| 5: All agents execute actions. |
| 6: Calculate reward according to Equation (10). |
| 7: Get new state . |
| 8: Store in , where , , |
| and . |
| 9: for agent i in do |
| 10: Sample a random minibatch of L samples from . |
| 11: Set |
| 12: Update critic by minimizing the loss:
|
| 13: Update actor using the sampled policy gradient:
|
| 14: end for |
| 15: Update the target networks for each agent i:
|
| 16: end for |
| 17: end for |
5.5. Implementation
6. Simulation and Performance Evaluation
- IDQN. The simplest approach of learning in multi-agent settings is to use independently learning agents, where each agent independently maximizes its individual reward and treats other agents as part of the environment. This is attempted with Q-learning in [46], which is called independent Q-learning (IQL). As Q-learning can be extended as DQN, IQL can be also upgraded to IDQN easily. In particular, IDQN uses the same state, action and reward with O-DCB. Besides, the hyperparameters of IDQN are also the same with O-DCB, such as the learning rate, the size of replay buffer and minibatch, the structure of DNN, etc.
- Random selection. Random selection is very straightforward. In time slot , for each AP i, the channel bonding parameter is randomly selected from its action space .
- Fixed configuration. Fixed Configuration (FC) is always used in real-life WLANs where the channel parameter is fixed for each AP and the widest channel is used.
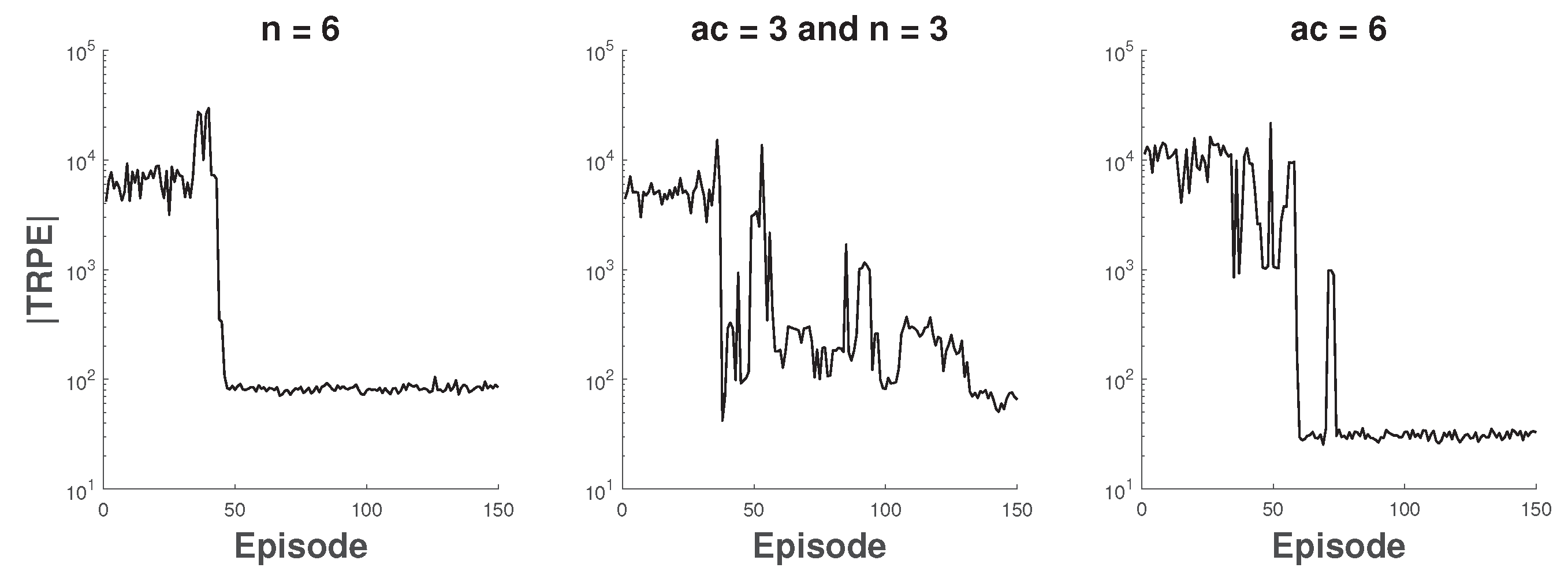
6.1. The Coexistence of 802.11n and 802.11ac
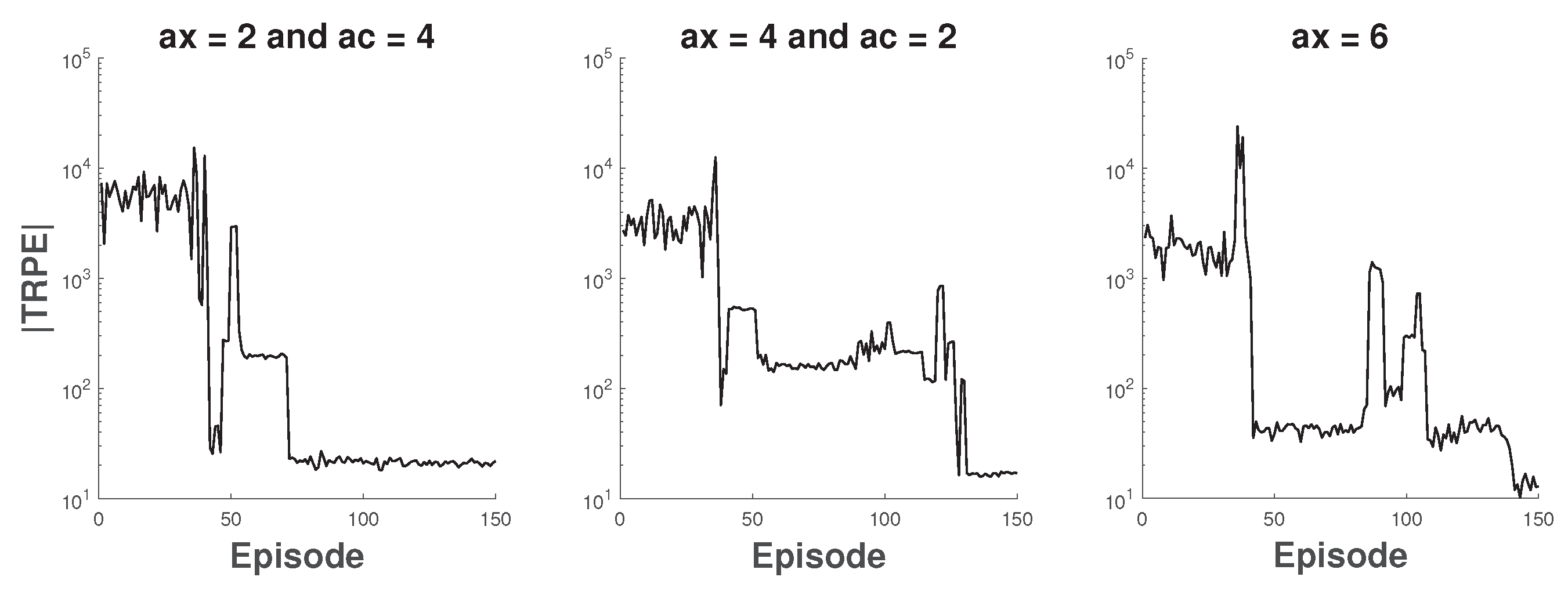
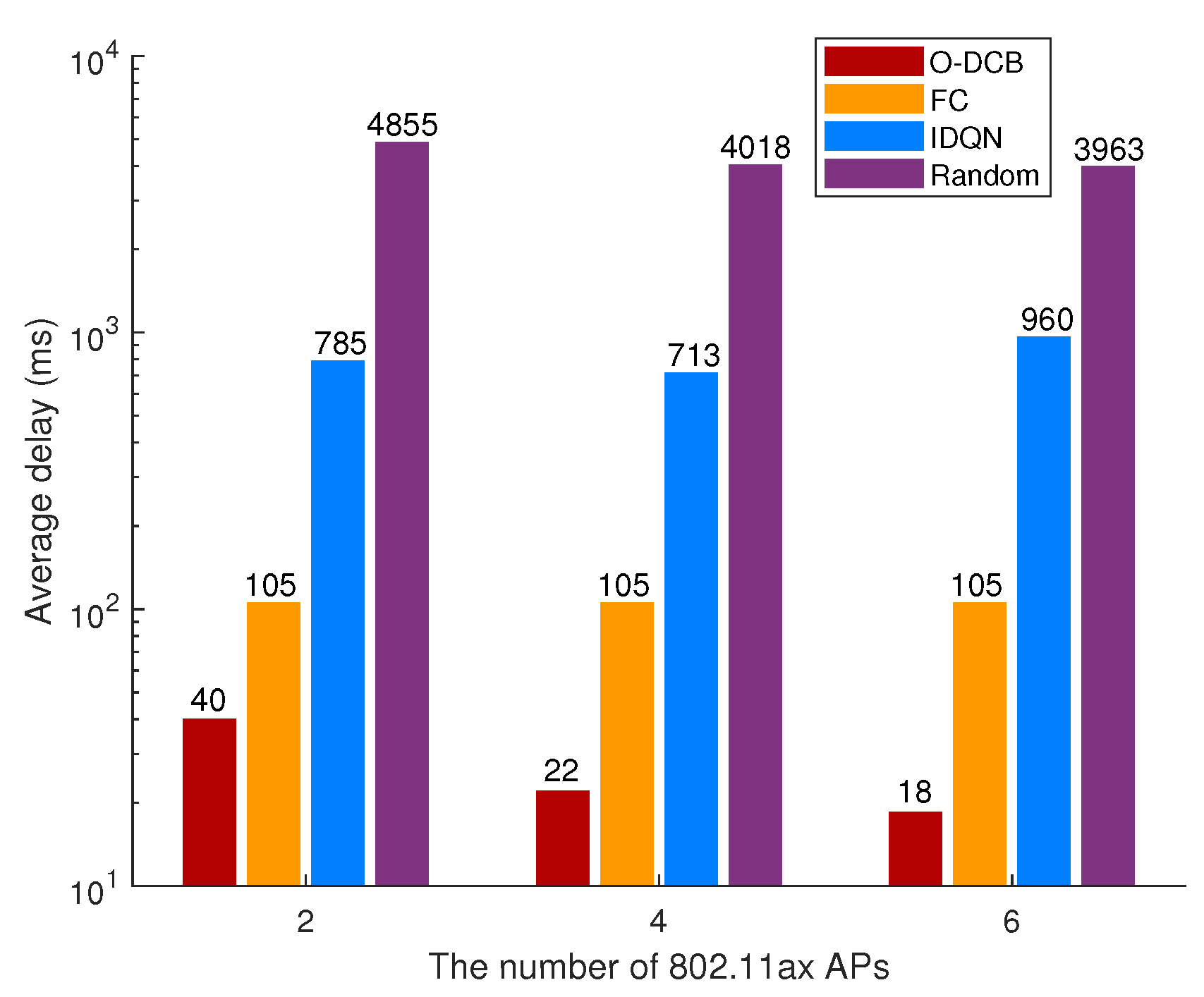
6.2. The Coexistence of 802.11ac and 802.11ax
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gast, M. 802.11 n: A Survival Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Gast, M. 802.11 ac: A Survival Guide: Wi-Fi at Gigabit and Beyond; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Khorov, E.; Kiryanov, A.; Lyakhov, A.; Bianchi, G. A tutorial on IEEE 802.11 ax high efficiency WLANs. IEEE Commun. Surv. Tutor. 2018, 21, 197–216. [Google Scholar] [CrossRef]
- Khairy, S.; Han, M.; Cai, L.X.; Cheng, Y.; Han, Z. A renewal theory based analytical model for multi-channel random access in IEEE 802.11 ac/ax. IEEE Trans. Mobile Comput. 2018, 18, 1000–1013. [Google Scholar] [CrossRef]
- Deek, L.; Garcia-Villegas, E.; Belding, E.; Lee, S.J.; Almeroth, K. The impact of channel bonding on 802.11 n network management. In Proceedings of the Seventh Conference on Emerging Networking EXperiments and Technologies, Tokyo, Japan, 6–9 December 2011; ACM: New York, NY, USA, 2011; pp. 1–12. [Google Scholar]
- Park, M. IEEE 802.11 ac: Dynamic bandwidth channel access. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5. [Google Scholar]
- Arslan, M.Y.; Pelechrinis, K.; Broustis, I.; Krishnamurthy, S.V.; Addepalli, S.; Papagiannaki, K. Auto-configuration of 802.11 n WLANs. In Proceedings of the 6th International Conference, Braga, Portugal, 1–3 September 2010; ACM: New York, NY, USA, 2010; pp. 1–12. [Google Scholar]
- Bellalta, B.; Faridi, A.; Barcelo, J.; Checco, A.; Chatzimisios, P. Channel bonding in short-range WLANs. In Proceedings of the European Wireless 2014 20th European Wireless Conference, Barcelona, Spain, 14–16 May 2014; pp. 1–7. [Google Scholar]
- Daldoul, Y.; Meddour, D.E.; Ksentini, A. IEEE 802.11 ac: Effect of channel bonding on spectrum utilization in dense environments. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Faridi, A.; Bellalta, B.; Checco, A. Analysis of dynamic channel bonding in dense networks of WLANs. IEEE Trans. Mobile Comput. 2016, 16, 2118–2131. [Google Scholar] [CrossRef]
- Moscibroda, T.; Chandra, R.; Wu, Y.; Sengupta, S.; Bahl, P.; Yuan, Y. Load-aware spectrum distribution in wireless LANs. In Proceedings of the 2008 IEEE International Conference on Network Protocols, Orlando, FL, USA, 19–22 October 2008; pp. 137–146. [Google Scholar]
- Hernández-Campos, F.; Karaliopoulos, M.; Papadopouli, M.; Shen, H. Spatio-temporal modeling of traffic workload in a campus WLAN. In Proceedings of the 2nd Annual International Workshop on Wireless Internet, Boston, MA, USA, 2–5 August 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Lee, S.S.; Kim, T.; Lee, S.; Kim, K.; Kim, Y.H.; Golmie, N. Dynamic Channel Bonding Algorithm for Densely Deployed 802.11 ac Networks. IEEE Trans. Commun. 2019, 67, 8517–8531. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Han, Z.; Lei, T.; Lu, Z.; Wen, X.; Zheng, W.; Guo, L. Artificial intelligence-based handoff management for dense WLANs: A deep reinforcement learning approach. IEEE Access 2019, 7, 31688–31701. [Google Scholar] [CrossRef]
- Liu, J.; Krishnamachari, B.; Zhou, S.; Niu, Z. DeepNap: Data-driven base station sleeping operations through deep reinforcement learning. IEEE Internet Things J. 2018, 5, 4273–4282. [Google Scholar] [CrossRef]
- Xu, L.; Wang, J.; Wang, H.; Gulliver, T.A.; Le, K.N. BP neural network-based ABEP performance prediction for mobile Internet of Things communication systems. Neural Comput. Appl. 2019. [Google Scholar] [CrossRef]
- Redondi, A.E.; Cesana, M.; Weibel, D.M.; Fitzgerald, E. Understanding the WiFi usage of university students. In Proceedings of the 2016 International Wireless Communications and Mobile Computing Conference (IWCMC), Paphos, Cyprus, 5–9 September 2016; pp. 44–49. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6379–6390. [Google Scholar]
- Bellalta, B.; Checco, A.; Zocca, A.; Barcelo, J. On the interactions between multiple overlapping WLANs using channel bonding. IEEE Trans. Veh. Technol. 2015, 65, 796–812. [Google Scholar] [CrossRef]
- Barrachina-Muñoz, S.; Wilhelmi, F.; Bellalta, B. Dynamic channel bonding in spatially distributed high-density WLANs. IEEE Trans. Mobile Comput. 2019, 4, 821–835. [Google Scholar] [CrossRef]
- Kim, M.S.; Ropitault, T.; Lee, S.; Golmie, N. A throughput study for channel bonding in IEEE 802.11 ac networks. IEEE Commun. Lett. 2017, 21, 2682–2685. [Google Scholar] [CrossRef]
- Barrachina-Muñoz, S.; Wilhelmi, F.; Bellalta, B. To overlap or not to overlap: Enabling channel bonding in high-density WLANs. Comput. Netw. 2019, 152, 40–53. [Google Scholar] [CrossRef]
- Han, M.; Khairy, S.; Cai, L.X.; Cheng, Y. Performance analysis of opportunistic channel bonding in multi-channel WLANs. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Gong, M.X.; Hart, B.; Xia, L.; Want, R. Channel bounding and MAC protection mechanisms for 802.11 ac. In Proceedings of the 2011 IEEE Global Telecommunications Conference-GLOBECOM, Houston, TX, USA, 5–9 December 2011; pp. 1–5. [Google Scholar]
- Stelter, A. Channel width selection scheme for better utilisation of WLAN bandwidth. Electron. Lett. 2014, 50, 407–409. [Google Scholar] [CrossRef]
- Kai, C.; Liang, Y.; Huang, T.; Chen, X. To bond or not to bond: An optimal channel allocation algorithm for flexible dynamic channel bonding in WLANs. In Proceedings of the 2017 IEEE 86th Vehicular Technology Conference (VTC-Fall), Toronto, ON, Canada, 24–27 September 2017; pp. 1–6. [Google Scholar]
- Jang, S.; Shin, K.G.; Bahk, S. Post-CCA and reinforcement learning based bandwidth adaptation in 802.11 ac networks. IEEE Trans. Mobile Comput. 2017, 17, 419–432. [Google Scholar] [CrossRef]
- Mammeri, S.; Yazid, M.; Bouallouche-Medjkoune, L.; Mazouz, A. Performance study and enhancement of multichannel access methods in the future generation VHT WLAN. Future Gener. Comput. Syst. 2018, 79, 543–557. [Google Scholar] [CrossRef]
- Hu, Z.; Wen, X.; Li, Z.; Lu, Z.; Jing, W. Modeling the TXOP sharing mechanism of IEEE 802.11ac enhanced distributed channel access in non-saturated conditions. IEEE Commun. Lett. 2015, 19, 1576–1579. [Google Scholar] [CrossRef]
- Khairy, S.; Han, M.; Cai, L.X.; Cheng, Y.; Han, Z. Enabling efficient multi-channel bonding for IEEE 802.11 ac WLANs. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Ko, B.J.; Rubenstein, D. Distributed self-stabilizing placement of replicated resources in emerging networks. IEEE/ACM Trans. Netw. 2005, 13, 476–487. [Google Scholar]
- Mishra, A.; Banerjee, S.; Arbaugh, W. Weighted coloring based channel assignment for WLANs. Mob. Comput. Commun. Rev. 2005, 9, 19–31. [Google Scholar] [CrossRef]
- Gong, D.; Zhao, M.; Yang, Y. Distributed channel assignment algorithms for 802.11 n WLANs with heterogeneous clients. J. Parallel Distrib. Comput. 2014, 74, 2365–2379. [Google Scholar] [CrossRef]
- Wang, X.; Derakhshani, M.; Le-Ngoc, T. Self-organizing channel assignment for high density 802.11 WLANs. In Proceedings of the 2014 IEEE 25th Annual International Symposium on Personal, Indoor, and Mobile Radio Communication (PIMRC), Washington, DC, USA, 2–5 September 2014; pp. 1637–1641. [Google Scholar]
- Rayanchu, S.; Shrivastava, V.; Banerjee, S.; Chandra, R. FLUID: Improving throughputs in enterprise wireless lans through flexible channelization. IEEE Trans. Mobile Comput. 2012, 11, 1455–1469. [Google Scholar] [CrossRef]
- Chandra, R.; Mahajan, R.; Moscibroda, T.; Raghavendra, R.; Bahl, P. A case for adapting channel width in wireless networks. Comput. Commun. Rev. 2008, 38, 135–146. [Google Scholar] [CrossRef]
- Nabil, A.; Abdel-Rahman, M.J.; MacKenzie, A.B. Adaptive channel bonding in wireless LANs under demand uncertainty. In Proceedings of the 2017 IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–7. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Tsitsiklis, J.N.; Van Roy, B. An analysis of temporal-difference learning with function approximation. IEEE Trans. Autom. Control 1997, 42, 674–690. [Google Scholar] [CrossRef]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparametrization with Gumble-Softmax. In Proceedings of the International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Google. TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 1 January 2020).
- Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the tenth International Conference on Machine Learning, Amherst, NY, USA, 27–29 June 1993; ACM: New York, NY, USA, 1993; pp. 330–337. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition | Value |
|---|---|---|
| N | The number of WLANs | 6 |
| K | The number of channels | 4 |
| Packet size | 3 kB | |
| Min. contention window | 16 | |
| Max. contention window | 1024 | |
| The transmission rate | 13, 27, 42.5, 58.5 Mbps | |
| The length of time slot | 6 min | |
| The weighting factor | −0.25 | |
| The weighting factor | −1 | |
| Learning rate | 0.001 | |
| The tracking parameter | 0.01 | |
| The size of replay buffer | 4096 | |
| L | The size of minibatch | 32 |
| The discount factor | 0.95 |
| Name | Number | Size | Activation Function |
|---|---|---|---|
| Input Layer | 1 | 2 | NA |
| Hidden Layer | 2 | ReLU, ReLU | |
| Output Layer | 1 | 8 (802.11n) 12 (802.11ac/ax) | NA |
| Name | Number | Size | Activation Function |
|---|---|---|---|
| Input Layer | 1 | NA | |
| Hidden Layer | 2 | ReLU, ReLU | |
| Output Layer | 1 | 1 | NA |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, H.; Huang, H.; Hu, Z.; Wen, X.; Lu, Z. On-Demand Channel Bonding in Heterogeneous WLANs: A Multi-Agent Deep Reinforcement Learning Approach. Sensors 2020, 20, 2789. https://doi.org/10.3390/s20102789
Qi H, Huang H, Hu Z, Wen X, Lu Z. On-Demand Channel Bonding in Heterogeneous WLANs: A Multi-Agent Deep Reinforcement Learning Approach. Sensors. 2020; 20(10):2789. https://doi.org/10.3390/s20102789
Chicago/Turabian StyleQi, Hang, Hao Huang, Zhiqun Hu, Xiangming Wen, and Zhaoming Lu. 2020. "On-Demand Channel Bonding in Heterogeneous WLANs: A Multi-Agent Deep Reinforcement Learning Approach" Sensors 20, no. 10: 2789. https://doi.org/10.3390/s20102789
APA StyleQi, H., Huang, H., Hu, Z., Wen, X., & Lu, Z. (2020). On-Demand Channel Bonding in Heterogeneous WLANs: A Multi-Agent Deep Reinforcement Learning Approach. Sensors, 20(10), 2789. https://doi.org/10.3390/s20102789