Bearing State Recognition Method Based on Transfer Learning Under Different Working Conditions


Abstract
1. Introduction
2. Basic Theory of the Methodology
2.1. Balanced Distribution Adaptation
2.2. Multi-Core Balanced Distribution Adaptation
- (1)
- Use SVM to train two-classifiers to distinguish source data from target data and obtain the loss value ;
- (2)
- Calculate between source data and target data, and the formula is as follows:
- (3)
- Calculate the balance factor , and the formula is as follows:where and respectively represent source data and target data after kernel mapping. and represent the values of . The larger the value is, the greater the difference between source data and target data after the kernel mapping, so the weight of the corresponding kernel function is smaller, and vice versa.
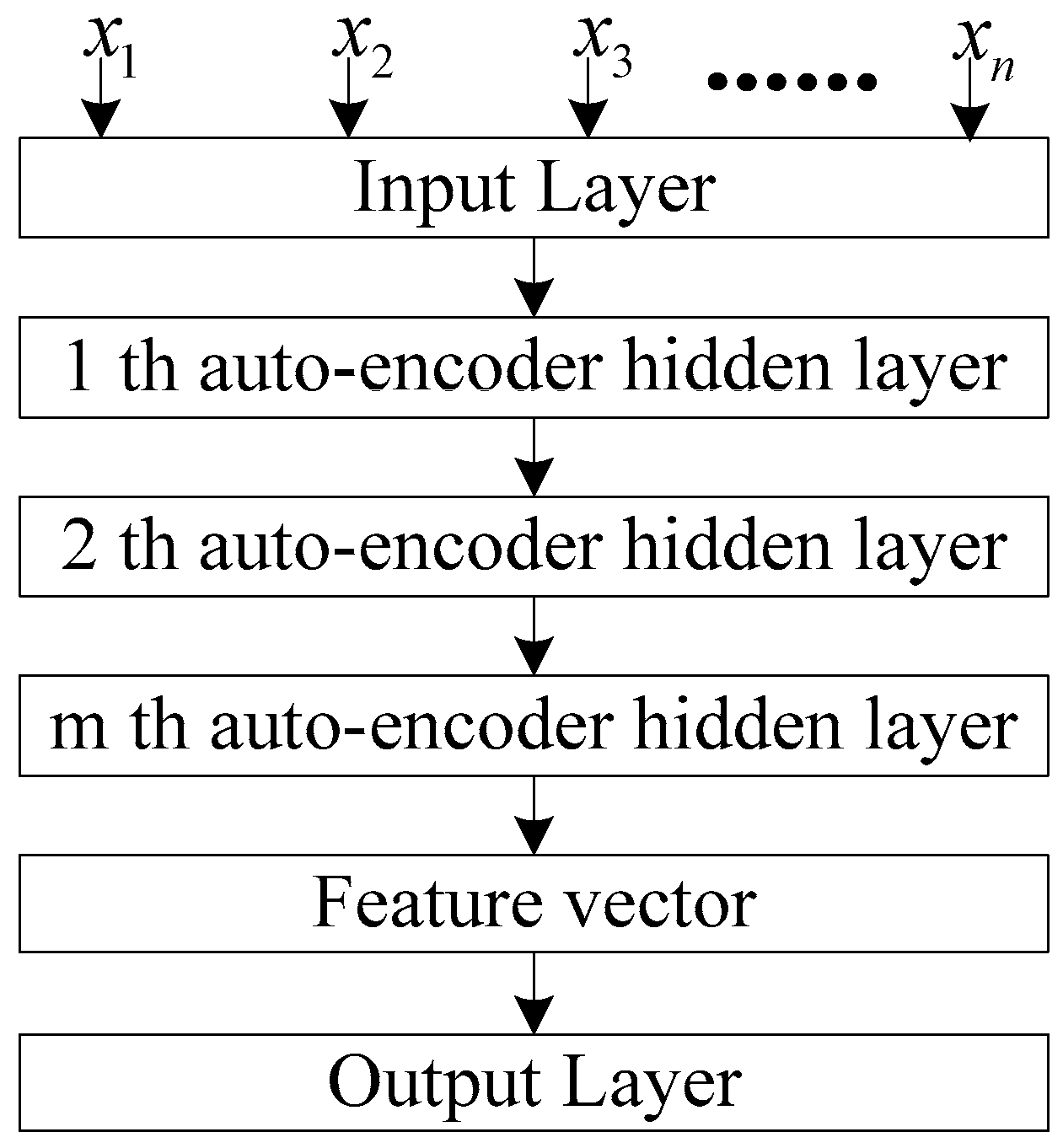
2.3. Stacked Autoencoder Neural Network
2.3.1. Autoencoder
- Coding phase: the information is transmitted from front to back.where, assuming the input layer is , the subscript in the formula indicates that there are training samples, and are the weight and bias of the encoding layer, respectively, and is the excitation function, which is usually a sigmoid or tanh function.
- Decoding phase: the information is transmitted from the back to the front:where is the output value of the decoding layer, and are the weights and bias of the decoding layer, respectively, and .
2.3.2. Stack Autoencoder Neural Network
- Model pre-training. The SAE neural network is constructed and the network model parameters are initialized through the unsupervised layer-by-layer training mode. Through pre-training, all hidden layers are obtained, and the features learned at each layer represent different levels of data characteristics.
- Model fine-tuning. Add a classification layer at the top of the SAE network and fine-tune the pre-training parameters to implement the classification function. Fine-tuning training takes all the layers of the SAE neural network as a whole model to train. At each iterative training, each parameter of the model is optimally adjusted. Therefore, fine-tuning training can improve the performance of SAE deep neural networks.
3. Bearing State Recognition Method and Process under Different Working Conditions
- Calculate the spectrum of labeled bearing data and unlabeled bearing data, and normalize the amplitude to the range of [0, 1]. Because the signal’s spectral amplitude is symmetrical about the origin, the positive frequency part is used as feature vectors. This not only ensures that information is not lost, but also reduces the number of calculations. The positive frequency domain amplitude of labeled bearing data is used as labeled source data, and the positive frequency domain amplitude of unlabeled bearing data is used as unlabeled target data.
- Map labeled source data and unlabeled target data in (1) to the same feature space by using the MBDA algorithm.
- The training process of SAE is also a feature self-learning process, which can further extract features. The training process of SAE includes two parts: unsupervised pre-training and supervised fine tuning. Unsupervised pre-training is used to initialize network parameters, and supervised fine-tuning implements classification by adding a classification layer on top of the network. Labeled source data after spatial mapping in (2) are used as training samples to train the model, and finally the training model is obtained. Unlabeled source data after spatial mapping in (2) are input into the model, and the rolling bearing state recognition results are obtained.
4. Experimental Verification
4.1. Experimental Data
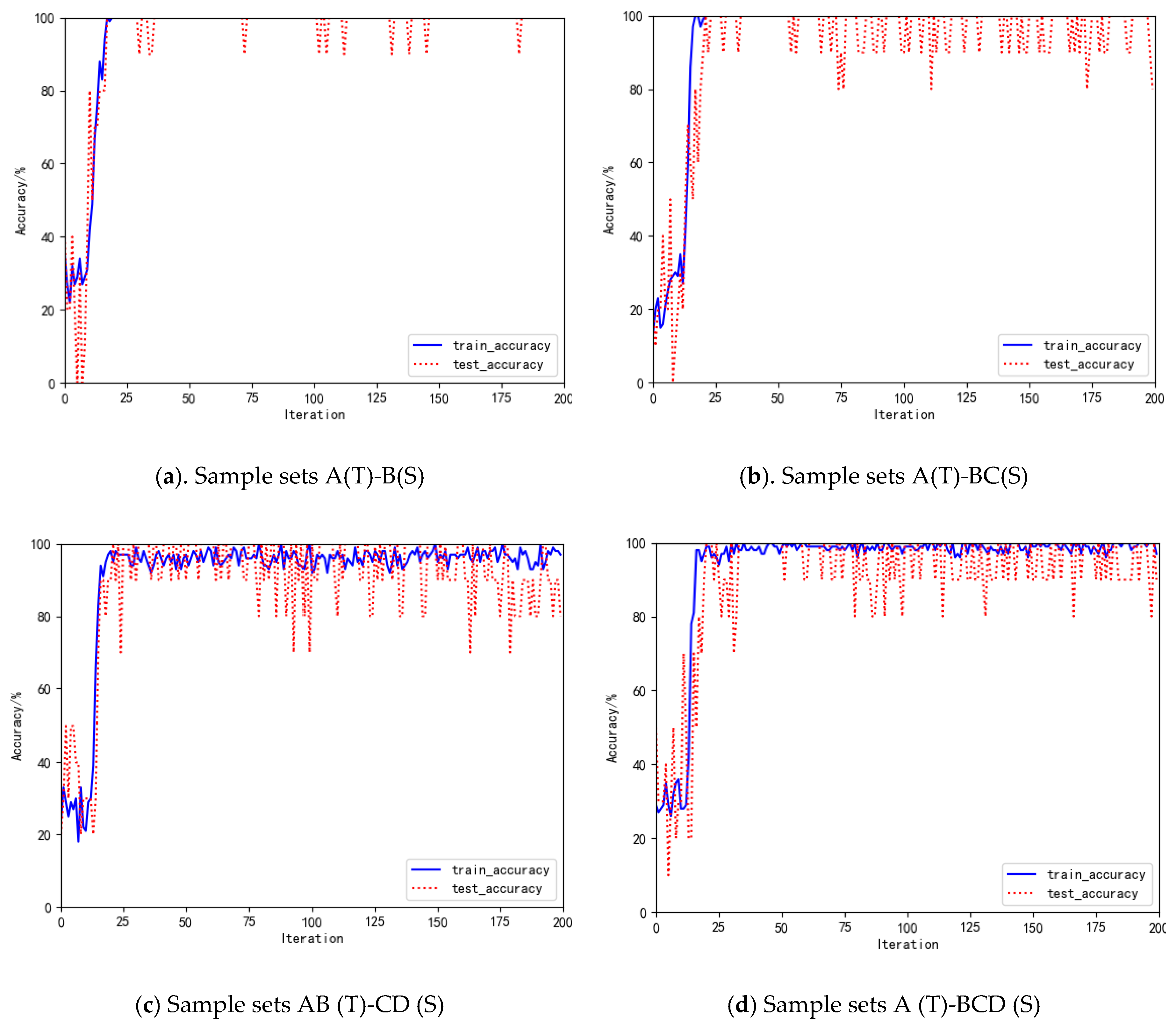
4.2. Model Performance Analysis
4.3. Analysis and Comparison of MBDA and other Algorithms
5. Conclusions
- (1)
- This method depends on BDA theory, and constructs a weighted mixed kernel function to map different working condition data to a unified feature space, which effectively minimizes the distribution divergence between different working conditions data. The MDBA method does not need to obtain the cross-characteristics of different working conditions data in advance, which simplifies data processing.
- (2)
- This paper adopts the algorithm to calculate the balance factor of the distribution and the balance factor of the kernel function. It can adaptively balance the importance of the marginal and conditional distribution and the importance of different kernel functions, and improve efficiency.
- (3)
- The MDBA method was compared to other transfer learning methods, such as TCA, JDA and BDA. In the case of a single/single condition A (T)-B (S), the accuracy of the bearing state recognition methods based on the JDA-SAE, BDA-SAE and MDBA-SAE methods reached more than 90%. However, the diagnostic accuracy based on the TCA-SAE method is 75%. In the case of multiple/multiple conditions AB (T)-CD (S), the state recognition accuracy of the method proposed in this paper reaches more than 90%. However, the accuracy of other methods is less than 80%. Therefore, the advantages of this method are more obvious under multiple/multiple conditions. Experiments showed that the MDBA method can better recognize the unknown state of rolling bearings under variable working conditions.
- (1)
- During the deep neural network training process, multiple experiments are required to determine better hyperparameters (such as the number of network layers, the number of neurons, the number of iterations, etc.), and then the setting of the hyperparameters will be studied;
- (2)
- The features extracted from the multi-layer network feature space will be visualized;
- (3)
- This article only studies bearing-related faults, and subsequent studies will distinguish other faults, such as unbalanced loads and broken rotor bars.
Author Contributions
Funding
Conflicts of Interest
References
- Sun, H.; He, Z.; Zi, Y.; Yuan, J.; Wang, X.; Chen, J.; He, S. Multiwavelet transform and its applications in mechanical fault diagnosis—A review. Mech. Syst. Signal Process. 2014, 43, 1–24. [Google Scholar] [CrossRef]
- Tse, P.W.; Peng, Y.H.; Yam, R. Wavelet analysis and envelope detection for rolling element bearing fault diagnosis - their effectiveness and flexibilities. J. Vib. Acoust. 2001, 123, 303–310. [Google Scholar] [CrossRef]
- Žvokelj, M.; Zupan, S.; Prebil, I. EEMD-based multiscale ICA method for slewing bearing fault detection and diagnosis. J. Sound Vib. 2016, 370, 394–423. [Google Scholar] [CrossRef]
- Ma, B.; Jiang, Z.N. Envelope analysis based on Hilbert transform and its application in rolling bearing fault diagnosis. J. B. Univ. Chem. Technol. 2004, 31, 36–39. [Google Scholar]
- Xu, Y.; Meng, Z.; Zhao, G. Study on compound fault diagnosis of rolling bearing based on dual-tree complex wavelet transform. Chin. J. Sci. Instrum. 2014, 35, 447–452. [Google Scholar]
- Ren, Z.; Zhou, S.; Chunhui, E.; Gong, M.; Li, B.; Wen, B. Crack fault diagnosis of rotor systems using wavelet transforms. Comput. Electr. Eng. 2015, 45, 33–41. [Google Scholar] [CrossRef]
- Chen, X.H.; Cheng, G.; Shan, X.L.; Hu, X.; Guo, Q.; Liu, H.G. Research of weak fault feature information extraction of planetary gear based on ensemble empirical mode decomposition and adaptive stochastic resonance. Measurement 2015, 73, 55–67. [Google Scholar] [CrossRef]
- Guo, L.; Gao, H.; Zhang, Y.; Huang, H. Research on Bearing State Recognition Based on Deep Learning Theory. J. Vib. Shock 2016, 35, 167–171. [Google Scholar]
- Kilundu, B.; Letot, C.; Dehombreux, P.; Chiementin, X. Early Detection of Bearing Damage by Means of Decision Trees. IFAC Proc. Vol. 2008, 41, 211–215. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, C.W.; Wu, P.H.; Ding, J.J.; Wang, C.C. Bearing fault diagnosis based on multiscale permutation entropy and support vector machine. Entropy 2012, 14, 1343–1356. [Google Scholar] [CrossRef]
- Satish, B.; Sarma, N.D.R. A fuzzy bp approach for diagnosis and prognosis of bearing faults in induction motors. In Proceedings of the IEEE Power Engineering Society General Meeting (PESGM), San Francisco, CA, USA, 12–16 June 2005; pp. 2291–2294. [Google Scholar]
- Li, H.; Zhang, H.; Qin, X.R.; Sun, Y.T. Fault diagnosis method for rolling bearings based on short-time Fourier transform and convolution neural network. J. Vib. Shock 2018, 37, 124–131. [Google Scholar]
- Wang, F.; Jiang, H.; Shao, H. An adaptive deep convolutional neural network for rolling bearing fault diagnosis. Meas. Sci. Technol. 2017, 28, 095005. [Google Scholar]
- Wang, F.; Liu, X.; Deng, G.; Yu, X.; Li, H.; Han, Q. Remaining Life Prediction Method for Rolling Bearing Based on the Long Short-Term Memory Network. Neural. Process Lett. 2019, 10, 1–18. [Google Scholar] [CrossRef]
- Hinchi, A.Z.; Tkiouat, M. Rolling element bearing remaining useful life estimation based on a convolutional long-short-term memory network. Procedia. Comput. Sci. 2018, 127, 123–132. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Wang, F.; Wang, Y. Rolling bearing fault diagnosis using adaptive deep belief network with dual-tree complex wavelet packet. ISA Trans. 2016, 69, 187–201. [Google Scholar] [CrossRef] [PubMed]
- Shao, H.; Jiang, H.; Zhang, X.; Niu, M. Rolling bearing fault diagnosis using an optimization deep belief network. Meas. Sci. Technol. 2015, 26, 115002. [Google Scholar] [CrossRef]
- Chen, R.X.; Yang, X.; Yang, L.X. Fault severity diagnosis method for rolling bearings based on a stacked sparse denoising auto-encoder. J. Vib. Shock 2017, 36, 125–131+137. [Google Scholar]
- Duan, L.; Tsang, I.W.; Xu, D. Domain transfer multiple kernel learning. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 465–479. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced Distribution Adaptation for Transfer Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November; pp. 1129–1134.
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Kang, S.Q.; Hu, M.W.; Wang, Y.J.; Xie, J.; Mikulovich, V.I. Fault Diagnosis Method of a Rolling Bearing Under Variable Working Conditions Based on Feature Transfer Learning. Proc. CSEE 2019, 39, 764–772. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE international conference on computer vision (ICCV 2013), Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Chen, C.; Shen, F.; Yan, R. Enhanced least squares support vector machine-based transfer learning strategy for bearing fault diagnosis. Chin. J. Sci. Instrum. 2017, 38, 33–40. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Different Working Conditions | RPM (r/min) | Motor Load (W) | Fault Diameter of IF, OF and BF (mm) | Fs (kHz) | Number of Samples |
|---|---|---|---|---|---|
| A | 1730 | 2.25 | 0.1778 | 12 | 1500 |
| B | 1750 | 1.5 | 0.3356 | 1500 | |
| C | 1772 | 0.75 | 0.5334 | 1500 | |
| D | 1797 | 0 | 0.7112 | 1500 |
| Sample Sets | Source Data | Target Data | Source Data Sample Number | Target Data Sample Number |
|---|---|---|---|---|
| Single/single conditions | B | A | 1500 | 1500 |
| Single/multiple conditions | BC | A | 3000 | 1500 |
| Multiple/multiple conditions | CD | AB | 3000 | 3000 |
| Single/multiple conditions | BCD | A | 4500 | 1500 |
| Different Methods/Sample Sets | A(T)-B(S) | A(T)-BC(S) | AB(T)-CD(S) | A(T)-BCD(S) | Average Accuracy |
|---|---|---|---|---|---|
| TCA-SAE | 75.00 | 69.00 | 62.00 | 54.00 | 65.00 |
| JDA-SAE | 92.00 | 77.00 | 69.52 | 69.00 | 76.88 |
| BDA-SAE | 96.99 | 88.00 | 83.10 | 77.00 | 86.27 |
| MBDA-SAE | 100.00 | 98.50 | 96.86 | 90.50 | 96.47 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, N.; Jiang, Z.; Gao, J.; Cui, B. Bearing State Recognition Method Based on Transfer Learning Under Different Working Conditions. Sensors 2020, 20, 234. https://doi.org/10.3390/s20010234
Cao N, Jiang Z, Gao J, Cui B. Bearing State Recognition Method Based on Transfer Learning Under Different Working Conditions. Sensors. 2020; 20(1):234. https://doi.org/10.3390/s20010234
Chicago/Turabian StyleCao, Ning, Zhinong Jiang, Jinji Gao, and Bo Cui. 2020. "Bearing State Recognition Method Based on Transfer Learning Under Different Working Conditions" Sensors 20, no. 1: 234. https://doi.org/10.3390/s20010234
APA StyleCao, N., Jiang, Z., Gao, J., & Cui, B. (2020). Bearing State Recognition Method Based on Transfer Learning Under Different Working Conditions. Sensors, 20(1), 234. https://doi.org/10.3390/s20010234