1. Introduction
Signals with strength higher than the detection threshold of the sensor are used as measurements for track initiation and track state update of target tracking. These measurements include not only the target measurements, but also clutter measurements due to environmental factors. Since the source of the measurements in the tracking system is not known in advance, target tracking performance may be significantly degraded if measurements generated by clutter are used when the track state is updated. It is essential to use a tracking algorithm based on data association that can statistically distinguish target and clutter measurements in a cluttered environment [
1,
2,
3,
4].
Since the number of targets existing in the surveillance region and information on the appearance and disappearance of the target cannot be known in advance, it is important to have a means for determining whether the target is being tracked by a tracking algorithm. For target tracking with track management, integrated probabilistic data association (IPDA) [
5,
6] and integrated track splitting (ITS) [
7,
8,
9] have been proposed as data association algorithms for single target tracking, which include a track management method that utilizes the target existence probability of each track for controlling the track status and track number or track label. Linear multitarget-IPDA (LM-IPDA) [
10], joint IPDA (JIPDA) [
11], and iterative JIPDA (iJIPDA) [
12] have been proposed for multiple target tracking by extending IPDA and ITS.
In the aforementioned data association algorithms, it is assumed that the number of clutter measurements is Poisson distributed with a parameter called the clutter measurement density, and the clutter measurements are assumed to be uniformly distributed in the surveillance space. The clutter measurement density is defined as the mean number of clutter measurements per unit volume of the surveillance space. The clutter measurement density is an important parameter used to calculate the data association probability and the target existence probability in the data association algorithms.
If the clutter measurement density is fixed to a design value for target tracking in heterogeneous clutter environments, the error in the clutter measurement density deteriorates not only the target state estimation performance, but also the false track discrimination (FTD) performance because prior information about the clutter measurement is unknown in actual target tracking environments. For accurate and robust target tracking in these environments, it is required to estimate the clutter measurement density adaptively. Clutter measurement density estimation methods are divided into track based estimation methods and measurement based estimation methods. In addition, they are divided into single scan estimation methods and multiple scan estimation methods depending on whether the memory is used in the calculation.
The clutter map method [
13,
14] is a multi-scan estimation method that uses the measurements from previous scans to calculate the clutter measurement density in the current scan. It divides the surveillance region into a finite number of cells and then estimates the clutter measurement density in each cell by statistically counting the number of existing measurements in the cell during a pre-determined multiple scan period. The clutter map can reduce the influence of bias caused by the target measurements, but estimation performance is sensitive to the parameters such as the cell size and the length of multiple scan period. It is difficult to apply the clutter map when the number of measurements and the spatial probability distribution are time varying.
In [
15,
16], the clutter measurement density estimation method based on the probability hypothesis density (PHD) filter [
17] was handled in conjunction with a target tracking algorithm based on data association. It was designed as a feedback structure that used the intensity of clutter estimated through PHD. However, since the clutter generator is assumed to be a Gaussian function with unknown mean and unknown covariance, it is difficult to use in practical implementations due to heavy computational loads. The work in [
18] proposed an interactive clutter measurement density estimator (ICMDE) based on a Gaussian mixture PHD (GM-PHD) filter [
19] to estimate the clutter measurement density adaptively in environments where the clutter measurement densities are nonuniform and time varying. In [
18], the Gaussian model for the clutter generator was assumed to have a known covariance for reducing the computational loads required to calculate the updated state PHD. By dividing the entire surveillance area, the clutter generator for each partition is represented as a component with the Gaussian model. These processes are performed for multiple scans to generate a reliable clutter map of the surveillance area. In [
20], a method of forming a clutter map as proposed by using the histogram probabilistic multi-hypothesis tracker (H-PMHT) based on expectation maximization for image target tracking with each scene composed of millions of pixels. This method forms a clutter map through many iterations until local convergence is guaranteed.
The track based and the measurement based clutter measurement density estimation methods are classified as single scan estimation methods in which the clutter measurement density of the previous scan does not affect the clutter measurement density of the current scan. The track based clutter measurement density estimation method uses the validation gate of the track and the validated measurements existing in this gate. There exist several methods such as the conditional mean estimator based on the target perceivability [
21] and the maximum likelihood estimator based on the assumption of unknown, but non-random clutter measurement density [
22]. The conditional mean estimator [
22] requires prior knowledge of clutter measurement density so that the maximum likelihood estimator may be used as an auxiliary estimator. For the track based clutter measurement density estimation methods, different clutter measurement densities are produced for the same measurement shared by the two tracks as the size of the validation gate of each track is different. This is a drawback of the track based clutter measurement density estimators.
The spatial clutter measurement density estimator (SCMDE) [
23] is a measurement based clutter measurement density estimation method that calculates the sparsity as the reciprocal of the clutter measurement density by evaluating the volume of the hyper-sphere centered at the measurement of interest and counting the number of measurements inside the volume. The number of measurements and the hyper-sphere volume are determined by the sparsity order. Unlike the track based clutter measurement density estimation methods, it produces a unique sparsity for each measurement regardless of the validation gate size of the track involved.
It was pointed out in [
23] that the existing SCMDE generates the unbiased estimates of clutter measurement density when the point of interest is the target detection for single target tracking environments. It produces biased and bigger clutter measurement density estimates than the actual ones when the point of interest is a clutter detection, which results in improved target tracking performance as the data association probabilities become smaller for the clutter detection. However, when the existing SCMDE is used for multi-target tracking environments, biased clutter measurement density estimation is expected from the nature of SCMDE that all the adjacent measurements to the point of interest are considered to be clutter detections. Through the study in this paper, a major source of biased clutter measurement density estimation of the existing SCMDE for multi-target tracking environments is analyzed, and remedies to reduce the biases are proposed. The new adaptive SCMDE for multi-target tracking (MTT-SCMDE) utilizes the clutter measurement probability to take into account only the clutter measurements for improved accuracy by reducing the biases in the clutter measurement density estimation. Through the analysis, an expansion of the volume of the hyper-sphere corresponding to each sparsity order from that of the existing SCMDE is proposed for more accurate clutter measurement density estimation.
A method that takes into account clutter-originated measurements in the clutter measurement density calculation was proposed in [
24]. The performance of the SCMDE algorithm for multi-target tracking was presented in [
24]. In this paper, we elaborated the theoretical development by analyzing the source of biases in the MTT-SCMDE algorithm for multi-target tracking, and refined its performance by increasing the hyper-sphere volume for the measurement of interest. The improvement was based on strict analysis presented in this paper. To verify the performance of the proposed clutter measurement density estimation method, a series of simulation runs was executed in heterogeneous clutter environments, and the results were analyzed by performance comparison to check how closely the estimated clutter measurement densities followed the true clutter measurement densities for multiple targets. In addition, the clutter measurement density estimation performance and the target tracking performance were tested for various sparsity orders and various numbers of targets involved. The proposed MTT-SCMDE was also applied to a set of real radar data for performance evaluation.
The remainder of this paper is organized as follows. The stochastic models in the target tracking algorithm are described in
Section 2.
Section 3 derives the LM-IPDA algorithm for multi-target tracking in a cluttered environment. The SCMDE method is briefly described in
Section 4.
Section 5 describes the proposed clutter measurement density estimation method in detail. The clutter measurement density estimation performance and multiple target tracking performance of the proposed method are analyzed through a series of Monte Carlo simulation runs in various tracking environments, as well as a set of real radar data in
Section 6, followed by the Conclusions. Performance analysis of the existing SCMDE used in multi-target tracking environments is presented in the
Appendix A.
2. Models
The following assumptions are applied for using multi-target tracking algorithms in a cluttered environment.
The sensor has infinite resolution; each measurement is generated only from one source; and its the origin can be either a target or clutter.
Each target generates at most one measurement at each scan according to the target detection probability .
Superscript
denotes a target, or the index of a track that follows the target. Target
’s trajectory state
is an
state vector. In this paper, the dynamics of the targets from scan
k to scan
are assumed to follow a linear dynamic model in a two-dimensional (2D) plane, such as:
where
is a
state vector consisting of the target position, velocity, and acceleration in a 2D plane,
is the state propagation matrix, and
is the coefficient matrix of
, which is a white Gaussian process noise with zero-mean and covariance matrix
. The last term of (
1) is white Gaussian with zero-mean and covariance matrix
, and its distribution is denoted by
. The state propagation matrix
and the coefficient matrix for the process noise
follow a nearly constant velocity (NCV) model or constant turn rate (CTR) model [
25].
For the NCV model, the state propagation matrix and the coefficient matrix for the process noise in (
1) become:
where
T is the sampling time of a discrete time interval,
is a
identity matrix,
is a
null matrix, and the variance of
is set to be
such that
of the NCV model represents the acceleration uncertainty; this implies
. For the NCV model, the acceleration components of
are set to be zero.
For the CTR model, the state propagation matrix and the coefficient matrix for the process noise in (
1) become:
of the CTR model represents the uncertainty in target jerk, and its variance is ; this implies . The turn rate is adaptively estimated using the target acceleration and velocity estimates while tracking.
Target measurement model
is an
vector, and it is expressed as:
where
is the measurement matrix denoted by:
In (
6),
is a white Gaussian measurement noise of the sensor with zero-mean and covariance matrix
.
The sensor obtains a set of measurements
at each scan
k.
is the
ith measurement of
, and the measurement vector of
can be expressed by:
where
and
represent the
x and
y positions in the 2D Cartesian coordinate system, respectively.
3. LM-IPDA Algorithm for Multi-Target Tracking
In a cluttered environment, multi-target tracking algorithms with data association such as global nearest neighbor (GNN) [
26,
27] and joint probabilistic data association (JPDA) [
28,
29,
30] have been widely used. However, these algorithms in general do not include an FTD procedure that can distinguish the true tracks generated by the target measurements from the false tracks generated by the clutter measurements. JIPDA and LM-IPDA are multi-target tracking algorithms with FTD functions for autonomous track management. JIPDA has optimal target tracking performance for single scan data association since it probabilistically takes into account all possible events between measurements and tracks in the cluster for each scan. However, it has heavy computational loads as the number of feasible joint events to be considered increases combinatorially depending on the number of measurements and the number of tracks. In this paper, LM-IPDA instead of JIPDA is used for multi-target tracking as the computation time increases linearly commensurate with the number of targets. In LM-IPDA, the state of track
is represented as a hybrid state that consists of the target existence event (discrete event) and the trajectory state (continuous variable) such as:
where
represents the existence event of target
at scan
, and the probability density function of the target state at scan
k satisfies:
The track recursion is composed of the following steps:
prediction of track state and existence probability,
selection of validated measurements,
calculation of modulated clutter measurement density,
update of track state and existence probability.
3.1. Prediction of Track State and Existence Probability
The existence event of a target in the surveillance region at scan
k is denoted by
as a random event, and
is the complement of
. The existence of a target propagates by the Markov chain one model [
5,
6]:
where
is the transition probability of target existence.
The trajectory state of each track
is propagated using the prediction step of the Kalman filter:
3.2. Selection of Validated Measurements
Since it is computationally inefficient to use all measurements in the entire surveillance region, the validation gate [
2,
3] is generated around the track predicted position, and the track is updated using only the measurements that exist inside the gate. If the measurement
satisfies the following equation for track
,
is regarded as a validated measurement. Otherwise, it is not used for updating the states of track
.
with:
where
is the size of the validation gate. The set of validated measurements selected by track
and the number of validated measurements are denoted by
and
, respectively.
3.3. Calculation of Modulated Clutter Measurement Density
The calculating process of the modulated clutter measurement density is a crucial part of the LM approach, which can significantly reduce the amount of computation of JIPDA, which evaluates the probabilities of all the feasible joint events that can occur in multiple target tracking for each scan.
The modulated clutter measurement density of measurement
can be obtained by adding the influence of other tracks to
by utilizing the probability that measurement
is generated from other targets to the pure clutter measurement density
at the position of measurement
. Let
denote the modulated clutter measurement density, then:
where
is a measure of the influence of track
on
, and it is represented by the prior probability that
is generated from target
such as:
where
is a likelihood function of measurement
with respect to track
such that:
where
is the gate probability [
2].
The modulated clutter measurement density of measurement is used for calculating the data association probabilities in the update step of track trajectory state, as well as the update step of the target existence probability.
3.4. Update of Track State and Existence Probability
Using the validated measurements selected by track , the posterior trajectory state of track and the posterior target existence probability are calculated.
Let
denote the data association probability that is conditioned on the target existence event
. The data association probability
is expressed for the event
, which indicates that the
ith validated measurement of track
is a target measurement, and the event
, which indicates that all the validated measurements of track
are regarded as clutter measurements.
where
is the measurement likelihood ratio of track
such that:
The posterior trajectory state of track
is calculated by the total probability theorem [
31] such as:
where
is a single Gaussian distribution as a posterior probability density function for the target trajectory state conditioned on the facts that target
exists and
is the target measurement.
where the conditional mean
and covariance
satisfy:
where
denote an
identity matrix, and the Kalman gain
is expressed by:
Using the data association probabilities for the validated measurements, the updated track state estimates are obtained in the form of a Gaussian mixture such as:
The posterior target existence probability is used as a track score for track management including confirmation and termination. It is obtained by using the prior target existence probability and the measurement likelihood ratio such as [
10]:
4. The Existing Spatial Clutter Measurement Density Estimator for Single Target Tracking
The clutter measurement density is an important parameter to calculate the data association probability and the posterior target existence probability for track maintenance. In particular, when the LM approach is used in a situation where multiple targets are located in the vicinity, the merging and switching phenomena of the tracks are reduced by utilizing the modulated clutter density with moderate computational loads [
10]. Therefore, it is crucial to estimate the clutter measurement density properly.
The clutter measurement density is defined as the average number of measurements that exist within a unit volume. For calculating the sparsity of
, the measurements are aligned in the ascending order of distance from
. If
denotes the set of the aligned measurements such as:
where
is the
lth nearest measurement from
. Let
denote the distance from
to the
nth nearest measurement,
in
. Then,
becomes:
The SCMDE estimates the sparsity of the measurements, which is the reciprocal of the clutter measurement density. The sparsity of
is obtained from:
where
n and
denote the sparsity order and the volume of the hyper-sphere with radius
for
, respectively.
is expressed by:
where
represents the dimension of the measurement space and
,
, and
.
Figure 1 schematically illustrates the hyper-spheres with various sparsity orders for
in a 2D measurement space.
In the process of deriving the sparsity, track information is not used. A measurement shared by two or more tracks has a unique clutter measurement density regardless of the track states.
6. Performance Tests
6.1. Simulation Experiments
The performance test was done to compare the results with respect to FTD performance and the accuracy of estimated clutter measurement density for the cases, which utilized:
True clutter measurement density (true CMD),
SCMDE with various sparsity orders,
MTT-SCMDE with various sparsity orders.
The sets of simulation experiments are presented for multi-target tracking in a heterogeneous environment with varying the number of targets.
The sampling time of sensor
T was 1 s, and the measurement noise covariance was
. The target detection probability
and the gate probability
were
and
, respectively. One simulation run consisted of 50 scans, and the total number of Monte Carlo simulation runs was 500. To initialize the track, the two point differencing method [
14] was employed if the calculated velocity obtained from two consecutive scans was smaller than the predetermined maximum velocity constraint
m/s.
In these simulations, the following four evaluation indices were calculated:
The confirmed track was defined as one whose posterior target existence probability calculated by (
29) was bigger than a predetermined confirmed threshold. Among confirmed tracks, the tracks satisfying the following equation were classified as the confirmed true tracks for tracking performance evaluation purposes:
where
and
are the state vector of the true target and the initial error covariance matrix of the confirmed track
, respectively. Conversely, each confirmed track met the following test, and it became a confirmed false track.
The confirmed true track rate (CTTR) is an evaluation index showing the statistical ratio of confirmed true tracks over time. The position root mean squared error is the distance error between the confirmed true track and the true target, and it was obtained only for the confirmed true tracks over time. The track retention test statistic is an evaluation index of the multi-target tracking algorithms and accumulates statistics on how much the confirmed true tracks are retained or lost between retention test start time (RST) and retention test end time (RET). In these simulations, RST and RET were designated to be 15 and 35, respectively. The retention test was to check the following items, and they were used to indicate the statistical ratio representing the robustness of each algorithm for the period in which the targets were located in the immediate vicinity:
nCase: the total number of CTTs at RST,
nOk: the percentage of nCase CTTs that still followed the original target at RET,
nSwitch: the percentage of nCase CTTs that did not follow the original target at RET,
nMerge: the percentage of merging two or more nCase CTTs during the retention test,
nLost: the percentage of nCase CTTs that were terminated during the retention test.
The clutter measurement density estimation performance is an evaluation index of how closely the estimated clutter measurement density follows the true clutter measurement density using the clutter measurement density estimation method. The performance of the proposed algorithm was tested in comparison with the existing SCMDE algorithm for multi-target tracking by varying the number of targets in a heterogeneous clutter environment. Simulations were performed for 3, 5, and 7 targets in three scenarios, and the performance of clutter measurement density estimation was analyzed as the number of targets increased. In addition, the effectiveness and the robustness of the tracking performance were verified through a test with real radar data.
6.1.1. The Number of Targets: 3
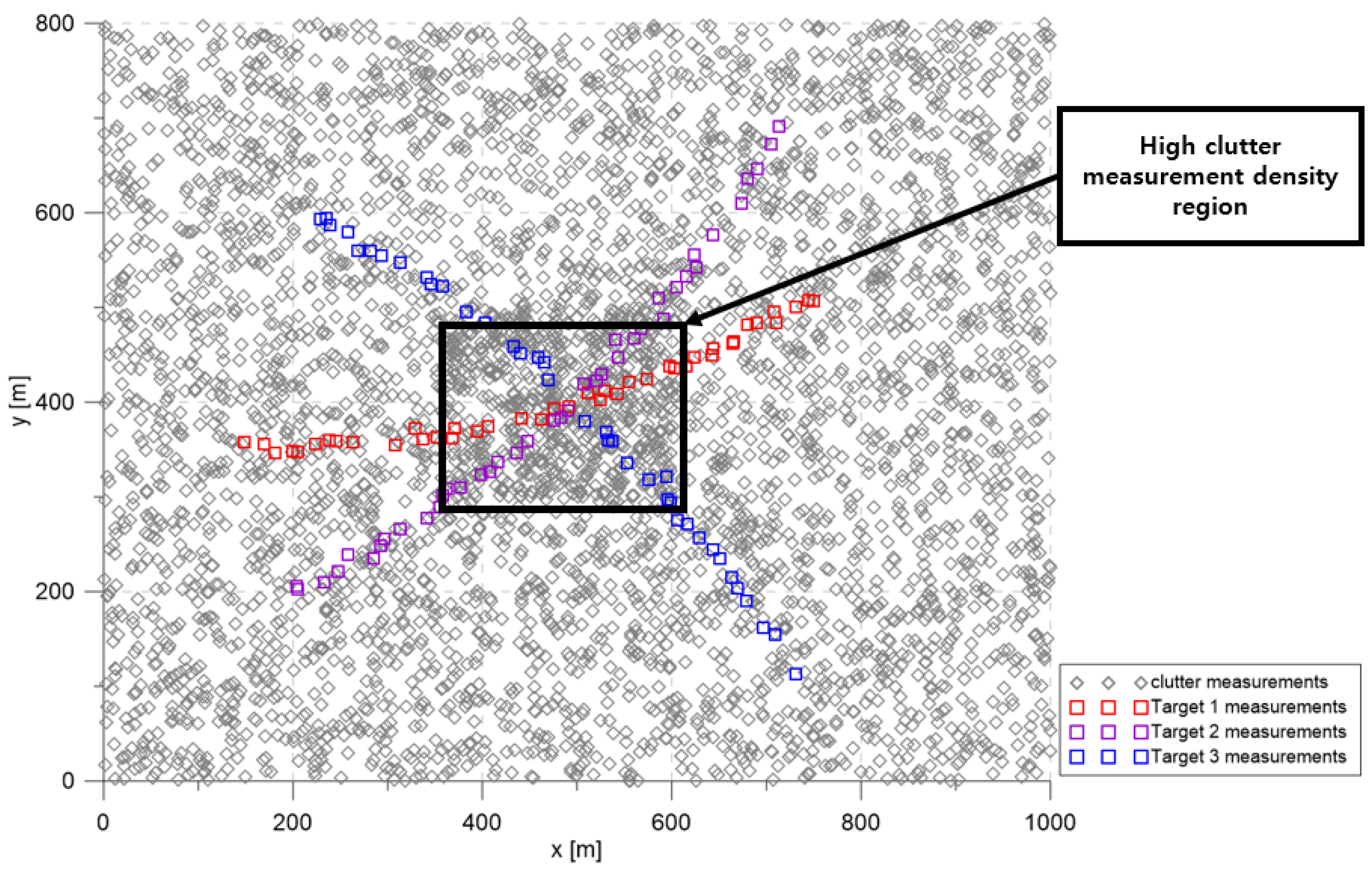
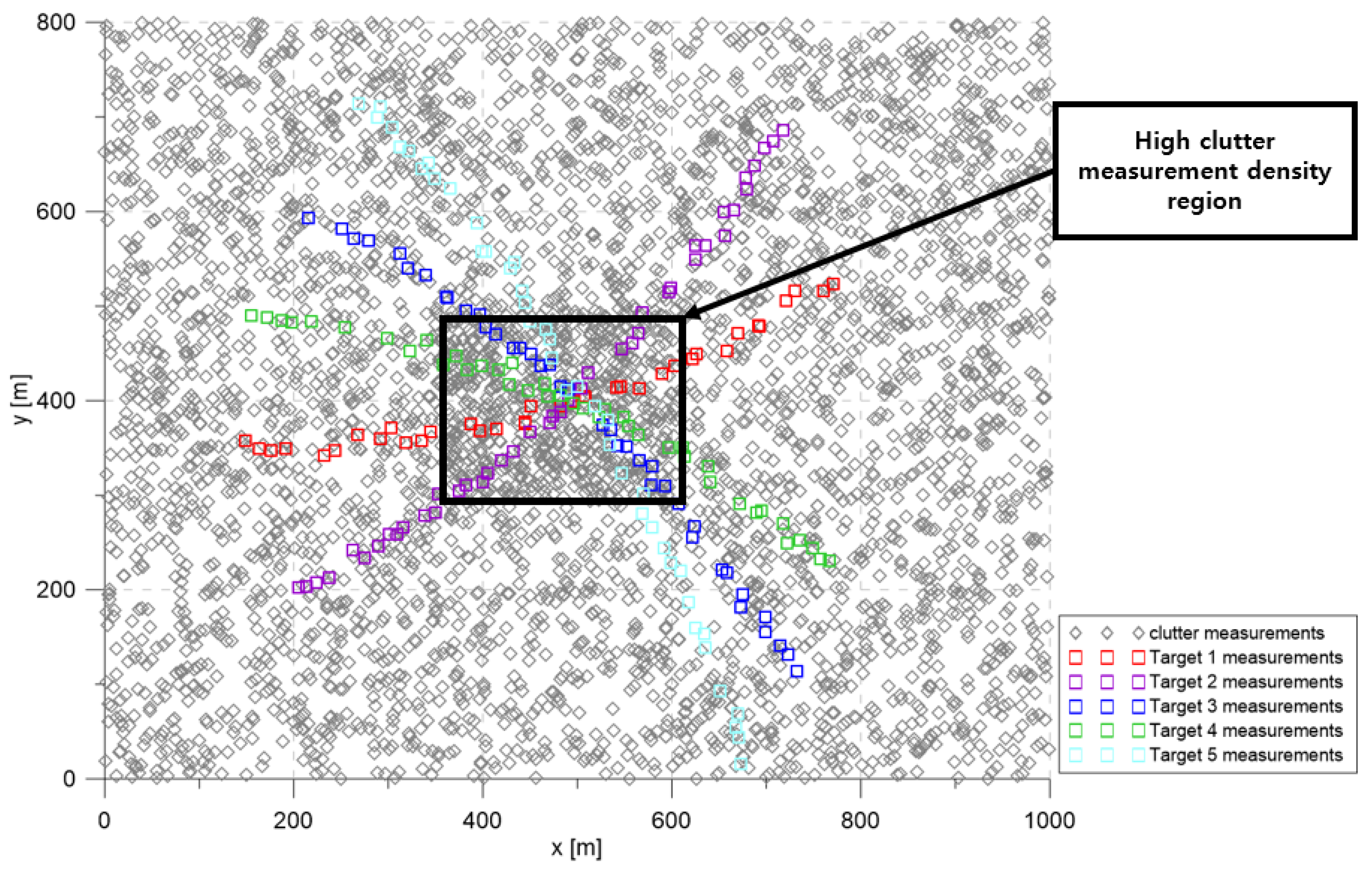
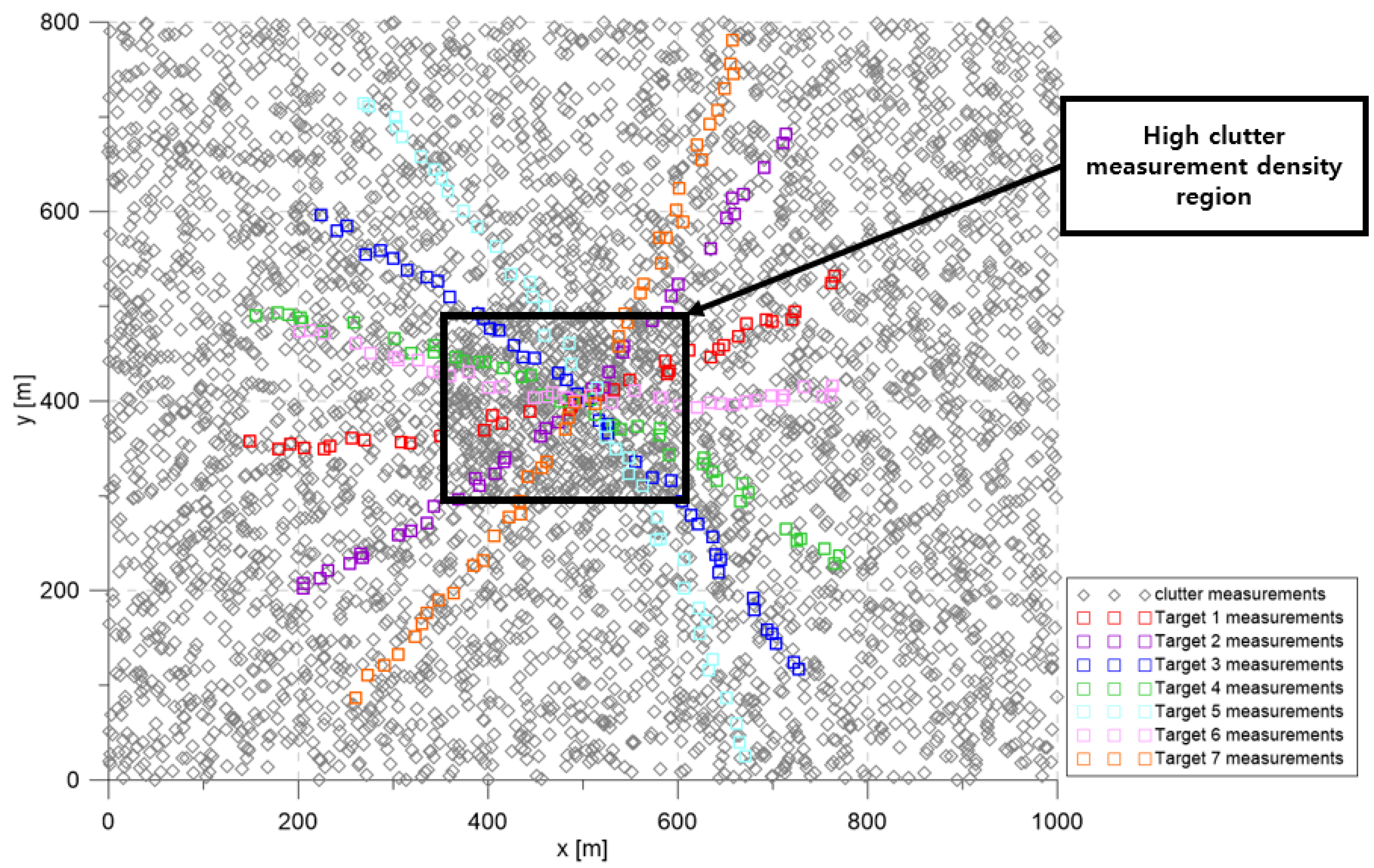
The simulation considered the 2D surveillance region depicted in
Figure 3. The targets maneuvered slightly to form curved trajectories within the surveillance region. To track maneuvering targets, the LM-IPDA-interacting multiple model (LM-IPDA-IMM) [
32] was employed. The LM-IPDA-IMM algorithm used in this study utilized the NCV model and the CTR model introduced in
Section 2. The targets were located apart at the beginning of the scenario, then they were located in the immediate vicinity at Scan 25, and then moved away from each other.
The base clutter measurement density was
scans/m
, and it increased to
scans/m
in the high clutter measurement density region; clutter measurements were spatially distributed with a uniform distribution inside each cluttered region for every scan. In
Figure 3, the squares represent the measurements of each target. The gray symbols represent the clutter measurements generated during a single simulation run.
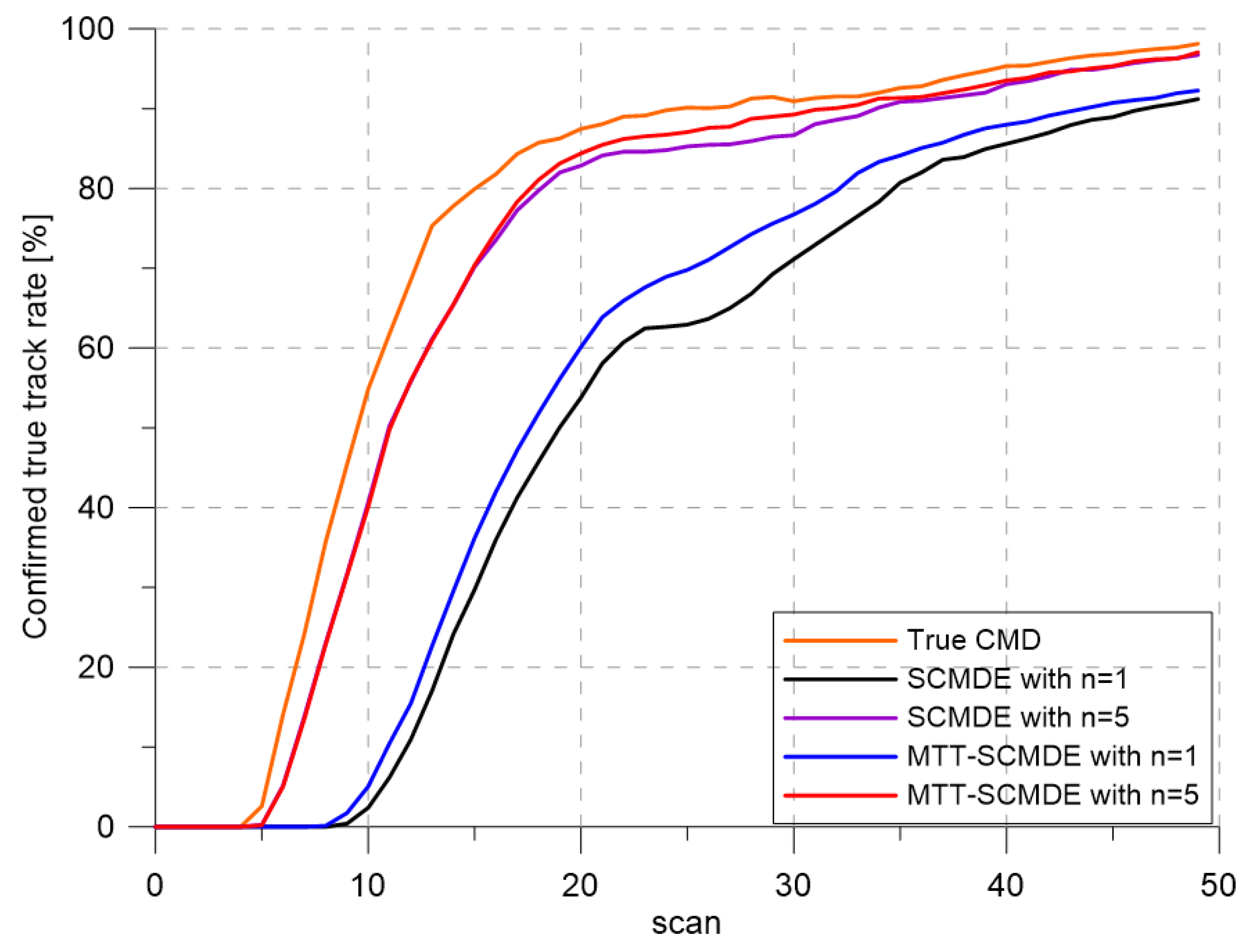
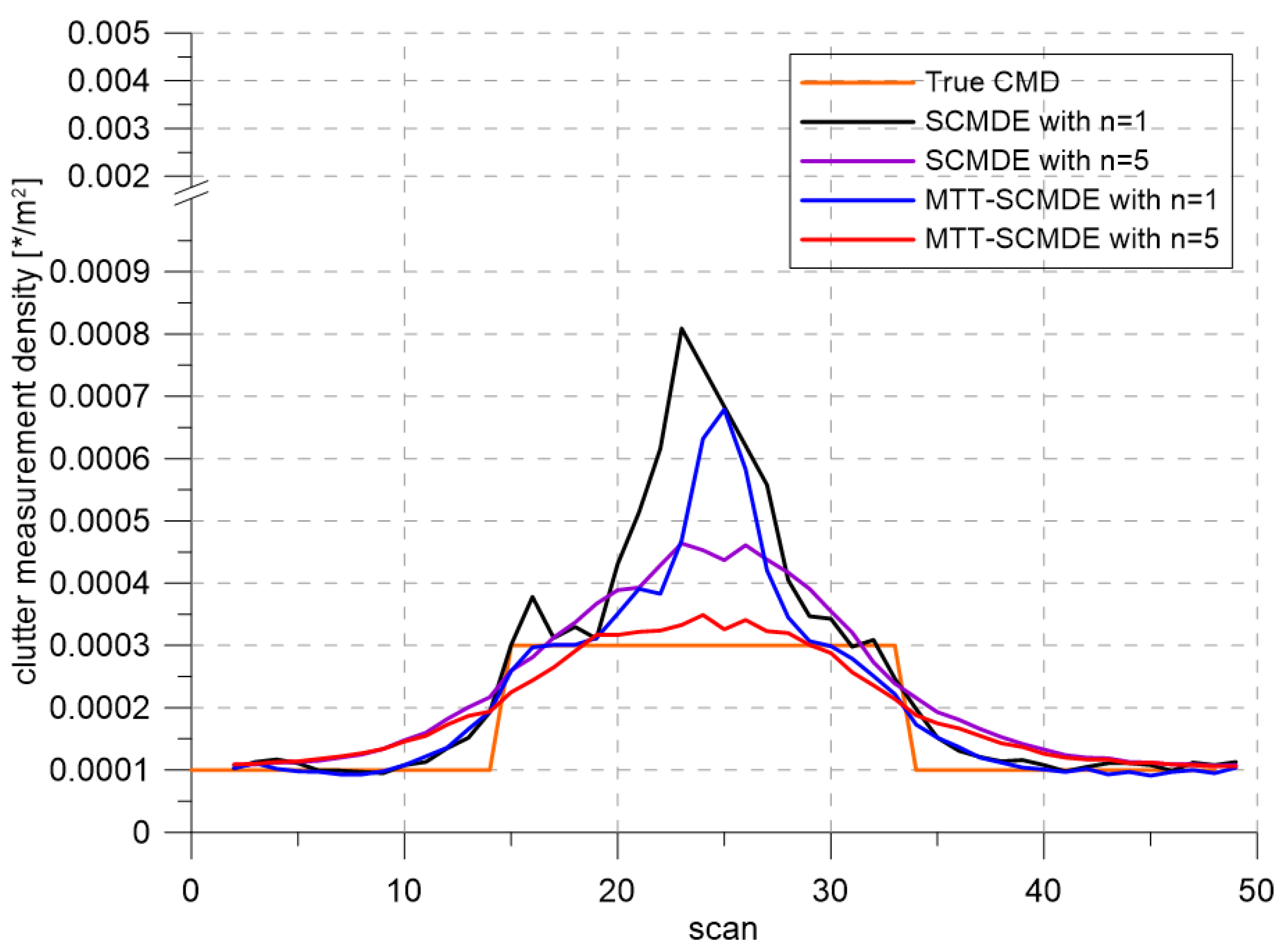
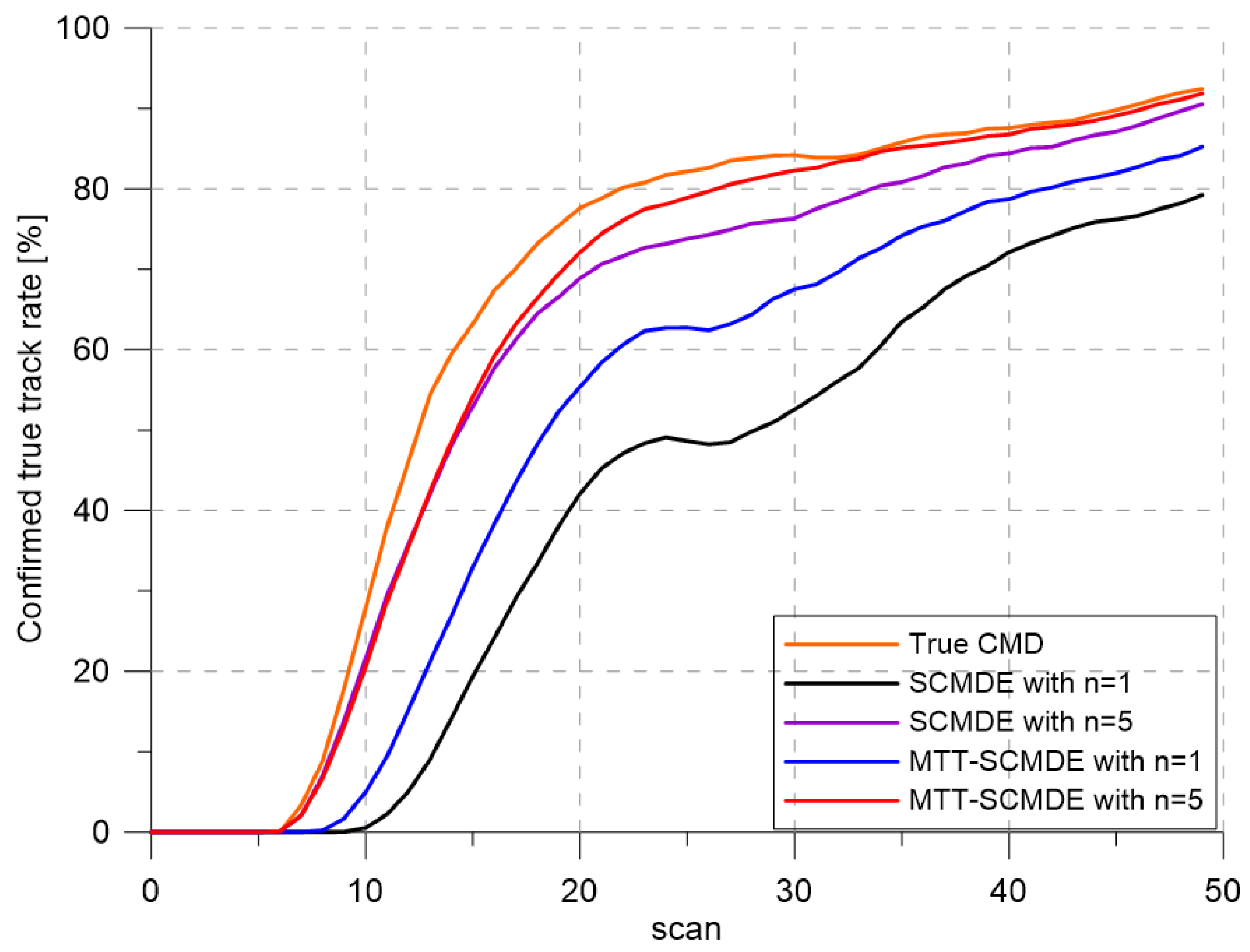
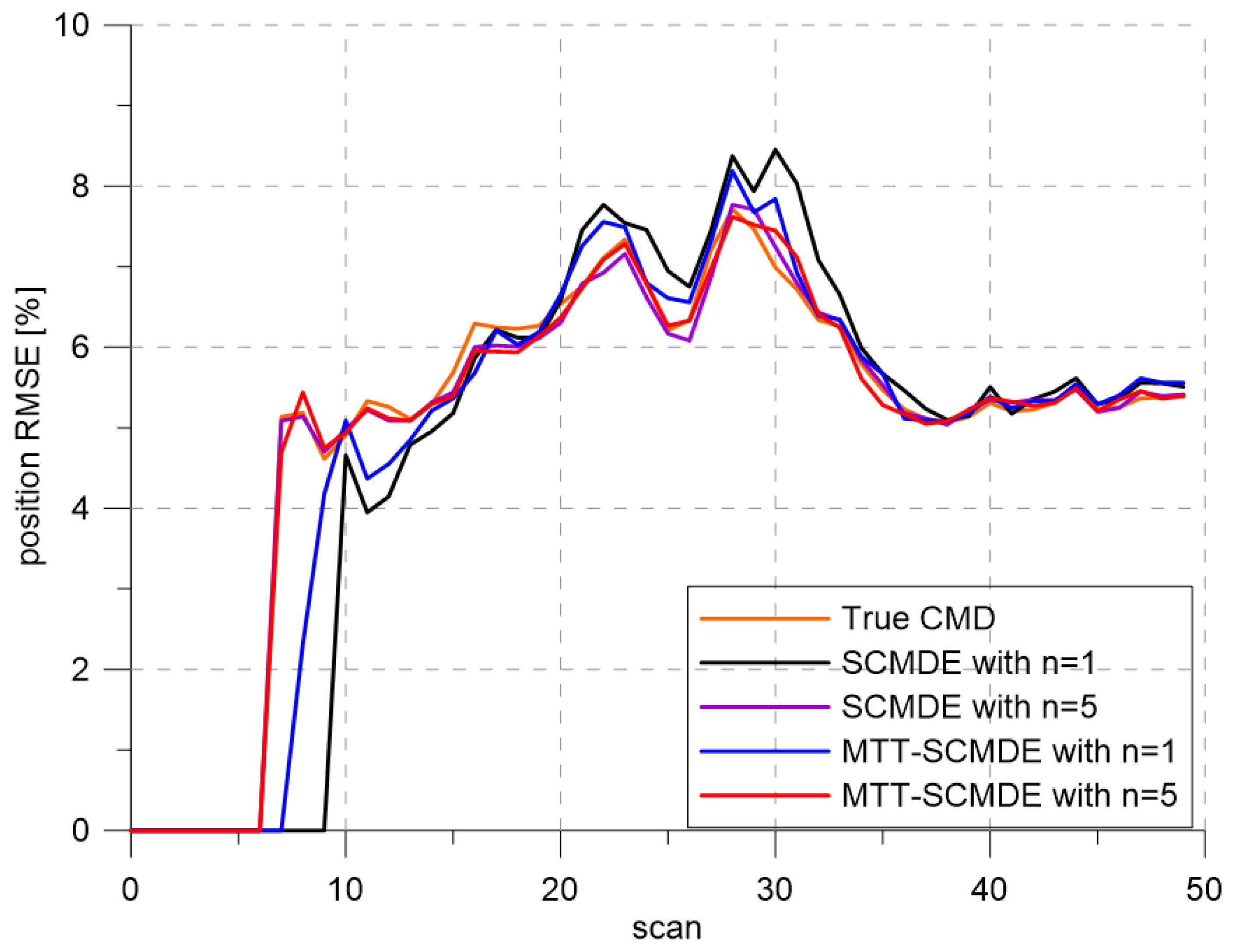
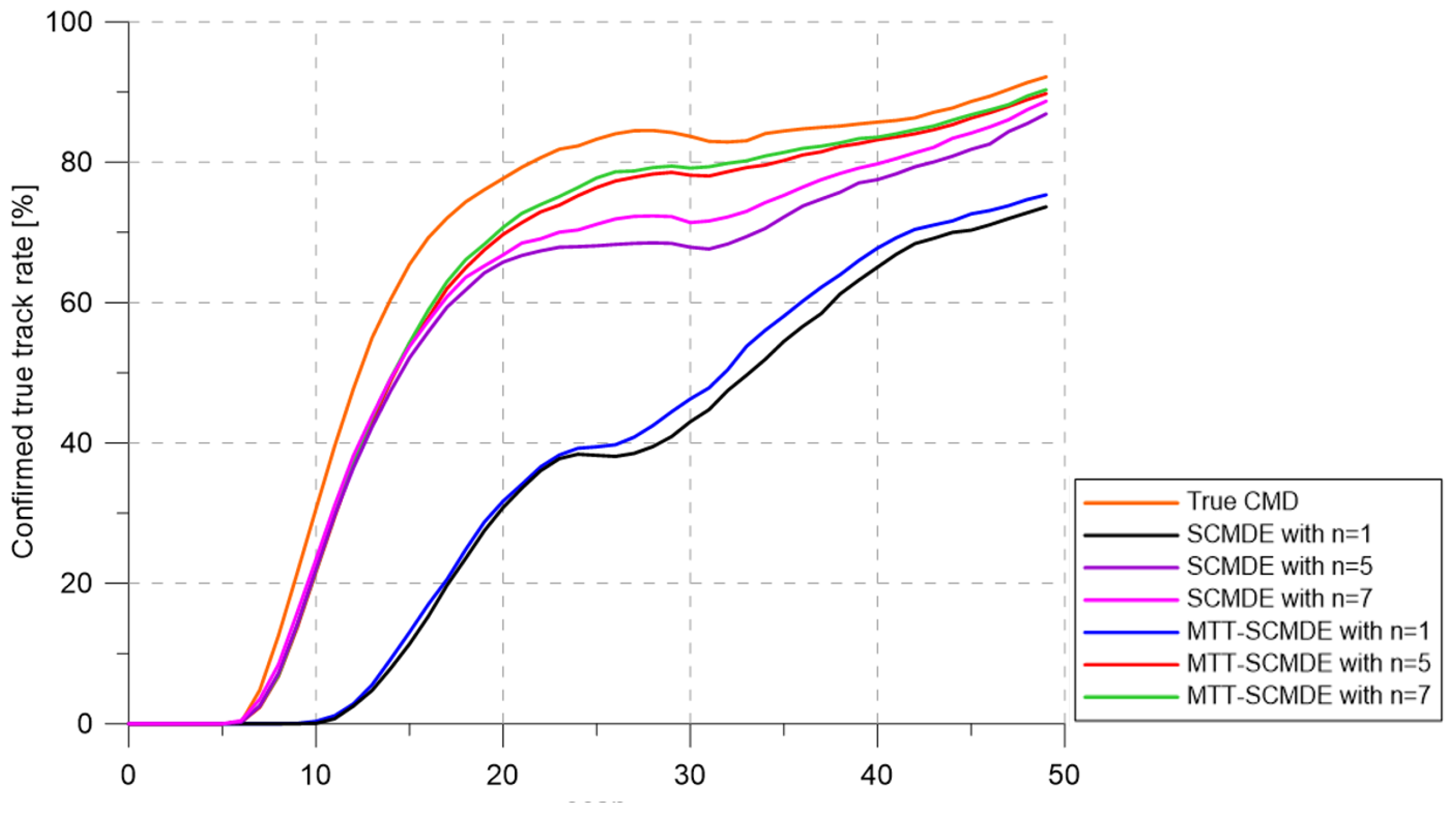
Figure 4 represents the CTTR for three targets in 500 Monte Carlo runs, and the position RMSE for Target 1 and the estimated clutter measurement density for Target 1 over time are listed in
Figure 5 and
Figure 6, respectively. For fair comparisons, the number of confirmed false tracks of each case was made to be almost 40 for all 500 Monte Carlo simulation runs by adjusting the initial target existence probability while the confirmation threshold was equal for all the algorithms in comparison. Using the true clutter measurement density showed that the CTTR had the fastest build-up. Even if the same sparsity order was applied, the proposed clutter measurement density estimation method provided better tracking results than the SCMDE. The closer to the true clutter measurement density the estimated clutter measurement density was, the better the performance was. At around Scan 25, when the targets were located in the immediate vicinity, the SCMDE estimated the clutter measurement density of the target measurement, which appeared to be bigger than the actual. This resulted in a slow build-up of the CTTR. By comparing the CTTR results for the sparsity order of
and
for the same clutter measurement density estimation methods, one could find that higher sparsity order resulted in better tracking performance because the higher the sparsity order was, the more accurate the estimated clutter measurement density was, as shown in
Figure 6. The position RMSEs shown in
Figure 5 were calculated for only the confirmed true tracks, which satisfied (
46) such that the RMSEs looked similar in the order of magnitudes for all the algorithms in comparison as the confirmed true tracks passed the condition of (
46). However, the number of samples involved in the RMSE calculation was quite different for each algorithms, as shown by the CTTR of
Figure 4, which implied high reliability in RMSE for the algorithms with high CTTR and low reliability in RMSE for the algorithms with low CTTR.
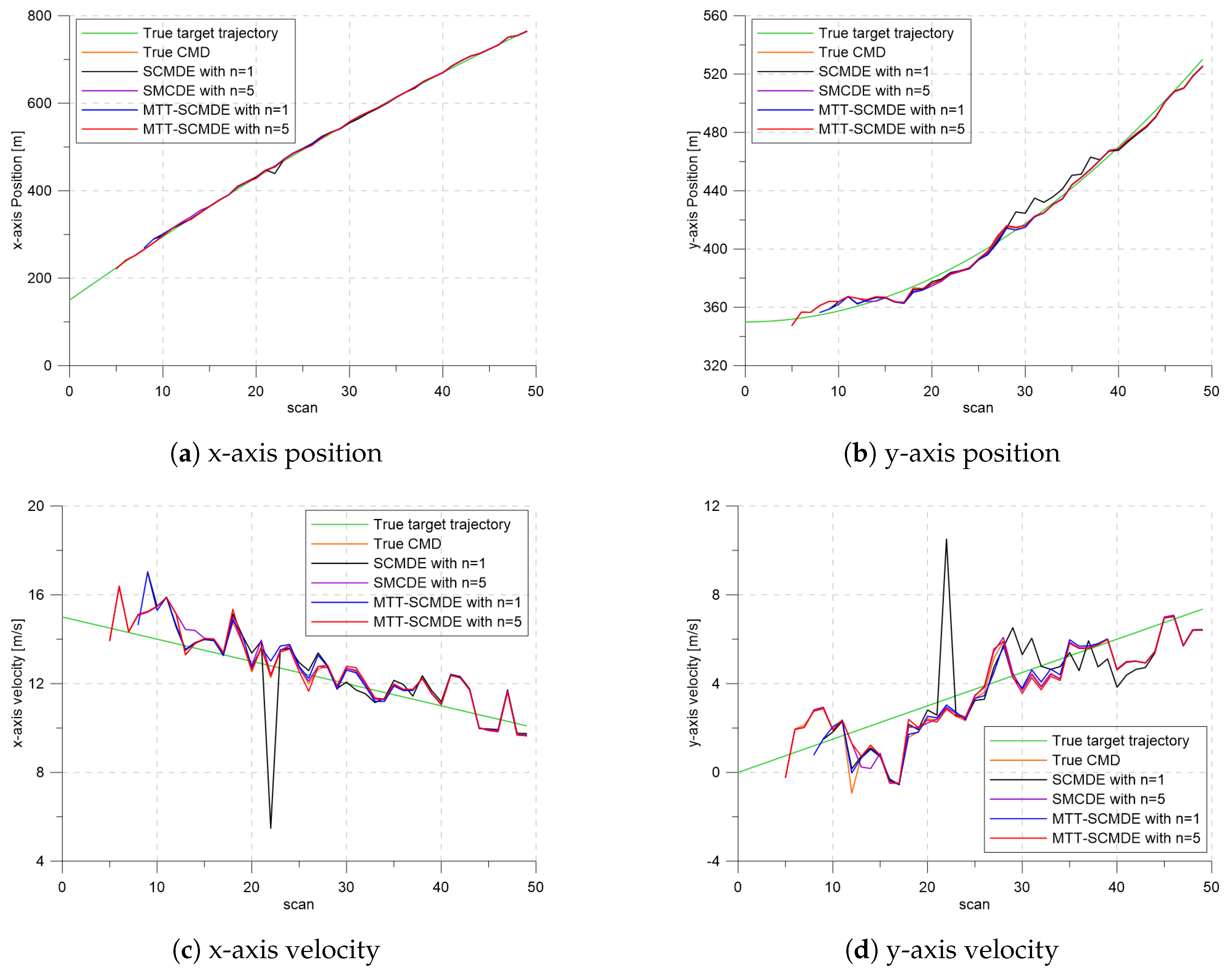
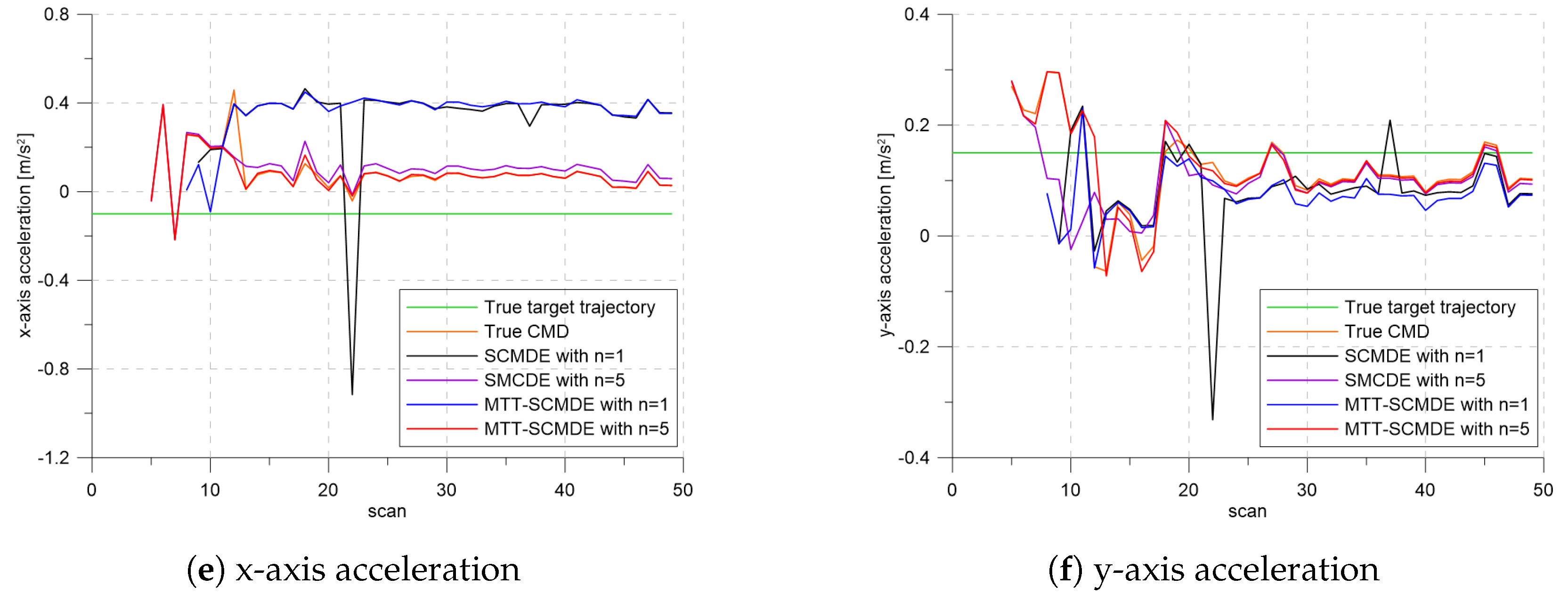
Figure 7 shows the true states and the estimated states of Target 1 over time for the position, velocity, and acceleration elements of each coordinate axis. Only the averaged state estimates of the confirmed tracks are shown in
Figure 7. The existing SCMDE with the sparsity order of
showed the worst estimation performance among the algorithms in comparison. The target tracking algorithm using the proposed MTT-SCMDE with the sparsity order of
showed similar estimation performance to the one using the true clutter measurement density, and its state estimates were close to the true target states. This implied that the proposed MTT-SCMDE produced more reliable and accurate estimates for multi-target tracking than the existing SCMDE.
Although the clutter measurement density was estimated close to the actual for the proposed method with sparsity order of , the tracking performance was slightly worse than using the true clutter measurement density. It produced the best tracking performance among the methods in comparison. Therefore, the proposed method with a high sparsity order was a viable solution for this environment.
Table 1 shows the statistics of the track retention test. The proposed clutter measurement density estimation method had a higher track maintenance performance in terms of true track confirmation and track losses including switch and merge than the SCMDE method with the same sparsity order.
6.1.2. The Number of Targets: 5
In this scenario, we analyzed the clutter measurement density estimation performance by increasing the number of targets to five, as shown in
Figure 8. The parameters except the number of targets were the same as in the previous scenario. The number of confirmed false tracks was made almost equal as in the previous scenario by adjusting the initial target existence probability.
Figure 9,
Figure 10 and
Figure 11 represent CTTR, position RMSE for Target 1, and the estimated clutter measurement density for Target 1 over time for the scenario, respectively. All the algorithms had the same trend in estimation performance as in the previous scenario. The proposed clutter measurement density estimation method with the sparsity order of
showed the best tracking performance among the methods in comparison because it estimated the clutter measurement density similar to the true clutter measurement density even if the number of closely located targets increased. As shown in
Table 2, nCase and nOk for the MTT-SCMDE with
represented the best tracking performance among the adaptive estimation methods in comparison.
6.1.3. The Number of Targets: 7
The measurement histories of the seven closely located targets are shown in
Figure 12. In this scenario, considering that the number of targets was seven, the simulation was performed by extending the sparsity order to 7 in addition to the 1 and 5 used in the previous scenarios. As in the previous scenarios, multiple targets were gathered in the high density clutter region.
Figure 13 shows the CTTR over time. As shown in
Figure 14, the estimation errors of with the sparsity order
were similar to the result using the true clutter measurement density. As the number of targets increased, increasing the sparsity order implied that better tracking results could be obtained, and the proposed MTT-SCMDE had better tracking performance compared to the existing SCMDE with the same sparsity order.
Figure 15 represents the estimated clutter measurement density over time and shows that even with a large number of closely located targets, the proposed method had the best performance of estimating the clutter measurement density. In
Table 3, the MTT-SCMDE with
showed more than
track retention performance, similar to the case with true clutter measurement density. It showed the best tracking performance among the adaptive estimation algorithms in comparison.
6.2. Test with Real Radar Data
In this section, a set of measurements obtained from a surveillance radar system is utilized for performance analysis of the proposed algorithm. The main focus of the analysis was to verify the robustness of the algorithm for tracking in clutter without track loss and switching, especially in the region where the multiple targets were located in the vicinity. For this data gathering experiment, there were no other reference sensors to measure the exact locations of the target. Therefore, it was not possible to analyze the accuracy of the target tracking, so we focused on the maintenance performance for the confirmed tracks and the discrimination performance for the false tracks caused by clutter.
The radar acquired measurements every one second. The 2D radar measurements consisted of distance and azimuth information. The measurements of the distance and azimuth information were converted to the
positions in the Cartesian coordinate system for the tracking algorithms. LM-IPDA with the NCV model in
Section 2 was used for tracking in this performance test, and the results of target tracking were compared for three cases, which employed a fixed value
scan/m
for the clutter measurement density, adaptive clutter measurement density estimation with the existing SCMDE, and the proposed MTT-SCMDE.
The initial target existence probability of the track was set to be . When the target existence probability of track was smaller than of the initial value, the track would be terminated, and if the target existence probability was bigger than , it was classified as a confirmed track.
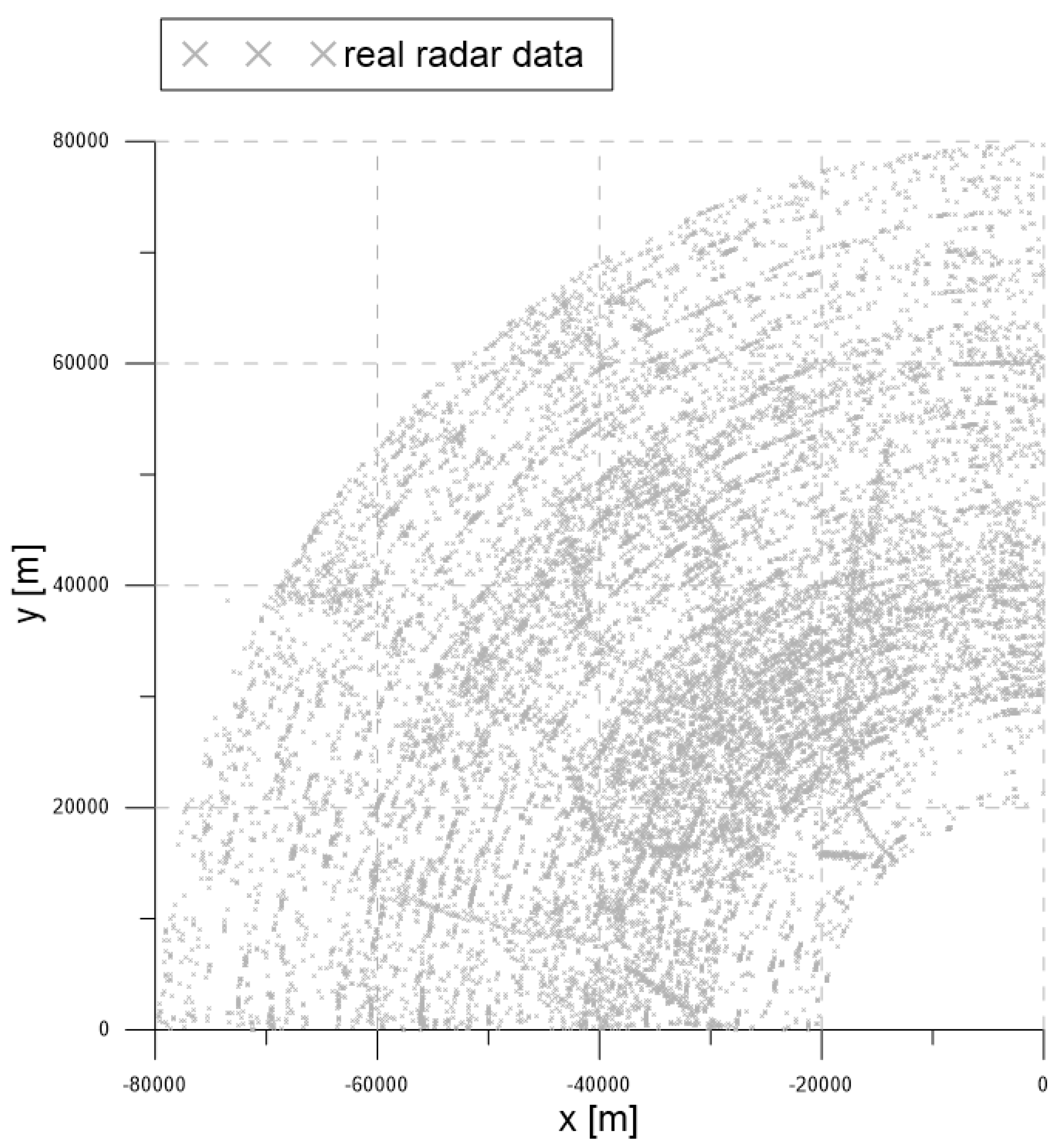
Figure 16 contains the measurement dataset for the entire period of 92 s. As shown in
Figure 16, the radar detection range was 90 km, and the radar measurements were used from −90
to 0
from the north. The gray symbols represent the measurements obtained from the radar.
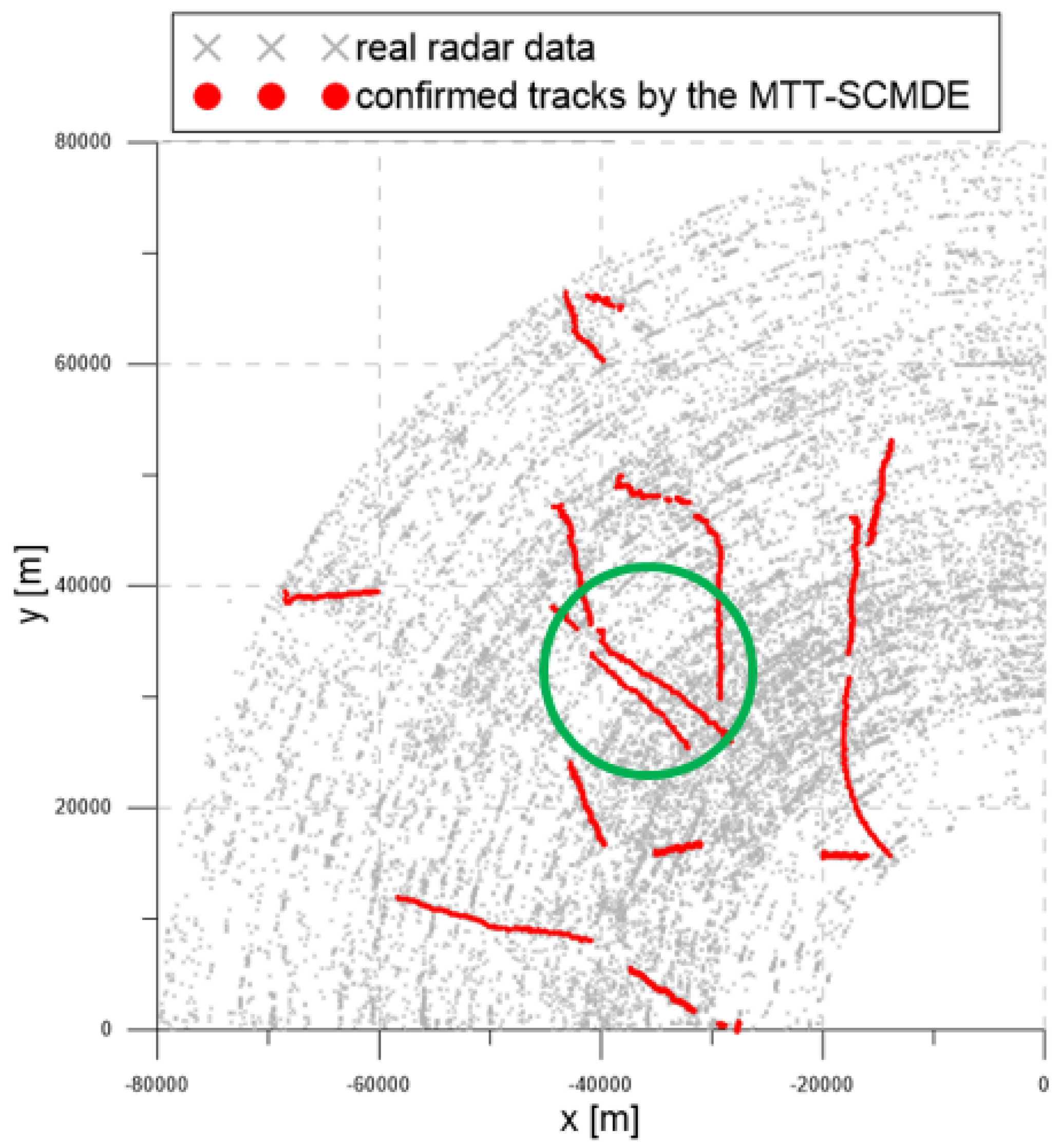
Figure 17,
Figure 18 and
Figure 19 show the trajectories of the confirmed tracks estimated by the LM-IPDA algorithm with the NCV model, which utilized fixed clutter measurement density, the SCMDE, and the MTT-SCMDE, respectively. The sparsity order
was used for the SCMDE and the MTT-SCMDE. The main difference in the tracking results of the three cases was shown for the two targets in a formation flight in the high clutter measurement density region, which was specified by a green circle of each figure. In the case of using the fixed clutter measurement density, no confirmed track was generated for the left of the two targets in a formation flight. When the SCDME was used, the tracks for both targets were confirmed in the beginning, but one of the confirmed tracks was lost as the distance between the two targets became smaller. As the SCMDE did not distinguish the nature of adjacent measurements when estimating the clutter measurement density, a bias in the clutter measurement density estimates was included for the closely located targets, and this bias decreased the data association probability of the true target measurement. This resulted in the loss of the confirmed track. However, in the case of the proposed MTT-SCMDE, it can be seen from
Figure 19 that the tracks for both targets were confirmed without loss of tracks. This demonstrated the robustness of the proposed MTT-SCMDE algorithm in practical applications.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}