Integrated Airborne LiDAR Data and Imagery for Suburban Land Cover Classification Using Machine Learning Methods


Abstract
1. Introduction
- (1)
- (2)
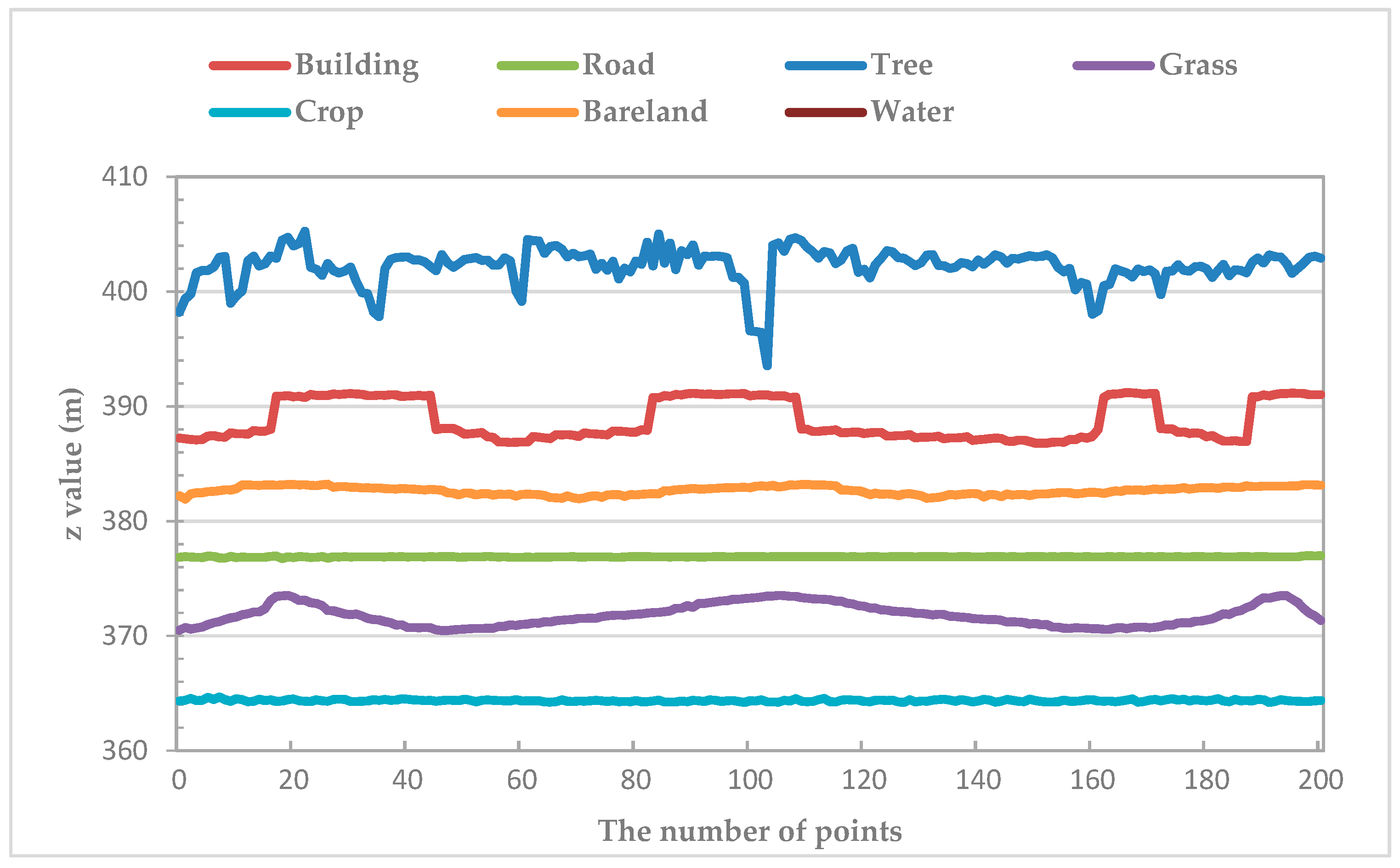
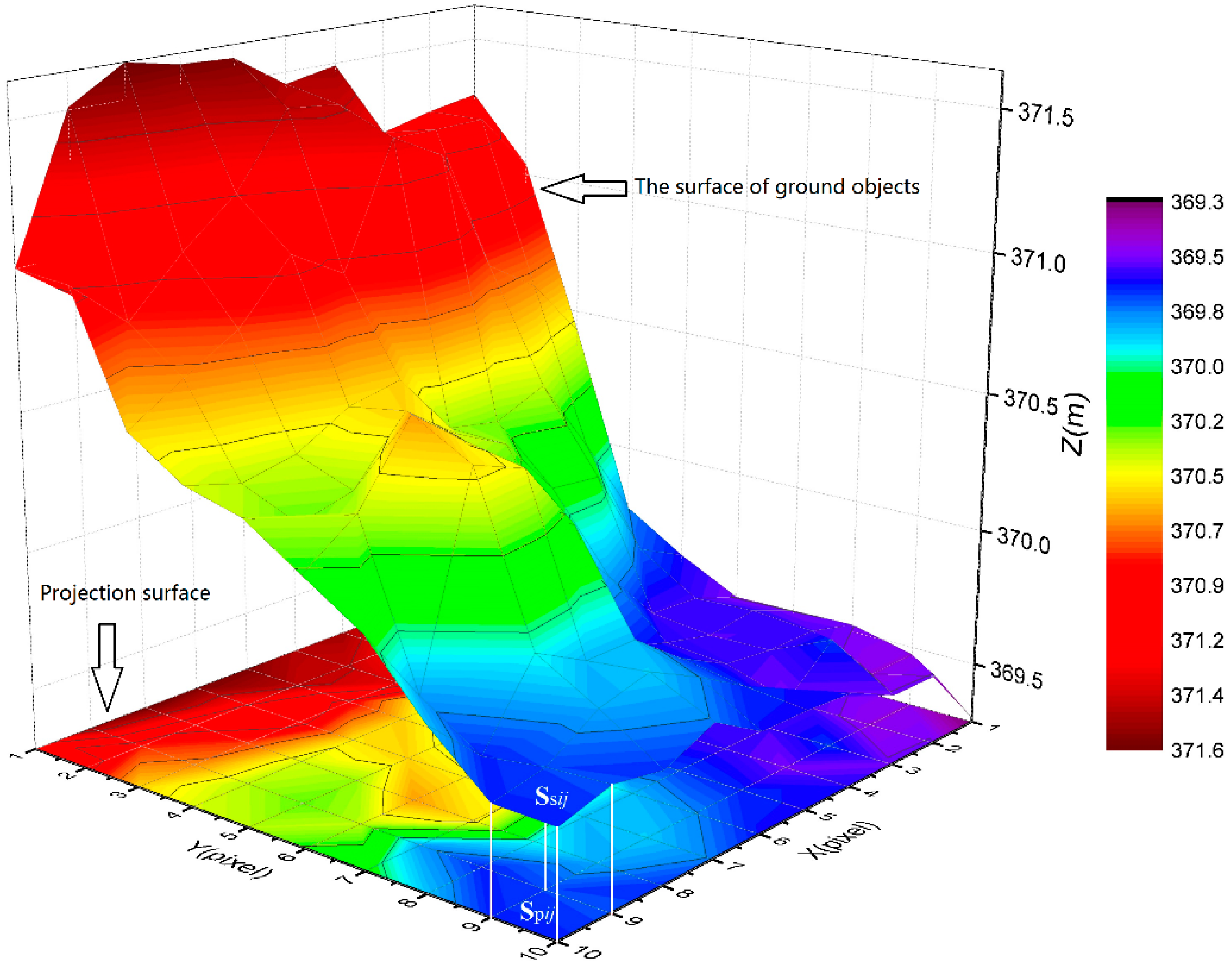
- Propose a new index, namely surface roughness model (RM), to describe and quantify the surface fluctuations of ground objects, and further evaluate the effects of RM to improve the land cover classification.
- (3)
- Calculate the contribution of various input variables, i.e., RGB, nDSM, RM, and IM, in the various scenarios, and determine the optimal combination scheme as well as the optimal classifier.
2. Materials and Methods
2.1. Study Area
2.2. Data Sources
- (1)
- Point clouds parameters: the density of the point clouds was approximately 20 points/m2. The horizontal and vertical resolution of the point clouds were approximately 0.17 m and 0.2 m, respectively. The maximum difference in altitude among the points was 138.94 m.
- (2)
- Aerial imagery parameters: the image size was 11,608 × 8708 pixels. The visible bands included red, green and blue.
2.3. Methods
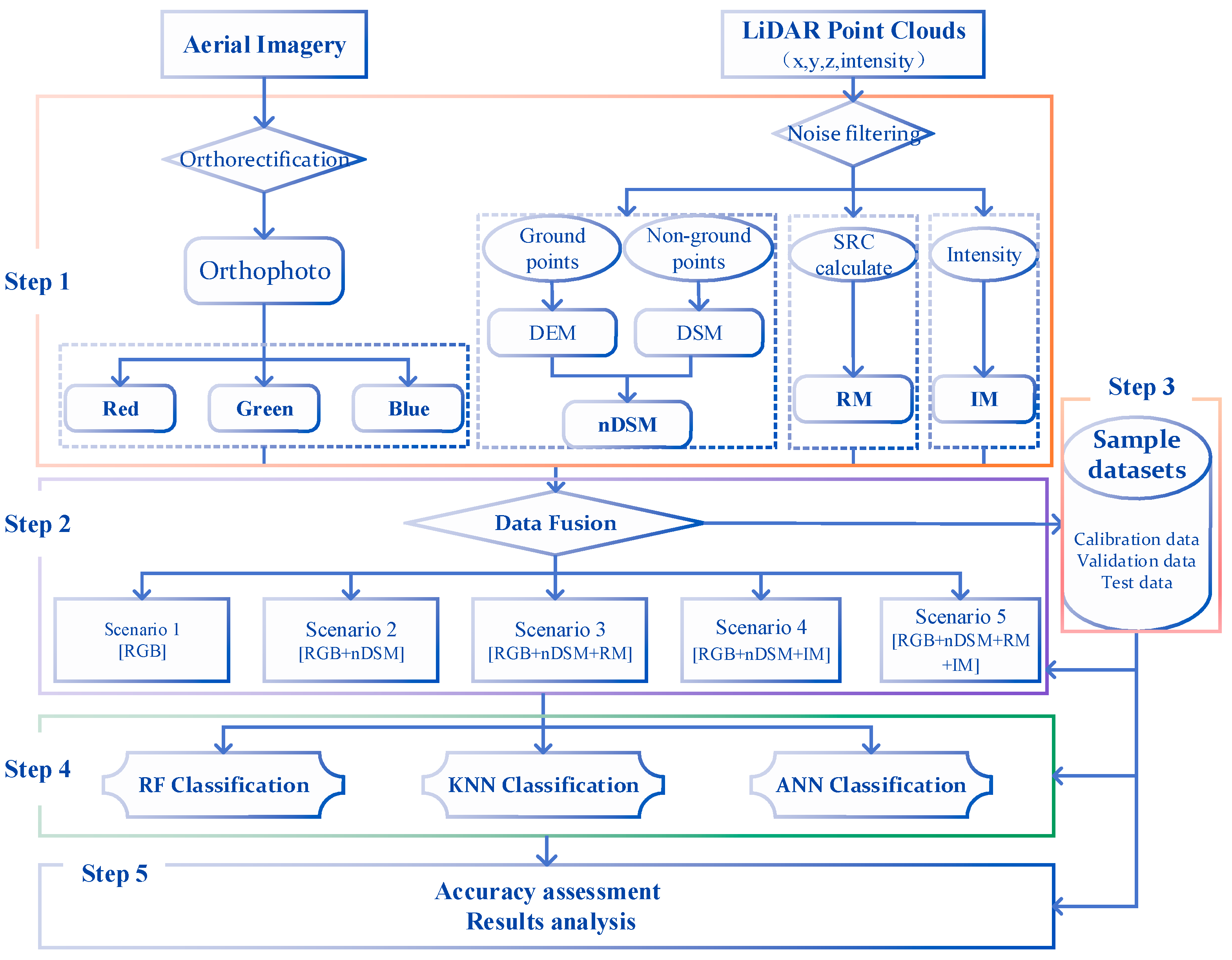
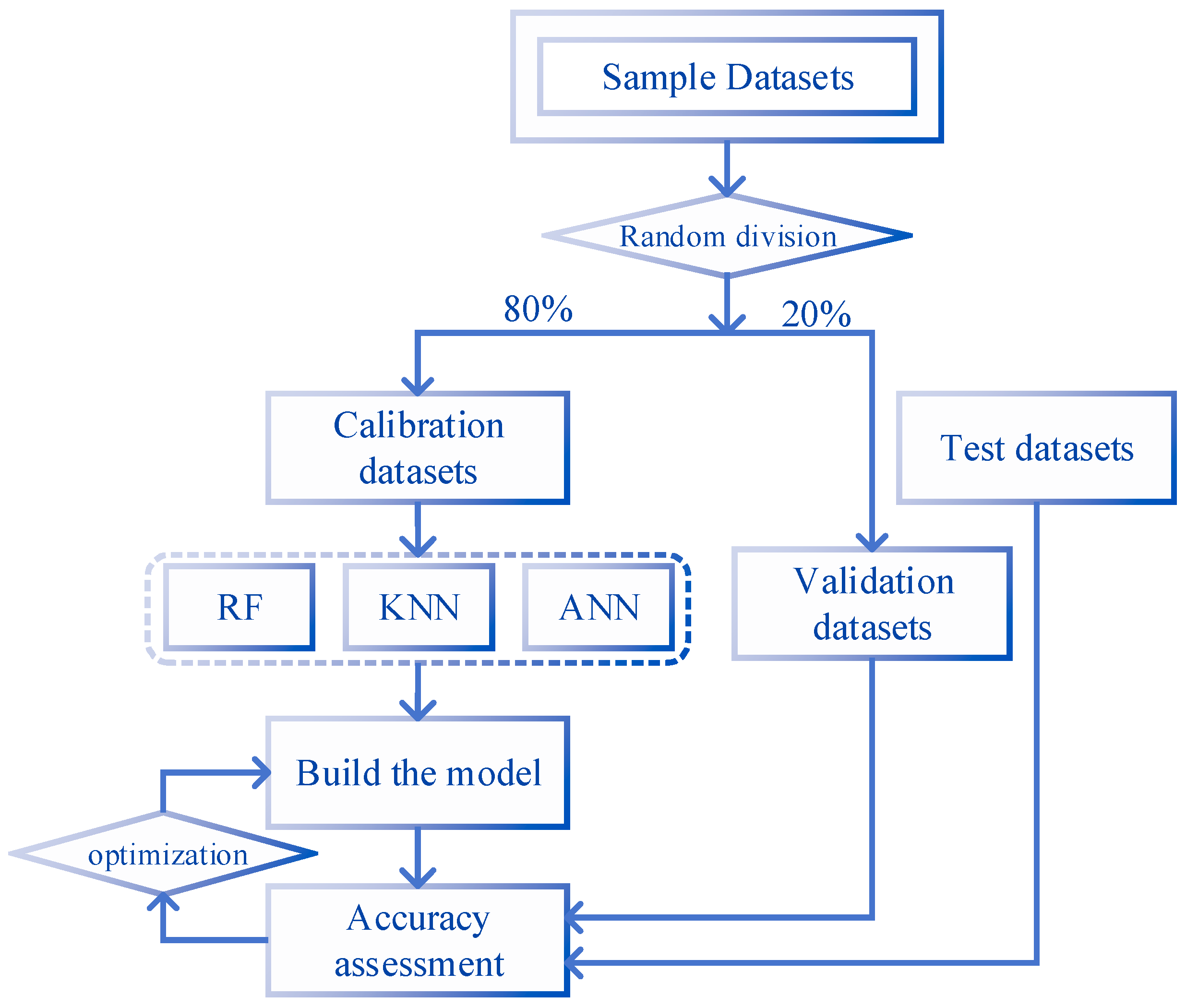
2.3.1. Research Scheme Description
2.3.2. Data Pre-processing
2.3.3. Data Fusion Schemes Design
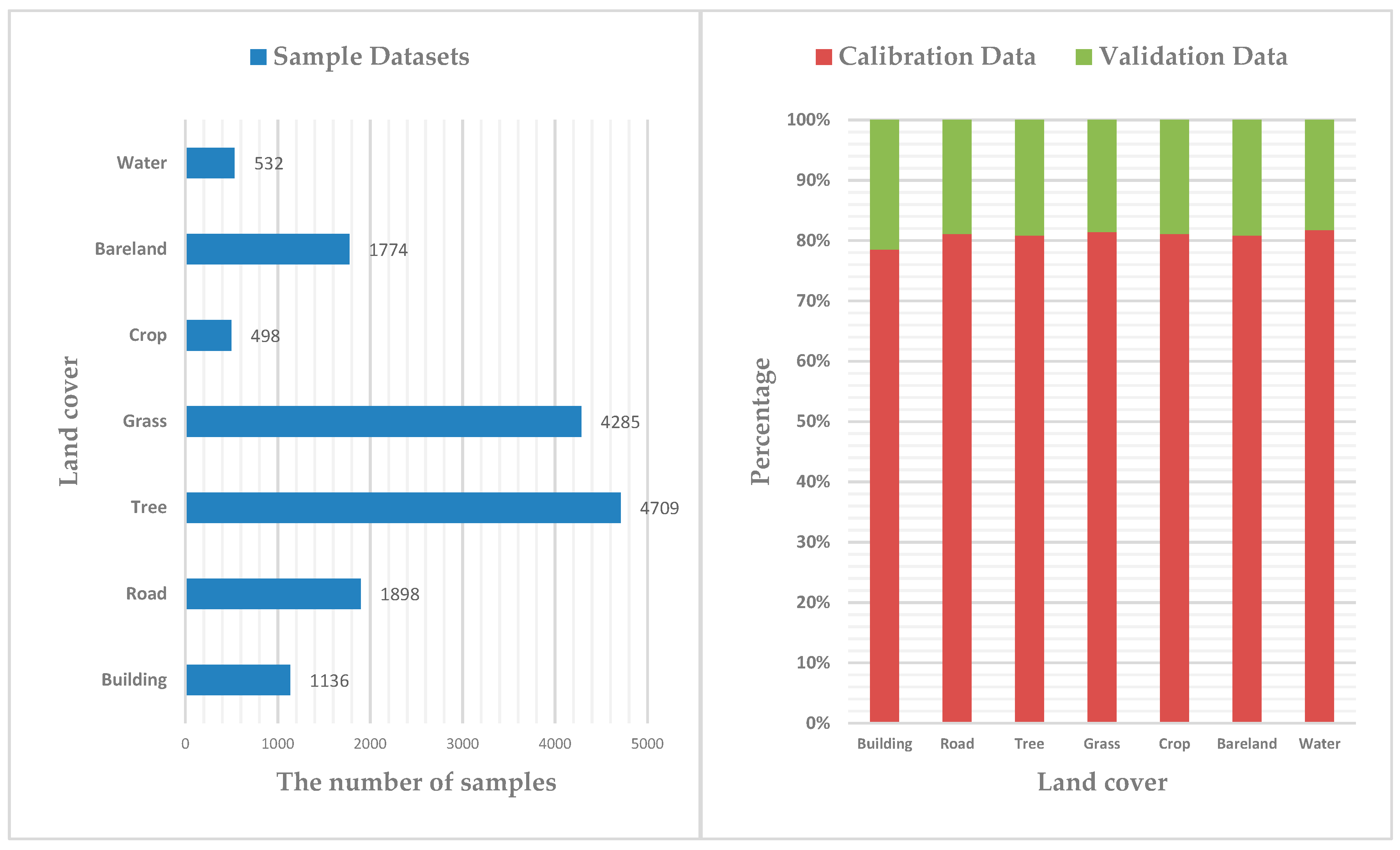
2.3.4. Classification Sample Datasets
2.3.5. Classifier Selection
2.3.6. Accuracy Assessment
3. Results
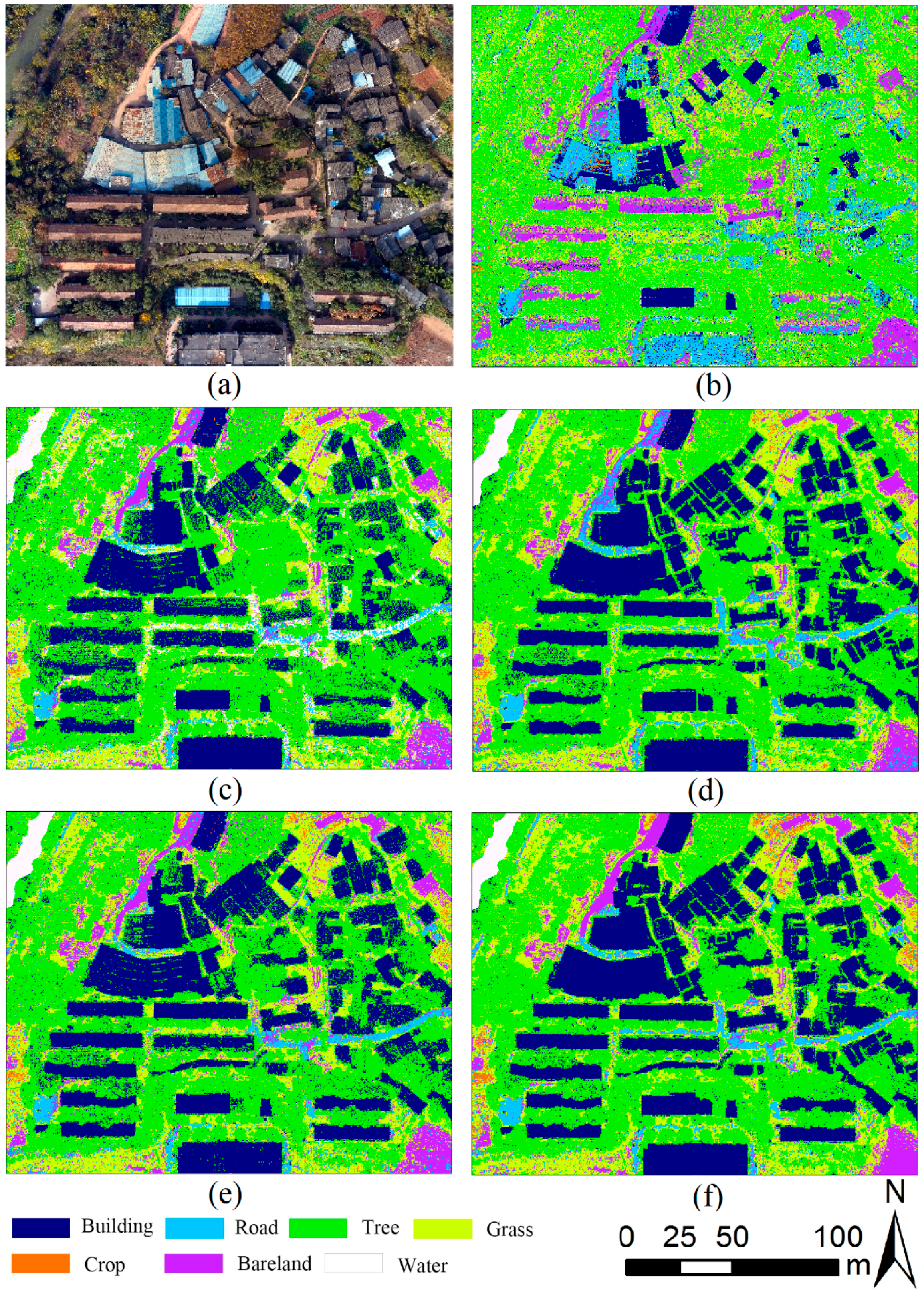
3.1. Classification Performance of Scenarios
- (1)
- Scenario 1 only used spectral information in the aerial imagery. Most classes were badly misclassified and confused, i.e., buildings and roads, or trees and grasses, because of similar spectral reflectance values, this resulting very low UA and PA by analyzing scenario 1 in Table 3. Additionally, in scenario 1, ANN gave the better performance than the other classifiers (OA = 50.18% and kappa coefficient = 0.35).
- (2)
- When the nDSM was combined with spectral information of aerial imagery (scenario 2), the accuracy of classification significantly improved. The OA and kappa coefficient of the three classifiers were dramatically improved comparing with scenario 1, the lowest OA was 68.75% of KNN which increased 21.57% and the highest was 77.97% of RF which increased 27.16%, the lowest kappa coefficient was 0.59 of KNN which improved 0.28 and the highest was 0.71 of RF which improved 0.36 (Table 2). Correspondingly, the significant decreases of misclassified rate between buildings and roads, and between trees and grasses were observed, where the UA and PA of trees were over 90% (Table 3). However, the distinction between low buildings and trees was not optimistic due to their few high differences.
- (3)
- In order to overcome the confusion between low buildings and trees, scenario 3 contained RBG, nDSM, and RM. In scenario 3, we found that RM plays a key role in distinguishing between the low buildings and trees. In addition, the OA of three classifiers ranged from 70.37% to 81.81%, which was 1.62% higher than the lowest of scenario 2 and 3.84% higher than the highest. The kappa coefficient was from 0.61 to 0.76, which was 0.02 higher than the lowest of scenario 2 and 0.05 higher than the highest (Table 2). The classification accuracies of the seven classes were further improved.
- (4)
- Previous research proved that IM has advantages in material surface differentiation [2,5,12,21,23]. To compare the effects of RM and IM in the suburban classification, we used IM in scenario 4 instead of RM in scenario 3. Few variations in OA and kappa coefficient were observed between scenario 3 and 4. Additionally, crops and waters have higher classification accuracy than scenario 3, roads, barelands, and grasses have the nearly accuracy as scenario 3, while buildings and trees have no higher accuracy than scenario 3 (Table 3).
- (5)
- Considering RM and IM have their own advantages, scenario 5 combined all the variables including RGB, nDSM, RM, and IM. Scenario 5 gave the best performance in classification among all the scenarios. The lowest OA was 72.99% of KNN, the highest was 84.75% of RF with 80.61% of ANN, the lowest kappa coefficient is 0.65 of KNN, and the highest was 0.80 of RF with 0.75 of ANN. The UA and PA of all classes get almost the highest level using RF classifier. However, there were some phenomena indicated that the classification results of KNN and ANN were not stable than RF. For example, in the process of KNN classifier, the PA of bareland was 0.29% lower than that of scenario 3 and 2.15% lower than that of scenario 4, the UA of the buildings was 0.82% lower than scenario 3, while the grasses was 1.39% lower than scenario 4; in the process of ANN classifier, the PA of barelands was 1.12% lower compared with scenario 3 and 5.29% lower compared with scenario 4, the UA of the roads and trees were not performance well than scenario 3 and 4, and the barelands accuracy was not higher than scenario 4.
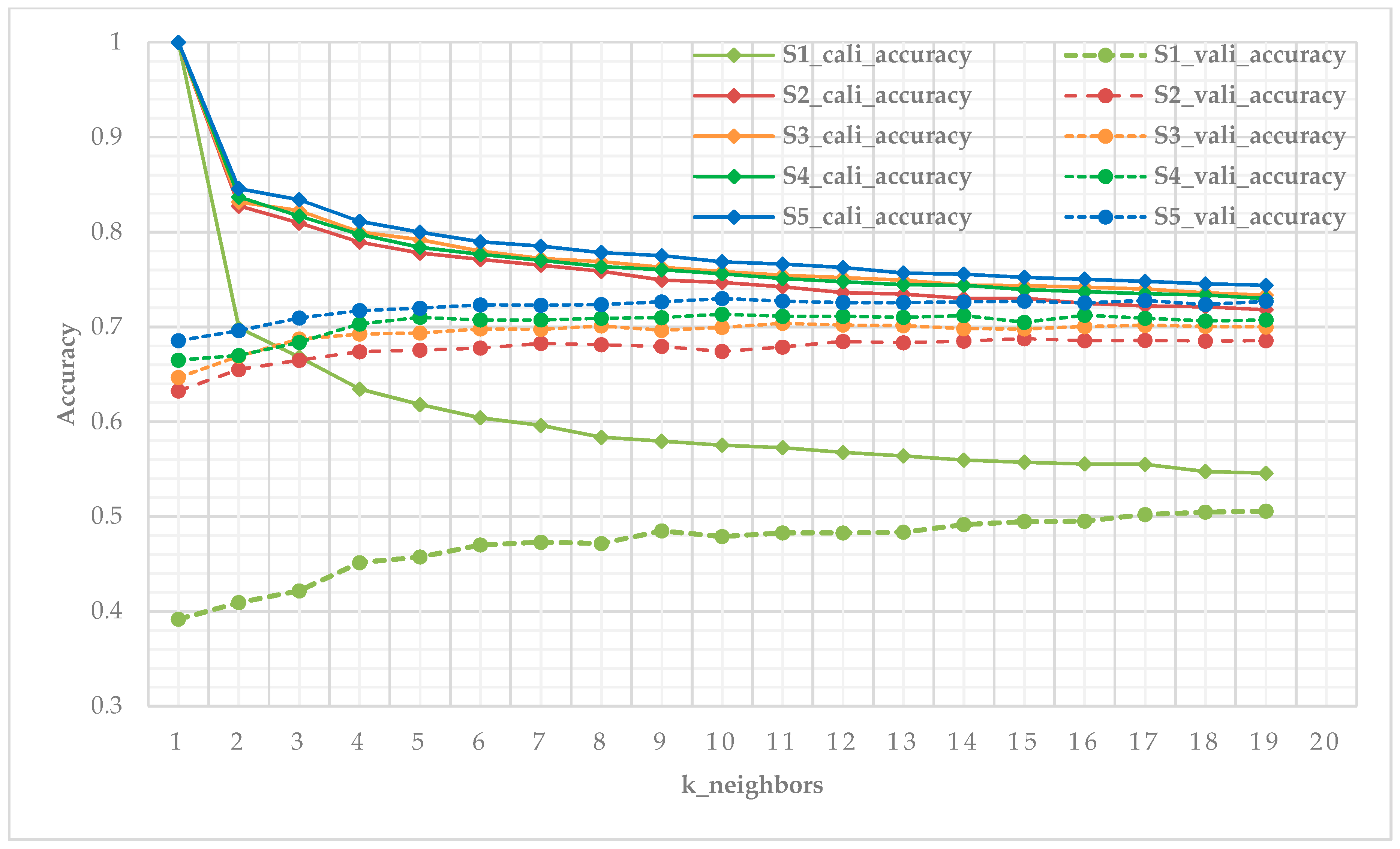
3.2. Performances of Classifiers
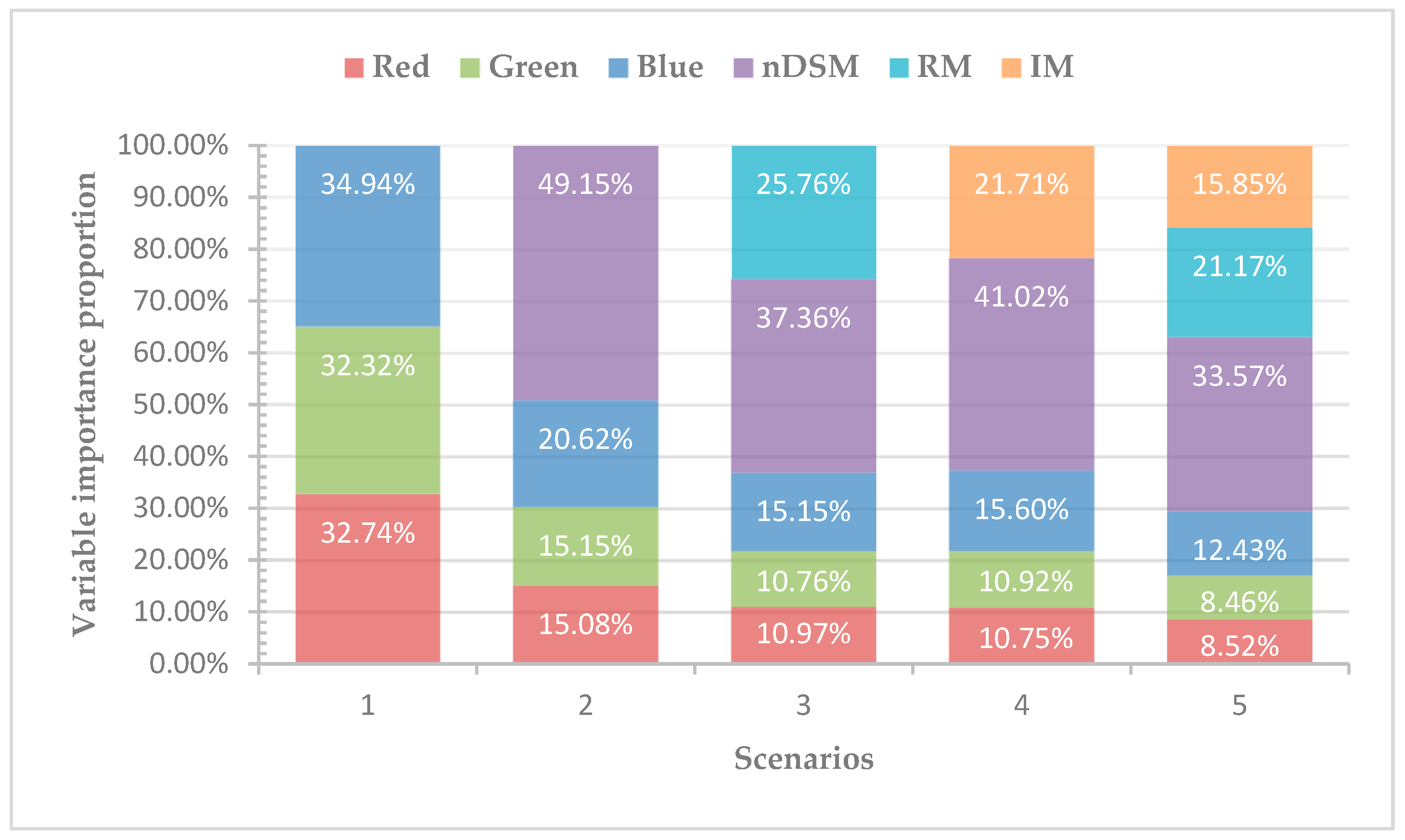
3.3. Variables Importance Representation
4. Discussion
5. Conclusions
- (1)
- The fusion of LiDAR-derived models (i.e., nDSM and IM) and spectral information of the aerial imagery significantly increased the classification accuracy in suburbs, where the landscape is disorderly distributed, the architectural style is not uniform, and the road repair is incomplete.
- (2)
- A new LiDAR-derived model (i.e., RM) was constructed for the classification. RM performs well in improving the accuracy of classification using three classifiers. Additionally, RM has an advantage in distinguishing buildings from trees. Moreover, the contribution of RM to classification is comparable to that of IM.
- (3)
- The fusion of all the variables (i.e., RGB, nDSM, RM, and IM) yielded the best classification results which were estimated by three classifiers, among which RF resulted in the highest classification accuracy (OA = 84.75%, kappa coefficient = 0.80). In addition, the VIP showed that nDSM contributed the most, followed by RM, IM, and spectral information.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hanna, E. Radiative Forcing of Climate Change: Expanding the Concept and Addressing Uncertainties. By the National Research Council (NRC); National Academies Press: Washington, DC, USA, 2005; p. 207. [Google Scholar]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.A.; et al. A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef]
- Dong, P.; Chen, Q. LiDAR Remote Sensing and Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Salehi, B.; Zhang, Y.; Zhong, M.; Dey, V. Object-based classification of urban areas using VHR imagery and height points ancillary data. Remote Sens. 2012, 4, 2256–2276. [Google Scholar] [CrossRef]
- Antonarakis, A.S.; Richards, K.S.; Brasington, J. Object-based land cover classification using airborne LiDAR. Remote Sens. Environ. 2008, 112, 2988–2998. [Google Scholar] [CrossRef]
- Guan, H.; Ji, Z.; Zhong, L.; Li, J.; Ren, Q. Partially supervised hierarchical classification for urban features from lidar data with aerial imagery. Int. J. Remote Sens. 2013, 34, 190–210. [Google Scholar] [CrossRef]
- Zarea, A.; Mohammadzadeh, A. A novel building and tree detection method from LiDAR data and aerial images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 1864–1875. [Google Scholar] [CrossRef]
- Zhang, C. Combining hyperspectral and LiDAR data for vegetation mapping in the Florida Everglades. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 80, 733–743. [Google Scholar] [CrossRef]
- Charaniya, A.P.; Manduchi, R.; Lodha, S.K. Supervised parametric classification of aerial LiDAR data. In Proceedings of the IEEE 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Bartels, M.; Wei, H. Rule-Based Improvement of Maximum Likelihood Classified LiDAR Data Fused with Coregistered Bands. Available online: https://pdfs.semanticscholar.org/48af/06630848fb5a89a01627c0e0192ded3fdc67.pdf (accessed on 27 April 2019).
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef]
- Wu, Q.; Zhong, R.; Zhao, W.; Song, K.; Du, L. Land-cover classification using GF-2 images and airborne lidar data based on Random Forest. Int. J. Remote Sens. 2018, 40, 2410–2426. [Google Scholar] [CrossRef]
- Zhou, W.; Huang, G.; Troy, A.; Cadenasso, M.L. Object-based land cover classification of shaded areas in high spatial resolution imagery of urban areas: A comparison study. Remote Sens. Environ. 2009, 113, 1769–1777. [Google Scholar] [CrossRef]
- Zhou, W. An object-based approach for urban land cover classification: Integrating LiDAR height and intensity data. IEEE Geosci. Remote Sens. Lett. 2013, 10, 928–931. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using random forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Priestnall, G.; Jaafar, J.; Duncan, A. Extracting urban features from LiDAR digital surface models. Comput. Environ. Urban Syst. 2000, 24, 65–78. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS-J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Gallego, A.J.; Calvo-Zaragoza, J.; Valero-Mas, J.J.; Rico-Juan, J.R. Clustering-based k-nearest neighbor classification for large-scale data with neural codes representation. Pattern Recognit. 2018, 74, 531–543. [Google Scholar] [CrossRef]
- Mas, J.F.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens. 2008, 29, 617–663. [Google Scholar] [CrossRef]
- Brennan, R.; Webster, T.L. Object-oriented land cover classification of lidar-derived surfaces. Can. J. Remote Sens. 2006, 32, 162–172. [Google Scholar] [CrossRef]
- Hartfield, K.A.; Landau, K.I.; Van Leeuwen, W.J.D. Fusion of high resolution aerial multispectral and LiDAR data: Land cover in the context of urban mosquito habitat. Remote Sens. 2011, 3, 2364–2383. [Google Scholar] [CrossRef]
- MacFaden, S.W.; O’Neil-Dunne, J.P.M.; Royar, A.R.; Lu, J.W.T.; Rundle, A.G. High-resolution tree canopy mapping for New York City using LIDAR and object-based image analysis. J. Appl. Remote Sens. 2012, 6, 063567. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. Wetland mapping with LiDAR derivatives, SAR polarimetric decompositions, and LiDAR–SAR fusion using a random forest classifier. Can. J. Remote Sens. 2013, 39, 290–307. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the International Conference on Document Analysis & Recognition, Washington, DC, USA, 14–15 August 1995. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using Random Forests. ISPRS-J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS-J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Sandri, M.; Zuccolotto, P. Variable Selection Using Random Forests. In Data Analysis, Classification and the Forward Search; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Sesnie, S.E.; Finegan, B.; Gessler, P.E.; Thessler, S.; Bendana, Z.R.; Smith, A.M.S. The multispectral separability of Costa Rican rainforest types with support vector machines and Random Forest decision trees. Int. J. Remote Sens. 2010, 31, 2885–2909. [Google Scholar] [CrossRef]
- Reese, H.; Nyström, M.; Nordkvist, K.; Olsson, H. Combining airborne laser scanning data and optical satellite data for classification of alpine vegetation. Int. J. Appl. Earth Obs. Geoinf. 2014, 27, 81–90. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Dudani, S.A. The distance-weighted k-nearest-neighbor rule. IEEE Trans. Syst. Man Cybern. 1976, 8, 325–327. [Google Scholar] [CrossRef]
- Khan, M.; Ding, Q.; Perrizo, W. k-nearest neighbor classification on spatial data streams using P-trees. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient knn classification with different numbers of nearest neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1774–1785. [Google Scholar] [CrossRef]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Miscellaneous Clustering Methods. Cluster Analysis, 5th ed.; Walter, A.S., Samuel, S.W., Eds.; John Wiley & Sons, Ltd.: Chichester, UK, 2011. [Google Scholar]
- Philipp, M.; Katri, S.; Ville, N.; Anton, K.; Markus, K.; Poika, I.; Jussi, R.; Mariaana, S.; Jari, V.; Pasi, K.; et al. Scent classification by K nearest neighbors using ion-mobility spectrometry measurements. Expert Syst. Appl. 2019, 115, 593–606. [Google Scholar]
- Riedmiller, M.; Braun, H. A Direct Adaptive Method for Faster Backpropagation Learning: The RPROP Algorithm. Available online: http://www.neuro.nigmatec.ru/materials/themeid_17/riedmiller93direct.pdf (accessed on 27 April 2019).
- Anastasiadis, A.D.; Magoulas, G.D.; Vrahatis, M.N. New globally convergent training scheme based on the resilient propagation algorithm. Neurocomputing 2005, 64, 253–270. [Google Scholar] [CrossRef]
- Keramitsoglou, I.; Sarimveis, H.; Kiranoudis, C.T.; Sifakis, N. Radial basis function neural networks classification using very high spatial resolution satellite imagery: An application to the habitat area of Lake Kerkini (Greece). Int. J. Remote Sens. 2005, 26, 1861–1880. [Google Scholar] [CrossRef]
- Song, H.; Xu, R.; Ma, Y.; Li, G. Classification of etm+ remote sensing image based on hybrid algorithm of genetic algorithm and back propagation neural network. Math. Probl. Eng. 2013, 2013, 211–244. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Ucar, Z.; Bettinger, P.; Merry, K.; Akbulut, R.; Siry, J. Estimation of urban woody vegetation cover using multispectral imagery and lidar. Urban For. Urban Green. 2018, 29, 248–260. [Google Scholar] [CrossRef]
- Králová, M. Accuracy assessment and classification efficiency of object-based image analysis of aerial imagery. AUC Geogr. 2013, 48, 15–23. [Google Scholar] [CrossRef][Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenarios | Datasets | Number of Bands |
|---|---|---|
| 1 | Aerial imagery spectral information(R, G, B) | 3 |
| 2 | Aerial imagery spectral information(R, G, B) + nDSM | 4 |
| 3 | Aerial imagery spectral information(R, G, B) + nDSM + RM | 5 |
| 4 | Aerial imagery spectral information(R, G, B) + nDSM + IM | 5 |
| 5 | Aerial imagery spectral information(R, G, B) + nDSM + RM+ IM | 6 |
| Scenario | OA (%) | Kappa Coefficient | ||||
|---|---|---|---|---|---|---|
| RF | KNN | ANN | RF | KNN | ANN | |
| 1 | 47.18 | 50.56 | 50.81 | 0.31 | 0.35 | 0.35 |
| 2 | 77.97 | 68.75 | 74.68 | 0.71 | 0.59 | 0.66 |
| 3 | 81.81 | 70.37 | 77.26 | 0.76 | 0.61 | 0.70 |
| 4 | 81.78 | 71.33 | 79.38 | 0.76 | 0.63 | 0.73 |
| 5 | 84.75 | 72.99 | 80.61 | 0.80 | 0.65 | 0.75 |
| Land Cover | PA (%) | UA (%) | ||||
|---|---|---|---|---|---|---|
| RF | KNN | ANN | RF | KNN | ANN | |
| Scenario1: Aerial imageries spectral information(R, G, B) | ||||||
| Building | 51.54 | 58.46 | 71.62 | 27.46 | 31.15 | 21.72 |
| Road | 49.88 | 50.87 | 47.29 | 59.05 | 65.46 | 70.47 |
| Tree | 52.51 | 53.95 | 54.62 | 58.09 | 64.41 | 68.18 |
| Grass | 38.58 | 43.32 | 43.23 | 42.46 | 45.6 | 44.1 |
| Crop | 41.67 | 44.44 | 0 | 15.96 | 4.26 | 0 |
| Bareland | 52.38 | 58.04 | 58.60 | 45.29 | 43.53 | 49.12 |
| Water | 35.62 | 40.98 | 0 | 26.80 | 25.77 | 0 |
| Scenario2: Aerial imageries spectral information(R, G, B) + nDSM | ||||||
| Building | 86.01 | 85.88 | 84.58 | 68.03 | 62.3 | 69.67 |
| Road | 69.65 | 56.46 | 64.17 | 67.13 | 69.36 | 64.35 |
| Tree | 91.5 | 89.11 | 90.26 | 96.78 | 78.94 | 96.56 |
| Grass | 70.41 | 58.6 | 62.86 | 82.54 | 79.15 | 85.68 |
| Crop | 56.52 | 51.61 | 0 | 27.66 | 17.02 | 0 |
| Bareland | 63.04 | 64.68 | 72.85 | 47.65 | 44.71 | 47.35 |
| Water | 80.58 | 48.65 | 0 | 85.57 | 37.11 | 0 |
| Scenario3: Aerial imageries spectral information(R, G, B) + nDSM + RM | ||||||
| Building | 93.3 | 91.33 | 90.29 | 79.92 | 64.75 | 76.23 |
| Road | 74.19 | 59.43 | 61.27 | 70.47 | 70.19 | 72.70 |
| Tree | 94.46 | 86.30 | 91.73 | 98.23 | 86.59 | 97.12 |
| Grass | 72.21 | 60.19 | 68.69 | 87.81 | 73.12 | 86.81 |
| Crop | 71.05 | 26.47 | 50 | 28.72 | 19.15 | 2.13 |
| Bareland | 66.39 | 64.17 | 73.19 | 47.06 | 47.94 | 50.59 |
| Water | 100 | 52 | 0 | 100 | 40.21 | 0 |
| Scenario4: Aerial imageries spectral information(R, G, B) + nDSM + IM | ||||||
| Building | 90.14 | 91.12 | 90.63 | 78.69 | 63.11 | 71.31 |
| Road | 74.26 | 60.83 | 67.09 | 69.92 | 69.64 | 73.82 |
| Tree | 93.89 | 82.12 | 90.75 | 97.12 | 83.48 | 96.78 |
| Grass | 73.25 | 60.61 | 69.85 | 87.06 | 75.38 | 84.42 |
| Crop | 75.51 | 78.38 | 0 | 39.36 | 30.85 | 0 |
| Bareland | 66.41 | 66.03 | 77.27 | 50 | 40.59 | 50 |
| Water | 100 | 96.97 | 93.07 | 100 | 98.97 | 96.91 |
| Scenario5: Aerial imageries spectral information(R, G, B) + nDSM + RM+ IM | ||||||
| Building | 94.17 | 94.55 | 94.04 | 86.07 | 63.93 | 84.02 |
| Road | 79.22 | 61.72 | 69.75 | 73.26 | 71.87 | 71.31 |
| Tree | 95.77 | 85.53 | 92.16 | 98 | 87.14 | 96.45 |
| Grass | 76.52 | 61.35 | 70.81 | 90.08 | 73.99 | 85.93 |
| Crop | 77.14 | 84.09 | 57.14 | 57.45 | 39.36 | 4.26 |
| Bareland | 70 | 63.88 | 71.98 | 51.47 | 42.65 | 49.12 |
| Water | 100 | 96.97 | 98.98 | 100 | 98.97 | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, Y.; Zhong, R.; Sun, H.; Wu, Q.; Du, L.; Geng, Y.; Cao, S. Integrated Airborne LiDAR Data and Imagery for Suburban Land Cover Classification Using Machine Learning Methods. Sensors 2019, 19, 1996. https://doi.org/10.3390/s19091996
Mo Y, Zhong R, Sun H, Wu Q, Du L, Geng Y, Cao S. Integrated Airborne LiDAR Data and Imagery for Suburban Land Cover Classification Using Machine Learning Methods. Sensors. 2019; 19(9):1996. https://doi.org/10.3390/s19091996
Chicago/Turabian StyleMo, You, Ruofei Zhong, Haili Sun, Qiong Wu, Liming Du, Yuxin Geng, and Shisong Cao. 2019. "Integrated Airborne LiDAR Data and Imagery for Suburban Land Cover Classification Using Machine Learning Methods" Sensors 19, no. 9: 1996. https://doi.org/10.3390/s19091996
APA StyleMo, Y., Zhong, R., Sun, H., Wu, Q., Du, L., Geng, Y., & Cao, S. (2019). Integrated Airborne LiDAR Data and Imagery for Suburban Land Cover Classification Using Machine Learning Methods. Sensors, 19(9), 1996. https://doi.org/10.3390/s19091996