Survey on Revocation in Ciphertext-Policy Attribute-Based Encryption



Abstract
:1. Introduction
2. Elliptic Curve Cryptography
- (a)
- Ɐ P E.
- (b)
- Ɐ P E.
- (c)
- Ɐ P, Q, R E.
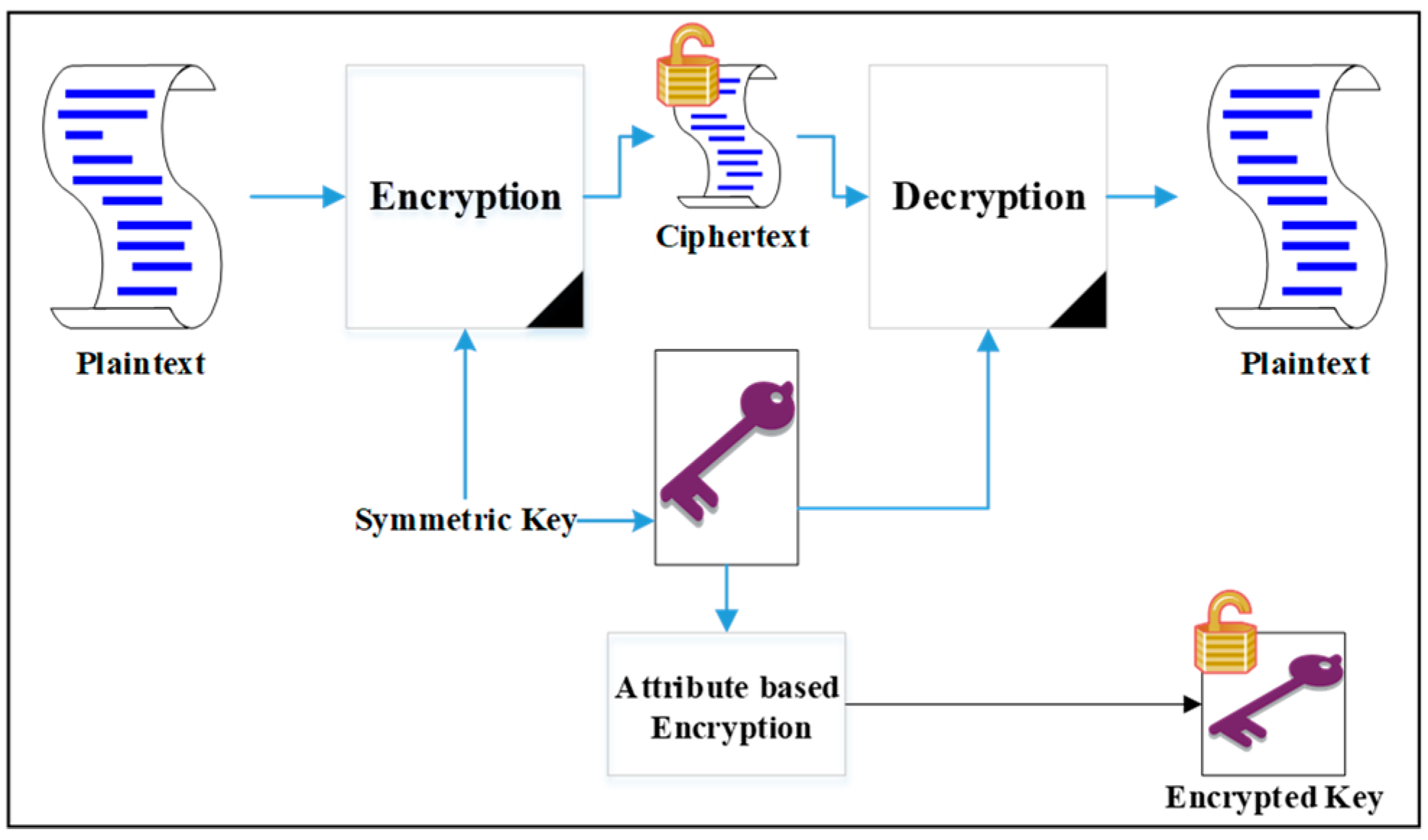
3. Attribute-Based Encryption
- Data confidentiality and privacy is a set of rules that protects a certain type of information by placing some restrictions on it. It is an essential requirement for cloud storage since the cloud service provider, which stores the data, is normally unauthorized to access its content. Thus, the data accessibility ought to be only for explicitly legitimate users. This is satisfied by using ABE to enable the legitimate data access even when the data encrypter is offline and the privacy preservation of the data users’ identities.
- Fine-grained access control is a key mechanism that grants different access privileges to different users even if they are in the same group according to their credentials given by the associated system, and flexibly specifies individual users’ access rights.
- Expressive access structure is important for the access policies specified by a data owner to be expressive in order to realize fine-grained access control. Moreover, ABE is required to support the expressiveness of the policies. This requirement makes the access control similar to a real-life access control.
- Collusion Resistance. The system has to prevent any collusion attacks from combining their information together to illegitimately gain unauthorized data through collaboration [15]. In the cloud environment, this type of attack can be either a group of misbehaving system users who collude with each other to combine their information and gain higher access rights, or a combination of a cloud server and malicious, revoked users who try to gain the original data.
- Forward and Backward Secrecy. Forward security means any revoked user ought to be prevented from accessing data and decrypting any new published ciphertext after leaving the system. In terms of backward security, to achieve this type of security, it needs a mechanism in which the ciphertexts which were published previously cannot be decrypted by any user who newly joins the system [16].
- Revocation. When a user is degraded or leaves the system, its access rights need to be reduced or revoked by the related access control scheme without incurring significant computational cost, respectively. In addition, attribute updating is not a straightforward process in ABE and is hard to address, as updating a single attribute could impact a large number of users accessing the same attribute.
- Scalability. The performance of the system should not be affected by the increase of system users.
- Computation overhead is essential to fulfill all the above requirements with minimal computation cost.
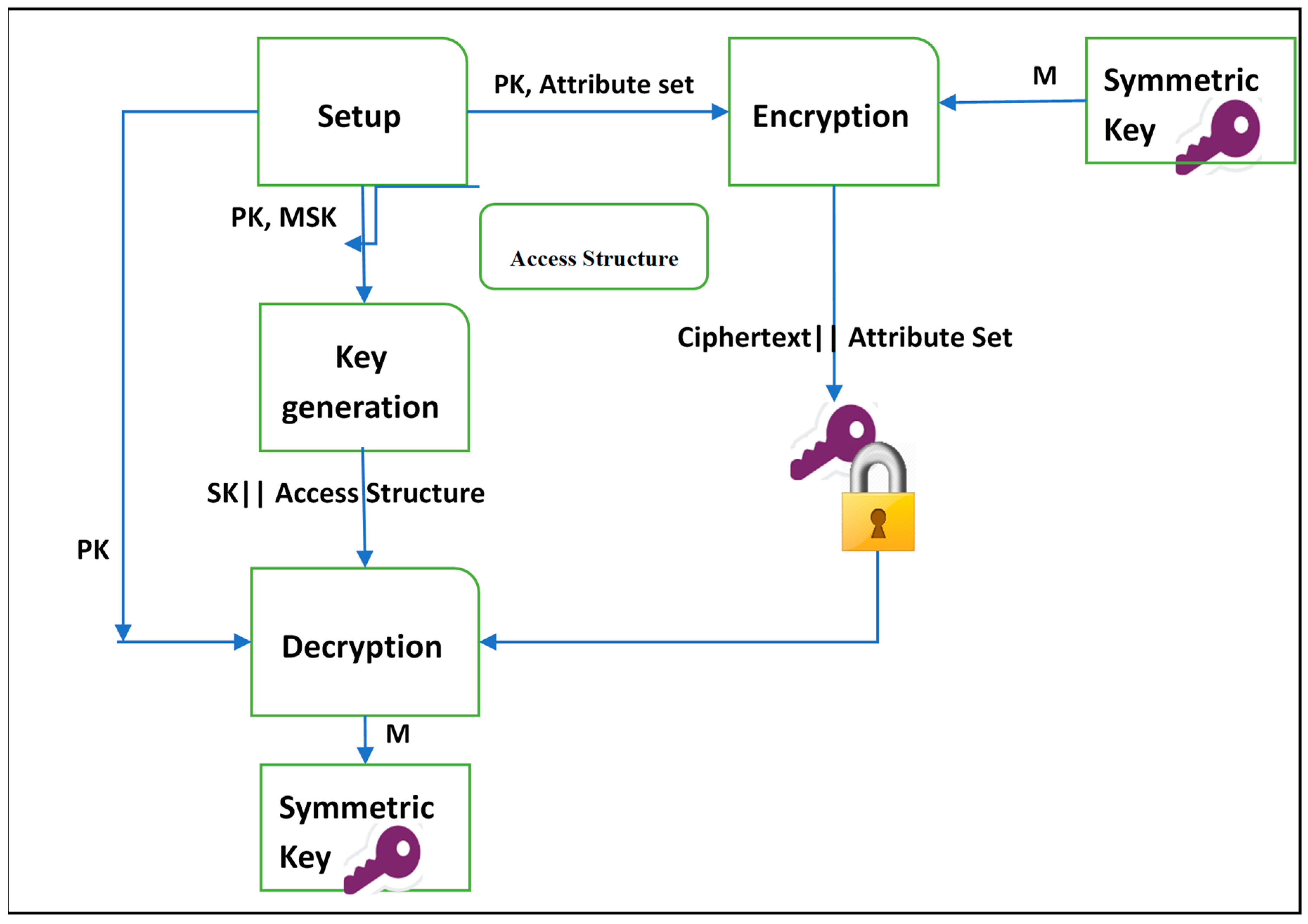
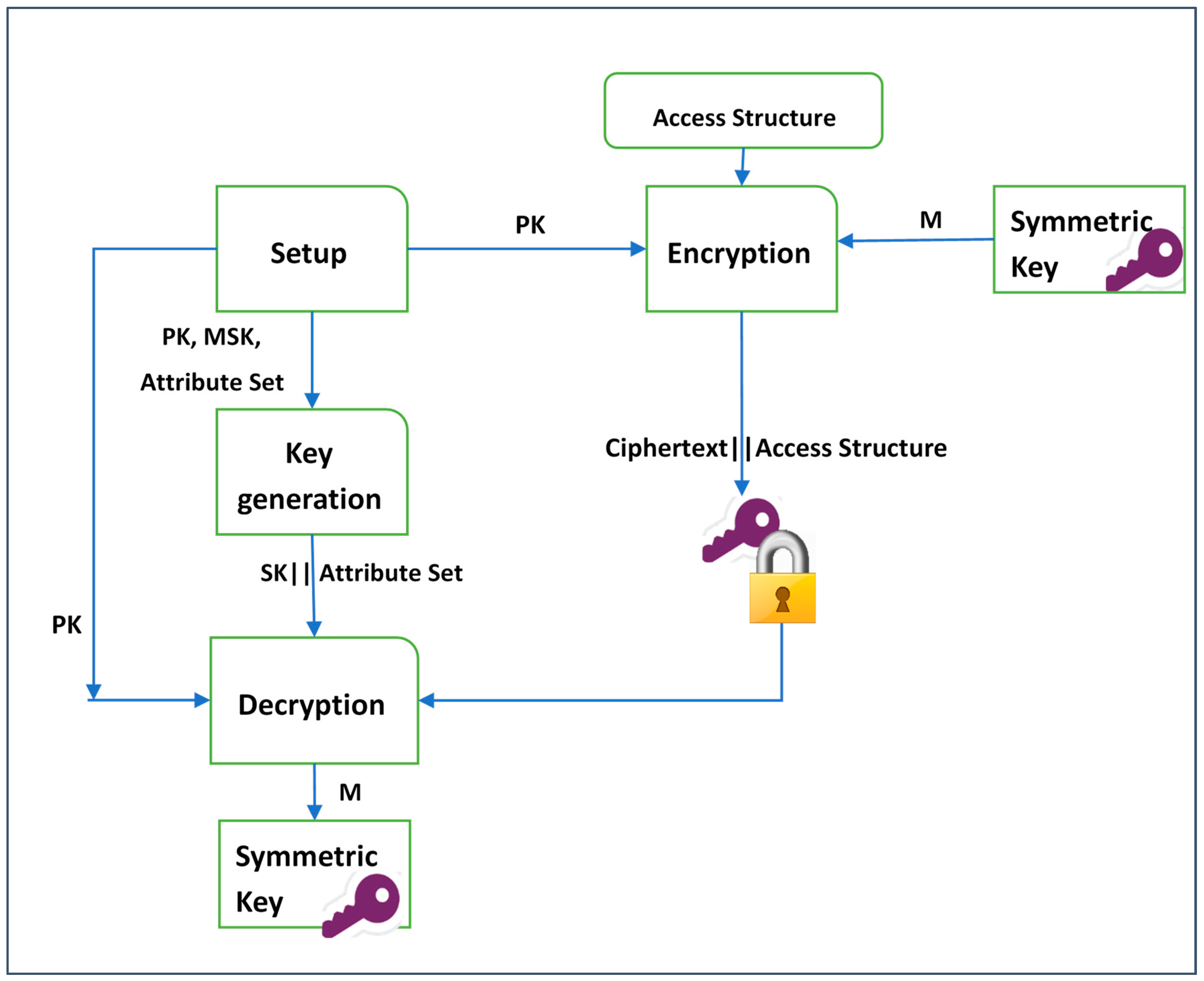
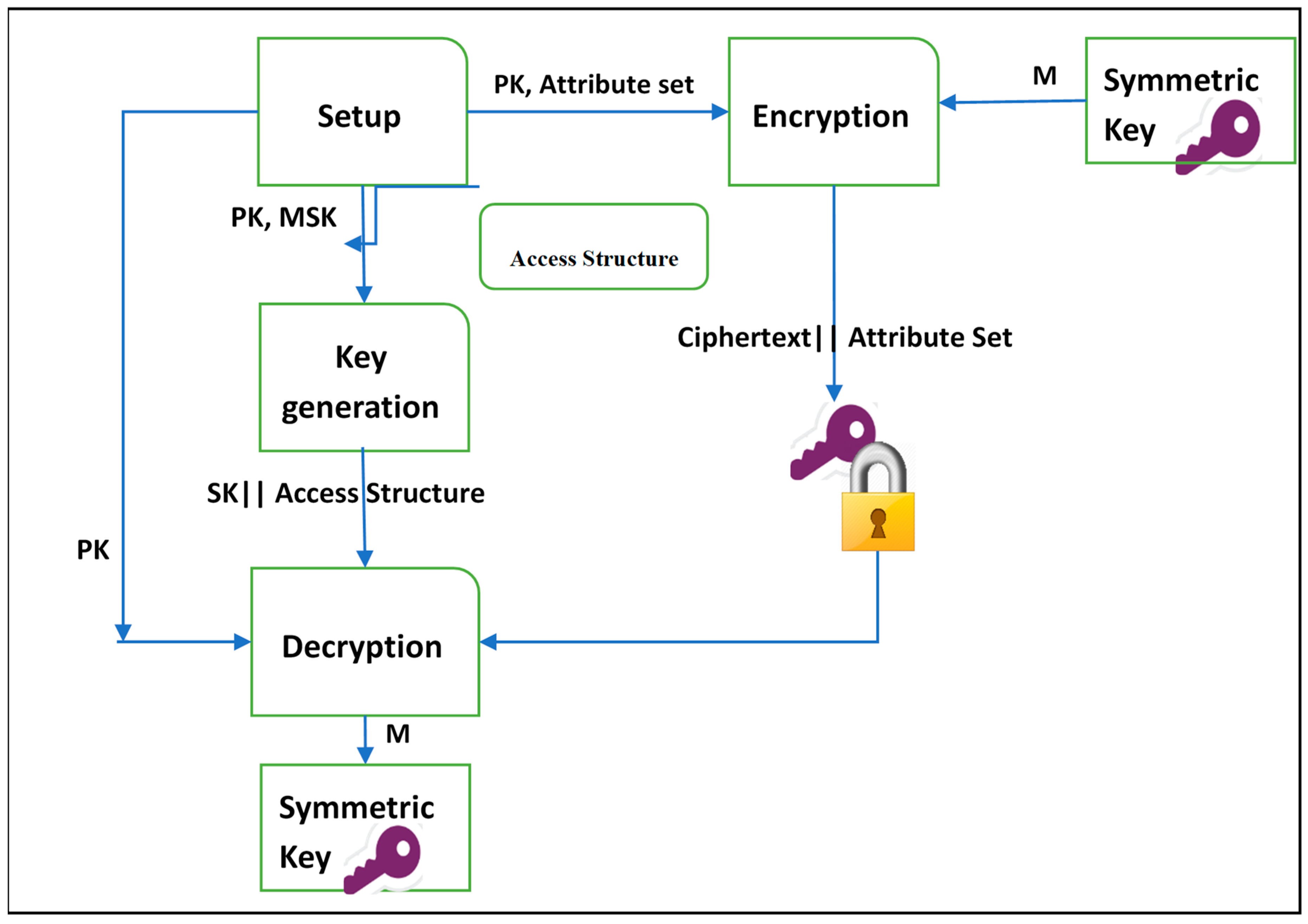
3.1. Ciphertext-Policy Attribute-Based Encryption (CP-ABE)
- : Takes a set of attributes in the system and an implicit security parameter (such as the type of the elliptic curve group used and the base finite field) as inputs to generate a public key PK and a master key MSK as outputs.
- : Takes as inputs a public key , an access structure , and a message M to be encrypted. The output will be a ciphertext CT.
- : In this algorithm, a master key MSK and a set of attributes S are taken as inputs. A user’s secret key SK is generated as output.
- : This algorithm takes as inputs a user’s secret key SK and a ciphertext CT. It returns a message M when the user’s attributes satisfy the access structure.
- Resolving the revocation problem.
- Covering a wide range of attributes needed by any system and eliminating a single point failure.
- Reducing the computation overhead.
3.2. The Revocation Problem
- Permit instantaneous banning of a malicious user.
- Resist collusion attacks or invalidate the secret keys of the revoked users [14] (which means the cloud cannot collude with a revoked user to illegally obtain encrypted data).
- Minimize the computation overhead of the revocation process.
- Support forward security which means any newly published ciphertext cannot be decrypted by any revoked user with revoked attributes [25].
4. The Types of the CP-ABE Scheme
4.1. The Single Authority Scheme
4.2. The Multiauthority Attribute Based Access Control System
- The first type of scheme (e.g., a scheme by Han et al. [56]) contains many authorities that have to work together, resulting in a high communication cost and lack of scalability since it is hard for authorities to join or leave freely. Furthermore, these authorities might collude with each other and combine their information to gain unauthorized data about the users.
- The second type needs a central authority to tie the work of all authorities together, and to be involved in issuing users’ secret keys besides having the master key (e.g., the work by Liu et al. [57]). The drawbacks of this type of scheme are that the concept seems contradictory to distributed control and it incurs low performance and a security bottleneck.
- Decentralized systems are the third type of the multiauthority access control system, which remove any central authority and employ independent attribute authorities, where the systems are scalable (e.g., the system proposed by Ruj et al. [58]). For this type of system, user revocation is hard to address, which incurs a heavy computation cost.
5. Research Challenges and Future Directions
- Management of joint attribute sets to efficiently generate users’ secret keys. The reason for this is that if each authority manages a different set of attributes, compromising or crashing an authority causes unavailability of the whole system, which presents a performance bottleneck.
- Dealing with the single point of security failure that all single authority systems and some multiauthority schemes suffer from. Furthermore, no one entity in a system should have full control of all the information.
- The handling of the revocation issues should enable the dynamicity and flexibility of customizing and managing users’ access privileges as well as protecting the system from collusion attacks.
- Outsourcing the expensive encryption and decryption operations to cloud servers should alleviate the computational burden on data owners and system users without revealing unauthorized information.
- Achieving accountability. In an untrusted environment, one of the potential research directions is to make an access control system accountable for protection against key exposure. Such exposure could occur when the secret decryption key of an authorized user is leaked. Since this key is valid, the decryption of the corresponding ciphertext is possible. Therefore, an effective mechanism is needed to protect the system from this threat.
- Reducing communication overhead. Investigating an approach to reduce communications among system entities would be one of the key aspects to improve the efficiency of that system.
- Hiding access policies. For sensitive policies, one of substantial future research tasks is to explore techniques to enforce the access policies in a ciphertext form for the protection of their private information during policy deployment.
- Using dynamic attributes. Another core property that the CP-ABE technique needs to be extended with is dynamic attributes (e.g., location or time). It is an open challenge that would improve the dynamicity of a system by adding attributes to users’ secret keys to restrict cloud data access in response to attribute changes and to enable a dynamic adaptation scheme.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Botta, A.; De Donato, W.; Persico, V.; Pescapé, A. Integration of cloud computing and internet of things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Zissis, D.; Lekkas, D. Addressing cloud computing security issues. Future Gener. Comput. Syst. 2012, 28, 583–592. [Google Scholar] [CrossRef]
- Bouabana-Tebibel, T.; Kaci, A. Parallel search over encrypted data under attribute based encryption on the Cloud Computing. Comput. Secur. 2015, 54, 77–91. [Google Scholar] [CrossRef]
- Toninelli, A.; Montanari, R.; Kagal, L.; Lassila, O. A semantic context-aware access control framework for secure collaborations in pervasive computing environments. In Proceedings of the International Semantic Web Conference, Athens, GA, USA, 5–9 November 2006; pp. 473–486. [Google Scholar]
- Akl, S.G.; Taylor, P.D. Cryptographic solution to a problem of access control in a hierarchy. ACM Trans. Comput. Syst. 1983, 1, 239–248. [Google Scholar] [CrossRef]
- Castiglione, A.; De Santis, A.; Masucci, B.; Palmieri, F.; Huang, X.; Castiglione, A. Supporting dynamic updates in storage clouds with the Akl–Taylor scheme. Inf. Sci. 2017, 387, 56–74. [Google Scholar] [CrossRef]
- Crampton, J.; Farley, N.; Gutin, G.; Jones, M.; Poettering, B. Cryptographic enforcement of information flow policies without public information via tree partitions 1. J. Comput. Secur. 2017, 25, 511–535. [Google Scholar] [CrossRef]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encrypted data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In Proceedings of the International Workshop on Public Key Cryptography, Taormina, Italy, 6–9 March 2011; pp. 53–70. [Google Scholar]
- Lai, J.; Deng, R.H.; Li, Y. Expressive CP-ABE with partially hidden access structures. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security, Seoul, Korea, 2–4 May 2012; pp. 18–19. [Google Scholar]
- Schoof, R. Elliptic curves over finite fields and the computation of square roots mod p. Math. Comput. 1985, 44, 483–494. [Google Scholar]
- Sahai, A.; Waters, B. Fuzzy identity-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005; pp. 457–473. [Google Scholar]
- Horváth, M. Attribute-based encryption optimized for cloud computing. In SOFSEM 2015: Theory and Practice of Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 566–577. [Google Scholar]
- Kasunde, D.S.; Manjrekar, A. Verification of multi-owner shared data with collusion resistant user revocation in cloud. In Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies (ICCTICT), New Delhi, India, 11–13 March 2016; pp. 182–185. [Google Scholar]
- Mete, V.I.; Gothawal, M.D.B. Cipher text policy Attribute Based Encryption for Secure Data Retrieval in DTNs. Int. J. Eng. Technol. 2016, 3, 1740–1745. [Google Scholar]
- Wang, G.; Liu, Q.; Wu, J. Hierarchical attribute-based encryption for fine-grained access control in cloud storage services. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 735–737. [Google Scholar]
- Lee, C.-C.; Chung, P.-S.; Hwang, M.-S. A Survey on Attribute-based Encryption Schemes of Access Control in Cloud Environments. IJ Netw. Secur. 2013, 15, 231–240. [Google Scholar]
- Li, Y.; Zhu, J.; Wang, X.; Chai, Y.; Shao, S. Optimized ciphertext-policy attribute-based encryption with efficient revocation. Int. J. Secur. Its Appl. 2013, 7, 385–394. [Google Scholar] [CrossRef]
- Wagh, S.A.; Padmavathi, B. Control Cloud Data Access Privilege with ABE Scheme and Efficient User Revocation. Int. J. Eng. Sci. 2016. [Google Scholar] [CrossRef]
- Kumar, V.; Kumar, P.V. A Lterature Survey on Revocable Multiauthority Cipher Text-Policy Attribute-Based Encryption (Cp-Abe) Scheme for Cloud Storage. Int. J. Adv. Res. Electron. Commun. Eng. 2014, 3, 1723–1728. [Google Scholar]
- Abraham, R.M.; Sriramya, P. Efficient and Secure Attribute Revocation of Data in Multi-Authority Cloud Storage. ARPN J. Eng. Appl. Sci. 2015, 10, 5588–5592. [Google Scholar]
- Sridhar, K.; Srinivas, V. Revocable Data Access Control for Multi-Authority Cloud Storage Using Cipher Text-Policy Attribute Based Encryption. Int. J. Res. 2016, 3, 427–435. [Google Scholar]
- Yang, K.; Jia, X.; Ren, K. Attribute-based fine-grained access control with efficient revocation in cloud storage systems. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 523–528. [Google Scholar]
- Liu, C.-W.; Hsien, W.-F.; Yang, C.-C.; Hwang, M.-S. A Survey of Attribute-based Access Control with User Revocation in Cloud Data Storage. Int. J. Netw. Secur. 2016, 18, 900–916. [Google Scholar]
- Wan, Z.; Liu, J.E.; Deng, R.H. HASBE: A hierarchical attribute-based solution for flexible and scalable access control in cloud computing. IEEE Trans. Inf. Forensics Secur. 2012, 7, 743–754. [Google Scholar] [CrossRef]
- Touati, L.; Challal, Y. Efficient cp-abe attribute/key management for iot applications. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, Liverpool, UK, 26–28 October 2015. [Google Scholar]
- Yang, K.; Jia, X. Expressive, efficient, and revocable data access control for multi-authority cloud storage. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1735–1744. [Google Scholar] [CrossRef]
- Chen, J.; Ma, H. Efficient decentralized attribute-based access control for cloud storage with user revocation. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 3782–3787. [Google Scholar]
- Jahid, S.; Mittal, P.; Borisov, N. EASiER: Encryption-based access control in social networks with efficient revocation. In Proceedings of the 6th ACM Symposium on Information, Computer and Communications Security, Hong Kong, China, 22–24 March 2011; pp. 411–415. [Google Scholar]
- Jahid, S.; Borisov, N. Piratte: Proxy-based immediate revocation of attribute-based encryption. arXiv, 2012; arXiv:1208.4877. [Google Scholar]
- Kuragod, S.; Nayak, P.; Kotari, M. Implementation of IBE with Outsourced Revocation technique in Cloud Computing. Int. J. Innov. Res. Electr. Electron. Instrum. Control Eng. 2016, 4, 190–193. [Google Scholar]
- Govindappa, S.; Shylaja, K.R. An Outsourced Key Revocation Technique for Secret key Management in Decentralized Identity Based Encryption Scheme. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 787–791. [Google Scholar]
- Xu, Z.; Martin, K.M. Dynamic user revocation and key refreshing for attribute-based encryption in cloud storage. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 844–849. [Google Scholar]
- Green, M.; Ateniese, G. Identity-based proxy re-encryption. In Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2007; pp. 288–306. [Google Scholar]
- Zu, L.; Liu, Z.; Li, J. New ciphertext-policy attribute-based encryption with efficient revocation. In Proceedings of the 2014 IEEE International Conference on Computer and Information Technology (CIT), Xi’an, China, 11–13 September 2014; pp. 281–287. [Google Scholar]
- Cheng, Y.; Wang, Z.-Y.; Ma, J.; Wu, J.-J.; Mei, S.-Z.; Ren, J.-C. Efficient revocation in ciphertext-policy attribute-based encryption based cryptographic cloud storage. J. Zhejiang Univ. Sci. C 2013, 14, 85–97. [Google Scholar] [CrossRef]
- Wang, G.; Wang, J. Research on Ciphertext-Policy Attribute-Based Encryption with Attribute Level User Revocation in Cloud Storage. Math. Probl. Eng. 2017, 2017, 4070616. [Google Scholar] [CrossRef]
- Yuan, W. Dynamic Policy Update for Ciphertext-Policy Attribute-Based Encryption. IACR Cryptol. Eprint Arch. 2016, 2016, 457. [Google Scholar]
- Kalmani, V.H.; Goyal, D.; Singla, S. An Efficient and Secure Solution for Attribute Revocation Problem Utilizing CP-ABE Scheme in Mobile Cloud Computing. Int. J. Comput. Appl. 2015, 129, 16–21. [Google Scholar]
- Odelu, V.; Das, A.K.; Rao, Y.S.; Kumari, S.; Khan, M.K.; Choo, K.-K.R. Pairing-based CP-ABE with constant-size ciphertexts and secret keys for cloud environment. Comput. Stand. Interfaces 2017, 54, 3–9. [Google Scholar] [CrossRef]
- Fu, X.; Nie, X.; Wu, T.; Li, F. Large universe attribute based access control with efficient decryption in cloud storage system. J. Syst. Softw. 2018, 135, 157–164. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Ling, J.; Liu, Z. Secure and fine-grained access control on e-healthcare records in mobile cloud computing. Future Gener. Comput. Syst. 2018, 78, 1020–1026. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Chen, X.; Xiang, Y. Secure attribute-based data sharing for resource-limited users in cloud computing. Comput. Secur. 2018, 72, 1–12. [Google Scholar] [CrossRef]
- Zhang, R.; Ma, H.; Lu, Y. Fine-grained access control system based on fully outsourced attribute-based encryption. J. Syst. Softw. 2017, 125, 344–353. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, Z.; Liu, J.K.; Liang, K.; Liu, H. An efficient access control scheme with outsourcing capability and attribute update for fog computing. Future Gener. Comput. Syst. 2018, 78, 753–762. [Google Scholar] [CrossRef]
- Karati, A.; Amin, R.; Biswas, G. Provably secure threshold-based abe scheme without bilinear map. Arab. J. Sci. Eng. 2016, 41, 3201–3213. [Google Scholar] [CrossRef]
- Hong, H.; Sun, Z. High efficient key-insulated attribute based encryption scheme without bilinear pairing operations. SpringerPlus 2016, 5, 131. [Google Scholar] [CrossRef]
- Kumar, C.; Kumar, D.; Reddy, A.K. Concrete Attribute-Based Encryption Scheme with Verifiable Outsourced Decryption. arXiv, 2014; arXiv:1407.3660. [Google Scholar]
- Zhang, Y.; Zheng, D.; Deng, R.H. Security and privacy in smart health: Efficient policy-hiding attribute-based access control. IEEE Internet Things J. 2018, 5, 2130–2145. [Google Scholar] [CrossRef]
- Cui, H.; Deng, R.H.; Lai, J.; Yi, X.; Nepal, S. An efficient and expressive ciphertext-policy attribute-based encryption scheme with partially hidden access structures, revisited. Comput. Netw. 2018, 133, 157–165. [Google Scholar] [CrossRef]
- Han, Q.; Zhang, Y.; Li, H. Efficient and robust attribute-based encryption supporting access policy hiding in Internet of Things. Future Gener. Comput. Syst. 2018, 83, 269–277. [Google Scholar] [CrossRef]
- Freeman, D.M. Converting pairing-based cryptosystems from composite-order groups to prime-order groups. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Monaco and Nice, France, 30 May–3 June 2010; pp. 44–61. [Google Scholar]
- Rajeshwari, K.; Parthasarathi, P. Multi-Authority Attribute Based Encryption in Cloud Computing for Agriculture. Int. J. Sci. Eng. Res. 2015, 3. [Google Scholar]
- Yang, Y.; Chen, X.; Chen, H.; Du, X. Improving Privacy and Security in Decentralizing Multi-Authority Attribute-Based Encryption in Cloud Computing. IEEE Access 2018, 6, 18009–18021. [Google Scholar] [CrossRef]
- Han, J.; Susilo, W.; Mu, Y.; Zhou, J.; Au, M.H.A. Improving privacy and security in decentralized ciphertext-policy attribute-based encryption. IEEE Trans. Inf. Forensics Secur. 2015, 10, 665–678. [Google Scholar]
- Liu, Z.; Cao, Z.; Huang, Q.; Wong, D.S.; Yuen, T.H. Fully secure multi-authority ciphertext-policy attribute-based encryption without random oracles. In Proceedings of the European Symposium on Research in Computer Security, Leuven, Belgium, 12–14 September 2011; pp. 278–297. [Google Scholar]
- Ruj, S.; Nayak, A.; Stojmenovic, I. DACC: Distributed access control in clouds. In Proceedings of the 2011 IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Changsha, China, 16–18 November 2011; pp. 91–98. [Google Scholar]
- Chase, M. Multi-authority attribute based encryption. In Proceedings of the Theory of Cryptography Conference, Amsterdam, The Netherlands, 21–24 February 2007; pp. 515–534. [Google Scholar]
- Yang, K.; Jia, X.; Ran, K.; Zhang, B. DAC-MACS: Effective data access control for multi-authority cloud storage systems. IEEE Trans. Inf. Forensics Secur. 2013, 11, 1790–1801. [Google Scholar] [CrossRef]
- Li, W.; Xue, K.; Xue, Y.; Hong, J. TMACS: A robust and verifiable threshold multi-authority access control system in public cloud storage. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1484–1496. [Google Scholar] [CrossRef]
- Kattimani, S.; Pachouly, S. A robust and verifiable threshold multi-authority access control system in public cloud storage. In Proceedings of the 2016 International Conference on Computing Communication Control and automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–4. [Google Scholar]
- More, M.; Gaikwad, S.Y. A Robust and Verifiable Threshold Multi-Authority Access Control System in Public Cloud Storage. Int. J. Adv Res. Ideas Innovations Technol. 2017, 3, 1220–1223. [Google Scholar]
- Xue, K.; Xue, Y.; Hong, J.; Li, W.; Yue, H.; Wei, D.S.; Hong, P. RAAC: Robust and auditable access control with multiple attribute authorities for public cloud storage. IEEE Trans. Inf. Forensics Secur. 2017, 12, 953–967. [Google Scholar] [CrossRef]
- Khan, F.; Li, H.; Zhang, L. Owner Specified Excessive Access Control for Attribute Based Encryption. IEEE Access 2016, 4, 8967–8976. [Google Scholar] [CrossRef]
- Zhong, H.; Zhu, W.; Xu, Y.; Cui, J. Multi-authority attribute-based encryption access control scheme with policy hidden for cloud storage. Soft Comput. 2018, 22, 243–251. [Google Scholar] [CrossRef]
- Li, J.; Chen, X.; Chow, S.S.; Huang, Q.; Wong, D.S.; Liu, Z. Multi-authority fine-grained access control with accountability and its application in cloud. J. Netw. Comput. Appl. 2018, 112, 89–96. [Google Scholar] [CrossRef]
- Ning, J.; Cao, Z.; Dong, X.; Liang, K.; Wei, L.; Choo, K.-K.R. CryptCloud+: Secure and Expressive Data Access Control for Cloud Storage. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Rudra, G.M.P.; Dhananjaya, V. Cloud++: A secure and timed data access control scheme for cloud. Int. J. Innov. Res. Sci. Eng. Technol. 2018, 7, 90–95. [Google Scholar]
- Ling, J.; Weng, A. A. A scheme of hidden-structure attribute-based encryption with multiple authorities. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; Volume 359, p. 012005. [Google Scholar]
- Lin, H.; Cao, Z.; Liang, X.; Shao, J. Secure threshold multi authority attribute based encryption without a central authority. In Proceedings of the International Conference on Cryptology in India, Kharagpur, India, 14–17 December 2008; pp. 426–436. [Google Scholar]
- Li, X.; Tang, S.; Xu, L.; Wang, H.; Chen, J. Two-factor data access control with efficient revocation for multi-authority cloud storage systems. IEEE Access 2017, 5, 393–405. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Scheme | Description | Revocation | Access Policy |
|---|---|---|---|
| Bethencourt et al. [9] | The first CP-ABE scheme using a tree access structure | Lack of Revocation | Less expressive |
| Waters [10] | The first fully expressive CP-ABE scheme using a linear secret sharing access structure | Lack of Revocation | Full expressive |
| Wang et al. [17] | The first hierarchical ABE scheme with a disjunctive normal form (DNF) policy | Addressing revocation | Not expressive |
| Scheme | Description | Revocation Type | The Problem |
|---|---|---|---|
| [26,27] | Add an attribute expiration time to a user’s key | User revocation | Periodically |
| [30,31] | Resist collusion attacks | Attribute and user revocation | Limited number |
| [19] | Revoke an unlimited number of users | User revocation | The ciphertext size increases linearly with the number of revoked users |
| [28] | Consume a lot of computing resources | Attribute revocation | High computation overhead |
| [32,33] | Alleviate the computation overhead | Periodic attribute revocation | Collusion attack |
| [24,29] | Issue versions of users’ secret keys | Attribute revocation | Collusion attack |
| [34] | Dynamic revocation | User revocation | No attribute revocation |
| [35] | Enable CP-ABE with proxy re-encryption | Attribute revocation | High computation overhead |
| [36] | Use two master keys | Attribute and user revocation | Collusion attack |
| [37] | Accelerate the revocation | User revocation | Computational burden on a data owner |
| [38] | Dynamic revocation | Attribute and user revocation | Collusion attack |
| [39] | Updated access policy | Attribute revocation | Computational burden on a data owner |
| Scheme | Description | Access Structure | The Problem |
|---|---|---|---|
| Odelu et al. [41] | Eliminate the computation cost for lightweight devices | AND gate | Lack of revocation |
| Fu et al. [42] | Provide large attribute universe based access control | LSSS | Lack of revocation |
| Liu et al. and Li et al. [43,44] | Offer online–offline techniques to eliminate most computations | LSSS | Lack of revocation |
| Zhang et al. [45] | Propose a fully outsourced ABE scheme | LSSS | Lack of revocation |
| Zhan et al. [46] | Outsource the heavy operations of CP-ABE to fog computing | Access Tree | Inefficient revocation |
| Karati et al. [47] | Reduce the computation cost of ABE by using pairing-free ABE | Threshold | Lack of revocation |
| Hong and Sun [48] | Reduce the computation cost of ABE by using pairing-free ABE | Access Tree | Periodical revocation |
| Kumar et al. [49] | Outsource and verify the decryption operation | Access Tree | Lack of revocation |
| Zhang et al. [50] | Hide an access policy in CP-ABE schemes | LSSS | Lack of revocation |
| Cui et al. and Han et al. [51,52] | Hide an access policy in CP-ABE schemes | LSSS | Lack of revocation |
| Scheme | Description | The Problem | Attribute Set |
|---|---|---|---|
| Han et al. [56] | The authorities have to work with each other | High communication cost | Disjoint |
| Liu et al. [57] | Using an active central authority to administrate attributes | Security bottleneck | Disjoint |
| Lin et al. [71] | Decentralized threshold authorities work together without a central authority | Lack of revocation | Disjoint |
| Ruj et al. [58] | Decentralized system without a central authority | Lack of revocation | Disjoint |
| Li et al. [72] | The central authority is not involved in generating secret keys | Support AND access structure which is not expressive | Disjoint |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Dahhan, R.R.; Shi, Q.; Lee, G.M.; Kifayat, K. Survey on Revocation in Ciphertext-Policy Attribute-Based Encryption. Sensors 2019, 19, 1695. https://doi.org/10.3390/s19071695
Al-Dahhan RR, Shi Q, Lee GM, Kifayat K. Survey on Revocation in Ciphertext-Policy Attribute-Based Encryption. Sensors. 2019; 19(7):1695. https://doi.org/10.3390/s19071695
Chicago/Turabian StyleAl-Dahhan, Ruqayah R., Qi Shi, Gyu Myoung Lee, and Kashif Kifayat. 2019. "Survey on Revocation in Ciphertext-Policy Attribute-Based Encryption" Sensors 19, no. 7: 1695. https://doi.org/10.3390/s19071695
APA StyleAl-Dahhan, R. R., Shi, Q., Lee, G. M., & Kifayat, K. (2019). Survey on Revocation in Ciphertext-Policy Attribute-Based Encryption. Sensors, 19(7), 1695. https://doi.org/10.3390/s19071695