Research on Modeling and Analysis of Generative Conversational System Based on Optimal Joint Structural and Linguistic Model



Abstract
:1. Introduction
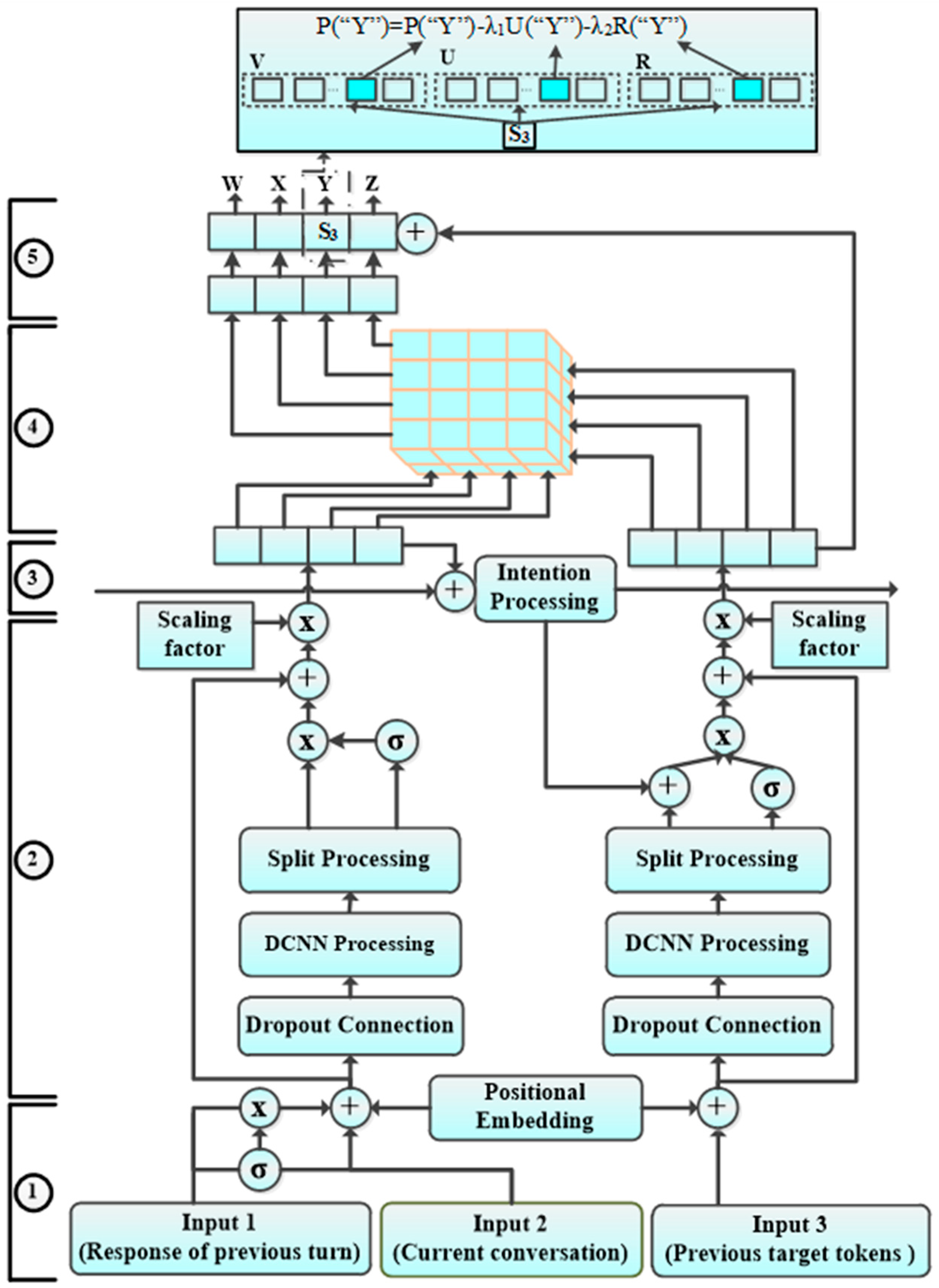
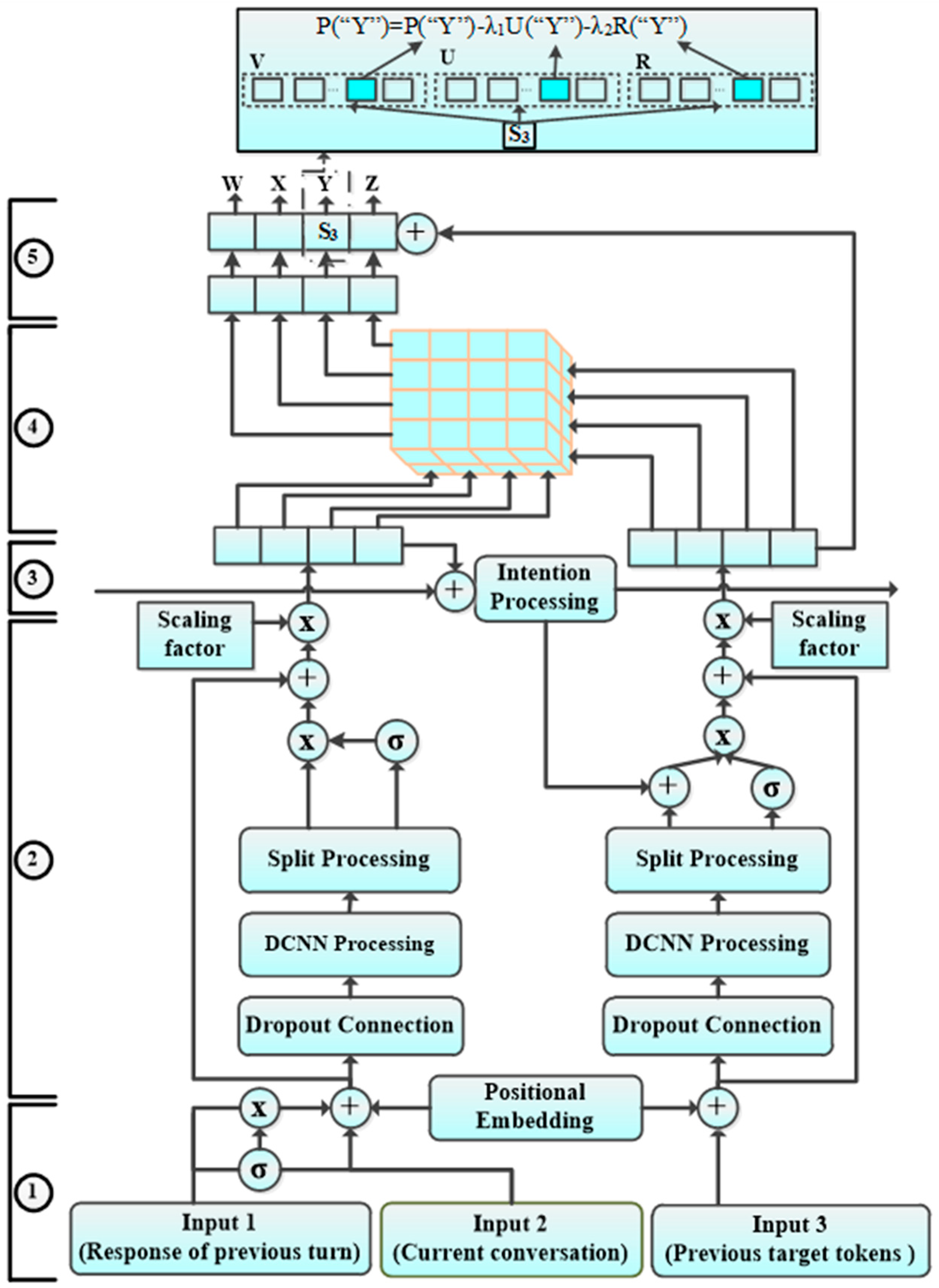
2. Model Architecture
2.1. Input Pre-Processing
2.2. Dual-Encoder
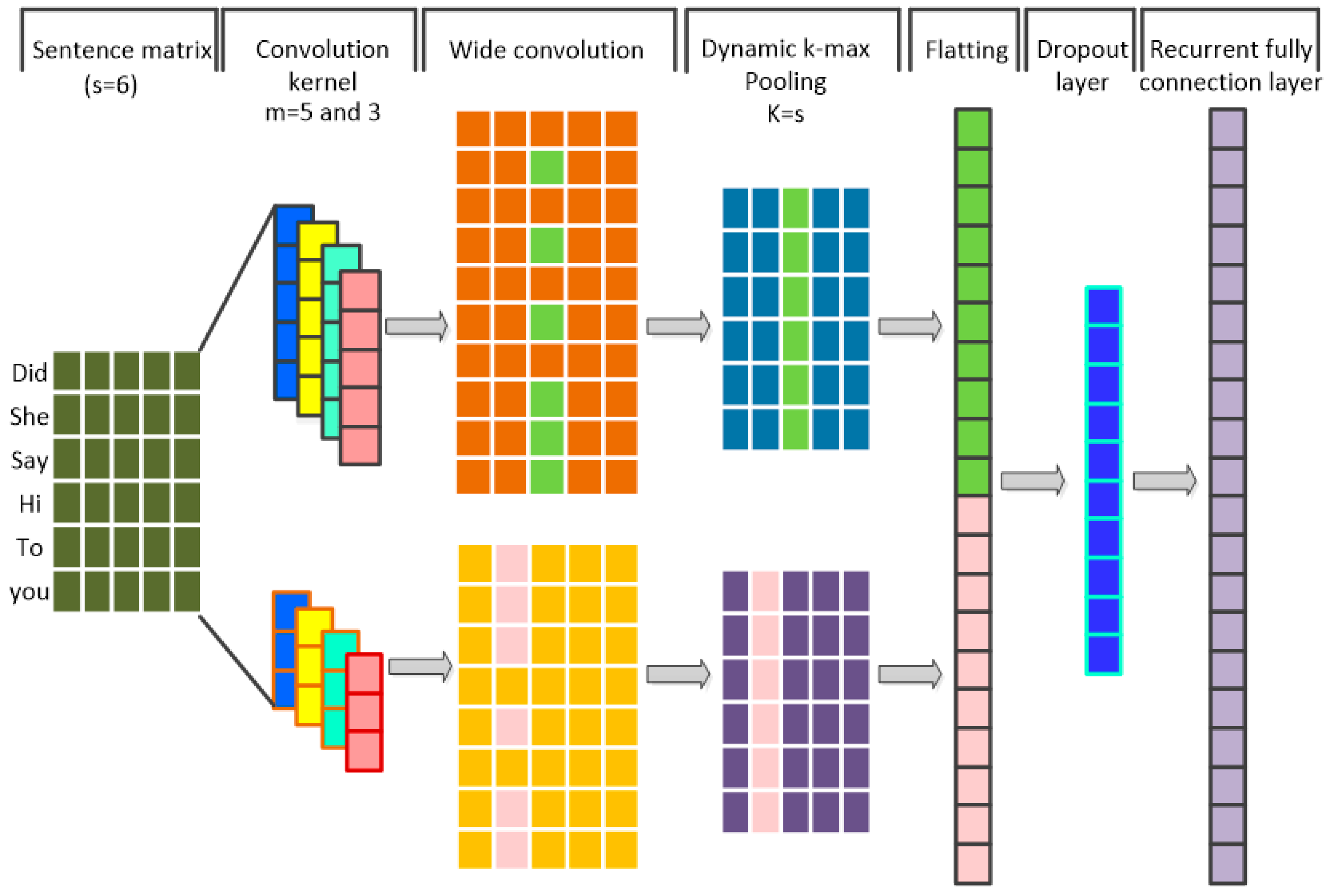
2.3. 1-D Dynamic Convolutional Neural Networks (DCNN)
2.4. Centralizing Intention
2.5. Intensity-Strengthening Attention
3. Linguistic Model Based on MMI and FPM
4. Experiments
4.1. Datasets and Training
4.2. Automatic Evaluations
4.3. Human Evaluation
- It is not fluent or is logically incorrect in responses;
- The response is fluent, but irrelevant to the question, including irrelevant regular responses;
- The response is fluent and weakly related to the question, but the response can answer the question;
- The response is fluent and strongly related to the question;
- The response is fluent and strongly related to the question. The response is close to human language.
5. Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xing, C.; Wu, W.; Wu, Y.; Liu, J.; Huang, Y.; Zhou, M.; Ma, W.Y. Topic Aware Neural Response Generation. In Proceedings of the AAAI’17 Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 3351–3357. [Google Scholar]
- Kaisheng, Y.; Baolin, P.; Geoffrey, Z.; Kam-Fai, W. An Attentional Neural Conversation Model with Improved Specificity. arXiv, 2016; arXiv:1606.01292. [Google Scholar]
- Cao, K.; Clark, S. Latent Variable Dialogue Models and their Diversity. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Short Papers, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 182–187. [Google Scholar]
- Sordoni, A.; Bengio, Y.; Vahabi, H.; Lioma, C.; Grue Simonsen, J.; Nie, J.Y. A Hierarchical Recurrent Encoder-Decoder for Generative Context-Aware Query Suggestion. In Proceedings of the CIKM ’15 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; Volume 19, pp. 553–562. [Google Scholar]
- Serban Iulian, V.; Sordoni, A.; Lowe, R.; Charlin, L.; Pineau, J.; Courville, A.; Bengio, Y. A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 3295–3310. [Google Scholar]
- Shen, X.; Su, H.; Li, Y.; Li, W.; Niu, S.; Zhao, Y.; Aizawa, A.; Long, G. A Conditional Variational Framework for Dialog Generation. Assoc. Comput. Linguist. 2017, 2, 504–509. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3122. [Google Scholar]
- Mou, L.; Song, Y.; Yan, R.; Li, G.; Zhang, L.; Jin, Z. Sequence to Backward and Forward Sequence: A Content-Introducing Approach to Generative Short-Text Conversation. Assoc. Comput. Linguist. 2016, 5, 3349–3358. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Michael, A.; Grangier, D. Language Modeling with gated convolu-tional networks. Int. Mach. Learn. Soc. 2017, 2, 1551–1559. [Google Scholar]
- Fuji, R.; Jiawen, D. Background Knowledge Based Multi-Stream Neural Network for Text Classification. Appl. Sci. 2018, 8, 2472. [Google Scholar] [CrossRef]
- Calvo-Zaragoza, J.; Francisco, J.C.; Gabriel, V.; Ichiro, F. Deep Neural Networks for Document Processing of Music Score Images. Appl. Sci. 2018, 8, 654. [Google Scholar] [CrossRef]
- Gehring, J.; Michael, A.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. Int. Mach. Learn. Soc. 2017, 3, 2029–2043. [Google Scholar]
- Zhang, Y.; Wallace, B.C. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification; Springer: Berlin/Heidelberg, Germany, 2017; Volume 6, pp. 253–263. [Google Scholar]
- Gehring, J.; Michael, A.; Grangier, D.; Yaun, N.D. A Convolutional Encoder Model for Neural Machine Translation. ACL 2016, 1, 123–135. [Google Scholar]
- Jiwei, L.; Michel, G.; Brockett, C.; Jianfeng, G.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the NAACL-HLT 2016, San Diego, CA, USA, 12–17 June 2016; pp. 110–119. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Jianfeng, G.; Jurafsky, D. Deep Reinforcement Learning for Dialogue Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1192–1202. [Google Scholar]
- Grosz, B. Attention, Intention, and the Structure of discourse. Comput. Linguist. 1986, 12, 175–204. [Google Scholar]
- Yao, K.; Zweig, G.; Peng, B. Attention with Intention for a Neural Network Conversation Model. In Proceedings of the NIPS 2015 Workshop on Machine Learning for Spoken Language Understanding and Interaction, Montreal, QC, Canada, 11 December 2015; pp. 1182–1189. [Google Scholar]
- Liu, C.W.; Lowe, R.; Serban, I.V.; Noseworthy, M.; Charlin, L.; Pineau, J. How Not to Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2122–2132. [Google Scholar]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; Volume 1, pp. 655–665. [Google Scholar]
- Minh-Thang, L.; Hieu, P.; Manning, C.D. Effective Approaches to Attentional-Based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Markus, F.; Yaser, A. Beam Search Strategies for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 4 August 2017; pp. 56–60. [Google Scholar]
- Vigayakumar, A.K.; Cogswell, M.; Selvaraju, R.R.; Sun, Q.; Stefan, L.; Crandall, D.; Batra, D. Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 7371–7379. [Google Scholar]
- Tiedemann, J. News from OPUS—A collection of multilingual parallel corpora with tools and interfaces. In Recent Advances in Natural Language Processing; John Benjamins Publishing: Amsterdam, The Netherlands, 2009; Volume 5, pp. 237–248. [Google Scholar]
- Pietquin, O.; Hastie, H. A Survey on Metrics for the Evaluation of User Simulations. Knowl. Eng. Rev. 2013, 28, 59–73. [Google Scholar] [CrossRef]
- Galley, M.; Brockett, C.; Sordoni, A.; Ji, Y.; Auli, M.; Quirk, C.; Mitchell, M.; Gao, J.; Dolan, B. δ BLEU: A discriminative metric for generation tasks with intrinsically diverse targets. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Short Papers), Beijing, China, 26–31 July 2015; pp. 445–450. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Zhang, H.; Lan, Y.; Guo, J.; Xu, J.; Cheng, X. Reinforcing coherence for sequence to sequence model in dialogue generation. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4567–4573. [Google Scholar]


{kind=link}
{kind=link}
| Models | Coherence | Diversity | Length |
|---|---|---|---|
| LSTM+Attention | 0.371 | 0.792 | 2.40 |
| LSTM+AWI | 0.466 | 0.695 | 2.95 |
| CNN+Attention | 0.341 | 0.801 | 2.14 |
| LSTM+AWI+MMI | 0.545 | 0.672 | 3.66 |
| SAWI-DCNN | 0.680 | 0.607 | 4.05 |
| SAWI-DCNN (except MMI+FMP) | 0.534 | 0.670 | 3.25 |
| Inputs | Responses |
|---|---|
| What are you doing? | 1. I am talking to you. |
| 2. I am looking for you | |
| 3. I want to talking to you. | |
| 4. I do nothing | |
| 5. I get out of here. | |
| 6. I am not sure. | |
| Wit beyond measure is man’s greatest treasure. | 1. Wisdom is the most precious, human beings should have it. |
| 2. Wisdom is the most precious, human beings should have. | |
| 3. Wit is greatest treasure. | |
| 4. Wit is biggest treasure. | |
| 5. Yes, we should possess greatest treasure. | |
| 6. Yes, we should possess. | |
| It is not our abilities that show what we truly are, it is our choices. | 1. Good choice is helpful to us, is not it? |
| 2. Good choice determines you are. | |
| 3. Abilities can not show we are. | |
| 4. Abilities it are. | |
| 5. I don’t know what you are talking. | |
| 6. I don’t know what you are talking about. |
| Models | Foolishness |
|---|---|
| SAWI-DCNN | 8% |
| SAWI-DCNN (except FMP) | 26% |
| #Input | What are you doing? |
| SAWI-DCNN | I am talking to you |
| LSTM+Attention | I do thinking. |
| LSTM+AWI | I want to talk to you |
| CNN+Attention | I am fun. |
| LSTM+AWI+MMI | I want to talk to you. |
| # Input | I mean. I have to talk to you. |
| SAWI-DCNN | Come on, let is talking about it. |
| LSTM+Attention | Ok. |
| LSTM+AWI | I know you are. |
| CNN+Attention | I don’t know. |
| LSTM+AWI+MMI | I mean. He is a good gun. |
| # Input | Wit beyond measure is man’s greatest treasure. |
| SAWI-DCNN | Wisdom is the most precious, human beings should have it. |
| LSTM+Attention | I don’t know. |
| LSTM+AWI | Yes. Man has greatest treasure. |
| CNN+Attention | I don’t know what are you talking about. |
| LSTM+AWI+MMI | Of course. wit is greatest treasure. |
| # Input | It is not our abilities that show what we truly are, it is our choices. |
| SAWI-DCNN | Good choices are helpful to us, do we? |
| LSTM+Attention | I don’t know. |
| LSTM+AWI | We should not choice abilities. |
| CNN+Attention | I do not know what you are talking. |
| LSTM+AWI+MMI | We should look at our choices correctly. |
| # Input | The things we lose have a way of coming back to us in the end, if not always in the way we expect. |
| SAWI-DCNN | The things comes back. |
| LSTM+Attention | I don’t know what you are talking about. |
| LSTM+AWI | I don’t know what you are talking about. |
| CNN+Attention | What? |
| LSTM+AWI+MMI | Yes it is |
| Models | 1 | 2 | 3 | 4 | 5 | AVE |
|---|---|---|---|---|---|---|
| LSTM+Attention | 17.2 | 32.7 | 28.1 | 17.4 | 4.6 | 17.30 |
| LSTM+AWI | 12.0 | 28.7 | 33.5 | 20.3 | 5.5 | 18.57 |
| CNN+Attention | 18.5 | 30.1 | 20.5 | 27.3 | 3.6 | 17.84 |
| LSTM+AWI+MMI | 12.5 | 21.8 | 29.4 | 25.5 | 10.8 | 20.02 |
| SAWI-DCNN | 10.6 | 19.0 | 19.9 | 40.3 | 10.2 | 21.37 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Jia, Y.; Li, L.; Huang, Z.; Wang, W. Research on Modeling and Analysis of Generative Conversational System Based on Optimal Joint Structural and Linguistic Model. Sensors 2019, 19, 1675. https://doi.org/10.3390/s19071675
Tian Y, Jia Y, Li L, Huang Z, Wang W. Research on Modeling and Analysis of Generative Conversational System Based on Optimal Joint Structural and Linguistic Model. Sensors. 2019; 19(7):1675. https://doi.org/10.3390/s19071675
Chicago/Turabian StyleTian, Yingzhong, Yafei Jia, Long Li, Zongnan Huang, and Wenbin Wang. 2019. "Research on Modeling and Analysis of Generative Conversational System Based on Optimal Joint Structural and Linguistic Model" Sensors 19, no. 7: 1675. https://doi.org/10.3390/s19071675
APA StyleTian, Y., Jia, Y., Li, L., Huang, Z., & Wang, W. (2019). Research on Modeling and Analysis of Generative Conversational System Based on Optimal Joint Structural and Linguistic Model. Sensors, 19(7), 1675. https://doi.org/10.3390/s19071675