2.2. Mobile Data Offloading Protocol
Previously, we proposed an MDOP that balances the load of the eNB while taking into consideration the locality of the demand [
5,
6].
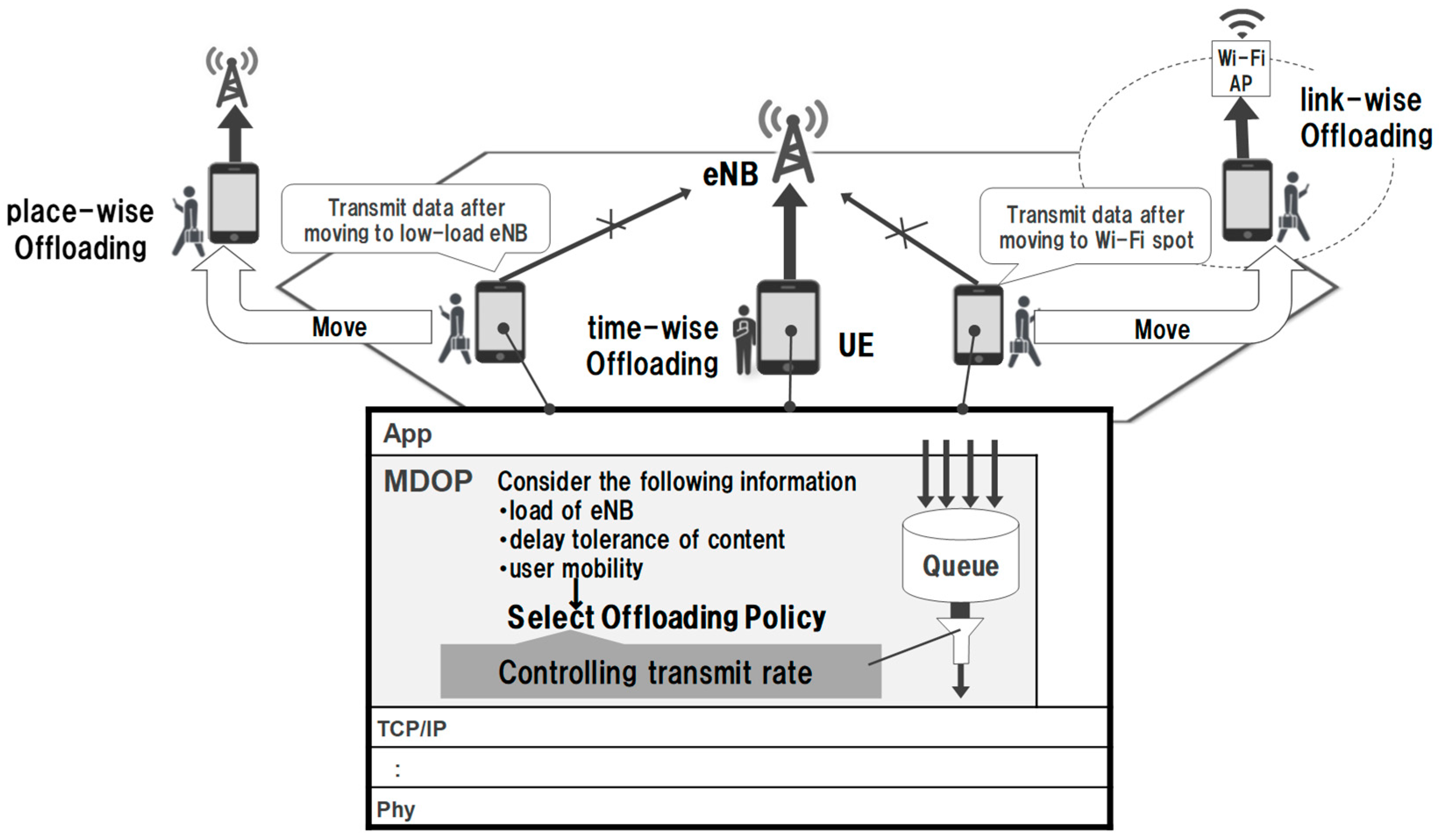
Figure 2 presents an overview of MDOP. MDOP is implemented by middleware located in the lower layer of the application layer. It realizes mobile data offloading by controlling the transmission rate in consideration of the delay tolerance when transmitting and receiving corresponding applications. MDOP has three methods of controlling the transmission rate as offloading policy. First, the time-wise offloading solves the time-wise locality by delaying the communication when the eNB has a high load. Second, place-wise offloading solves the regional locality by delaying the communication of the UE connected to a high-load eNB until it connects to a low-load eNB. Finally, link-wise offloading is used to reduce the traffic on a mobile data channel by delaying the communication of the UE until a connection to a Wi-Fi access point is established. MDOP selects the offloading policy from these three methods according to the state of the delay tolerance of the data and the state of the UE and eNB. MDOP then executes transmission rate control using the selected policy.
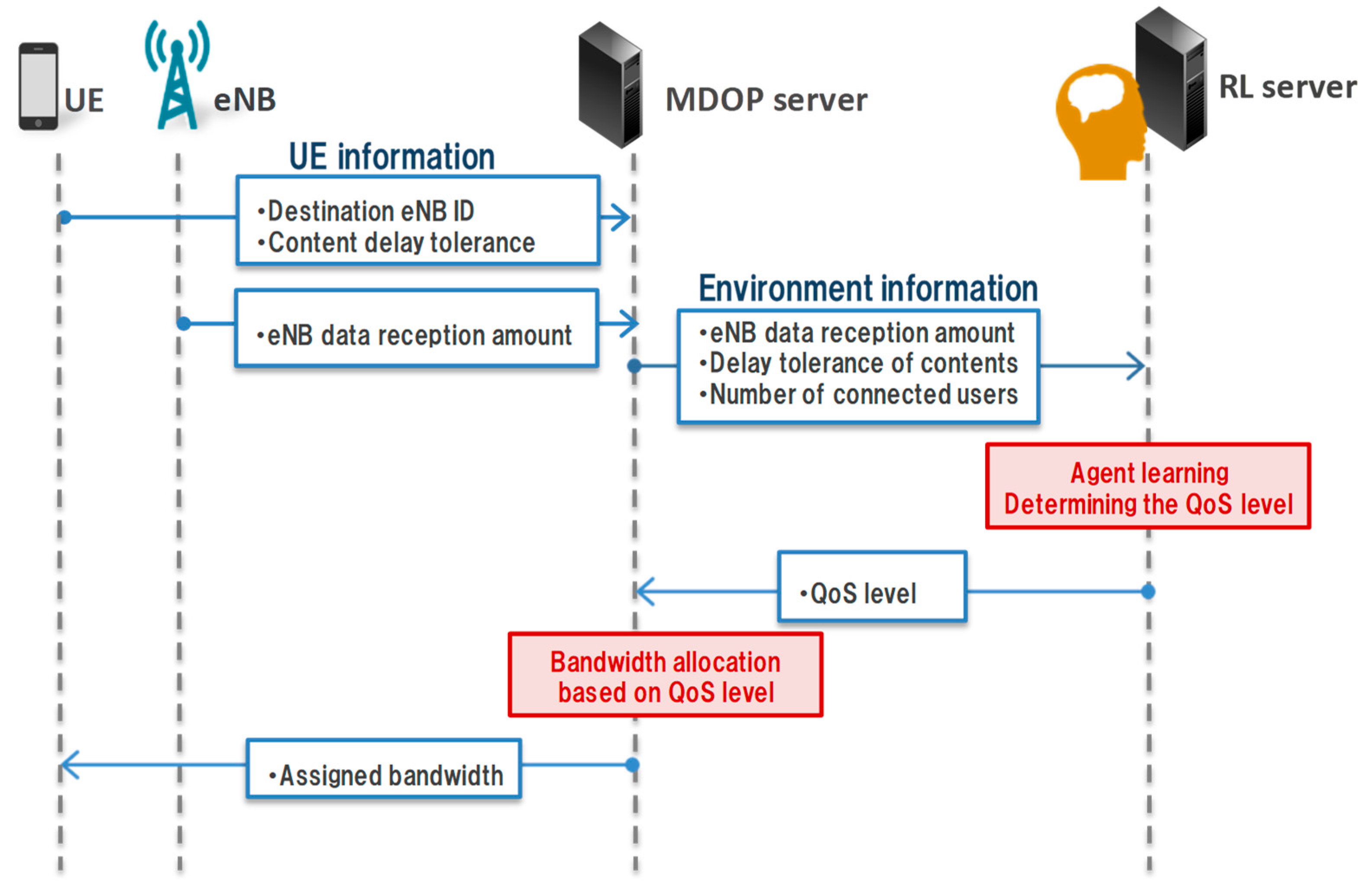
In MDOP, an MDOP server periodically collects content information from UEs, load information from eNB, and performs band allocation. When an MDOP server notifies the UE of the allocated band, the UE can transmit content with the allocated band. When band allocation is performed, the maximum band is allocated to UE if the content does not have delay tolerance. Also, if the content has delay tolerance, the bandwidth is divided equally.
MDOP controls the transmission rate to accommodate a load within the control target value. We defined an ideal load as the control target value. The ideal load is set in order to prevent the occurrence of situations where packet loss and the allowable amount of eNB is exceeded when burst traffic occurs. MDOP reduces the locality of the demand by accommodating the eNB load within the ideal load to smooth the eNB load. When the content delay tolerance is exceeded, the content is transmitted at the maximum transmission rate without taking into consideration the ideal load.
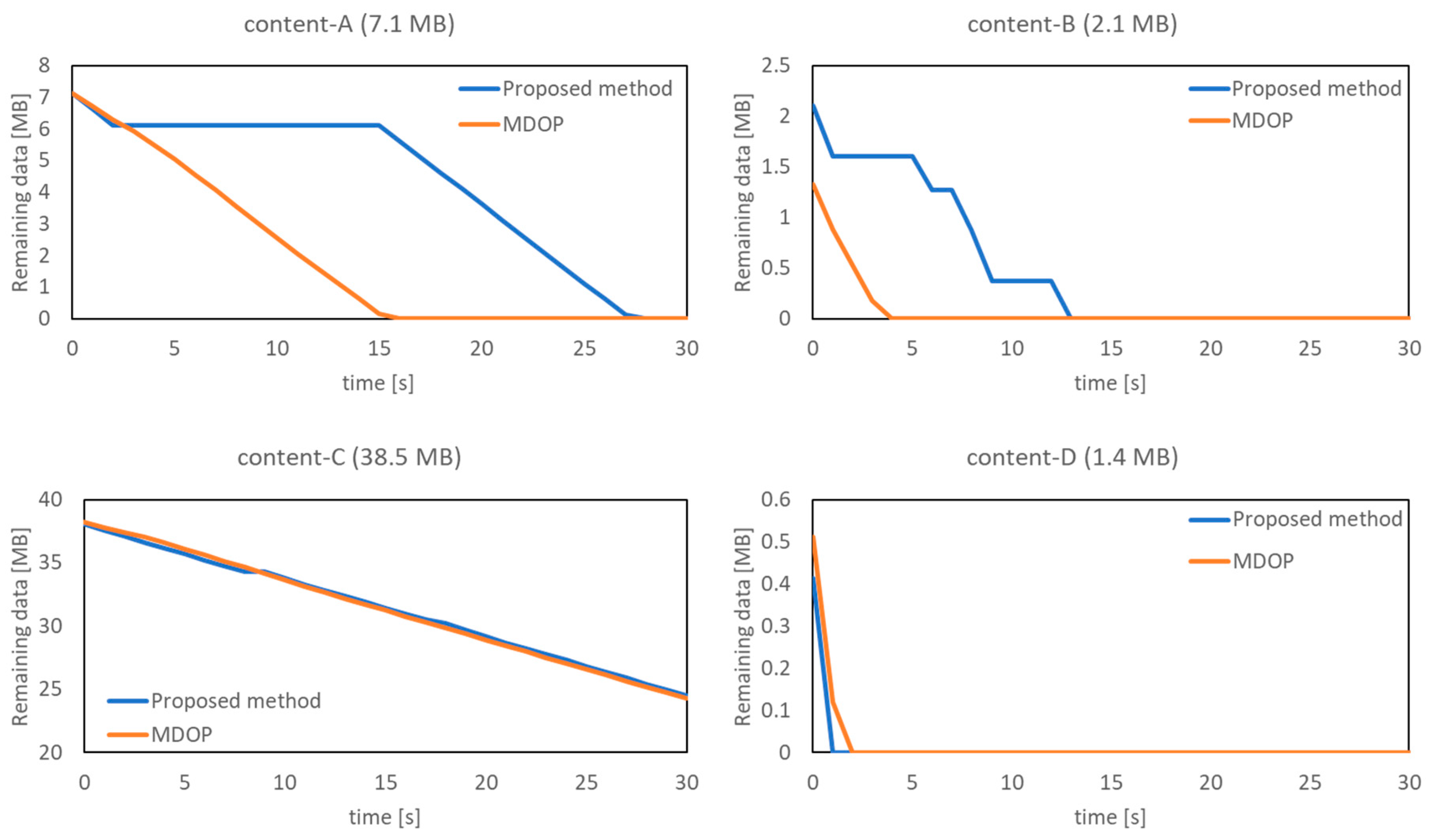
Similar to the problem of the previous MDOP, the delay tolerance of the content is not taken into consideration. Therefore, the short delay tolerance content has the possibility to exceed delay tolerance because the same control is applied to all the content regardless of the delay tolerance. The proposed method focuses on the delay tolerance of the content and clarifying the priority to assign the bandwidth. The proposed method can balance the time-wise concentrated load by realizing the delay-tolerance-based bandwidth allocated method of UE. By using deep reinforcement learning, it is possible to determine the appropriate priority of bandwidth allocation under various situations when deciding the priority.
2.3. Transmission Control by Deep Reinforcement Learning
We determine the transmission control of the UE by using deep reinforcement learning, and the RL server learns using a double deep Q-network (DDQN) [
20]. DDQN is a reinforcement learning method that uses deep learning with Q-learning [
21]. Q-learning is focused on maximizing a function
.
represents the value of action
taken in state
. Q-learning updates
at time
as follows:
where
is the learning rate, and
is the discount factor. Each parameter is defined as
. Furthermore, Q-learning selects the action with the highest Q-value. If we use Q-learning to perform learning, it is necessary to prepare a table function
which is a combination of all states
and actions
in advance. However, it is difficult to prepare this table function because there are innumerable situations in mobile networks. In the case of such a problem, deep Q-network (DQN) is used, which approximates
with a neural network [
15]. Although a method for approximating
with a neural network has been previously proposed, it was known that the learning diverges as the number of parameters increases. Because the correlation between the data is high, the policy of the selecting action is changed significantly on updating
. In order to prevent the divergence of the learning, DQN uses experience replay and neural fitted Q. Experience replay stabilizes the learning by using randomly sampled states and actions of the past. Neural-fitted Q fixes parameters to be approximated with a neural network for stabilizing the learning. DQN updates the Q value using the loss function
as follows:
However, DQN overestimates the action because
selection and
estimation models are the same. In contrast, the DDQN uses different models for the selection and estimation. Thus, the overestimation of the action in the case of DDQN is reduced compared with that in the case of DQN. In addition, we apply dueling-network architecture to DDQN [
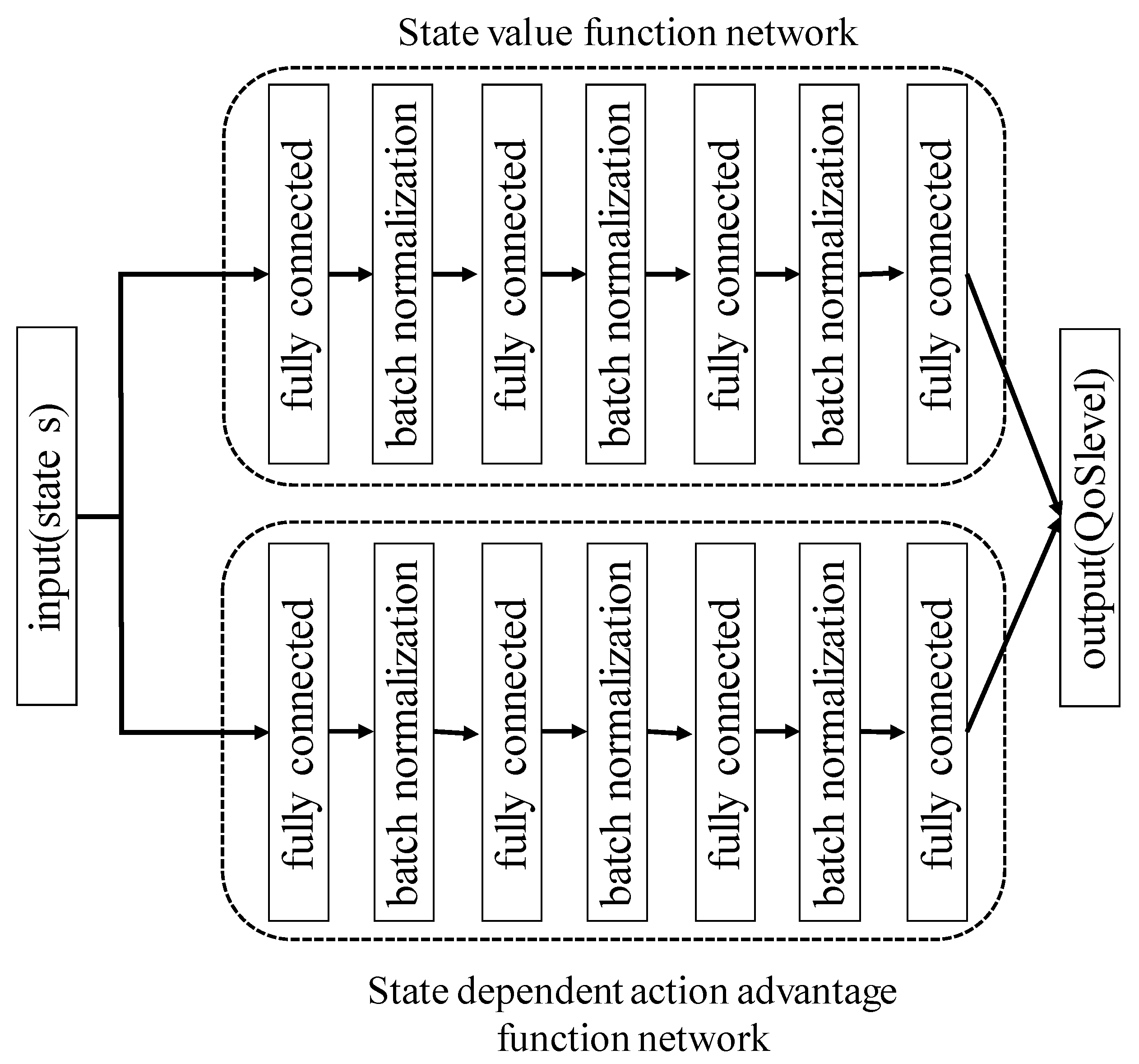
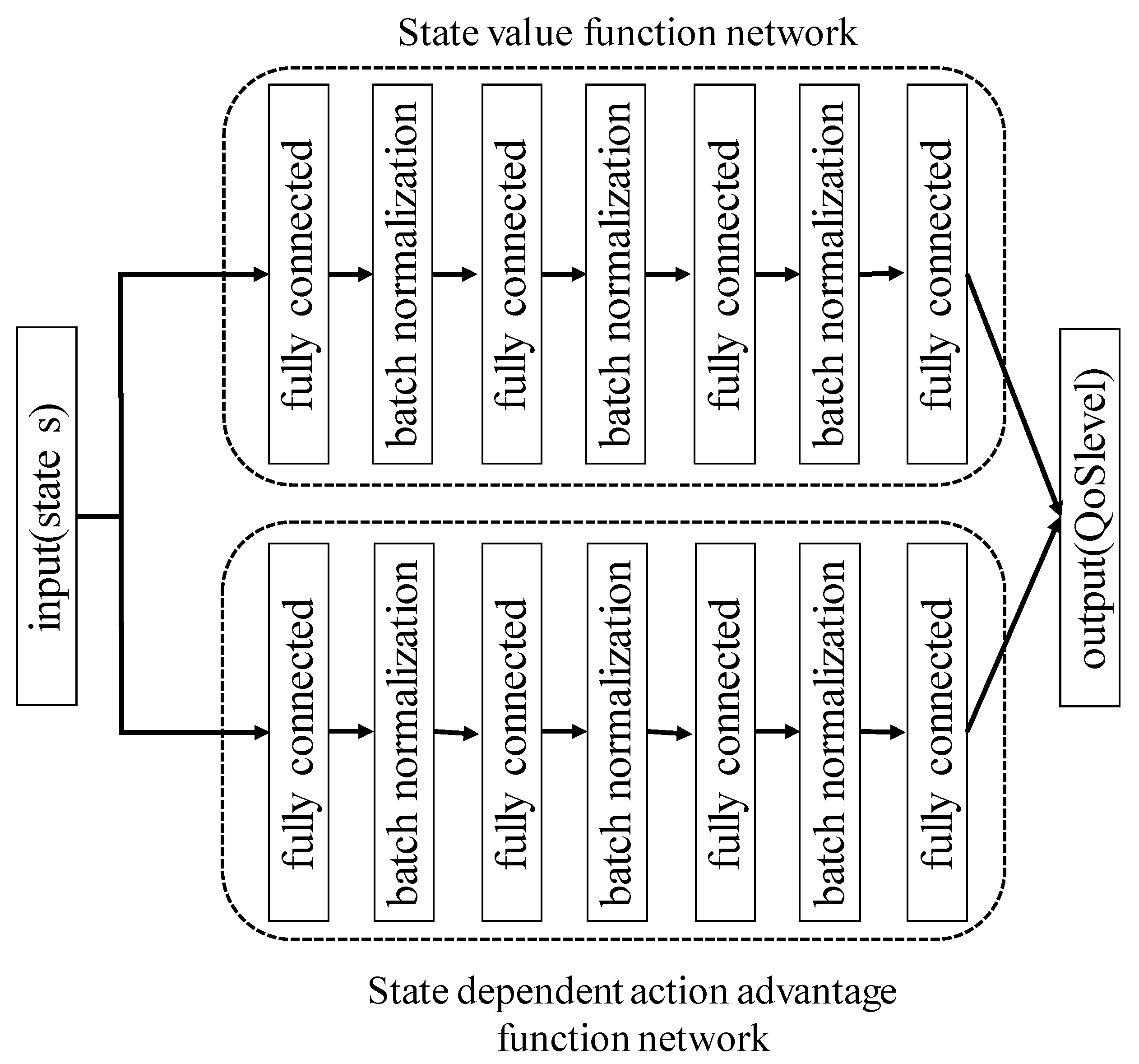
22]. Dueling-network represents
as follows:
is a state value function and
is a state-dependent action advantage function.
shows the worth of a particular state
, and
represents a relative measure of the importance of each action
. On using dueling-network architecture, it is possible to directly express a value of the state without using the value of the action. Furthermore, it is confirmed that the convergence of the state value occurs faster as a result. Hence, we use DDQN and dueling-network architecture to construct a transmission rate control model.
Defining the states, actions, and reward is essential for learning using deep reinforcement learning.
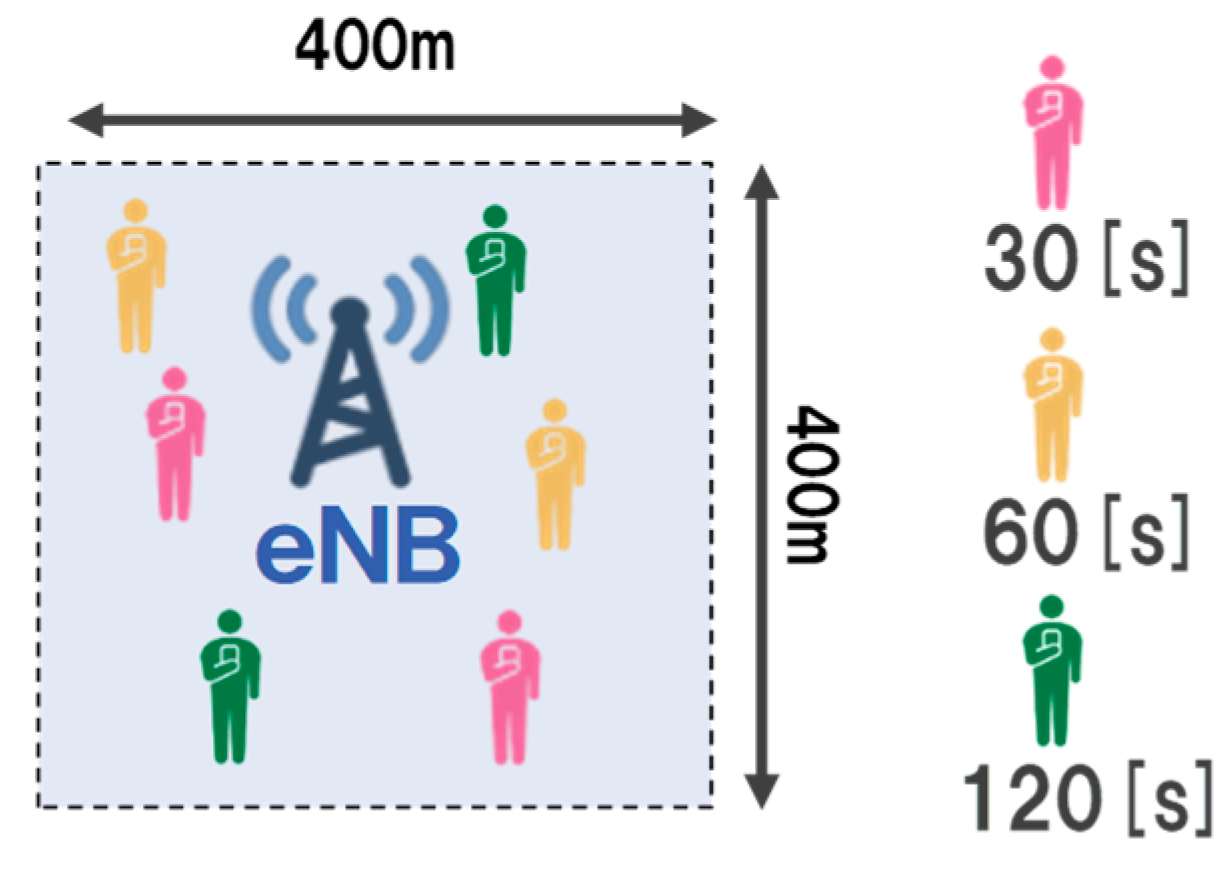
Table 1 lists the learning parameters of the proposed method at
. In our method, we construct a transmission rate control model for each eNB. Additionally, when multiple UE exists in the same eNB, the MDOP server aggregates UE information from each UE. Besides, the RL server determines the QoS level for each UE and performs bandwidth allocation. We define the environment information as state
. The RL server periodically receives environment information from the MDOP server. The environment information includes UE information and connected eNB information. The UE information includes the remaining amount of content (
contentra), the content delay tolerance (
contentdt), and the destination eNB ID. Moreover, the eNB information is that gathered by the MDOP server, such as the available bandwidth and current load of the eNB.
As the input parameter of the RL server, the UE information consists of the control target UE and the UE connecting to the same eNB. Although the QoS level can be determined based only on and of the control target UE, we introduce relative information to assign the UE priority in detail. The relative information to be introduced includes the maximum, median, and minimum values of and . We can expect that the RL server decides the QoS level to be assigned to control the target UE in consideration of the UE connected to the same eNB by sending the relative information of the UE to the RL server. We also define the current time as a learning parameter, because it is used to evaluate the action of the RL server while taking the time information into consideration. Furthermore, we define all the parameters as one parameter in order to avoid learning that not converging too many states although a parameter can be defined for each QoS level.
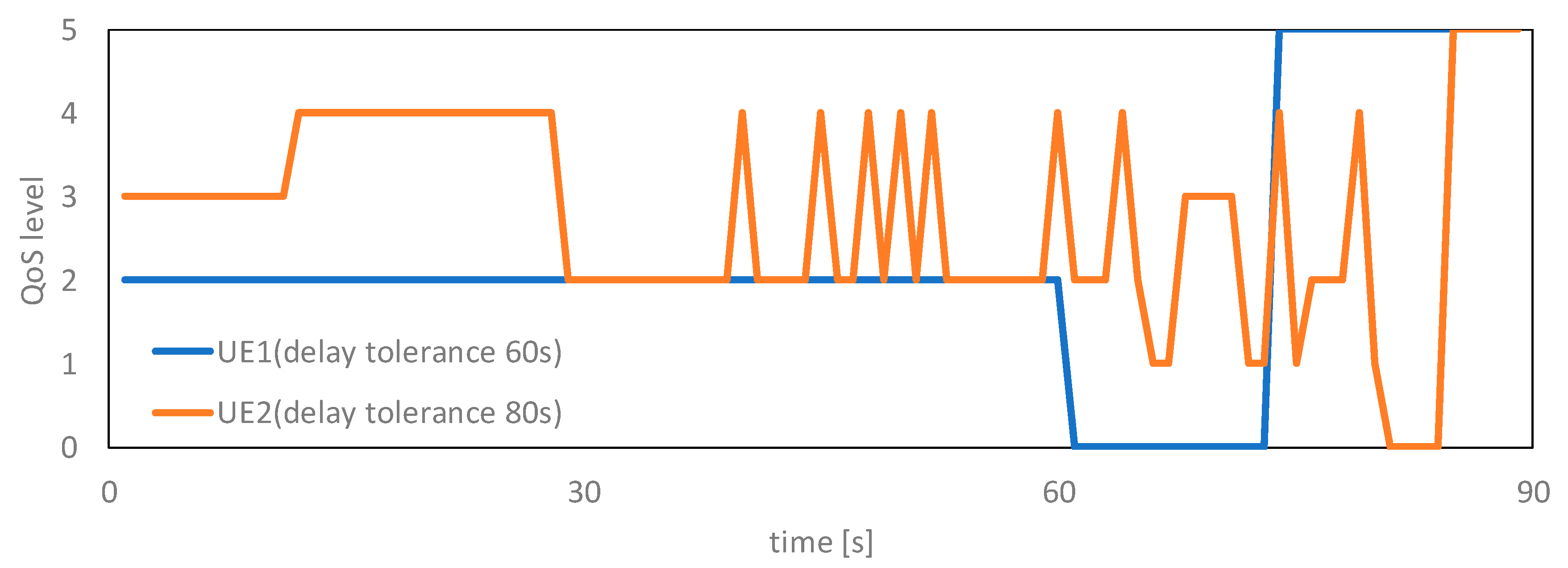
We define the priority of the bandwidth allocated to the UE as action There are five QoS levels. The bandwidths are allocated in the order of QoS1 to QoS3. Furthermore, we assign QoS0 to a non-MDOP UE and an MDOP UE that has content that exceeds the delay tolerance. In MDOP, the content is sent at the maximum transmission rate when the delay tolerance of the content is exceeded. Moreover, we assign QoS4 to the UE that does not need to allocate bandwidth. Although as the learning progresses, the RL server can learn to avoid allocating a bandwidth to a specific UE, and the learning will become efficient if this control is given to the RL server as an action. Hence, the RL server assigns one of QoS1 to QoS4 to the UE. The role of the RL server is to determine action using collected UE and eNB information via the MDOP server, which is the priority of the bandwidth to be allocated to the UE. The actual transmission rate is determined by the MDOP server based on the QoS level assigned by the RL server. The MDOP server allocates the bandwidth in order from the UE with a high QoS level.
Finally, the reward
is derived by comparing the current load
and the ideal load
for each eNB.
is constant regardless of time. Action
is evaluated using the reward function. The RL server then learns based on this evaluation result. A reward function of the proposed method is shown in Algorithm 1. First, we compare
with
in order to evaluate action
in terms of whether the load balancing of eNB is achieved. Reward
is a positive reward when
is lower than
. In contrast, reward
is a negative reward when
exceeds
. Thus, we set that the positive reward as +1 and the negative reward as the value determined according to the difference of
and
. If the negative reward value is a fixed discrete value, action
is evaluated in the same manner regardless of the difference of
and
when
exceeds
. Therefore, we define a negative reward using continuous values to avoid such an evaluation. However, despite action
,
sometimes exceeds
. In this situation, the RL server should not allocate the bandwidth to the UE. Thus, reward
is zero value when the RL server outputs QoS4 as action
in this situation. Furthermore, we weight reward
by the elapsed time. In the proposed method, it is preferable to delay the mobile data communication and maintain the eNB load within
. However, the control becomes increasingly difficult as the elapsed time increases in the case of delaying and controlling the mobile data communication. Hence, in Algorithm 1, the longer the control elapsed time, the greater the positive reward when the RL server gets a reward. Conversely, the shorter the control elapsed time, the greater the negative reward. The episode end time is set by assuming that the RL server periodically controls within a certain time range, such as 1 day. Accordingly, the RL server can balance the load by considering the content delay tolerance while not exceeding
, since reinforcement learning learns the action to maximize the reward.
| Algorithm 1 Reward function of the proposed method |
| 1 | Current load of connecting eNB: |
| 2 | Ideal load that is control target value: |
| 3 | Available bandwidth of connecting eNB: |
| 4 | Select action at time : |
| 5 | Episode end time: |
| 6 | Normalization variable: |
| 7 | ifthen |
| 8 | |
| 9 | else |
| 10 | if and then |
| 11 | |
| 12 | else |
| 13 | ) |
| 14 | end if |
| 15 | end if |
| 16 | return |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}