Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset


Abstract
1. Introduction
2. Materials and Methods
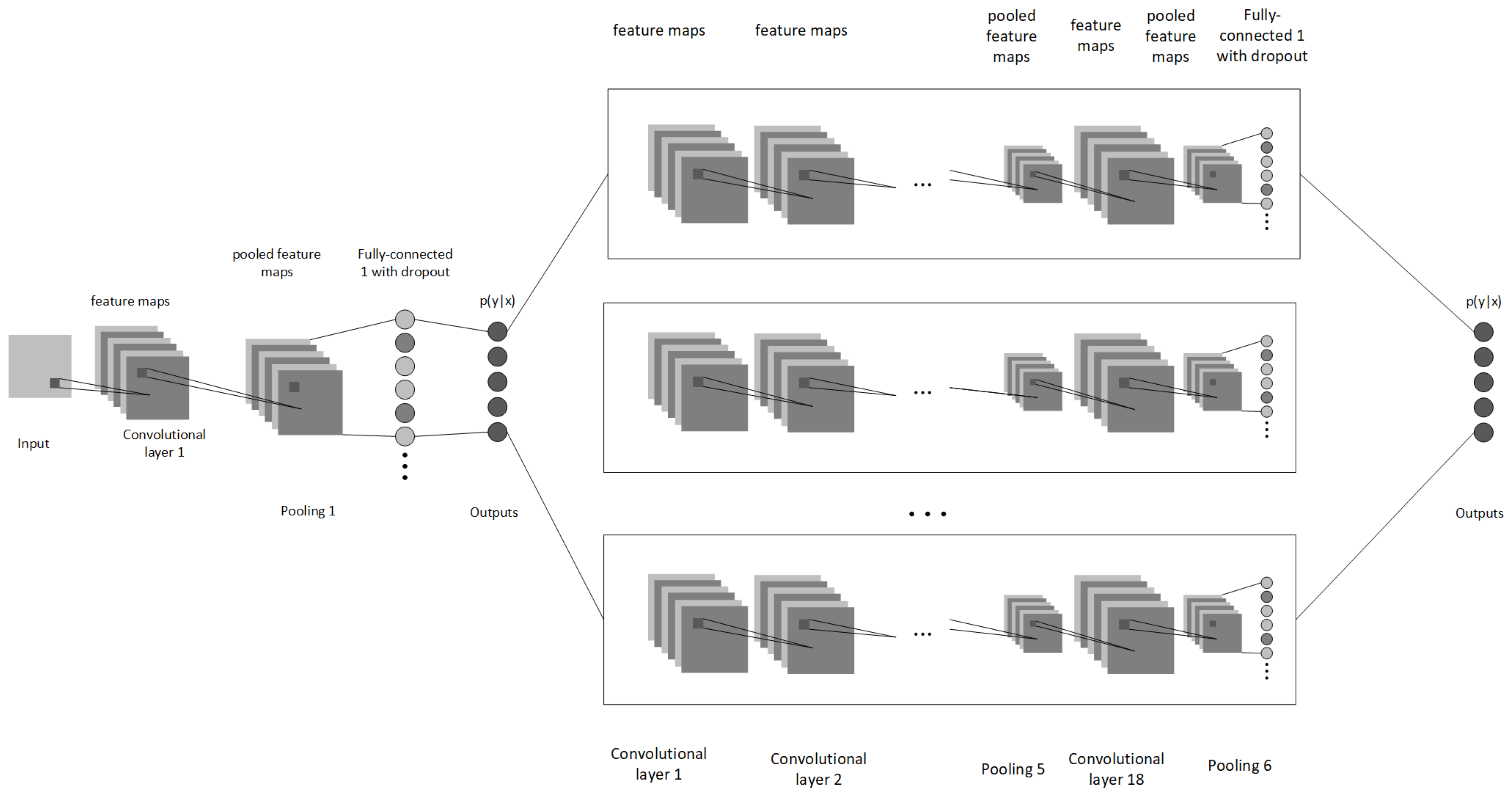
2.1. Architecture of Hybrid Neural Network
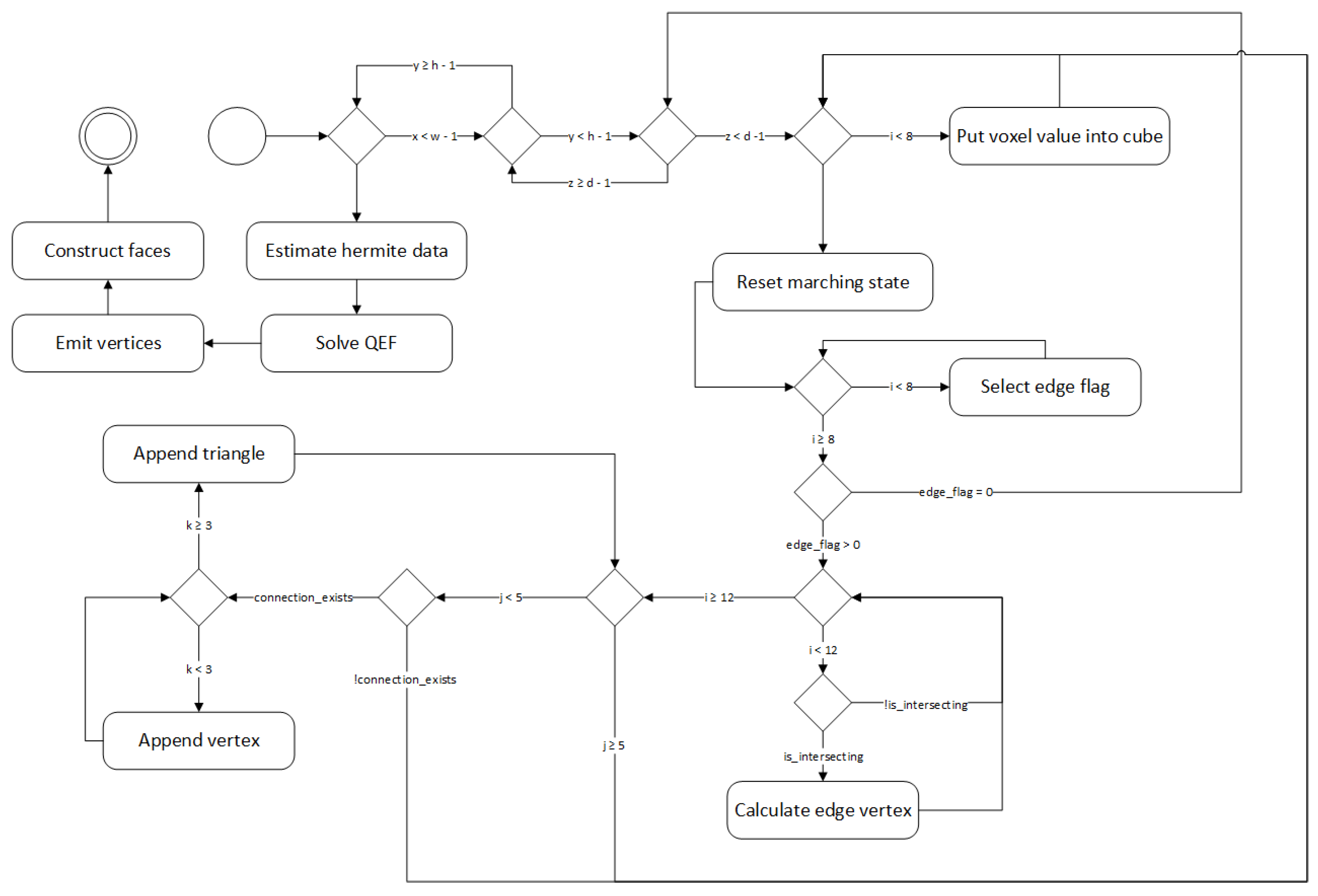
2.2. Reconstruction Algorithm
2.3. Network Training
2.4. Dataset
2.5. Evaluation
3. Results
3.1. Experimental Settings
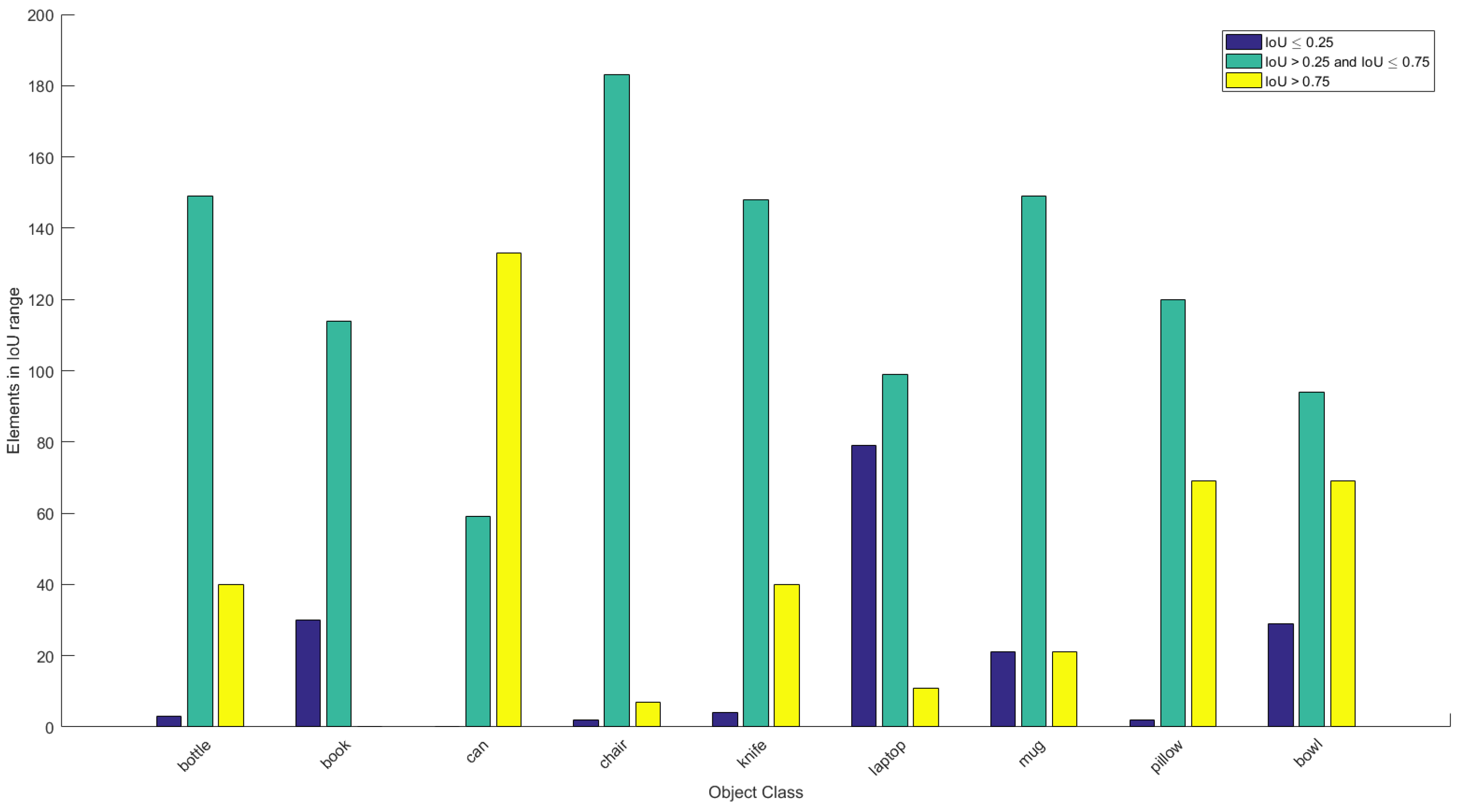
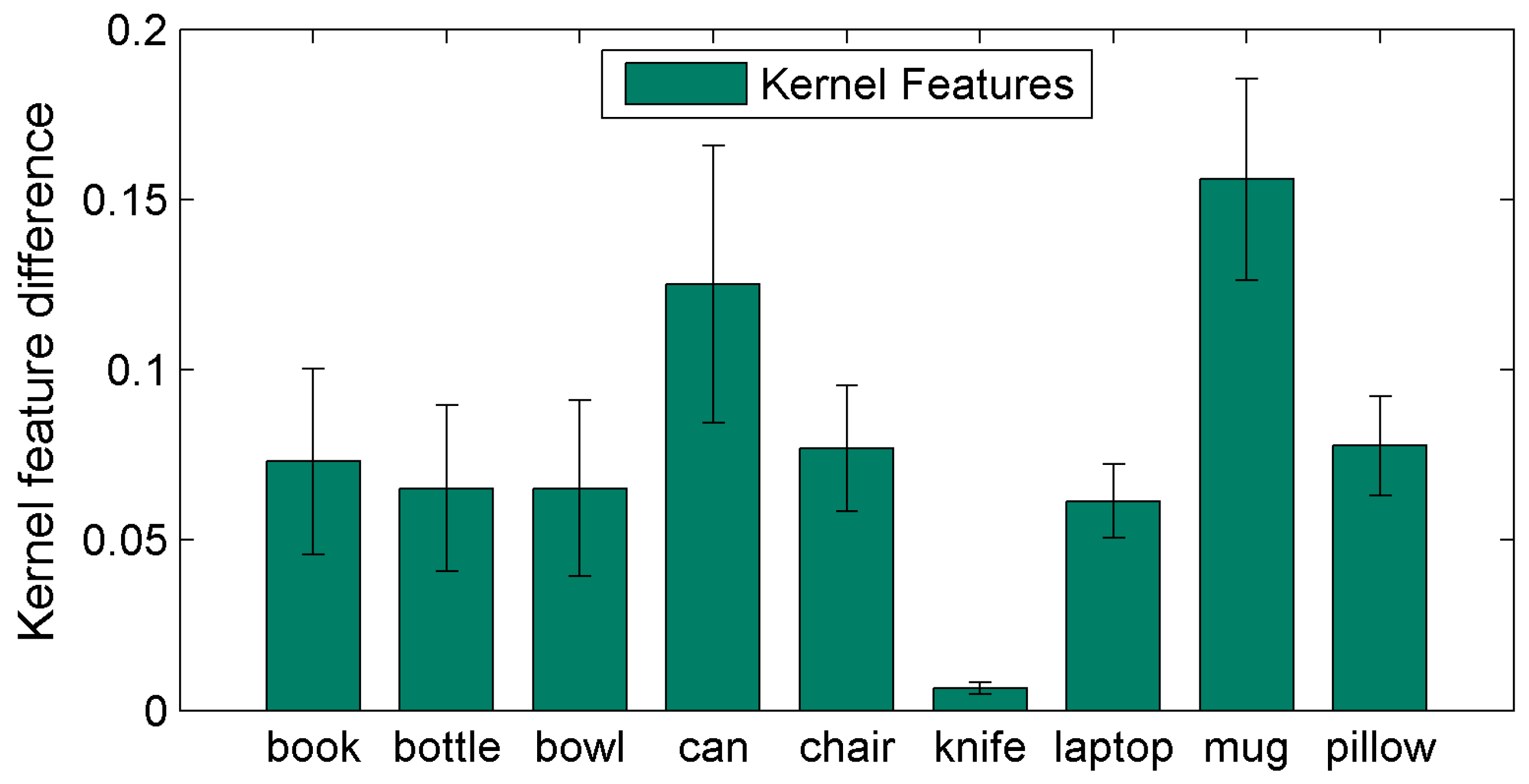
3.2. Quantitative Results
3.3. Visual Comparison of Reconstruction Results
4. Discussion and Concluding Remarks
4.1. Discussion
4.2. Threats to Validity
4.3. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Fanini, B.; Pagano, A.; Ferdani, D. A Novel Immersive VR Game Model for Recontextualization in Virtual Environments: The uVRModel. Multimodal Technol. Interact. 2018, 2, 20. [Google Scholar] [CrossRef]
- Liao, B.; Li, J.; Ju, Z.; Ouyang, G. Hand Gesture Recognition with Generalized Hough Transform and DC-CNN Using Realsense. In Proceedings of the 2018 Eighth International Conference on Information Science and Technology (ICIST), Cordoba, Spain, 30 June–6 July 2018. [Google Scholar] [CrossRef]
- Chen, C.; Yang, B.; Song, S.; Tian, M.; Li, J.; Dai, W.; Fang, L. Calibrate Multiple Consumer RGB-D Cameras for Low-Cost and Efficient 3D Indoor Mapping. Remote Sens. 2018, 10, 328. [Google Scholar] [CrossRef]
- Jusas, V.; Birvinskas, D.; Gahramanov, E. Methods and Tools of Digital Triage in Forensic Context: Survey and Future Directions. Symmetry 2017, 9, 49. [Google Scholar] [CrossRef]
- Haleem, A.; Javaid, M. 3D scanning applications in medical field: A literature-based review. Clin. Epidemiol. Glob. Health 2018. [Google Scholar] [CrossRef]
- Macher, H.; Landes, T.; Grussenmeyer, P. From Point Clouds to Building Information Models: 3D Semi-Automatic Reconstruction of Indoors of Existing Buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Shi, H.; Sun, J.; Zhao, L.; Seah, H.; Quah, C.; Tandianus, B. Multi-Channel Convolutional Neural Network Based 3D Object Detection for Indoor Robot Environmental Perception. Sensors 2019, 19, 893. [Google Scholar] [CrossRef] [PubMed]
- Remondino, F. Heritage Recording and 3D Modeling with Photogrammetry and 3D Scanning. Remote Sens. 2011, 3, 1104–1138. [Google Scholar] [CrossRef]
- Chu, P.M.; Sung, Y.; Cho, K. Generative Adversarial Network-Based Method for Transforming Single RGB Image into 3D Point Cloud. IEEE Access 2019, 7, 1021–1029. [Google Scholar] [CrossRef]
- Wald, J.; Tateno, K.; Sturm, J.; Navab, N.; Tombari, F. Real-Time Fully Incremental Scene Understanding on Mobile Platforms. IEEE Robot. Autom. Lett. 2018, 3, 3402–3409. [Google Scholar] [CrossRef]
- Daudelin, J.; Campbell, M. An Adaptable, Probabilistic, Next-Best View Algorithm for Reconstruction of Unknown 3-D Objects. IEEE Robot. Autom. Lett. 2017, 2, 1540–1547. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ascencio, J.R.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2012, 43, 55–81. [Google Scholar] [CrossRef]
- Zollhöfer, M.; Stotko, P.; Görlitz, A.; Theobalt, C.; Niessner, M.; Klein, R.; Kolb, A. State of the Art on 3D Reconstruction with RGB-D Cameras. Comput. Graph. Forum 2018, 37, 625–652. [Google Scholar] [CrossRef]
- Kutulakos, K.N.; Seitz, S.M. A theory of shape by space carving. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1, pp. 307–314. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2463–2471. [Google Scholar]
- Li, C.; Zia, M.Z.; Tran, Q.; Yu, X.; Hager, G.D.; Chandraker, M. Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 388–397. [Google Scholar] [CrossRef]
- Yang, B.; Rosa, S.; Markham, A.; Trigoni, N.; Wen, H. Dense 3D Object Reconstruction from a Single Depth View. arXiv, 2018; arXiv:1802.00411. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel(R) RealSense(TM) Stereoscopic Depth Cameras. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Tang, L.; Yang, Z.; Jia, K. Canonical Correlation Analysis Regularization: An Effective Deep Multi-View Learning Baseline for RGB-D Object Recognition. IEEE Trans. Cognit. Dev. Syst. 2018, 11, 107–118. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef]
- Tian, G.; Liu, L.; Ri, J.; Liu, Y.; Sun, Y. ObjectFusion: An object detection and segmentation framework with RGB-D SLAM and convolutional neural networks. Neurocomputing 2019. [Google Scholar] [CrossRef]
- Zeng, H.; Yang, B.; Wang, X.; Liu, J.; Fu, D. RGB-D Object Recognition Using Multi-Modal Deep Neural Network and DS Evidence Theory. Sensors 2019, 19, 529. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, F.F.; Souza, A.A.S.; Fernandes, M.A.C.; Gomes, R.B.; Goncalves, L.M.G. Efficient 3D Objects Recognition Using Multifoveated Point Clouds. Sensors 2018, 18, 2302. [Google Scholar] [CrossRef]
- Khoshelham, K.; Elberink, S.O. Accuracy and Resolution of Kinect Depth Data for Indoor Mapping Applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef]
- Carfagni, M.; Furferi, R.; Governi, L.; Servi, M.; Uccheddu, F.; Volpe, Y. On the Performance of the Intel SR300 Depth Camera: Metrological and Critical Characterization. IEEE Sens. J. 2017, 17, 4508–4519. [Google Scholar] [CrossRef]
- Stutz, D.; Geiger, A. Learning 3D Shape Completion Under Weak Supervision. Int. J. Comput. Vis. 2018. [Google Scholar] [CrossRef]
- Wiles, O.; Zisserman, A. Learning to Predict 3D Surfaces of Sculptures from Single and Multiple Views. Int. J. Comput. Vis. 2018. [Google Scholar] [CrossRef]
- Cao, Y.; Shen, C.; Shen, H.T. Exploiting Depth From Single Monocular Images for Object Detection and Semantic Segmentation. IEEE Trans. Image Process. 2017, 26, 836–846. [Google Scholar] [CrossRef] [PubMed]
- Hisatomi, K.; Kano, M.; Ikeya, K.; Katayama, M.; Mishina, T.; Iwadate, Y.; Aizawa, K. Depth Estimation Using an Infrared Dot Projector and an Infrared Color Stereo Camera. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2086–2097. [Google Scholar] [CrossRef]
- Du, Y.; Fu, Y.; Wang, L. Representation Learning of Temporal Dynamics for Skeleton-Based Action Recognition. IEEE Trans. Image Process. 2016, 25, 3010–3022. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2015; arXiv:1412.6980. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Bartsch, M.; Weiland, T.; Witting, M. Generation of 3D isosurfaces by means of the marching cube algorithm. IEEE Trans. Magn. 1996, 32, 1469–1472. [Google Scholar] [CrossRef]
- Ju, T.; Losasso, F.; Schaefer, S.; Warren, J. Dual Contouring of Hermite Data. ACM Trans. Graph. 2002, 21, 339–346. [Google Scholar] [CrossRef]
- Kainz, F.; Bogart, R.R.; Hess, D.K. The OpenEXR Image File Format. In GPU Gems: Programming Techniques, Tips and Tricks for Real-Time Graphics; Addison-Wesley Professional: Boston, MA, USA, 2004. [Google Scholar]
- Pantaleoni, J. VoxelPipe: A programmable pipeline for 3D voxelization. In Proceedings of the ACM SIGGRAPH Symposium on High Performance Graphics (HPG ’11), Vancouver, BC, Canada, 5–7 August 2011; pp. 99–106. [Google Scholar] [CrossRef]
- Baldwin, D.; Weber, M. Fast Ray-Triangle Intersections by Coordinate Transformation. J. Comput. Graph. Techol. 2016, 5, 39–49. [Google Scholar]
- Chang, A.X.; Funkhouser, T.A.; Guibas, L.J.; Hanrahan, P.; Huang, Q.X.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv, 2015; arXiv:1512.03012. [Google Scholar]
- Marin-Jimenez, M.J.; Zisserman, A.; Eichner, M.; Ferrari, V. Detecting People Looking at Each Other in Videos. Int. J. Comput. Vis. 2013, 106, 282–296. [Google Scholar] [CrossRef]
- Rutzinger, M.; Rottensteiner, F.; Pfeifer, N. A Comparison of Evaluation Techniques for Building Extraction From Airborne Laser Scanning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 11–20. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, X.; Zurada, J.M. A Novel Pruning Algorithm for Smoothing Feedforward Neural Networks Based on Group Lasso Method. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2012–2024. [Google Scholar] [CrossRef]
- Huang, G.B.; Saratchandran, P.; Sundararajan, N. A generalized growing and pruning RBF (GGAP-RBF) neural network for function approximation. IEEE Trans. Neural Netw. 2005, 16, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Arifovic, J.; Gençay, R. Using genetic algorithms to select architecture of a feedforward artificial neural network. Phys. A Stat. Mech. Its Appl. 2001, 289, 574–594. [Google Scholar] [CrossRef]
- Połap, D.; Kęsik, K.; Woźniak, M.; Damaševičius, R. Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space. Appl. Sci. 2018, 8, 293. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinectfusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology UIST, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Guo, Q.; Yi, Z. Recurrent Neural Networks With Auxiliary Memory Units. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1652–1661. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, J.; Boden, M. The applicability of recurrent neural networks for biological sequence analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2005, 2, 243–253. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, C.; Wu, X.; Chen, W. An Effective 3D Shape Descriptor for Object Recognition with RGB-D Sensors. Sensors 2017, 17, 451. [Google Scholar] [CrossRef] [PubMed]
- Hsu, G.J.; Liu, Y.; Peng, H.; Wu, P. RGB-D-Based Face Reconstruction and Recognition. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2110–2118. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Classification Correctness | Number of Unique Testing Set Objects per Class | Number of Unique Testing Set Objects per Class |
|---|---|---|---|
| Bottle | 0.850 | 399 | 99 |
| Book | 0.754 | 68 | 17 |
| Can | 0.844 | 87 | 21 |
| Chair | 0.777 | 2289 | 572 |
| Knife | 0.898 | 340 | 85 |
| Laptop | 0.772 | 460 | 115 |
| Mug | 0.949 | 172 | 42 |
| Pillow | 0.863 | 77 | 20 |
| Bowl | 0.843 | 149 | 36 |
| Mean | 0.839 | 449 | 112 |
| Object | Percentage of Good and Excellent Reconstructions | |||
|---|---|---|---|---|
| Bottle | 0.220 | 0.578 | 0.980 | 98.438 |
| Book | 0.104 | 0.389 | 0.707 | 79.167 |
| Can | 0.524 | 0.798 | 0.996 | 100 |
| Chair | 0.239 | 0.440 | 0.986 | 98.958 |
| Knife | 0.201 | 0.608 | 0.944 | 97.917 |
| Laptop | 0.044 | 0.333 | 0.984 | 58.201 |
| Mug | 0.149 | 0.446 | 0.952 | 89.005 |
| Pillow | 0.229 | 0.681 | 0.995 | 98.953 |
| Bowl | 0.106 | 0.617 | 0.995 | 84.896 |
| Mean | 0.202 | 0.543 | 0.949 | 89.504 |
| RGB | Depth | Normalized Depth | Voxel Cloud | Mesh | Training Data |
|---|---|---|---|---|---|
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
| RGB | Infrared | Depth | Normalized Depth | Voxel Cloud | Mesh |
|---|---|---|---|---|---|
 |  |  |  |  |  |
 |  |  |  |  |  |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Misra, S. Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset. Sensors 2019, 19, 1553. https://doi.org/10.3390/s19071553
Kulikajevas A, Maskeliūnas R, Damaševičius R, Misra S. Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset. Sensors. 2019; 19(7):1553. https://doi.org/10.3390/s19071553
Chicago/Turabian StyleKulikajevas, Audrius, Rytis Maskeliūnas, Robertas Damaševičius, and Sanjay Misra. 2019. "Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset" Sensors 19, no. 7: 1553. https://doi.org/10.3390/s19071553
APA StyleKulikajevas, A., Maskeliūnas, R., Damaševičius, R., & Misra, S. (2019). Reconstruction of 3D Object Shape Using Hybrid Modular Neural Network Architecture Trained on 3D Models from ShapeNetCore Dataset. Sensors, 19(7), 1553. https://doi.org/10.3390/s19071553