Contextual Action Cues from Camera Sensor for Multi-Stream Action Recognition


Abstract
1. Introduction
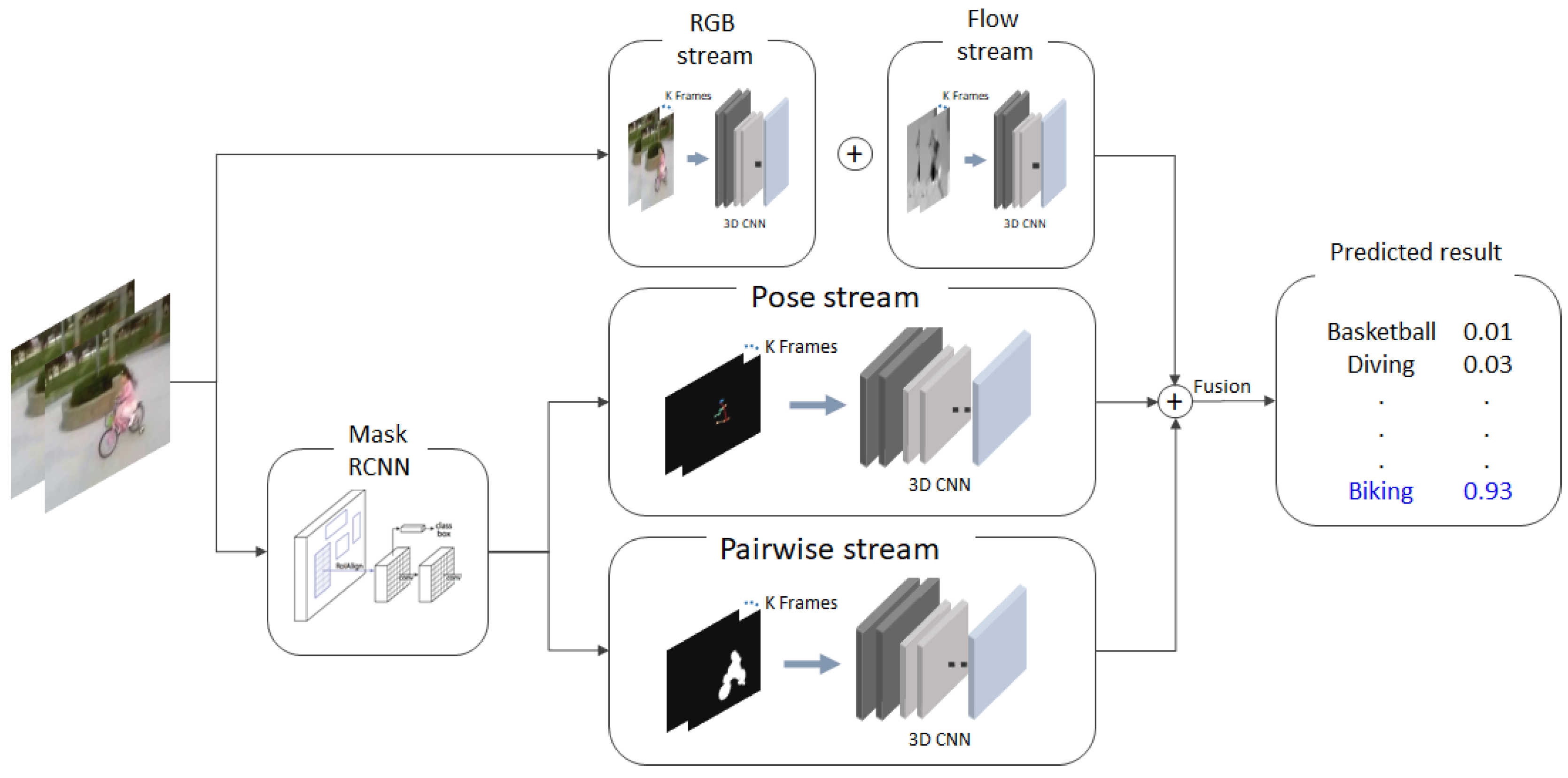
- In addition to the two streams (RGB and optical flow), we propose to use additional pose and pairwise streams to improve the performance of action recognition.
- Our proposed pairwise stream does not require related object and interaction annotations. To construct a pairwise stream, object detection and interaction recognition are required. Datasets for existing human-object interaction (HOI) studies should be trained using a fully-annotated dataset with the related object location and interaction label. Furthermore, the candidates of the interaction between object and human are all pre-defined. However, in our work, we modeled a pairwise stream in action recognition datasets, for which such annotations are not available.
- Instead of using the bounding box-based approach, we suggest using a mask-based pairwise stream. We show that the mask-based pairwise stream further improves the performance.
- We propose the pose stream, which can deliver explicit and robust information for classifying the action category.
2. Related Work
2.1. Action Recognition
2.2. Action Recognition Using Human Pose
2.3. Human-Object-Interaction
3. Proposed Method
3.1. RGB/Flow Stream
3.2. Pairwise Stream
3.3. Pose Stream
3.4. Multi-Stream Fusion
4. Experiments’ Settings
4.1. Datasets
4.2. Networks
5. Results and Analysis
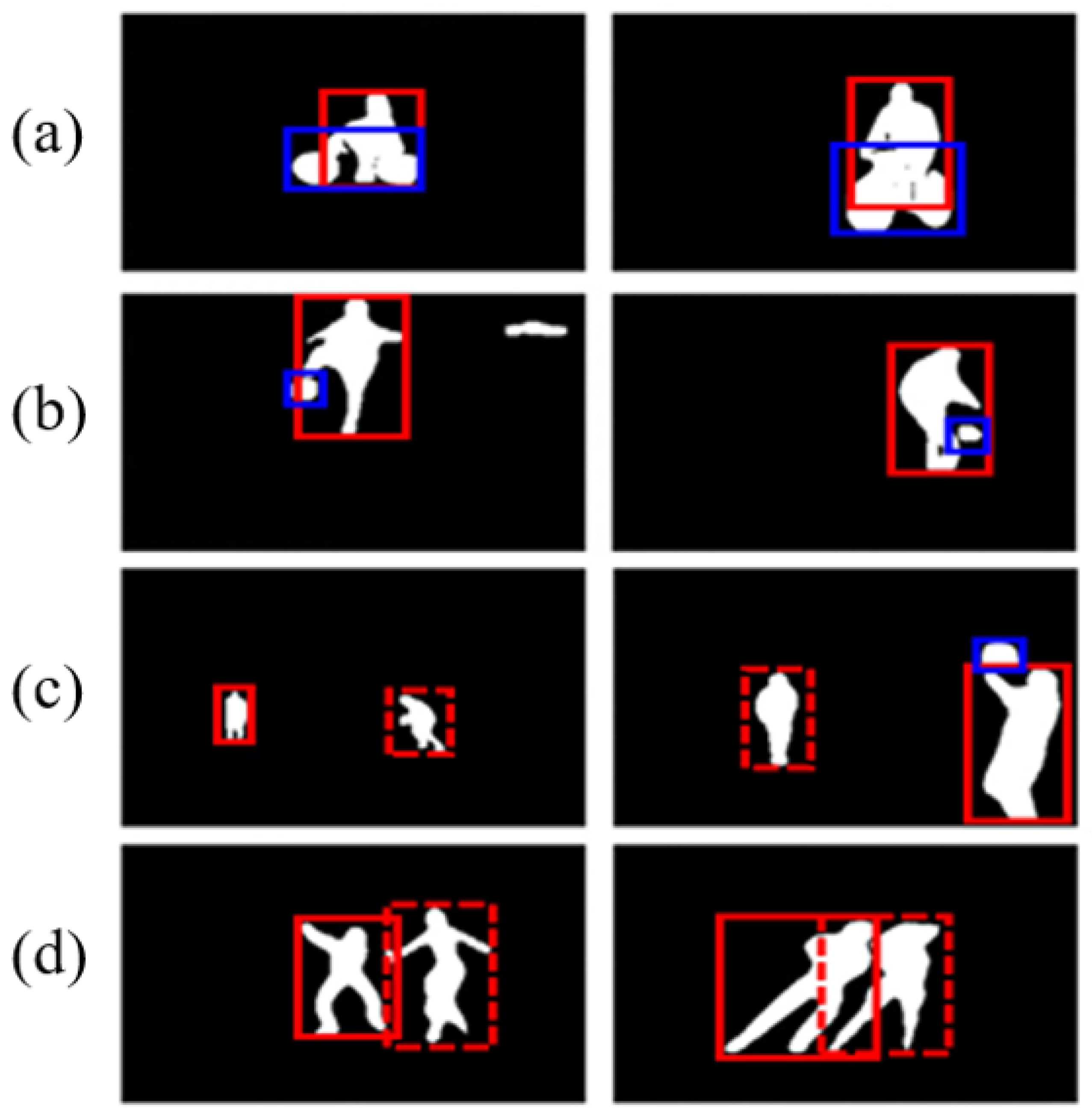
5.1. Mask vs. Bounding Box
5.2. Results
5.3. Comparison with Existing Methods
5.4. System Limitations
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Roudposhti, K.K.; Nunes, U.; Dias, J. Probabilistic Social Behavior Analysis by Exploring Body Motion-Based Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1679–1691. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Shi, J.; Wang, W.; Jia, J. Fast Abnormal Event Detection. Int. J. Comput. Vis. 2018. [Google Scholar] [CrossRef]
- Li, X.; Ye, M.; Liu, Y.; Zhang, F.; Liu, D.; Tang, S. Accurate object detection using memory-based models in surveillance scenes. Pattern Recognit. 2017, 67, 73–84. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the Advances in Neural Information Processing Systems 27, Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Peng, X.; Schmid, C. Multi-region Two-Stream R-CNN for Action Detection. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 744–759. [Google Scholar] [CrossRef]
- Nie, B.X.; Xiong, C.; Zhu, S. Joint action recognition and pose estimation from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1293–1301. [Google Scholar] [CrossRef]
- Du, W.; Wang, Y.; Qiao, Y. RPAN: An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 3745–3754. [Google Scholar] [CrossRef]
- Chao, Y.; Liu, Y.; Liu, X.; Zeng, H.; Deng, J. Learning to Detect Human-Object Interactions. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 381–389. [Google Scholar] [CrossRef]
- Sun, J.; Wu, X.; Yan, S.; Cheong, L.F.; Chua, T.; Li, J. Hierarchical spatio-temporal context modeling for action recognition. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 2004–2011. [Google Scholar] [CrossRef]
- Torralba, A.; Murphy, K.P.; Freeman, W.T.; Rubin, M.A. Context-based vision system for place and object recognition. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV 2003), Nice, France, 14–17 October 2003; pp. 273–280. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV 2003), Nice, France, 14–17 October 2003; pp. 1470–1477. [Google Scholar] [CrossRef]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C. Action recognition by dense trajectories. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Zach, C.; Pock, T.; Bischof, H. A Duality Based Approach for Realtime TV-L1 Optical Flow. In Proceedings of the 29th DAGM Symposium on Pattern Recognition, Heidelberg, Germany, 12–14 September 2007; pp. 214–223. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Ng, J.Y.; Hausknecht, M.J.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar] [CrossRef]
- Gammulle, H.; Denman, S.; Sridharan, S.; Fookes, C. Two Stream LSTM: A Deep Fusion Framework for Human Action Recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV 2017), Santa Rosa, CA, USA, 24–31 March 2017; pp. 177–186. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar] [CrossRef]
- Chao, Y.; Wang, Z.; He, Y.; Wang, J.; Deng, J. HICO: A Benchmark for Recognizing Human-Object Interactions in Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; pp. 1017–1025. [Google Scholar] [CrossRef]
- Gkioxari, G.; Girshick, R.B.; Dollár, P.; He, K. Detecting and Recognizing Human-Object Interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8359–8367. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.A.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2011), Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv, 2017; arXiv:1705.06950. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Multiplier Networks for Video Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy (%) | Bounding Box | Mask |
|---|---|---|
| Pairwise stream | 49.80 | 76.02 |
| Fusion | 97.83 | 98.02 |
| Method | UCF-101 | HMDB-51 |
|---|---|---|
| C3D-RGB—(our implementation) | 84.17 | - |
| C3D-Pose | 80.35 | - |
| C3D-Pairwise | 79.87 | - |
| C3D-(RGB and Pairwise and Pose) | 91.04 | - |
| I3D-RGB | 94.69 | 74.84 |
| I3D-Flow | 94.14 | 77.52 |
| I3D-Pose | 69.15 | 51.57 |
| I3D-Pairwise | 76.02 | 51.83 |
| I3D-(RGB and Flow)—(our implementation) | 97.33 | 80.07 |
| I3D-(RGB and Flow and Pairwise) | 97.46 | 80.33 |
| I3D-(RGB and Flow and Pose) | 97.89 | 80.85 |
| I3D-(RGB and Flow and Pairwise and Pose) | 98.02 | 80.92 |
| Class | Baseline | Proposed (Improved) |
|---|---|---|
| HandstandPushups | 82.14 | 98.43 (+14.29) |
| HandstandWalking | 82.35 | 91.18 (+8.82) |
| CricketShot | 89.80 | 95.92 (+6.12) |
| FrontCrawl | 91.89 | 97.30 (+5.41) |
| Punch | 89.74 | 94.87 (+5.13) |
| Shotput | 93.48 | 97.83 (+4.35) |
| BoxingPunchingBag | 73.47 | 77.55 (+4.08) |
| PullUps | 96.43 | 100.00 (+3.57) |
| BodyWeightSquats | 96.67 | 100.00 (+3.33) |
| HammerThrow | 82.83 | 85.86 (+3.03) |
| FloorGymnastics | 91.67 | 94.44 (+2.78) |
| WalkingWithDog | 94.44 | 97.22 (+2.78) |
| Archery | 95.12 | 97.56 (+2.44) |
| SoccerPenalty | 97.56 | 97.22 (+2.78) |
| BaseballPitch | 90.70 | 93.02 (+2.33) |
| PlayingCello | 97.73 | 100.00 (+2.27) |
| Model | UCF-101 | HMDB-51 |
|---|---|---|
| LSTM (as reported in [13]) | 86.8 | 49.7 |
| 3D-ConvNet (as reported in [13]) | 79.9 | 49.4 |
| Convolutional Two-Stream Network [33] | 90.4 | 58.63 |
| 3D-Fused (as reported in [13]) | 91.5 | 66.5 |
| Temporal Segment Networks [18] | 93.5 | - |
| Spatiotemporal Multiplier Networks [34] | 94.0 | 69.02 |
| Two-Stream I3D [13] | 97.6 | 81.3 |
| Multi-stream I3D (Proposed) | 98.02 | 80.92 |
| LSTM | 91.0 | 53.4 |
| Two-Stream | 94.2 | 66.6 |
| 3D-Fused | 94.2 | 71.0 |
| Two-Stream I3D | 98.0 | 81.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.; Cho, B.; Hong, Y.W.; Byun, H. Contextual Action Cues from Camera Sensor for Multi-Stream Action Recognition. Sensors 2019, 19, 1382. https://doi.org/10.3390/s19061382
Hong J, Cho B, Hong YW, Byun H. Contextual Action Cues from Camera Sensor for Multi-Stream Action Recognition. Sensors. 2019; 19(6):1382. https://doi.org/10.3390/s19061382
Chicago/Turabian StyleHong, Jongkwang, Bora Cho, Yong Won Hong, and Hyeran Byun. 2019. "Contextual Action Cues from Camera Sensor for Multi-Stream Action Recognition" Sensors 19, no. 6: 1382. https://doi.org/10.3390/s19061382
APA StyleHong, J., Cho, B., Hong, Y. W., & Byun, H. (2019). Contextual Action Cues from Camera Sensor for Multi-Stream Action Recognition. Sensors, 19(6), 1382. https://doi.org/10.3390/s19061382