In this section, the multi-objective optimization problem, PSO algorithm, and GT are briefly introduced. Then, the multi evaluation criterion function of the proposed method is provided. Finally, the implementation steps of the proposed method are described in detail.
2.1. An Overview of Multi-Objective Optimization Problems
In reality, many research and engineering problems should simultaneously optimize multiple targets. However, many targets have mutual constraints. In the optimization of one target, other targets become affected and worsen because optimizing multiple targets is difficult. The solution of multi-objective optimization problems is often standard, but a compromise solution set, which is called a Pareto-optimal set or nondominated set, exists. The general representation of the multi-objective optimization problem is as follows:
A multi-objective optimization problem is assumed to be a maximization problem, which is composed of
N decision variables,
m objective functions, and
K constraints:
where
x is the decision vector,
y is the target vector,
X is the decision space,
Y is the target space, and the constraint condition,
e(
x), is the range of the decision volume.
In the early stage, the multi-objective optimization problem is usually converted into a single objective optimization problem through the weighting method and solved through mathematical programming. However, objective and constraint functions may be nonlinear and discontinuous, and mathematical programming cannot achieve ideal results. The intelligent search algorithm has self-organizing, self-adaptive, and self-learning characteristics and is non-restricted by the nature of the problem. The intelligent search algorithm can be used to solve the multi-objective optimization problem, which is high dimensional, dynamic, and complex. In 1967, Rosenberg proposed to use the intelligent search algorithm to solve multi-objective optimization problems, but it was not implemented. After the birth of the genetic algorithm (GA), Schaffer proposed a vector evaluation GA, which was the first time that the intelligent search algorithm was combined with the multi-objective optimization problem. The intelligent search algorithm has been developed into the mainstream algorithm for multi-objective optimization problem solving. Moreover, a number of classical algorithms have been designed.
2.2. PSO Algorithm
PSO shows a simple concept, provides easy programming, and requires few parameter adjustments. Some scholars confirmed that the multi-objective PSO algorithm has obvious advantages in three aspects, namely, speed, convergence, and distribution [
21,
22].
A group with n particles is randomly initialized, assuming that the population is in a D-dimension search space. When particles fly at a certain speed in space, the position state property of particle i is set as follows: Vector: . The fitness values corresponding to each particle position can be calculated based on the objective function. The speed vector of particle i is , and the individual optimal position vector is . At the same time, another important attribute of the population is the group extremum. The group extremum position vector is .
Each particle updates its speed and position through the following iteration formula:
where
is the inertia weight;
;
;
is the number of current iterations;
is the speed of the particle;
and
are nonnegative constants, also called acceleration factors; and
and
are random numbers in the (0,1) interval. Particles are usually restricted to a certain range, where
and
are the lower and upper limits of the search space, respectively, and
and
are the minimum and maximum velocities, respectively. In general, these velocities are defined as
, where
.
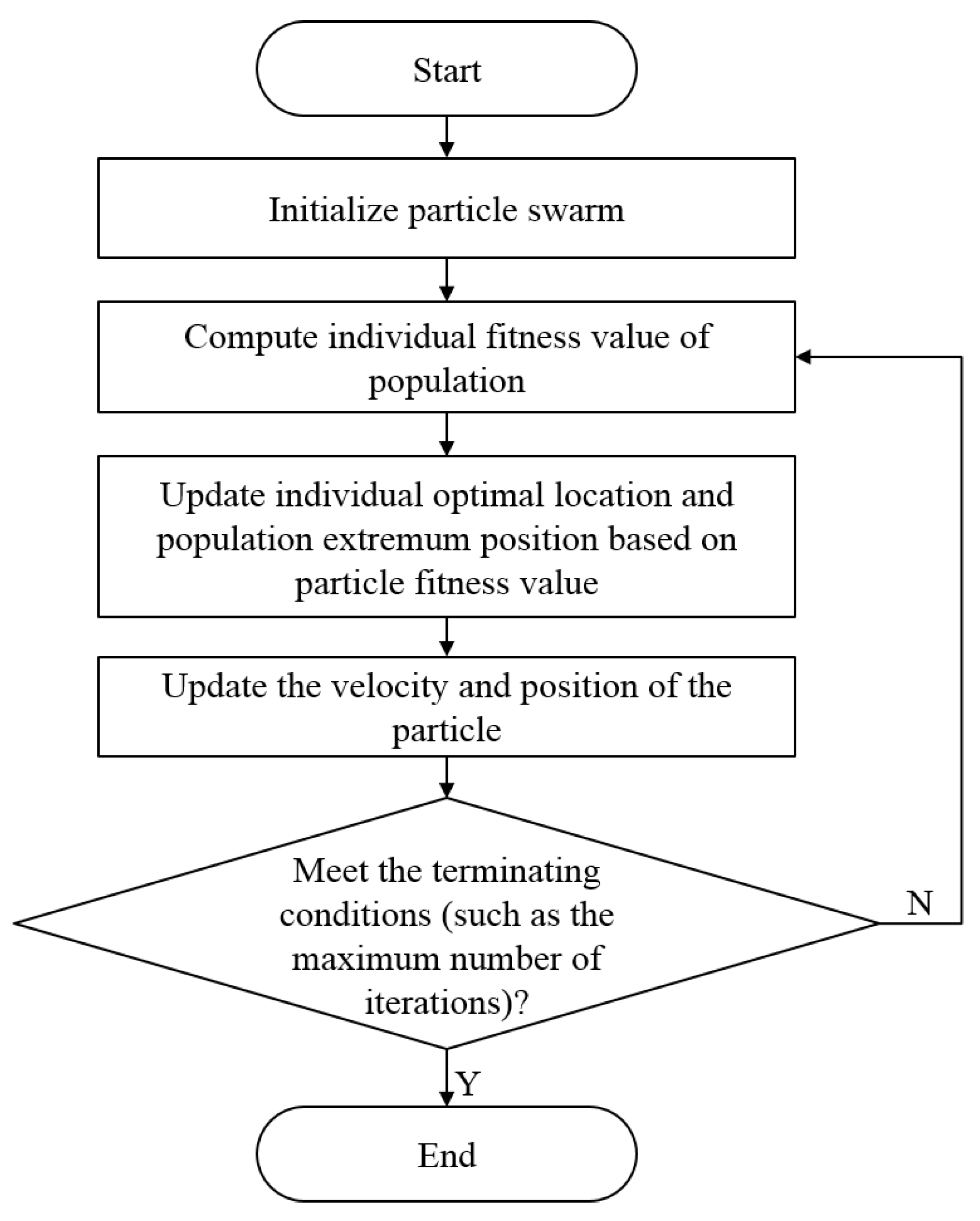
The PSO algorithm has formed specific theoretical and experimental systems, which have been verified by many scientists. Thus, the PSO algorithm has a flowchart and steps. With in-depth research, its specific flowchart has been widely recognized and investigated. The specific steps of the process of the standard PSO algorithm [
23] are as follows:
Initialize the particle population, and customize the initial speed and position of the particles.
- (1)
According to the fitness function, determine the fitness function value of each particle initialized.
- (2)
Compare the fitness value of each particle in the old position with that in the new position to determine the best position of the particle with high fitness. If the value of the particle in the new position is better, then the optimal position, , of the particle, i, is replaced by the new location. If the fitness value of the new position is not as good as the fitness value of the original position, then retain as the optimal position.
- (3)
Compare the fitness value of each particle with that of other particles to determine the best position of particles with high fitness. If the new position is good, that is, the fitness value of the new particle is optimal, then the position of the new particle becomes . If the fitness value of the particle in the original global optimal position, , is better, then remains as the global optimal position.
- (4)
According to Formulas (1) and (2), update the speed and position of each particle.
- (5)
If the termination condition is not satisfied, then return to Step 2. Otherwise, terminate this algorithm.
The flowchart of the specific standard PSO algorithm is shown in
Figure 1.
2.5. Dimension Reduction Steps
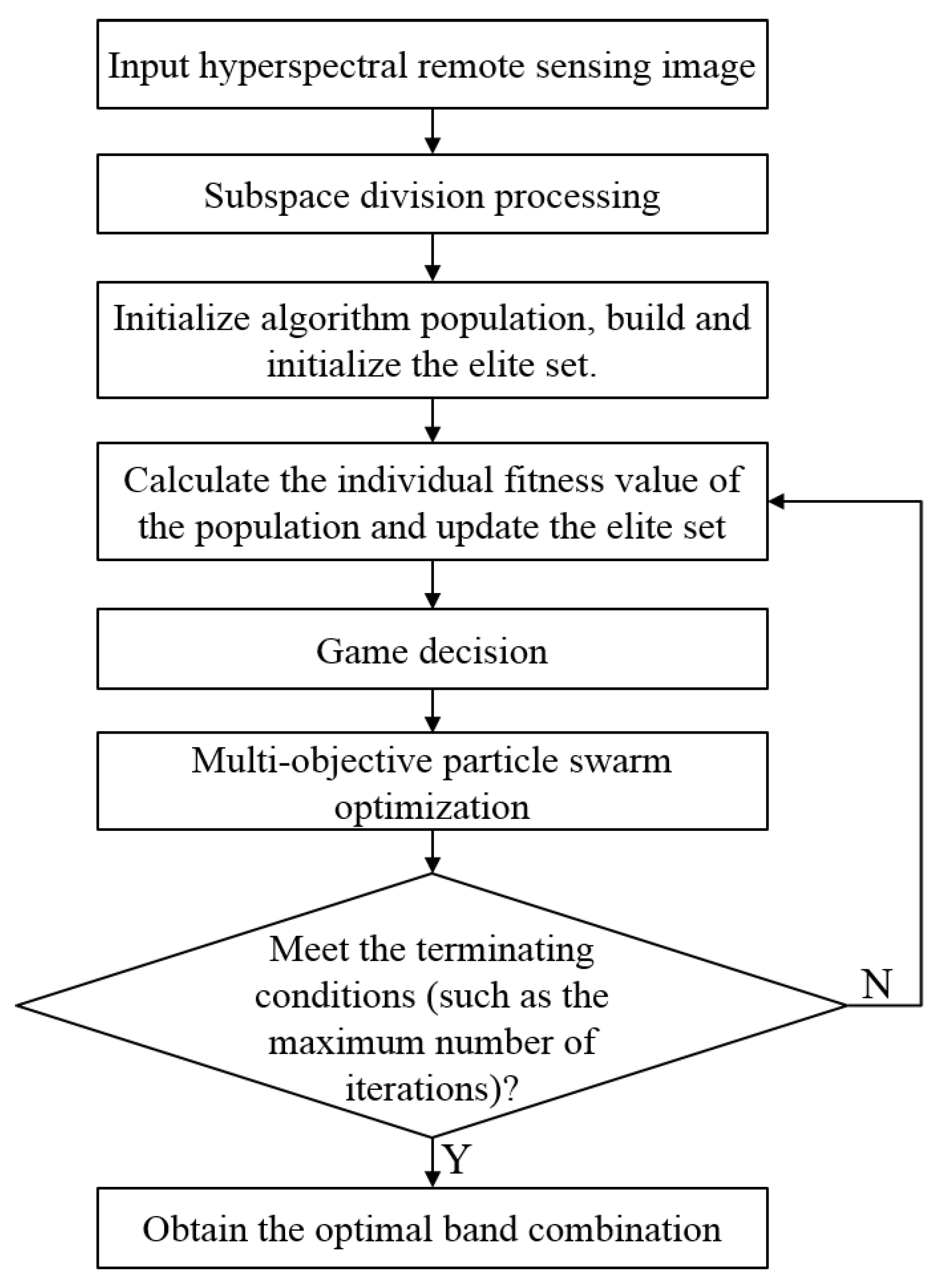
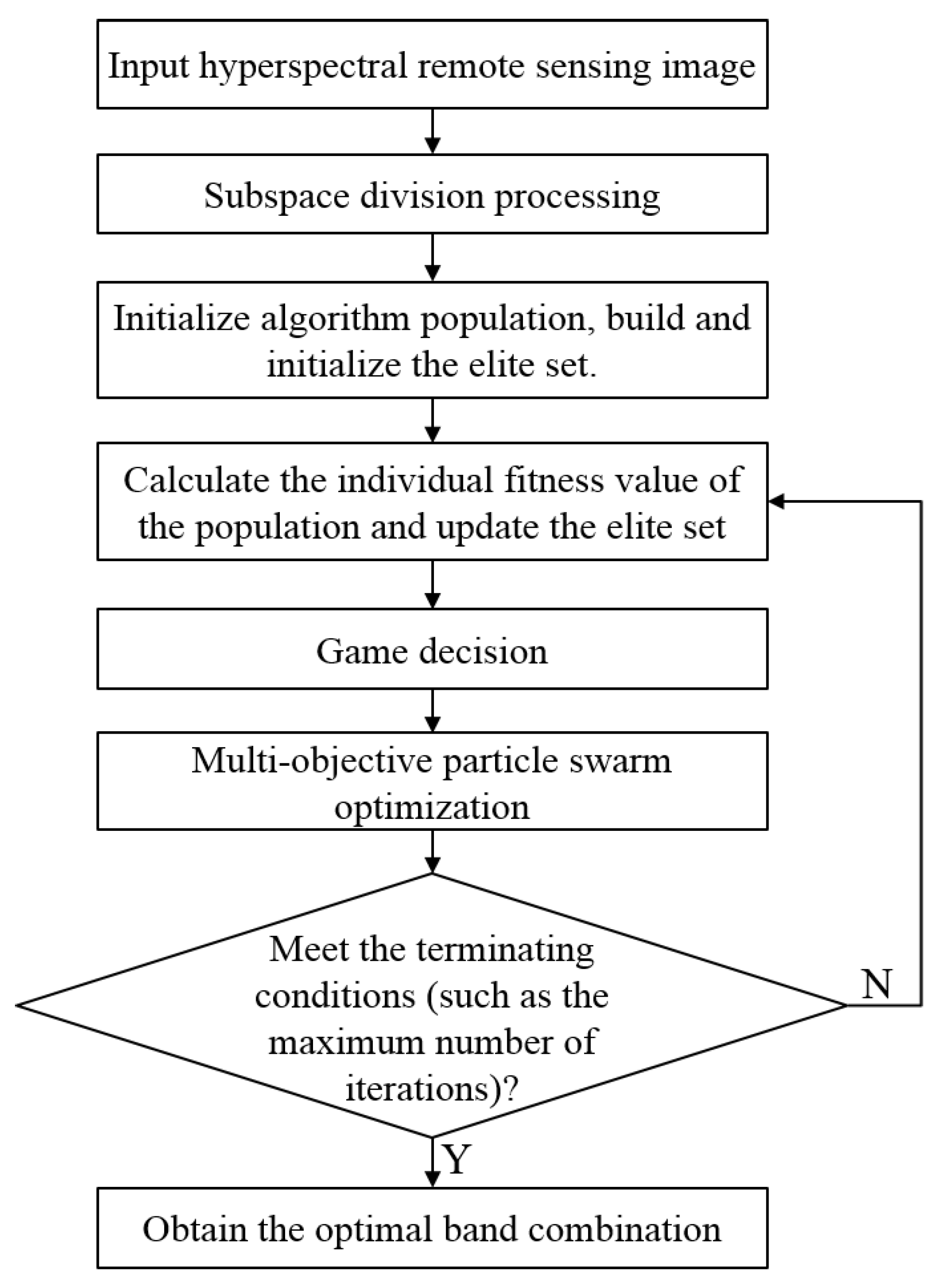
From the perspective of combining multiple evaluation criteria, this work considers dimension reduction as a multi-objective optimization problem because conflicts exist in the optimization process of multiple targets and optimizing multiple targets at the same time is difficult. GT is introduced to coordinate the relationship between multiple targets to make the goals as optimal as possible. The specific algorithm steps are as follows:
(1) Subspace Division
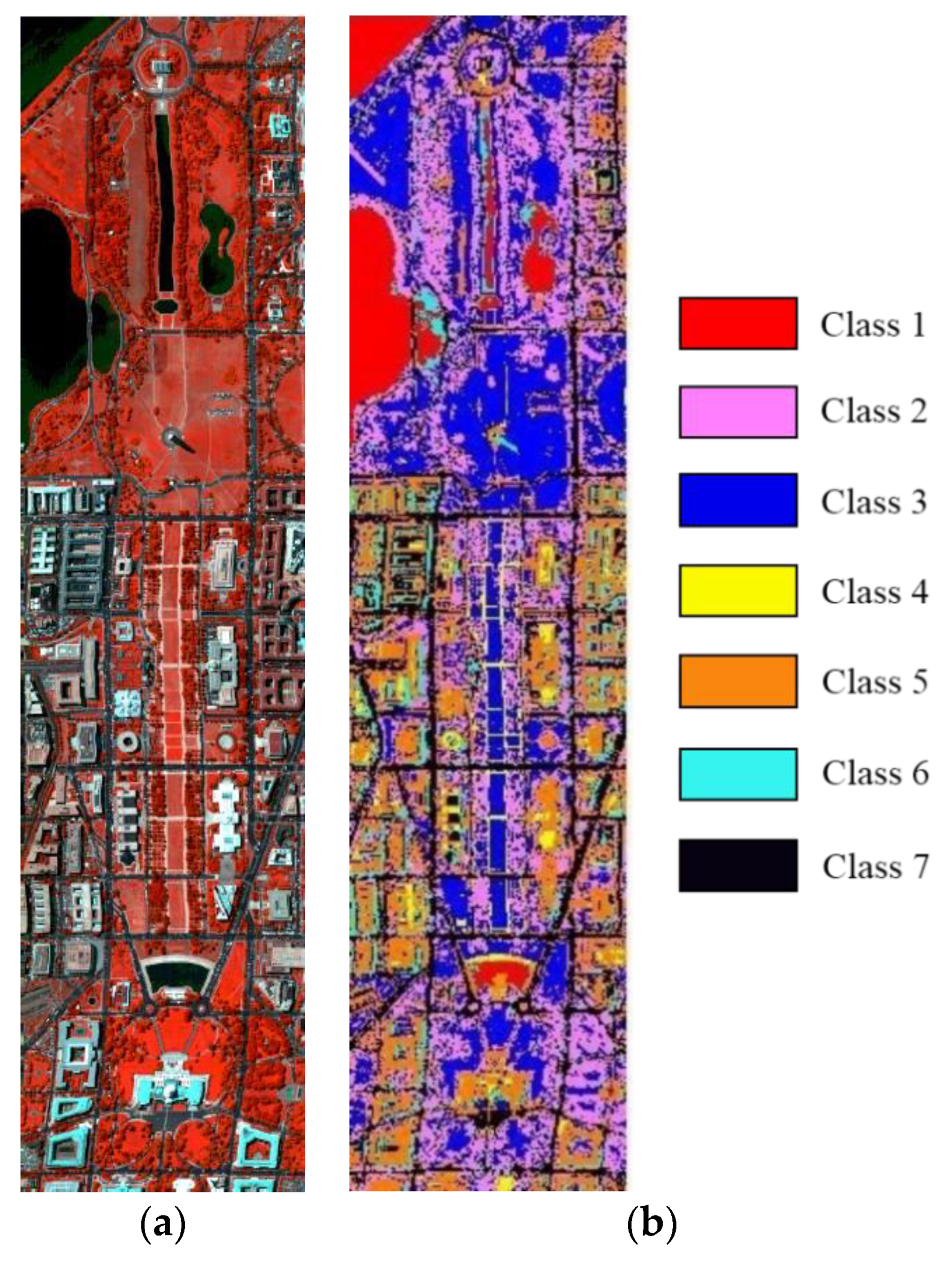
Some of the most important characteristics of hyperspectral image data are the large number of spectral bands and the high correlation and redundancy between adjacent bands. If the selection bands from all bands are bound to lose some of the key local characteristics, then the selected band combination may not help in improving the classification accuracy. The basic idea of solving these problems is to divide all bands into several subspaces and conduct band selection. Many subspace partitioning methods have been commonly used. This work adopts the adaptive subspace decomposition (ASD) method based on correlation filtering. This method was proposed by Zhang Junping et al. [
28]. The method calculates the correlation coefficient,
, between two bands, where
i and
j denote the
i and
j bands, respectively. The range of
is
. The greater the absolute value of the correlation coefficient is, the stronger the correlation between bands. The closer the value is to 0, the weaker the correlation. The definition of
is expressed as follows:
where
and
are the mean values of
and
, respectively, and
represents the mathematical expectation for the functions in brackets. According to the correlation coefficient matrix,
, obtained using Formula (5), the corresponding threshold,
T, is set, and the continuous wave band satisfying
is combined into a new subspace. By adjusting
T, the number of bands and the number of subspaces in each subspace can be adaptively changed. With the increase in
T, the number of bands in each space decreases and the number of subspaces increases. The correlation between the spectral bands of hyperspectral images has a partitioned feature, and the correlation coefficient matrix,
R, can quantitatively reflect this block feature, thus dividing the strong continuous band in a subspace according to the feature of the block. Then, bands are selected in each subspace to form a band combination to reduce the correlation between bands.
(2) Initialization of Particle Swarm
Each particle consists of a hyperspectral image band combination, inertia weight, , and acceleration factor, C. In the initial population, the three parts of the particles mentioned previously are randomly generated, and the initial velocity and location of the particles are defined. The initial population size is reasonably set according to the complexity of the calculation to ensure that the initial population contains more possible solutions. The total number of individuals in the population is assumed to be m, and N subspace is divided under the subspace division method in Step (1). Then, the M bands are randomly selected in each subspace, and the band combination of N × M bands is used as the individual in the population. In this manner, m individuals can be initialized randomly under the constraint of subspace partition.
(3) Establishing an Elite Solution Set
The fitness values of the particles in the population are compared, the eligible particles are detected, and the qualified particles are placed in the non-inferior solution set. In solving multi-objective optimization problems, the most important thing is to solve non-inferior solutions and non-inferior solution sets. The so-called non-inferiority solution is the existence of a problem solution in the feasible domain of the multi-objective optimization problem, so that other feasible solutions are not inferior to the solution. Then, the solution is called a non-inferior solution, and the set of all non-inferior solutions is a non-inferior solution set. In the process of reducing the dimension, the band combination with large information entropy and a large B distance between the selected classes, a and b, at the same time is a non-inferior solution and is placed in the non-inferior solution set. The solution in a non-inferior solution set is the optimal location of the individual history. In the zeroth generation, a global optimum is selected from the individual historical optimal location.
An elite solution set is set up. The elite solution set is initialized as empty sets, and at the beginning of the algorithm, a solution extracted from the zeroth generation is stored in the elite solution set. The non-inferiority hierarchy of the new species group is calculated by the non-dominated solution sorting method presented in the literature [
29]. The band combination that is non-inferior and a high level is the elite solution band combination and is added to the elite solution concentration. The elite solution set is used to preserve the band combination of these elite solutions. Then, in the process of algorithm iteration, the band combination of these elite solutions is added to the algorithm population to participate in an iterative search. The competition of the elite band combination and the algorithm population in the subsequent iteration to produce the next-generation population and maintain the excellent population is advantageous.
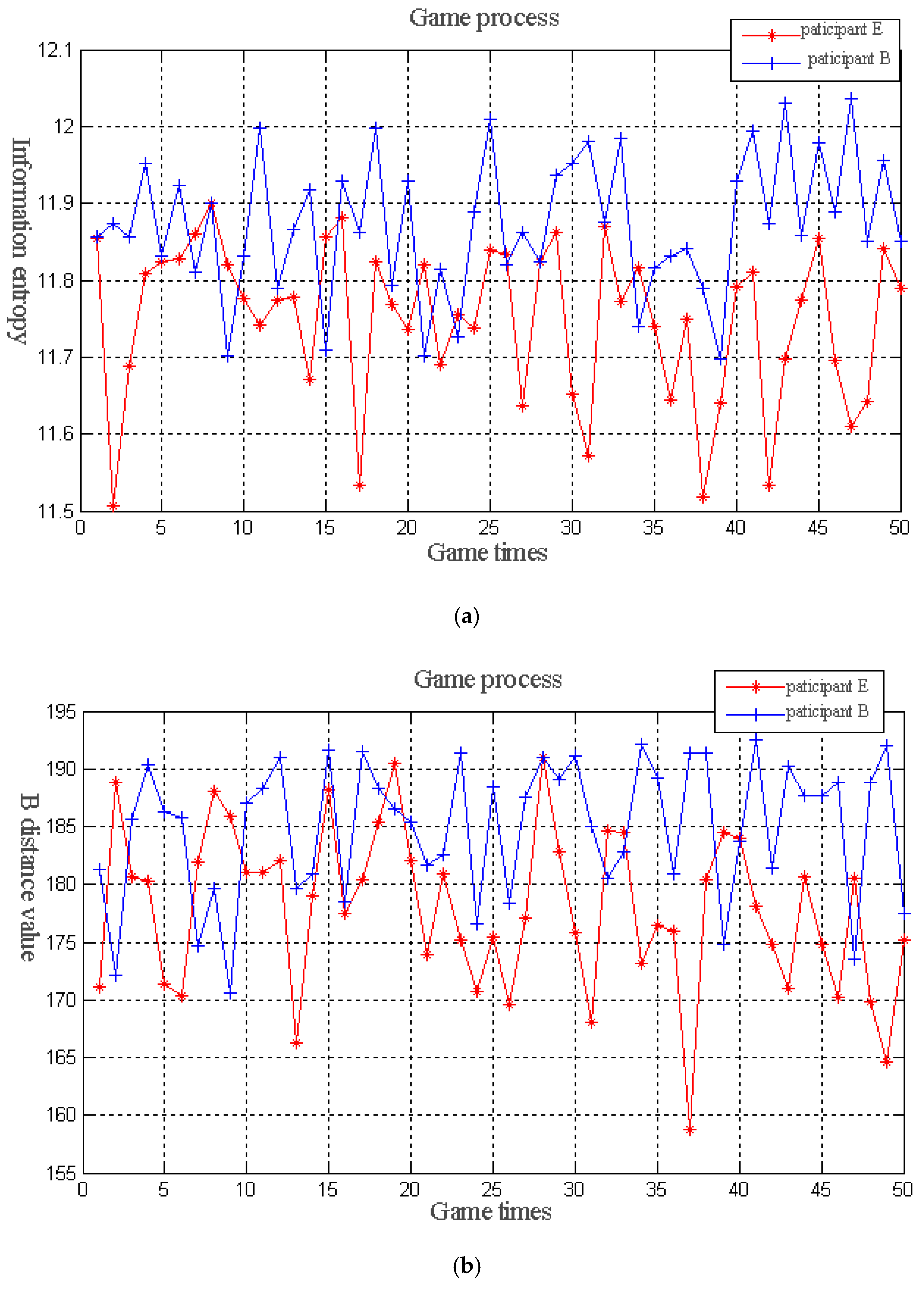
(4) Game Decision Making
In the literature [
30], a clonal selection algorithm is proposed to solve preference multi-objective optimization. Inspired by this algorithm, this work constructs a finite repeated game model based on goal preference. The information entropy and
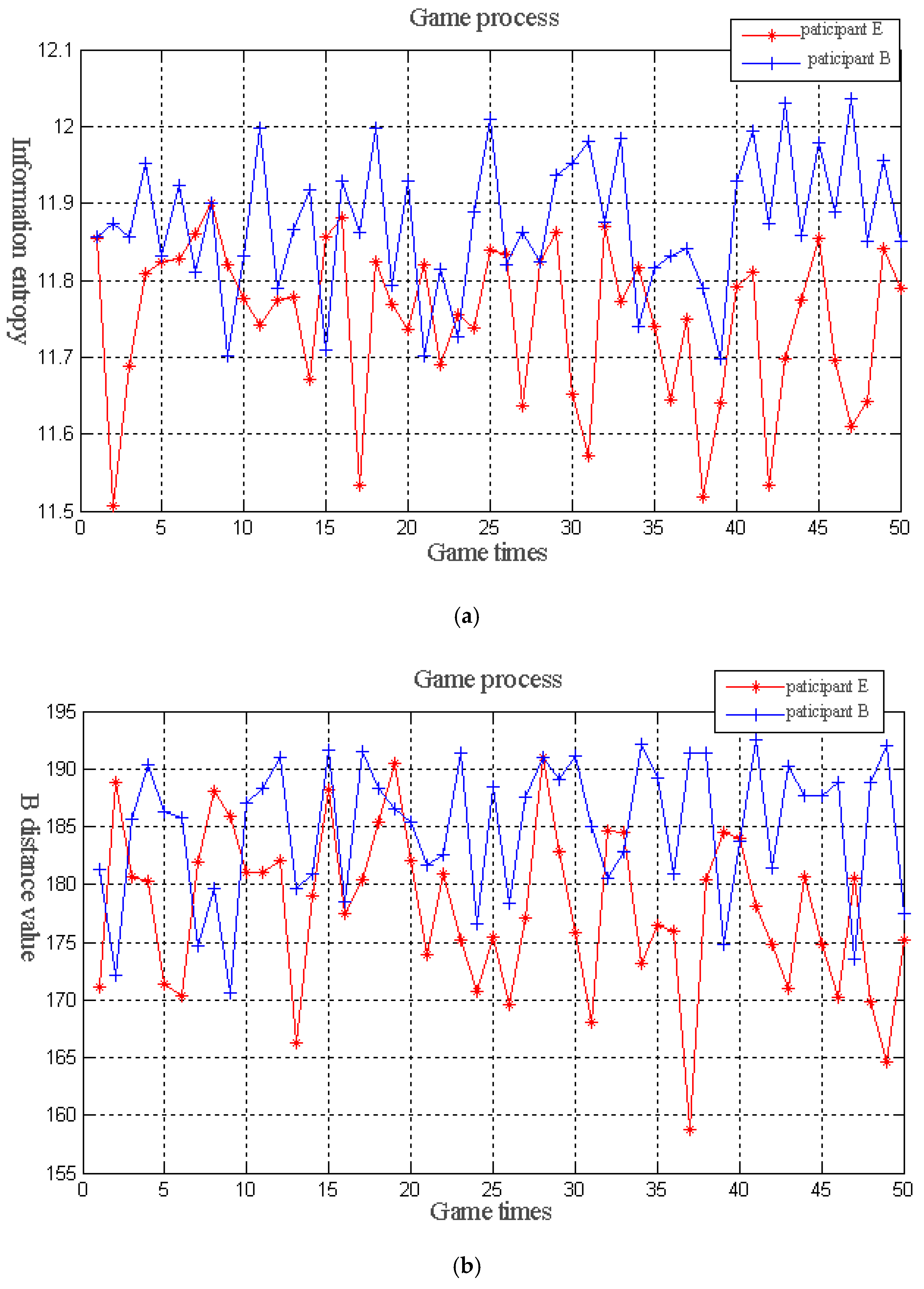
B distance are regarded as the participants of the game. The two participants perform a limited repeated game in the iterative process of the algorithm. Given that the game repeats many times, the rational participants need to weigh the immediate and long-term interests when they select the strategic action at the current game stage. The participants may give up their immediate interests for achieving the long-term interests. Then, the strategy that can maximize the profits may not be selected in the current game. Therefore, in the game process, cooperation and confrontation exist among the participants. According to the earnings of the previous stage, deciding whether to select cooperation or confrontation in the subsequent stage of the game is possible. The specific game model is as follows:
The fitness values of the entire population in information entropy and the
B distance are expressed as
and
, respectively. In the subsequent iteration of
T, the fitness matrix,
, can be expressed as follows:
where
m is the total number of individuals in the population. Then, a utility matrix is established and is used to represent the income of each participant in the strategy. The utility matrix,
, is expressed as follows:
where
represents the income value brought by participant
p to participant
q. The ultimate goal of each participant is to obtain maximum benefits. The maximized benefit in dimension reduction is to determine the maximum entropy or
B distance in the band combination.
At the beginning of the game, the participants attempt to make some strategic actions and expect their own and the game’s final strategic actions to make their own gains as much as possible. If the strategic action made in the previous stage makes the income increase, then the follow-up stage selects the reward strategy as much as possible in the strategic action choice. Otherwise, the penalty strategy is selected. Therefore, the policy set,
, is defined. Two participants share a strategy set, where
indicates reward and
indicates punishment. A reward selection probability matrix,
, is set up as follows:
where
indicates that the probability value of the reward selection strategy for participant
q is selected by participant
p. Accordingly, the probability value of the punishment strategy is
. The participant,
q, can adjust the reward selection probability matrix value of participant
p to
according to his actual income. If
indicates that the strategic action taken by participant
p eventually increases the benefit obtained by participant
q, then participant
q adjusts the
matrix and increases the reward selection probability,
, for participant
p. Conversely, participant
q reduces
.
Based on the previously presented definition, a weight matrix,
, of the preference degree is established to reflect the strategic actions taken by the participants and expressed as follows:
where
indicates the degree of preference of participant
p to participant
q. If participant
p selects the reward strategy for participant
q, then the value of
increases; otherwise, it decreases. Given that the information entropy and
B distance may be different, the normalization method is used to return the fitness values of each target to [0,1] to prevent the small numerical information from being flooded by large numerical information. Therefore, the mapping fitness function value of the multi-objective fitness function value of individual
k on participant
i is expressed as
, as follows:
where
denotes the normalized information entropy and
denotes the normalized
B distance. After a game is completed by two participants, the subsequent iteration process of the multi-objective PSO is performed with the mapping fitness function values of the two participants.
(5) Iteration of Multi-Objective PSO
According to Formula (1), the velocity of the particles in a population is calculated. The velocity of the particles is affected by the global and individual optimum particles. Among them, the global optimum particle is a randomly selected particle from the non-inferior solution set. After the particle velocity is updated, the new speed of the particle is observed to exceed the speed limit. Thus, the speed changes according to Formula (1). According to Formula (2), the position of the particles in the population is updated, so that the location of the new particles exceeds the location band. In the updating process, we determine whether the new position exceeds the range of the band group in which it is located, for example, the velocity of a particle is moved to the boundary. Moreover, the velocity and direction of the particle are rearranged, the velocity direction of the particle is changed, and the velocity of the particle is reduced to make the particle move in the opposite direction. During the line search, the individual historical optimal location and group historical location of the population are updated. The updating process can be divided into two steps. First, the new non-inferior solution set is combined with the old non-inferior solution set. Then, the new non-inferior solutions are removed from the newly generated non-inferior solution set, and the new set of non-inferior solutions is selected. The non-inferiority level of the set is computed and added to the elite solution set if it is an elitist solution.
(6) Check the End Condition
If the check satisfies the termination condition (such as the maximum number of iterations), then it satisfies, terminates, and outputs the non-dominated band combination solution in the external set. The process of the proposed hyperspectral image dimension reduction method based on multi-objective PSO and GT is shown in
Figure 2.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}