Deep Residual CNN-Based Ocular Recognition Based on Rough Pupil Detection in the Images by NIR Camera Sensor


Abstract
1. Introduction
2. Related Works
3. Contributions
- We propose a NIR camera-based ocular recognition method using deep features without iris segmentation, as shown in Table 1.
- It uses a roughly selected eye area for recognition, without executing a specific process for detecting the pupil and iris boundary, the eyelid, and the eyelashes, as this process has a long processing time and its performance is affected by the image quality. To prevent a decrease in recognition performance due to the roughly selected eye area, an ocular area that is somewhat larger than the iris area is used to perform recognition. In addition, it uses a deep ResNet to resolve the problem of misalignment between the enrolled and recognition images that can occur due to recognition based on a roughly detected eye area, as well as the problem of reduced recognition performance caused by this misalignment.
- We analyze the feature maps from various convolutional layers of the deep ResNet in order to examine the features that are important for ocular recognition in each of the layers.
- We make our algorithm for rough pupil detection and ResNet models trained with three open databases (Dongguk CNN Model for NIR Ocular Recognition (DC4NO)) available to other researchers for the fair comparisons as shown in [39].
4. Proposed Method
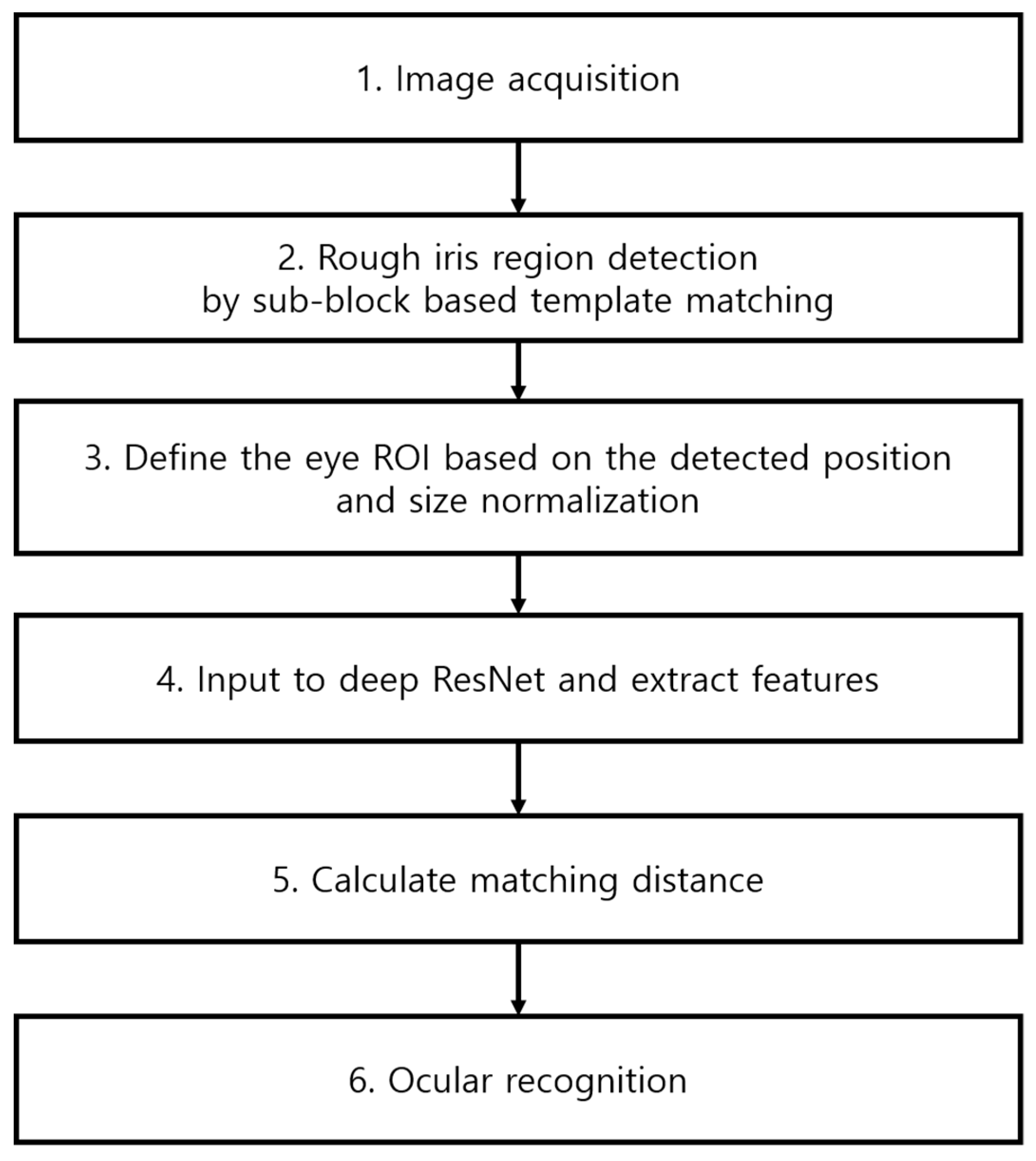
4.1. Overall Procedure of Proposed Ocular Recognition Method
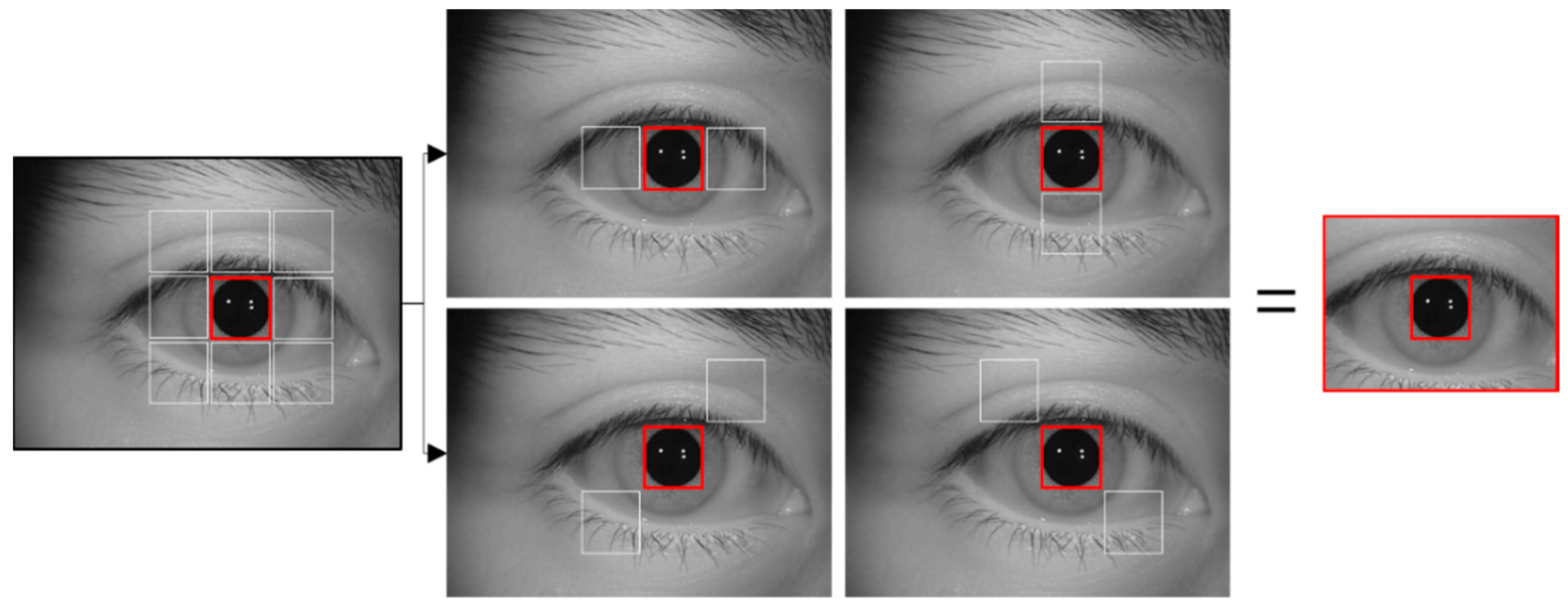
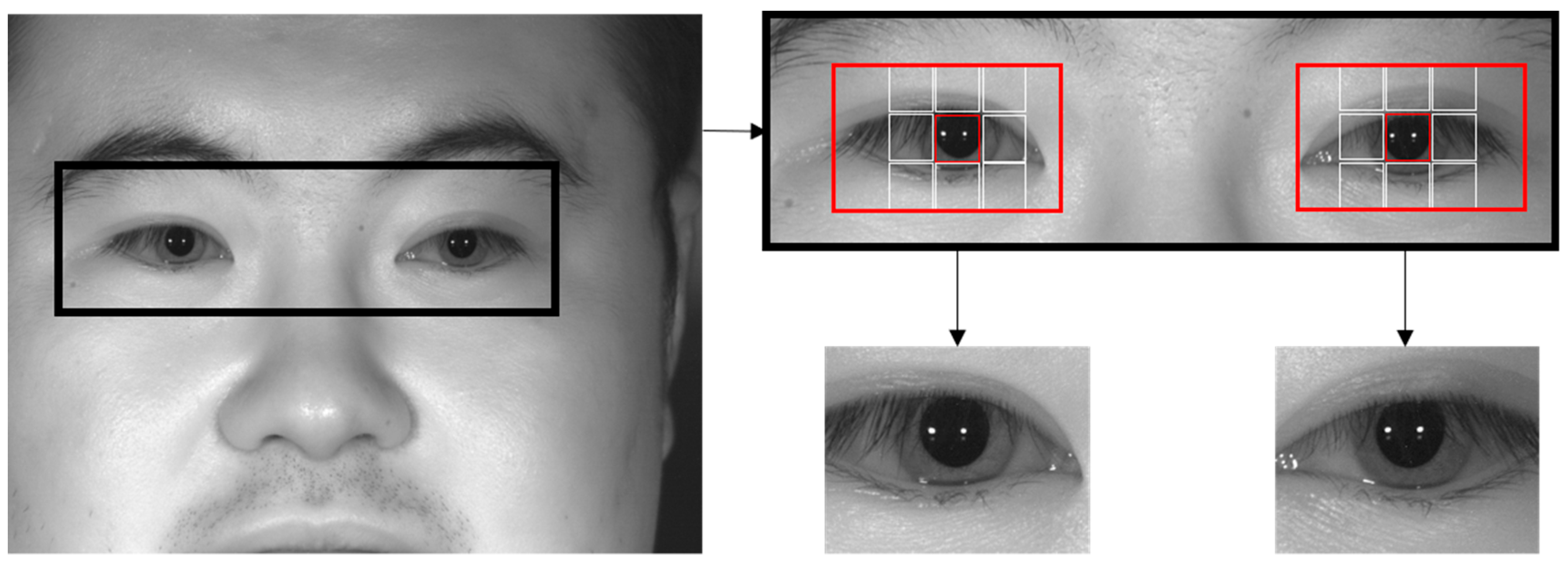
4.2. Rough Pupil Detection and Defining Ocular ROI
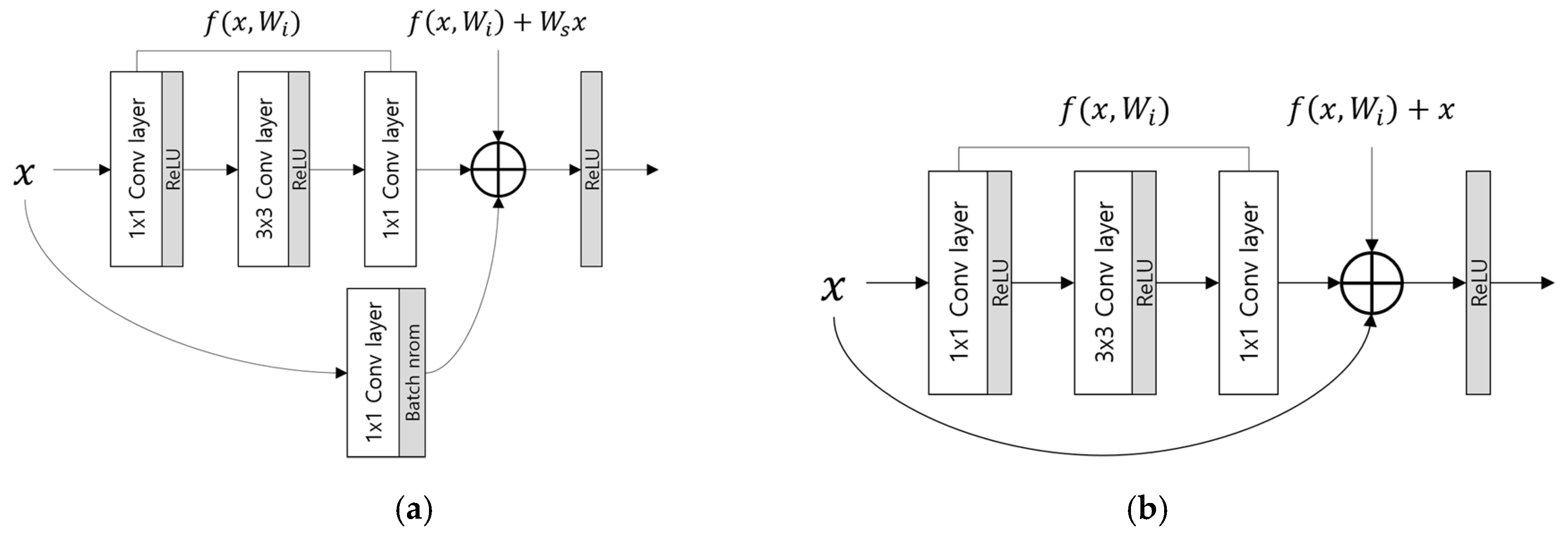
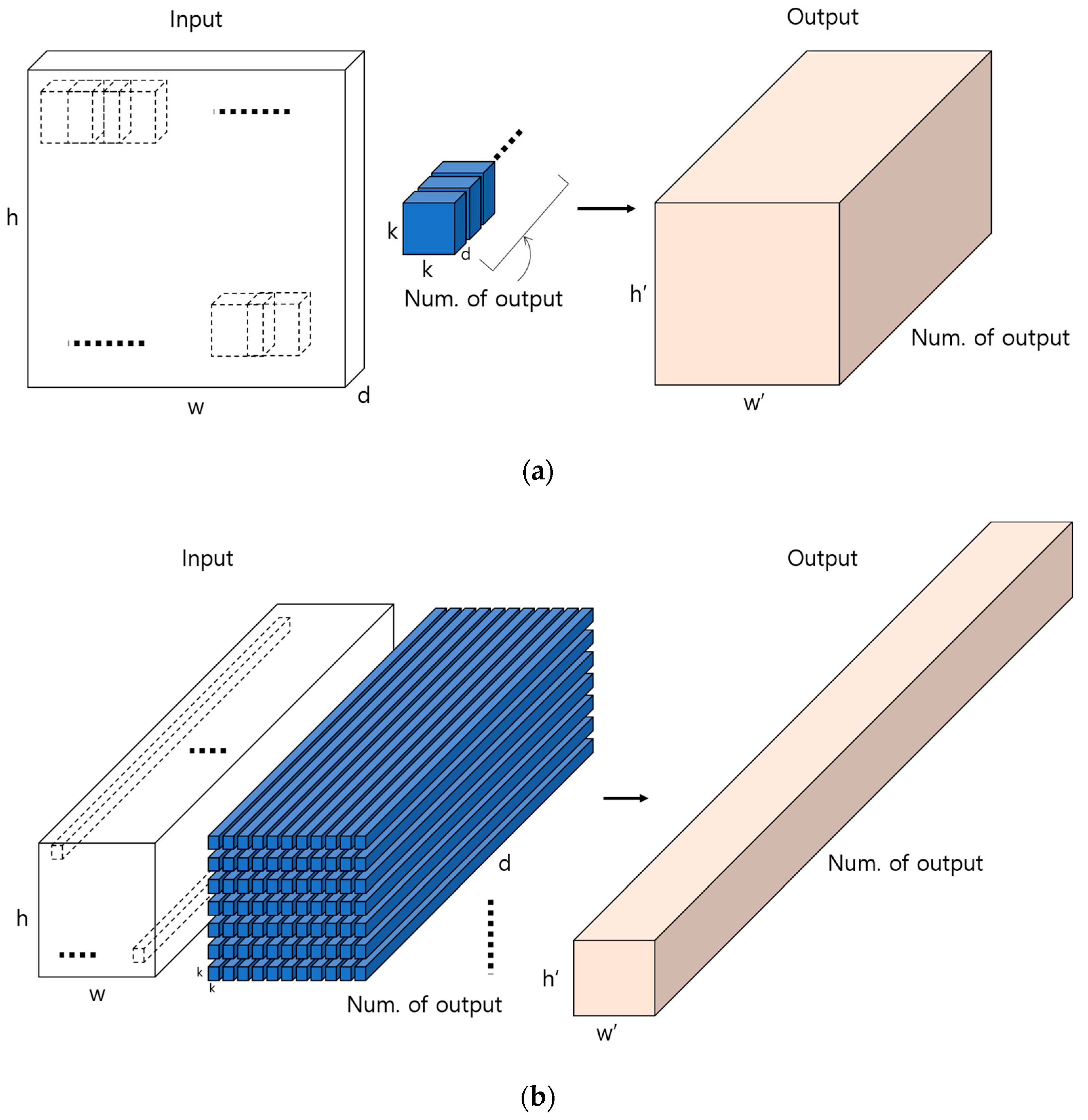
4.3. Deep ResNet-Based Ocular Recognition.
4.4. Extracting Feature Vector and Calculating Matching Distance
5. Experimental Results with Analysis
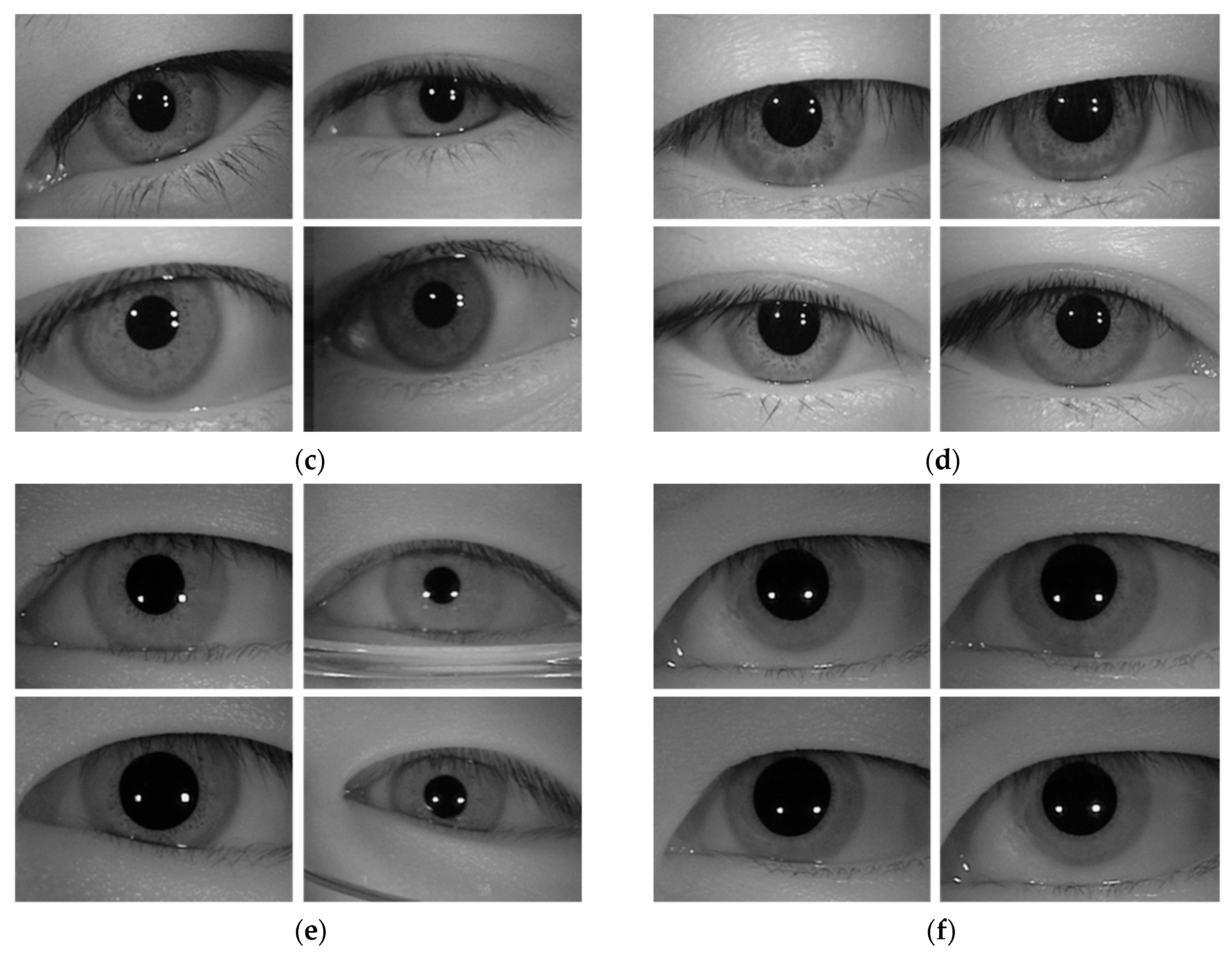
5.1. Datasets and Data Augmentation
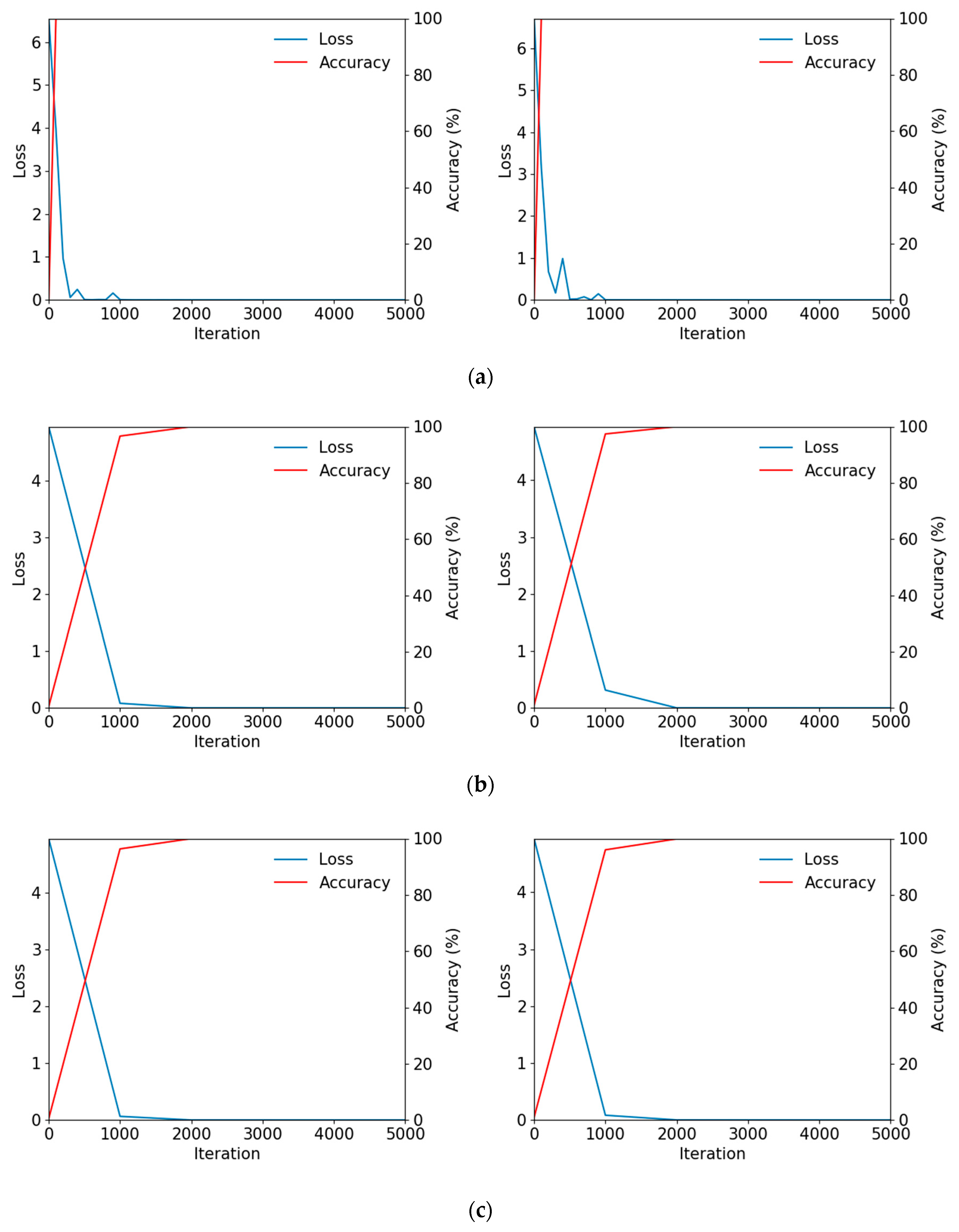
5.2. Training of CNN Model
5.3. Testing of Proposed CNN-Based Ocular Recognition
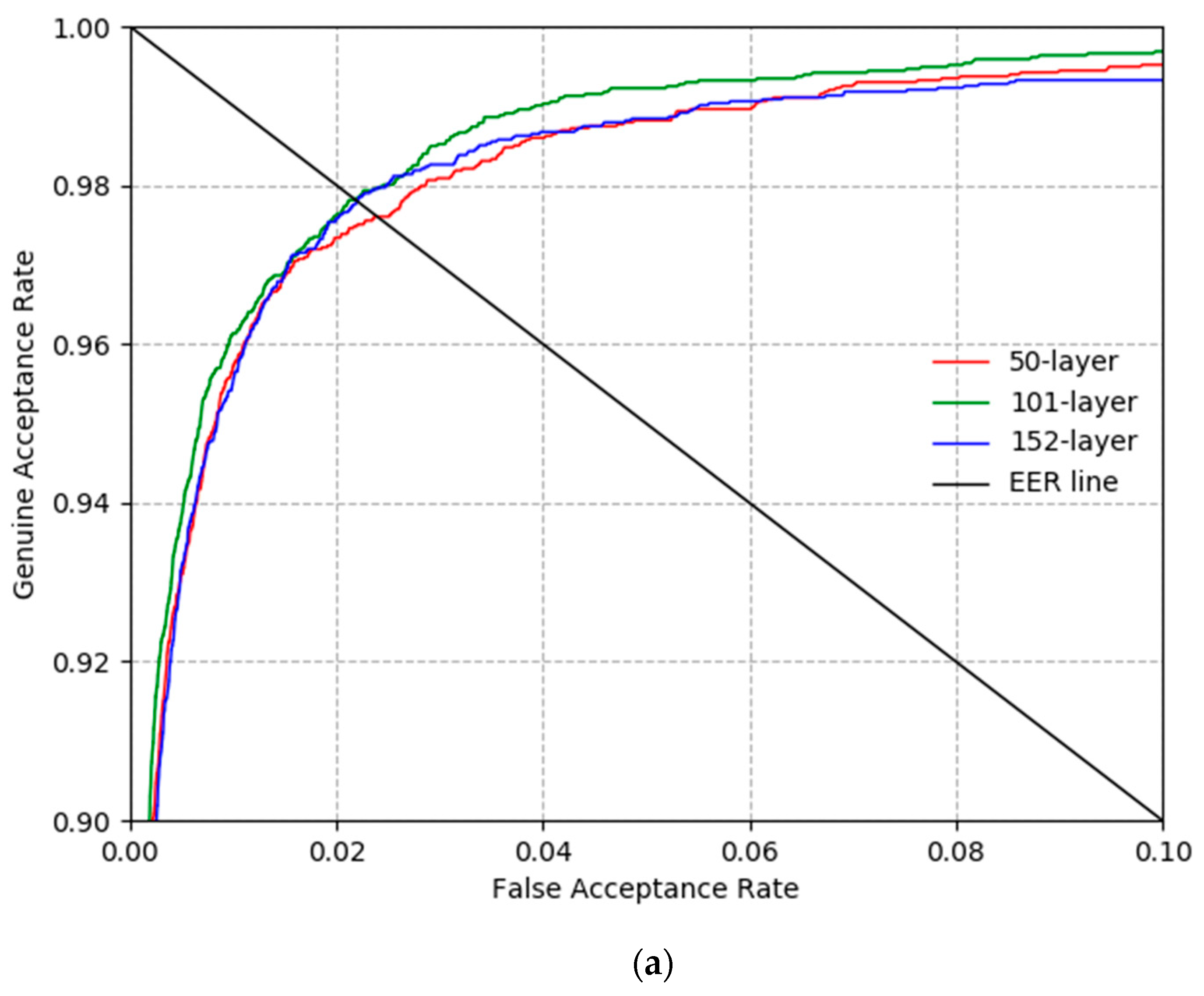
5.4. Comparisons with Proposed and Existing Methods
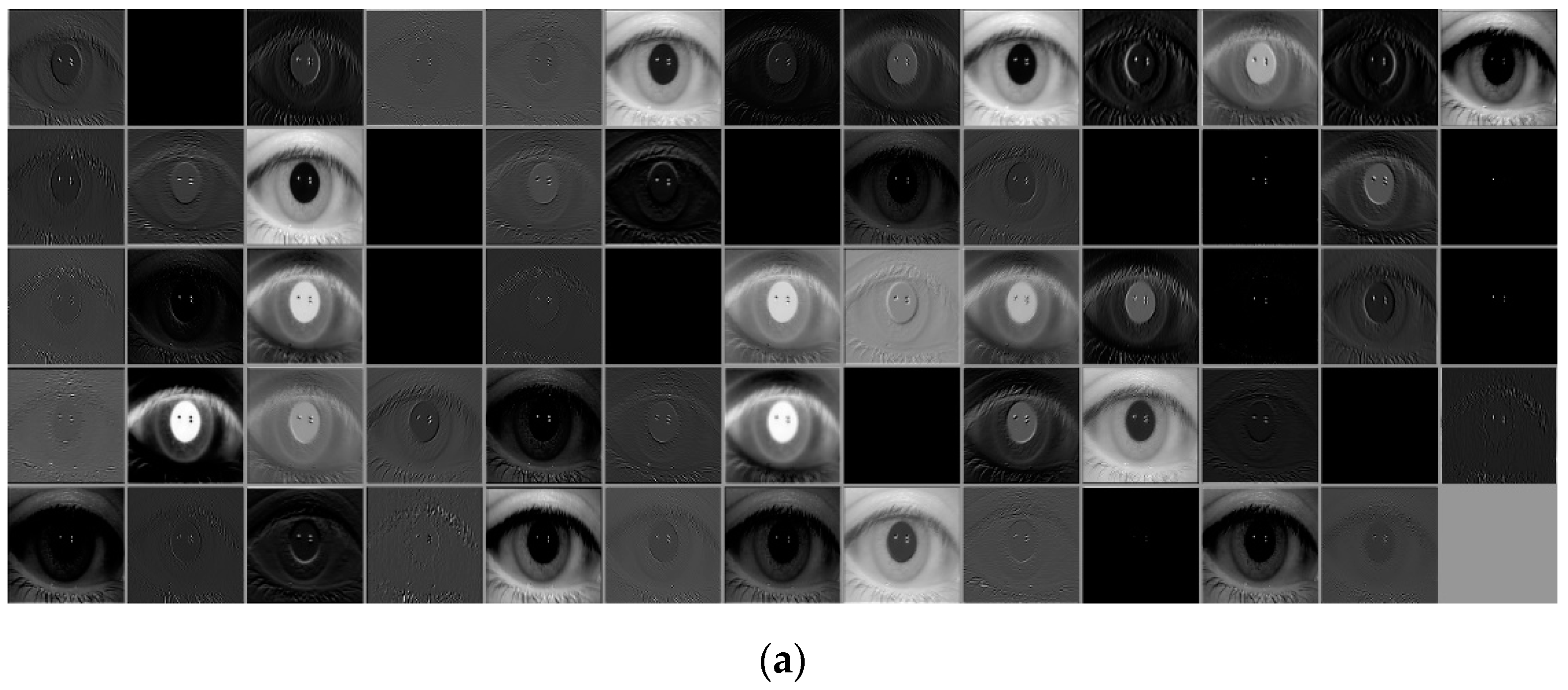
5.5. Analysis of Feature Maps Extracted from CNN Convolutional Layers and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgements
Conflicts of Interest
References
- Iris Recognition by Samsung Galaxy S8. Available online: http://www.samsung.com/global/ galaxy/galaxy-s8/security/ (accessed on 11 October 2018).
- Flom, L.; Safir, A. Iris Recognition System. U.S. Patent US4641349, 3 February 1987. [Google Scholar]
- Daugman, J.G. Biometric Personal Identification System Based on IRIS Analysis. U.S. Patent US5291560, 1 March 1994. [Google Scholar]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef]
- Daugman, J.G. The importance of being random: Statistical principles of iris recognition. Pattern Recognit. 2003, 36, 279–291. [Google Scholar] [CrossRef]
- Daugman, J.G. How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Shin, K.Y.; Nam, G.P.; Jeong, D.S.; Cho, D.H.; Kang, B.J.; Park, K.R.; Kim, J. New iris recognition method for noisy iris images. Pattern Recognit. Lett. 2012, 33, 991–999. [Google Scholar] [CrossRef]
- Shin, K.Y.; Kim, Y.G.; Park, K.R. Enhanced iris recognition method based on multi-unit iris images. Opt. Eng. 2013, 52, 047201. [Google Scholar] [CrossRef]
- Connaughton, R.; Sgroi, A.; Bowyer, K.; Flynn, P.J. A multialgorithm analysis of three iris biometric sensors. IEEE Trans. Inf. Forensic Secur. 2012, 7, 919–931. [Google Scholar] [CrossRef]
- Daugman, J.G. New methods in iris recognition. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2007, 37, 1167–1175. [Google Scholar] [CrossRef]
- Monro, D.M.; Rakshit, S.; Zhang, D. DCT-based iris recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 586–595. [Google Scholar] [CrossRef]
- Park, H.-A.; Park, K.R. Iris recognition based on score level fusion by using SVM. Pattern Recognit. Lett. 2007, 28, 2019–2028. [Google Scholar] [CrossRef]
- Li, P.; Ma, H. Iris recognition in non-ideal imaging conditions. Pattern Recognit. Lett. 2012, 33, 1012–1018. [Google Scholar] [CrossRef]
- De Marsico, M.; Nappi, M.; Riccio, D. Noisy iris recognition integrated scheme. Pattern Recognit. Lett. 2012, 33, 1006–1011. [Google Scholar] [CrossRef]
- Păvăloi, I.; Ignat, A. Iris recognition using statistics on pixel position. In Proceedings of the IEEE International Conference on E-Health and Bioengineering, Sinaia, Romania, 22–24 June 2017; pp. 422–425. [Google Scholar]
- Tan, T.; Zhang, X.; Sun, Z.; Zhang, H. Noisy iris image matching by using multiple cues. Pattern Recognit. Lett. 2012, 33, 970–977. [Google Scholar] [CrossRef]
- Park, U.; Ross, A.; Jain, A.K. Periocular biometrics in the visible spectrum: A feasibility study. In Proceedings of the 3rd IEEE International Conference on Biometrics: Theory, Applications, and Systems, Washington, DC, USA, 28–30 September 2009; pp. 1–6. [Google Scholar]
- Ross, A.; Jillela, R.; Smereka, J.M.; Boddeti, V.N.; Kumar, B.V.K.V.; Barnard, R.; Hu, X.; Pauca, P.; Plemmons, R. Matching highly non-ideal ocular images: An information fusion approach. In Proceedings of the 5th IAPR International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012; pp. 446–453. [Google Scholar]
- Rattani, A.; Derakhshani, R. Ocular biometrics in the visible spectrum: A survey. Image Vis. Comput. 2017, 59, 1–16. [Google Scholar] [CrossRef]
- Cho, S.R.; Nam, G.P.; Shin, K.Y.; Nguyen, D.T.; Pham, T.D.; Lee, E.C.; Park, K.R. Periocular-based biometrics robust to eye rotation based on polar coordinates. Multimed. Tools Appl. 2017, 76, 11177–11197. [Google Scholar] [CrossRef]
- Rodriguez, A.; Panza, J.; Kumar, B.V.K.V. Segmentation-free ocular detection and recognition. In Proceedings of the SPIE Defense, Security, and Sensing, Orlando, FL, USA, 25–29 April 2011; p. 80291W. [Google Scholar]
- Boddeti, V.N.; Smereka, J.M.; Kumar, B.V.K.V. A comparative evaluation of iris and ocular recognition methods on challenging ocular images. In Proceedings of the IEEE International Joint Conference on Biometrics, Washington, DC, USA, 11–13 October 2011; pp. 1–8. [Google Scholar]
- Verma, S.; Mittal, P.; Vatsa, M.; Singh, R. At-a-distance person recognition via combining ocular features. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3131–3135. [Google Scholar]
- Oishi, S.; Ichino, M.; Yoshiura, H. Fusion of iris and periocular user authentication by adaboost for mobile devices. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 9–12 January 2015; pp. 428–429. [Google Scholar]
- Tan, C.-W.; Kumar, A. Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans. Image Process. 2013, 22, 3751–3765. [Google Scholar]
- Lee, M.B.; Hong, H.G.; Park, K.R. Noisy ocular recognition based on three convolutional neural networks. Sensors 2017, 17, 2933. [Google Scholar]
- Ahuja, K.; Islam, R.; Barbhuiya, F.A.; Dey, K. Convolutional neural networks for ocular smartphone-based biometrics. Pattern Recognit. Lett. 2017, 91, 17–26. [Google Scholar] [CrossRef]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. Openface: A General-Purpose Face Recognition Library with Mobile Applications; CMU-CS-16-118; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, June 2016; pp. 1–20. [Google Scholar]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F. Iris super-resolution using CNNs: Is photorealism important to iris recognition? IET Biom. 2019, 8, 69–78. [Google Scholar] [CrossRef]
- Zhao, Z.; Kumar, A. Improving periocular recognition by explicit attention to critical regions in deep neural network. IEEE Trans. Inf. Forensic Secur. 2018, 13, 2937–2952. [Google Scholar] [CrossRef]
- Drozdowski, P.; Struck, F.; Rathgeb, C.; Busch, C. Detection of glasses in near-infrared ocular images. In Proceedings of the International Conference on Biometrics, Gold Coast, Australia, 20–23 February 2018; pp. 202–208. [Google Scholar]
- Mahmood, A.; Uzair, M.; Al-Maadeed, S. Multi-order statistical descriptors for real-time face recognition and object classification. IEEE Access 2018, 6, 12993–13004. [Google Scholar] [CrossRef]
- Reddy, N.; Noor, D.F.; Li, Z.; Derakhshani, R. Multi-frame super resolution for ocular biometrics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 566–574. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Sharifi, O.; Eskandari, M. Optimal face-iris multimodal fusion scheme. Symmetry 2016, 8, 48. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Ross, A.; Sridharan, S. Iris recognition with off-the-shelf CNN features: A deep learning perspective. IEEE Access 2018, 6, 18848–18855. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, M.; Li, H.; Sun, Z.; Tan, T. DeepIris: Learning pairwise filter bank for heterogeneous iris verification. Pattern Recognit. Lett. 2016, 82, 154–161. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar]
- Dongguk CNN Model for NIR Ocular Recognition (DC4NO) with Algorithm. Available online: http://dm.dgu.edu/link.html (accessed on 27 November 2018).
- Kim, B.-S.; Lee, H.; Kim, W.-Y. Rapid eye detection method for non-glasses type 3D display on portable devices. IEEE Trans. Consum. Electron. 2010, 56, 2498–2505. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Heaton, J. Artificial Intelligence for Humans; Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015; Volume 3. [Google Scholar]
- Multinomial Logistic Loss. Available online: http://caffe.berkeleyvision.org/doxygen/classcaffe_1_1MultinomialLogisticLossLayer.html (accessed on 30 November 2018).
- CASIA-Iris Version 4. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20 Databases%20CH.asp (accessed on 9 November 2018).
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin, Germany, 2012; pp. 421–436. [Google Scholar]
- NVIDIA GeForce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/ 10series/geforce-gtx-1070/ (accessed on 27 November 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Sensitivity Index. Available online: https://en.wikipedia.org/wiki/Sensitivity_index (accessed on 27 November 2018).
- Rattani, A.; Derakhshani, R. On fine-tuning convolutional neural networks for smartphone based ocular recognition. In Proceedings of the IEEE International Joint Conference on Biometrics, Denver, CO, USA, 1–4 October 2017; pp. 762–767. [Google Scholar]
- Shekar, B.H.; Bhat, S.S. Iris recognition using partial sum of second order Taylor series expansion. In Proceedings of the 10th Indian Conference on Computer Vision, Graphics and Image Processing, Guwahati, India, 18–22 December 2016; pp. 1–8. [Google Scholar]
- Tan, C.-W.; Kumar, A. Accurate iris recognition at a distance using stabilized iris encoding and Zernike moments phase features. IEEE Trans. Image Process. 2014, 23, 3962–3974. [Google Scholar] [CrossRef]
- Uhl, A.; Wild, P. Multi-stage visible wavelength and near infrared iris segmentation framework. In Proceedings of the 9th International Conference on Image Analysis and Recognition, Aveiro, Portugal, 25–27 June 2012; pp. 1–10. [Google Scholar]
- Abdullah, M.A.M.; Dlay, S.S.; Woo, W.L. Fast and accurate method for complete iris segmentation with active contour and morphology. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, Santorini, Greece, 14–17 October 2014; pp. 123–128. [Google Scholar]
- Proença, H.; Neves, J.C. IRINA: Iris recognition (even) in inaccurately segmented data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6747–6756. [Google Scholar]
- Nigam, A.; Krishna, V.; Bendale, A.; Gupta, P. Iris recognition using block local binary patterns and relational measures. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–6. [Google Scholar]
- Zhang, M.; Sun, Z.; Tan, T. Deformed iris recognition using bandpass geometric features and lowpass ordinal features. In Proceedings of the IEEE International Conference on Biometrics, Madrid, Spain, 4–7 June 2013; pp. 1–6. [Google Scholar]
- Li, X.; Sun, Z.; Tan, T. Predict and improve iris recognition performance based on pairwise image quality assessment. In Proceedings of the IEEE International Conference on Biometrics, Madrid, Spain, 4–7 June 2013; pp. 1–6. [Google Scholar]
- Zhang, Q.; Li, H.; Sun, Z.; Tan, T. Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans. Inf. Forensic Secur. 2018, 13, 2897–2912. [Google Scholar] [CrossRef]
- Wang, Z.; Li, C.; Shao, H.; Sun, J. Eye recognition with mixed convolutional and residual network (MiCoRe-Net). IEEE Access 2018, 6, 17905–17912. [Google Scholar] [CrossRef]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust iris segmentation using densely connected fully convolutional networks in the images by visible light and near-infrared light camera sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iris Segmentation | Periocular Region | Using Feature | Method | Accuracy | Advantage | Disadvantage |
|---|---|---|---|---|---|---|
| Included | Not used | Hand-crafted feature | Log Gabor filter, LDA, and BSA [35] | EER of 3.12~3.465% (A) | Captured iris images are less affected by external light than those from a visible light camera | Equipment becomes large-sized and expensive due to use of NIR camera and NIR lighting |
| Pre-classification and in-plane rotation angle estimation for both eyes, then matching via bit-shifting [8] | EER of 4.3006% (A) | |||||
| Used | Fusion-OTSDF, correlation filtering, and MAP estimation [22] | EER of 23.83~26.81% (C) | ||||
| Fusion and classification with RDF using PHOG and gist method [23] | GAR of 61.5% at 0.1% FAR (A) GAR of 21% at 1% FAR (C) | |||||
| Adaboost and OSIRIS [24] | EER of 3.6~3.9% (A) | |||||
| Deep feature | Using three CNNs [26] | EER of 3.04~3.08% (A) EER of 10.36% (B) EER of 16.25~17.9% (E) | By using visible light camera without NIR lighting, equipment is small-sized and low cost, has no reflected light due to NIR lighting | - Iris quality is slightly lower than a normal NIR environment image due to nearby lighting noise and ghost effects - Difficult to capture iris patterns in visible light for races with little melanin pigment | ||
| Fusion of the recognitions by iris, ocular, and the area larger than ocular [27] | EER of 5.7% (E) | |||||
| Not included | Hand-crafted feature | GOH, PDM, m-SIFT, and fusion by weighted SUM rule [18] | EER of 18.8% (C) | Captured iris images are less affected by external light than those from a visible light camera | Equipment becomes large-sized and expensive due to use of NIR camera and NIR lighting | |
| Quadratic correlation filter [21] | Classification accuracy of 75% (H) | |||||
| Conversion of periocular region into polar-coordinates and matching via LBP and adaptive bit shifting [20] | EER of 10.0172% (A) | |||||
| Multi-order statistical descriptors [32] | Classification accuracy of 93.33% (M) | Intensive training is not required | Performance enhancement is limited by using hand-crafted feature | |||
| Multi-frame super resolution reconstruction based on deblurring by CNN [33] | EER of 19.54~28.06% (N) | Image resolution and blurring of ocular image can be enhanced | Using hand-crafted feature and unsophisticated matcher produces low recognition accuracy | |||
| Included | Not used | Deep feature | Iris recognition with off-the-shelf CNN features [36] | Recognition accuracy of 98.8% (G) Recognition accuracy of 98.7% (H) | High recognition accuracy | - Performance is affected by the accurate iris segmentation - The complexity of DenseNet-201 is large, which requires huge training time. |
| DeepIris based on pairwise filter bank [37] | EER of 0.15% (I) EER of 0.31% (J) | Measure the accuracies according to various capturing distances and types of camera sensors | - Performance is affected by the accurate iris segmentation - Performance enhancement is limited by using shallow CNN | |||
| DeepIrisNet [38] | EER of 2.19% (K) EER of 1.82~2.4% (L) | Compare the accuracies according to various types of segmentation method, in-plane rotations, input size, train size, and network size. | - Performance is affected by the accurate iris segmentation - Performance enhancement is limited by using shallow CNN | |||
| Not included | Used | Deep ResNet-based recognition (Proposed method) | EER of 2.1625% (A) EER of 1.595% (F) EER of 1.331% (G) | Not require iris segmentation while maintaining the accuracy by deep ResNet | Require the procedure of intensive training of ResNet |
| Layer Name | Size of Feature Map (Height × Width × Channel) | Number of Filters | Size of Filter | Number of Padding | Number of Strides | Number Iteration of Residual Block |
|---|---|---|---|---|---|---|
| Input | 224 × 224 × 3 | |||||
| Conv1 | 112 × 112 × 64 | 64 | 7 × 7 × 3 | 3 | 2 | 1 |
| Max-pool | 56 × 56 × 64 | 1 | 3 × 3 × 1 | 0 | 2 | 1 |
| Conv2 | 56 × 56 × 256 | 64 | 1× 1 × 64 | 0 | 1 | 3 |
| 64 | 3 × 3 × 64 | 1 | ||||
| 256 | 1 × 1 × 64 | 0 | ||||
| (short-cut) | 56 × 56 × 256 | 256 | 1 × 1 × 64 | 0 | 1 | |
| Conv3 | 28 × 28 × 512 | 128 | 1 × 1 × 256 | 0 | 1(2*) | - 4 in case of ResNet-50 and ResNet-101 - 8 in case of ResNet-152 |
| 128 | 3 × 3 × 128 | 1 | 1 | |||
| 512 | 1 × 1 × 128 | 0 | ||||
| (short-cut) | 28 × 28 × 512 | 512 | 1 × 1 × 256 | 0 | 2** | |
| Conv4 | 14 × 14 × 1024 | 256 | 1 × 1 × 512 | 0 | 1(2*) | - 6 in case of Resnet-50 - 23 in case of Resnet-101 - 36 in case of Resnet-152 |
| 256 | 3 × 3 × 256 | 1 | 1 | |||
| 1024 | 1 × 1 × 256 | 0 | ||||
| (short-cut) | 14 × 14 × 1024 | 1024 | 1 × 1 × 512 | 0 | 2** | |
| Conv5 | 7 × 7 × 2048 | 512 | 1 × 1 × 1024 | 0 | 1(2*) | 3 |
| 512 | 3 × 3 × 512 | 1 | 1 | |||
| 2048 | 1 × 1 × 512 | 0 | ||||
| (short-cut) | 7 × 7 × 2048 | 2048 | 1 × 1 × 1024 | 0 | 2** | |
| Average pooling layer | 1 × 1 × 2048 | 1 | 7 × 7 × 1 | 0 | 1 | 1 |
| Fully connected layer (Softmax) | 1 × number of classes | 1 |
| Category | Number of Classes | Number of Images | ||||
|---|---|---|---|---|---|---|
| Before Augmentation | After Augmentation | |||||
| DB1 | DB2 | DB1 | DB2 | DB1 | DB2 | |
| CASIA-Iris-Distance | 142 | 140 | 2080 | 2056 | 351,520 | 347,464 |
| CASIA-Iris-Lamp | 408 | 408 | 8054 | 8036 | 1,361,126 | 1,358,084 |
| CASIA-Iris-Thousand | 1000 | 1000 | 9946 | 9946 | 1,680,874 | 1,680,874 |
| ResNet Model | CASIA-Iris-Distance | CASIA-Iris-Lamp | CASIA-Iris-Thousand | ||||||
|---|---|---|---|---|---|---|---|---|---|
| DB1 | DB2 | Average | DB1 | DB2 | Average | DB1 | DB2 | Average | |
| 50-layer | 2.576 | 1.971 | 2.2735 | 1.505 | 1.685 | 1.595 | 2.091 | 2.524 | 2.3075 |
| 101-layer | 2.138 | 2.187 | 2.1625 | 1.702 | 1.738 | 1.72 | 1.431 | 2.570 | 2.0005 |
| 152-layer | 2.103 | 2.264 | 2.1835 | 5.203 | 4.372 | 4.7875 | 1.588 | 1.074 | 1.331 |
| 500 × 400 Pixels | 500 × 280 Pixels | 380 × 400 Pixels | 380 × 280 Pixels | 300 × 260 Pixels | |
|---|---|---|---|---|---|
| EER | 2.184 | 2.282 | 3.334 | 2.163 | 2.955 |
| Method | DB1 | DB2 | Average |
|---|---|---|---|
| Pre-trained ResNet without fine-tuning | 11.504 | 9.728 | 10.616 |
| Fine-tuned ResNet (proposed method) | 2.138 | 2.187 | 2.1625 |
| Method | EER |
|---|---|
| Cho et al. [20] | 10.0172 |
| Shekar et al. [55] | 8.64 |
| Zhao et al. [30] | 4.9 |
| Shin et al. [8] | 4.3006 |
| Oishi et al. [24] | 3.6~3.9 |
| Sharifi et al. [35] | 3.12~3.465 |
| Lee et al. [26] | 3.04~3.08 |
| Tan et al. [56] | 2.9 |
| Proposed method | 2.1625 |
| Method | EER |
|---|---|
| Uhl et al. [57] | 12.9 |
| Ribeiro et al. [29] | 3.92 |
| Abdullah et al. [58] | 2.37 |
| Proença et al. [59] | 2.6 |
| Nigam et al. [60] | 2.13 |
| Zhang et al. [61] | 2.05 |
| Li et al. [62] | 2.02 |
| Proposed method | 1.595 |
| Method | EER |
|---|---|
| Drozdowski et al. [31] | 8.27 |
| Proença et al. [59] | 3 |
| Li et al. [62] | 2.59 |
| Proposed method | 1.331 |
| Method | EER |
|---|---|
| Using periocular region without iris area | 5.2506 |
| Using iris area without periocular region | 3.8952 |
| Using whole ocular region (proposed method) | 2.1625 |
| Method | EER |
|---|---|
| Using iris area without periocular region | 9.5069 |
| Using periocular region (proposed method) | 2.1625 |
| The fusion of iris and periocular regions [63] | 6.2207 |
| Method | EER |
|---|---|
| Training with augmented database based on affine transform [64] | 4.2352 |
| Training with our augmented database | 2.1625 |
| Method | EER |
|---|---|
| Training with CASIA-Iris-Thousand database | 2.5471 |
| Training with our augmented database | 2.1625 |
| Proposed Method (Sub-Block Based Template Matching) | Two-Circular Edge Detector [6] | CNN-Based Iris Segmentation [65] | Ocular Recognition (Feature Extraction + Distance Matching) | |
|---|---|---|---|---|
| Processing time per an image | 73 | 986 | 210 | 115 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.W.; Kim, K.W.; Hoang, T.M.; Arsalan, M.; Park, K.R. Deep Residual CNN-Based Ocular Recognition Based on Rough Pupil Detection in the Images by NIR Camera Sensor. Sensors 2019, 19, 842. https://doi.org/10.3390/s19040842
Lee YW, Kim KW, Hoang TM, Arsalan M, Park KR. Deep Residual CNN-Based Ocular Recognition Based on Rough Pupil Detection in the Images by NIR Camera Sensor. Sensors. 2019; 19(4):842. https://doi.org/10.3390/s19040842
Chicago/Turabian StyleLee, Young Won, Ki Wan Kim, Toan Minh Hoang, Muhammad Arsalan, and Kang Ryoung Park. 2019. "Deep Residual CNN-Based Ocular Recognition Based on Rough Pupil Detection in the Images by NIR Camera Sensor" Sensors 19, no. 4: 842. https://doi.org/10.3390/s19040842
APA StyleLee, Y. W., Kim, K. W., Hoang, T. M., Arsalan, M., & Park, K. R. (2019). Deep Residual CNN-Based Ocular Recognition Based on Rough Pupil Detection in the Images by NIR Camera Sensor. Sensors, 19(4), 842. https://doi.org/10.3390/s19040842