Deep Learning-Based Multinational Banknote Type and Fitness Classification with the Combined Images by Visible-Light Reflection and Infrared-Light Transmission Image Sensors


Abstract
:1. Introduction
2. Related Works
3. Contributions
- This is the first study on multinational banknote classification of both type and fitness. Considering the related works, each category of banknote type and banknote fitness was reported in the separate studies.
- Our proposed method can simultaneously classify banknote of three types of currency, which are INR, KRW, and USD with three fitness levels in the cases of INR and KRW (namely fit, normal, and unfit) and two levels in the case of USD (namely fit and unfit), into separate classes of currency type, denomination, input direction and fitness levels. To handle with the huge number of output classes, we adopt CNN for the multinational banknote classification of both type and fitness.
- We also estimate the fitness value of input banknote by using CNN regression with the average pixel values of multiple trials of the banknote. For evaluating the estimation results, we considered the consistency of the regression testing results among trials of banknotes, and proposed a criteria called AQE.
- Dongguk Banknote Type and Fitness Database (DF-DB3) and a trained CNN model with algorithms are made available in Reference [20] for fair comparison by other researchers.
4. Proposed Method
4.1. Overview of the Proposed Method
4.2. Acquisition and Preprocessing of Banknote Images
4.3. CNN Models for Banknote Classification
4.4. Banknote Fitness Value Estimation by CNN Regression
5. Experimental Results
5.1. The Experimental Banknote Image Dataset
5.2. Training and Testing for Banknote Type and Fitness Classification
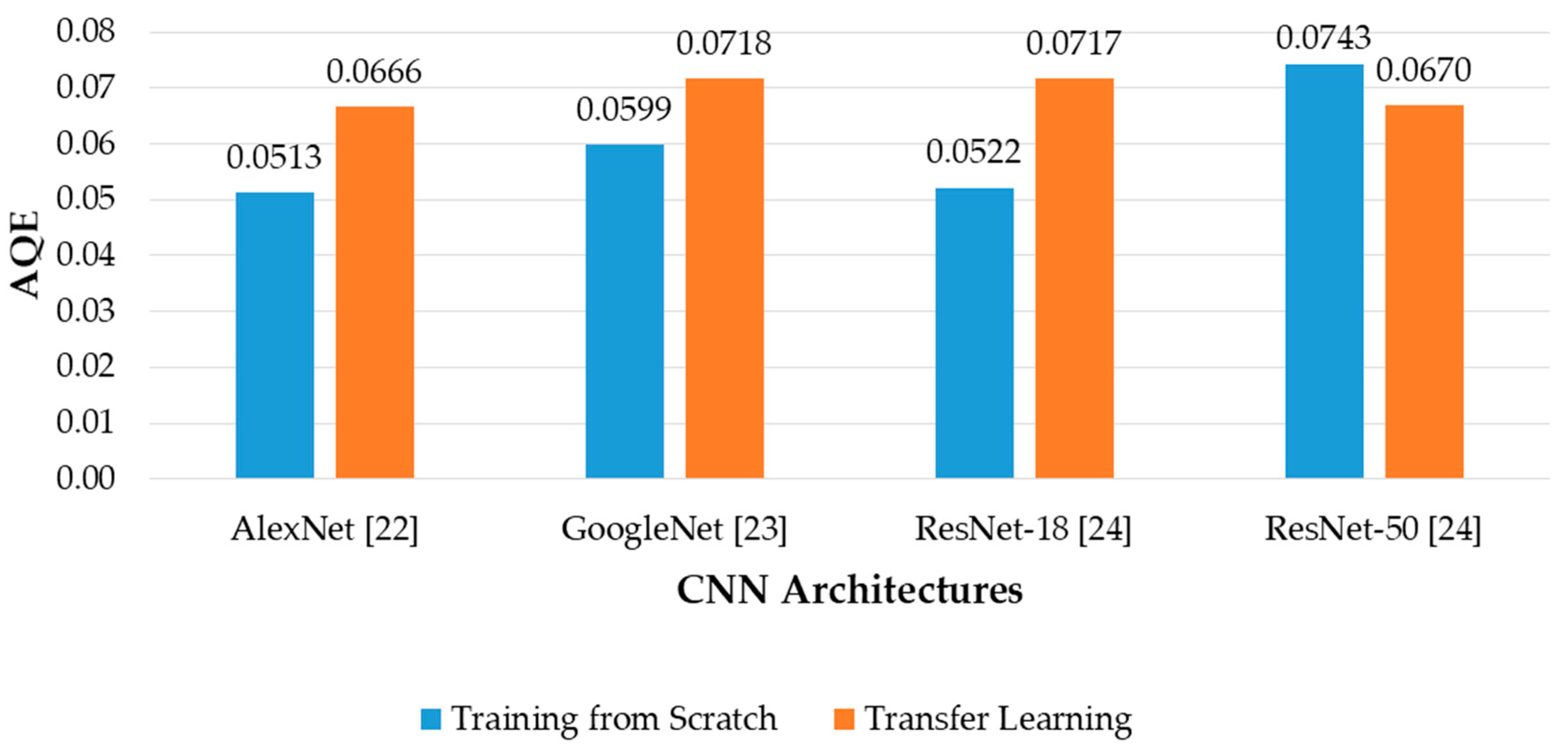
5.3. Training and Testing for Banknote Fitness Value Estimation with CNN Regression
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bala, N.; Rani, U. A Review: Paper currency recognition. Int. J. Emerg. Res. Manag. Technol. 2014, 3, 77–81. [Google Scholar]
- Lee, J.W.; Hong, H.G.; Kim, K.W.; Park, K.R. A survey on banknote recognition methods by various sensors. Sensors 2017, 17, 313. [Google Scholar] [CrossRef] [PubMed]
- Bhurke, C.; Sirdeshmukh, M.; Kanitkar, M.S. Currency recognition using image processing. Int. J. Innov. Res. Comput. Commun. Eng. 2015, 3, 4418–4422. [Google Scholar]
- Gai, S.; Yang, G.; Wan, M. Employing quaternion wavelet transform for banknote classification. Neurocomputing 2013, 118, 171–178. [Google Scholar] [CrossRef]
- Pham, T.D.; Park, Y.H.; Kwon, S.Y.; Park, K.R.; Jeong, D.S.; Yoon, S. Efficient banknote recognition based on selection of discriminative regions with one-dimensional visible-light line sensor. Sensors 2016, 16, 328. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.D.; Kim, K.W.; Kang, J.S.; Park, K.R. Banknote recognition based on optimization of discriminative regions by genetic algorithm with one-dimensional visible-light line sensor. Pattern Recognit. 2017, 72, 27–43. [Google Scholar] [CrossRef]
- Takeda, F.; Nishikage, T.; Matsumoto, Y. Characteristics Extraction of Paper Currency Using Symmetrical Masks Optimized by GA and Neuro-Recognition of Multi-national Paper Currency. In Proceedings of the IEEE International Joint Conference on Neural Networks, Anchorage, AK, USA, 4–9 May 1998; pp. 634–639. [Google Scholar]
- Youn, S.; Choi, E.; Baek, Y.; Lee, C. Efficient multi-currency classification of CIS banknotes. Neurocomputing 2015, 156, 22–32. [Google Scholar] [CrossRef]
- Pham, T.D.; Lee, D.E.; Park, K.R. Multi-national banknote classification based on visible-light line sensor and convolutional neural network. Sensors 2017, 17, 1595. [Google Scholar] [CrossRef] [PubMed]
- Hassanpour, H.; Farahabadi, P.M. Using hidden Markov models for paper currency recognition. Expert Syst. Appl. 2009, 36, 10105–10111. [Google Scholar] [CrossRef]
- Pham, T.D.; Nguyen, D.T.; Kang, J.K.; Park, K.R. Deep learning-based multinational banknote fitness classification with a combination of visible-light reflection and infrared-light transmission images. Symmetry 2018, 10, 431. [Google Scholar] [CrossRef]
- Lee, S.; Baek, S.; Choi, E.; Baek, Y.; Lee, C. Soiled banknote fitness determination based on morphology and Otsu’s thresholding. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 8–10 January 2017; pp. 450–451. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Sys. Man. Cyber. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Kwon, S.Y.; Pham, T.D.; Park, K.R.; Jeong, D.S.; Yoon, S. Recognition of banknote fitness based on a fuzzy system using visible light reflection and near-infrared light transmission images. Sensors 2016, 16, 863. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.D.; Nguyen, D.T.; Kim, W.; Park, S.H.; Park, K.R. Deep learning-based banknote fitness classification using the reflection images by a visible-light one-dimensional line image sensor. Sensors 2018, 18, 472. [Google Scholar] [CrossRef] [PubMed]
- Aoba, M.; Kikuchi, T.; Takefuji, Y. Euro banknote recognition system using a three-layered perceptron and RBF networks. IPSJ Trans. Math. Model. Appl. 2003, 44, 99–109. [Google Scholar]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Ensemble of convolutional neural networks for bioimage classification. Appl. Comput Inform. 2018, in press. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Dongguk Banknote Type and Fitness Database (DF-DB3) & CNN Model with Algorithms. Available online: http://dm.dgu.edu/link.html (accessed on 31 December 2018).
- Newton. Available online: http://kisane.com/our-service/newton/ (accessed on 31 December 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Cui, J.; Wang, Y.; Huang, J.; Tan, T.; Sun, Z. An Iris Image Synthesis Method based on PCA and Super-Resolution. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 471–474. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Pretrained Convolutional Neural Networks—MATLAB & Simulink. 2018. Available online: https://www.mathworks.com/help/deeplearning/ug/pretrained-convolutional-neural-networks.html (accessed on 31 December 2018).
- Deep Learning with Images—MATLAB & Simulink. 2018. Available online: https://www.mathworks.com/help/deeplearning/deep-learning-with-images.html (accessed on 31 December 2018).
- Intel® CoreTM i7-3770K Processor (8 M Cache, up to 3.90 GHz) Product Specifications. Available online: https://ark.intel.com/products/65523/Intel-Core-i7-3770K-Processor-8M-Cache-up-to-3_90-GHz (accessed on 31 December 2018).
- GeForce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070-ti/#specs (accessed on 31 December 2018).
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Schindler, A.; Lidy, T.; Rauber, A. Comparing Shallow versus Deep Neural Network Architectures for Automatic Music Genre Classification. In Proceedings of the Forum Media Technology 2016, St. Polten, Austria, 23–24 November 2016. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantage | Disadvantage | |
|---|---|---|---|---|
| Banknote recognition | Single Currency Recognition | - Using HSV color features and template matching [3]. - Using QWT, GGD feature extraction, and NN classifier [4]. - Using similarity map, PCA, and K-means-based classifier [5,6]. | Simple in image acquisition and classification as recognition process is conducted on separated currency types with visible light image. | Currency types need to be manually selected before recognition. |
| Multiple Currency Recognition | - Using GA for optimizing feature extraction and NN for classifying [7]. - Using multi-templates and correlation matching [8]. - Using CNN [9]. - Using HMM for modeling banknote texture characteristic [10]. | Multinational banknote classification methods do not require the pre-selection of currency type. | Classification task becomes complex as the number of classes increase. | |
| Banknote fitness classification | Using Single Sensor | - Using image morphology and Otsu’s thresholding [12]. - Using CNN with VR images [15]. | Simple in image acquisition because of using only one type of visible-light banknote image. | Currency types need to be manually selected. |
| Using Multiple Sensors | - Using fuzzy system on VR and NIRT banknote images [14]. - Using CNN with VR and IRT images for multinational banknote fitness classification [11]. | Performance can be enhanced by using multiple imaging sensors. | Complexity and expensiveness in the implementation of hardware. | |
| Banknote type and fitness classification (proposed method) | Using CNN for banknote recognition and fitness classification of banknotes from multiple countries with VR and IRT images. | Take advantage of deep learning technique on CNN for a large number of classes when combining banknote recognition and fitness classification into one classifier. | Time consuming procedure for CNN training is required. | |
| Category | Ref. | Currency Type | Output Description | Dataset Availability | |
|---|---|---|---|---|---|
| Banknote Recognition | Single Currency Recognition | [3] | INR, AUD, EUR, SAR, USD | 2 denominations for each of INR, AUD, EUR, and SAR. USD was not reported. | N/A |
| [4] | USD, RMB, EUR | 24 classes of USD, 20 classes of RMB, and 28 classes of EUR. | N/A | ||
| [5] | USD, Angola (AOA), Malawi (MWK), South Africa (ZAR) | 68 classes of USD, 36 classes of AOA, 24 classes of MWK, and 40 classes of ZAR. | N/A | ||
| [6] | Hongkong (HKD), Kazakhstan (KZT), Colombia (COP), USD | 128 classes of HKD, 60 classes of KZT, 32 classes of COP, and 68 classes of USD. | N/A | ||
| Multiple Currency Recognition | [7] | Japan (JPN), Italy (ITL), Spain (ESP), France (FRF) | 23 denominations. | N/A | |
| [8] | KRW, USD, EUR, CNY, RUB | 55 denominations. | N/A | ||
| [9] | CNY, EUR, JPY, KRW, RUB, USD | 248 classes of 62 denominations. | DMC-DB1 [9] | ||
| [10] | 23 countries (USD, RUB, KZT, JPY, INR, EUR, CNY, etc.) | 101 denominations. | N/A | ||
| Banknote Fitness Classification | [11] | INR, KRW, USD | 5 classes with 3 classes of case 1 (fit, normal and unfit) and 2 classes of case 2 (fit and unfit). | DF-DB2 [11] | |
| [12] | EUR, RUB | 2 classes (fit and unfit). | N/A | ||
| [14] | USD, KRW, INR | 2 classes (fit and unfit). | N/A | ||
| [15] | KRW, INR, USD | 3 classes of KRW and INR (fit, normal, and unfit), 2 classes of USD (fit and unfit). | DF-DB1 [15] | ||
| Banknote type and fitness classification (proposed method) | INR, KRW, USD | 116 classes of banknote kinds and fitness levels. | DF-DB3 [20] | ||
| Layer Name | Filter Size | Stride | Padding | Number of Filters | Output Feature Map Size | |
|---|---|---|---|---|---|---|
| Image Input Layer | 120 × 240 × 3 | |||||
| Conv1 | Conv. | 7 × 7 × 3 | 2 | 0 | 96 | 57 × 117 × 96 |
| CCN | ||||||
| Max Pooling | 3 × 3 | 2 | 0 | 28 × 58 × 96 | ||
| Conv2 | Conv. | 5 × 5 × 96 | 1 | 2 | 128 | 28 × 58 × 128 |
| CCN | ||||||
| Max Pooling | 3 × 3 | 2 | 0 | 13 × 28 × 128 | ||
| Conv3 | Conv. | 3 × 3 × 128 | 1 | 1 | 256 | 13 × 28 × 256 |
| Conv4 | Conv. | 3 × 3 × 256 | 1 | 1 | 256 | 13 × 28 × 256 |
| Conv5 | Conv. | 3 × 3 × 256 | 1 | 1 | 128 | 13 × 28 × 128 |
| Max Pooling | 3 × 3 | 2 | 0 | 6 × 13 × 128 | ||
| Fully Connected Layers | Fc1 | 4096 | ||||
| Fc2 | 2048 | |||||
| Dropout | ||||||
| Fc3 | 116 | |||||
| Softmax | ||||||
| Layer Name | Filter Size/Stride | Number of Filters | Output Feature Map Size | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Conv. 1 × 1 | Conv. 1 × 1 (a) | Conv. 3 × 3 | Conv. 1 × 1 (b) | Conv. 5 × 5 | Conv. 1 × 1 (c) | |||||
| Image Input Layer | 120 × 240 × 3 | |||||||||
| Conv1 | Conv. | 7 × 7/2 | 64 | 60 × 120 × 64 | ||||||
| Max Pooling | 3 × 3/2 | 30 × 60 × 64 | ||||||||
| CCN | ||||||||||
| Conv2 | Conv. | 1 × 1/1 | 64 | 30 × 60 × 64 | ||||||
| Conv. | 3 × 3/1 | 192 | 30 × 60 × 192 | |||||||
| CCN | ||||||||||
| Max Pooling | 3 × 3/2 | 15 × 30 × 192 | ||||||||
| Conv3 | Inception3a | 64 | 96 | 128 | 16 | 32 | 32 | 15 × 30 × 256 | ||
| Inception3b | 128 | 128 | 192 | 32 | 96 | 64 | 15 × 30 × 480 | |||
| Max Pooling | 3 × 3/2 | 7 × 15 × 480 | ||||||||
| Conv4 | Inception4a | 192 | 96 | 208 | 16 | 48 | 64 | 7 × 15 × 512 | ||
| Inception4b | 160 | 112 | 224 | 24 | 64 | 64 | 7 × 15 × 512 | |||
| Inception4c | 128 | 128 | 256 | 24 | 64 | 64 | 7 × 15 × 512 | |||
| Inception4d | 112 | 144 | 288 | 32 | 64 | 64 | 7 × 15 × 528 | |||
| Inception4e | 256 | 160 | 320 | 32 | 128 | 128 | 7 × 15 × 832 | |||
| Max Pooling | 3 × 3/2 | 3 × 7 × 832 | ||||||||
| Conv5 | Inception5a | 256 | 160 | 320 | 32 | 128 | 128 | 3 × 7 × 832 | ||
| Inception5b | 384 | 192 | 384 | 48 | 128 | 128 | 3 × 7 × 1024 | |||
| Average Pooling | 3 × 7/1 | 1 × 1 × 1024 | ||||||||
| Fully-Connected Layer | Dropout | |||||||||
| Fc | 116 | |||||||||
| Softmax | ||||||||||
| Layer Name | Filter Size | Stride | Padding | Number of Filters | Output Feature Map Size | ||
|---|---|---|---|---|---|---|---|
| Image Input Layer | 120 × 240 × 3 | ||||||
| Conv1 | Conv. | 7 × 7 × 3 | 2 | 3 | 64 | 60 × 120 × 64 | |
| BN | |||||||
| Max Pooling | 3 × 3 | 2 | 1 | 30 × 60 × 64 | |||
| Conv2 | Res2a | Conv. | 3 × 3 × 64 | 1 | 1 | 64 | 30 × 60 × 64 |
| Conv. | 3 × 3 × 64 | 1 | 1 | 64 | |||
| Res2b | Conv. | 3 × 3 × 64 | 1 | 1 | 64 | 30 × 60 × 64 | |
| Conv. | 3 × 3 × 64 | 1 | 1 | 64 | |||
| Conv3 | Res3a | Conv. | 3 × 3 × 64 | 2 | 1 | 128 | 15 × 30 × 128 |
| Conv. | 3 × 3 × 128 | 1 | 1 | 128 | |||
| Conv. (Shortcut) | 1 × 1 × 64 | 2 | 0 | 128 | |||
| Res3b | Conv. | 3 × 3 × 128 | 1 | 1 | 128 | 15 × 30 × 128 | |
| Conv. | 3 × 3 × 128 | 1 | 1 | 128 | |||
| Conv4 | Res4a | Conv. | 3 × 3 × 128 | 2 | 1 | 256 | 8 × 15 × 256 |
| Conv. | 3 × 3 × 256 | 1 | 1 | 256 | |||
| Conv. (Shortcut) | 1 × 1 × 128 | 2 | 0 | 256 | |||
| Res4b | Conv. | 3 × 3 × 256 | 1 | 1 | 256 | 8 × 15 × 256 | |
| Conv. | 3 × 3 × 256 | 1 | 1 | 256 | |||
| Conv5 | Res5a | Conv. | 3 × 3 × 256 | 2 | 1 | 512 | 4 × 8 × 512 |
| Conv. | 3 × 3 × 512 | 1 | 1 | 512 | |||
| Conv. (Shortcut) | 1 × 1 × 256 | 2 | 0 | 512 | |||
| Res5b | Conv. | 3 × 3 × 512 | 1 | 1 | 512 | 4 × 8 × 512 | |
| Conv. | 3 × 3 × 512 | 1 | 1 | 512 | |||
| Average Pooling | 4 × 8 | 0 | 1 × 1 × 512 | ||||
| Fully-Connected Layers | Fc | 116 | |||||
| Softmax | |||||||
| Layer Name | Filter Size | Stride | Padding | Number of Filters | Output Feature Map Size | ||
|---|---|---|---|---|---|---|---|
| Image Input Layer | 120 × 240 × 3 | ||||||
| Conv1 | Conv. | 7 × 7 × 3 | 2 | 3 | 64 | 60 × 120 × 64 | |
| BN | |||||||
| Max Pooling | 3 × 3 | 2 | 1 | 29 × 59 × 64 | |||
| Conv2 | Res2a | Conv. | 1 × 1 × 64 | 1 | 0 | 64 | 29 × 59 × 256 |
| Conv. | 3 × 3 × 64 | 1 | 1 | 64 | |||
| Conv. | 1 × 1 × 64 | 1 | 0 | 256 | |||
| Conv. (Shortcut) | 1 × 1 × 64 | 1 | 0 | 256 | |||
| Res2b-c | Conv. | 1 × 1 × 256 | 1 | 0 | 64 | 29 × 59 × 256 | |
| Conv. | 3 × 3 × 64 | 1 | 1 | 64 | |||
| Conv. | 1 × 1 × 64 | 1 | 0 | 256 | |||
| Conv3 | Res3a | Conv. | 1 × 1 × 256 | 2 | 0 | 128 | 15 × 30 × 512 |
| Conv. | 3 × 3 × 128 | 1 | 1 | 128 | |||
| Conv. | 1 × 1 × 128 | 1 | 0 | 512 | |||
| Conv. (Shortcut) | 1 × 1 × 256 | 2 | 0 | 512 | |||
| Res3b-d | Conv. | 1 × 1 × 512 | 1 | 0 | 128 | 15 × 30 × 512 | |
| Conv. | 3 × 3 × 128 | 1 | 1 | 128 | |||
| Conv. | 1 × 1 × 128 | 1 | 0 | 512 | |||
| Conv4 | Res4a | Conv. | 1 × 1 × 512 | 2 | 0 | 256 | 8 × 15 × 1024 |
| Conv. | 3 × 3 × 256 | 1 | 1 | 256 | |||
| Conv. | 1 × 1 × 256 | 1 | 0 | 1024 | |||
| Conv. (Shortcut) | 1 × 1 × 512 | 2 | 0 | 1024 | |||
| Res4b-f | Conv. | 1 × 1 × 1024 | 1 | 0 | 256 | 8 × 15 × 1024 | |
| Conv. | 3 × 3 × 256 | 1 | 1 | 256 | |||
| Conv. | 1 × 1 × 256 | 1 | 0 | 1024 | |||
| Conv5 | Res5a | Conv. | 1 × 1 × 1024 | 2 | 0 | 512 | 4 × 8 × 2048 |
| Conv. | 3 × 3 × 512 | 1 | 1 | 512 | |||
| Conv. | 1 × 1 × 512 | 1 | 0 | 2048 | |||
| Conv. (Shortcut) | 1 × 1 × 1024 | 2 | 0 | 2048 | |||
| Res5b-c | Conv. | 1 × 1 × 2048 | 1 | 0 | 512 | 4 × 8 × 2048 | |
| Conv. | 3 × 3 × 512 | 1 | 1 | 512 | |||
| Conv. | 1 × 1 × 512 | 1 | 0 | 2048 | |||
| Average Pooling | 4 × 8 | 1 | 0 | 1 × 1 × 2048 | |||
| Fully Connected Layers | Fc | 116 | |||||
| Softmax | |||||||
| Banknote Type | Number of Banknotes | Number of Banknotes after Data Augmentation | ||||
|---|---|---|---|---|---|---|
| Fit | Normal | Unfit | Fit | Normal | Unfit | |
| INR10 | 1299 | 553 | 196 | 2598 | 2212 | 1960 |
| INR20 | 898 | 456 | 57 | 2694 | 2280 | 1425 |
| INR50 | 719 | 235 | 206 | 1438 | 1175 | 2060 |
| INR100 | 1477 | 1464 | 243 | 2954 | 2928 | 1944 |
| INR500 | 1399 | 435 | 130 | 2798 | 2175 | 1950 |
| INR1000 | 153 | 755 | 71 | 1530 | 2265 | 1775 |
| KRW1000 | 3690 | 3344 | 2695 | 3690 | 3344 | 2695 |
| KRW5000 | 3861 | 3291 | 3196 | 3861 | 4045 | 3196 |
| KRW10000 | 3900 | 3779 | N/A | 3900 | 3779 | N/A |
| KRW50000 | 3794 | 3799 | N/A | 3794 | 3799 | N/A |
| USD5 | 177 | N/A | 111 | 3540 | N/A | 2775 |
| USD10 | 384 | N/A | 83 | 3072 | N/A | 2075 |
| USD20 | 390 | N/A | 51 | 3120 | N/A | 1275 |
| USD50 | 851 | N/A | 42 | 4255 | N/A | 1050 |
| USD100 | 772 | N/A | 90 | 3860 | N/A | 2250 |
| Method | AlexNet | ResNet-18 | ||||
|---|---|---|---|---|---|---|
| Banknote Recognition Accuracy | Fitness Classification Accuracy | Overall Accuracy | Banknote Recognition Accuracy | Fitness Classification Accuracy | Overall Accuracy | |
| Using Original Banknote Image | 99.535 | 97.035 | 96.773 | 99.608 | 97.532 | 97.408 |
| Using Segmented Banknote Image (Proposed Method) | 99.935 | 97.928 | 97.926 | 99.936 | 97.678 | 97.690 |
| Method | Banknote Type and Fitness Classification Accuracy (unit: %) | Banknote Fitness Value Estimation | ||||
|---|---|---|---|---|---|---|
| Banknote Recognition Accuracy | Fitness Classification Accuracy | Overall Accuracy | RMSE | AQE | ||
| Using VR Images and AlexNet [9,15] | 99.955 | 95.040 | 95.038 | 1.048 | 0.0688 | |
| Using IRT, VR images and CNNs (Proposed Method) | AlexNet | 99.935 | 97.928 | 97.926 | 0.920 | 0.0513 |
| ResNet-18 | 99.963 | 97.678 | 97.690 | 1.041 | 0.0522 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, T.D.; Nguyen, D.T.; Park, C.; Park, K.R. Deep Learning-Based Multinational Banknote Type and Fitness Classification with the Combined Images by Visible-Light Reflection and Infrared-Light Transmission Image Sensors. Sensors 2019, 19, 792. https://doi.org/10.3390/s19040792
Pham TD, Nguyen DT, Park C, Park KR. Deep Learning-Based Multinational Banknote Type and Fitness Classification with the Combined Images by Visible-Light Reflection and Infrared-Light Transmission Image Sensors. Sensors. 2019; 19(4):792. https://doi.org/10.3390/s19040792
Chicago/Turabian StylePham, Tuyen Danh, Dat Tien Nguyen, Chanhum Park, and Kang Ryoung Park. 2019. "Deep Learning-Based Multinational Banknote Type and Fitness Classification with the Combined Images by Visible-Light Reflection and Infrared-Light Transmission Image Sensors" Sensors 19, no. 4: 792. https://doi.org/10.3390/s19040792
APA StylePham, T. D., Nguyen, D. T., Park, C., & Park, K. R. (2019). Deep Learning-Based Multinational Banknote Type and Fitness Classification with the Combined Images by Visible-Light Reflection and Infrared-Light Transmission Image Sensors. Sensors, 19(4), 792. https://doi.org/10.3390/s19040792