Hybrid reference-based Video Source Identification



Abstract
:1. Introduction
2. Digital Video Source Device Identification Based on Sensor Pattern Noise
3. Hybrid Sensor Pattern Noise Analysis
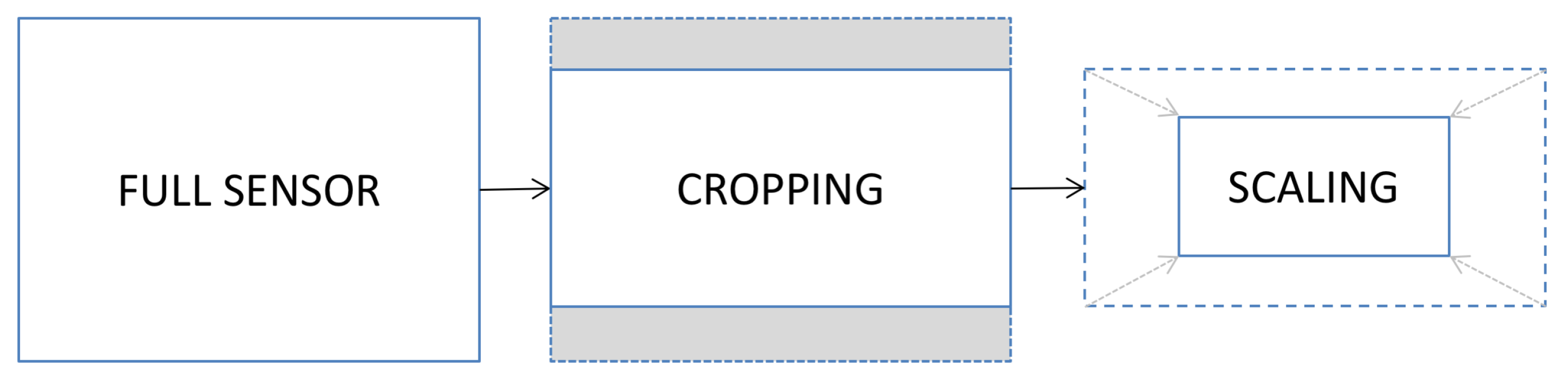
- the resize and cropping factors are determined by the device model (and, possibly, firmware). It is thus possible to build a lookup table that eliminates the need for an exhaustive search when information about the reference model is available;
- even when no information about the model is available, it is not necessary to repeat the whole search on all frames. Once a sufficiently high correlation is found for a given scale, the search can be restricted around it.
3.1. Source Identification of Digitally Stabilized Videos
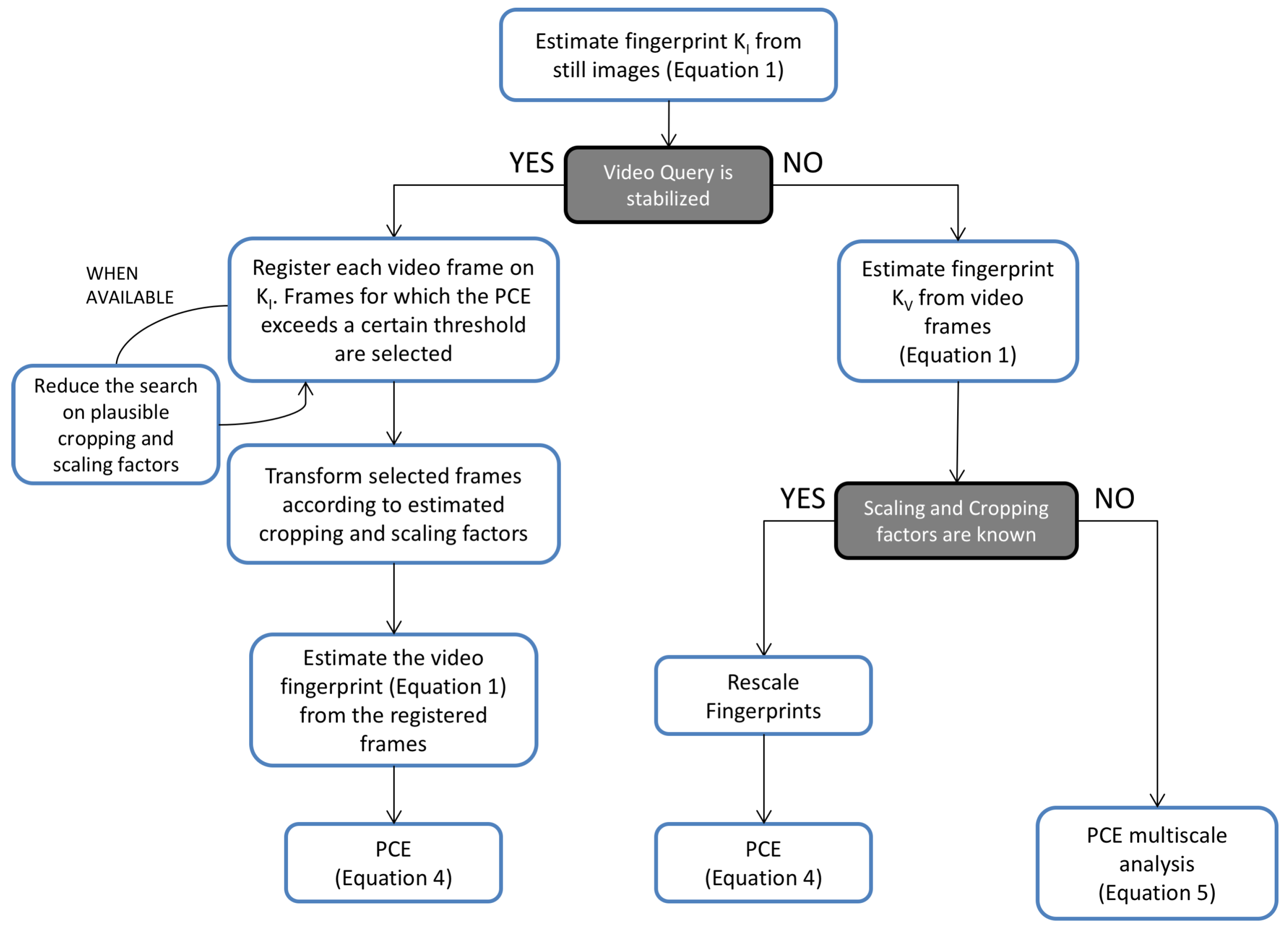
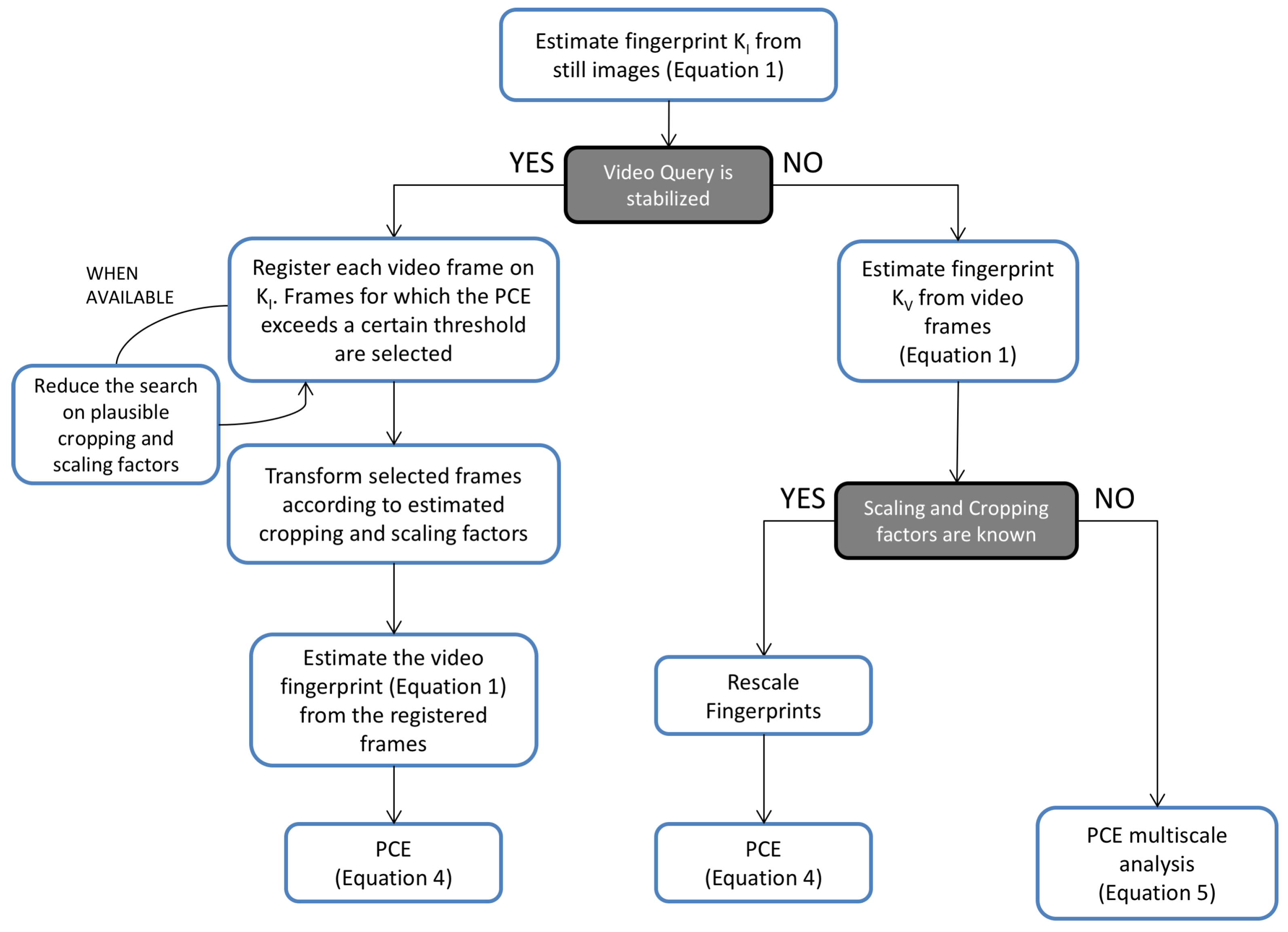
3.2. Hybrid Reference-Based Video Source Identification Pipeline
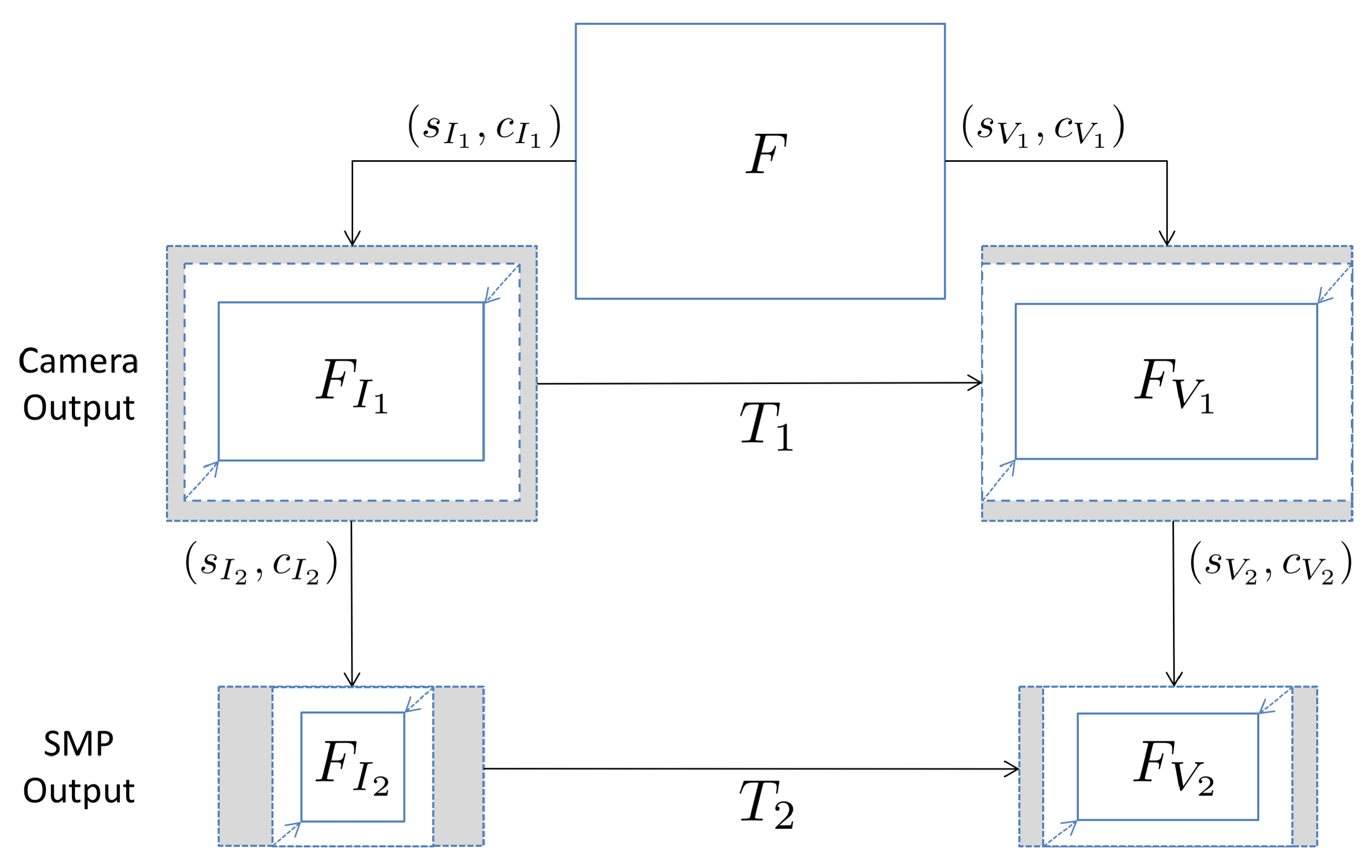
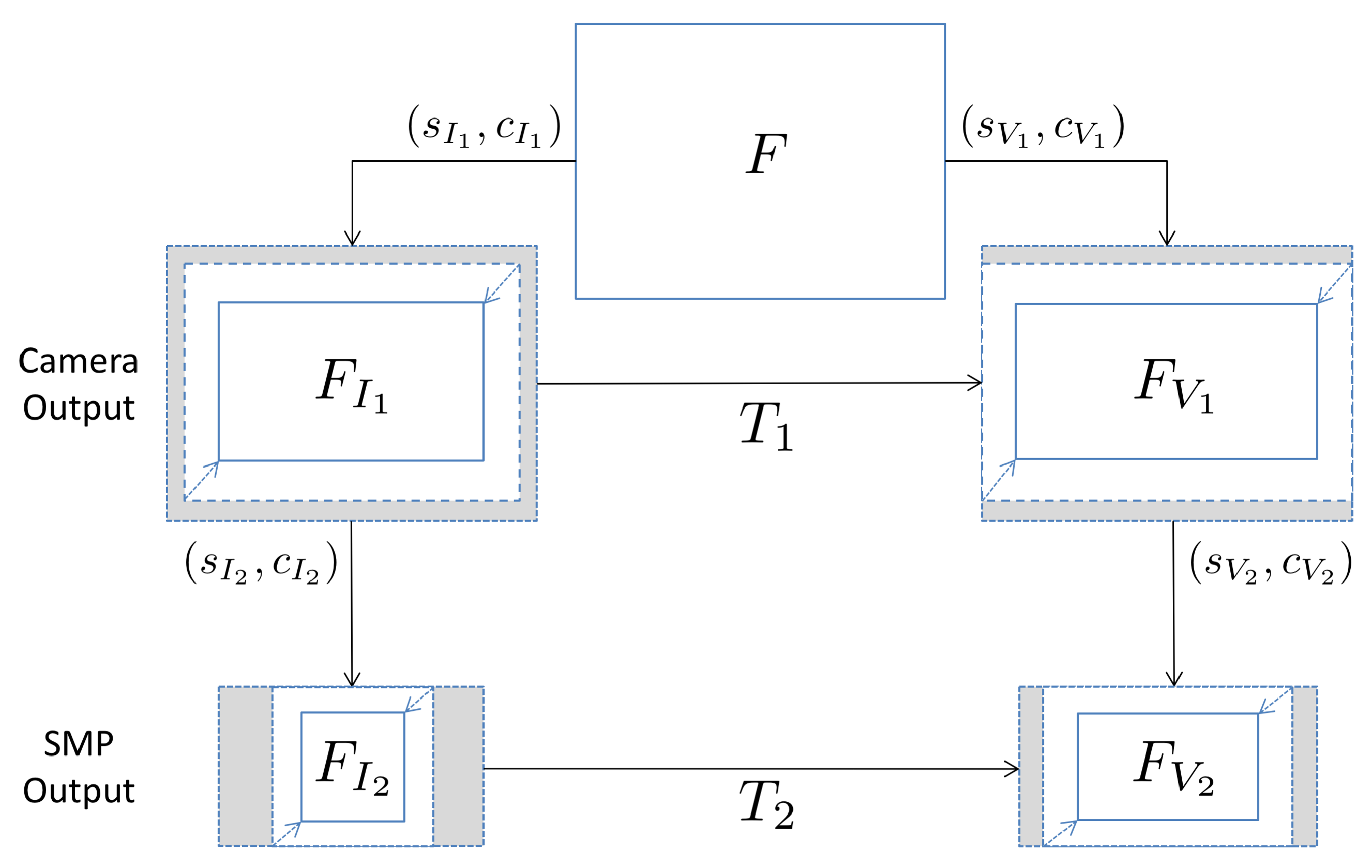
3.3. Extension to Contents Shared on Social Media Platforms
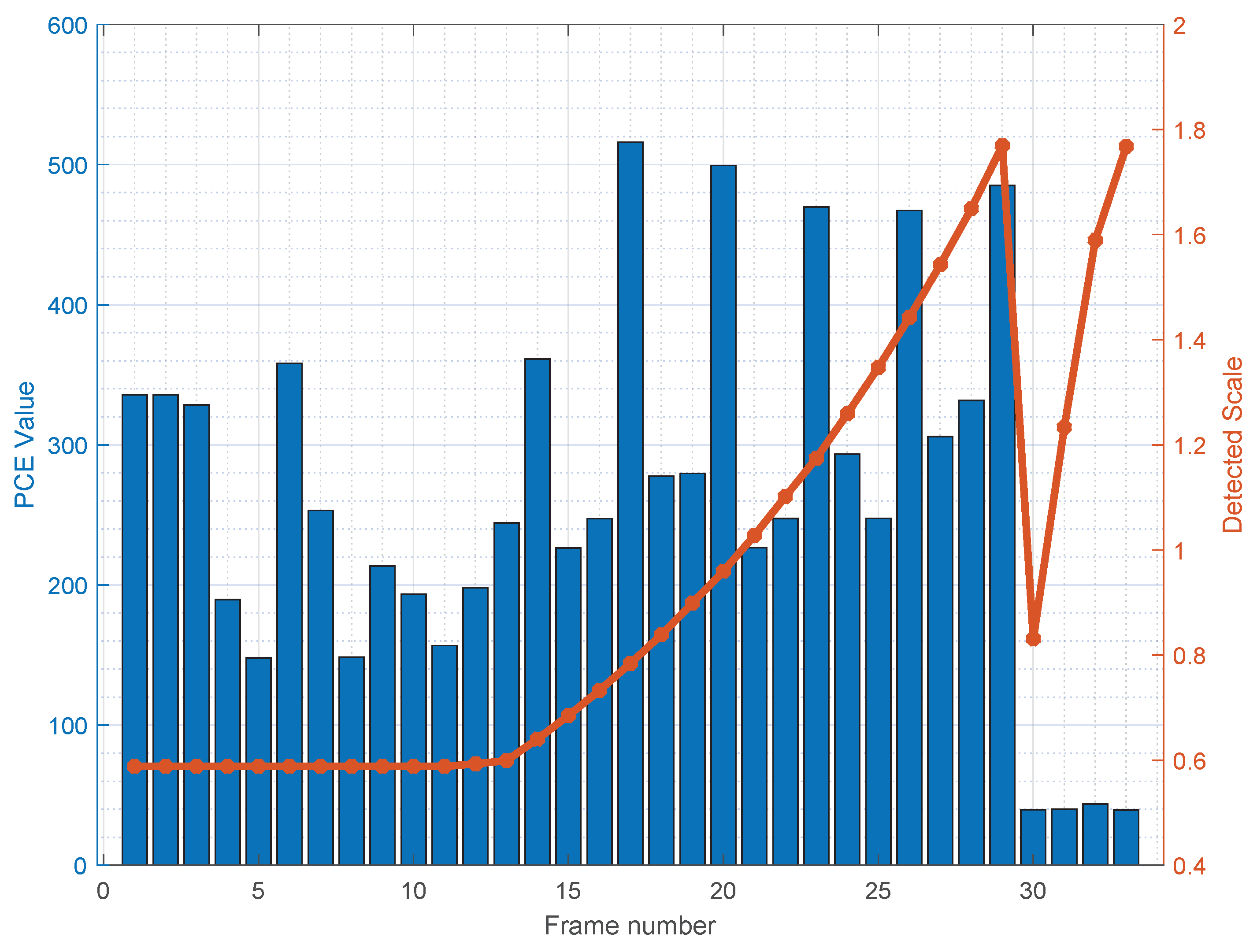
3.4. Extension to Digital Zoom
4. Dataset for HSI
- On the reference side: 100 flat-field images depicting skies or walls; 150 images of indoor and outdoor scenes; 1 video of the sky captured with slow camera movement, longer than 10 s;
- On the query side: videos of flat surfaces, indoor scenes and outdoor scenes. For each of the video categories (flat, indoor and outdoor) at least 3 different videos have been captured considering the three different scenarios available in the Dataset: (i) still camera, (ii) walking operator and (iii) panning and rotating camera. We will refer to them as still, move and panrot videos respectively. Thus, each device has at least 9 videos, each one lasting more than 60 s.
5. Experimental Validation
- We determine the cropping and scaling parameters applied by each device model in the considered set;
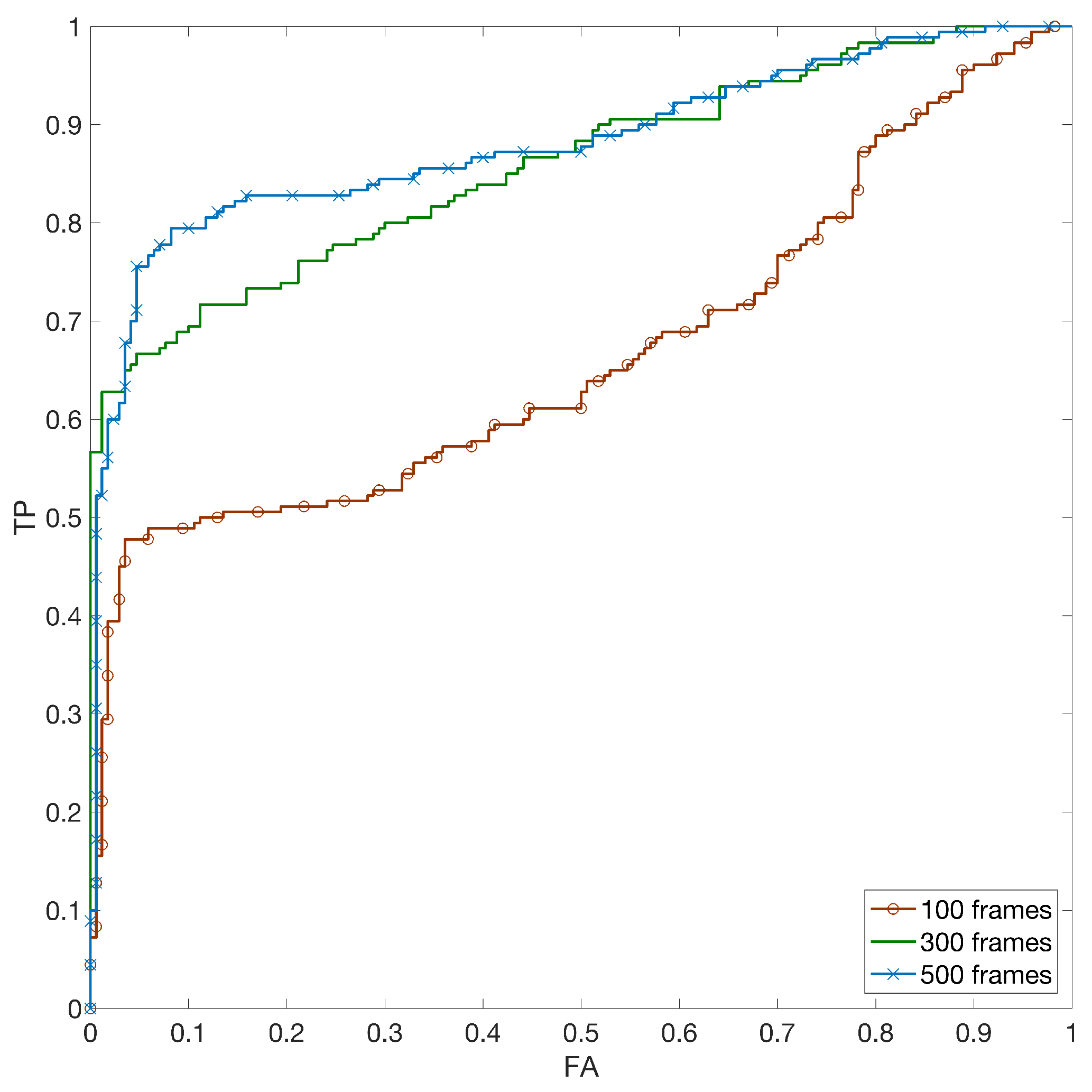
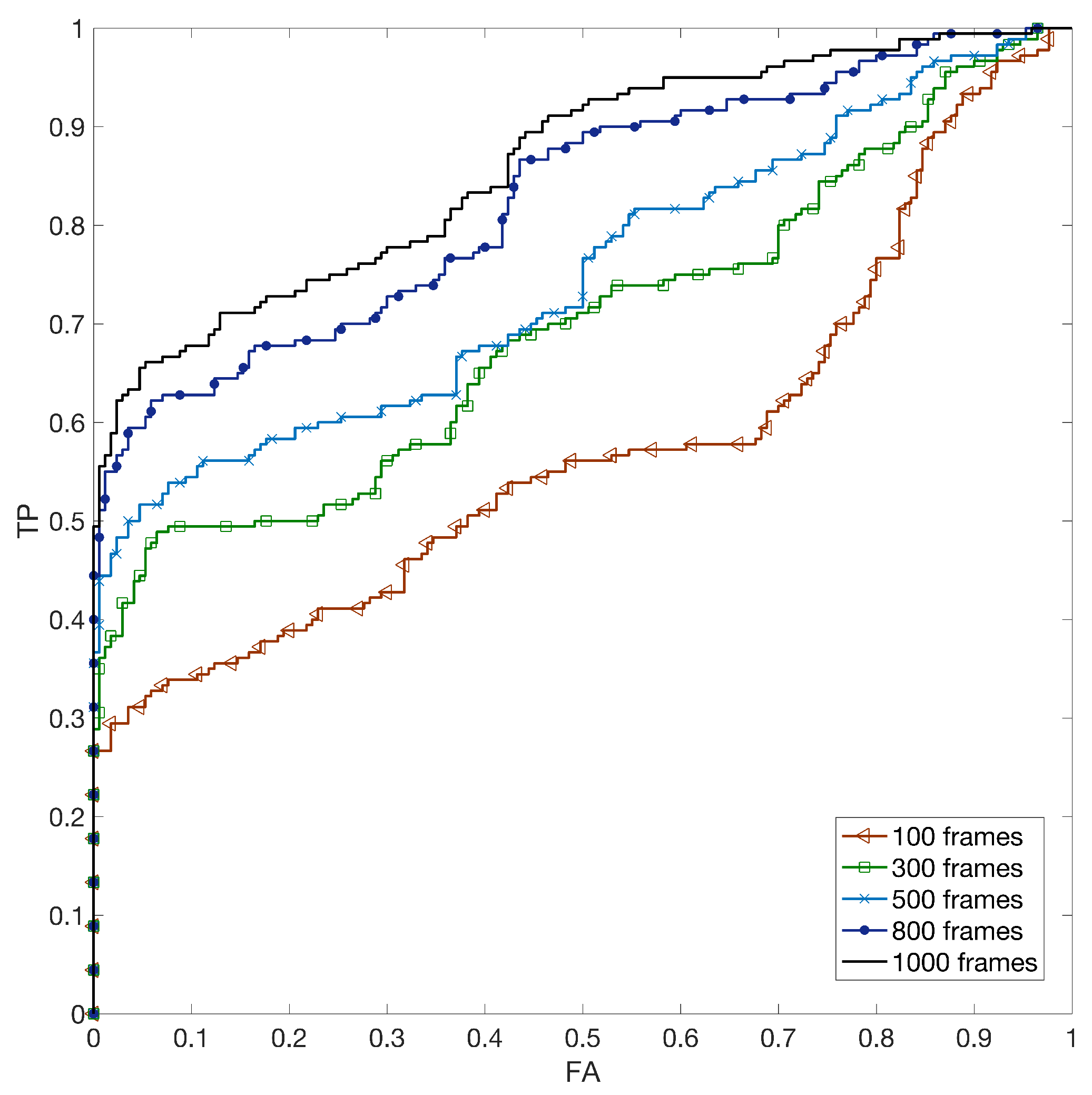
- We verify that, in the case of non-stabilized video, the performance of the hybrid approach is comparable with the source identification based on a video reference;
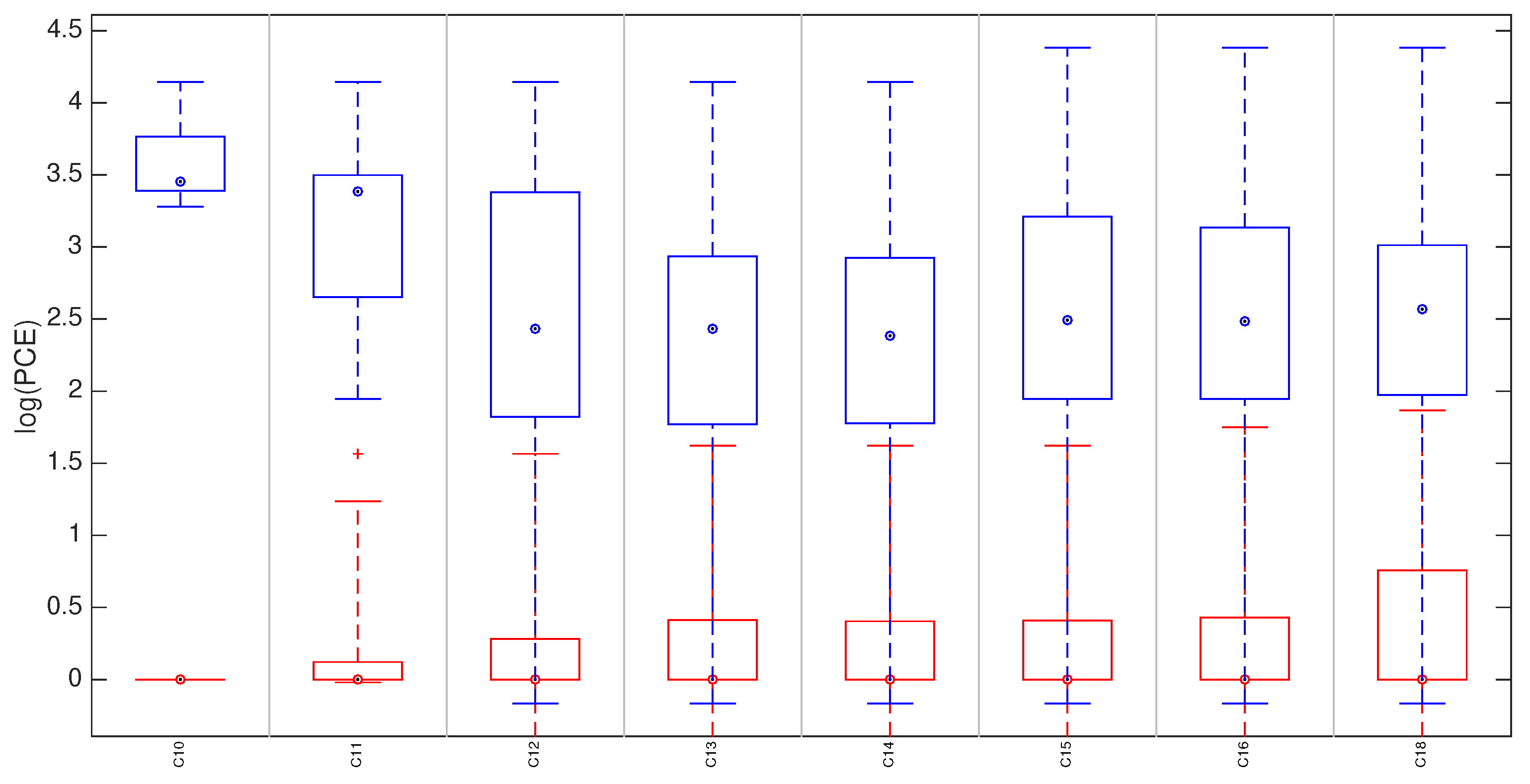
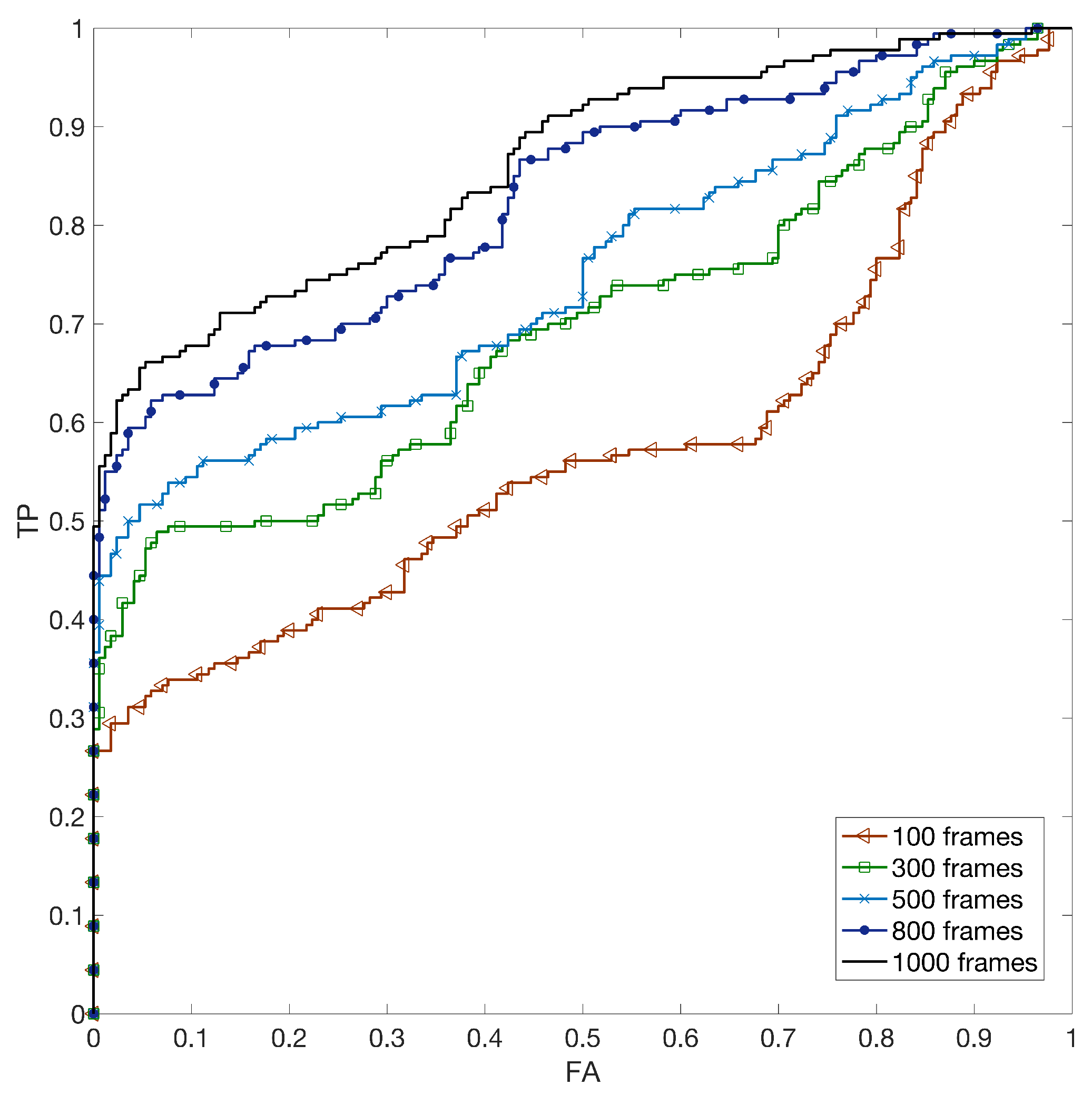
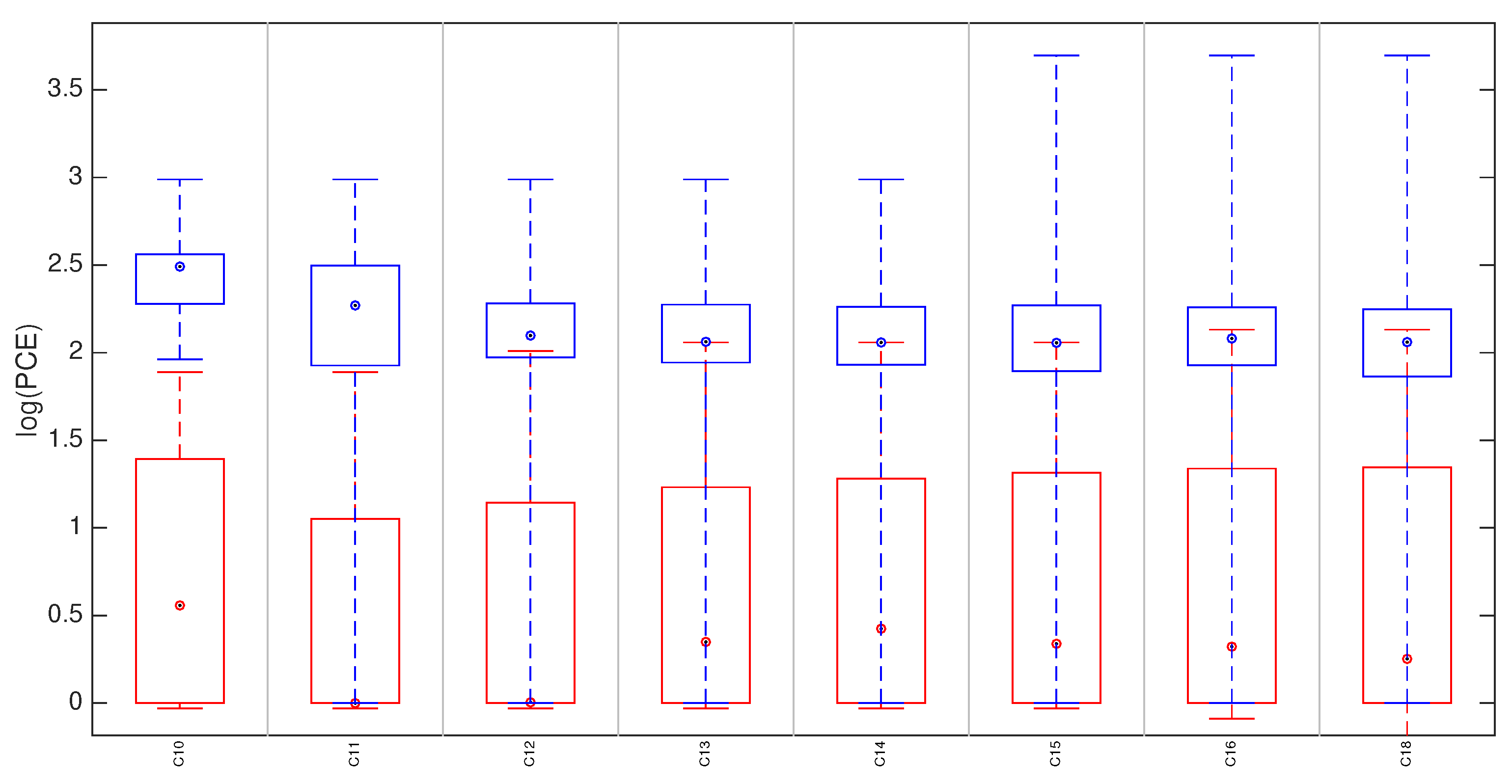
- We show the effectiveness in identifying the source of in-camera digitally stabilized videos;
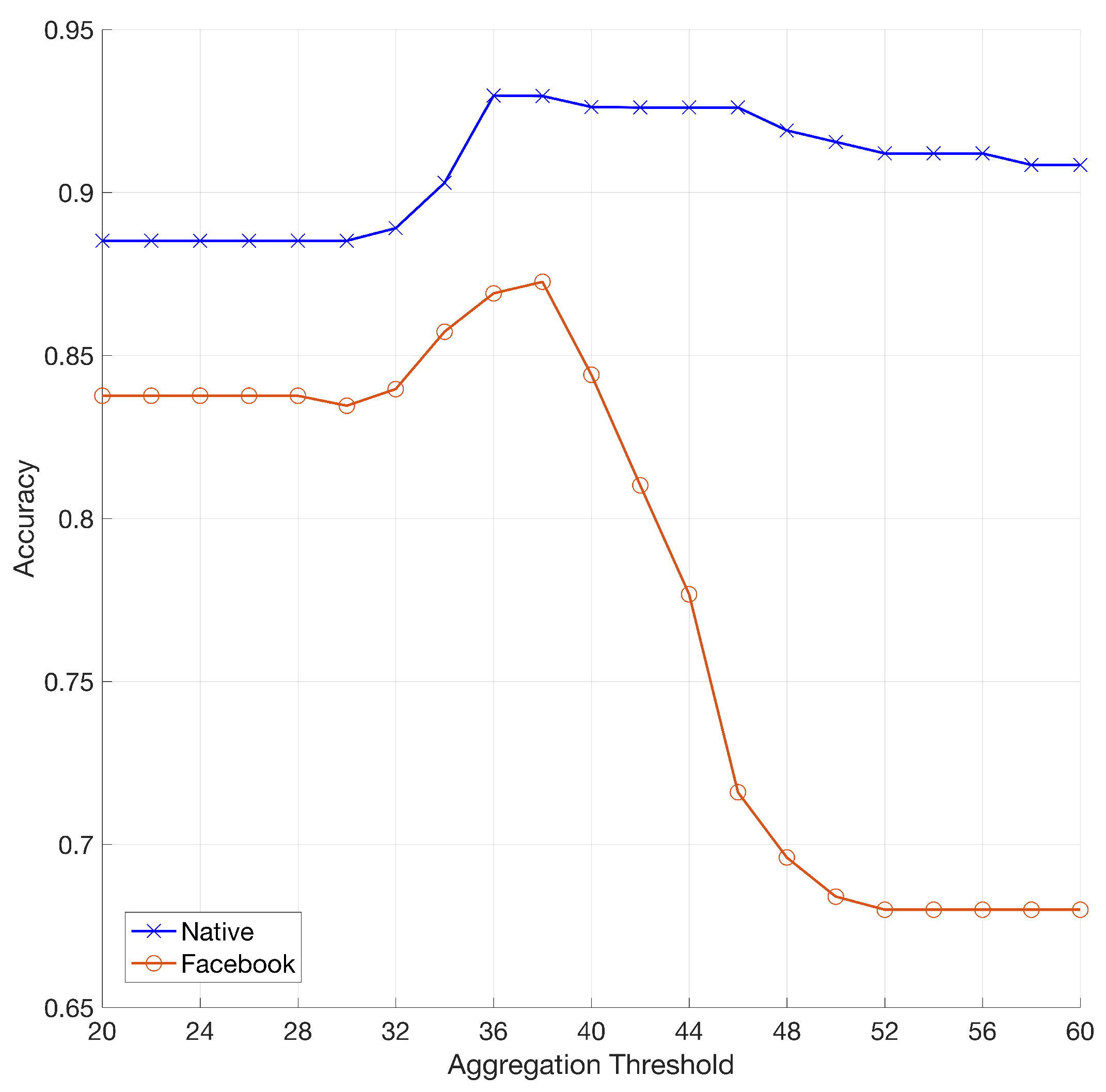
- We show the performance in linking Facebook and YouTube profiles;
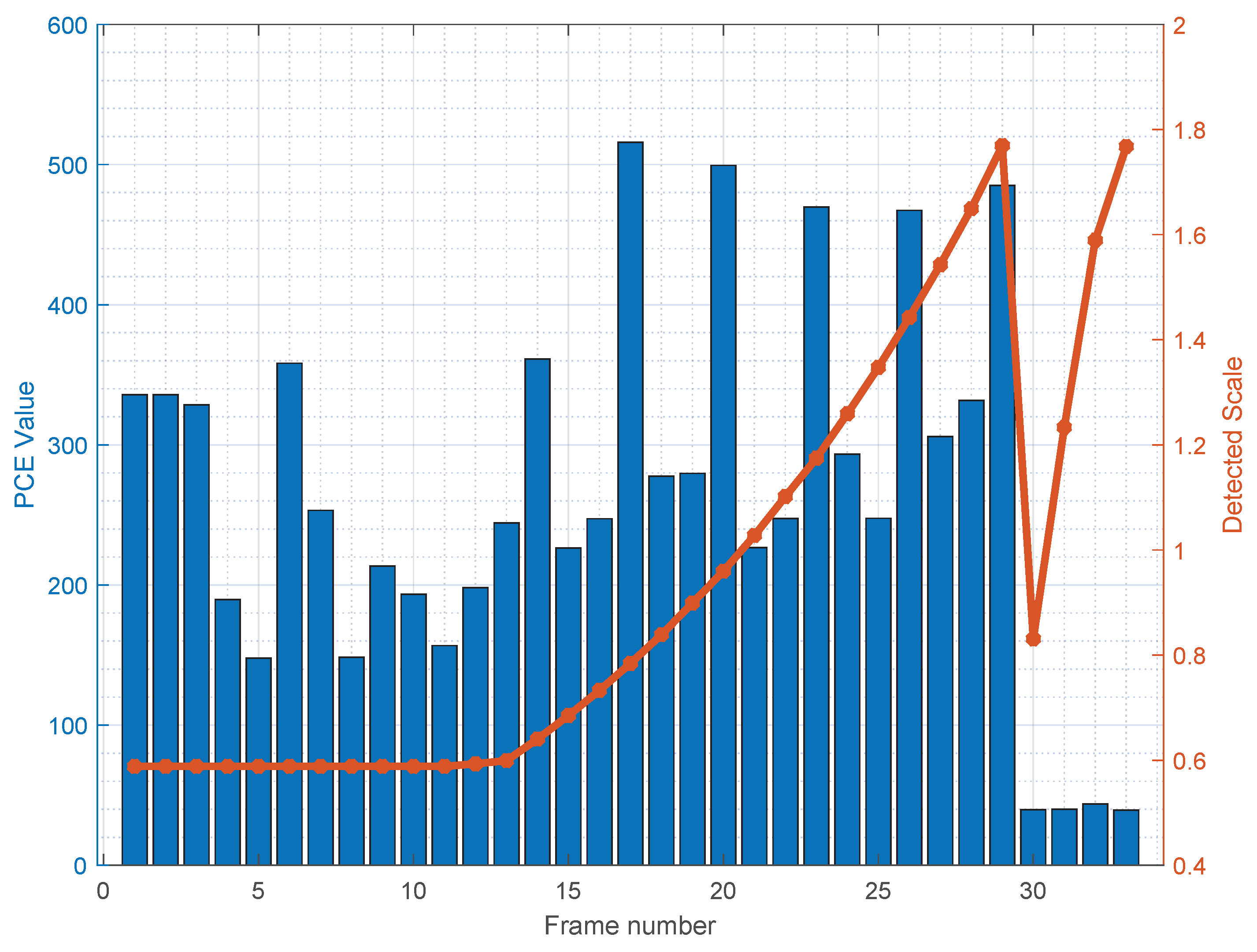
- We demonstrate the effectiveness of the method in the presence of digital zoom.
5.1. Fingerprints Matching Parameters
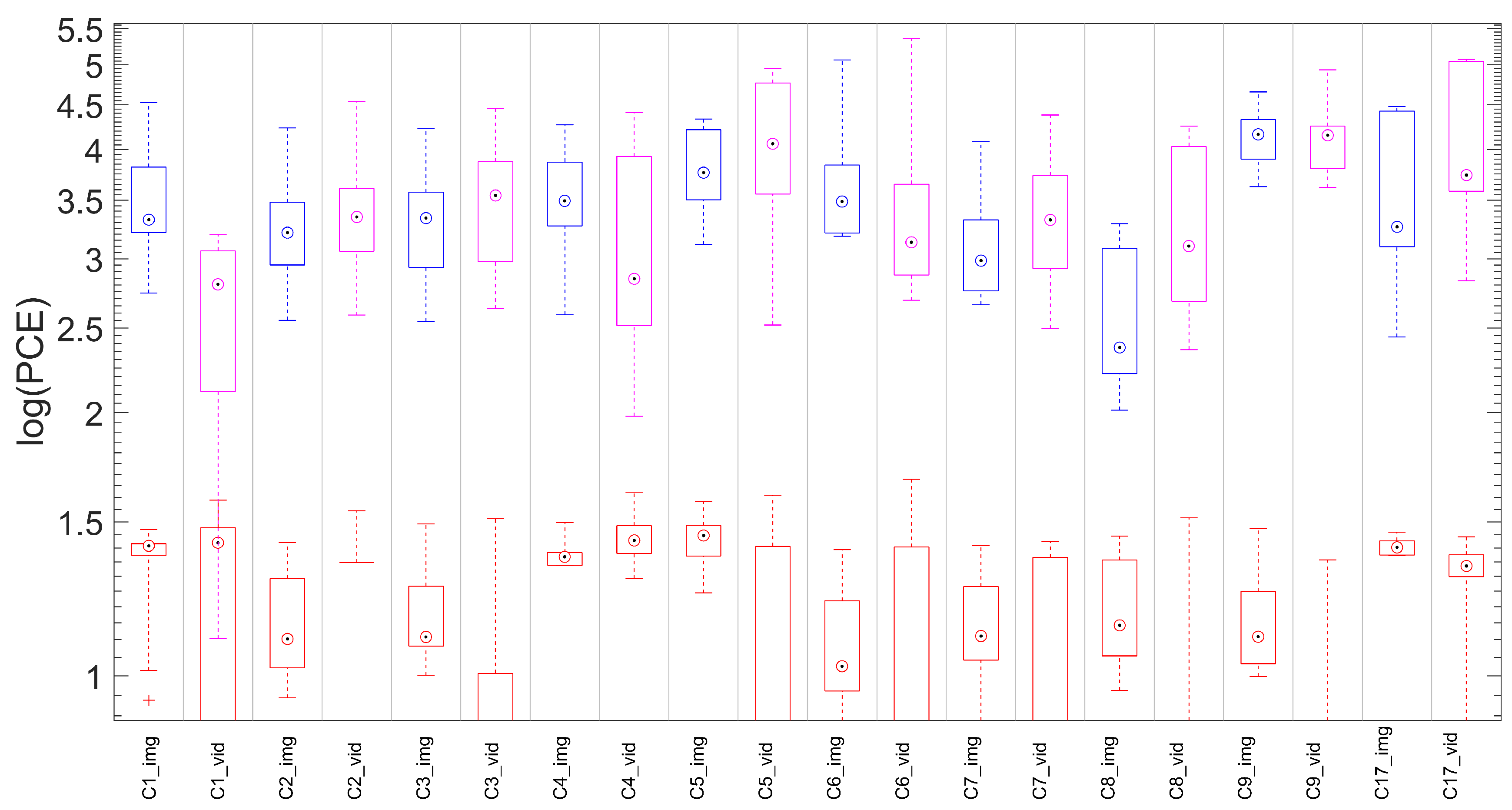
5.2. Hybrid Reference-Based Video Source Identification Performance
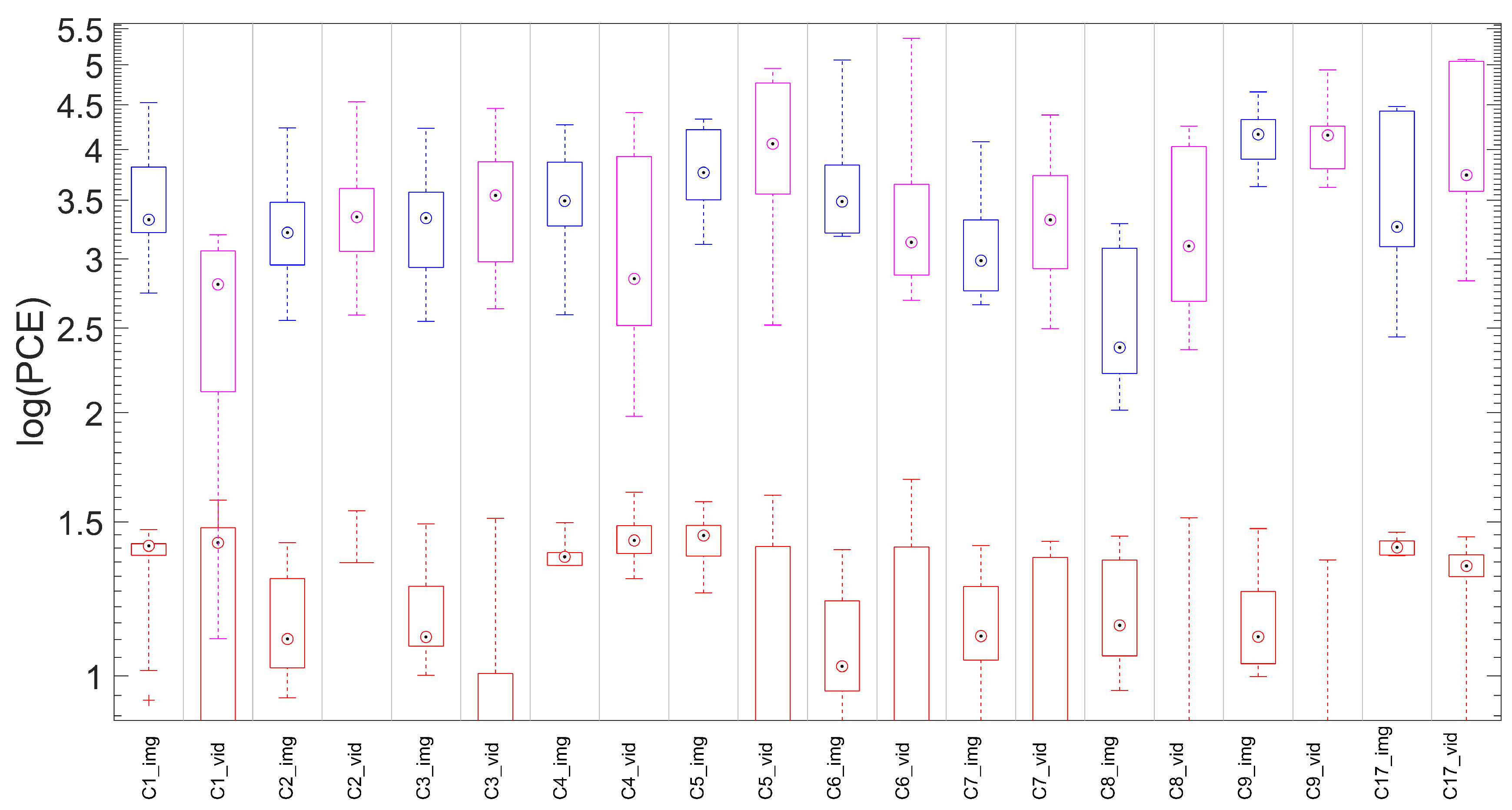
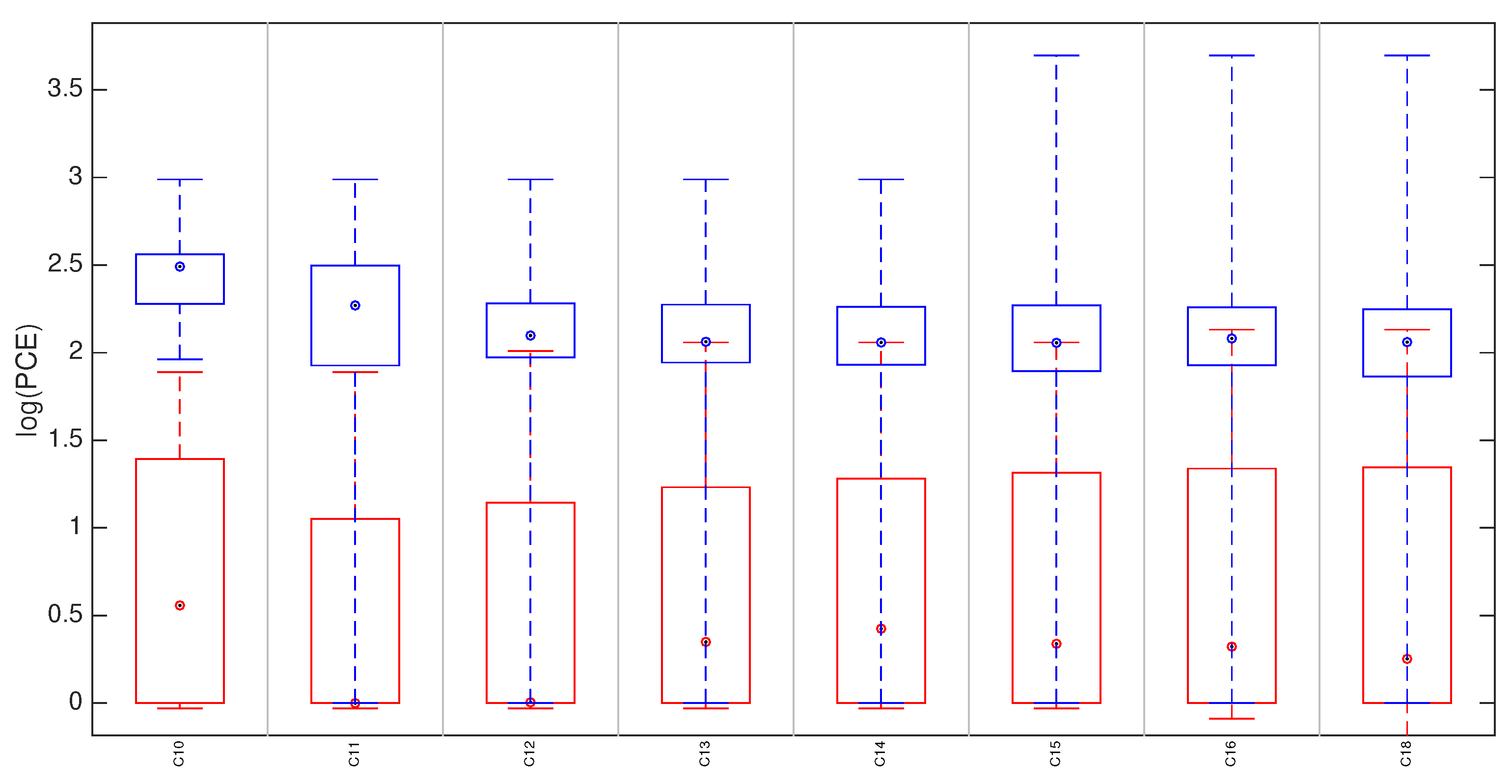
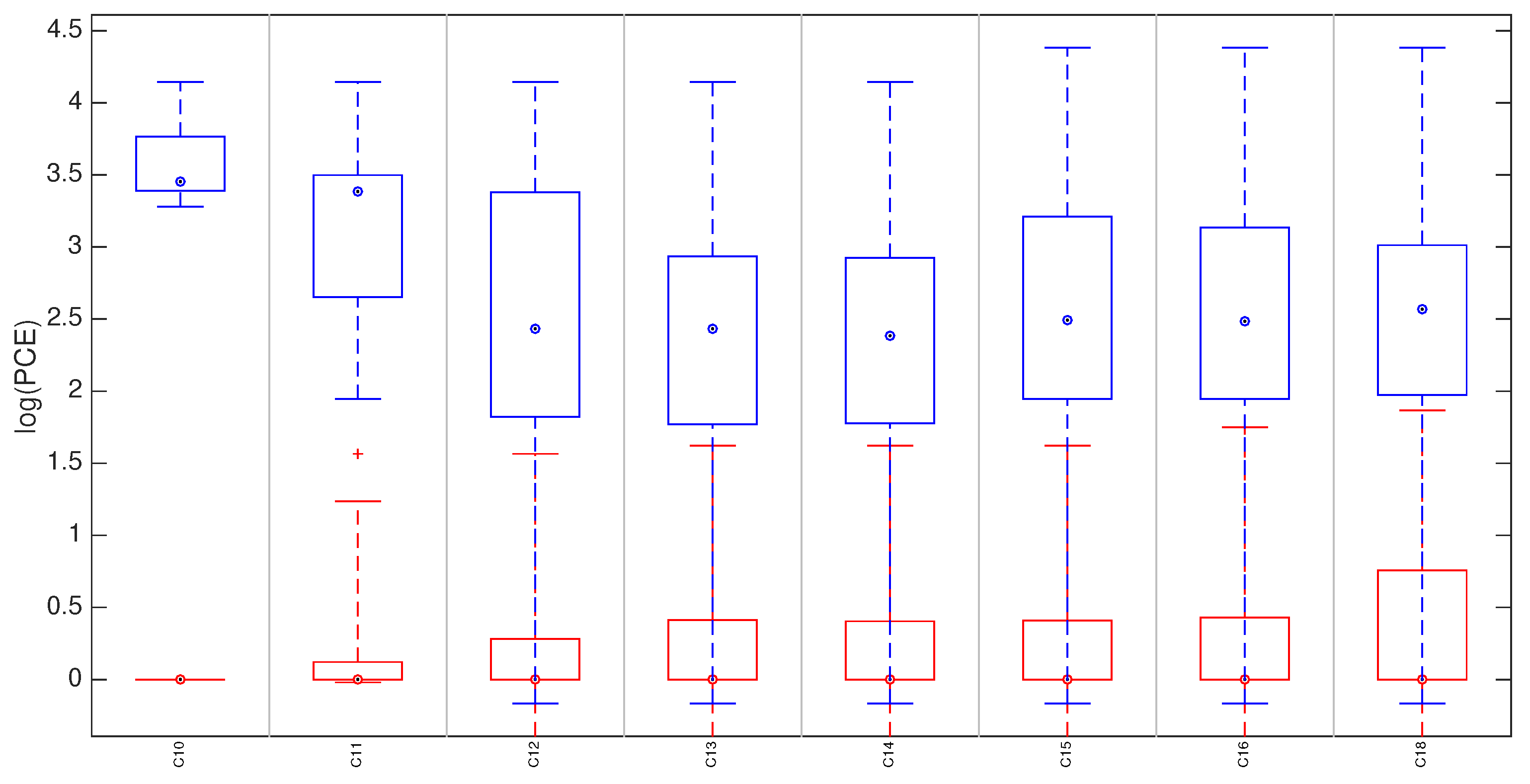
5.3. Hybrid Reference-Based Video Source Identification Performance on Stabilized Videos
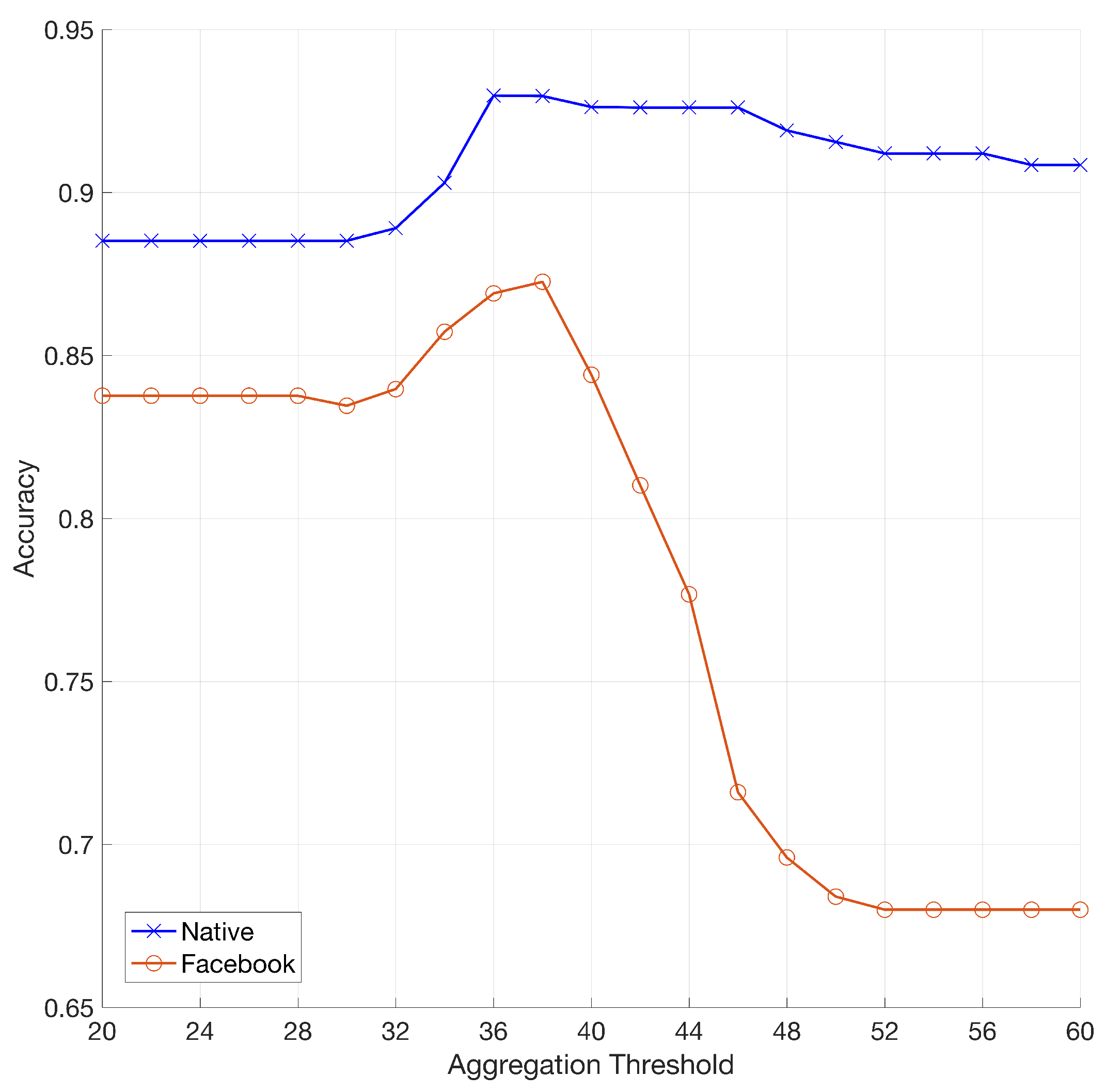
5.4. Results on Contents from SMPs
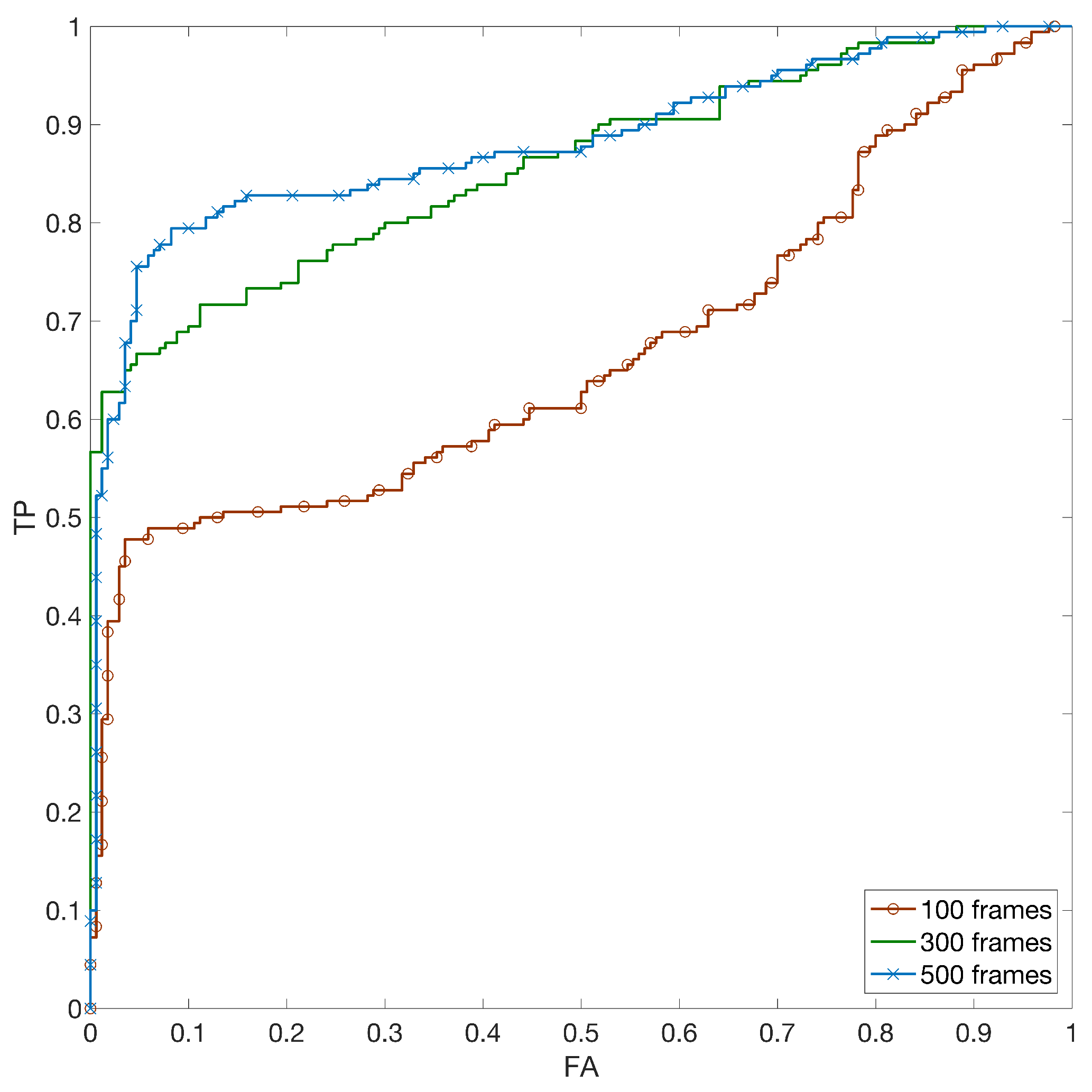
5.5. Results on Digitally Zoomed Videos
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Peterson, T. Facebook Users Are Posting 75% More Videos Than Last Year. 2016. Available online: https://goo.gl/e8yQFp (accessed on 22 January 2019).
- Beck, M. Reversal of Facebook: Photo Posts Now Drive Lowest Organic Reach. 2015. Available online: https://goo.gl/dqT69v (accessed on 22 January 2019).
- Maxwell, R. Camera vs. Smartphone: Infographic Shares the Impact Our Smartphones Have Had on Regular Cameras. 2016. Available online: https://goo.gl/2VVZfp (accessed on 22 January 2019).
- Piva, A. An overview on image forensics. ISRN Signal Process. 2013. [Google Scholar] [CrossRef]
- Lukas, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Castiglione, A.; Cattaneo, G.; Cembalo, M.; Petrillo, U.F. Experimentations with source camera identification and online social networks. J. Ambient Intell. Hum. Comput. 2013, 4, 265–274. [Google Scholar] [CrossRef]
- Bertini, F.; Sharma, R.; Iannı, A.; Montesi, D.; Zamboni, M.A. Social media investigations using shared photos. In Proceedings of the International Conference on Computing Technology, Information Security and Risk Management (CTISRM), Dubai, UAE, 2–4 March 2016; pp. 47–60. [Google Scholar]
- Chen, M.; Fridrich, J.; Goljan, M.; Lukáš, J. Source digital camcorder identification using sensor photo response non-uniformity. In Security, Steganography, and Watermarking of Multimedia Contents IX; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6505, p. 65051G. [Google Scholar]
- Mondaini, N.; Caldelli, R.; Piva, A.; Barni, M.; Cappellini, V. Detection of malevolent changes in digital video for forensic applications. In Security, Steganography, and Watermarking of Multimedia Contents IX; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6505, p. 65050T. [Google Scholar]
- Taspinar, S.; Mohanty, M.; Memon, N. Source camera attribution using stabilized video. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, UAE, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Dirik, A.E.; Sencar, H.T.; Memon, N. Digital single lens reflex camera identification from traces of sensor dust. IEEE Trans. Inf. Forensics Secur. 2008, 3, 539–552. [Google Scholar] [CrossRef]
- Geradts, Z.J.; Bijhold, J.; Kieft, M.; Kurosawa, K.; Kuroki, K.; Saitoh, N. Methods for identification of images acquired with digital cameras. In Enabling Technologies for Law Enforcement; International Society for Optics and Photonics: Bellingham, WA, USA, 2001; pp. 505–512. [Google Scholar]
- Bayram, S.; Sencar, H.T.; Memon, N.; Avcibas, I. Source camera identification based on CFA interpolation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Genova, Italy, 14 September 2005; Volume 3. [Google Scholar] [CrossRef]
- Goljan, M.; Fridrich, J.; Filler, T. Large scale test of sensor fingerprint camera identification. In Media Forensics and Security; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; Volume 7254, p. 72540I. [Google Scholar]
- Cattaneo, G.; Roscigno, G.; Petrillo, U.F. A scalable approach to source camera identification over Hadoop. In Proceedings of the IEEE International Conference on Advanced Information Networking and Applications (AINA), Victoria, BC, Canada, 13–16 May 2014; pp. 366–373. [Google Scholar]
- Gloe, T.; Böhme, R. The Dresden image database for benchmarking digital image forensics. J. Digit. Forensic Pract. 2010, 3, 150–159. [Google Scholar] [CrossRef]
- Liu, B.b.; Wei, X.; Yan, J. Enhancing sensor pattern noise for source camera identification: An empirical evaluation. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ’15), Portland, OR, USA, 17–19 June 2015; pp. 85–90. [Google Scholar]
- Valsesia, D.; Coluccia, G.; Bianchi, T.; Magli, E. Compressed fingerprint matching and camera Iientification via random projections. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1472–1485. [Google Scholar] [CrossRef]
- Marra, F.; Poggi, G.; Sansone, C.; Verdoliva, L. Blind PRNU-based image clustering for source identification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2197–2211. [Google Scholar] [CrossRef]
- Van Houten, W.; Geradts, Z. Source video camera identification for multiply compressed videos originating from Youtube. Digit. Investig. 2009, 6, 48–60. [Google Scholar] [CrossRef]
- Yannick, S.; van der Lelie, J.; Geradts, Z.; Worring, M. Camera identification on Youtube. Chin. J. Forensic Sci. 2012, 5, 19–30. [Google Scholar]
- Chuang, W.H.; Su, H.; Wu, M. Exploring compression effects for improved source camera identification using strongly compressed video. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 1953–1956. [Google Scholar]
- Chen, S.; Pande, A.; Zeng, K.; Mohapatra, P. Live video forensics: Source identification in lossy wireless networks. IEEE Trans. Inf. Forensics Secur. 2015, 10, 28–39. [Google Scholar] [CrossRef]
- Hoglund, T.; Brolund, P.; Norell, K. Identifying camcorders using noise patterns from video clips recorded with image stabilisation. In Proceedings of the International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 4–6 September 2011; pp. 668–671. [Google Scholar]
- Mihcak, M.K.; Kozintsev, I.; Ramchandran, K. Spatially adaptive statistical modeling of wavelet image coefficients and its application to denoising. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Phoenix, AZ, USA, 15–19 March 1999; Volume 6, pp. 3253–3256. [Google Scholar]
- Chen, M.; Fridrich, J.; Goljan, M.; Lukáš, J. Determining image origin and integrity using sensor noise. IEEE Trans. Inf. Forensics Secur. 2008, 3, 74–90. [Google Scholar] [CrossRef]
- Holt, C.R. Two-channel likelihood detectors for arbitrary linear channel distortion. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 267–273. [Google Scholar] [CrossRef]
- Goljan, M.; Fridrich, J. Camera identification from cropped and scaled images. In Security, Forensics, Steganography, and Watermarking of Multimedia Contents X; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; Volume 6819, p. 68190E. [Google Scholar]
- Mandelli, S.; Bestagini, P.; Verdoliva, L.; Tubaro, S. Facing device attribution problem for stabilized video sequences. arXiv, 2018; arXiv:1811.01820. [Google Scholar]
- Moltisanti, M.; Paratore, A.; Battiato, S.; Saravo, L. Image manipulation on Facebook for forensics evidence. In Proceedings of the International Conference on Image Analysis and Processing (ICIAP), Genoa, Italy, 7–11 September 2015; pp. 506–517. [Google Scholar]
- Giammarrusco, Z.P. Source Identification of High Definition Videos: A Forensics Analysis of Downloaders and Youtube Video Compression Using a Group of Action Cameras. Ph.D. Thesis, University of Colorado, Denver, CO, USA, 2014. [Google Scholar]
- Shullani, D.; Fontani, M.; Iuliani, M.; Al Shaya, O.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 15. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Model | Image Resolution | Video Resolution | Digital Stab |
|---|---|---|---|---|
| C1 | Galaxy S3 | off | ||
| C2 | Galaxy S3 Mini | off | ||
| C3 | Galaxy S3 Mini | off | ||
| C4 | Galaxy S4 Mini | off | ||
| C5 | Galaxy Tab 3 10.1 | off | ||
| C6 | Galaxy Tab A 10.1 | off | ||
| C7 | Galaxy Trend Plus | off | ||
| C8 | Ascend G6 | off | ||
| C9 | Ipad 2 | off | ||
| C10 | Ipad Mini | on | ||
| C11 | Iphone 4s | on | ||
| C12 | Iphone 5 | on | ||
| C13 | Iphone 5c | on | ||
| C14 | Iphone 5c | on | ||
| C15 | Iphone 6 | on | ||
| C16 | Iphone 6 | on | ||
| C17 | Lumia 640 | off | ||
| C18 | Xperia Z1c | on |
| ID | Scaling | Central Crop along x and y axes |
|---|---|---|
| C1 | 0.59 | [0 307] |
| C2 | 0.5 | [0 228] |
| C3 | 0.5 | [0 228] |
| C4 | 0.59 | [0 0] |
| C5 | 1 | [408 354] |
| C6 | 0.49 | [0 246] |
| C7 | 0.5 | [0 240] |
| C8 | 0.39 | [0 306] |
| C9 | 1 | [−160 0] |
| C17 | 0.59 | [0 1] |
| ID | Scaling | Central Crop along x and y | Rotation (CCW) |
|---|---|---|---|
| C10 | [0.806 0.815 0.821] | [243 256 261] [86 100 103] | [−0.2 0 0.2] |
| C11 | [0.748 0.750 0.753] | [380 388 392] [250 258 265] | [−0.2 0 0.2] |
| C12 | [0.684 0.689 0.691] | [287 294 304] [135 147 165] | [−0.2 0 0.6] |
| C13 | [0.681 0.686 0.691] | [301 318 327] [160 181 195] | [−0.4 0 1] |
| C14 | [0.686 0.686 0.689] | [261 301 304] [119 161 165] | [−0.4 0 0] |
| C15 | [0.696 0.703 0.713] | [298 322 345] [172 190 218] | [−0.2 0.2 1.6] |
| C16 | [0.703 0.706 0.708] | [315 323 333] [178 187 201] | [−0.2 0.2 0.4] |
| C18 | [0.381 0.384 0.387] | [548 562 574] [116 121 126] | [0 0 0] |
| Reference | Query | TPR [10] | FPR [10] |
|---|---|---|---|
| Non-stabilized | Stabilized | 0.83 | 0 |
| Stabilized | Stabilized | 0.65 | 0 |
| Aggregation Threshold () | Accuracy | TPR | FPR |
|---|---|---|---|
| 30 | 89% | 0.79 | 0.02 |
| 32 | 89% | 0.82 | 0.05 |
| 34 | 90% | 0.84 | 0.03 |
| 36 | 93% | 0.87 | 0.01 |
| 38 | 93% | 0.86 | 0 |
| 40 | 93% | 0.87 | 0.01 |
| 42 | 93% | 0.85 | 0 |
| 44 | 93% | 0.85 | 0 |
| 46 | 93% | 0.85 | 0 |
| 48 | 92% | 0.84 | 0 |
| 50 | 92% | 0.83 | 0 |
| 52 | 91% | 0.82 | 0 |
| 54 | 91% | 0.82 | 0 |
| Test Case | Max | Scale |
|---|---|---|
| Zoom only (1080p video) | 1.3085 | |
| Zoom and YouTube @1080p | 1.3085 | |
| Zoom and YouTube @720p | 0.8722 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iuliani, M.; Fontani, M.; Shullani, D.; Piva, A. Hybrid reference-based Video Source Identification. Sensors 2019, 19, 649. https://doi.org/10.3390/s19030649
Iuliani M, Fontani M, Shullani D, Piva A. Hybrid reference-based Video Source Identification. Sensors. 2019; 19(3):649. https://doi.org/10.3390/s19030649
Chicago/Turabian StyleIuliani, Massimo, Marco Fontani, Dasara Shullani, and Alessandro Piva. 2019. "Hybrid reference-based Video Source Identification" Sensors 19, no. 3: 649. https://doi.org/10.3390/s19030649
APA StyleIuliani, M., Fontani, M., Shullani, D., & Piva, A. (2019). Hybrid reference-based Video Source Identification. Sensors, 19(3), 649. https://doi.org/10.3390/s19030649