Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring †

 ,
,  , , , ,
, , , , 
Abstract
1. Introduction and Motivation
- detailed formal description of the proposed methodology;
- detailed analysis on the influence of different sensors on the CSSM’s performance;
- extension of the model to allow the recognition of single pooled and multiple goals;
- detailed comparison between state-of-the-art methods and our proposed approach.
2. Related Work
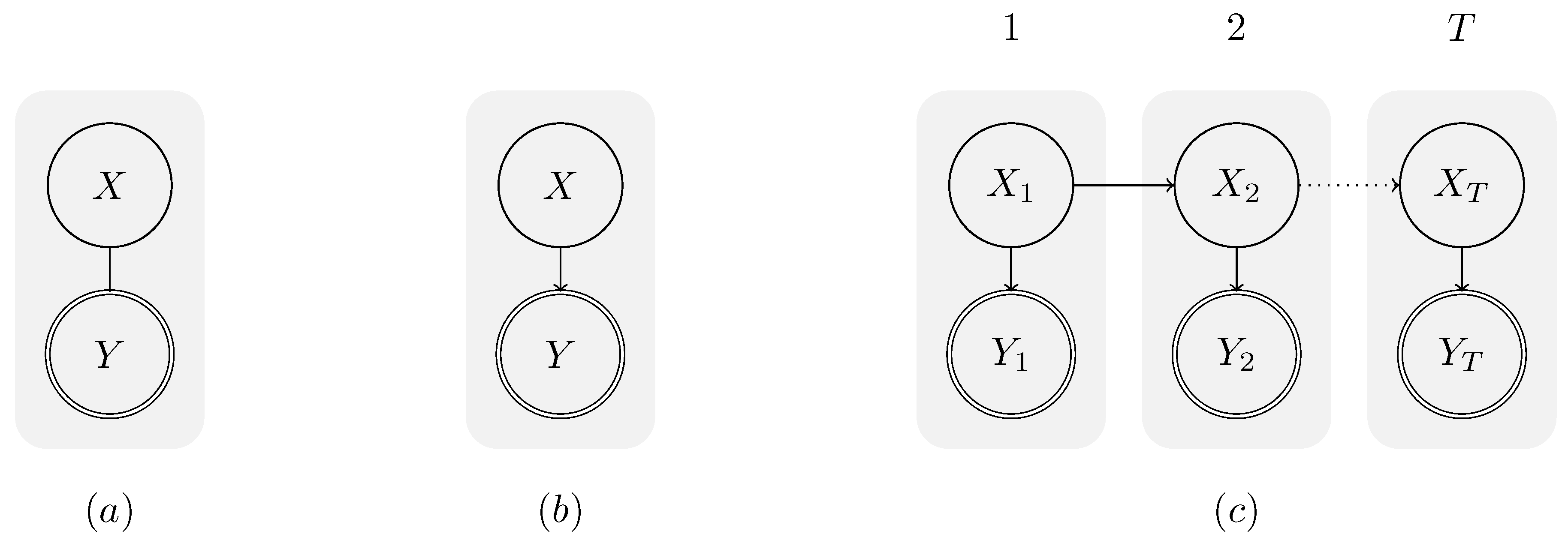
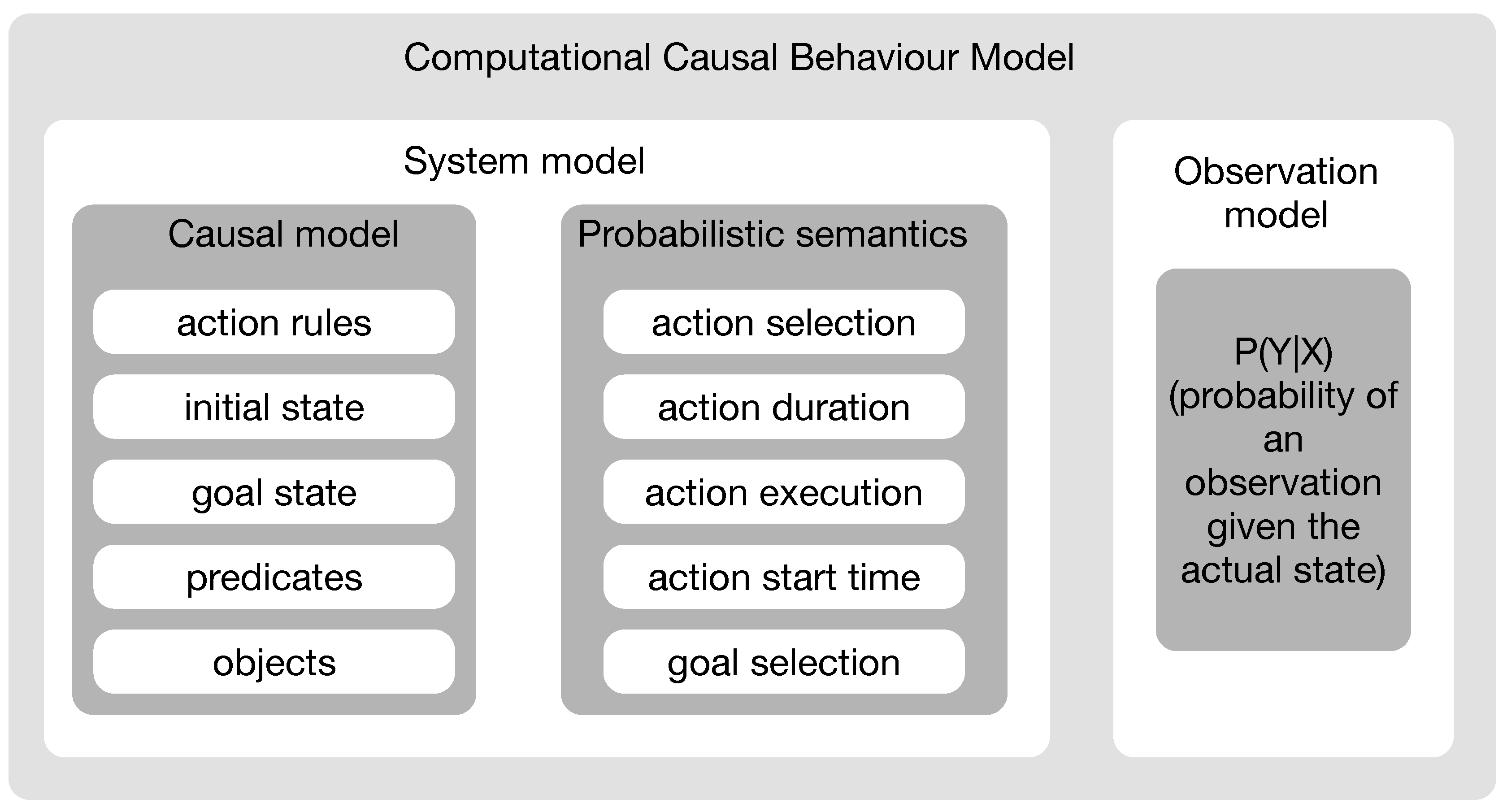
3. Computational Causal Behaviour Models
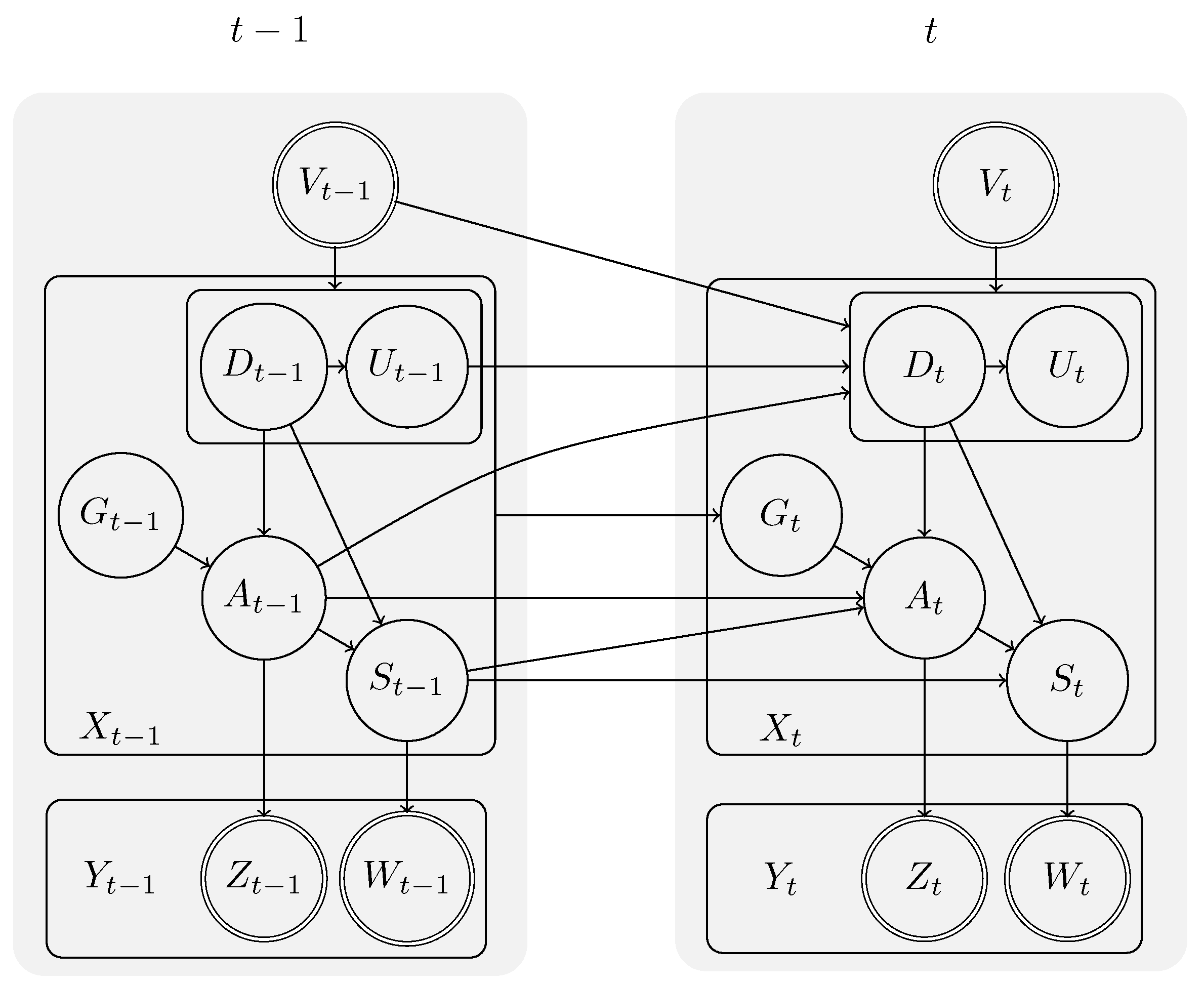
3.1. Causal Model
3.2. Probabilistic Semantics
- goal-directed actions are preferred, but
- deviations from the “optimal” action sequence are possible.
3.3. Observation Model
4. Experimental Setup and Model Development
4.1. Data Collection
4.2. Data Processing
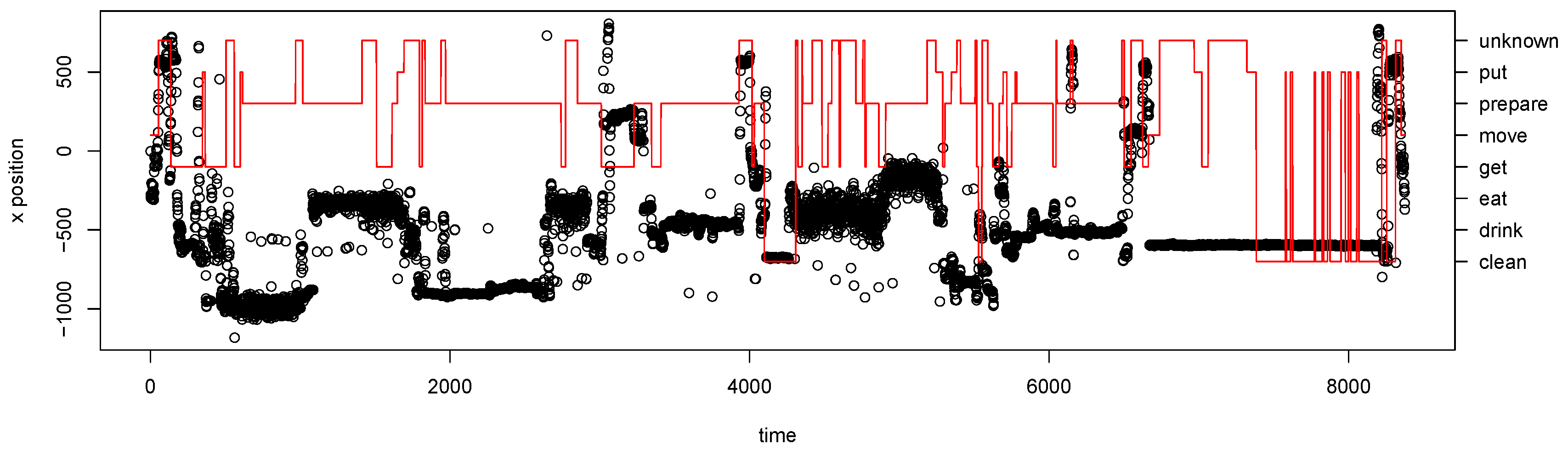
4.3. Data Annotation
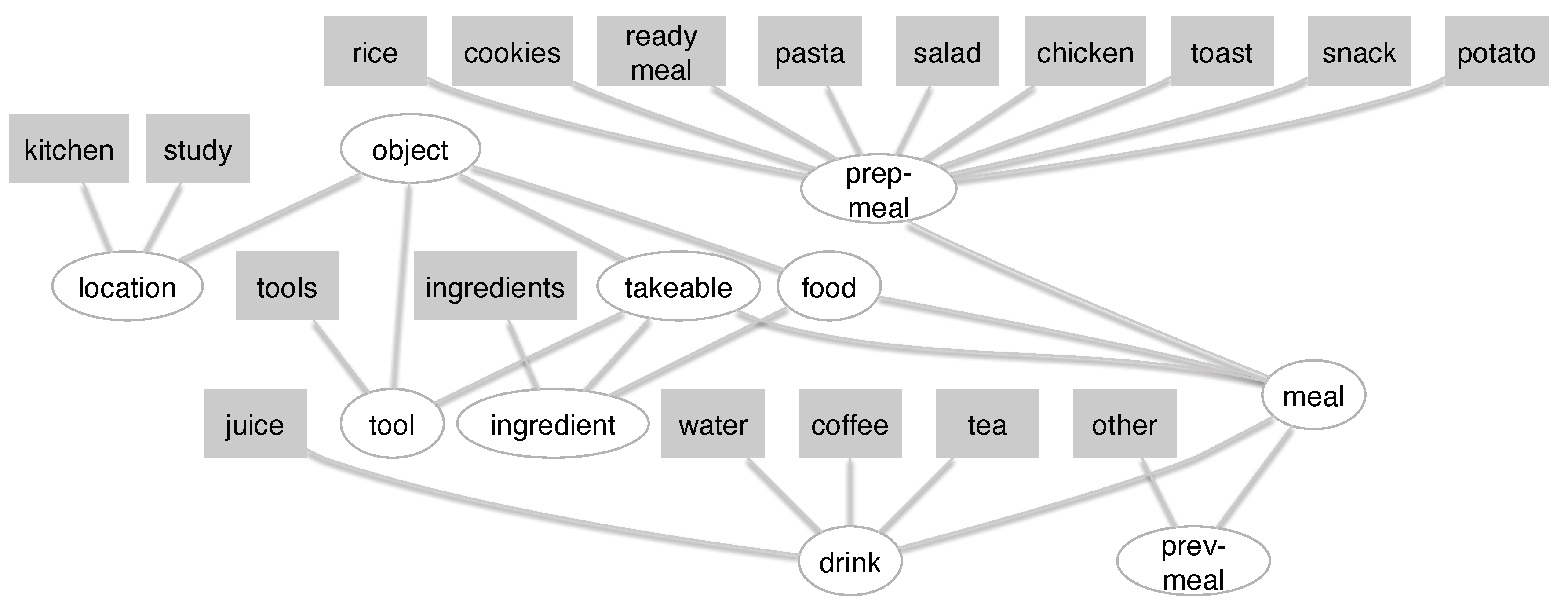
4.3.1. Ontology
4.3.2. Annotation
4.4. Model Development
4.4.1. CCBM Models
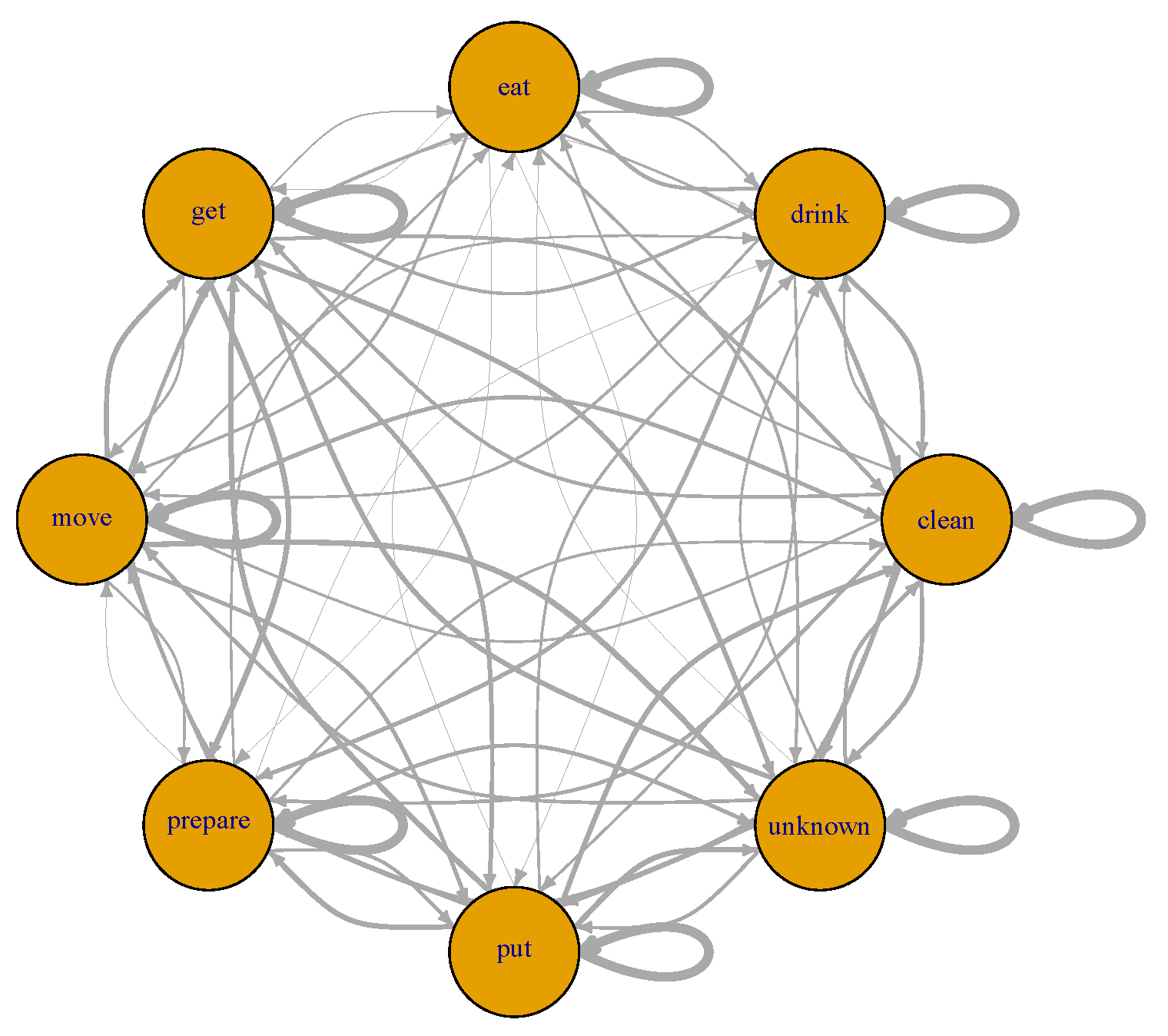
Causal Model
Goals in the Model
- Type of meal being prepared: Here, we have 13 goals, which represent the different meals and drinks the person can prepare (see Table 4).
- healthy/unhealthy meal/drink (4 goals): Here, we made the assumption that coffee, toast, and ready meals are unhealthy, while tea and freshly prepared meals are healthy (see Table 2). This assumption was made based on brainstorming with domain experts.
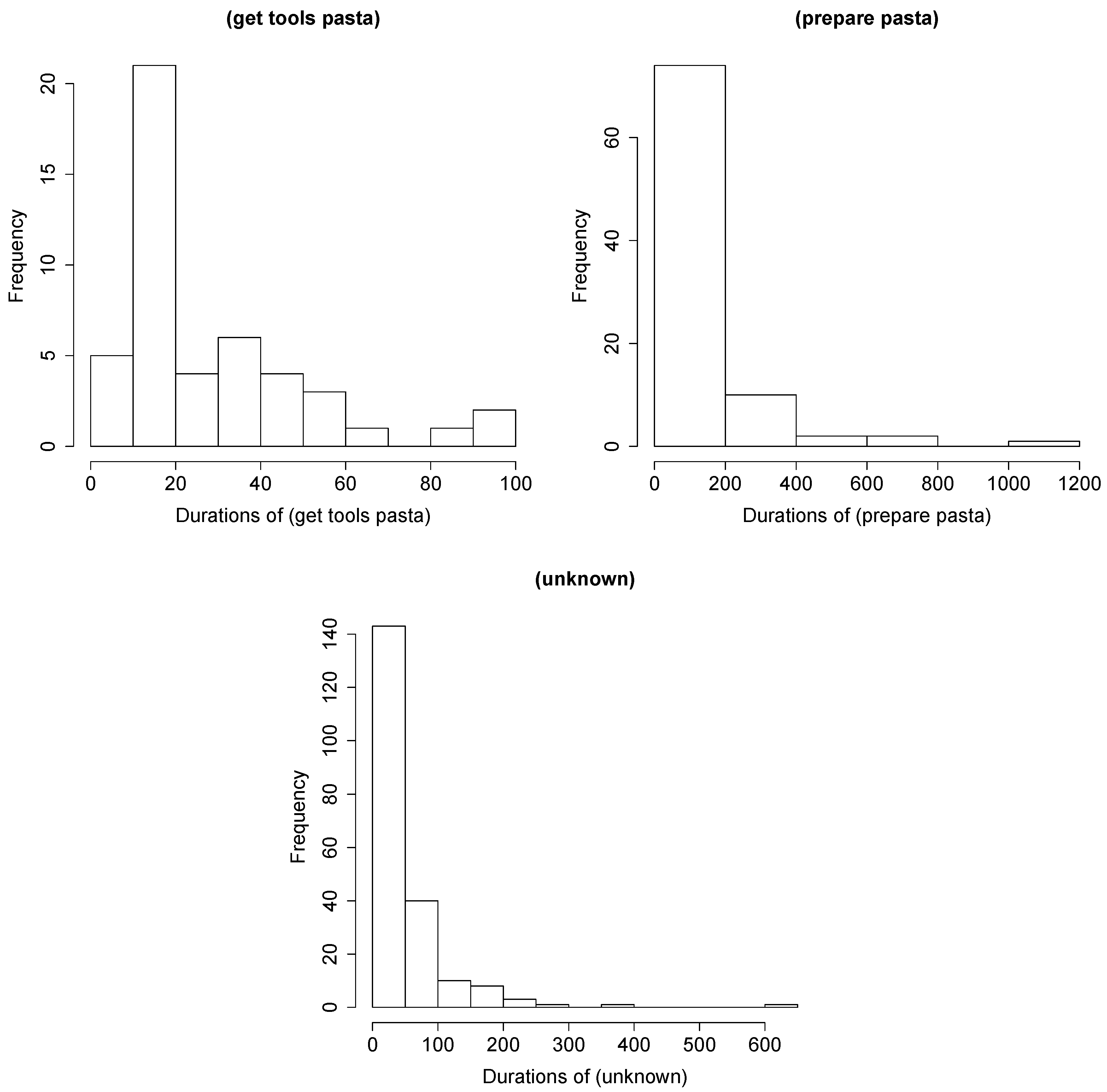
Duration Model
Observation Model
- Fridge electricity consumption: For this sensor, we expected to see more electricity consumption when the door of the fridge is open, which would indicate an ingredient being taken from the fridge.
- Kitchen cupboard sensors (top left, top right, sink) show whether a cupboard door is open, which could indicate that an ingredient or a tool has been taken from the cupboard;.
- Kitchen drawer sensors (middle, bottom): As with the cupboard sensors, they provide information on whether a drawer has been opened.
- temperature sensor measures the room temperature and increasing temperature can potentially indicate the oven or stoves being used.
- Humidity sensor measures the room humidity and increased humidity can indicate cooking (especially when boiling water for the pasta).
- Movement sensor provides information whether a person is moving in the room. This is useful especially for the eating actions, when the person leaves the kitchen and eats in the study.
- Water consumption (hot and cold) shows the water consumption in the kitchen. This is useful especially in the cleaning phase.
- Kettle electricity consumption: As with the fridge, we expected to see more electricity consumption when the kettle is on and somebody is boiling water.
- Depth cameras: The position of the person was estimated through the depth cameras. We expected that adding the position will increase the model performance.
- : We used all data to train the OM and the the same data to test the model (o denotes “optimistic”). This is an over-fitted model and we assumed it should provide the best performance for the given system model and sensor data. Although this model is not realistic, it gives us information about the capabilities of the approach under optimal conditions.
- : We used the first run for training and the rest to test the model (p denotes “pessimistic”). We chose the first run as it is the only one containing all actions. This observation model gives us information about the performance of the system model in the case of very fuzzy observations.
4.4.2. Hidden Markov Model
- estimating the transition model from the data of all runs (general HMM, which we call ); and
- estimating the transition model separately for each run (specialised HMM, which we call ).
Goal Recognition with HMM
4.5. Evaluation Procedure
- Feature selection of the best combination of sensors: This experiment was performed to select the sensors that at most contribute to the model performance. The selected combination was later used when comparing the CCBM and HMM models.
- Activity recognition of the action classes was tested with DT, HMM, and CCBM models.
- Goal recognition of the types of meals and drinks as well as preparation of healthy/unhealthy meal/drink was studied.
4.5.1. Feature Selection
- We started by comparing the mean performance for the different feature combinations.
- We decided that f may produce noise when the performance of the models which contain f is below the accuracy of the rest of the models;
- For the model comparison, chose the feature combination with the highest accuracy.
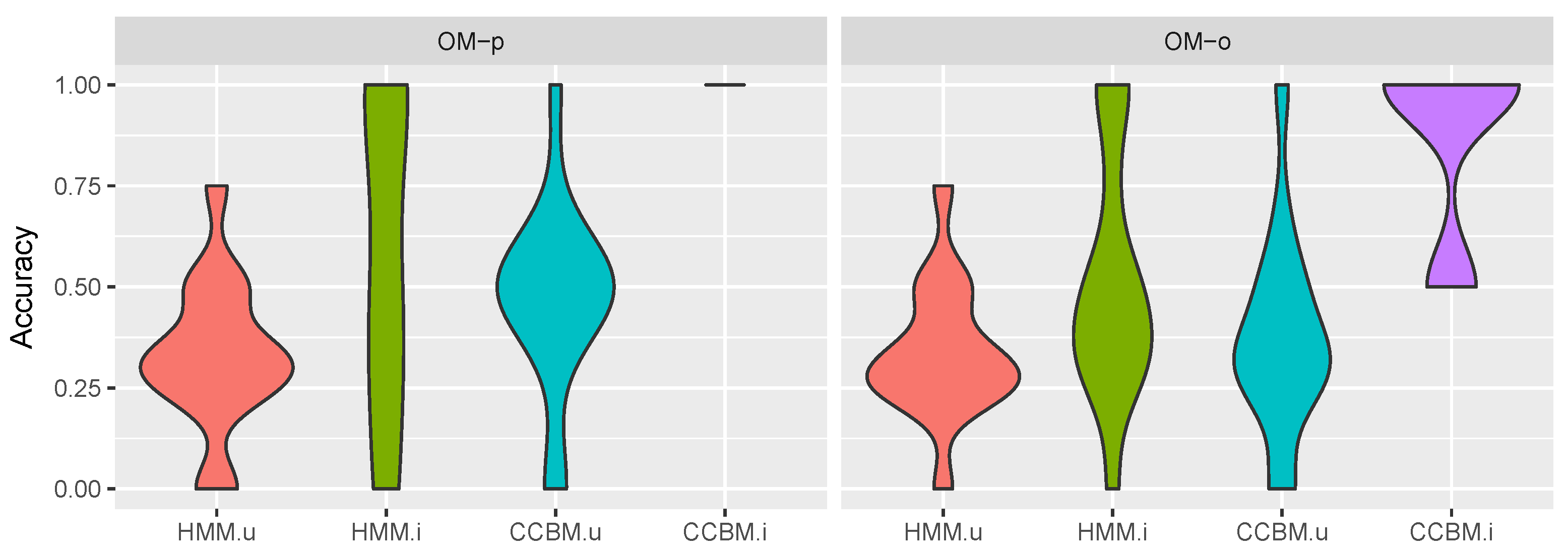
4.5.2. Activity Recognition
- Algorithm: This factor considered the different approaches to be compared (DT, HMM, and CCBM). The decision tree was our baseline and it gave information about the performance when applying only the observation model. In that sense, we expected the HMM and CCBM models to perform better that the DT.
- Observation model: (optimistic pessimistic);
- System model: (general/specific). In the case of DT, we did not have different system models.
4.5.3. Goal Recognition
- Meal goals: pasta, coffee, tea, salad, chicken, toast, juice, potato, rice, water, cookies, and ready meal
- Healthy/unhealthy goals: healthy drink, unhealthy drink, healthy meal, and unhealthy meal
- Uniform priors (uninformed): In this case, all priors (i.e., ) have the same probability.
- Informed priors: Here, the correct goal has two times the likelihood than the rest of the goals.
- algorithm (HMM/CCBM);
- goal target (Meal/Healthy);
- type of multigoal recognition (multiple goals/single, “pooled” goals); and
- prior (informed/uninformed).
5. Results
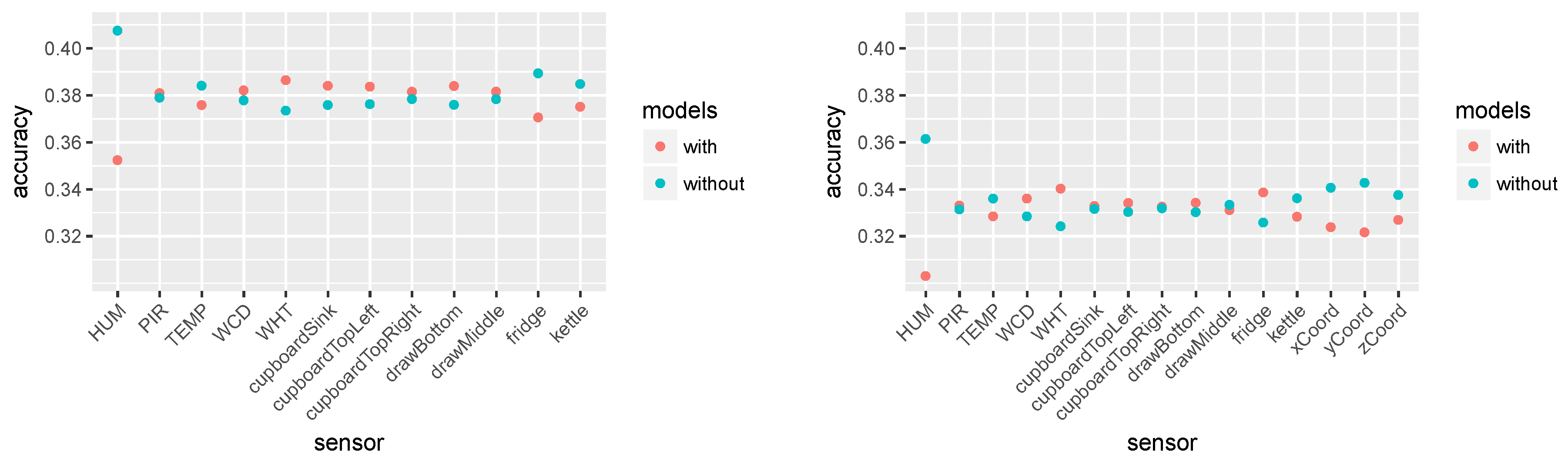
5.1. Feature Selection without the Depth Camera Features
5.2. Feature Selection with Locational Data from Depth Cameras
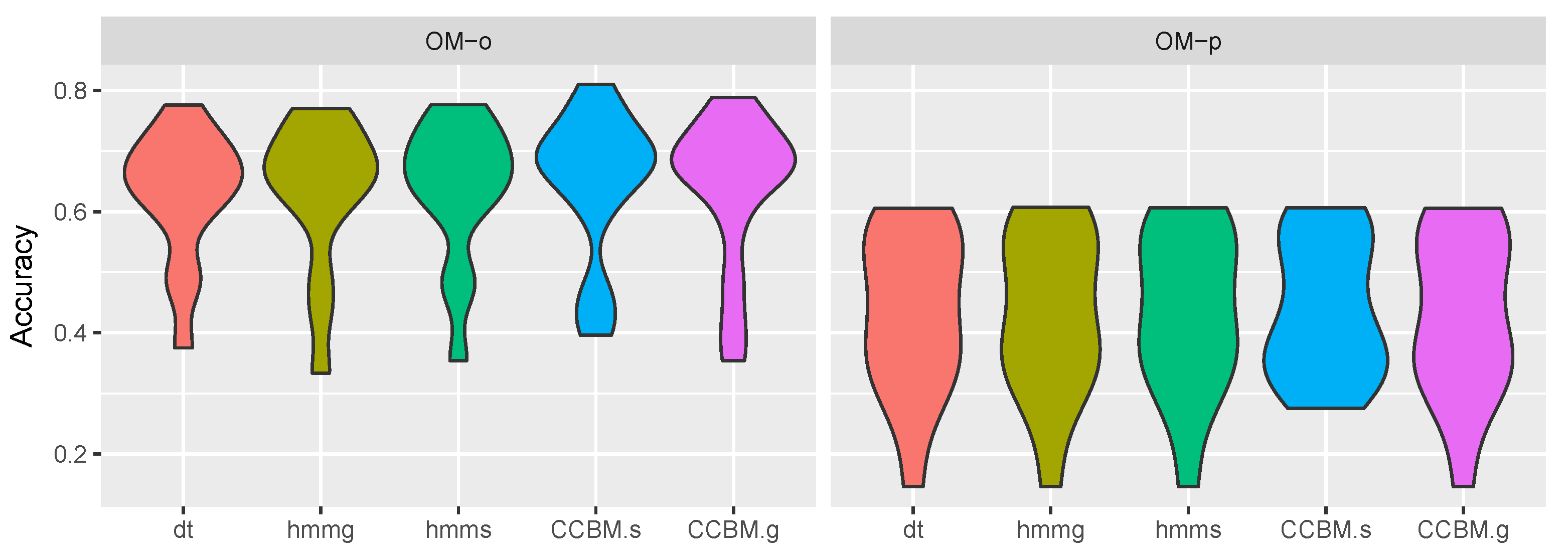
5.3. Activity Recognition
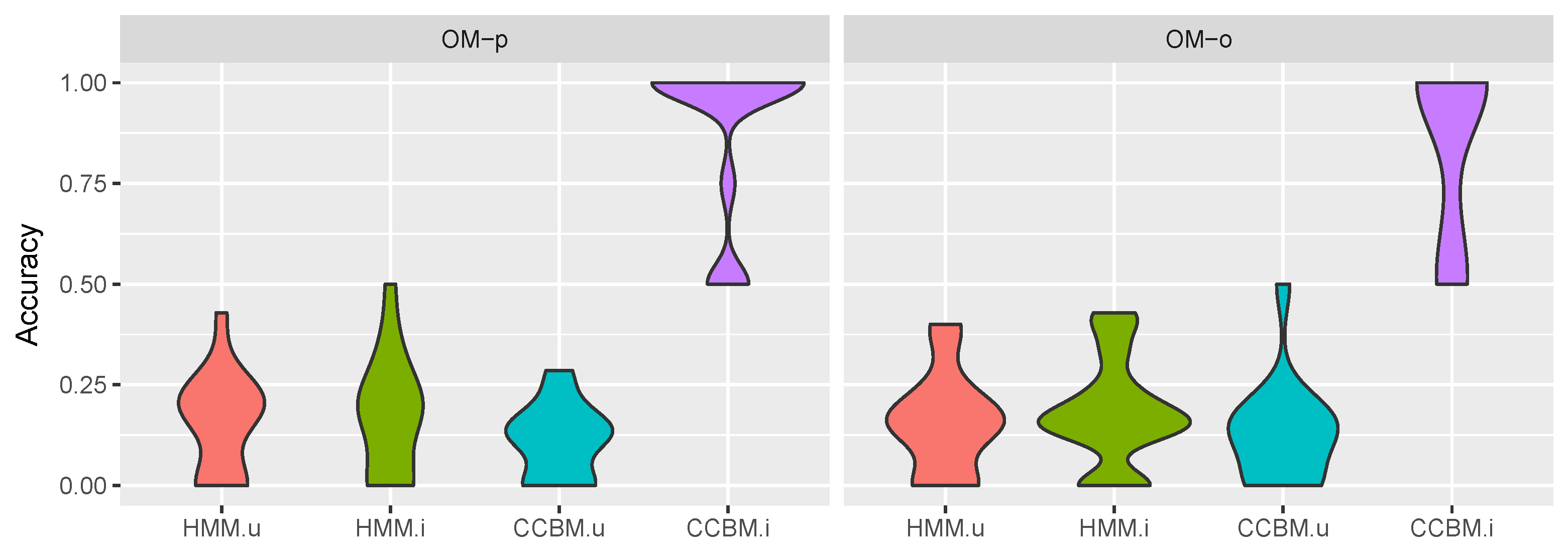
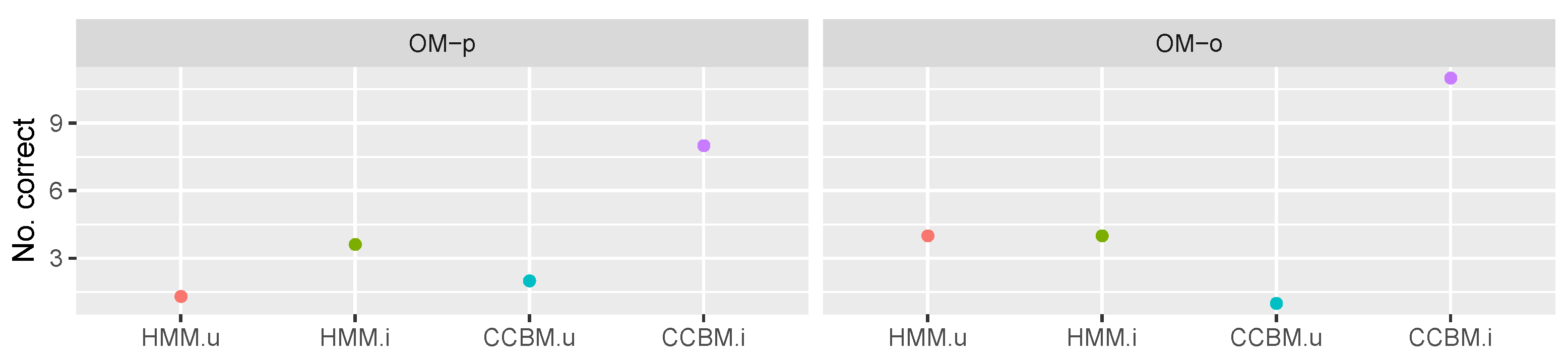
5.4. Goal Recognition
5.4.1. Multigoal Model
5.4.2. “Pooled” Goals
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AR | Activity Recognition |
| CCBM | Computational Causal Behaviour Model |
| CSSM | Computational State Space Model |
| DS-KCF | Depth Scaling Kernelised Correlation Filter |
| DT | Decision Tree |
| ELAN | Multimedia Annotator |
| GR | Goal Recognition |
| HMM | Hidden Markov Model |
| JSON | JavaScript Object Notation |
| KCF | Kernelised Correlation Filter |
| OM | Observation Model |
| PDDL | Planning Domain Definition Language |
| PR | Plan Recognition |
| SPHERE | Sensor Platform for HEalthcare in a Residential Environment |
References
- Ohlhorst, S.D.; Russell, R.; Bier, D.; Klurfeld, D.M.; Li, Z.; Mein, J.R.; Milner, J.; Ross, A.C.; Stover, P.; Konopka, E. Nutrition research to affect food and a healthy lifespan. Adv. Nutr. Int. Rev. J. 2013, 4, 579–584. [Google Scholar] [CrossRef] [PubMed]
- Serna, A.; Pigot, H.; Rialle, V. Modeling the Progression of Alzheimer’s Disease for Cognitive Assistance in Smart Homes. User Model. User-Adapt. Interact. 2007, 17, 415–438. [Google Scholar] [CrossRef]
- Helal, A.; Cook, D.J.; Schmalz, M. Smart Home-Based Health Platform for Behavioral Monitoring and Alteration of Diabetes Patients. J. Diabetes Sci. Technol. 2009, 3, 141–148. [Google Scholar] [CrossRef] [PubMed]
- Hoey, J.; Poupart, P.; Bertoldi, A.V.; Craig, T.; Boutilier, C.; Mihailidis, A. Automated Handwashing Assistance for Persons with Dementia Using Video and a Partially Observable Markov Decision Process. Comput. Vis. Image Underst. 2010, 114, 503–519. [Google Scholar] [CrossRef]
- Krüger, F.; Yordanova, K.; Burghardt, C.; Kirste, T. Towards Creating Assistive Software by Employing Human Behavior Models. J. Ambient Intell. Smart Environ. 2012, 4, 209–226. [Google Scholar] [CrossRef]
- Roy, P.C.; Giroux, S.; Bouchard, B.; Bouzouane, A.; Phua, C.; Tolstikov, A.; Biswas, J. A Possibilistic Approach for Activity Recognition in Smart Homes for Cognitive Assistance to Alzheimer’s Patients. In Activity Recognition in Pervasive Intelligent Environments; Atlantis Press: Paris, France, 2011; pp. 33–58. [Google Scholar] [CrossRef]
- Chen, L.; Nugent, C.; Okeyo, G. An Ontology-Based Hybrid Approach to Activity Modeling for Smart Homes. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 92–105. [Google Scholar] [CrossRef]
- Salguero, A.G.; Espinilla, M.; Delatorre, P.; Medina, J. Using Ontologies for the Online Recognition of Activities of Daily Living. Sensors 2018, 18, 1202. [Google Scholar] [CrossRef] [PubMed]
- Hiatt, L.M.; Harrison, A.M.; Trafton, J.G. Accommodating Human Variability in Human-robot Teams Through Theory of Mind. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence; AAAI Press: Barcelona, Spain, 2011; pp. 2066–2071. [Google Scholar] [CrossRef]
- Ramírez, M.; Geffner, H. Goal Recognition over POMDPs: Inferring the Intention of a POMDP Agent. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence; AAAI Press: Menlo Park, CA, USA, 2011; pp. 2009–2014. [Google Scholar] [CrossRef]
- Yordanova, K.; Kirste, T. A Process for Systematic Development of Symbolic Models for Activity Recognition. ACM Trans. Interact. Intell. Syst. 2015, 5, 20:1–20:35. [Google Scholar] [CrossRef]
- Krüger, F.; Nyolt, M.; Yordanova, K.; Hein, A.; Kirste, T. Computational State Space Models for Activity and Intention Recognition. A Feasibility Study. PLoS ONE 2014, 9, e109381. [Google Scholar] [CrossRef]
- Sukthankar, G.; Goldman, R.P.; Geib, C.; Pynadath, D.V.; Bui, H.H. Introduction. In Plan, Activity, and Intent Recognition; Sukthankar, G., Goldman, R.P., Geib, C., Pynadath, D.V., Bui, H.H., Eds.; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Yordanova, K.; Whitehouse, S.; Paiement, A.; Mirmehdi, M.; Kirste, T.; Craddock, I. What’s cooking and why? Behaviour recognition during unscripted cooking tasks for health monitoring. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 18–21. [Google Scholar] [CrossRef]
- Baxter, R.; Lane, D.; Petillot, Y. Recognising Agent Behaviour During Variable Length Activities. In Proceedings of the 19th European Conference on Artificial Intelligence (ECAI’10); IOS Press: Amsterdam, The Netherlands, 2010; pp. 803–808. [Google Scholar]
- Krüger, F. Activity, Context and Intention Recognition with Computational Causal Behavior Models. Ph.D. Thesis, Universität Rostock, Rostock, Germany, 2016. [Google Scholar]
- Ng, A.Y.; Jordan, M.I. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and naive Bayes. In Advances in Neural Information Processing Systems 14; MIT Press: Vancouver, BC, Canada, 2001; pp. 841–848. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 33:1–33:33. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S. Activity Recognition from User-Annotated Acceleration Data. In Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3001, pp. 1–17. [Google Scholar] [CrossRef]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity Recognition from Accelerometer Data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence—Volume 3 (IAAI’05); AAAI Press: Pittsburgh, PA, USA, 2005; pp. 1541–1546. [Google Scholar]
- Brdiczka, O.; Reignier, P.; Crowley, J. Detecting Individual Activities from Video in a Smart Home. In Knowledge-Based Intelligent Information and Engineering Systems; Springer: Vietri su Mare, Italy, 2007; Volume 4692, pp. 363–370. [Google Scholar] [CrossRef]
- Casale, P.; Pujol, O.; Radeva, P. Human Activity Recognition from Accelerometer Data Using a Wearable Device. In Pattern Recognition and Image Analysis; Vitrià, J., Sanches, J.M., Hernández, M., Eds.; Springer: Las Palmas de Gran Canaria, Spain, 2011; Volume 6669, pp. 289–296. [Google Scholar] [CrossRef]
- Stein, S.; McKenna, S.J. Combining Embedded Accelerometers with Computer Vision for Recognizing Food Preparation Activities. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 729–738. [Google Scholar] [CrossRef]
- Carberry, S. Techniques for plan recognition. User Model. User-Adapt. Interact. 2001, 11, 31–48. [Google Scholar] [CrossRef]
- Armentano, M.G.; Amandi, A. Plan Recognition for Interface Agents. Artif. Intell. Rev. 2007, 28, 131–162. [Google Scholar] [CrossRef]
- Sadri, F. Logic-based approaches to intention recognition. In Handbook of Research on Ambient Intelligence: Trends and Perspectives; Chong, N.Y., Mastrogiovanni, F., Eds.; IGI Global: Hershey, PA, USA, 2011; pp. 346–375. [Google Scholar] [CrossRef]
- Han, T.A.; Pereira, L.M. State-of-the-Art of Intention Recognition and its use in Decision Making. AI Commun. 2013, 26, 237–246. [Google Scholar] [CrossRef]
- Kautz, H.A.; Allen, J.F. Generalized Plan Recognition. In Proceedings of the 5th National Conference on Artificial Intelligence (AAAI’86); Morgan Kaufmann: Philadelphia, PA, USA, 1986; pp. 32–37. [Google Scholar]
- Roy, P.; Bouchard, B.; Bouzouane, A.; Giroux, S. A hybrid plan recognition model for Alzheimer’s patients: Interleaved-erroneous dilemma. In Proceedings of the IEEE/WIC/ACM International Conference on Intelligent Agent Technology (IAT’07), Silicon Valley, CA, USA, 2–5 November 2007; pp. 131–137. [Google Scholar] [CrossRef]
- Baker, C.L.; Saxe, R.; Tenenbaum, J.B. Action understanding as inverse planning. Cognition 2009, 113, 329–349. [Google Scholar] [CrossRef] [PubMed]
- Geib, C.W.; Goldman, R.P. Partial observability and probabilistic plan/goal recognition. In Proceedings of the IJCAI Workshop on Modeling others from Observations (MOO’05), Edinburgh, UK, 30 July 2005. [Google Scholar]
- Krüger, F.; Yordanova, K.; Hein, A.; Kirste, T. Plan Synthesis for Probabilistic Activity Recognition. In Proceedings of the 5th International Conference on Agents and Artificial Intelligence (ICAART 2013); Filipe, J., Fred, A.L.N., Eds.; SciTePress: Barcelona, Spain, 2013; pp. 283–288. [Google Scholar] [CrossRef]
- Ramírez, M.; Geffner, H. Probabilistic Plan Recognition using off-the-shelf Classical Planners. In Proceedings of the 24th National Conference of Artificial Intelligence (AAAI); AAAI: Atlanta, GA, USA, 2010; pp. 1211–1217. [Google Scholar]
- Trafton, J.G.; Hiatt, L.M.; Harrison, A.M.; Tamborello, F.P.; Khemlani, S.S.; Schultz, A.C. ACT-R/E: An Embodied Cognitive Architecture for Human-Robot Interaction. J. Hum.-Robot Interact. 2013, 2, 30–55. [Google Scholar] [CrossRef]
- Yue, S.; Yordanova, K.; Krüger, F.; Kirste, T.; Zha, Y. A Decentralized Partially Observable Decision Model for Recognizing the Multiagent Goal in Simulation Systems. Discret. Dyn. Nat. Soc. 2016, 2016, 1–15. [Google Scholar] [CrossRef]
- Schröder, M.; Bader, S.; Krüger, F.; Kirste, T. Reconstruction of Everyday Life Behaviour based on Noisy Sensor Data. In Proceedings of the 8th International Conference on Agents and Artificial Intelligence, Rome, Italy, 24–26 February 2016; pp. 430–437. [Google Scholar] [CrossRef]
- Whitehouse, S.; Yordanova, K.; Paiement, A.; Mirmehdi, M. Recognition of unscripted kitchen activities and eating behaviour for health monitoring. In Proceedings of the 2nd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2016); INSPEC: London, UK, 2016. [Google Scholar] [CrossRef]
- Hierons, R.M.; Bogdanov, K.; Bowen, J.P.; Cleaveland, R.; Derrick, J.; Dick, J.; Gheorghe, M.; Harman, M.; Kapoor, K.; Krause, P.; et al. Using formal specifications to support testing. ACM Comput. Surv. (CSUR) 2009, 41, 9:1–9:76. [Google Scholar] [CrossRef]
- Ghallab, M.; Howe, A.; Knoblock, C.A.; McDermott, D.V.; Ram, A.; Veloso, M.; Weld, D.; Wilkins, D. PDDL—The Planning Domain Definition Language; Technical Report CVC TR-98-003/DCS TR-1165; Yale Center for Computational Vision and Control: New Haven, CT, USA, 1998. [Google Scholar]
- Patterson, D.J.; Liao, L.; Gajos, K.; Collier, M.; Livic, N.; Olson, K.; Wang, S.; Fox, D.; Kautz, H. Opportunity Knocks: A System to Provide Cognitive Assistance with Transportation Services. In UbiComp 2004: Ubiquitous Computing; Davies, N., Mynatt, E., Siio, I., Eds.; Springer: Nottingham, UK, 2004; Volume 3205, pp. 433–450. [Google Scholar] [CrossRef]
- Richter, S.; Westphal, M. The LAMA Planner: Guiding Cost-based Anytime Planning with Landmarks. J. Artif. Intell. Res. 2010, 39, 127–177. [Google Scholar] [CrossRef]
- Kirste, T.; Krüger, F. CCBM—A Tool for Activity Recognition Using Computational Causal Behavior Models; Technical Report CS-01-12; Institut für Informatik, Universität Rostock: Rostock, Germany, 2012. [Google Scholar]
- Zhu, N.; Diethe, T.; Camplani, M.; Tao, L.; Burrows, A.; Twomey, N.; Kaleshi, D.; Mirmehdi, M.; Flach, P.; Craddock, I. Bridging e-Health and the Internet of Things: The SPHERE Project. IEEE Intell. Syst. 2015, 30, 39–46. [Google Scholar] [CrossRef]
- Hall, J.; Hannuna, S.; Camplani, M.; Mirmehdi, M.; Damen, D.; Burghardt, T.; Tao, L.; Paiement, A.; Craddock, I. Designing a video monitoring system for AAL applications: The SPHERE case study. In Proceedings of the 2nd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2016); IET: London, UK, 2016. [Google Scholar] [CrossRef][Green Version]
- Whitehouse, S.; Yordanova, K.; Lüdtke, S.; Paiement, A.; Mirmehdi, M. Evaluation of cupboard door sensors for improving activity recognition in the kitchen. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom Workshops), Athens, Greece, 19–23 March 2018. [Google Scholar]
- Mirmehdi, M.; Kirste, T.; Paiement, A.; Whitehouse, S.; Yordanova, K. SPHERE Unscripted Kitchen Activities; University of Bristol: Bristol, UK, 2016; Available online: https://data.bris.ac.uk/data/dataset/raqa2qzai45z15b4n0za94toi (accessed on 2 February 2019).
- van Kasteren, T.L.M.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate Activity Recognition in a Home Setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.; Cook, D.; Yu, Z. Sensor-Based Activity Recognition. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Yordanova, K.; Krüger, F.; Kirste, T. Providing Semantic Annotation for the CMU Grand Challenge Dataset. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom Workshops), Athens, Greece, 19–23 March 2018. [Google Scholar]
- Yordanova, K.; Krüger, F. Creating and Exploring Semantic Annotation for Behaviour Analysis. Sensors 2018, 18, 2778. [Google Scholar] [CrossRef] [PubMed]
- Lausberg, H.; Sloetjes, H. Coding gestural behavior with the NEUROGES-ELAN system. Behav. Res. Methods 2009, 41, 841–849. [Google Scholar] [CrossRef] [PubMed]
- Burghardt, C.; Wurdel, M.; Bader, S.; Ruscher, G.; Kirste, T. Synthesising generative probabilistic models for high-level activity recognition. In Activity Recognition in Pervasive Intelligent Environments; Springer: Berlin, Germany, 2011; pp. 209–236. [Google Scholar] [CrossRef]
- Hannuna, S.; Camplani, M.; Hall, J.; Mirmehdi, M.; Damen, D.; Burghardt, T.; Paiement, A.; Tao, L. DS-KCF: A real-time tracker for RGB-D data. J. Real-Time Image Process. 2016. [Google Scholar] [CrossRef]
- Krüger, F.; Yordanova, K.; Köppen, V.; Kirste, T. Towards Tool Support for Computational Causal Behavior Models for Activity Recognition. In Proceedings of the 1st Workshop: “Situation-Aware Assistant Systems Engineering: Requirements, Methods, and Challenges”, Braunschweig, Germany, 1 September 2012; pp. 561–572. [Google Scholar]
- Nguyen, T.A.; Kambhampati, S.; Do, M. Synthesizing Robust Plans under Incomplete Domain Models. In Advances in Neural Information Processing Systems 26; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2472–2480. [Google Scholar]
- Yordanova, K.Y.; Monserrat, C.; Nieves, D.; Hernández-Orallo, J. Knowledge Extraction from Task Narratives. In Proceedings of the 4th International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 21–22 September 2017; pp. 7:1–7:6. [Google Scholar] [CrossRef]
- Yordanova, K. Extracting Planning Operators from Instructional Texts for Behaviour Interpretation. In Proceedings of the German Conference on Artificial Intelligence, Berlin, Germany, 24–28 September 2018. [Google Scholar] [CrossRef]
- Schröder, M.; Lüdtke, S.; Bader, S.; Krüger, F.; Kirste, T. LiMa: Sequential Lifted Marginal Filtering on Multiset State Descriptions. In KI 2017: Advances in Artificial Intelligence: 40th Annual German Conference on AI, Dortmund, Germany, 25–29 September 2017; Kern-Isberner, G., Fürnkranz, J., Thimm, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 222–235. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Plan Rec. | Durations | Action Sel. | Probability | Noise | Latent Infinity | Simulation | Multiple Goals | Unscripted Scenario |
|---|---|---|---|---|---|---|---|---|---|
| [31] | ■ | □ | ■ | ■ | □ | ■ | no | □ | □ |
| [9] | ■ | □ | ■ | ■ | □ | ■ | yes | ■ | □ |
| [33] | □ | ■ | ■ | ■ | ■ | ■ | no | □ | □ |
| [12] | ■ | ■ | ■ | ■ | ■ | ■ | no | □ | □ |
| [11] | ■ | ■ | ■ | ■ | ■ | ■ | no | □ | □ |
| [34] | ■ | □ | ■ | ■ | □ | ■ | yes | □ | □ |
| [10] | ■ | □ | ■ | ■ | ■ | ■ | yes | □ | □ |
| [35] | ■ | □ | ■ | ■ | □ | ■ | yes | ■ | □ |
| [36] | ■ | □ | ■ | ■ | □ | ■ | yes | ■ | □ |
| Dataset | # Actions | Time | Meal |
|---|---|---|---|
| D1 | 153 | 6502 | pasta (healthy), coffee (unhealthy), tea (healthy) |
| D2 | 13 | 602 | pasta (healthy) |
| D3 | 18 | 259 | salad (healthy) |
| D4 | 112 | 3348 | chicken (healthy) |
| D5 | 45 | 549 | toast (unhealthy), coffee (unhealthy) |
| D6 | 8 | 48 | juice (healthy) |
| D7 | 56 | 805 | toast (unhealthy) |
| D8 | 21 | 1105 | potato (healthy) |
| D9 | 29 | 700 | rice (healthy) |
| D10 | 61 | 613 | toast (unhealthy), water (healthy), tea (healthy) |
| D11 | 85 | 4398 | cookies (unhealthy) |
| D12 | 199 | 3084 | ready meal (unhealthy), pasta (healthy) |
| D13 | 21 | 865 | pasta (healthy) |
| D14 | 40 | 1754 | salad (healthy) |
| D15 | 72 | 1247 | pasta (healthy) |
| 1) () | 5) () |
| 2) () | 6) () |
| 3) () | 7) () |
| 4) () | 8) () |
| Meal | chicken, coffee, cookies, juice, pasta, potato, readymeal, rice, salad, snack, tea, toast, water, other |
| Item | ingredients, tools |
| Location | kitchen, study |
| Time | Label |
|---|---|
| 1 | (unknown) |
| 3401 | (move study kitchen) |
| 7601 | (unknown) |
| 10,401 | (prepare coffee) |
| 31,101 | (unknown) |
| 34,901 | (clean) |
| 47,301 | (unknown) |
| 52,001 | (get tools pasta) |
| 68,001 | (get ingredients pasta) |
| 86,301 | (prepare pasta) |
| 202,751 | (get tools pasta) |
| 221,851 | (get ingredients pasta) |
| 228,001 | (prepare pasta) |
| Parameters | ||
|---|---|---|
| Action classes | 8 | 8 |
| Ground actions | 92 | 10–28 |
| States | 450,144 | 40–1288 |
| Valid plans | 21,889 393 | 162–15,689 |
| 10 Worst Combinations | |
| Features | Accuracy |
| fridge, drawer middle, drawer bottom, humidity, movement | 0.2688 |
| fridge, drawer middle, drawer bottom, humidity, movement, water cold | 0.2691 |
| fridge, drawer bottom, humidity, movement, water cold | 0.2692 |
| fridge, drawer bottom, humidity, movement | 0.2692 |
| fridge, cupboard top left, humidity, movement | 0.2694 |
| fridge, cupboard top left, drawer middle, humidity, movement | 0.2694 |
| fridge, humidity, movement, water cold | 0.2695 |
| fridge, drawer middle, humidity, movement, water cold | 0.2695 |
| fridge, cupboard sink, humidity, movement, water cold | 0.2695 |
| fridge, draw middle, humidity, movement | 0.2695 |
| 10 Best Combinations | |
| Features | Accuracy |
| drawer bottom, cupboard sink, water hot, water cold | 0.4307 |
| drawer middle, drawer bottom, water hot, water cold | 0.4308 |
| cupboard top left, drawer middle, drawer bottom, water hot, water cold | 0.4308 |
| drawer middle, drawer bottom, cupboard top right, water hot, water cold | 0.4308 |
| fridge, drawer bottom, movement, water hot, water cold | 0.4325 |
| fridge, movement, water hot, water cold | 0.4330 |
| fridge, cupboard top left, movement, water hot, water cold | 0.4330 |
| fridge, draw middle, movement, water hot, water cold | 0.4330 |
| fridge, cupboard sink, movement, water hot, water cold | 0.4330 |
| fridge, cupboard top right, movement, water hot, water cold | 0.4332 |
| 10 Worst Combinations | |
| Features | Accuracy |
| fridge, cupboard top left, drawer bottom, cupboard top right, humidity, xCoord | 0.2199 |
| fridge, cupboard top left, drawer bottom, cupboard sink, humidity, xCoord | 0.2199 |
| fridge, cupboard top left, drawer middle, cupboard sink, humidity, movement, xCoord | 0.2194 |
| fridge, cupboard top left, drawer middle, humidity, movement, xCoord | 0.2189 |
| fridge, cupboard top left, cupboard sink, humidity, movement, xCoord | 0.2170 |
| fridge, cupboard top left, drawer middle, cupboard top right, cupboard sink, humidity, xCoord | 0.2167 |
| fridge, cupboard top left, drawer middle, cupboard top right, humidity, xCoord | 0.2162 |
| fridge, cupboard top left, drawer middle, cupboard sink, humidity, xCoord | 0.2162 |
| fridge, cupboard top left, drawer middle, humidity, xCoord | 0.2158 |
| fridge, cupboard top left, cupboard top right, cupboard sink, humidity, xCoord | 0.2149 |
| 10 Best Combinations | |
| Features | Accuracy |
| kettle, cupboard top left, drawer bottom, temperature, movement | 0.4911 |
| kettle, cupboard top left, drawer bottom, cupboard top right, temperature, movement | 0.4911 |
| kettle, cupboard top left, drawer bottom, cupboard sink, temperature, movement | 0.4911 |
| kettle, cupboard top left, drawer bottom, cupboard top right, cupboard sink, temperature, movement | 0.4911 |
| kettle, cupboard top left, cupboard sink, temperature, movement | 0.4902 |
| kettle, cupboard top left, cupboard top right, cupboard sink, temperature, movement | 0.4901 |
| kettle, cupboard top left, drawer middle, drawer bottom, cupboard sink, temperature, movement | 0.4901 |
| kettle, cupboard top left, drawer middle, drawer bottom, cupboard top right, cupboard sink, temperature, movement | 0.4901 |
| kettle, drawer bottom, cupboard sink, temperature, movement | 0.4892 |
| kettle, drawer bottom, cupboard top right, cupboard sink, temperature, movement | 0.4892 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yordanova, K.; Lüdtke, S.; Whitehouse, S.; Krüger, F.; Paiement, A.; Mirmehdi, M.; Craddock, I.; Kirste, T. Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring. Sensors 2019, 19, 646. https://doi.org/10.3390/s19030646
Yordanova K, Lüdtke S, Whitehouse S, Krüger F, Paiement A, Mirmehdi M, Craddock I, Kirste T. Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring. Sensors. 2019; 19(3):646. https://doi.org/10.3390/s19030646
Chicago/Turabian StyleYordanova, Kristina, Stefan Lüdtke, Samuel Whitehouse, Frank Krüger, Adeline Paiement, Majid Mirmehdi, Ian Craddock, and Thomas Kirste. 2019. "Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring" Sensors 19, no. 3: 646. https://doi.org/10.3390/s19030646
APA StyleYordanova, K., Lüdtke, S., Whitehouse, S., Krüger, F., Paiement, A., Mirmehdi, M., Craddock, I., & Kirste, T. (2019). Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring. Sensors, 19(3), 646. https://doi.org/10.3390/s19030646