Analyzing of Gender Behaviors from Paths Using Process Mining: A Shopping Mall Application




Abstract
1. Introduction
2. Related Works
Original Aspect of the Study
3. Methodology
- The parallel acceptor tree algorithm step produces process trees to start and end the time of events and their parallelism.
- The onward merge step fuses all branches of the tree. The algorithm checks for each node that the following two branches are equivalent. If so, they are fused. If all nodes and transitions use the same token for the same process in the two branches, it is said that the two branches are equivalent.
- The parallel merge step merges nodes that are sequential and represent the same event.
- The delete repeated transitions step deletes repeated transitions.
- The delete unused nodes step deletes unused nodes.
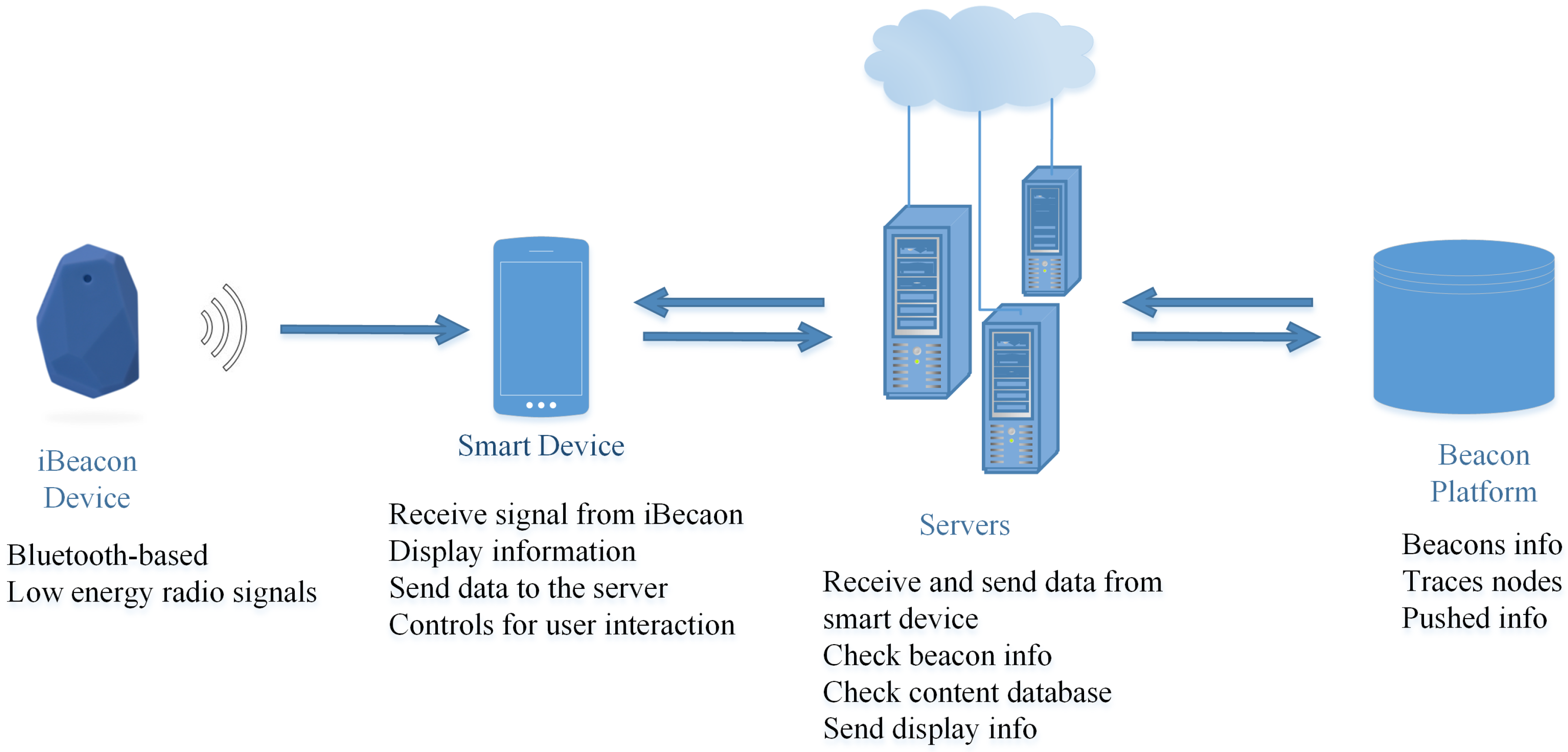
4. iBeacon ILS
- ID: For each captured datum, a unique number is defined to use different analysis. The ID column is not used in our study.
- Dongle columns: Because, in some cases, iBeacon devices are located near each other, one customer can be seen in three different locations. According to the proximity of the customer to the stores, iBeacon devices gather three different position data. Dongle_1 shows the nearest store where customer data were captured; on the other hand, Dongle_3 represents the farthest store location. In the study, we ignore Dongle_2 and Dongle_3 localization data.
- Timestamp: This is a date and time value that represents the moment at which data are captured by the iBeacon device for the related store. The timestamp format is dd.mm.yyyy hh:mm:ss.
- SubscriberID: This number shows the customer identification number associated with the mobile device.
5. Experimental Results
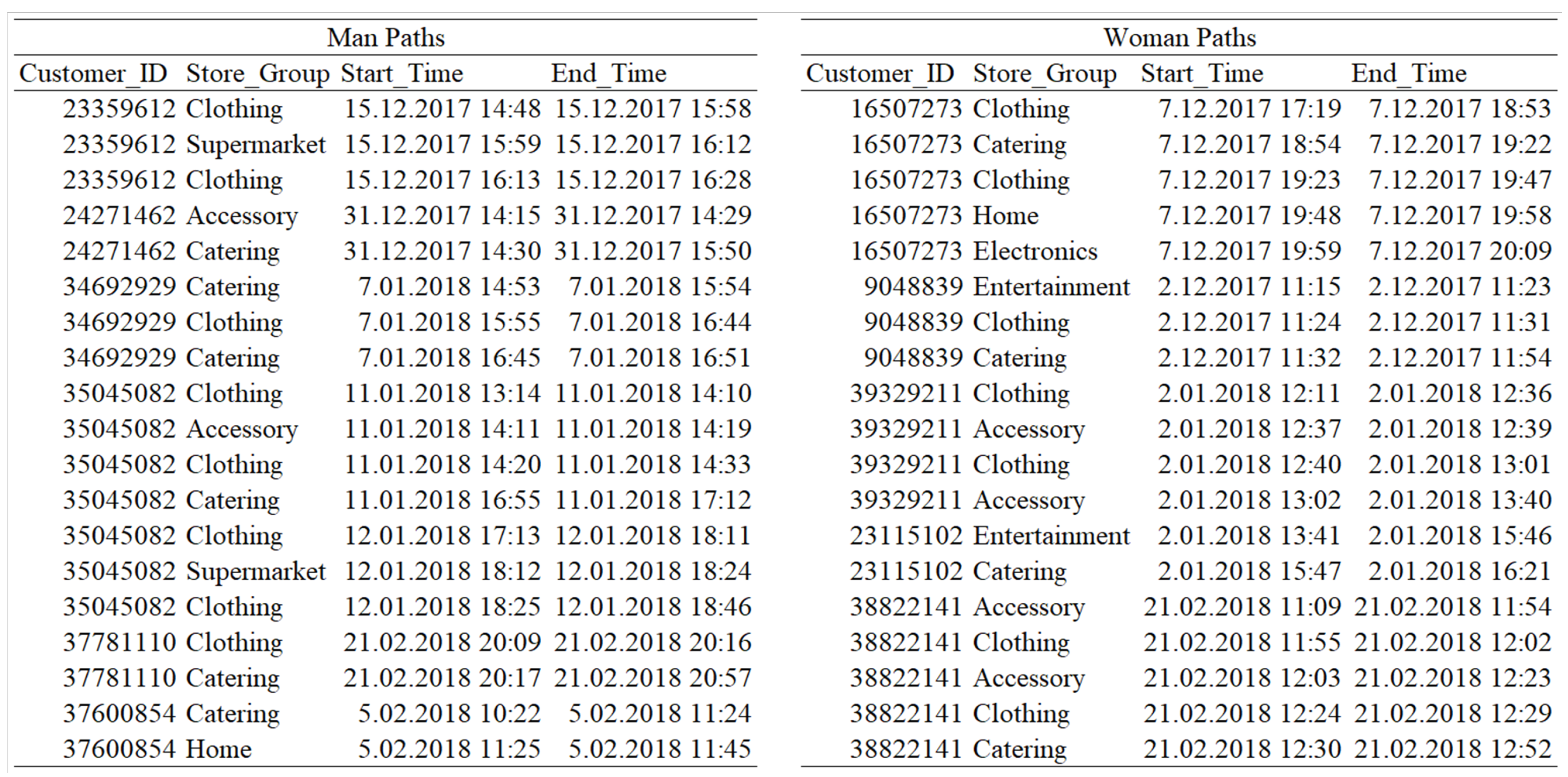
5.1. Data Preparation
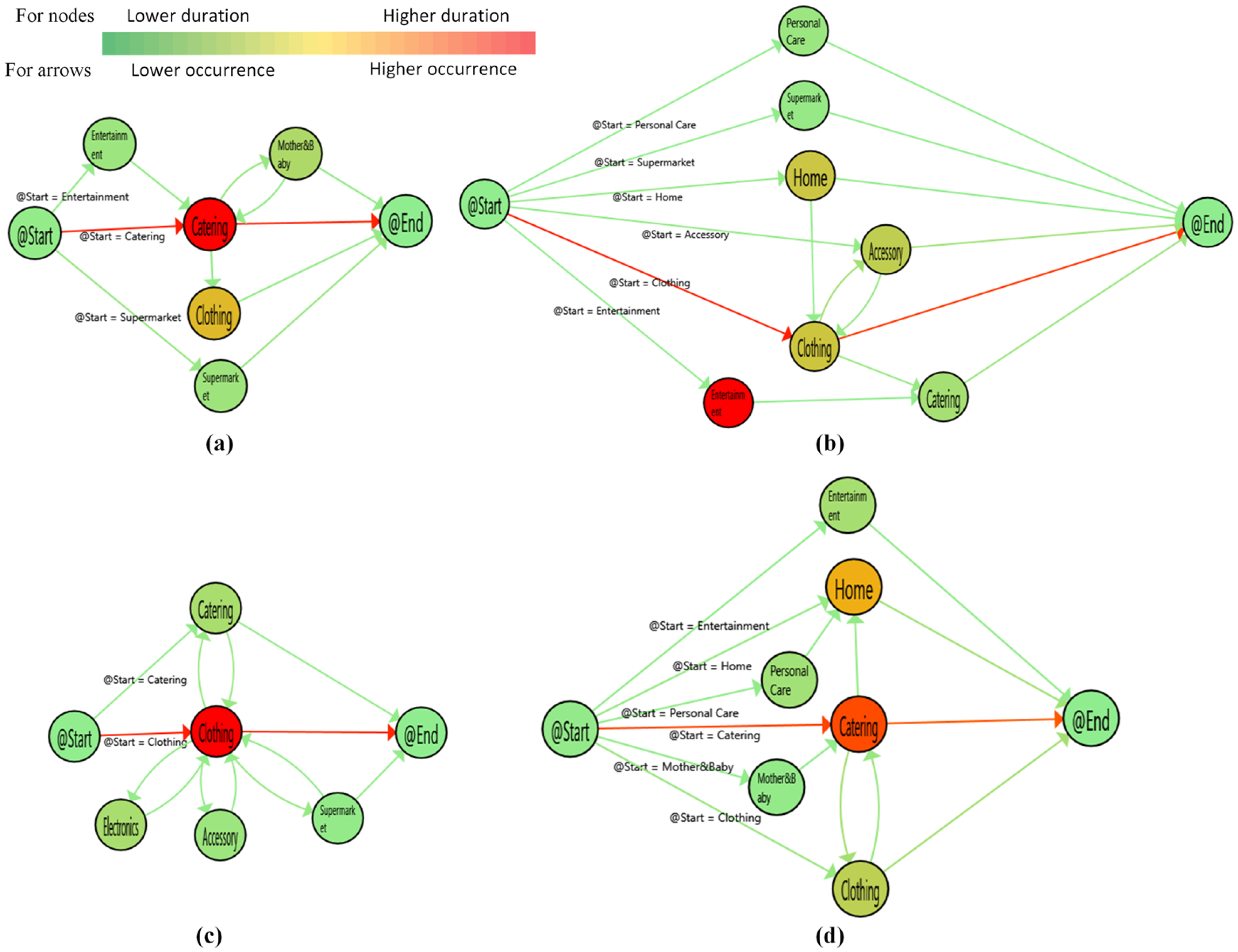
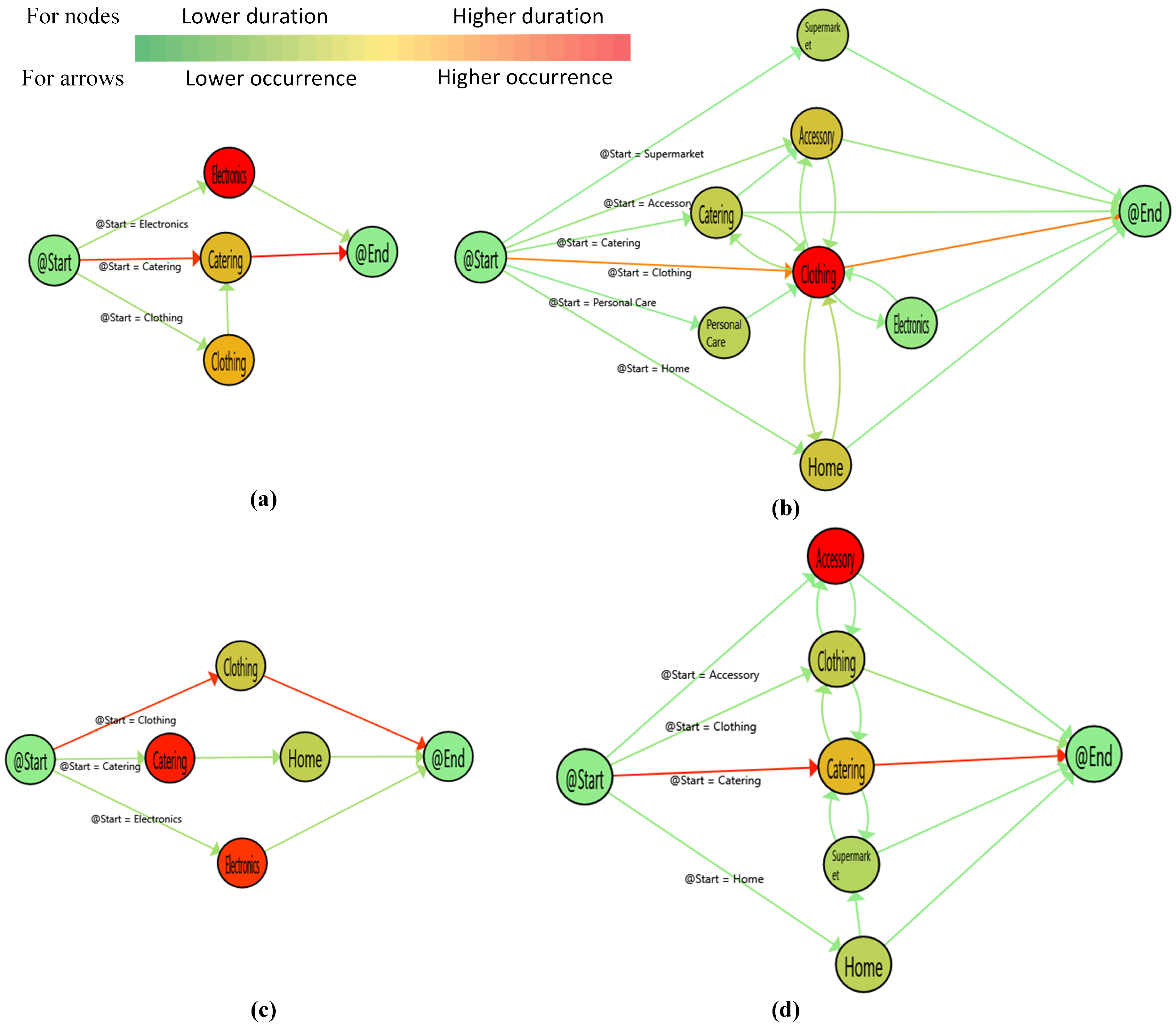
5.2. Process Mining
6. Discussion and Conclusions
7. Future Research and Limitations
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Infosys Corp. Consumers Worldwide Will Allow Access to Personal Data; Infosys Corp.: Bengaluru, India, 2013. [Google Scholar]
- Shave, L. Driving Customer Engagement Inside and Out of the Store through Personalized Digital Experiences; Microsoft Enterprise: Redmond, WA, USA, 2016. [Google Scholar]
- Walker Corp. Customers 2020: The Future of B-to-B Customer Experience; Walker—Customer Experience Consulting: Indianapolis, IN, USA, 2013. [Google Scholar]
- RetailNext Corp. Retail’s Main Event: Brick & Mortar vs. Online; RetailNext Corp.: San Jose, CA, USA, 2017. [Google Scholar]
- Oosterlinck, D.; Benoit, D.F.; Baecke, P.; Van de Weghe, N. Bluetooth tracking of humans in an indoor environment: An application to shopping mall visits. Appl. Geogr. 2017, 78, 55–65. [Google Scholar] [CrossRef]
- Merad, D.; Aziz, K.E.; Iguernaissi, R.; Fertil, B.; Drap, P. Tracking multiple persons under partial and global occlusions: Application to customers’ behavior analysis. Pattern Recognit. Lett. 2016, 81, 11–20. [Google Scholar] [CrossRef]
- Wu, Y.k.; Wang, H.C.; Chang, L.C.; Chou, S.C. Customer’s flow analysis in physical retail store. Procedia Manuf. 2015, 3, 3506–3513. [Google Scholar] [CrossRef]
- Hurjui, C.; Graur, A.; Turcu, C. Monitoring the shopping activities from the supermarkets based on the intelligent basket by using the RFID technology. Elektron. Elektrotech. 2008, 83, 7–10. [Google Scholar]
- Dogan, O.; Oztaysi, B. In-store behavioral analytics technology selection using fuzzy decision making. J. Enterp. Inf. Manag. 2018, 31, 612–630. [Google Scholar] [CrossRef]
- Hwang, I.; Jang, Y.J. Process mining to discover shoppers’ pathways at a fashion retail store using a WiFi-base indoor positioning system. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1786–1792. [Google Scholar] [CrossRef]
- Abedi, N.; Bhaskar, A.; Chung, E.; Miska, M. Assessment of antenna characteristic effects on pedestrian and cyclists travel-time estimation based on Bluetooth and WiFi MAC addresses. Transp. Res. Part C Emerg. Technol. 2015, 60, 124–141. [Google Scholar] [CrossRef]
- Mou, S.; Robb, D.J.; DeHoratius, N. Retail store operations: Literature review and research directions. Eur. J. Oper. Res. 2017, 265, 399–422. [Google Scholar] [CrossRef]
- Fernandez-Llatas, C.; Lizondo, A.; Monton, E.; Benedi, J.M.; Traver, V. Process mining methodology for health process tracking using real-time indoor location systems. Sensors 2015, 15, 29821–29840. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.; van Dongen, B.F.; Herbst, J.; Maruster, L.; Schimm, G.; Weijters, A.J. Workflow mining: A survey of issues and approaches. Data Knowl. Eng. 2003, 47, 237–267. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process Mining Discovery, Conformance and Enhancement of Business Processes; Springer: Berlin, Germany, 2011. [Google Scholar]
- Ou-Yang, C.; Winarjo, H. Petri-net integration—An approach to support multi-agent process mining. Expert Syst. Appl. 2011, 38, 4039–4051. [Google Scholar] [CrossRef]
- Partington, A.; Wynn, M.; Suriadi, S.; Ouyang, C.; Karnon, J. Process mining for clinical processes: A comparative analysis of four Australian hospitals. ACM Trans. Manag. Inf. Syst. (TMIS) 2015, 5, 19. [Google Scholar] [CrossRef]
- Yoo, S.; Cho, M.; Kim, E.; Kim, S.; Sim, Y.; Yoo, D.; Hwang, H.; Song, M. Assessment of hospital processes using a process mining technique: outpatient process analysis at a tertiary hospital. Int. J. Med. Inform. 2016, 88, 34–43. [Google Scholar] [CrossRef] [PubMed]
- Funkner, A.A.; Yakovlev, A.N.; Kovalchuk, S.V. Towards evolutionary discovery of typical clinical pathways in electronic health records. Procedia Comput. Sci. 2017, 119, 234–244. [Google Scholar] [CrossRef]
- Jans, M.; Alles, M.; Vasarhelyi, M. The case for process mining in auditing: Sources of value added and areas of application. Int. J. Account. Inf. Syst. 2013, 14, 1–20. [Google Scholar] [CrossRef]
- Fernandez-Llatas, C.; Valdivieso, B.; Traver, V.; Benedi, J.M. Using Process Mining for Automatic Support of Clinical Pathways Design. In Data Mining in Clinical Medicine; Fernández-Llatas, C., García-Gómez, J.M., Eds.; Number 1246 in Methods in Molecular Biology; Springer: New York, NY, USA, 2015; pp. 79–88. [Google Scholar]
- Yoshimura, Y.; Sobolevsky, S.; Ratti, C.; Girardin, F.; Carrascal, J.P.; Blat, J.; Sinatra, R. An analysis of visitors’ behavior in the Louvre Museum: A study using Bluetooth data. Environ. Plan. B Plan. Des. 2014, 41, 1113–1131. [Google Scholar] [CrossRef]
- De Leoni, M.; van der Aalst, W.M.; Dees, M. A general process mining framework for correlating, predicting and clustering dynamic behavior based on event logs. Inf. Syst. 2016, 56, 235–257. [Google Scholar] [CrossRef]
- Rebuge, Á.; Ferreira, D.R. Business process analysis in healthcare environments: A methodology based on process mining. Inf. Syst. 2012, 37, 99–116. [Google Scholar] [CrossRef]
- Arroyo, R.; Yebes, J.J.; Bergasa, L.M.; Daza, I.G.; Almazán, J. Expert video-surveillance system for real-time detection of suspicious behaviors in shopping malls. Expert Syst. Appl. 2015, 42, 7991–8005. [Google Scholar] [CrossRef]
- Popa, M.C.; Rothkrantz, L.J.; Shan, C.; Gritti, T.; Wiggers, P. Semantic assessment of shopping behavior using trajectories, shopping related actions, and context information. Pattern Recognit. Lett. 2013, 34, 809–819. [Google Scholar] [CrossRef]
- Kang, L.; Hansen, M. Behavioral analysis of airline scheduled block time adjustment. Transp. Res. Part E Logist. Transp. Rev. 2017, 103, 56–68. [Google Scholar] [CrossRef]
- Chen, S.; Fern, A.; Todorovic, S. Multi-object tracking via constrained sequential labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1130–1137. [Google Scholar]
- Rovani, M.; Maggi, F.M.; de Leoni, M.; van der Aalst, W.M. Declarative process mining in healthcare. Expert Syst. Appl. 2015, 42, 9236–9251. [Google Scholar] [CrossRef]
- Mans, R.; Reijers, H.; van Genuchten, M.; Wismeijer, D. Mining processes in dentistry. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; ACM: New York, NY, USA, 2012; pp. 379–388. [Google Scholar]
- Fernández-Llatas, C.; Benedi, J.M.; García-Gómez, J.M.; Traver, V. Process mining for individualized behavior modeling using wireless tracking in nursing homes. Sensors 2013, 13, 15434–15451. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.; Reijers, H.A.; Weijters, A.J.; van Dongen, B.F.; de Medeiros, A.A.; Song, M.; Verbeek, H. Business process mining: An industrial application. Inf. Syst. 2007, 32, 713–732. [Google Scholar] [CrossRef]
- Valle, A.M.; Santos, E.A.; Loures, E.R. Applying process mining techniques in software process appraisals. Inf. Softw. Technol. 2017, 87, 19–31. [Google Scholar] [CrossRef]
- Rubin, V.A.; Mitsyuk, A.A.; Lomazova, I.A.; van der Aalst, W.M. Process mining can be applied to software tool. In Proceedings of the 8th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Torino, Italy, 18–19 September 2014; ACM: New York, NY, USA, 2014; p. 57. [Google Scholar]
- Gupta, M.; Sureka, A.; Padmanabhuni, S. Process mining multiple repositories for software defect resolution from control and organizational perspective. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; ACM: New York, NY, USA, 2014; pp. 122–131. [Google Scholar]
- Juhaňák, L.; Zounek, J.; Rohlíková, L. Using process mining to analyze students’ quiz-taking behavior patterns in a learning management system. Comput. Hum. Behav. 2017, 92, 496–506. [Google Scholar] [CrossRef]
- Sedrakyan, G.; De Weerdt, J.; Snoeck, M. Process-mining enabled feedback: “Tell me what I did wrong” vs. “tell me how to do it right”. Comput. Hum. Behav. 2016, 57, 352–376. [Google Scholar] [CrossRef]
- Schoor, C.; Bannert, M. Exploring regulatory processes during a computer-supported collaborative learning task using process mining. Comput. Hum. Behav. 2012, 28, 1321–1331. [Google Scholar] [CrossRef]
- Werner, M.; Gehrke, N. Multilevel process mining for financial audits. IEEE Trans. Serv. Comput. 2015, 8, 820–832. [Google Scholar] [CrossRef]
- de Weerdt, J.; Schupp, A.; Vanderloock, A.; Baesens, B. Process Mining for the multi-faceted analysis of business processes—A case study in a financial services organization. Comput. Ind. 2013, 64, 57–67. [Google Scholar] [CrossRef]
- Herbert, L.; Hansen, Z.N.L.; Jacobsen, P.; Cunha, P. Evolutionary optimization of production materials workflow processes. Procedia CIRP 2014, 25, 53–60. [Google Scholar] [CrossRef]
- Yim, J.; Jeong, S.; Gwon, K.; Joo, J. Improvement of Kalman filters for WLAN based indoor tracking. Expert Syst. Appl. 2010, 37, 426–433. [Google Scholar] [CrossRef]
- Van Eck, M.L.; Sidorova, N.; van der Aalst, W.M. Enabling process mining on sensor data from smart products. In Proceedings of the 2016 IEEE Tenth International Conference on Research Challenges in Information Science (RCIS), Grenoble, France, 1–3 June 2016; pp. 1–12. [Google Scholar]
- Diamantini, C.; Genga, L.; Marozzo, F.; Potena, D.; Trunfio, P. Discovering Mobility Patterns of Instagram Users through Process Mining Techniques. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 485–492. [Google Scholar]
- Yoshimura, Y.; Girardin, F.; Carrascal, J.P.; Ratti, C.; Blat, J. New Tools for Studying Visitor Behaviors in Museums: A Case Study at the Louvre; Springer: Berlin, Germany, 2012. [Google Scholar]
- Delafontaine, M.; Versichele, M.; Neutens, T.; Van de Weghe, N. Analysing spatiotemporal sequences in Bluetooth tracking data. Appl. Geogr. 2012, 34, 659–668. [Google Scholar] [CrossRef]
- Frisby, J.; Smith, V.; Traub, S.; Patel, V.L. Contextual computing: A Bluetooth based approach for tracking healthcare providers in the emergency room. J. Biomed. Inform. 2017, 65, 97–104. [Google Scholar] [CrossRef]
- Yoshimura, Y.; Krebs, A.; Ratti, C. An analysis of visitors’ length of stay through noninvasive Bluetooth monitoring in the Louvre Museum. arXiv, 2016; arXiv:1605.00108. [Google Scholar]
- Yoshimura, Y.; Krebs, A.; Ratti, C. Noninvasive Bluetooth Monitoring of Visitors. IEEE Pervasive Comput. 2017, 16, 26–34. [Google Scholar] [CrossRef]
- Celikkan, U.; Somun, G.; Kutuk, U.; Gamzeli, I.; Cinar, E.D.; Atici, I. Capturing supermarket shopper behavior using SmartBasket. In Digital Information Processing and Communications; Springer: Berlin, Germany, 2011; pp. 44–53. [Google Scholar]
- Cao, Q.; Jones, D.R.; Sheng, H. Contained nomadic information environments: Technology, organization, and environment influences on adoption of hospital RFID patient tracking. Inf. Manag. 2014, 51, 225–239. [Google Scholar] [CrossRef]
- Larson, J.S.; Bradlow, E.T.; Fader, P.S. An exploratory look at supermarket shopping paths. Int. J. Res. Mark. 2005, 22, 395–414. [Google Scholar] [CrossRef]
- Vukovic, M.; Lovrek, I.; Kraljevic, H. Discovering Shoppers’ Journey in Retail Environment by Using RFID; KES: San Sebastian, Spain, 2012; pp. 857–866. [Google Scholar]
- Leemans, S.J.; Fahland, D.; van der Aalst, W.M. Discovering block-structured process models from incomplete event logs. In Proceedings of the International Conference on Applications and Theory of Petri Nets and Concurrency, Tunis, Tunisia, 23–27 June 2014; Springer: Cham, Switzerland, 2014; pp. 91–110. [Google Scholar]
- Buijs, J. Flexible Evolutionary Algorithms for Mining Structured Process Models. Ph.D. Thesis, Technische Universiteit Eindhoven, Eindhoven, The Netherlands, 2014. [Google Scholar]
- Fernandez-Llatas, C.; Martinez-Millana, A.; Martinez-Romero, A.; Benedi, J.M.; Traver, V. Diabetes care related process modelling using Process Miningtechniques. Lessons learned in the application of InteractivePattern Recognition: Coping with the Spaghetti Effect. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 2127–2130. [Google Scholar] [CrossRef]
- Conca, T.; Saint-Pierre, C.; Herskovic, V.; Sepúlveda, M.; Capurro, D.; Prieto, F.; Fernandez-Llatas, C. Multidisciplinary Collaboration in the Treatment of Patients With Type 2 Diabetes in Primary Care: Analysis Using Process Mining. J. Med. Internet Res. 2018, 20, e127. [Google Scholar] [CrossRef]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the INFOCOM 2000, Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar]
- Petre, A.C.; Chilipirea, C.; Baratchi, M.; Dobre, C.; van Steen, M. WiFi tracking of pedestrian behavior. In Smart Sensors Networks; Elsevier: New York, NY, USA, 2017; pp. 309–337. [Google Scholar]
- Mans, R.; van der Aalst, W.; Vanwersch, R.J. Process Mining in Healthcare: Evaluating and Exploiting Operational Healthcare Processes; Springer: Berlin, Germany, 2015. [Google Scholar]
- Weijters, A.; Ribeiro, J. Flexible heuristics miner (FHM). In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 310–317. [Google Scholar]
- De Medeiros, A.K.A.; Weijters, A.J.; van der Aalst, W.M. Genetic process mining: An experimental evaluation. Data Min. Knowl. Discov. 2007, 14, 245–304. [Google Scholar] [CrossRef]
- Fernández-Llatas, C.; Meneu, T.; Benedi, J.M.; Traver, V. Activity-based process mining for clinical pathways computer aided design. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 6178–6181. [Google Scholar]
- Fernandez-Llatas, C.; Pileggi, S.F.; Traver, V.; Benedi, J.M. Timed parallel automaton: A mathematical tool for defining highly expressive formal workflows. In Proceedings of the 2011 Fifth Asia Modelling Symposium (AMS), Kuala Lumpur, Malaysia, 24–26 May 2011; pp. 56–61. [Google Scholar]
- Heyer, L.J.; Kruglyak, S.; Yooseph, S. Exploring expression data: Identification and analysis of coexpressed genes. Genome Res. 1999, 9, 1106–1115. [Google Scholar] [CrossRef] [PubMed]
- Vidal, E.; Rulot, H.; Valiente, J.M.; Andreu, G. Application of the error-correcting grammatical inference algorithm (ECGI) to planar shape recognition. In Proceedings of the IEE Colloquium on Grammatical Inference: Theory, Applications and Alternatives, Colchester, UK, 22–23 April 1993. [Google Scholar]
- Öztayşi, B.; Gokdere, U.; Simsek, E.N.; Oner, C.S. A novel approach to segmentation using customer locations data and intelligent techniques. In Handbook of Research on Intelligent Techniques and Modeling Applications in Marketing Analytics; IGI Global: Hershey, PA, USA, 2017; pp. 21–39. [Google Scholar]
- Yang, W.S.; Hwang, S.Y. A process-mining framework for the detection of healthcare fraud and abuse. Expert Syst. Appl. 2006, 31, 56–68. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Purposes | Studies |
|---|---|
| To determine some parameters (average number of places visited by people, the average time spent by them, most visited/least visited places) with descriptive statistics | [22] |
| To discover routes followed by customers | [7,22] |
| To estimate the next places visited | [42] |
| To determine where the customer is located at any time | [5,28] |
| Study | CBA | Technology | PM | Implementation Area |
|---|---|---|---|---|
| [45] | ✔ | Bluetooth | Museum | |
| [22] | ✔ | Bluetooth | Museum | |
| [46] | ✔ | Bluetooth | Exhibition | |
| [5] | ✔ | Bluetooth | Store/Shopping Mall | |
| [47] | ✔ | Bluetooth | Hospital | |
| [48] | ✔ | Bluetooth | Museum | |
| [49] | ✔ | Bluetooth | Museum | |
| [7] | ✔ | Camera | Store/Shopping Mall | |
| [25] | ✔ | Camera | Store/Shopping Mall | |
| [26] | ✔ | Camera | Store/Shopping Mall | |
| [50] | ✔ | Camera | Store/Shopping Mall | |
| [6] | ✔ | Camera | Store/Shopping Mall | |
| [51] | RFID | Hospital | ||
| [52] | ✔ | RFID | Store/Shopping Mall | |
| [53] | ✔ | RFID | Store/Shopping Mall | |
| [8] | ✔ | RFID | Store/Shopping Mall | |
| [10] | ✔ | WiFi | ✔ | Store/Shopping Mall |
| [31] | ✔ | RFID | ✔ | Hospital |
| [44] | ✔ | Other | ✔ | Exhibition |
| [43] | ✔ | Other | Manufacturing |
| ID | Dongle_1 | Dongle_2 | Dongle_3 | Timestamp | SubscriberID |
|---|---|---|---|---|---|
| 1028333326 | 121527 | 11.12.2017 00:14:42 | 17399446 | ||
| 1028334382 | 121498 | 11.12.2017 00:16:48 | 39081930 | ||
| 1028334406 | 121498 | 121404 | 11.12.2017 00:16:50 | 39081930 | |
| 1028334421 | 121498 | 11.12.2017 00:16:53 | 39081930 | ||
| 1028492822 | 121436 | 121510 | 121446 | 11.12.2017 07:23:47 | 29078632 |
| 1028492925 | 121510 | 121372 | 11.12.2017 07:23:59 | 29078632 | |
| 1028492939 | 121436 | 121510 | 121446 | 11.12.2017 07:24:01 | 29078632 |
| 1028495185 | 121446 | 121436 | 121510 | 11.12.2017 07:28:23 | 29078632 |
| Customer Data | |
|---|---|
| Total Customer (Man/Woman) | 642 (165/477) |
| Total Number of Cases | 1293 |
| Maximum Number of Visit Sessions | 52 |
| Localization Events | 2749 |
| December 2017 | January 2018 | February 2018 | |
|---|---|---|---|
| Total Customer (Man/Woman) | 290 (89/201) | 181 (47/134) | 171 (29/142) |
| Total Number of Cases | 450 | 444 | 399 |
| Maximum Number of Visit Sessions | 45 | 52 | 43 |
| Localization Events | 957 | 1088 | 704 |
| Number_Occurrence | Duration_Total | |||||||||||
| December | January | February | December | January | February | |||||||
| Nodes | Man | Woman | Man | Woman | Man | Woman | Man | Woman | Man | Woman | Man | Woman |
| Accessory | 14 | 62 | 4 | 66 | 4 | 81 | 02:41:59 | 1.03:05:59 | 00:25:59 | 1.20:10:59 | 02:42:59 | 3.01:53:59 |
| Catering | 79 | 200 | 53 | 123 | 26 | 154 | 2.03:18:59 | 4.12:33:59 | 1.15:48:59 | 3.07:43:59 | 10:27:59 | 3.16:57:59 |
| Clothing | 93 | 223 | 60 | 189 | 17 | 242 | 9.18:33:59 | 4.00:46:59 | 8.19:34:59 | 5.14:16:59 | 05:10:59 | 17.18:42:59 |
| Electronics | 23 | 16 | 6 | 217 | 10 | 12 | 12:39:59 | 05:22:59 | 02:22:59 | 4.17:05:59 | 07:54:59 | 02:26:59 |
| Entertainment | 6 | 20 | 4 | 19 | 1 | 10 | 02:08:59 | 14:21:59 | 01:47:59 | 09:15:59 | 00:20:59 | 01:40:59 |
| Home | 24 | 77 | 10 | 252 | 6 | 76 | 06:51:59 | 1.04:35:59 | 02:44:59 | 5.11:04:59 | 06:54:59 | 2.01:46:59 |
| Mother and Baby | 10 | 24 | 6 | 27 | 0 | 31 | 02:30:59 | 09:08:59 | 02:09:59 | 11:00:59 | 00:00:00 | 2.02:08:59 |
| Personal Care | 8 | 33 | 0 | 22 | 1 | 13 | 01:23:59 | 09:20:59 | 00:00:00 | 05:37:59 | 01:03:59 | 06:32:59 |
| Supermarket | 19 | 26 | 7 | 23 | 5 | 15 | 05:44:59 | 11:26:59 | 02:28:59 | 07:25:59 | 00:54:59 | 05:15:59 |
| Duration_Average_by_Case | Duration_Average | |||||||||||
| December | January | February | December | January | February | |||||||
| Nodes | Man | Woman | Man | Woman | Man | Woman | Man | Woman | Man | Woman | Man | Woman |
| Accessory | 00:13:29 | 00:29:33 | 00:06:29 | 00:47:20 | 00:40:44 | 01:04:15 | 00:11:34 | 00:26:13 | 00:06:29 | 00:40:09 | 00:40:44 | 00:54:44 |
| Catering | 00:44:37 | 00:35:24 | 00:46:50 | 00:42:20 | 00:24:09 | 00:37:19 | 00:38:58 | 00:32:34 | 00:45:04 | 00:38:53 | 00:24:09 | 00:34:39 |
| Clothing | 02:53:45 | 00:30:43 | 03:59:31 | 00:48:32 | 00:19:26 | 02:19:08 | 02:31:19 | 00:26:02 | 03:31:34 | 00:42:37 | 00:18:17 | 01:45:47 |
| Electronics | 00:34:32 | 00:20:11 | 00:23:49 | 02:41:34 | 00:47:29 | 00:12:14 | 00:33:02 | 00:20:11 | 00:23:49 | 00:31:16 | 00:47:29 | 00:12:14 |
| Entertainment | 00:25:47 | 00:45:22 | 00:26:59 | 00:30:53 | 00:20:59 | 00:10:05 | 00:21:29 | 00:43:05 | 00:26:59 | 00:29:15 | 00:20:59 | 00:10:05 |
| Home | 00:19:37 | 00:25:14 | 00:18:19 | 01:39:33 | 01:09:09 | 00:45:15 | 00:17:09 | 00:22:17 | 00:16:29 | 00:31:12 | 01:09:09 | 00:39:18 |
| Mother and Baby | 00:15:05 | 00:22:52 | 00:25:59 | 00:25:25 | 00:00:00 | 02:10:49 | 00:15:05 | 00:22:52 | 00:21:39 | 00:24:28 | 00:00:00 | 01:37:03 |
| Personal Care | 00:10:29 | 00:17:31 | 00:00:00 | 00:15:21 | 01:03:59 | 00:30:13 | 00:10:29 | 00:16:59 | 00:00:00 | 00:15:21 | 01:03:59 | 00:30:13 |
| Supermarket | 00:18:09 | 00:26:25 | 00:21:17 | 00:19:23 | 00:13:44 | 00:21:03 | 00:18:09 | 00:26:25 | 00:21:17 | 00:19:23 | 00:10:59 | 00:21:03 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dogan, O.; Bayo-Monton, J.-L.; Fernandez-Llatas, C.; Oztaysi, B. Analyzing of Gender Behaviors from Paths Using Process Mining: A Shopping Mall Application. Sensors 2019, 19, 557. https://doi.org/10.3390/s19030557
Dogan O, Bayo-Monton J-L, Fernandez-Llatas C, Oztaysi B. Analyzing of Gender Behaviors from Paths Using Process Mining: A Shopping Mall Application. Sensors. 2019; 19(3):557. https://doi.org/10.3390/s19030557
Chicago/Turabian StyleDogan, Onur, Jose-Luis Bayo-Monton, Carlos Fernandez-Llatas, and Basar Oztaysi. 2019. "Analyzing of Gender Behaviors from Paths Using Process Mining: A Shopping Mall Application" Sensors 19, no. 3: 557. https://doi.org/10.3390/s19030557
APA StyleDogan, O., Bayo-Monton, J.-L., Fernandez-Llatas, C., & Oztaysi, B. (2019). Analyzing of Gender Behaviors from Paths Using Process Mining: A Shopping Mall Application. Sensors, 19(3), 557. https://doi.org/10.3390/s19030557