1. Introduction
The brain-computer interface (BCI) is an alternative method of communication between a user and system that depends on neither the brain’s normal output nerve pathways nor the muscles. The process generally begins by recording the user’s brain activities and continues to signal-processing to detect the user’s intentions. Then, the appropriate signal is sent to the external device, which is then controlled according to the detected signal. One of the important goals of BCI research is to enhance certain functions for a healthy person via a new signal pathway. BCI is currently being studied in a fairly wide application range, including communication tools for locked-in state (CLIS) patients [
1,
2,
3].
Studies have proved that the electroencephalogram (EEG) signals produced while mentally imagining different movements can be translated into different commands. In this paper, we refer to the brain potentials related to motor imagery tasks as control signals. In motor imagery (MI)-based BCI systems, the imagining of body movements is accompanied by a circumscribed event-related synchronization/desynchronization (event-related synchronization (ERS)/event-related desynchronization (ERD)) [
4,
5]. Thus, motor imagery has had widespread use as a major approach in BCI systems [
6,
7].
Pattern recognition techniques enable information extraction from EEG recordings of brain activity, which is why it is extremely important in EEG-based research and applications. Machine learning is the core of EEG-based BCI systems. Many studies have investigated numerous feature extraction and classification approaches to MI task recognition. In MI-based BCI systems, common spatial pattern (CSP) is a very popular and powerful feature extraction method [
8,
9]. It constructs very few new time series whose variances contain the most discriminative information. In recent years, the CSP algorithm has been further developed. Several approaches have been proposed, including filter bank CSP (FBCSP) [
10], augmented common spatial pattern (ACSP) [
11], etc. For the classification component, several major model types, such support vector machine (SVM) [
12], linear discriminant analysis (LDA) [
13] and Bayesian classifier [
14] have been used [
15].
Nevertheless, despite all the improvements that have been achieved in BCI systems, there is still room for enhancement, especially in interpretability, accuracy, and online application usability. To address these issues and construct a pattern recognition model with high descriptive power, a new category of strategies and methods, called deep learning, was recently developed, and it is prevalent in both academia and industry [
16,
17].
Deep learning methods have been rarely applied to the EEG-based BCI system, as they are quite hard to apply to the development of a perfect EEG classification framework due to various impacting factors, such as noise, the correlation between channels, and the high dimensional EEG data. An ideal classification framework should contain a data preparation stage, where signals undergo a reduction in dimensionality and are represented by new data without significant information loss. Subsequent to data preparation is the second stage of this framework-that is, the network architecture-where meaningful features of the inputs are all extracted. Taking into account all the challenges mentioned above, the successful implementation of deep learning methods for the classification of EEG signals is quite an achievement.
In one study [
18], a Boltzmann Machine model was applied for two-class MI classification. Convolutional neural networks (CNN) are also used in some EEG studies. For instance, in [
19], three CNNs with different architectures were used to classify MI EEG signals, with the number of convolutional layers ranging from 2 layers to a 5-layer deep ConvNet up to a 31-layer residual network (ResNet). In a recent study [
20], a network was proposed which employs a recurrent convolutional neural network (RCNN) architecture to understand the cognitive events in EEG data. A new form that combines CNN and stacked autoencoders (SAEs) was proposed in [
21] for MI classification.
Several studies have used different methods to convert EEG signals to an image representation before applying a CNN. In [
10], filter bank common spatial pattern (FBCSP) features were generated based on pairwise projection matrices. This can be considered an extraction of the CSP features from a multilevel decomposition of different frequency ranges. In [
20], the authors proposed a new form of features that preserves the spatial, spectral, and temporal structure of the EEG. In this method, the power spectrum of the signal from each electrode is estimated and the sum of squared absolute values are computed for three selected frequency bands. Then, the polar projection method is used to map the electrode locations from 3D to 2D and construct the input images.
A new form of input that combines frequency, time, and multichannel information is introduced in this study. The time series of an EEG is converted into two-dimensional images with the use of the short-time Fourier transform (STFT) method. The mu and beta frequency band spectral contents are made apparent by preserving the patterns of activation at various locations, times, and frequencies.
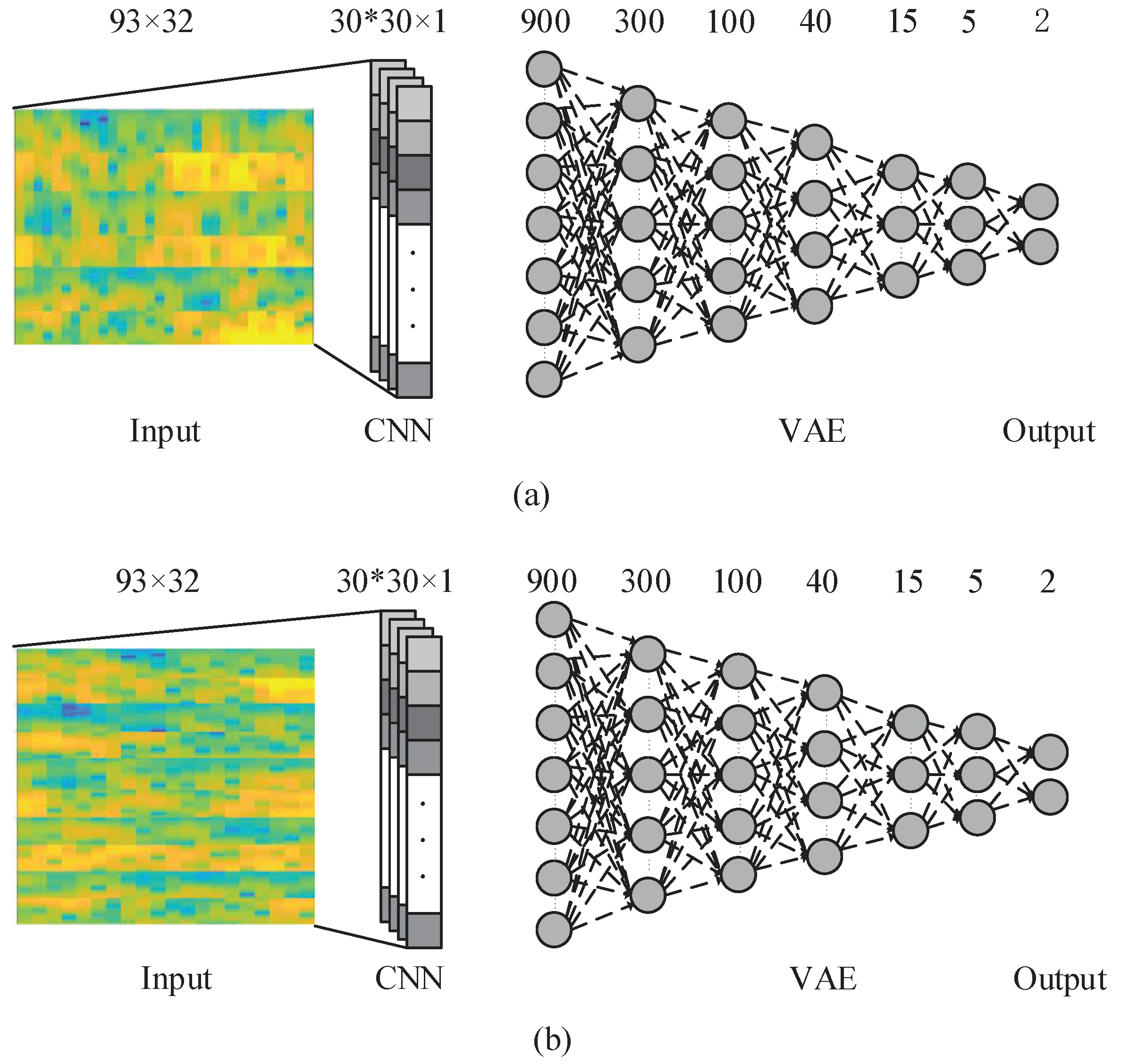
In our approach, the input data is used by the CNN [
22] to learn the activation patterns of different MI signals. Convolution is applied only to the time axis, rather than frequency and location. Therefore, the shape of the activation patterns (i.e., power values from different frequencies) and their location (i.e., EEG channel) are learned in the convolutional layer. Then, a variational autoencoder (VAE) [
23,
24] with five hidden layers improves the classification through a deep network. Based on our current knowledge, EEG signals are characterized by a Gaussian distribution. For this reason, we used a decoder with Gaussian outputs to fit the distribution of EEG signals [
25,
26]. Learning an undercomplete representation forces the autoencoder to capture the most salient features of the EEG data. To compare the performance of the proposed CNN-VAE network, CNN-SAE, CNN, and VAE networks were also tested separately to assess their classification abilities.
BCI Competition IV dataset 2b was used in the analysis and evaluation of the methods proposed in the present study [
27]. The results of the approaches described in this paper were compared with the results of current state-of-the-art algorithms used in this area of study. To test the proposed methods on another dataset, we also used these methods with the same testing protocol with our own dataset and compared the results with those of current state-of-the-art studies.
The rest of this paper is organized as follows. The dataset is presented in
Section 2. Input data forms and deep learning networks, including the CNN, VAE, and combined CNN-VAE, are explained in
Section 3. The experiment and its results are presented and discussed in
Section 4. Finally,
Section 5 concludes this study.
3. Deep Learning Framework
3.1. Input Form
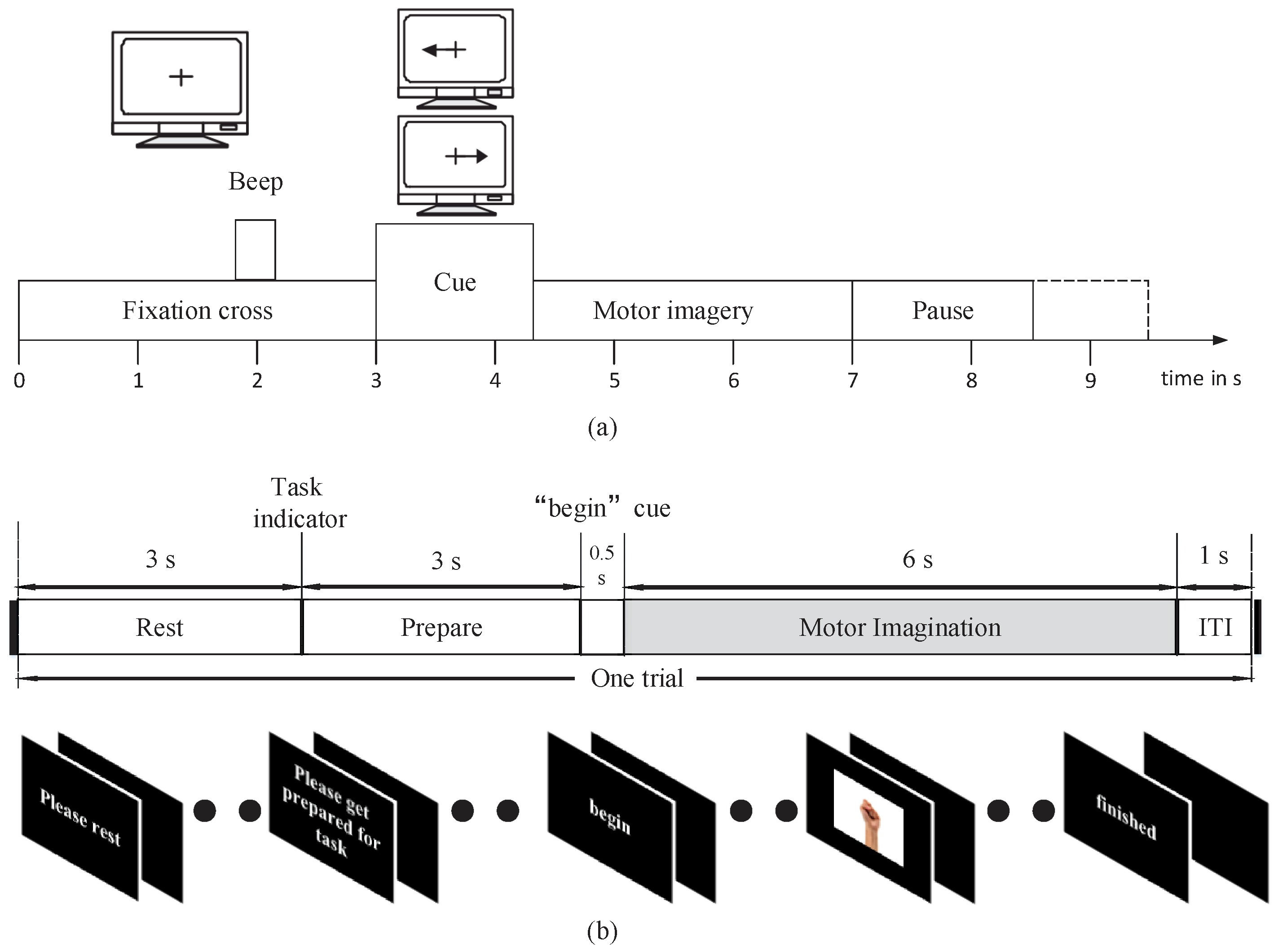
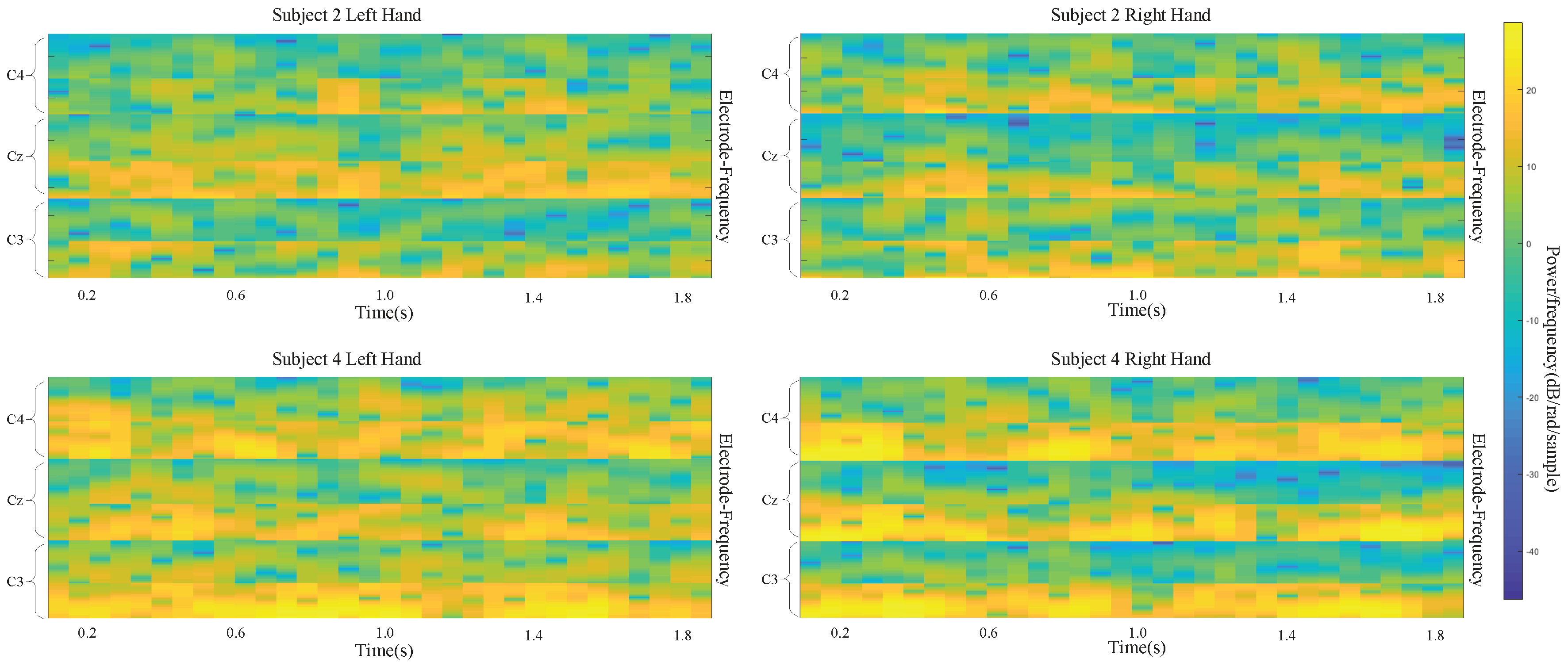
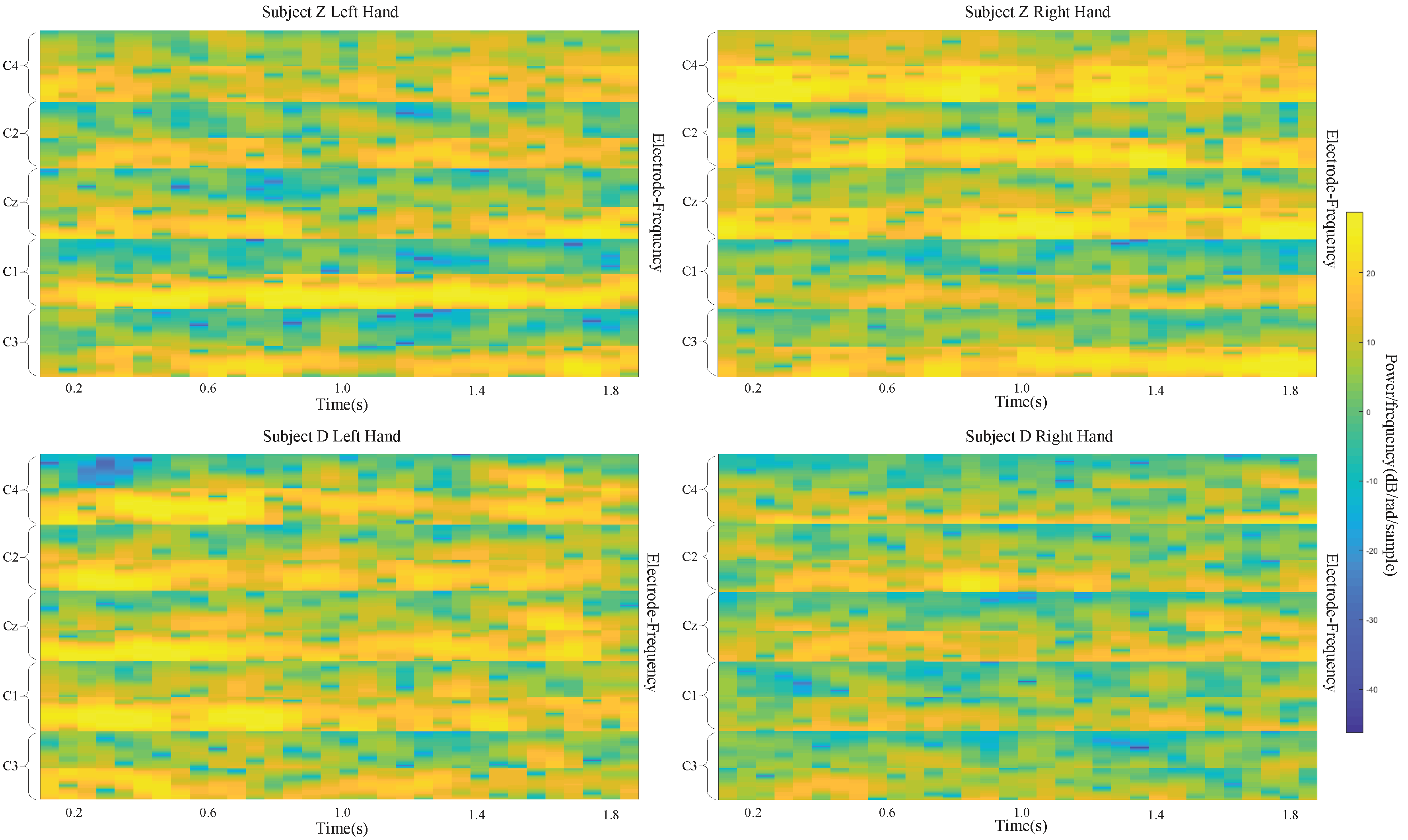
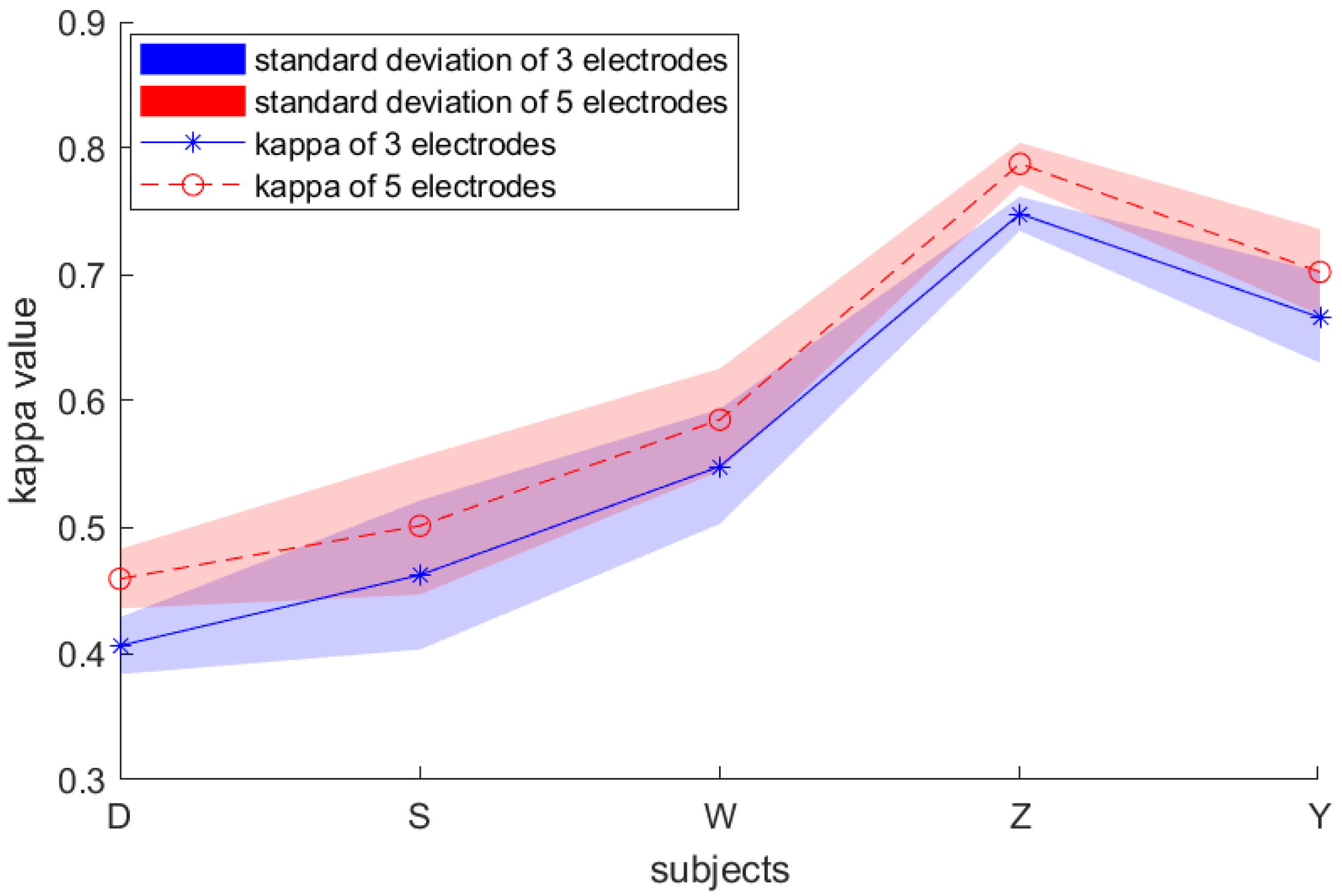
The datasets that we used in this study include recordings from three electrodes (C3, Cz, and C4) and five electrodes (C3 C1, Cz, C2, and C4) to capture signals during left/right-handed MI task. These electrode points are located on the motor area of the brain.
It is shown in [
5,
21] that the power spectrum in mu band (6∼13 Hz) observed in the primary motor cortex of the brain decreases when performing an MI task. This desynchronization is called ERD. An MI task also causes the power spectrum in the beta band (13∼30 Hz) to increase, which is called ERS. The imagining of body movements is accompanied by a circumscribed event-related synchronization/desynchronization (ERS/ERD). Left-and right-handed movement can affect the signals in the right and left sides of the motor cortex at the C4 (C4, C2) and C3 (C3, C1) electrode sites, respectively. Cz is also affected by the MI task. With these facts, we designed a deep learning framework input that takes advantage of the time and frequency information of the data.
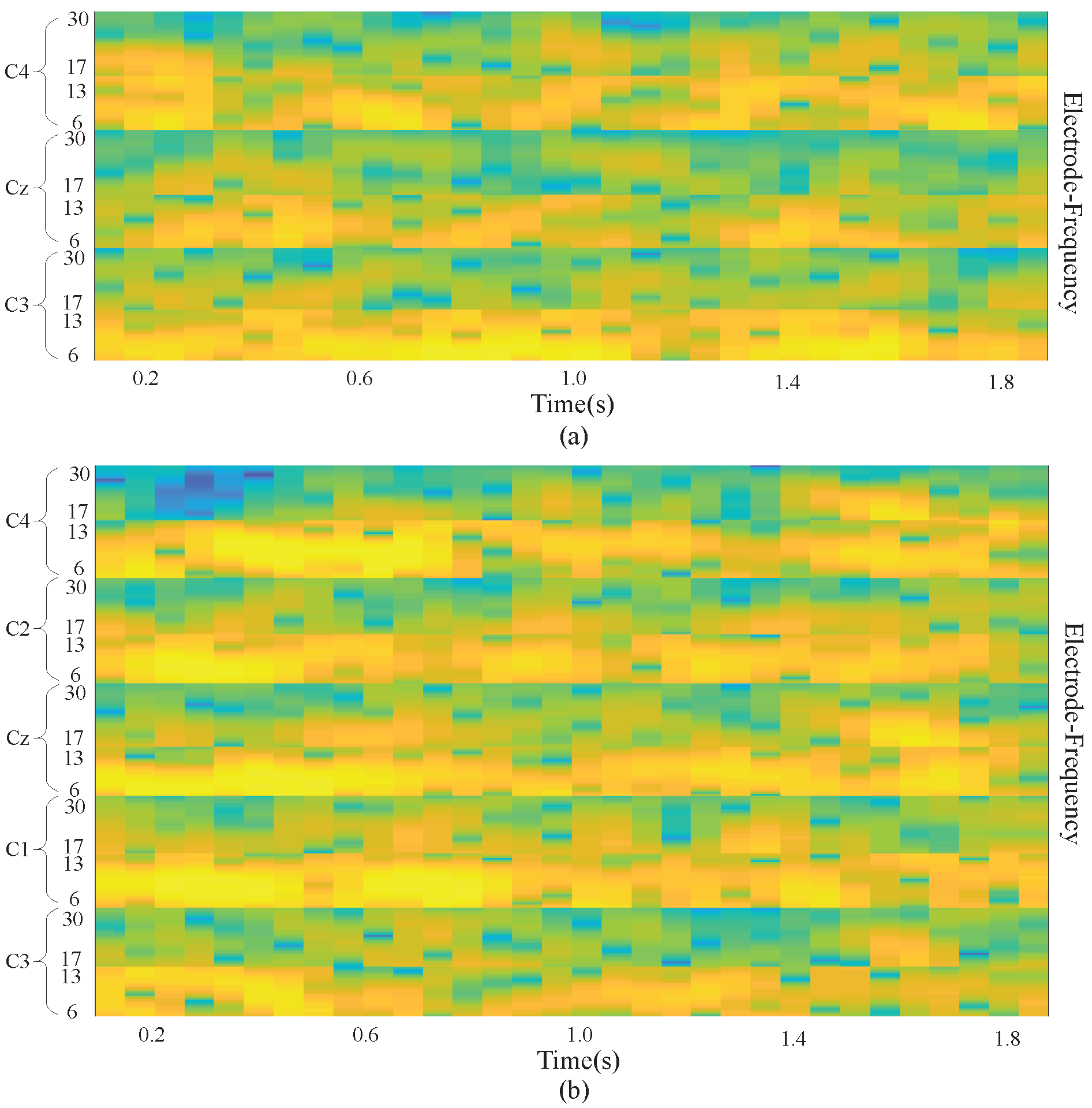
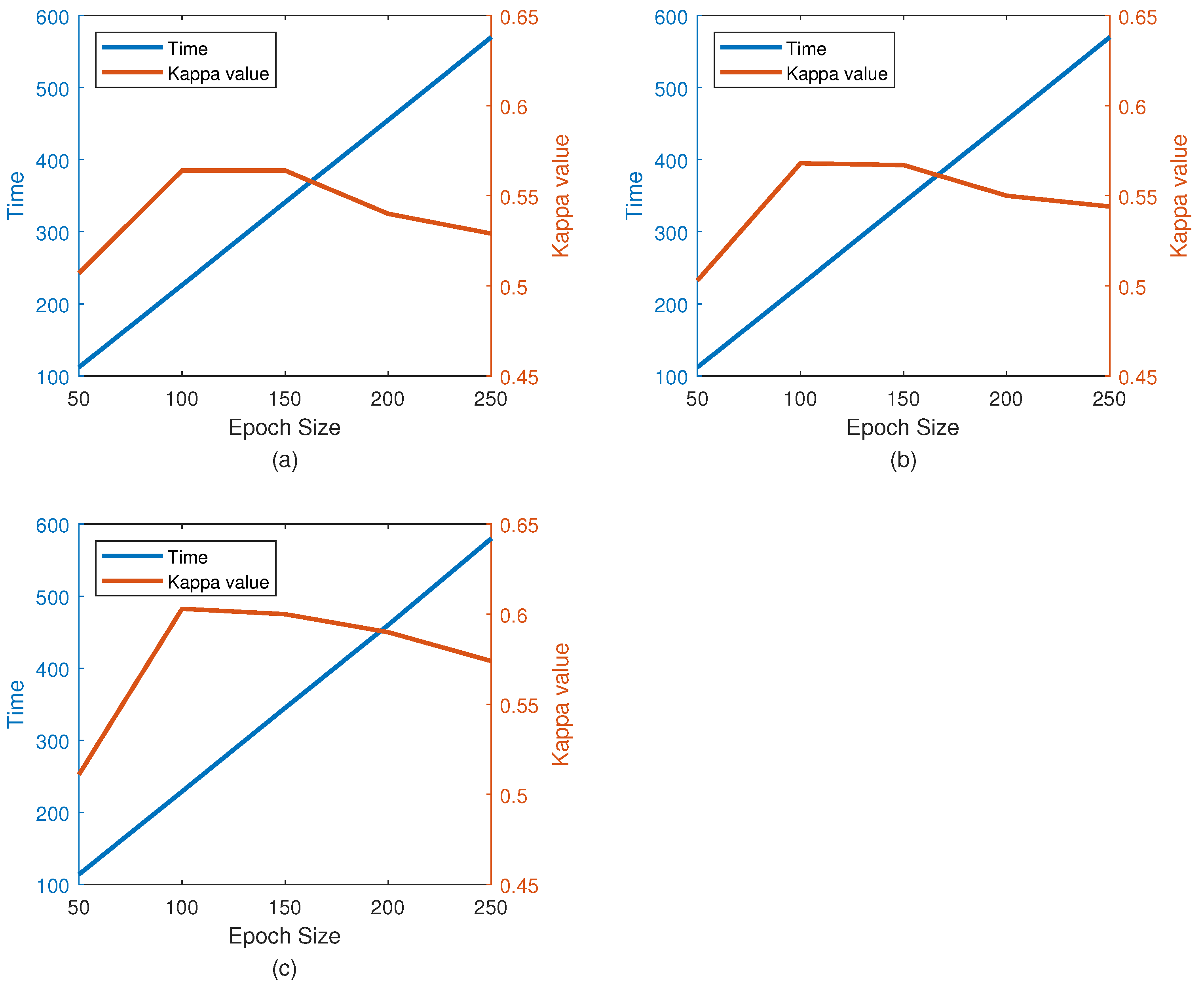
We extracted EEG signals with a length of 2 s from each MI EEG recording. Because the EEG signals were sampled at 250 Hz, each 2 s long time series corresponds to 500 samples. Then, the STFT was applied to the time series. The STFT was conducted with time lapses = 14 and window size = 64. Among all 500 samples, the STFT was computed for 32 windows on the first 498 samples, with the remaining 2 samples simply overlooked in the end. Therefore, a image is produced, where the numbers 32 and 257 represent the samples on the axes of time and frequency, respectively. Subsequently, the beta and mu frequency bands were extracted from the spectrum of the output. Frequency bands of 6∼13 and 17∼30 were taken as the mu and beta bands, respectively. Despite the slight difference between these frequency bands and those presented in the literature, better data representation was obtained in the present experiment. The extracted images for beta and mu have sizes of and , respectively. The cubic interpolation method was then used to resize the beta frequency band to to ensure similar effects of both bands. After that, all the images were appropriately combined with each other and eventually made into an image, in which and .
There were
electrodes (C3, Cz, and C4) used to measure the signals for BCI Competition IV dataset 2b, and the result was combined with the preserved neighboring information of the electrodes. As a result, an input image was obtained with a size of
, in which
. In addition, in our own dataset, there were
electrodes including C3, C1, Cz C2, and C4. So
in our dataset equals
.
Figure 2 demonstrates a sample input image which is composed of the MI task signals from three electrodes (a) and five electrodes (b). With the use of the proposed approach, brain activation on both sides of the brain motor cortex led to different patterns of activation in the brain vertical cortex.
3.2. Convolutional Neural Network (CNN)
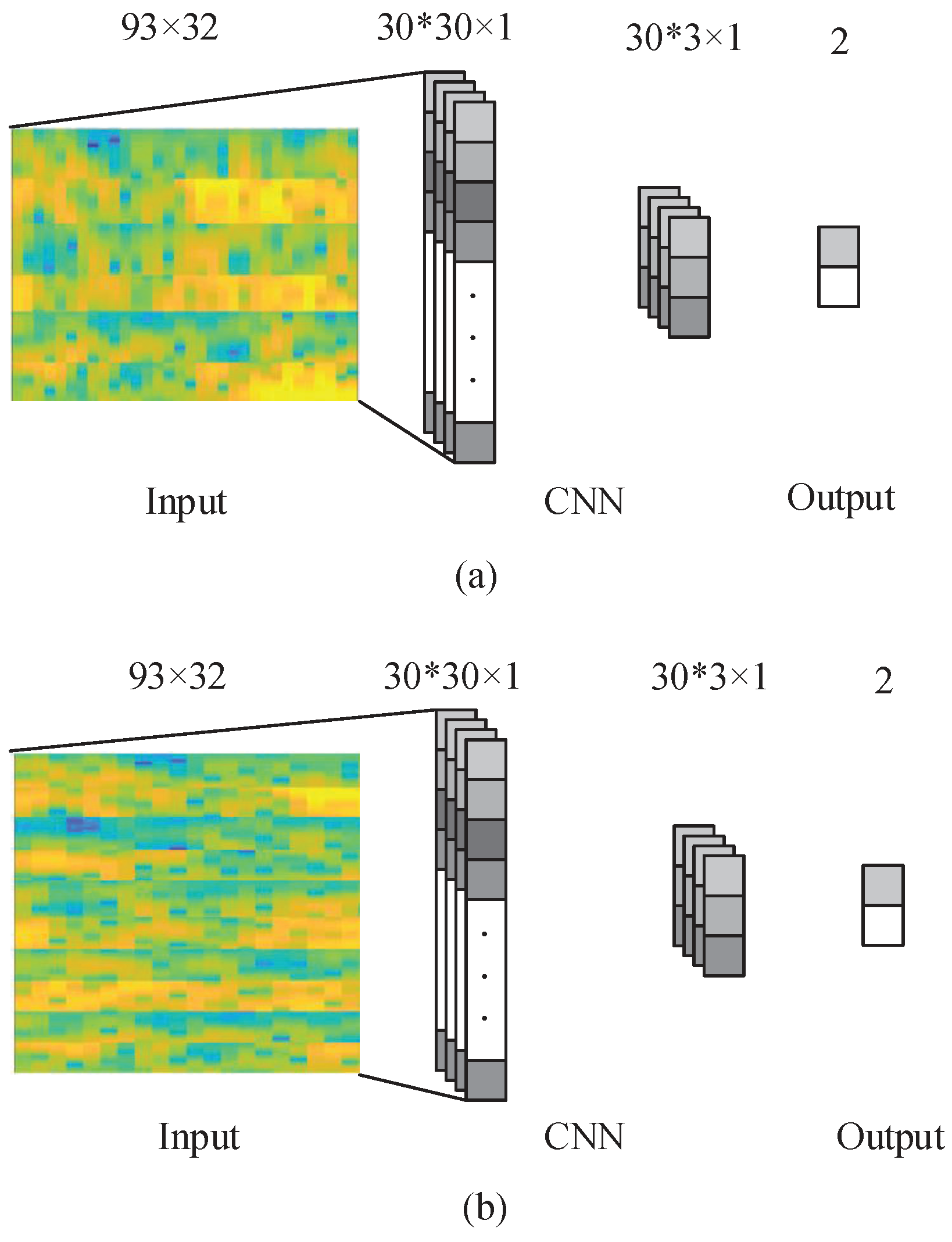
A CNN is a neural network with multiple layers, including several convolution pooling layer pairs, as well as a completely connected output layer [
22]. The design of the standard CNN aims at the recognition the image shapes can remain partly invariant to the shape location. In the convolutional layer, the input images were convolved with several 2-D filters. For example, if we use a 2-D image I as our input, we probably also want to use a 2-D convolutional kernel
K:
Then the feature map after convolutional kernel were down-sized into a smaller sample in the pooling layer. The network weights and filters(kernel) in the convolutional layer are learned by a back-propagation algorithm to reduce classification errors.
In our data, electrode location, time, and frequency data are all used at the same time. For the input images, activation at vertical locations is of great importance for the classification performance, while, in contrast, the horizontal locations of activation are not as significant. Hence, in the present experiment, the kernel applied were as high as the input image, while, on the horizontal axis, the filters applied were 1D throughout.
The network was used to train a total of
filters of the size
. The proposed CNN structure is shown in
Figure 3. The input images were convolved with the kernels to be trained and were then put through
f-the output function-to generate the map of output in the convolution layer. In a given layer, the map of
k-th features can be obtained as
where x denotes the input image,
represents the weight matrix for filter
k and
represents the bias value, for
In the present experiment where the 1D filtering has
sized filters,
and
. The output function
f is selected as rectified linear unit (ReLU) function. ReLU is defined as
where a is as defined in Equation (
1).
The output of the convolutional layer is
vectors with
dimension. In the max-pooling layer, zero padding and a sampling factor of 10 are applied. Hence, the map of the output obtained in the previous layer is subsampled into
vectors with 1D. The layer following the max-pooling layer is a completely connected layer with two outputs that represent the MI of the right and left hand, respectively. The back-propagation algorithm is used to learn CNN parameters. With the proposed approach, the network is fed with the labeled training set, and the error
E is computed taking into account the fact that the desired output is different from the output of the network. Subsequently, the gradient descent method is applied to minimize the error E occurring with changes in the network parameters, which is demonstrated in Equations (4) and (5).
where
is the learning rate of the algorithm, while
represents the weight matrix for kernel
k and
represents the bias value, just like the previous definition. At last, the network that has been trained is used to classify the new samples in the test set.
3.3. Variational Autoencoder (VAE)
An autoencoder (AE) is a neural network that is trained to attempt to copy its input to its output. Internally, it has a hidden layer h that describes a code used to represent the input. The network may be viewed as consisting of two parts: an encoder function and a decoder that produces a reconstruction . Where x is the input data. One way to obtain useful features from the autoencoder is to constrain z to have smaller dimension than x. An autoencoder whose code dimension is less than the input dimension is called undercomplete. Learning an undercomplete representation forces the autoencoder to capture the most salient features of the training data.
The variational autoencoder (VAE) is a directed model that uses learned approximate inference and can be trained purely with gradient-based methods [
23].
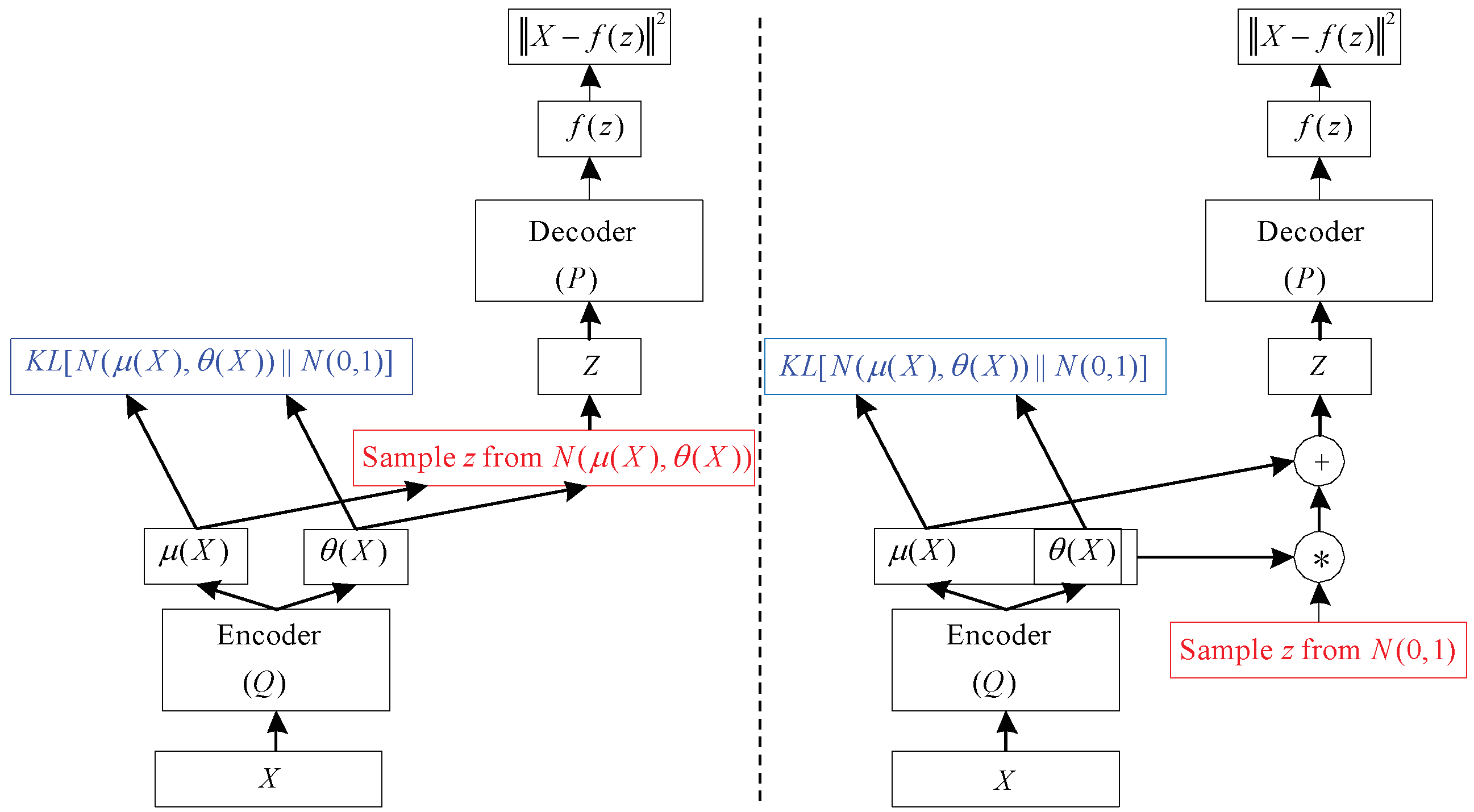
To generate a sample from the model, the VAE first draws a sample
z from the code distribution
. The sample is then run through a differentiable generator network g(z). Finally,
x is sampled from a distribution
. However, during training, the approximate inference network (or encoder)
is used to obtain
z and
is then viewed as a decoder network. The key insight behind variational autoencoders is that they may be trained by maximizing the variational lower bound
associated with data point
x:
In Equation (
6), we recognize the first term as the joint log-likelihood of the visible and hidden variables under the approximate posterior over the latent variables. We recognize also a second term, the entropy of the approximate posterior. When
q is chosen to be a Gaussian distribution, with noise added to a predicted mean value, maximizing this entropy term encourages increasing the standard deviation of this noise. More generally, this entropy term encourages the variational posterior to place high probability mass on many
z values that could have generated
x, rather than collapsing to a single point estimate of the most likely value. In Equation (
7), we recognize the first term as the reconstruction log-likelihood found in other autoencoders. The second term tries to make the approximate posterior distribution
and the model prior
approach each other. The network described in Equation (
7) is much like the network shown in
Figure 4 (left). Stochastic gradient descent on back-propagation can handle stochastic inputs, but not stochastic units within the network. The solution, called the “reparameterization trick”, is to move the sampling to an input layer. we can sample from
by sampling
, then computing
. Where
and
are the mean and covariance of
. Thus, Equation (
7) can be computed as
This is shown schematically in
Figure 4 (right) VAE is composed of an input layer, several AEs, and an output layer. Each AE layer is trained separately in an unsupervised manner, and the output of the hidden layer in the previous AE is used as input to the next layer in the deep network. After this unsupervised pre-training step, a supervised fine-tuning step is applied to learn the whole network’s parameters by using the back-propagation algorithm [
22]. The VAE network used in this study is shown in the VAE part of
Figure 4. This model is composed of one input layer, five hidden layers, and one output layer. The number of nodes at each layer is indicated at the top of the figure.
3.4. Combined CNN-VAE
The useful information from an EEG signal is very weak and thus susceptible to noise [
7]. Artifacts, such as eye-blinking and muscle movement, are another source of disturbance that cause irrelevant effects that corrupt the desired brain pattern. The channel correlation, presence of artifacts (i.e., movement), and high dimensionality of EEG data make it challenging to design an ideal EEG classification framework. To address these issues, we propose a new deep learning model that implements a CNN followed by a VAE. The model is presented in
Figure 5.
In this deep learning model, at first the CNN Introduced in
Section 3.2 is employed over the input data and the kernels and network parameters are learned. Then, the CNN output is used as an input to the VAE network. Input layer of the VAE has 900 neurons which is the output of 30 neurons in the convolutional layer for each of 30 kernels trained in CNN. By using this framework, we aim to improve the classification accuracy by using CNN-VAE model to consider the time, frequency, and position information of EEG data.
The computational complexity of CNN-VAE used for testing is O() + O (). The first term is the computational complexity of the CNN portion of the network, where is the input image size, is the number of convolution kernels, and is the kernel size. The second term is the computational complexity of the VAE part, where is the number of layers; since the VAE layer is fully connected, the complexity has a squared term.
5. Conclusions
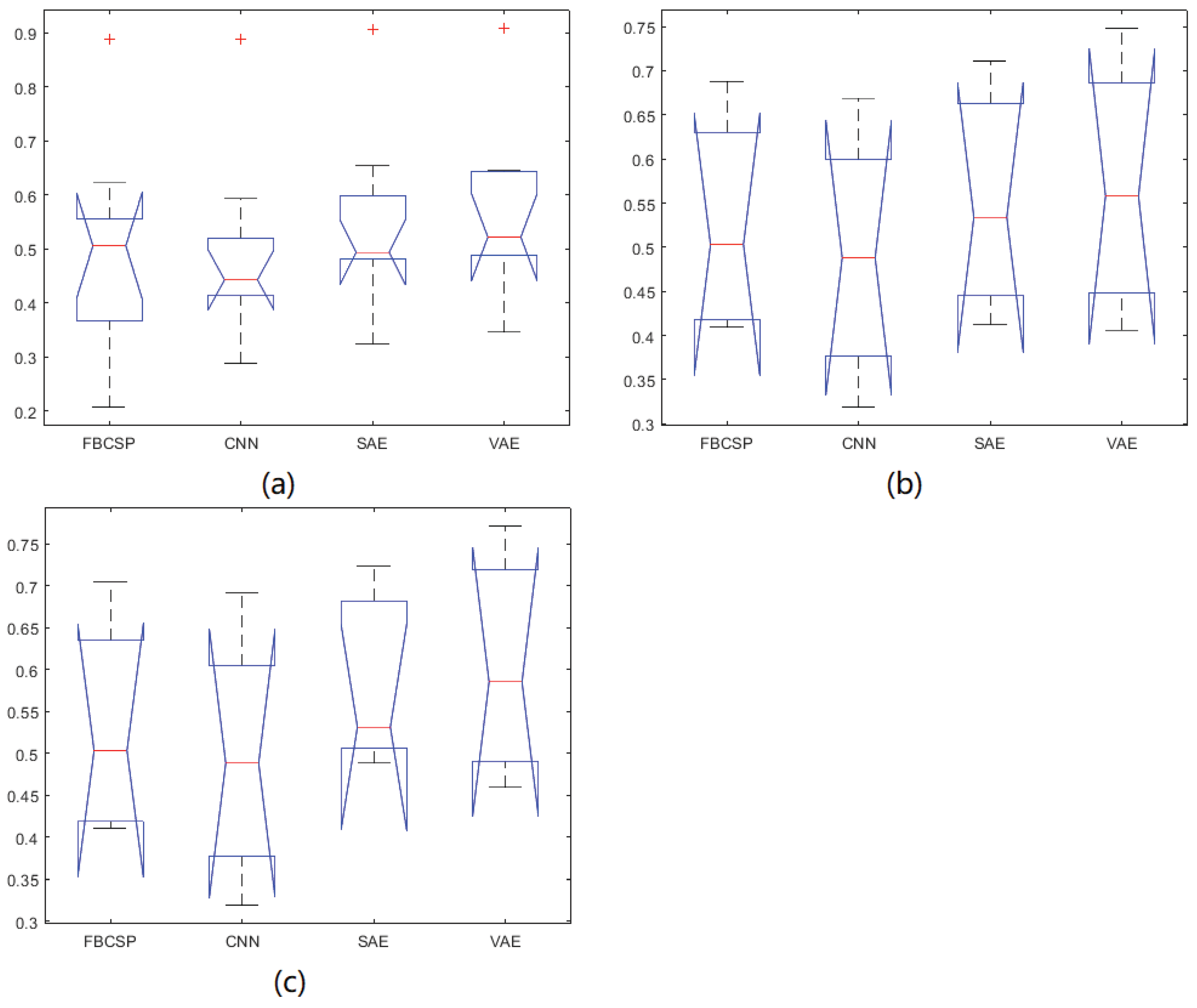
In this paper, we propose a new approach that combines the CNN and VAE networks. In this framework, the input images built by EEG signals are first trained for feature extraction by the CNN. After that, the extracted features are classified by the VAE model. After comparing the results of the CNN-VAE method with those of other existing approaches, it is shown that the approach in our study yields the most accurate results using BCI Competition IV dataset 2b and our own dataset. Yet there are no statistically significant differences among the compared methods. In future work, some new approaches will be employed to overcome the low signal-to-noise ratio of EEG signals.
The filters of the CNN consider neighboring regions, yet the CNN provides no such information, which suggests a greater contribution of the filters to the performance of classification compared with their role in the other methods. Furthermore, the undercomplete representation by the VAE follows the Gaussian distribution, which is the distribution of EEG signals. Therefore, when the outputs of the CNN model are input into the VAE, the advantages of the two networks are combined, thus increasing the ultimate classification performance. In conclusion, CNN-VAE is a novel, promising framework for the classification of EEG signals generated during MI tasks.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}