SLIC Superpixel-Based l2,1-Norm Robust Principal Component Analysis for Hyperspectral Image Classification




Abstract
:
1. Introduction
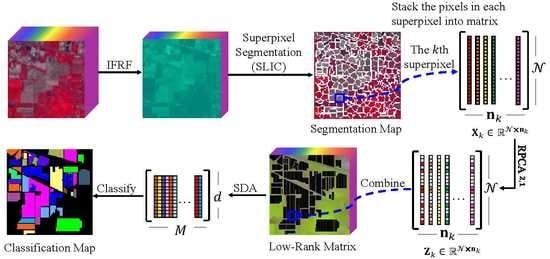
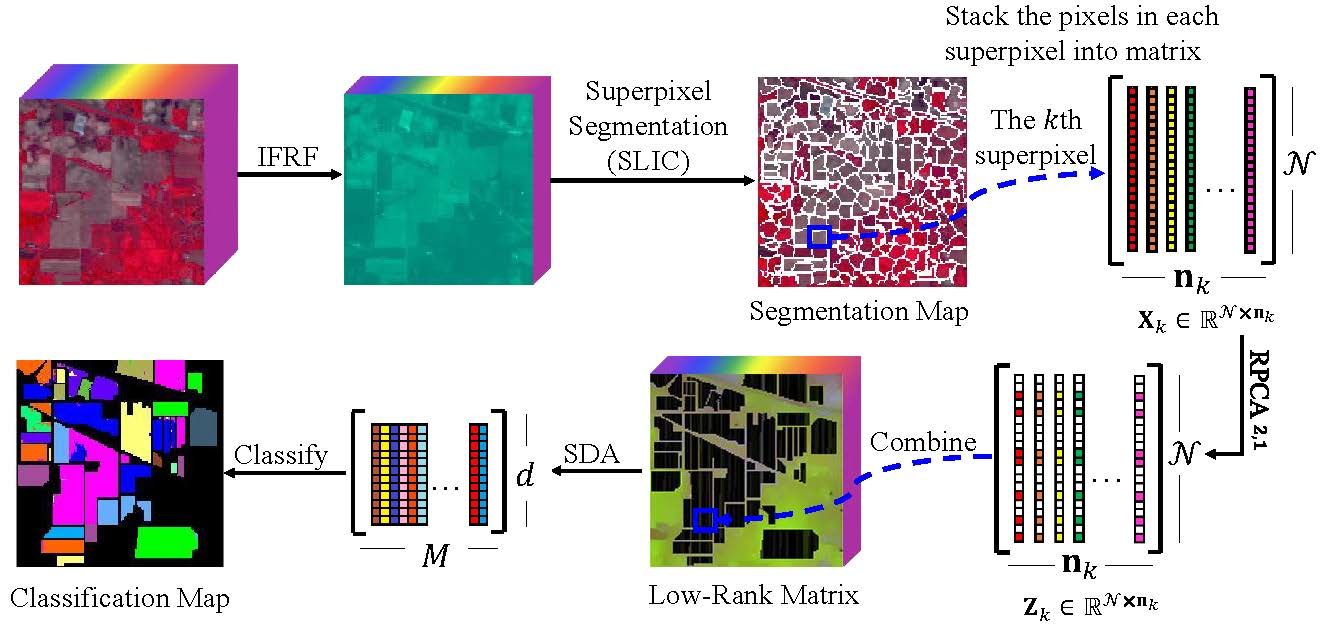
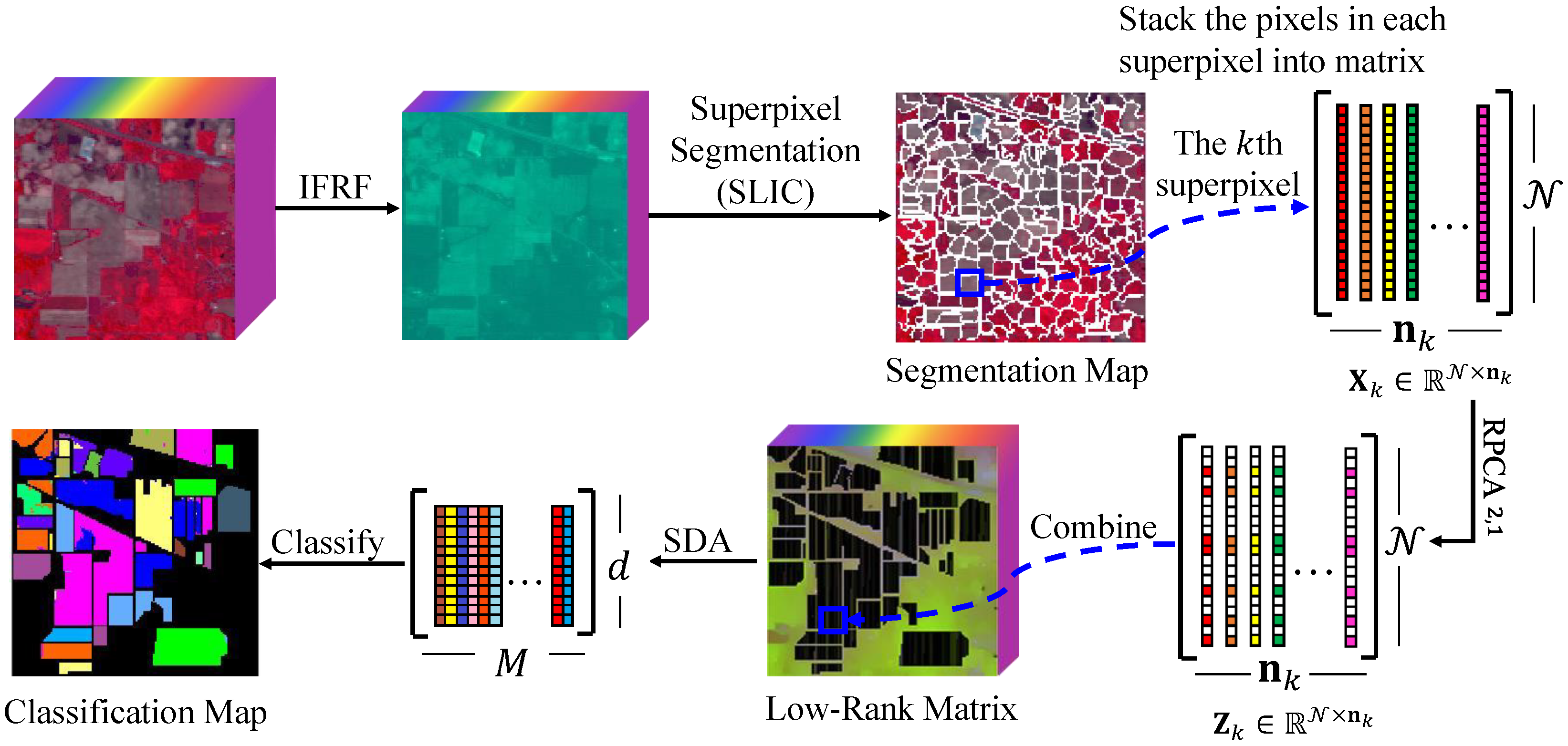
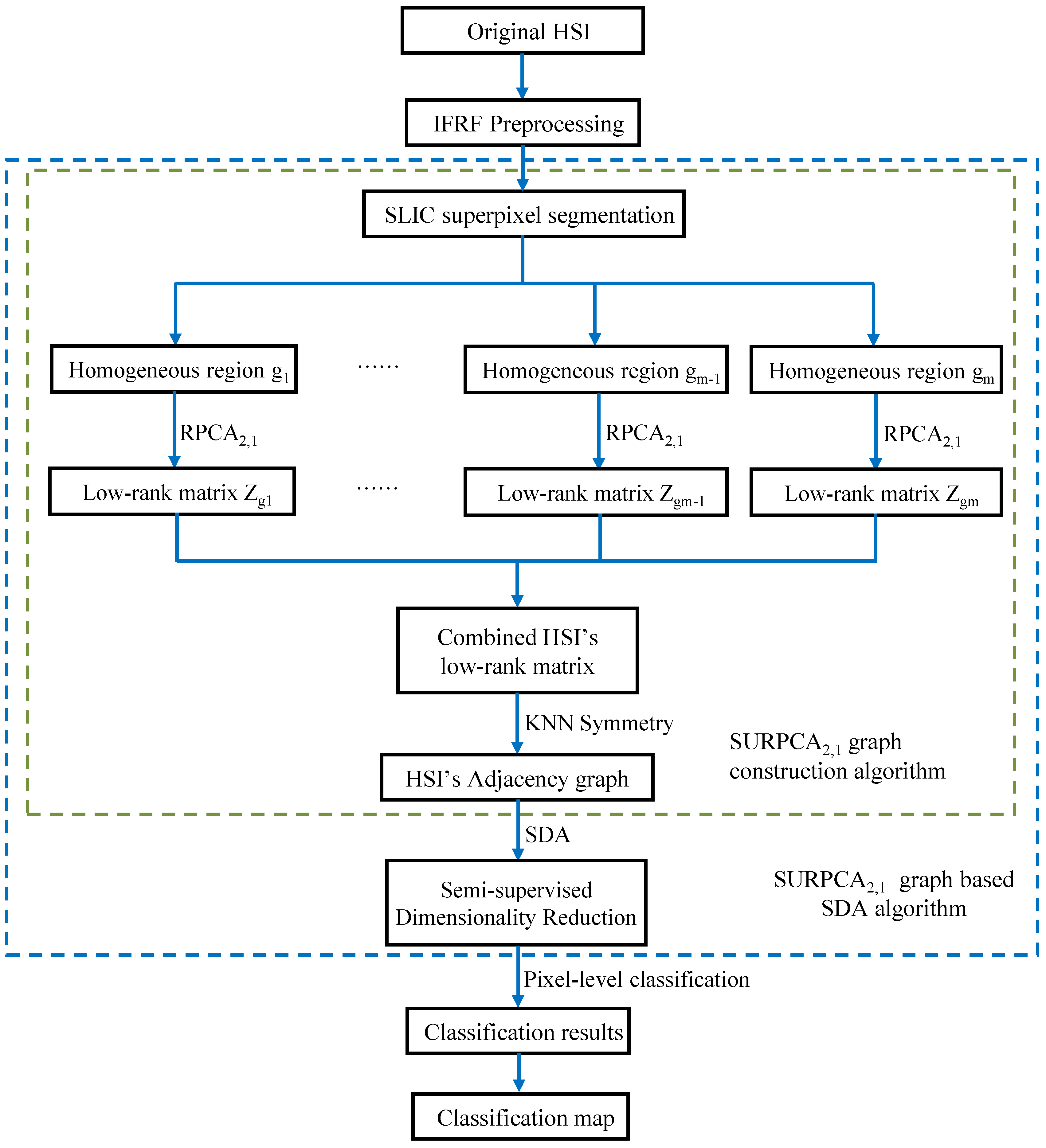
- Inspired by robust principal component analysis and superpixel segmentation, we put forward a novel graph construction method, SLIC superpixel-based -norm robust principal component analysis. The superpixel-based -norm RPCA extracts the low-rank spectral structure of all pixels in each uniform region, respectively.
- The simple linear iterative clustering addresses the spatial characteristics of hyperspectral images. Consequently, the SURPCA2,1 graph model can classify pixels more accurately.
- To investigate the performance of the SLIC superpixel-based -norm robust principal component analysis graph model, we conducted extensive experiments on several real multi-class hyperspectral images.
2. Scientific Background
2.1. Graph-Based Semi-Supervised Dimensionality Reduction Method
- Fully Connected graphs [21,52]: In the fully connected graph, all nodes are connected by edges whose weights are not zero. The fully connected graphs are easy to construct and have good performance for semi-supervised learning methods. However, the disadvantage of the fully connected graphs is that it requires processing all nodes, which would lead to high computational complexity.
- k-nearest neighbor graph [21]: Each node in the k-nearest neighbor graph is only connected with k neighbor in a certain distance. The samples and are considered as neighbor if is among the k nearest neighbor of or is among the k-nearest neighbor of .
- -ball graph [21]: In the -ball graph, the connections between data points occur in the neighborhood of radius . That is to say, if the distance between and exists , there will be a neighbor relationship between these two nodes. Therefore, the connectivity of the graph is largely influenced by the parameter .
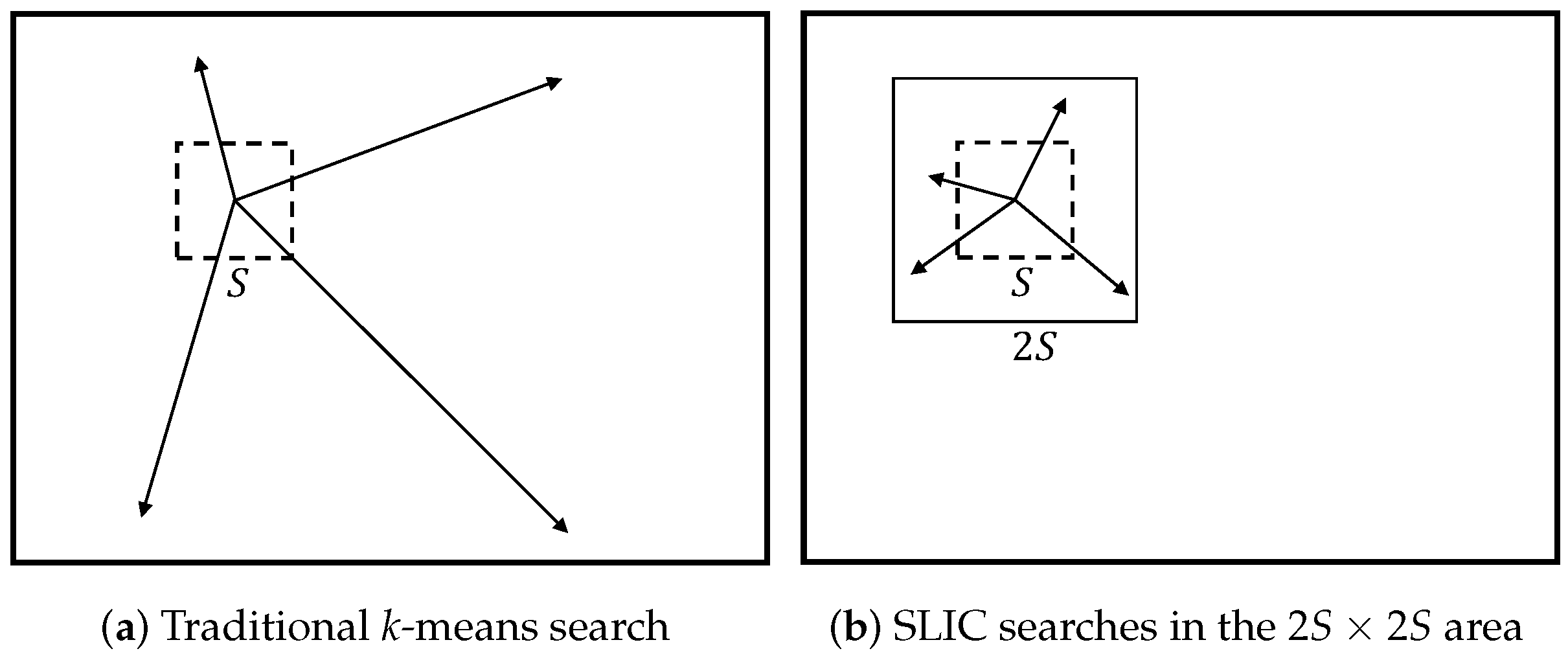
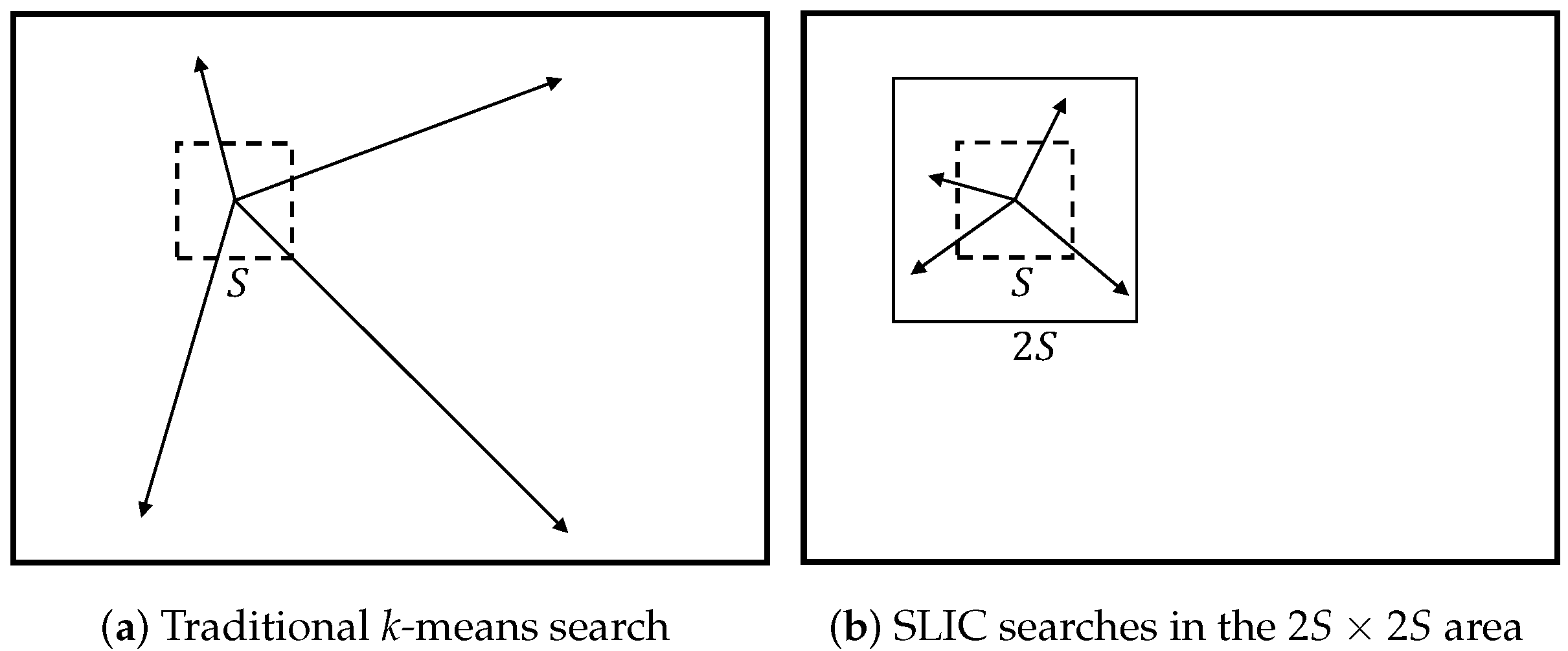
2.2. Simple Linear Iterative Clustering
2.3. Robust Principal Component Analysis
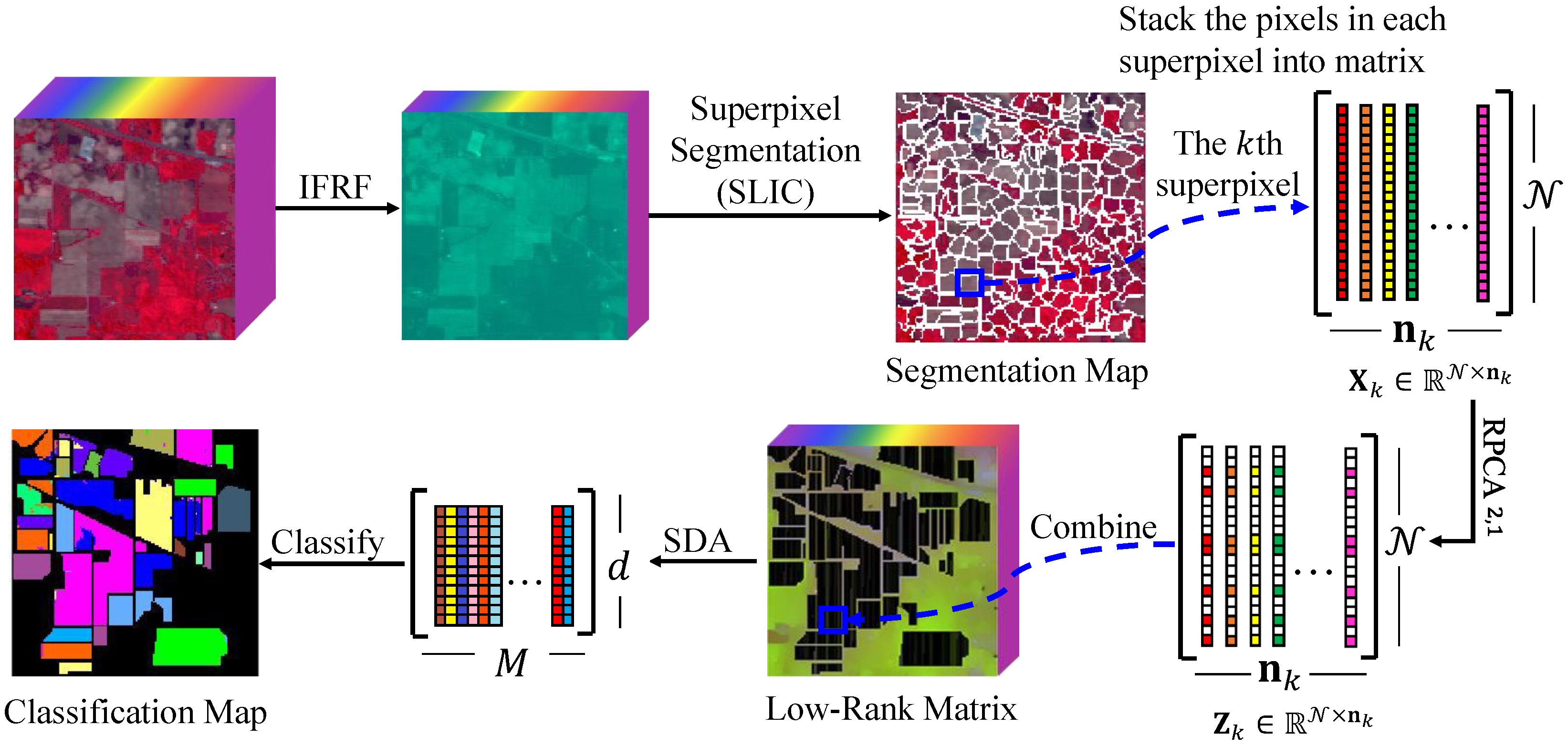
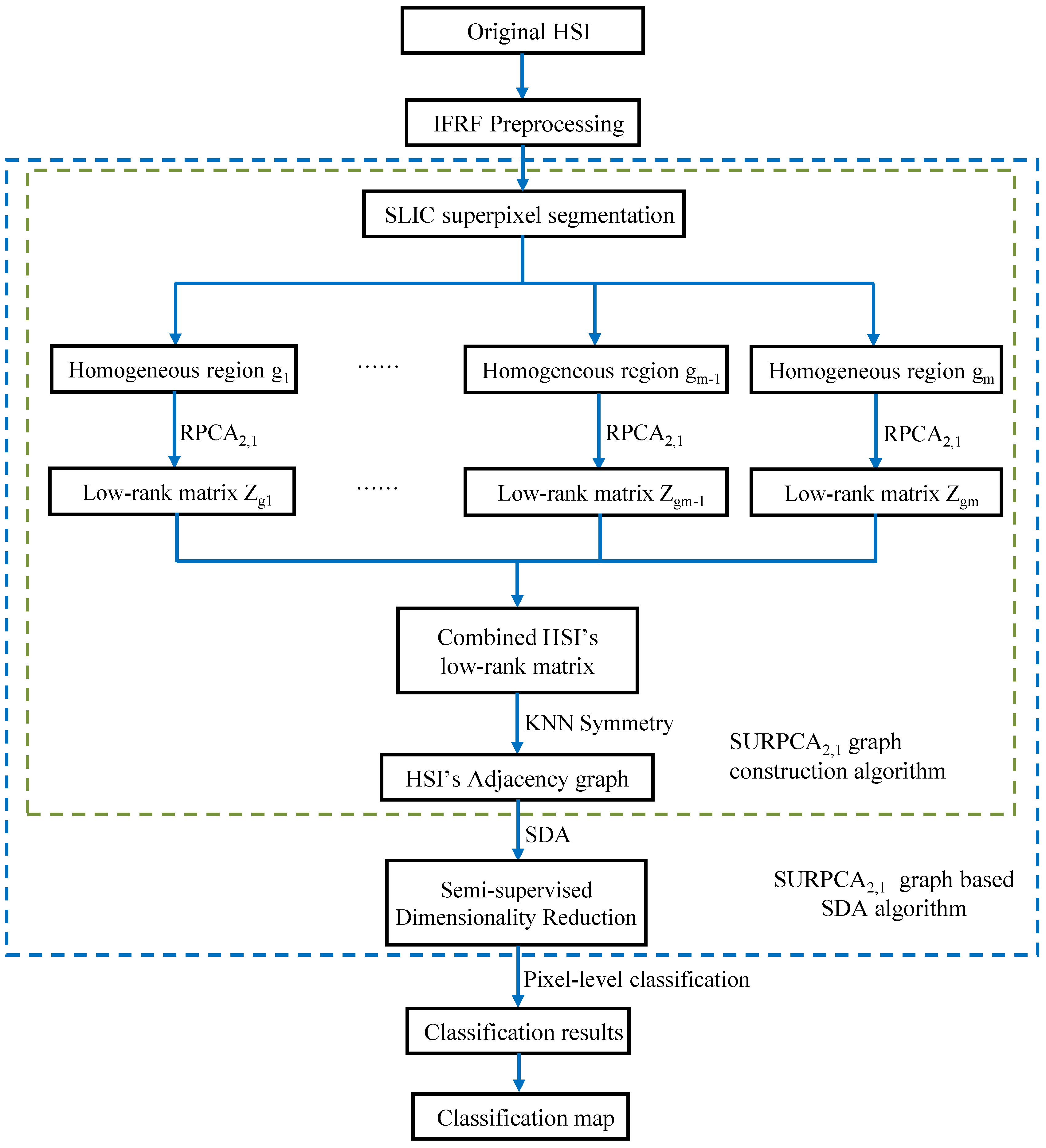
3. Methodology
3.1. Superpixel Segmentation and -Norm Robust Principal Component Analysis
| Algorithm 1 SLIC superpixel segmentation. |
|
| Algorithm 2 Inexact ALM method for solving RPCA. |
|
3.2. HSIs’ Classification Based on the SURPCA2,1 Graph
4. Experiments and Analysis
4.1. Experimental Setup
4.1.1. Hyperspectral Images
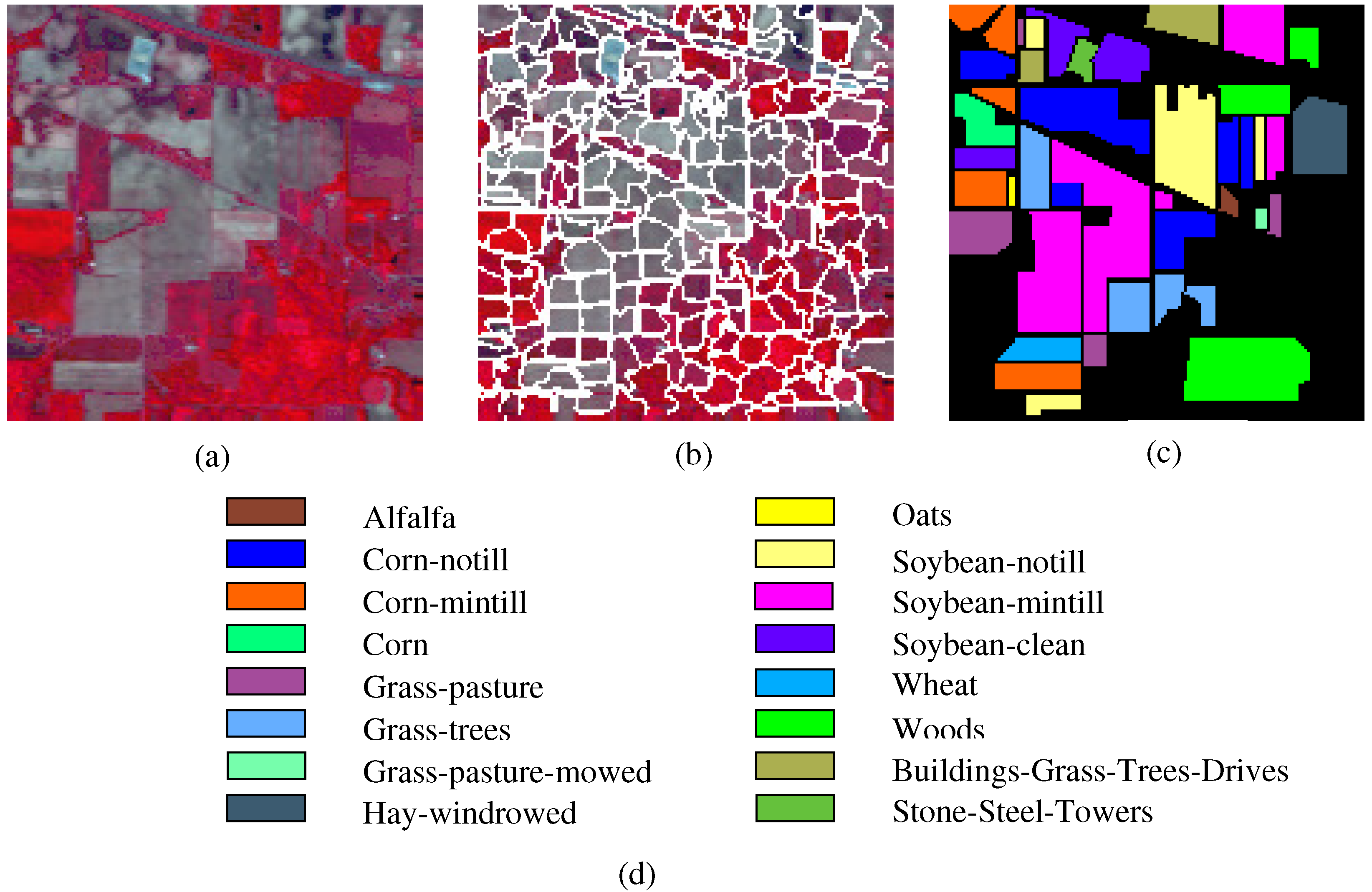
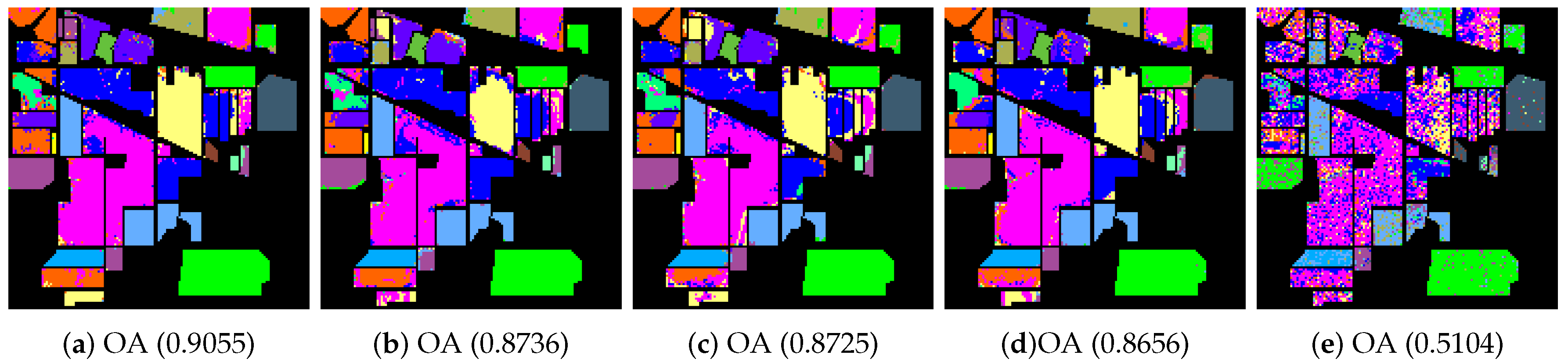
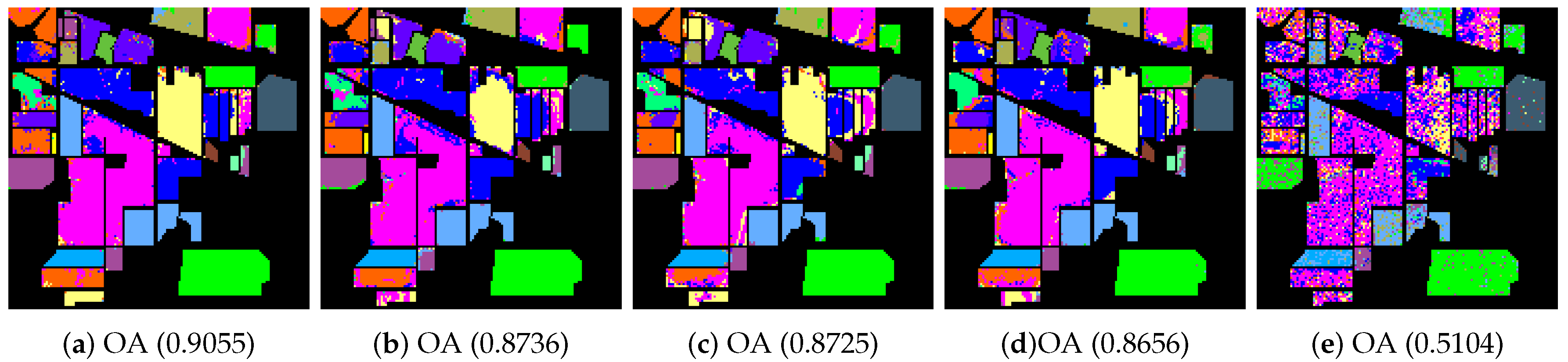
- The Indian Pines image is for the agricultural Indian Pine test site in Northwestern Indiana, which was a 220 Band AVIRIS Hyperspectral Image Data Set: 12 June 1992 Indian Pine Test Site 3. It was acquired over the Purdue University Agronomy farm northwest of West Lafayette and the surrounding area. The data were acquired to support soils research being conducted by Prof. Marion Baumgardner and his students [70]. The wavelength is from 400 to 2500 nm. The resolution is 145 × 145 pixels. Because some of the crops present (e.g., corn and soybean) are in the early stages of growth in June, the coverage is minuscule—approximately less than 5%. The ground truth is divided into sixteen classes, and are not all mutually exclusive. The Indian Pines false-color image and the ground truth image are presented in Figure 4.
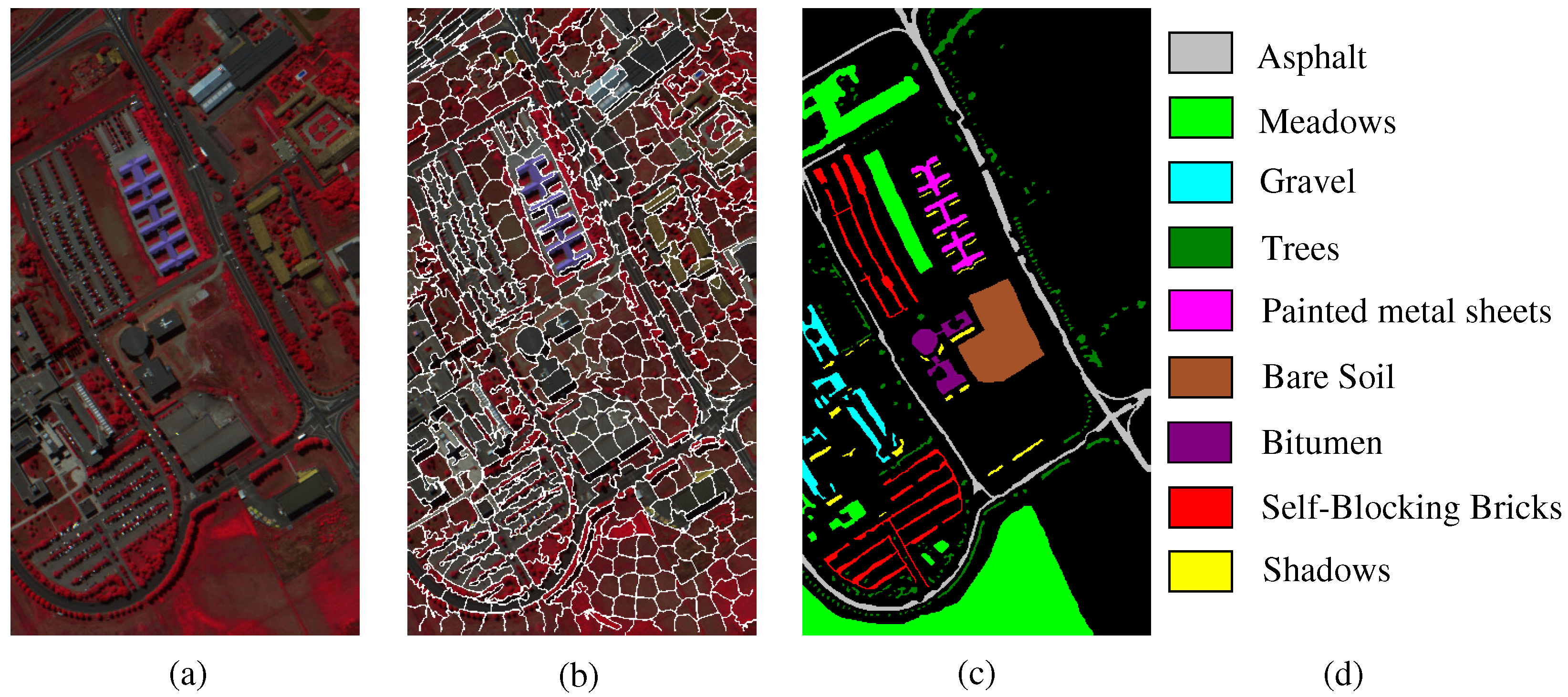
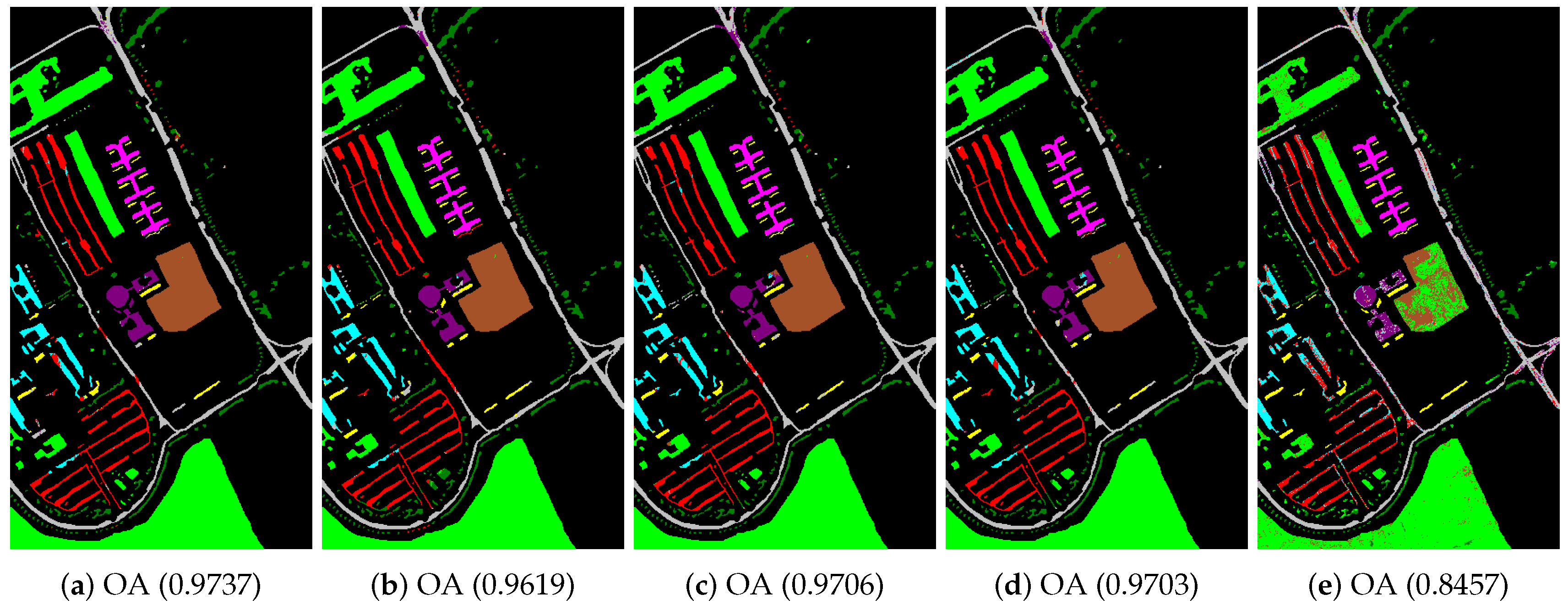
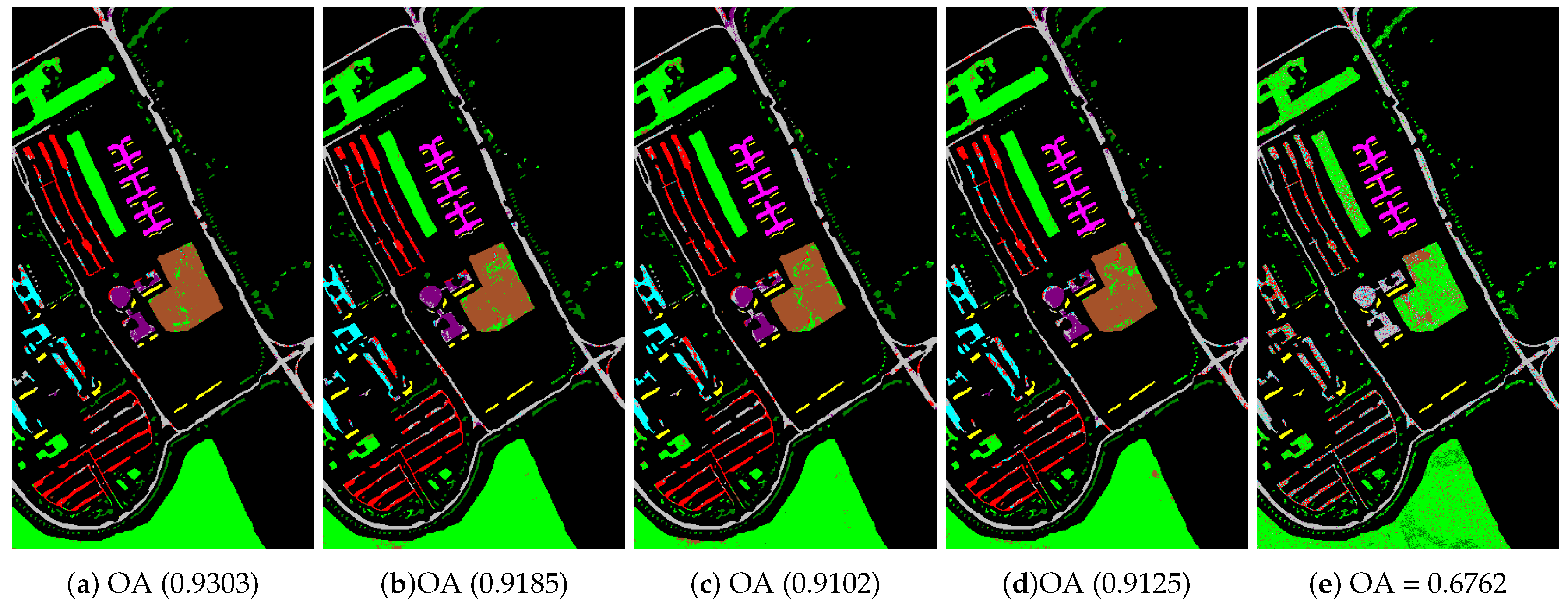
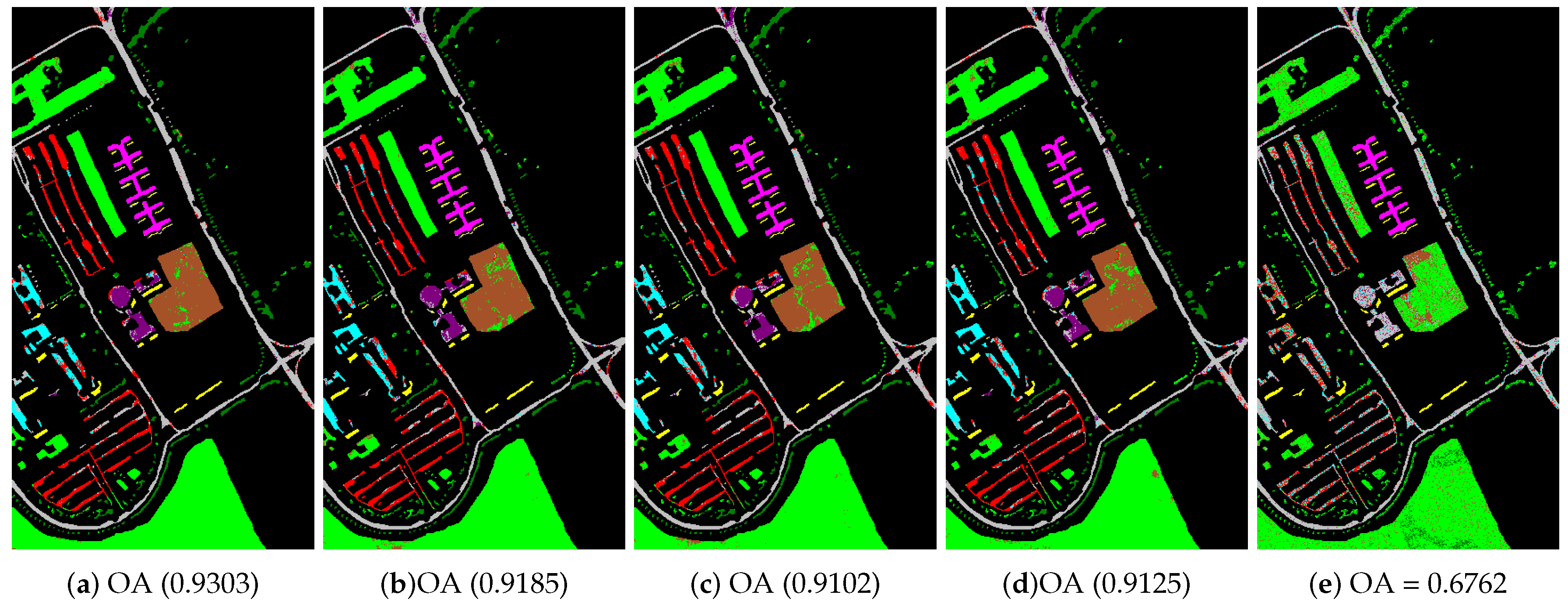
- The Pavia University scene was obtained from an urban area surrounding the University of Pavia, Italy on 8 July 2002 with a spatial resolution of 1.3 m. The wavelength ranges from 0.43 to 0.86 μm. There are 115 bands with size 610 × 340 pixels in the image. After removing 12 water absorption bands, 103 channels were left for testing. The Pavia University scene’s false-color image and the corresponding ground truth image are shown in Figure 5.
- The Salinas image is from the Salinas Valley, California, USA, which was obtained from an AVIRIS sensor with 3.7 m spatial resolution. The image includes a size of 512 × 217 with 224 bands. Twenty water absorption bands were discarded here. There are 16 classes containing vegetables, bare soil, vineyards, etc. Figure A1 displays the Salinas image’s false-color and ground truth images.
4.1.2. Evaluation Criteria
4.1.3. Comparative Algorithms
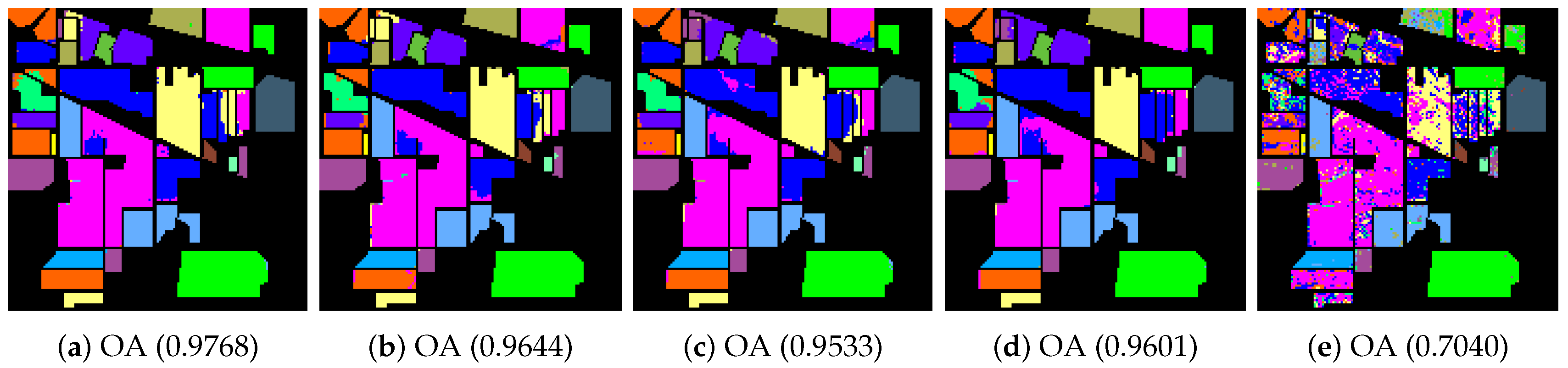
- RPCA (robust principal component analysis) method [63]: The original robust principal component analysis with -norm.
- IFRF (image fusion and recursive filtering) algorithm.
- Origin: Original bands of the unprocessed image.
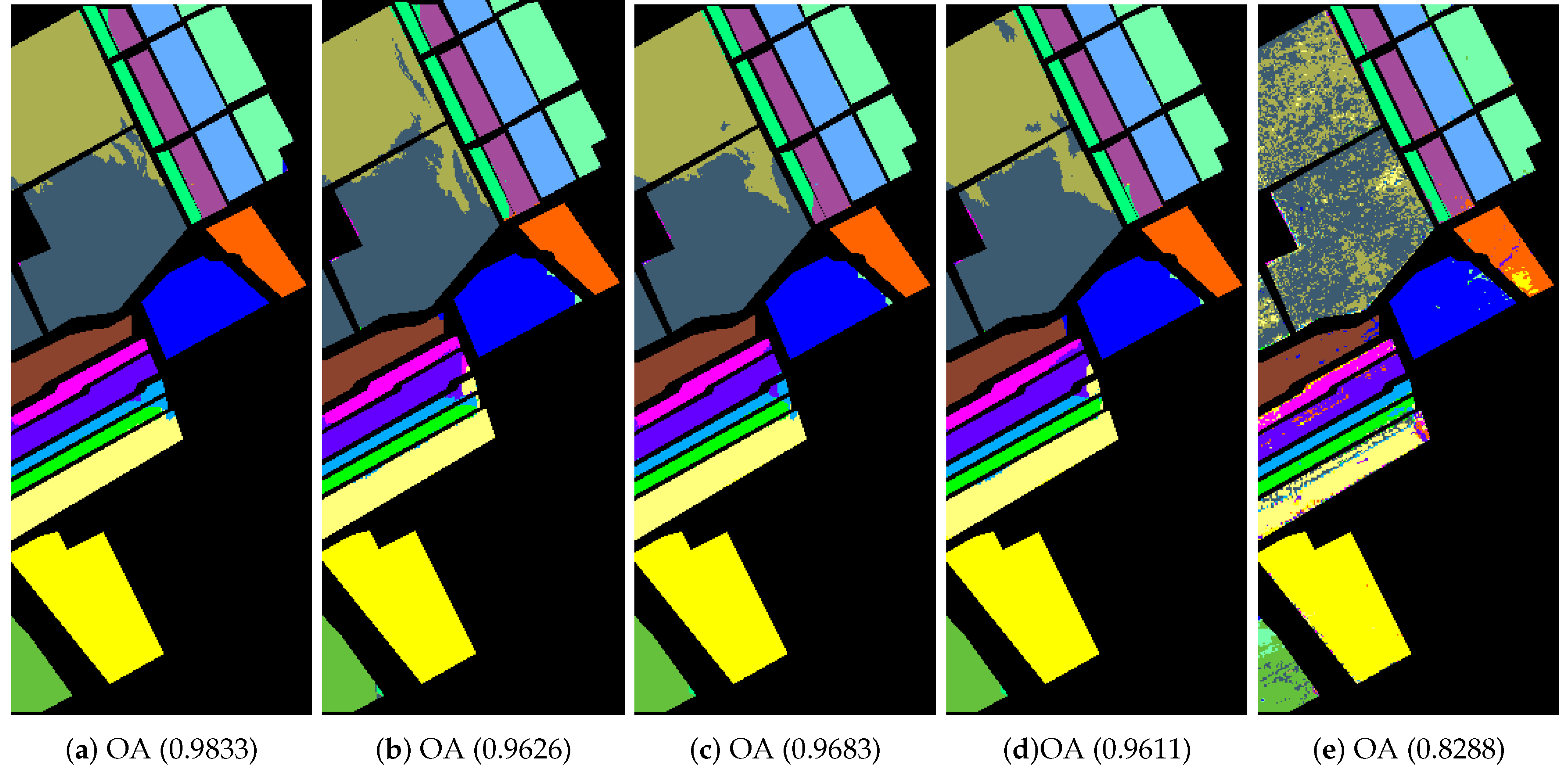
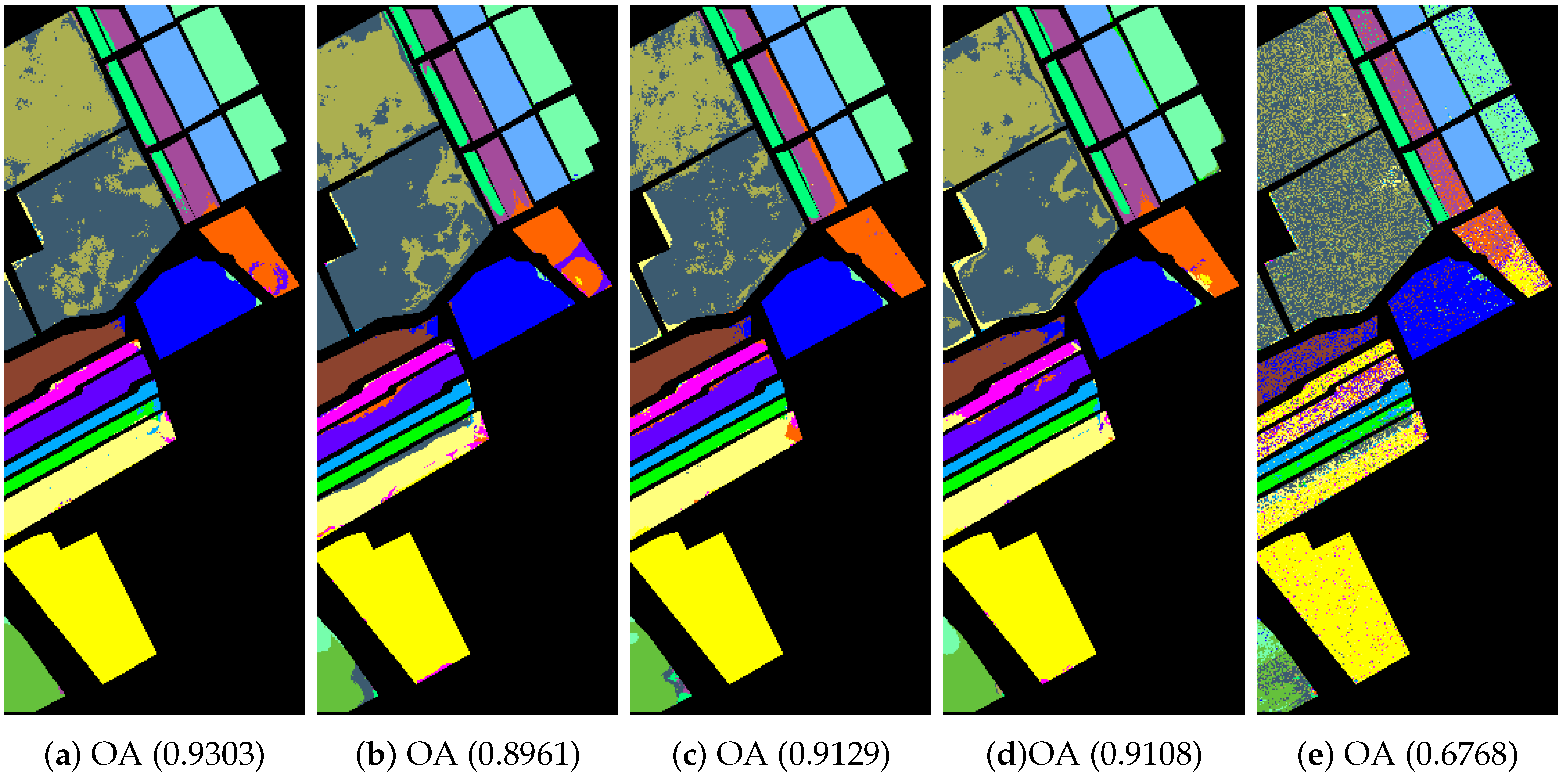
4.2. Classification of Hyperspectral Images
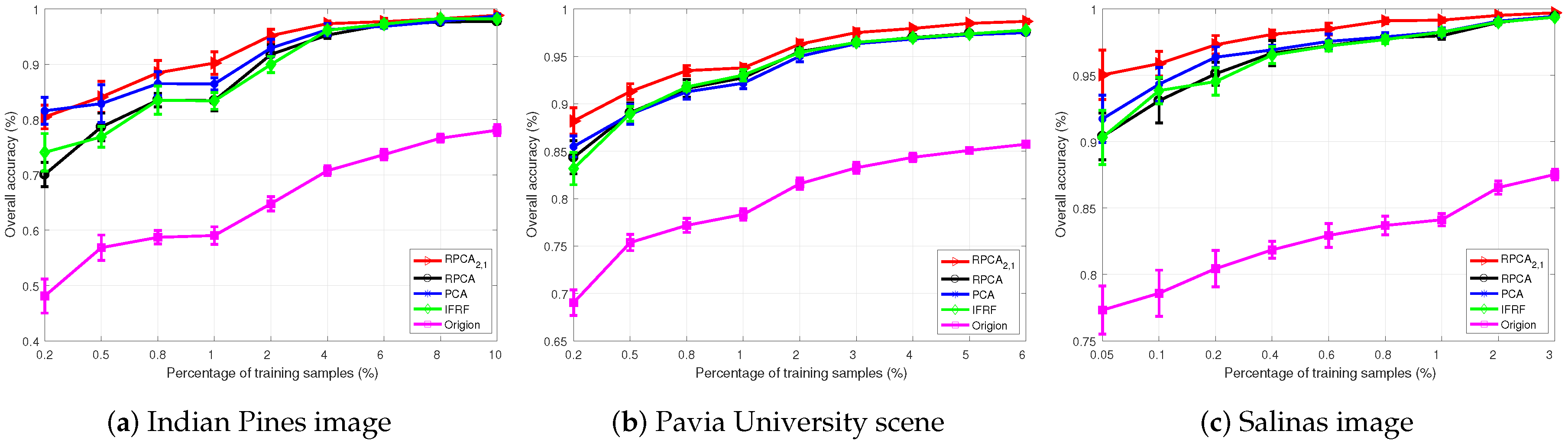
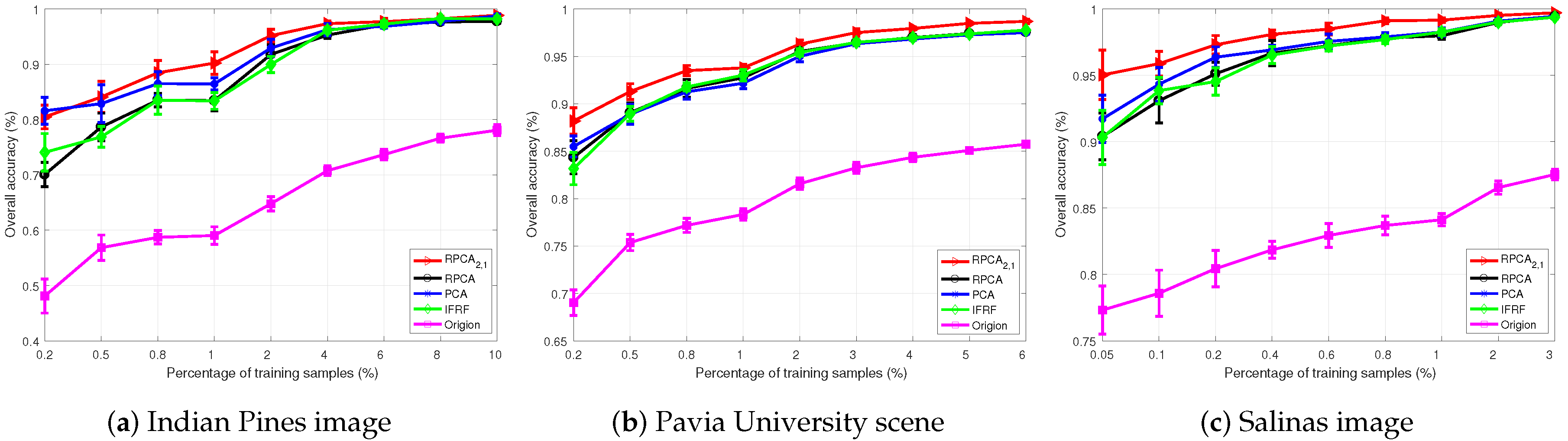
4.3. Robustness of the SURPCA2,1 Graph
4.3.1. Labeled Size Robustness
4.3.2. Noise Robustness
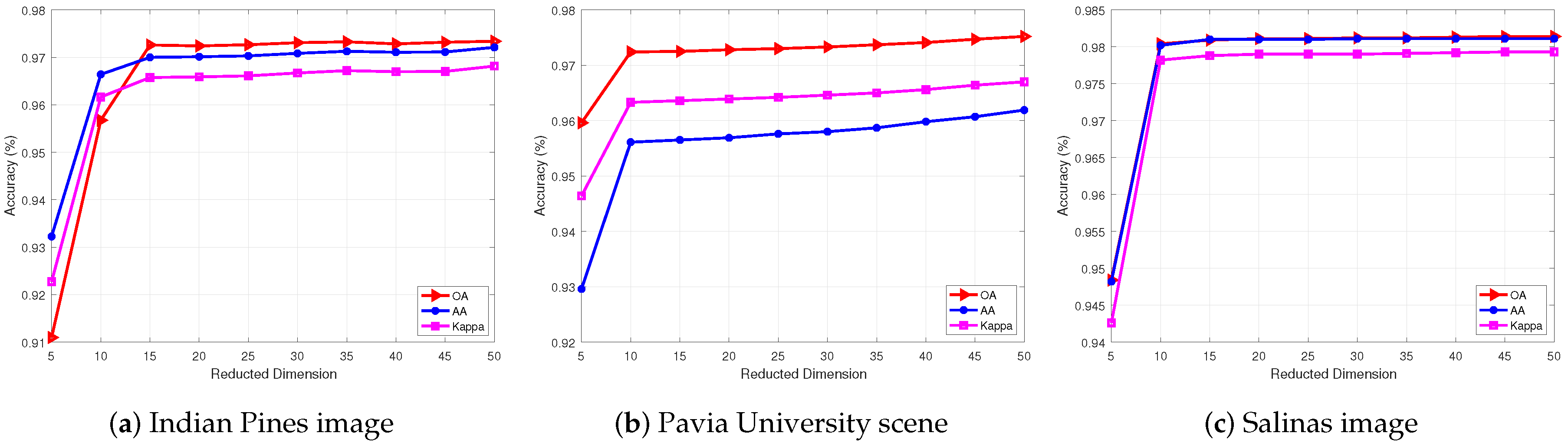
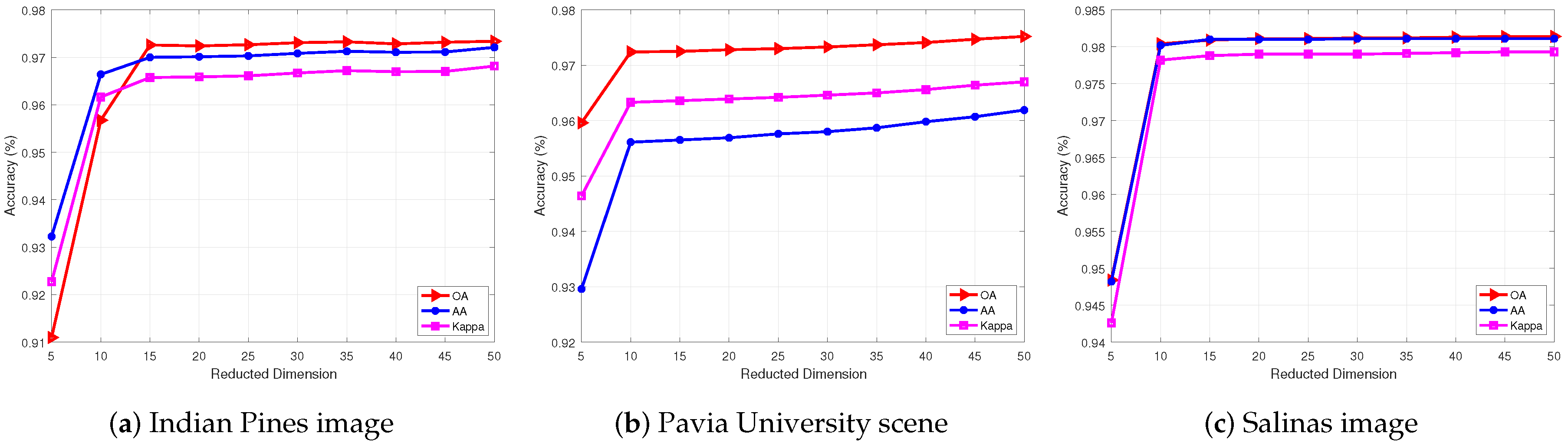
4.4. Parameters of SURPCA2,1 Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RPCA2,1 | RPCA | PCA | IFRF | Origion | RPCA2,1 | RPCA | PCA | IFRF | Origin |
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | NN | SVM | ||||||||
| C1 | 1 | 0.9999 | 1 | 0.932 | 0.9726 | 1 | 1 | 1 | 1 | 0.9982 |
| C2 | 0.9994 | 0.9929 | 0.9952 | 0.9651 | 0.9796 | 0.9926 | 0.9959 | 0.9969 | 0.9789 | 0.9913 |
| C3 | 0.9969 | 0.997 | 0.9949 | 0.9501 | 0.8262 | 0.9990 | 0.9984 | 0.9986 | 0.9982 | 0.9652 |
| C4 | 0.9633 | 0.916 | 0.9081 | 0.8496 | 0.9703 | 0.9745 | 0.9718 | 0.9715 | 0.9542 | 0.9685 |
| C5 | 0.9903 | 0.966 | 0.983 | 0.9592 | 0.9581 | 0.9997 | 0.9991 | 0.9986 | 0.9990 | 0.9001 |
| C6 | 1 | 1 | 1 | 0.9952 | 0.9958 | 0.9997 | 0.9997 | 0.9998 | 0.9916 | 0.9997 |
| C7 | 0.9971 | 0.9881 | 0.9901 | 0.9692 | 0.9202 | 0.9991 | 0.9975 | 0.9986 | 0.9900 | 0.9989 |
| C8 | 0.9882 | 0.9666 | 0.9714 | 0.8995 | 0.6584 | 0.9958 | 0.9925 | 0.9927 | 0.9881 | 0.7304 |
| C9 | 0.9999 | 0.9947 | 0.9976 | 0.9932 | 0.9408 | 0.9998 | 0.9995 | 0.9995 | 0.9979 | 0.9592 |
| C10 | 0.9969 | 0.9905 | 0.9946 | 0.9681 | 0.8393 | 0.9957 | 0.9888 | 0.9931 | 0.9886 | 0.9283 |
| C11 | 0.9961 | 0.982 | 0.9926 | 0.9548 | 0.851 | 1 | 0.9994 | 0.9989 | 0.9866 | 0.951 |
| C12 | 0.9563 | 0.9481 | 0.9631 | 0.9259 | 0.8886 | 0.9907 | 0.9786 | 0.9819 | 0.9903 | 0.8949 |
| C13 | 0.9394 | 0.8897 | 0.9354 | 0.7101 | 0.763 | 0.9999 | 0.9982 | 0.993 | 0.9406 | 0.8367 |
| C14 | 0.9865 | 0.9845 | 0.9725 | 0.9791 | 0.9145 | 0.9759 | 0.9835 | 0.9688 | 0.9837 | 0.864 |
| C15 | 0.9195 | 0.8994 | 0.8874 | 0.7298 | 0.5459 | 0.9980 | 0.9966 | 0.9983 | 0.9771 | 0.6202 |
| C16 | 1 | 0.9998 | 0.9994 | 0.9944 | 0.9398 | 0.9996 | 0.9993 | 0.9999 | 0.9911 | 0.9955 |
| OA | 0.9809 | 0.9668 | 0.9692 | 0.9653 | 0.8185 | 0.9964 | 0.9947 | 0.9951 | 0.9867 | 0.866 |
| AA | 0.9831 | 0.9697 | 0.9741 | 0.9705 | 0.8727 | 0.995 | 0.9937 | 0.9931 | 0.9847 | 0.9126 |
| Kappa | 0.9787 | 0.963 | 0.9657 | 0.9614 | 0.7976 | 0.996 | 0.9941 | 0.9945 | 0.9852 | 0.8506 |
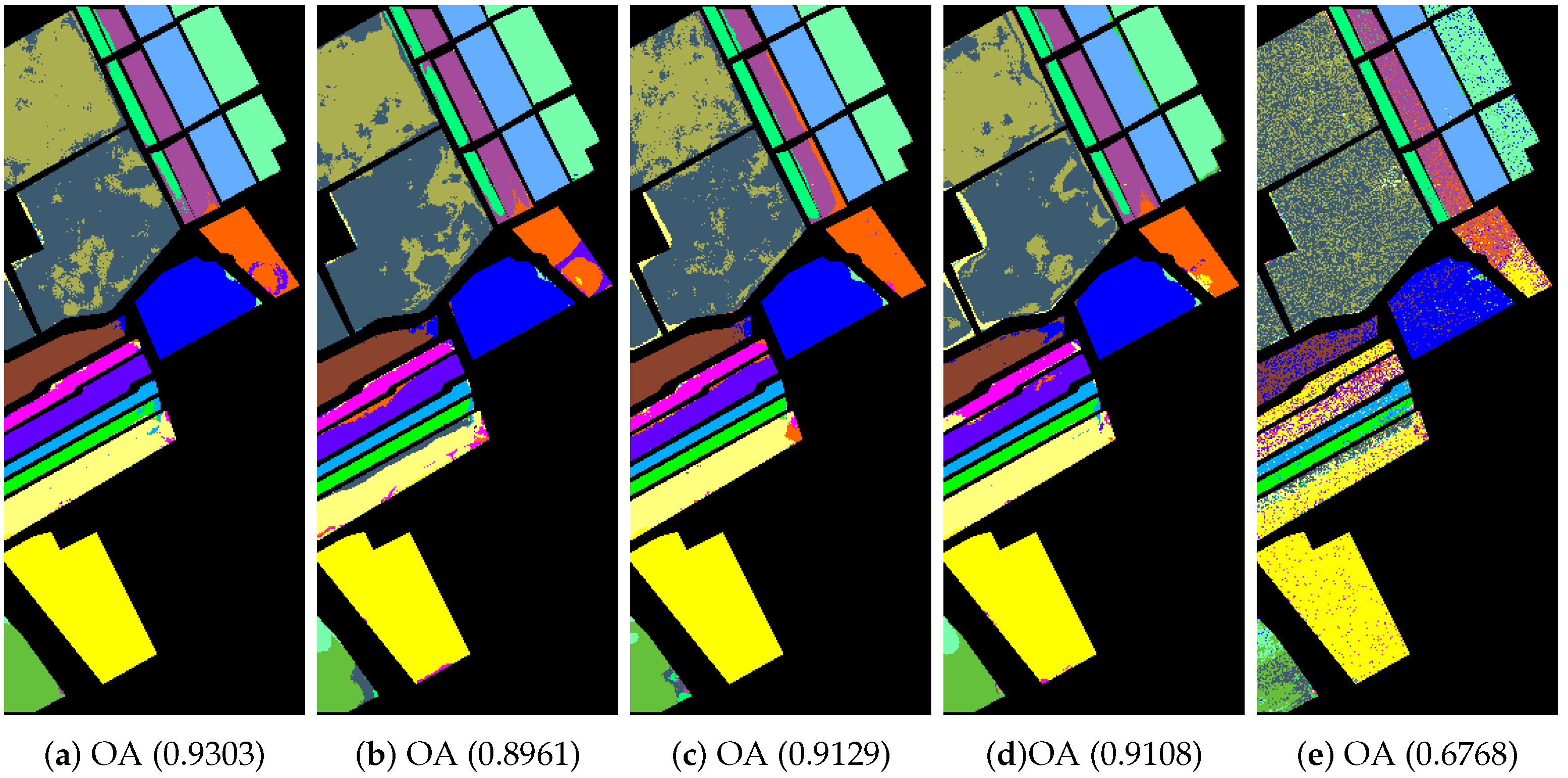
References
- Xu, L.; Zhang, H.; Zhao, M.; Chu, D.; Li, Y. Integrating spectral and spatial features for hyperspectral image classification using low-rank representation. In Proceedings of the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; pp. 1024–1029. [Google Scholar]
- Ustin, S.L.; Roberts, D.A.; Gamon, J.A.; Asner, G.P.; Green, R.O. Using imaging spectroscopy to study ecosystem processes and properties. AIBS Bull. 2004, 54, 523–534. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Pattey, E.; Zarco-Tejada, P.J.; Strachan, I.B. Hyperspectral vegetation indices and novel algorithms for predicting green LAI of crop canopies: Modeling and validation in the context of precision agriculture. Remote Sens. Environ. 2004, 90, 337–352. [Google Scholar] [CrossRef]
- Dorigo, W.A.; Zurita-Milla, R.; de Wit, A.J.; Brazile, J.; Singh, R.; Schaepman, M.E. A review on reflective remote sensing and data assimilation techniques for enhanced agroecosystem modeling. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 165–193. [Google Scholar] [CrossRef]
- Cocks, T.; Jenssen, R.; Stewart, A.; Wilson, I.; Shields, T. The HyMapTM airborne hyperspectral sensor: The system, calibration and performance. In Proceedings of the 1st EARSeL workshop on Imaging Spectroscopy (EARSeL), Paris, France, 6–8 October 1998; pp. 37–42. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Vescovo, L.; Gianelle, D. The role of spectral resolution and classifier complexity in the analysis of hyperspectral images of forest areas. Remote Sens. Environ. 2009, 113, 2345–2355. [Google Scholar] [CrossRef]
- De Morsier, F.; Borgeaud, M.; Gass, V.; Thiran, J.P.; Tuia, D. Kernel low-rank and sparse graph for unsupervised and semi-supervised classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3410–3420. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Heinz, D.C. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef]
- Kruse, F.A.; Boardman, J.W.; Huntington, J.F. Comparison of airborne hyperspectral data and EO-1 Hyperion for mineral mapping. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1388–1400. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Q.; Wang, H.; You, D.; Zhang, Y. Multiple kernel learning via low-rank nonnegative matrix factorization for classification of hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2739–2751. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Feature extraction of hyperspectral images with image fusion and recursive filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3742–3752. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley: New York, NY, USA, 2001; Volume 55. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Sacha, D.; Zhang, L.; Sedlmair, M.; Lee, J.A.; Peltonen, J.; Weiskopf, D.; North, S.C.; Keim, D.A. Visual interaction with dimensionality reduction: A structured literature analysis. IEEE Trans. Vis. Comput. Graph. 2017, 23, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Shuiwang, J.; Jieping, Y. Generalized linear discriminant analysis: a unified framework and efficient model selection. IEEE Trans. Neural Netw. 2008, 19, 1768. [Google Scholar] [CrossRef] [PubMed]
- Stone, J.V. Independent component analysis: An introduction. Trends Cogn. Sci. 2002, 6, 59–64. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Hoyer, P.O.; Inki, M. Topographic independent component analysis. Neural Comput. 2001, 13, 1527–1558. [Google Scholar] [CrossRef]
- Draper, B.A.; Baek, K.; Bartlett, M.S.; Beveridge, J.R. Recognizing faces with PCA and ICA. Comput. Vis. Image Underst. 2003, 91, 115–137. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Zhang, Z.; Pasolli, E.; Yang, L.; Crawford, M.M. Multi-metric Active Learning for Classification of Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1007–1011. [Google Scholar] [CrossRef]
- Zhang, Z.; Crawford, M.M. A Batch-Mode Regularized Multimetric Active Learning Framework for Classification of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1–16. [Google Scholar] [CrossRef]
- Ul Haq, Q.S.; Tao, L.; Sun, F.; Yang, S. A fast and robust sparse approach for hyperspectral data classification using a few labeled samples. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2287–2302. [Google Scholar] [CrossRef]
- Kuo, B.C.; Chang, K.Y. Feature extractions for small sample size classification problem. IEEE Trans. Geosci. Remote Sens. 2007, 45, 756–764. [Google Scholar] [CrossRef]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with local and global consistency. In Proceedings of the Advances in Neural Information Processing Systems, Whistler, BC, Canada, 9–11 December 2003; pp. 321–328. [Google Scholar]
- Guo, Z.; Zhang, Z.; Xing, E.P.; Faloutsos, C. Semi-supervised learning based on semiparametric regularization. In Proceedings of the 2008 SIAM International Conference on Data Mining (SIAM), Atlanta, GA, USA, 24–26 April 2008; pp. 132–142. [Google Scholar]
- Subramanya, A.; Talukdar, P.P. Graph-based semi-supervised learning. Synth. Lect. Artif. Intell. Mach. Learn. 2014, 8, 1–125. [Google Scholar] [CrossRef]
- Zheng, M.; Bu, J.; Chen, C.; Wang, C.; Zhang, L.; Qiu, G.; Cai, D. Graph regularized sparse coding for image representation. IEEE Trans. Image Process. 2011, 20, 1327–1336. [Google Scholar] [CrossRef] [PubMed]
- Tian, X.; Gasso, G.; Canu, S. A multiple kernel framework for inductive semi-supervised SVM learning. Neurocomputing 2012, 90, 46–58. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar] [PubMed]
- Gao, S.; Tsang, I.W.H.; Chia, L.T.; Zhao, P. Local features are not lonely—Laplacian sparse coding for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Liu, G.; Lin, Z.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 663–670. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Binge, C.; Zongqi, F.; Xiaoyun, X.; Yong, Z.; Liwei, Z. A Novel Feature Extraction Method for Hyperspectral Image Classification. In Proceedings of the 2016 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Changsha, China, 17–18 December 2016; pp. 51–54. [Google Scholar]
- Nie, Y.; Chen, L.; Zhu, H.; Du, S.; Yue, T.; Cao, X. Graph-regularized tensor robust principal component analysis for hyperspectral image denoising. Appl. Opt. 2017, 56, 6094–6102. [Google Scholar] [CrossRef]
- Chen, G.; Bui, T.D.; Quach, K.G.; Qian, S.E. Denoising hyperspectral imagery using principal component analysis and block-matching 4D filtering. Can. J. Remote Sens. 2014, 40, 60–66. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Wei, Z. Spectral–spatial classification of hyperspectral image based on low-rank decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2370–2380. [Google Scholar] [CrossRef]
- Fan, F.; Ma, Y.; Li, C.; Mei, X.; Huang, J.; Ma, J. Hyperspectral image denoising with superpixel segmentation and low-rank representation. Inf. Sci. 2017, 397, 48–68. [Google Scholar] [CrossRef]
- Zhang, S.; Li, S.; Fu, W.; Fang, L. Multiscale superpixel-based sparse representation for hyperspectral image classification. Remote Sens. 2017, 9, 139. [Google Scholar] [CrossRef]
- Sun, L.; Jeon, B.; Soomro, B.N.; Zheng, Y.; Wu, Z.; Xiao, L. Fast Superpixel Based Subspace Low Rank Learning Method for Hyperspectral Denoising. IEEE Access 2018, 6, 12031–12043. [Google Scholar] [CrossRef]
- Mei, X.; Ma, Y.; Li, C.; Fan, F.; Huang, J.; Ma, J. Robust GBM hyperspectral image unmixing with superpixel segmentation based low rank and sparse representation. Neurocomputing 2018, 275, 2783–2797. [Google Scholar] [CrossRef]
- Tong, F.; Tong, H.; Jiang, J.; Zhang, Y. Multiscale union regions adaptive sparse representation for hyperspectral image classification. Remote Sens. 2017, 9, 872. [Google Scholar] [CrossRef]
- Zu, B.; Xia, K.; Du, W.; Li, Y.; Ali, A.; Chakraborty, S. Classification of Hyperspectral Images with Robust Regularized Block Low-Rank Discriminant Analysis. Remote Sens. 2018, 10, 817. [Google Scholar] [CrossRef]
- Maier, M.; Luxburg, U.V.; Hein, M. Influence of graph construction on graph-based clustering measures. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1025–1032. [Google Scholar]
- Zhu, X.; Goldberg, A.B.; Brachman, R.; Dietterich, T. Introduction to Semi-Supervised Learning. Semi-Superv. Learn. 2009, 3, 130. [Google Scholar] [CrossRef]
- Zhu, X. Semi-Supervised Learning Literature Survey; Department of Computer Science, University of Wisconsin-Madison: Madison, WI, USA, 2006; Volume 2, p. 4. [Google Scholar]
- Stickel, M.E. A Nonclausal Connection-Graph Resolution Theorem-Proving Program; Technical Report; Sri International Menlo Park Ca Artificial Intelligence Center: Menlo Park, CA, USA, 1982. [Google Scholar]
- Cortes, C.; Mohri, M. On transductive regression. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Volume 19, p. 305. [Google Scholar]
- Ren, X.; Malik, J. Learning a Classification Model for Segmentation. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar]
- Moore, A.P.; Prince, S.J.D.; Warrell, J.; Mohammed, U.; Jones, G. Superpixel lattices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic Superpixels; EPFL Technical Report; EPFL: Lausanne, Switzerland, 2010. [Google Scholar]
- Zitnick, C.L.; Kang, S.B. Stereo for Image-Based Rendering using Image Over-Segmentation. Int. J. Comput. Vis. 2007, 75, 49–65. [Google Scholar] [CrossRef]
- Ren, C.Y.; Reid, I. gSLIC: A Real-Time Implementation of SLIC Superpixel Segmentation; University of Oxford: Oxford, UK, 2011. [Google Scholar]
- Gastal, E.S.; Oliveira, M.M. Domain transform for edge-aware image and video processing. ACM Trans. Graph. 2011, 30, 69. [Google Scholar] [CrossRef]
- Ren, C.-X.; Dai, D.-Q.; Yan, H. Robust classification using L 2,1-norm based regression model. Pattern Recognit. 2012, 45, 2708–2718. [Google Scholar] [CrossRef]
- Nie, F.; Huang, H.; Cai, X.; Ding, C.H. Efficient and robust feature selection via joint L 2, 1-norms minimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1813–1821. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv, 2010; arXiv:1009.5055. [Google Scholar]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [PubMed]
- Cai, D.; He, X.; Han, J. Semi-supervised discriminant analysis. In Proceedings of the IEEE 11th International Confece on IEEE Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–7. [Google Scholar]
- Yan, S.; Wang, H. Semi-supervised Learning by Sparse Representation. In Proceedings of the 2009 SIAM International Confece on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 792–801. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Zu, B.; Xia, K.; Pan, Y.; Niu, W. A Novel Graph Constructor for Semisupervised Discriminant Analysis: Combined Low-Rank and-Nearest Neighbor Graph. Comput. Intell. Neurosci. 2017, 2017, 9290230. [Google Scholar] [CrossRef] [PubMed]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3. 2015. Available online: https://purr.purdue.edu/publications/1947/1 (accessed on 18 January 2018).
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Richards, J.A.; Richards, J. Remote Sensing Digital Image Analysis; Springer: Berlin, Germany, 1999; Volume 3. [Google Scholar]
- Thompson, W.D.; Walter, S.D. A reappraisal of the kappa coefficient. J. Clin. Epidemiol. 1988, 41, 949–958. [Google Scholar] [CrossRef]
- Gwet, K. Kappa statistic is not satisfactory for assessing the extent of agreement between raters. Stat. Methods Inter-Rater Reliab. Assess. 2002, 1, 1–6. [Google Scholar]
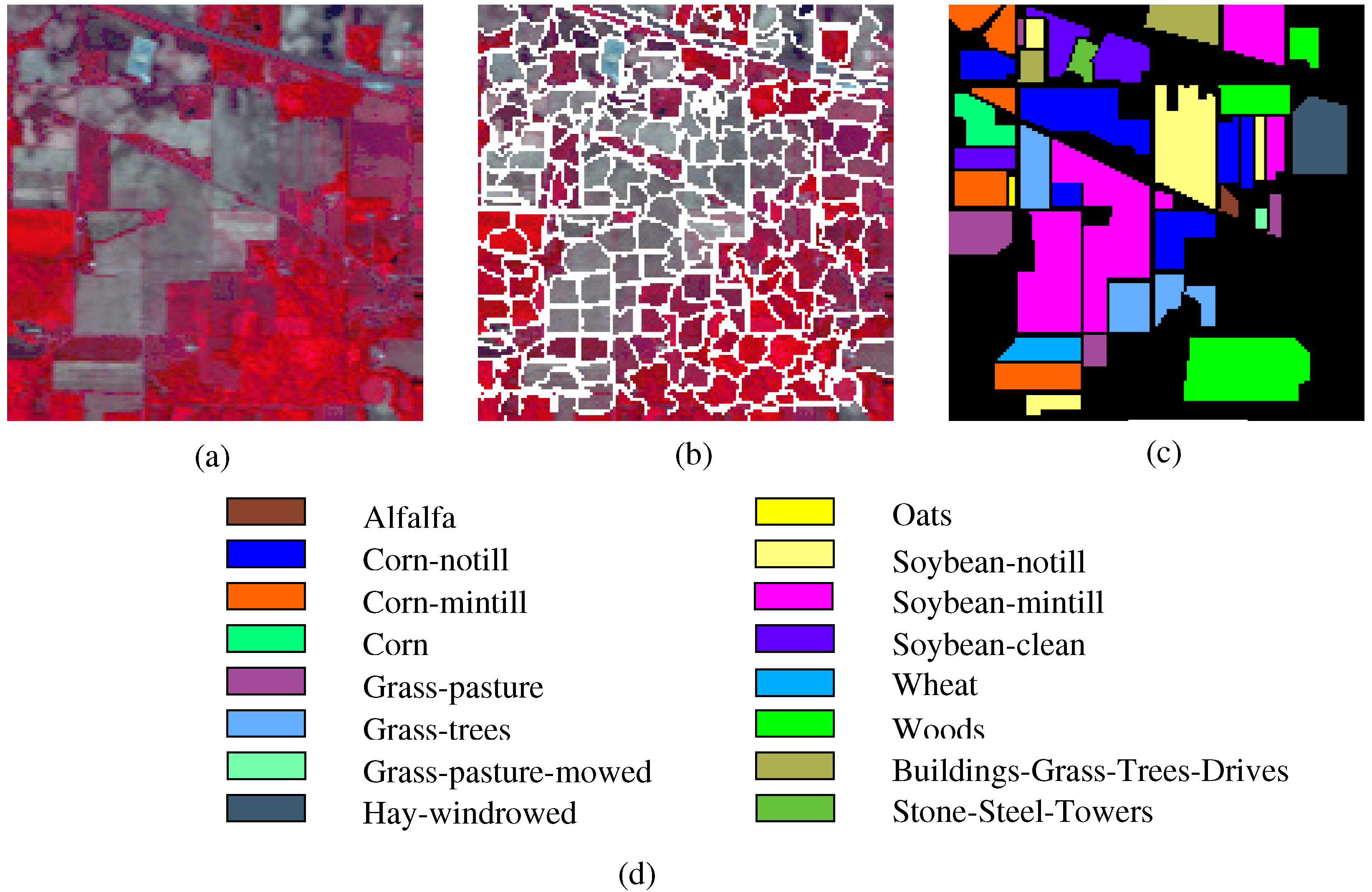
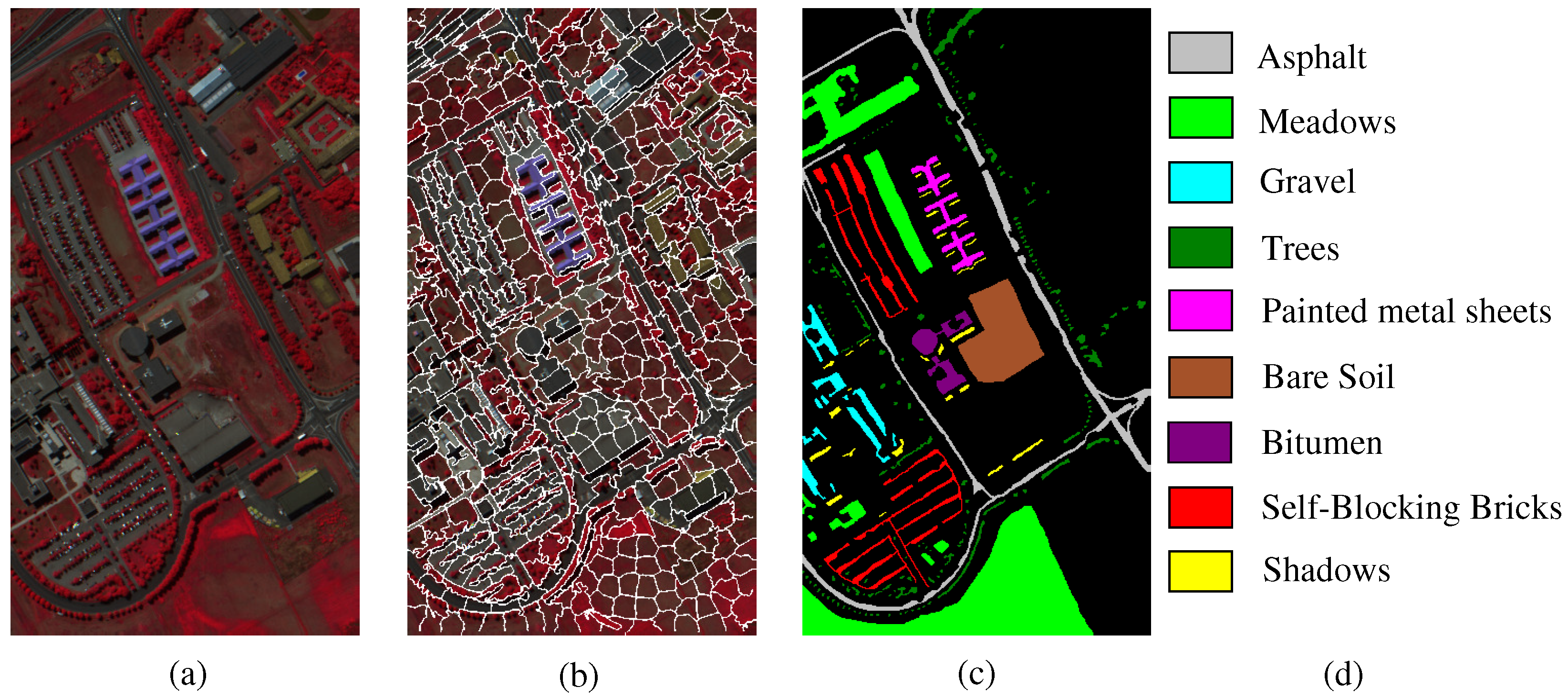
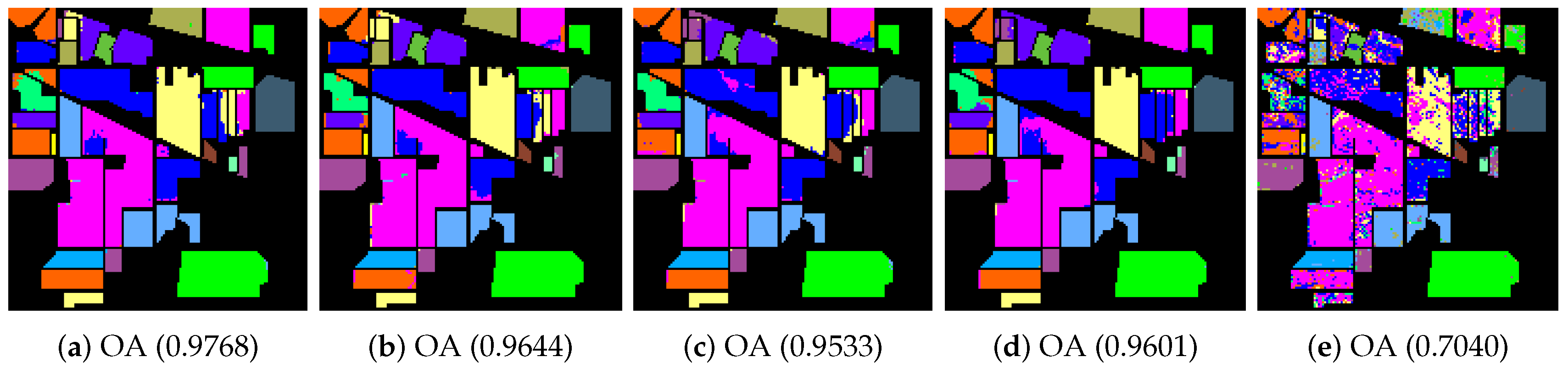
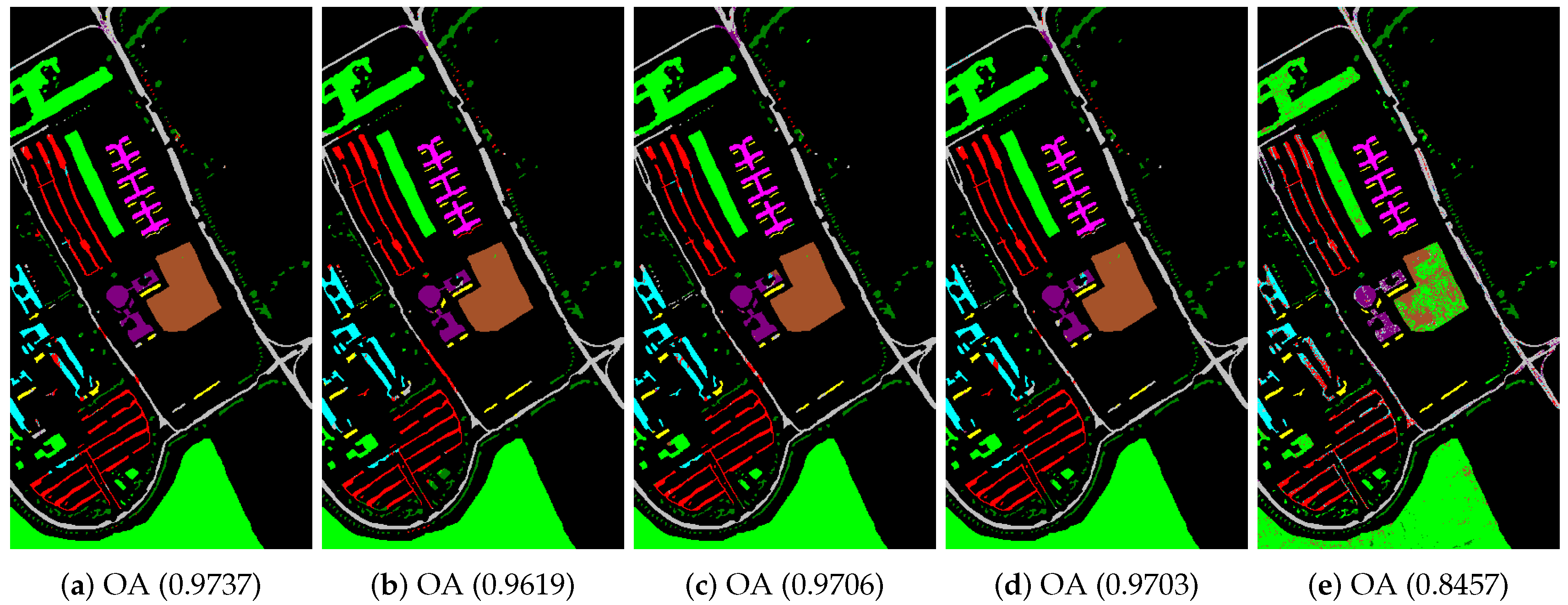

| Class | Indian Pines Image | Pavia University Scene | Salinas Image | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Sample No. | Train | Test | Sample No. | Train | Test | Sample No. | |
| C1 | 7 | 39 | 46 | 205 | 6426 | 6631 | 14 | 1995 | 2009 |
| C2 | 63 | 1365 | 1428 | 565 | 18,084 | 18,649 | 20 | 3706 | 3726 |
| C3 | 39 | 791 | 830 | 69 | 2030 | 2099 | 13 | 1963 | 1976 |
| C4 | 15 | 222 | 237 | 97 | 2967 | 3064 | 11 | 1383 | 1394 |
| C5 | 25 | 458 | 483 | 46 | 1299 | 1345 | 16 | 2662 | 2678 |
| C6 | 35 | 695 | 730 | 156 | 4873 | 5029 | 21 | 3938 | 3959 |
| C7 | 7 | 21 | 28 | 45 | 1285 | 1330 | 20 | 3559 | 3579 |
| C8 | 25 | 453 | 478 | 116 | 3566 | 3682 | 51 | 11,220 | 11,271 |
| C9 | 6 | 14 | 20 | 34 | 913 | 947 | 30 | 6173 | 6203 |
| C10 | 44 | 928 | 972 | - | - | - | 19 | 3259 | 3278 |
| C11 | 104 | 2351 | 2455 | - | - | - | 10 | 1058 | 1068 |
| C12 | 29 | 564 | 593 | - | - | - | 13 | 1914 | 1927 |
| C13 | 14 | 191 | 205 | - | - | - | 9 | 907 | 916 |
| C14 | 56 | 1209 | 1265 | - | - | - | 10 | 1060 | 1070 |
| C15 | 21 | 365 | 386 | - | - | - | 35 | 7233 | 7268 |
| C16 | 9 | 84 | 93 | - | - | - | 13 | 1794 | 1807 |
| Total | 702 | 9547 | 10,249 | 1762 | 41,014 | 42,776 | 305 | 53,824 | 54,129 |
| Method | RPCA2,1 | RPCA | PCA | IFRF | Origion | RPCA2,1 | RPCA | PCA | IFRF | Origin |
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | NN | SVM | ||||||||
| C1 | 1 | 1 | 0.9870 | 0.9809 | 0.8051 | 1 | 1 | 1 | 1 | 0.9473 |
| C2 | 0.9686 | 0.9442 | 0.9380 | 0.9487 | 0.4961 | 0.9676 | 0.9701 | 0.9295 | 0.9482 | 0.5169 |
| C3 | 0.9667 | 0.9524 | 0.9718 | 0.9342 | 0.6572 | 0.9659 | 0.9679 | 0.9426 | 0.9574 | 0.3793 |
| C4 | 0.9578 | 0.9698 | 0.9589 | 0.9122 | 0.3964 | 0.9819 | 0.9133 | 0.9383 | 0.9420 | 0.5671 |
| C5 | 0.9868 | 0.9463 | 0.9384 | 0.9687 | 0.8225 | 0.9933 | 0.9856 | 0.9821 | 0.9868 | 0.8809 |
| C6 | 0.9837 | 0.9833 | 0.9394 | 0.9483 | 0.7568 | 1 | 1 | 0.9986 | 0.9986 | 0.8476 |
| C7 | 0.8686 | 0.7254 | 0.6164 | 0.8107 | 0.6786 | 1 | 0.9375 | 1 | 0.9886 | 0.9188 |
| C8 | 1 | 1 | 1 | 1 | 0.9486 | 1 | 1 | 1 | 1 | 0.9367 |
| C9 | 0.9800 | 0.7812 | 0.8496 | 0.7469 | 0.5042 | 1 | 1 | 1 | 1 | 0.8042 |
| C10 | 0.9342 | 0.9139 | 0.9215 | 0.8742 | 0.6777 | 0.9647 | 0.9618 | 0.9743 | 0.9471 | 0.4916 |
| C11 | 0.9721 | 0.9700 | 0.9748 | 0.9749 | 0.6933 | 0.9672 | 0.9604 | 0.9626 | 0.9677 | 0.5560 |
| C12 | 0.9602 | 0.9024 | 0.9753 | 0.9344 | 0.6833 | 0.9854 | 0.9908 | 0.9658 | 0.9701 | 0.6454 |
| C13 | 0.9705 | 1 | 0.9748 | 0.9935 | 0.9240 | 1 | 1 | 1 | 0.9987 | 0.9909 |
| C14 | 0.9952 | 0.9895 | 0.9939 | 0.9915 | 0.9217 | 0.9954 | 0.9996 | 0.9975 | 0.9975 | 0.9190 |
| C15 | 0.9624 | 0.9711 | 0.9768 | 0.9379 | 0.6666 | 0.9916 | 0.9937 | 0.9958 | 0.9897 | 0.7551 |
| C16 | 0.9905 | 0.9881 | 0.9881 | 0.9881 | 0.9871 | 0.9866 | 0.9859 | 0.9712 | 0.9846 | 0.9825 |
| OA | 0.9706 | 0.9585 | 0.9594 | 0.9514 | 0.7077 | 0.9786 | 0.9759 | 0.9682 | 0.9713 | 0.6536 |
| AA | 0.9686 | 0.9399 | 0.9378 | 0.9341 | 0.7262 | 0.9875 | 0.9792 | 0.9787 | 0.9798 | 0.7587 |
| Kappa | 0.9664 | 0.9527 | 0.9536 | 0.9446 | 0.6633 | 0.9755 | 0.9724 | 0.9636 | 0.9672 | 0.6000 |
| Method | RPCA2,1 | RPCA | PCA | IFRF | Origion | RPCA2,1 | RPCA | PCA | IFRF | Origin |
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | NN | SVM | ||||||||
| C1 | 0.9581 | 0.9630 | 0.9632 | 0.9581 | 0.8969 | 0.9771 | 0.9745 | 0.9698 | 0.9657 | 0.8119 |
| C2 | 0.9925 | 0.9942 | 0.9935 | 0.9944 | 0.8491 | 0.9957 | 0.996 | 0.9956 | 0.9951 | 0.8676 |
| C3 | 0.9465 | 0.9420 | 0.9212 | 0.9543 | 0.6836 | 0.9758 | 0.9678 | 0.9715 | 0.9578 | 0.6425 |
| C4 | 0.9923 | 0.9841 | 0.9865 | 0.9880 | 0.9360 | 0.9918 | 0.9889 | 0.9938 | 0.9895 | 0.8802 |
| C5 | 0.9993 | 0.9989 | 0.9957 | 0.9985 | 0.9929 | 0.917 | 0.9377 | 0.9433 | 0.9355 | 0.9972 |
| C6 | 0.9966 | 0.9953 | 0.9921 | 0.9981 | 0.7228 | 0.9965 | 0.9963 | 0.9953 | 0.9977 | 0.7286 |
| C7 | 0.9177 | 0.9090 | 0.8921 | 0.8822 | 0.7385 | 0.9751 | 0.9689 | 0.9642 | 0.963 | 0.6193 |
| C8 | 0.9169 | 0.9082 | 0.9182 | 0.9135 | 0.7990 | 0.9656 | 0.9589 | 0.9575 | 0.9574 | 0.7057 |
| C9 | 0.9353 | 0.9302 | 0.9369 | 0.9509 | 1 | 0.964 | 0.9577 | 0.9546 | 0.9575 | 0.9996 |
| OA | 0.9751 | 0.9744 | 0.9734 | 0.9748 | 0.8425 | 0.9849 | 0.9839 | 0.9832 | 0.9815 | 0.8238 |
| AA | 0.9617 | 0.9583 | 0.9555 | 0.9598 | 0.8465 | 0.9732 | 0.9719 | 0.9717 | 0.9688 | 0.8058 |
| Kappa | 0.9670 | 0.9660 | 0.9647 | 0.9666 | 0.7869 | 0.98 | 0.9787 | 0.9777 | 0.9754 | 0.7628 |
| Method | RPCA2,1 | RPCA | PCA | IFRF | Origion | RPCA2,1 | RPCA | PCA | IFRF | Origin |
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | NN | SVM | ||||||||
| Indian Pines image | 16.73 | 21.62 | 5.16 | 5.31 | 5.69 | 27.94 | 34.53 | 14.39 | 16.90 | 17.34 |
| University of Pavia | 83.89 | 100.31 | 54.28 | 56.92 | 47.11 | 115.84 | 135.86 | 88.52 | 90.26 | 116.61 |
| Salinas image | 15.55 | 18.14 | 4.24 | 4.27 | 3.22 | 28.56 | 32.61 | 14.39 | 14.32 | 15.29 |
| Images | RPCA2,1 | RPCA | PCA | IFRF | Origin | |
|---|---|---|---|---|---|---|
| Indian Pines image | OA | 0.9004 ± 0.0103 | 0.8615 ± 0.0137 | 0.8736 ± 0.0067 | 0.86261 ± 0.0937 | 0.5008 ± 0.006 |
| AA | 0.9198 ± 0.0179 | 0.8481 ± 0.0261 | 0.8573 ± 0.024 | 0.8367 ± 0.0231 | 0.4530 ± 0.0256 | |
| Kappa | 0.8863 ± 0.011 | 0.8426 ± 0.0143 | 0.8561 ± 0.0257 | 0.8434 ± 0.00763 | 0.4230 ± 0.0069 | |
| University of Pavia image | OA | 0.9261 ± 0.0041 | 0.9156 ± 0.004 | 0.9116 ± 0.0057 | 0.9182 ± 0.0035 | 0.6721 ± 0.0079 |
| AA | 0.9212 ± 0.0054 | 0.9085 ± 0.0066 | 0.9055 ± 0.0107 | 0.9105 ± 0.0077 | 0.6162 ± 0.0088 | |
| Kappa | 0.9012 ± 0.0055 | 0.8871 ± 0.0055 | 0.8815 ± 0.0078 | 0.8906 ± 0.0048 | 0.5527 ± 0.0097 | |
| Salinas image | OA | 0.9329 ± 0.0078 | 0.911 ± 0.0062 | 0.9125 ± 0.0072 | 0.9095 ± 0.0108 | 0.6658 ± 0.0101 |
| AA | 0.9523 ± 0.0051 | 0.9268 ± 0.0054 | 0.9294 ± 0.0089 | 0.9247 ± 0.0102 | 0.7088 ± 0.0098 | |
| Kappa | 0.9253 ± 0.0086 | 0.901 ± 0.0069 | 0.9027 ± 0.008 | 0.8994 ± 0.012 | 0.625 ± 0.0106 |
| Images | No. m of Superpixels | OA | AA | Kappa | Time (s) |
|---|---|---|---|---|---|
| Indian Pines image | 104 | 0.9633 ± 0.0072 | 0.9507 ± 0.027 | 0.9581 ± 0.0091 | 12.43 |
| 226 | 0.9703 ± 0.006 | 0.9687 ± 0.032 | 0.9661 ± 0.0062 | 17.96 | |
| 329 | 0.9721 ± 0.0053 | 0.9657 ± 0.0254 | 0.9682 ± 0.0069 | 21.80 | |
| University of Pavia image | 195 | 0.9697 ± 0.0035 | 0.9473 ± 0.0061 | 0.9598 ± 0.0047 | 75.15 |
| 386 | 0.9711 ± 0.0043 | 0.9564 ± 0.0084 | 0.9616 ± 0.0058 | 78.33 | |
| 594 | 0.9753 ± 0.0026 | 0.9614 ± 0.0046 | 0.9672 ± 0.0035 | 81.20 | |
| 813 | 0.975 ± 0.0018 | 0.9596 ± 0.0053 | 0.9668 ± 0.0024 | 85.97 | |
| Salinas image | 187 | 0.9666 ± 0.0059 | 0.9743 ± 0.0064 | 0.9629 ± 0.0065 | 87.71 |
| 389 | 0.978 ± 0.0042 | 0.9813 ± 0.003 | 0.9755 ± 0.0047 | 92.96 | |
| 593 | 0.9823 ± 0.0037 | 0.9826 ± 0.003 | 0.9804 ± 0.0041 | 98.91 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zu, B.; Xia, K.; Li, T.; He, Z.; Li, Y.; Hou, J.; Du, W. SLIC Superpixel-Based l2,1-Norm Robust Principal Component Analysis for Hyperspectral Image Classification. Sensors 2019, 19, 479. https://doi.org/10.3390/s19030479
Zu B, Xia K, Li T, He Z, Li Y, Hou J, Du W. SLIC Superpixel-Based l2,1-Norm Robust Principal Component Analysis for Hyperspectral Image Classification. Sensors. 2019; 19(3):479. https://doi.org/10.3390/s19030479
Chicago/Turabian StyleZu, Baokai, Kewen Xia, Tiejun Li, Ziping He, Yafang Li, Jingzhong Hou, and Wei Du. 2019. "SLIC Superpixel-Based l2,1-Norm Robust Principal Component Analysis for Hyperspectral Image Classification" Sensors 19, no. 3: 479. https://doi.org/10.3390/s19030479
APA StyleZu, B., Xia, K., Li, T., He, Z., Li, Y., Hou, J., & Du, W. (2019). SLIC Superpixel-Based l2,1-Norm Robust Principal Component Analysis for Hyperspectral Image Classification. Sensors, 19(3), 479. https://doi.org/10.3390/s19030479