Abstract
The rapid development of sensor technology gives rise to the emergence of huge amounts of tensor (i.e., multi-dimensional array) data. For various reasons such as sensor failures and communication loss, the tensor data may be corrupted by not only small noises but also gross corruptions. This paper studies the Stable Tensor Principal Component Pursuit (STPCP) which aims to recover a tensor from its corrupted observations. Specifically, we propose a STPCP model based on the recently proposed tubal nuclear norm (TNN) which has shown superior performance in comparison with other tensor nuclear norms. Theoretically, we rigorously prove that under tensor incoherence conditions, the underlying tensor and the sparse corruption tensor can be stably recovered. Algorithmically, we first develop an ADMM algorithm and then accelerate it by designing a new algorithm based on orthogonal tensor factorization. The superiority and efficiency of the proposed algorithms is demonstrated through experiments on both synthetic and real data sets.
1. Introduction
In recent years, different types of tensor data have emerged with the significant progress of modern sensor technology, such as color images [1], videos [2], functional MRI data [3], hyper-spectral images [4], point could data [5], traffic stream data [6], etc. Thanks to its multi-way nature, tensor-based methods have natural superiority over vector and matrix-based methods in analyzing and processing ubiquitous modern multi-way data, and have found extensive applications in computer vision [1,7], data mining [5], machine learning [2], signal processing [8], to name a few. In real applications, the acquired tensor data may often suffer from noises and gross corruptions owing to many different reasons such as sensor failure, lens pollution, communication interference, occlusion in videos, or abnormalities in a sensor network [9], etc. At the same time, many real-world tensor data, such as face images or videos, have been shown to have some low-dimensional structure and can be well approximated by a smaller number of “principal components” [8]. Then, a question naturally arises: how to pursue the principal components of an observed tensor data in the presence of both noises and gross corruptions? We will answer this question in this paper and refer to the proposed methodology as Stable Tensor Principal Component Pursuit (STPCP).
The tensor low-rankness is an ideal model of the property that a tensor data can be well approximated by a small number of principal components [8]. In the last decade, low-rank tensor models have attracted much attention in many fields [10]. There are multiple low-rank tensor models since there exist different definitions of tensor rank. Among these models, the low CP rank model [11] and the low Tucker rank model [1] should be the most famous two. The low CP rank model approximates the underlying tensor by the sum of a small number of rank-1 tensors, whereas the low Tucker rank model assumes the unfolding matrix along each mode are low rank. To estimate an unknown low-rank tensor from corrupted observations, it is a natural option to consider the rank minimization problem which chooses the tensor of lowest rank as the solution from a certain feasible set. However, tensor rank minimization, even in its 2-way (matrix) case, is generally NP-hard [12] and even harder in higher-way cases [13]. For tractable solutions, researchers turn to a variety of convex surrogates for tensor rank [1,14,15,16,17,18] to replace the tensor rank in rank minimization problem. Methods based on surrogates for the tensor CP rank and Tucker rank have been extensively explored in both the theoretical side and the application side [14,17,19,20,21,22,23,24].
Recently, the low-tubal-rank model [16,25] has shown better performance than traditional tensor low-rank models in many tensor recover tasks such as image/video inpainting/denoising/ sensing [2,25,26], moving object detection [27], multi-view learning [28], seismic data completion [29], WiFi fingerprint [30], MRI imaging [16], point cloud data inpainting [31], and so on. The tubal rank is a new complexity measure of tensor defined through the framework of tensor singular value decomposition (t-SVD) [32,33]. At the core of existing low-tubal-rank models is the tubal nuclear norm (TNN) which is a convex surrogate for the tubal rank. In contrast to CP-based tensor nuclear norms or Tucker-based tensor nuclear norms which models low-rankness in the original domain, TNN models low-rankness in the Fourier domain. It is pointed out in [25,34,35] that TNN has superiority over traditional tensor nuclear norms in exploiting the ubiquitous “spatial-shifting” property in real-world tensor data.
Inspired by the superior performance of TNN, this paper adopts TNN as a low-rank regularizer in the proposed STPCP model. Specifically, the proposed STPCP aims to estimate the underlying tensor data from an observation tensor polluted by both small dense noises and sparse gross corruptions as follows:
where is a tensor denoting the sparse corruptions and is a tensor representing small dense noises. Model (1) is also known as robust tensor decomposition in [36,37].
Our STPCP model is first formulated as a TNN-based convex problem. Then, our theoretical analysis gives upper bound on the estimation error of and . In contrast to the analysis in [37], the proposed STPCP can exactly recovery the underlying tensor and the sparse corruption tensor when the noise term vanishes. For efficient solution of the proposed STPCP model, we develop two algorithms with extensions to a more challenging scenario where missing observations are also considered. The first algorithm is an ADMM algorithm and the second algorithm accelerates it using tensor factorization. Experiments show the effectiveness and the efficiency of the designed algorithms.
We organize the rest of this paper as follows. In Section 2, we briefly introduce basic preliminaries for t-SVD and some related works. The proposed STPCP model is formulated and analyzed theoretically in Section 3. We design two algorithms in Section 4 and report experimental results in Section 5. This work is concluded in Section 6. The proofs of theorems, propositions, and lemmas are given in the appendix.
2. Preliminaries and Related Works
In this section, some preliminaries of t-SVD are first introduced. Then, the related works are presented.
Notations. We denote vectors by bold lower-case letters, e.g., , matrices by bold upper-case letters, e.g., , and tensors by underlined upper-case letters, e.g., . For a given 3-way tensor, we define its fiber as a vector given through fixing all indices but one, and its slice as a matrix obtained by fixing all indices but two. For a given 3-way tensor , we use to denote its -th element; is used to denote its k-th frontal slice. is used to denote the tensor after performing 1D Discrete Fourier Transformation (DFT) on all tube fibers of , , which can be efficiently computed by the Matlab command . We use and to represent the 1D DFT and inverse DFT along the tube fibers of 3-way tensors, i.e.,
For a given matrix , define the nuclear norm and spectral norm of respectively as:
where , and are the singular values of in a non-ascending order. The -norm, -norm, Frobenius norm, -norm of a tensor is defined as:
where is an indicator function whose value is 1 if the condition C is true, and 0 otherwise.
Given two matrices , we define their inner product as follows:
where denotes conjugate transpose of matrix and denotes the conjugation of complex number . Given two 3-way tensors , we define their inner product as follows:
2.1. Tensor Singular Value Decomposition
We first define 3 operators based on block matrices which are introduced in [33]. For a given 3-way tensor , we define its block vectorization and the inverse operation in the following equation:
We further define the block circulant matrix of any 3-way tensor as follows:
Equipped with above defined operators, we are now in a position to define the t-product of 3-way tensors.
Definition 1
(t-product [33]). Given two tensors and , the t-product of and is a new 3-way tensor with size :
A more intuitive interpretation of t-SVD is as follows [33]. If we treat a 3-way tensor as a matrix of size whose entries are the tube fibers, then the tensor t-product can be analogously understood as the “matrix multiplication” where the standard scalar product is replaced with the vector circular convolution between the tubes (i.e., vectors):
where ⋆ represent the operation of circular convolution [33] of two vectors defined as .
We also define the block diagonal matrix of any 3-way tensor and its inverse as follows:
We also use (or ) to denote the block diagonal matrix of tensor (i.e., the Fourier version of ) i.e.,
Then the relationship between DFT and circular convolution further indicates that the conducting t-product in the original domain is equivalent to performing standard matrix product on the Fourier block diagonal matrices [33]. Since matrix product on the Fourier block diagonal matrices can be parallel written as matrix product of all the frontal slices in the Fourier domain, we have the following relationships:
The relationship between the t-product and FFT also indicates that the inner product of two 3-way tensors and the inner product of their corresponding Fourier block diagonal matrices satisfy the following relationship:
When , one has:
We further define the concepts of tensor transpose, identity tensor, f-diagonal tensor and orthogonal tensor as follows.
Definition 2
(tensor transpose [33]). Given a tensor , then define its transpose tensor of size which can be formed through first transposing all the frontal slices of and then exchanging each k-th transposed frontal slice with the -th transposed frontal slice for all .
For example, consider 3-way tensor with 4 frontal slices, the tensor transpose of is:
Definition 3
(identity tensor [33]). The identity tensor is a tensor whose first frontal slice is the n-by-n identity matrix with all other frontal slices are zero matrices.
Definition 4
(f-diagonal tensor [33]). We call a 3-way tensor f-diagonal if all the frontal slices of it are diagonal matrices.
Definition 5
(orthogonal tensor [33]). We call a tensor an orthogonal tensor if the following equations hold:
Then, the tensor singular value decomposition (t-SVD) can be given as follows.
Definition 6
(Tensor singular value decomposition, and Tensor tubal rank [38]). Given any 3-way tensor , then it has the following factorization called tensor singular value decomposition (t-SVD):
where the left and right factor tensors and are orthogonal, and the middle tensor is a rectangular f-diagonal tensor.
A visual illustration for the t-SVD is shown in Figure 1. It can be computed efficiently by FFT and IFFT in the Fourier domain according to Equation (4). For more details, see [2].
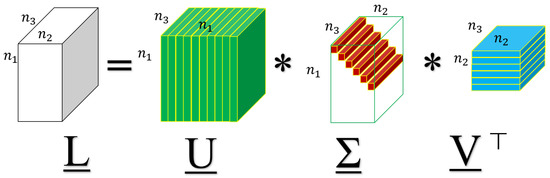
Figure 1.
A visual illustration of t-SVD.
Definition 7
(Tensor tubal rank [38]). The tensor tubal rank of any 3-way tensor is defined as the number of non-zero tubes of in its t-SVD shown in Equation (5), i.e.,
Definition 8
(Tubal average rank [38]). The tubal average rank of any 3-way tensor is defined as the averaged rank of all frontal slices of as follows,
Definition 9
(Tensor operator norm [2,38]). The tensor operator norm of any 3-way tensor is defined as follows:
The relationship between t-product and FFT indicates that:
Definition 10
(Tensor spectral norm [38]). The tensor spectral norm of any 3-way tensor is defined as the matrix spectral norm of , i.e.,
We further define the tubal nuclear norm.
Definition 11
(Tubal nuclear norm [2]). For any tensor with t-SVD , the tubal nuclear norm (TNN) of is defined as:
where .
To understand the tubal nuclear norm, first note that:
where (i) holds because of the definition of DFT [2], (ii) holds by the property of -norm, and (iii) is a result of DFT [2]. Thus, the tubal rank of is also the number of non-zero diagonal elements of , i.e., the first frontal slice of tensor in the t-SVD of . Similar to the matrix singular values, the values are also called the singular values of tensor . As the matrix nuclear norm is the sum of matrix singular values, the tubal nuclear norm can be similarly understood as the sum of tensor singular values.
One can also verify by the property of DFT [2] that:
which indicates that the TNN of is also the averaged nuclear norm all frontal slices of . Thus, TNN indeed models the low-rankness of Fourier domain.
Now, we will show that the low-tubal-rank model is ideal to some real-world tensor data, such as color images and videos.
First, we consider a natural image of size , shown in Figure 2a. In Figure 2b, we plot the distribution of its singular values, i.e., the values of along with the index i. As can be seen from Figure 2b, there are only a small number of singular values with large magnitude, and most of the singular values are close to 0. Then, we can say that some natural color images are approximately low tubal rank.
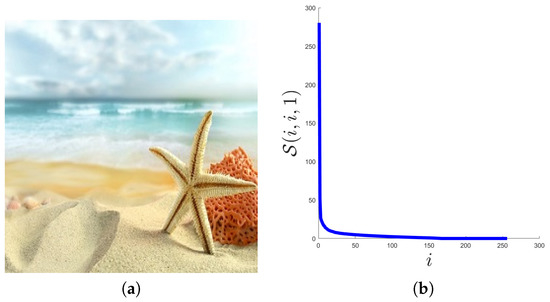
Figure 2.
The distribution of tensor singular values in a natural color image. (a) the sample image, (b) the distribution of .
Then, consider a commonly used YUV sequence Mother-daughter_qcif (These data can be download from the following link https://sites.google.com/site/subudhibadri/fewhelpfuldownloads.) whose first frame is shown in Figure 3a. We use the Y components of the first 30 frames, and get a tensor of size and show the distribution of tensor singular values in Figure 3b. We can see from Figure 3b that similar to Figure 2b, there are only a small number of singular values with large magnitude, and most of the singular values are close to 0. Then, we can say that some videos can be well approximately low tubal rank.
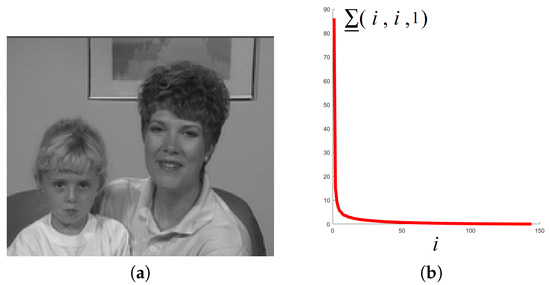
Figure 3.
The distribution of tensor singular values in a video sequence. (a) the first frame of the video, (b) the distribution of .
For TNN and tensor spectral norm, we highlight the following two lemmas.
Lemma 1.
[2] TNN is the convex envelop of the tensor average rank in the unit ball of tensor spectral norm .
Lemma 2.
[2] The TNN and the tensor spectral norm are dual norms to each other.
2.2. Related Works
In this subsection, we briefly introduce some related works. The proposed STPCP is tightly related to the Tensor Robust Principal Component Analysis (TRPCA) which aims to recover a low-rank tensor and a sparse tensor from their sum . This is a special case of our measurement Model (1) where the noise tensor is a zero tensor.
In [39], the SNN-based TRPCA model is proposed by modeling the underlying tensor as a low Tucker rank one:
where SNN (Sum of Nuclear Norms) is defined as where and is the mode-k matricization of [40].
Model (14) indeed assumes the underlying tensor to be low Tucker rank, which can be too strong for some real tensor data. The TNN-based TRPCA model uses TNN to impose low-rankness in the final solution as follows:
As shown in [2], when the underlying tensor satisfy the tensor incoherent conditions, by solving Problem (15), one can exactly recover the underlying tensor and with high probability with parameter .
When the noise tensor is not zero, the robust tensor decomposition based on SNN is proposed in [36] as follows:
where and are positive regularization parameters. The estimation error on and is analyzed with an upper bound in [36].
In [37], the TNN-based RTD model is proposed as follows:
where is an upper estimate of -norm of the underlying tensor . An upper bound on the estimation error is also established. However, in the analysis of Model (17), the error does not vanish as the noise tensor vanishes which means the analysis cannot guarantee exact recovery in the noiseless setting (which can be provided by the analysis of TNN-based TRPCA (15) by Lu et al. [2]).
The Bayesian approach is also used for robust tensor recovery. The CP decomposition under sparse corruption and small dense noise is considered [41], and tensor rank estimation is achieved using Bayesian approach. In [42], CP decomposition under missing value and small dense noise is considered with rank estimation similar to [41]. A sparse Bayesian CP model is proposed in [43] to recover a tensor with missing value, outliers and noises. In [44], a fully Bayesian treatment is proposed to recover a low-tubal-rank tensor corrupted by both noises and outliers.
3. Theoretical Guarantee for Stable Tensor Principal Component Pursuit
In this section, we formulate the proposed STPCP model and give the main theoretical result which upper bounds the estimation error and guarantees exact recovery in the noiseless setting.
3.1. The Proposed STPCP
As for the measurement Model (1), we further assume that the noise tensor has bounded energy measured in F-norm, i.e., . Please note that the limited energy assumption is very mild, since most signals are of limited energy.
To recover the low-rank tensor and the sparse tensor , we first produce the following optimization problem:
where is a positive parameter balancing the two regularizers. The motivation is to use TNN as a low-rank regularization term to exploit the low-dimensional structure in the signal tensor, whereas tensor -norm is used to impose sparsity in the corruption tensor (since we assumes it to be sparse).
The relationship between Model (18) and existing models are discussed in Remark 1 and Remark 2.
Remark 1.
The following models can be seen as special cases as the proposed STPCP Model (18);
- (I).
- When , i.e., in the noiseless case, the proposed model degenerates to the TRPCA Model (15) [2].
- (II).
- When , then the stable tensor PCP Model (18) degenerates to the Stable Principal Component Pursuit (SPCP) [45] which aims to pursuit the principal components modeled by low-rank matrix from it observation corrupted by both noises and sparse corruptions . The SPCP is formulated as follows:
- (III).
- When and , the proposed STPCP further degenerates to Robust Principal Component Analysis (RPCA) [46] given as follows:
Remark 2.
3.2. A Theorem for Stable Recovery
To analyze the statistical performance of Model (18), we should assume on the underlying low-rank tensor that it is not sparse. Only by this assumption, can be identified from its mixture with sparse . Such an assumption can be described by the tensor incoherence condition [2,47], which is used to provide an identifiablility for low-rank .
Definition 12
(Tensor incoherence condition [2,47]). Given a 3-way tensor with tubal rank r, suppose it has the skinny t-SVD , where are orthogonal tensors, and is an f-diagonal tensor. Then, is said to satisfy the tensor incoherent condition (TIC) with parameter if the following inequalities hold:
where is a tensor column basis with only the -th element being 1 and all the others being 0, and is also a tensor column basis with only the -th element being 1 and all the others being 0.
Assumption 1.
Suppose the true tensor in the measurement model (1) satisfies tensor incoherence condition with parameter μ.
Assumption 1 intrinsically ensures that the row bases and column bases of do not align well with the canonical row and column bases. Thus, the low-rank is not sparse, which avoids the ambiguity that low-rank component can also be sparse in the measurement Model (1).
We should also force the sparse component in Model (1) is not low rank.
Assumption 2.
Assume the support Ω of is drawn uniformly at random.
Now we can establish an upper bound on the estimation error of and in Problem (18).
Theorem 1
(An Upper Bound on the Estimation Error). Suppose and satisfy Assumption 1 and Assumption 2, respectively. If the tubal rank r of and the sparsity (i.e., the -norm) s of are respectively upper bounded as follows:
where and are two sufficiently small numerical constants independent on the dimensions , and . Then the estimator defined in Model (18) satisfy the following inequalities:
with probability at least (over the choice of support of ), where and are positive constants independent on the dimensions , and .
The proof of Theorem 1 are given in the appendix. In Theorem 1, estimation errors on and are separately established. It indicates that the estimation error scales linearly with the noise level , which is in consistence with the result in [37].
Remark 3.
A significant progress over [37] is that in the noiseless setting where vanishes, our analysis can provide exact recovery guarantee of and . This is because the tensor incoherence condition adopted in our analysis intrinsically ensures that the low-rank tensor is not sparse and thus can be separated from the sparse corruption tensor, whereas the non-spiky condition adopted in [37] fails to provide identifiability in the measurement Model (1).
For Theorem 1, we also give the following remark.
Remark 4.
The error bounds established in Theorem 1 are consistent with the theoretical analysis for the special cases shown in Remark 1.
- (I).
- When , i.e., in the noiseless case, the error bounds in Theorem 1 will vanish, which means exact recovery of and can be guaranteed. This result is consistent with the analysis in [2] for TNN-based TRPCA Model (15).
- (II).
- When , the error bound on the sparse component in Theorem 1 is consistent with the error bound shown in Equation (8) of [45]. The upper bound on error of the low-rank component in Theorem 1 is sharper than that given in Equation (8) of [45].
- (III).
- When and , the proposed STPCP has consistent theoretical guarantee with the analysis of RPCA [46].
4. Algorithms
In this section, we design two algorithms. The first algorithm is based on the framework of ADMM [48] which has been extensively used in convex optimization with good convergence behavior. However, ADMM requires full SVDs on large matrices in each iteration which is high computational burden in high-dimensional settings. Thus, the second algorithm is proposed to solve this issue by using a factorization trick which can instead conducting SVDs on much smaller matrices.
4.1. An ADMM Algorithm
The proposed estimator (18) is equivalent to the following unconstrained problem:
where is a positive parameter balancing the data fidelity term and the regularization term.
Besides being corrupted by noises and outliers, the observed tensor may also suffer from missing entries which can be taken as outliers with known positions in many applications. Thus, it is more practical to consider the recovery of against outliers , noises and missing entries shown in the following measurement model:
where tensor denote the missing mask where , if the -th entry of is observed and otherwise, and ⊙ denotes element-wise multiplication. Taking into consideration of missing entries, Model (26) can be further modified as:
By adding auxiliary variables to Problem (28), we obtain:
The Augmented Lagrangian (AL) of Problem (29) is given as follows:
where are Lagrangian multipliers and is a penalty parameter.
According the strategy of ADMM, we update prime variables and by alternative minimization of AL in Problem (29) as follows
- Update . We update by minimizing with other variables fixed as follows:Taking derivatives of the right-hand side of Equation (31) with respect to and respectively, and setting the results zero, we obtain:Resolving the above equation group yields:where ⊘ denotes entry-wise division and denotes the tensor all whose entries are 1.
- Update . We update by minimizing with other variables fixed as followsPlease note that Problem (34) can further be solved separately as follows:andwhere is the proximity operator of TNN [5]. and is the proximity operator of tensor -norm given as follows [49]:In [5], a closed-form expression of is given as follows:Lemma 3.(Proximity operator of TNN [5]) For any 3D tensor with reduced t-SVD , where and are orthogonal tensors and is the f-diagonal tensor of singular tubes, the proximity operator at can be computed by:
- Update . The Lagrangian multipliers are updated by gradient ascent as follows:
The algorithm is summarized in Algorithm 1. The convergence analysis of Algorithm 1 is established in Theorem 2.
| Algorithm 1 Solving Problem (29) using ADMM. |
Theorem 2
(Convergence of Algorithm 1). For any , if the unaugmented Lagrangian has a saddle point, then the iterations in Algorithm 1 satisfy the residual convergence, objective convergence and dual variable convergence of Problem (29) as .
The proof of Theorem 2 is given in the Appendix A.
In a single iteration of Algorithm 1, the main cost comes from updating which involves computing FFT, IFFT and SVDs of matrices [47]. Hence Algorithm 1 has per-iteration complexity of order . Thus, if the total iteration number is T, then the total computational complexity is:
4.2. A Faster Algorithm
To reduce the cost of computing TNN which is a main cost of Algorithm 1, we propose the following lemma which indicates that TNN is orthogonal invariant.
Lemma 4.
Given a tensor , let a two semi-orthogonal tensors, i.e., and . Then, we have the following relationship:
The proof of Lemma 4 can be found in the appendix. Equipped with Lemma 4, we decompose the low-rank component in Problem (28) as follows:
where is an identity tensor. The similar strategy has been used in low-rank matrix recovery from gross corruptions by [50]. Furthermore, we propose the following model for Problem (28):
where r is an upper estimation of tubal rank of the underlying tensor .
In contrast to Model (28), the proposed Model (39) is a non-convex optimization problem. That means Model (39) may have many local minima. We establish a connection between the proposed Model (39) with Model (28) in the following theorem.
Theorem 3
The proof of Theorem 3 can be found in the appendix. Theorem 3 states that the global optimal point of the (non-convex) Model (39) coincides with solution of the (convex) Model (28). It further indicates that the accuracy of Model (39) cannot exceed Model (28), which can be validated numerically in the experiment section.
To solve Model (39), we also use the ADMM framework.
First, by adding auxiliary variables, we have the following problem:
The augmented Lagrangian of Problem (40) is:
According the strategy of ADMM, we update prime variables and by alternative minimization of AL in Problem (41) as follows
- Update : We update by minimizing with other variables fixed as follows:Taking derivatives of the right-hand side with respect to and respectively, and setting the results zero, we obtain:Resolving the above equation group yields:
- Update . We update by minimizing with other variables fixed as followswhere operator is defined in Lemma 5 as follows.Lemma 5.([51]) Given any tensors , suppose tensor has t-SVD , where and . Then, the problem:has a closed-form solution as:
- Update :We update by minimizing with other variables fixed as follows:The equality in Equation (49) holds because according to , we have:
- Update . The Lagrangian multipliers are updated by gradient ascent as follows:
The algorithmic steps are summarized in Algorithm 2. The complexity analysis is given as follows.
In each iteration of Algorithm 2, the update of requires FFT/IFFT, and multiplications of -by-r and r-by- matrices, which costs ; updating costs ; updating of involves FFT/IFFT and SVDs of -by-r matrices, which costs ; updating involves FFT/IFFT and SVDs of r-by-, which costs . Then, the per-iteration computational complexity of Algorithm 2 is dominated by:
Since the low-tubal-rank assumption is adopted in this paper, the per-iteration of Algorithm 2 is much lower than Algorithm 1.
| Algorithm 2 Solving Problem (40) using ADMM. |
5. Experiments
5.1. Synthetic Data
We first verify the correctness of Theorem 1. Specifically, we check whether the following two statements indicated in Theorem 1 hold in experiments on synthetic data sets:
- (I).
- (Exact recovery in the noiseless setting.) Our analysis guarantees that the underlying low-rank tensor and sparse tensor can be exactly recovered in the noiseless setting. This statement will be checked in Section 5.1.1.
- (II).
- (Linear scaling of errors with the noise level.) In Theorem 1, the estimation errors on and scales linearly with the noise level . This statement will be checked in Section 5.1.2.
Signal Generation. With a given tubal rank , we first generate the underlying tensor by , where tensors and are generated with i.i.d. standard Gaussian elements. Then, the sparse corruption tensor is generated by choosing its support uniformly at random. The non-zero elements of will be i.i.d. sampled from a certain distribution that will be specified afterwards. Furthermore, the noise tensor is generated with entries sampled i.i.d. from with , where we set constant c is to control the signal noise ratio. Finally, the observed tensor is formed by .
5.1.1. Exact Recovery in the Noiseless Setting
We first check Statement (I), i.e., exact recovery in the noiseless setting. Specifically, we will show that Algorithm 1 and Algorithm 2 can exactly recover the underlying tensor and the sparse corruption . We first test the recovery performance of different tensor sizes by setting and , with . The non-zero elements of tensor is sampled from i.i.d. symmetric Bernoulli distribution, i.e., the possibility of being 1 or −1 are 1/2. The results are shown in Table 1. It can be seen that both Algorithm 1 and Algorithm 2 can obtain relative standard error (RSE) smaller than by which we can say that and are exact recovered. We can also see that Algorithm 2 runs much faster than Algorithm 1.

Table 1.
Performance of Algorithm 1 and Algorithm 2 in both accuracy and speed for different tensor sizes when the gross corruption. Outliers from symmetric Bernoulli, observation tensor , , , , noise level , .
We then test whether the recovery performance can be affected by the distribution of the corruptions. This is done by choosing the non-zeros elements of from i.i.d. standard Gaussian distribution. The experimental results are reported in Table 2. We can find that both Algorithm 1 and Algorithm 2 can exactly recover the true and and Algorithm 2 runs much faster than Algorithm 1.
Table 2.
Performance of Algorithm 1 and Algorithm 2 in both accuracy and speed for different tensor sizes when the gross corruption. Outliers from standard Gaussian distribution, observation tensor , , , , noise level , .
We also conduct STPCP by Algorithm 1 and Algorithm 2 with missing entries. After generating , and , we get the observation by Model (27). We choose the support of uniformly at random with possibility and then set elements in the chosen support to be 1. Thus, %20 of the entries are missing. The corrupted observation M is then formed by . We show the recover results in Table 3. We can see that the underlying low-rank tensor can be exactly recovered and the observed part of the corruption tensor can also be exactly recovered (Please note that it is impossible to recover the unobserved entries of a sparse tensor [52]).
Table 3.
Performance of Algorithm 1 and Algorithm 2 in both accuracy and speed for different tensor sizes when the gross corruption. Outliers from symmetric Bernoulli, observation tensor , , , , noise level , , with random missing entries.
5.1.2. Linear Scaling of Errors with the Noise Level
We then verify Statement (II) that the estimation errors have linear scale behavior with respect to the noise level. The estimation errors are measured using the mean-squared-error (MSE):
for the low rank component and the sparse component , respectively. We test tensors of 3 different size by choosing and . The tubal rank of and sparsity s of are set as . We vary the signal noise ratio which is in proportional of the noise level . We run the proposed Algorithm 1, test 50 trials, and report the averaged MSEs. The MSEs of and versus are shown in sub-figures (a) and (b) in Figure 4. We can see that the estimation error has linear scaling behavior along with the noise level as Theorem 1 indicates. Since the results for and are quite similar to the case of , they are simply omitted.
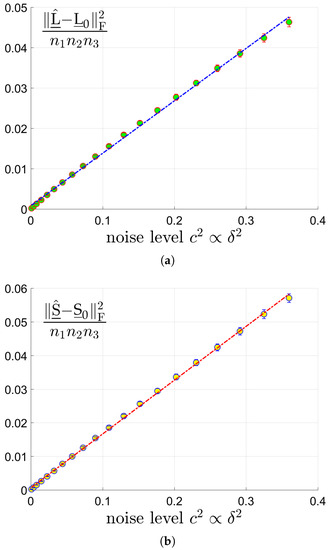
Figure 4.
The MSEs of and versus for tensors of size where the tubal rank of and sparsity s of are set as . (a): MSE of vs . (b): MSE of vs .
5.2. Real Data Sets
In this section, experiments on real data sets (color images and videos) are carried out to evaluate the effectiveness and efficiency of the proposed Algorithms 1 and 2. Besides noises and sparse corruptions, we also consider missing values which is more challenging. The proposed algorithms are compared with the following typical models:
- (I).
- NN-I: tensor recovery based on matrix nuclear norms of frontal slices formulated as follows:This model will be used for image restoration in Section 5.2.1. Please note that Model (53) is equivalent to parallel matrix recovery on each frontal slice.
- (II).
- NN-II: tensor recovery based on matrix nuclear norm formulated as follows:where with defined as the vectorization [40] of frontal slices , for all . This model will be used for video restoration in Section 5.2.2.
- (III).
- SNN: tensor recovery based on SNN formulated as follows:where is the mode-i matriculation of tensor , for all .
We solve the above Model (53)–(55) using ADMM implemented by ourselves in Matlab. The effectiveness of the algorithms is measured by Peaks Signal Noise Ratio (PSNR):
Please note that a larger PSNR value indicates higher quality of .
5.2.1. Color Images
Color images are the most commonly used 3-way tensors. We test the twenty 256-by-256-by-3 color images which have been used in [37], and carry out robust tensor recovery with missing entries (see Figure 5). Following [37], for a color image , we choose its support uniformly at random with ratio and fill in the values with i.i.d. symmetric Bernoulli variables to generate . The noise tensor is generated with i.i.d. zero-mean Gaussian entries whose standard deviation is given by . Then, we form the binary observation mask by choosing its support uniformly at random with ratio . Finally, the partially observed corruption are formed.

Figure 5.
The 20 color images used.
We consider two scenarios by setting . For NN (Model (53)), we set the regularization parameters (suggested by [46]), and set parameter where is estimated as (suggested by [5]). For SNN, the parameters are chosen to satisfy , . For Algorithm 1 and Algorithm 2, we set , and . The initialized rank r in Algorithm 2 is set as 60. In each setting, we test each color image for 10 times and report the averaged PSNR and time. For quantitative comparison, we show the PSNR values and running times in Figure 6 and Figure 7 for settings of and , respectively. Several visual examples are shown in Figure 8 for qualitative comparison for the setting of . We can see from Figure 6, Figure 7 and Figure 8 that the proposed Algorithm 1 has the highest recovery quality and the proposed Algorithm 2 has the second highest quality but the fastest running time.
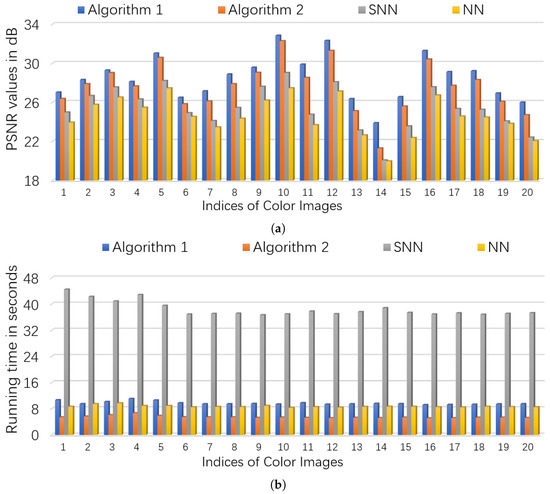
Figure 6.
The quantitative comparison in PSNR and time on color images. First, entries of each image is corrupted by i.i.d. symmetric Bernoulli variable, then polluted by Gaussian noise of noise level , and finally of the corrupted entries are missing uniformly at random. (a): the PSNR values of each algorithm; (b): the running time of each algorithm.
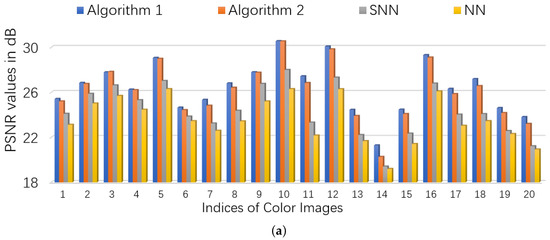
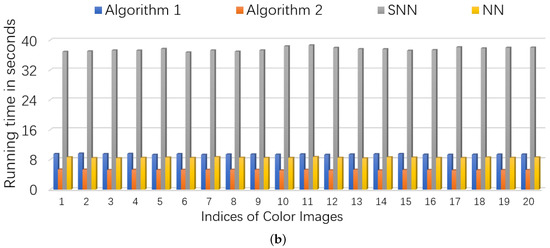
Figure 7.
The quantitative comparison in PSNR and time on color images. First, entries of each image is corrupted by i.i.d. symmetric Bernoulli variable, then polluted by Gaussian noise of noise level , and finally of the corrupted entries are missing uniformly at random. (a): the PSNR values of each algorithm; (b): the running time of each algorithm.

Figure 8.
The visual results for image recovery of different algorithms. First, entries of each image is corrupted by i.i.d. symmetric Bernoulli variable, then polluted by Gaussian noise of noise level , and finally of the corrupted entries are missing uniformly at random. (a): the original image; (b): the corrupted image; (c) image recovered by Algorithm 1; (d) image recovered by Algorithm 2; (e) image recovered by the matrix nuclear norm (NN)-based Model (53); (f) image recovered by the SNN-based Model (55).
5.2.2. Videos
In this subsection, video restoration experiments are conducted on four broadly used YUV videos (They can be downloaded from https://sites.google.com/site/subudhibadri/fewhelpfuldownloads: Akiyo_qcif, Scilent_qcif, Carphone_qcif, and Claire_qcif.) Owing to computational limitation, we simply use the first 32 frames of the Y components of all the videos which results in four 144-by-176-by-30 tensors. For a 3-way data tensor , To generate corruption , the support is chosen uniformly at random with ratio and then elements in the support are filled in with i.i.d. symmetric Bernoulli variables. The noise tensor is also generated with i.i.d. zero-mean Gaussian entries whose standard deviation is given by . Then, the binary observation mask is formed thorough choosing its support uniformly at random with ratio . Finally, the partially observed corruption are formed.
We also consider two scenarios by setting . NN-II Model (54) is used in video restoration. For NN-II, we set the regularization parameters (suggested by [46]), and set parameter where is estimated as (suggested by [5]). For SNN, the parameters are chosen to satisfy , . For Algorithm 1 and Algorithm 2, we set , and after careful parameter tuning. The initialized rank r in Algorithm 2 is set as 60. In each setting, we test each video for 10 times and report the averaged PSNR and time. For quantitative comparison, we show the PSNR values and running times in Table 4. It can be seen that Algorithm 1 has the highest recovery quality and the proposed Algorithm 2 has the second highest quality but the fastest running time.
Table 4.
PSNR values and running time (in seconds) of different algorithms on video data. First, entries of each image is corrupted by i.i.d. symmetric Bernoulli variable, then polluted by Gaussian noise of noise level , and finally of the corrupted entries are missing uniformly at random. The items with highest PSNR values are highlighted with bold face, and the items with shortest running time are highlighted with underline.
6. Conclusions
This paper studied the problem of stable tensor principal component pursuit which aims to recover a tensor from noises and sparse corruptions. We proposed a constrained tubal nuclear norm-based model and established upper bounds on the estimation error. In contrast to prior work [37], our theory can guarantee exact recovery in the noiseless setting. We also designed two algorithms, the first ADMM algorithm can be accelerated by the second Algorithm which adopts a factorization strategy. We validated the correctness of our theory by simulations on synthetic data, and evaluated the effectiveness and efficiency of the proposed algorithms via experiments on color images and videos.
For future directions, it is a natural and interesting extension to consider recovery of 4-way tensors [35] with arbitrary linear transformation [53,54]. It is also interesting to use tensor factorization-based methods [55,56] for STPCP. Another challenging future direction is developing tools to verify whether the unknown tensor satisfies the tensor incoherence condition from its incomplete or corrupted observations.
For extensions of the proposed approach to higher-way tensors, we produce the following two ideas:
- By recursively applying DFT over successive modes higher than 3 and then unfolding the obtained tensor into 3-way [57], the proposed algorithms and theoretical analysis can be extended to higher-way tensors.
- By using the overlapped orientation invariant tubal nuclear norm [58], we can extend the proposed algorithm to higher-order cases and obtain orientation invariance.
Author Contributions
Conceptualization, W.F. Data curation, D.W. and R.Z. Formal analysis, W.F. Methodology, W.F., D.W and R.Z. Software, D.W. and R.Z. Writing, original draft, W.F., D.W. and R.Z.
Funding
This research was funded by the Key Projects of Natural Science Research in Universities in Anhui Province under grant number KJ2019A0994.
Acknowledgments
We sincerely thank Andong Wang who shared the codes of [37] and gave us some suggestions of the proof.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of Lemmas and Theorems
Appendix A.1. The Proof of Theorem 1
Appendix A.1.1. Key Lemmas for the Proof of Theorem 1
Before Proving Theorem 1, we should define some notations and operators first.
Suppose with tubal rank r has the skinny t-SVD , where are orthogonal tensors, and is an f-diagonal tensor. Define the following set:
Then, define the projector onto for any tensor as follows:
Let be the complement of which is the support of . Then, define two operators as follows:
for any .
Define two sets and as follows:
Then, for any tensors , the projectors of the tensor into the sets and are given as follows, respectively:
For any tensors , define two operators on as follows:
Also define two norms as follows:
where is a constant that will be determined afterwards.
We first give Lemma A1 which can be seen as a modified version of Lemma C.1 in [2].
Lemma A1.
Assume that , and . Suppose there exists a tensor satisfying the following conditions:
Then for any perturbation , one has:
Proof.
Let , i.e., any sub-gradient of at , then it satisfies:
and . According to the convexity of and , we have:
By choosing , where and comes from the skinny t-SVD of , one has:
Also, by choosing , one has:
Also note that:
which leads to:
Putting things together, we have:
Since , it holds that:
for any perturbation . □
Lemma A2.
Suppose that , then for any , we have:
Proof.
According to the definitions of and , we have:
Then, we have:
Hence completes the proof. □
Appendix A.1.2. Proof of Theorem 1
Proof.
For , define . Let ,. According to the optimality of and the feasibility of , we directly have:
Let , . Then, we have:
Define the pair of error tensors . The goal is to bound .
First, we use the decomposition , and let for simplicity. Then, we have:
Please note that , thus can be bounded easily as follows:
Then, it remains to bound . Due to the triangular inequality:
(A) bound . According to the convexity of we have:
Using Lemma A1, we have:
Then, with , we reach a bound on as follows:
(B) bound . Please note that:
which means:
According to Lemma A2, we have:
Since , we have:
which indicates that:
Moreover, according to the analysis in [2], the conditions and Equation (A8) in Lemma A1 hold with probability at least , where and are positive constants.
In this way, the proof of Theorem 1 is completed. □
Appendix A.2. Proof of Theorem 2
Proof.
The key idea is to rewrite Problem (29) into a standard two-block ADMM problem. For notational simplicity, let:
where and are defined as follows:
and denotes an operation of tensor vectorization (see [40]).
It can be verified that and are closed, proper convex functions. Then, Problem (29) can be re-written as follows:
According to the convergence analysis in [48], we have:
where are the optimal values of , , respectively. Variable is a dual optimal point defined as:
where is the dual component of a saddle point of the unaugmented Lagrangian . □
Appendix A.3. Proof of Lemma 4
Proof.
Let the full t-SVD of be , where are orthogonal tensors and is f-diagonal. Then:
Then . Since
we obtain that:
Thus, . □
Appendix A.4. Proof of Theorem 3
Proof.
Please note that is a feasible point of Problem (28), then we have:
By the assumption that , there exists a decomposition , such that is also a feasible point of Problem (39).
Moreover, since is a global optimal solution to Problem (39), then we have that
By , we have:
Thus, we deduce:
In this way, is also the optimal solution to Problem (28). □
References
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Xu, Y.; Hao, R.; Yin, W.; Su, Z. Parallel matrix factorization for low-rank tensor completion. Inverse Probl. Imaging 2015, 9, 601–624. [Google Scholar] [CrossRef]
- Liu, Y.; Shang, F. An Efficient Matrix Factorization Method for Tensor Completion. IEEE Signal Process. Lett. 2013, 20, 307–310. [Google Scholar] [CrossRef]
- Wang, A.; Wei, D.; Wang, B.; Jin, Z. Noisy Low-Tubal-Rank Tensor Completion Through Iterative Singular Tube Thresholding. IEEE Access 2018, 6, 35112–35128. [Google Scholar] [CrossRef]
- Tan, H.; Feng, G.; Feng, J.; Wang, W.; Zhang, Y.J.; Li, F. A tensor-based method for missing traffic data completion. Transp. Res. Part C 2013, 28, 15–27. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.L. Discriminative extreme learning machine with supervised sparsity preserving for image classification. Neurocomputing 2017, 261, 242–252. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; Phan, H.A. Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Vaswani, N.; Bouwmans, T.; Javed, S.; Narayanamurthy, P. Robust subspace learning: Robust PCA, robust subspace tracking, and robust subspace recovery. IEEE Signal Process. Mag. 2018, 35, 32–55. [Google Scholar] [CrossRef]
- Cichocki, A.; Lee, N.; Oseledets, I.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor Networks for Dimensionality Reduction and Large-scale Optimization: Part 1 Low-Rank Tensor Decompositions. Found. Trends® Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef]
- Yuan, M.; Zhang, C.H. On Tensor Completion via Nuclear Norm Minimization. Found. Comput. Math. 2016, 16, 1–38. [Google Scholar] [CrossRef]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. IEEE Trans. Inf. Theory 2010, 56, 2053–2080. [Google Scholar] [CrossRef]
- Hillar, C.J.; Lim, L. Most Tensor Problems Are NP-Hard. J. ACM 2009, 60, 45. [Google Scholar] [CrossRef]
- Yuan, M.; Zhang, C.H. Incoherent Tensor Norms and Their Applications in Higher Order Tensor Completion. IEEE Trans. Inf. Theory 2017, 63, 6753–6766. [Google Scholar] [CrossRef]
- Tomioka, R.; Suzuki, T. Convex tensor decomposition via structured schatten norm regularization. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1331–1339. [Google Scholar]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-Based Formulation and Nuclear Norm Regularization for Multienergy Computed Tomography. IEEE Trans. Image Process. 2014, 23, 1678–1693. [Google Scholar] [CrossRef]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square Deal: Lower Bounds and Improved Relaxations for Tensor Recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 73–81. [Google Scholar]
- Zhao, Q.; Meng, D.; Kong, X.; Xie, Q.; Cao, W.; Wang, Y.; Xu, Z. A Novel Sparsity Measure for Tensor Recovery. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 271–279. [Google Scholar]
- Wei, D.; Wang, A.; Wang, B.; Feng, X. Tensor Completion Using Spectral (k, p) -Support Norm. IEEE Access 2018, 6, 11559–11572. [Google Scholar] [CrossRef]
- Tomioka, R.; Hayashi, K.; Kashima, H. Estimation of low-rank tensors via convex optimization. arXiv 2010, arXiv:1010.0789. [Google Scholar]
- Chretien, S.; Wei, T. Sensing tensors with Gaussian filters. IEEE Trans. Inf. Theory 2016, 63, 843–852. [Google Scholar] [CrossRef]
- Ghadermarzy, N.; Plan, Y.; Yılmaz, Ö. Near-optimal sample complexity for convex tensor completion. arXiv 2017, arXiv:1711.04965. [Google Scholar] [CrossRef]
- Ghadermarzy, N.; Plan, Y.; Yılmaz, Ö. Learning tensors from partial binary measurements. arXiv 2018, arXiv:1804.00108. [Google Scholar] [CrossRef]
- Liu, Y.; Shang, F.; Fan, W.; Cheng, J.; Cheng, H. Generalized Higher-Order Orthogonal Iteration for Tensor Decomposition and Completion. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1763–1771. [Google Scholar]
- Zhang, Z.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3842–3849. [Google Scholar]
- Lu, C.; Feng, J.; Lin, Z.; Yan, S. Exact Low Tubal Rank Tensor Recovery from Gaussian Measurements. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1948–1954. [Google Scholar]
- Jiang, J.Q.; Ng, M.K. Exact Tensor Completion from Sparsely Corrupted Observations via Convex Optimization. arXiv 2017, arXiv:1708.00601. [Google Scholar]
- Xie, Y.; Tao, D.; Zhang, W.; Liu, Y.; Zhang, L.; Qu, Y. On Unifying Multi-view Self-Representations for Clustering by Tensor Multi-rank Minimization. Int. J. Comput. Vis. 2018, 126, 1157–1179. [Google Scholar] [CrossRef]
- Ely, G.T.; Aeron, S.; Hao, N.; Kilmer, M.E. 5D seismic data completion and denoising using a novel class of tensor decompositions. Geophysics 2015, 80, V83–V95. [Google Scholar] [CrossRef]
- Liu, X.; Aeron, S.; Aggarwal, V.; Wang, X.; Wu, M. Adaptive Sampling of RF Fingerprints for Fine-grained Indoor Localization. IEEE Trans. Mob. Comput. 2016, 15, 2411–2423. [Google Scholar] [CrossRef]
- Wang, A.; Lai, Z.; Jin, Z. Noisy low-tubal-rank tensor completion. Neurocomputing 2019, 330, 267–279. [Google Scholar] [CrossRef]
- Sun, W.; Chen, Y.; Huang, L.; So, H.C. Tensor Completion via Generalized Tensor Tubal Rank Minimization using General Unfolding. IEEE Signal Process. Lett. 2018, 25, 868–872. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef]
- Liu, X.Y.; Aeron, S.; Aggarwal, V.; Wang, X. Low-tubal-rank tensor completion using alternating minimization. arXiv 2016, arXiv:1610.01690. [Google Scholar]
- Liu, X.Y.; Wang, X. Fourth-order tensors with multidimensional discrete transforms. arXiv 2017, arXiv:1705.01576. [Google Scholar]
- Gu, Q.; Gui, H.; Han, J. Robust tensor decomposition with gross corruption. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1422–1430. [Google Scholar]
- Wang, A.; Jin, Z.; Tang, G. Robust tensor decomposition via t-SVD: Near-optimal statistical guarantee and scalable algorithms. Signal Process. 2020, 167, 107319. [Google Scholar] [CrossRef]
- Zhang, Z.; Aeron, S. Exact Tensor Completion Using t-SVD. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Goldfarb, D.; Qin, Z. Robust low-rank tensor recovery: Models and algorithms. SIAM J. Matrix Anal. Appl. 2014, 35, 225–253. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Cheng, L.; Wu, Y.C.; Zhang, J.; Liu, L. Subspace identification for DOA estimation in massive/full-dimension MIMO systems: Bad data mitigation and automatic source enumeration. IEEE Trans. Signal Process. 2015, 63, 5897–5909. [Google Scholar] [CrossRef]
- Cheng, L.; Xing, C.; Wu, Y.C. Irregular Array Manifold Aided Channel Estimation in Massive MIMO Communications. IEEE J. Sel. Top. Signal Process. 2019, 13, 974–988. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhou, G.; Zhang, L.; Cichocki, A.; Amari, S.I. Bayesian robust tensor factorization for incomplete multiway data. IEEE Trans. Neural Networks Learn. Syst. 2016, 27, 736–748. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheung, Y. Bayesian Low-Tubal-Rank Robust Tensor Factorization with Multi-Rank Determination. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Wright, J.; Candes, E.; Ma, Y. Stable principal component pursuit. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 12–18 June 2010; pp. 1518–1522. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.L. Robust structured sparse representation via half-quadratic optimization for face recognition. Multimed. Tools Appl. 2017, 76, 8859–8880. [Google Scholar] [CrossRef]
- Liu, G.; Yan, S. Active subspace: Toward scalable low-rank learning. Neural Comput. 2012, 24, 3371–3394. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Jin, Z.; Yang, J. A Factorization Strategy for Tensor Robust PCA; ResearchGate: Berlin, Germany, 2019. [Google Scholar]
- Jiang, Q.; Ng, M. Robust Low-Tubal-Rank Tensor Completion via Convex Optimization. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2649–2655. [Google Scholar]
- Kernfeld, E.; Kilmer, M.; Aeron, S. Tensor–tensor products with invertible linear transforms. Linear Algebra Its Appl. 2015, 485, 545–570. [Google Scholar] [CrossRef]
- Lu, C.; Peng, X.; Wei, Y. Low-Rank Tensor Completion With a New Tensor Nuclear Norm Induced by Invertible Linear Transforms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5996–6004. [Google Scholar]
- Liu, X.Y.; Aeron, S.; Aggarwal, V.; Wang, X. Low-tubal-rank tensor completion using alternating minimization. In Proceedings of the SPIE Defense+ Security, Baltimore, MD, USA, 17–21 April 2016; International Society for Optics and Photonics: Bellingham, DC, USA, 2016; p. 984809. [Google Scholar]
- Zhou, P.; Lu, C.; Lin, Z.; Zhang, C. Tensor Factorization for Low-Rank Tensor Completion. IEEE Trans. Image Process. 2018, 27, 1152–1163. [Google Scholar] [CrossRef] [PubMed]
- Martin, C.D.; Shafer, R.; Larue, B. An Order-p Tensor Factorization with Applications in Imaging. SIAM J. Sci. Comput. 2013, 35, A474–A490. [Google Scholar] [CrossRef]
- Wang, A.; Jin, Z. Orientation Invariant Tubal Nuclear Norms Applied to Robust Tensor Decomposition. Available online: https://www.researchgate.net/publication/329116872_Orientation_Invariant_Tubal_Nuclear_Norms_Applied_to_Robust_Tensor_Decomposition (accessed on 3 December 2019).









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).