5.2. Statistical Features Approach
Here we provide the results for the application of the statistical features approach. As mentioned before, one of the hyper-parameters (common to both to the features approach and the spectral approach) is the choice of the component and the direction.
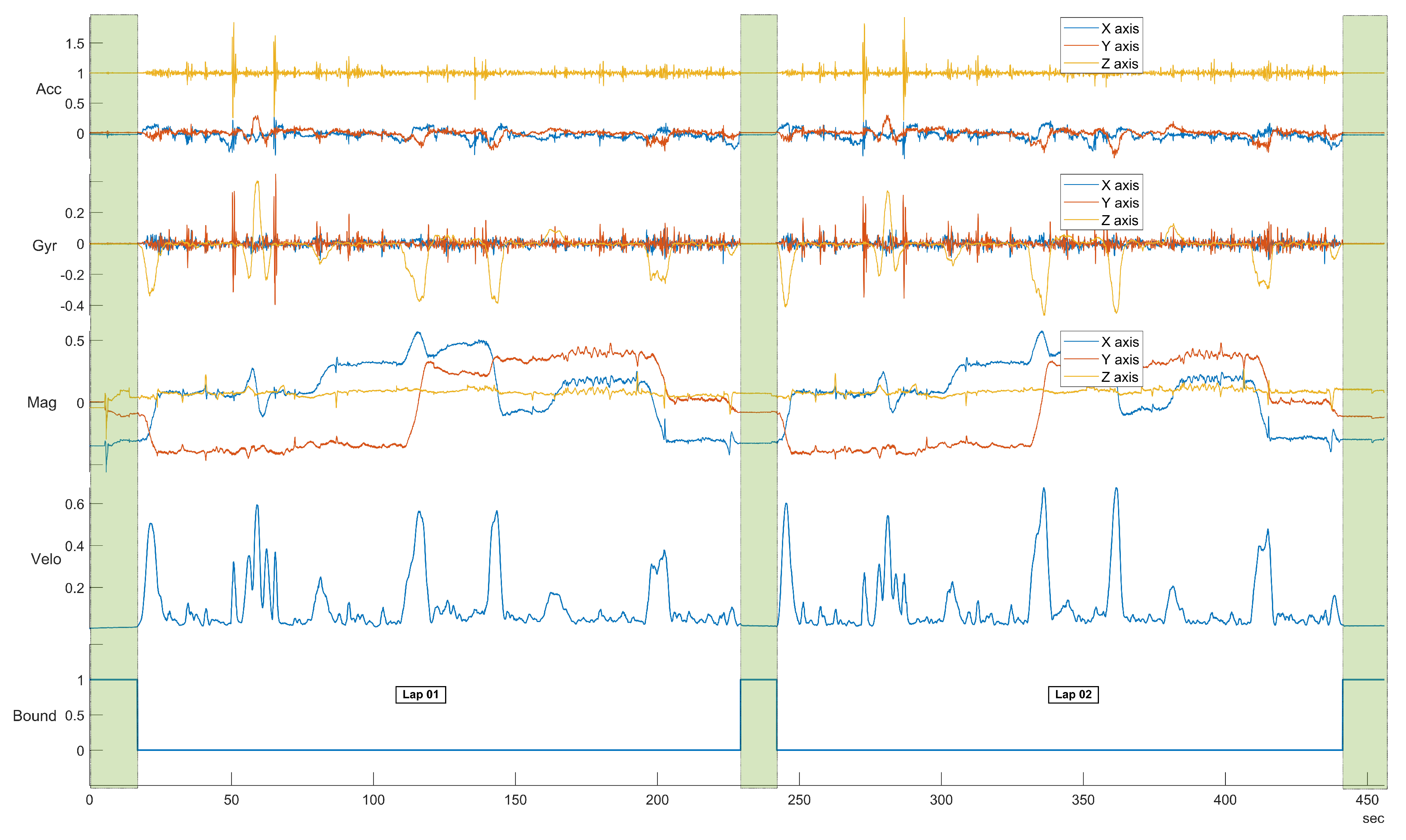
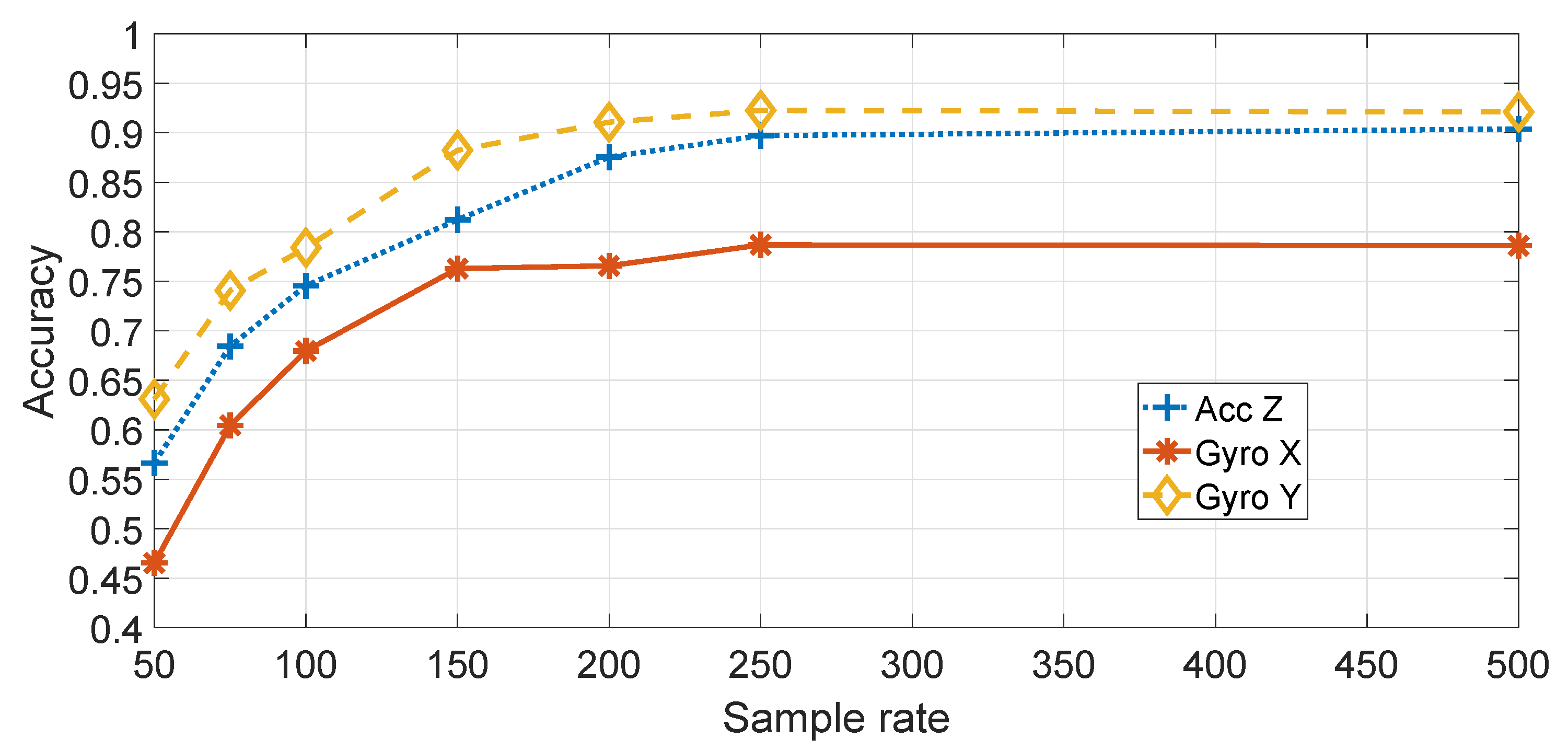
Figure 9 shows a comparison of the different components (e.g., accelerometers and gyroscopes) and directions (e.g.,
) for the application of the statistical features approach on the basis of different sample rates. The SVM machine learning algorithm was used. As discussed before, only the Accelerometer in the
Z direction (
in the rest of this paper), the Gyroscope in the
X direction (
in the rest of this paper) and the Gyroscope in the
Y direction (
in the rest of this paper) are considered. As discussed before, the direction has been adjusted from the initial recordings to be in the direction of travel of the vehicle.
Figure 9 shows that the highest classification accuracy is obtained by using
, which is reasonable, because the pitch of the vehicle is more strongly stimulated by irregularities in the road surface.
Figure 9 also shows that the accuracy improves with the increase of the sample rate. This result may be explained by the consideration that a higher sample rate provides more details and more discriminating power in the application of the features or the spectral transform with the machine learning classification. Evidence from studies on device identification in general supports this hypothesis [
26]. As the classification is higher with
, the subsequent results are based on
.
In the rest of this section, it is discussed more in detail how the statistical features were selected to produce the results of
Figure 9.
As discussed in the methodology
Section 4, the approach based on the statistical features uses the 10 features described in
Section 3, but a subset of features is selected using the RelieFF algorithm, where the best four features are selected. The number four was chosen because it was found out that other features do not contribute significantly on the basis of the weight ranking and to avoid the curse of dimensionality because of the small sampling set.
The histogram in
Figure 10 shows the occurrences of the best four ranked features of RelieFF across all the best seven selected segments and the different samples rates (i.e., for each segment and each sample rate the highest four ranking features are selected) for
. The histogram shows that the most relevant features are—feature 1 (Variance), feature 8 (Permutation Entropy with
) and feature 9 (Approximate Entropy).
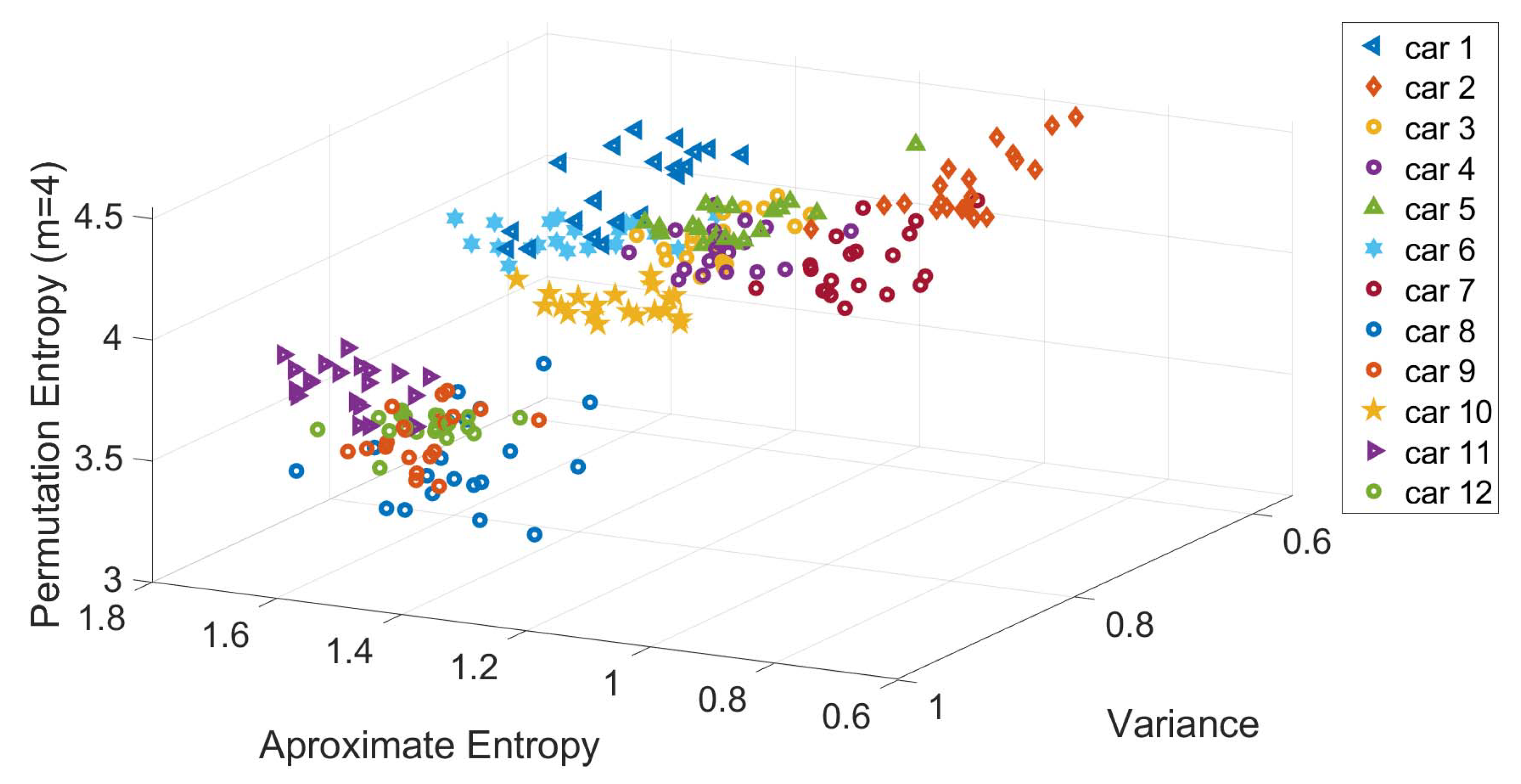
A visual representation on how the features identified from
Figure 10 are relevant for the classification of the specific vehicles is shown in
Figure 11, where a scatter plot for three selected features mentioned above (i.e., Variance, Permutation Entropy and Approximate Entropy) is shown. The scatter plot is based on Gyroscope Y with a sample rate of 500 Hz. Each of the points shown in the scatter plot of
Figure 11 represents each of the EL for each vehicle.
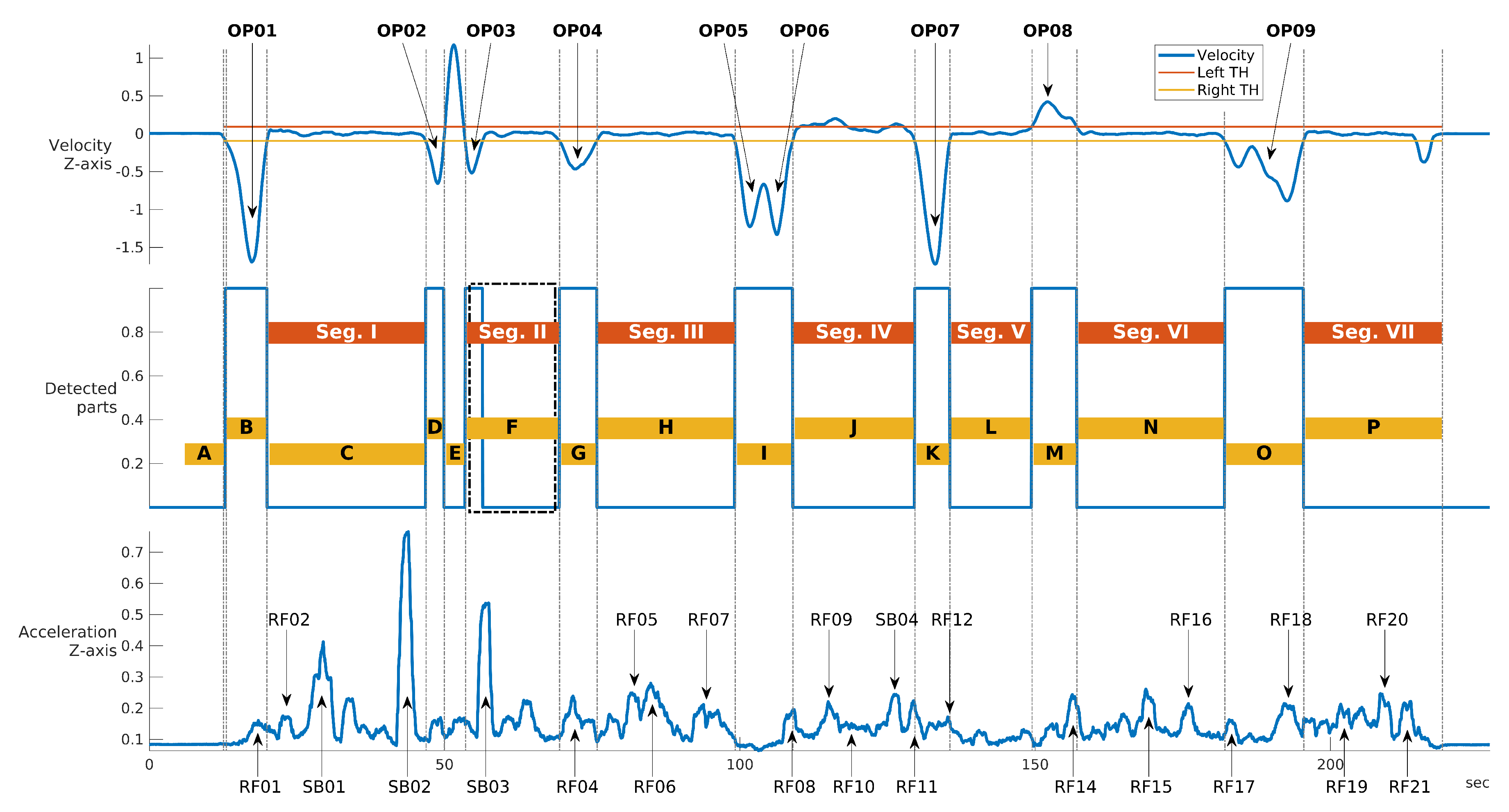
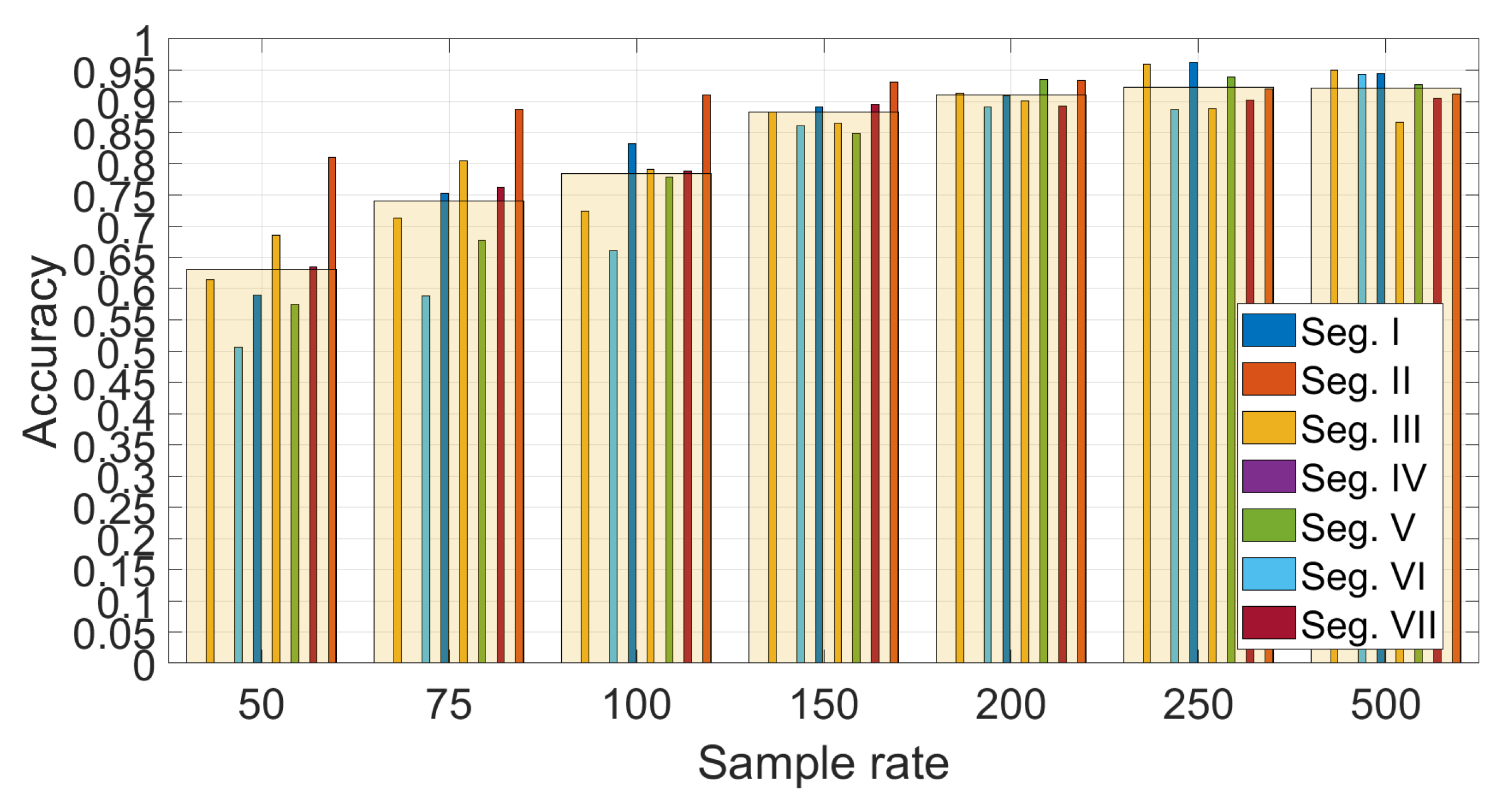
Figure 12 shows the detail on the accuracy obtained foreach segment using
and SVM with optimized hyper-parameters (
and
). The average values across segments are also indicated with a transparent bar for each sample rate. The
Figure 12 provides two significant results—the first is that the sample rate greatly impacts the classification accuracy. a higher sample rate provides more discriminative value than a lower sample rate as the identification accuracy increase steadily with the sample rate from 50 Hz to sample rate equal to 250 Hz. Then, an even higher sample rate does not improve the identification accuracy. This is an important result, because it shows that there is no need to use very high sample rates, which would not be practical for a deployment of continuous authentication using smartphones (i.e., current mass market smartphones have a sample rate around 100 Hz–200 Hz). The second result is that the choice of the segment can impact the identification accuracy. The Figure shows that the identification accuracy can vary greatly among the different segments and these results for the statistical features approach (a similar analysis is provided below for the spectral approach) can provide an insight into which road segments can be preferred in this authentication approach. For example, it can be seen that the segment III provides across all the sample rates a lower identification accuracy than the other segments. If we compare the results in
Figure 12 with the results in
Figure 7, it can be seen that segment II provides in general a higher identification accuracy (especially with sample rates at 150 Hz and 200 Hz) which can be related to a higher variance of the accelerometer in the Z direction due to the presence of irregularities of the road surface including the speed bump SB03. Then, we can conclude that the presence of irregularities on the road surface or a greater road roughness can provide a higher identification accuracy. This also means that smooth surfaces like a highway may provide a lower identification accuracy. Segment III, which does not provide a high classification accuracy, does not have specific road surface irregularities (see the map in
Figure 1) and it could be considered similar to the Highway case.
The results, shown in the previous figures, confirm that it is possible to obtain a significant classification accuracy—higher than
in the case of a sample rate of 200, 250 and 500 Hz for SVM and
. On the other side, it will be demonstrated in the subsequent sections that it is possible to obtain an even higher classification accuracy using the spectral approach whose results are presented in
Section 5.3.
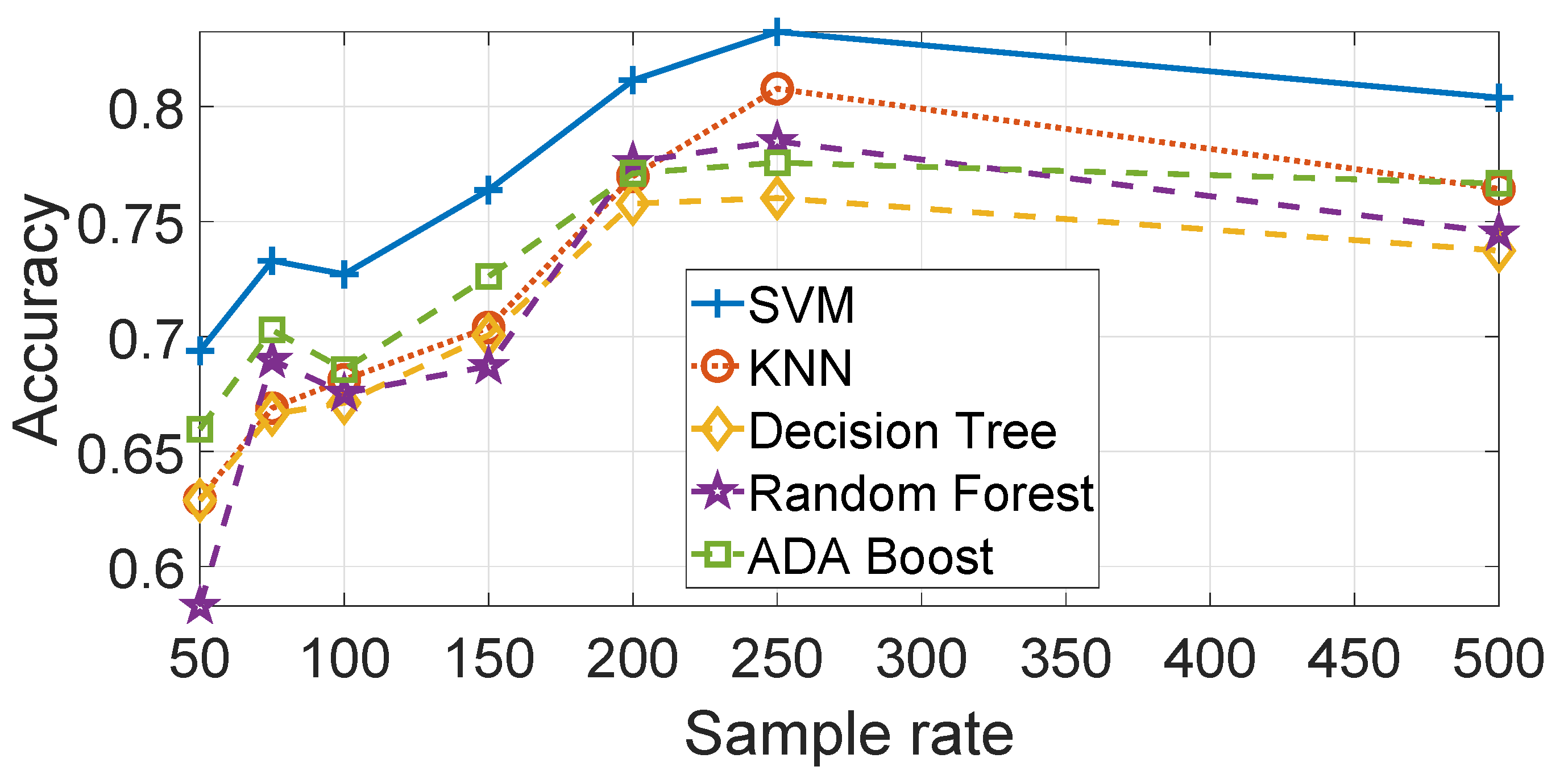
As discussed in the
Section 4, different machine learning algorithms are used to produce the results. A comparison of the results using the
data are provided in
Figure 13. Each of the machine learning algorithms have been optimized in relation to their hyper-parameters. The optimized ML parameters are—SVM with
and
, KNN with Euclidean Distance and
and Decision Trees with maximum number of splits
. The Random Forest and Ada Boost algorithms (based on the Decision Tree) have also been optimized using the auto-optimization function of Matlab.
Figure 13 shows that SVM has a better performance accuracy than the other machine learning algorithms, in particular KNN and the Decision Tree. Random Forest and Ada Boost performs better than the Decision Tree but less than SVM. The result is consistent for all the sample rates. Similar results are obtained for
and
but they are not presented to avoid an excessive length of this paper.
As the identification accuracy may not provide a comprehensive view of the false positive or false negative, confusion matrices are provided for at different sample rates. In all confusion matrices, the SVM algorithm was used.
The confusions matrices are shown in
Figure 14a–c (respectively at 100, 200 and 500 Hz) for
and they are calculated for Segment I (similar results are obtained for the other segments) for the sample rate and IMU components indicated in the figure. They confirm the previous results on the identification accuracy where smaller sample rates decrease the identification accuracy and provide more insights on how the specific vehicles are classified. In particular, the confusion matrices show that the first 6 vehicles (e.g., of the same model Fiat Panda) are more difficult to classify with high accuracy as the number of False Positive and False Negatives is relevant. It is also noted that the 7th car (e.g., Fiat Punto) is of the same brand and it shares similar features of the Panda (e.g., age and vehicle class).
We have also calculated the time needed to process the data, perform the training and testing for a specific segment (i.e., segment II) for the statistical features approach. This evaluation is useful for a practical application of this technique. We present the result for the Ada Boost algorithm (based on the Decision Tree) as this algorithm had the longest computational time among all the algorithms. The results are presented in the bar stacked in
Figure 15a for the training phase and in the bar stacked in
Figure 15b for the testing phase for different sample rates. We note that the calculation of the statistical features require the larger portion of the processing time, while the selection feature with RelieFF is negligible (it can be detected with difficulty in the figures). Obviously, the computational time increases with the sample rate as a greater sample rate means a higher number of sample to be processed by the feature extraction process. The time needed to identify and authenticate a car is only few seconds on the computing platform used to perform the computation—a laptop with Intel I7-8550U with a clock at 1.8 GHz with 16 GB of RAM. A more powerful computing platform would be able to considerably reduce this processing time. Taking in consideration that the optimal sample rate for the accuracy was 250 Hz, the identification time would be approximately 2 s in the optimal case. Similar considerations are repeated for the spectral approach in the next section with a much shorter time-frame because of absence of a feature extraction process.
5.3. Spectral Approach
As described in the methodology
Section 4 the spectral approach (i.e., in the frequency domain) is based on the application of the FFT to the IMU recordings. Then, the frequency representation is divided in an equal number of frequency bands and the total amplitude power is calculated for each band. The obtained values (i.e., the coefficients) are used for classification. As in the case of the features, the dimensionality reduction is significant:
(e.g., from 200 Hz to 6 coefficients).
In this approach, the hyper-parameter is the number of coefficients in the spectral domain. Then, the optimal value of
must be identified but
cannot be large because of the curse of the dimensionality, then it is decided that
is limited to 6. On the other side, a feature selection process as in the feature approaches can be used with a value of
greater than 6.
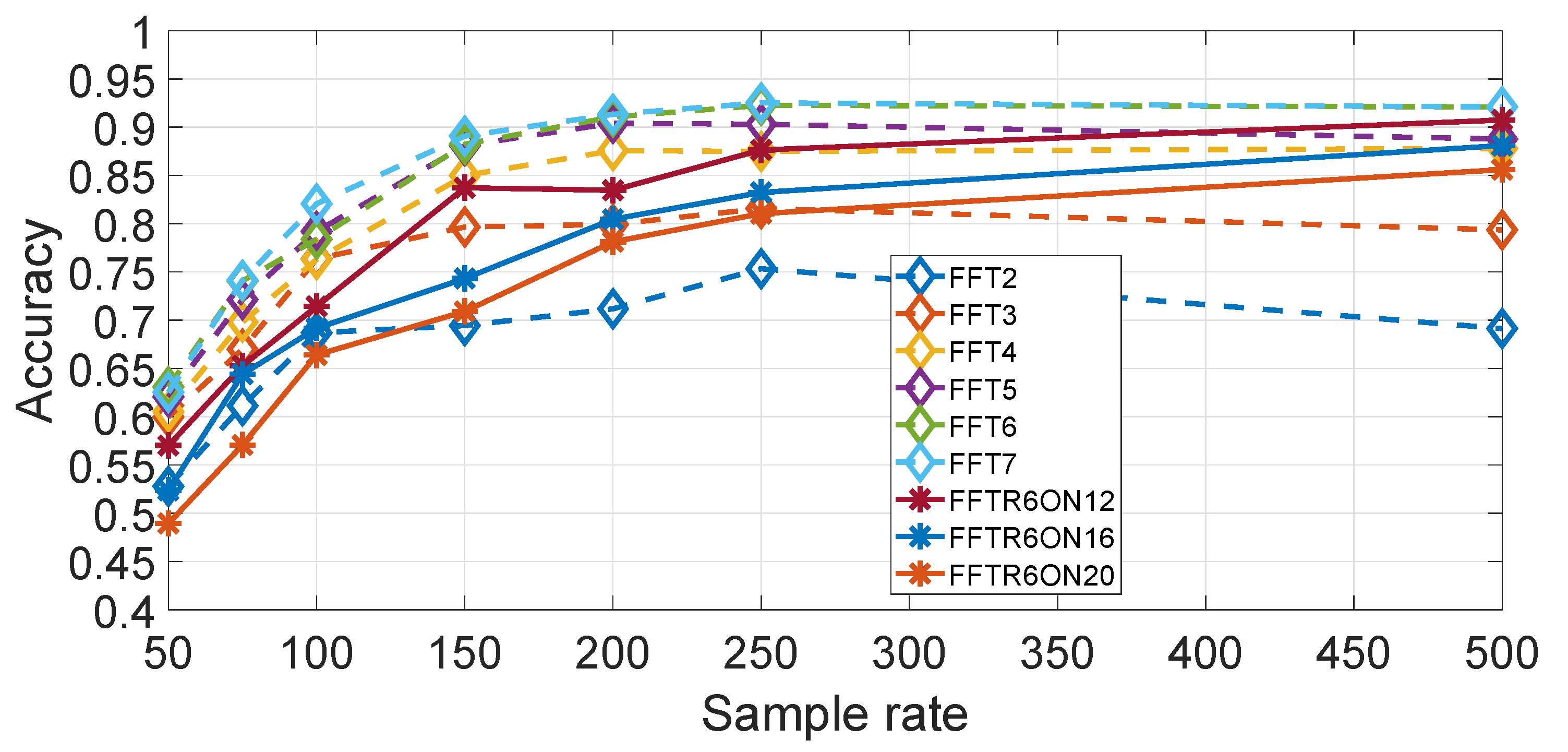
Figure 16 shows a comparison of different values of
using
for different values of the sample rates, where only a limited set is used when
is greater than 6. It can be seen that the optimal performance curve is obtained for
. We note that a value of
was also used to make a comparison (thus contrary to the rule defined above), but it can be seen that there is no significant improvement of
against
. The use of higher numbers than
(
,
and
) in combination with RelieFF shows that the identification accuracy is worst than with
. By comparison, the results obtained in the previous section for the feature approach, it can be concluded that a higher accuracy is obtained by using the spectral approach than the feature approach. Two potential explanations are possible. One explanation is related to the physical response of the vehicle against irregularities in the road as different vehicles types have different automotive suspension components (e.g., coil springs and control arms), which produce a different frequency response on the same road segment. This can be a more distinguishing factor for vehicle types than the designed statistical features used in the feature approach. The second aspect is that the selected features in the feature approach are derived from the research literature on continuous authentication of human beings, which may not be fully appropriate to the continuous authentication of vehicles.
The results are obtained using the
direction and by averaging the results across the 7 segments selected in the study. A more detailed study for the different segments is shown is provided in
Figure 17 for
, which confirms the previous results.
In a similar way to the features approach, a comparison was made among the main IMU components and directions and the results are presented in
Figure 18, which confirms the result of the features approach, as the best identification accuracy is obtained with
. The results are obtained by averaging the results across all segments, using SVM withe optimized values of the machine learning hyper-parameters.
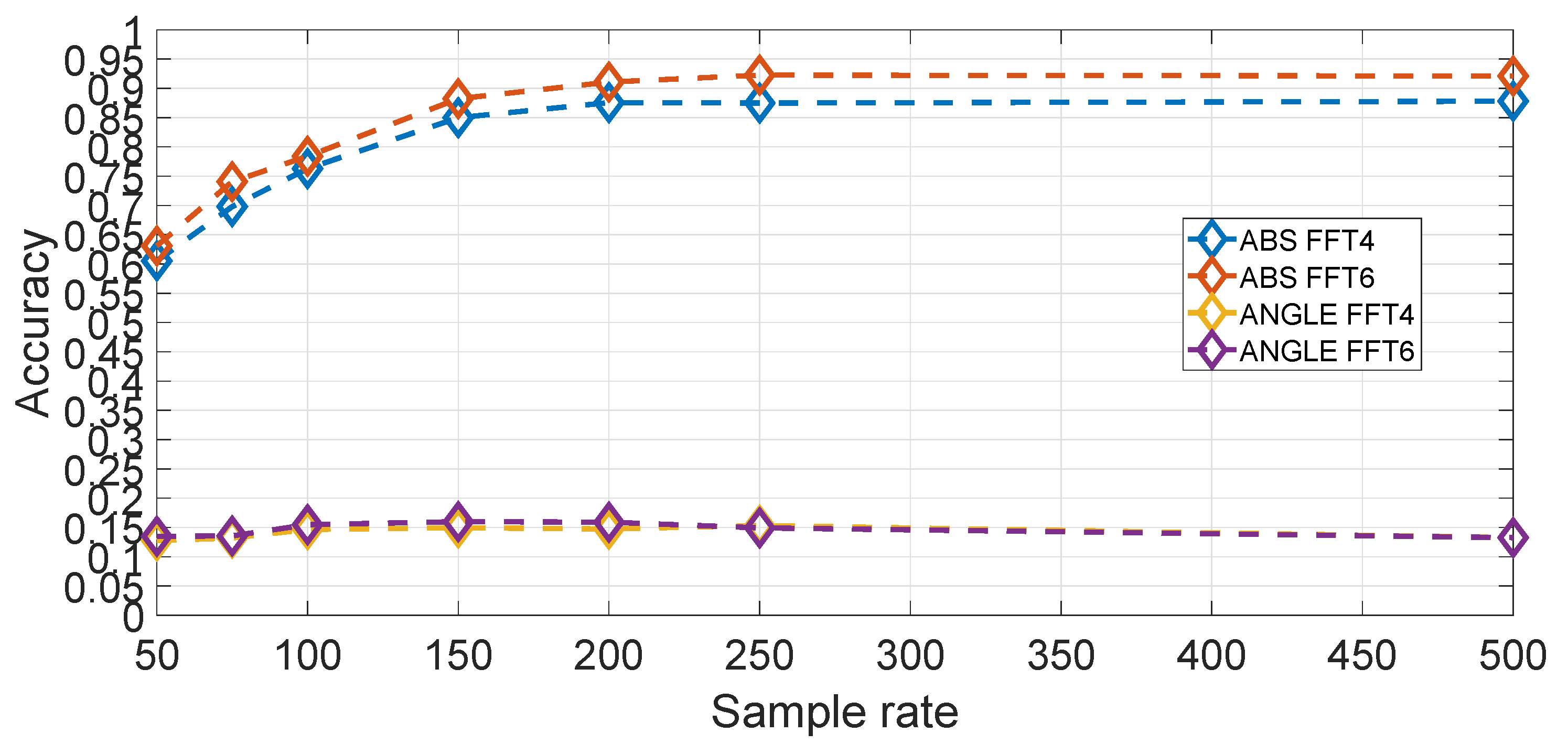
In comparison to the feature based approach, another hyper-parameter to select is the amplitude or phase component as the FFT provides complex values. An evaluation using
,
and averaged on all segments for different sample rates is shown in
Figure 19. It can be seen that the amplitude component is much more significant than the phase component. The reason is that the amplitude part is directly related to the frequency response of the mechanical components (i.e., coil springs and wheels) of the vehicle while the phase is not (e.g., the reaction of vehicle to a bumper is mostly related to the speed of the vertical acceleration).
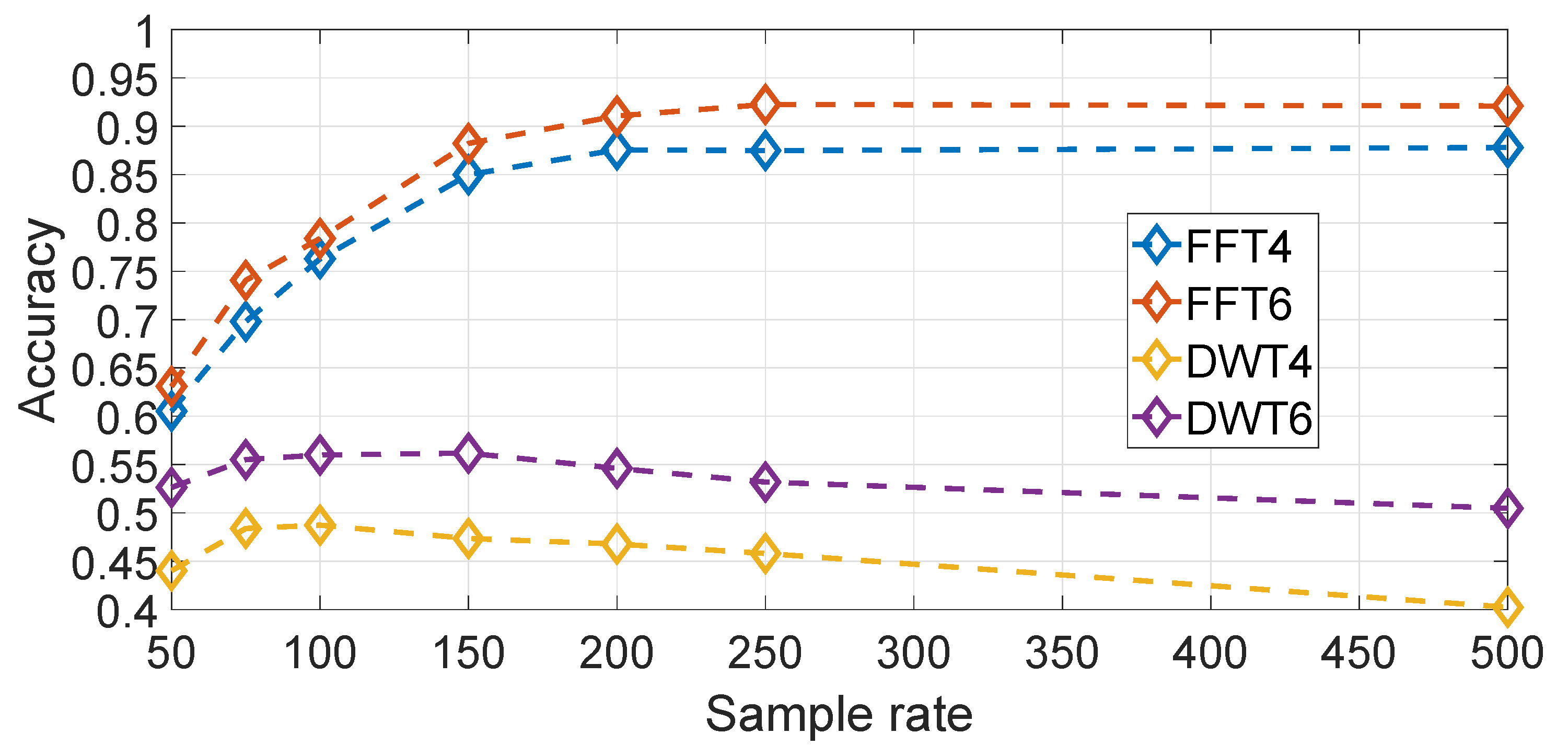
It could also be imagined that other transforms rather than the FFT transform could give better classification results. This hypothesis is evaluated in
Figure 20 where a wavelet based transform (i.e., based on a Daubechies wavelet of order 10) is compared against the frequency domain approach for different sample rates,
and
both for wavelet and frequency domains representations. In both cases, the amplitude component of both transforms have been used. The result in
Figure 20 shows clearly that the FFT based approach is significantly better than the wavelet based approach. Different wavelets have also been used with similar results.
All the previous results are obtained by using the SVM machine learning algorithm. As in the feature based approach, a comparison is performed among the SVM, KNN and Decision Tree algorithms and the results are shown in
Figure 21. The results are created by averaging the classification accuracy results for all the segments. It can be seen that SVM outperforms KNN, Decision Tree and the related ensemble methods like Random Forest and AdaBoost. The optimized ML parameters are: SVM with
and
, KNN with Euclidean Distance and
and Decision Trees with maximum number of splits = 5. The Random Forest and Ada Boost algorithms (based on the Decision Tree) have also been optimized using the auto-optimization function of Matlab.
As in the case of the feature based approach, confusion matrices are presented in the rest of this section. The confusion matrices are calculated by averaging the results across all the segments for the sample rate and IMU component indicated in the respective figure.
Figure 22a–c show the confusion matrices using the spectral approach with Gyroscope Y for Segment I (similar results are obtained for the other segments) and with an IMU recording sampled respectively at 100 Hz, 200 Hz and 500 Hz. The confusion matrices confirm the previous Figures obtained for the identification accuracy. As in the case of the feature based approach, the first 6 vehicles (i.e., of the same Panda model) are more difficult to distinguish than the other vehicles as expected because they have similar mechanical features.
As in the previous case of the statistical feature approach, we have also calculated the time needed to process the data, perform the training and testing for a specific segment (i.e., segment II) for the spectral approach. We present the result for the Ada Boost algorithm (based on the Decision Tree) as this algorithm had the longest computational time among all the algorithms. The results are presented in the bar stacked
Figure 23a for the training phase and in bar stacked
Figure 23b for the testing phase for different sample rates. In comparison to the statistical feature approach, the processing time is much lower and it is possible to perform an identification and authentication in less than a second (0.4 s for sample rate at 250 Hz).






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}