1. Introduction
Extended target tracking (ETT) draws lots of attention in recent years because of its wide range of applications in traffic control [
1], autonomous driving [
2,
3,
4], person tracking [
5,
6] and etc. [
7,
8,
9,
10,
11]. Since one extended target generates more than one measurement per time step, its shape information can be obtained. Using this information, the kinematic state and extent of the target can be estimated simultaneously. The extent of the target including the size, shape, and orientation can be further used for target identification.
The difference between point target tracking and extended target tracking lies in the measurement model and hypotheses. Point target generates at most one measurement per time step, while the extended target generates multiple measurements. Many algorithms were proposed to track point target based on point target hypothesis, such as probability hypothesis density (PHD) filter [
12] and cardinalized PHD (CPHD) filter [
13]. Since the extended target violates one measurement hypothesis, the number of targets will be overestimated if point target tracking algorithms are directly used for tracking extended targets. To address this problem, Mahler proposed an extended target tracking algorithm based on the inhomogeneous Poisson Point Process model (PPP model) [
14] in random finite sets (RFSs) frame, namely extended target probability hypothesis density (ET-PHD) [
15], Jiang et al. [
16] proposed a novel time-matching ET-PHD filter, a Gaussian mixture implementation of the ET-PHD, called the extended target Gaussian inverse Wishart probability hypothesis density (ET-GIW-PHD) filter, has been presented in [
17]. However, ET-PHD only estimates the kinematic state of the target (such as position, velocity) and does not estimate the extent of the target. Therefore, this method cannot extract the shape of the target. Nevertheless, the estimation of the target extent is important because it can be used to classify target and improve tracking accuracy [
18,
19,
20].
Measurement partition is an important step in ETT. In ETT, measurements are partitioned into several non-empty subsets, each subset contains measurements that are all from the same source, either a single target or a clutter source, the subset is defined as cell. In ETT, the increase of measurements gives rise to the quick increase of the set partitions, thus the partition algorithm should be designed to achieve tractable computational complexity. Distance partition [
17] is the most widely used method. Modified Bayesian adaptive resonance theory (MB-ART) [
21] can also achieve good performance. For more details about other partition algorithms, please see [
22,
23,
24].
One of the most important works in extended target tracking is how to model the target extent. To address this problem, the stick model is used for bicycle and pedestrian tracking [
25,
26]. The object extension is represented by a symmetric positive definite (SPD) random matrix [
27], namely a random matrix (RM) model. Feldmann et al. [
28] adapted the RM model for the case when the sensor error cannot be ignored. Lan et al. [
29] took into account time variation and distortion of target extension in RM frame. In order to handle irregular shapes, a random hypersurface model (RHM) is introduced in [
30,
31,
32]. Gaussian Processes (GP) was used to represent the target shape and achieved good performance [
33,
34,
35,
36]. Since shape estimation is similar to curving fitting, Kaulbersch et al. [
37] applied a curve fitting method for shape estimation.
et al. [
38] proposed an extension model for specific sensor.
et al. [
39] proposed extended target Gaussian inverse Wishart PHD (ET-GIW-PHD) filter to incorporate widely used RM model into PHD filter and approximate the estimated PHD with an unnormalized mixture of Gaussian inverse Wishart (GIW) distributions. Later,
et al. [
40] proposed extended target Gamma Gaussian inverse Wishart PHD (ET-GGIW-PHD) filter to estimate the measurement rate and target state simultaneously. The combination of several RM model was used to model nonelliptic targets in [
41,
42]. As mentioned in [
39], more experiments that test ET-GIW-PHD filters are needed, e.g., for data that contains more clutter than typical laser data does, this provides the general motivation for this paper. We found that the number of targets will be overestimated which degrades the final performance when severe clutters are partitioned into one cell in ET-GIW-PHD. More analyses are presented in
Section 3. In this paper, we proposed an anti-clutter ET-GIW-PHD filter for better cardinality estimation performance.
The main contributions of this paper are twofold. First, the reason why ET-GIW-PHD overestimates the number of targets is discussed detailedly, and the probability of the measurement generated by clutter against different scenario parameters is presented. Second, in order to deal with the cardinality overestimation in ET-GIW-PHD, we proposed an anti-clutter ET-GIW-PHD filter which revises the correction step of ET-GIW-PHD with hypothesis testing. Hypothesis testing is introduced to determine the source of measurements in the cell, hypothesis testing results are integrated into the correction step in ET-GIW-PHD. In order to deal with the source of measurements correctly, the essential differences between the measurements of targets and clutter should be recognized. Since the variation of target state over time follows certain rules (motion model and shape transition model), the state of targets could be predicted while clutter could not. Then, the likelihood functions of targets and clutter are deduced. The likelihood functions are built based on not only the number of measurements but also the target state and spatial distribution of clutter. Since the likelihood ratio test statistic is proved to be subject to chi-square distribution, a threshold corresponding to the confidence coefficient is introduced, this threshold is used to determine the source of measurements in the cell. It worth note that the perfect sensor resolution is advocated as a theoretical hypothesis in this paper. In reality, the results in the
Section 5 will be affected by the limited sensor resolution. Future work will tackle the sensor’s limited resolution.
The rest of the paper is outlined as follows.
Section 2 reviews the ET-GIW-PHD filter.
Section 3 discusses the reason why ET-GIW-PHD overestimates the number of targets. Our anti-clutter ET-GIW-PHD is presented detailedly in
Section 4. We conduct experiments in different simulation scenarios to demonstrate the effectiveness of our proposed approach in
Section 5; Conclusion is drawn in
Section 6.
2. ET-GIW-PHD Review
In ET-GIW-PHD, both predicted PHD and corrected PHD can be approximated as an unnormalized mixture of Gaussian inverse Wishart distributions. Let
be the sufficient statistics of the GIW components at time which contains kinematical state
and extension state
which is mathematically described by a symmetric and positively definite (SPD) random matrix. The iterative formulae for
are obtained in [
39]. More implementation details, such as pruning and merging, can also be found in [
39].
Prediction:
where
is the probability of survival,
is the state transition density,
is the birth PHD, new target spawning is omitted [
39].
Correction:
The corrected PHD
can be summarized as:
where
means that the measurement sets
are partitioned into non-empty cells,
means that the cell
W is in the partition
.
handles the undetected target case, because
is approximated as an unnormalized mixture of Gaussian inverse Wishart distributions, it is given by
where
is the number of components of predicted PHD,
is the weight of GIW component.
means that a vector
is subject to Gaussian distribution with mean
and covariance
,
means that a matrix is subject to inverse Wishart distribution with degree of freedom
v and inverse scale matrix
. ⊗ is the Kronecker product.
handles the detected target case, which is given by
can be obtained by
where
presents the likelihood of the GIW component given the measurements of the cell, is the weight of partition, is the detection probability of GIW component, is the expected number of measurements generated by GIW component, is the mean number of clutter measurements, is the spatial distribution of the clutter over the surveillance volume, is the Kronecker delta, is the the number of measurements in the cell, is innovation factor, is the multivariate Gamma function.
3. Analysis of ET-GIW-PHD
In ET-GIW-PHD, the calculation of is important. If the measurements in cell are generated by clutter, is expected to be smaller than the pruning threshold, then the corresponding component will be eliminated and the clutter will be eliminated.
In Equation (
5),
contains two parts, one is the weight of the
partition, denoted by
, the other is the weight of
cell in partition. Without loss of generality, only one partition is considered for clarity, therefore
. Substituting Equation (
6) into Equation (
5), we arrive at
From Equation (
9), the numerator is a part of denominator, the measurements of
cell is used to correct each GIW component, then
can be obtained,
can be given based on some prior parameters, such as
,
,
and
(for brevity, the subscript and superscript are omitted here).
If the measurements in the cell are generated by clutter, the likelihood
of each GIW component will be very small since clutter does not obey the kinematic and extent model of target. If the number of clutter measurements in the cell is equal to one, then
,
,
will be much smaller than 1 because the likelihood
achieves a small value mentioned above and other parameters can be considered as constants, the value of
will be close to 0 and is smaller than the pruning threshold, then the corresponding component will be eliminated and the clutter is eliminated. However, if the number of clutter measurements in the cell is more than one, then
,
, Equation (
9) is the normalization process. Although
is close to zero,
can still take a large value. In this case, ghost targets will emerge and the number of targets will be overestimated. Further details on numerical implementation can be found in
Section 5.
According to the analysis above, if the measurement in the cell is clutter,
(denoted by
) in Equation (
9) should be added by 1. Otherwise, it should be added by 0 and the clutter can be eliminated. However, from Equation (
9), if the cell contains only one measurement,
is added by 1, it means that the cell contains only one measurement is considered as clutter in ET-GIW-PHD. Otherwise, it is considered as a target if the cell contains more than one measurement. In fact, this assumption can be violated under strong clutter. The criterion whether measurements in the cell are generated by clutter based on only the number of measurements can be erroneous. A simple numerical calculation is shown below to illustrate this point.
In ET-GIW-PHD, the probability of the measurements of the cell generated by clutter is obtained based on the Bayesian theorem, see Equation (
10). Note that, only the number of measurement is considered in this calculation.
where
presents the measurements in cell,
is the number of measurements in cell,
and
mean clutter and target respectively,
and
are the prior information.
The number of measurements generated by the target is subject to Poisson distribution with Poisson rate
, the detection probability is
, then
where
denotes the combinatorial number of the events that
m out of
n.
Remark:
is not equal to
in Equation (
6).
is the probability that one measurement generated by target or clutter is detected, while
is the probability that an extended target will generate a measurement set [
15].
can be derived if
is already known.
The clutter measurements are assumed to be uniformly distributed over the surveillance area, and the number of clutter is subject to Poisson distribution with Poisson rate
. So we have
When the number of measurements is 1, the probability of the measurement in the cell generated by clutter is shown in
Table 1 with different
and
. In this simulation, the prior information is set to 0.5, then
.
From
Table 1 we can see that when
,
and
,
. Although the cell contains only one measurement, the probability of the measurement in the cell generated by clutter is close to 0. Consequently, the criterion of ET-GIW-PHD does not work well in this case. when
and
,
. In this case, the clutter is distinguished correctly based on the criterion of ET-GIW-PHD. In summary, the determination whether measurements are generated by clutter based on only the number of measurements can be erroneous.
4. Anti-Clutter ET-GIW-PHD
The difference between ET-GIW-PHD and anti-clutter ET-GIW-PHD is how to determine the source of measurements in the cell, specifically, the difference is how to obtain
in Equation (
6). Using only the number of measurements in ET-GIW-PHD to determine whether the measurements in the cell is the target or not may be erroneous. In contrast, our anti-clutter ET-GIW-PHD uses hypothesis testing to deal with this problem. The number of measurements, the kinematic state and extent state of target and clutter spatial distribution are taken into account to obtain the likelihood ratio test statistic.
There are two hypotheses:
where
is the measurements of
cell,
is the number of the measurements,
and
represent clutter and target respectively.
The likelihood ratio test statistic for hypothese is given by
where
and
are the likelihood to measure the set
given
and
respectively and
and
will be presented later.
If
is applied to Equation (
15),
can be obtained.
Because is monotony increase, is also the test statistic for hypothesis versus . If these measurements are generated by the target, will achieve a large value and will be small. Consequently, the statistics will grow to a large value. Using a threshold, we can distinguish between targets and clutter. Specifically, if is greater than the threshold, the measurements in the cell is considered to be generated by targets. Otherwise, these measurements are considered to be clutter. The expression of and are given below, the setting of the threshold is discussed.
If the measurements are generated by a target, different extent models lead to a different expression of
. In this paper,
is deduced based on the model in [
27],
where
is an unit matrix with
d dimension,
is the extension of target at time
k,
is the 1D observation matrix.
The clutters are assumed to be uniformly distributed over the surveillance area [
27], then
where
,
is the mean number of clutter measurements,
is the spatial distribution of the clutter over the surveillance volume.
Substitute Equations (
17) and (
18) into Equation (
16), we have
where
Because
is subject to Gaussian distribution with mean
and covariance
,
, thus
where
G is subject to chi-square distribution with degree of freedom
. In Equation (
21),
,
and
are priori known, the volume of the target extension is proportional to
, the size of the target could be assumed to be unchanged, then
D could be considered as a constant.
The confidence coefficient is set to
and a threshold is introduced (denoted by
g), suppose hypothesi
is true, then
then
where
From Equation (
23), the probability of
is
. Generally,
is set to be a value close to 1 and
is a small probability event. If
is satisfied, hypothesi
should be rejected. Finally, we have
If
, the measurements are generated by clutter, then
If
,the measurements are generated by targets, then
The pseudo-code for anti-clutter ET-GIW-PHD is illustrated in
Table 2.
The difference between ET-GIW-PHD and anti-clutter ET-GIW-PHD lies in correction step. Pseudo-code for anti-clutter ET-GIW-PHD filter correction is shown in
Table 3, pseudo-code for other steps (prediction, prune and merge etc) can be found in [
39].
5. Simulation
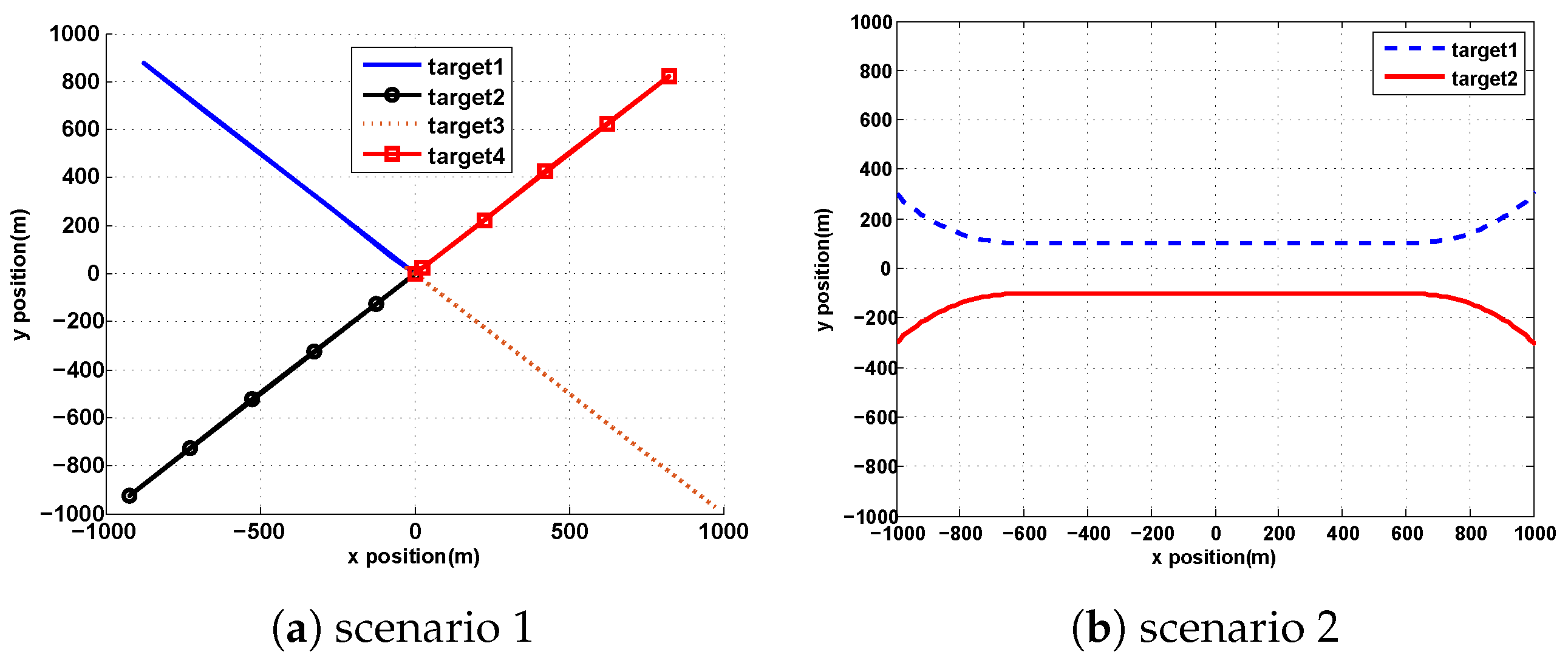
In this section, the effectiveness of ET-GIW-PHD and anti-clutter ET-GIW-PHD were tested. Two scenarios with multiple targets were established. The surveillance area was set as , then is under the assumption that clutter is uniformly distributed over the surveillance area. We set totally 100 time steps and the sampling time is 1 s.
In the first scenario, four targets moving along different lines were generated:
where
is the initial state of
target,
is the born time of
target,
is the end time of
target. The birth intensity in the first scenario is
where
,
,
,
.
In the second scenario, two targets were born at (−1000 m, 300 m) and (−1000 m, −300 m), respectively at
(
k is time step). Next, they moved close gradually and then moved in parallel before separating. The birth intensity in the second scenario is
where
,
,
,
,
,
. The true trajectories of two scenario are shown in
Figure 1.
The dynamic and measurement model are shown below. The target kinematic state is denoted as
, where
and
is the position and velocity in the
x direction, likewise of
y direction. The time evolution of kinematic state given by
where
is the target state of
target at time
k,
is the process noise of
target and is the Gaussian white noise with zero mean and covariance
,
is the kinematic state transition matrix of
target, given by
where
t is the sampling time and
represents the acceleration error,
and
in this simulation.
In this simulation, the major and minor axes are 20 m and 15 m respectively for all targets. The major axis was aligned with the direction of motion of the target and the extent of these targets remained unchanged.
The measurement model can be expressed as
where
is the measurements generated by the
target at time
k,
is the measurement noise and is the Gaussian white noise with zero mean and covariance
,
is the observation matrix, given by
where
,
.
In our experiment, the confidence coefficient
of anti-clutter ET-GIW-PHD is set to 0.99. A distance partition algorithm [
17] is used for both filters, a measurement partition that contains several cells can be obtained for a given distance threshold. Clutter Poisson rate
is set to 35, then clutter density
is
(the clutter density in this paper is higher than that of related references, such as [
18,
21]). The expected number of measurements generated by targets
is set to 15. The probability of survival
and the detection probability
are assumed to be state independent and set to 0.99 and 0.98, respectively. The probability
is set to 0.99.
Tracking results are evaluated using the optimal subpattern assignment metric (OSPA) [
43], which is widely used to evaluate multiple-target tracking performance [
39,
40,
41,
42].
The OSPA distance is defined by
where
,
is the true RFS at time k,
is the estimated RFS,
is the assignment results which assign
to
,
p means
,
c is the penalty cost for cardinality mismatch. In this simulation,
and
.
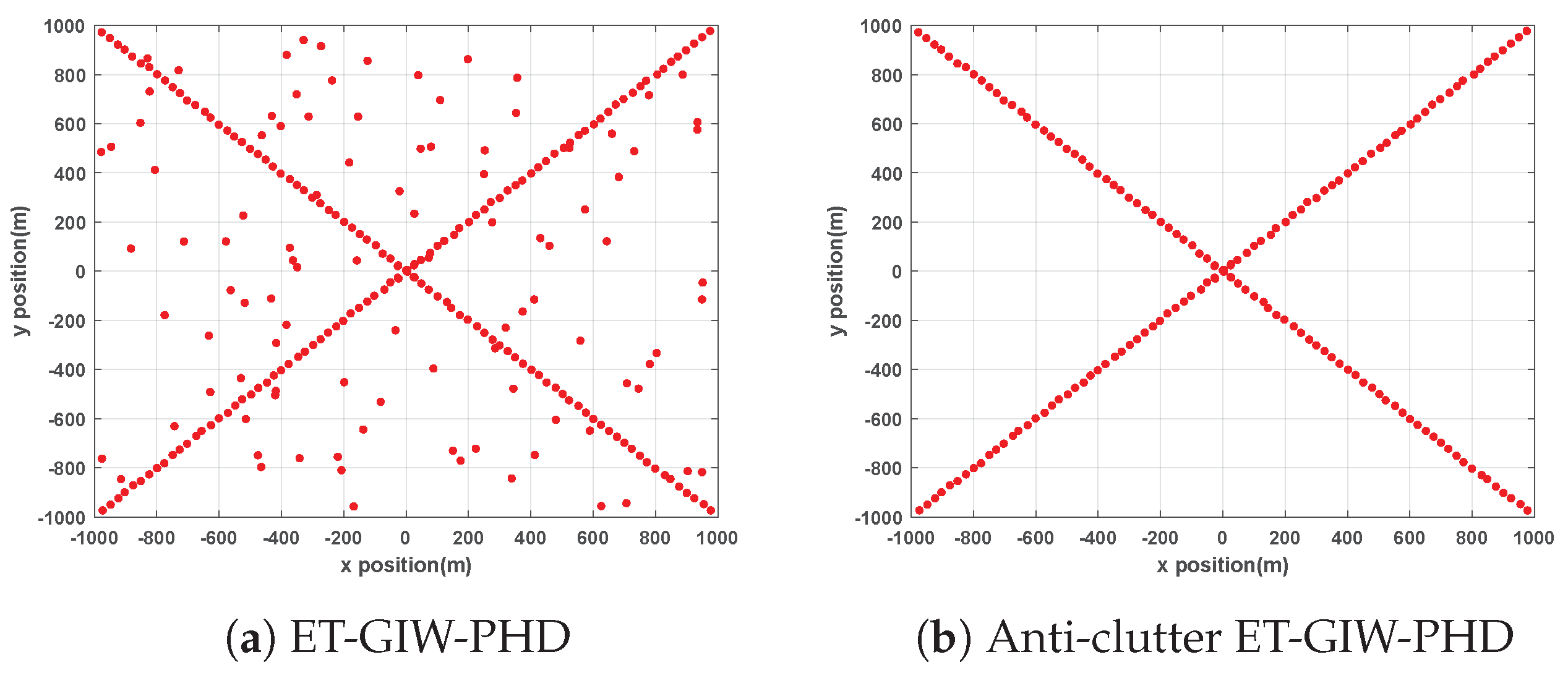
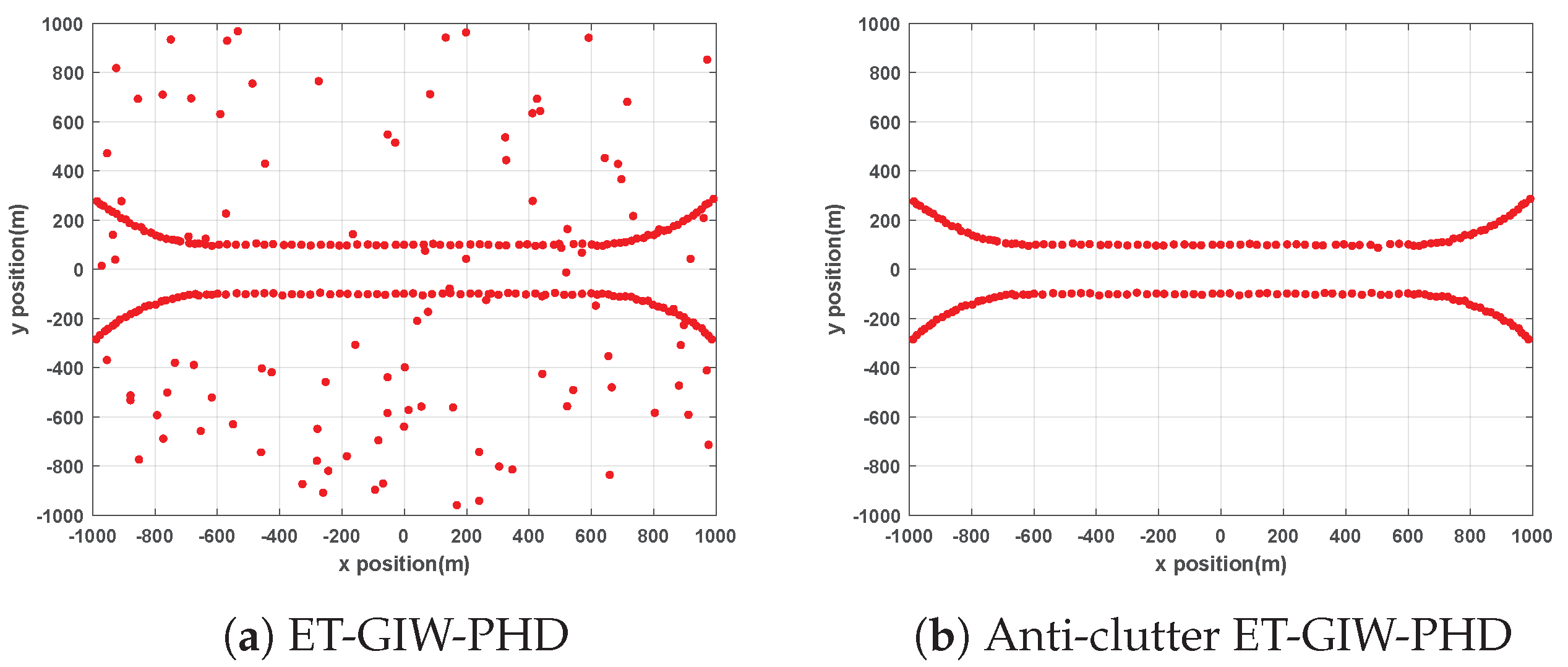
ET-GIW-PHD and anti-clutter ET-GIW-PHD are applied to two scenarios mentioned above for performance evaluation. The trajectories generated by these two methods are presented in
Figure 2 and
Figure 3.
From
Figure 2 and
Figure 3 we can see that the trajectories of anti-clutter ET-GIW-PHD are almost identical to the true trajectories. Note that, in the results of ET-GIW-PHD, some peices of clutter are incorrectly considered as targets. However, our anti-clutter ET-GIW-PHD can deal with the clutter more correctly and achieves better performance.
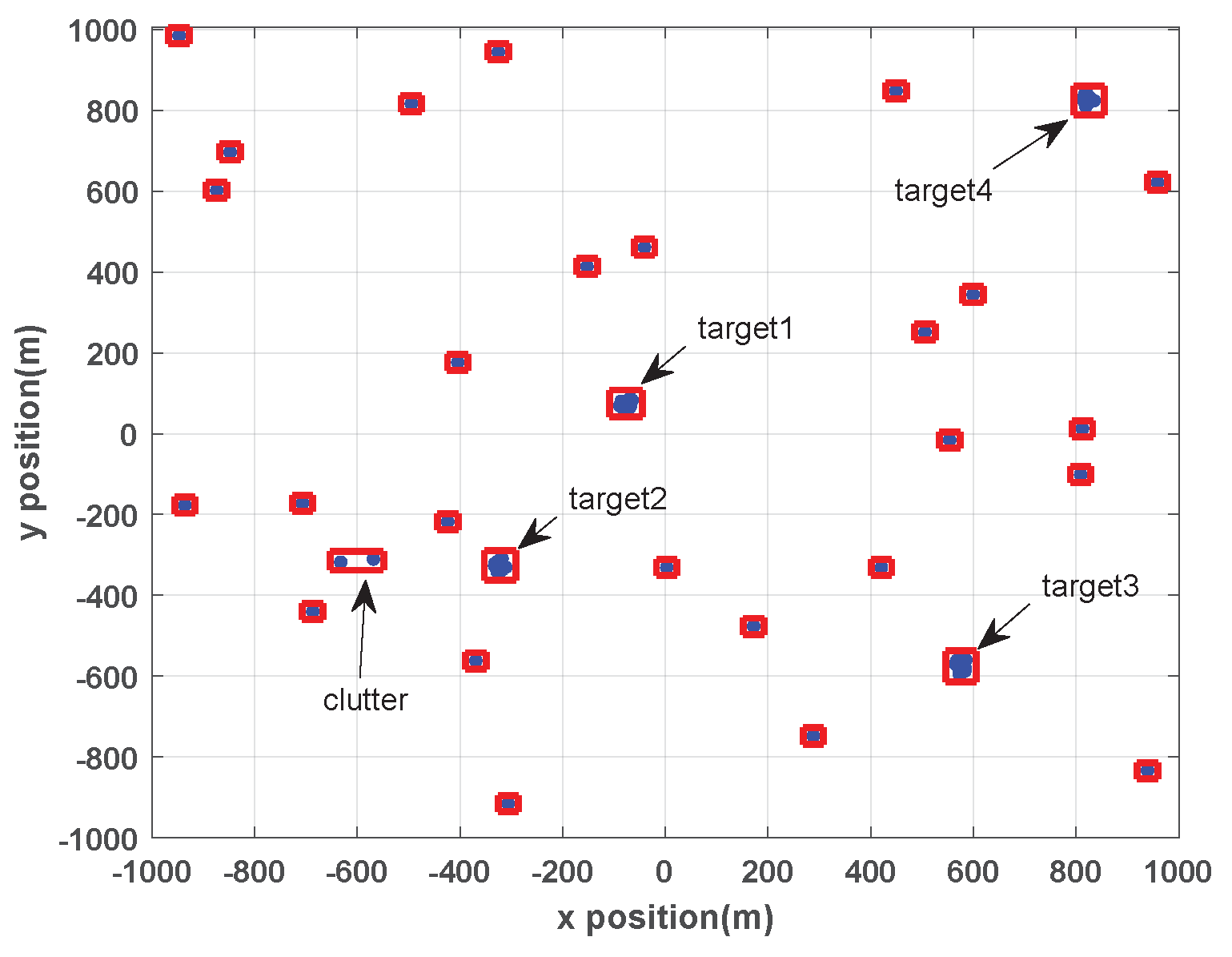
To further verify the analysis in
Section 3, the calculation of
in Equation (
9) at
(
k is time step) in scenario 1 is shown below. The partition result at
is given firstly in
Figure 4.
From
Figure 4 we can see that the measurements of four targets are correctly clustered, and two clutter (marked with arrows in
Figure 4) are incorrectly partitioned into one cell.
is denoted as
for
GIW component in the
cell, then
From simulation results, the number of components of predicted PHD is 14 at
, then
,
of the clutter cell (marked with arrows in
Figure 4) is obtained and shown in
Table 4.
The likelihood
of each GIW component in this cell is very small since clutter does not obey the kinematic and extent model of target, therefore
achieve small value as shown in
Table 4.
Because the number of measurement in this cell is two, Equation (
37) is represent as
Equation (
38) is a normalization process,
of the clutter cell is shown in
Table 5.
Although is small, may achieve a large value () and results in a ghost target. At , the estimated number of targets was 5 while true number is 4. That is, the number of targets was overestimated.
To test the influence of the clutter density on tracking performance, ET-GIW-PHD and anti-clutter ET-GIW-PHD were tested under different numbers of clutter modeled as Poisson distribution with Poisson rate
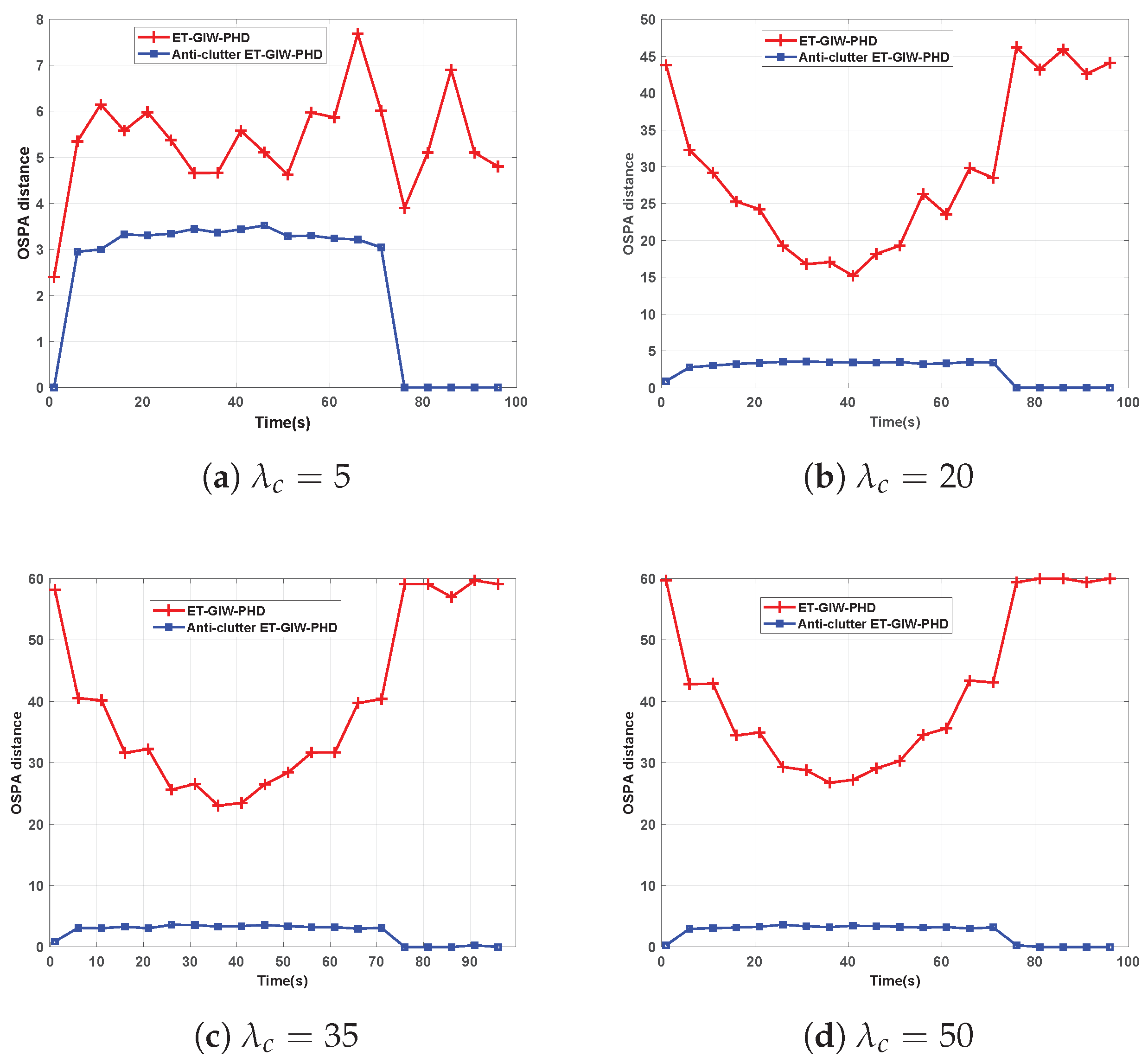
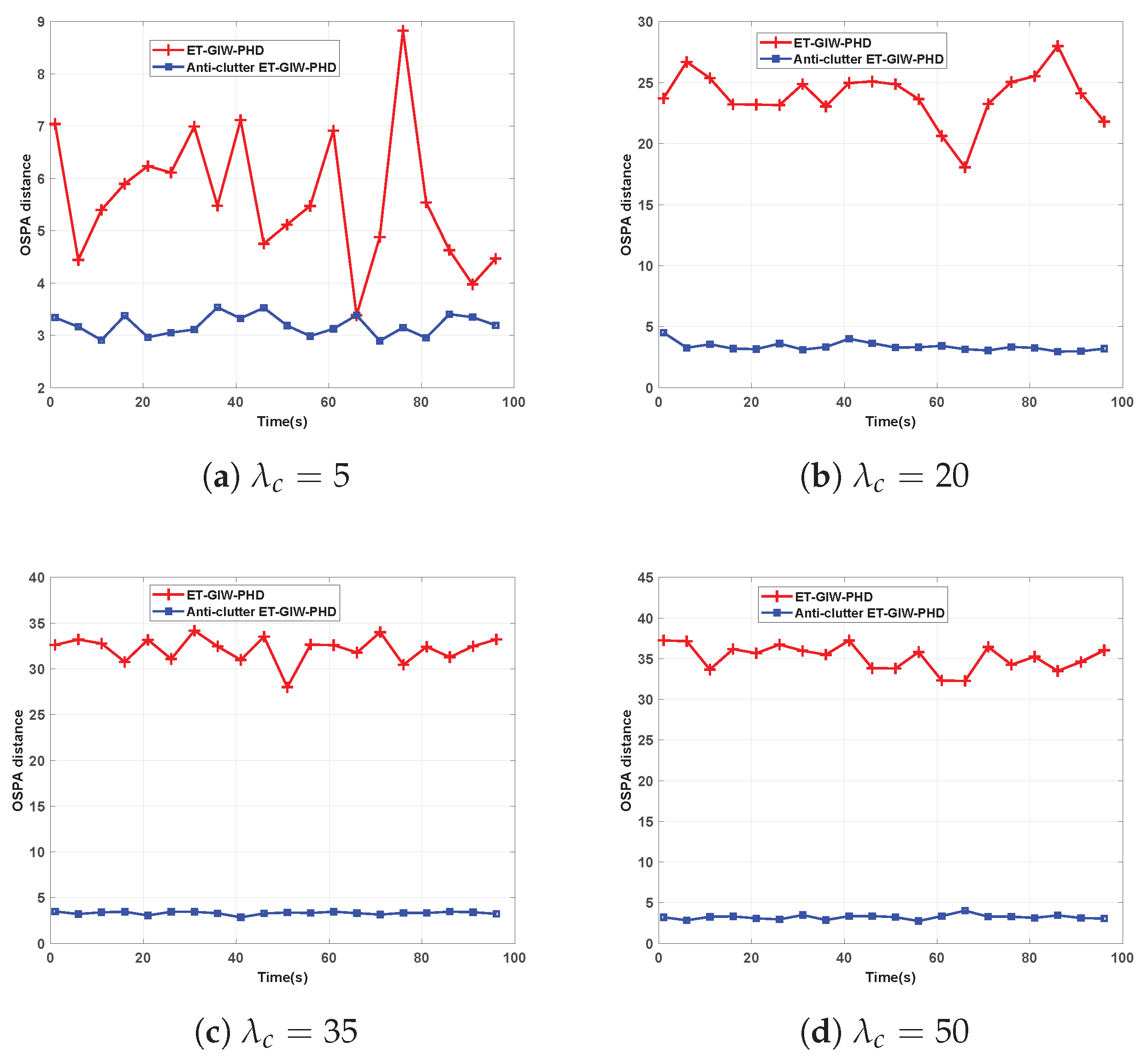
. The clutter measurements are assumed to be uniformly distributed over the surveillance area. The OSPA distance of these two filters under different Poisson rate
is shown in
Figure 5 and
Figure 6.
As we can see from
Figure 5 and
Figure 6, when
is small, ET-GIW-PHD achieves good performance. However, as
increases, the performance of ET-GIW-PHD degrades significantly. In contrast, our anti-clutter ET-GIW-PHD achieves superior performance with varying
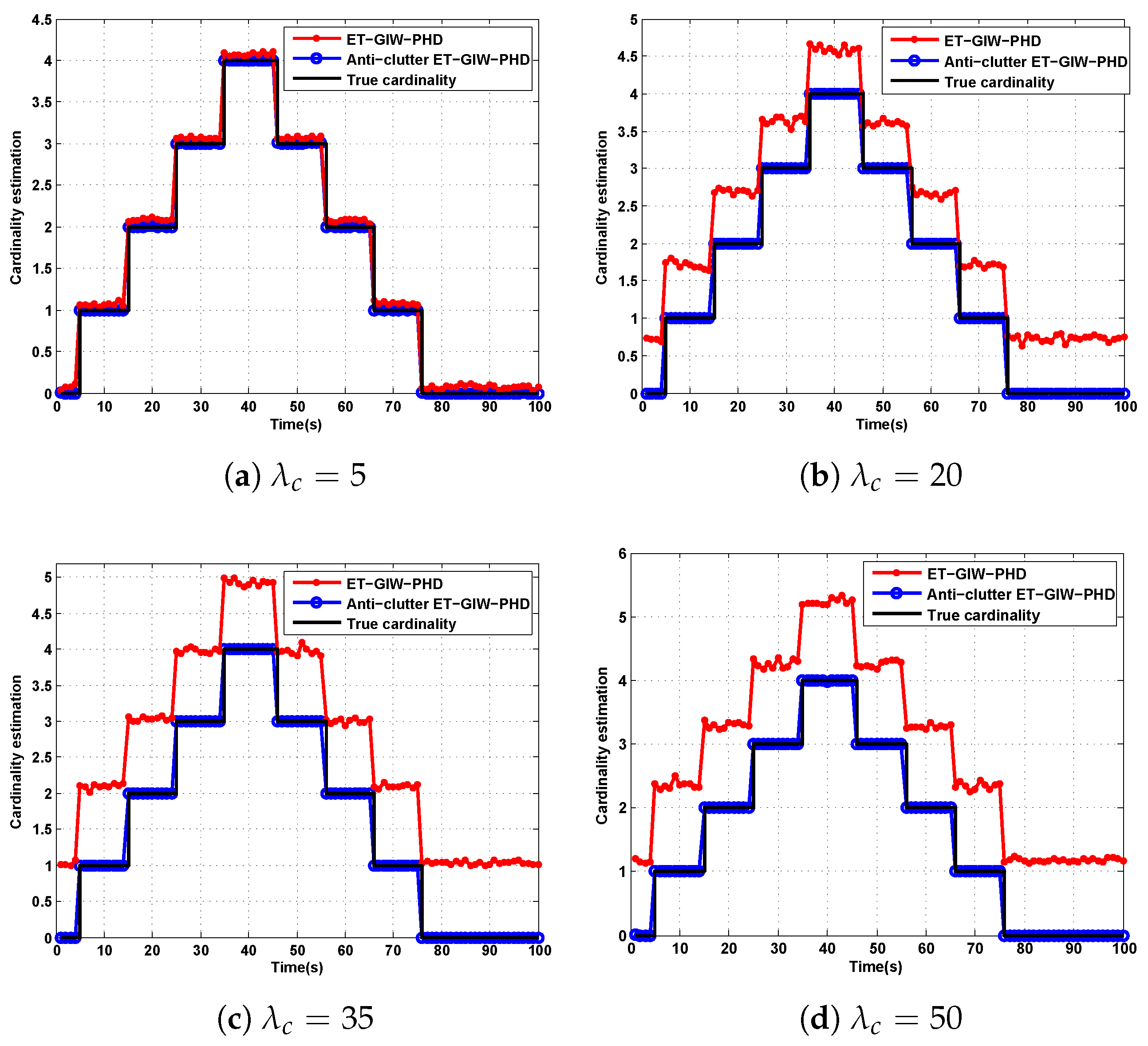
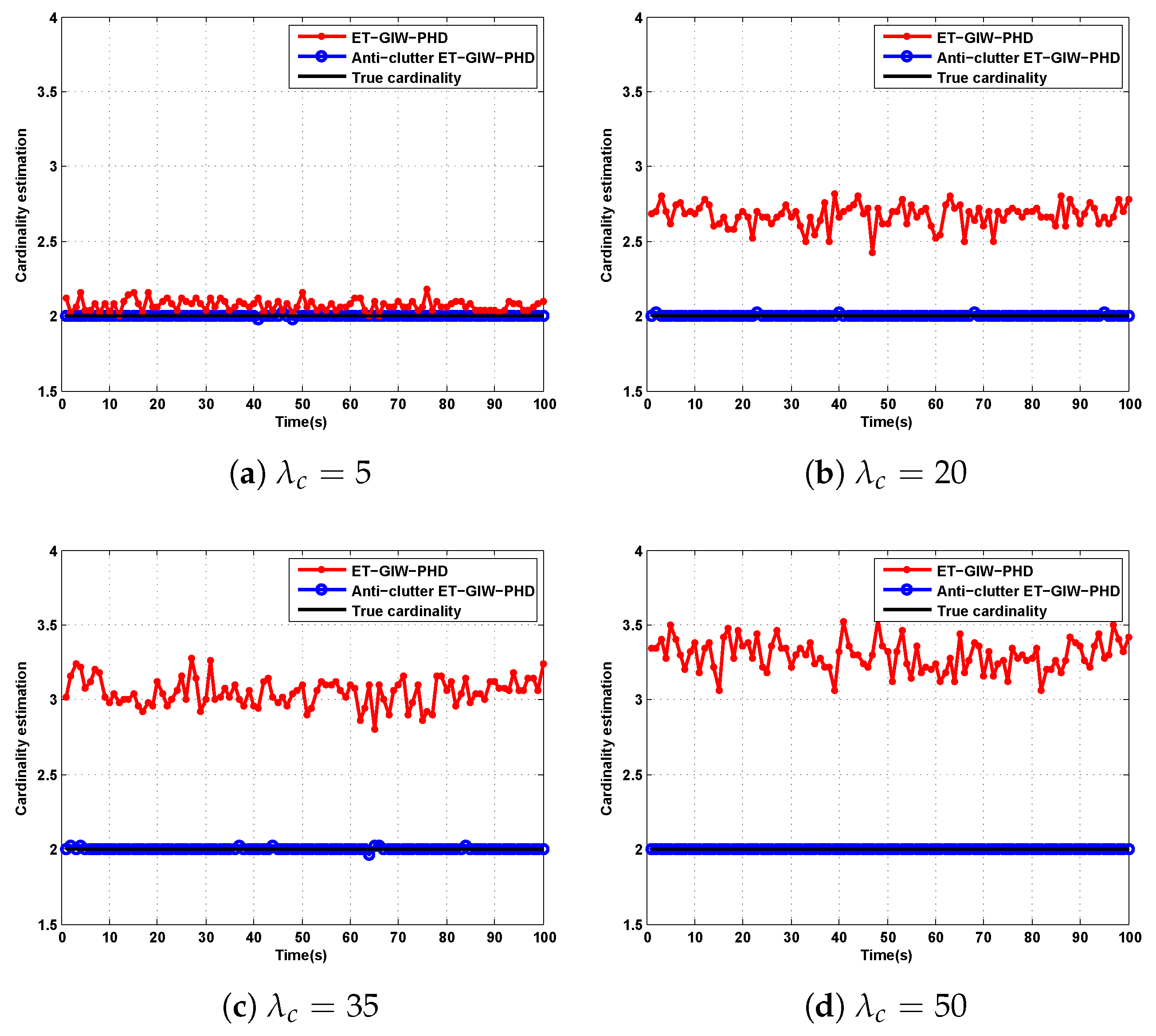
, which demonstrates that anti-clutter ET-GIW-PHD is more robust to clutter than ET-GIW-PHD. The results of cardinality estimation are shown in
Figure 7 and
Figure 8.
From
Figure 7 and
Figure 8 we can see that the cardinality estimation error of ET-GIW-PHD increases as the
grows. That is, ET-GIW-PHD cannot avoid the overestimation of cardinality under high clutter density. When clutter density is small, the clutter spreads apart. Thus, it is unlikely to partition more than one clutter into one cell. In the presence of severe clutter, the probability that multiple clutter being partitioned into one cell increases, and thus ET-GIW-PHD could overestimate the cardinality. However, our anti-clutter ET-GIW-PHD uses not only the number of measurement, but also target state and spatial distribution of clutter for better cardinality estimation performance. Using hypothesis testing, the measurements can be distinguished more correctly. Therefore, a better tracking performance can be achieved. Extensive experiments have demonstrated the effectiveness of anti-clutter ET-GIW-PHD.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}