1. Introduction
The diversification and popularization of embedded mobile devices enable innumerable user-centric mobile crowd sensing (MCS) applications (e.g., traffic monitoring, pollution monitoring, and indoor positioning) [
1,
2,
3,
4,
5,
6,
7,
8,
9]. A typical MCS system includes two entities (i.e., users and platform), where users not only publish tasks to acquire information from the platform but also collect sensing data for the platform. As a bridge between task publishers and participants, the platform helpfully selects suitable participants to complete tasks for publishers. Generally, sensing tasks in a MCS system are allocated to multiple participants and accomplished cooperatively [
10,
11,
12,
13,
14].
It is crucial for a MCS system to provide task publishers with reliable services. The task sensing process of MCS system relies on massive participants whose sensing positivity and sensing capacity are diverse for different tasks. If a task is randomly assigned to participants, the quality of its results may be severely affected, the credibility of collected sensing data may be reduced, and the corresponding computing resource consumption may increase [
15,
16,
17,
18,
19,
20]. Therefore, task assignment strategies should be reasonably designed to eliminate the above uncertainties, which can dramatically enhance the philosophy behind MCS participant collaborations [
21,
22,
23].
Technically, how to objectively evaluate the matching accuracy of task assignment strategies is a major challenge and remains in dispute. In response to this challenge, many studies presented solutions using varying methods and with different emphases. Jin, H et al. assigned MCS tasks to participants according to their capabilities to maximize sensing coverage [
24]. The authors of [
25,
26] assigned tasks based on the history of submitted high-quality results. However, they had different definitions of data quality. Yue, W et al. mainly considered the coverage quality of sensing results [
25], while Sabrina, K.N.M et al. measured the data quality based on the actual evaluation of data [
26]. Liu, S et al. evaluated participant’s service quality based on its context and cost, and developed a Modified Thompson Sampling Worker Selection (MTS-WS) algorithm to select workers in a reinforcement learning manner [
27]. Addressing the problem of performance maximization in MCS, a context-aware hierarchical online learning algorithm was proposed in [
28]. In detail, a local controller (LC) in the mobile device of a participant regularly observed the participant’s context, based on which the participant’s context-specific performance could be estimated and the participants could be selected. Although the authors of [
24,
25,
26,
27,
28] considered multiple task-related factors, there are still some limitations and factors that may intuitively affect MCS performance (e.g., task difficulty, task history, sensing capacity, and sensing positivity were omitted). Besides, the quality of data uploaded for different task types was not clearly modeled in these studies. Consequently, it may be impossible for the platform to assign tasks reasonably and accurately, resulting in low matching accuracy/task completion rate, high computing resource consumption, and incredibility of data.
Focusing on above limitations, we propose a service benefit aware (SBAMA) multi-task assignment strategy for MCS. The service benefit of participants is first modeled. Subsequently, we propose an enhanced Fuzzy C-Means (FCM) algorithm to dynamically cluster users in terms of their task preferences. Finally, an iterative participant search method based on gradient descent is designed to match participants with the best service benefit in each cluster quickly and accurately. The proposed SBAMA multi-task assignment strategy offers an interest tradeoff between participants and platform given a fixed budget and a certain movement distance. Simulation results verify that SBAMA can quickly and accurately find the most appropriate participants for all types of tasks. Therefore, task completion rate based on the proposed strategy is convincingly high. The main contributions of our paper can be summarized as follows:
- (1)
A service benefit evaluation model is established, from several different perspectives of tasks and participants, to comprehensively interpret impacts of task difficulty, task history, sensing capacity, and sensing positivity on service benefit received by the platform.
- (2)
An enhanced FCM algorithm is designed to cluster users. Specifically, a task preference threshold allows participants to join more than one cluster if such participants have similar task preferences. The generated clusters can effectively reduce the time consumption of the optimization problem while increasing participant matching accuracy.
- (3)
An iterative gradient descent algorithm is proposed to tune the tradeoff between interests of participants and platform. Particularly, it decouples the service benefit from movement distance such that the most appropriate participants for tasks can be found accurately and quickly.
The rest of this paper is organized as follows. Related works are introduced in
Section 2.
Section 3 presents the task assignment framework. The service benefit model is proposed in
Section 4.
Section 5 elaborates on the task assignment strategy. Simulation results validating our proposed SBAMA are given in
Section 6. Finally,
Section 7 concludes this paper and discusses future work.
2. Related Works
In recent years, task assignment for MCS systems has been attracting increasing research attention. Wei, G et al. proposed a heterogeneous multi-task allocation mechanism based on spatiotemporal correlation [
29]. The reference and non-reference tasks were distinguished through utilizing granularity settings based on which the best triple (i.e., worker-cycle-region) was obtained. Besides, to improve the task assignment efficiency, a decomposition and combination framework was designed in [
29] for large-scale scenarios. In [
30], a location-based online task assignment method was proposed under constraints of distance and budget, incorporating quality/progress-based, task-density-based, travel-distance-balance-based, and bio-inspired-travel-distance-balance-based algorithms, to search for the optimal participants maximizing the overall task quality. Wang, J et al. studied the deterministic model and random model of trajectories in vehicle-based MCS and proposed an effective vehicle recruitment algorithm to minimize the overall recruitment cost [
31]. However, the authors of [
29,
30,
31] only considered either the mobility of participants or the spatiotemporal correlation among tasks, where impacts of task requirements and service benefits were ignored. A failure to consider these critical factors together may result in an inaccurate participant matching during the task assignment process, which reduces the task completion rate.
The criterion of participant selection in task assignment has been extensively studied. Considering various factors affecting the task participant selection, a task assignment framework was proposed in [
32]. Specifically, a unified estimation function was employed to calculate the feasibility of task assignments and the optimal task assignment using a greedy algorithm was obtained. Wang, L et al. and Alsayasneh, M et al. focused on the context information of participants to enhance the task completion rate and MCS quality [
28,
33]. In particular, a diverse task composition scheme was studied in terms of participant personalities to dramatically improve user experience [
33]. Mavridis, P et al. inferred skills required for tasks from available skill sets and modeled a hierarchical skill tree to match participants with tasks, which was however computationally intensive and therefore inapplicable to scenarios with massive users and tasks [
34]. Besides, the credibility of data submitted by participants could not be guaranteed only based on their skills. Although the authors of [
28,
32,
33,
34] assigned tasks to relatively appropriate participants to ensure the data credibility, when evaluating the participant selection, key factors such as participant positivity and task difficulty should be carefully considered for the matching accuracy. Therefore, in this paper, we comprehensively evaluate the service benefits of participants as the matching criterion and propose the SBAMA multi-task assignment strategy to enhance MCS performance.
3. Task Assignment Framework
The proposed SBAMA framework is shown in
Figure 1. Since tasks arrive randomly, tasks assigned by the platform can be divided into
n identical time intervals, denoted as
. At the beginning of
, task publishers
submit tasks of different types
to the platform. Each publisher can only submit one type of tasks within each time interval. Note that each task type contains
q subtasks, i.e.,
. Specifically, a task has several requirements (i.e., deadline, location, data format, and ID), denoted as
, where
refers to the time range from task start
to task end
(i.e.,
) and participants must submit sensing results before this deadline. The specific locations for subtasks of task
are denoted by
. Due to different content types for each task, the format of collected data also varies. Without loss of generality, the data format is identified by
, where
specifies the content type acceptable for each task.
The platform then publishes tasks to all potential participants satisfying task requirements . Task candidates then submit a subset of the received tasks to the platform indicating their task preferences. Subsequently, the platform employs task assignment strategy to select participants with high service benefits and low costs to perform tasks. In other words, the optimal task participants are found.
When tasks are completed, the platform compensates the selected participants according to their costs and task difficulties. Finally, upon receiving feedback from the platform, task publishers score the service quality of the participants. Apparently, the scores should be exploited by the platform as an important reference to evaluate and update the service benefit, which further serves as an indicator for the next rounds of task assignments.
Generally, MCS tasks are location-dependent and participants have to travel a certain distance to perform the tasks. Therefore, movement distances are an inevitable cost for participants, i.e., cost
of participant
performing task
should be a function of movement distance
and sensing cost
. Evidently,
is proportional to the distances traveled by participants (i.e.,
) and its growth rate also should increase with the distance (i.e.,
). The cost
is defined as follows
In Equation (
1),
and
are pre-defined system parameters and
is constant. Participants expect to get rewards from the platform after completing tasks. Specifically, the reward depends on the task difficulty and movement distance. Given a difficult task, its price per meter should be high, and prices of different types of tasks are denoted by
. Besides, the reward should not exceed the budget. Note that participants can perform different subtasks in the same time interval to maximize their incomes, only when their locations are not in conflict. Thus, the income of participants can be easily calculated through deducting the cost from the reward; there holds
For the platform, its profit mainly comes from service benefits contributed by participants. Intuitively, participants with greater service benefits generate more profits for the platform and therefore should be prioritized. However, the growth rate of the profit should be slowly attenuated because the participant service benefits become smaller and smaller after the participant is selected. The profit obtained from completing task can be calculated as follows
where system coefficient
is determined by the platform for each task type. Apparently, both the platform and participants want to maximize their profits or incomes. Hence, a reasonable task assignment strategy should select participants with low sensing costs and high service benefits, where a tradeoff between the platform and participants must also be made under constraints of the maximum movement distance
and budget of each type of tasks
. Rationally, the reward should be more than the cost to motivate participants to travel within
. Eventually, the task assignment can be formulated as the following optimization problem.
4. Service Benefit Evaluation
Service benefit is an important indicator for the platform to estimate the potential profit gained from a certain participant, which often relates to task requirements. In this paper, task difficulty, task history, sensing capacity, and sensing positivity are employed, from perspectives of tasks, participants, and publishers, to comprehensively evaluate the service benefit of all types of tasks, so as to achieve accurate participant matching and reliable MCS data collection.
4.1. Sensing Positivity
Sensing positivity refers to the motivation of participants in performing sensing tasks, which is a dynamic process. Given the same sensing capacity, a higher sensing positivity signifies a greater contribution to the platform. Interactions between participants and the platform are employed to measure the sensing positivity, where interaction frequency and task performance are two major observable indicators for these interactions. Specifically, performance
p is a function of response time
and cost
. If a participant has a relatively low
and
, the platform deems his/her performance positive. Due to the restrictive task deadline and movement distance,
p decreases with the growing
and
, and then gradually stabilizes. Therefore, performance
of participant
in task
can be calculated by
where
,
.
is the time participant
starts task
and obviously
if
is equal to task start time
, which generates the value of maximum performance is 1. Conversely, the minimum performance 0 can be obtained when
. Besides, when
is infinitely large,
reaches 0 (i.e.,
), as bounded by
Interaction frequency is another important indicator for sensing positivity. Apparently, a high interaction frequency signifies a stable and positive sensing behavior, and thereby the interaction frequency has the equivalent weight with the task performance in sensing positivity. Therefore, the sensing positivity of participant
in task
can be obtained as
In Equation (
9),
refers to the tasks participated by
, and
h denotes the latest task. The sensing positivity for different types of tasks is represented by a vector
.
4.2. Task Difficulty
The task difficulty challenges the sensing capacity of participants, and we utilize a difficulty coefficient to measure it in this paper, where a small coefficient signifies a difficult task. However, dynamic MCS tasks are large in number and rich in type. Evaluating the task difficulty in real time will inevitably consume massive computing power of the platform, which is prohibitively expensive. Therefore, we employ an offline method evaluating the completion rate in task history to obtain the difficulty coefficient. Specifically, the completion rate is defined as the ratio of completed subtasks
to all published subtasks
q,
and
. Note that the completion rate of different types of tasks is denoted by a vector
. Intuitively, a high completion rate signifies a simple task. Besides, the completion time must be before the deadline. Here, we exploit a theoretical completion time
to evaluate the actual completion time
, and they are calculated by
and
, where
q is the total number of published subtasks. If
is within
, this task can be completed. Eventually, the difficulty coefficient can be obtained as
It is also worth noting that the task difficulty is relative. If the sensing capacity of a participant is low, the platform will not assign a difficult task to him/her. We denote the varying sensing capacity of participants with a vector
, where
is a constant determined by hardware specifications of sensing devices. Therefore, the relative difficulty coefficient of participant
performing task
can be easily calculated and normalized using logarithmic function, as shown in the following
Relative difficulty coefficients are further denoted by matrix
, as shown in Equation (
12), where rows represent participants and columns indicate tasks.
4.3. Task History
Generally, subjective feedback from task publishers is an effective benchmark for the credibility of data submitted by participants. However, due to insufficient labeled MCS data, it is challenging to objectively evaluate the data credibility. We exploit historical records of participants including ID, collected data format
,
and reward
,
, as denoted by
, to evaluate data credibility. Collected data format
is compared with task requirements
defined by
, and a small gap signifies the complete data, which can be indicated by
. Besides, the more data formats the platform receives, the higher data credibility a task can obtain. Generally, the value of data is defined as a quotient of frequency and the residual of
in the task history of publisher
. The value of the historical data is estimated by linear regression model
, where
Y and
are both
dimension vector,
denotes the number of participants,
X is a
matrix, and
is a
dimension vector. Therefore, the residual between the actual data value and the estimated is
, where
is a hat matrix and a small residual indicates high data credibility. Consequently, the data credibility of participant
for task
can be obtained as
. Moreover, a publisher gives a high score to participants requiring relatively low task payments, and the score given to participants can be obtained as follows
We further adopt the logarithm to normalize the score, as shown in the following
Then, the score matrix
can thus be obtained as follows
where rows represent task publishers and columns represent participants.
4.4. Service Benefit
Mathematically, the service benefit of participants is a function of task score
, relative task difficulty
, and sensing positivity
, where
serves as the weight of the service benefit indicating the motivation of participants. In addition, the service benefit grows monotonically with the increasing task score and difficulty. As marginal benefits of submitted data gradually decrease, the growth rate of service benefits drops and stabilizes. Thus, the service benefit of
to
can be formulated through the following inverse trigonometric function
However, the evaluation of service benefits depends on task history, which is inapplicable to new participants. Therefore, we propose to set the default value of service benefits to 0.5, indicating an uncertain service benefit for strange participants. Besides, 0.5 also serves as a threshold to distinguish participants with low service benefits. Based on their task histories, we can reformulate the service benefit of participants as
Similarly, service benefits of participants for different types of tasks can also be denoted by matrix .
5. Service Benefit Aware Multi-Task Assignment
Technically, the optimization goal of MCS task assignment is to select participants with high service benefits and low costs, so as to balance the interests of participants and the platform, given constraints of movement distance and budget. To solve this optimization problem, we first cluster users (i.e., task candidates) according to their task preferences, and then exploit a gradient descent algorithm to find the optimal participants in each cluster.
5.1. User Clustering Based on Task Preference
In MCS scenarios with massive users, the matching accuracy of optimization algorithms always suffers from the large search range of task candidates. Therefore, we propose to employ the similarity among task preferences to cluster task candidates. Specifically, task preferences indicate the interest of users in certain tasks, which can be reflected by task acceptance rate and task performance. The task acceptance rate is defined as the proportion of tasks submitted by user
to the total number of tasks submitted by all the selected participants, calculated by
, which further serves as the weight of the task preference. Intuitively, the acceptance rate of participant, calculated by
, which further serves as the weight of the task preference. Intuitively, the acceptance rate of participant
for different types of tasks can be denoted by vector
. The task preferences of users
are also perceived by the platform, which can be calculated similarly with Equation (
8). Therefore, task preferences can be denoted by the product of the task acceptance rate and task performance (i.e.,
), and its matrix holds as
where rows represent users and columns represent tasks.
The number of MCS clusters depends on the number of published tasks in each time interval, which varies dynamically with the task preference. Note that a user may be interested in multiple tasks and therefore belongs to more than one cluster, which makes Fuzzy C-Means (FCM) algorithm a perfect clustering method for this scenario. In terms of the task preference defined above, we employ cosine similarity to replace the Euclidean distance in standard FCM and modify it into similarity FCM (SFCM). The cosine similarity of task preferences indicating the preference similarity between cluster center
and user
in SFCM can be calculated by
In FCM, the fuzzy weighted exponent
m is commonly employed to determine the fuzzy degree of clustering results, and its optimal value is usually set to
. We take
and the objective function of SFCM can be obtained as follows
In Equation (
20),
represents the membership degree of user
to cluster
. The membership matrix can then be denoted by
and the cluster center matrix is
, which can be calculated in the following
We set the iteration times to l and the stop parameter to , respectively. Given the user preference matrix , SFCM randomly generates an initial membership matrix and calculates initial cluster centers . According to cluster center matrix , both cosine similarity and membership matrix can be obtained. For instance, if , membership degree of to is 1. Finally, the iteration is stopped, if , to generate clustering results and obtain cluster center matrix . Otherwise, iterations continue to update and until reaching iteration times l or stop parameter .
Generally, FCM constructs clusters according to the membership matrix (i.e.,
,
). However, users clustered by FCM can only belong to one cluster according to her/his highest task preference, which is against the intuition that users with similar preferences for several tasks may simultaneously belong to multiple clusters. Therefore, we define clustering threshold
to establish these characteristic overlapping clusters. Specifically, the maximum membership value of a user in the cluster is compared with the other memberships value that he/she belongs to, then all comparison values are sorted, the largest comparison value are got among them as the threshold, which calculated by
,
. The true label is obtained by the maximum average preference value among different types of tasks in a cluster; there holds
where
is the total number of users in cluster
.
5.2. Optimization Problem Based on Lagrange Duality
5.2.1. Problem Reformulation
Since the task price per meter is fixed, the income of participants can be maximized by reducing the movement distances, whereas the platform maximizes its profit by selecting participants with high service benefits. Therefore, the optimization problems in Equations (
4)–(
6) can be rewritten as follows
In Equation (
24),
and
represent the service benefits obtained by the platform and the costs consumed by participants, respectively.
5.2.2. Lagrange Duality
Equation (
24) shows that the objective function is convex with respect to
and
. Hence, the Lagrange multiplier can be employed to solve this unconstrained dual problem; there holds
In Equation (
25), the Lagrange multiplier is denoted by matrix
,
and
. Since the service benefit of participants is already evaluated, the dual problem can be defined by
In Equation (
26),
and
. Because the original objective function is convex, the strong duality must satisfy the Slater condition to generate the optimal solution for this dual problem.
5.2.3. Optimization Algorithm
We employ a gradient descent algorithm to iteratively solve the dual problem. The variables of the dual problem can be updated as follows
In Equation (
27),
is the variable of the original optimization problem in the
lth iteration,
and
are the variables of the dual problem in the
lth iteration, and
is the learning step size. Participants with the best service benefits and optimal movement distances can be obtained iteratively by the platform. First, in the iteration of service benefits, participants with the best benefits in the
lth iteration can be obtained. Then, in the gradient descent algorithm, dual variables
and
of the
lth iteration are obtained. Finally,
,
and
are all set for Equation (
28) to generate the optimal movement distance. The iteration process does not stop until convergence conditions are met. Algorithms 1 and 2 are updated as Equations (
28) and (
29).
Specifically, the complexity of Algorithm 1 is , where n is number of task candidate. The complexity of Algorithm 2 is , where m is the number of task cluster. The complexity of overall assignment strategy is .
When the best participants are selected for each type of task, the platform pays their task reward, updates their service benefits, and exploits scores from task publishers for the next round participant selection.
| Algorithm 1 Service benefits. |
Input: potential participants set U; service benefit matrix S; Task set A Output: the optimal participants W for Task ; Profit Initialize , the number of iterations Select participant randomly, Receive from user Calculate the profit of each task of through Equation ( 5) while or do if then Select participant and corresponding Calculate the profit of the platform through Equation ( 5)) return break else return to Line 5 end if end while return
|
| Algorithm 2 Iterative of progress. |
Initialization fordo Receive from platform Compute the new value of and using Equation ( 27) if and , where is a tunable little real number then Return to Line 3 else return break end if end for
|
6. Experiment
Gowalla, employed in this study to validate the proposed SBAMA, is a location-based real world social network dataset that allows users to share their information, including ID, access time, longitude, latitude, and location tags. The dataset collected all public check-in data between February 2009 and October 2010. There are 19,6591 nodes and 950,327 edges in Gowalla. Gowalla is mainly used to study human mobility [
35]. Specifically, 500 locations and 1000 users were extracted from Gowalla as task locations and candidates, respectively. Subsequently, these 1000 task candidates were clustered into five groups, where each group maintains a task preference matrix and a corresponding service benefit matrix, containing five types of tasks. In addition, SFCM clustering algorithm and optimization algorithm in SBAMA were compared with original FCM algorithm and greedy algorithm in Dynamic Trust-Based Recruitment Framework (DTRF) [
20] on MATLAB platform, respectively. Simulation parameters are given in
Table 1.
6.1. Advantages of SFCM
The objective function iteration and clustering accuracy of SFCM were compared with those of FCM to verify the effectiveness of SFCM. Objectively, both FCM and SFCM adopt the same initial membership matrix and the simulation was repeated 100 times, where seven tests were randomly selected for observation.
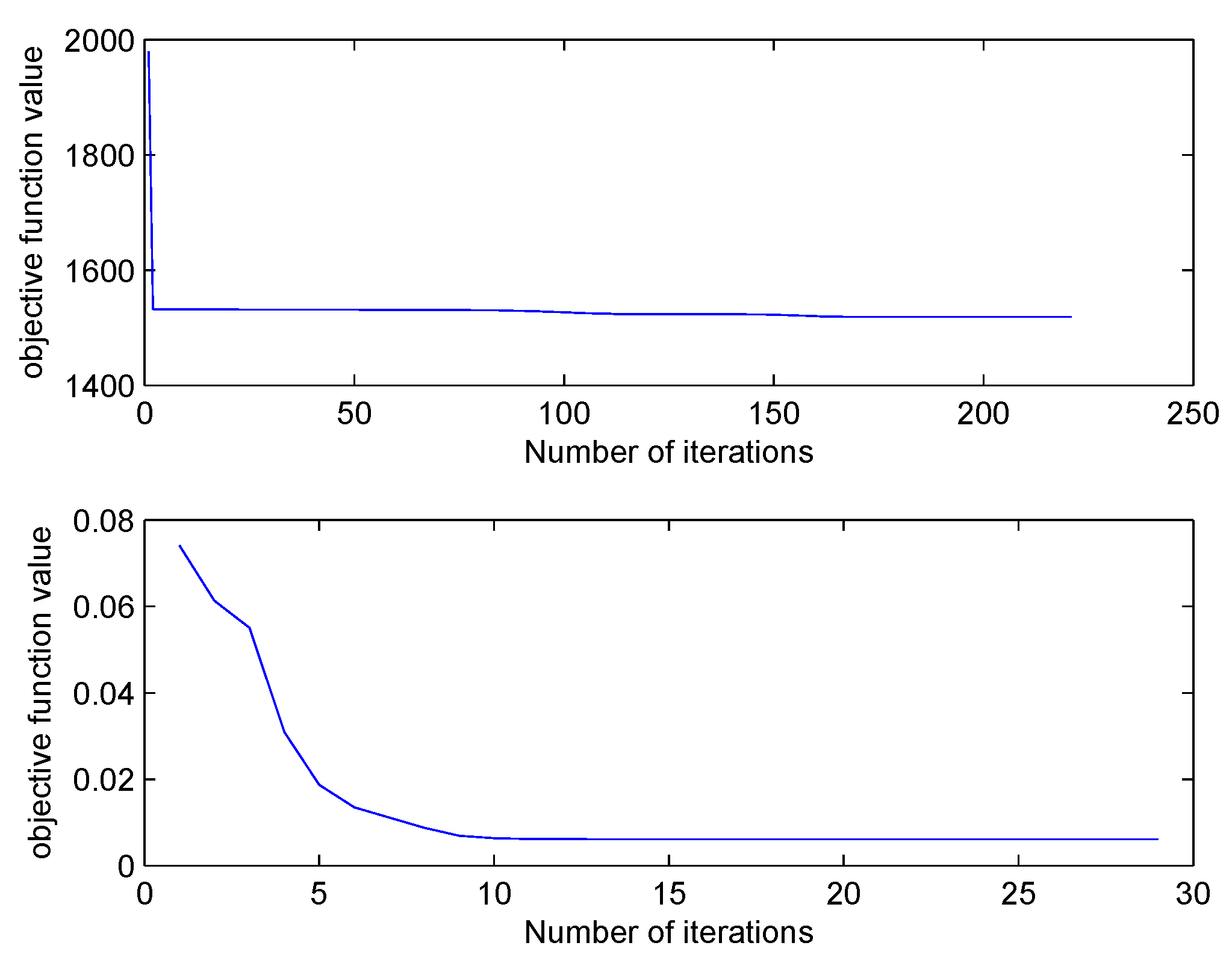
The iteration times needed by FCM and SFCM for objective function convergence are shown in
Figure 2. Compared with FCM, SFCM requires a stably lower number of iterations around 30. In addition, SFCM converges quickly and has significantly short clustering time.
Figure 3 illustrates the iteration of their objective function values, where the initial value of SFCM is notably much smaller than that of FCM, because the Euclidean distance in FCM is replaced by cosine similarity of SFCM to reduce the membership value.
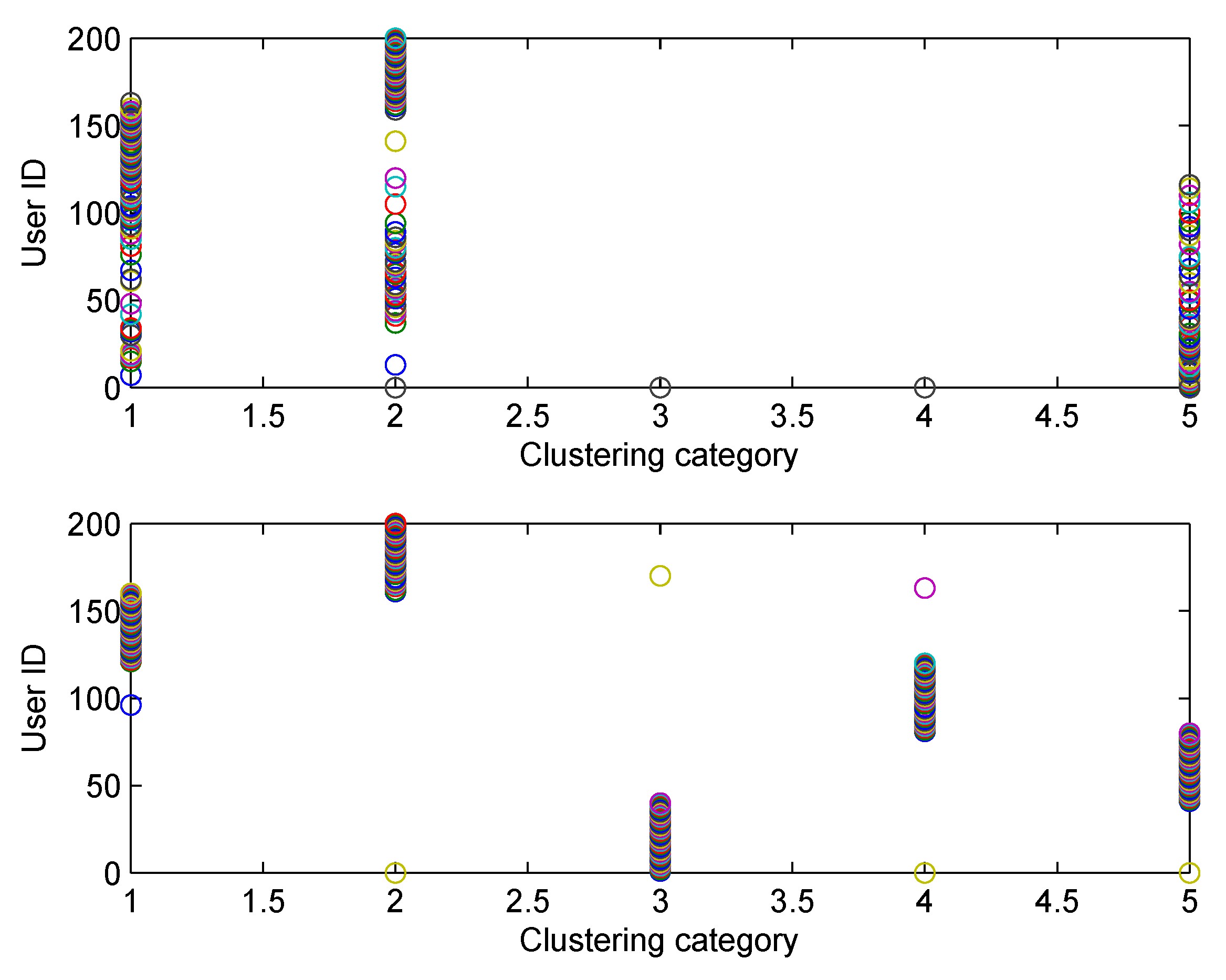
The clustering accuracy of FCM and SFCM, given the maximum membership value, is shown in
Figure 4, which is measured based on the original dataset with labels. The clustering accuracy of SFCM is generally higher than 95%, whereas the worst case of FCM is only 74.5%. Similarly, given the maximum membership value, randomly selected clustering results of FCM and SFCM are shown in
Figure 5, where SFCM has a significantly better clustering result.
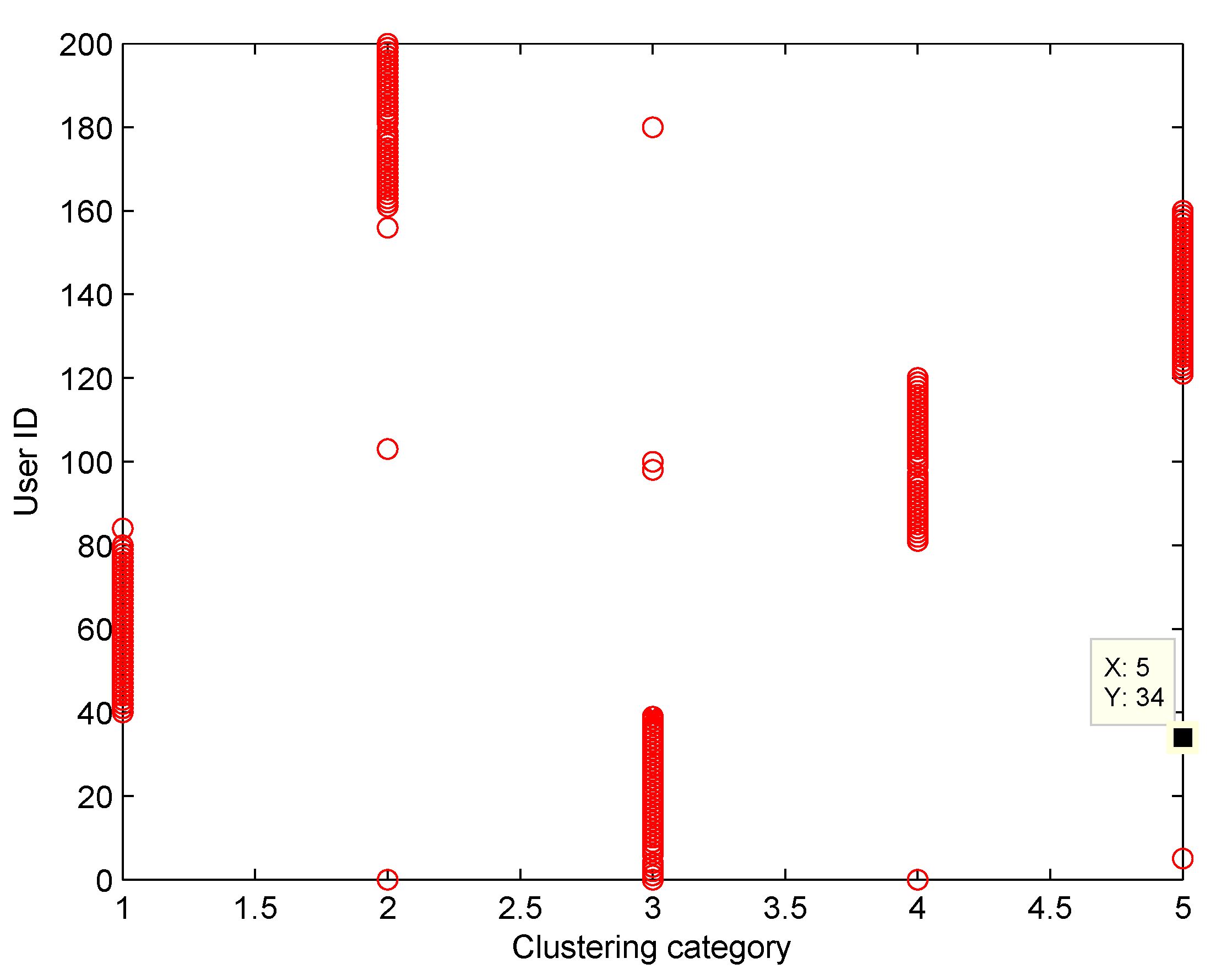
Figure 6 shows the final membership matrix value of users from a random test. Cluster labels can be determined by Equation (
22). For example, the cluster for Task A1 almost includes Users 40–80. However, according to their membership matrices, Users 34, 84, 100, 103, and 156 have similar membership values for different types of tasks. As shown in
Table 2, the membership values of User 34 for Tasks A3 and A5 only differ by approximately 0.074. Besides, Users 103 and 156 have membership differences only within 0.1 for Tasks A2/A4 and Tasks A2/A5, respectively. Therefore, the task preference threshold is set to 0.1 for overlapping clustering and the clustering result of SFCM based on this threshold is shown in
Figure 7. Compared with
Figure 5, clusters overlap and User 34 belongs to clusters of Tassk A3 and A5 simultaneously, which is more practical for real world MCS scenarios. In short, SFCM with membership threshold can cluster users with similar task preferences, which is an effective underpinning for the subsequent optimization problem.
6.2. Analysis of Optimization Algorithm
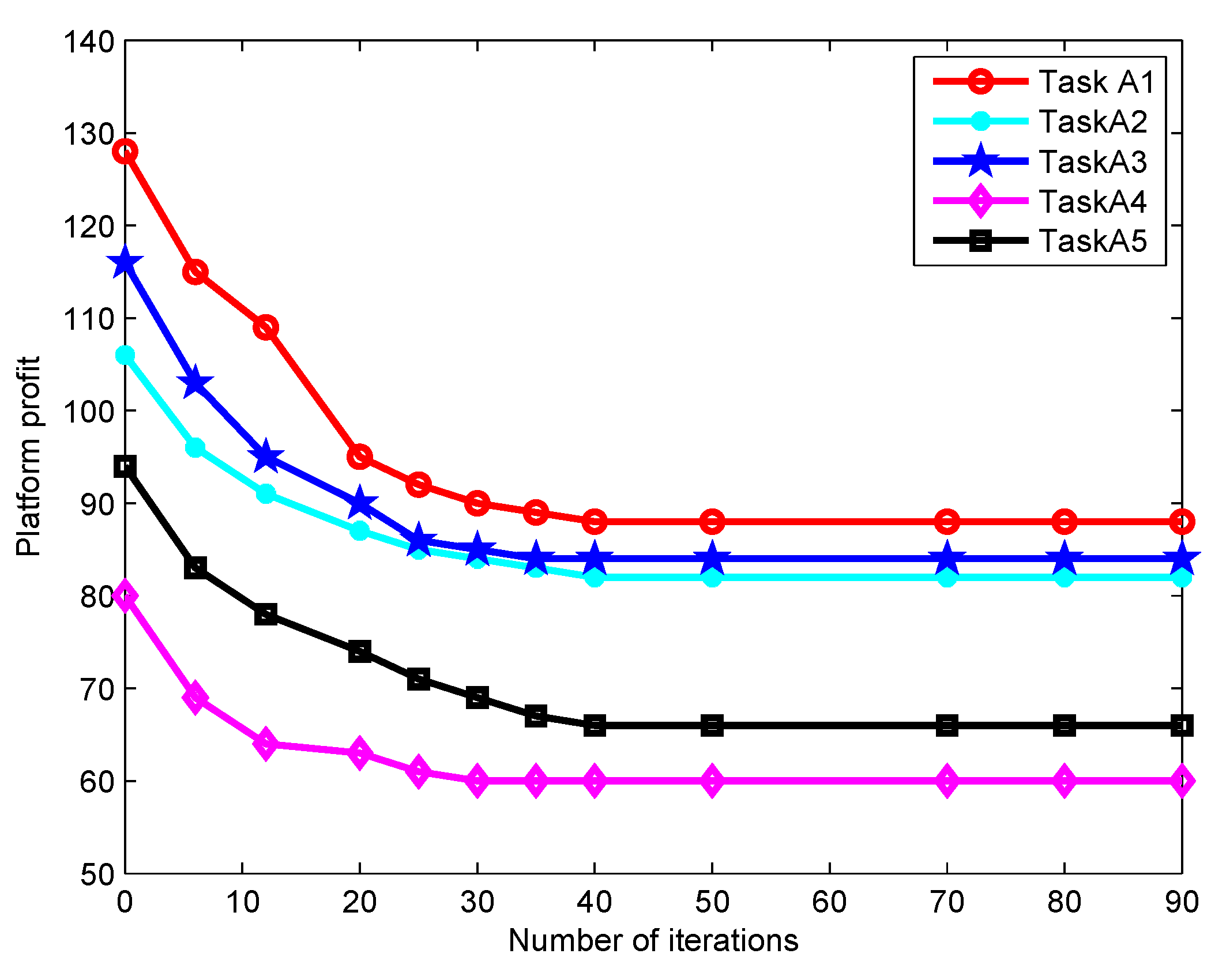
Figure 8 shows how the platform profit gained from each type of task varies with the number of iterations. It is observed that the platform profit converges to the optimal value when the number of iterations reaches about 45, which implies the platform can stably match appropriate participants to tasks. Besides, the platform profit increases as the average service benefit increases. In
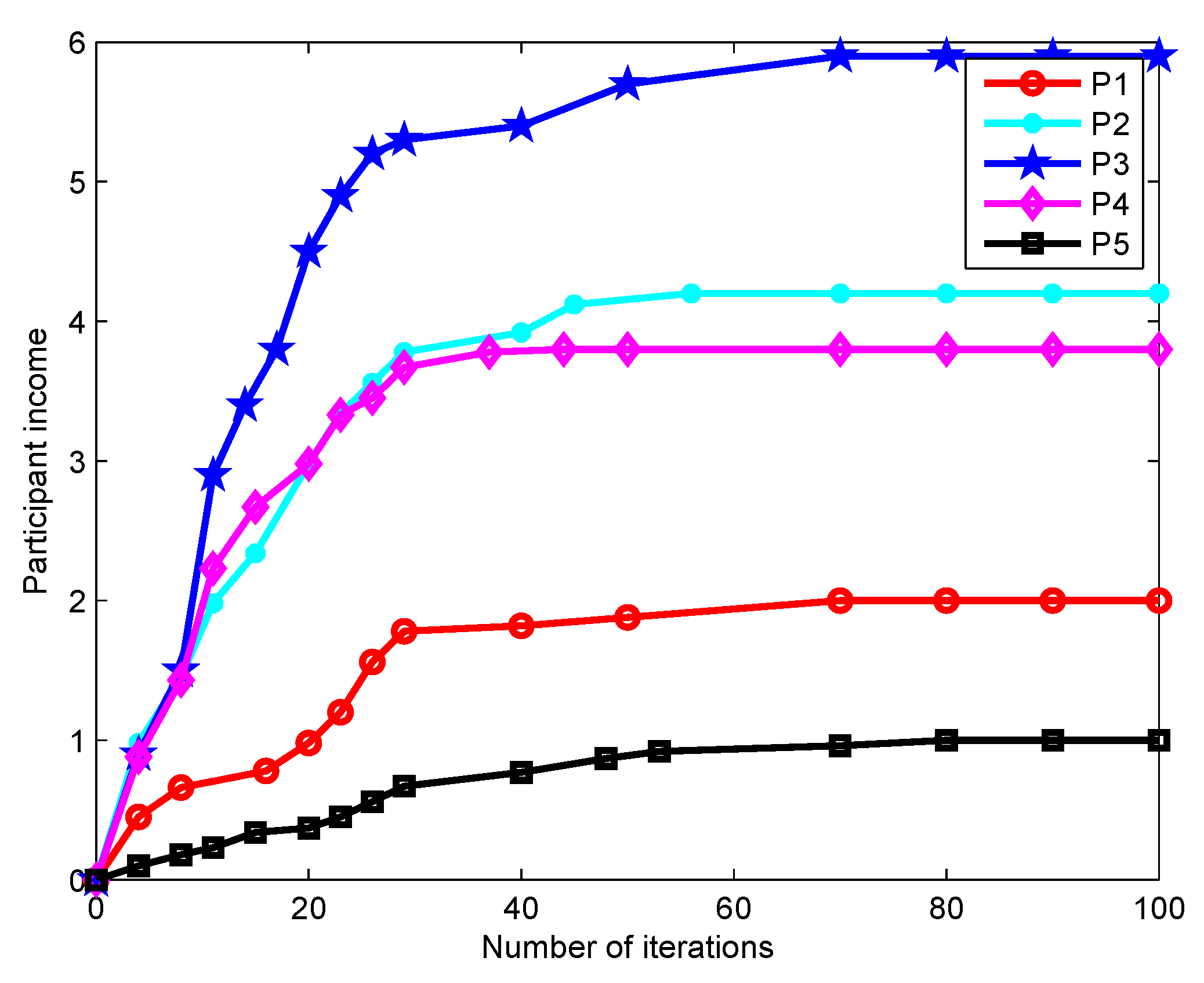
Figure 9, the impact of the number of iterations on the participant income is depicted. For a fixed task price
, the participant income first grows sharply as the number of iterations increases and then tends to be stable. The income of Participant 3 is significantly higher than those of others. This is because his/her task is more difficult to be performed and requires a stronger sensing capacity, which thereby receives a higher payment from the platform. In
Figure 8 and
Figure 9, the fast iteration convergence of the proposed gradient descent algorithm for achieving the best task participants is validated.
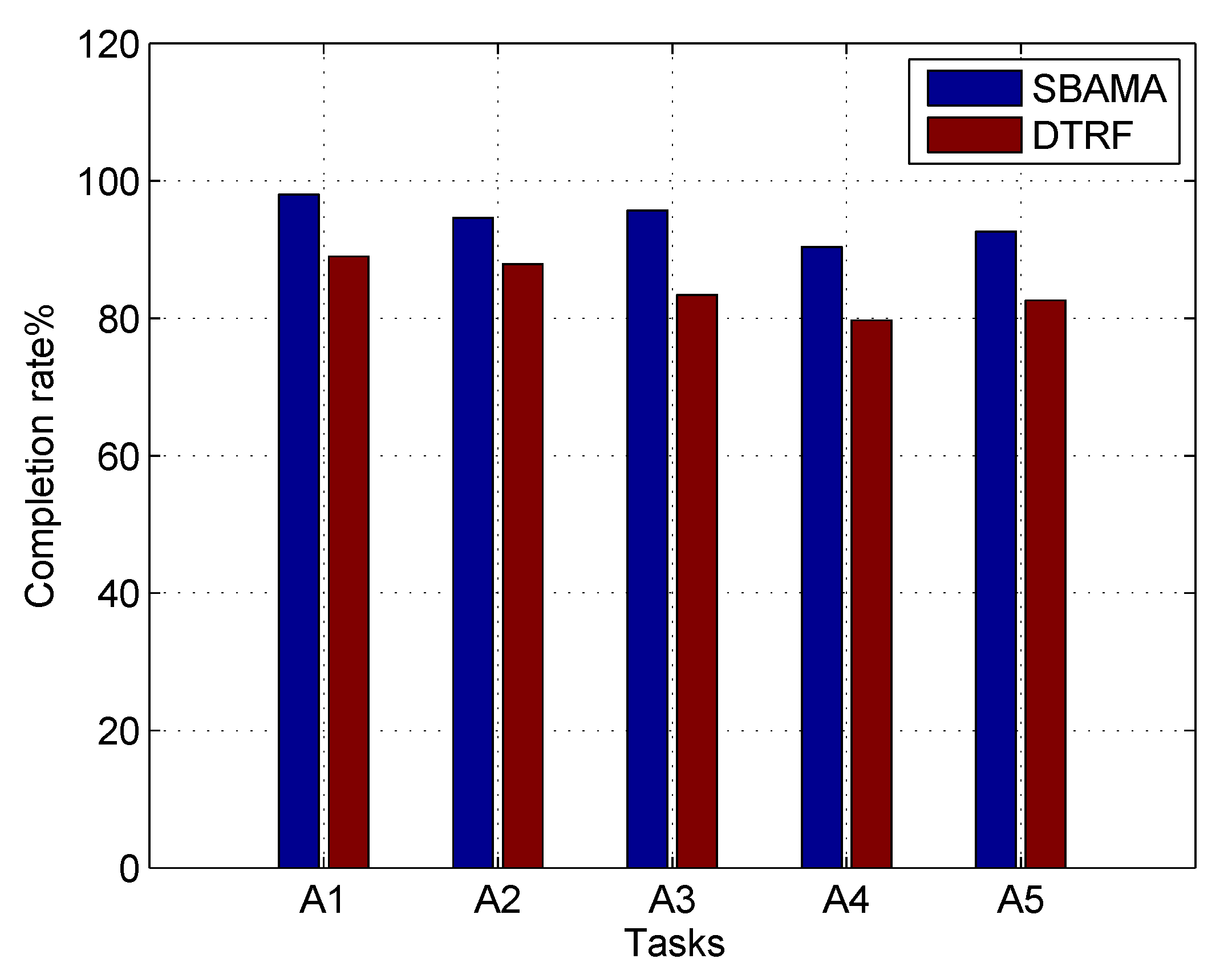
In
Figure 10, the task completion rates of DTRF and SBAMA are compared. In addition to sensing quality considered by DTRF, the proposed SBAMA also takes service benefits of participants, task preferences and real-time feedbacks from task publishers. Hence, SBAMA acquires 8% higher task completion rate.
In short, through narrowing the search range of task candidates, SBAMA effectively improves the matching accuracy of tasks assignment with fast algorithm convergence.
7. Conclusions
In this paper, we propose the SBAMA to quickly and accurately match MCS tasks with the most appropriate participants to improve the task completion rate and data credibility. Firstly, the service benefit of participants is modeled based on their task difficulty, task history, sensing capacity and sensing positivity to improve the accuracy of task assignment. Then, task candidates are clustered according to their task preference to narrow the search range. Finally, the gradient descent algorithm is designed to select the optimal participants in each cluster. Simulation results verify that the proposed SBAMA can quickly find the most appropriate participants to meet the requirements of multiple concurrent types of tasks under a massive user scenario, for example, crowded road condition monitoring. Although the proposed SBAMA can be applied to the scenario of massive users and numerous concurrent tasks, the strategy still has some limitations for the scenario where participants are sparse, which can lead to a low matching accuracy between the task and the participant. In the future, we will focus on the sparse participant scenario and study the associated task assignment strategy.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}