Detecting and Monitoring Hate Speech in Twitter

 ,
,
Abstract
1. Introduction
- Hate Speech Detection: tweet collection and classification
- Social Network Analyzer
- The design and implementation of a novel intelligent system for monitoring hate speech in SM. In particular, HaterNet acts as a visual thermometer of emotions that allows to map the hate state of a region and its evolution by targeting, aspects, emitters, and receivers of hate.
- A novel addition to the literature on predictive policing, as HaterNet has been developed to carry out policing tasks. Note that it could be used in other investigation fields, such as journalism or social analysis.
- The definition of a methodology that combines text classification and social network analysis to monitor the evolution of classes of documents (in this case, hate speech) in SM and identify the main actors and groups involved.
- The introduction of a new approach based on double deep learning neural networks.
- A novel public dataset in Spanish on hate speech, comprised of two million untagged tweets and 6000 tagged tweets.
- A thorough comparison of text classification methodologies on datasets from the literature and on a new real-world corpus, where the results show that the model proposed in this paper provides better performance than previous models in all the datasets considered.
- A study on the significance of including suffixes in text classification models. To the best of the authors knowledge, this is the first model to explicitly consider suffixes in the Spanish language.
2. Related Work
2.1. State-of-the-Art on Predictive Policing
- Methods for predicting felonies: used to forecast places and times with crime escalation.
- Methods for predicting transgressors: used to identify individuals at risk of committing a felony in the future.
- Methods for predicting transgressors’ identities: used to shape profiles that precisely match likely transgressors with specific past felonies.
- Methods for predicting victims of felonies: used to identify groups, prototypes, or, in some cases, individuals who are likely to become victims of a felony.
2.2. State-of-the-Art on Twitter Data for Predictive Analytics
2.3. State-of-the-Art on Text Classification
- Deep learning techniques [43], which learn complex features using deep neural networks.
- So far, prediction results in sentiment analysis have been poor due to the informal and noisy nature of SM, which creates problems for NLP tools [42]. However, as illustrated in Section 5.3, HaterNet obtains an AUC of 0.828, which denotes a reliable classification.
2.4. State-of-the-Art on Hate Speech Detection
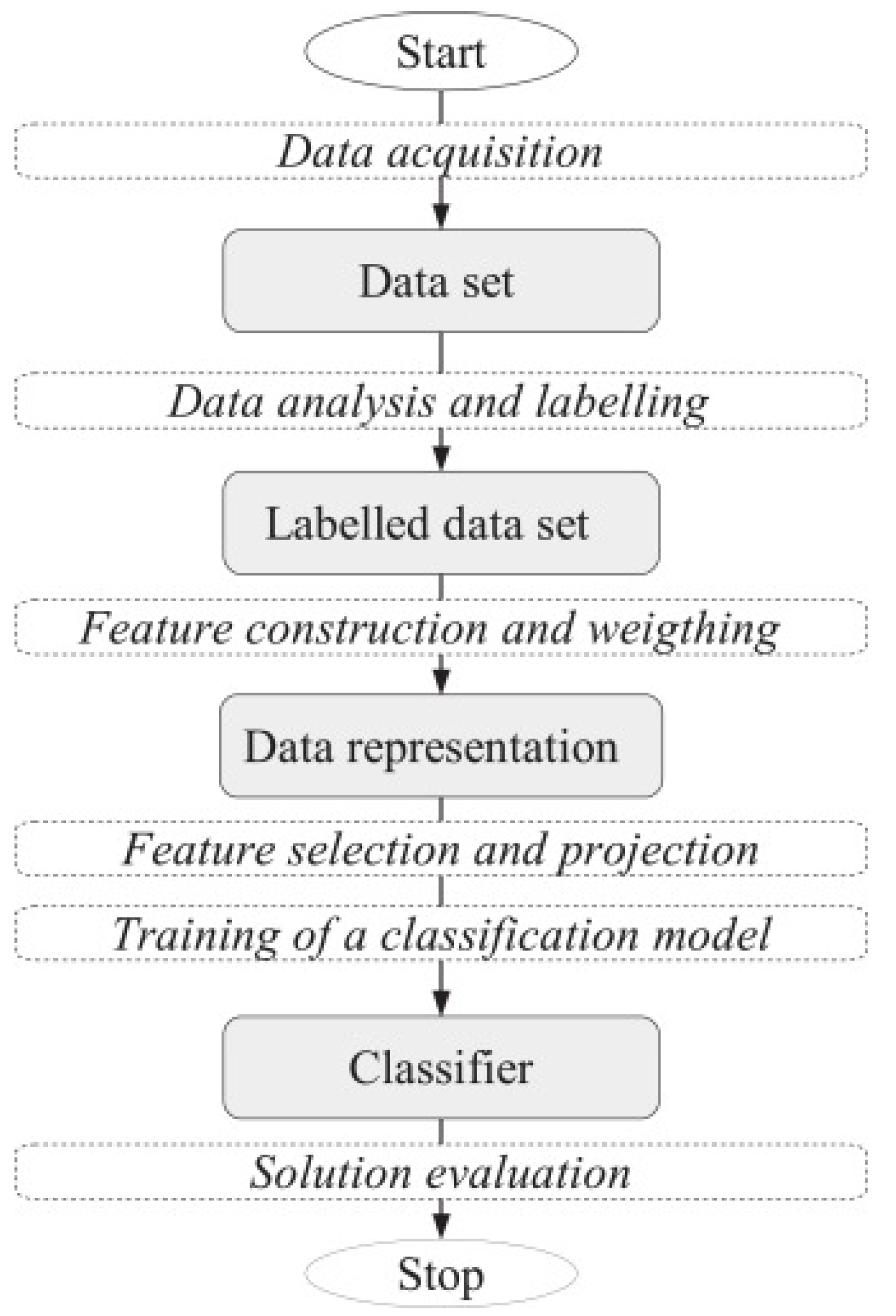
3. Hate Speech Detection: Design and Theoretical Concepts
3.1. Corpus Collection and Cleaning
3.2. Document Selection
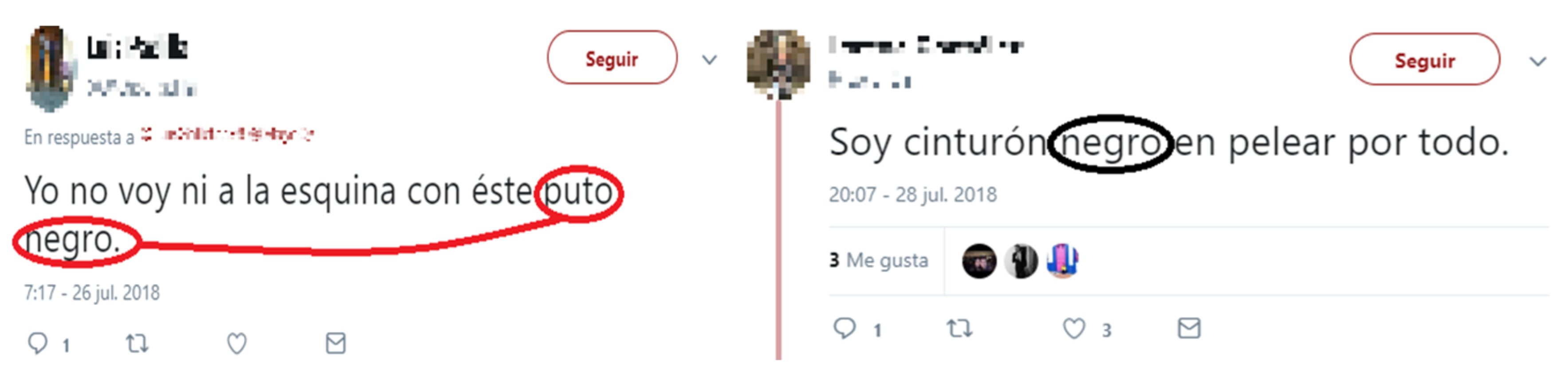
3.3. Document Labeling
3.4. Document Representation and Feature Extraction
- Frequency-based: Computed for unigrams, POS tags, emojis, suffixes, and expression tokens. All the following types of frequencies are considered for each feature.
- -
- Absolute frequency, : the number of times that term t occurs in document d.
- -
- Binary transformation, : equals 1 if , and 0 otherwise.
- -
- Logarithm transformation, .
- -
- Ratio transformation, . Adjusts the absolute frequency to the document length.
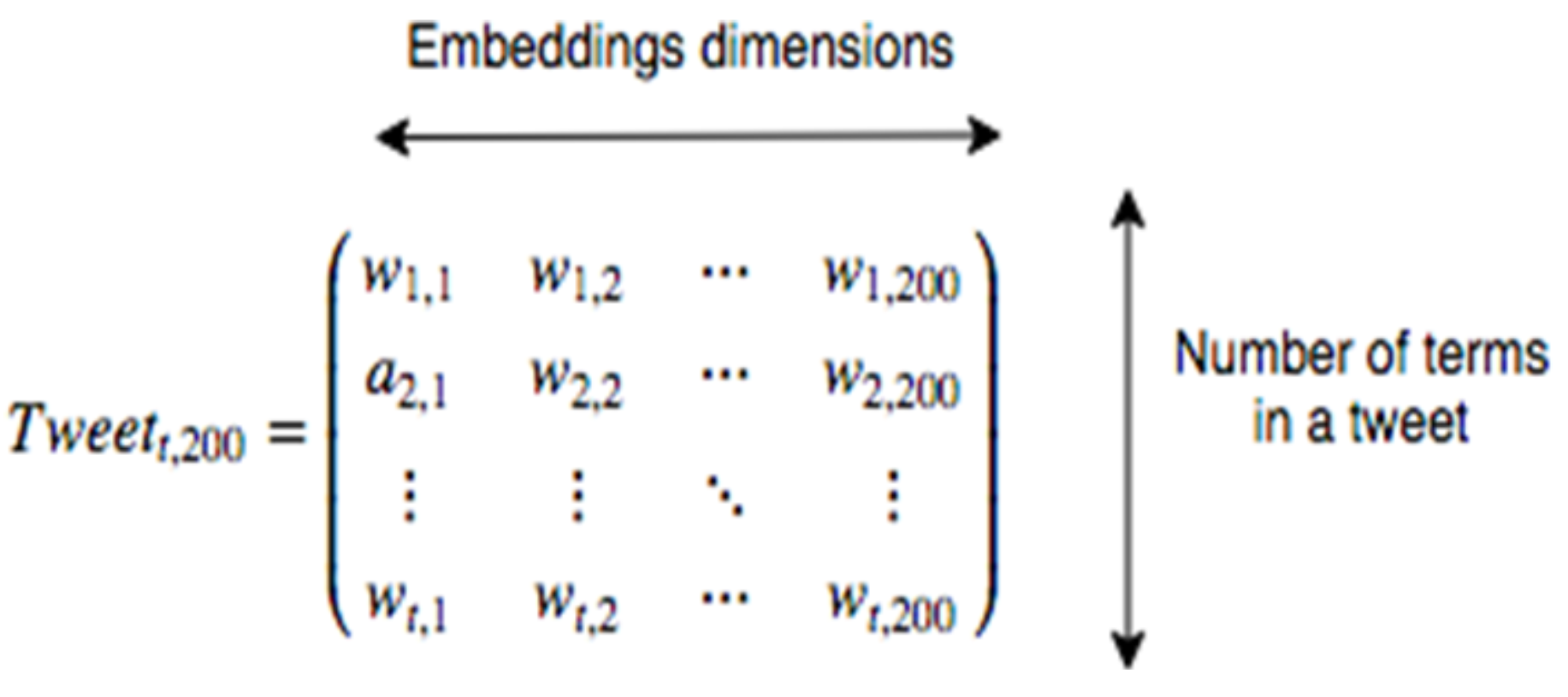
- Embeddings-based: Words, emojis, suffixes, and tokens embeddings are obtained using word2vec. These embeddings can be extended by attaching them POS tags (transformed using one-hot encoding) and Text Frequency-Inverse Document Frequency (tf-idf) Kusner et al. [61] information. Tf-idf represents the importance of a term in a document relative to the whole corpus. It is based on the idea that a term that appears many times inside a document must be relevant for that document, but if it appears many times in other documents, its relevance decreases.
3.5. Feature Selection
3.6. Document Classification
- Logistic regression (LR) uses features(predictors) for building a linear model that estimates the probability that an observation belongs to a class. It is possible to apply feature selection or shrinkage by introducing L1 (lasso) or L2 (ridge) penalizations, respectively.
- Random Forests (RF): Ensemble classifiers whose construction is based on the use of several decision trees [68]. Each decision tree is trained with a sample bootstrapped from the training dataset and using a random subset of the features. Decision trees partition the factor space according to value tests, therefore resulting in a nonlinear classification. The nodes of the trees are determined so as to maximize the information gain. There are different criteria for determining this information gain being Gini and entropy two of the most common.
- Support Vector Machines (SVM) are classifiers whose result is based on a decision boundary generated by support vectors, i.e., the points closest to the decision boundary. The shape of the boundary is determined by a kernel function. In this way, it is possible to solve problems that cannot be solved by a linear boundary. Intuitively, a good separation is achieved by the hyperplane that has the largest distance to the support vectors, as, in general, the larger the margin the lower the generalization error of the classifier.
- Linear Discriminant Analysis (LDA) is a classifier based on Bayes’ theorem, which requires modeling the distribution function of continuous features. Classification is made by using Bayes’ rule to compute the posterior probability of each class, given the vector of the observed attribute values. Bayes rule assumes that the features are conditionally independent given the category.
- Quadratic Discriminant Analysis (QDA), as LDA, is a classifier based on Bayes’ theorem. However, QDA assumes that each class has its own covariance matrix.
- Neural Networks are one of the most popular classifiers currently used in ML and crime prediction [69]. There are two important types of neural networks: (i) Feedforward Networks (FFN), that have no loops and (ii) Recurrent Neural Networks (RNN), which both process sequences of data and take into account the instant of time that each piece of data is processed. Therefore, they are more useful for solving NLP problems. In these types of network, the output of the neurons is not only based on the input values, but also on the previous outputs. For this reason, RNN are generally trained using back-propagation through time (BPTT) [70].
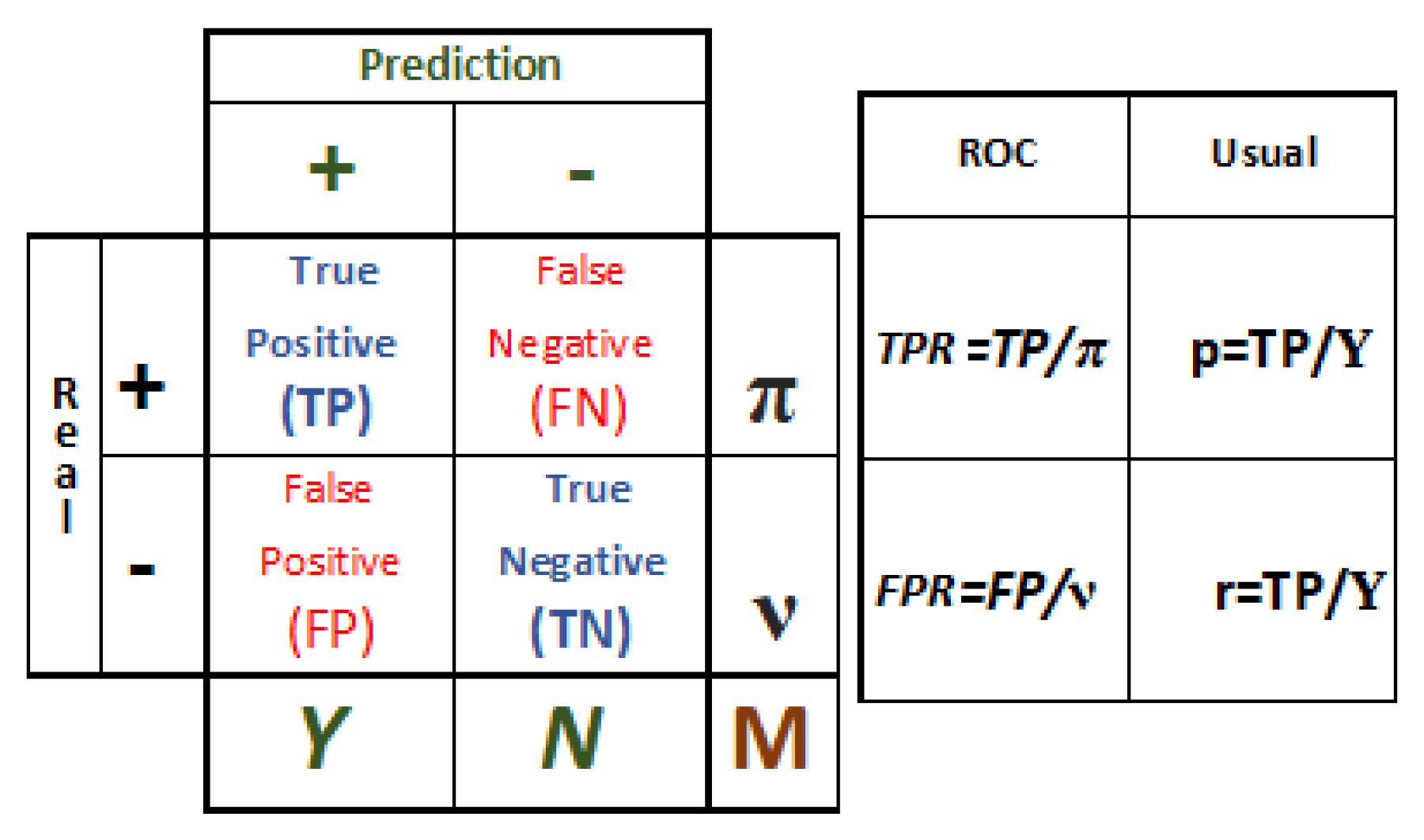
Classification Metrics
- Accuracy measures the overall performance of the classifier.Unfortunately, accuracy is not a significant performance measure when the dataset is imbalanced. Thus, other metrics, such as the following, should be considered.
- Precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances:
- Recall (also called sensitivity or true positive rate) is the fraction of relevant instances that have been retrieved over the total amount of relevant instances:
- F1 score is the harmonic mean of precision and recall:
- False positive rate is the fraction of nonrelevant instances that are consider relevant over the total amount of relevant instances:
- ROC curve and Area under the ROC curve (also called AUC or AUCROC). The ROC curve is obtained by plotting the true positive rate (TPR) against the false positive rate (FPR). The AUC is the area under the resulting ROC curve.
4. Hate Speech Detection: Implementation
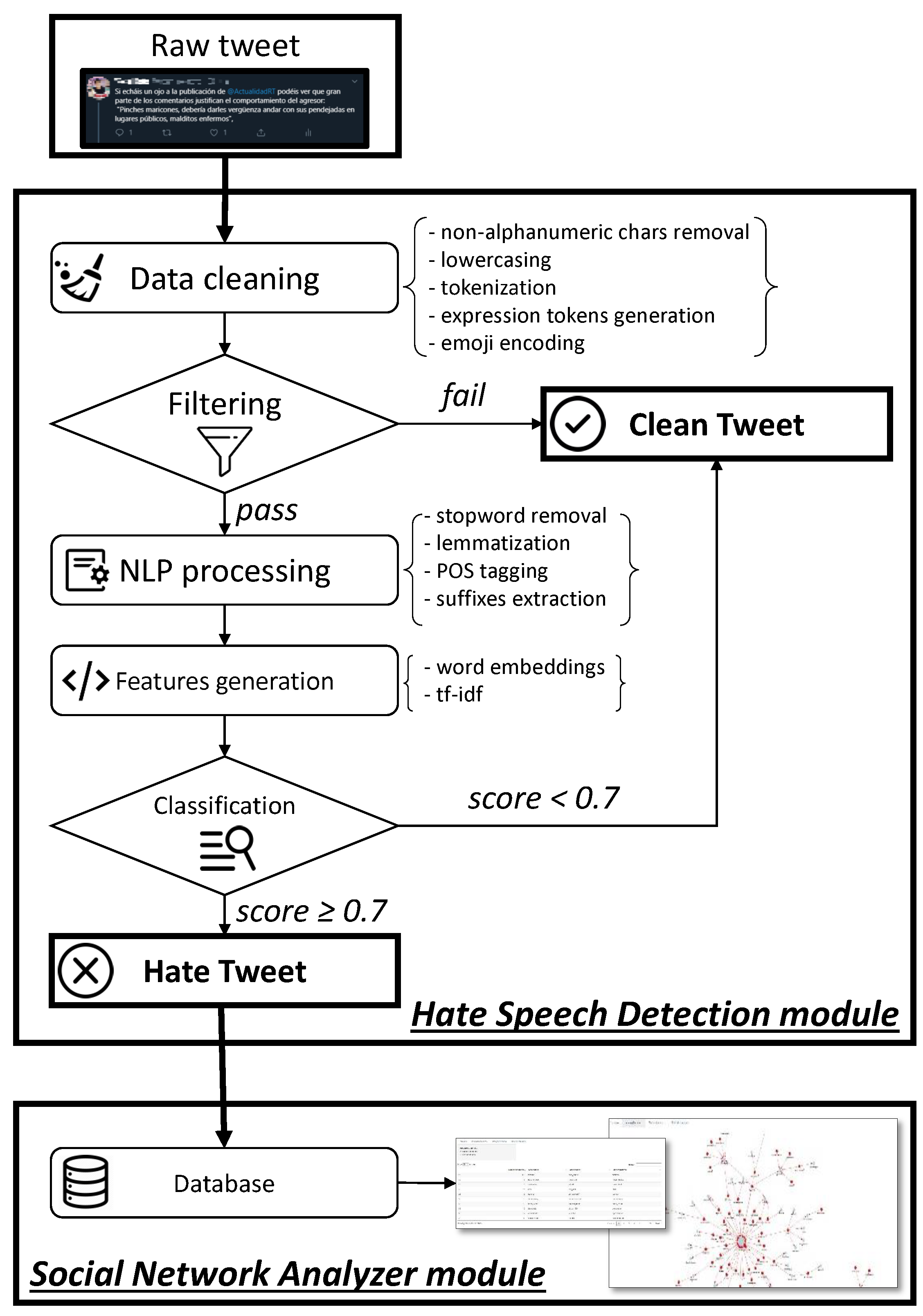
4.1. Tweet Collection and Cleaning
Data Cleaning
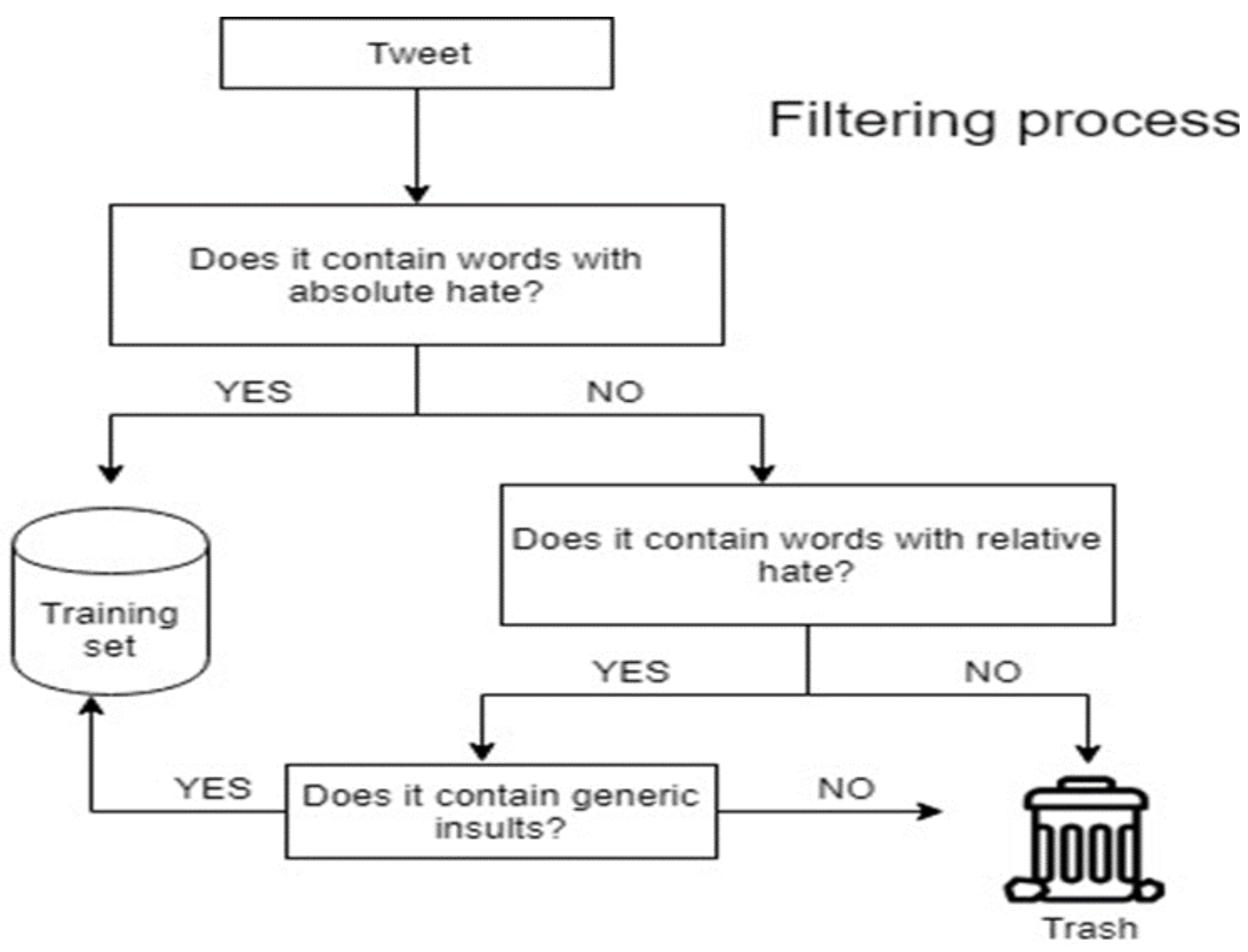
4.2. Tweet Selection
4.3. Tweet Labeling
- -
- Labeler A: 44-year-old, public servant.
- -
- Labeler B: 23-year-old, Psychology graduate.
- -
- Labeler C: 24-year-old, Law graduate.
- -
- Labeler D: 23-year-old, Criminology graduate.
4.4. Tweet Representation
4.4.1. Frequency-Based Representation
4.4.2. Embeddings-Based Representation
4.5. Feature Selection
4.6. Classification
4.6.1. Frequency-Based Representation
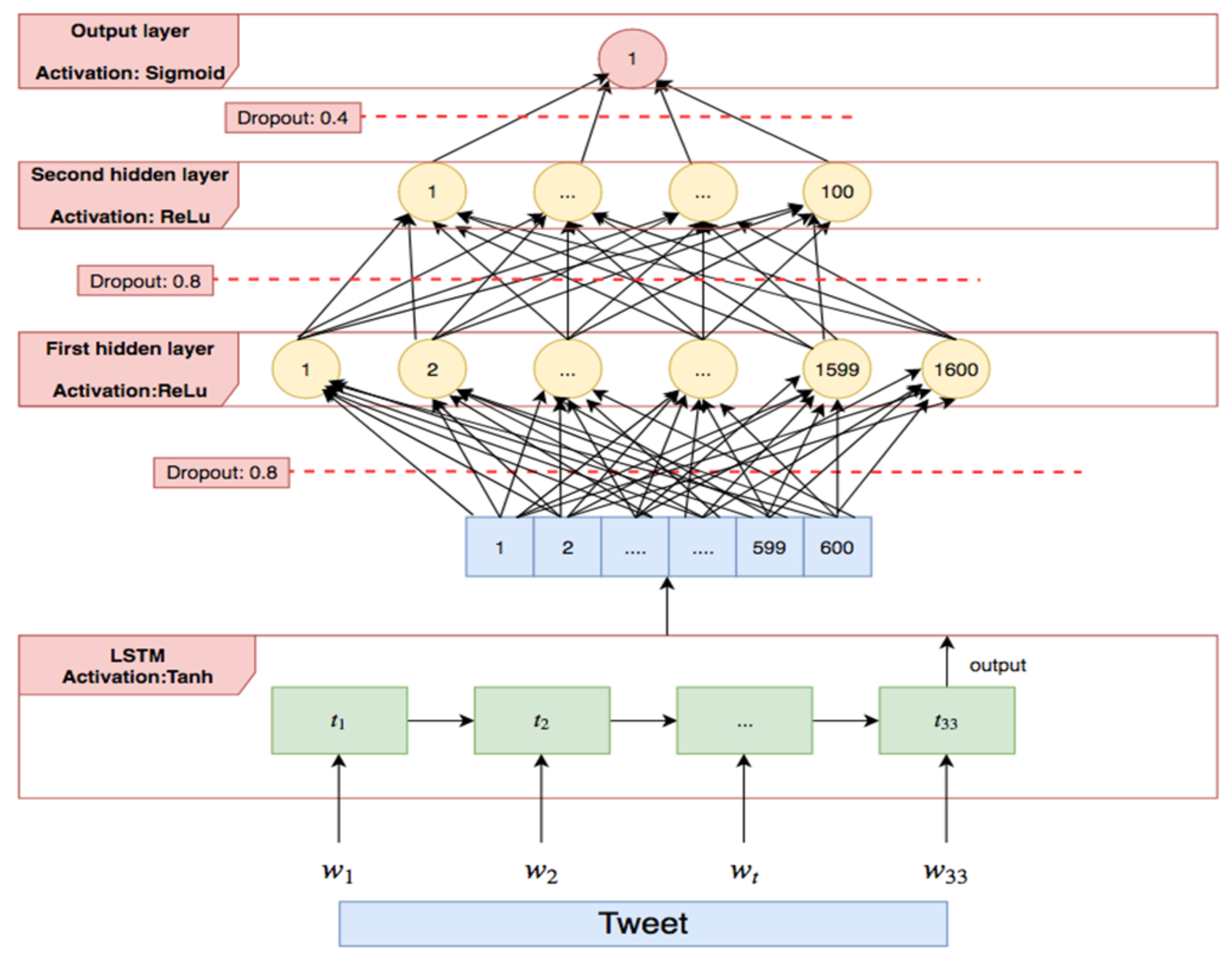
4.6.2. Embeddings-Based Representation
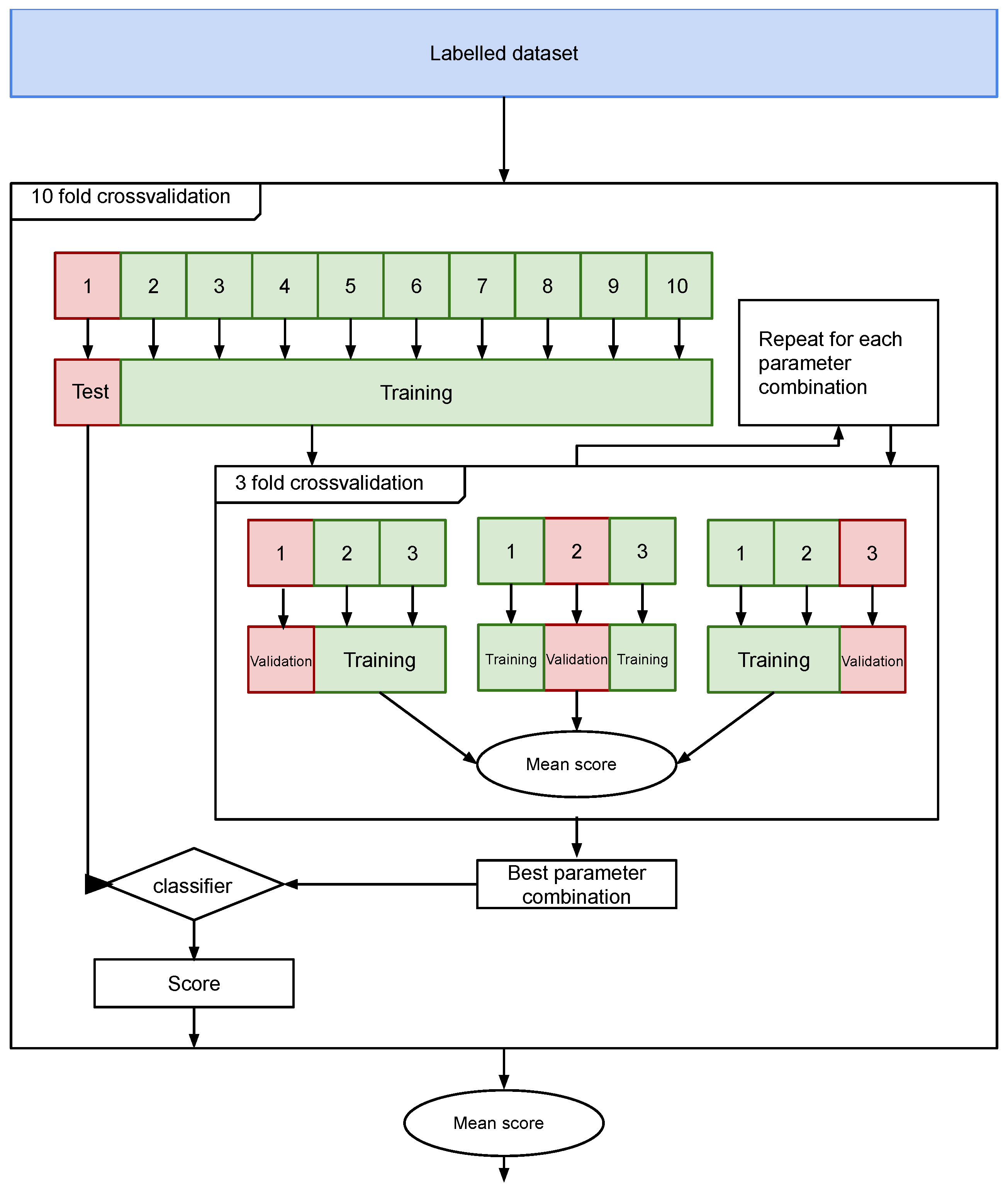
4.6.3. Parameter Estimation
5. Results
5.1. Labelers’ Inter-Rater Agreement
5.2. Word Embeddings Representativeness
5.3. Classifiers’ Performance Results
6. Comparison of HaterNet against State-Of-The-Art Approaches and Discussion
- Regarding the employed datasets, most approaches use the same datasets to compare themselves against [5,6,8,9,10,11]. These datasets were originally proposed in [5], where authors manually annotated 16k tweets labeled as “sexist”, “racist”, or “clean”, and in [6], where authors designed a new dataset of 6k tweets (3k being part of the previous dataset), using both expert and amateur annotators. These datasets, along with the one presented in [7], are, to the best of our knowledge, the only publicly available hate speech datasets. Unfortunately, it is no longer possible to use the first two datasets as benchmarks as the authors provided only the ids of the tweets to be downloaded; as also reported in [8], Twitter has deleted several of them, mainly due to their offensive content. For instance, out of Waseem and Hovy [5] original 16k tweets, only 11k are available. Therefore, it is not possible to compare to the results reported using these datasets. This reality stresses the importance of one of this paper’s contributions, that is, the necessity of providing open datasets for reproducibility and benchmarking.
- Regarding the inter-annotator agreement, only the datasets described in [5,56] reported their coefficient being 0.57 and 0.26, respectively. Again the lack of details in the related literature hinders more profound and transversal analysis. However, it allows us to (i) conclude that our reported parameter of falls within normal boundaries and (ii) agree with the conclusion reached in Waseem [6], Del Vigna et al. [56], and Ross et al. [55], that the annotation of hate speech is a hard task.
- Regarding the studied features, the models achieving the best results on the datasets in the literature are [9,11]. All of them make use of embeddings: [9] combines character and word embeddings, whereas [11] uses random word embeddings. Also, HaterNet relies on embeddings; specifically, on word, emoji, and expression embeddings. Differently from the previous models, in HaterNet, the embeddings are enriched by adding the tf-idf which, as explained in Section 5.3, helps the classification and improves the performance of the embedding-based models. This analysis suggests that, in the context of hate speech detection in Twitter, embedding-based methods outperform frequency-based models.
- Regarding the implemented classification approaches, different classical machine learning models have been studied throughout the years, with LR, NB, DT, RF, and SVM being the most common Most studies have so far reported that SVM outperforms the others; this is the case in [7,53,57]. However, as pointed out by [7], LR has the advantage of allowing a more transparent and comprehensible interpretation of the results, being the observed performance sometimes even better or not significantly different. Our results reported in Table 6 and [23] support this affirmation.Also, a significant group of researchers have applied neural network-based approaches to implement classifiers that detect hate speech in social media content [8,9,10,11,56]. When comparing this approaches to other machine learning methods, the performance of NN clearly outperforms the latter; this conclusion is supported by this paper’s results and those of the related literature [10].
- Regarding this paper’s novelty and contribution with respect to other hate classifiers, as previously mentioned, not having public datasets makes it difficult to benchmark. Besides, the lack of details given in the papers in the literature also makes it difficult to reproduce their results; this is, for example, in the case of [9]. As previously reported in Section 2.4, only three of the reviewed papers provide the source code or enough implementation details). However, the approaches presented in [5,6,7,52,53,54,57] make use of either LR, SVM, NB, or RF methods. These have been shown, both in [10,11,56] and in this research, to be inferior when compared to NN methodologies. Therefore, we can conclude that this paper’s model would essentially outperform all of them.With regards to the papers that implement a NN approach, all of them, except for [56], test their approaches on common previously published datasets. However, it is currently not possible to obtain all the tweets comprising the datasets as some of them have been removed from Twitter, as previously explained. Due to the impossibility of testing our best model on these datasets, a fair comparison could be obtained by testing the best models in the literature [9,11] on our dataset. However, as mentioned earlier, [9] does not provide neither the source code nor sufficient details for the reimplementation of their methodology. Therefore, we could test on our dataset only the combination of LSTM with Random Embedding and GBDT by Badjatiya et al. [11]. The results are illustrated in Table 8.The model by Badjatiya et al. [11] obtains an AUC of 0.788, which is inferior to the AUC obtained by our best model, 0.828. Therefore, in the context of our data, model 7 is preferable to the model by Badjatiya et al. [11].The main difference between these models is that, in the case of Badjatiya et al. [11], the word embeddings are generated using only the labeled tweets; whereas, in the present case, we use the full dataset of 2M tweets. A second significant discrepancy is that Badjatiya et al. [11] generate document embeddings by averaging the word embedding, which could result in a significant loss of information. Finally, we include emojis and tokens embeddings and enrich all the embeddings with additional tf-idf information. These differences in the implementation could cause the gap in terms of performance and should be further investigated in future research.All in all, to the best of our knowledge, it can be concluded that our double deep learning approach, which uses token embeddings enriched with the tf-idf, outperforms the best models from the literature on text classification.
7. Social Network Analyzer
- The Hate Speech Detection module output, i.e., the set of tweets classified as hate speech containers and the associated probability.
- The most common terms in the selected tweets, their frequency, and a list of the document indexes where they appear. This ranking only includes adjectives, nouns, and emojis.
- Word embeddings reduced to two dimensions using a t-distributed stochastic neighbor embedding (t-SNE) technique, which is a dimensional reduction technique for maintaining relative distances between words in the new space [92].
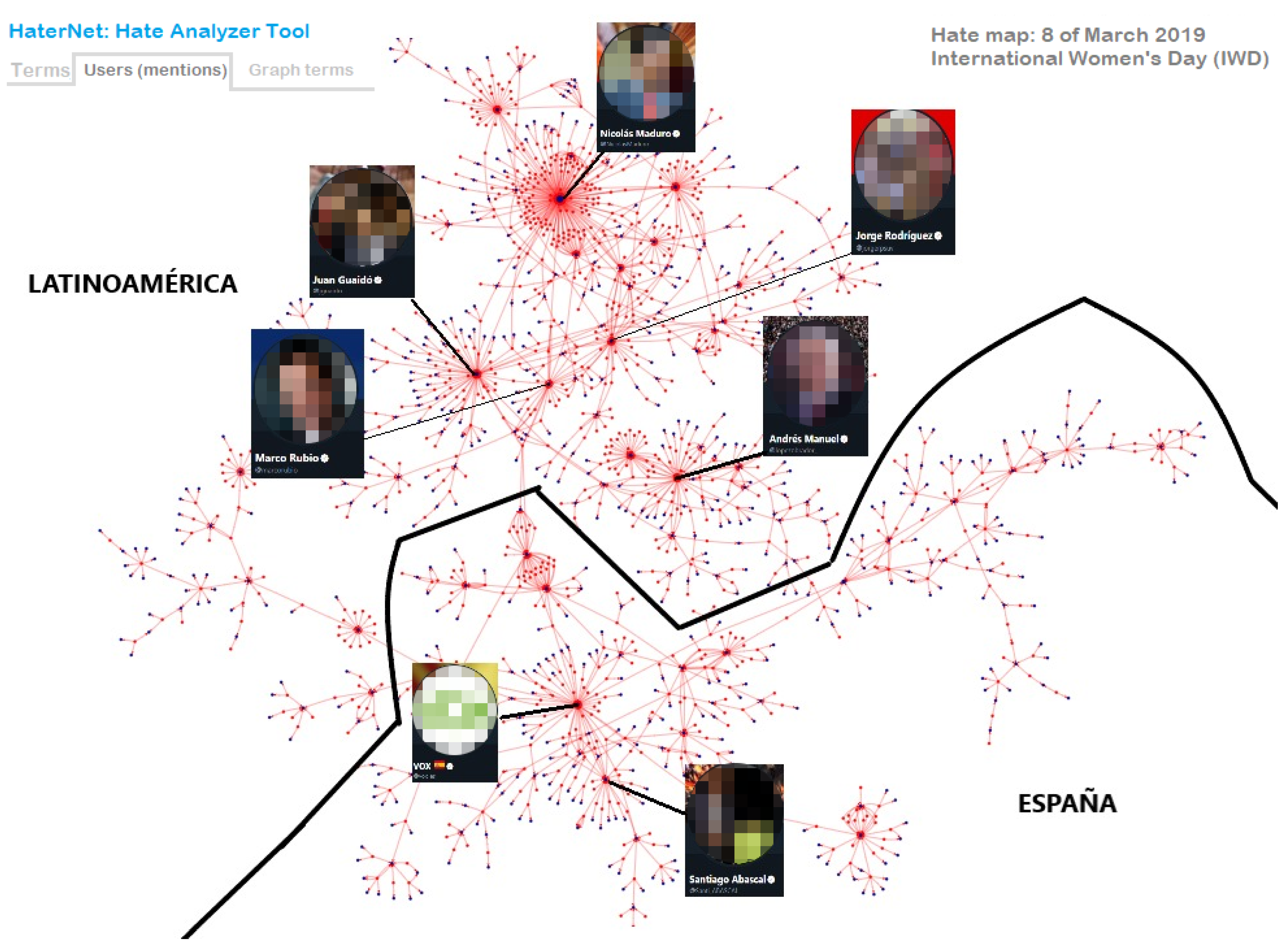
- A directed graph built on user’s mentions. In the graph, nodes represent users and an arc (A,B) is created when user A mentions B in a tweet.
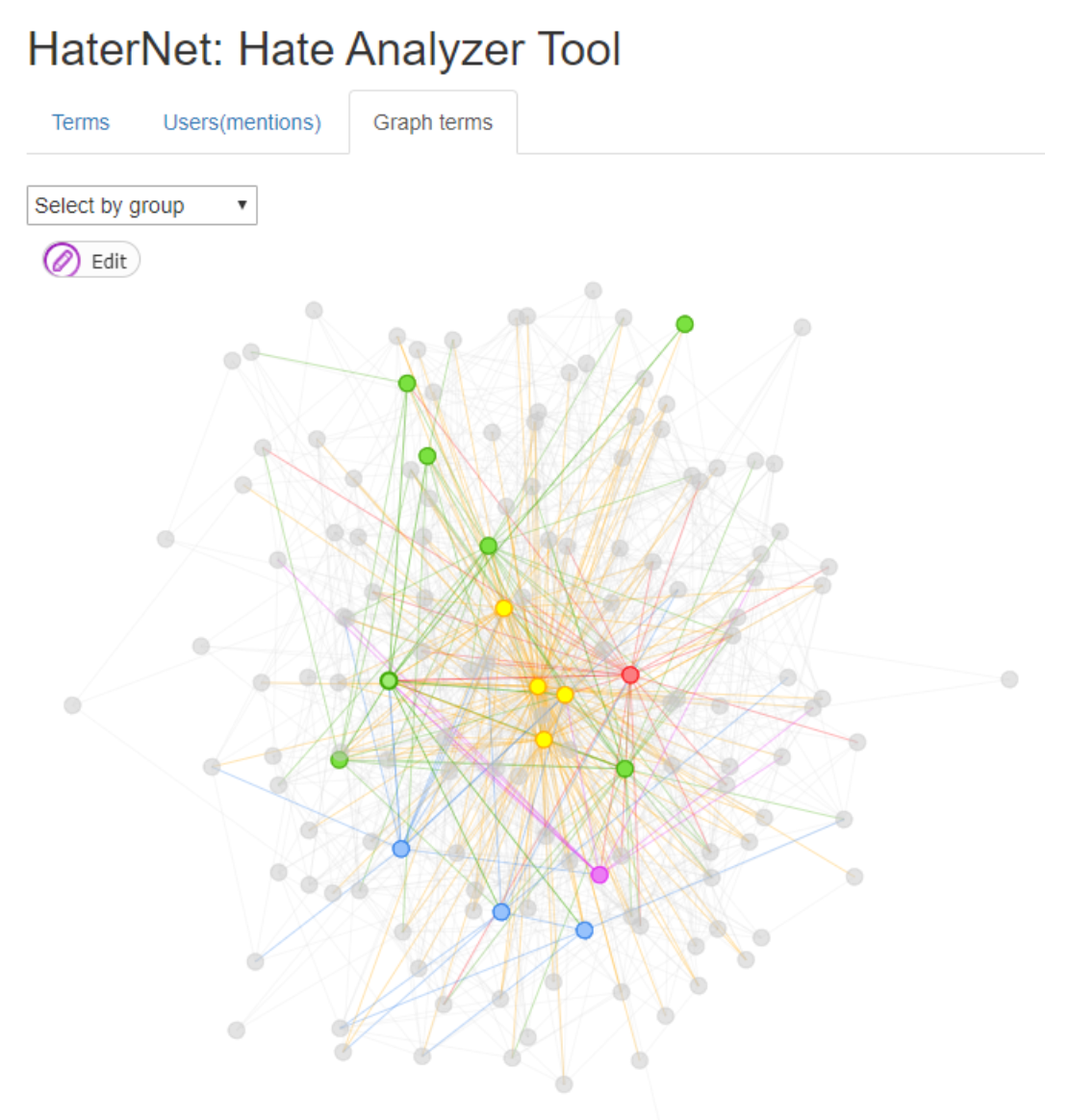
- A non-directed words concurrency graph based on document appearance. In the graph, the nodes represent words and two nodes are connected by an edge if the corresponding words appear in the same tweet.
7.1. Word Cloud Tab
7.2. Users’ Mentions Tab
7.3. Terms’ Tab
7.4. Applications
- Analysis of tweets tagged by HaterNet as hate speech containers including their symbology (e.g., emojis).
- Analysis and classification of “tweeter” communities that share messages with toxic content, as well as the permanence and evolution of hate speech in networks produced by a relevant social events.
- Statistics on relevant events, words and terms, used as a support tool for the police units with Twitter “Trusted Flagger” licenses, for the elimination of hate content.
8. Implemented Architecture
9. Conclusions
- Classification of tweets according to the type of hate expressed, e.g., racist, homophobic, and xenophobic. This classification could be used as an open source of information by organizations, observatories, or specialized NGOs.
- Adapting the system to other domains aimed at police investigation, e.g., terrorism, gender violence, or cyberbullying.
- Strengthening knowledge and capacities of institutions and civil society by having an online hate speech thermometer.
- Establishing an early warning alert that allows to take action against the potential impact of hate speech.
- Understanding the correlation between hate speech and crimes with hate motivation finally reported to the police. This would allow testing of the hypothesis that hate speech is the prelude to hate crime.
- Automatically removing toxic content from SM, or penalizing its appearance in the rankings. Also, HaterNet could be used to identify possible criminal content, as a previous step to safeguarding this information, and then pursuit of possible legal prosecution.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SM | Social Media |
| SES | Security of the Ministry of Interior |
| SNOAHC-SES | Spanish National Office Against Hate Crimes |
| NLP | Natural Language Processing |
| ML | Machine Learning |
| DNN | deep neural network |
| KDE | Kernel Density Estimation |
| BOW | Bag Of Words |
| POS | Part-of-Speech tagging |
| AUC | Area Under the Curve |
| SVM | Support Vector Machines |
| CNN | Convolutional Neural Network |
| RF | Random Forests |
| DT | Decision Trees |
| LDA | Linear Discriminant Analysis |
| QDA | Quadratic Discriminant Analysis |
| FNN | Feedforward Networks |
| RNN | Recurrent Neural Networks |
| BPTT | back-propagation through time |
| GDBT | Gradient Boosted Decision Trees |
| MLP | Multilayer Perceptron |
| LSTM | Long Short-Term Memory |
| GRU | GRU Gated Recurrent Unit Networks |
| LR | Logistic Regression |
References
- Office of the United Nations High Commissioner for Human Rights. Report of the United Nations High Commissioner for Human Rights on the Expert Workshops on the Prohibition of Incitement to National, Racial or Religious Hatred; Office of the United Nations High Commissioner for Human Rights: Geneva, Switzerland, 2013. [Google Scholar]
- Downs, A. 2.1. Up and Down with Ecology: The” Issue-Attention Cycle. In The Politics of American Economic Policy Making; Peretz, P., Ed.; M.E. Shape, Inc: Armonk, NY, USA, 1996; Volume 48. [Google Scholar]
- Sui, X.; Chen, Z.; Wu, K.; Ren, P.; Ma, J.; Zhou, F. Social media as sensor in real world: Geolocate user with microblog. In Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 229–237. [Google Scholar]
- Scanlon, J.R.; Gerber, M.S. Forecasting violent extremist cyber recruitment. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2461–2470. [Google Scholar] [CrossRef]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? Predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 13–15 June 2016; pp. 88–93. [Google Scholar]
- Waseem, Z. Are you a racist or am i seeing things? annotator influence on hate speech detection on twitter. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 5 November 2016; pp. 138–142. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017. [Google Scholar]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 30 July-4 August 2017; pp. 85–90. [Google Scholar]
- Park, J.H.; Fung, P. One-step and Two-step Classification for Abusive Language Detection on Twitter. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 41–45. [Google Scholar]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on twitter using a convolution-gru based deep neural network. In European Semantic Web Conference; Springer: Cham, Switzerland, 2018; pp. 745–760. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep learning for hate speech detection in tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Fortuna, P.; Nunes, S. A survey on automatic detection of hate speech in text. ACM Comput. Surv. CSUR 2018, 51, 85. [Google Scholar] [CrossRef]
- Kaminski, M.E. The right to explanation, explained. Berkeley Tech. LJ 2019, 34, 189. [Google Scholar] [CrossRef]
- Sap, M.; Card, D.; Gabriel, S.; Choi, Y.; Smith, N.A. The risk of racial bias in hate speech detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, July 28–2 August 2019; pp. 1668–1678. [Google Scholar]
- Schwartz, H.A.; Ungar, L.H. Data-driven content analysis of social media: A systematic overview of automated methods. ANNALS Am. Acad. Political Soc. Sci. 2015, 659, 78–94. [Google Scholar] [CrossRef]
- Yoon, H.G.; Kim, H.; Kim, C.O.; Song, M. Opinion polarity detection in Twitter data combining shrinkage regression and topic modeling. J. Inf. 2016, 10, 634–644. [Google Scholar] [CrossRef]
- Franch, F. (Wisdom of the Crowds) 2: 2010 UK election prediction with social media. J. Inf. Technol. Politics 2013, 10, 57–71. [Google Scholar] [CrossRef]
- He, W.; Guo, L.; Shen, J.; Akula, V. Social media-based forecasting: A case study of tweets and stock prices in the financial services industry. J. Organ. End User Comput. JOEUC 2016, 28, 74–91. [Google Scholar] [CrossRef]
- Perry, W.L. Predictive Policing: The Role of Crime Forecasting in Law Enforcement Operations; Rand Corporation: Santa Monica, CA, USA, 2013. [Google Scholar]
- Cohen, J.; Gorr, W.L.; Olligschlaeger, A.M. Leading indicators and spatial interactions: A crime-forecasting model for proactive police deployment. Geogr. Anal. 2007, 39, 105–127. [Google Scholar] [CrossRef]
- Yu, C.H.; Ward, M.W.; Morabito, M.; Ding, W. Crime forecasting using data mining techniques. In Proceedings of the International Conference on Data Mining, ICDM’11, Vancouver, BC, Canada, 11 December 2011; pp. 779–786. [Google Scholar]
- Kang, H.W.; Kang, H.B. Prediction of crime occurrence from multi-modal data using deep learning. PLoS ONE 2017, 12, e0176244. [Google Scholar] [CrossRef]
- Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, J.; Camacho-Collados, M. Applying automatic text-based detection of deceptive language to police reports: Extracting behavioral patterns from a multi-step classification model to understand how we lie to the police. Knowl.-Based Syst. 2018, 149, 155–168. [Google Scholar] [CrossRef]
- Chainey, S.; Tompson, L.; Uhlig, S. The utility of hotspot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, F.; Guin, C.; Zhu, H. A spatio-temporal kernel density estimation framework for predictive crime hotspot mapping and evaluation. Appl. Geogr. 2018, 99, 89–97. [Google Scholar] [CrossRef]
- Camacho-Collados, M.; Liberatore, F. A decision support system for predictive police patrolling. Decis. Support Syst. 2015, 75, 25–37. [Google Scholar] [CrossRef]
- Mohler, G.O.; Short, M.B.; Brantingham, P.J.; Schoenberg, F.P.; Tita, G.E. Self-exciting point process modeling of crime. J. Am. Stat. Assoc. 2011, 106, 100–108. [Google Scholar] [CrossRef]
- Bendler, J.; Ratku, A.; Neumann, D. Crime Mapping through Geo-Spatial Social Media Activity. In Proceedings of the Thirty FifthInternational Conference on Information Systems, Auckland, New Zwaland, 14–17 December 2014. [Google Scholar]
- De Choudhury, M.; Sundaram, H.; John, A.; Seligmann, D.D. Analyzing the dynamics of communication in online social networks. In Handbook of Social Network Technologies and Applications; Springer: Boston, MA, USA, 2010; pp. 59–94. [Google Scholar]
- Bermingham, A.; Smeaton, A. On using Twitter to monitor political sentiment and predict election results. In Proceedings of the Workshop on Sentiment Analysis Where AI meets Psychology (SAAIP 2011), Chiang Mai, Thailand, 13 November 2011; pp. 2–10. [Google Scholar]
- St Louis, C.; Zorlu, G. Can Twitter predict disease outbreaks? BMJ 2012, 344, e2353. [Google Scholar] [CrossRef]
- Kalampokis, E.; Tambouris, E.; Tarabanis, K. Understanding the predictive power of social media. Internet Res. 2013, 23, 544–559. [Google Scholar] [CrossRef]
- Culotta, A. Towards detecting influenza epidemics by analyzing Twitter messages. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, Canada, 25–28 July 2010; pp. 115–122. [Google Scholar]
- Wang, X.; Brown, D.E.; Gerber, M.S. Spatio-temporal modeling of criminal incidents using geographic, demographic, and Twitter-derived information. In Proceedings of the 2012 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 11–14 June 2012; pp. 36–41. [Google Scholar]
- Rui, H.; Whinston, A. Designing a social-broadcasting-based business intelligence system. ACM Trans. Manag. Inf. Syst. TMIS 2011, 2, 22. [Google Scholar] [CrossRef]
- Earle, P.S.; Bowden, D.C.; Guy, M. Twitter earthquake detection: earthquake monitoring in a social world. Ann. Geophys. 2012, 54. [Google Scholar] [CrossRef]
- Choi, H.; Varian, H. Predicting the present with Google Trends. Econ. Rec. 2012, 88, 2–9. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Gerber, M.S. Predicting crime using Twitter and kernel density estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Chen, X.; Cho, Y.; Jang, S.Y. Crime prediction using twitter sentiment and weather. In Proceedings of the Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 24 April 2015; pp. 63–68. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Metaxas, P.T.; Mustafaraj, E.; Gayo-Avello, D. How (not) to predict elections. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 165–171. [Google Scholar]
- Araque, O.; Corcuera-Platas, I.; Sanchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Sahın, E.; Aydos, M.; Orhan, F. Spam/ham e-mail classification using machine learning methods based on bag of words technique. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding deceptive opinion spam by any stretch of the imagination. In Proceedings of the Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 309–319. [Google Scholar]
- Ott, M.; Cardie, C.; Hancock, J.T. Negative Deceptive Opinion Spam. In Proceedings of the HLT-NAACL, 9–14 June 2013; pp. 497–501. [Google Scholar]
- Hernández Fusilier, D.; Montes-y Gómez, M.; Rosso, P.; Guzmán Cabrera, R. Detection of opinion spam with character n-grams. In International Conference on Intelligent Text Processing and Computational Linguistics; Springer: Cham, Switzerland, 2015; pp. 285–294. [Google Scholar]
- Cagnina, L.C.; Rosso, P. Detecting Deceptive Opinions: Intra and Cross-Domain Classification Using an Efficient Representation. Int. J. Uncertainty Fuzziness Knowl.-Based Syst. 2017, 25, 151–174. [Google Scholar] [CrossRef]
- Mihalcea, R.; Strapparava, C. The Lie Detector: Explorations in the Automatic Recognition of Deceptive Language. In Proceedings of the International Joint Conference on Natural Language Processing, AFNLP’09, Singapore, 4 August 2009; pp. 309–312. [Google Scholar]
- Li, J.; Ott, M.; Cardie, C.; Hovy, E. Towards a general rule for identifying deceptive opinion spam. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 1566–1576. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate speech detection with comment embeddings. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 29–30. [Google Scholar]
- Zia, T.; Akram, M.; Nawaz, M.; Shahzad, B.; Abdullatif, A.; Mustafa, R.; Lali, M. Identification of hatred speeches on Twitter. In Proceedings of the 52nd The IRES International Conference, 13 May 2016; pp. 27–32. [Google Scholar]
- Silva, L.; Mondal, M.; Correa, D.; Benevenuto, F.; Weber, I. Analyzing the targets of hate in online social media. In Proceedings of the Tenth International AAAI Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016. [Google Scholar]
- Ross, B.; Rist, M.; Carbonell, G.; Cabrera, B.; Kurowsky, N.; Wojatzki, M. Measuring the reliability of hate speech annotations: The case of the european refugee crisis. arXiv 2017, arXiv:1701.08118. [Google Scholar]
- Del Vigna, F.; Cimino, A.; Dell’Orletta, F.; Petrocchi, M.; Tesconi, M. Hate me, hate me not: Hate speech detection on facebook. In Proceedings of the First Italian Conference on Cybersecurity, Venice, Italy, 17–20 January 2017; pp. 86–95. [Google Scholar]
- Salminen, J.; Almerekhi, H.; Milenković, M.; Jung, S.G.; An, J.; Kwak, H.; Jansen, B.J. Anatomy of online hate: developing a taxonomy and machine learning models for identifying and classifying hate in online news media. In Proceedings of the Twelfth International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Schimid, H. Probabilistic Part-of-Speech Tagging Using Decision Trees. 1994. Available online: https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/data/tree-tagger1.pdf (accessed on 26 October 2019).
- Schmid, H. Spanish Tagset Documentation. 2019. Available online: https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/data/spanish-tagset.txt (accessed on 18 October 2019).
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 957–966. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 454. [Google Scholar]
- Liu, H.; Setiono, R. Feature selection and classification-a probabilistic wrapper approach. In Proceedings of the 9th International Conference on Industrial and Engineering Applications of AI and ES, Fukuoka, Japan, 4–7 June 1996; pp. 419–424. [Google Scholar]
- Uysal, A.K.; Gunal, S. A novel probabilistic feature selection method for text classification. Knowl.-Based Syst. 2012, 36, 226–235. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lin, Y.L.; Yen, M.F.; Yu, L.C. Grid-based crime prediction using geographical features. ISPRS Int. J. Geo-Inf. 2018, 7, 298. [Google Scholar] [CrossRef]
- Haykin, S.S. Neural Networks and Learning Machines/Simon Haykin; Prentice Hall: New York, NY, USA, 2009. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and f-measure to roc., informedness, markedness & correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Twitter Inc. Twitter Developers. 2019. Available online: https://developer.twitter.com/en.html (accessed on 18 October 2019).
- Real Academia Española. Diccionario de la lengua española [Dictionary of the Spanish Language], 23rd ed.; Espasa: Madrid, Spain, 2014. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: New York, NY, USA, 2012. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Cohen, J. Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. Psychol. Bull. 1968, 70, 213. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23-24 June 2014; pp. 55–60. [Google Scholar]
- Narayanan, V.; Arora, I.; Bhatia, A. Fast and accurate sentiment classification using an enhanced Naive Bayes model. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2013; pp. 194–201. [Google Scholar]
- Smedt, T.D.; Daelemans, W. Pattern for python. J. Mach. Learn. Res. 2012, 13, 2063–2067. [Google Scholar]
- Loria, S. Textblob Documentation. 2018. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/dev/textblob.pdf (accessed on 26 October 2019).
- Kathuria, P. Sentiment wsd github repository. 2015. Available online: https://github.com/kevincobain2000/sentiment$_$classifier (accessed on 26 October 2019).
- Hutto, C.J.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gold. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), Turin, Italy, 3 December 2013. [Google Scholar]
- Otte, E.; Rousseau, R. Social network analysis: A powerful strategy, also for the information sciences. J. Inf. Sci. 2002, 28, 441–453. [Google Scholar] [CrossRef]
- Heidemann, J.; Klier, M.; Probst, F. Online social networks: A survey of a global phenomenon. Comput. Netw. 2012, 56, 3866–3878. [Google Scholar] [CrossRef]
- Hachaj, T.; Ogiela, M.R. Clustering of trending topics in microblogging posts: A graph-based approach. Future Gener. Comput. Syst. 2017, 67, 297–304. [Google Scholar] [CrossRef]
- Sasaki, Y.; Kawai, D.; Kitamura, S. The anatomy of tweet overload: How number of tweets received, number of friends, and egocentric network density affect perceived information overload. Telemat. Inform. 2015, 32, 853–861. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Xing, W.; Ghorbani, A. Weighted pagerank algorithm. In Proceedings of the Second Annual Conference on Communication Networks and Services Research, Fredericton, NB, Canada, 21 May 2004; pp. 305–314. [Google Scholar]
- Choudhury, D.; Paul, A. Community detection in social networks: An overview. Int. J. Res. Eng. Technol. 2013, 2, 6–13. [Google Scholar]
- Pérez Colomé, J. This Is How Hate Spreads When There Are Elections in Spain (Así se reparte el odio cuando hay elecciones en España). 2019. Available online: https://elpais.com/tecnologia/2019/05/28/actualidad/1559039892_332196.html (accessed on 18 October 2019).
- La Moncloa (Spanish Presidency). The Secretary of State for the Digital Advancement Organizes a Conference on Protection of LGTBI Rights on the Internet (La Secretaría de Estado para el Avance Digital organiza una jornada sobre protección de derechos LGTBI en Internet). 2019. Available online: http://www.mineco.gob.es/portal/site/mineco/menuitem.ac30f9268750bd56a0b0240e026041a0/?vgnextoid=b1ad544a1929b610VgnVCM1000001d04140aRCRD&vgnextchannel=864e154527515310VgnVCM1000001d04140aRCRD (accessed on 18 October 2019).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | Features | Model | Dataset | Available | Accuracy | Precision | Recall | F1 Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|
| Djuric et al. [52] | 2015 | BOW, TF, TF-IDF, paragraph2vec embeddings | LR | 951,736 Yahoo Finance user comments | No | - | - | - | - | 0.8007 |
| Zia et al. [53] | 2016 | unigrams, TF-IDF, retweets, favourites, page autenticity | SVM, NB, kNN | tweets | No | - | 0.971 | 0.97 | 0.971 | - |
| Silva et al. [54] | 2016 | sentence structure | rule based | 27.55M whispers and 512M tweets, unlabeled. 100 labeled messages. | No | - | 1 | - | - | - |
| Waseem and Hovy [5] | 2016 | Author gender, length of tweets, length of user description, location, char n-grams, word n-grams | LR | 16,914 annotated tweets | Yes * | - | 0.7293 | 0.7774 | 0.7393 | - |
| Waseem [6] | 2016 | char n-grams, word n-grams, skip-grams, tweet length, author gender, clusters, POS, Author Historical Salient Terms (AHST) | LR | 6909 annotated tweets | Yes * | - | 0.9250 | 0.9249 | 0.9119 | - |
| Badjatiya et al. [11] | 2017 | char n-grams, TF-IDF, BoWV, random embeddings, GloVe embeddings | LR, RF, SVM, GBDT, DNN, CNN, LTSM | [5] | Yes * | - | 0.930 | 0.930 | 0.930 | - |
| Davidson et al. [7] | 2017 | n-grams, TF-IDF, POS, readability, sentiment, hashtags, mentions, retweets, URLs, length | LR, NB, DT, RF, SVM | 24,802 labeled tweets | Yes | - | 0.91 | 0.90 | 0.90 | - |
| Gambäck and Sikdar [8] | 2017 | word2vec embeddings, random embeddings, char n-grams | CNN | 6655 tweets from [6] | Yes | - | 0.8566 | 0.7214 | 0.7829 | - |
| Park and Fung [9] | 2017 | char embeddings, word embeddings | CharCNN, WordCNN, and HybridCNN | [5,6] | Yes * | - | 0.827 | 0.827 | 0.827 | - |
| Del Vigna et al. [56] | 2017 | POS, sentiment analysis, word2vec embeddings, CBOW, n-grams, text features, word polarity | SVM, LSTM | 6502 annotated Facebook comments | No | 0.7523 | 0.732 | 0.7371 | 0.731 | - |
| Salminen et al. [57] | 2018 | n-grams, semantic and syntactic, TF-IDF, word2vec embeddings, doc2vec embeddings | LR, DT, RF, Adabost, SVM | 5143 labeled comments YouTube and Facebook videos | No | - | - | - | 0.96 | - |
| Zhang et al. [10] | 2018 | n-grams, POS, TF-IDF, mentions, hastags, length, readability, sentiment, mispellings, emojis, punctuation, capitalisation, word embeddings | SVM, CNN + GRU | [5,6,7] and 2435 annotated tweets | Yes * [5]; Yes * [6]; Yes [7]; No [10] | - | - | - | 0.82 in [5]; 0.92 in [6]; 0.82 in [5,6]; 0.94 in [7]; 0.92 in [10] | - |
| Semantic | Token Type |
|---|---|
| URL | TOKENURL |
| Mention | USER |
| Hashtag | HASHTAG |
| Question mark | TOKENQUES |
| Exclamation mark | TOKEXC |
| Laughing face: XD | TOKENXD |
| Quotation marks | TOKENCOMI |
| Laughs: jaja, ajaj, jajaj | TOKENLAUGH |
| Surprise: WTF, wtf | TOKENWTF |
| Emoji | Code |
|---|---|
 | :smiling_face_with_open_mouth: |
 | :kissing_face_with_closed_eyes: |
 | :pile_of_poo: |
 | :oncoming_fist::light_skin_tone: |
 | :oncoming_fist::dark_skin_tone: |
| Term\Nearest n. | 1st | 2nd | 3rd | 4th | 5th |
|---|---|---|---|---|---|
| red | yellow | green | blue | orange | white |
| head | back | leg | neck | belly | stomach |
| january | march | september | february | june | august |
| samsung | galaxy | xiaomi | lg | snapdragon | huawei |
| food | dinner | supper | snack | eat | breakfast |
| messi | neymar | ney | cristiano | umtiti | mathieu |
| Reference Embedding | Nearest Neighbor |
|---|---|
| smacker |  |
| sandwich |  |
 | shit |
 |  |
| Model ID | Features Type | Features Considered | Classification Model | Classification Threshold | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|---|---|---|
| #1 | Frequency based | Unigrams, POS tags | Ridge R. | 0.5 | 0.655 | 0.382 | 0.483 | 0.798 |
| #2 | SVM | 0.685 | 0.329 | 0.445 | 0.79 | |||
| #3 | RF | 0.809 | 0.167 | 0.277 | 0.769 | |||
| #4 | QDA | 0.341 | 0.789 | 0.476 | 0.651 | |||
| #5 | LDA | 0.641 | 0.42 | 0.507 | 0.796 | |||
| #6 | Embeddings based | Words, emojis, and expression tokens | LSTM+MLP | 0.62 | 0.572 | 0.595 | 0.823 | |
| #7 | Words, emojis, expression tokens, and tf-idf | 0.625 | 0.598 | 0.611 | 0.828 | |||
| #8 | Frequency based | Unigrams, POS tags, suffixes, emojis, expression tokens | Ridge R. | 0.639 | 0.417 | 0.505 | 0.794 | |
| #9 | SVM | 0.629 | 0.392 | 0.483 | 0.777 | |||
| #10 | RF | 0.746 | 0.165 | 0.27 | 0.766 | |||
| #11 | QDA | 0.386 | 0.71 | 0.5 | 0.71 | |||
| #12 | LDA | 0.622 | 0.422 | 0.503 | 0.79 | |||
| #13 | Embeddings based | Words, emojis, expression tokens, suffixes, POS tags, tf-idf | LSTM+MLP | 0.625 | 0.598 | 0.611 | 0.828 | |
| #14 | Frequency based | Unigrams, POS tags, suffixes, emojis, expression tokens | Ridge R. | 0.7 | 0.794 | 0.219 | 0.343 | 0.794 |
| #15 | SVM | 0.786 | 0.19 | 0.306 | 0.777 | |||
| #16 | RF | 1 | 0.005 | 0.001 | 0.766 | |||
| #17 | QDA | 0.382 | 0.72 | 0.495 | 0.71 | |||
| #18 | LDA | 0.741 | 0.272 | 0.398 | 0.079 | |||
| #19 | Embeddings based | Words, emojis, expression tokens, suffixes, POS tags, tf-idf | LSTM+MLP | 0.784 | 0.333 | 0.467 | 0.828 |
| Dataset | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| Vader | 0.923 | 0.890 | 0.906 | 0.925 |
| STS-Gold | 0.898 | 0.888 | 0.893 | 0.914 |
| Threshold | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| 0.7 | 0.787 | 0.123 | 0.212 | 0.782 |
| 0.5 | 0.647 | 0.394 | 0.490 | 0.782 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and Monitoring Hate Speech in Twitter. Sensors 2019, 19, 4654. https://doi.org/10.3390/s19214654
Pereira-Kohatsu JC, Quijano-Sánchez L, Liberatore F, Camacho-Collados M. Detecting and Monitoring Hate Speech in Twitter. Sensors. 2019; 19(21):4654. https://doi.org/10.3390/s19214654
Chicago/Turabian StylePereira-Kohatsu, Juan Carlos, Lara Quijano-Sánchez, Federico Liberatore, and Miguel Camacho-Collados. 2019. "Detecting and Monitoring Hate Speech in Twitter" Sensors 19, no. 21: 4654. https://doi.org/10.3390/s19214654
APA StylePereira-Kohatsu, J. C., Quijano-Sánchez, L., Liberatore, F., & Camacho-Collados, M. (2019). Detecting and Monitoring Hate Speech in Twitter. Sensors, 19(21), 4654. https://doi.org/10.3390/s19214654