1. Introduction
Outdoor scene understanding based on mobile laser scanning (MLS) point cloud data are a fundamental ability for unmanned vehicles and autonomous mobile robots navigating in urban environments. Recently, a variety of laser point cloud processing methods have been presented to recognize the main elements of road environment [
1], to accomplish robust place recognition [
2], to extract parameters of trees [
3], and so on. Moreover, the point clouds obtained from a laser scanner can also be utilized to accomplish real-time shape acquisition [
4], outdoor 3D laser data classification [
5], and outdoor scene understanding [
6]. A state-of-the-art review for object recognition, segmentation, and classification of MLS Point Clouds was also given in [
7].
In order to reduce the computational complexity of feature extraction and classification, some scholars have converted 3D laser point clouds into 2D images and used image processing methods to process 3D point clouds, such as range image [
8], reflectance image [
9], and bearing angle image (BA image) [
10]. The BA image was originally used to solve the calibration problem between camera and laser scanner [
10]. Since the BA image has clearer texture details than range image and reflectance image, it is also used to solve the laser point cloud classification problem in outdoor or indoor scenes. Zhuang et al. used a 2D BA image to represent the outdoor 3D point cloud [
11]. By extracting texture features from the BA image, the scene understanding of the 3D point cloud was realized. Zhang et al. studied the problem of 3D object detection in a cluttered indoor environment and transformed the 3D laser point cloud into a 2D BA image, which enabled the robot to complete the task of scene understanding at a lower computational cost [
12]. However, the quality of the BA image depends on the selection of the viewpoint position. If the viewpoint is not selected properly, the image will be indistinct. In addition, the BA image also has the problem of grayscale change for the same object.
It is very important to determine the neighborhood range of laser points for feature extraction [
13]. There are two kinds of neighborhood selection methods: fixed-scale neighborhood selection and multi-scale neighborhood selection. Fixed-scale neighborhood selection depends heavily on experience. If the scale is too small, the whole view cannot be seen clearly. If the scale is too large, the details can easily be ignored [
14]. Therefore, the multi-scale feature extraction of 3D point clouds is a good choice, which is very helpful for improving classification performance.
Many classifiers can be used for point cloud classification, such as Support Vector Machine classifier, Nearest Neighbor classifier, K Nearest Neighbor classifier, and Naive Bayesian classifier [
15]. When the selected feature dimension is very high (over 100 dimensions) and there are a lot of redundant features, the Random Forest classifier can process the high-dimensional data and complete the feature screening [
16]. In addition, some classification methods based on contextual information of the point cloud are also widely used. Munoz et al. proposed a point cloud classification framework based on the Markov Random Field. Based on the contextual information, the classification of vehicular laser point cloud was realized [
17]. Najafi et al. introduced a non-associative higher-order Markov Random Field to address the problem of semantic 3D point classification, which took into account the non-associative geometric context between different classes [
18].
In this paper, a novel image model named PBA image is firstly proposed to represent the MLS point cloud data, which shows superior performance to display a large-scale scene with a panoramic view. Compared with the traditional BA model, the PBA model can still transform the unordered laser scanning data to a 2D image without fixed scan sequence relationships. To improve the accuracy and robustness of scene understanding results, multiple-scale features are extracted not only from the PBA images but also from the corresponding original LiDAR point clouds. In our work, the Random Forest algorithm is adopted to build the classifier which can complete feature screening and improve the generalization ability of classification. After the initial classification, superpixel segmentation is performed on the PBA images, which considers the contextual information between laser points in 2D images. Within each superpixel block, reclassification algorithm is performed based on the results of the initial classification, so as to correct partial misclassification points. A series of experimental results from both ETH Zurich and MINES ParisTech datasets are given to test the validity and robustness of the proposed approach.
2. Panoramic Bearing Angle Images Generating from 3D Laser Point Clouds
Generally speaking, there are two ways to obtain 3D laser point clouds to represent large-scale outdoor scenes in the field of mobile robotics. The first one is to install a 2D laser scanner on a mobile robot to perform on-the-fly scanning or fixed-point scanning. As shown in
Figure 1, the left one is a driverless car using two lateral SICK LMS 511 laser ranger finders (produced by SICK AG, Waldkirch, Germany) to capture groups of sequenced 2D laser points in the on-the-fly scanning mode, while the right one is a mobile robot using a pitch rotating SICK LMS 511 to obtain 3D point clouds in fixed-point scanning mode. In these cases, the 3D point clouds are composed of sequential 2D laser scanning points and can be represented by a matrix, which can be transformed to grayscale images by using the Bearing Angle (BA) image model.
The other method is to use the 3D laser scanner to obtain the 3D point clouds directly. However, these 3D point clouds are composed of several groups of scanning data and are always unordered when stored, so they cannot be represented by a matrix. In addition, in most public laser scanning datasets, there are no scan sequence relationships stored between different laser scans. To solve this problem, a novel Panoramic Bearing Angle (PBA) image model is proposed in this paper and introduced as follows.
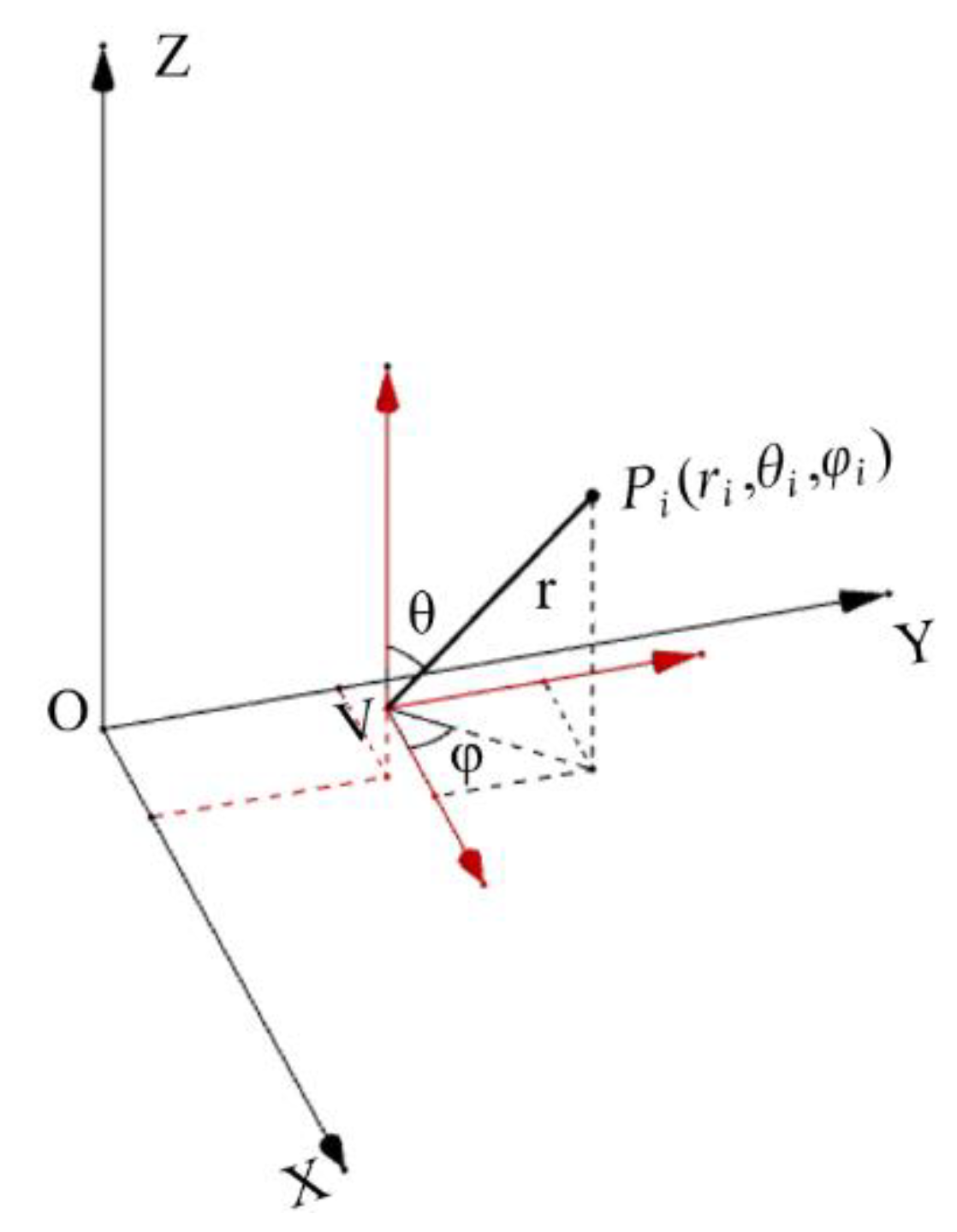
2.1. Projection of 3D Laser Point Cloud to Pixel Plane
Viewpoint selection is a crucial step for 2D images generating from 3D laser point clouds. For fixed-point scanning, the location of the rotating 2D laser range finder is selected as the viewpoint. For on-the-fly scanning, the viewpoint is usually selected on the trajectory of the moving laser range finder. Suppose that a selected viewpoint of a 3D point cloud is
V(
xv,
yv,
zv), a laser point in the cloud is
Pi (
xi,
yi,
zi), and the matrix size for the 2D image to be generated is
M×
N. As shown in
Figure 2, a spherical coordinate system is established in which the viewpoint
V is the center of the sphere. It should be noted that the size of the panoramic image is only related to the resolution of the image (the size of the image matrix) regardless of the size of the projection surface. According to (1), the original 3D laser point
Pi (
xi,
yi,
zi) is converted from the global coordinate system to the spherical coordinate system with the viewpoint
V as the center of the sphere. The point in the spherical coordinate system is
Pi(
ri,
θi,
φi).
where
.
According to (2),
M warps
lm and
N + 1 wefts
lp are drawn which can divide the sphere into
M × N independent grids. The left image in
Figure 3 is a spherical coordinate system which is divided into 64 grids by eight warps and nine wefts (two poles are included).
Take the center of the sphere
V as the starting point and make a ray through each laser scanning point
Pi(ri,θi,φi), so that the laser point can be projected to a grid of the sphere. If there are more than one projections of laser points in a grid, the one closest to the center of the sphere is retained. Then cut the spherical surface along the 0-degree warp and spread it to the horizontal plane to obtain the 2D matrix of the PBA (see the right image of
Figure 3).
As shown in
Figure 4a, a 3D laser point cloud is obtained in the fixed scanning point
V, and
Figure 4b is the corresponding panoramic image, which is displayed in the binary value. The white pixel indicates that there is a laser scanning point corresponding to it, while the black pixel indicates that no laser point corresponds to it.
2.2. Calculating of Image Gray Value
There are many classical image models to represent laser points stored in the 2D matrix, such as reflectance image, range image and bearing angle (BA) image. However, the reflectance image is less robust and the edge description in range image is not clear enough, especially in large-scale scenes. The quality of the BA image depends on the selection of the viewpoint position. In addition, grayscale change may appear in the BA image. As shown in
Figure 5, the gray values for the same railing are inconsistent, which is not beneficial to feature extraction and classification.
In order to overcome the above limitations, a novel PBA image model is proposed in this paper inspired by the BA model, which is not related to the selection of viewpoints. Moreover, the PBA image model can provide stable gray values for the same object and also ensure clear texture and high image contrast with high computational efficiency.
Here we will explain how to calculate the gray value of each pixel in the PBA image. As shown in
Figure 6, there are
M rows in the image matrix, and the image pixel corresponding to the laser scanning point
P is defined as
Px,y, which is located in row x and column
y. Two neighboring laser points
Pl and
Pr for point
P are chosen as:
where
(
∙) represents the image pixel of a laser point. If the pixel is in the upper part of the image, its upper left and upper right pixels are selected as neighboring pixels; otherwise, the lower left and right lower pixels are selected as neighboring pixels.
The pixel gray value of
Px,y is defined as:
where
α is the angle between
P and its neighboring laser scanning points
Pl and
Pr, which can be obtained as follows:
where
VP, VPl,
VPr represent the distances between the center of the sphere
V and laser points
P, Pl,
Pr, respectively.
An example of a PBA gray image is given in
Figure 7. Compared with the BA image in
Figure 5, the gray values for the same railing are consistent, and the boundaries of the objects in the scene are clearer.
3. Laser Point Clouds Classification Using Multi-Scale PBA Image Features and Point Cloud Features
It is important to select the neighborhood range of the laser points in the feature extraction step. In our work, the image pyramid model is adopted to extract the texture features of PBA images on multiple scales. The point cloud pyramid model is then used to extract the local features of the 3D point cloud on multiple scales.
3.1. Multi-Scale PBA Image Feature Extraction
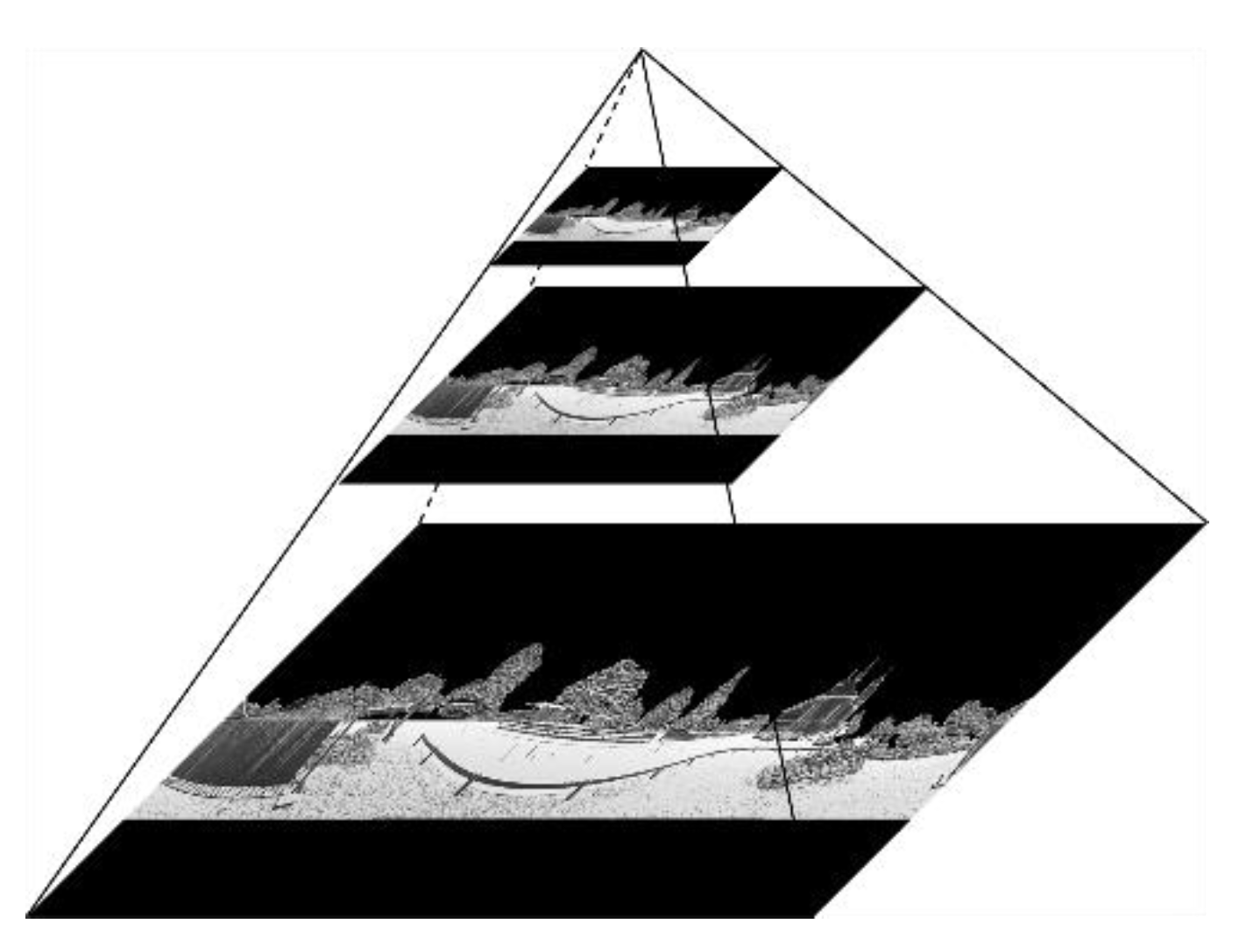
In our work, feature extraction is accomplished in 2D gray images on multiple scales. When the scale is large, the computational cost is very high. Therefore, the PBA image is downsampled by using the image pyramid model [
19]. The image pyramid model for PBA images is given in
Figure 8. It should be noted that the image in each layer of the pyramid model is generated directly from the 3D laser point cloud, rather than from the downsampling of the original image.
Local Binary Pattern (LBP) is a kind of image texture feature, which is extracted from multi-resolution PBA images. For the classic LBP feature, eight fixed neighborhood pixels are selected (see
Figure 9a). In order to extract multi-scale texture features an improved neighborhood selection method [
20] is adopted for LBP feature extraction in our work, in which a circular neighborhood is selected with variable radius
r. The pixel coordinate of the neighborhood points (
xp,
yp) can be obtained as follows:
where (
xc,
yc) is the pixel coordinate of the center pixel. As shown in
Figure 9a,b,
r is selected as 1 and 2, respectively.
Reduce the original 256-level gray PBA image to 3-level and the pixel gray value
Gnew of the simplified 3-level image can be obtained as follows:
where
Gold is the pixel gray value of the original PBA image.
Figure 10 shows an example of the simplified 3-level PBA image (black-0; gray-127; white-255), and four categories of typical local scenes also show distinct texture features, which are artificial ground (top left), natural ground (bottom left), buildings (top right), and vegetation (bottom right).
When feature extraction in different layers of the image pyramid model for the PBA images is completed, these features in different layers need to be fused. Starting from the top layer image of the pyramid, the image features are upsampled, and then superimposed with the image features of the next layer. These two steps are repeated until the features in all layers are superimposed on the image at the bottom layer of the image pyramid model.
In summary, the (P + 1) layer image pyramid model of PBA images is built from the original laser point cloud, and each layer of PBA images is converted to a 3-level gray image. LBP features are then extracted in each image pixel on m scales. Finally, the features in different layers are superimposed together from the top layer to the bottom layer. Therefore, there are m × (P + 1) image features for every pixel in the original PBA image.
3.2. Multi-Scale Point Cloud Feature Extraction
In our work, features are extracted from 3D laser point clouds on multiple scales. However, when the neighborhood radius is expanded at a linear rate, the number of neighborhood points of a laser point is approximately increased at a cubic speed, which greatly increases the computational burden. In order to solve this problem, the point cloud pyramid model is derived which is inspired by the image pyramid model in image processing.
Similar to the image pyramid model, the downsampling algorithm is utilized for the original point clouds to build the point cloud pyramid model. The voxel model is used to divide the laser point cloud to be downsampled into different 3D grids. Then the center of gravity of the laser points in each voxel (3D grid) is calculated to represent all the points in the voxel. An illustration of the point cloud pyramid model is shown in
Figure 11, in which the bottom layer is the original laser point cloud. Then a fixed number of laser points are selected as neighborhood points in different layers of the point cloud pyramid model.
After determining the neighborhood range of each laser point, feature extraction will be performed which includes statistical features, geometric morphological features, and histogram features.
3.2.1. Statistical Features
Let the total number of laser points in the current neighborhood be (k + 1), and the coordinate of the lowest point in the neighborhood be hmin. In our work, five statistical features are extracted, which are:
h, the absolute height of the laser point;
, the relative height between the laser point and the lowest laser point in the neighborhood;
, the standard deviation of the laser point’s height in the neighborhood;
r, the radius of the maximum bounding sphere of the neighborhood;
, the density of the laser points in the neighborhood.
3.2.2. Morphological Features
According to the summary in [
15], a covariance matrix is adopted to describe the 3D laser point cloud in the neighborhood, where
pc is the current query point and
pi is the neighborhood point around the query point. The covariance matrix can be expressed as:
which is a three-dimensional positive definite matrix. By eigen decomposition, three eigenvalues
λ1,
λ2,
λ3 (let
λ1 ≥
λ2 ≥
λ3 ≥ 0) and three eigenvectors
e1,
e2,
e3 corresponding to
λ1,
λ2,
λ3 are obtained, respectively. In our work, nine morphological features are extracted, which are Linearity
Lλ, Planarity
Pλ, Sphericity
Sλ, Omnivariance
Oλ, Anisotropy
Aλ, Eigenentropy
Eλ, Sum Σ
λ, Change of Curvature
Cλ and Verticality
Vλ. These features can be calculated as follows:
3.2.3. Histogram Features
Fast point feature histograms (FPFH) is a set of 33-dimensional histogram features [
21]. Compared to morphological features, FPFH can describe the geometric features in the query point’s neighborhood in more detail and represent the roughness of the plane effectively, which can be used to distinguish two typical road surfaces (artificial ground and natural ground). As shown in
Figure 12a, FPFH consists of two Simplified Point Feature Histograms (SPFH). One is composed of the query point
p and its neighborhood point
pk (the points in the red circle) and the other one is composed of each neighborhood point
pk and its neighborhood points (the points in the blue circle). FPFH can be defined as follows:
where
k stands for the number of neighborhood points around the query point
p,
wk stands for distance weight which is used to measure the density between neighborhood points and query points.
SPFH is composed of Simplified Point Features (SPF). SPF is a three-dimensional angular feature descriptor that represents the position relationship between two laser points. As shown in
Figure 12b, P
2 is a laser point in the neighborhood of P
1, and
n1 and
n2 are the normal vectors of P
1 and P
2. According to (12), the UVW coordinate system is established with P1 as the coordinate origin:
The angular parameter
δ,
α,
θ are used to describe the position relationship between two laser points, which can be defined as follows:
Although FPFH can describe the geometric characteristics of the laser point cloud in more detail, it increases the computational burden significantly. Therefore, we only extract FPFH features for the laser point at the bottom of the point cloud pyramid, while the other 14-point cloud features (five statistical features and nine morphological features) are extracted for each laser point of the point cloud pyramid.
3.3. Classification with Random Forest and Reclassification Based on the Contextual Information
In this paper, the Random Forest classifier is used to perform feature screening on the extracted high-dimensional features, and the initial classification of the 3D laser point clouds is implemented. Since this method does not consider the contextual information between laser points, the credibility of classification results is low for the objects with similar local features (such as eaves and vegetation). In order to make full use of the contextual information between laser points, the classification results are remapped into the PBA images, and superpixel segmentation is performed on the PBA images. Within each superpixel block, the classification is performed again based on the results of the initial classification, so as to correct partial misclassification points and further improve the classification accuracy.
The Random Forest classifier is composed of multiple decision tree classifiers. In the training stage, some training samples are randomly selected to complete the training for each decision tree. In the classification stage, some decision trees are randomly selected and the mode of their output categories is taken as the final classification result.
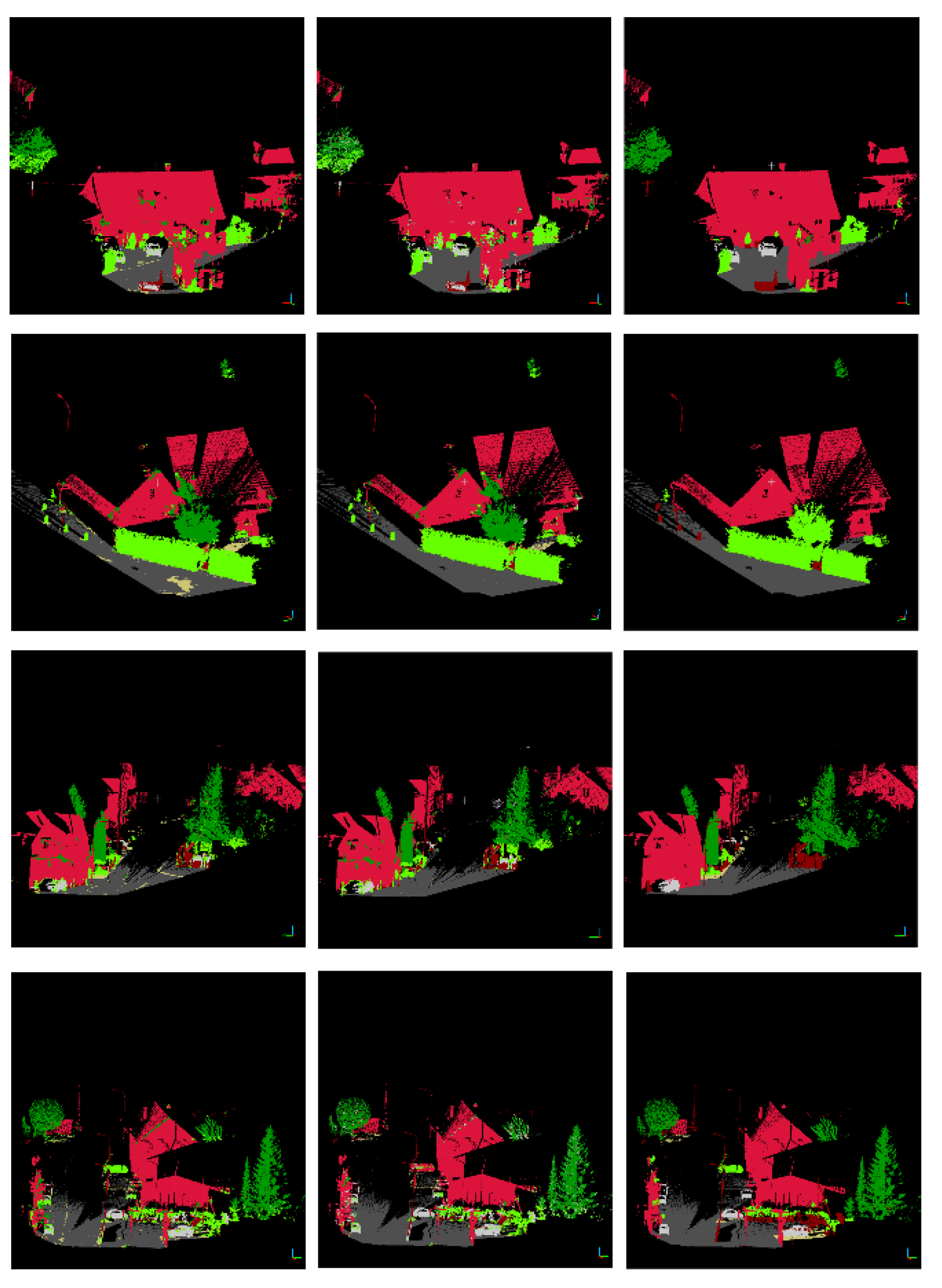
Figure 13 shows the classification results by using the Random Forest classifier and the ground truth. Seven different colors are used to represent seven different categories: dark gray for artificial ground, yellow for natural ground, dark green for high vegetation, light green for low vegetation, red for buildings, dark brown for railings, and silver for cars. From the classification results, we can see that the main objects, such as buildings, ground, cars, and vegetation, can be effectively classified.
By comparing the classification results with the ground truth, we can find that a large number of laser points that do not belong to vegetation are classified into vegetation. This is due to the cluttered distribution of these laser points, and the local features of these laser points are very close to those of the vegetation. Therefore, the laser point clouds will be reclassified by considering the contextual information of the 3D laser point clouds based on the PBA images.
In this paper, the SEEDS-based superpixel segmentation is performed on the PBA images [
22]. For each superpixel block, if the pixel proportion of vegetation is less than a threshold, the laser points corresponding to vegetation will be reclassified into the category with the highest pixel proportion in the block. This strategy makes full use of the contextual information of the 3D laser point cloud in 2D images, which can reduce the error rate of the point cloud classification
As shown in
Figure 14, the initial classification result based on the Random Forest classifier is at the top left and the reclassification result is at the top right. The bottom left images and the bottom right images are local details in enlarged images of the initial classification result and reclassification result, respectively. After reclassification, most of the point clouds that were previously misclassified are corrected.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}