Delay-Aware Reverse Approach for Data Aggregation Scheduling in Wireless Sensor Networks




Abstract
1. Introduction
- We enumerate the role of each node in a network based on a Breadth First Search (BFS) tree by calculating a novel node metric called Minimum Aggregation Time (MAT). MAT of a node represents the delay lower bound to collect data to it through the BFS tree, and therefore draws useful information about the aggregation load at the node. A node with higher MAT probably should take a later transmission time slot than the smaller MAT ones. Such information can be used to guide the scheduling priority.
- We propose a reverse approach for scheduling that both takes into account the degree of link conflict and the MAT of the sender. While the link conflict degree is helpful to select as many concurrent transmissions in a time slot as possible, MAT helps to be aware of the senders that potentially need more time to aggregate data from their descendants. The algorithm iteratively seeks for a maximum number of concurrent transmissions time slot by time slot, and, at the same time, put the node with higher MAT ahead.
- We conduct an extensive simulation to compare the proposed scheme with the state-of-the-art ideas. We also evaluate the impact of the metrics under various circumstances. Results show that our scheme consistently dominates others at least in terms of aggregation delay, and the peak improvement is almost .
2. Network Model and Problem Statement
3. Related Work
3.1. Sequential Approach
3.2. Simultaneous Approach
4. Delay-Aware Reverse Approach for Scheduling
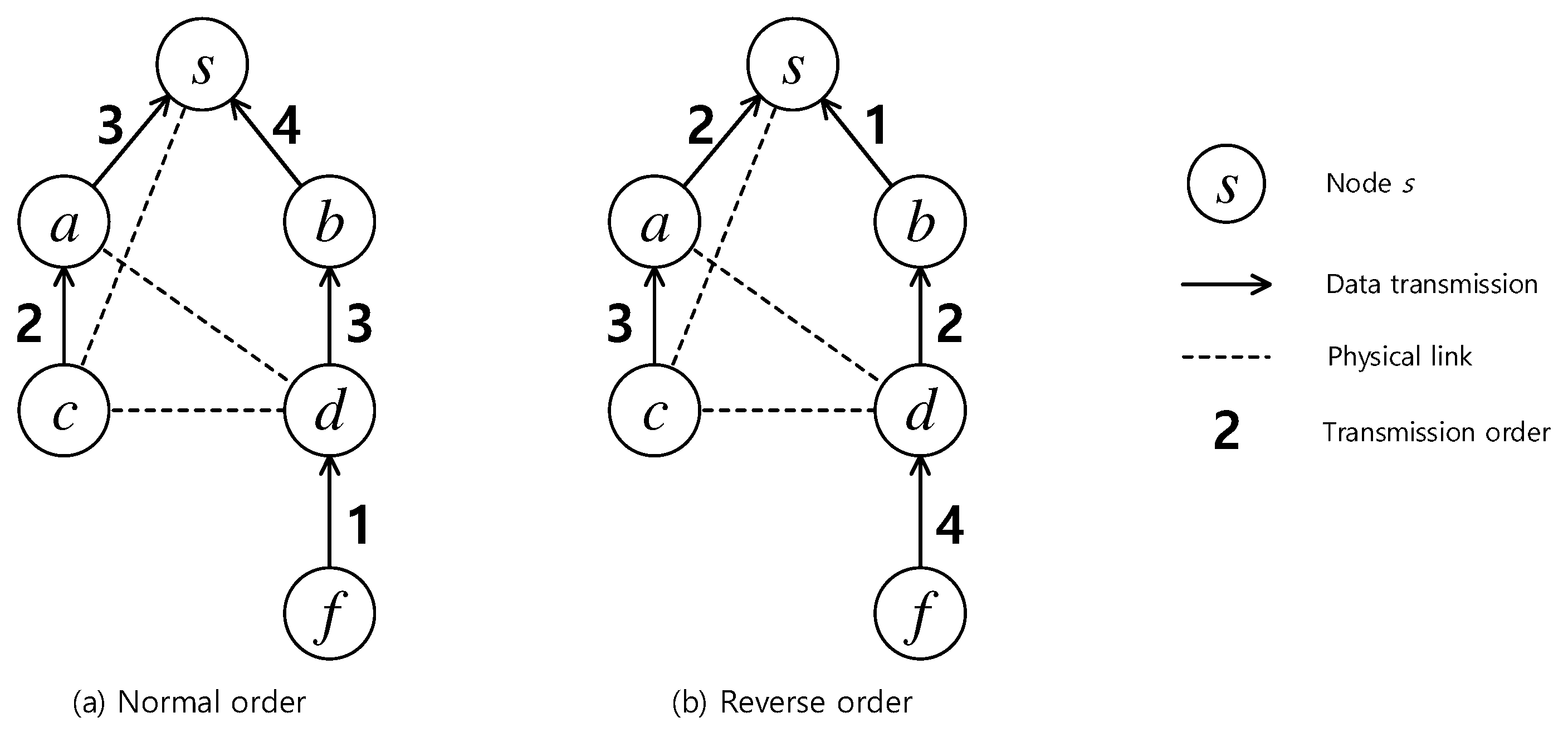
4.1. Motivation and Overall Idea
| Algorithm 1 Reverse Approach for Aggregation Scheduling. |
| Input: Output: A time slot assignment for all nodes
|
4.2. Scheduling Priority Metrics
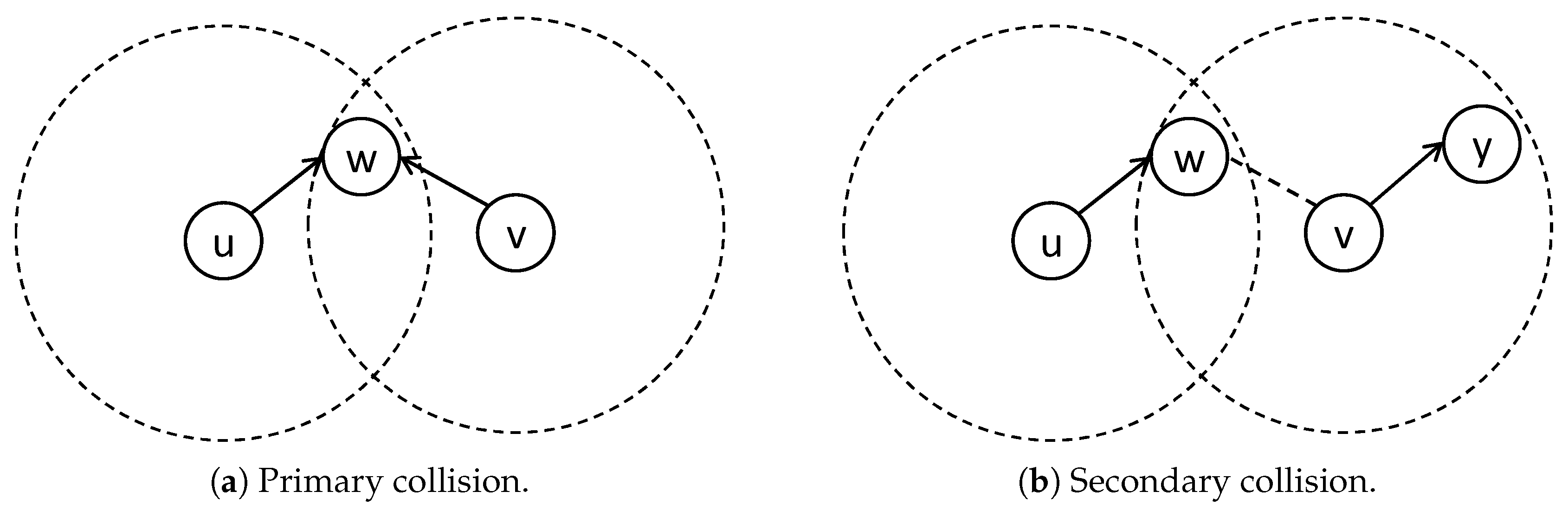
4.2.1. Link-Based Metric
| Algorithm 2 Link Conflict Degree Calculation. |
| Input: set of links , link Output:
|
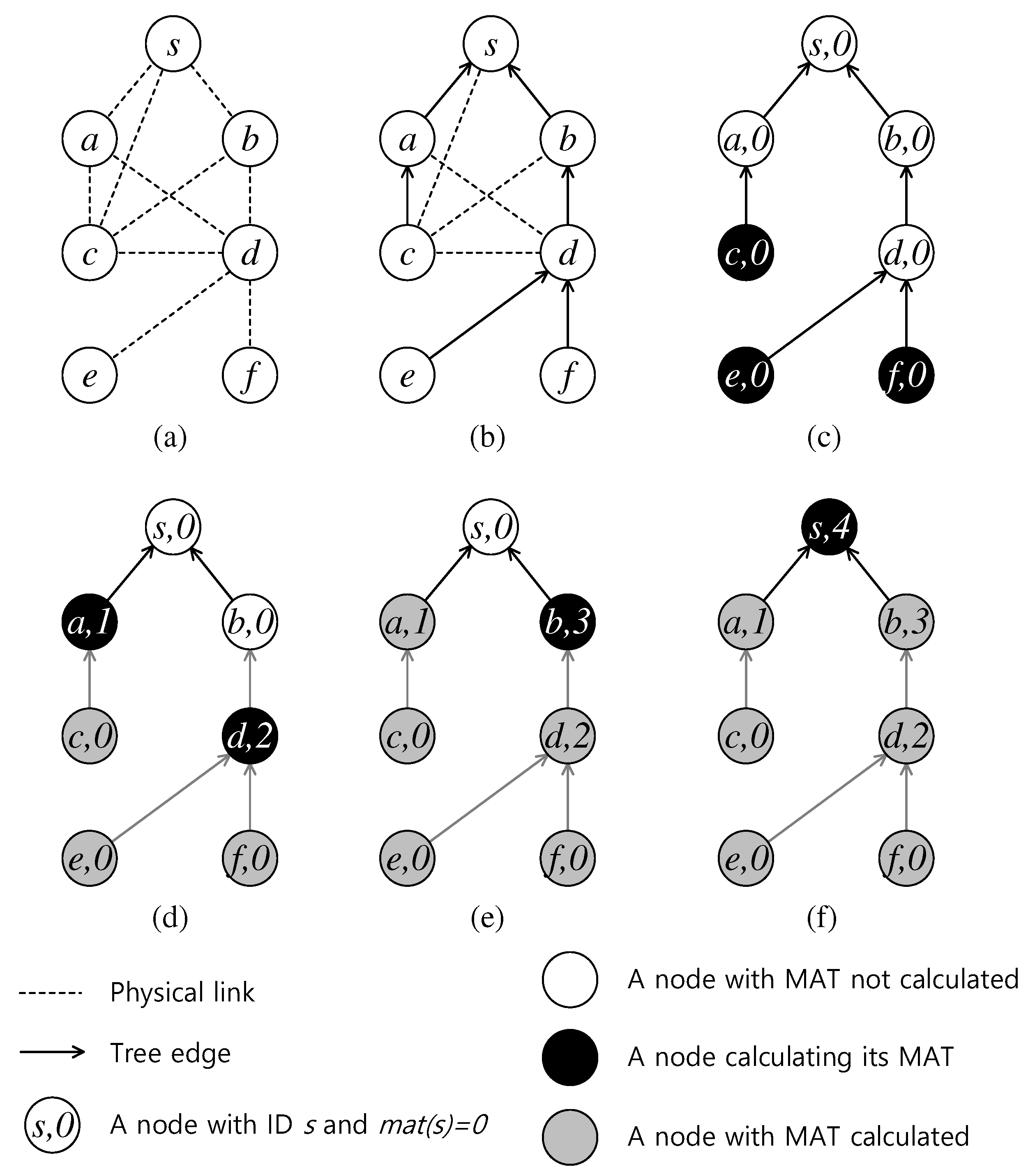
4.2.2. Node-Based Metric
| Algorithm 3 Computing Minimum Aggregation Time. |
| Input: A tree T built on Output: MATs of all nodes in V
|
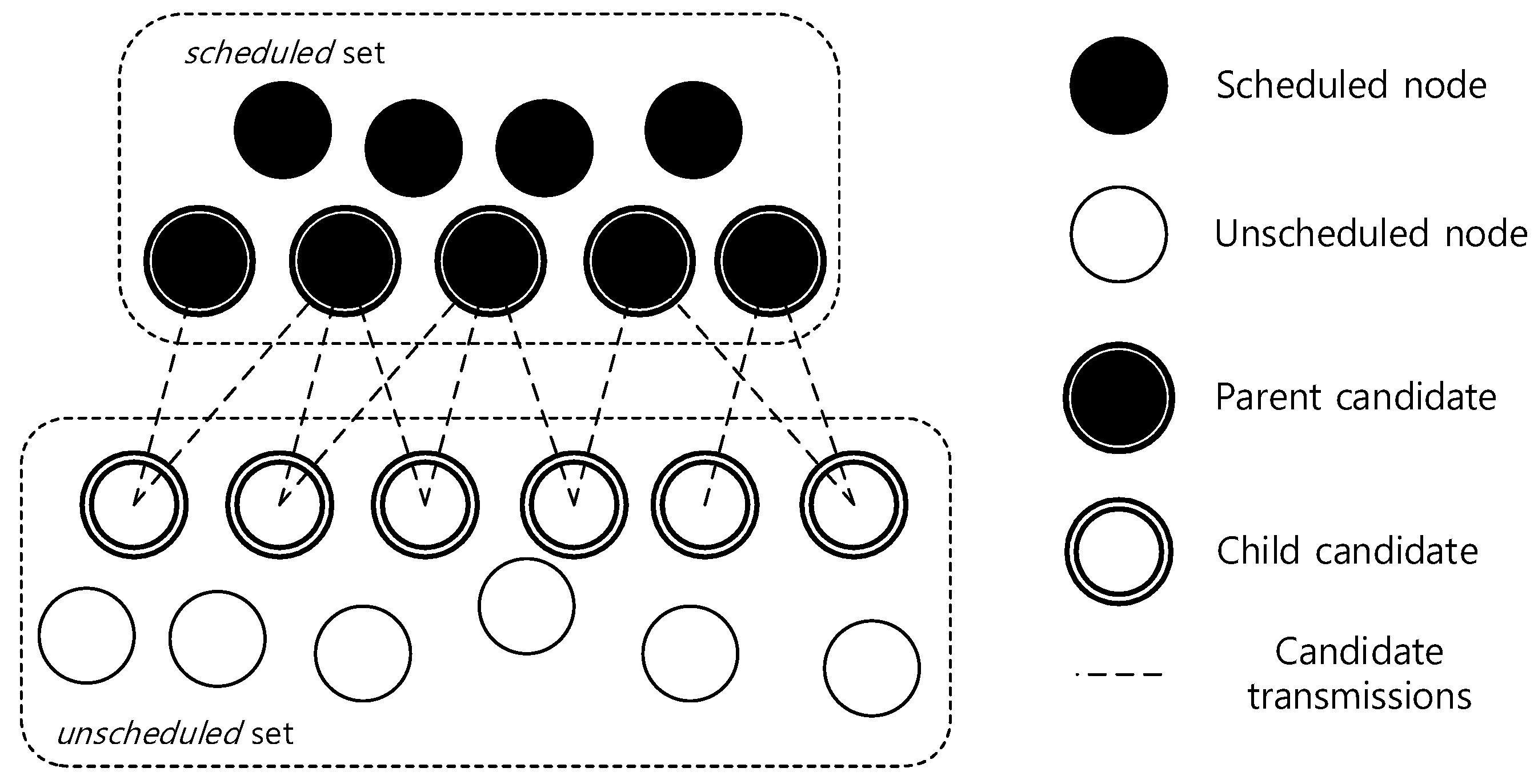
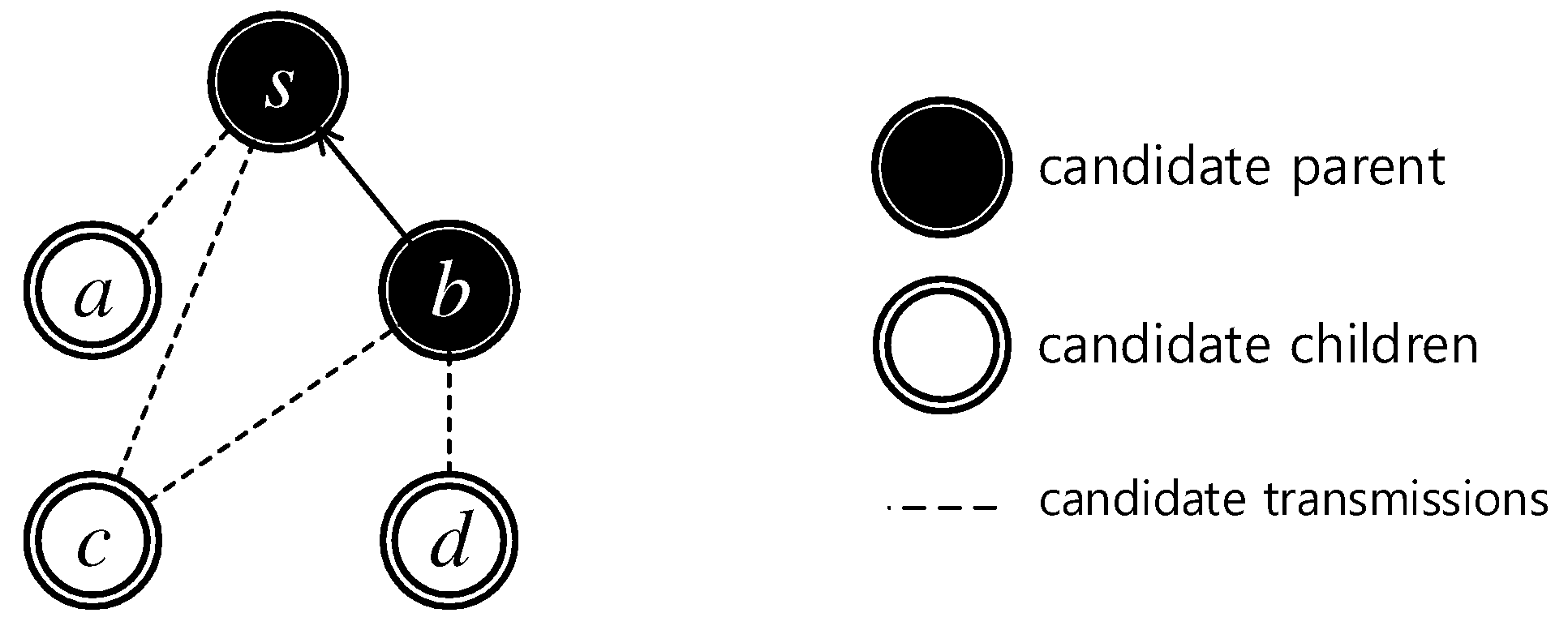
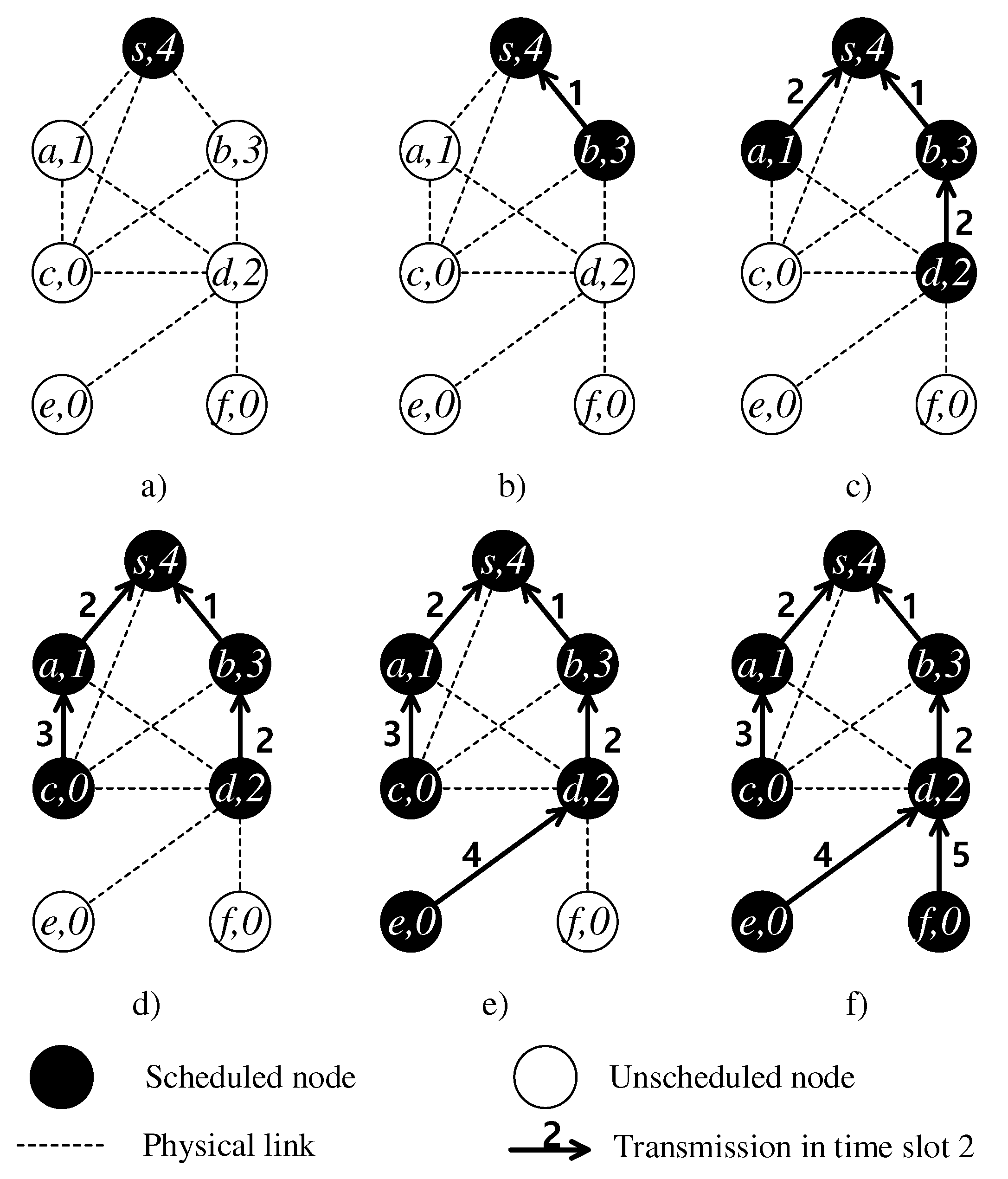
4.3. Delay-Aware Maximum Matching
| Algorithm 4 Delay-aware Maximum Matching. |
| Input: ; C: set of child candidates, P: set of parent candidates Output: Set of links without conflict
|
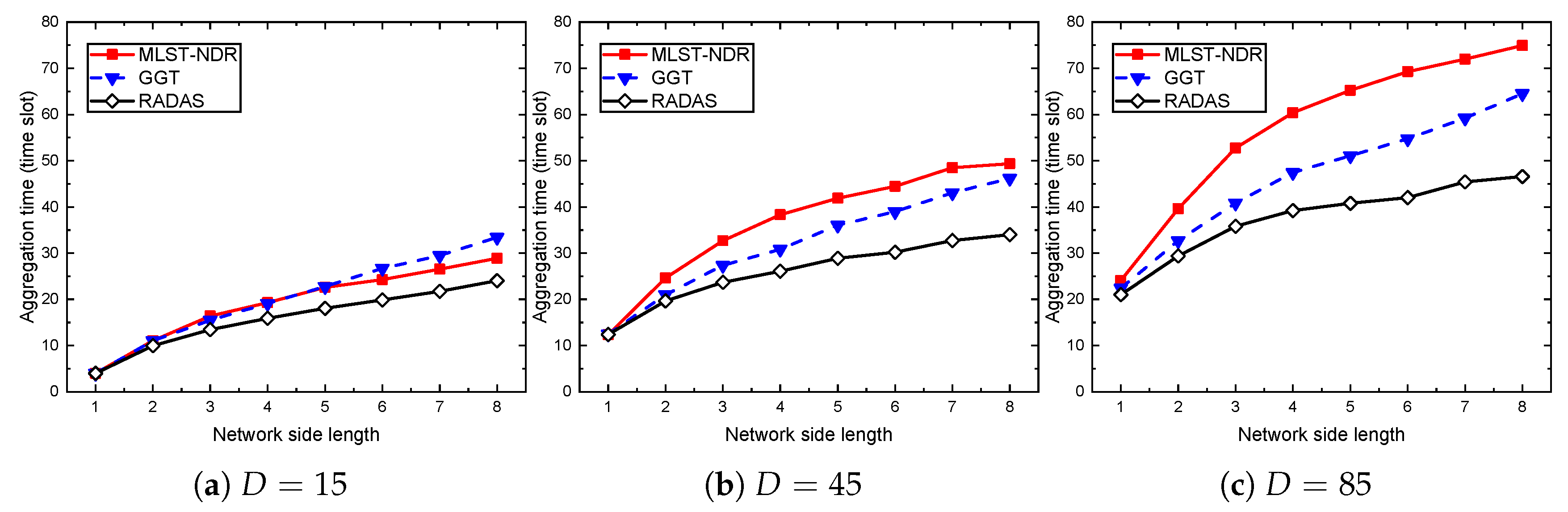
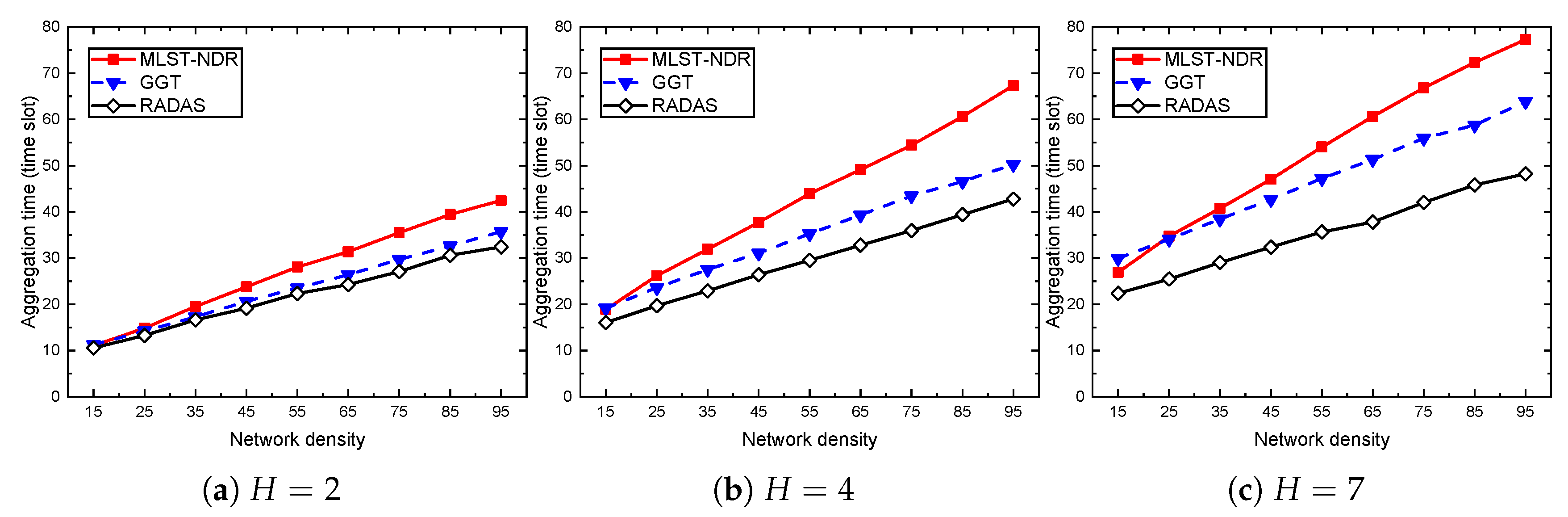
5. Performance Evaluation
5.1. Simulation Settings and Methodology
5.2. Baseline Schemes
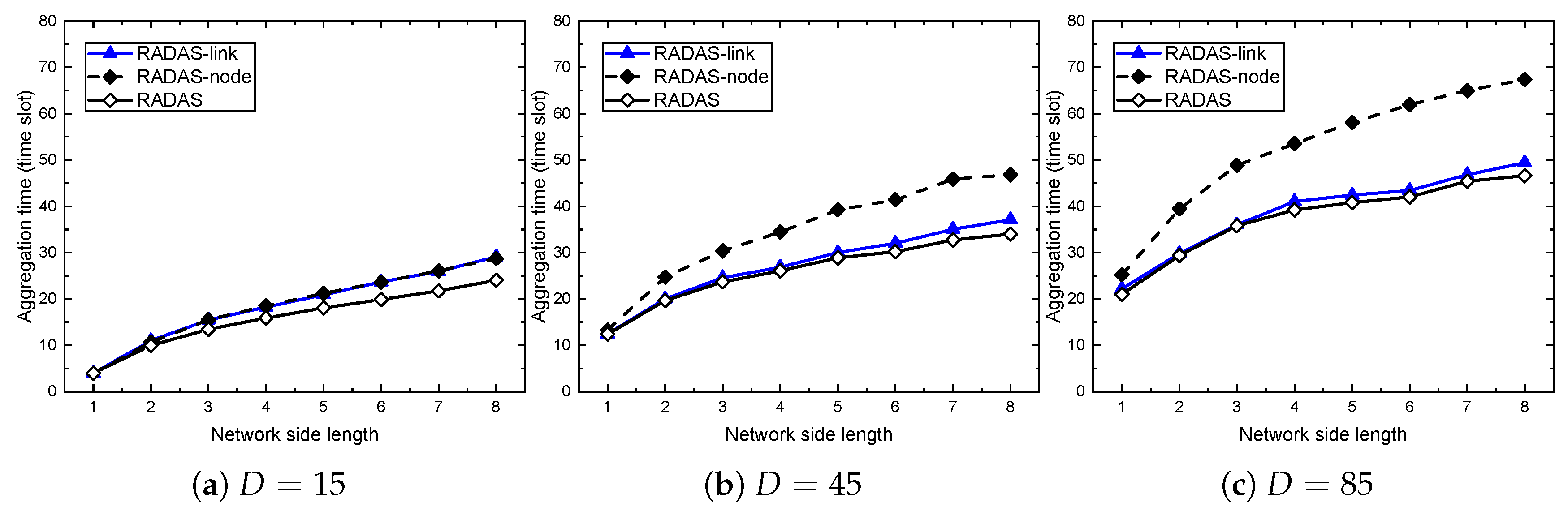
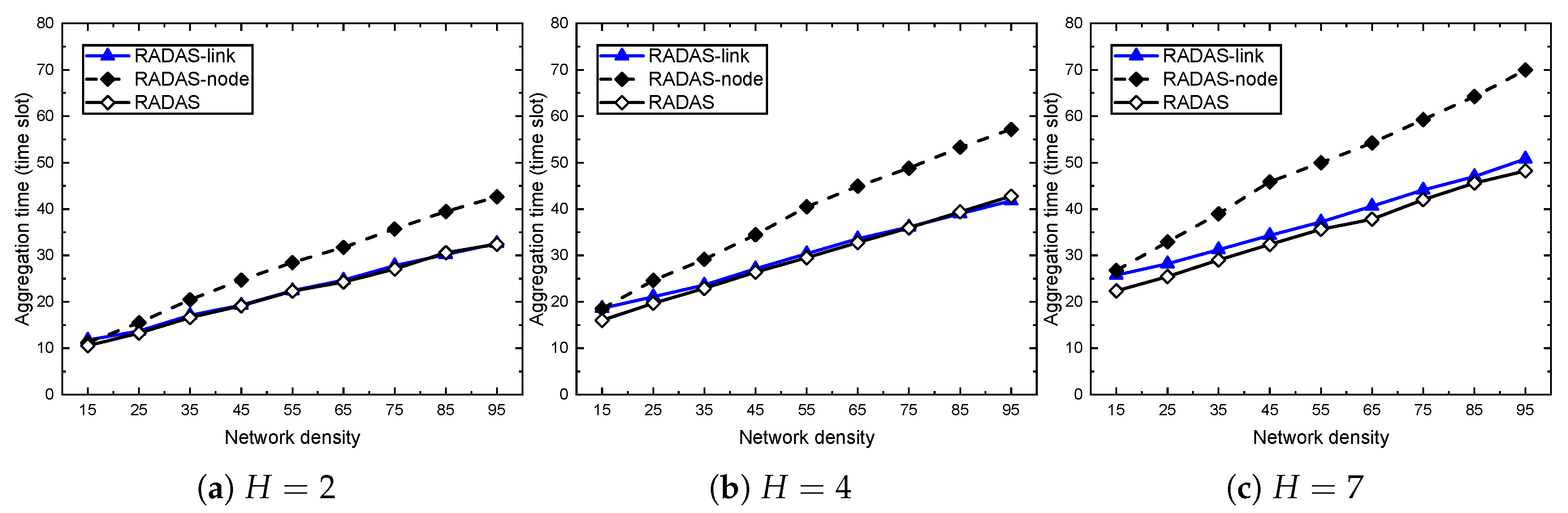
5.3. Impact of Metrics
5.4. Comparison with Existing Solutions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Ning, Z.; Xia, F.; Ullah, N.; Kong, X.; Hu, X. Vehicular social networks: Enabling smart mobility. IEEE Commun. Mag. 2017, 55, 16–55. [Google Scholar] [CrossRef]
- Zguira, Y.; Rivano, H.; Meddeb, A. Internet of bikes: A DTN protocol with data aggregation for urban data collection. Sensors 2018, 18, 2819. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Gao, H.; Cai, Z.; Chen, Q.; Li, J. Distributed energy-adaptive aggregation scheduling with coverage guarantee for battery-free wireless sensor networks. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1018–1026. [Google Scholar]
- Adamo, F.; Attivissimo, F.; Di Nisio, A.; Carducci, C.G.C.; Spadavecchia, M.; Guagnano, A.; Goh, M.K. Comparison of current sensors for power consumption assessment of wireless sensors network nodes. In Proceedings of the 2017 IEEE International Workshop on Measurement and Networking (M&N), Naples, Italy, 27–29 September 2017; pp. 1–4. [Google Scholar]
- Guo, L.; Li, Y.; Cai, Z. Minimum-latency aggregation scheduling in wireless sensor network. J. Comb. Optim. 2016, 31, 279–310. [Google Scholar] [CrossRef]
- Xia, C.; Jin, X.; Kong, L.; Zeng, P. Bounding the demand of mixed-criticality industrial wireless sensor networks. IEEE Access 2017, 5, 7505–7516. [Google Scholar] [CrossRef]
- Bagaa, M.; Challal, Y.; Ksentini, A.; Derhab, A.; Badache, N. Data aggregation scheduling algorithms in wireless sensor networks: Solutions and challenges. IEEE Commun. Surv. Tutor. 2014, 16, 1339–1368. [Google Scholar] [CrossRef]
- Li, X.; Liu, W.; Xie, M.; Liu, A.; Zhao, M.; Xiong, N.; Dai, W. Differentiated data aggregation routing scheme for energy conserving and delay sensitive wireless sensor networks. Sensors 2018, 18, 2349. [Google Scholar] [CrossRef] [PubMed]
- Wan, P.J.; Huang, S.C.H.; Wang, L.; Wan, Z.; Jia, X. Minimum-latency aggregation scheduling in multihop wireless networks. In Proceedings of the Tenth ACM International Symposium on Mobile ad Hoc Networking and Computing, New Orleans, LA, USA, 18–21 May 2009; pp. 185–194. [Google Scholar]
- Tian, C.; Jiang, H.; Wang, C.; Wu, Z.; Chen, J.; Liu, W. Neither shortest path nor dominating set: Aggregation scheduling by greedy growing tree in multihop wireless sensor networks. IEEE Trans. Veh. Technol. 2011, 60, 3462–3472. [Google Scholar] [CrossRef]
- Gagnon, J.; Narayanan, L. Efficient scheduling for minimum latency aggregation in wireless sensor networks. In Proceedings of the 2015 IEEE Wireless Communications and Networking Conference (WCNC), New Orleans, LA, USA, 9–12 March 2015; pp. 1024–1029. [Google Scholar]
- Luo, D.; Zhu, X.; Wu, X.; Chen, G. Maximizing lifetime for the shortest path aggregation tree in wireless sensor networks. In Proceedings of the 2011 IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 1566–1574. [Google Scholar]
- Malhotra, B.; Nikolaidis, I.; Nascimento, M.A. Aggregation convergecast scheduling in wireless sensor networks. Wirel. Netw. 2011, 17, 319–335. [Google Scholar] [CrossRef]
- Pan, C.; Zhang, H. A time efficient aggregation convergecast scheduling algorithm for wireless sensor networks. Wirel. Netw. 2016, 22, 2469–2483. [Google Scholar] [CrossRef]
- Clark, B.N.; Colbourn, C.J.; Johnson, D.S. Unit disk graphs. Discret. Math. 1990, 86, 165–177. [Google Scholar] [CrossRef]
- Minoli, D.; Sohraby, K.; Occhiogrosso, B. IoT considerations, requirements, and architectures for smart buildings—Energy optimization and next-generation building management systems. IEEE Internet Things J. 2017, 4, 269–283. [Google Scholar] [CrossRef]
- Ye, W.; Heidemann, J.; Estrin, D. An energy-efficient MAC protocol for wireless sensor networks. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002; Volume 3, pp. 1567–1576. [Google Scholar]
- Kang, B.; Nguyen, P.K.H.; Zalyubovskiy, V.; Choo, H. A distributed delay-efficient data aggregation scheduling for duty-cycled WSNs. IEee Sens. J. 2017, 17, 3422–3437. [Google Scholar] [CrossRef]
- Chen, Q.; Gao, H.; Cai, Z.; Cheng, L.; Li, J. Energy-collision aware data aggregation scheduling for energy harvesting sensor networks. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 117–125. [Google Scholar]
- Gao, Y.; Li, X.; Li, J.; Gao, Y. Distributed and Efficient Minimum-Latency Data Aggregation Scheduling for Multi-Channel Wireless Sensor Networks. IEEE Internet Things J. 2019, 6, 8482–8495. [Google Scholar] [CrossRef]
- Jiao, X.; Lou, W.; Guo, S.; Yang, L.; Feng, X.; Wang, X.; Chen, G. Delay Efficient Scheduling Algorithms for Data Aggregation in Multi-Channel Asynchronous Duty-Cycled WSNs. IEEE Trans. Commun. 2019, 67, 6179–6192. [Google Scholar] [CrossRef]
- Li, J.; Cheng, S.; Cai, Z.; Yu, J.; Wang, C.; Li, Y. Approximate holistic aggregation in wireless sensor networks. Acm Trans. Sens. Netw. 2017, 13, 11. [Google Scholar] [CrossRef]
- Chen, X.; Hu, X.; Zhu, J. Minimum data aggregation time problem in wireless sensor networks. In Proceedings of the International Conference on Mobile ad-hoc and Sensor Networks, Wuhan, China, 13–15 December 2005; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Li, Y.; Guo, L.; Prasad, S.K. An energy-efficient distributed algorithm for minimum-latency aggregation scheduling in wireless sensor networks. In Proceedings of the 2010 International Conference on Distributed Computing Systems ICDCS 2010, Genova, Italy, 21–25 June 2010; pp. 827–836. [Google Scholar]
- Xu, X.; Li, X.-Y.; Mao, X.; Tang, S.; Wang, S. A delay-efficient algorithm for data aggregation in multihop wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 163–175. [Google Scholar]
- Incel, O.D.; Ghosh, A.; Krishnamachari, B.; Chintalapudi, K. Fast data collection in tree-based wireless sensor networks. IEEE Trans. Mob. Comput. 2012, 11, 86–99. [Google Scholar] [CrossRef]
- Gibbons, A. Algorithmic Graph Theory; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- Cheng, C.T.; Chi, K.T.; Lau, F.C. A delay-aware data collection network structure for wireless sensor networks. IEEE Sens. J. 2010, 11, 699–710. [Google Scholar] [CrossRef]
- Jakob, M.; Nikolaidis, I. A top-down aggregation convergecast schedule construction. In Proceedings of the 2016 9th IFIP Wireless and Mobile Networking Conference (WMNC), Colmar, France, 11–13 July 2016; pp. 17–24. [Google Scholar]
- Erzin, A.; Pyatkin, A. Convergecast scheduling problem in case of given aggregation tree: The complexity status and some special cases. In Proceedings of the 2016 10th International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP), Prague, Czech Republic, 20–22 July 2016; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The modeled communication graph G, vertex set V and link set E | |
| s | Sink node, |
| Neighbors of node u | |
| A link between the sender u and the intended receiver v | |
| The conflict degree of link in the set of links | |
| The parent of node u | |
| The child set of node u | |
| Minimum Aggregation Time at node u | |
| Transmitting time slot of node u to its parent avoiding all collisions |
| Name | Explanation |
|---|---|
| Network density (D) | 15–95 |
| Network side length (H) | 1–8 |
| Sink position | corner |
| Number of experiments | 30 |
| Name | Explanation |
|---|---|
| MLST-NDR | running the NDR scheduling algorithm on MLST [14] |
| GGT | GGT scheme [10] |
| RADAS-link | our Reverse Approach for Data Aggregation Scheduling using link conflict degree |
| RADAS-node | our Reverse Approach for Data Aggregation Scheduling using MAT |
| RADAS | our Reverse Approach for Data Aggregation Scheduling using link conflict degree and MAT |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.T.; Le, D.-T.; Kim, M.; Choo, H. Delay-Aware Reverse Approach for Data Aggregation Scheduling in Wireless Sensor Networks. Sensors 2019, 19, 4511. https://doi.org/10.3390/s19204511
Nguyen DT, Le D-T, Kim M, Choo H. Delay-Aware Reverse Approach for Data Aggregation Scheduling in Wireless Sensor Networks. Sensors. 2019; 19(20):4511. https://doi.org/10.3390/s19204511
Chicago/Turabian StyleNguyen, Dung T., Duc-Tai Le, Moonseong Kim, and Hyunseung Choo. 2019. "Delay-Aware Reverse Approach for Data Aggregation Scheduling in Wireless Sensor Networks" Sensors 19, no. 20: 4511. https://doi.org/10.3390/s19204511
APA StyleNguyen, D. T., Le, D.-T., Kim, M., & Choo, H. (2019). Delay-Aware Reverse Approach for Data Aggregation Scheduling in Wireless Sensor Networks. Sensors, 19(20), 4511. https://doi.org/10.3390/s19204511