1. Introduction
One of the key roles of precision pasture management is to ensure that the herbage allowance is well maintained and utilised for the individual cows through the applications of smart farming technologies. In order for economical and efficient usage of the technologies, it is extremely important that the procedure analyses the recorded data to assist farmers in diverse decision-making processes. The RumiWatchSystem, consisting of a noseband pressure sensor [
1] and a pedometer [
2], is such a sensor-based technology in which the physical activities as well as grazing and ruminating behaviour of individual cows can be recorded. The reliability and validity of sensor data and their applications in precision farming were studied in a wide range of literature. For example, Greenwood, et al. [
3] proposed simple initial algorithms for predicting pasture intake by individual cattle using sensor data. Other studies (e.g., [
4,
5]) addressed the scope of developing the support systems that could assist farmers with proper feed allowances, physical activities and behavioural changes, estimation of herbage dry matter and locomotion behaviour of the cattle.
In a similar context, the present study considers the problem of identifying the cows with insufficient herbage allowance based on a set of RumiWatchSystem recorded variables. Since direct measurement of herbage intake of cows on pasture is difficult, time consuming and expensive, this study explored the scope of using the variables as predictors of a decision class in binary classification, i.e., sufficient or insufficient herbage allowance. The data were collected from a study where a group of spring calving dairy cows had access to 100% of their intake capacity as herbage allowance, whereas another group had 60% of their intake capacity [
6]. Each cow was equipped with an automated noseband pressure sensor and a pedometer, which continuously recorded the feeding and activity related variables. For the present study, the recorded variables were summarised (total or mean) to extract the features in 24-h windows. The rationale of this study lies in the fact that the complexities of herbage intake measurements can be reduced substantially if a classification model is found that efficiently predicts the insufficient allowance using the extracted features, towards a decision support system for optimal pasture management.
The subsequent sections of this article are organised as follows. The datasets used in this study, exploratory analysis for variable selection, commonly used machine-learning (ML) models in R [
7] and the performance metrics used for evaluating and comparing the models are discussed in
Section 2.
Section 3 demonstrates the results of validation studies for the commonly used ML models and generalised linear model (GLM). This section further identifies the important variables, observed thresholds and the marginal effects of the variables on the model prediction.
Section 4 discusses the study findings followed by a summary of this article in
Section 5.
2. Materials and Methods
2.1. Data Collection
Data were collected for this study from a larger overall experiment at Teagasc, Moorepark Dairy Research Farm, Animal & Grassland Research and Innovation Centre, Fermoy, Co. Cork, Ireland. The experiment was conducted in spring time 2016 using 105 calving cows to examine the effects of restricted herbage allowance on milk production, immunology and indicators of reproductive health of grazing dairy cows. Ethical approval was received from Teagasc Animal Ethics Committee (TAEC; TAEC100/2015) and the procedure authorisation was granted by the Irish Health Products Regulatory Authority (HPRA).
For the present study, 40 focal cows were selected for recording the feeding behaviour and activities using the RumiWatchSystem. Out of these, 10 cows were randomly selected to have 100% of their intake capacity. The remaining 30 cows had restricted herbage allowance, i.e., 60% of their intake capacity. The 60% group was further divided into six blocks with respect to the period of restriction (two-week or six-week) and stages of lactation at the commencement of restriction: start (S: restriction started at the beginning of experiment), mid (M: two weeks after the S restriction commenced) or late (L: four weeks after the S restriction commenced). The behaviour of cows in the 100% group was monitored over a 10-week period. The three blocks S2, M2 and L2, which received two-week restriction of herbage allowance, had their behaviour recorded during the full two-week period, whereas the behaviour of blocks M6 and L6, which received six-week restriction, were recorded during the last two weeks of the restriction period. The S6 block was monitored during the entire six-week restriction period in order to mitigate the imbalance frequency of rows for the 100% and 60% groups in the combined data.
The RumiWatchSystem recorded pressure and accelerometer data in a 10 Hz resolution. The raw data were then converted into one-hour summaries by generic algorithms included in the RumiWatch Converter V.7.3.36, which were later summarised in individual daily records (features) per animal. There was some data loss and changing cows due to injuries and breakdown of sensors. As a result, there were 63 individual daily records per cow in the 100% group over a 10-week period included and 12 or 13 daily records per individual cow in the 60% group (except S6 block) depending on the application time of the sensor, as only complete daily records during the two-week period were considered. Only two cows had less than 12 daily records, due to technical issues with the sensor device. In case of S6 block, there were 38 individual daily records for four cows and 36 daily records for one cow during the six-week period included. The missing and incomplete rows were removed for the safety and strictness in comparing the prediction performance of the competing models.
Thus, the combined dataset included 1096 rows and 21 columns with 629 rows for the cows with 100% herbage allowance and 467 rows for the cows with 60% allowance. Each column included the extracted features (daily mean or total) of individual cows based on the recorded feeding behaviour or activity related variable. Out of the 21 features (variables), those listed in
Table 1 were, on average, significantly different in the 100% and 60% allowance groups, hence considered as model predictors in this study. The study design is further discussed in [
6].
The combined dataset were divided into six subsets based on the blocks of cows in the 60% allowance group. Throughout this paper, S2, S6, M2, M6, L2 and L6 denote the blocks of cows with restricted allowance as well as the datasets, which contained the respective rows from the 60% and 100% herbage allowance groups. In addition, the 100% and 60% groups are called sufficient allowance and insufficient allowance in the prediction of decision classes. The S2, M2 and L2 datasets were merged to create W2, which comprised the recorded features for two-week duration. Similarly, S6, M6 and L6 datasets were merged to create W6. These additional subsets of combined data were used to compare the changes in prediction performance as the duration of 60% herbage allowance increased from two to six weeks, regardless the lactation stages of the cows. Thus, the number of rows which corresponded to the cows with unrestricted and restricted allowance in the subsets S2, S6, M2, M6, L2 and L6 were (130, 65), (130, 65), (119, 60), (130, 56), (130, 52), and (120, 38), respectively.
In the present study, a number of predictive models were first applied to the combined data and the performance was compared based on leave-out-one-animal (LOOA [
8]) approach to validation and cross validation (CV) studies. The models were further compared using the subsets of combined data based on CV studies.
2.2. Variable Selection
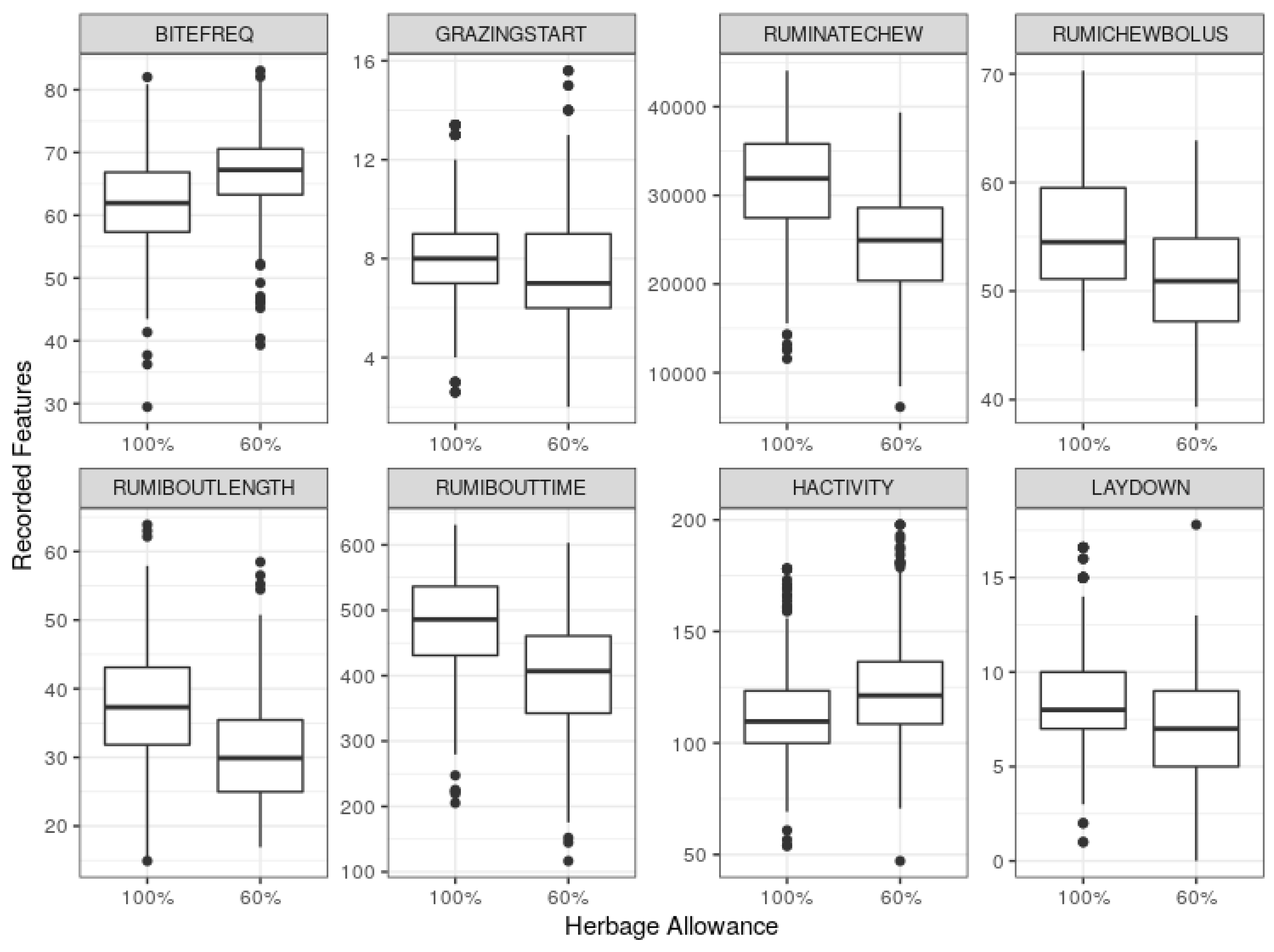
A set of predictor variables was selected based on the exploratory analysis, i.e., box plots (
Figure 1),
t-tests (
Table A1 and
Table A2) and analysis of variance (
Table A3). The selected variables were broadly classified as grazing behaviour, rumination behaviour and activity. The definitions, measurement units and notations used to denote the variables are presented in
Table 1. For each variable, the measurement unit indicates the extracted feature (using 24-h window) considered in this study. Throughout this paper, the variable names will refer to the corresponding features extracted from the sensor data.
On average, the RumiWatchSystem-recorded measures of these variables in the sufficient allowance group was significantly different from at least one of the blocks of insufficient allowance group. For example, using the combined data, the side-by-side box plots in
Figure 1 show that most of the selected variables centred higher in the 100% group than 60% group, except bite frequency per minute (BITEFREQ) and head activity index (HACTIVITY), which centred higher in the 60% group. In this study, GLM and ML models used these variables as predictors of the herbage allowance classes.
2.3. Classification Models
The commonly used ML models and GLM with binomial family were considered for the binary classification problem. For convenience, the dependent variable
herbage allowance is denoted by
y where
and 0 refer to the insufficient and sufficient herbage allowance class, respectively. Given a set of predictor variables
X for
n observations, the GLM with logit link (Equation (
1)) predicts insufficient herbage allowance if the estimated logit,
or sufficient allowance if
.
Here,
denotes the probability of insufficient allowance and
denotes the probability of sufficient allowance for the
ith observation
. The GLM was implemented using the
function of the
package in R [
7].
Table 2 presents the list of ML methods considered in this study, and the packages that implement the methods in R. In each case, the underlying classification model used the variables of
Table 1 as predictors. For more details and familiarising with hyper-parameters of specific ML, see the R package
[
10].
In this study, first the performance of the ML models and GLM was compared using combined data. At this stage, the predictive performance of the models was evaluated based on LOOA approach and CV studies. Then, GLM and selected ML models, which achieved desirable performance, were further compared based on CV studies using S2, M2, L2, S6, M6, L6, W2 and W6 datasets. Thus, the effect of restriction period on predictive performance was examined for separate blocks and regardless the lactation stages of the calving cows. Finally, the important variables and partial dependencies of model prediction were examined for random forest (RF).
2.4. Evaluation Metrics
The prediction performance of the candidate models was compared based on a number of classification evaluation metrics. The metrics were estimated in validation studies using the confusion matrix (
Table 3) of actual and predicted classes for the test cases.
Table 4 shows the estimation formulae for the list of metrics considered in this study.
For binary classification, one way to evaluate the performance of a predictive model is the estimation of accuracy, i.e., the rate of correctly predicting the class of a test case. Accuracy is a commonly used evaluation metric since it takes into account both true negative and true positive rates. Here, negative means sufficient allowance and positive means insufficient allowance. However, in the case of imbalance training data, accuracy is often overestimated. The area under receiver operating characteristic curve (AUC [
16]) also considers true negative and true positive rates and is often used along with other evaluation metrics. In the context of present study, AUC denotes the probability that a randomly chosen cow with insufficient allowance is ranked higher than a cow with sufficient allowance. Both accuracy and AUC range in value from 0 to 1, a higher value indicating greater ability to discriminate one class from the other. According to Steensels, et al. [
17], a diagnostic test is usually classified as excellent (AUC =
), good (AUC =
), fair (AUC =
), poor (AUC =
) or fail (AUC =
).
Since the subsets of the combined data were unbalanced, accuracy and AUC were not sufficient in this study to validate the performance of the competing models.
Moreover, in the case of an animal monitoring model, it is often more important to identify cows with insufficient feed allowance than sufficient allowance. Thus, additional metrics, namely specificity, sensitivity, positive predictive value (PPV) and F-score, were considered in this study. Here, specificity (rate of predicting sufficient allowance given the cow had sufficient allowance) assesses the prediction performance for the test cows in the 100% herbage allowance group. Conversely, sensitivity, PPV and F-score focus on the correct prediction rate for cows with insufficient herbage allowance. Sensitivity of a model estimates the rate at which insufficient allowance was predicted when a randomly selected cow actually had 60% allowance. The PPV metric further estimates the proportion of predicted insufficient allowance that were actually insufficient. The F-score considers both sensitivity and PPV since it is the harmonic mean of these two metrics. Thus, a high F-score implies that the model is highly efficient in predicting insufficient herbage allowance.
In this study, the performance of the candidate models was compared based on the estimates of these metrics using validation studies. For the combined data, the estimates were first obtained based on LOOA approach, where data from one animal create the test set while the remaining animals create the training set. Since the candidate models are trained with no overlapping features that come from the same animal in the test set, the LOOA approach gives the estimated metrics that are more reliable in the prediction of new (unseen) animal. However, in the present context, since the previous data of cows on pasture can be included in the training set, the evaluation metrics were further estimated based on CV studies. This approach identified the models, which may perform relatively better when a support system continuously updates the training data with the previous records of cows on pasture. Given a dataset, the CV study was conducted as follows.
- i.
Randomly split the observations into a training and a test set such that each observation has 70% chance to be included in the training set and 30% chance to be included in the test set.
- ii.
Train the ML models (fit the GLM) in the training set and apply them for predicting the herbage allowance classes in the test set.
- iii.
Create a confusion matrix for each model and estimate the evaluation metrics of
Table 4.
- iv.
Repeat Steps i–iii a large number (1000) of times and summarise the results by the mean and standard error of the estimates for each model.
4. Discussion
The results of LOOA and CV approaches for combined data identified a set of ML models, which achieved relatively higher accuracy than GLM. The observed differences in the estimates using the two approaches indicate that while most ML models and GLM may be equally reliable in predicting the insufficient allowance of new calving cows, the SVM, XGBoost and RF models may perform relatively better, when the previous records of cows on pasture can be included in the training set. Since the aim of this study is to assist developing a support system, which continuously updates the data of all cows, in the present context, it is more practical that a portion of overlapping features in the training and test set may come from the same cows. Thus, the present study highlights validation of model performance based on CV studies.
The results of CV studies demonstrate that RF and XGBoost out performed GLM and all other ML models in predicting both sufficient and insufficient allowance classes. The SVM model also showed desirable performance in most cases. NNET is one of the most popular ML methods, which performs well for large and complex datasets. However, the present study involved a relatively small dataset and applied a simple (single layer) NNET due to an insufficient training set for a more sophisticated NNET. The single layer NNET performed similar to GLM, LDA, and NB models but did not perform as good as RF or XGBoost in CV studies.
The separate CV studies using the subsets of combined data indicate that the predictive performance was affected by the duration of restricted allowance among the 60% herbage allowance groups. Intuitively, if the restricted herbage allowance affects the feeding behaviour and activities, it is reasonable to assume that, in general, cows with a longer restriction period would exhibit a greater difference from the unrestricted group than those with a shorter restriction period. Thus, a good predictive model would distinguish the herbage allowance classes more efficiently when applied to the test cases from S6, M6, L6 and W6 data compared to S2, M2, L2 and W2 data. In this study, it was demonstrated that the estimated performance metrics for the RF and XGBoost models were consistently higher in cases of longer restriction periods.
Additionally, the ML methods have advantage over GLM since the underlying models consider nonlinear relationships and do not rely on strict assumptions. Rather the algorithms learn from the training datasets, develop a classification rule based on the learning and validate the rule to the unseen cases before generalising the model for applications to the new cases. For example, the decision tree (DT) model learns how to best split the dataset into smaller and smaller subsets for predicting the target classes. The splitting process continues until no further knowledge gain can be made or a pre-set rule is met (e.g., reaches the maximum depth of the tree). The learning process of DT is further improved in more advanced and efficient algorithms such as the RF and XGBoost algorithms, which build multiple DTs from randomly selected subsets of the training set and merge the knowledge together to generate a final model. Thus, RF and XGBoost usually achieve greater accuracy and stable prediction as shown in CV studies. However, in case of LOOA approach, these models performed similar to other ML models and GLM in predicting insufficient allowance class but attained relatively lower specificity. Since our specific aim in this study is to assist creating a decision support system, which may include the previous records in training the models, and identify cows with insufficient allowance for farmers, the CV approach further demonstrated that the additional data improved the prediction performance of RF, XGBoost and SVM, relatively better than all other candidate models.
Using CV studies the estimated AUC of the RF, XGBoost and SVM models was above 90% in most cases, which indicate that these models, in general, achieved excellent classification performance. The results from the combined data further show that the estimates of all other metrics were close to 80% or higher. Using the subsets of combined data, while the estimated specificity was more than 80% in all cases, the sensitivity estimates were relatively low using W2 and W6 data. Moreover, the PPV and F-score estimates for the RF and XGBoost models were higher than SVM in all subsets. One possible reason for the alterations in the results for W2–W6 data and separate blocks can be the effect of lactation stages, i.e., the variation of predictors among the lactation stages in the combined datasets. In general, the RF, XGBoost and SVM model showed relatively better performance in the separate analyses using the pairs (S2, S6), (M2, M6) and (L2, L6) compareed to the merged datasets W2 and W6.
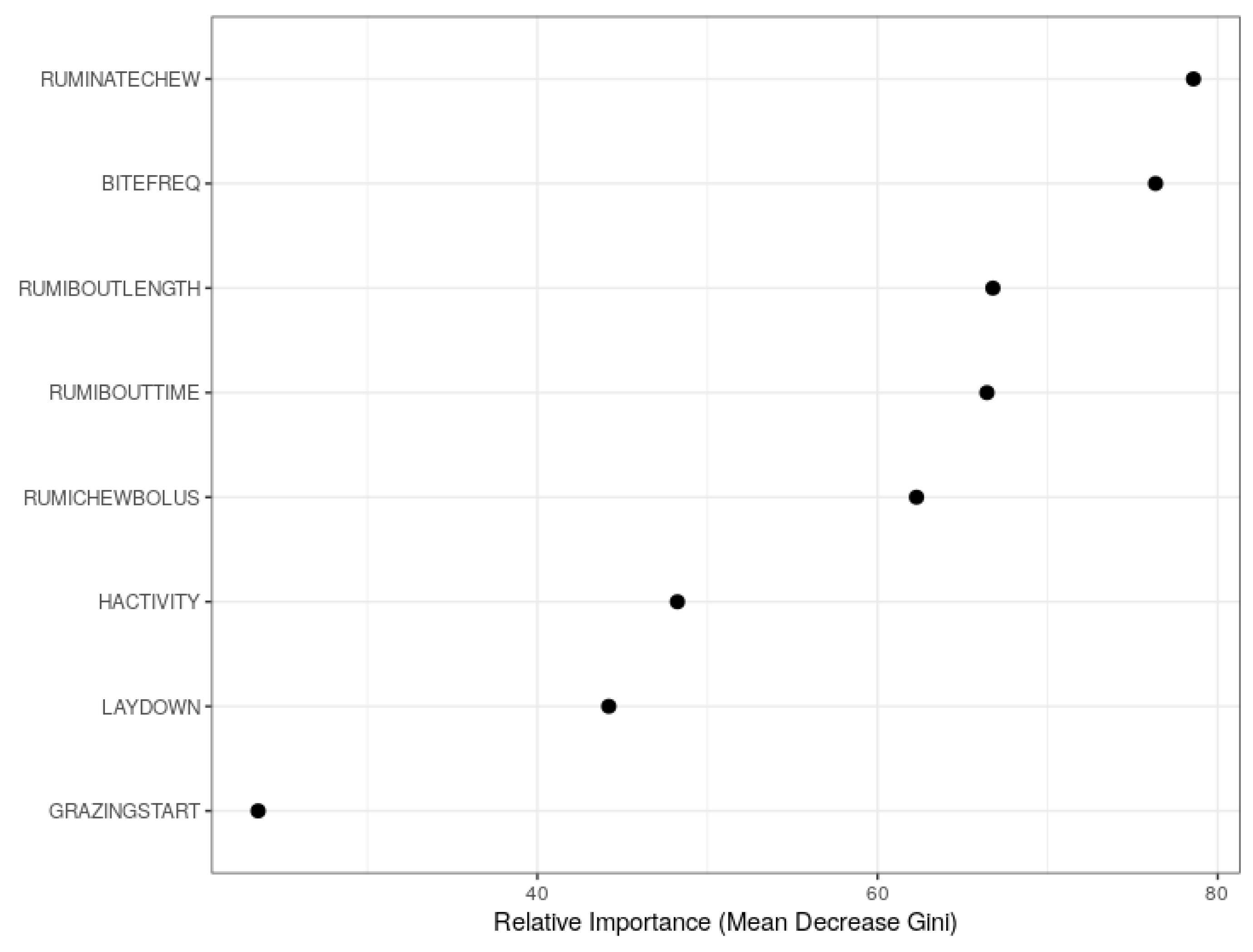
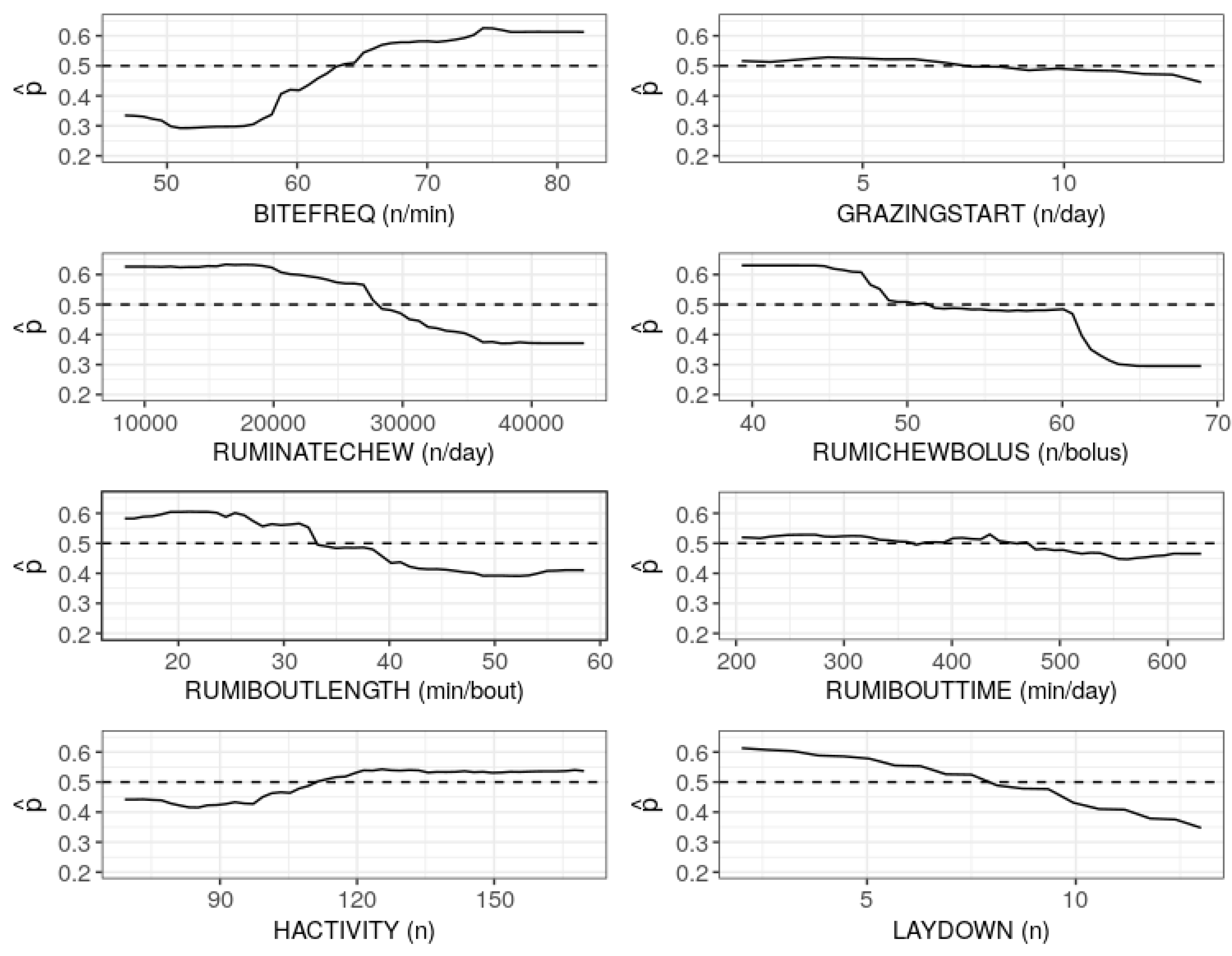
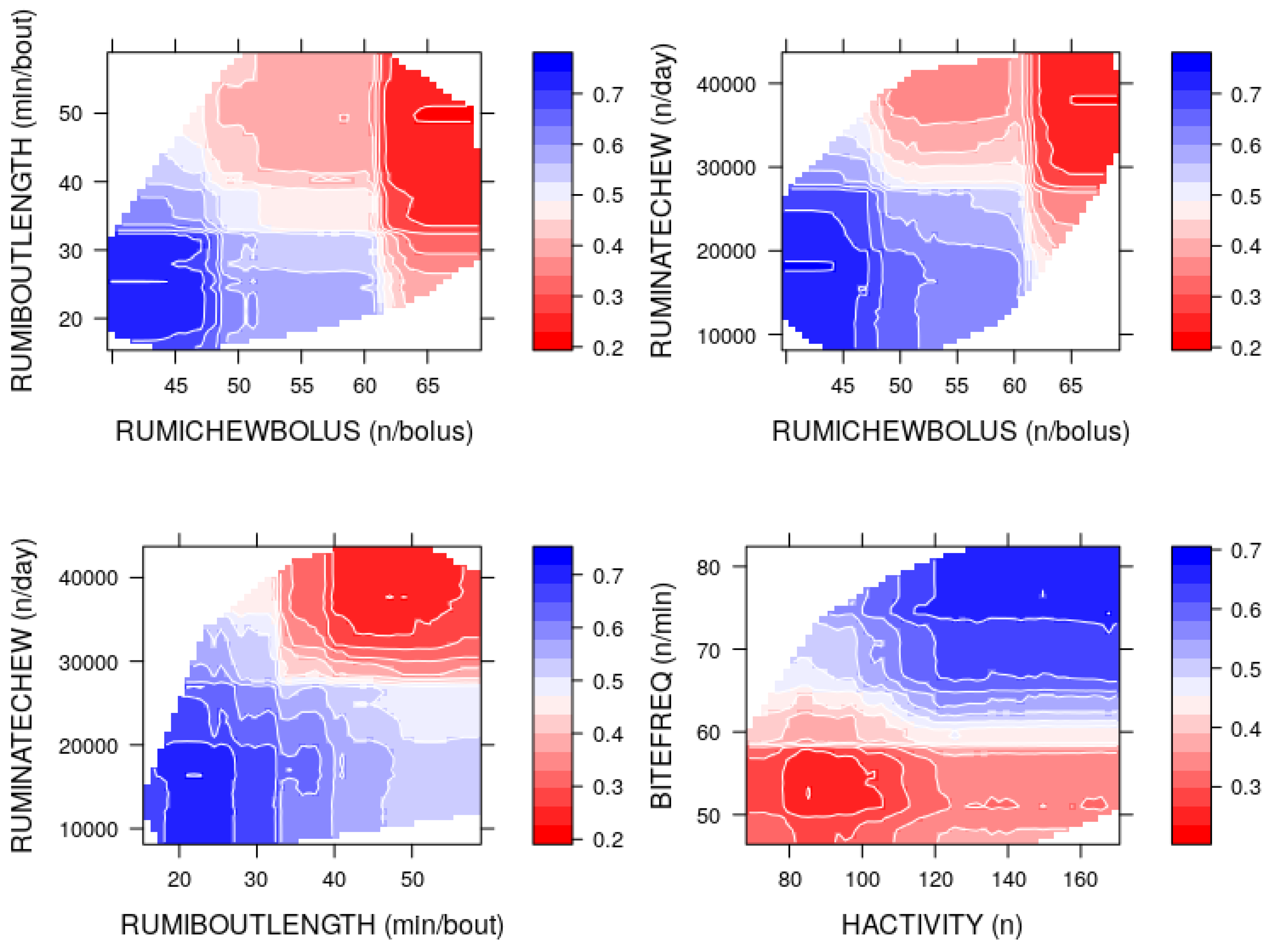
In practice, since the duration of insufficient allowance is usually unknown, the relative importance and marginal effects of the predictors were studied using the combined data. The importance plots indicated that the number of rumination chews per day, grazing bites per minute, mean duration of a rumination bout, time of rumination within all rumination bouts and mean number of rumination chews per bolus were relatively more important predictors. The partial dependence plots further revealed that grazing bites per minute and head activity index had positive marginal effects while the number of rumination chews per day, mean number of rumination chews per bolus, mean duration of a rumination bout and standing or lying frequency index had negative marginal effects on the RF model. The effects of number of grazing bout starts and time of rumination within all rumination bouts were not significant.
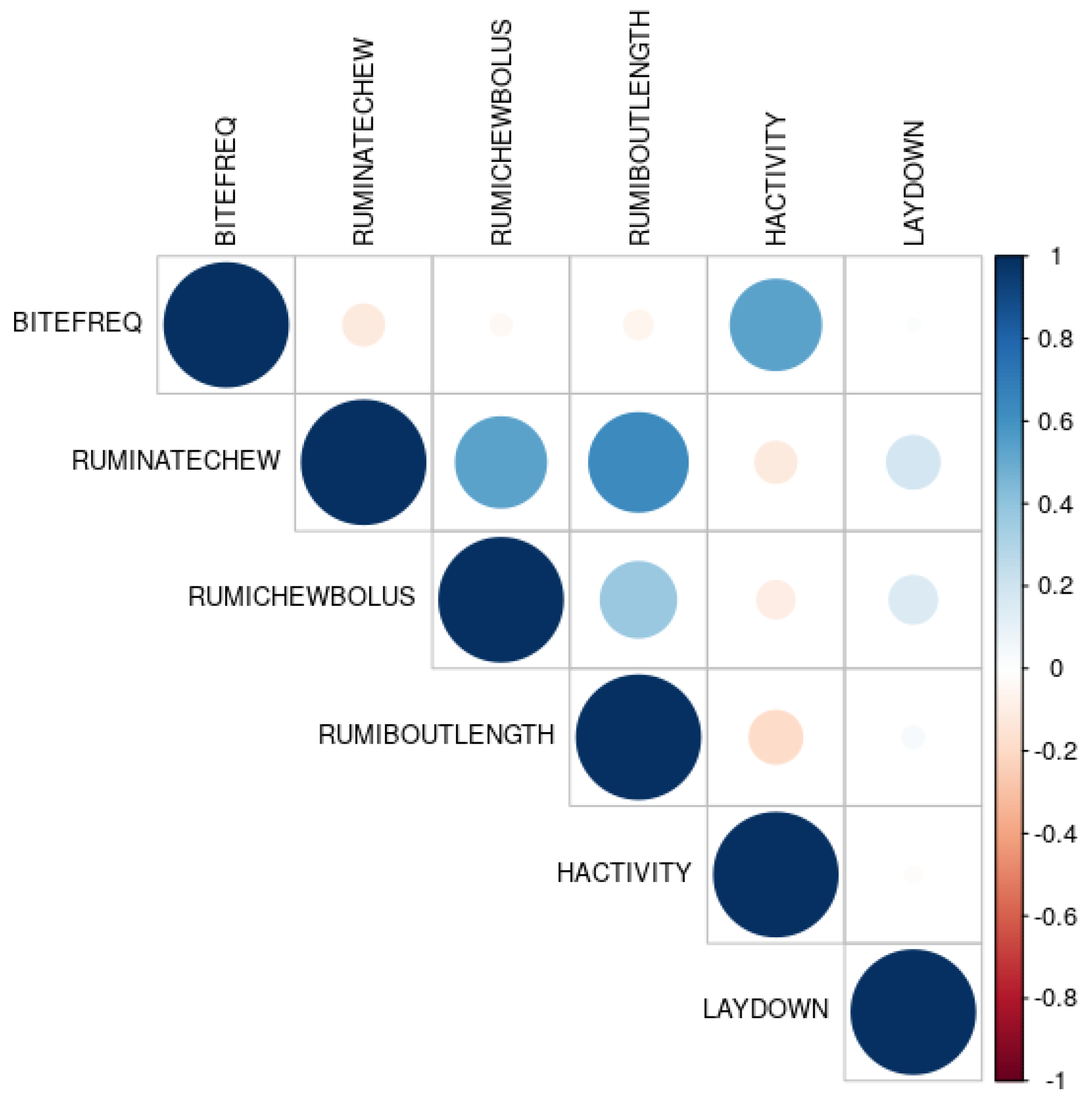
As the correlation among the important predictors was taken into account, the contour plots further revealed the observed ranges for the correlated predictors, at which the RF model was more likely to declare sufficient and insufficient herbage allowance class. It was observed that the RF model would predict insufficient allowance when the RumiWatchSystem recorded higher values for BITEFREQ >64/min) and HACTIVITY (>111), and lower values for RUMINATECHEW (>27,685/day), RUMICHEWBOLUS (>50/bolus), RUMIBOUTLENGTH (>32 min/bout), LAYDOWN (>7) and GRAZINGSTART (>7/day).
As one of the key roles of precision pasture management is to ensure that herbage allowance is well maintained and utilised for the individual cows, our findings have important implications in the quest to develop precise and reliable decision support systems for pasture management in order to assist farmers. With growing consumer demands for animal welfare [
19] and the worldwide human population increase [
20], there is pressure on farmers to optimally utilise the world’s grasslands. Since grassland is heterogenic, herbage growth is almost unpredictable, and individual feed intake differs between cows, pasture management is difficult and laborious. However, at the onset of pasture management, farm staff know that the cows on pasture have enough herbage to cover their requirement. It can therefore be of great help for farmers to detect the point of change from sufficient to insufficient pasture allocation for the individual cows. As the support system is aimed to regularly update the behavioural data, the current records can be added to improve the allocation prediction. Thus, all the previously recorded features of the cows feed into the model for predicting their decision classes. In this context, the cross-validation results in this study indicate that a decision support system using the RF and XGBoost models could correctly predict the sufficient or insufficient allowance of the cows at a rate around 80% or higher including the different subsets.
In a real world system, the observed thresholds may be useful for prediction (i.e., the current data can be used as training set) under the assumption that the cows on pasture are similar, the recorded features lie within the observed ranges, and the extraneous factors such as temperature, climate condition, pasture condition, grass quality, etc. are also similar to the ones in this study. However, it is important to note that the thresholds are approximate since the underlying algorithms were trained by the randomly selected subsets of the data used in this study. In general, care needs to be taken while applying the thresholds for future predictions. Since the present study identified more than one models that attained relatively higher accuracy in different conditions, it is further recommended to apply GLM, NB, LDA and NNET along with SVM, XGBoost and RF, and determine the decision class for new calving cows based on majority voting. In the case of different environment, pasture conditions or different cow breeds, the models should be trained with new datasets and checked for validity of the observed thresholds. Nonetheless, the results obtained in this study provide a strong foundation towards ML based predictions of insufficient herbage allowance through decision support systems in precision pasture management. Especially, the methods RF and XGBoost have shown their strength in the context of present study, across the different subsets of data and are, therefore, particularly well-suited for a decision support system.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




