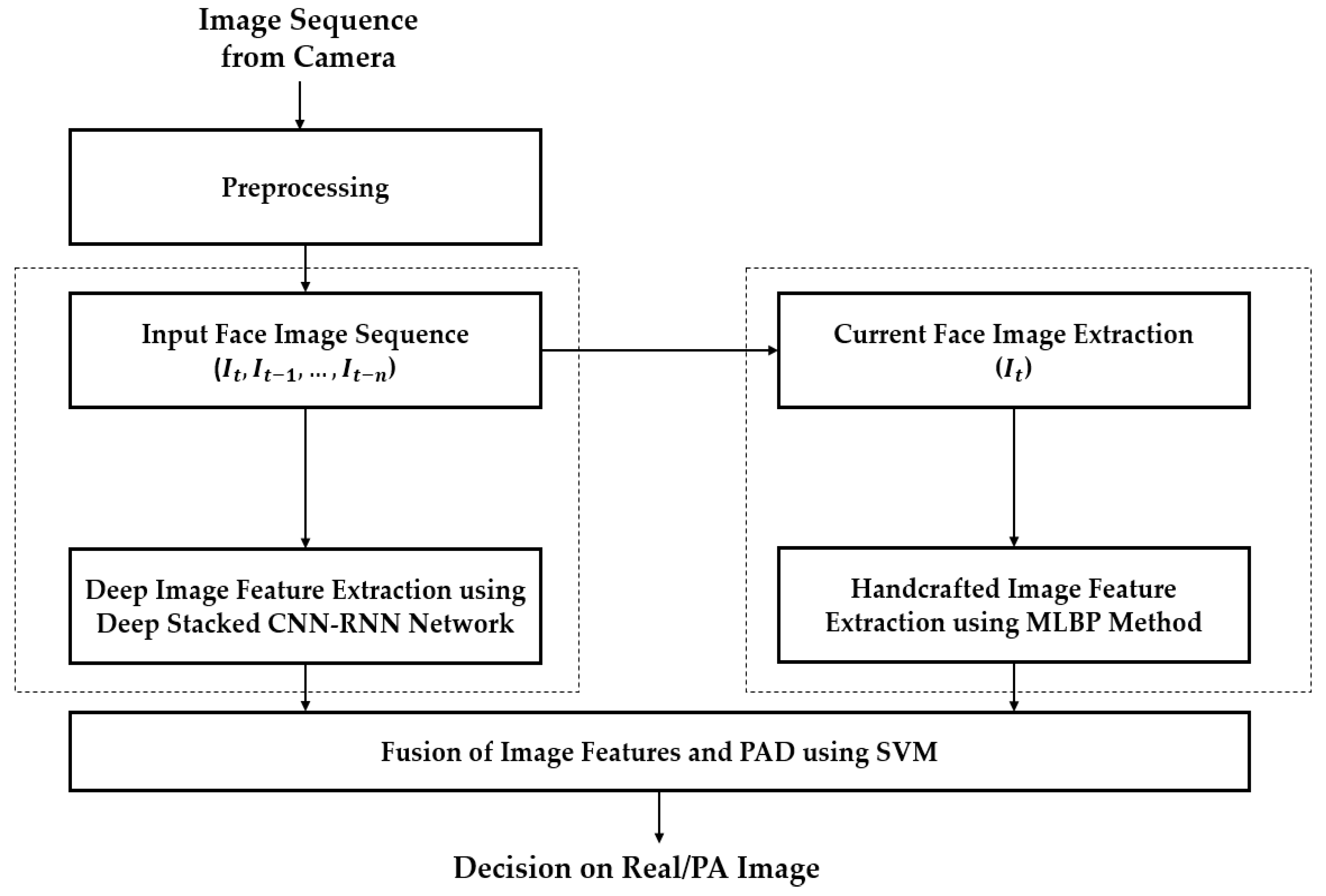
5.3.1. Experiment Using the CASIA Dataset
In this experiment, we used the CASIA dataset to evaluate the detection performance of the proposed method mentioned in
Section 4. We considered that the CASIA dataset was made of three different PAIs, i.e., wrap-photo, cut-photo, and video display, to simulate three possible attack methods based on wrap-photo, cut-photo, or video display. First, we trained the stacked CNN-RNN network mentioned in
Section 4.3 using the training dataset. Because the CASIA dataset was pre-divided into two sub-datasets (training and testing), we only used the augmented training dataset presented in
Table 4 for this experiment. The result of this experiment is shown in
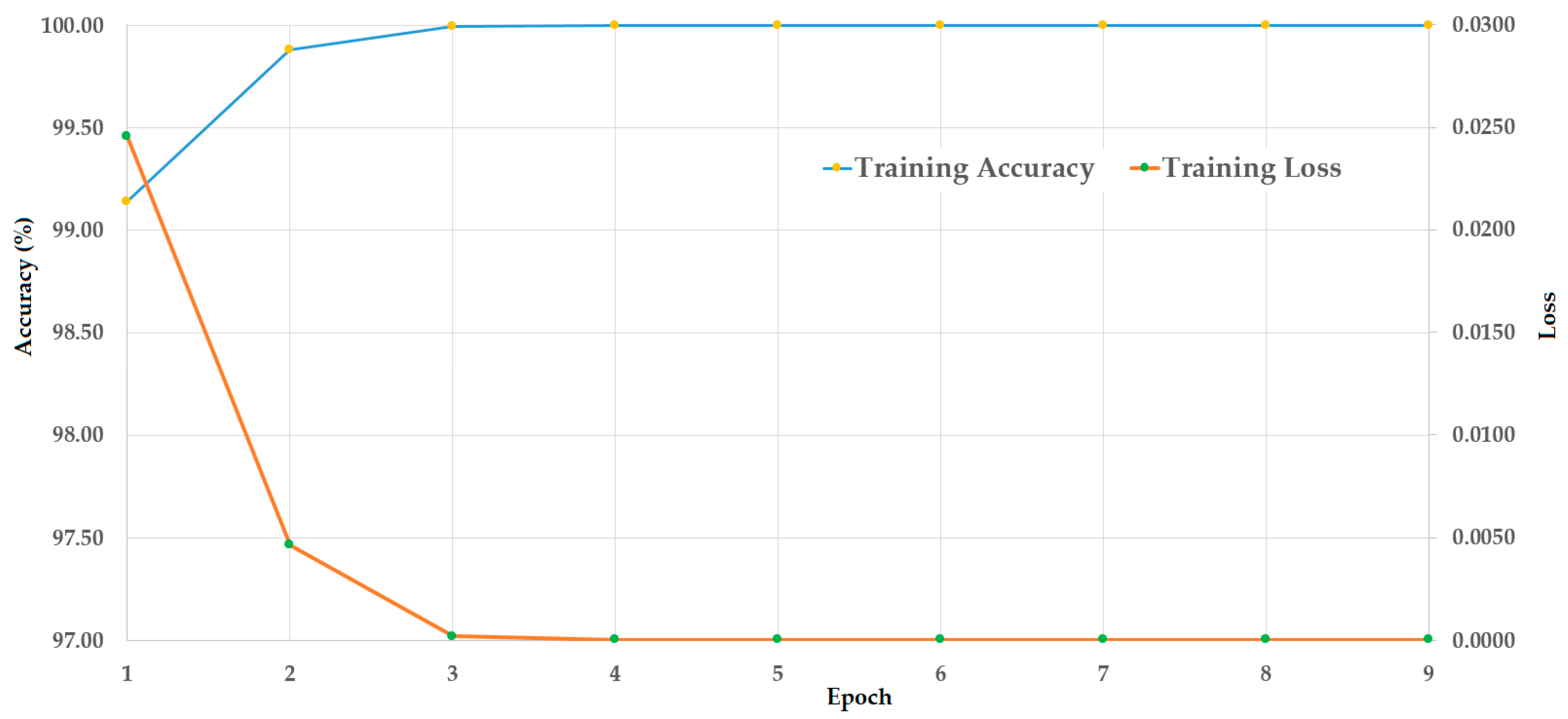
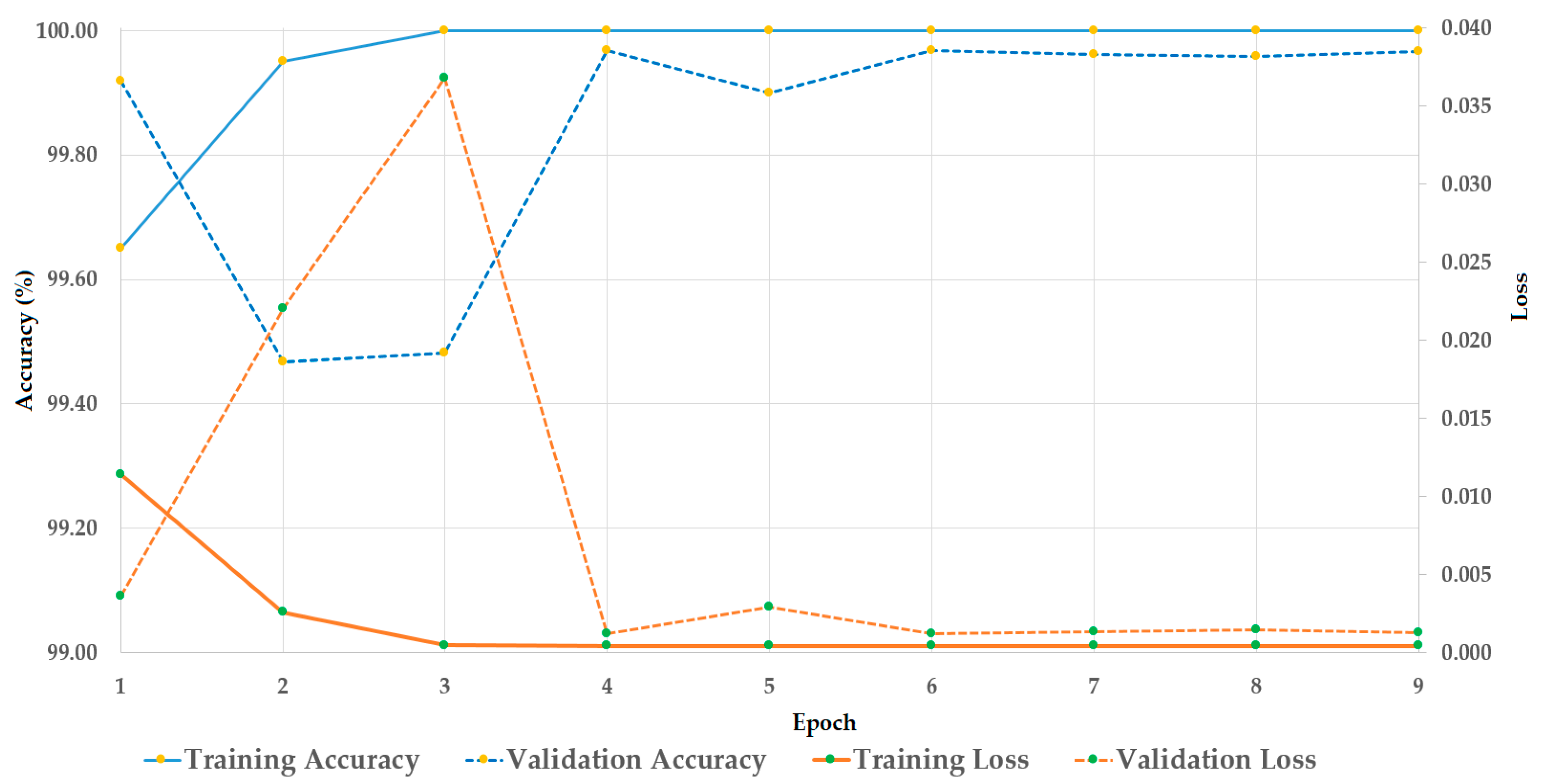
Figure 8. As seen from
Figure 8, the training of the stacked CNN-RNN network was successfully performed by causing the loss to reduce to reach zero, and increasing the accuracy to reach 100%, with the increase of training epoch.
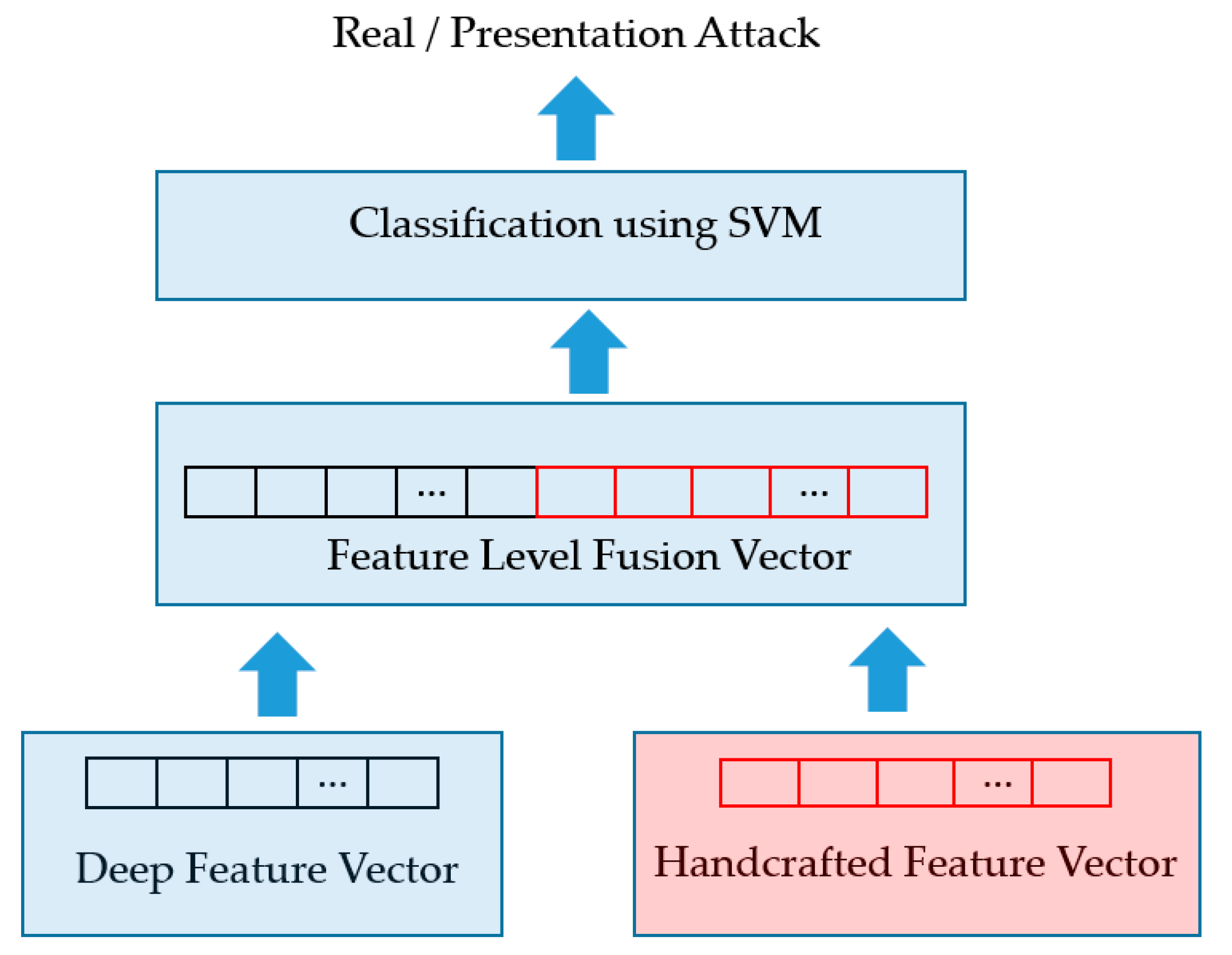
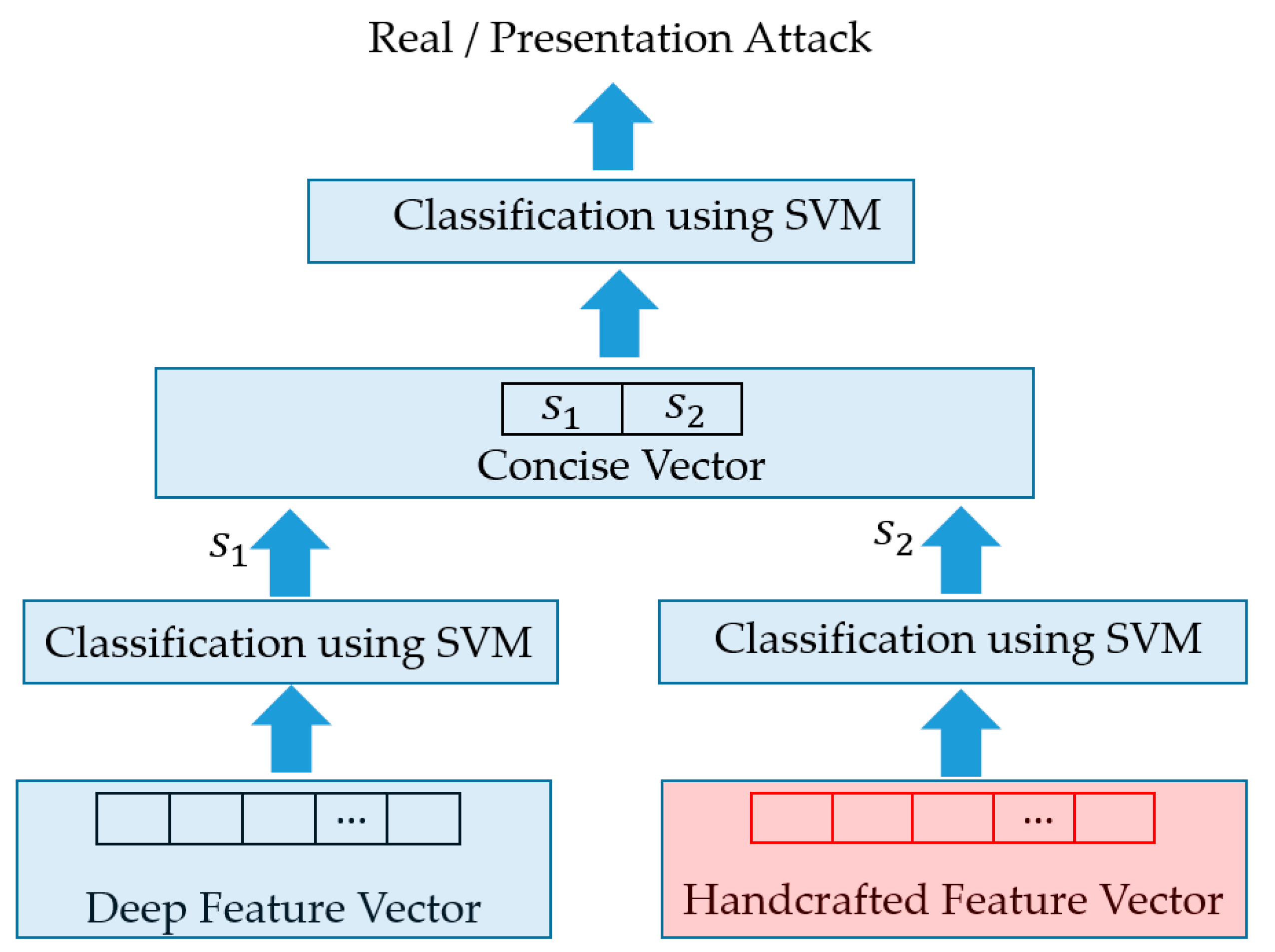
With the pre-trained stacked CNN-RNN model, we continued performing experiments with our proposed method using the SVM on the extracted deep and handcrafted image features. Detailed experimental results are provided in
Table 6 to be used for the testing dataset. In this table, we provided the experimental results for four system configurations, i.e., the face-PAD system only using deep features extracted using the stacked CNN-RNN network, the face-PAD system only using MLBP features, and our proposed approach using feature level fusion (FLF) and score level fusion (SLF). As explained in
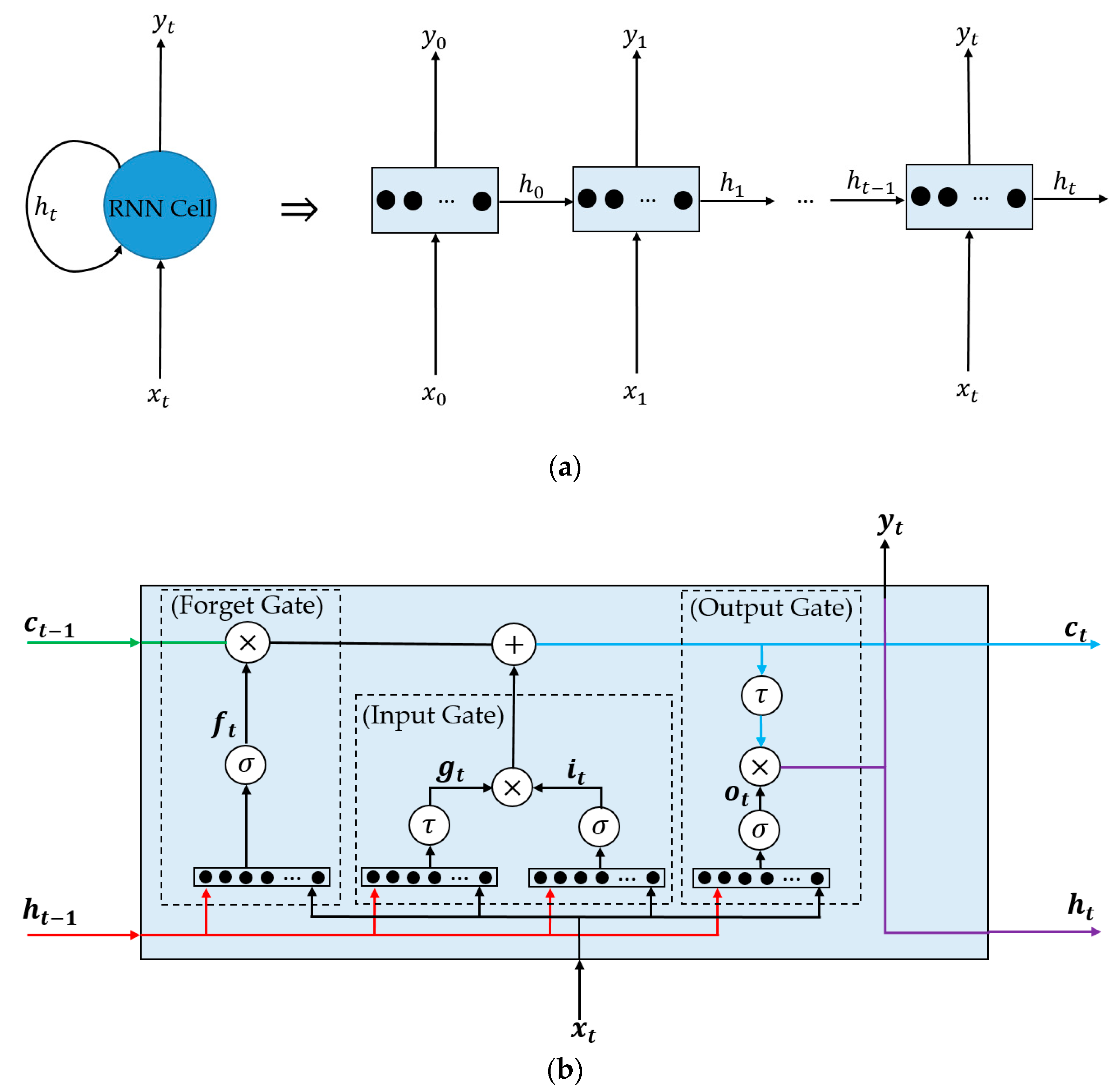
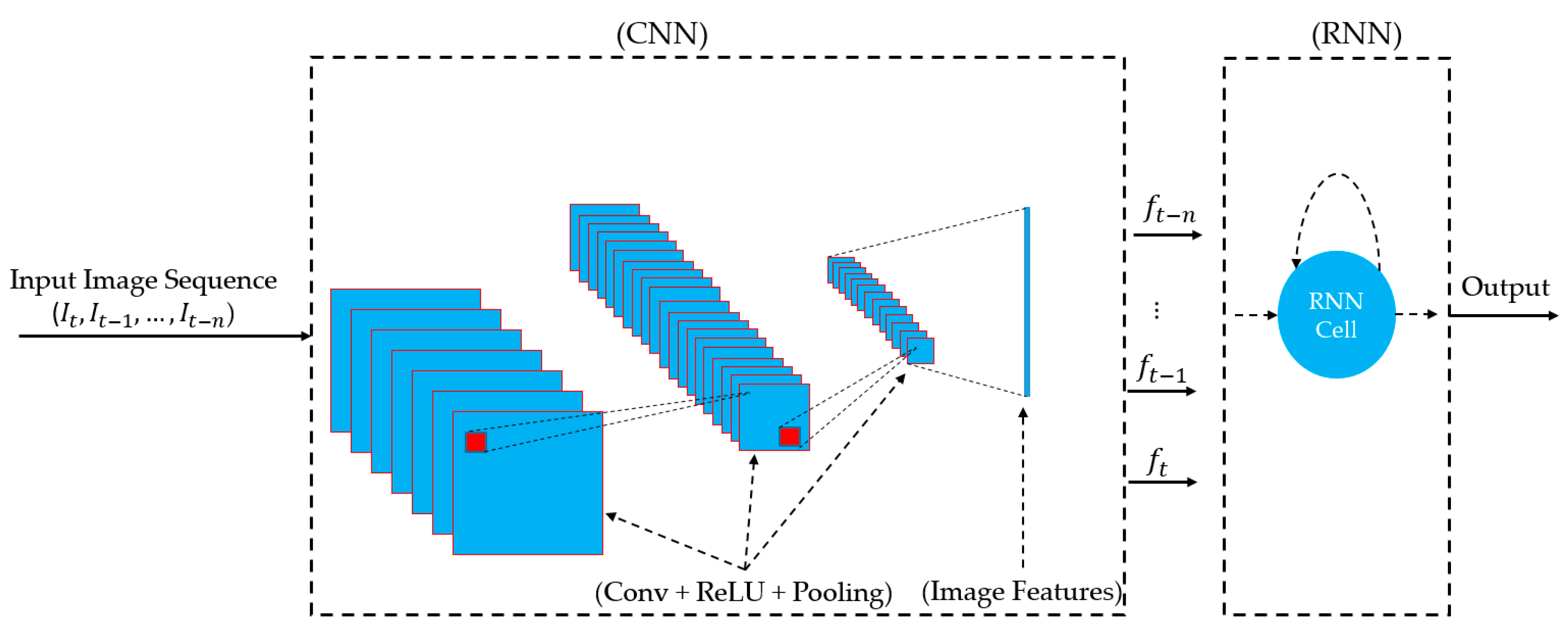
Section 4.3, most of previous studies used CNN for deep feature extraction. To demonstrate the influences of our architecture that uses RNN for image feature extraction instead of using only CNN architecture, we also provided the detection performance of face-PAD system that uses deep features by CNN in
Table 6. For this purpose, we performed experiments using the method proposed by Nguyen et al. [
27] in which the VGG-19 network architecture was invoked for deep feature extraction. However, as shown in
Table 2, our approach uses a stacked CNN-RNN network to extract a 1024-dimiensional feature vector for each sequence of image while the work by Nguyen et al. [
27] used the original VGG-19 network to extract a 4096-dimensional feature vector of each input image. The use of original network architectures as Nguyen et al. [
27] in this experiment makes an unbalanced comparison because of the different size of extracted image feature vectors. Therefore, we reduced the number of neurons in the last two fully-connected layers of the VGG-19 network from 4096 to 1024 in our experiment. By using this set-up, we extract a same-size feature vector for an input of each network, and therefore, we can fairly compare the detection accuracy of the two network architectures. It can be inferred from
Table 6 that the deep features outperform the MLBP features for the face-PAD problem. The face-PAD system based on deep CNN-RNN features produced errors (ACER) of 1.458%, 0.858%, and 1.108% for the use of wrap-photo, cut-photo, and video display, respectively. Because the wrap-photo produced the worst APCER value compared with cut-photo and video access, the final error of face-PAD system using deep CNN-RNN features is about 1.458%. As shown in the first row of
Table 6, the face-PAD system based on deep features extracted only by CNN network [
27] has an error of 3.373%. This error is much higher than the error produced by our face-PAD system based on deep CNN-RNN features. Through this experimental result, we observed the positive influence of RNN architecture over the CNN architecture for the face-PAD system.
Using only the MLBP features, we obtained the ACERs of 9.738%, 10.181%, and 9.884% for the use of wrap-photo, cut-photo, and video display, respectively. As a result, the overall error of the face-PAD system using only the MLBP features is about 10.181%. This error is much higher than that produced by the system that only uses deep CNN-RNN features (1.458% vs. 10.181%). As mentioned in
Section 4.4, our study uses the MLBP method to extract spatial image features besides the deep features extracted by a stacked CNN-RNN network. By combining several LBP features at different scales and resolutions, we can extract more powerful image features than the conventional LBP method. Although the LBP method has been widely used for the face-PAD problem in previous research [
17,
19,
22], it is still a handcrafted image feature extraction method. Therefore, it just captures limited aspects of the face-PAD problem. By definition, the LBP method is designed to capture texture (spatial) features on face regions by accumulating histograms of uniform and non-uniform micro-texture features such as edge, corner, blob, and flat regions. Because of this design, the LBP method can be affected by noise and/or background regions. As a result, the performance of LBP method is limited. As shown in a previous study conducted by Benlamoudi et al. [
22], the LBP method produced a PAD error of about 13.1% using the CASIA dataset. In another study, Boulkenafet et al. [
19] showed that the LBP features extracted from color face images work better than LBP features extracted from gray-scale face images. They showed a PAD error of about 6.2% with the CASIA dataset. These results are consistent with that (9.488%) in our experiments shown in
Table 6, and they confirm that although the LBP features can be used for face-PAD, their performance is limited compared with the deep features. Although the performance of the face-PAD system using MLBP features is worse than that of the system using deep features, the use of both handcrafted and deep features of our study help enhance the detection performance of the face-PAD system. As shown in the lower part of
Table 6, the score level fusion approach produced an overall error of about 1.286%, which is much smaller than 1.458% for the system using only deep features or 10.181% for the system using only handcrafted features. In addition,
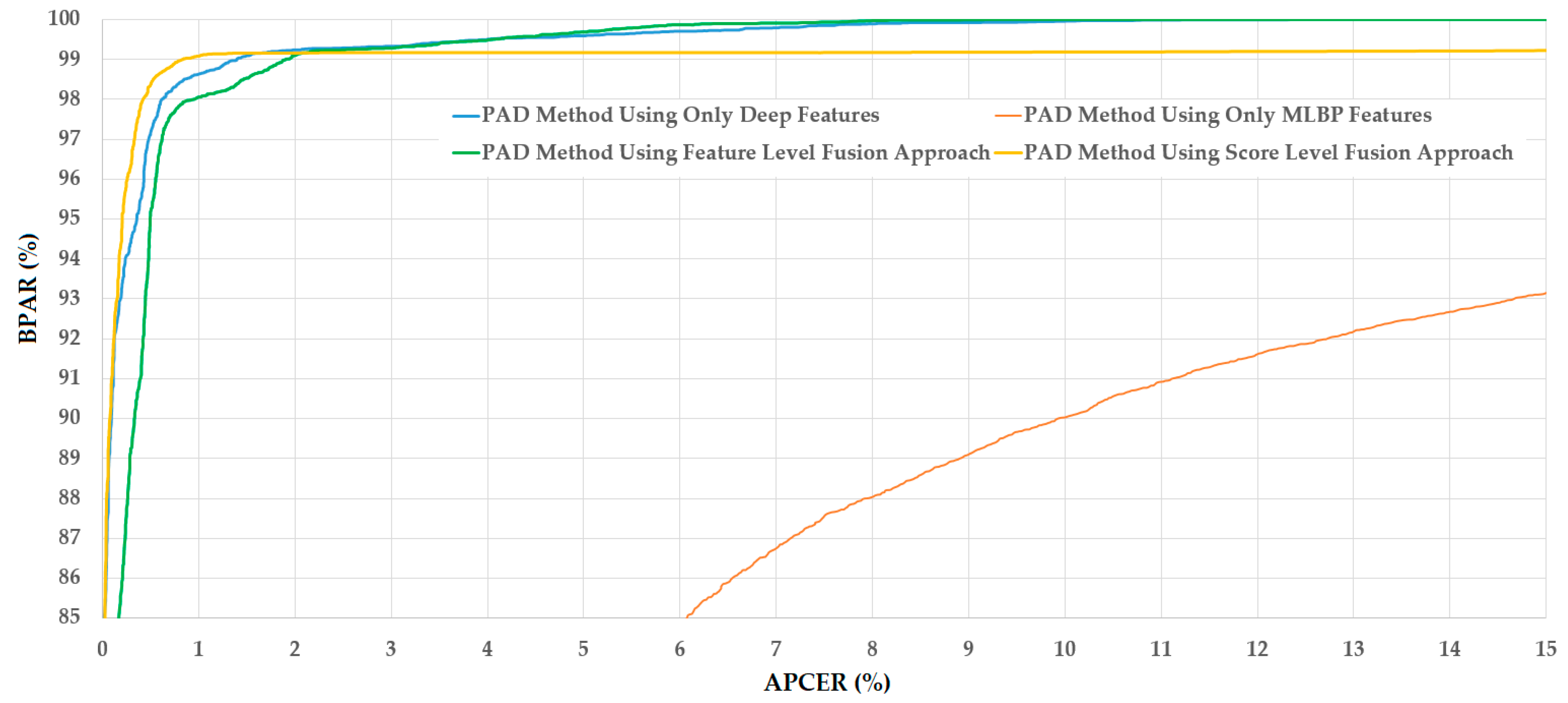
Table 6 shows the HTERs of 0.954%, 9.488%, and 0.910% for the face-PAD system that only uses deep features, only MLBP features, and score level fusion approach, respectively. This result again confirms that the combination of deep and handcrafted image features is sufficient to enhance the detection accuracy of the face-PAD system. This phenomenon is reasonable because deep and handcrafted feature extraction methods work on two different aspects (learning and non-learning). Therefore, they can complement each other and consequently enhance the performance of a face-PAD system. For demonstration, the detection error tradeoff (DETs) curves of the four system configurations used in this experiment are shown in
Figure 9. In this figure, we drew the change of APCER according to the change of bona-fide presentation acceptance rate (BPAR). The BPAR is measured as (100 – BPCER) (%). As a result, the shape of DET curves are obtained as presented in
Figure 9, and the curve at the higher position indicates better detection performance of the face-PAD system. As shown in this figure, the score level fusion approach outperforms the other configuration.
In some previous studies which used the CASIA dataset for performance evaluation, the detection performance was not only evaluated using the entire CASIA dataset, but also with several subsets of this dataset to validate the detection performance according to the quality of faces and type of attack samples [
13,
18,
19,
24,
27]. Therefore, we performed similar experiments to evaluate the detection performance of our proposed method as well as compare the results with previous studies. For this purpose, we first divided the entire CASIA dataset into six subsets according to the quality of face regions and the type of attack method. As a result, we obtained six new datasets, i.e., “Low quality”, “Normal Quality”, “High Quality”, “Wrap-Photo”, “Cut-Photo”, and “Video Display”. Detailed descriptions of these datasets are provided in
Table 7. For each sub-dataset, the training data and testing data are obtained by taking the corresponding data in the entire training dataset and testing dataset, respectively. Therefore, the training and testing dataset of each sub-dataset do not contain the overlapped data of the same people. Similar to the experiment with the entire CASIA dataset, we used the training data of each sub-dataset to train the classification model, and used the testing dataset to evaluate the detection performance. The detailed experimental results of this experiment are provided in
Table 8. As shown in this table, we obtained the smallest detection errors (ACER) using our proposed method for all six sub-datasets. Among the six sub-datasets, we obtained the smallest detection errors of 1.417%, 0.004%, 1.085%, and 1.423% using the score level fusion approach for “Low Quality”, “Normal Quality”, “High Quality”, and “Video Display” datasets, respectively. For the “Wrap-Photo” and “Cut-Photo” datasets, we obtained the smallest errors of 1.886% and 0.425%, respectively, using the feature level fusion approach. However, as shown in
Table 8, the difference between the feature level fusion and score level fusion for these two datasets is very small (0.119% for “Wrap-Photo” dataset and 0.003% for “Cut-Photo” dataset). From this result, it can be concluded that the proposed method with the score level fusion approach performs well with the CASIA dataset, and outperforms all previous studies using the same dataset.
As the final experiment in this section, we performed a comparison between the detection performances of our proposed method and those produced by previous studies. As shown in
Table 9, the baseline method produced presented a detection error of about 17.000% [
13]. This error decreased to 13.1%, 6.2%, 5.4% and 5.07% in later research [
18,
19,
22,
23]. In a recent study conducted by Nguyen et al. [
27], they presented an error of about 1.696%. Compared with all of these detection accuracies, the proposed approach produced the lowest detection error. Based on this result, we conclude that our proposed method is sufficient for PAD for the face recognition system, and it is the state-of-the-art result obtained using the CASIA dataset.
5.3.2. Experiment Using the Replay-Mobile Dataset
As shown in our experiments in
Section 5.3.1, our proposed method demonstrated a better detection accuracy than other previous studies using the CASIA dataset. In our next experiment, we use an additional public dataset, namely, Replay-mobile, to evaluate the detection performance of our proposed method. The use of this additional dataset helps in the evaluation of the performance of our proposed method under various working environments of the face recognition system. This is a significantly large dataset that was collected for the purpose of detecting presentation attack face images for mobile devices. In our experiments, we grouped the presentation attack images into two different PAIs, i.e., matte-screen (photos and videos of people are displayed on a Philips 227ELH monitor, Philips, Amsterdam, Netherlands), and print (hard-copies of high-resolution digital photographs of people are printed on A4 matte paper). Different from the CASIA dataset, the Replay-mobile dataset was pre-divided into three subsets of training, validation, and testing. In this experiment, we used the training dataset to train the stacked CNN-RNN model for deep feature extraction, as well as the SVM model for final classification. The threshold for classification of an input face sequence into real or presentation attack classes is optimally selected using the validation dataset such that the real and presentation attack data are best separated. Finally, the performance of the detection system with actual data is evaluated using the testing dataset.
Similar to the experiments with the CASIA dataset, we first performed a training procedure to train the stacked CNN-RNN network for the deep feature extraction model.
Figure 10 shows the result of this experiment. Because the Replay-mobile dataset also provides a validation set for validation purposes, we also measured the accuracy and loss of this dataset; these results are shown in
Figure 10. The training procedure was successfully done using the training dataset by producing a classification accuracy of 100%, and causing the loss value to reduce to 0. Using the validation dataset, a similar result was obtained with a slightly lower performance than the case of using the training dataset.
In
Table 10, the detection performance of five face-PAD system configurations using the Replay-mobile dataset is provided. In this table, the optimal threshold for real and presentation attack classifications is selected at the equal error rate (EER) point of the validation set. As shown in this table, the face-PAD system that only uses deep features extracted by our stacked CNN-RNN network produced an EER of 0.002%, and the face-PAD system that only uses the deep features extracted by CNN network [
27] produced an error (EER) of 0.067% for the validation dataset. By applying the classification model to the testing dataset, we obtained the final detection errors (ACER) of 0.015% and 0.0045% using the deep features extracted by our stacked CNN-RNN and CNN networks, respectively. From these results, we can see that the RNN architecture is more efficient than the CNN architecture in extracting distinguish information from input face images. Using only the MLBP features, we obtained an EER of 4.659% for the validation dataset and a final ACER of 5.379% for the testing dataset. Similar to the experiment with the CASIA dataset, the detection performance using handcrafted features is worse than that produced using the deep features. However, the detection error was reduced to 0% for both validation and testing datasets using the feature level fusion approach. Using the score level fusion approach, the detection performance was maintained the same as that produced by the face-PAD system that only uses the deep features. However, as shown in
Table 10, the error is very small and was caused by a single incorrect image sequence from the total of 32169 real sequences. From these results, we conclude that our proposed method performs well with the Replay-mobile dataset. The important reason that our proposed method works better with the Replay-mobile dataset than the CASIA dataset is that the CASIA dataset contains larger variation of a presentation attack scenario than the Replay-mobile dataset. As mentioned in
Section 5.2, the CASIA dataset contains presentation attack images with three different quality of face images (low, normal, and high qualities), and three attack materials (wrap-photo, cut-photo, and video display), whereas the Replay-mobile dataset only contains the video display and print photo. Therefore, it is harder to detect presentation attack images when using the CASIA dataset than the Replay-mobile dataset. Because the detection error produced by this experiment was almost 0.000%, we do not show the DET curve for these experiments.
To demonstrate the efficiency of our proposed method, we compared our detection result with that of the baseline method. In the study conducted by Costa-Pazo et al. [
14] (the author of Replay-mobile dataset), they presented an HTER of about 7.8% and ACER of about 13.64% using the image quality measurement (IQM) method, and an HTER of about 9.13% and ACER of about 9.53% using the Gabor-jets feature extraction method. It can be clearly seen that the detection errors of our method (0% using feature level fusion and 0.0015% using score level fusion approach) are much smaller than the errors produced by the baseline method reported by Costa-Pazo el al. [
14]. This comparison demonstrates that our proposed method is sufficient for face-PAD and outperforms the previous studies using the same working dataset.
Because the deep learning-based method normally needs to use a huge amount of data to successfully train a network, it takes long time for the training procedure. The training time is mainly dependent on two factors, i.e., the network architecture (the amount of trainable parameters and the depth/wide of network) and the amount of training data. Using our proposed method and the CASIA dataset that contains 133936 image sequences for training (with data augmentation), it takes about 5 h per epoch. With the Replay-mobile dataset that contains 219011 training image sequences (with data augmentation), it takes about 7 h per epoch for training our network. As shown in
Table 3, we trained the detection model using 9 epochs. Consequently, it takes about 45 h and 63 h for the CASIA and Replay-mobile datasets, respectively.
5.3.3. Cross-Dataset Detection
In this experiment, we performed cross-dataset testing to evaluate the effect of difference in the image capturing conditions and setup. For this purpose, we performed experiments for two scenarios. In the first scenario, we trained the detection model using the CASIA dataset and validated the detection performance using the Replay-mobile dataset. In the second scenario, we exchanged the rule of the two datasets in the first experiment, i.e., we trained the detection model using the Replay-mobile dataset, and validated the detection performance using the CASIA dataset.
As a result, we obtained the experimental results as shown in
Table 11 and
Table 12, for the first and second scenarios, respectively. For the first scenario, we obtained an HTER of 12.459% and ACER of 13.509% using the feature level fusion approach. Using the score level fusion approach, the errors increased to an HTER of 20.632% and ACER of 23.589%. For the second scenario, the errors were higher with an HTER of 42.785% and ACER of 48.466% using the feature level fusion approach, and an HTER of 46.201% and ACER of 51.037% using the score level fusion approach, as shown in
Table 12. These detection errors are very high compared to those reported in
Section 5.3.1 and
Section 5.3.2. Based on these results, we conclude that the cross-dataset classification is still challenging and needs to be addressed in future work. In addition, the detection model trained on the CASIA dataset performs better than that trained on the Replay-mobile dataset. The reason is that the CASIA dataset contains more general attack methods than the Replay-mobile dataset, as mentioned in
Section 5.2. As a result, the classification model trained on CASIA dataset works as a more general case compared to the model trained on Replay-mobile dataset. This result suggests that we can obtain an efficient face-PAD model by collecting maximum data that can simulate all possible kinds of attacking methods.
As the final experiment, we compared the detection performance of our proposed method with a previous study conducted by Peng et al. [
53] for cross-dataset testing. In the study by Peng et al. [
53], they used two methods for image feature extraction, i.e., a combination of LBP and the guided scale LBP (GS-LBP) and local guided binary pattern (LGBP). A detailed comparison is provided in
Table 13. As shown in this table, the study by Peng et al. produced errors of 41.25% and 51.29% for the use of LBP+GS-LBP and the LGBP feature extraction methods, respectively, in the case of using the CASIA dataset for training and Replay-mobile dataset for testing. Using our proposed method, we obtained an error of 12.459%, which is much smaller than that produced in the study by Peng et al. [
53]. For the second case of using the Replay-mobile dataset for training and CASIA dataset for testing, our proposed method produced an error of 42.785%. Although this error is very high, it is still lower than 48.59% and 50.04% produced by the study by Peng et al. for the case of using LBP+GS-LBP and LGBP, respectively. In addition, we performed experiments for the face-PAD system based on deep features extracted by the CNN method to evaluate the influence of stacked CNN-RNN architecture on learning temporal information over the CNN architecture with the cross-dataset. Using the deep image features extracted by the CNN method [
27], we obtained an error rate (HTER) of 21.496% for the case of using the CASIA dataset for training and the Replay-mobile dataset for testing. In the opposite way, we obtained an error of 34.530% for the case of using the Replay-mobile dataset for training and the CASIA dataset for testing. As shown in
Table 13, our proposed method outperforms the face-PAD system based on CNN [
27] in the case of using the CASIA dataset for training and the Replay-mobile dataset for testing with an error of 12.459% versus 21.496%. However, the error produced by our method is higher than that of the CNN-based method. The reason for this is that the CASIA dataset contains more general presentation attack methods than the Replay-mobile dataset. Therefore, although the detection model works well on the Replay-mobile dataset, it performs poorly in the CASIA dataset. Through these comparisons, we conclude that our proposed method outperforms the previous work conducted by Peng et al. [
53] for the cross-dataset setup. In addition, we see that we should collect data from as many as possible presentation attack methods for training to ensure the PAD performance in the cross-dataset testing scenario.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}