Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network

 ,
,
Abstract
1. Introduction
- Different from previous FCN-based methods, instance segmentation framework is applied into building detection and segmentation, which can better deal with closely adjacent small buildings and some other tough problems.
- We adapt rotatable anchors into the RPN stage of Mask R-CNN framework, which regress a minimum area bounding rectangle (MABR) likely rotation bounding box and eliminate redundant background pixels around buildings.
- We use several RFB modules to boost the segmentation branch of Mask R-CNN framework, which can better accommodate to multi-scale building targets by parallel connecting multi-branch receptive fields with varying eccentricities.
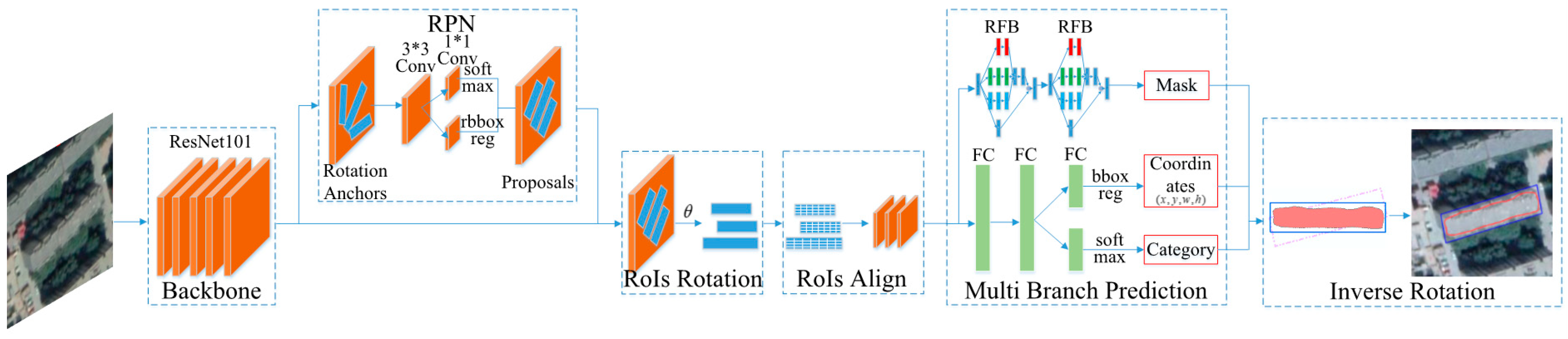
2. Methods of Building Extraction from Remote Sensing Images
2.1. Rotation Region Proposal Network
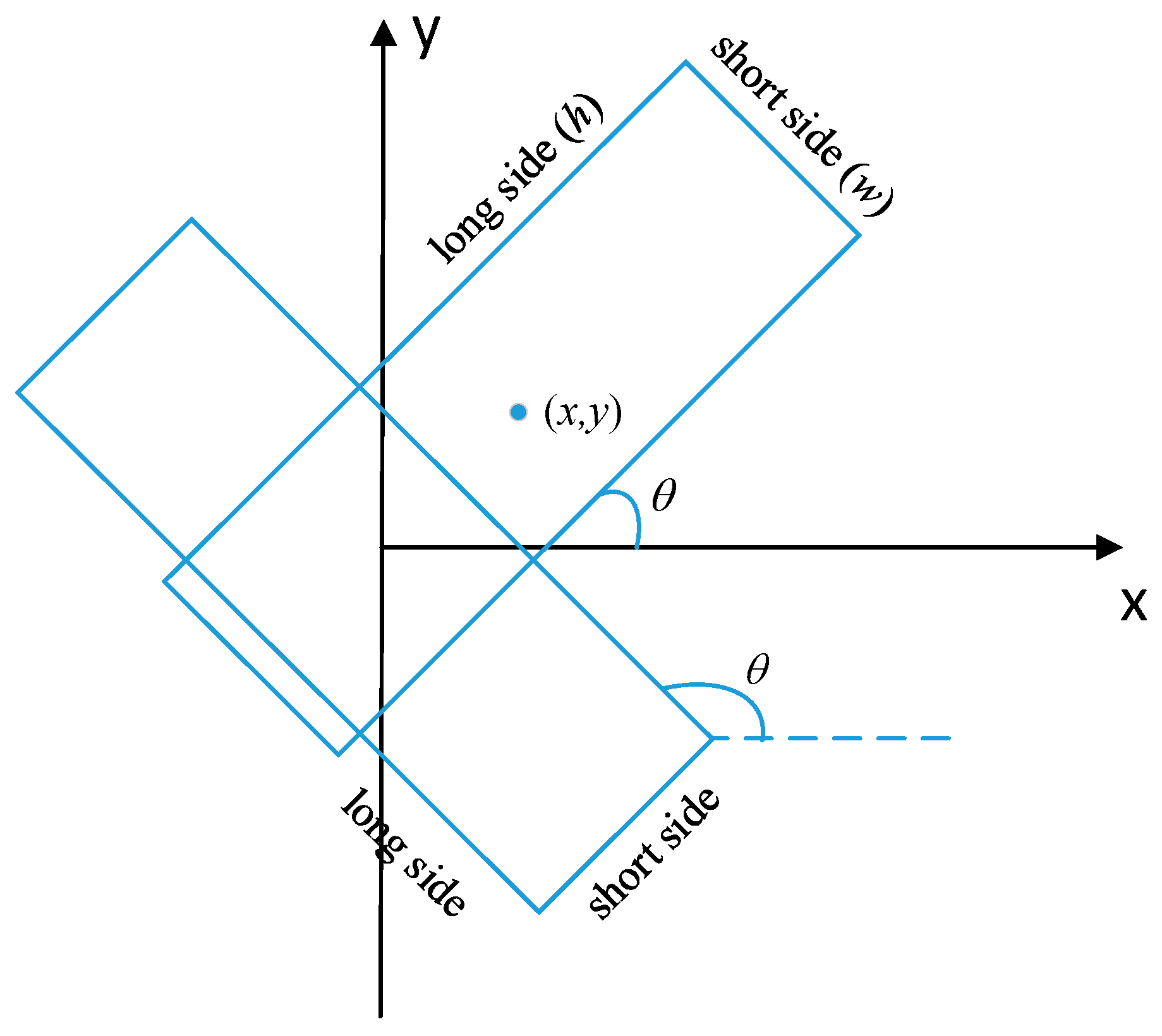
2.1.1. Rotation Bounding Box
2.1.2. Rotation Anchor
2.1.3. Leveling ROIs
2.2. Multi-Branch Prediction Network
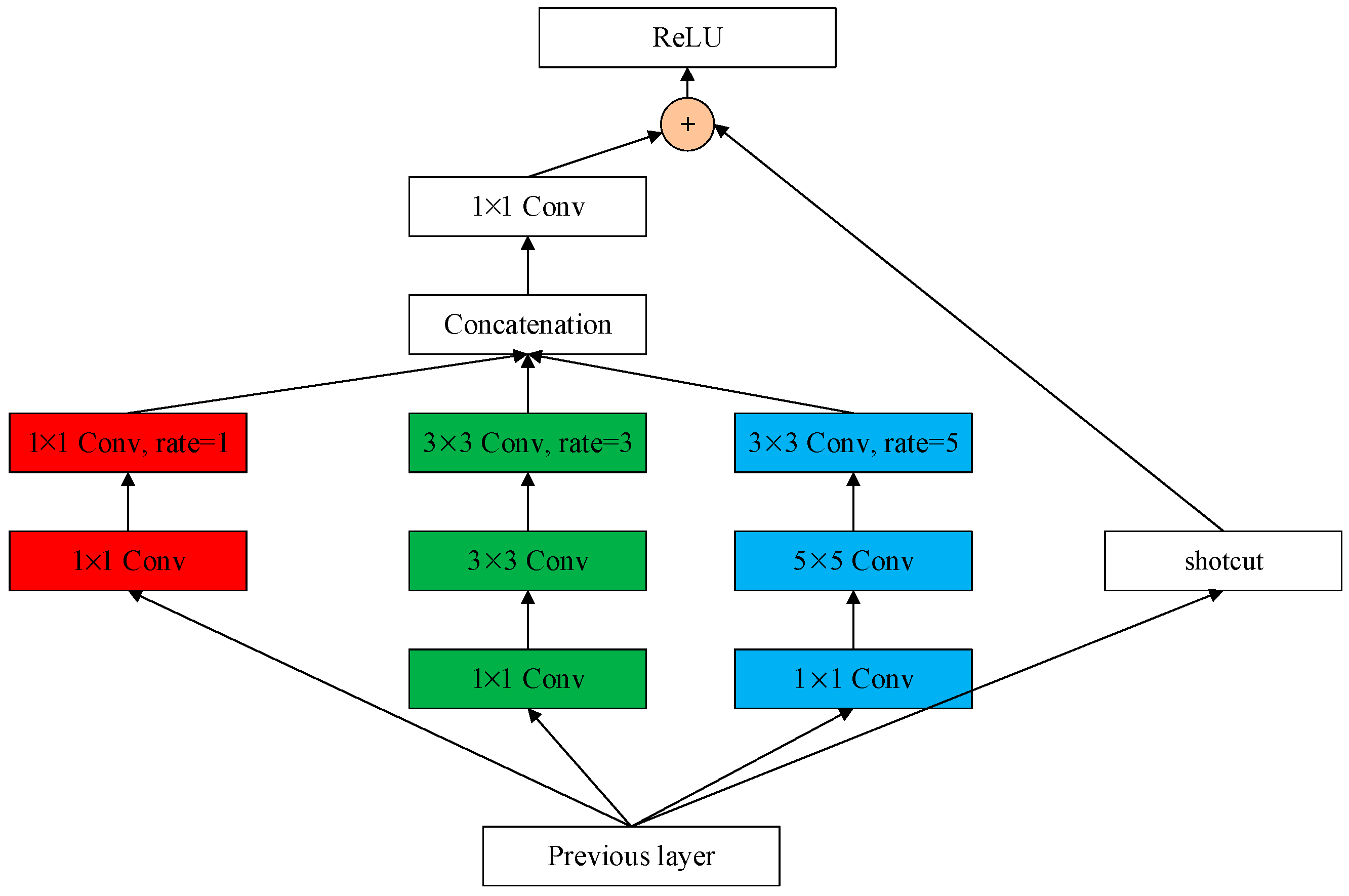
2.2.1. Receptive Field Block
2.2.2. RFB Stacked Segmentation Network Branch
2.2.3. Inverse Rotation of Mask
2.3. Loss Function
3. Results
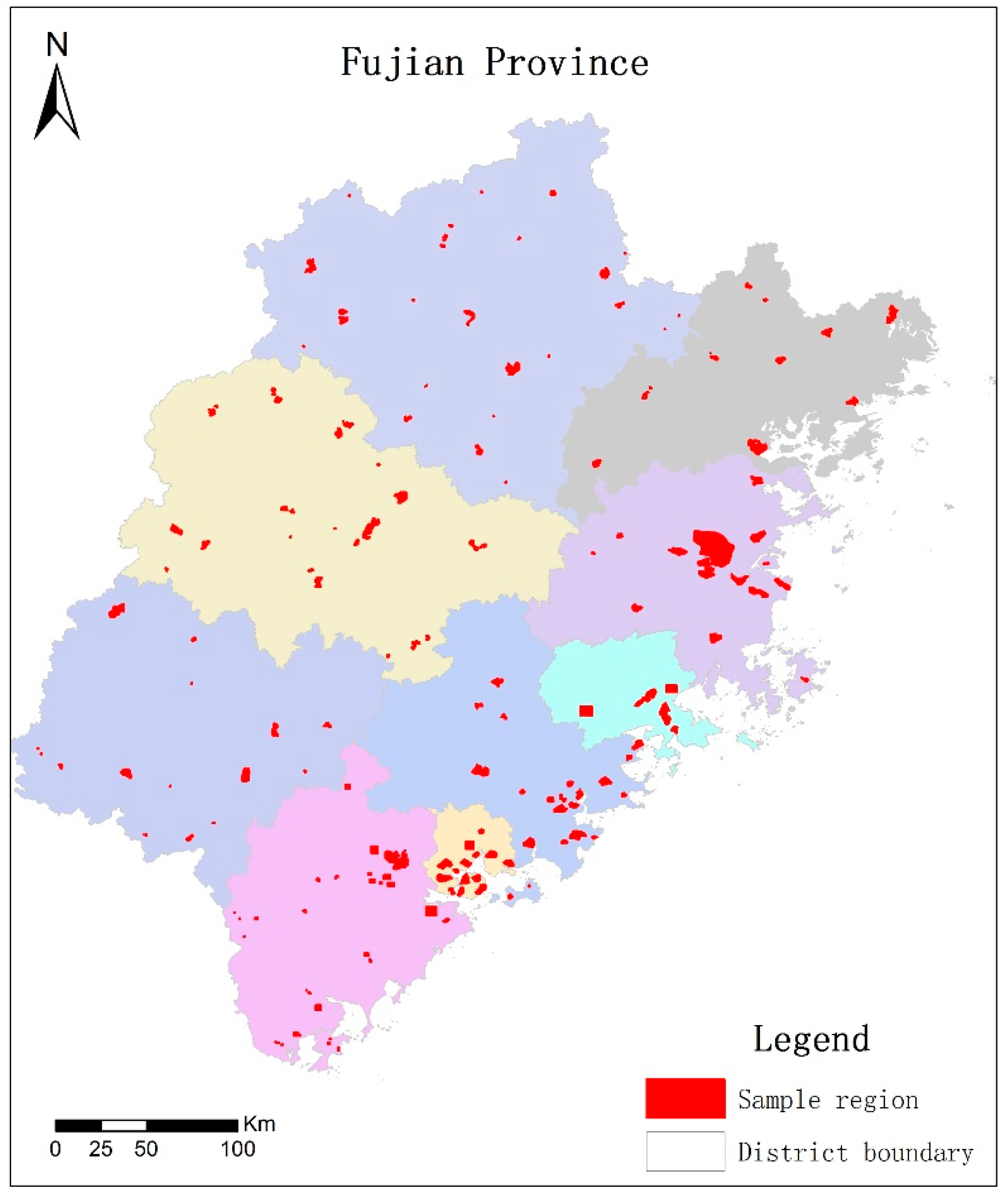
3.1. Data and Research Area
3.2. Implementation Details
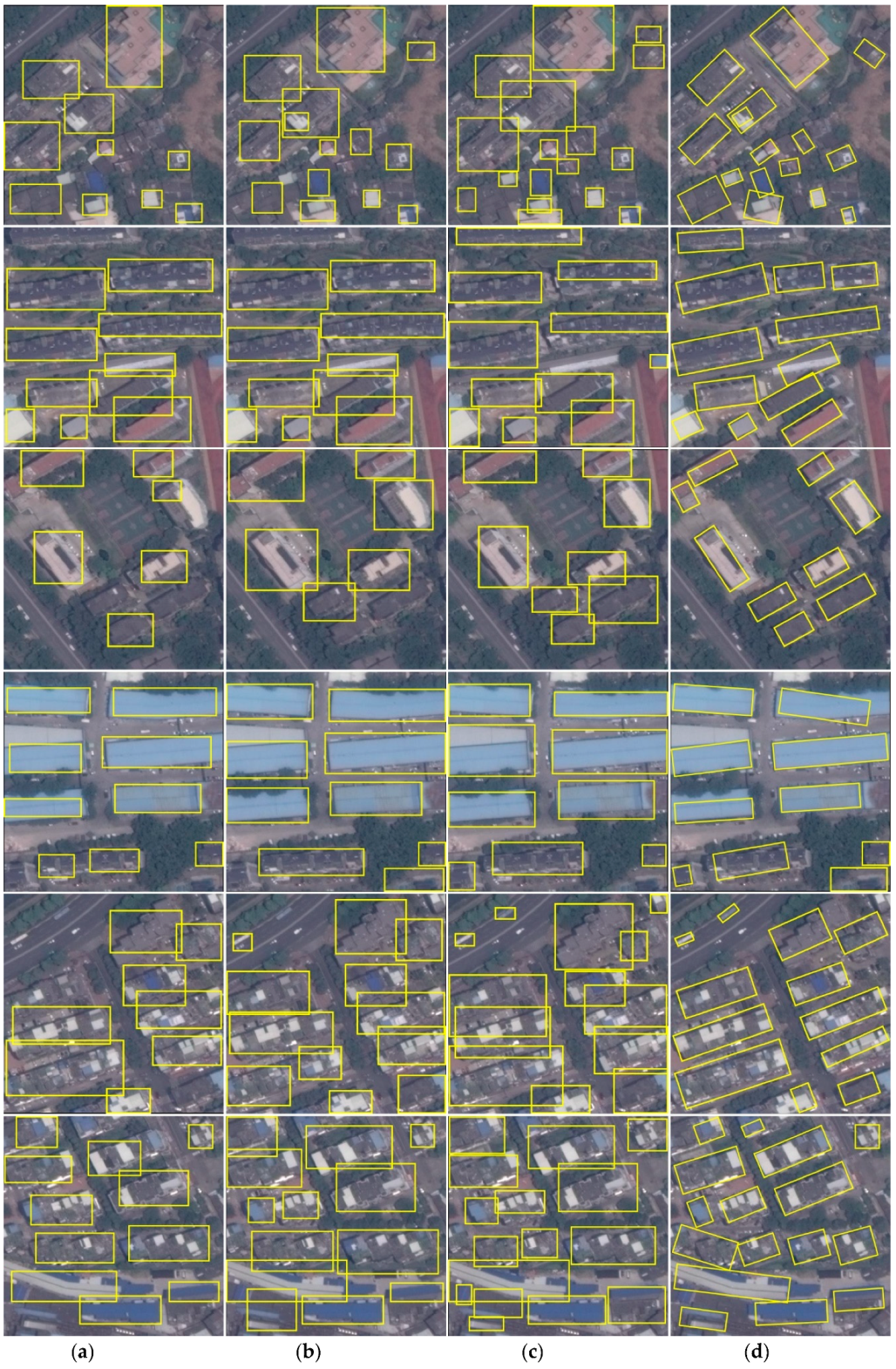
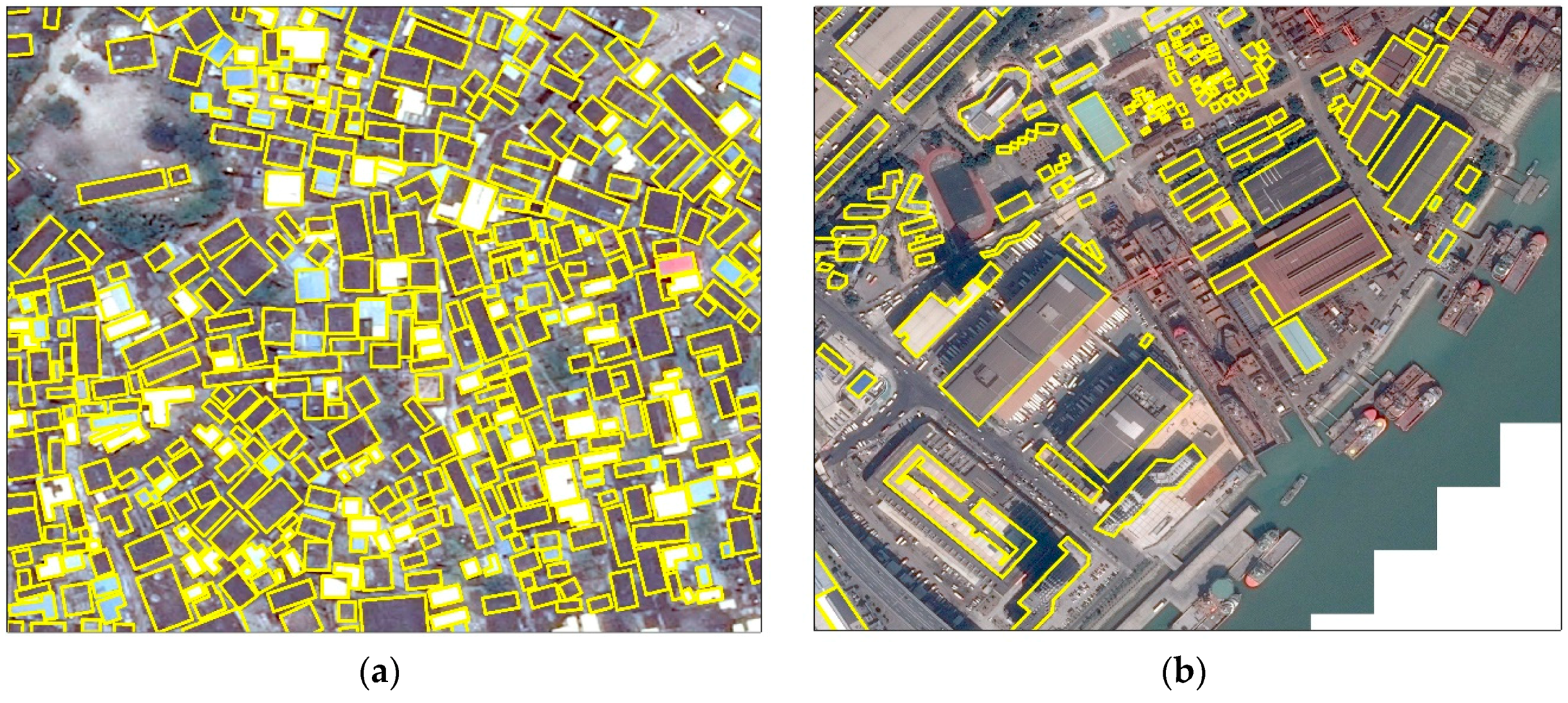
3.3. Evaluation of Detection Task
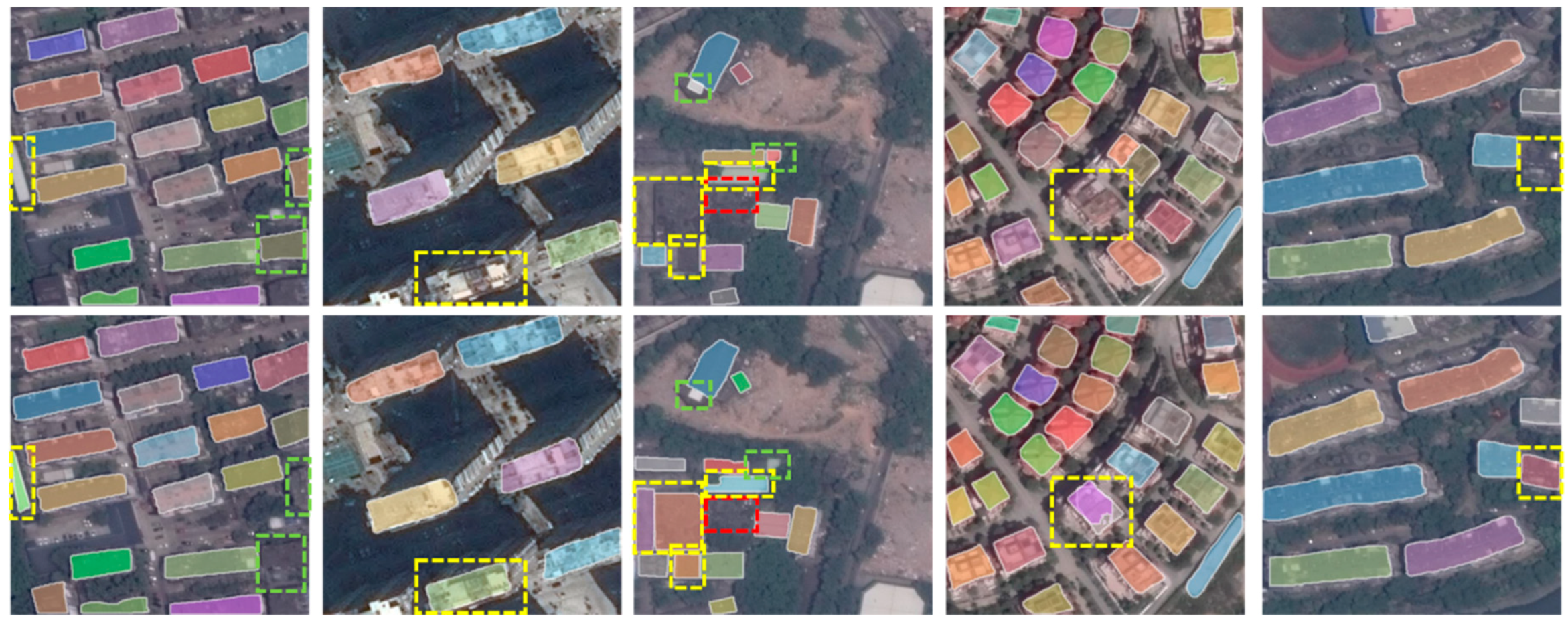
3.4. Evaluation of Segmentation Task
4. Discussion
- More and diversity building samples. Deep neural networks are data hungry models, requiring a huge volume of training samples. Although we have labeled thousands of buildings to train our network, providing more samples will further boost the performance. In addition, buildings have diversity sizes, structures. For instance, factory buildings and residential houses possess distinctly different features. Even residential houses, buildings from city and village are with different sizes, aspect ratio and shapes. To detect them all, samples should cover as many instances as possible. Moreover, complex backgrounds could be distractions to the detector, especially there are objects with similar appearance, such as vehicle, ships, roads, and so on. An example is shown in Figure 10. It is better to label a certain amount of buildings under complex backgrounds.
- Refine rotated angle of bounding box. In this work, the value of a rotated angle is regressed from the RPN stage. Since there is only one category i.e., buildings to be detected, ROIs generated by the RPN network should be close to that of detection branch, thus we use angles from the RPN as the final rotation angles. However, we believed that, similar to bounding boxes regression they can be further refined by the second stage. In future, we will focus on two solutions. The first one is designing a new branch and adding it after the second stage to refine the rotated angle. The new branch will accept the rotated mask as input and predict the angle. The second one is transforming the vertical ROIs generated by RPN to the second stage. The vertical ROIs consist of rotation information thus can be used to infer the angle value. Since ROI Align is applied in the RPN stage, we will obtain more accurate angles.
- Network compression. Mask R-CNN framework has a huge number of parameters, which will consume large amount of computation resource and lead to decrease in inference time. In recent years, with the rapid development of mobile device and the demand for real-time computation, researchers have attempted to compress the size of the deep models while maintaining their performance. These methods resolve the network compression problem from three aspects: designing light network, network pruning and kernel sparsity. Both the backbone of the Mask R-CNN and the proposed method are based on residual network, which could be pruned to produce a lighter backbone. In addition to this, some inborn light networks such as ShuffleNet [33], CornerNet [34] can be used to design the proposed method.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- UNISDR UNO. Sendai framework for disaster risk reduction 2015–2030. In Proceedings of the 3rd United Nations World Conference on DRR, Sendai, Japan, 14–18 March 2015. [Google Scholar]
- Chiroiu, L. Damage assessment of the 2003 Bam, Iran, earthquake using Ikonos imagery. Earthq. Spectra 2005, 21, S219–S224. [Google Scholar] [CrossRef]
- Corbane, C.; Saito, K.; Dell’Oro, L.; Bjorgo, E.; Gill, S.P.D.; Piard, B.E.; Huyck, C.K.; Kemper, T.; Lemoine, G.; Spence, R.; et al. A comprehensive analysis of building damage in the 12 January 2010 Mw7 Haiti Earthquake using high-resolution satellite and aerial imagery. Photogramm. Eng. Remote Sens. 2011, 77, 997–1009. [Google Scholar] [CrossRef]
- Fan, Y.; Wen, Q.; Wang, W.; Wang, P.; Li, L.; Zhang, P. Quantifying Disaster Physical Damage Using Remote Sensing Data—A Technical Work Flow and Case Study of the 2014 Ludian Earthquake in China. Int. J. Disaster Risk Sci. 2017, 8, 471–488. [Google Scholar] [CrossRef]
- Wang, J.; Qin, Q.; Ye, X.; Wang, J.; Yang, X.; Qin, X. A Survey of Building Extraction Methods from Optical High Resolution Remote Sensing Imagery. Remote Sens. Technol. Appl. 2016, 31, 653–662. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Boston, MA, USA, 14–18 September 2015; pp. 234–241. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2015; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 21–37. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Zuo, T.; Feng, J.; Chen, X. HF-FCN: Hierarchically Fused Fully Convolutional Network for Robust Building Extraction. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2016; pp. 291–302. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to label aerial images from noisy data. In Proceedings of the International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012; pp. 567–574. [Google Scholar]
- Zhang, Q.; Liu, Q.; Liu, X.; Wang, W. CNN based suburban building detection using monocular high-resolution google earth images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 661–664. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipoll, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Fu, K.; Gao, X.; Yan, M.; Sun, X.; Zhang, H. Building extraction from remote sensing images with deep learning in a supervised manner. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017; pp. 1672–1675. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic Building Segmentation of Aerial Imagery UsingMulti-Constraint Fully Convolutional Networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Doll´ar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Multi-Scale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–5 February 2017; pp. 4278–4284. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP |
|---|---|
| Faster R-CNN-VGG | 0.6958 |
| Faster R-CNN-ResNet101 | 0.8976 |
| Mask R-CNN-ResNet101 | 0.8996 |
| Proposed | 0.9063 |
| Method | Precision | Recall | F1-score |
|---|---|---|---|
| Mask R-CNN-ResNet101 | 0.8627 | 0.8951 | 0.8786 |
| Proposed | 0.8720 | 0.9041 | 0.8878 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors 2019, 19, 333. https://doi.org/10.3390/s19020333
Wen Q, Jiang K, Wang W, Liu Q, Guo Q, Li L, Wang P. Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors. 2019; 19(2):333. https://doi.org/10.3390/s19020333
Chicago/Turabian StyleWen, Qi, Kaiyu Jiang, Wei Wang, Qingjie Liu, Qing Guo, Lingling Li, and Ping Wang. 2019. "Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network" Sensors 19, no. 2: 333. https://doi.org/10.3390/s19020333
APA StyleWen, Q., Jiang, K., Wang, W., Liu, Q., Guo, Q., Li, L., & Wang, P. (2019). Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors, 19(2), 333. https://doi.org/10.3390/s19020333