Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution

Abstract
1. Introduction
2. Related Work
3. The Proposed Approach
3.1. Directional Spatial Aggregation Module
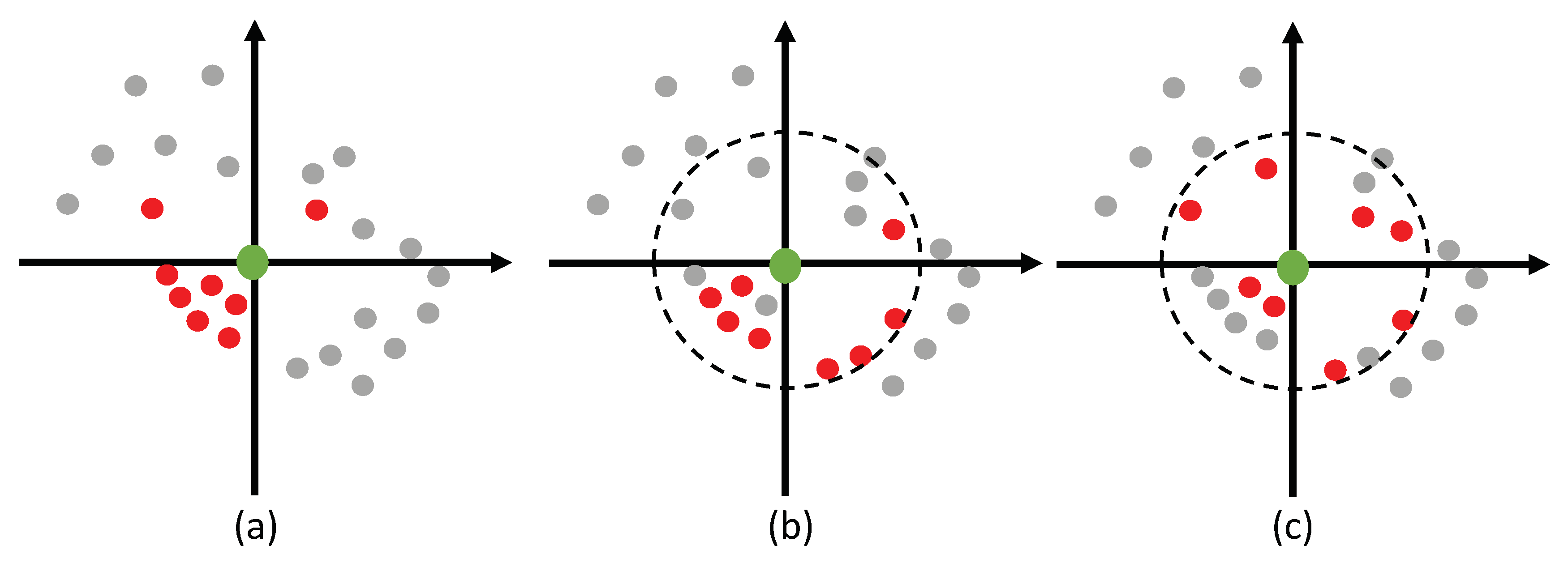
3.1.1. Octant-Search for Neighbor Point Searching
3.1.2. Multi-Directional Convolution
3.2. Overall Architecture
4. Experiments
4.1. Experimental Setup and Implementation Details
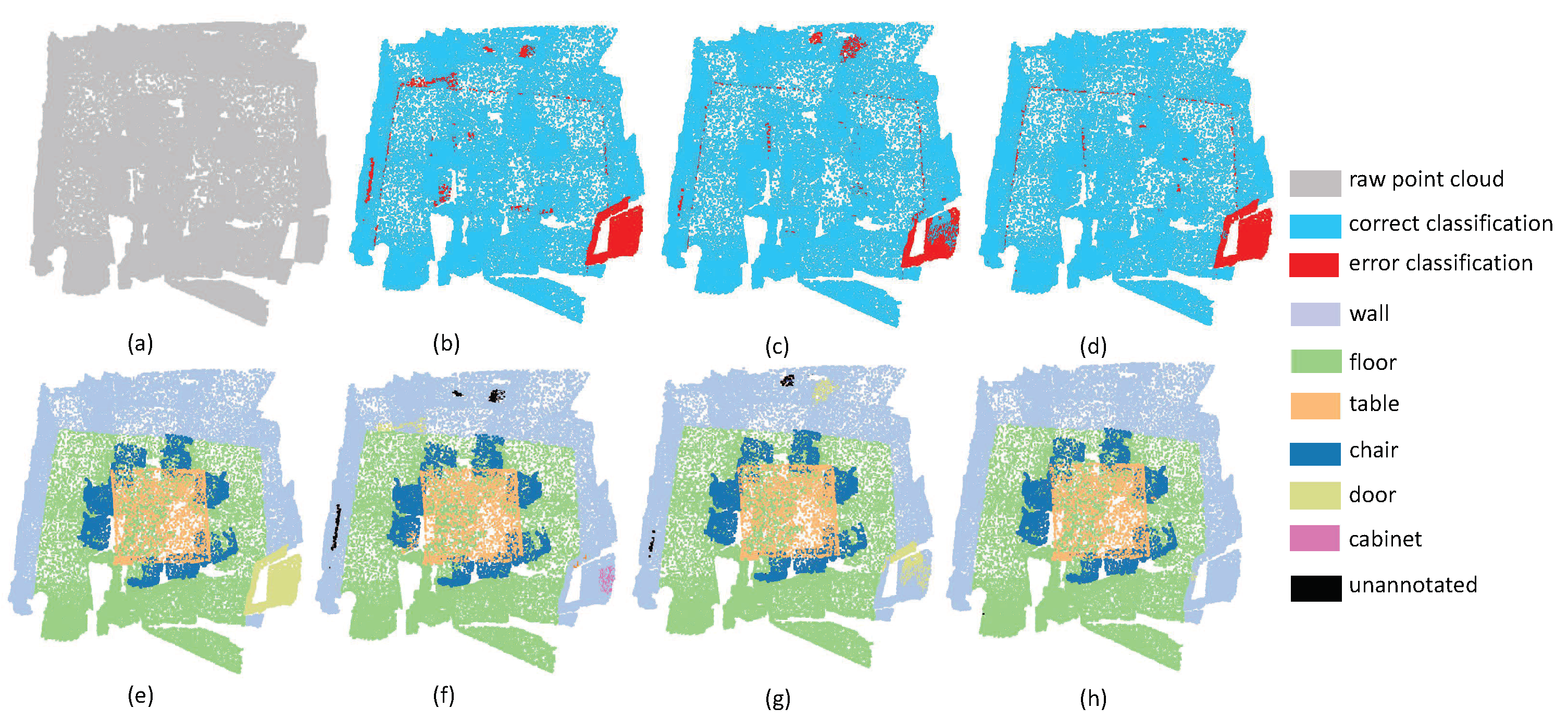
4.2. The Results on ScanNet
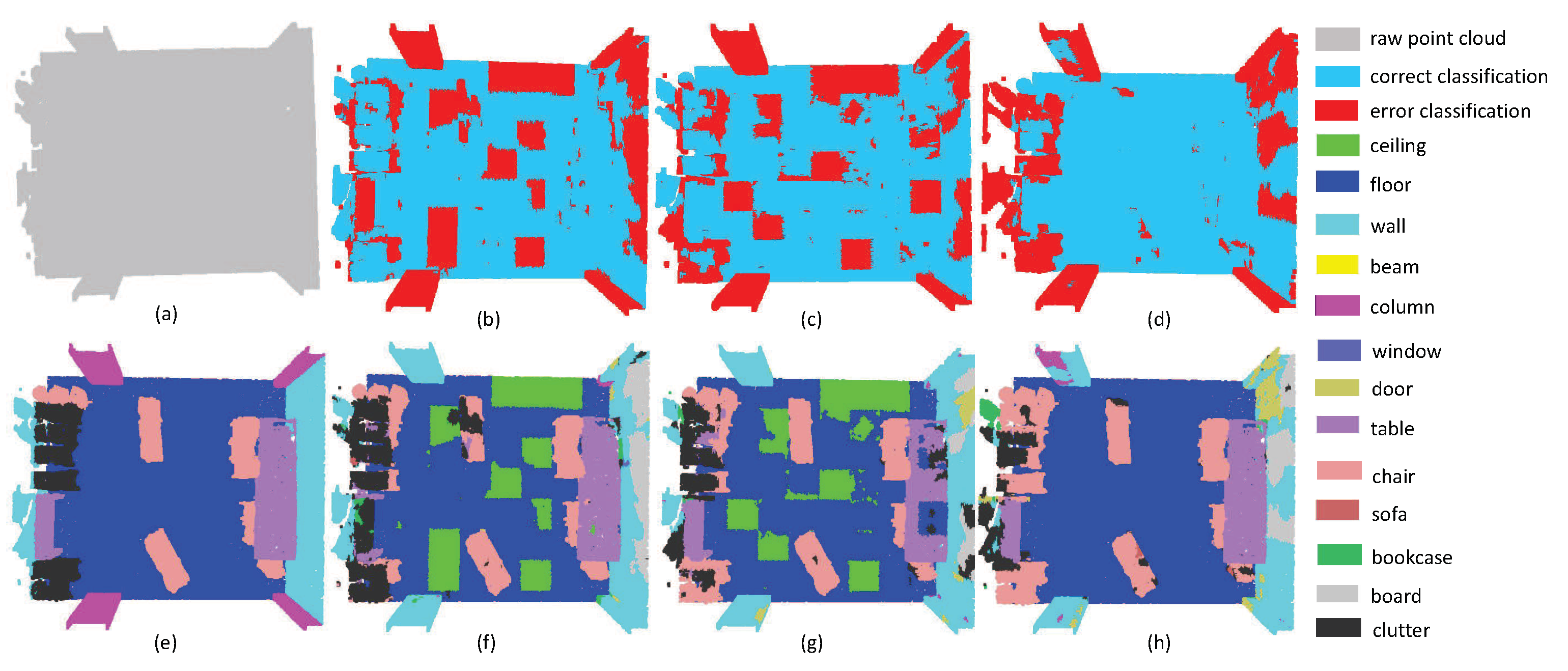
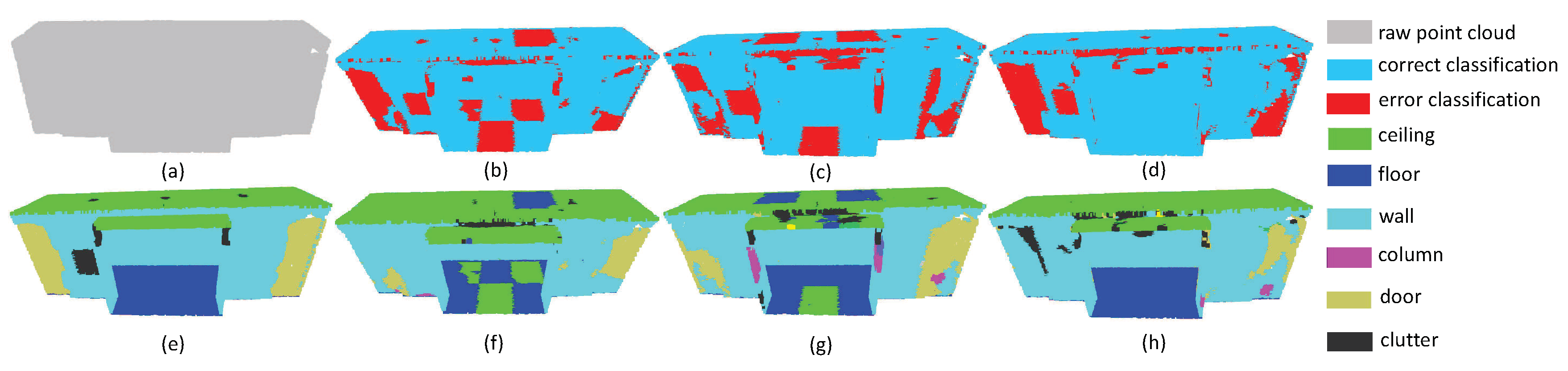
4.3. The Results on S3DIS
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3D convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. arXiv 2018, arXiv:1801.07791v4. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3D point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Conference on Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Qi, C.R.; Su, H.; Niessner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3D data. arXiv 2016, arXiv:1604.03265. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Xie, Y.; Tian, J.; Zhu, X.X. A Review of Point Cloud Semantic Segmentation. arXiv 2019, arXiv:1908.08854. [Google Scholar]
- Roveri, R.; Rahmann, L.; Oztireli, A.C.; Gross, M.H. A network architecture for point cloud classification via automatic depth images generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Su, J.; Gahelda, M.; Wang, R.; Maji, S. A deeper look at 3D shape classifiers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Milz, S.; Simon, M.; Fischer, K.; Popperl, M. Points2Pix: 3D Point-Cloud to Image Translation using conditional Generative Adversarial Networks. arXiv 2019, arXiv:1901.09280. [Google Scholar]
- Han, Z.; Shang, M.; Liu, Y.; Zwicker, M. View inter-prediction gan: Unsupervised representation learning for 3D shapes by learning global shape memories to support local view predictions. arXiv 2018, arXiv:1811.02744. [Google Scholar] [CrossRef]
- You, Y.; Lou, Y.; Liu, Q.; Ma, L.; Wang, W.; Tai, Y.; Lu, C. PRIN: Pointwise Rotation-Invariant Network. arXiv 2018, arXiv:1811.09361. [Google Scholar]
- Asako, K.; Matsushita, Y.; Nishida, Y. Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Che, E.; Olsen, M.J. Multi-scan segmentation of terrestrial laser scanning data based on normal variation analysis. ISPRS J. Photogramm. Remote Sens. 2018, 143, 233–248. [Google Scholar] [CrossRef]
- Che, E.; Olsen, M.J. An Efficient Framework for Mobile Lidar Trajectory Reconstruction and Mo-norvana Segmentation. Remote Sens. 2019, 11, 836. [Google Scholar] [CrossRef]
- Barnea, S.; Filin, S. Segmentation of terrestrial laser scanning data using geometry and image information. ISPRS J. Photogramm. Remote Sens. 2013, 76, 33–48. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. Fpnn: Field probing neural networks for 3D data. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 307–315. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, X.; Han, Z.; Liu, Y.; Zwicker, M. Point2Sequence: Learning the shape representation of 3D point clouds with an attention-based sequence to sequence network. arXiv 2018, arXiv:1811.02565. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3D point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Eldar, Y.; Lindenbaum, M.; Porat, M.; Zeevi, Y.Y. The farthest point strategy for progressive image sampling. IEEE Trans. Image Process. 1997, 6, 1305–1315. [Google Scholar] [CrossRef] [PubMed]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.A.; Niebner, M. Scannet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy (%) | Time (ms) |
|---|---|---|
| 3DCNN [32] | 70.0 | - |
| PointNet [3] | 73.9 | 7 |
| PointNet++ [4] | 84.5 | 52 |
| PointCNN [5] | 85.1 | 74 |
| PointSIFT [6] | 86.0 | 82 |
| Ours1 | 84.9 | 52 |
| Ours2 | 85.1 | 52 |
| Methods | Accuracy (%) |
|---|---|
| PointNet [3] | 70.46 |
| PointNet++ [4] | 75.66 |
| PointSIFT [6] | 76.61 |
| SAN | 74.16 |
| SAN | 78.39 |
| SAN | 76.31 |
| Category | SAN (%) | PointNet++ (%) | PointSIFT (%) |
|---|---|---|---|
| ceiling | 98.83 | 92.46 | 92.84 |
| floor | 98.17 | 89.97 | 91.31 |
| wall | 83.43 | 86.92 | 87.31 |
| beam | 60.14 | 44.48 | 38.46 |
| column | 54.97 | 22.67 | 11.91 |
| window | 50.95 | 46.41 | 33.93 |
| door | 70.94 | 74.73 | 66.91 |
| table | 80.15 | 73.47 | 75.06 |
| chair | 86.09 | 84.61 | 84.76 |
| sofa | 72.42 | 68.56 | 63.04 |
| bookcase | 71.14 | 77.28 | 75.42 |
| board | 54.03 | 73.55 | 60.99 |
| clutter | 78.50 | 79.77 | 76.70 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, G.; Jiang, Z.; Wang, Z.; Huang, S.; Chen, K.; Ge, X.; Wu, Y. Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution. Sensors 2019, 19, 4329. https://doi.org/10.3390/s19194329
Cai G, Jiang Z, Wang Z, Huang S, Chen K, Ge X, Wu Y. Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution. Sensors. 2019; 19(19):4329. https://doi.org/10.3390/s19194329
Chicago/Turabian StyleCai, Guorong, Zuning Jiang, Zongyue Wang, Shangfeng Huang, Kai Chen, Xuyang Ge, and Yundong Wu. 2019. "Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution" Sensors 19, no. 19: 4329. https://doi.org/10.3390/s19194329
APA StyleCai, G., Jiang, Z., Wang, Z., Huang, S., Chen, K., Ge, X., & Wu, Y. (2019). Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution. Sensors, 19(19), 4329. https://doi.org/10.3390/s19194329