Intelligent Lecturer Tracking and Capturing System Based on Face Detection and Wireless Sensing Technology



Abstract
:1. Introduction
- Proposing an intelligent lecturer tracking and capturing system with low-cost, real-time, stable, self-adjusting, and contactless devices.
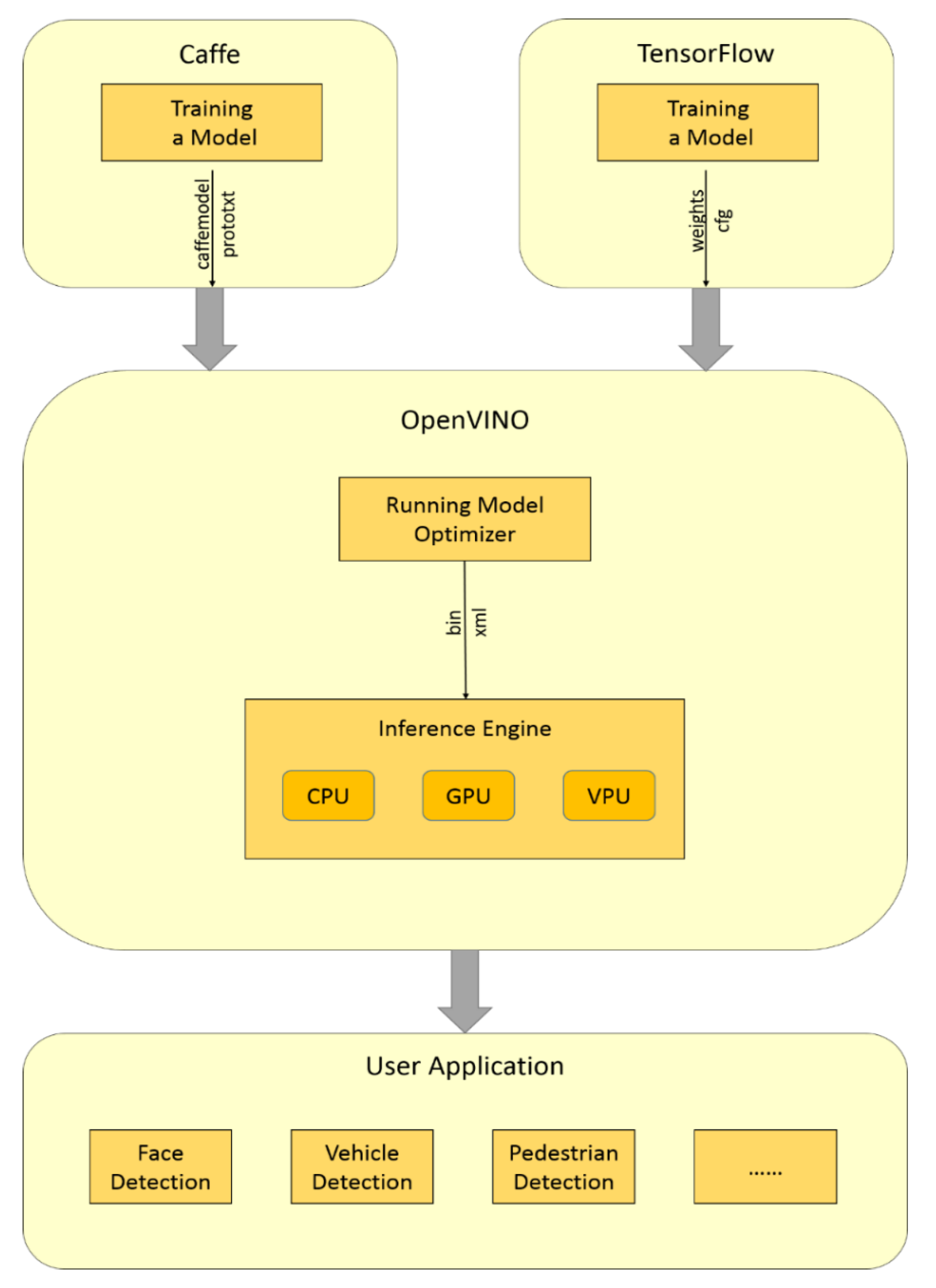
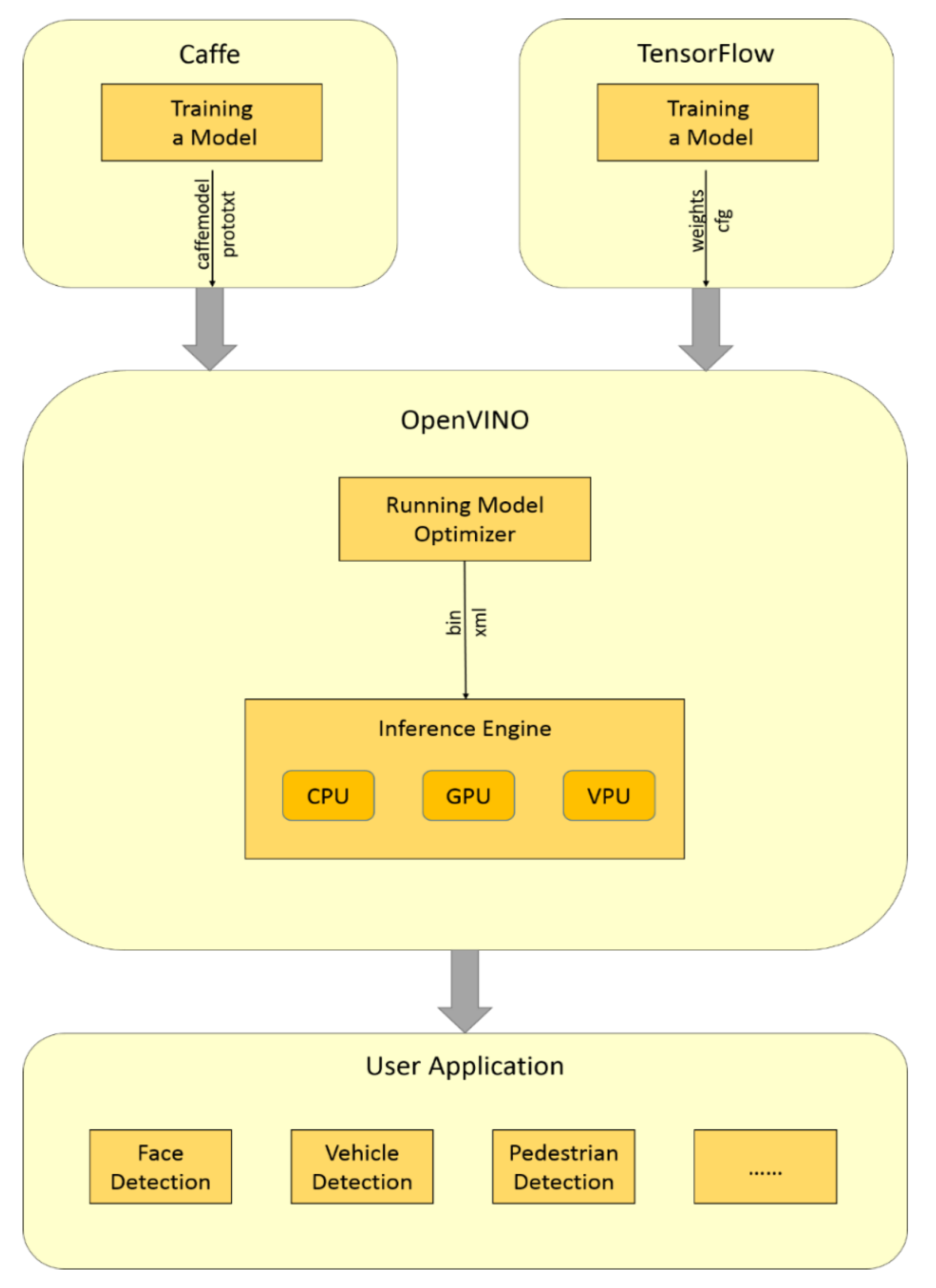
- Realizing face detection and capturing by one camera and optimizing the network model with Intel OpenVINO Toolkit to implement the system on CPU in real-time without pre-installing Caffe or TensorFlow.
- Preventing detection failure caused by abrupt and rapid movements in face detection and solving the non-real-time sensing problem for IR thermal sensors through the combination of face detection and wireless sensing technology.
2. Proposed Method
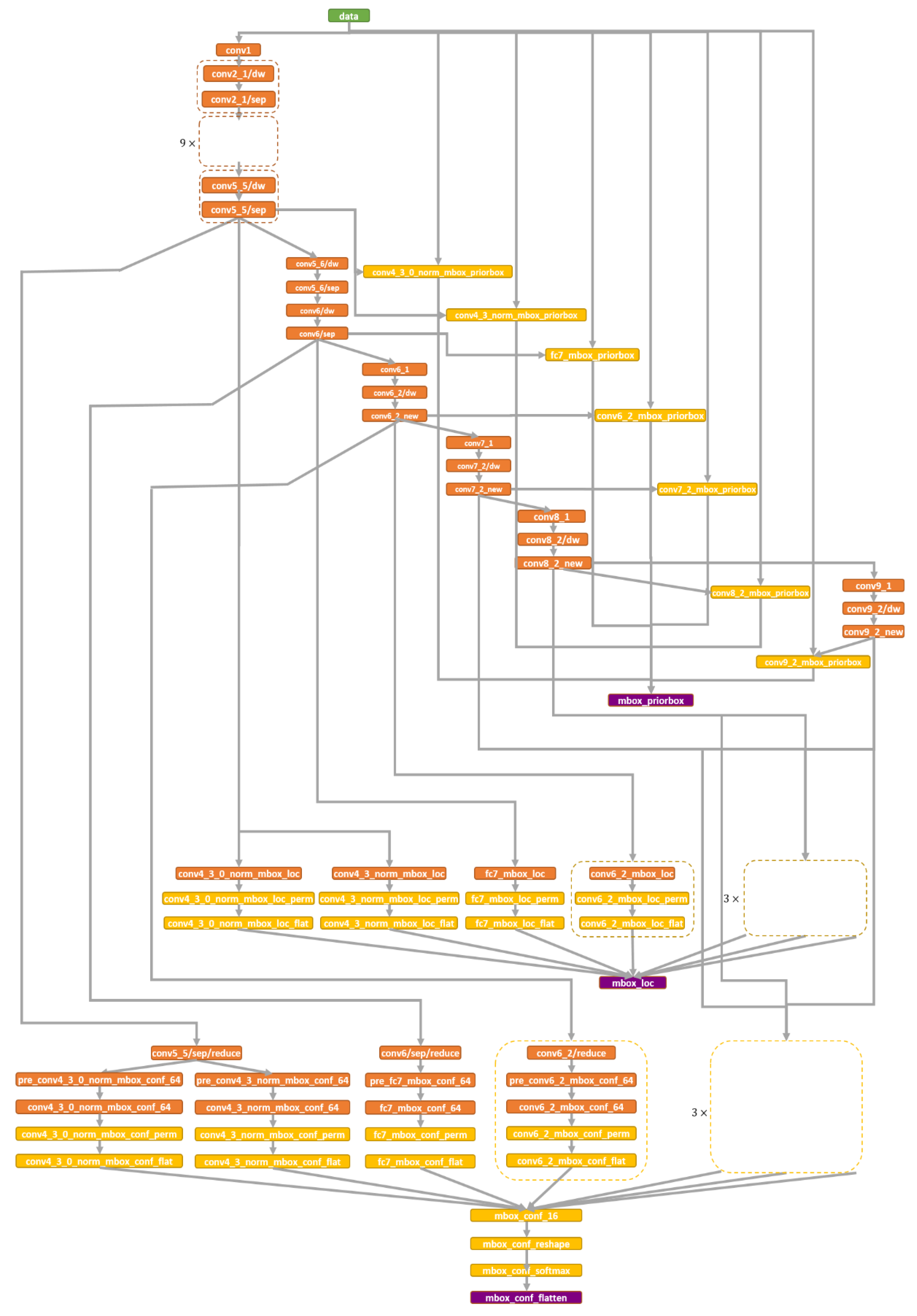
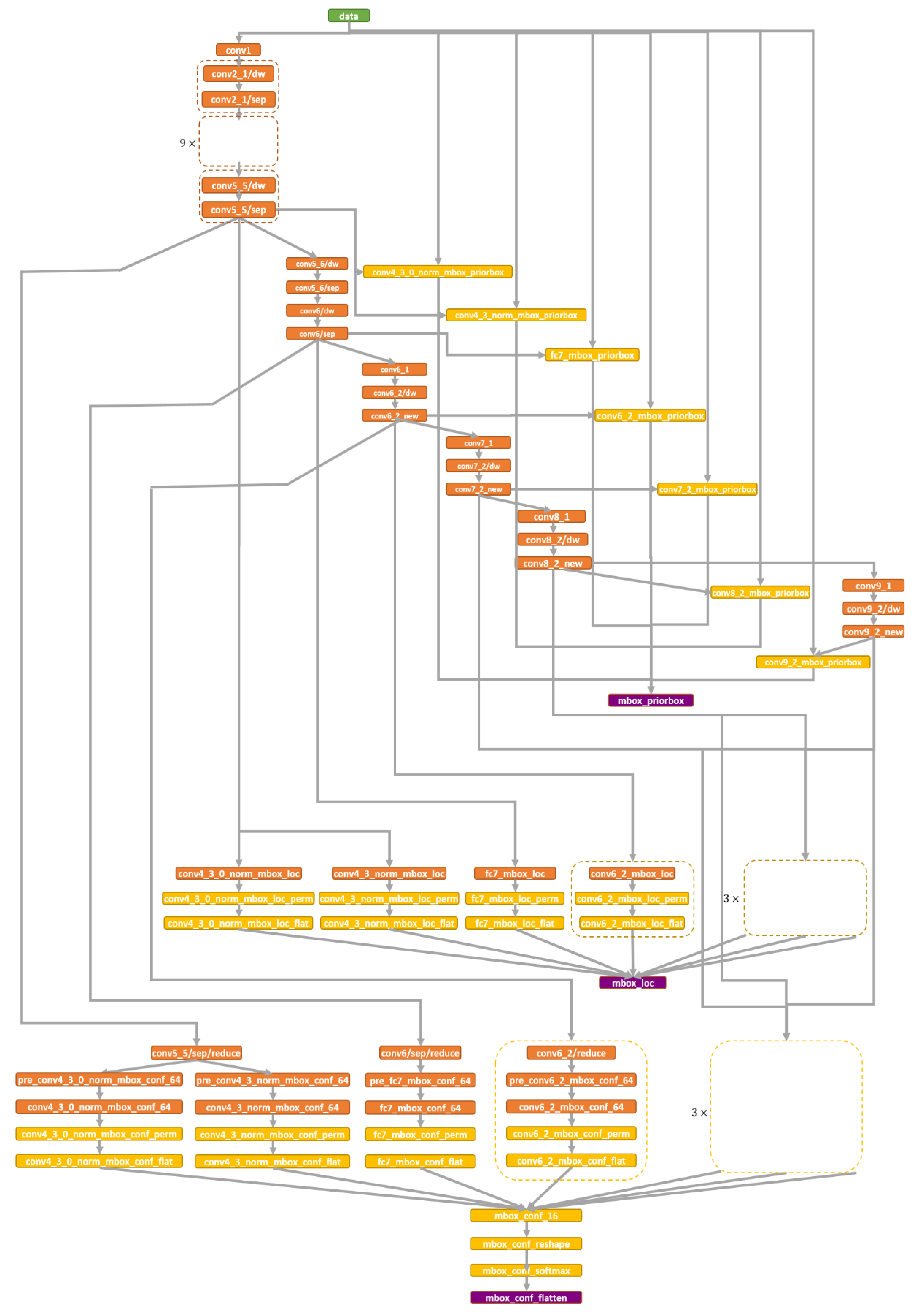
2.1. Face Detection Module
2.1.1. Backbone
2.1.2. OpenVINO
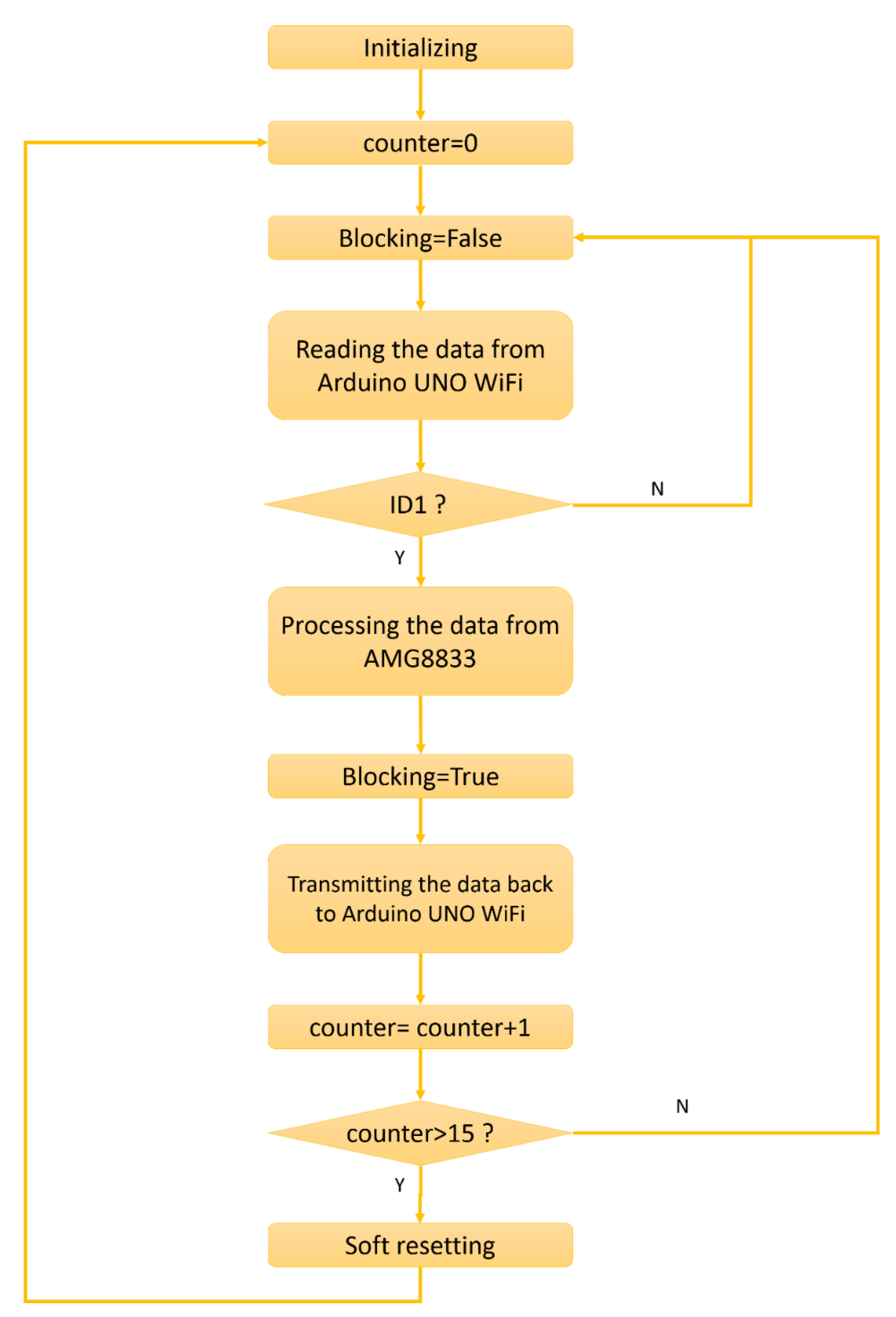
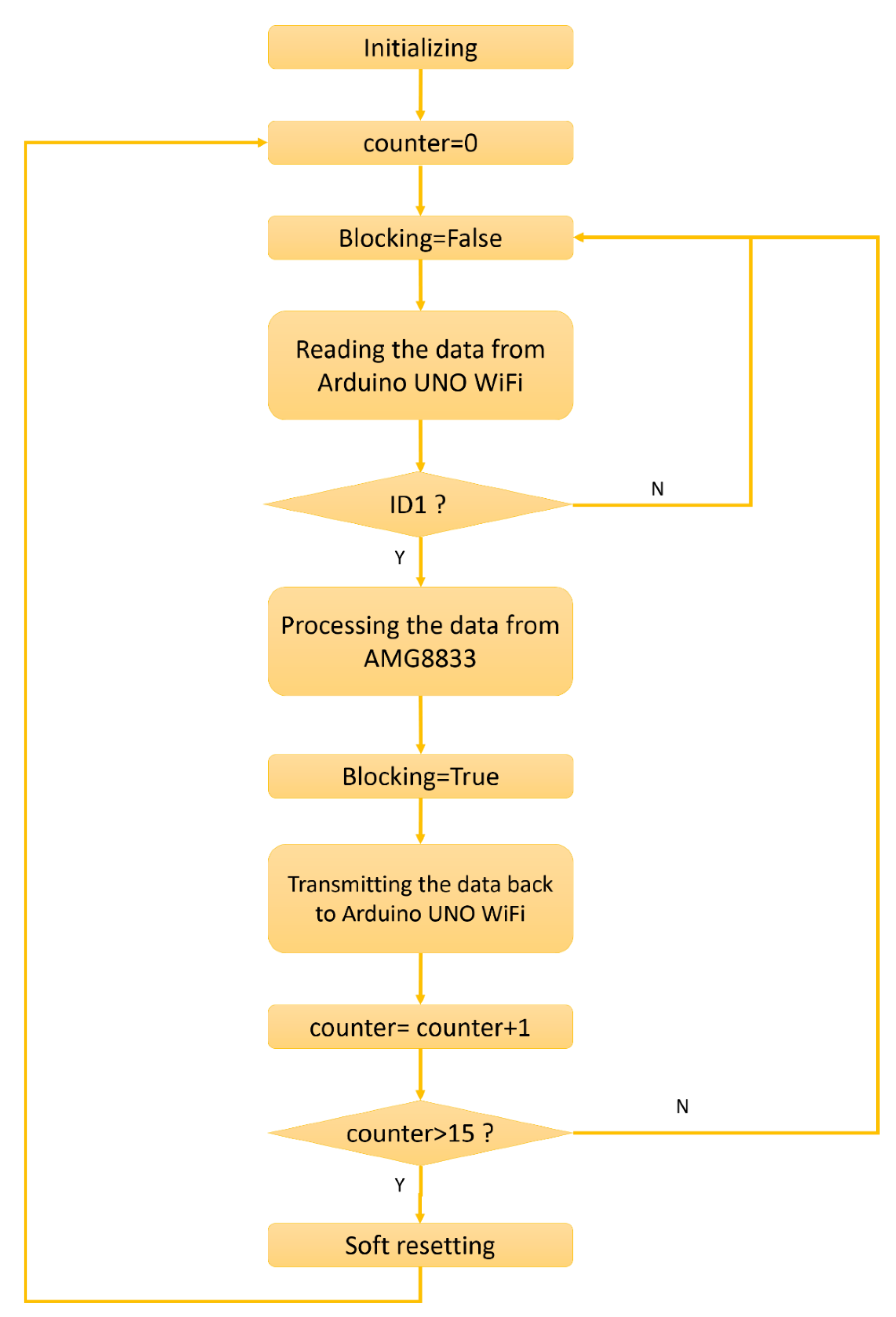
2.2. Capturing Module
- Communicating with the computer via the universal serial bus.
- Controlling the servo motor to rotate the camera mounted on the motor.
- Receiving data collected by wireless stations, which are connected with IR thermal sensors.
2.3. Infrared Tracking Module
2.3.1. IR Thermal Sensors
2.3.2. Wireless Communication
3. Experimental Results
3.1. Experimental Environment
3.2. Qualitative Analysis
3.3. Quantitative Analysis
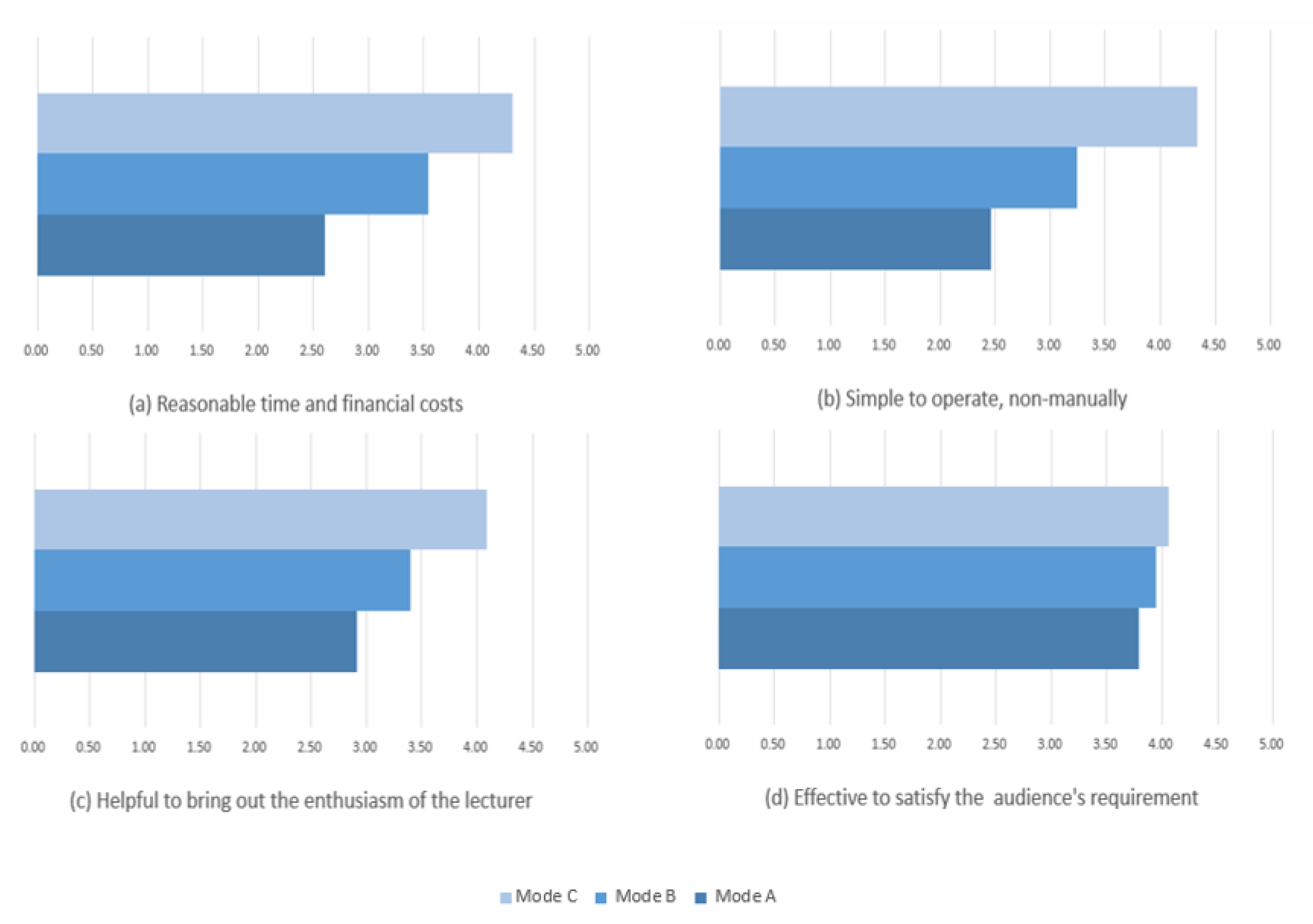
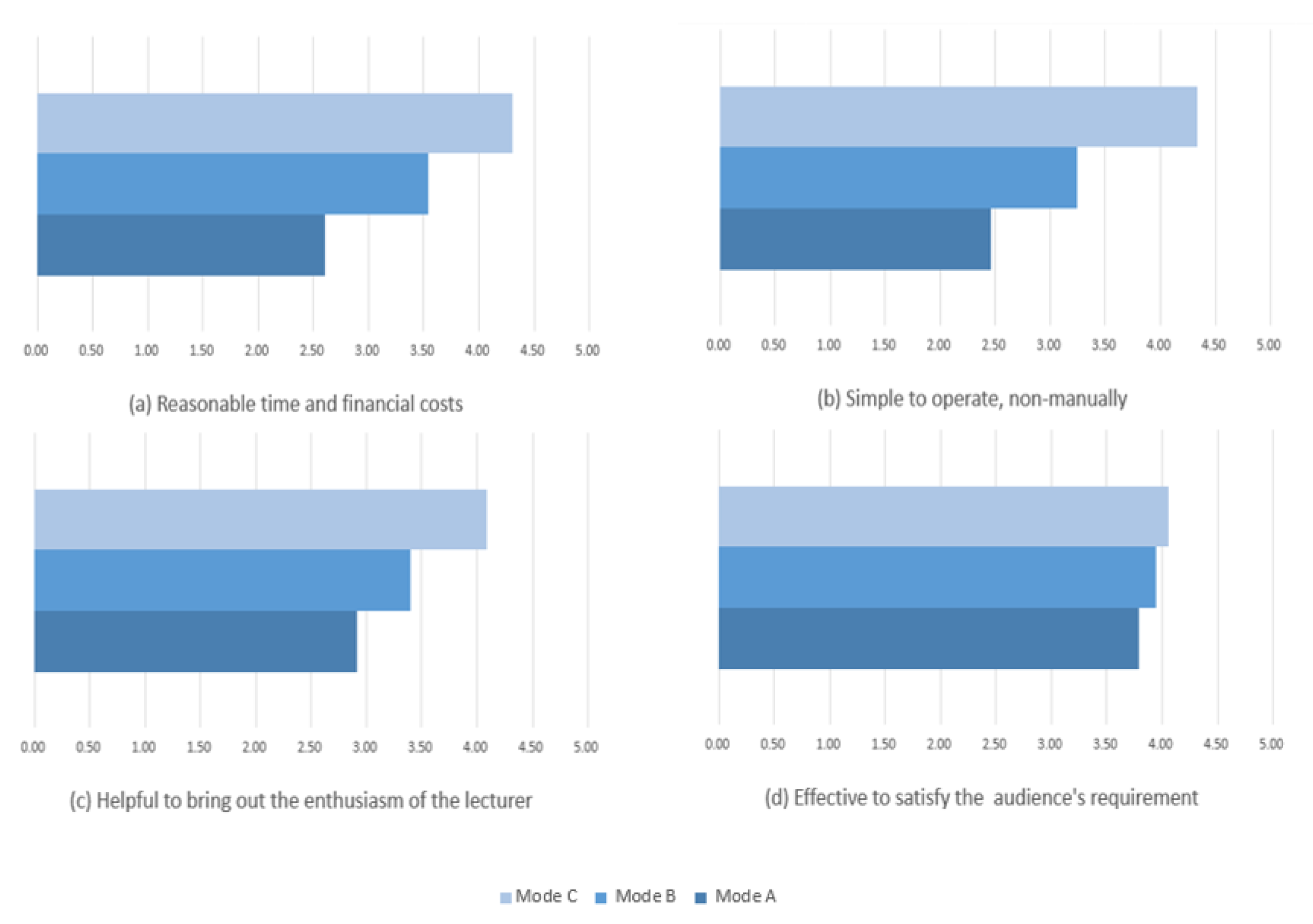
3.4. Survey
- Mode A: Capturing in office or professional studio.
- Mode B: Capturing with static camera in classroom.
- Mode C: Auto tracking and capturing in classroom.
- Acceptability: reasonable time and financial costs.
- Simplicity: simple to operate, non-manually.
- Appeal: helpful to bring out the enthusiasm of the lecturer.
- Effectiveness: effective to satisfy the audience’s requirement.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pappano, L. The Year of the MOOC. The New York Times, 2 November 2012. [Google Scholar]
- Stanford; Coursera. Available online: https://www.coursera.org/ (accessed on 1 July 2019).
- Harvard; MIT; edX. Available online: https://www.edx.org/ (accessed on 1 July 2019).
- Coursera. AI for Everyone. Available online: https://www.coursera.org/learn/ai-for-everyone/home/week/4 (accessed on 1 August 2019).
- Kellogg, S. Online learning: How to make a MOOC. Nature 2013, 499, 369–371. [Google Scholar] [CrossRef] [PubMed]
- Kolowich, S. The professors who make the MOOCs. The Chronicle of Higher Education, 18 March 2013. [Google Scholar]
- Guo, P.J.; Kim, J.; Rubin, R. How video production affects student engagement: An empirical study of MOOC videos. In Proceedings of the First ACM Conference on Learning@ Scale Conference, Atlanta, GA, USA, 4–5 March 2014. [Google Scholar]
- Stanford. CS231n. Available online: https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk (accessed on 1 August 2019).
- Chou, H.P.; Wang, J.M.; Fuh, C.S.; Lin, S.C.; Chen, S.W. Automated lecture recording system. In Proceedings of the 2010 international conference on system science and engineering, Taipei, Taiwan, 1–3 July 2010. [Google Scholar]
- Sun, Y.; Meng, W.; Li, C.; Zhao, N.; Zhao, K.; Zhang, N. Human localization using multi-source heterogeneous data in indoor environments. IEEE Access 2017, 5, 812–822. [Google Scholar] [CrossRef]
- Liao, H.C.; Pan, M.H.; Chang, M.C.; Lin, K.W. An automatic lecture recording system using pan-tilt-zoom camera to track lecturer and handwritten data. Int. J. Appl. Sci. Eng. 2015, 13, 1–18. [Google Scholar]
- Liu, P.; Yang, P.; Wang, C.; Huang, K.; Tan, T. A semi-supervised method for surveillance-based visual location recognition. IEEE Trans. Cybern. 2016, 47, 3719–3732. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Shmaliy, Y.S.; Li, Y.; Chen, X. UWB-based indoor human localization with time-delayed data using EFIR filtering. IEEE Access 2017, 5, 16676–16683. [Google Scholar] [CrossRef]
- Shu, Y.; Bo, C.; Shen, G.; Zhao, C.; Li, L.; Zhao, F. Magicol: Indoor localization using pervasive magnetic field and opportunistic WiFi sensing. IEEE J. Sel. Areas Commun. 2015, 33, 1443–1457. [Google Scholar] [CrossRef]
- Yasir, M.; Ho, S.W.; Vellambi, B.N. Indoor position tracking using multiple optical receivers. J. Lightwave Technol. 2015, 34, 1166–1176. [Google Scholar] [CrossRef]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Intel. Model Zoo. Available online: http://docs.openvinotoolkit.org/2019_R1/_face_detection_adas_0001_description_face_detection_adas_0001.html (accessed on 1 August 2019).
- Intel. OpenVINO Toolkit. Available online: https://software.intel.com/en-us/openvino-toolkit (accessed on 1 August 2019).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. Ssd: Single shot multibox detector. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arxiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kozlov, A.; Osokin, D. Development of Real-Time ADAS Object Detector for Deployment on CPU. arXiv 2018, arXiv:1811.05894. [Google Scholar]
- Osokin, D. Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose. arXiv 2018, arXiv:1811.12004. [Google Scholar]
- Arduino. Arduino UNO WiFi. Available online: https://store.arduino.cc/usa/arduino-uno-wifi (accessed on 1 August 2019).
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yun, S.; Choi, J.; Yoo, Y.; Yun, K.; Young Choi, J. Action-decision networks for visual tracking with deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Adafruit. AMG8833. Available online: https://www.adafruit.com/product/3538 (accessed on 1 August 2019).
- Gochoo, M.; Tan, T.H.; Huang, S.C. Novel IoT-Based Privacy-Preserving Yoga Posture Recognition System Using Low-Resolution Infrared Sensors and Deep Learning. IEEE Internet Things J. 2019, 6, 7192–7200. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.H.; Jean, F.R.; Huang, S.C.; Kuo, S.Y. Device-free non-invasive front-door event classification algorithm for forget event detection using binary sensors in the smart house. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017. [Google Scholar]
- Di Stefano, L.; Bulgarelli, A. A simple and efficient connected components labeling algorithm. In Proceedings of the 10th International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999. [Google Scholar]
- Pycom. WiPy 3.0. Available online: https://pycom.io/product/wipy-3-0/ (accessed on 1 August 2019).
- Pycom. Troubleshooting Guide. Available online: https://docs.pycom.io/gettingstarted/troubleshooting-guide/ (accessed on 1 August 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Classroom | 2.85 m | 2.69 m | 1.50 m | 3.60 m |
| Laboratory | 2.02 m | 3.30 m | 1.52 m | 2.45 m |
| Hardware | Software |
|---|---|
| Arduino UNO WiFi | Arduino IDE 1.8.9 |
| Servo Motor MG996R | Pycharm in Python 3.6 |
| Logitech C170 webcamera | |
| Adafruit AMG8833 IR thermal sensor | ATOM 1.37.0 |
| Pycom WiPy 3.0 |
| Technology | Pros | Cons |
|---|---|---|
| Panoramic camera and WiFi [10] | Convenient construction and low cost | Distorted images, not suitable for great varying illumination and blurred face |
| Multi cameras [12] | Indoor and outdoor localizations under different time and weather condition | Selected places, multi cameras, contact devices and non-real-time system |
| Ultra wide band [13] | More robust time-delay localization | Contact devices and non-real-time system |
| Magnetic field and WiFi [14] | Convenient construction and high accuracy | Contact devices in a fixed body position |
| Accelerometer and optical receivers [15] | High accuracy | Sensitive to light noise, contact devices |
| Multi-domain convolutional neural networks [26] | Fast and accurate | GPU-only, fail to track object with abrupt or rapid movement |
| deep reinforcement learning [27] | Semi-supervised learning and high accuracy | 15 fps on GPU, fail to track object with abrupt or rapid movement |
| Camera, WiFi and IR thermal sensors (the proposed ILTC System) | Low cost, real-time stable performance, contactless devices and convenient construction | Temporary detecting failure |
| Video | Entire System | Without AMG8833 | ||||
|---|---|---|---|---|---|---|
| Frame_Num | Center_Rate (%) | In_Rate (%) | Frame_Num | Center_Rate (%) | In_Rate (%) | |
| Video1 | 1705 | 55.72 | 83.28 | 1124 | 43.68 | 69.13 |
| Video2 | 2405 | 60.50 | 91.10 | 1215 | 41.07 | 71.77 |
| Video3 | 1928 | 59.02 | 85.53 | 1531 | 53.23 | 66.04 |
| Video4 | 1945 | 66.02 | 89.97 | 1693 | 52.22 | 66.69 |
| Video5 | 1999 | 63.08 | 86.99 | 2234 | 46.20 | 65.76 |
| Video6 | 2259 | 64.81 | 83.05 | 1978 | 49.80 | 66.73 |
| Video7 | 2181 | 58.28 | 84.09 | 2089 | 41.31 | 61.51 |
| Video8 | 2405 | 60.29 | 87.03 | 1355 | 48.63 | 65.17 |
| Video9 | 2086 | 65.00 | 92.14 | 1475 | 45.36 | 63.73 |
| Video10 | 2401 | 63.81 | 86.30 | 1666 | 38.90 | 59.00 |
| Average | 2131 | 61.65 | 86.95 | 1636 | 46.04 | 65.55 |
| Video Captured in the Laboratory | Center_Num | In_Num | Frame_Num | Center_Rate (%) | In_Rate (%) |
| Video1 | 950 | 1420 | 1705 | 55.72 | 83.28 |
| Video2 | 1455 | 2191 | 2405 | 60.50 | 91.10 |
| Video3 | 1138 | 1649 | 1928 | 59.02 | 85.53 |
| Video4 | 1284 | 1750 | 1945 | 66.02 | 89.97 |
| Video5 | 1261 | 1739 | 1999 | 63.08 | 86.99 |
| Video6 | 1464 | 1876 | 2259 | 64.81 | 83.05 |
| Video11 | 1546 | 2030 | 2261 | 68.38 | 89.78 |
| Average | 1300 | 1808 | 2072 | 62.50 | 87.10 |
| Video Captured in the Classroom | Center_Num | In_Num | Frame_Num | Center_Rate (%) | In_Rate (%) |
| Video7 | 1271 | 1834 | 2181 | 58.28 | 84.09 |
| Video8 | 1450 | 2093 | 2405 | 60.29 | 87.03 |
| Video9 | 1356 | 1922 | 2086 | 65.00 | 92.14 |
| Video10 | 1532 | 2072 | 2401 | 63.81 | 86.30 |
| Video12 | 2067 | 2773 | 2953 | 70.00 | 93.90 |
| Video13 | 2096 | 2742 | 3190 | 65.71 | 85.96 |
| Video14 | 1857 | 2460 | 2716 | 68.37 | 90.57 |
| Video15 | 2231 | 2784 | 3065 | 72.79 | 90.83 |
| Video16 | 1880 | 2482 | 2834 | 66.34 | 87.58 |
| Video17 | 1657 | 2446 | 2762 | 59.99 | 88.56 |
| Video18 | 2953 | 4060 | 4614 | 64.00 | 87.99 |
| Video19 | 2421 | 3679 | 3965 | 61.06 | 92.79 |
| Video20 | 2800 | 3651 | 4223 | 66.30 | 86.46 |
| Average | 1967 | 2692 | 3030 | 64.76 | 88.78 |
| Total Average | 1733 | 2383 | 2695 | 63.97 | 88.20 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, T.-H.; Kuo, T.-Y.; Liu, H. Intelligent Lecturer Tracking and Capturing System Based on Face Detection and Wireless Sensing Technology. Sensors 2019, 19, 4193. https://doi.org/10.3390/s19194193
Tan T-H, Kuo T-Y, Liu H. Intelligent Lecturer Tracking and Capturing System Based on Face Detection and Wireless Sensing Technology. Sensors. 2019; 19(19):4193. https://doi.org/10.3390/s19194193
Chicago/Turabian StyleTan, Tan-Hsu, Tien-Ying Kuo, and Huibin Liu. 2019. "Intelligent Lecturer Tracking and Capturing System Based on Face Detection and Wireless Sensing Technology" Sensors 19, no. 19: 4193. https://doi.org/10.3390/s19194193
APA StyleTan, T.-H., Kuo, T.-Y., & Liu, H. (2019). Intelligent Lecturer Tracking and Capturing System Based on Face Detection and Wireless Sensing Technology. Sensors, 19(19), 4193. https://doi.org/10.3390/s19194193