Time-Series Laplacian Semi-Supervised Learning for Indoor Localization †

Abstract
:1. Introduction
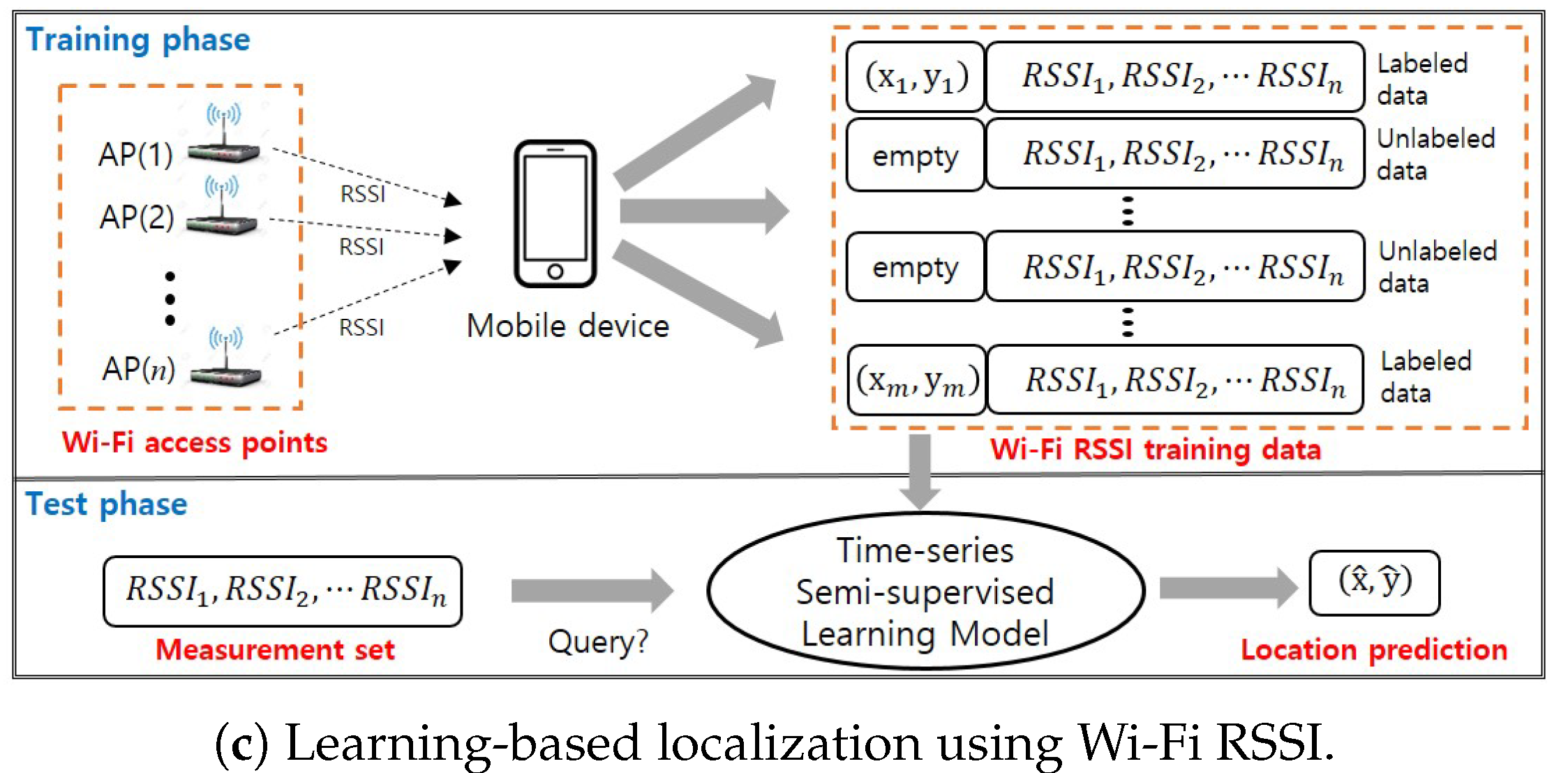
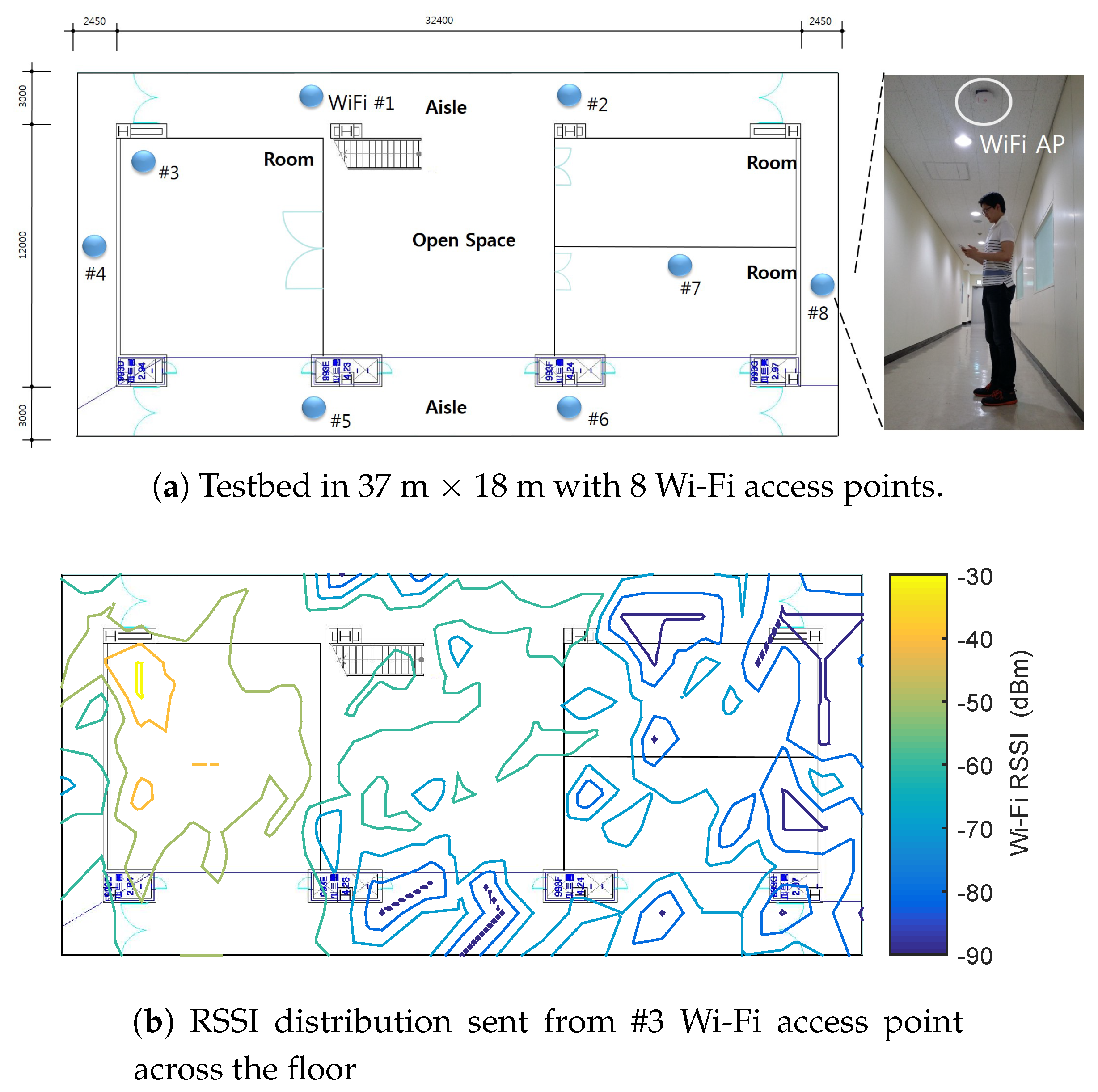
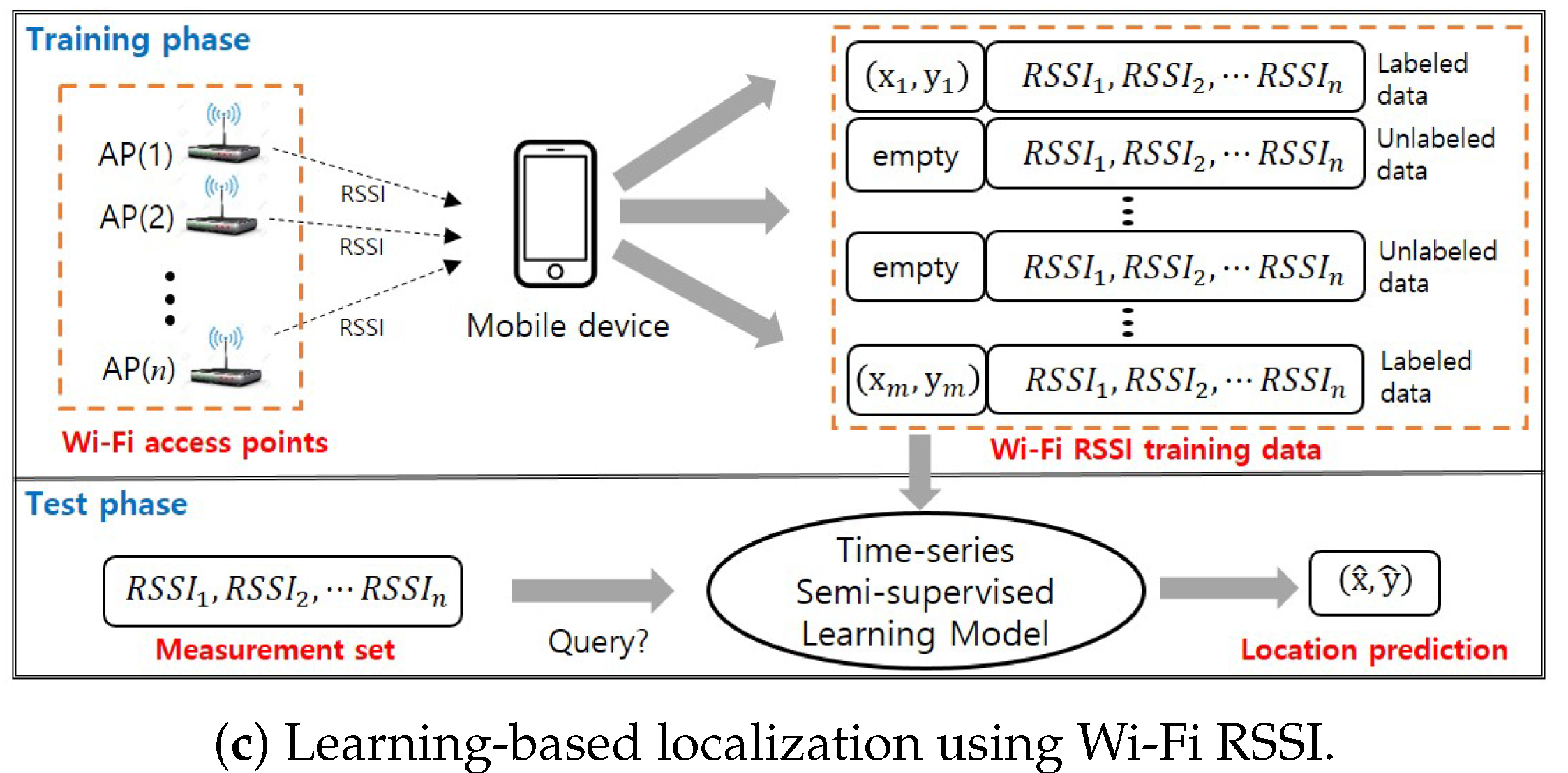
2. Learning-Based Indoor Localization
3. Semi-Supervised Learning
3.1. Basic Semi-Supervised SVM Framework
3.2. Laplacian Least Square (LapLS)
3.3. Laplacian Embedded Regularized Least Square (LapERLS)
4. Time-Series Semi-Supervised Learning
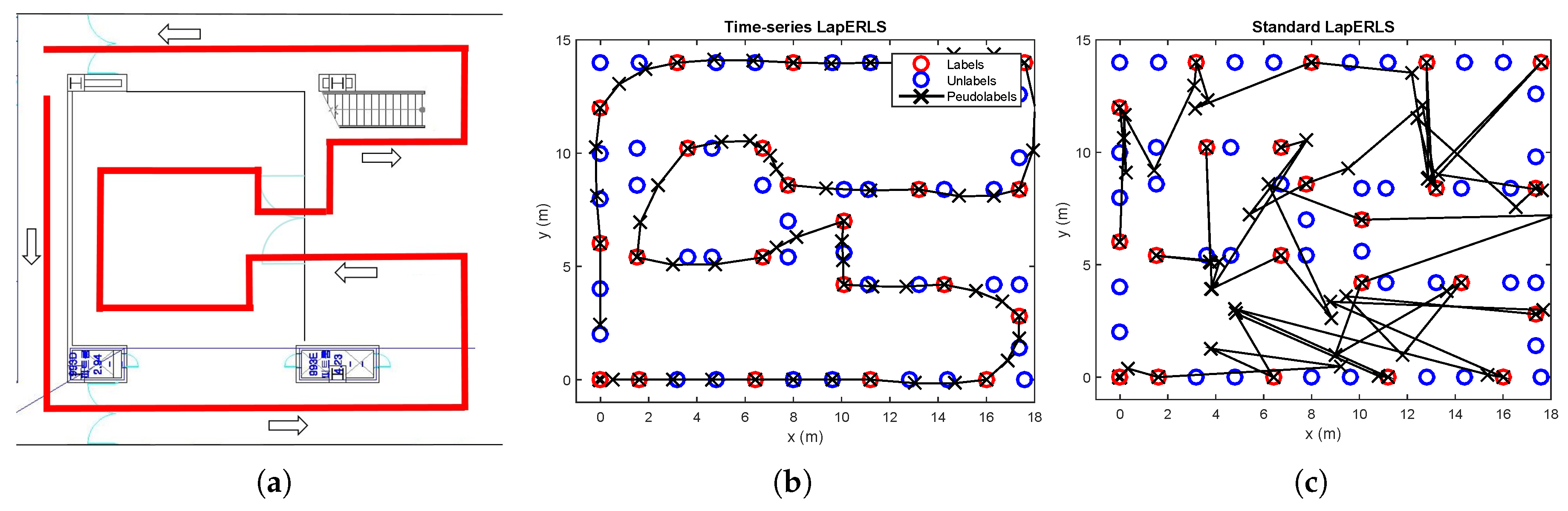
4.1. Time-Series LapERLS
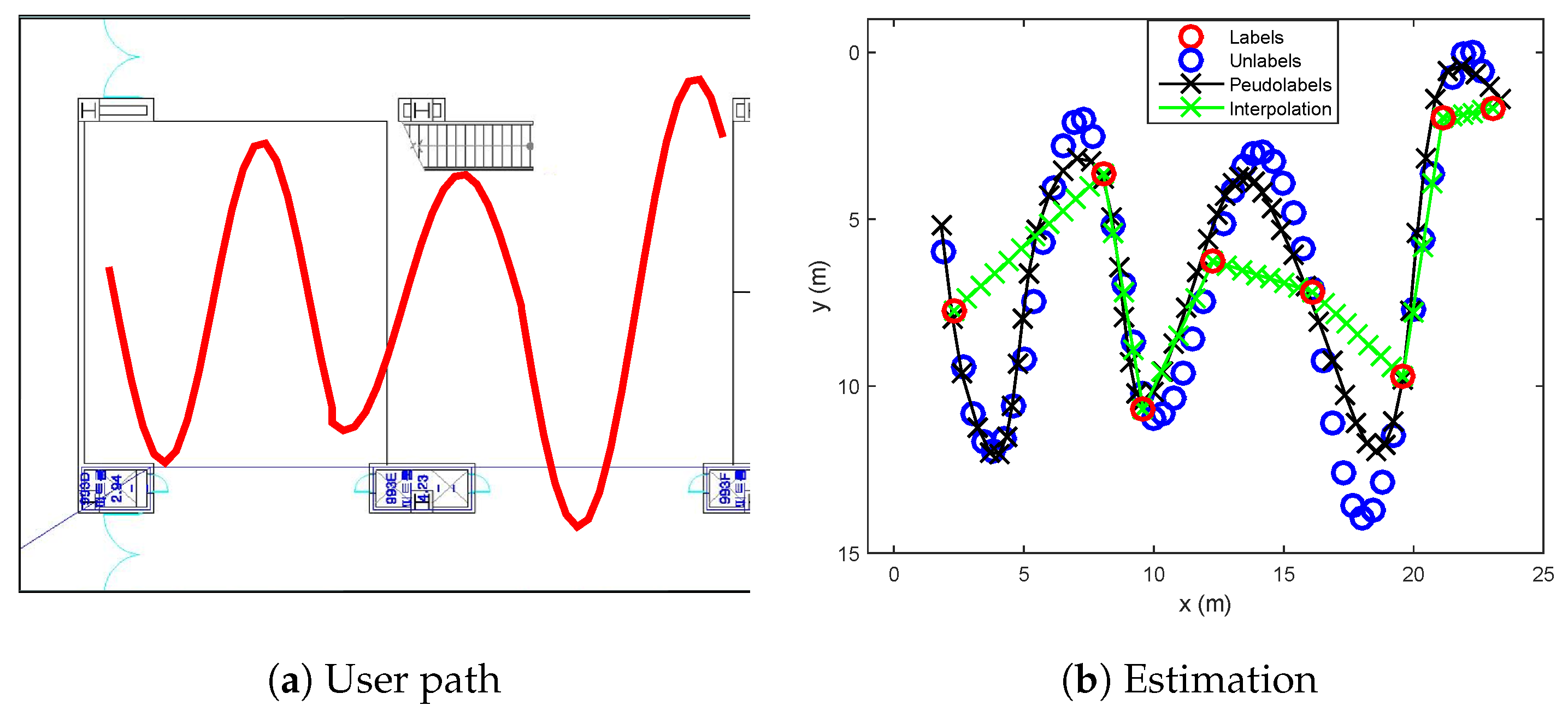
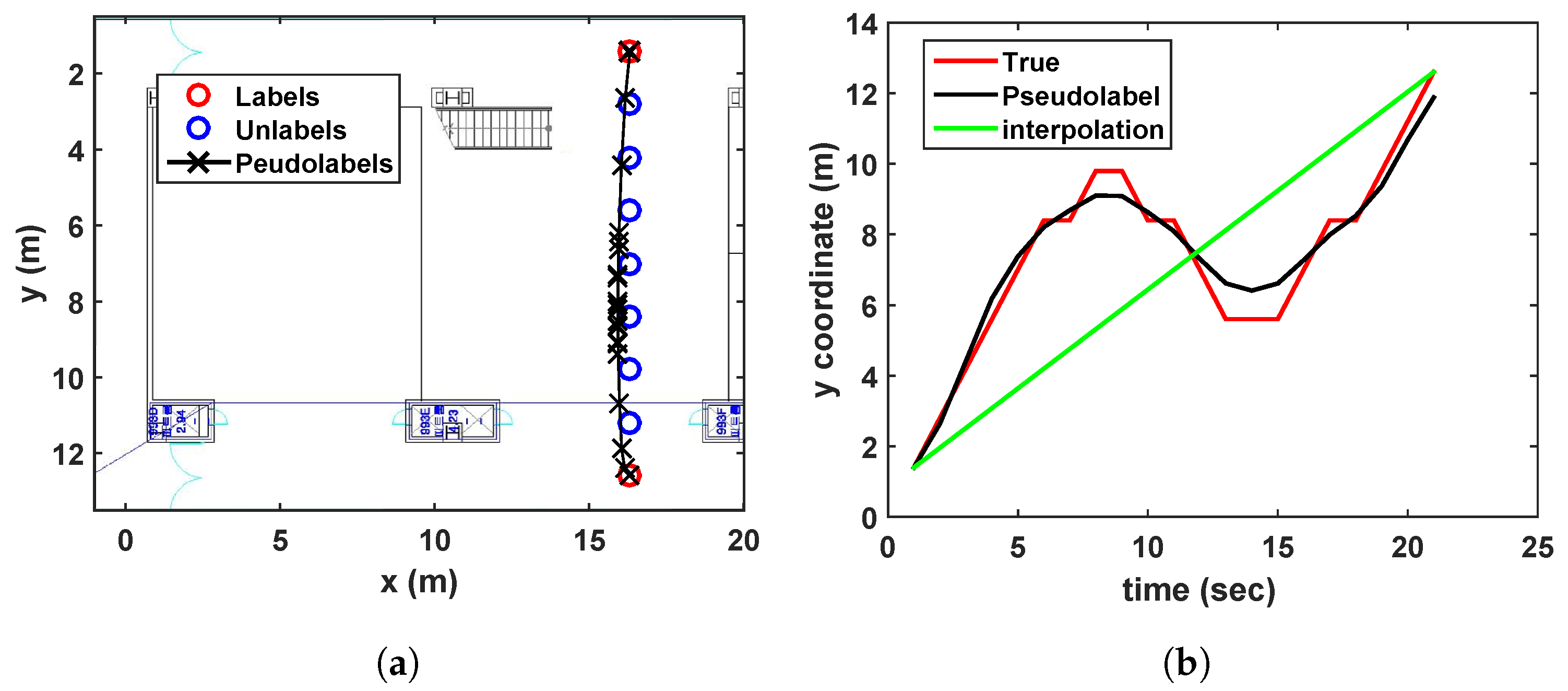
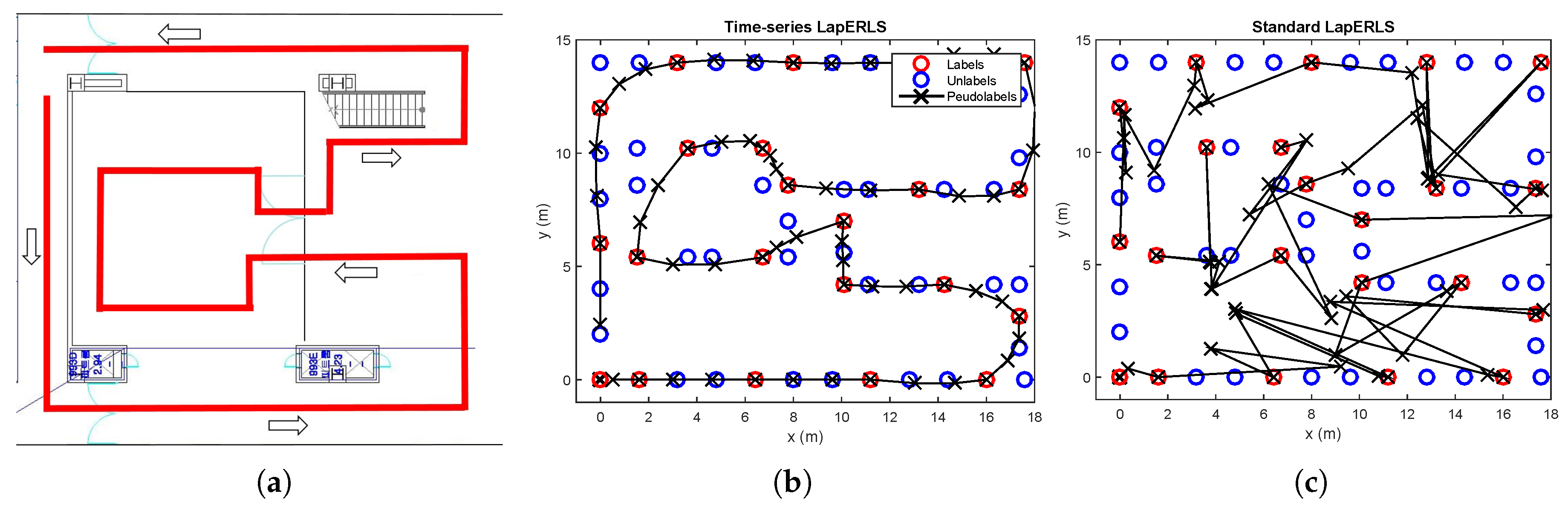
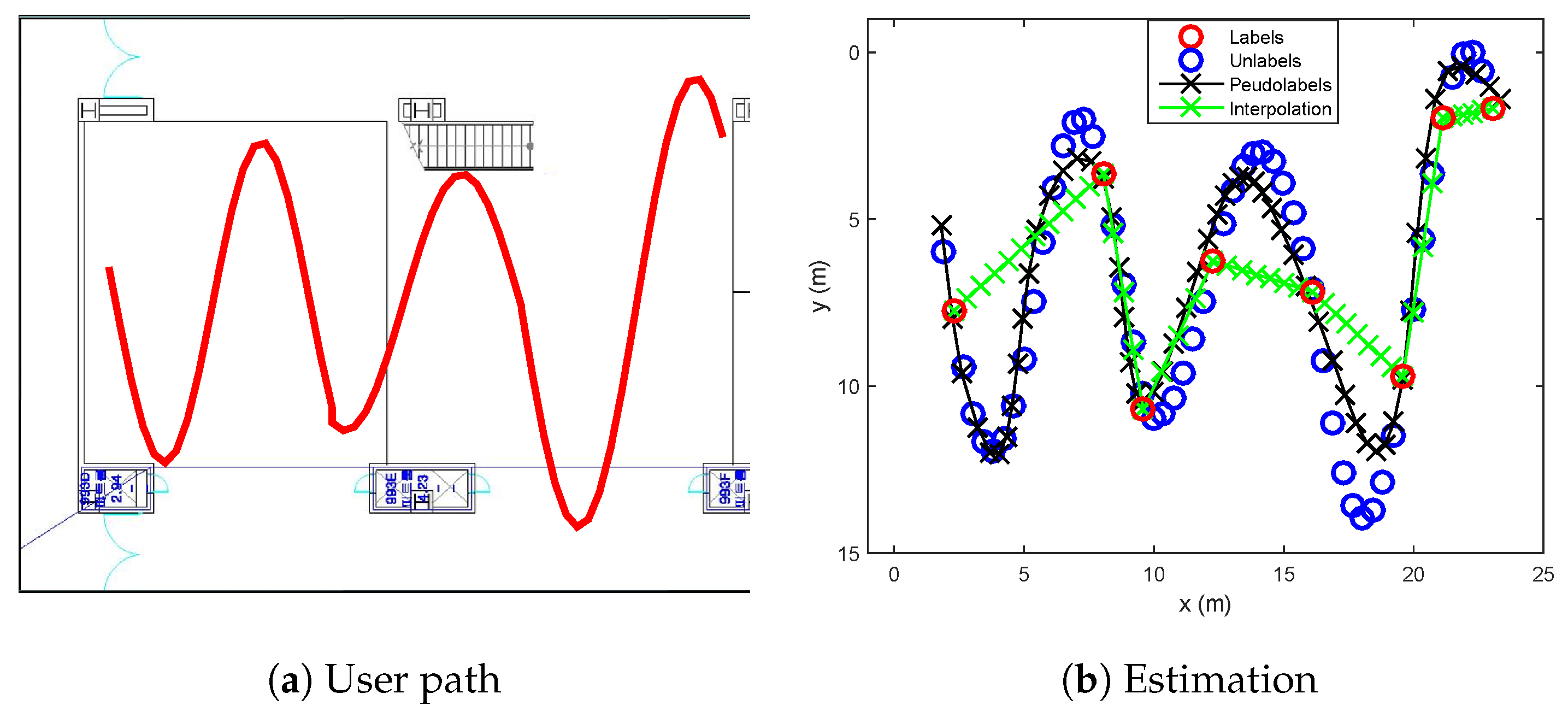
- Sinusoidal trajectory:A situation that a user moves a sinusoidal trajectory as described in Figure 4a is considered. The linear interpolation produces the pseudolabels laying on the straight line between two consecutive labeled points. On the other hand, because the proposed algorithm considers both spatial and temporal relation by using manifold and time-series learning, the result of the suggested algorithm can generate accurate pseudolabels as shown in Figure 4b.
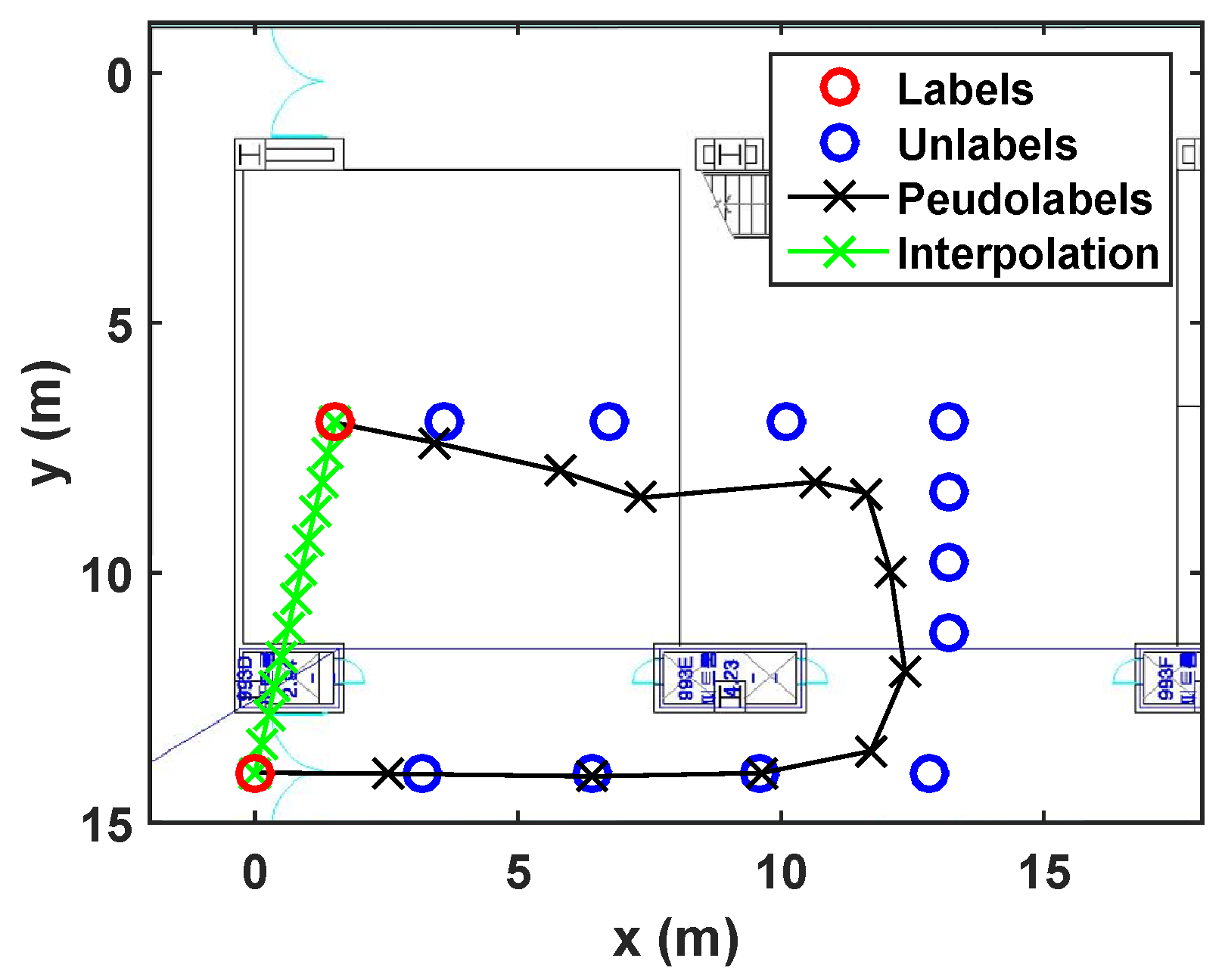
- Wandered trajectory:The other case in which the linear interpolation is not useful is when the user does not walk straight forward to a destination. For example, in Figure 5, the user wanders around middle of the path. Because there are only two labeled data (one is at bottom, and the other is at top), the linear interpolation could not represent the wandered trajectory. In Figure 5b, it is shown that the developed algorithm generates accurate pseudolabels with respect to the wandered motion of the user.
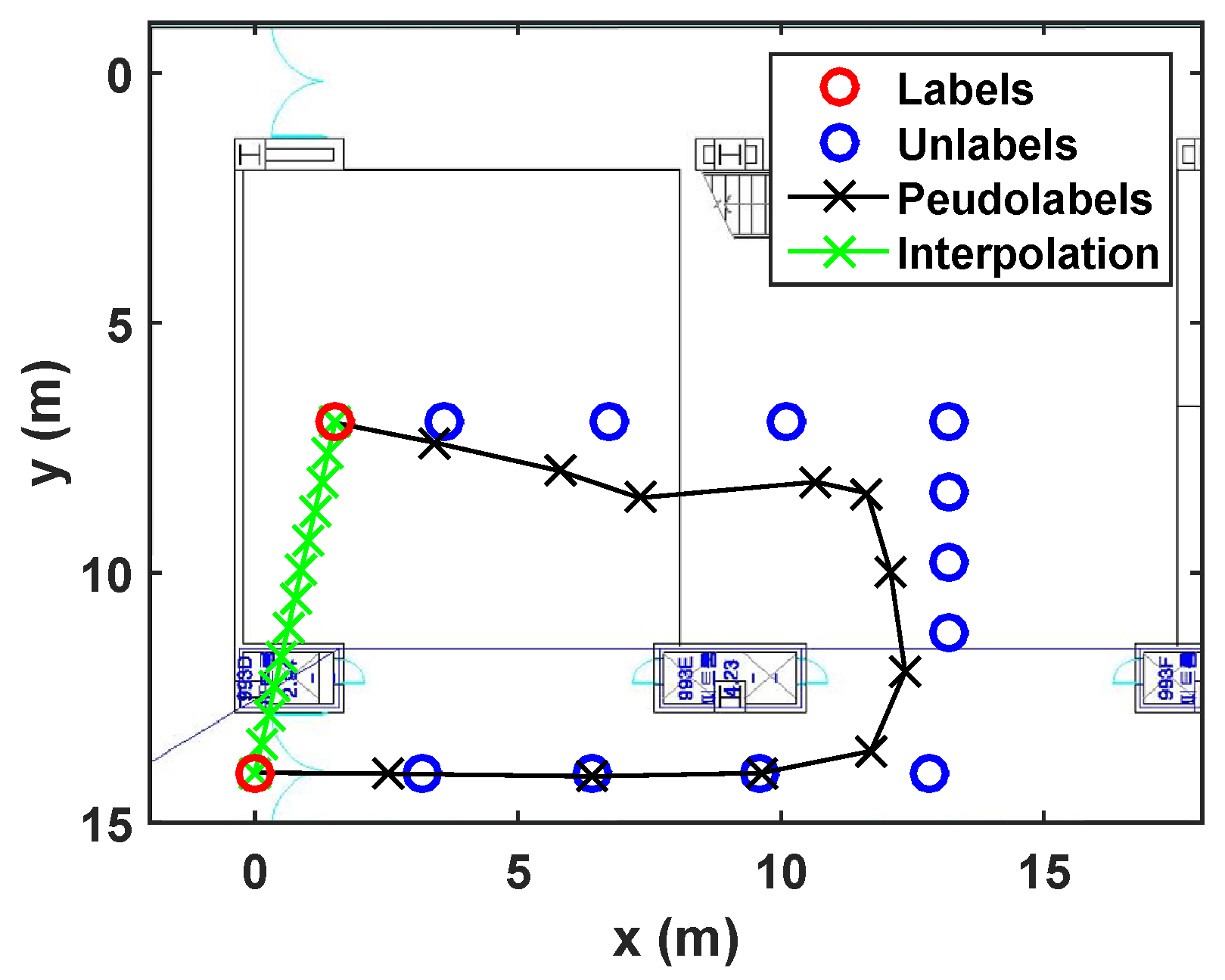
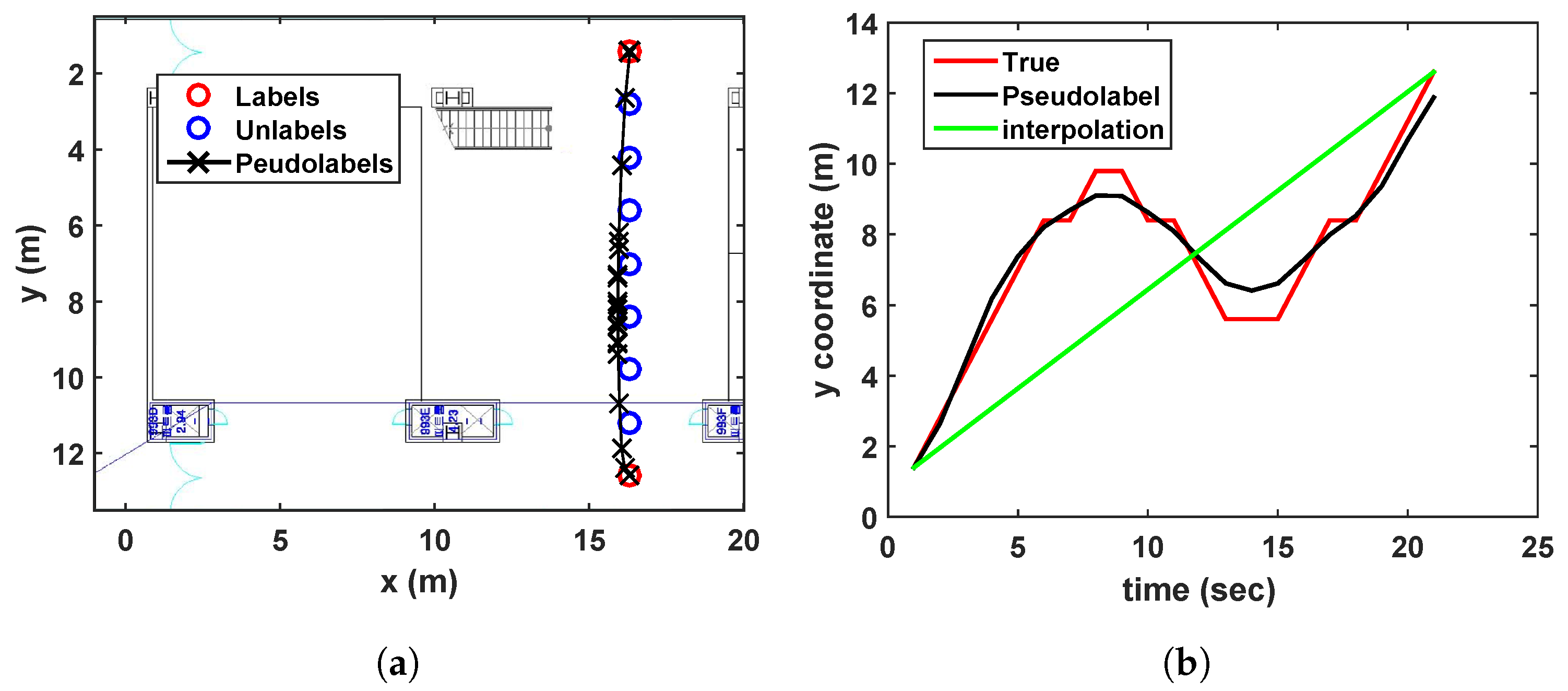
- Revisiting the learned trajectory:The user used to revisit the same site during collecting training data. Suppose that the locations corresponding to the Wi-Fi RSSI measurements are not recorded during walking a path, except the start and end points as shown in Figure 6. It is assumed that we have already learned those area. The result under this situation is shown in Figure 6, where the developed algorithm generates accurate pseudolabels, while the linear interpolation cannot reflect the reality.
4.2. Balancing Labeled and Pseudolabeled Data
| Algorithm 1 Proposed semi-supervised learning for localization |
5. Experiments
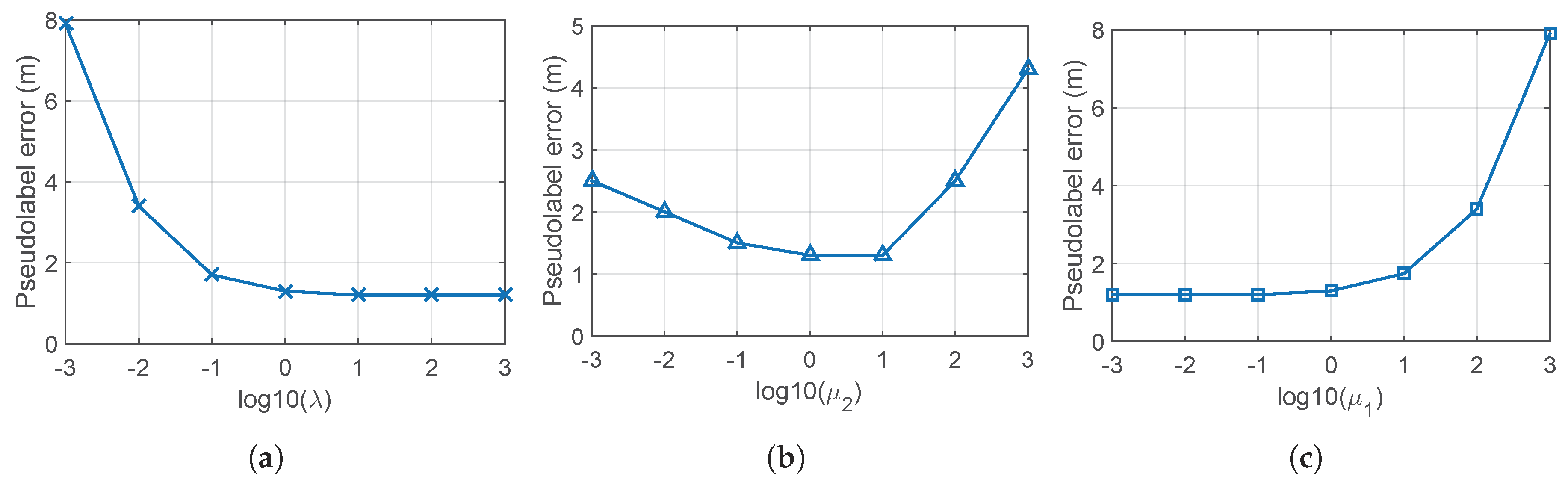
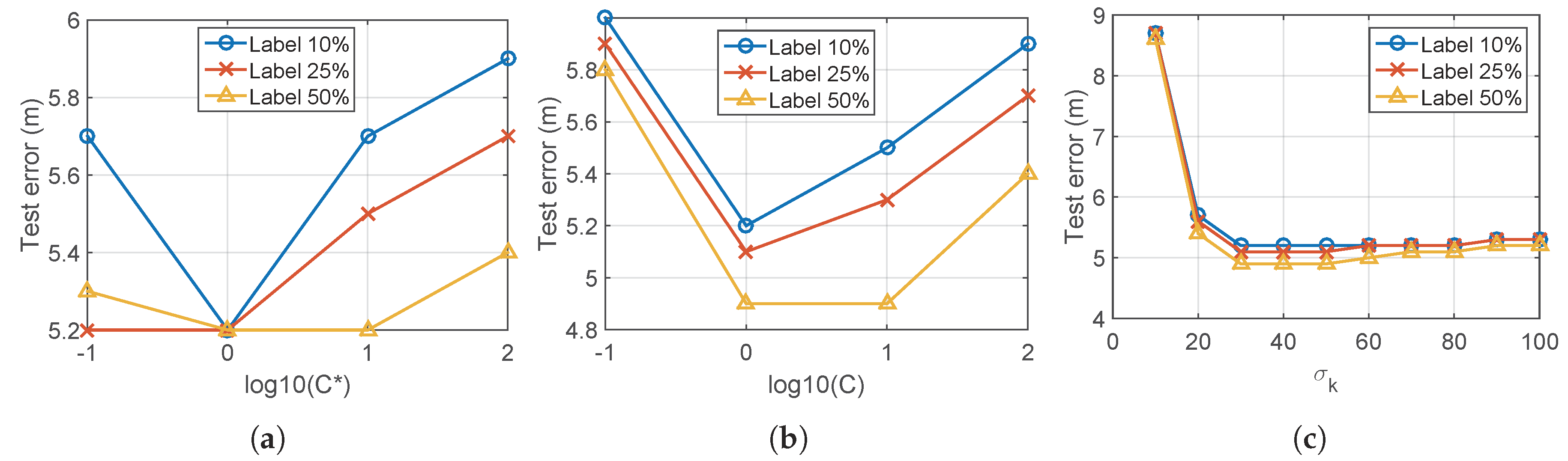
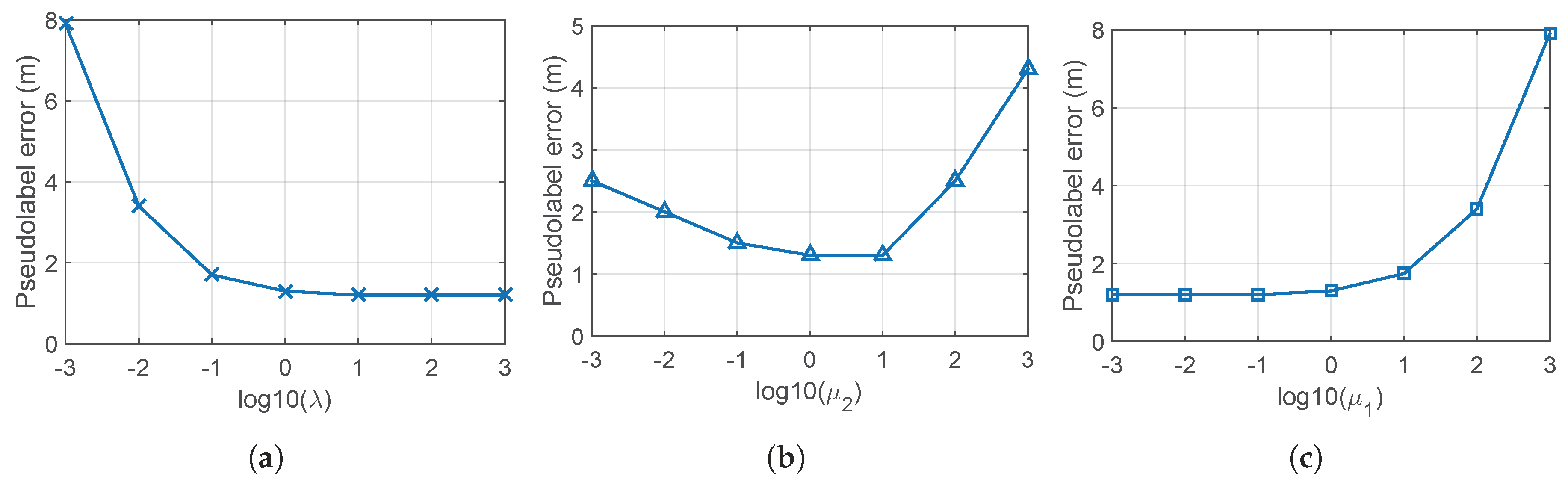
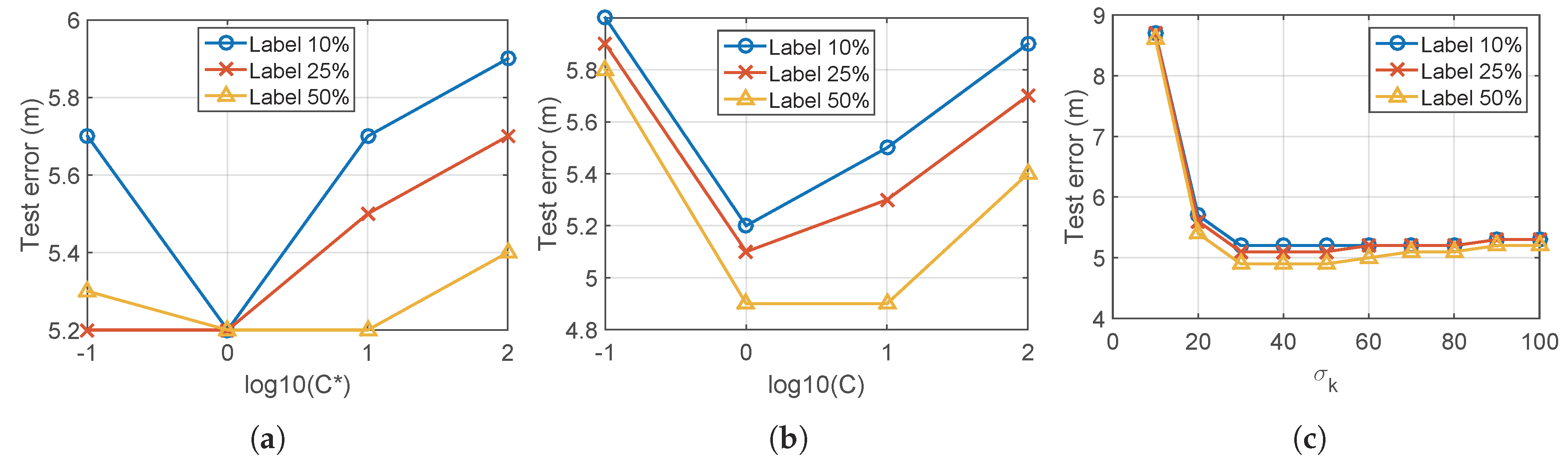
5.1. Parameter Setting
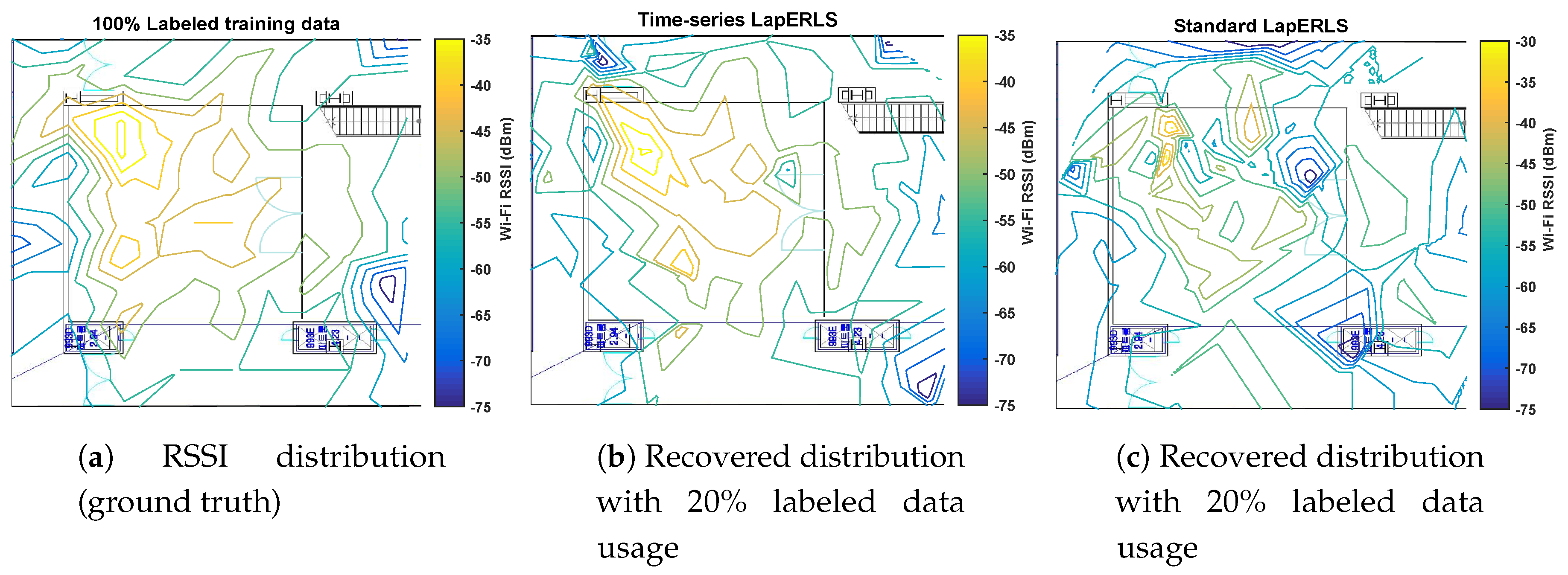
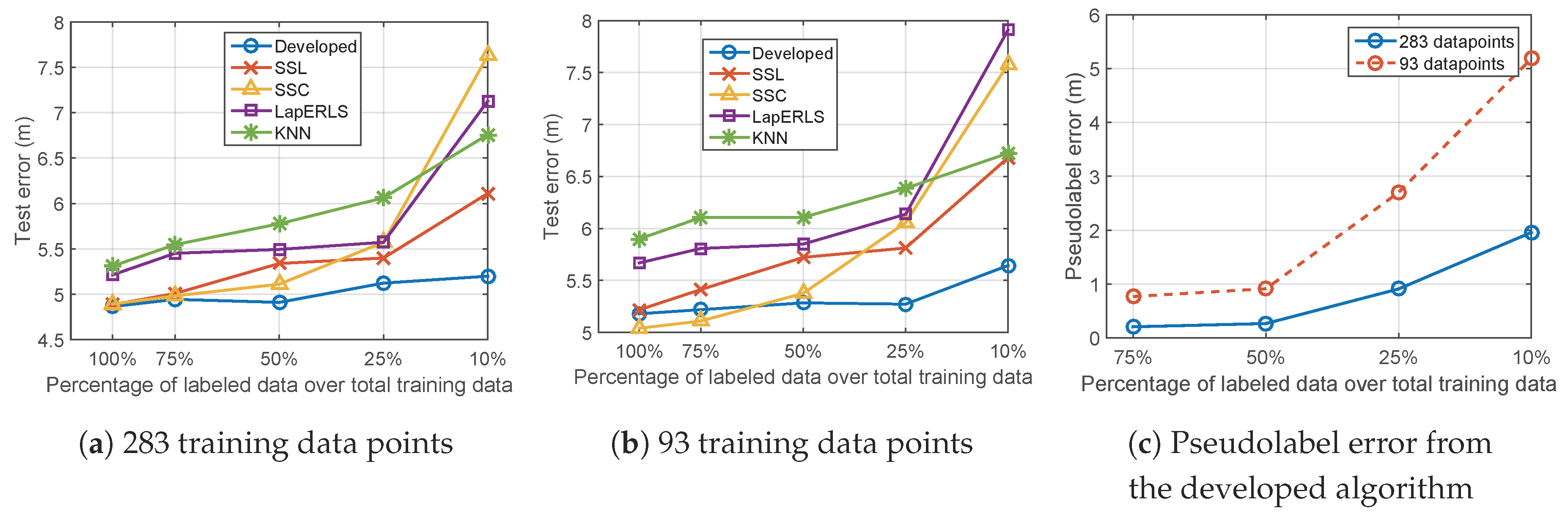
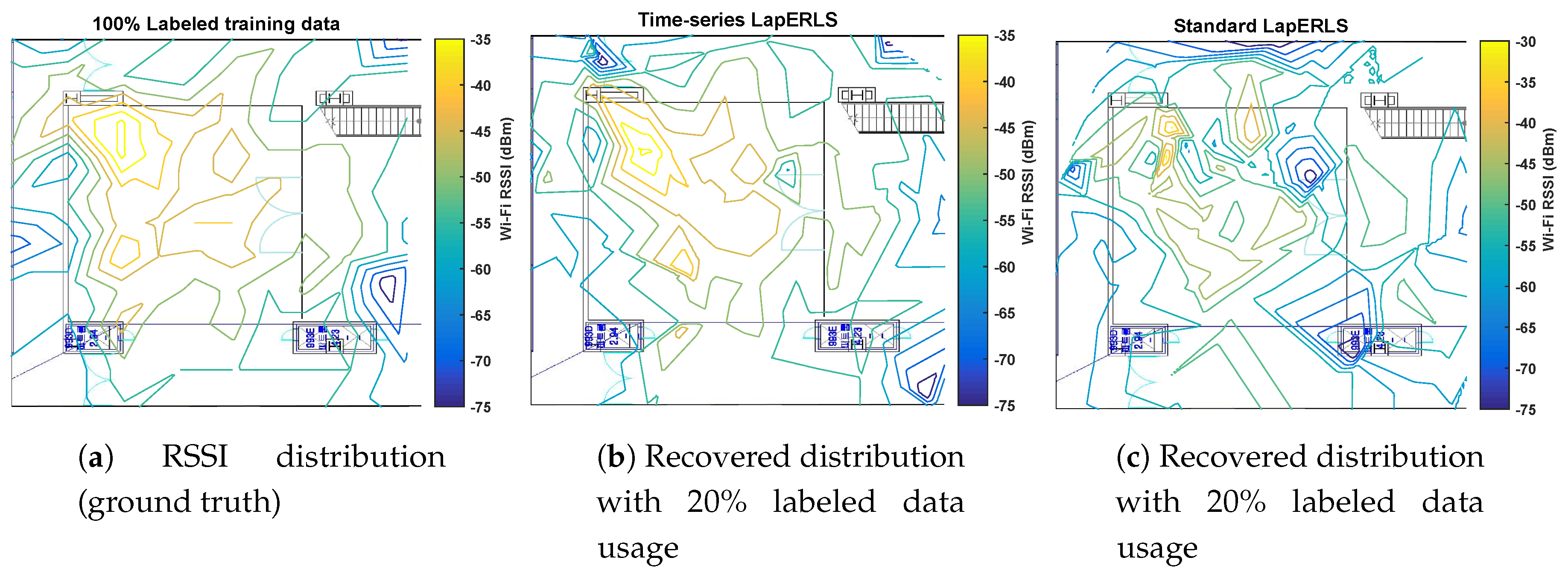
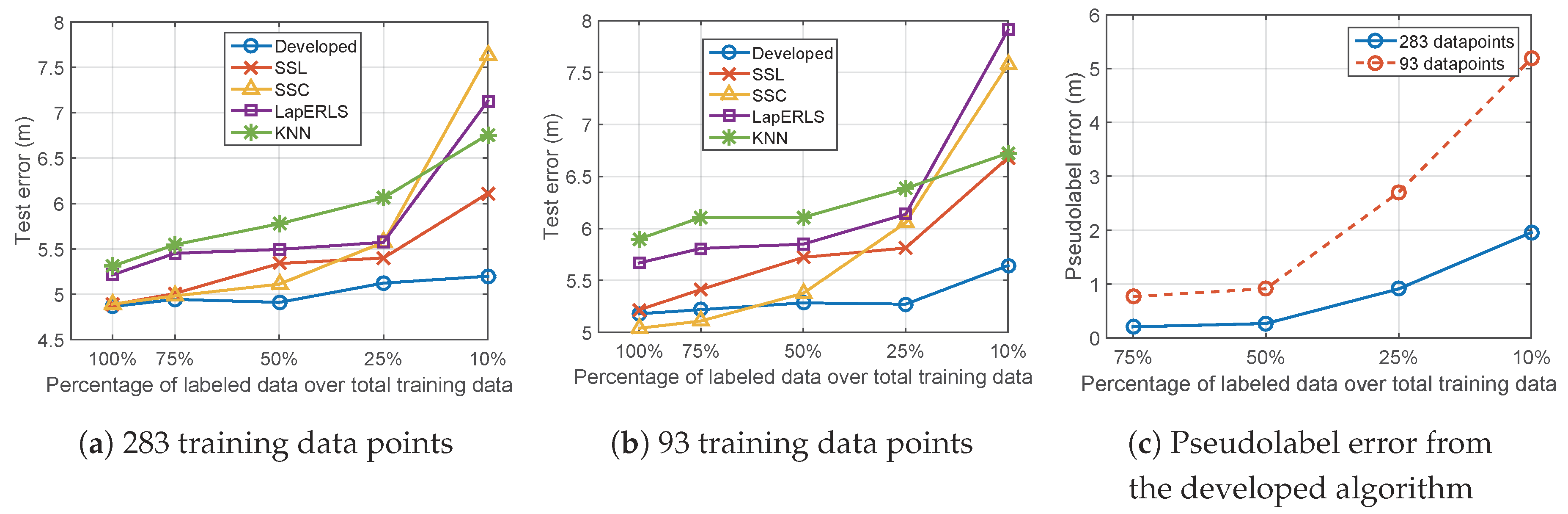
5.2. Variation of Number of Training Data
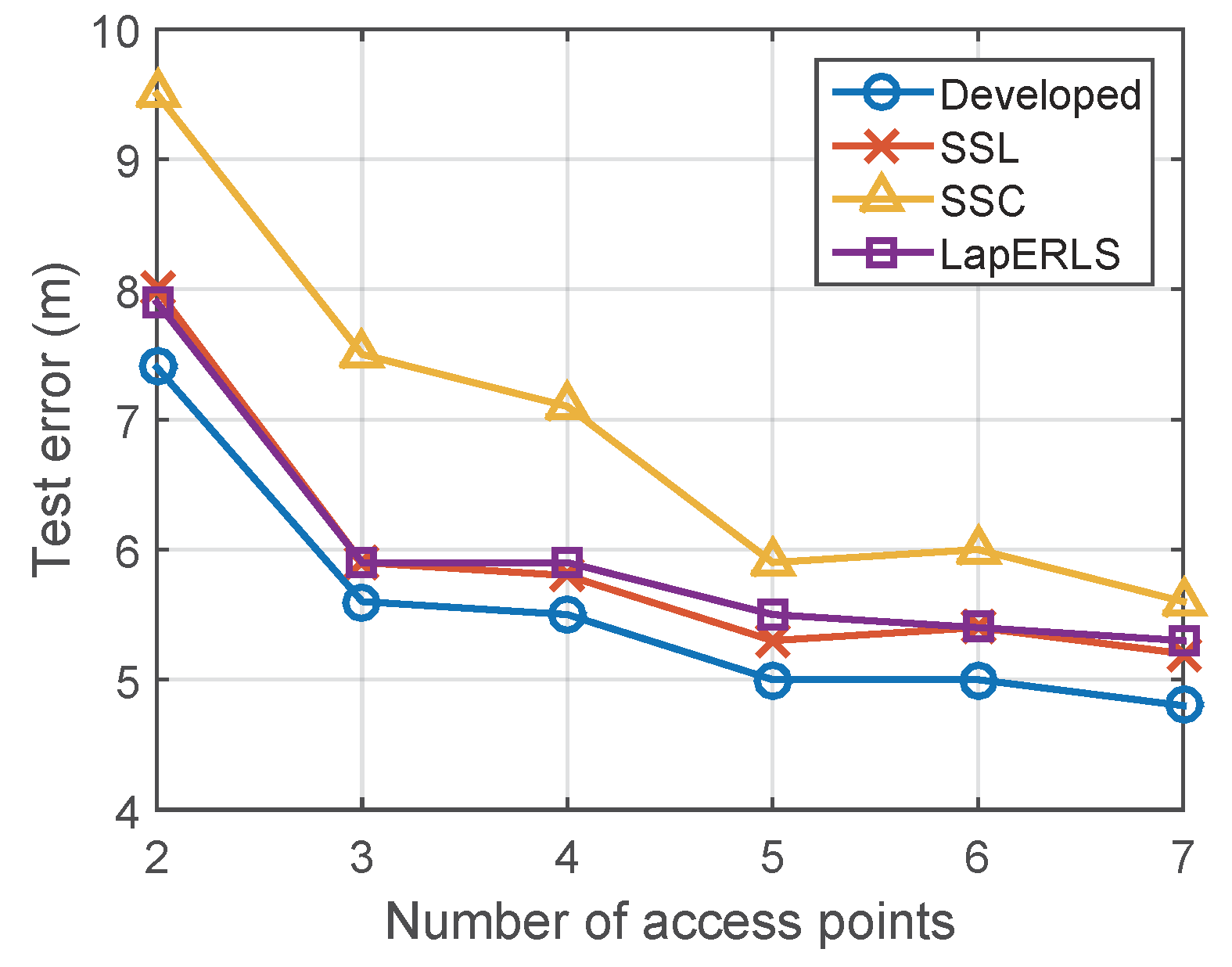
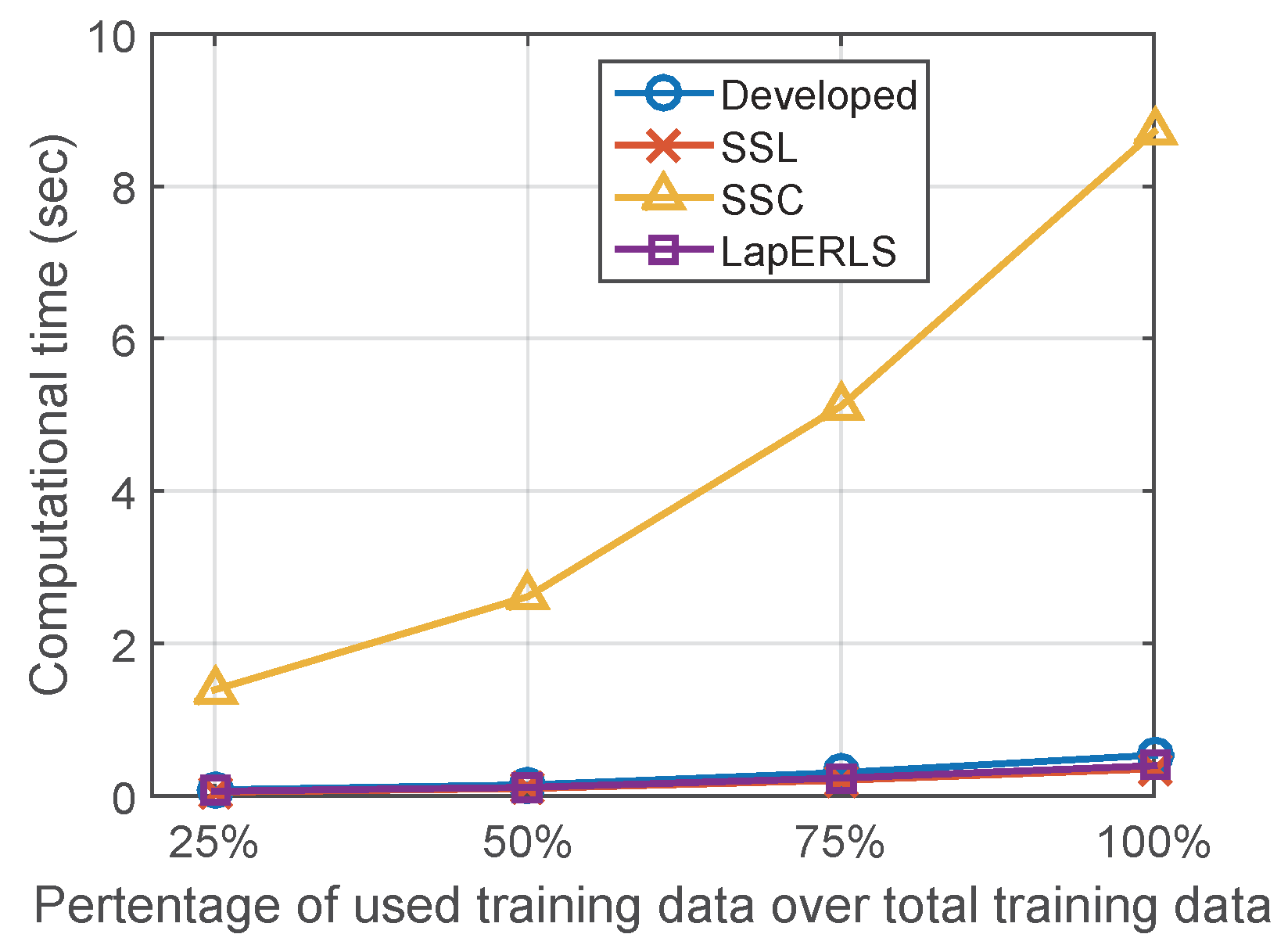
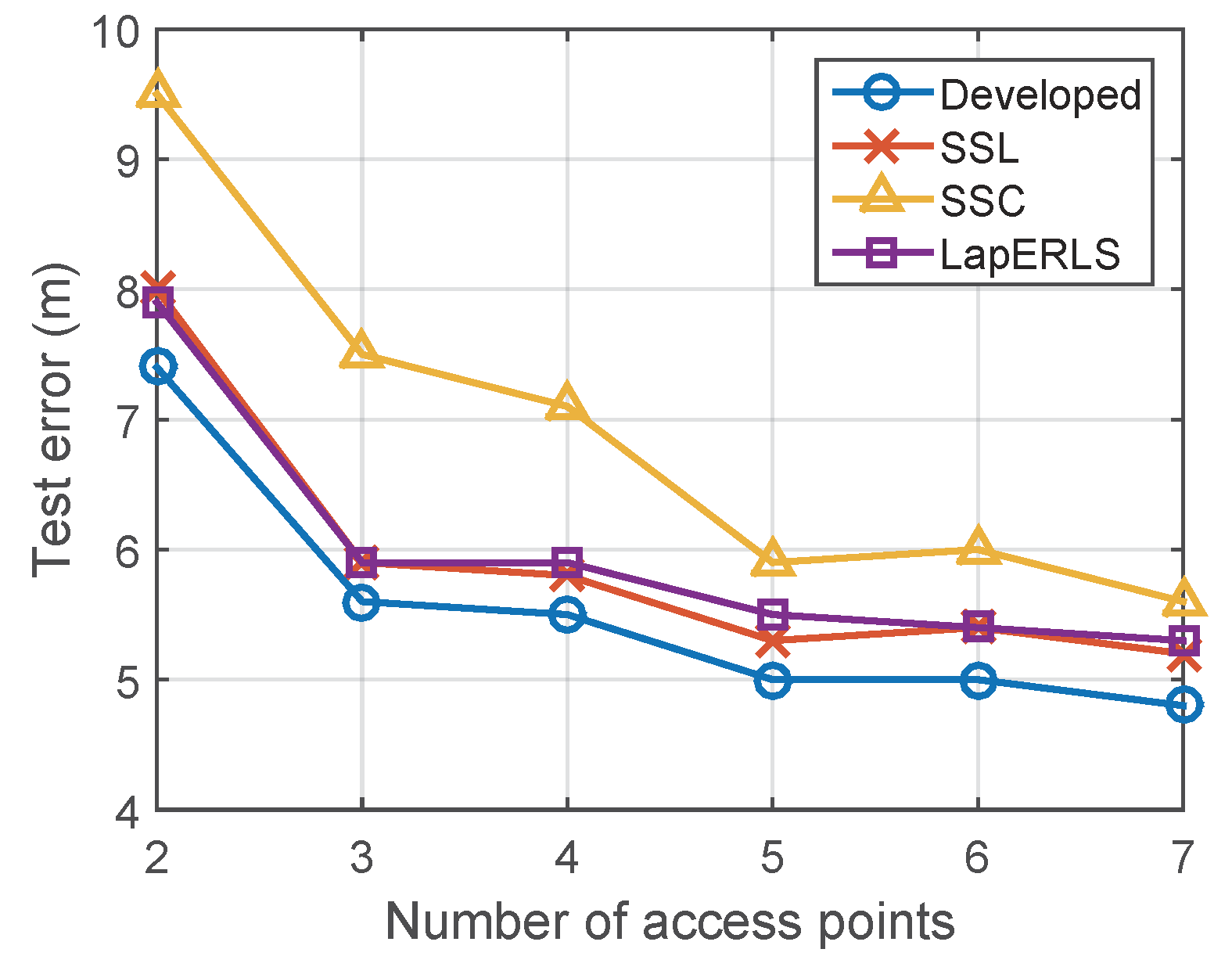
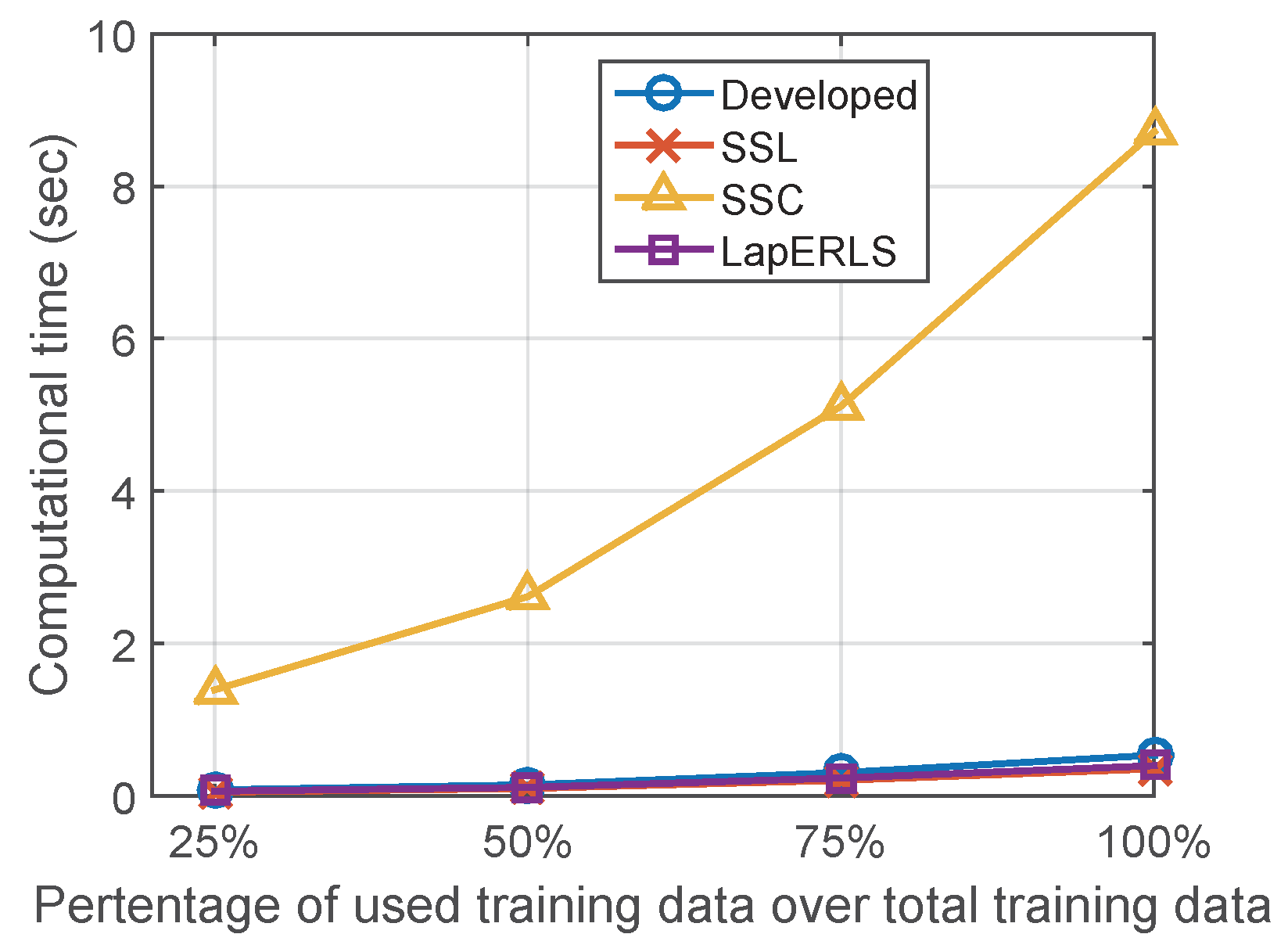
5.3. Variation of Number of Wi-Fi Access Points and Computational Time
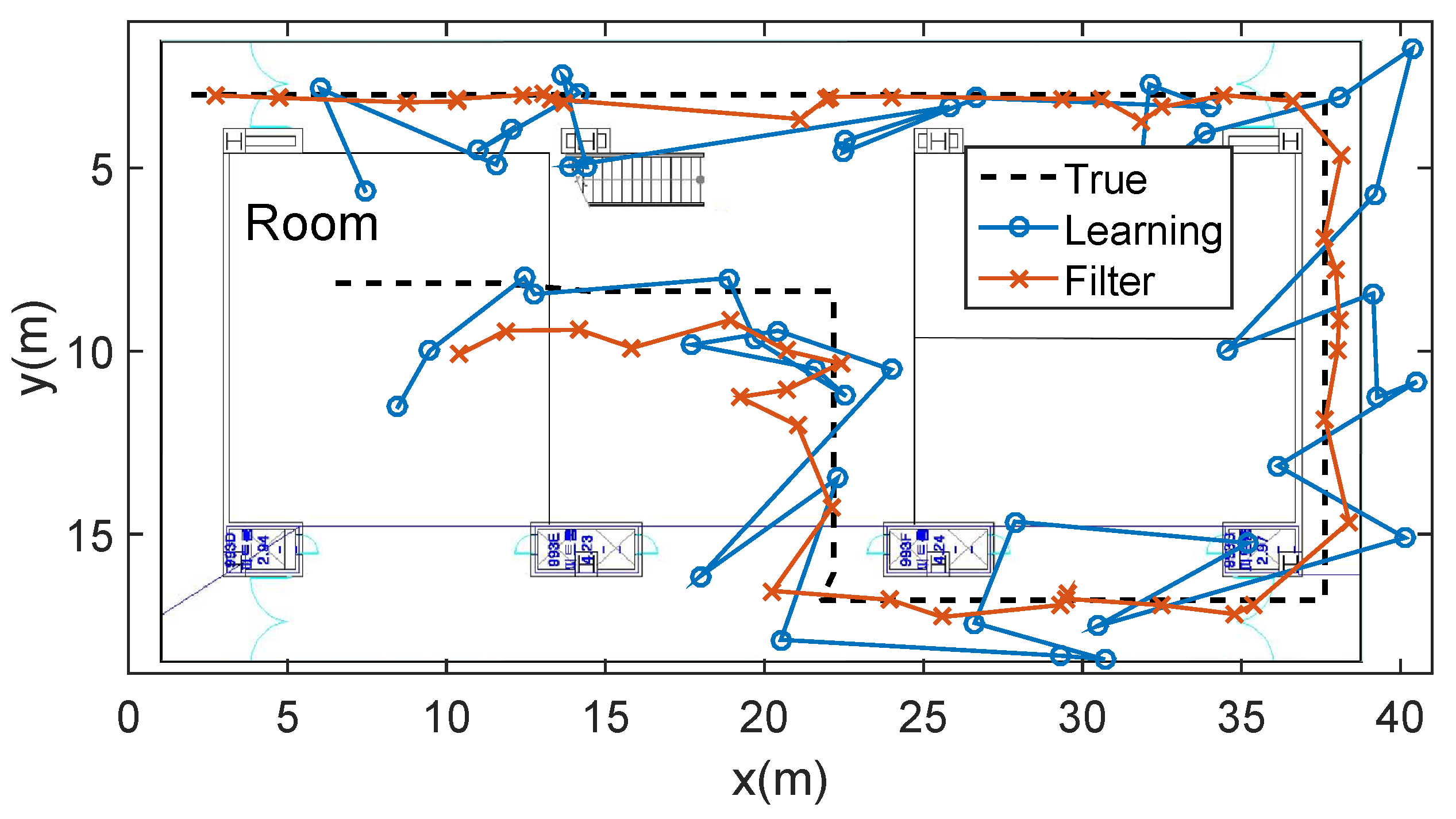
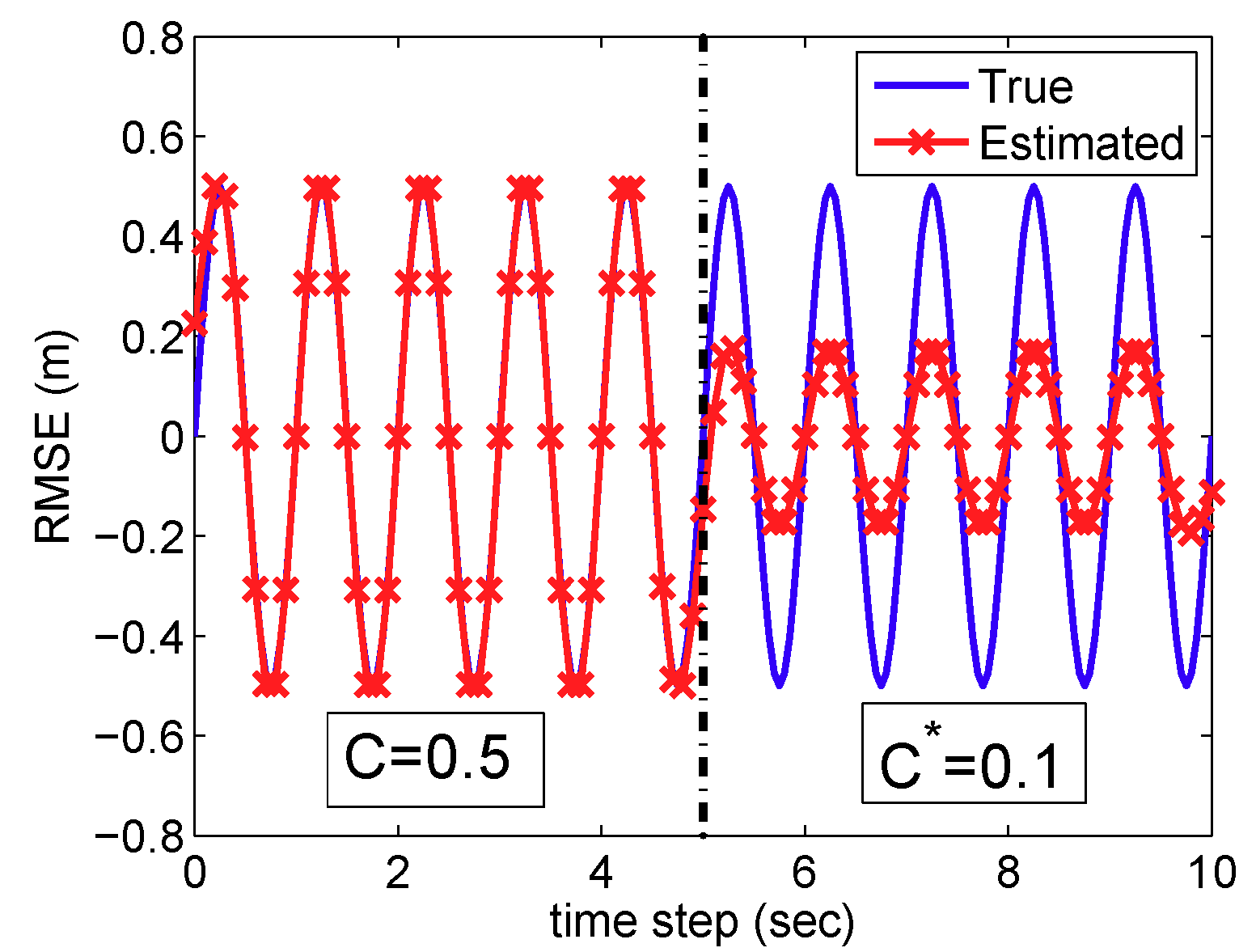
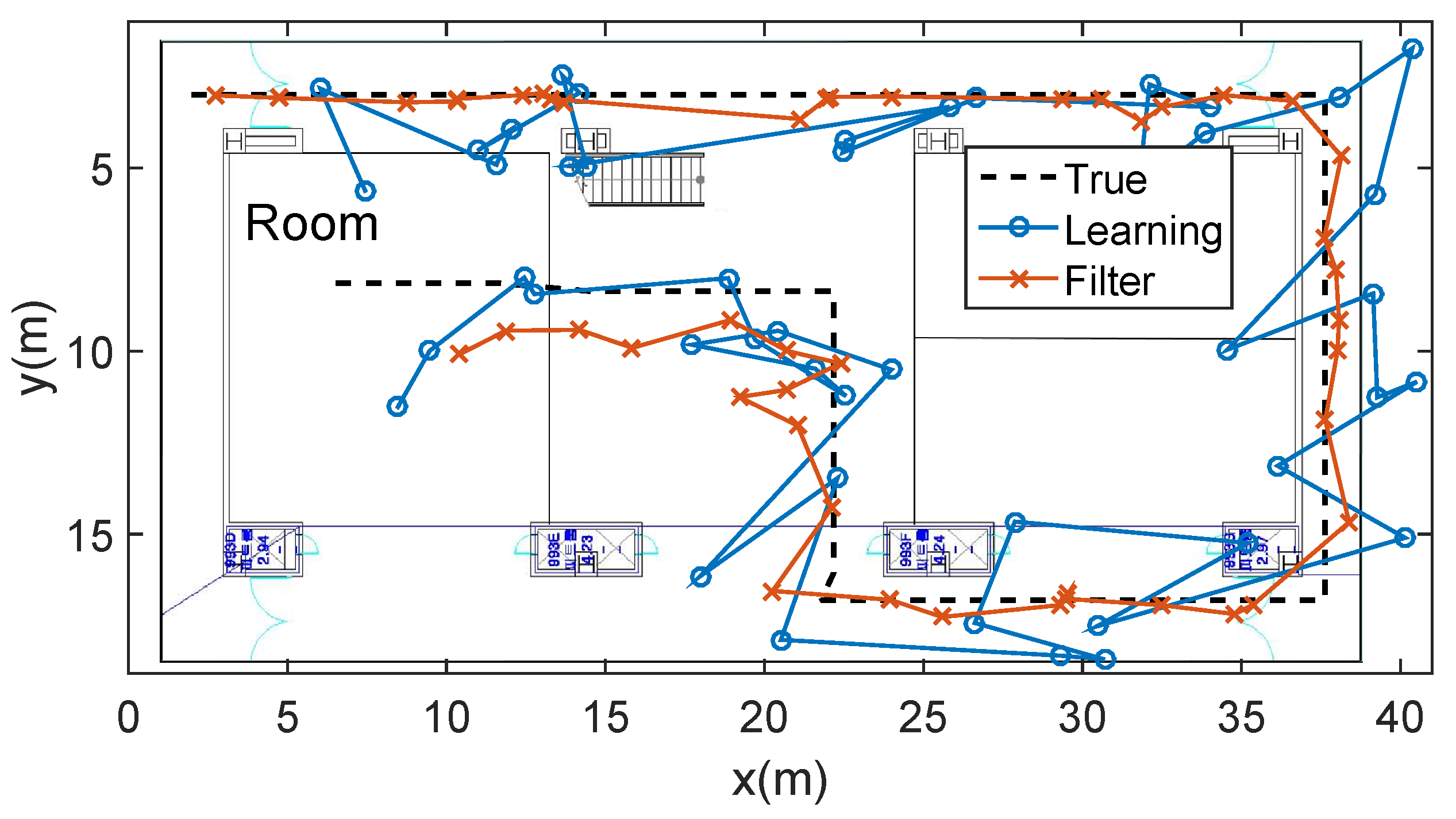
5.4. Combination with Particle Filter
6. Conclusions
Funding
Conflicts of Interest
References
- Hernández, N.; Ocaña, M.; Alonso, J.; Kim, E. Continuous space estimation: Increasing WiFi-based indoor localization resolution without increasing the site-survey effort. Sensors 2017, 17, 147. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Hu, B.; Chen, H. A high accuracy time-reversal based WiFi indoor localization approach with a single antenna. Sensors 2018, 18, 3437. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xiu, C.; Zhang, X.; Yang, D. WiFi indoor localization with CSI fingerprinting-based random forest. Sensors 2018, 18, 2869. [Google Scholar] [CrossRef] [PubMed]
- Nuño-Maganda, M.; Herrera-Rivas, H.; Torres-Huitzil, C.; Marisol Marin-Castro, H.; Coronado-Pérez, Y. On-Device learning of indoor location for WiFi fingerprint approach. Sensors 2018, 18, 2202. [Google Scholar] [CrossRef] [PubMed]
- Botta, M.; Simek, M. Adaptive distance estimation based on RSSI in 802.15. 4 network. Radioengineering 2013, 22, 1162–1168. [Google Scholar]
- Zhou, M.; Tang, Y.; Nie, W.; Xie, L.; Yang, X. GrassMA: Graph-based semi-supervised manifold alignment for indoor WLAN localization. IEEE Sens. J. 2017, 17, 7086–7095. [Google Scholar] [CrossRef]
- Zhang, L.; Valaee, S.; Xu, Y.; Ma, L.; Vedadi, F. Graph-based semi-supervised learning for indoor localization using crowdsourced data. Appl. Sci. 2017, 7, 467. [Google Scholar] [CrossRef]
- Du, B.; Xinyao, T.; Wang, Z.; Zhang, L.; Tao, D. Robust graph-based semisupervised learning for noisy labeled data via maximum correntropy criterion. IEEE Trans. Cybern. 2018, 49, 1440–1453. [Google Scholar] [CrossRef]
- Wang, M.; Fu, W.; Hao, S.; Tao, D.; Wu, X. Scalable semi-supervised learning by efficient anchor graph regularization. IEEE Trans. Knowl. Data Eng. 2016, 28, 1864–1877. [Google Scholar] [CrossRef]
- Yoo, J.; Kim, H. Target localization in wireless sensor networks using online semi-supervised support vector regression. Sensors 2015, 15, 12539–12559. [Google Scholar] [CrossRef]
- Chen, L.; Tsang, I.W.; Xu, D. Laplacian embedded regression for scalable manifold regularization. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 902–915. [Google Scholar] [CrossRef] [PubMed]
- Nie, F.; Xu, D.; Li, X.; Xiang, S. Semisupervised dimensionality reduction and classification through virtual label regression. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2011, 41, 675–685. [Google Scholar]
- Kumar Mallapragada, P.; Jin, R.; Jain, A.K.; Liu, Y. Semiboost: Boosting for semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2000–2014. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, R.W.; Wong, A.K.S.; Lea, C.T.; Chiang, M. Indoor location estimation with reduced calibration exploiting unlabeled data via hybrid generative/discriminative learning. IEEE Trans. Mobile Comput. 2012, 11, 1613–1626. [Google Scholar] [CrossRef]
- Jain, V.K.; Tapaswi, S.; Shukla, A. RSS Fingerprints Based Distributed Semi-Supervised Locally Linear Embedding (DSSLLE) Location Estimation System for Indoor WLAN. Wirel. Pers. Commun. 2013, 71, 1175–1192. [Google Scholar] [CrossRef]
- Xia, Y.; Ma, L.; Zhang, Z.; Wang, Y. Semi-Supervised Positioning Algorithm in Indoor WLAN Environment. In Proceedings of the IEEE Vehicular Technology Conference, Glasgow, UK, 11–14 May 2015; pp. 1–5. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Guizani, M.; Oh, J.S. Semisupervised deep reinforcement learning in support of IoT and smart city services. IEEE Internet Things J. 2017, 5, 624–635. [Google Scholar] [CrossRef]
- Gu, Y.; Chen, Y.; Liu, J.; Jiang, X. Semi-supervised deep extreme learning machine for Wi-Fi based localization. Neurocomputing 2015, 166, 282–293. [Google Scholar] [CrossRef]
- Khatab, Z.E.; Hajihoseini, A.; Ghorashi, S.A. A fingerprint method for indoor localization using autoencoder based deep extreme learning machine. IEEE Sens. Lett. 2017, 2, 1–4. [Google Scholar] [CrossRef]
- Jiang, X.; Chen, Y.; Liu, J.; Gu, Y.; Hu, L. FSELM: Fusion semi-supervised extreme learning machine for indoor localization with Wi-Fi and Bluetooth fingerprints. Soft Comput. 2018, 22, 3621–3635. [Google Scholar] [CrossRef]
- Yoo, J.; Johansson, K.H. Semi-supervised learning for mobile robot localization using wireless signal strengths. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation, Sapporo, Japan, 18–21 September 2017; pp. 1–8. [Google Scholar]
- Pan, J.J.; Pan, S.J.; Yin, J.; Ni, L.M.; Yang, Q. Tracking mobile users in wireless networks via semi-supervised colocalization. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 587–600. [Google Scholar] [CrossRef]
- Chapelle, O.; Vapnik, V.; Weston, J. Transductive Inference for Estimating Values of Functions. In Proceedings of the Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; Volume 12, pp. 421–427. [Google Scholar]
- Belkin, M.; Niyogi, P. Semi-supervised learning on Riemannian manifolds. Mach. Learn. 2004, 56, 209–239. [Google Scholar] [CrossRef]
- Tran, D.A.; Zhang, T. Fingerprint-based location tracking with Hodrick-Prescott filtering. In Proceedings of the IFIP Wireless and Mobile Networking Conference, Vilamoura, Portugal, 20–22 May 2014; pp. 1–8. [Google Scholar]
- Ravn, M.O.; Uhlig, H. On adjusting the Hodrick-Prescott filter for the frequency of observations. Rev. Econ. Stat. 2002, 84, 371–376. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the IJCAI, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Yoo, J.; Kim, H.J. Online estimation using semi-supervised least square svr. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, San Diego, CA, USA, 5–8 October 2014; pp. 1624–1629. [Google Scholar]
- Chapelle, O. Training a support vector machine in the primal. Neural Comput. 2007, 19, 1155–1178. [Google Scholar] [CrossRef] [PubMed]
- Chapelle, O.; Zien, A. Semi-Supervised Classification by Low Density Separation. In Proceedings of the AISTATS, Bridgetown, Barbados, 6–8 January 2005; pp. 57–64. [Google Scholar]
- Gao, Z.; Mu, D.; Zhong, Y.; Gu, C. Constrained Unscented Particle Filter for SINS/GNSS/ADS Integrated Airship Navigation in the Presence of Wind Field Disturbance. Sensors 2019, 19, 471. [Google Scholar] [CrossRef] [PubMed]
- Dampf, J.; Frankl, K.; Pany, T. Optimal particle filter weight for bayesian direct position estimation in a gnss receiver. Sensors 2018, 18, 2736. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Wang, W.; Zhu, H.; Huang, G.; Wu, D.; Du, Z. Robust Radiation Sources Localization Based on the Peak Suppressed Particle Filter for Mixed Multi-Modal Environments. Sensors 2018, 18, 3784. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value of | Value of | Value of | Value of | Value of | Value of |
|---|---|---|---|---|---|
| 10 | 5 | 2 | 10 | 1 | 30 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, J. Time-Series Laplacian Semi-Supervised Learning for Indoor Localization. Sensors 2019, 19, 3867. https://doi.org/10.3390/s19183867
Yoo J. Time-Series Laplacian Semi-Supervised Learning for Indoor Localization. Sensors. 2019; 19(18):3867. https://doi.org/10.3390/s19183867
Chicago/Turabian StyleYoo, Jaehyun. 2019. "Time-Series Laplacian Semi-Supervised Learning for Indoor Localization" Sensors 19, no. 18: 3867. https://doi.org/10.3390/s19183867
APA StyleYoo, J. (2019). Time-Series Laplacian Semi-Supervised Learning for Indoor Localization. Sensors, 19(18), 3867. https://doi.org/10.3390/s19183867