Intelligent 3D Perception System for Semantic Description and Dynamic Interaction

 ,
,  , , , ,
, , , , 

Abstract
:1. Introduction
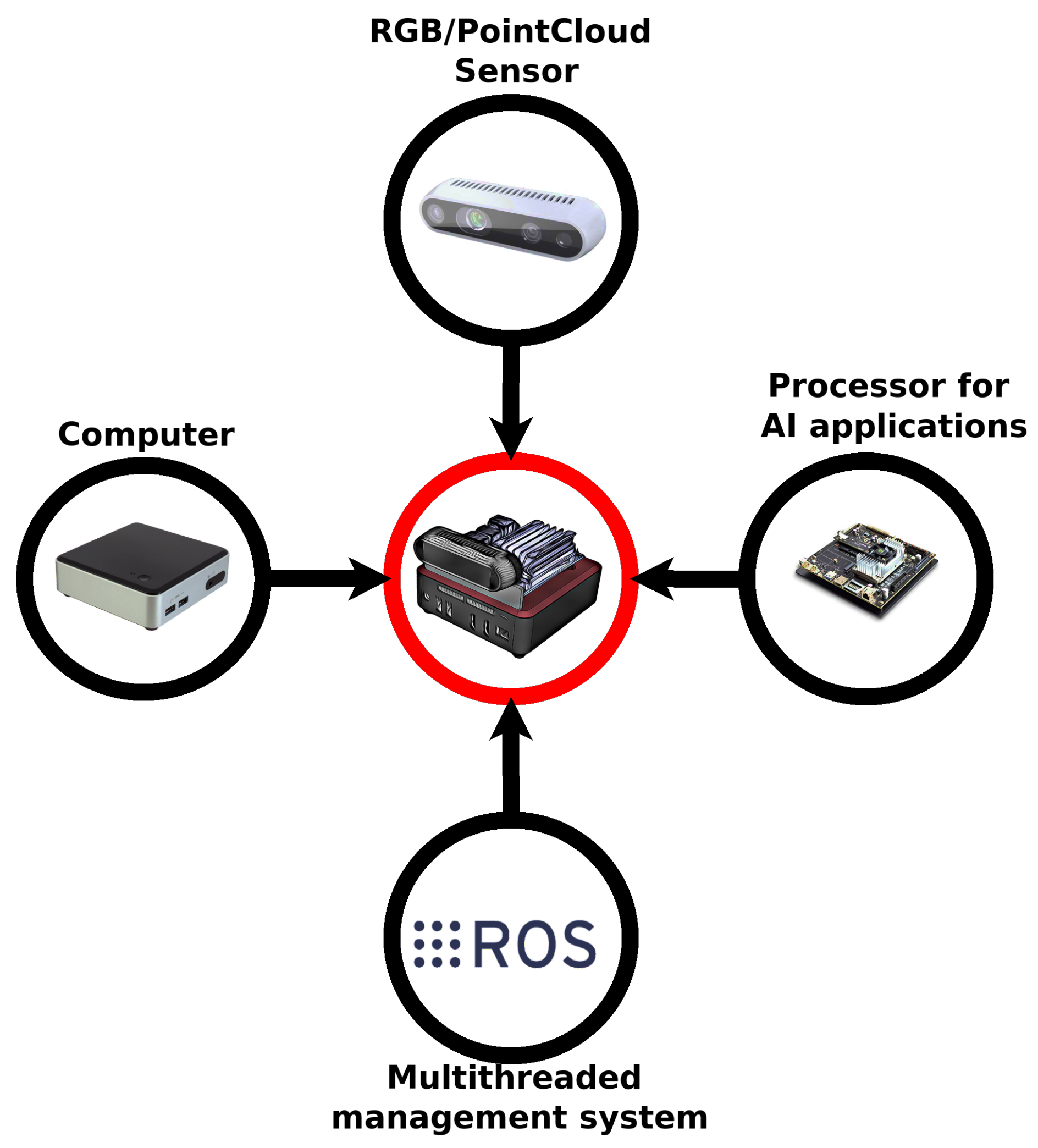
2. Overview of Used 3D Perception Sources
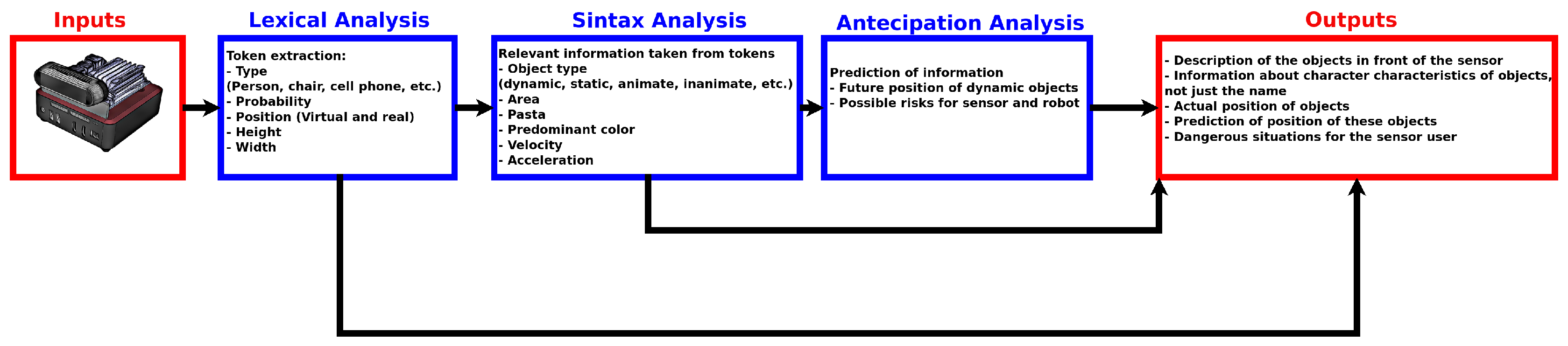
3. Semantic Description and Dynamic Interaction (SD2I)
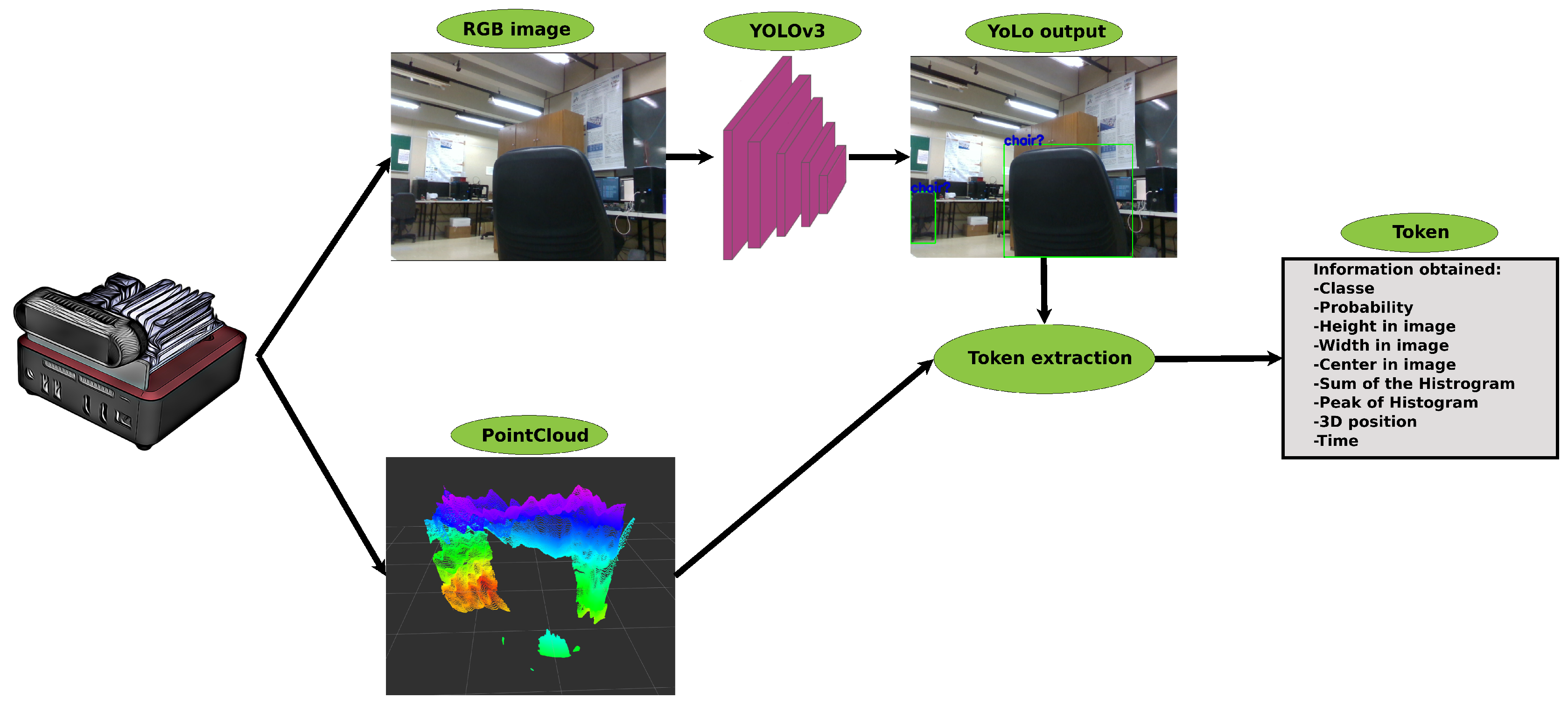
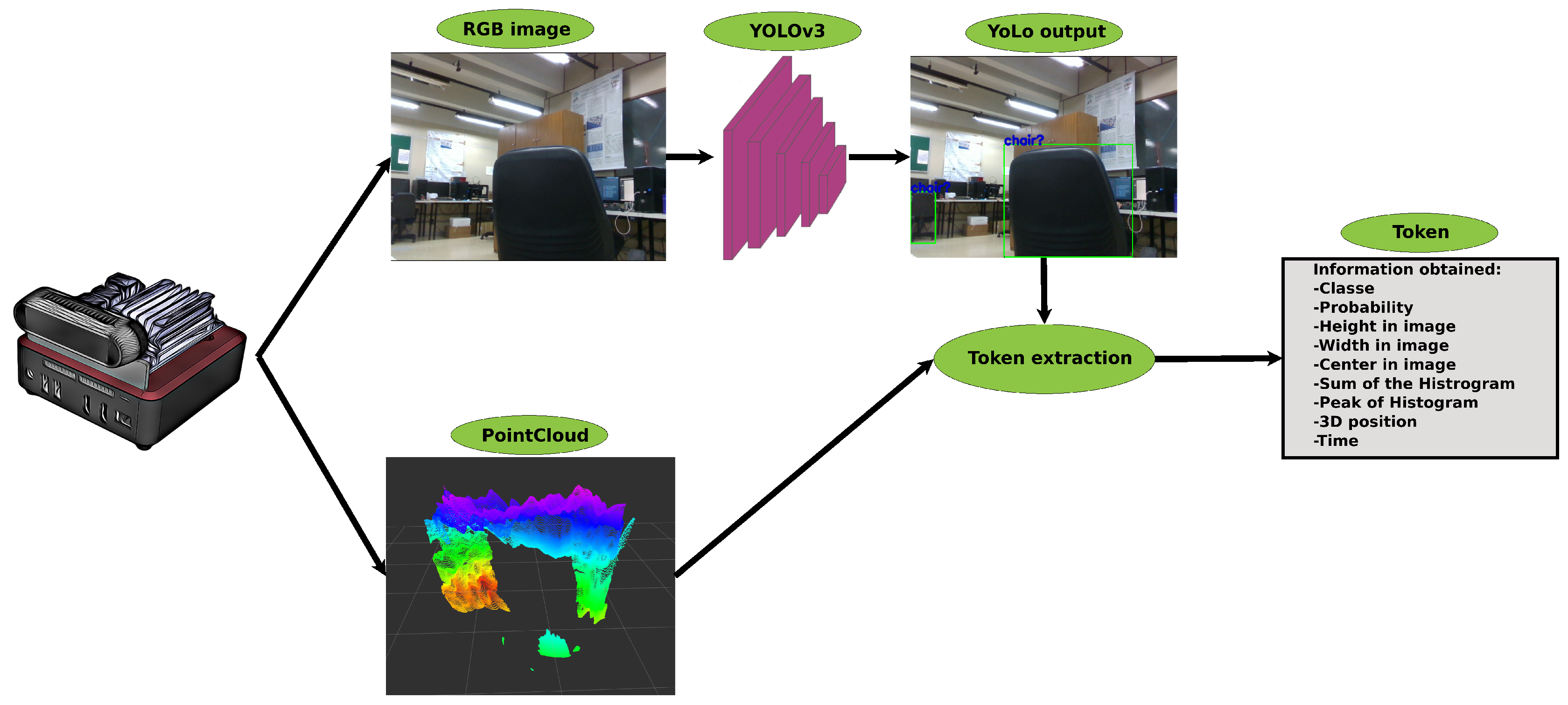
3.1. Lexical Analysis
| Algorithm 1: Identification of the object’s 3D center. |
 |
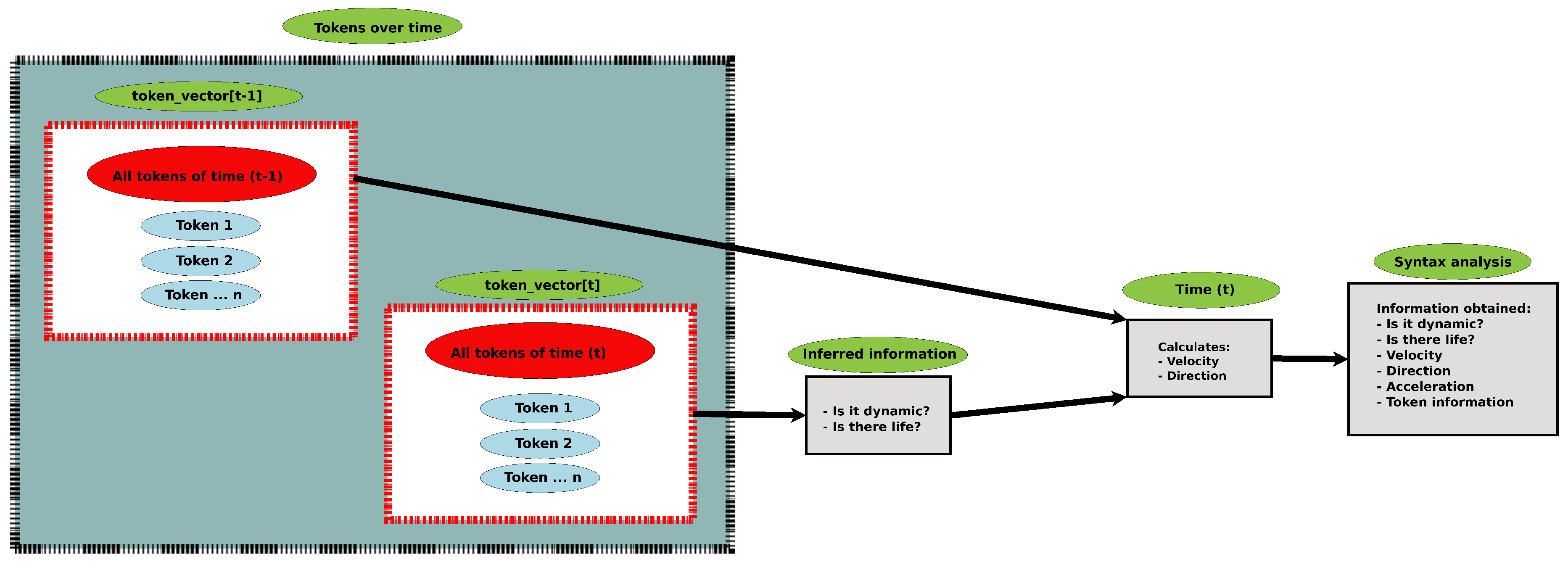
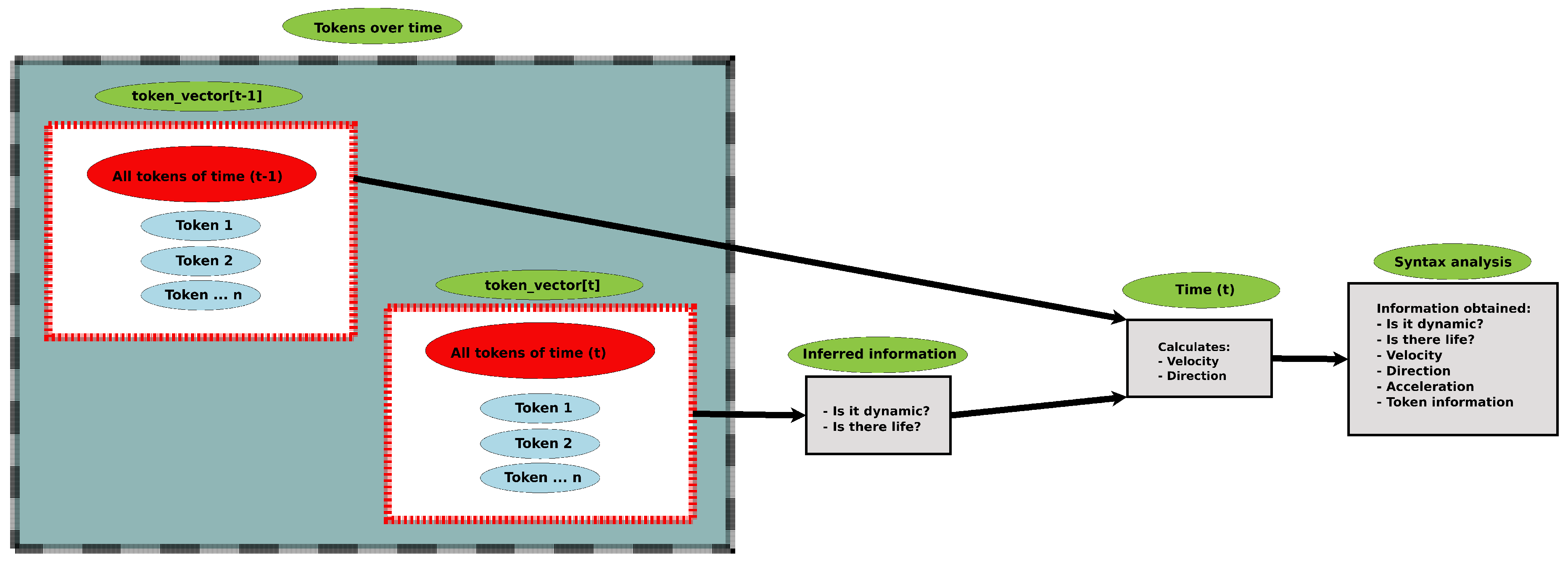
3.2. Syntax Analysis
| Algorithm 2: Identify the same object in two instants of time. |
 |
| Algorithm 3: Calculate the direction of the dynamic object. |
 |
| Algorithm 4: Calculate the velocity of the dynamic object. |
 |
| Algorithm 5: Calculate the acceleration of the dynamic object. |
 |
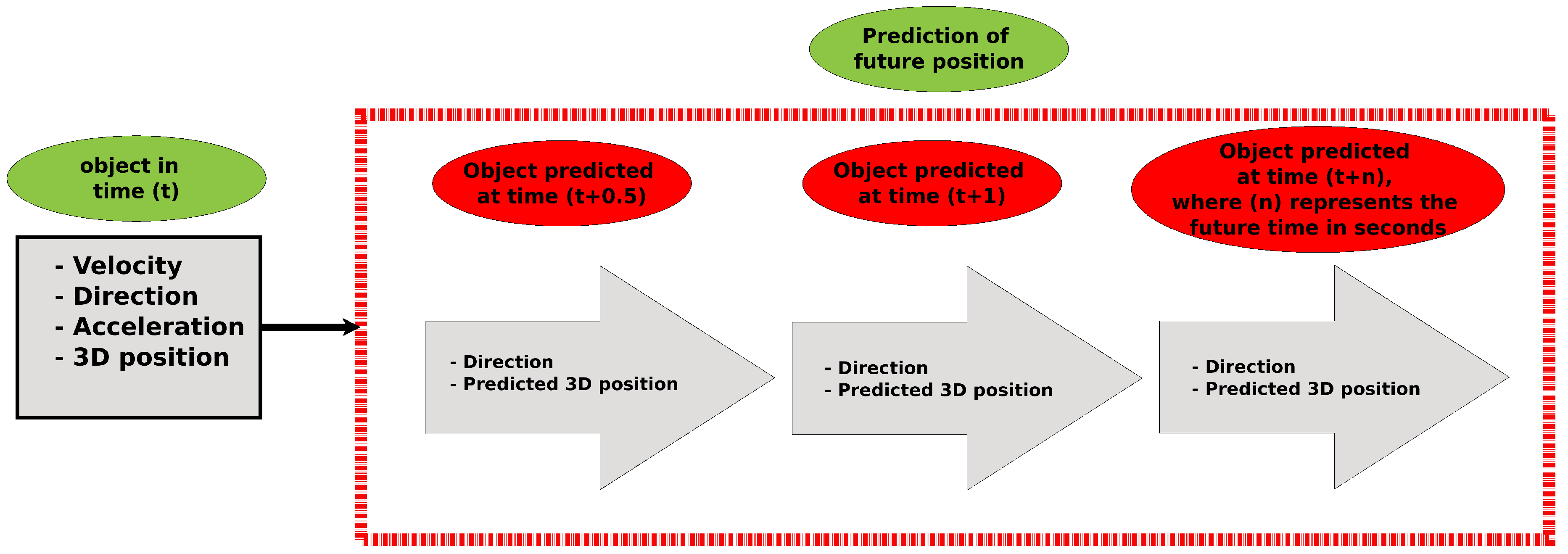
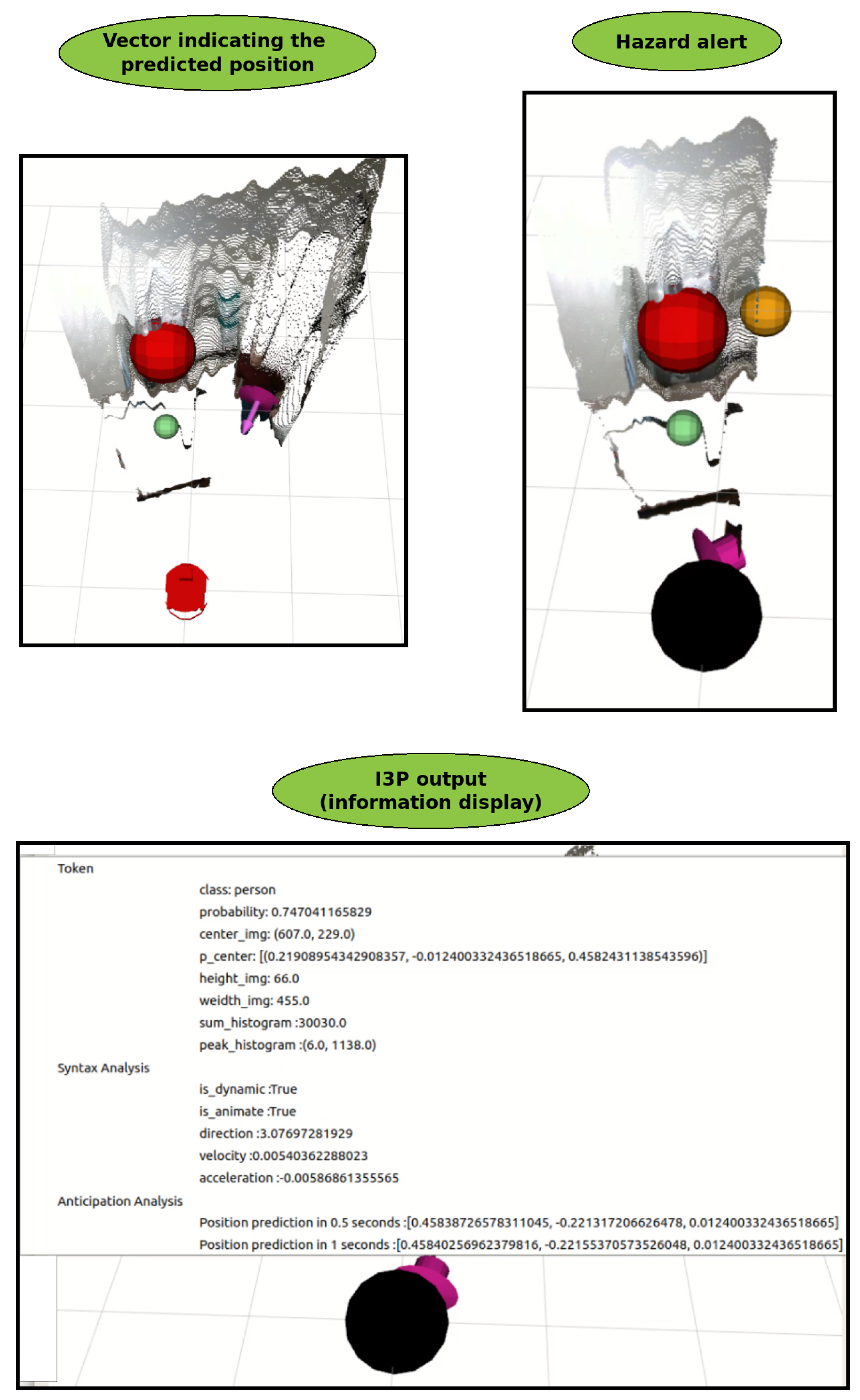
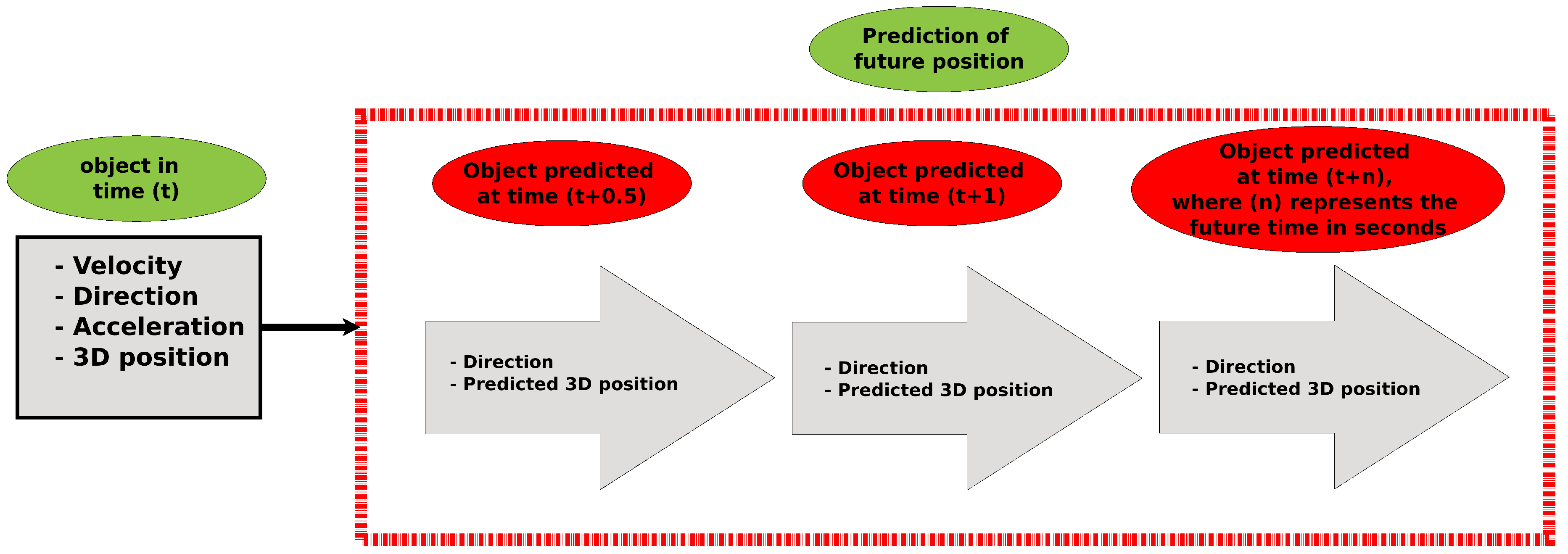
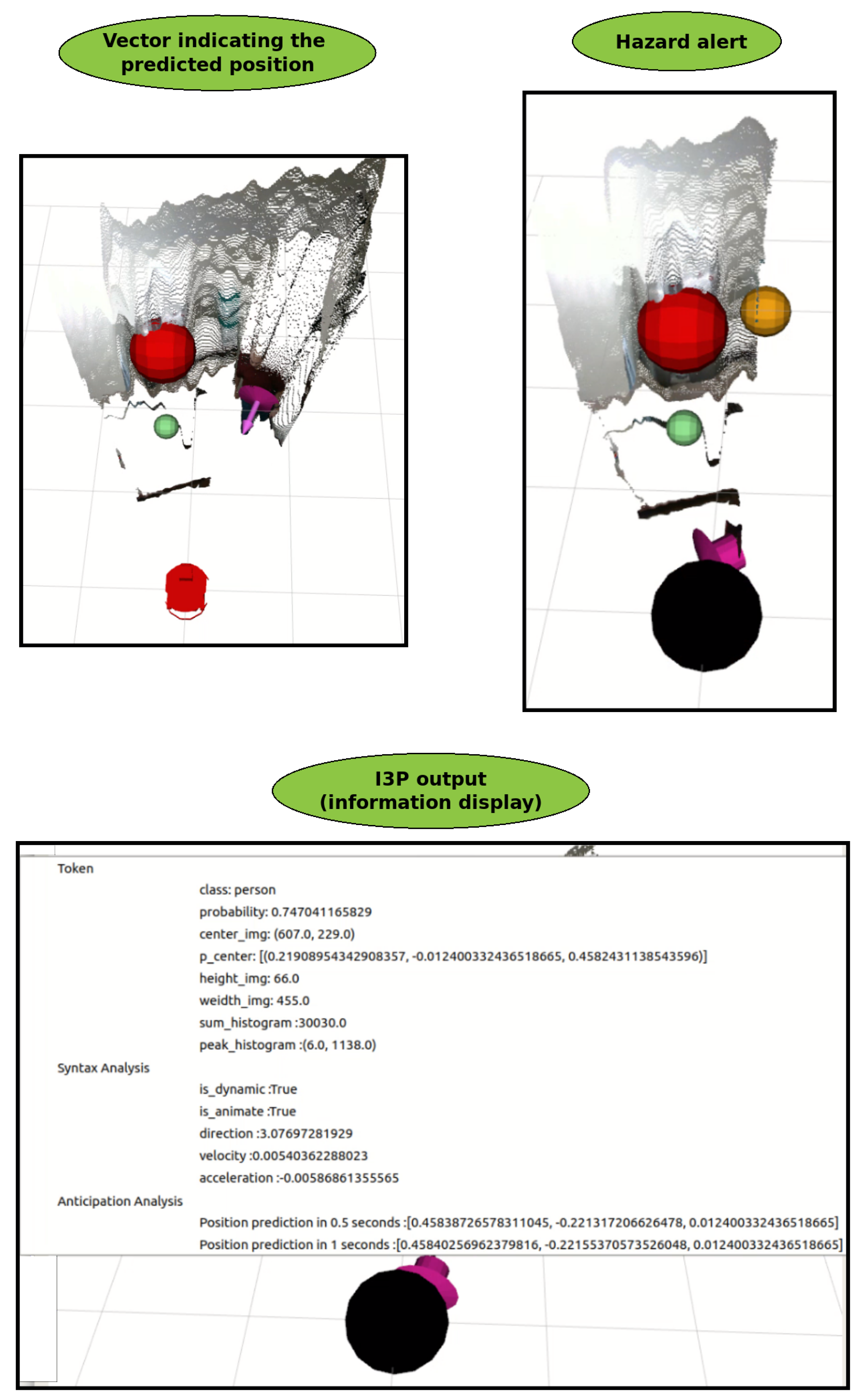
3.3. Anticipation Analysis
4. Experiments and Results
Accuracy and Precision
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D.; Arkin, R.C. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Jones, J.L.; Seiger, B.A.; Flynn, A.M. Mobile Robots: Inspiration to Implementation; AK Peters/CRC Press: Boca Raton, FL, USA, 1998. [Google Scholar]
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar]
- Bahrin, M.A.K.; Othman, M.F.; Azli, N.N.; Talib, M.F. Industry 4.0: A review on industrial automation and robotic. J. Teknol. 2016, 78, 137–143. [Google Scholar]
- Benotsmane, R.; Kovács, G.; Dudás, L. Economic, Social Impacts and Operation of Smart Factories in Industry 4.0 Focusing on Simulation and Artificial Intelligence of Collaborating Robots. Soc. Sci. 2019, 8, 143. [Google Scholar] [CrossRef]
- Cardona, G.A.; Calderon, J.M. Robot Swarm Navigation and Victim Detection Using Rendezvous Consensus in Search and Rescue Operations. Appl. Sci. 2019, 9, 1702. [Google Scholar] [CrossRef]
- Murphy, R.R. Human-robot interaction in rescue robotics. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2004, 34, 138–153. [Google Scholar]
- Davis, M.; Sahin, F. HOG feature human detection system. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–16 October 2016; pp. 002878–002883. [Google Scholar]
- Everett, H. Sensors for Mobile Robots; AK Peters/CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Kehoe, B.; Patil, S.; Abbeel, P.; Goldberg, K. A survey of research on cloud robotics and automation. IEEE Trans. Autom. Sci. Eng. 2015, 12, 398–409. [Google Scholar]
- Fiala, M. ARTag, a fiducial marker system using digital techniques. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 590–596. [Google Scholar]
- Fiala, M. Designing highly reliable fiducial markers. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1317–1324. [Google Scholar] [CrossRef]
- Cui, J.; Zhang, J.; Sun, G.; Zheng, B. Extraction and Research of Crop Feature Points Based on Computer Vision. Sensors 2019, 19, 2553. [Google Scholar] [CrossRef]
- Tan, D.S.; Lin, J.M.; Lai, Y.C.; Ilao, J.; Hua, K.L. Depth Map Upsampling via Multi-Modal Generative Adversarial Network. Sensors 2019, 19, 1587. [Google Scholar] [CrossRef]
- Tan, D.S.; Yao, C.Y.; Ruiz, C.; Hua, K.L. Single-Image Depth Inference Using Generative Adversarial Networks. Sensors 2019, 19, 1708. [Google Scholar] [CrossRef]
- Teixeira, M.A.S.; Santos, H.B.; de Oliveira, A.S.; Arruda, L.V.; Neves, F. Robots Perception Through 3D Point Cloud Sensors. In Robot Operating System (ROS); Springer: New York, NY, USA, 2017; pp. 525–561. [Google Scholar]
- Jokela, M.; Kutila, M.; Pyykönen, P. Testing and Validation of Automotive Point-Cloud Sensors in Adverse Weather Conditions. Appl. Sci. 2019, 9, 2341. [Google Scholar] [CrossRef]
- Xu, H.; Chen, G.; Wang, Z.; Sun, L.; Su, F. RGB-D-Based Pose Estimation of Workpieces with Semantic Segmentation and Point Cloud Registration. Sensors 2019, 19, 1873. [Google Scholar] [CrossRef] [PubMed]
- Yen, S.H.; Tang, P.C.; Lin, Y.C.; Lin, C.Y. Development of a Virtual Force Sensor for a Low-Cost Collaborative Robot and Applications to Safety Control. Sensors 2019, 19, 2603. [Google Scholar] [CrossRef]
- Shin, M.; Paik, W.; Kim, B.; Hwang, S. An IoT Platform with Monitoring Robot Applying CNN-Based Context-Aware Learning. Sensors 2019, 19, 2525. [Google Scholar] [CrossRef]
- He, W.; Li, Z.; Chen, C.P. A survey of human-centered intelligent robots: issues and challenges. IEEE/CAA J. Autom. Sin. 2017, 4, 602–609. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R. A review of point cloud registration algorithms for mobile robotics. Found. Trends Robot. 2015, 4, 1–104. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F.; Chen, Z.; Liu, D. Fast traffic sign recognition via high-contrast region extraction and extended sparse representation. IEEE Trans. Intell. Transp. Syst. 2015, 17, 79–92. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv, 2015; arXiv:1506.01497v3. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Min, W.; Cui, H.; Han, Q.; Zou, F. A Scene Recognition and Semantic Analysis Approach to Unhealthy Sitting Posture Detection during Screen-Reading. Sensors 2018, 18, 3119. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel (r) realsense (tm) stereoscopic depth cameras. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1267–1276. [Google Scholar]
- Pagliari, D.; Pinto, L. Calibration of kinect for xbox one and comparison between the two generations of microsoft sensors. Sensors 2015, 15, 27569–27589. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: New York, NY, USA, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Nvidia. AUTONOMOUS MACHINES. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/ (accessed on 22 June 2019).
- Intel. INTEL® NUC. Available online: https://www.intel.com/content/www/us/en/products/boards-kits/nuc.html (accessed on 22 June 2019).
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the IEEE International Conference on Robotics and Automation: Workshop on Open Source Software (ICRA), Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Macedo, J.; Marques, L.; Costa, E. A Comparative Study of Bio-Inspired Odour Source Localisation Strategies from the State-Action Perspective. Sensors 2019, 19, 2231. [Google Scholar] [CrossRef] [PubMed]
- Luo, Z.; Ding, J.; Zhao, L.; Wu, M. An Enhanced Non-Coherent Pre-Filter Design for Tracking Error Estimation in GNSS Receivers. Sensors 2017, 17, 2668. [Google Scholar] [CrossRef]
- Teixeira, M.A.S.; Dalmedico, N.; de Oliveira, A.S.; de Arruda, L.V.R.; Neves-Jr, F. A pose prediction approach to mobile objects in 2D costmaps. In Proceedings of the 2017 Latin American Robotics Symposium (LARS) and 2017 Brazilian Symposium on Robotics (SBR), Curitiba, Brazil, 8–11 November 2017; IEEE: Piscatway, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Gossow, D.; Leeper, A.; Hershberger, D.; Ciocarlie, M. Interactive markers: 3-d user interfaces for ros applications [ros topics]. IEEE Robot. Autom. Mag. 2011, 18, 14–15. [Google Scholar] [CrossRef]
- Carfagni, M.; Furferi, R.; Governi, L.; Santarelli, C.; Servi, M.; Uccheddu, F.; Volpe, Y. Metrological and Critical Characterization of the Intel D415 Stereo Depth Camera. Sensors 2019, 19, 489. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Class | |
|---|---|
| Is it dynamic? | person, bicycle, car, motorbike, aeroplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, frisbee, snowboard, sports ball, skateboard, surfboard tennis racket, chair |
| Is there life? | person, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe |
| Time | Tokens | Tokens per Second | Tokens with Speed/Direction/Acceleration | Tokens with Calculation Error | Error Percentage | |
|---|---|---|---|---|---|---|
| 32.19 | 100 | 3.107 | 94 | 6 | 6.000 | |
| 46.37 | 247 | 5.327 | 235 | 12 | 4.858 | |
| 38.74 | 128 | 3.304 | 122 | 6 | 4.688 | |
| 69.58 | 227 | 3.262 | 215 | 12 | 5.286 | |
| 35.18 | 111 | 3.155 | 110 | 1 | 0.901 | |
| 58.44 | 185 | 3.166 | 180 | 5 | 2.703 | |
| 51.98 | 233 | 4.482 | 221 | 12 | 5.150 | |
| 76.31 | 355 | 4.652 | 311 | 44 | 12.394 | |
| 40.39 | 130 | 3.219 | 126 | 4 | 3.077 | |
| 47.96 | 152 | 3.169 | 147 | 5 | 3.289 | |
| Average | 49.71 | 186.8 | 3.684 | 186.8 | 10.7 | 4.835 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teixeira, M.A.S.; Nogueira, R.d.C.M.; Dalmedico, N.; Santos, H.B.; Arruda, L.V.R.d.; Neves-Jr, F.; Pipa, D.R.; Ramos, J.E.; Oliveira, A.S.d. Intelligent 3D Perception System for Semantic Description and Dynamic Interaction. Sensors 2019, 19, 3764. https://doi.org/10.3390/s19173764
Teixeira MAS, Nogueira RdCM, Dalmedico N, Santos HB, Arruda LVRd, Neves-Jr F, Pipa DR, Ramos JE, Oliveira ASd. Intelligent 3D Perception System for Semantic Description and Dynamic Interaction. Sensors. 2019; 19(17):3764. https://doi.org/10.3390/s19173764
Chicago/Turabian StyleTeixeira, Marco Antonio Simoes, Rafael de Castro Martins Nogueira, Nicolas Dalmedico, Higor Barbosa Santos, Lucia Valeria Ramos de Arruda, Flavio Neves-Jr, Daniel Rodrigues Pipa, Julio Endress Ramos, and Andre Schneider de Oliveira. 2019. "Intelligent 3D Perception System for Semantic Description and Dynamic Interaction" Sensors 19, no. 17: 3764. https://doi.org/10.3390/s19173764
APA StyleTeixeira, M. A. S., Nogueira, R. d. C. M., Dalmedico, N., Santos, H. B., Arruda, L. V. R. d., Neves-Jr, F., Pipa, D. R., Ramos, J. E., & Oliveira, A. S. d. (2019). Intelligent 3D Perception System for Semantic Description and Dynamic Interaction. Sensors, 19(17), 3764. https://doi.org/10.3390/s19173764