Fusion of Video and Inertial Sensing for Deep Learning–Based Human Action Recognition



Abstract
1. Introduction
2. UTD-MHAD Dataset
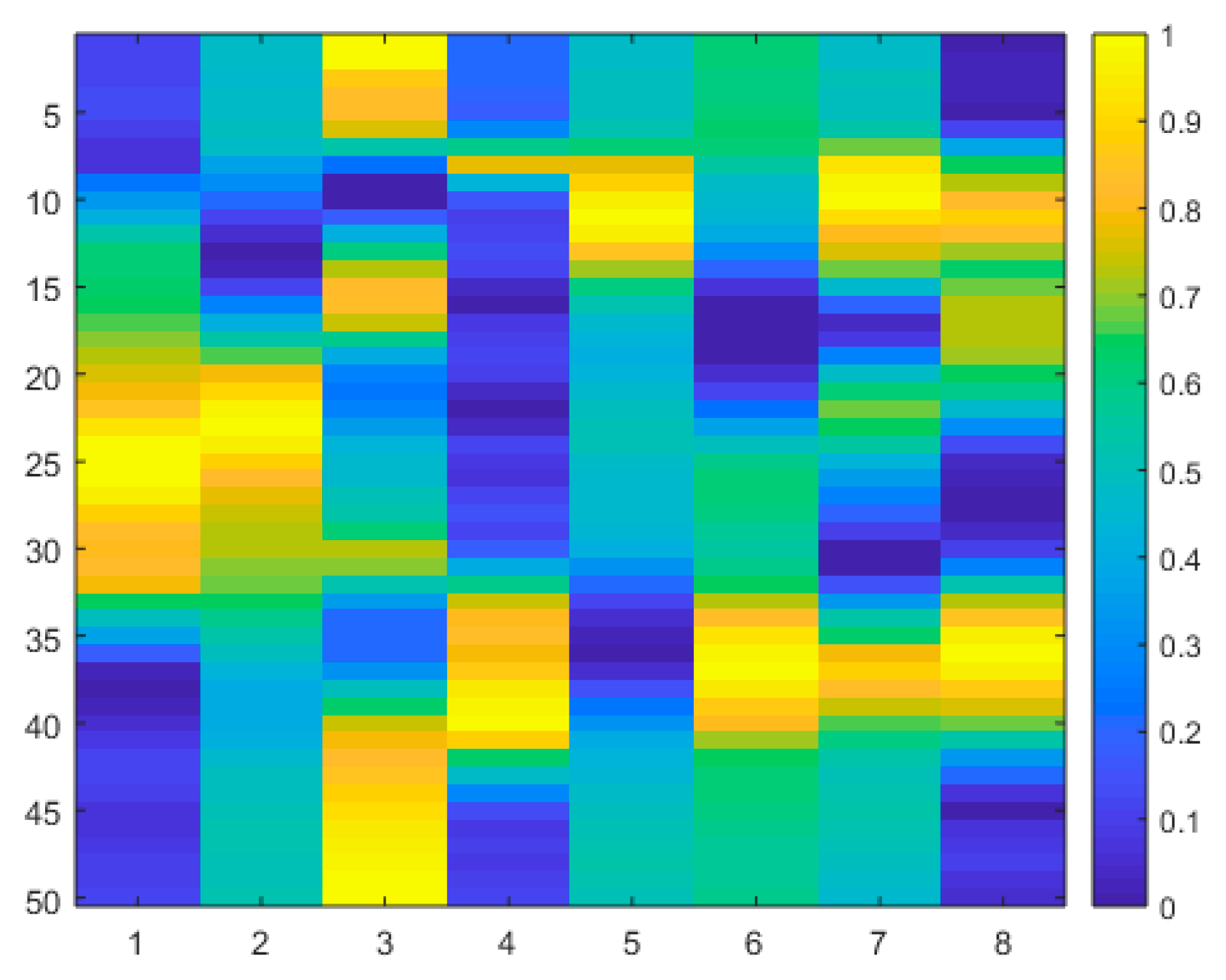
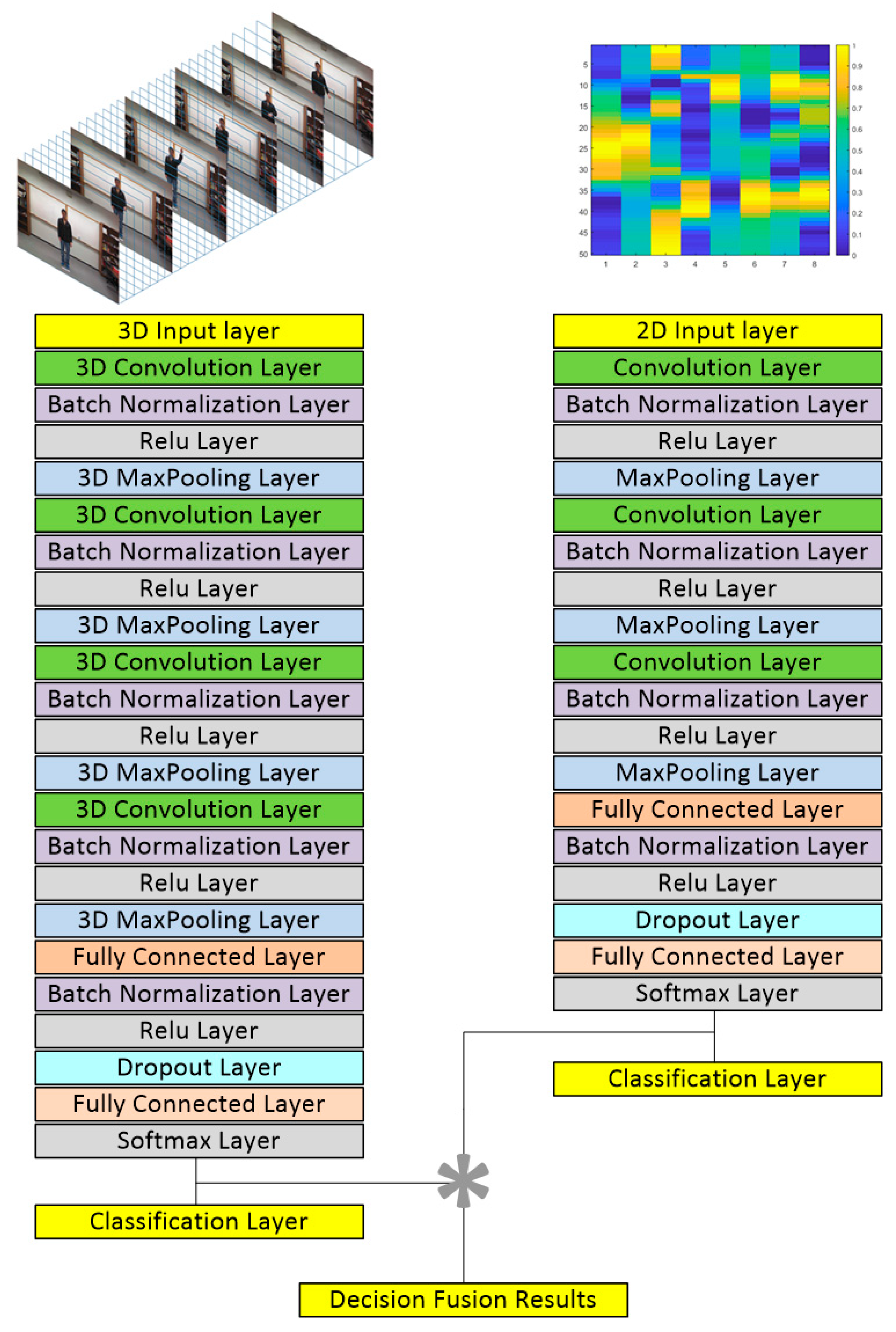
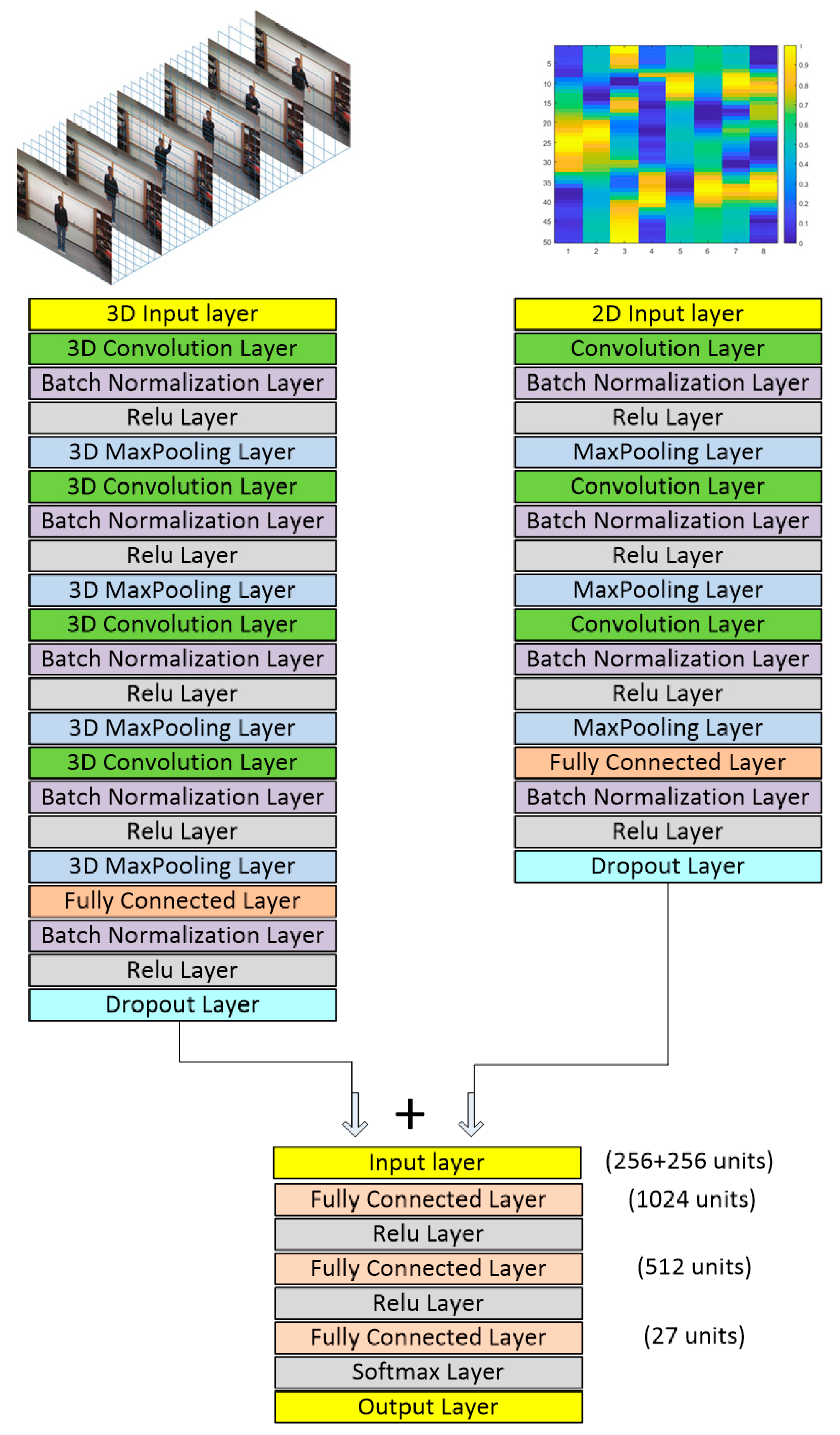
3. Deep Learning Models
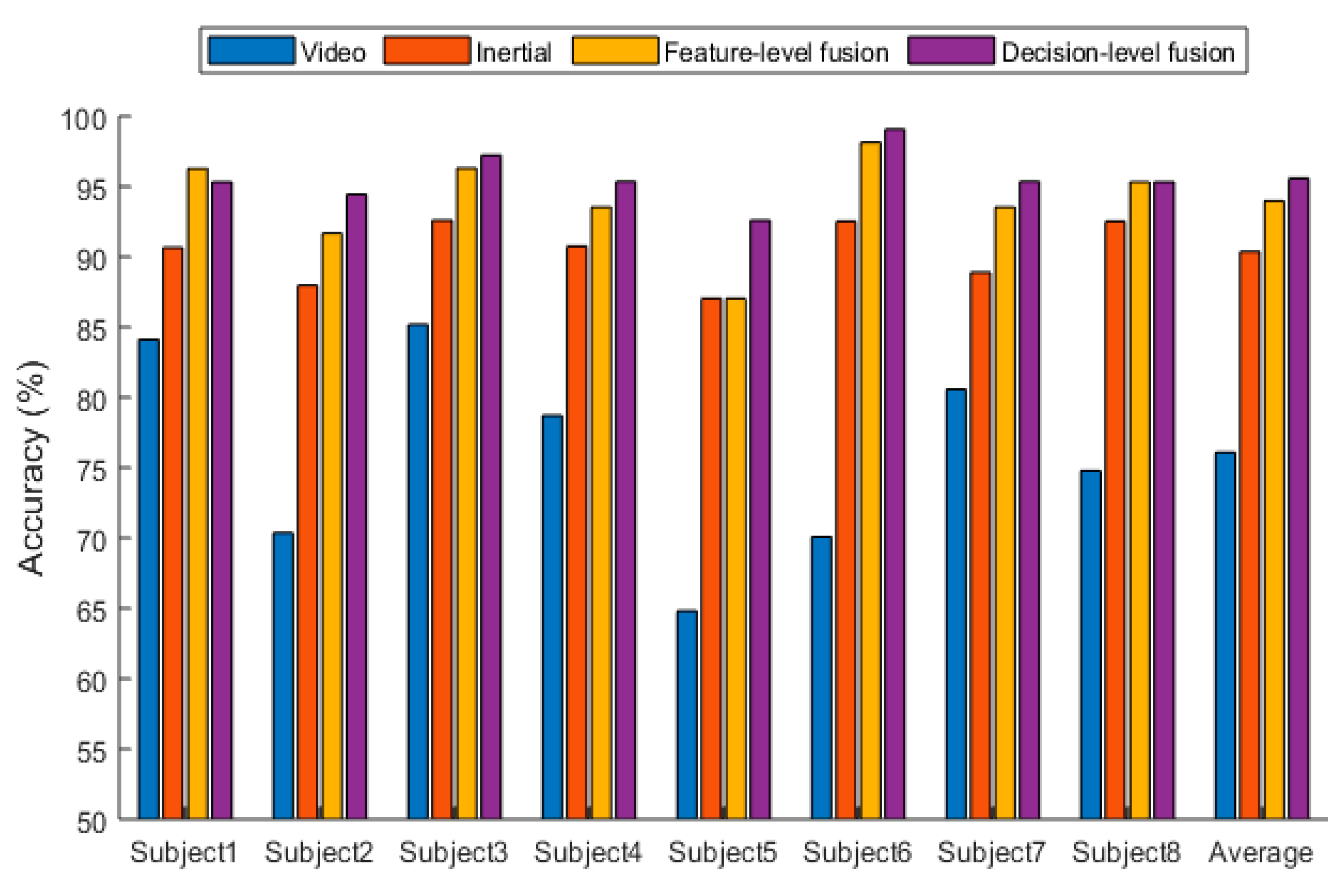
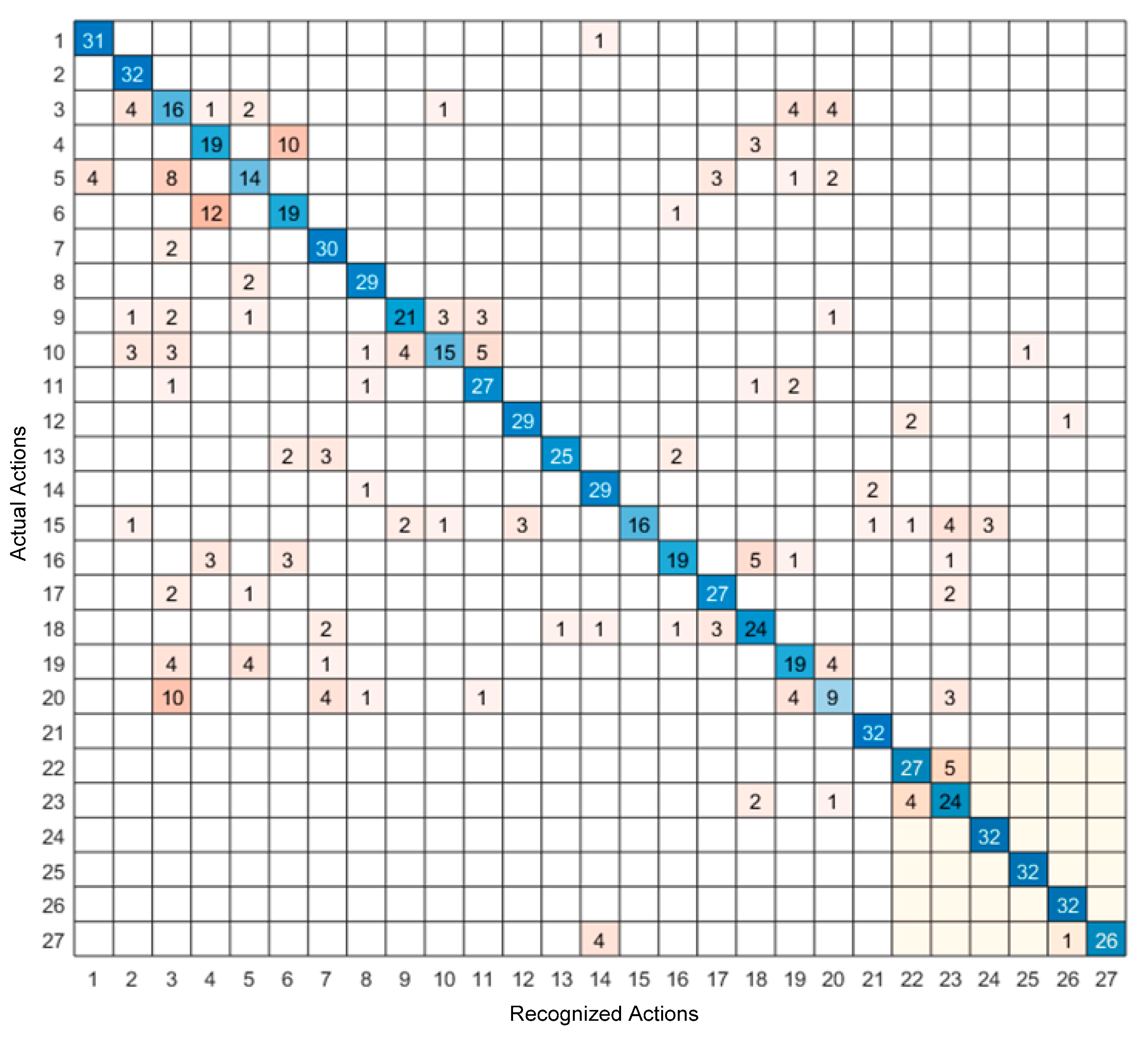
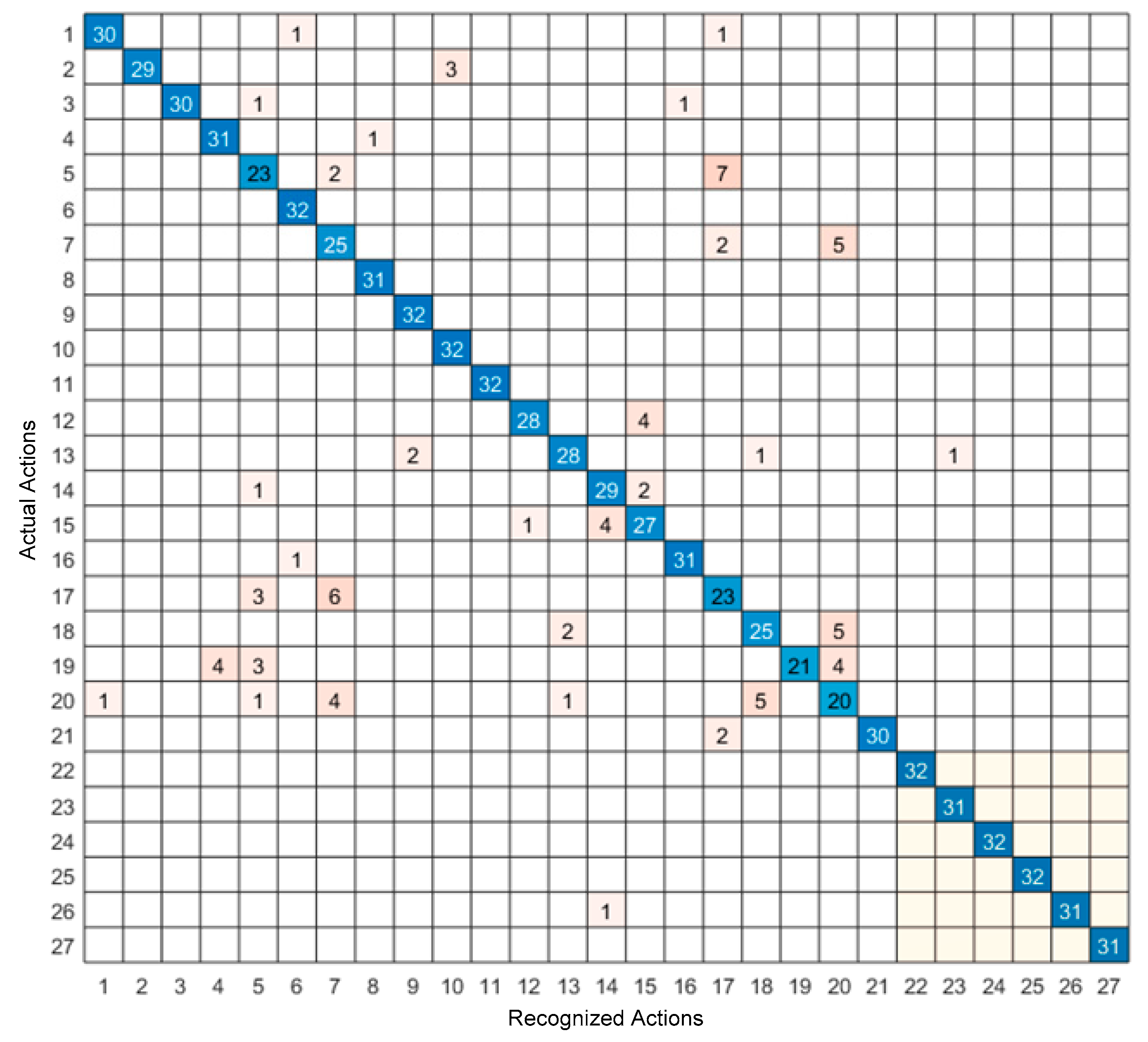
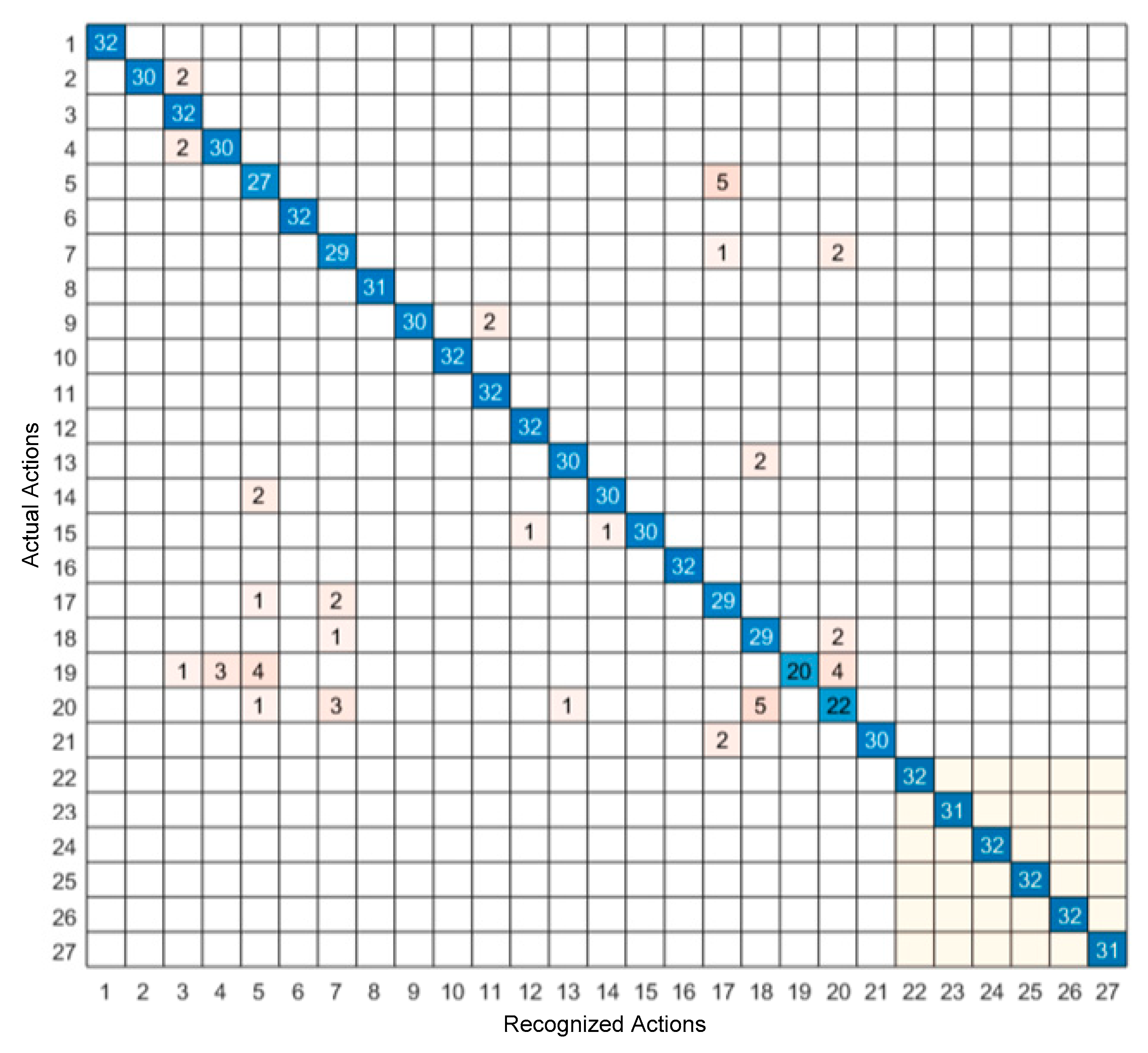
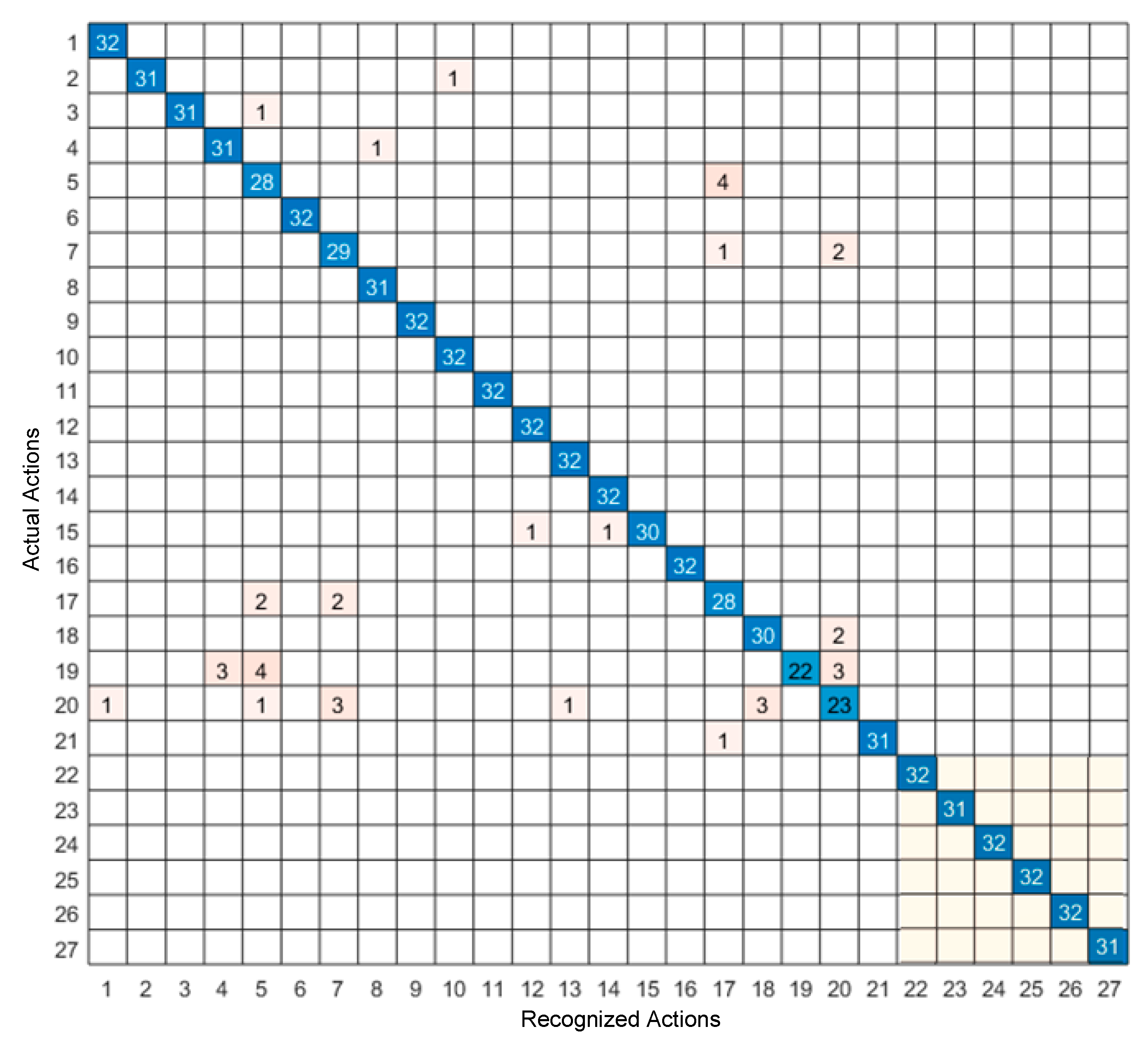
4. Experimental Results
5. Discussion of Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Presti, L.L.; Cascia, M.L. 3D Skeleton-based Human Action Classification: A Survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Dawar, N.; Kehtarnavaz, N. Continuous detection and recognition of actions of interest among actions of non-interest using a depth camera. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 4227–4231. [Google Scholar]
- Eum, H.; Yoon, C.; Lee, H.; Park, M. Continuous human action recognition using depth-MHI-HOG and a spotter model. Sensors 2015, 15, 5197–5227. [Google Scholar] [CrossRef] [PubMed]
- Chu, X.; Ouyang, W.; Li, H.; Wang, X. Structured feature learning for pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4715–4723. [Google Scholar]
- Chaaraoui, A.A.; Padilla-Lopez, J.R.; Ferrandez-Pastor, F.J.; Nieto-Hidalgo, M.; Florez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef] [PubMed]
- Wei, H.; Laszewski, M.; Kehtarnavaz, N. Deep Learning-Based Person Detection and Classification for Far Field Video Surveillance. In Proceedings of the 13th IEEE Dallas Circuits and Systems Conference, Dallas, TX, USA, 2–12 November 2018; pp. 1–4. [Google Scholar]
- Ziaeefard, M.; Bergevin, R. Semantic human activity recognition: A literature review. Pattern Recognit. 2015, 48, 2329–2345. [Google Scholar] [CrossRef]
- Wei, H.; Kehtarnavaz, N. Semi-Supervised Faster RCNN-Based Person Detection and Load Classification for Far Field Video Surveillance. Mach. Learn. Knowl. Extr. 2019, 1, 756–767. [Google Scholar] [CrossRef]
- Van Gemert, J.C.; Jain, M.; Gati, E.; Snoek, C.G. APT: Action localization proposals from dense trajectories. In Proceedings of the British Machine Vision Conference 2015: BMVC 2015, Swansea, UK, 7–10 September 2015; p. 4. [Google Scholar]
- Zhu, H.; Vial, R.; Lu, S. Tornado: A spatio-temporal convolutional regression network for video action proposal. In Proceedings of the CVPR, Venice, Italy, 22–29 October 2017; pp. 5813–5821. [Google Scholar]
- Bloom, V.; Makris, D.; Argyriou, V. G3D: A gaming action dataset and real time action recognition evaluation framework. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 7–12. [Google Scholar]
- Wang, Y.; Yu, T.; Shi, L.; Li, Z. Using human body gestures as inputs for gaming via depth analysis. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hannover, Germany, 26 April–23 June 2008; pp. 993–996. [Google Scholar]
- Wang, L.; Zang, J.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network. Sensors 2018, 7, 1979. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Avilés-Cruz, C.; Ferreyra-Ramírez, A.; Zúñiga-López, A.; Villegas-Cortéz, J. Coarse-Fine Convolutional Deep-Learning Strategy for Human Activity Recognition. Sensors 2019, 19, 1556. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Kehtarnavaz, N.; Jafari, R. A medication adherence monitoring system for pill bottles based on a wearable inertial sensor. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 4983–4986. [Google Scholar]
- Yang, A.Y.; Jafari, R.; Sastry, S.S.; Bajcsy, R. Distributed recognition of human actions using wearable motion sensor networks. J. Ambient Intell. Smart Environ. 2009, 1, 103–115. [Google Scholar]
- Nathan, V.; Paul, S.; Prioleau, T.; Niu, L.; Mortazavi, B.J.; Cambone, S.A.; Veeraraghavan, A.; Sabharwal, A.; Jafari, R. A Survey on Smart Homes for Aging in Place: Toward Solutions to the Specific Needs of the Elderly. IEEE Signal Process. Mag. 2018, 35, 111–119. [Google Scholar] [CrossRef]
- Wu, J.; Jafari, R. Orientation independent activity/gesture recognition using wearable motion sensors. IEEE Internet Things J. 2018, 6, 1427–1437. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Z.; Zhong, L.; Wickramasuriya, J.; Vasudevan, V. uWave: Accelerometer-Based Personalized Gesture Recognition and Its Applications. In Proceedings of the Seventh Annual IEEE International Conference on Pervasive Computing and Communications (PerCom 2009), Galveston, TX, USA, 9–13 March 2009. [Google Scholar]
- Alves, J.; Silva, J.; Grifo, E.; Resende, C.; Sousa, I. Wearable Embedded Intelligence for Detection of Falls Independently of on-Body Location. Sensors 2019, 19, 2426. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Improving human action recognition using fusion of depth camera and inertial sensors. IEEE Trans. Hum. Mach. Syst. 2015, 45, 51–61. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A real-time human action recognition system using depth and inertial sensor fusion. IEEE Sens. J. 2016, 16, 773–781. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Dawar, N.; Kehtarnavaz, N. A convolutional neural network-based sensor fusion system for monitoring transition movements in healthcare applications. In Proceedings of the IEEE 14th International Conference on Control and Automation, Anchorage, AK, USA, 12–15 June 2018; pp. 482–485. [Google Scholar]
- Dawar, N.; Kehtarnavaz, N. Action detection and recognition in continuous action streams by deep learning-based sensing fusion. IEEE Sens. J. 2018, 18, 9660–9668. [Google Scholar] [CrossRef]
- Rwigema, J.; Choi, H.R.; Kim, T. A Differential Evolution Approach to Optimize Weights of Dynamic Time Warping for Multi-Sensor Based Gesture Recognition. Sensors 2019, 19, 1007. [Google Scholar] [CrossRef] [PubMed]
- Dawar, N.; Kehtarnavaz, N. Real-time continuous detection and recognition of subject-specific smart tv gestures via fusion of depth and inertial sensing. IEEE Access 2018, 6, 7019–7028. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Chen, C.; Liu, K.; Jafari, R.; Kehtarnavaz, N. Home-based senior fitness test measurement system using collaborative inertial and depth sensors. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 4135–4138. [Google Scholar]
- Wei, H.; Kehtarnavaz, N. Determining Number of Speakers from Single Microphone Speech Signals by Multi-Label Convolutional Neural Network. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 2706–2710. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Tao, F.; Busso, C. Aligning audiovisual features for audiovisual speech recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Wang, Z.; Kong, Z.; Changra, S.; Tao, H.; Khan, L. Robust High Dimensional Stream Classification with Novel Class Detection. In Proceedings of the IEEE 35th International Conference on Data Engineering, Macao, China, 8–11 April 2019; pp. 1418–1429. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Number | Hands Actions | Action Number | Legs Actions |
|---|---|---|---|
| 1 | right arm swipe to the left | 22 | jogging in place |
| 2 | right arm swipe to the right | 23 | walking in place |
| 3 | right hand wave | 24 | sit to stand |
| 4 | two hand front clap | 25 | stand to sit |
| 5 | right arm throw | 26 | forward lunge (left foot forward) |
| 6 | cross arms in the chest | 27 | squat (two arms stretch out) |
| 7 | basketball shoot | ||
| 8 | right hand draw x | ||
| 9 | right hand draw circle (clockwise) | ||
| 10 | right hand draw circle (counter clockwise) | ||
| 11 | draw triangle | ||
| 12 | bowling (right hand) | ||
| 13 | front boxing | ||
| 14 | baseball swing from right | ||
| 15 | tennis right hand forehand swing | ||
| 16 | arm curl (two arms) | ||
| 17 | tennis serve | ||
| 18 | two hand push | ||
| 19 | right hand knock on door | ||
| 20 | right hand catch an object | ||
| 21 | right hand pick up and throw |
| Layers and Training Parameters | Values |
|---|---|
| Input layer | 320 × 240 × 32 |
| 1st 3D convolutional layer | 16 filters, filter size 3 × 3 × 3, stride 1 × 1 × 1 |
| 2nd 3D convolutional layer | 32 filters, filter size 3 × 3 × 3, stride 1 × 1 × 1 |
| 3rd 3D convolutional layer | 64 filters, filter size 3 × 3 × 3, stride 1 × 1 × 1 |
| 4th 3D convolutional layer | 128 filters, filter size 3 × 3 × 3, stride 1 × 1 × 1 |
| All 3D max pooling layer | pooling size 2 × 2 × 2, stride 2 × 2 × 2 |
| 1st fully connected layer | 256 units |
| 2nd fully connected layer | 27 units |
| dropout layer | 50% |
| Initial learn rate | 0.0016 |
| Learning rate drop factor | 0.5 |
| Learn rate drop period | 4 |
| Max epochs | 20 |
| Layers and Training Parameters | Values |
|---|---|
| Input layer | 8 × 50 |
| 1st 2D convolutional layer | 16 filters, filter size 3 × 3, stride 1 × 1 |
| 2nd 2D convolutional layer | 32 filters, filter size 3 × 3, stride 1 × 1 |
| 3rd 2D convolutional layer | 64 filters, filter size 3 × 3, stride 1 × 1 |
| All 2D max pooling layer | pooling size 2 × 2, stride 2 × 2 |
| 1st fully connected layer | 256 units |
| 2nd fully connected layer | 27 units |
| dropout layer | 50% |
| Initial learn rate | 0.0016 |
| Learning rate drop factor | 0.5 |
| Learn rate drop period | 4 |
| Max epochs | 20 |
| Approaches | Average Accuracy (%) |
|---|---|
| Video only | 76.0 |
| Inertial only | 90.3 |
| Feature-level fusion of video and inertial | 94.1 |
| Decision-level fusion of video and inertial | 95.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Jafari, R.; Kehtarnavaz, N. Fusion of Video and Inertial Sensing for Deep Learning–Based Human Action Recognition. Sensors 2019, 19, 3680. https://doi.org/10.3390/s19173680
Wei H, Jafari R, Kehtarnavaz N. Fusion of Video and Inertial Sensing for Deep Learning–Based Human Action Recognition. Sensors. 2019; 19(17):3680. https://doi.org/10.3390/s19173680
Chicago/Turabian StyleWei, Haoran, Roozbeh Jafari, and Nasser Kehtarnavaz. 2019. "Fusion of Video and Inertial Sensing for Deep Learning–Based Human Action Recognition" Sensors 19, no. 17: 3680. https://doi.org/10.3390/s19173680
APA StyleWei, H., Jafari, R., & Kehtarnavaz, N. (2019). Fusion of Video and Inertial Sensing for Deep Learning–Based Human Action Recognition. Sensors, 19(17), 3680. https://doi.org/10.3390/s19173680