Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images


Abstract
1. Introduction
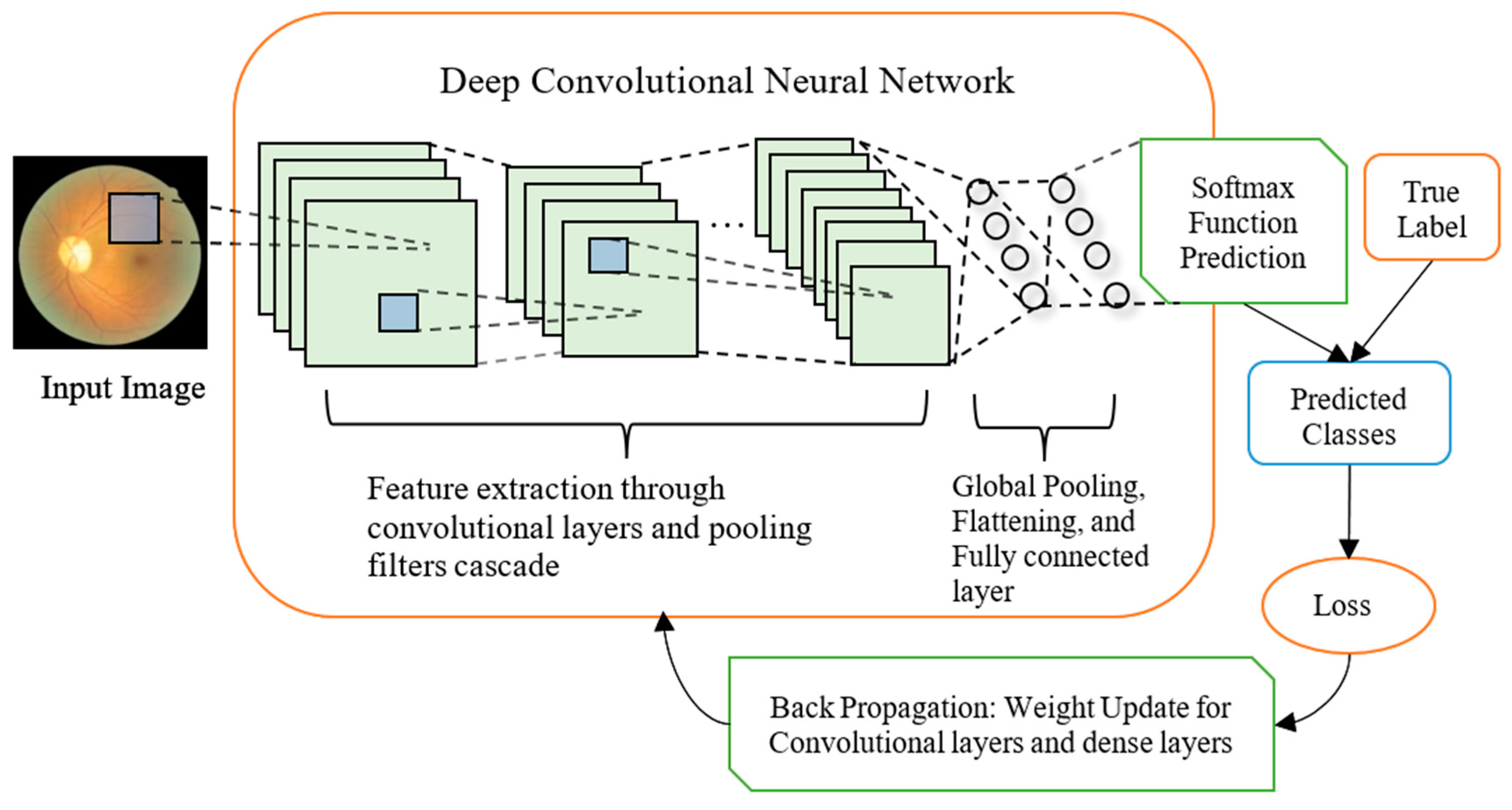
2. Computational Methods
2.1. Model Design
2.2. Choosing Hyperparameters
3. Predicting Air Pollutant Type from Apparatus Readings
3.1. Data Preparation and Augmentation
3.2. Training Process and Results
4. Classification of DR Fundus Images Using CNNs
4.1. Data Set Preparation
4.2. Training a CNN Instance with Feedforward Model of Dual Modules
4.3. Training a CNN Instance on Higher Resolution Samples
5. Analyzing the effects of deepening CNN architecture
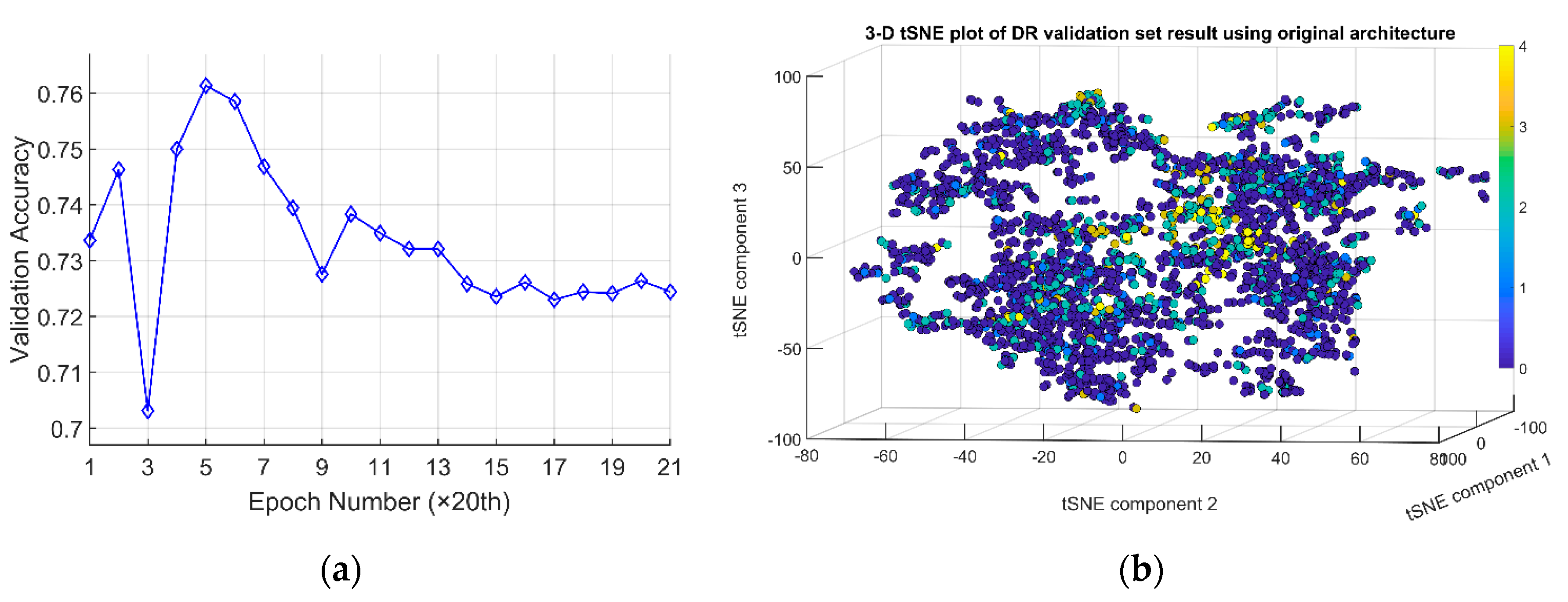
5.1. Experiment Details
5.2. Training Results Analysis
5.3. Revised Deepened Architecture
5.4. Training Using Inception Resnet v2 Model
5.5. Comparison of CNNs of Five Different Architectures
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, S.-R.; Lee, C.-G.; Lee, K.-S.; Kim, Y. Deep learning–based real-time query processing for wireless sensor network. Int. J. Distrib. Sens. Netw. 2017, 13. [Google Scholar] [CrossRef]
- Tan, J.; Noureldeen, N.; Mao, K.; Shi, J.; Li, Z.; Xu, T.; Yuan, Z. Deep Learning Convolutional Neural Network for the Retrieval of Land Surface Temperature from AMSR2 Data in China. Sensors 2019, 19, 2987. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Li, H.; Lou, C.; Liang, T.; Liu, X.; Wang, H. A New Approach to Fall Detection Based on Improved Dual Parallel Channels Convolutional Neural Network. Sensors 2019, 19, 2814. [Google Scholar] [CrossRef] [PubMed]
- Akbari, E.; Buntat, Z.; Enzevaee, A.; Ebrahimi, M.; Yazdavar, A.H.; Yusof, R. Analytical modeling and simulation of I–V characteristics in carbon nanotube based gas sensors using ANN and SVR methods. Chemom. Intell. Lab. Syst. 2014, 137, 173–180. [Google Scholar] [CrossRef]
- Liu, G.; Gao, X.; You, D.; Zhang, N. Prediction of high power laser welding status based on PCA and SVM classification of multiple sensors. J. Intell. Manuf. 2019, 30, 821–832. [Google Scholar] [CrossRef]
- Khanmohammadi, M.; Garmarudi, A.B.; Khoddami, N.; Shabani, K.; Khanlari, M. A novel technique based on diffuse reflectance near-infrared spectrometry and back-propagation artificial neural network for estimation of particle size in TiO2 nano particle samples. Microchem. J. 2010, 95, 337–340. [Google Scholar] [CrossRef]
- Sacha, G.M.; Varona, P. Artificial intelligence in nanotechnology. Nanotechnology 2013, 24, 452002. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Dang, L.M.; Hassan, S.I.; Im, S.; Lee, J.; Lee, S.; Moon, H. Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network. Appl. Sci. 2018, 8, 2610. [Google Scholar] [CrossRef]
- Mansour, R.F. Deep-learning-based automatic computer-aided diagnosis system for diabetic retinopathy. Biomed. Eng. Lett. 2018, 8, 41–57. [Google Scholar] [CrossRef]
- Alakwaa, F.M.; Chaudhary, K.; Garmire, L.X. Deep Learning Accurately Predicts Estrogen Receptor Status in Breast Cancer Metabolomics Data. J. Proteome Res. 2018, 17, 337–347. [Google Scholar] [CrossRef] [PubMed]
- Albrecht, T.; Slabaugh, G.; Alonso, E.; Al-Arif, S.M.M.R. Deep learning for single-molecule science. Nanotechnology 2017, 28, 423001. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.N.; Lee, S.; Nguyen-Xuan, H.; Lee, J. A novel analysis-prediction approach for geometrically nonlinear problems using group method of data handling. Comput. Methods Appl. Mech. Eng. 2019, 354, 506–526. [Google Scholar] [CrossRef]
- Angermueller, C.; Pärnamaa, T.; Parts, L.; Stegle, O. Deep learning for computational biology. Mol. Syst. Biol. 2016, 12, 878. [Google Scholar] [CrossRef]
- Zemouri, R.; Zerhouni, N.; Racoceanu, D. Deep Learning in the Biomedical Applications: Recent and Future Status. Appl. Sci. 2019, 9, 1526. [Google Scholar] [CrossRef]
- Xu, K.; Feng, D.; Mi, H. Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image. Molecules 2017, 22, 2054. [Google Scholar] [CrossRef]
- Eulenberg, P.; Köhler, N.; Blasi, T.; Filby, A.; Carpenter, A.E.; Rees, P.; Theis, F.J.; Wolf, F.A. Reconstructing cell cycle and disease progression using deep learning. Nat. Commun. 2017, 8, 463. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Liang, M.; Hu, X. Recurrent Convolutional Neural Network for Object Recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3367–3375. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? arXiv 2018, arXiv:1805.11604. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Optimization: Stochastic Gradient Descent. 2018. Available online: http://ufldl.stanford.edu/tutorial/supervised/OptimizationStochasticGradientDescent/ (accessed on 6 June 2018).
- Broecker, P.; Carrasquilla, J.; Melko, R.G.; Trebst, S. Machine learning quantum phases of matter beyond the fermion sign problem. Sci. Rep. 2017, 7, 8823. [Google Scholar] [CrossRef] [PubMed]
- Cuadros, J.; Bresnick, G. EyePACS: An adaptable telemedicine system for diabetic retinopathy screening. J. Diabetes Sci. Technol. 2009, 3, 509–516. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Characteristics |
|---|---|
| Deep feedforward convolutional neural network [17] | Learning a hierarchy of features including simple curves and edges to global motifs from raw images. Sensitive to crucial minute details yet insensitive to large irrelevant variations in image. |
| Group method of data handling [13] | Self-organizing deep learning method for time series forecasting problems without requirement of big data |
| Ada-CGFace framework [9] | Uses Adaboost classifier in place of softmax. Contains dropout layers for avoiding overfitting and trained using adaptive moment estimation instead of stochastic gradient descent. |
| Deep CNN with dual modules (our method) | Has certain level of scale invariability to target object. 1 × 1 convolutional kernel induces small computational cost. |
| Inception Resnet v2 [18] | Residual connection improves training speed greatly. Inception is computationally efficient. It can abstract features at different scales simultaneously |
| Module Name | Kernel Size (Width × Height × Channel), Number and Stride | Output Size |
|---|---|---|
| Input Raw image | N/A | (224 × 224 × 3) |
| Simple Convolution | 9 × 9 × 3 Conv (96 stride 3) | (74 × 74 × 96) |
| Normal dual-path modules 1 | 1 × 1 × 96 Conv (32 stride 1), 3 × 3 × 96 Conv (32 stride 1) | (74 × 74 × 64) |
| Normal dual-path modules 2 | 1 × 1 × 64 Conv (32 stride 1), 3 × 3 × 64 Conv (48 stride 1) | (74 × 74 × 80) |
| Dual-path reduction module 1 | 3 × 3 × 80 Conv (80 stride 2), 3 × 3 Max pooling (1 stride 2) | (37 × 37 × 160) |
| Normal dual-path modules 3 | 1 × 1 × 160 Conv (112 stride 1), 3 × 3 × 160 Conv (48 stride 1) | (37 × 37 × 160) |
| Normal dual-path modules 4 | 1 × 1 × 160 Conv (96 stride 1), 3 × 3 × 160 Conv (64 stride 1) | (37 × 37 × 160) |
| Normal dual-path modules 5 | 1 × 1 × 160 Conv (80 stride 1), 3 × 3 × 160 Conv (80 stride 1) | (37 × 37 × 160) |
| Normal dual-path modules 6 | 1 × 1 × 160 Conv (48 stride 1), 3 × 3 × 160 Conv (96 stride 1) | (37 × 37 × 144) |
| Dual-path reduction module 2 | 3 × 3 × 144 Conv (96 stride 2), 3 × 3 Max pooling (1 stride 2) | (19 × 19 × 240) |
| Normal dual-path modules 7 | 1 × 1 × 240 Conv (176 stride 1), 3 × 3 × 240 Conv (160 stride 1) | (19 × 19 × 336) |
| Normal dual-path modules 8 | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (19 × 19 × 336) |
| Dual-path reduction module 3 | 3 × 3 × 336 Conv (96 stride 2), 3 × 3 Max pooling (1 stride 2) | (10 × 10 × 432) |
| Normal dual-path modules 9 | 1 × 1 × 432 Conv (176 stride 1), 3 × 3 × 432 Conv (160 stride 1) | (10 × 10 × 336) |
| Normal dual-path modules 10 | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (10 × 10 × 336) |
| Pooling layer | 10 × 10 Average pooling (1 stride 1) | (1 × 1 × 336) |
| Flatten | N/A | (336 × 1) |
| Fully connected layer | Hidden nodes (5) | (5 × 1) |
| Softmax layer | N/A | (5 × 1) |
| Class | DR Classification | No. of Images | Percentage (%) | Imbalanced Ratio |
|---|---|---|---|---|
| 0 | Normal | 25,810 | 73.48 | 1.01 |
| 1 | Mild NPDR | 2443 | 6.96 | 1.84 |
| 2 | Moderate NPDR | 5292 | 15.07 | 1.26 |
| 3 | Severe NPDR | 873 | 2.48 | 2.76 |
| 4 | Proliferative DR | 708 | 2.01 | 2.89 |
| Module Name | Kernel size (Width × Height × Channel), Number and Stride | Output Size |
|---|---|---|
| Input Raw Image | N/A | (224 × 224 × 3) |
| Simple Convolution | 3 × 3 × 3 Conv (96 stride 1) | (224 × 224 × 96) |
| Normal dual-path modules 1 | 1 × 1 × 96 Conv (32 stride 1), 3 × 3 × 96 Conv (32 stride 1) | (224 × 224 × 64) |
| Normal dual-path modules 2 | 1 × 1 × 64 Conv (32 stride 1), 3 × 3 × 64 Conv (48 stride 1) | (224 × 224 × 80) |
| Dual-path reduction module 1 | 3 × 3 × 80 Conv (80 stride 2), 3 × 3 Max pooling (1 stride 2) | (112 × 112 × 160) |
| Normal dual-path modules 3 | 1 × 1 × 160 Conv (112 stride 1), 3 × 3 × 160 Conv (48 stride 1) | (112 × 112 × 160) |
| Normal dual-path modules 4 | 1 × 1 × 160 Conv (96 stride 1), 3 × 3 × 160 Conv (64 stride 1) | (112 × 112 × 160) |
| Normal dual-path modules 5 | 1 × 1 × 160 Conv (80 stride 1), 3 × 3 × 160 Conv (80 stride 1) | (112 × 112 × 160) |
| Normal dual-path modules 6 | 1 × 1 × 160 Conv (48 stride 1), 3 × 3 × 160 Conv (96 stride 1) | (112 × 112 × 144) |
| Dual-path reduction module 2 | 3 × 3 × 144 Conv (96 stride 2), 3 × 3 Max pooling (1 stride 2) | (56 × 56 × 240) |
| Normal dual-path modules 7 | 1 × 1 × 240 Conv (176 stride 1), 3 × 3 × 240 Conv (160 stride 1) | (56 × 56 × 336) |
| Normal dual-path modules 8 | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (56 × 56 × 336) |
| Dual-path reduction module 3 | 3 × 3 × 336 Conv (96 stride 2), Max pooling 3 × 3 (1 stride 2) | (28 × 28 × 432) |
| Normal dual-path modules 9 | 1 × 1 × 432 Conv (176 stride 1), 3 × 3 × 432 Conv (160 stride 1) | (28 × 28 × 336) |
| Normal dual-path modules 10 | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (28 × 28 × 336) |
| Dual-path reduction module 4 | 3 × 3 × 336 Conv (112 stride 2), 3 × 3 Max pooling (1 stride 2) | (14 × 14 × 448) |
| Normal dual-path modules 11 | 1 × 1 × 448 Conv (224 stride 1), 3 × 3 × 448 Conv (192 stride 1) | (14 × 14 × 416) |
| Normal dual-path modules 12 | 1 × 1 × 416 Conv (224 stride 1), 3 × 3 × 416 Conv (192 stride 1) | (14 × 14 × 416) |
| Dual-path reduction module 5 | 3 × 3 × 416 Conv (112 stride 2), 3 × 3 Max pooling (1 stride 2) | (7 × 7 × 528) |
| Normal dual-path modules 13 | 1 × 1 × 528 Conv (224 stride 1); 3 × 3 × 528 Conv (192 stride 1) | (7 × 7 × 4160 |
| Normal dual-path modules 14 | 1 × 1 × 416 Conv (224 stride 1); 3 × 3 × 416 Conv (192 stride 1) | (7 × 7 × 416) |
| Pooling layer | 7 × 7 Average pooling (1 stride 1) | (1 × 1 × 416) |
| Flatten | N/A | (416 × 1) |
| Fully connected layer | Hidden nodes (5) | (5 × 1) |
| Softmax layer | N/A | (5 × 1) |
| Module Type | Kernel Size (Width × Height × Channel), Number and Stride | Output Size |
|---|---|---|
| Reduction Dual-path Module | 3 × 3 × 336 Conv (96 stride 2), 3 × 3 Max pooling (1 stride 2) | (14 × 14 × 432) |
| Normal Dual-path Module | 1 × 1 × 432 Conv (176 stride 1), 3 × 3 × 432 Conv (160 stride 1) | (14 × 14 × 336) |
| Normal Dual-path Module | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (14 × 14 × 336) |
| Reduction Dual-path Module | 3 × 3 × 336 Conv (96 stride 2), 3 × 3 Max pooling (1 stride 2) | (7 × 7 × 432) |
| Normal Dual-path Module | 1 × 1 × 432 Conv (176 stride 1, 3 × 3 × 432 Conv (160 stride 1) | (7 × 7 × 336) |
| Normal Dual-path Module | 1 × 1 × 336 Conv (176 stride 1), 3 × 3 × 336 Conv (160 stride 1) | (7 × 7 × 336) |
| Global Pooling Layer | 7 × 7 Average pooling | (1 × 1 × 336) |
| CNN Architecture | Validation Accuracy (%) | Appeared Epoch | Training Time (hours/100 h) |
|---|---|---|---|
| Original Architecture | 76.3068 | 95 | N/A |
| Reduction Architecture | 80.7823 | 100 | 6 |
| Deepened Architecture | 81.3068 | 93 | 23 |
| Revised Deepened Architecture | 81.9294 | 100 | 15 |
| Inception Resnet v2 | 78.708 | 17 | 42 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, W.; Zhang, Y.; Li, L. Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images. Sensors 2019, 19, 3584. https://doi.org/10.3390/s19163584
Hu W, Zhang Y, Li L. Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images. Sensors. 2019; 19(16):3584. https://doi.org/10.3390/s19163584
Chicago/Turabian StyleHu, Weijun, Yan Zhang, and Lijie Li. 2019. "Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images" Sensors 19, no. 16: 3584. https://doi.org/10.3390/s19163584
APA StyleHu, W., Zhang, Y., & Li, L. (2019). Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images. Sensors, 19(16), 3584. https://doi.org/10.3390/s19163584