Intelligent Fault Diagnosis of Diesel Engines via Extreme Gradient Boosting and High-Accuracy Time–Frequency Information of Vibration Signals



Abstract
1. Introduction
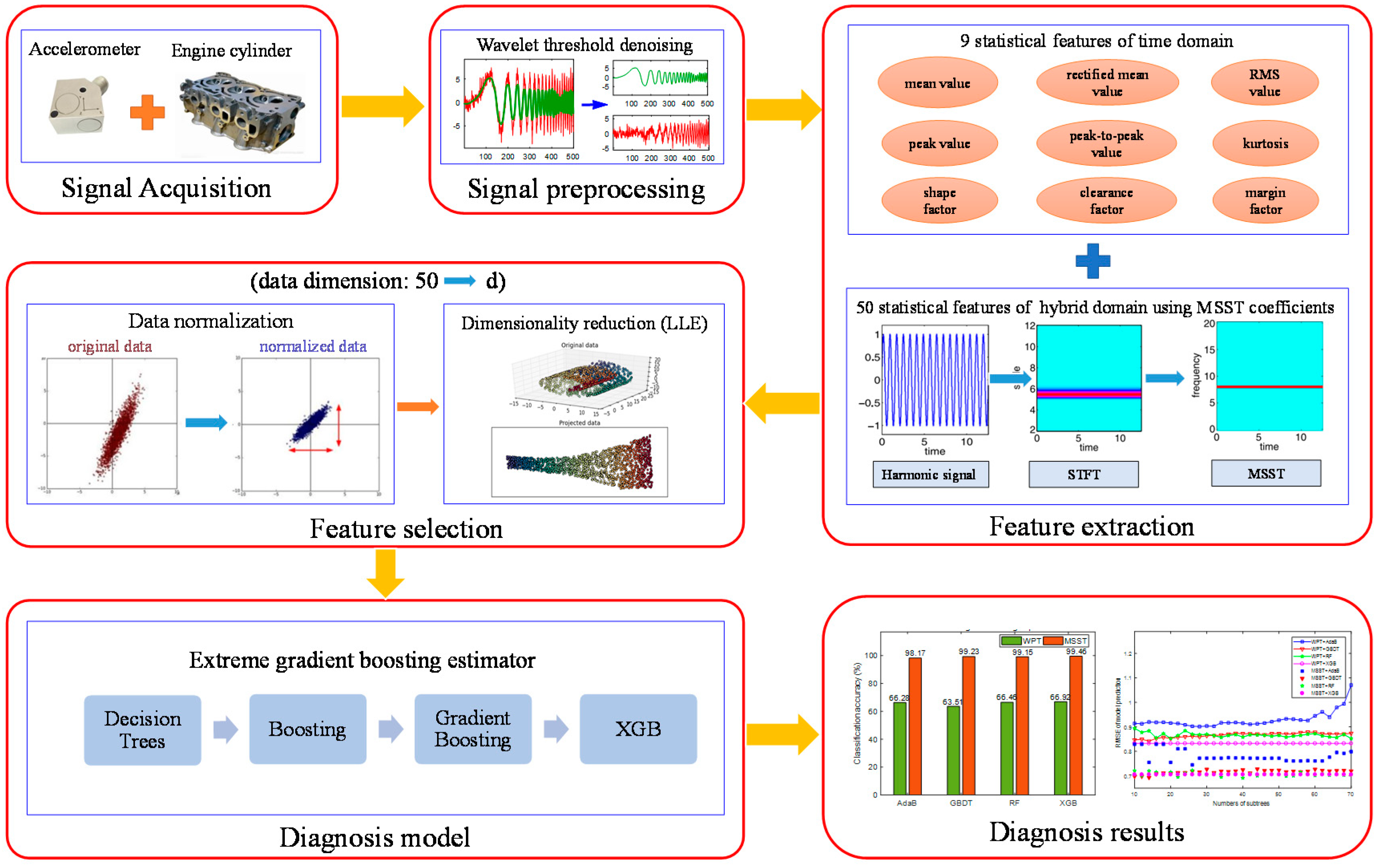
2. The Proposed Extreme Gradient Boosting-Based Diagnosis Method
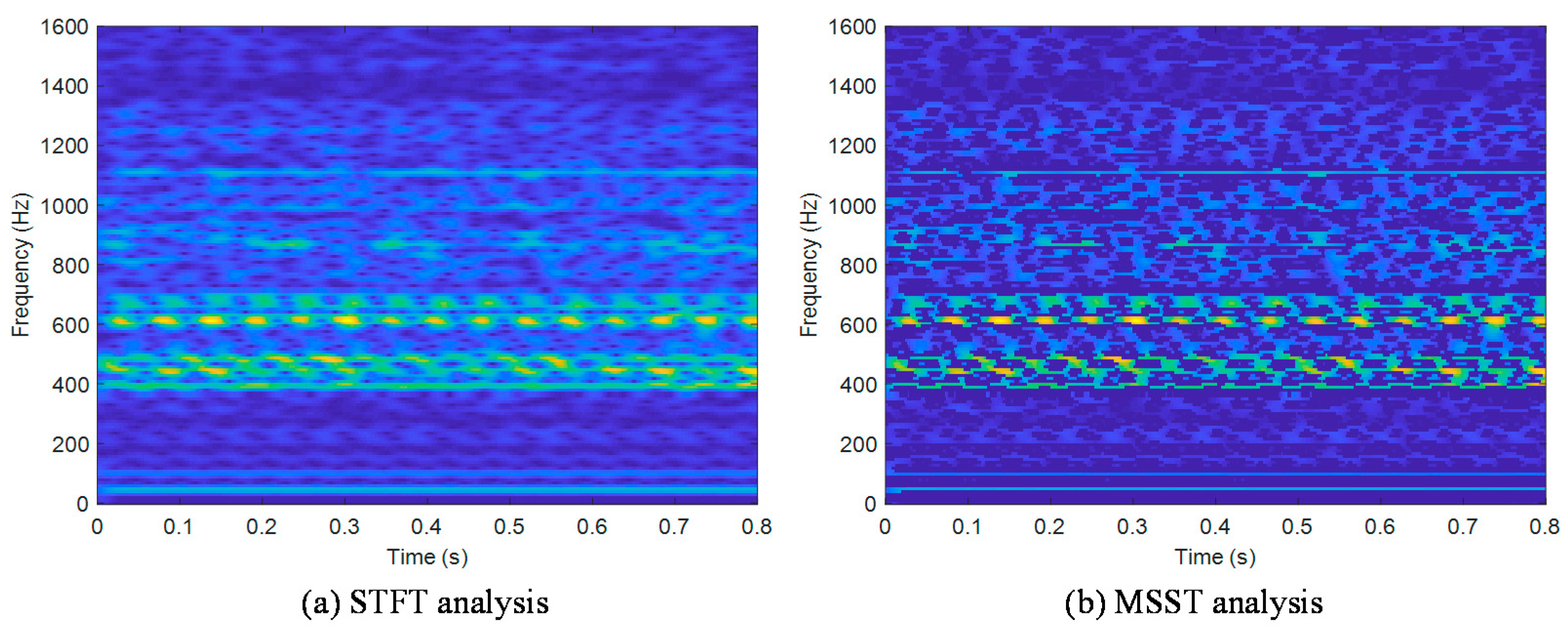
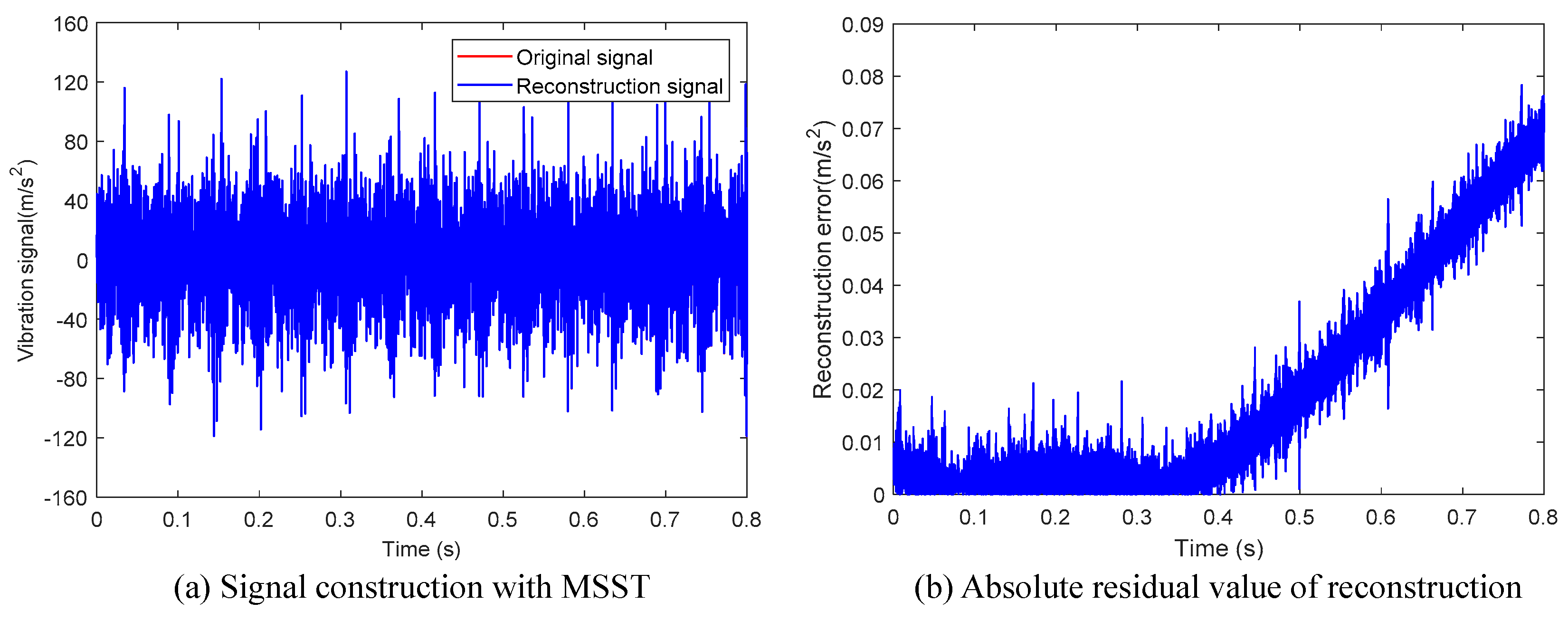
2.1. Multisynchrosqueezing Transform
2.2. Extreme Gradient Boosting Evaluator
3. Experimental Setup and Signal Preprocessing
3.1. Diesel Engine Rig Test
3.2. Signal Preprocessing
4. Experimental Results and Discussion
4.1. Feature Extraction
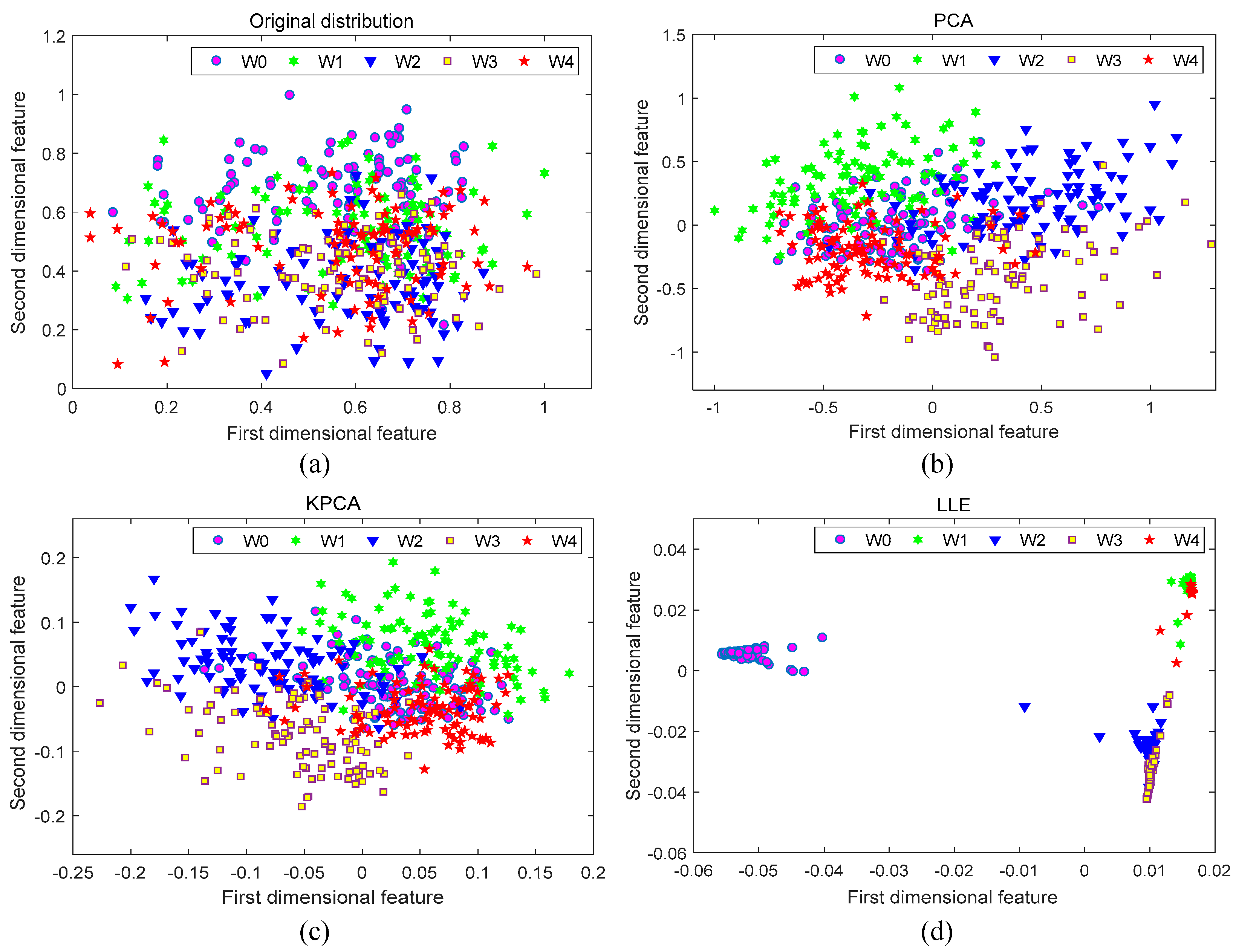
4.2. Feature Dimensionality Reduction
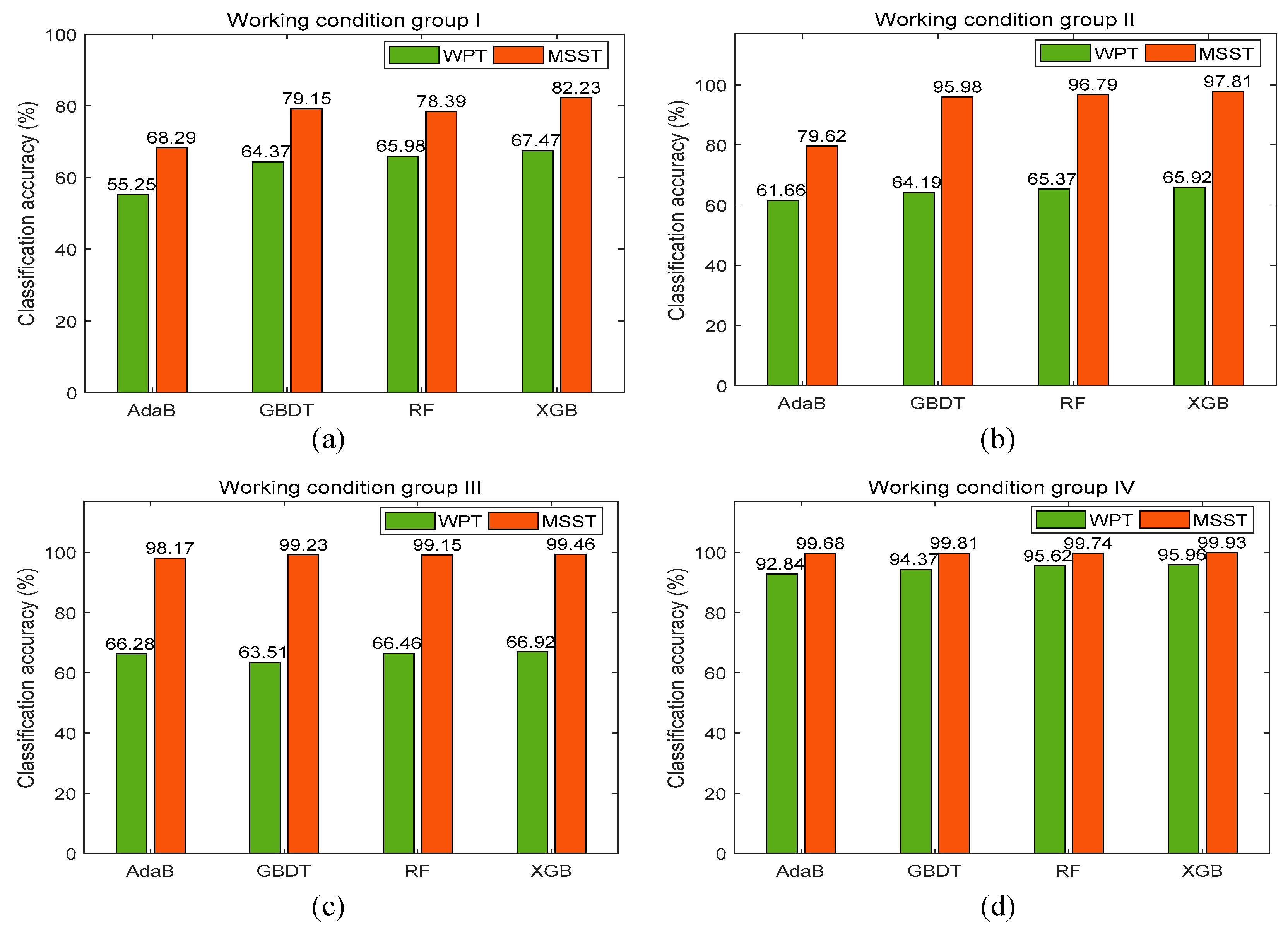
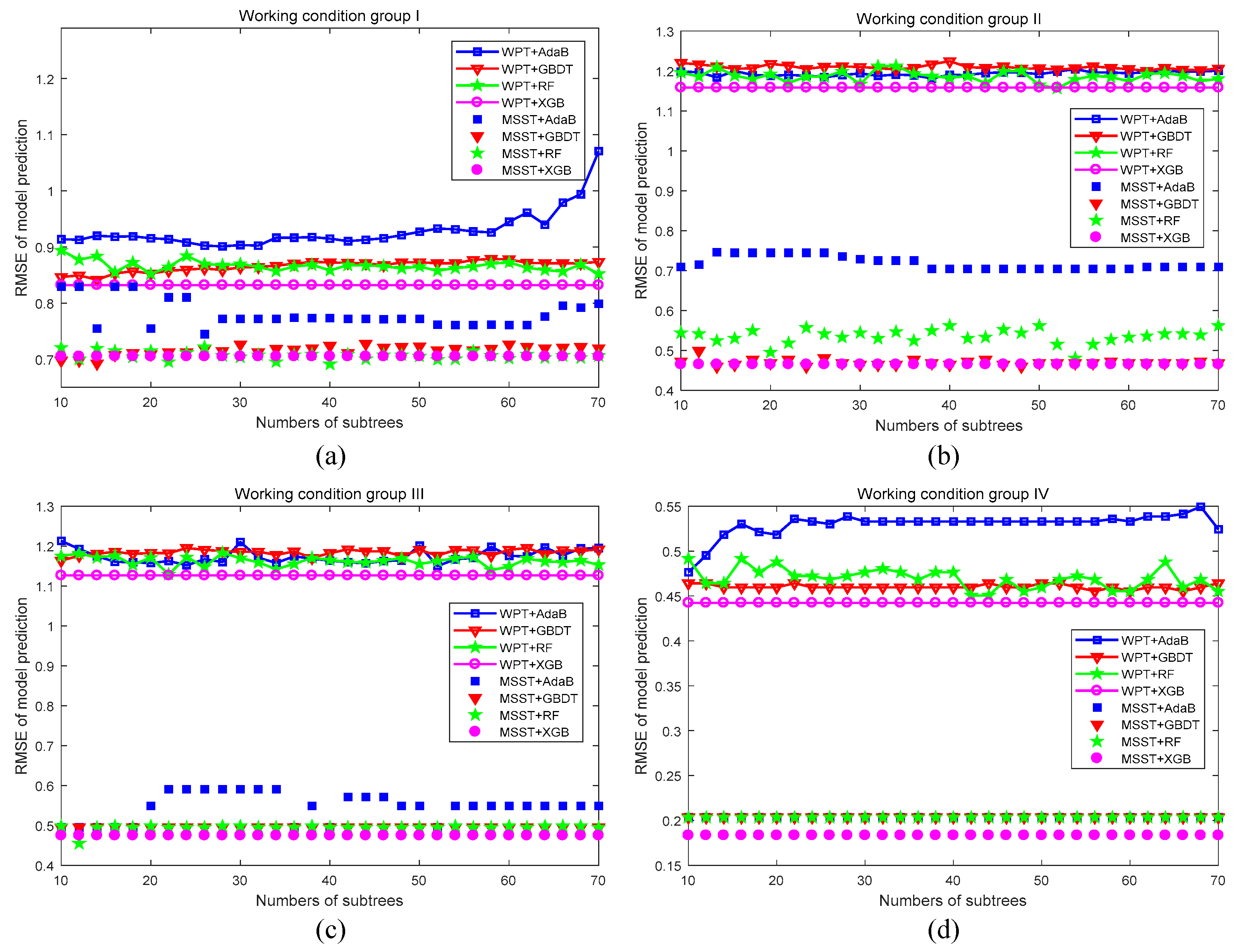
4.3. Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Data and Code Availability
References
- Allam, S.; Abdo, M.; Rabie, M. Diesel Engine Fault Detection Using Vibration and Acoustic Emission Signals. Int. J. Adv. Sci. Res. Eng. 2018, 4, 86–93. [Google Scholar] [CrossRef]
- Devasenapati, S.B.; Ramachandran, K.I.; Sugumaran, V. Misfire detection in a spark ignition engine using support vector machines. Int. J. Comput. Appl. 2010, 5, 25–29. [Google Scholar] [CrossRef]
- Devasenapati, S.B.; Sugumaran, V.; Ramachandran, K.I. Misfire identification in a four-stroke four-cylinder petrol engine using decision tree. Expert Syst. Appl. 2010, 37, 2150–2160. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, J.H.; Qin, K.J.; Xu, Y.Y. Diesel engine fault diagnosis using intrinsic time-scale decomposition and multistage Adaboost relevance vector machine. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2018, 332, 881–894. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part II: Fault diagnosis with knowledge-based and hybrid/active-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Djeziri, M.A.; Benmoussa, S.; Sanchez, R. Hybrid method for remaining useful life prediction in wind turbine systems. Renew. Energy 2018, 116, 173–187. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Djeziri, M.; Ananou, B.; Ouladsine, M.; Pinaton, J. Fault prognosis for batch production based on percentile measure and gamma process: Application to semiconductor manufacturing. J. Process Control 2016, 48, 72–80. [Google Scholar] [CrossRef]
- Benmoussa, S.; Djeziri, M.A. Remaining useful life estimation without needing for prior knowledge of the degradation features. IET Sci. Meas. Technol. 2017, 11, 1071–1078. [Google Scholar] [CrossRef]
- Isermann, R. Diesel engine fault diagnosis using intrinsic time-scale decomposition and multistage Adaboost relevance vector machine. Annu. Rev. Control 2005, 29, 71–85. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Jung, D.; Eriksson, L.; Frisk, E.; Krysander, M. Development of misfire detection algorithm using quantitative FDI performance analysis. Control Eng. Pract. 2015, 34, 49–60. [Google Scholar] [CrossRef]
- Wang, Y.; Chu, F. Real-time misfire detection via sliding mode observer. Mech. Syst. Signal Process. 2005, 19, 900–912. [Google Scholar] [CrossRef]
- Kiencke, U. Engine misfire detection. Control Eng. Pract. 1999, 7, 203–208. [Google Scholar] [CrossRef]
- Wong, P.K.; Zhong, J.; Yang, Z.; Vong, C.M. Sparse Bayesian extreme learning committee machine for engine simultaneous fault diagnosis. Neurocomputing 2016, 174, 331–343. [Google Scholar] [CrossRef]
- Singh, S.; Potala, S.; Mohanty, A.R. An improved method of detecting engine misfire by sound quality metrics of radiated sound. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2018. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, C.; Zhang, F.; Cui, T.; Su, J. Misfire detection of a turbocharged diesel engine by using artificial neural networks. Appl. Therm. Eng. 2013, 55, 26–32. [Google Scholar] [CrossRef]
- Chen, S.K.; Mandal, A.; Chien, L.C.; Ortiz-Soto, E. Machine Learning for Misfire Detection in a Dynamic Skip Fire Engine. SAE Int. J. Engines 2018, 11, 965–976. [Google Scholar] [CrossRef]
- Chen, J.; Randall, R.B. Improved automated diagnosis of misfire in internal combustion engines based on simulation models. Mech. Syst. Signal Process. 2015, 64, 58–83. [Google Scholar] [CrossRef]
- Sharma, A.; Sugumaran, V.; Devasenapati, S.B. Misfire detection in an IC engine using vibration signal and decision tree algorithms. Measurement 2014, 50, 370–380. [Google Scholar] [CrossRef]
- Wu, J.D.; Liu, C.H. An expert system for fault diagnosis in internal combustion engines using wavelet packet transform and neural network. Expert Syst. Appl. 2009, 36, 4278–4286. [Google Scholar] [CrossRef]
- Hu, C.; Li, A.; Zhao, X. Multivariate statistical analysis strategy for multiple misfire detection in internal combustion engines. Mech. Syst. Signal Process. 2011, 25, 694–703. [Google Scholar] [CrossRef]
- Szabó, J.Z.; Bakucz, P. Real-time misfire detection of large gas engine using big data analytics. In Proceedings of the IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 000215–000220. [Google Scholar]
- Babu, A.K.; Raj, V.A.A.; Kumaresan, G. Misfire Detection in A Multi-Cylinder Diesel Engine: A Machine Learning Approach. J. Eng. Sci. Technol. 2016, 11, 278–295. [Google Scholar]
- Jafarian, K.; Mobin, M.; Jafari-Marandi, R.; Rabiei, E. Misfire and valve clearance faults detection in the combustion engines based on a multi-sensor vibration signal monitoring. Measurement 2018, 128, 527–536. [Google Scholar] [CrossRef]
- Han, Y.; Tang, B.; Deng, L. Multi-level wavelet packet fusion in dynamic ensemble convolutional neural network for fault diagnosis. Measurement 2018, 127, 246–255. [Google Scholar] [CrossRef]
- Wang, X.; Liu, C.; Bi, F.; Bi, X.; Shao, K. Fault diagnosis of diesel engine based on adaptive wavelet packets and EEMD-fractal dimension. Mech. Syst. Signal Process. 2013, 41, 581–597. [Google Scholar] [CrossRef]
- Daubechies, I.; Lu, J.; Wu, H.T. Synchrosqueezed wavelet transforms: An empirical mode decomposition-like tool. Appl. Comput. Harmon. Anal. 2011, 30, 243–261. [Google Scholar] [CrossRef]
- Oberlin, T.; Meignen, S.; Perrier, V. Second-order synchrosqueezing transform or invertible reassignment? Towards ideal time-frequency representations. IEEE Trans. Signal Process. 2015, 63, 1335–1344. [Google Scholar] [CrossRef]
- Yu, G.; Wang, Z.; Zhao, P. Multisynchrosqueezing transform. IEEE Trans. Ind. Electron. 2018, 66, 5441–5455. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E.; Baciu, M. Machine learning–XGBoost analysis of language networks to classify patients with epilepsy. Brain Inform. 2017, 4, 159–169. [Google Scholar] [CrossRef]
- Friedman, J.H.; Popescu, B.E. Importance sampled learning ensembles. J. Mach. Learn. Res. 2003, 94305, 1–32. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Saul, L.K.; Roweis, S.T. Think globally, fit locally: Unsupervised learning of low dimensional manifolds. J. Mach. Learn. Res. 2003, 4, 119–155. [Google Scholar] [CrossRef][Green Version]
- Kouropteva, O.; Okun, O.; Hadid, A.; Soriano, M.; Marcos, S.; Pietikäinen, M. Beyond Locally Linear Embedding Algorithm; Technical Report MVG-01-2002; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Rotating Speed n (r/min) | Working Condition |
|---|---|---|
| 1 | 1300 | Normal operation |
| 2 | 1300 | Misfire of first cylinder |
| 3 | 1300 | Misfire of second cylinder |
| 4 | 1300 | Misfire of third cylinder |
| 5 | 1300 | Misfire of fourth cylinder |
| 6 | 1800 | Normal operation |
| 7 | 1800 | Misfire of first cylinder |
| 8 | 1800 | Misfire of second cylinder |
| 9 | 1800 | Misfire of third cylinder |
| 10 | 1800 | Misfire of fourth cylinder |
| 11 | 2200 | Normal operation |
| 12 | 2200 | Misfire of first cylinder |
| 13 | 2200 | Misfire of second cylinder |
| 14 | 2200 | Misfire of third cylinder |
| 15 | 2200 | Misfire of fourth cylinder |
| 16 | 1800 | Normal operation |
| 17 | 1800 | Misfire of second cylinder |
| 18 | 1800 | Misfire of second and third cylinders |
| 19 | 1800 | Misfire of second and fourth cylinders |
| 20 | 1800 | Misfire of first and second cylinders |
| Wavelet Basis | Threshold Function | Threshold Processing Criteria | Decomposition Layer |
|---|---|---|---|
| db4 | Soft threshold | Unbiased likelihood estimation | 4 |
| Time-Domain Feature | Equation | Time-Domain Feature | Equation |
|---|---|---|---|
| 1. Mean | 6. Kurtosis | ||
| 2. Rectified mean | 7. Shape factor | ||
| 3. RMS | 8. Clearance factor | ||
| 4. Peak | 9. Margin factor | ||
| 5. Peak-to-peak |
| Dimensionality | Signal Energy Ratio of Top n Features (%) | ||||
|---|---|---|---|---|---|
| W0 | W1 | W2 | W3 | W4 | |
| 20 | 90.89 | 93.64 | 91.35 | 92.32 | 93.28 |
| 30 | 95.34 | 96.23 | 95.77 | 95.89 | 96.13 |
| 50 | 98.97 | 99.08 | 98.47 | 98.95 | 98.84 |
| 100 | 99.05 | 99.10 | 98.74 | 99.02 | 98.91 |
| Group I, II, and III | Group IV | ||
|---|---|---|---|
| Working Condition | Label | Working Condition | Label |
| Normal | 1 | Normal | 1 |
| No.1 cylinder misfire | 2 | No.2 cylinder misfire | 2 |
| No.2 cylinder misfire | 3 | No.2 and No.3 cylinder misfire | 3 |
| No.3 cylinder misfire | 4 | No.2 and No.4 cylinder misfire | 4 |
| No.4 cylinder misfire | 5 | No.1 and No.2 cylinder misfire | 5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, J.; Qin, C.; Li, W.; Liu, C. Intelligent Fault Diagnosis of Diesel Engines via Extreme Gradient Boosting and High-Accuracy Time–Frequency Information of Vibration Signals. Sensors 2019, 19, 3280. https://doi.org/10.3390/s19153280
Tao J, Qin C, Li W, Liu C. Intelligent Fault Diagnosis of Diesel Engines via Extreme Gradient Boosting and High-Accuracy Time–Frequency Information of Vibration Signals. Sensors. 2019; 19(15):3280. https://doi.org/10.3390/s19153280
Chicago/Turabian StyleTao, Jianfeng, Chengjin Qin, Weixing Li, and Chengliang Liu. 2019. "Intelligent Fault Diagnosis of Diesel Engines via Extreme Gradient Boosting and High-Accuracy Time–Frequency Information of Vibration Signals" Sensors 19, no. 15: 3280. https://doi.org/10.3390/s19153280
APA StyleTao, J., Qin, C., Li, W., & Liu, C. (2019). Intelligent Fault Diagnosis of Diesel Engines via Extreme Gradient Boosting and High-Accuracy Time–Frequency Information of Vibration Signals. Sensors, 19(15), 3280. https://doi.org/10.3390/s19153280