RETRACTED: The Novel Sensor Network Structure for Classification Processing Based on the Machine Learning Method of the ACGAN

 , ,
, ,
Abstract
:1. Introduction
2. Generative Adversarial Networks and Their Deformation
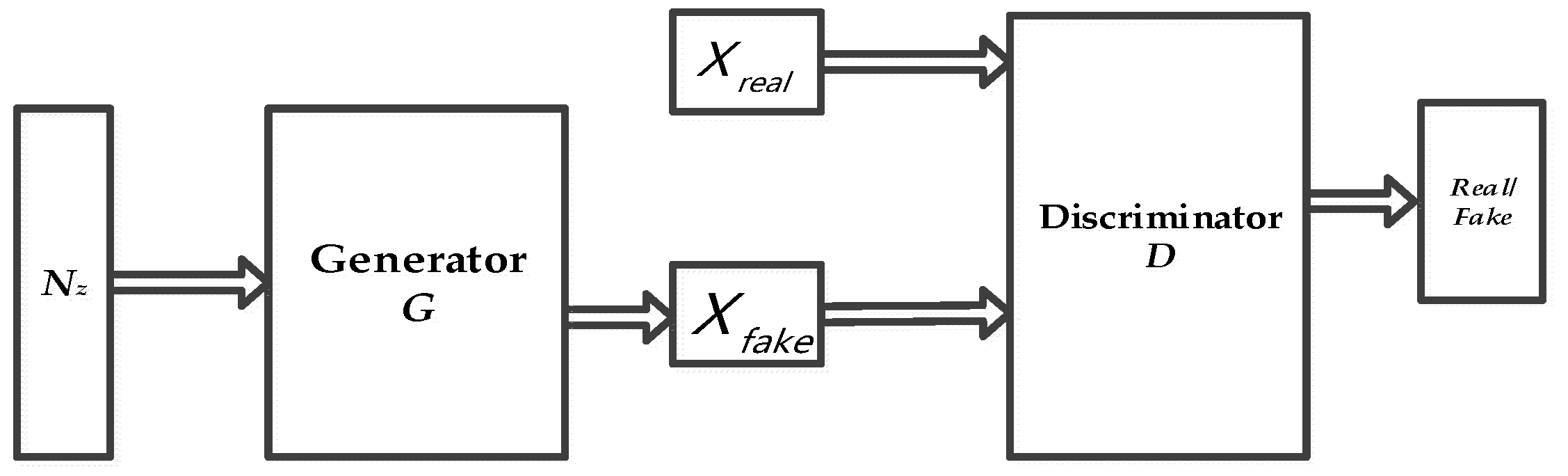
2.1. Generative Adversarial Networks
2.2. Deep Convolutional Generative Adversarial Networks
- (1).
- The pooling layer in the CNN has been canceled; strided convolutions are used in the discriminator, while fractional strided convolutions are used in the generator (G).
- (2).
- In addition to the generative output layer and the discriminative input layer, another layer has been added, namely a batch norm (BN). The BN can help to reduce the excessive dependence of the network on the initial parameters, as well as prevent the initialization parameters from being subpar. It further prevents the gradient from disappearing and transfers the gradient to each layer of the network; moreover, it prevents the generator from converging to the same point, thereby improving the diversity of the generated samples. This also reduces the network oscillation and improves the stability of network training.
- (3).
- The full connection layer has also been cancelled. In the generator (G), while the activation function Tanh is used in the final output layer, the activation function ReLU is used in all other layers. The leaky activation function ReLU is used in all layers of the discriminator.
2.3. Auxiliary Classifier Generative Adversarial Networks
3. Image Classification Processing Algorithm Using ACGAN
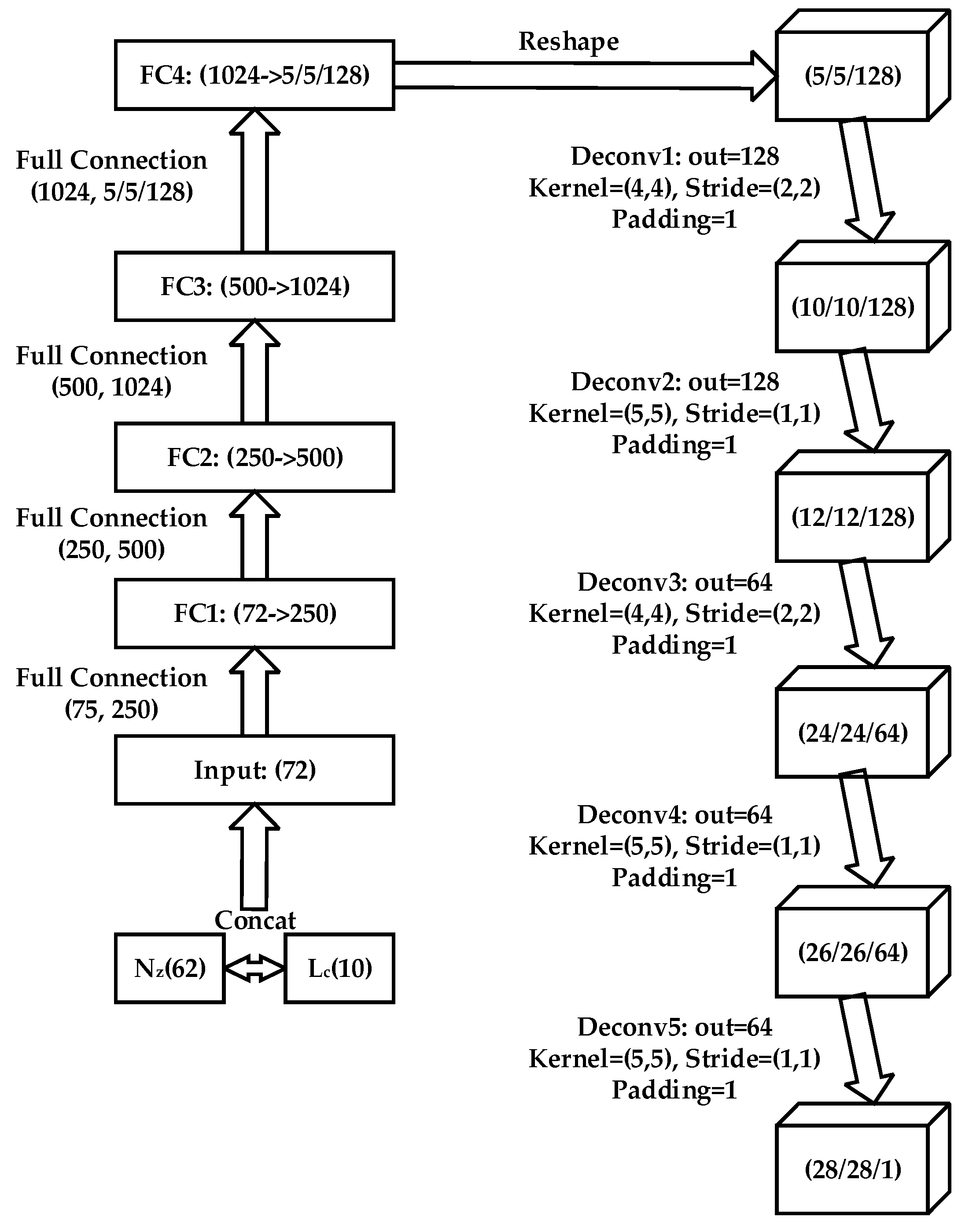
3.1. Applied ACGAN for Image Classification
3.2. The CP-ACGAN Algorithm
3.2.1. Feature Matching Operation
3.2.2. Improved Loss Function
3.2.3. The Pooling Method
3.3. Details of the Proposed Algorithm
| Algorithm 1. CP-ACGAN |
| Step 1: Reading the image f and the area mask M; Step 2: According to the ACGAN model, the structure image of u is obtained by image f; Step 3: Determine the set of image pixels on the to be classified on the boundary of S; Step 4: For the structural image u and p to be patched, each is centered from an image slice. According to Equation (13), the confidence item C(p) is calculated. According to Equation (14), data item D(p) is calculated, while priority P(p) is calculated according to Equation (15). Step 5: Determine the highest priority point P, as well as the corresponding image block W in the corresponding , and record the location of . Step 6: According to the optimization model from Equation (16), we determine the optimal matching block and location information in , then replace with to complete the repair of p point’s image slices. Meanwhile, in the u of structural components, we have used images to replace the corresponding images of p points corresponding to u. Step 7: Update M and ; Step 8: Determine whether the mask M is empty. If it is empty, the algorithm ends; otherwise, return to step 3. |
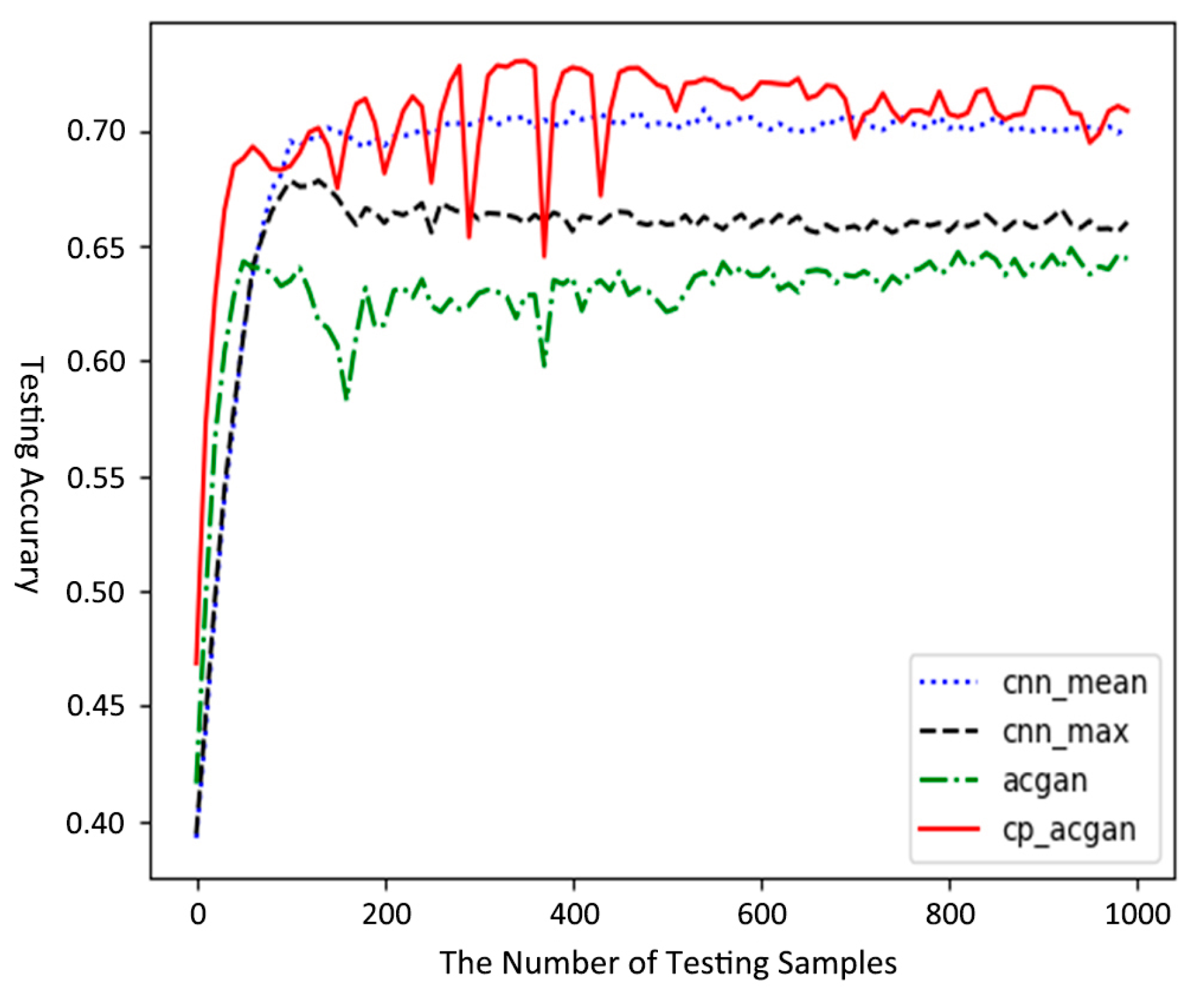
4. The Experimental Results and Analysis
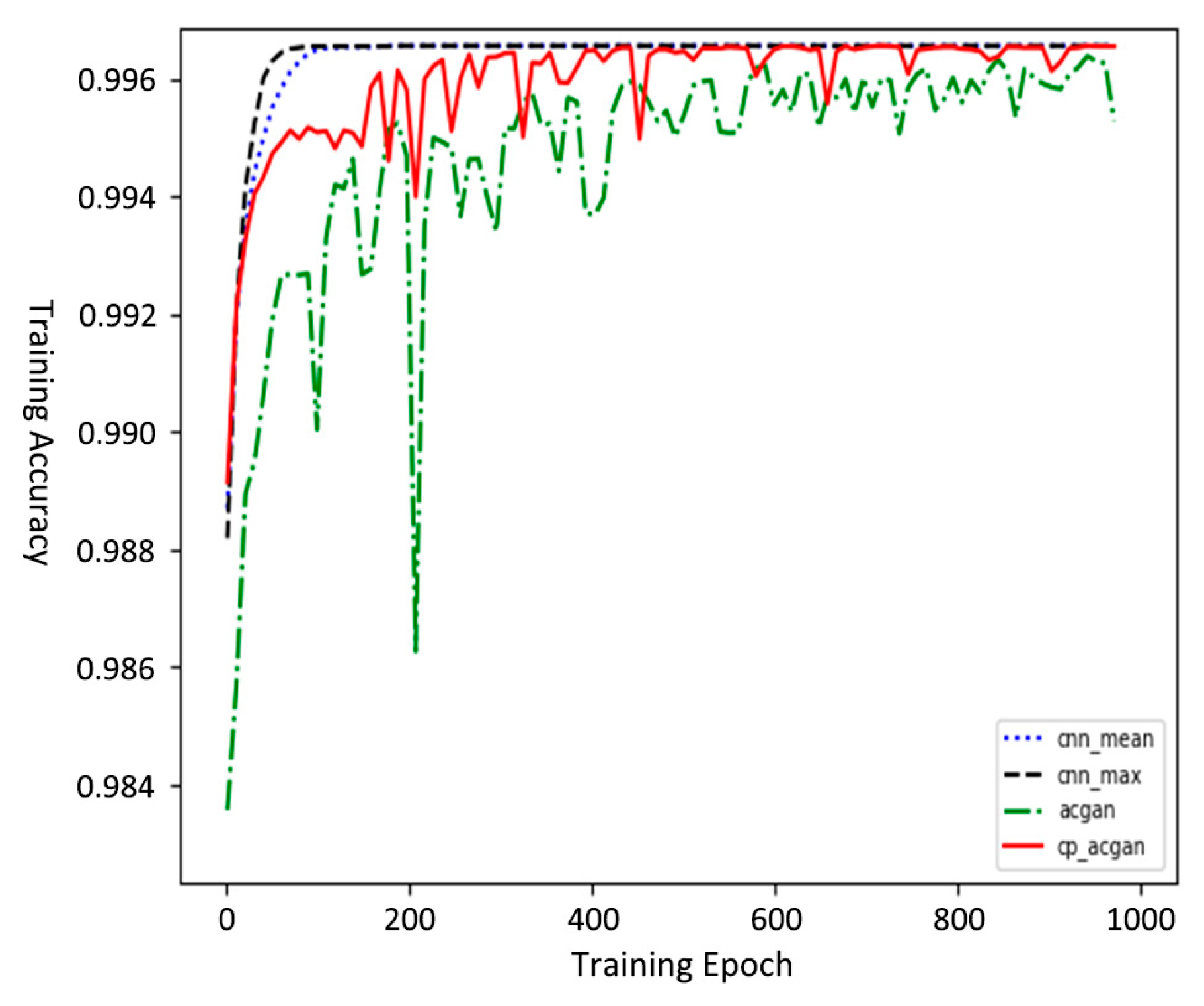
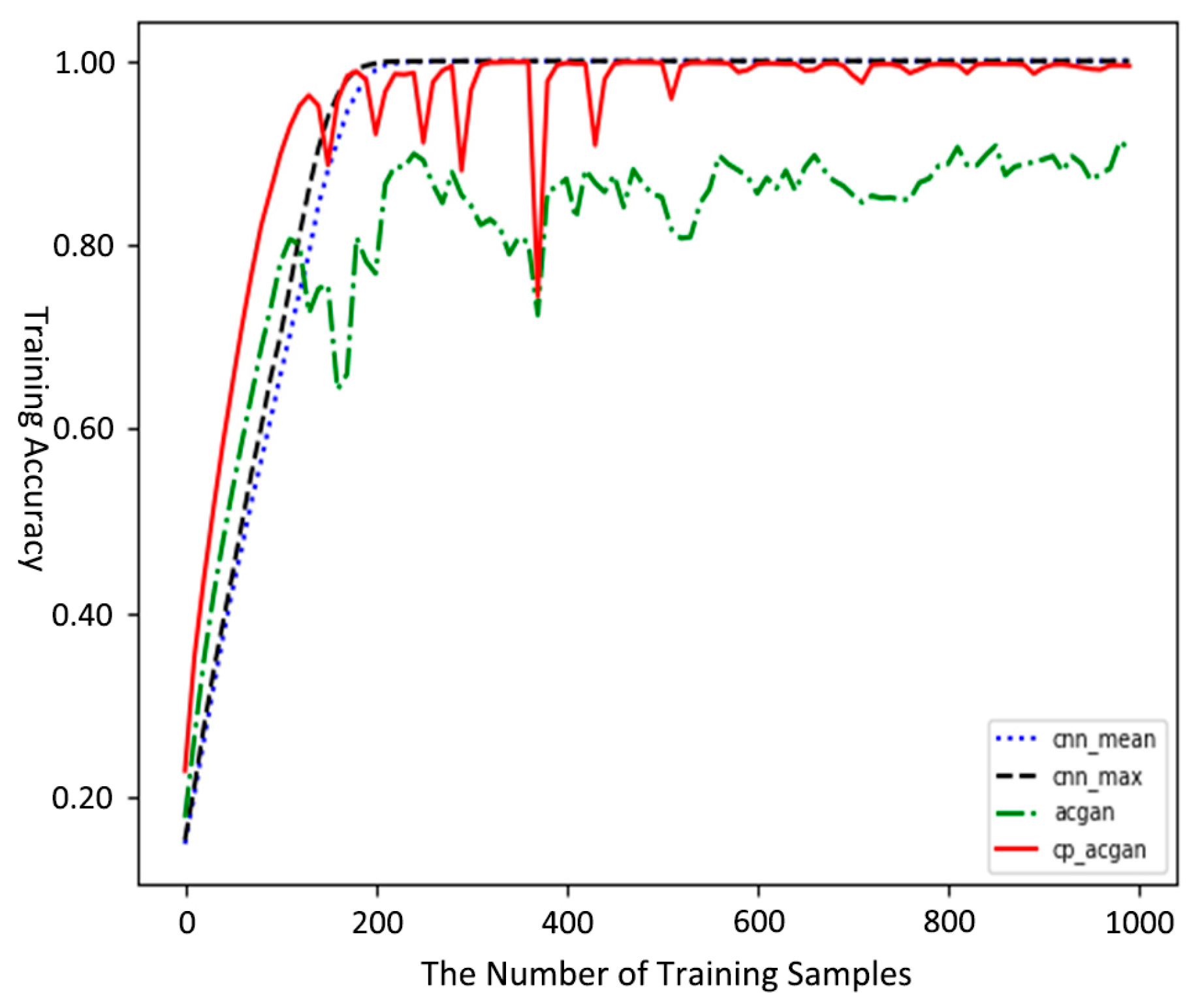
4.1. MNIST Dataset Experiment
4.2. The CIFAR10 Dataset Experiment
4.3. The CIFAR100 Dataset Experiment
4.4. The Efficiency Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 2012 Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, J.H.; Zhang, B. Collaborative Representation Using Non-Negative Samples for Image Classification. Sensors 2019, 19, 3609. [Google Scholar] [CrossRef] [PubMed]
- Gao, G.W.; Zhu, D.; Yang, M.; Lu, H.M.; Yang, W.K.; Gao, H. Face Image Super-Resolution with Pose via Nuclear Norm Regularized Structural Orthogonal Procrustes Regression. Neural Comput. Appl. 2018. [Google Scholar] [CrossRef]
- Zhou, S.W.; He, Y.; Xiang, S.Z.; Li, K.Q.; Liu, Y.H. Region-based compressive networked storage with lazy encoding. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1390–1402. [Google Scholar] [CrossRef]
- Donati, L.; Iotti, E.; Mordonini, G.; Prati, A. Fashion Product Classification through Deep Learning and Computer Vision. Appl. Sci. 2019, 9, 1385. [Google Scholar] [CrossRef]
- Turajlic, E.; Begović, A.; Škaljo, N. Application of Artificial Neural Network for Image Noise Level Estimation in the SVD domain. Appl. Sci. 2019, 8, 163. [Google Scholar] [CrossRef]
- Wang, W.L.; Li, Z.R. Advances in Generative Adversarial Network. J. Commun. 2018, 39, 135–148. [Google Scholar]
- Goodfellow, I.; Pouget-Adadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 2014 Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, A.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 2017 International Conference on Learning Representations, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Kingma, D.P.; Rezende, D.J.; Mohamed, S.; Welling, M. Semi-Supervised Learning with Deep Generative Models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3581–3589. [Google Scholar]
- Gui, Y.; Zeng, G. Joint Learning of Visual and Spatial Features for Edit Propagation from a Single Image. Vis. Comput. 2019. [Google Scholar] [CrossRef]
- Zhang J., M.; Lu C., Q.; Li X., D.; Kim, H.J.; Wang, J. A Full Convolutional Network Based on DenseNet for Remote Sensing Scene Classification. Math. Biosci. Eng. 2019, 16, 3345–3367. [Google Scholar] [CrossRef]
- Xia, X.J.; Togneri, R.; Sohel, F.; Huang, D.D. Auxiliary Classifier Generative Adversarial Network with Soft Labels in Imbalanced Acoustic Event Detection. IEEE Trans. Multimed. 2019, 21, 1359–1371. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2226–2234. [Google Scholar]
- Yin, Y.Y.; Chen, L.; Xu, Y.S.; Wan, J.; Zhang, H.; Mai, Z.D. QoS Prediction for Service Recommendation with Deep Feature Learning in Edge Computing Environment. Mob. Netw. Appl. 2019. [Google Scholar] [CrossRef]
- Chen, X.Y.; Xu, C.; Yang, X.K.; Song, L.; Tao, D.C. Gated-GAN: Adversarial Gated Networks for Multi-Collection Style Transfer. IEEE Trans. Image Process. 2019, 28, 546–560. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.M.; Qian, J.J.; Gao, J.B.; Yang, J.; Xu, C.Y. Scalable Proximal Jacobian Iteration Method with Global Convergence Analysis for Nonconvex Unconstrained Composite Optimizations. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef] [PubMed]
- Koniusz, P.; Yan, F.; Gosselin, P.; Mikolajczyk, K. Higher-order Occurrence Pooling for Bags-of-words: Visual Concept Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 313–326. [Google Scholar] [CrossRef] [PubMed]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual Categoryzation with Bags of Keypoints. In Workshop on Statistical Learning in Computer Vision, in Conjunction Conference on Computer Vision; ECCV: Prague, Czech, 2004; Volume 1, pp. 1–2. [Google Scholar]
- Chen, Y.T.; Xiong, J.; Xu, W.H.; Zuo, J.W. A Novel Online Incremental and Decremental Learning Algorithm Based on Variable Support Vector Machine. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Yin, Y.Y.; Chen, L.; Xu, Y.S.; Wan, J. Location-Aware Service Recommendation with Enhanced Probabilistic Matrix Factorization. IEEE Access 2018, 6, 62815–62825. [Google Scholar] [CrossRef]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, L.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Wang, J.; Gao, Y.; Liu, W.; Sangaiah, A.K.; Kim, H.J. An Intelligent Data Gathering Schema with Data Fusion Supported for Mobile Sink in WSNs. Int. J. Distrib. Sens. Netw. 2019. [Google Scholar] [CrossRef]
- Tan, D.S.; Lin, J.M.; Lai, Y.C.; Liao, J.; Hua, K.L. Depth Map Upsampling via Multi-Modal Generative Adversarial Network. Sensors 2019, 19, 1587. [Google Scholar] [CrossRef]
- Zhang, J.M.; Jin, X.K.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and Semantic Convolutional Features for Robust Visual Object Tracking. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Adversarial Generator-Encoder Networks. arXiv 2017, arXiv:1704.02304. [Google Scholar]
- Scherer, D.; Muller, A.; Behnke, S. Evaluation of Pooling Operation in Convolutional Architecture for Object Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- Boureau, Y.L.; Ponce, J.; LeCun, Y. A Theoretical Analysis of Feature Pooling in Visual Recognition. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Zhan, Y.; Hu, D.; Wang, Y.T.; Yu, X.C. Semisupervised Hyperspectral Image Classification Based on Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 212–216. [Google Scholar] [CrossRef]
- Chen, Y.T.; Wang, J.; Chen, X.; Sangaiah, A.K.; Yang, K.; Cao, Z.H. Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks. Appl. Sci. 2019, 9, 2316. [Google Scholar] [CrossRef]
- Dong, C.; Chen, C.L.; He, K.M.; Tang, X.O. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–303. [Google Scholar] [CrossRef] [PubMed]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Kumar, V.; Mukherjee, J.; Mandal, S.K.D. Image Inpainting Through Metric Labelling Via Guided Patch Mixing. IEEE Trans. Image Process. 2016, 25, 5212–5226. [Google Scholar] [CrossRef] [PubMed]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.T.; Wang, Z.; Lin, W.S. Unified Blind Quality Assessment of Compressed Natural, Graphic, and Screen Content Images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Khan, R.; Barat, C.; Muselet, D.; Ducottet, C. Spatial Histograms of Soft Pairwise Similar Patches to Improve the Bag-of-visual-words model. Comput. Vis. Image Underst. 2014, 132, 102–112. [Google Scholar] [CrossRef]
- Metropolis, N.; Ulam, S. The Monte Carlo Method. J. Am. Stat. Assoc. 1949, 44, 335–341. [Google Scholar] [CrossRef]
- Xiang, L.Y.; Shen, X.B.; Qin, J.H.; Hao, W. Discrete Multi-Graph Hashing for Large-scale Visual Search. Neural Process. Lett. 2019. [Google Scholar] [CrossRef]
- Chen, Y.T.; Xu, W.H.; Zuo, J.W.; Yang, K. The Fire Recognition Algorithm Using Dynamic Feature Fusion and IV-SVM Classifier. Clust. Comput. 2018. [Google Scholar] [CrossRef]
- Sun, R.X.; Shi, L.F.; Yin, C.Y.; Wang, J. An Improved Method in Deep Packet Inspection Based on Regular Expression. J. Supercomput. 2019, 75, 3317–3333. [Google Scholar] [CrossRef]
- Kofler, C.; Muhr, R.; Spock, G. Classifying Image Stacks of Specular Silicon Wafer Back Surface Regions: Performance Comparison of CNNs and SVMs. Sensors 2019, 19, 2056. [Google Scholar] [CrossRef] [PubMed]
- Acremont, A.; Fablet, R.; Baussard, A.; Quin, G. CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems. Sensors 2019, 19, 2040. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.T.; Wang, J.; Xia, R.L.; Zhang, Q.; Cao, Z.H.; Yang, K. The Visual Object Tracking Algorithm Research Based on Adaptive Combination Kernel. J. Ambient Intell. Humaniz. Comput. 2019. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Chen, Y.T.; Wang, J.; Chen, X.; Zhu, M.W.; Yang, K.; Wang, Z.; Xia, R.L. Single-Image Super-Resolution Algorithm Based on Structural Self-Similarity and Deformation Block Features. IEEE Access 2019, 7, 58791–58801. [Google Scholar] [CrossRef]
- Du, P.J.; Gan, L.; Xia, J.S.; Wang, D.M. Multikernel Adaptive Collaborative Representation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4664–4677. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.S.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Yu, Y.; Tang, S.H.; Aizawa, K.; Aizawa, A. Category-Based Deep CCA for Fine-Grained Venue Discovery from Multimodal Data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1250–1258. [Google Scholar] [CrossRef]
- Chen, Y.T.; Xia, R.L.; Wang, Z.; Zhang, J.M.; Yang, K.; Cao, Z.H. The visual saliency detection algorithm research based on hierarchical principle component analysis method. Multimed. Tools Appl. 2019. [Google Scholar] [CrossRef]
- He, S.M.; Xie, K.; Chen, W.W.; Zhang, D.F.; Wen, J.G. Energy-aware Routing for SWIPT in Multi-hop Energy-constrained Wireless Network. IEEE Access 2018, 6, 17996–18008. [Google Scholar] [CrossRef]
- Qiao, T.T.; Zhang, J.; Xu, D.Q.; Tao, D.C. MirrorGAN: Learning Text-to-image Generation by Redescription. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Available online: https://arxiv.org/pdf/1903.05854.pdf (accessed on 16 June 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MNIST | CIFAR10 | CIFAR100 |
|---|---|---|---|
| Mean Pooling CNN | 0.9951 | 0.7796 | 0.4594 |
| Maximum Pooling CNN | 0.9943 | 0.7639 | 0.4283 |
| ACGAN | 0.9950 | 0.7306 | 0.3989 |
| CP-ACGAN | 0.9962 | 0.7907 | 0.4803 |
| Model | Mean Value | Maximum Value | Minimum Value | Variance |
|---|---|---|---|---|
| Mean Pooling CNN | 0.9949 | 0.9949 | 0.9865 | 6.0 × 10−9 |
| Maximum Pooling CNN | 0.9941 | 0.9941 | 0.9865 | 3.3 × 10−9 |
| ACGAN | 0.9940 | 0.9945 | 0.9835 | 4.1 × 10−7 |
| CP-ACGAN | 0.9956 | 0.9961 | 0.9890 | 1.9 × 10−7 |
| Model | The Number of Testing Samples | Mean Value | Maximum Value | Minimum Value | Variance |
|---|---|---|---|---|---|
| Mean Pooling CNN | 200 | 0.7654 | 0.7765 | 0.5705 | 3.96 × 10−6 |
| 600 | 0.7665 | 0.7775 | 0.5800 | 3.88 × 10−6 | |
| 1000 | 0.7670 | 0.7795 | 0.5883 | 3.79 × 10−6 | |
| Maximum Pooling CNN | 200 | 0.7517 | 0.7605 | 0.5800 | 3.88 × 10−6 |
| 600 | 0.7535 | 0.7645 | 0.5890 | 3.76 × 10−6 | |
| 1000 | 0.7550 | 0.7690 | 0.5960 | 3.67 × 10−6 | |
| ACGAN | 200 | 0.7196 | 0.7305 | 0.5700 | 5.88 × 10−5 |
| 600 | 0.7203 | 0.7335 | 0.5780 | 5.76 × 10−5 | |
| 1000 | 0.7220 | 0.7365 | 0.5890 | 5.69 × 10−5 | |
| CP-ACGAN | 200 | 0.7682 | 0.7850 | 0.6700 | 3.28 × 10−5 |
| 600 | 0.7699 | 0.7885 | 0.6790 | 3.19 × 10−5 | |
| 1000 | 0.7715 | 0.7905 | 0.6899 | 3.14 × 10−5 |
| Model | The Number of Testing Samples | Mean Value | Maximum Value | Minimum Value | Variance |
|---|---|---|---|---|---|
| Mean Pooling CNN | 200 | 0.6752 | 0.7105 | 0.4000 | 4.92 × 10−6 |
| 600 | 0.6792 | 0.7185 | 0.4500 | 4.88 × 10−6 | |
| 1000 | 0.6810 | 0.7252 | 0.4800 | 4.75 × 10−6 | |
| Maximum Pooling CNN | 200 | 0.6514 | 0.6750 | 0.3900 | 5.25 × 10−6 |
| 600 | 0.6560 | 0.6790 | 0.4200 | 5.18 × 10−6 | |
| 1000 | 0.6600 | 0.6830 | 0.4500 | 5.15 × 10−6 | |
| ACGAN | 200 | 0.6188 | 0.6480 | 0.4200 | 4.05 × 10−5 |
| 600 | 0.6212 | 0.6505 | 0.4400 | 4.00 × 10−5 | |
| 1000 | 0.6258 | 0.6595 | 0.4500 | 3.96 × 10−5 | |
| CP-ACGAN | 200 | 0.7028 | 0.7300 | 0.4700 | 3.75 × 10−5 |
| 600 | 0.7088 | 0.7380 | 0.4900 | 3.70 × 10−5 | |
| 1000 | 0.7122 | 0.7455 | 0.5022 | 3.64 × 10−5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Tao, J.; Wang, J.; Chen, X.; Xie, J.; Xiong, J.; Yang, K. RETRACTED: The Novel Sensor Network Structure for Classification Processing Based on the Machine Learning Method of the ACGAN. Sensors 2019, 19, 3145. https://doi.org/10.3390/s19143145
Chen Y, Tao J, Wang J, Chen X, Xie J, Xiong J, Yang K. RETRACTED: The Novel Sensor Network Structure for Classification Processing Based on the Machine Learning Method of the ACGAN. Sensors. 2019; 19(14):3145. https://doi.org/10.3390/s19143145
Chicago/Turabian StyleChen, Yuantao, Jiajun Tao, Jin Wang, Xi Chen, Jingbo Xie, Jie Xiong, and Kai Yang. 2019. "RETRACTED: The Novel Sensor Network Structure for Classification Processing Based on the Machine Learning Method of the ACGAN" Sensors 19, no. 14: 3145. https://doi.org/10.3390/s19143145
APA StyleChen, Y., Tao, J., Wang, J., Chen, X., Xie, J., Xiong, J., & Yang, K. (2019). RETRACTED: The Novel Sensor Network Structure for Classification Processing Based on the Machine Learning Method of the ACGAN. Sensors, 19(14), 3145. https://doi.org/10.3390/s19143145