Adaptive Data Acquisition with Energy Efficiency and Critical-Sensing Guarantee for Wireless Sensor Networks


Abstract
1. Introduction
2. Related Work and Motivation
2.1. Compressed Sensing Approaches
2.2. Prediction-Based Approaches
2.3. Summary and Motivation
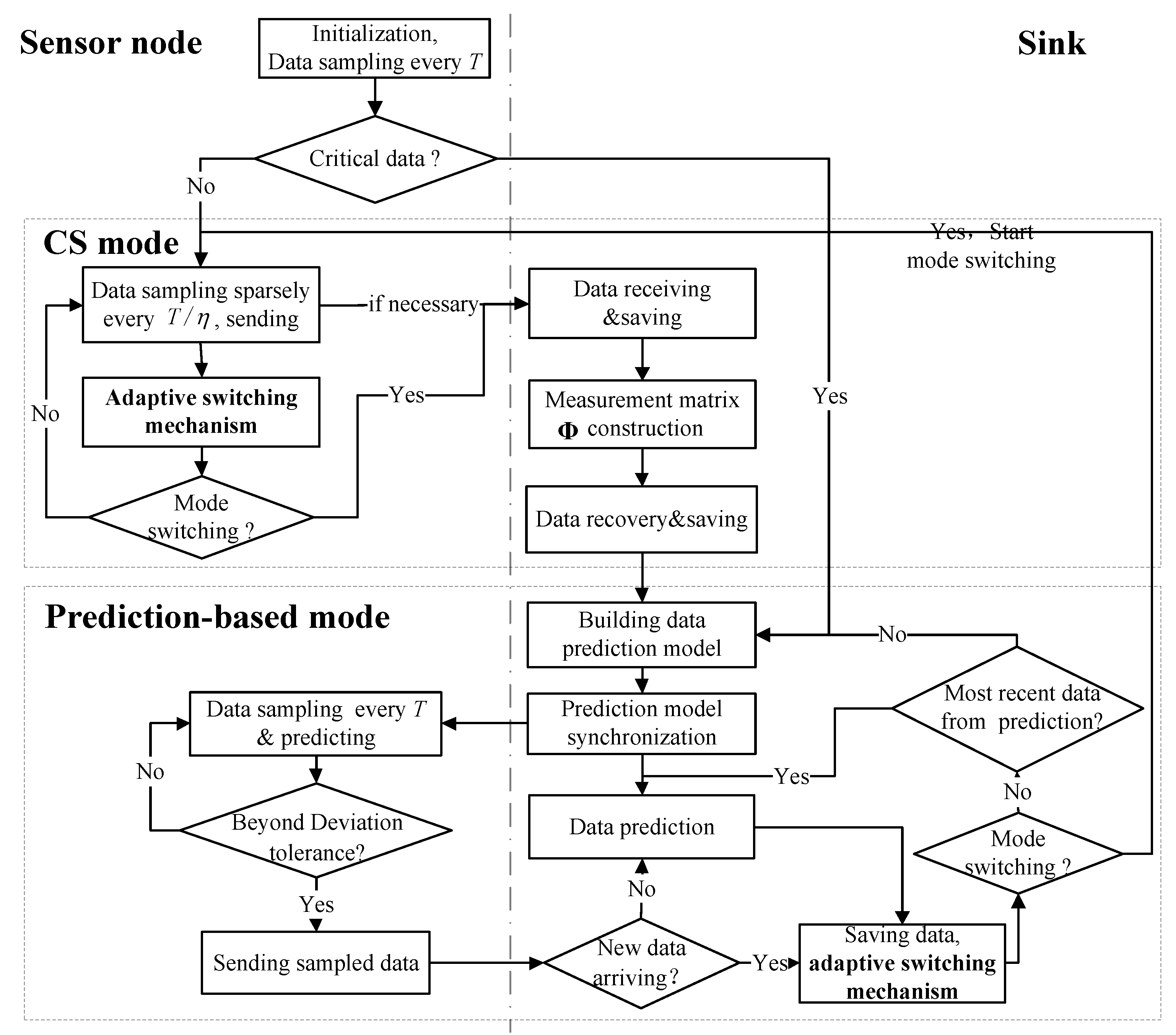
3. Adaptive Data Acquisition Scheme
3.1. Data Acquisition Framework
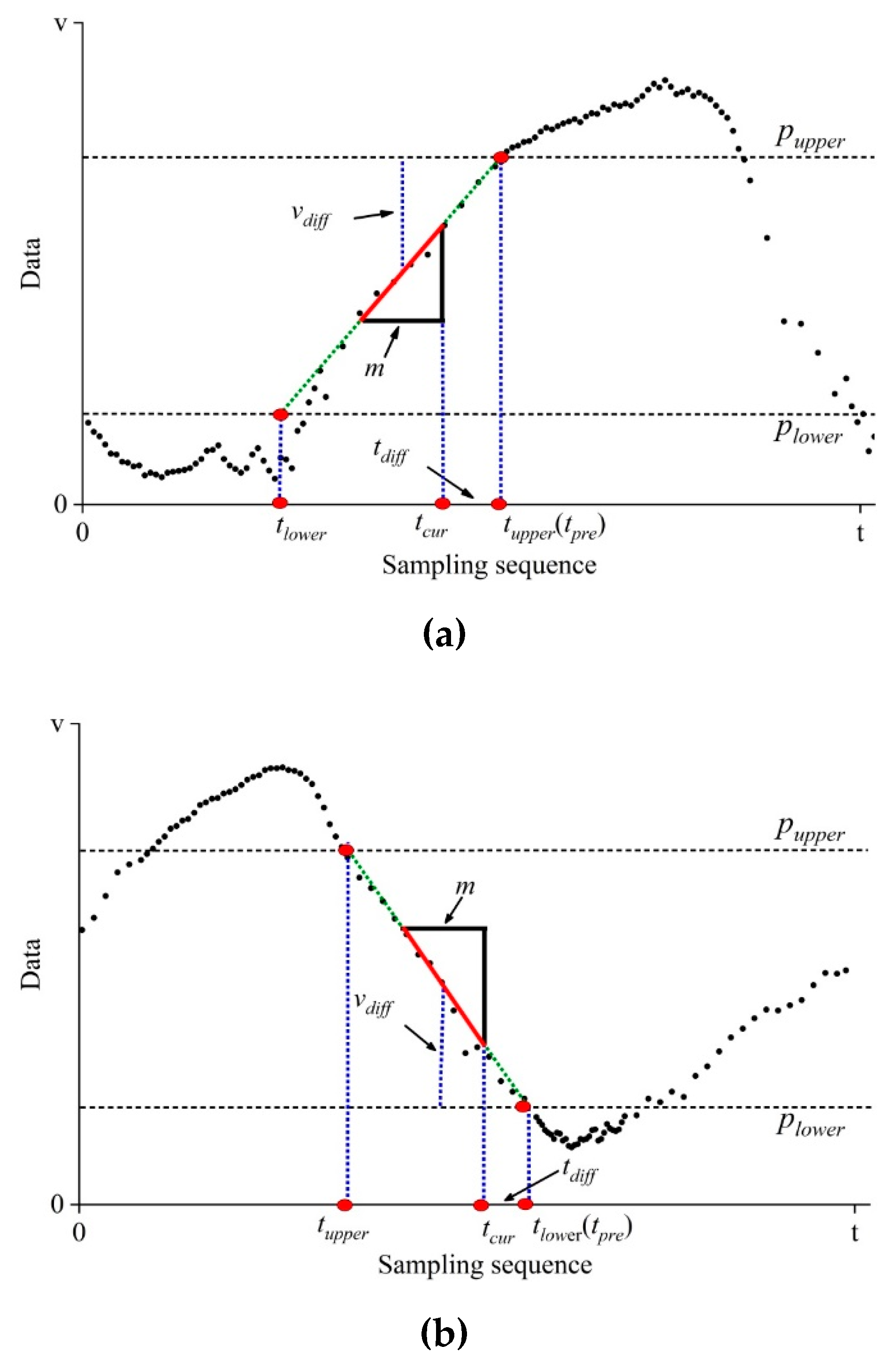
3.2. Adaptive Deviation Tolerance
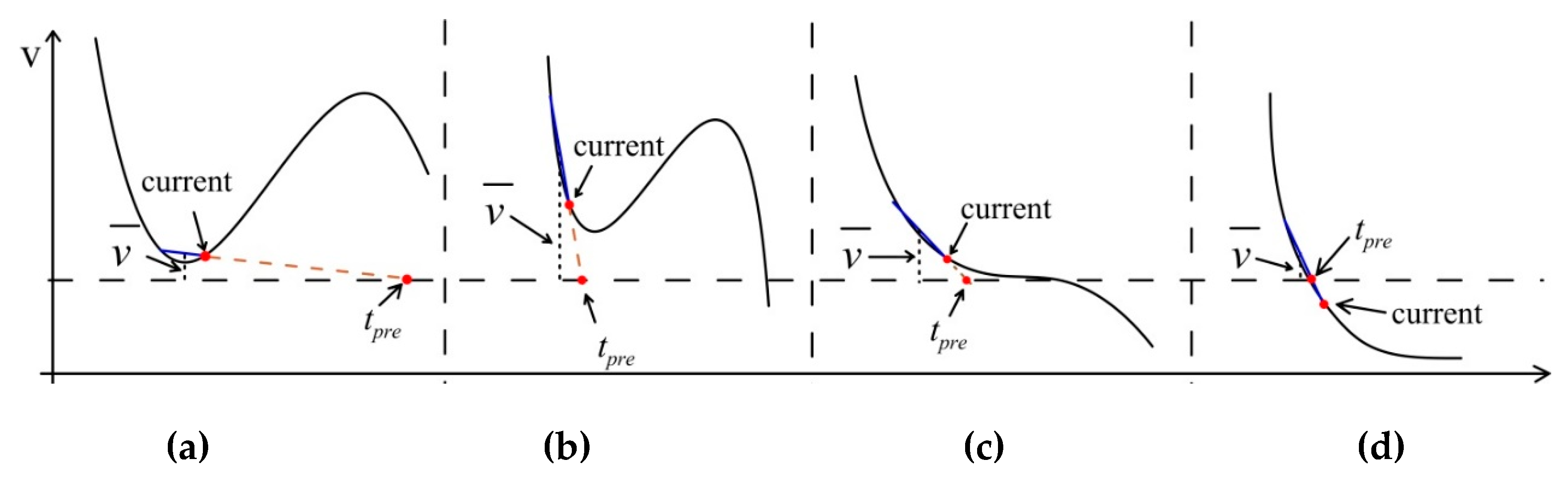
3.3. Adaptive Switching Mechanism
4. Results and Discussion
4.1. Switching Performance
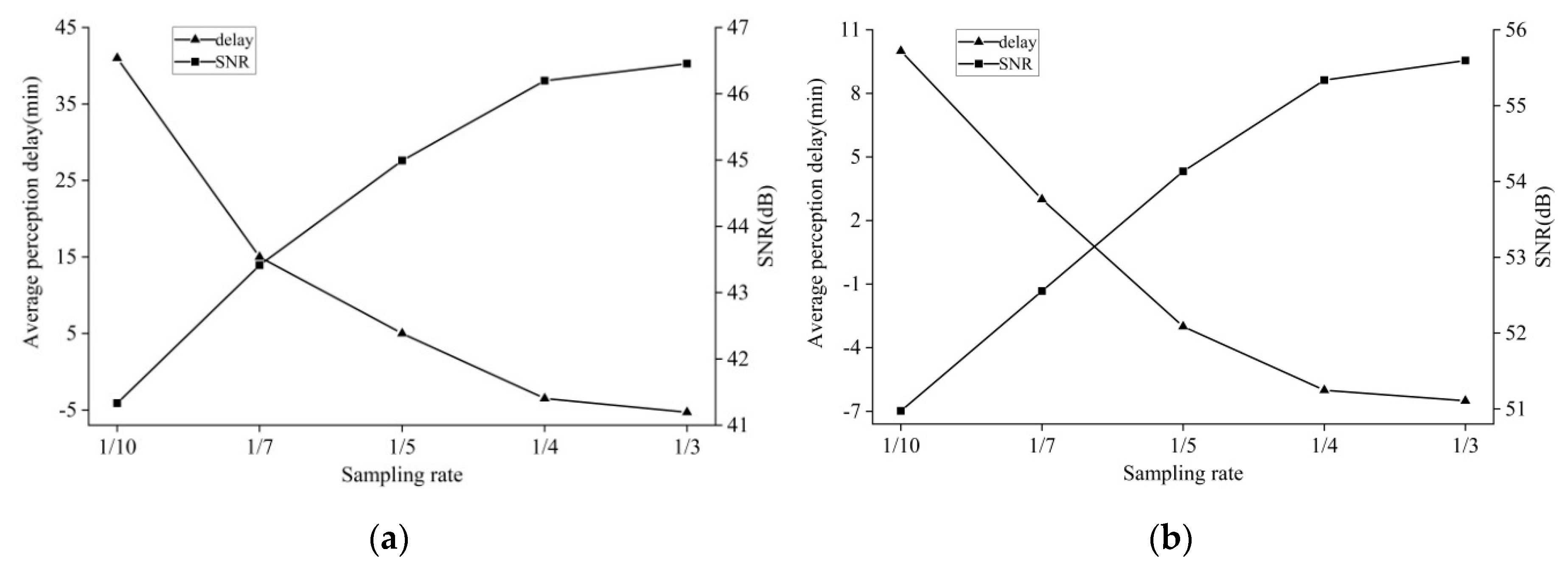
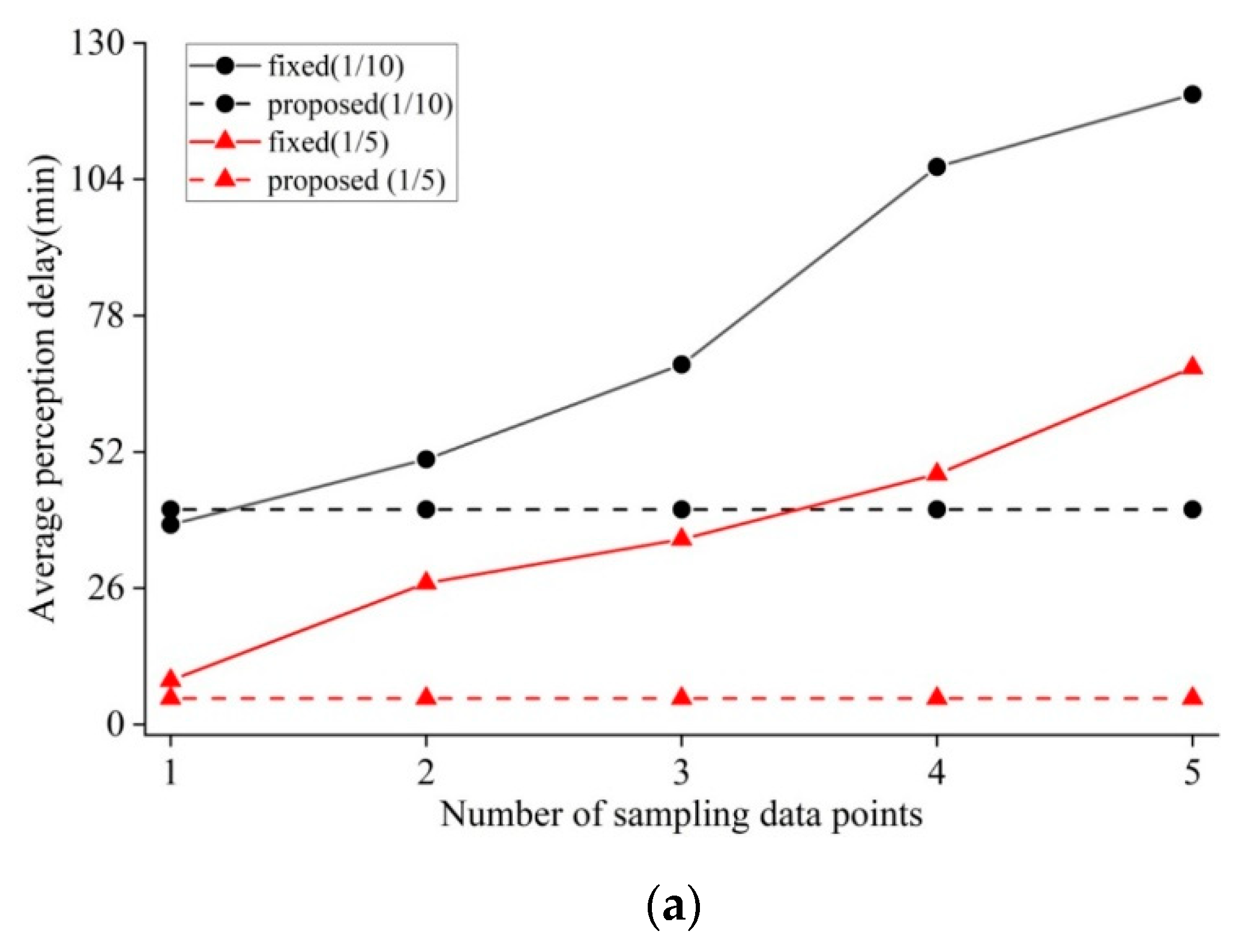
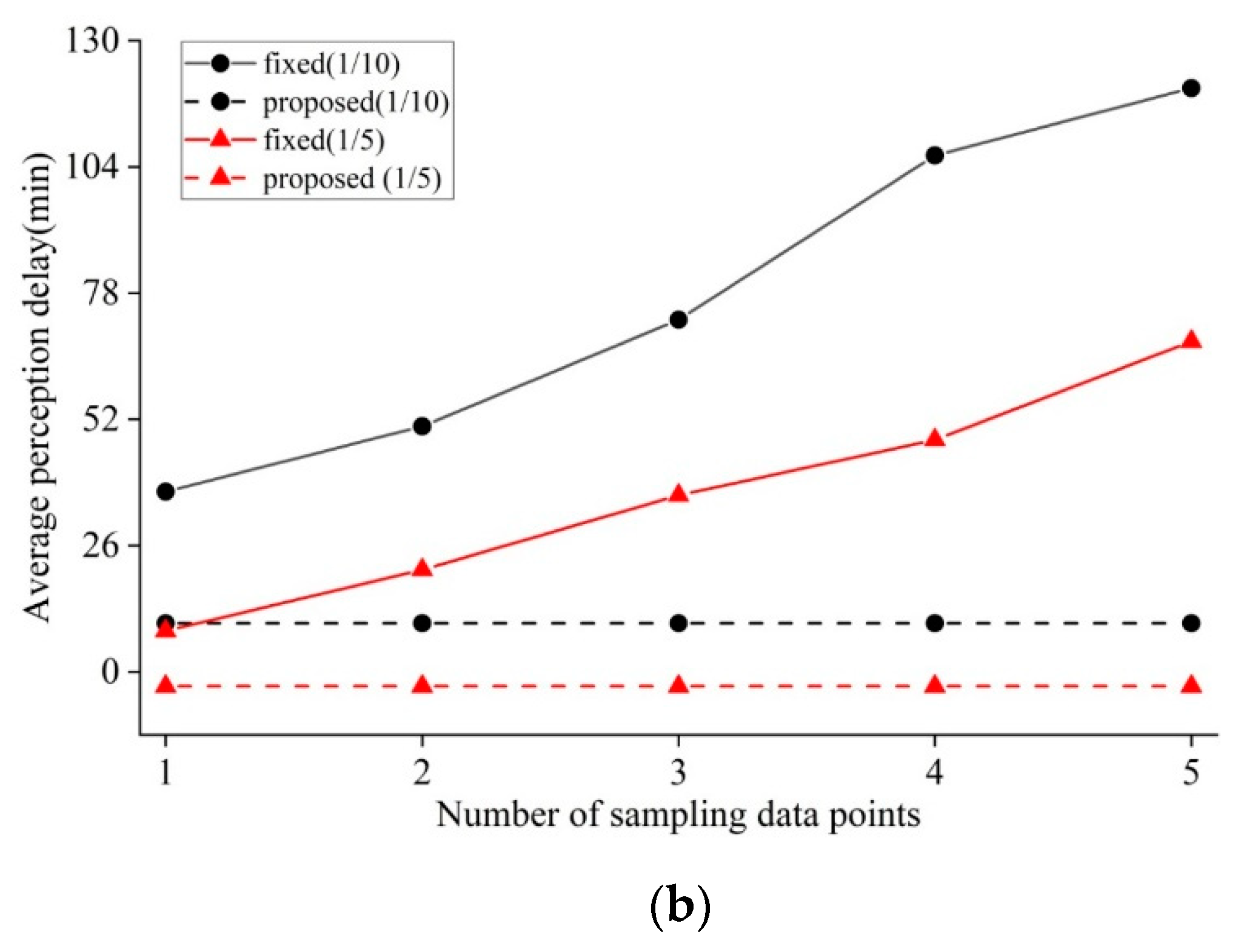
4.1.1. Determination of Parameter Values
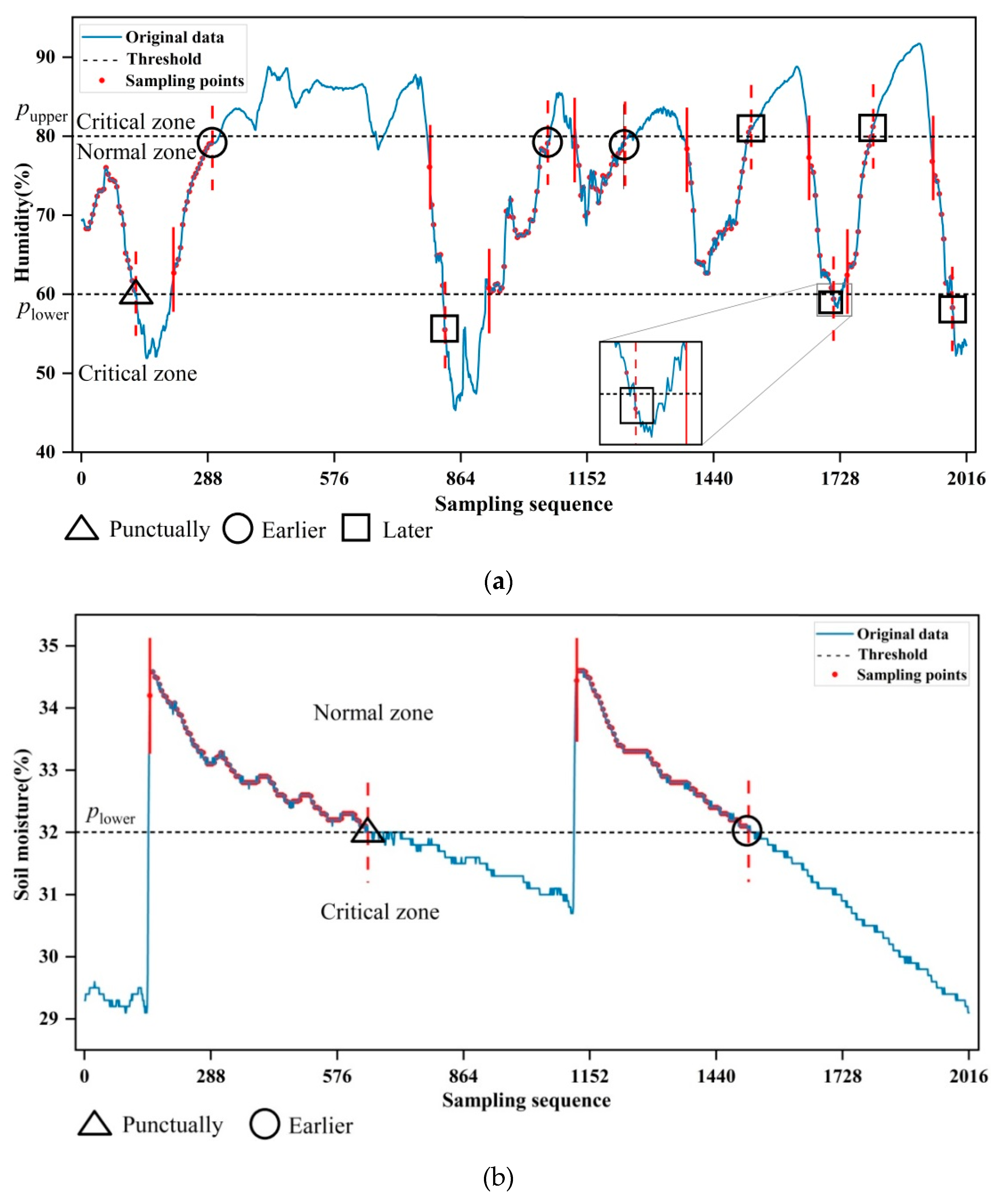
4.1.2. Investigation of Switching Behavior
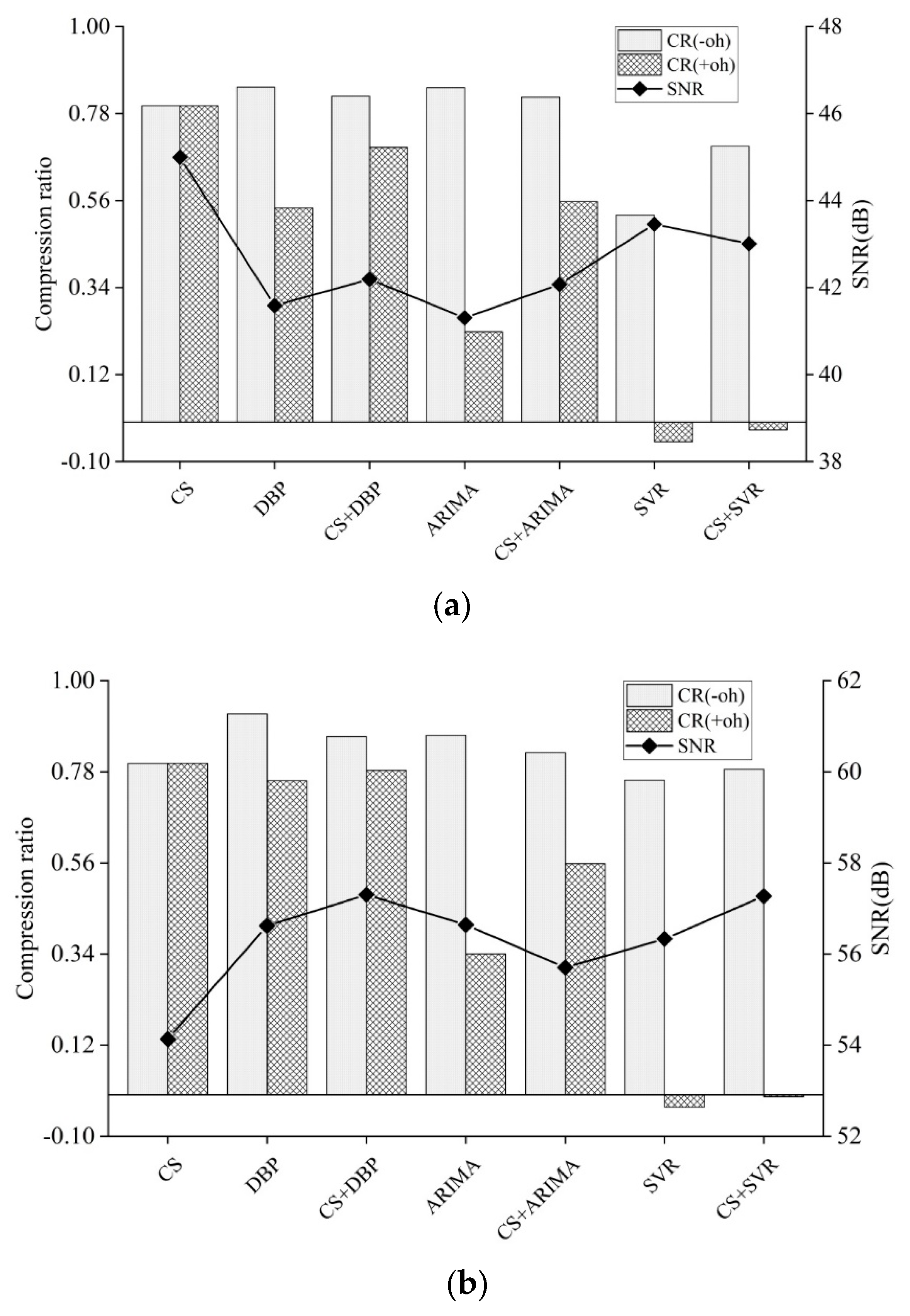
4.2. Compression Ratio and Data Quality
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rashid, B.; Rehmani, M.H. Applications of wireless sensor networks for urban areas: A survey. J. Netw. Comput. Appl. 2016, 60, 192–219. [Google Scholar] [CrossRef]
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.S.; Chi, K.; Zhang, J. Two-tiered relay node placement for WSN-based home health monitoring system. Peer-to-Peer Netw. Appl. 2019, 12, 589–603. [Google Scholar] [CrossRef]
- Banđur, Đ.; Jakšić, B.; Banđur, M.; Jović, S. An analysis of energy efficiency in Wireless Sensor Networks (WSNs) applied in smart agriculture. Comput. Electron. Agric. 2019, 156, 500–507. [Google Scholar] [CrossRef]
- Alaiad, A.; Zhou, L. Patients’ Adoption of WSN-Based Smart Home Healthcare Systems: An Integrated Model of Facilitators and Barriers. IEEE Trans. Prof. Commun. 2017, 60, 4–23. [Google Scholar] [CrossRef]
- Rao, Y.; Deng, C.; Zhao, G.; Qiao, Y.; Fu, L.-Y.; Shao, X.; Wang, R.-C. Self-adaptive implicit contention window adjustment mechanism for QoS optimization in wireless sensor networks. J. Netw. Comput. Appl. 2018, 109, 36–52. [Google Scholar] [CrossRef]
- Wu, M.; Tan, L.; Xiong, N. Data prediction, compression, and recovery in clustered wireless sensor networks for environmental monitoring applications. Inf. Sci. (NY) 2016, 329, 800–818. [Google Scholar] [CrossRef]
- Chong, L.; Kui, W.; Min, T. Energy efficient information collection with the ARIMA model in wireless sensor networks. In Proceedings of the GLOBECOM—IEEE Global Telecommunications Conference, St. Louis, MO, USA, 28 November–2 December 2005. [Google Scholar]
- Wang, C.; Li, J.; Yang, Y.; Ye, F. Combining Solar Energy Harvesting with Wireless Charging for Hybrid Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2017, 17, 560–576. [Google Scholar] [CrossRef]
- Dias, G.M.; Bellalta, B.; Oechsner, S. A Survey about Prediction-Based Data Reduction in Wireless Sensor Networks. ACM Comput. Surv. 2016, 49, 58. [Google Scholar] [CrossRef]
- Razzaque, M.A.; Bleakley, C.; Dobson, S. Compression in wireless sensor networks: A survey and comparative evaluation. ACM Trans. Sens. Netw. 2013, 10, 5. [Google Scholar] [CrossRef]
- Qiao, J.; Zhang, X. Compressed sensing based data gathering in wireless sensor networks: A survey. J. Comput. Appl. 2017, 37, 3261–3269. [Google Scholar]
- Aderohunmu, F.A.; Brunelli, D.; Deng, J.D.; Purvis, M.K. A data acquisition protocol for a reactive wireless sensor network monitoring application. Sensors 2015, 15, 10221–10254. [Google Scholar] [CrossRef] [PubMed]
- Hao, J.; Zhang, B.; Jiao, Z.; Mao, S. Adaptive compressive sensing based sample scheduling mechanism for wireless sensor networks. Pervasive Mob. Comput. 2015, 22, 113–125. [Google Scholar] [CrossRef]
- Sun, B.; Guo, Y.; Li, N.; Peng, L.; Fang, D. TDL: Two-dimensional localization for mobile targets using compressive sensing in wireless sensor networks. Comput. Commun. 2016, 78, 45–55. [Google Scholar] [CrossRef]
- Mangia, M.; Pareschi, F.; Rovatti, R.; Setti, G. Adaptive Matrix Design for Boosting Compressed Sensing. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 65, 1016–1027. [Google Scholar] [CrossRef]
- Zhao, G.; Rao, Y.; Zhu, J.; Li, S. Sparse sampling decision-making based on compressive sensing for agricultural monitoring nodes. J. Chang. Univ. Ed. 2019, 16, 79–87. [Google Scholar]
- Abbasi-Daresari, S.; Abouei, J. Toward cluster-based weighted compressive data aggregation in wireless sensor networks. Ad Hoc Netw. 2016, 36, 368–385. [Google Scholar] [CrossRef]
- Lv, C.; Wang, Q.; Yan, W.; Shen, Y. Energy-balanced compressive data gathering in Wireless Sensor Networks. J. Netw. Comput. Appl. 2016, 61, 102–114. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Teague, K.A. Compressive sensing based random walk routing in wireless sensor networks. Ad Hoc Netw. 2017, 54, 99–110. [Google Scholar] [CrossRef]
- Tuan Nguyen, M.; Teague, K.A.; Rahnavard, N. CCS: Energy-efficient data collection in clustered wireless sensor networks utilizing block-wise compressive sensing. Comput. Netw. 2016, 106, 171–185. [Google Scholar] [CrossRef]
- Lan, K.-C.; Wei, M.-Z. A Compressibility-Based Clustering Algorithm for Hierarchical Compressive Data Gathering. IEEE Sens. J. 2017, 17, 2550–2562. [Google Scholar] [CrossRef]
- Xiao, F.; Ge, G.; Sun, L.; Wang, R. An energy-efficient data gathering method based on compressive sensing for pervasive sensor networks. Pervasive Mob. Comput. 2017, 41, 343–353. [Google Scholar] [CrossRef]
- Wu, X.; Wang, Q.; Liu, M. In-situ soil moisture sensing: Measurement scheduling and estimation using sparse sampling. ACM Trans. Sens. Netw. 2014, 11, 26. [Google Scholar] [CrossRef]
- Wang, G.; Jiang, Y.; Mo, L.; Sun, Y.; Zhou, G. Dynamic sampling scheduling policy for soil respiration monitoring sensor networks based on compressive sensing. Sci. Sin. Inf. 2013, 43, 1326–1341. [Google Scholar]
- Song, Y.; Huang, Z.; Zhang, Y.; Li, M. Dynamic sampling method for wireless sensor network based on compressive sensing. J. Comput. Appl. 2017, 37, 183–187. [Google Scholar]
- Meira, E.M.; Cyrino, F.L. Forecasting mid-long term electric energy consumption through bagging ARIMA and exponential smoothing methods. Energy 2018, 144, 776–788. [Google Scholar]
- Raza, U.; Camerra, A.; Murphy, A.L.; Palpanas, T.; Picco, G. Pietro Practical Data Prediction for Real-World Wireless Sensor Networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 2231–2244. [Google Scholar] [CrossRef]
- Duan, Q.; Xiao, X.; Liu, Y.; Zhang, L. Anomaly Data Real-time Detection Method of Livestock Breeding Internet of Things Based on SW-SVR. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 2017, 157, 581–588. [Google Scholar]
- Rao, Y.; Xu, W.; Zhao, G.; Arthur, G.; Li, S. Model-driven in-situ data compressive gathering. ACTA Agric. Zhejiangensis 2018, 30, 2102–2111. [Google Scholar]
- Tan, L.; Wu, M. Data Reduction in Wireless Sensor Networks: A Hierarchical LMS Prediction Approach. IEEE Sens. J. 2016, 16, 1708–1715. [Google Scholar] [CrossRef]
- Dias, G.M.; Bellalta, B.; Oechsner, S. The impact of dual prediction schemes on the reduction of the number of transmissions in sensor networks. Comput. Commun. 2017, 112, 58–72. [Google Scholar] [CrossRef]
- Raspberry Pi. Available online: www.raspberrypi.org (accessed on 3 March 2018).
- Das, S. Development of a Suitable Environment Control Chamber to Study Effects of Air Conditions on Physicochemical Changes During Withering and Oxidation of Tea. Ph.D. Thesis, IIT, Kharagpur, India, 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| T | 5 |
| 0.05 | |
| m | 3 |
| 1/10,1/7,1/5,1/4,1/3 |
| Models | DBP | ARIMA | SVR |
|---|---|---|---|
| Content | α,β | ||
| Amount(Byte) | 8 | 16 | 50 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, Y.; Zhao, G.; Wang, W.; Zhang, J.; Jiang, Z.; Wang, R. Adaptive Data Acquisition with Energy Efficiency and Critical-Sensing Guarantee for Wireless Sensor Networks. Sensors 2019, 19, 2654. https://doi.org/10.3390/s19122654
Rao Y, Zhao G, Wang W, Zhang J, Jiang Z, Wang R. Adaptive Data Acquisition with Energy Efficiency and Critical-Sensing Guarantee for Wireless Sensor Networks. Sensors. 2019; 19(12):2654. https://doi.org/10.3390/s19122654
Chicago/Turabian StyleRao, Yuan, Gang Zhao, Wen Wang, Jingyao Zhang, Zhaohui Jiang, and Ruchuan Wang. 2019. "Adaptive Data Acquisition with Energy Efficiency and Critical-Sensing Guarantee for Wireless Sensor Networks" Sensors 19, no. 12: 2654. https://doi.org/10.3390/s19122654
APA StyleRao, Y., Zhao, G., Wang, W., Zhang, J., Jiang, Z., & Wang, R. (2019). Adaptive Data Acquisition with Energy Efficiency and Critical-Sensing Guarantee for Wireless Sensor Networks. Sensors, 19(12), 2654. https://doi.org/10.3390/s19122654