An Adaptive Track Segmentation Algorithm for a Railway Intrusion Detection System


Abstract
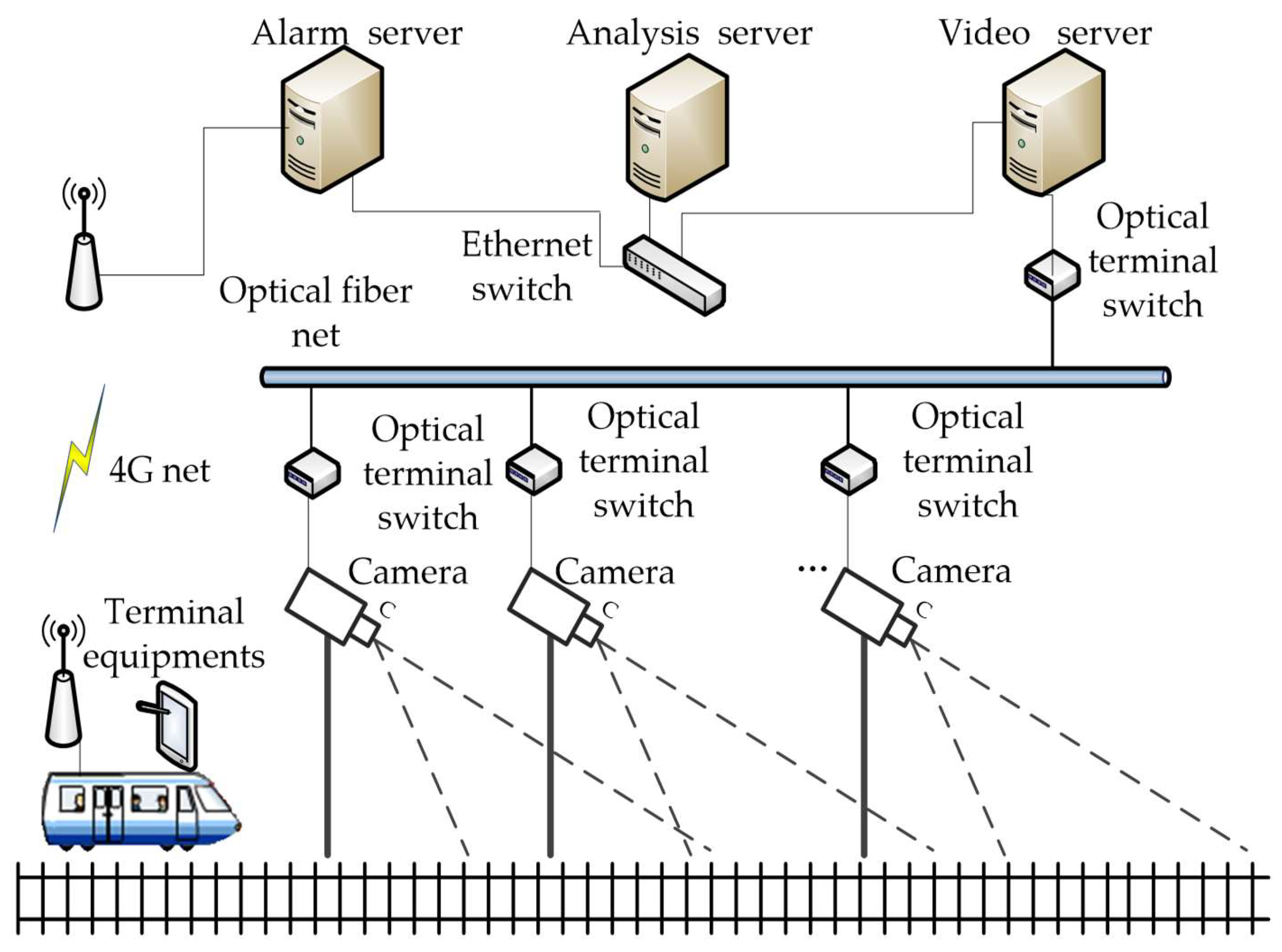
:1. Introduction
- To accelerate the generation of small fragmented regions, we propose a method to find the optimal set of Gaussian kernels with adaptive directions for each specific scene. By making full use of the straight-line characters of the railway scene, a smaller number of adaptive directions are calculated according to the maximum points in Hough transformation rather than being chosen from a set of fixed angles in the traditional way. As a result, the calculation time for the boundary extraction and fragmented region generation is cut in half;
- A new clustering rule based on the boundary weight and the size of the region is set up to accelerate the combination of the regions into local areas. The number of regions is reduced in the process of weak boundary point removal by filtration, and the smallest remaining region is combined with its neighbor region, which shares the weakest boundary;
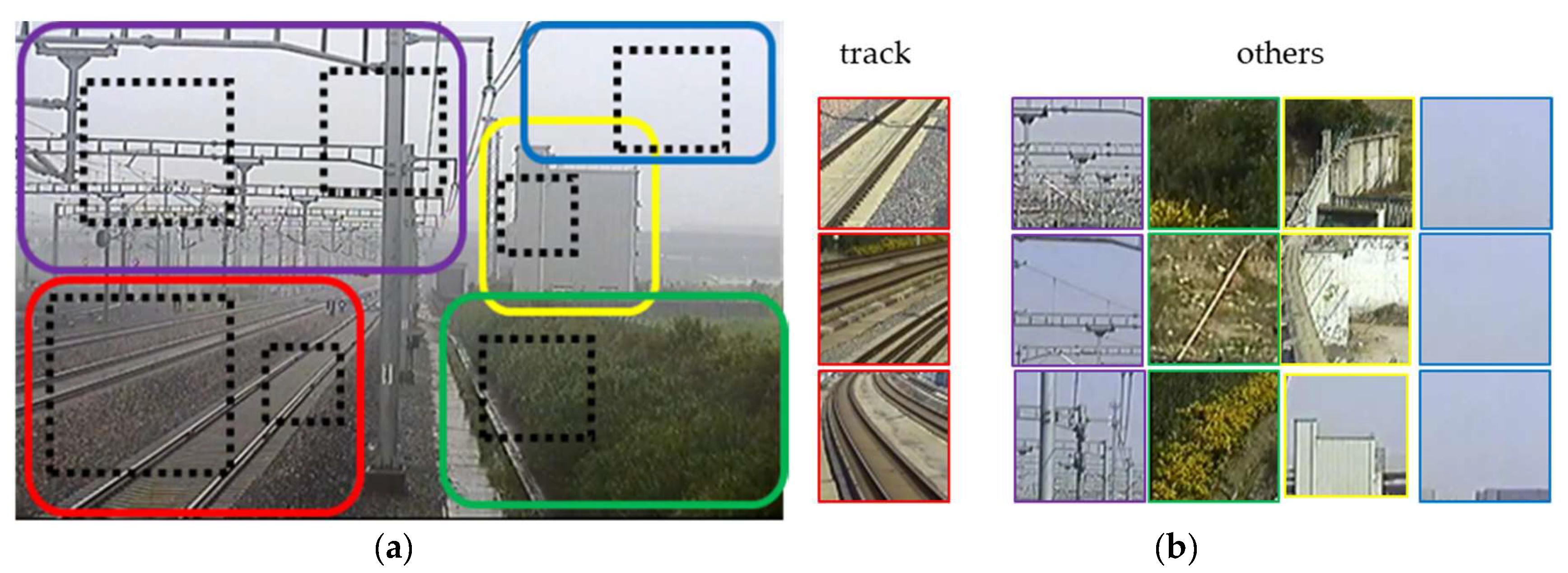
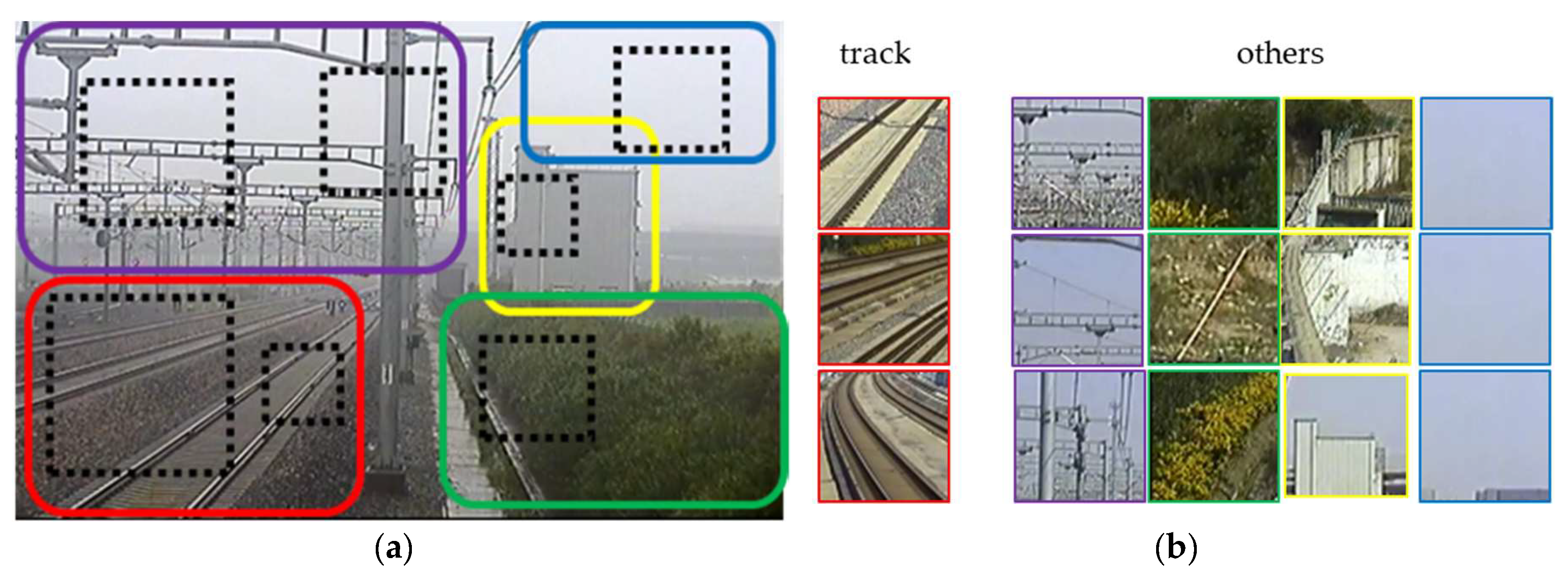
- We propose a specially designed CNN model to achieve the fast classification of local areas without the need of GPU. The local areas are divided into two categories: the track area which is used to judge the intrusion behavior and the rest area which is unrelated to the intrusion. The convolution kernels are pre-trained, and a sparsity penalty term is added into the loss function to enhance the diversity of the convolutional feature maps.
2. Related Work
2.1. Image Parsing by Traditional Methods
2.2. Image Parsing by Deep Learning Methods
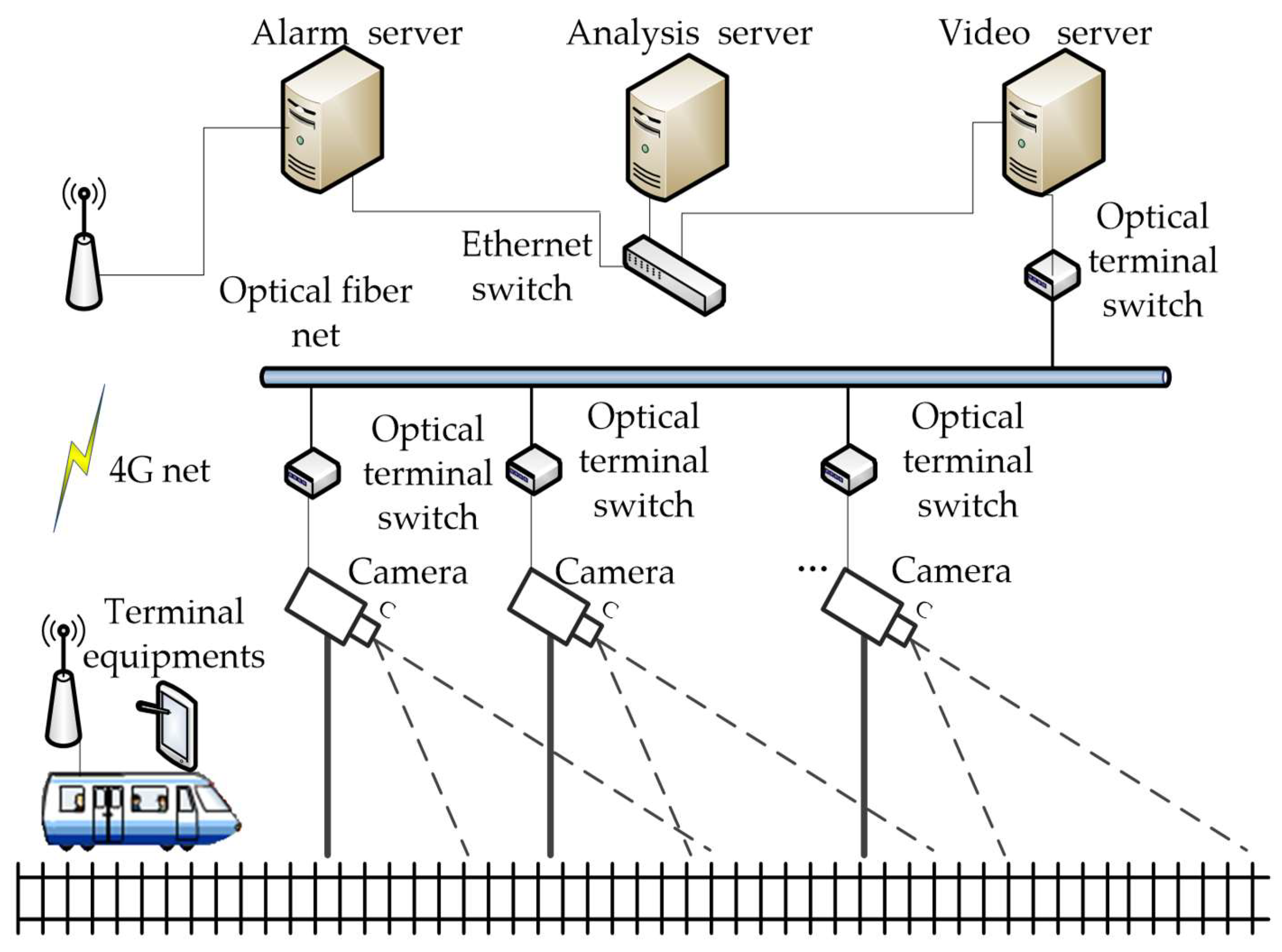
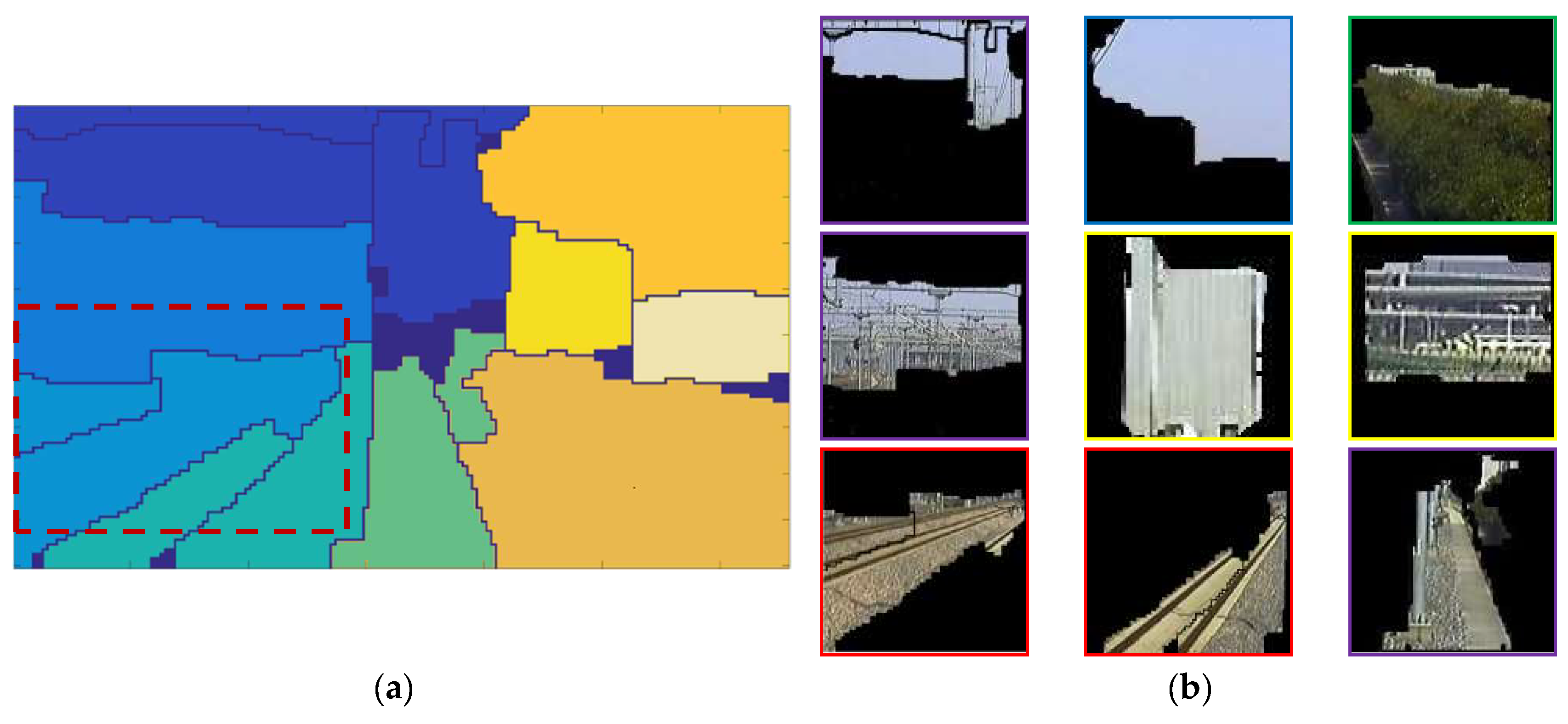
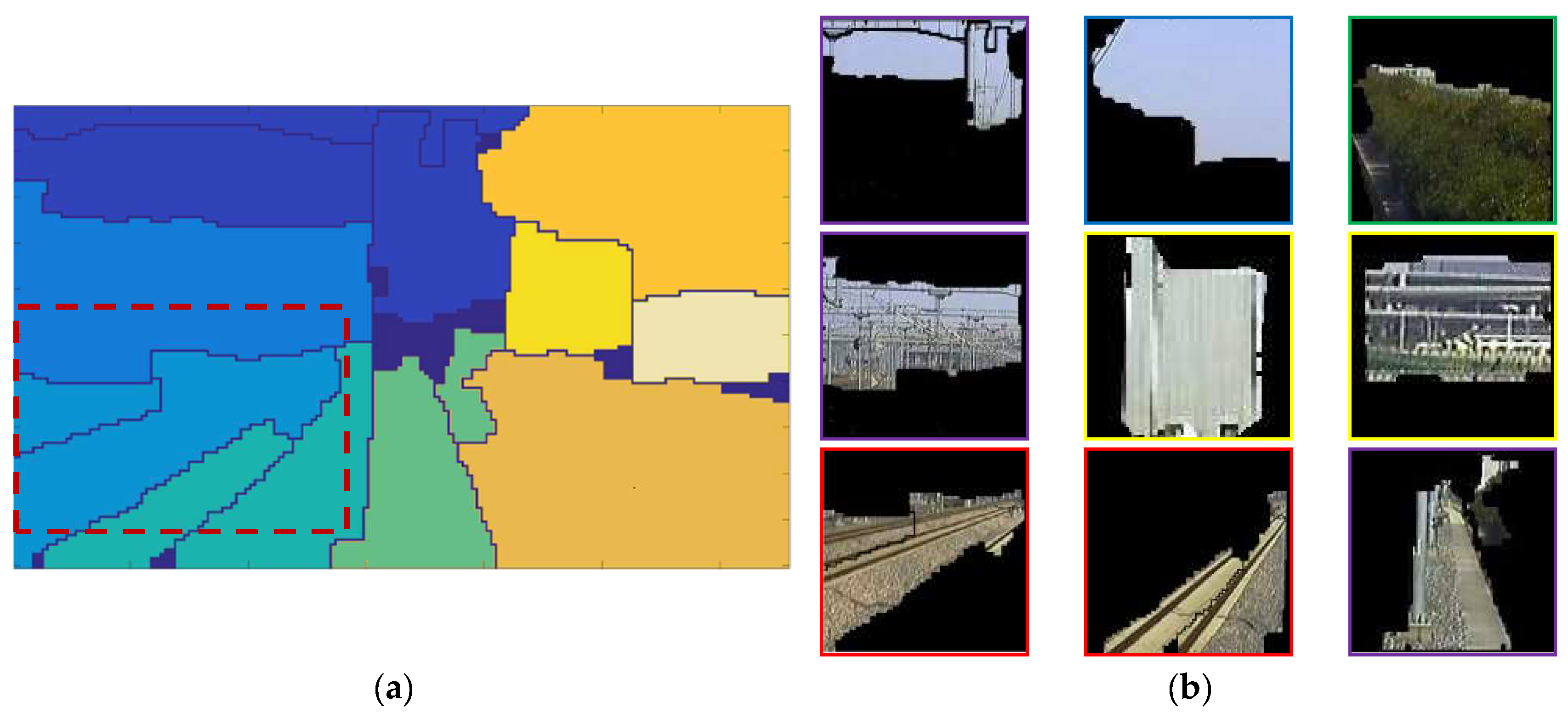
3. Railway Scene Segmentation
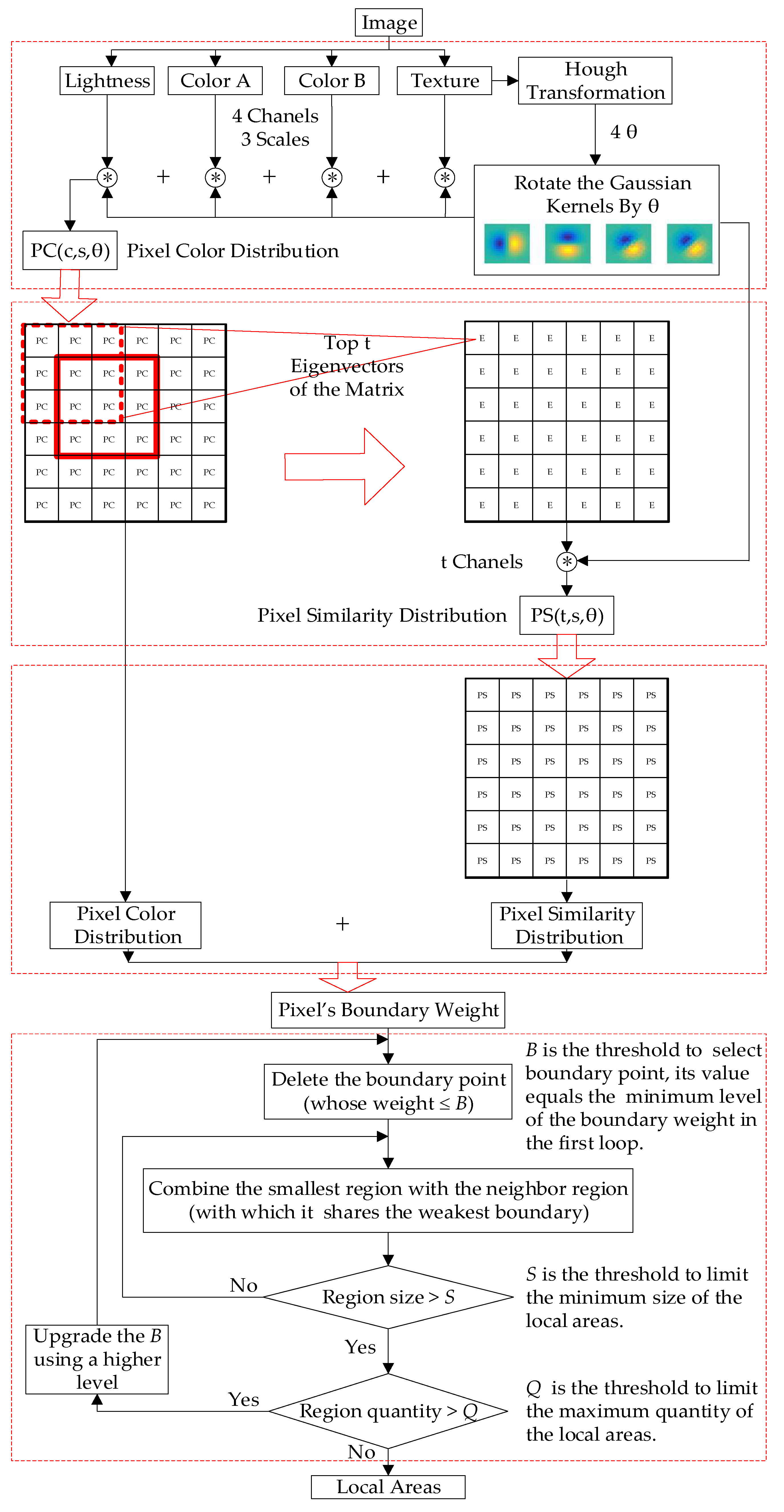
3.1. Generation of Fragmented Regions
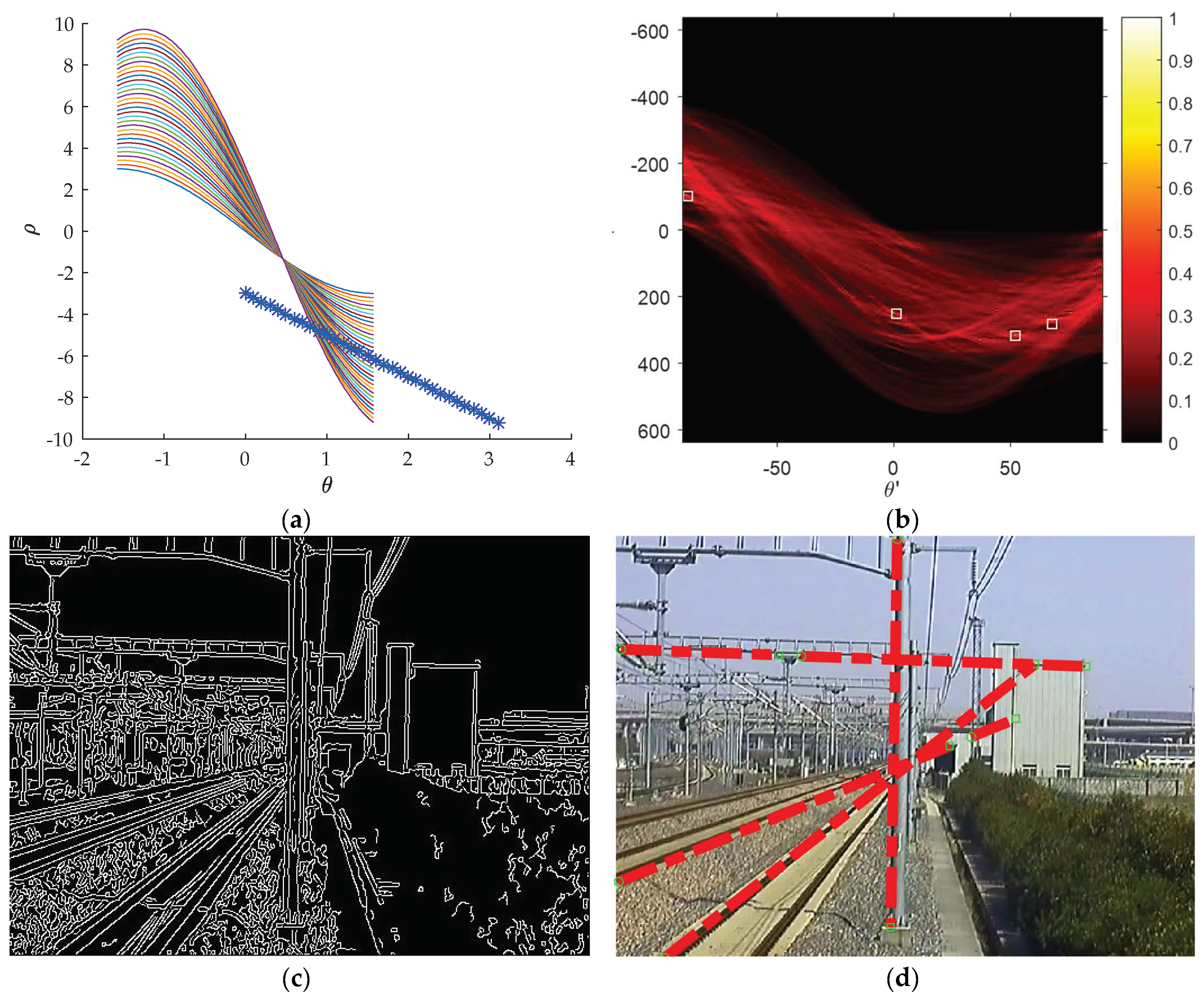
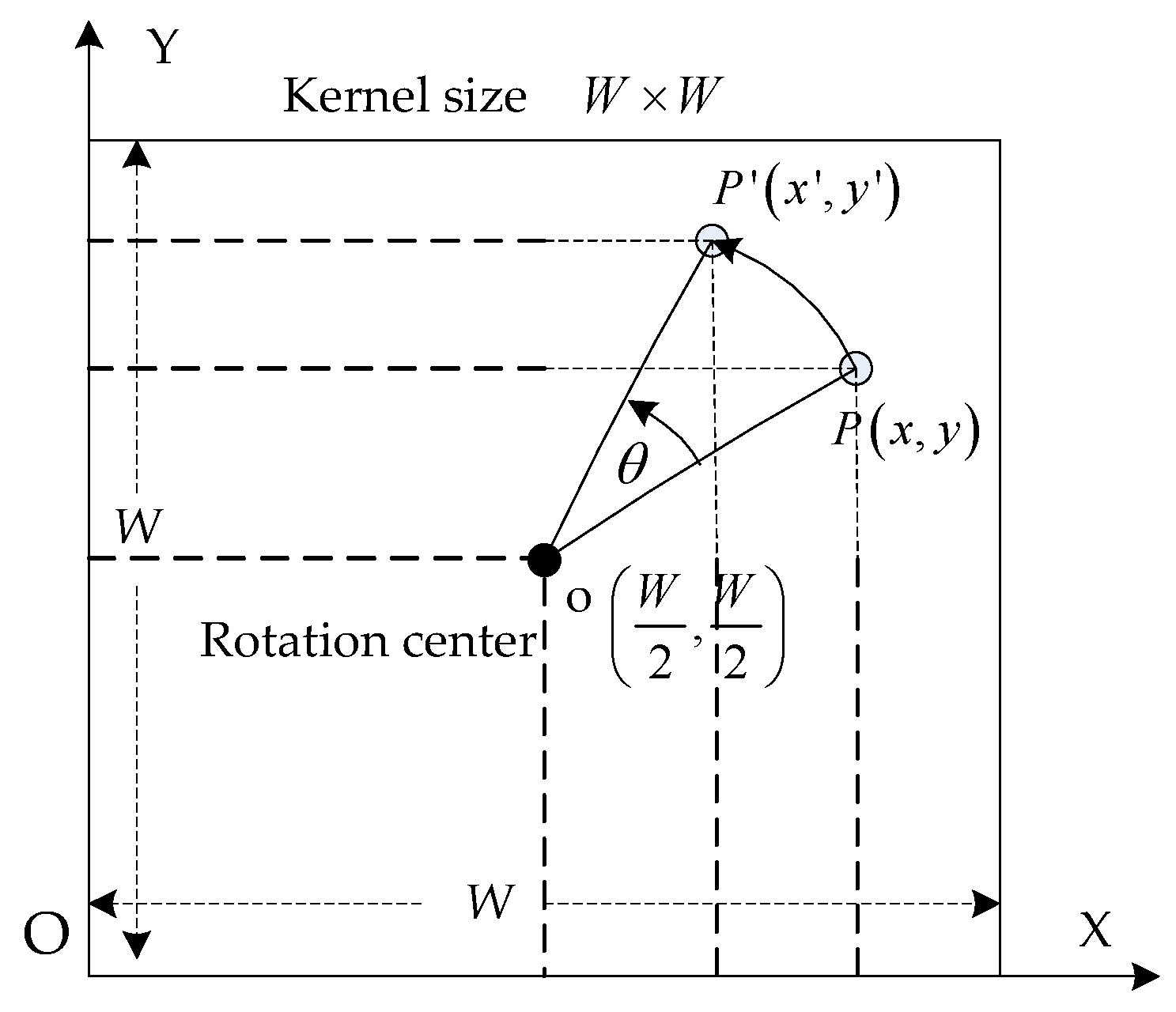
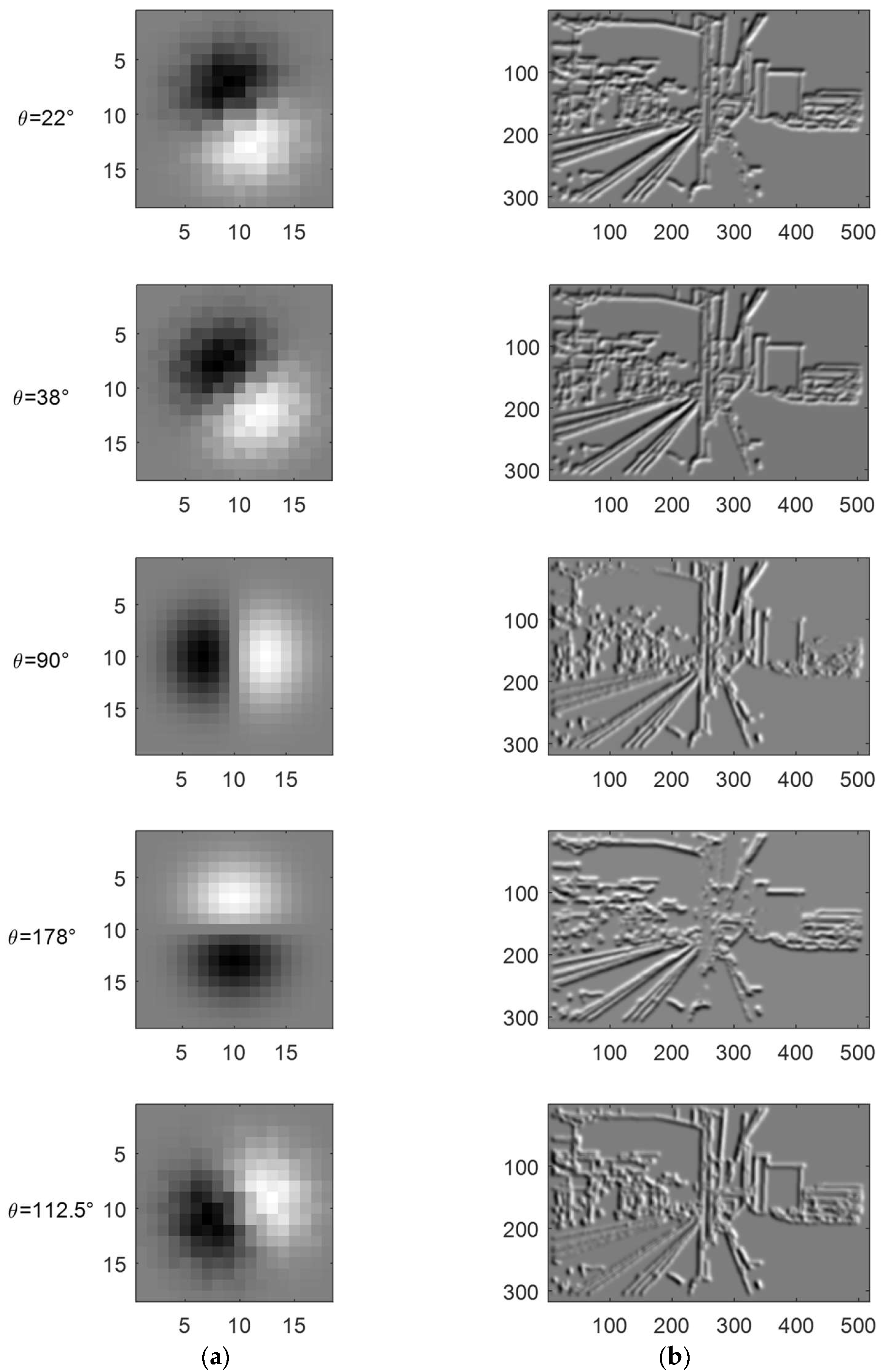
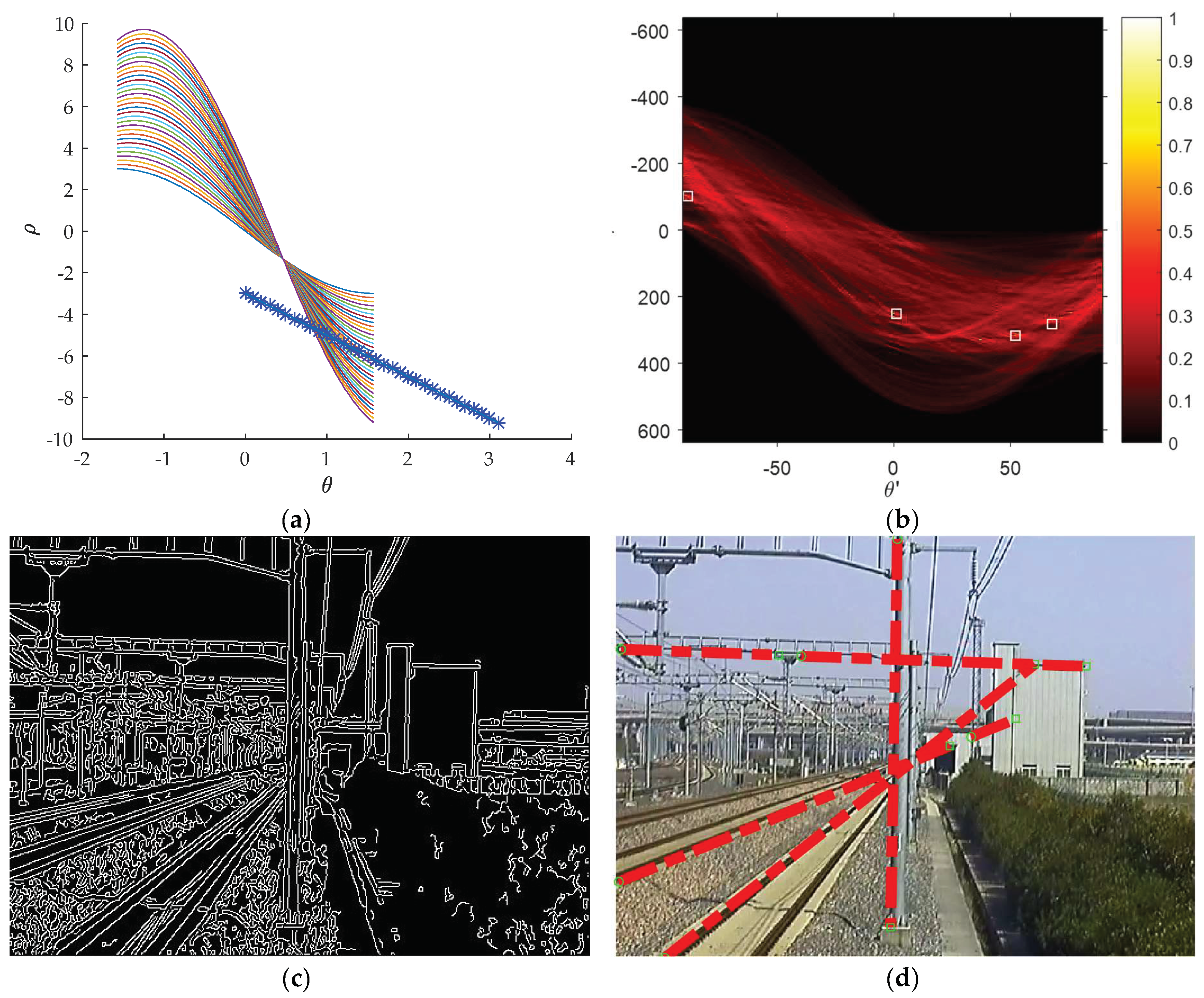
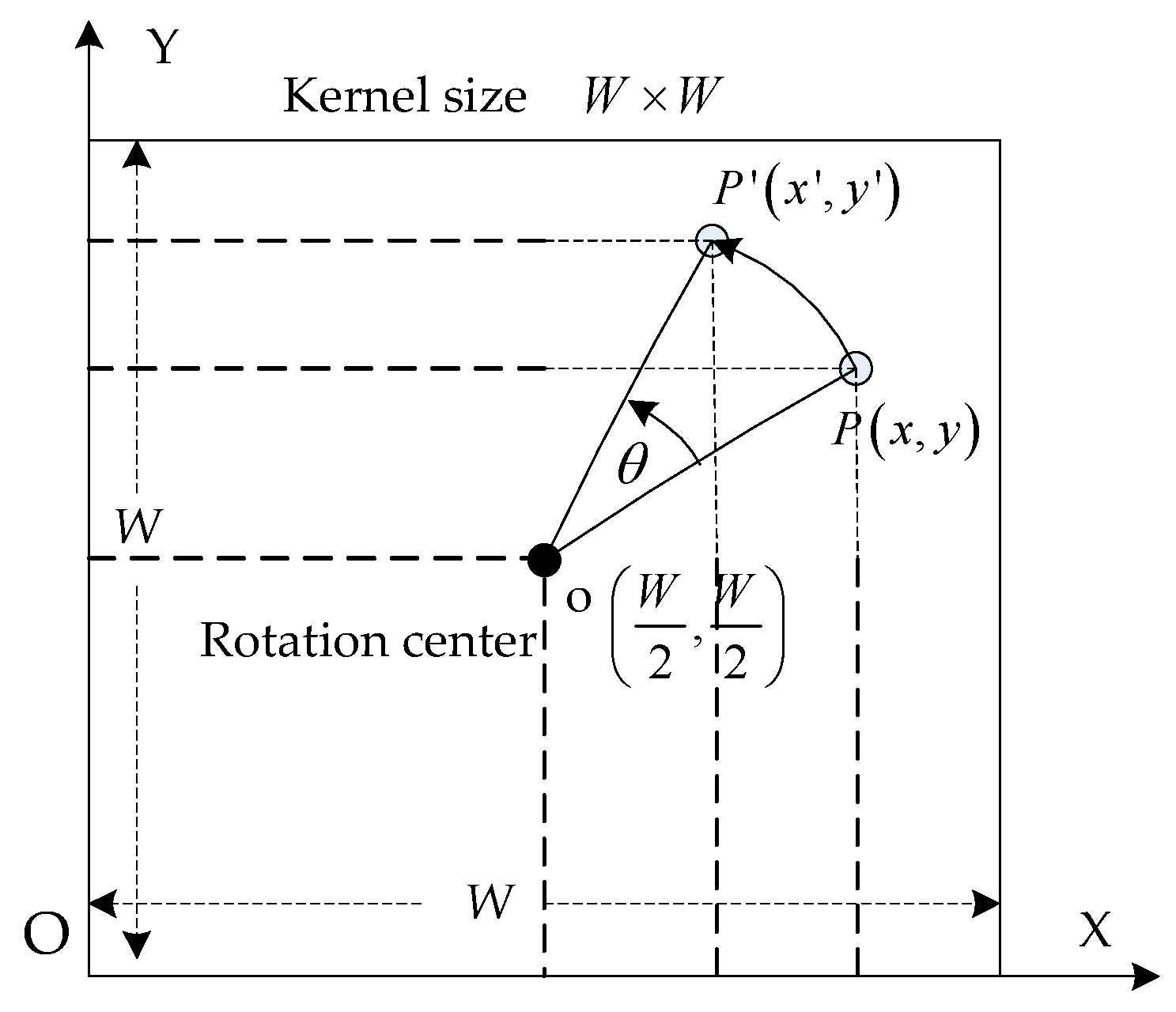
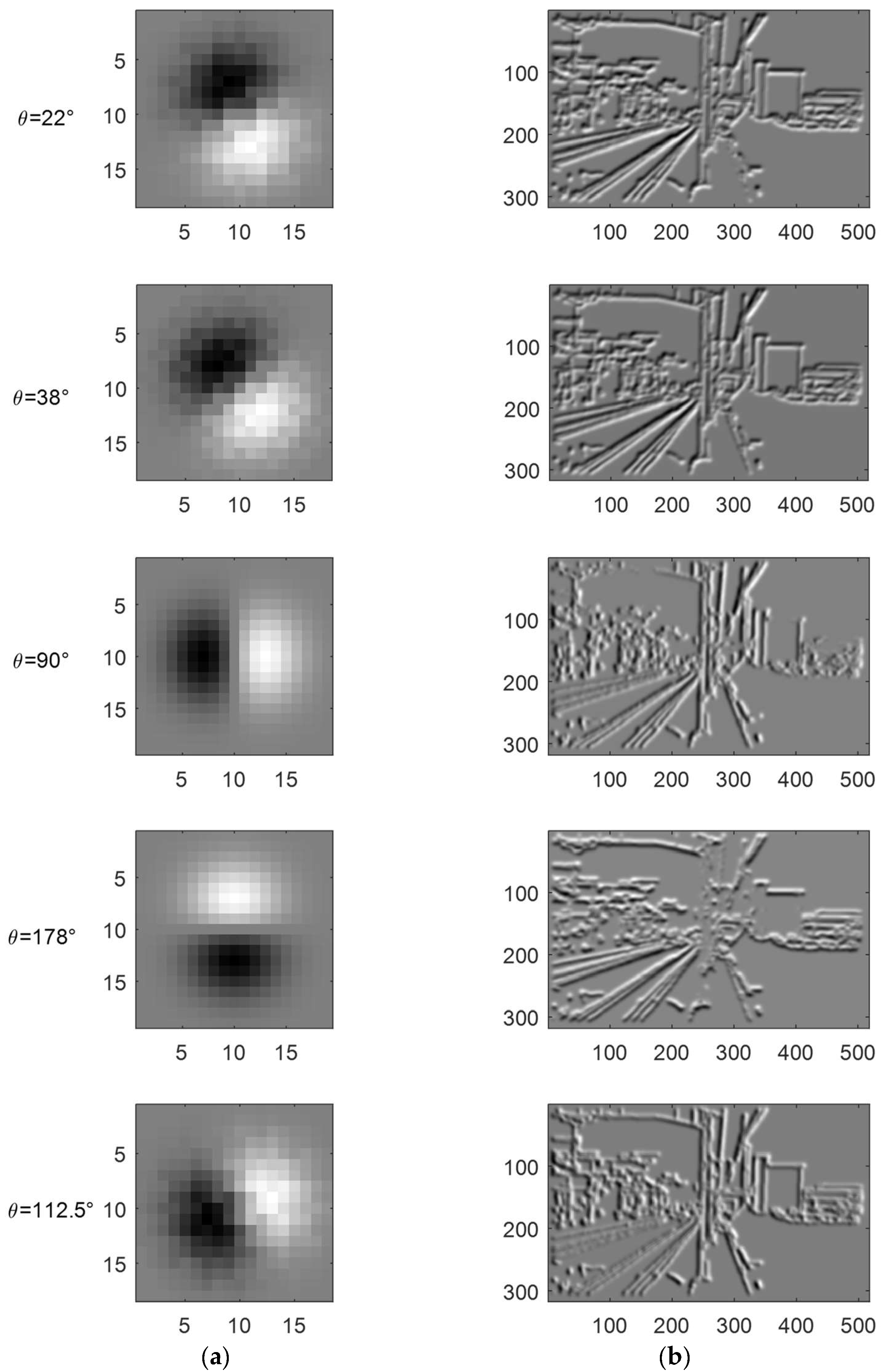
3.2. Finding the Optimal Set of Gaussian Kernels
3.3. Combination Rule
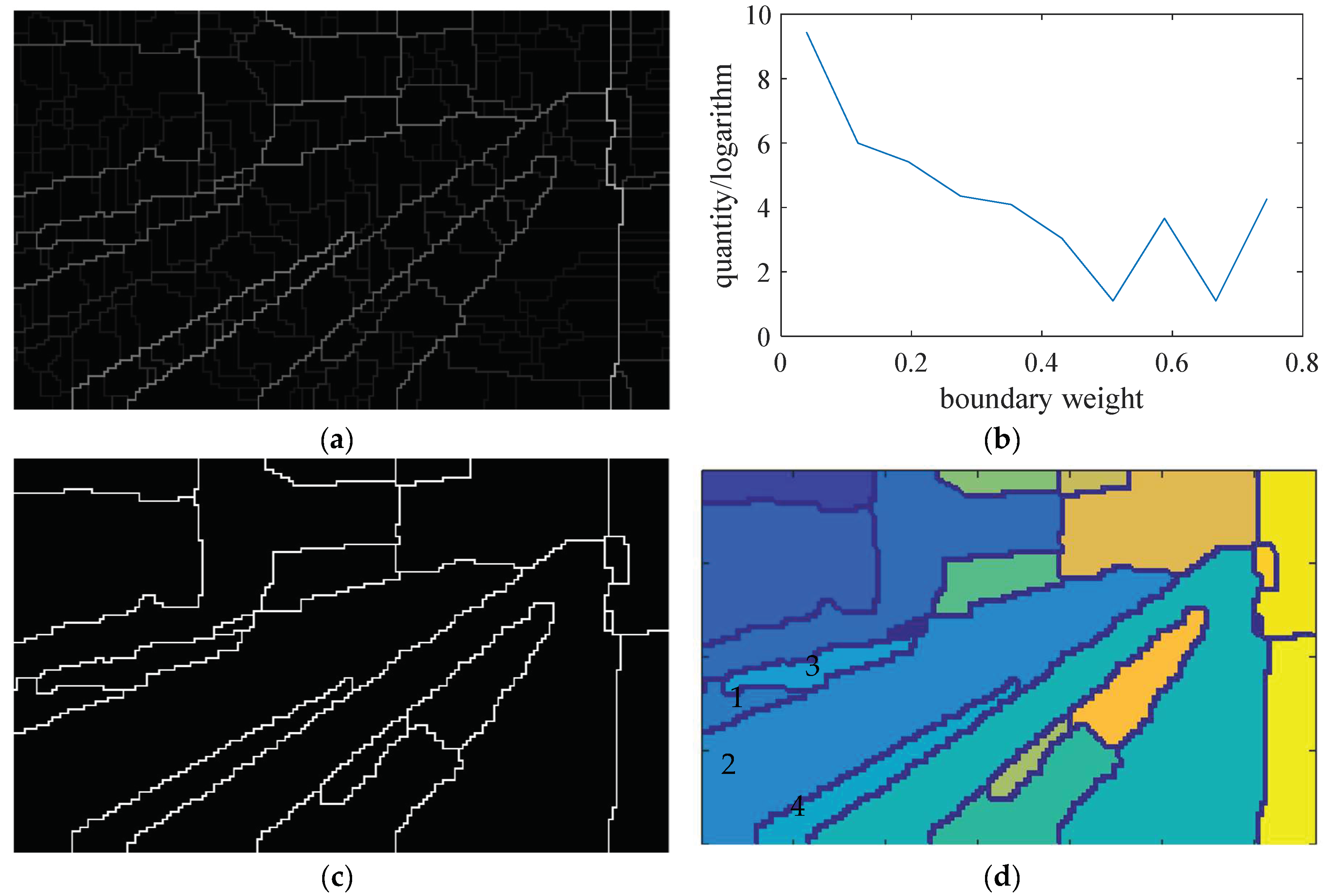
- Let be the normalized value of the boundary point’s weight , where , and is the total number of boundary points:
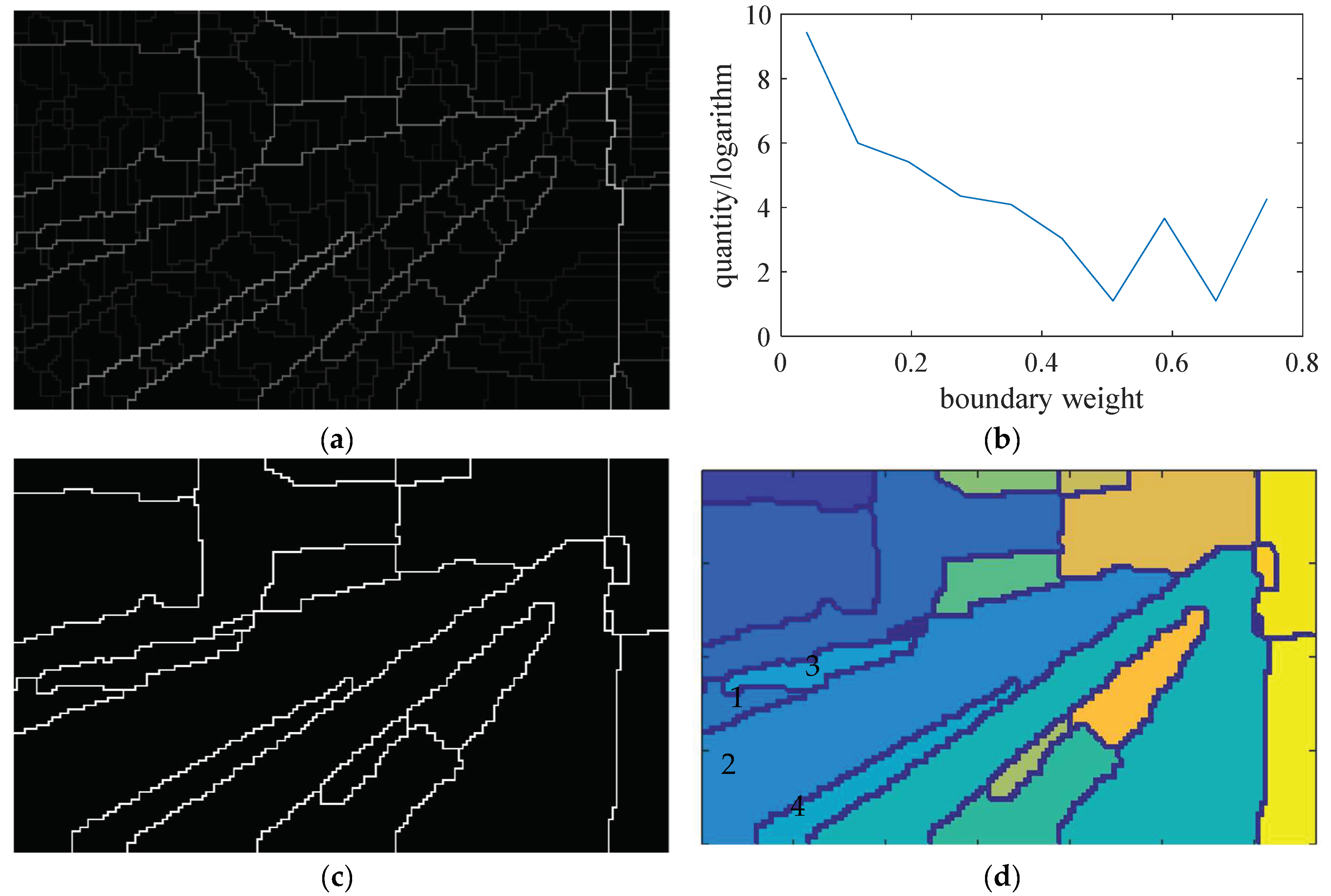
- The statistical distribution of the boundary point weight is shown in Figure 7b. There are many levels of boundary point weights. Choose the minimum level as the threshold to delete the weak boundary points ;
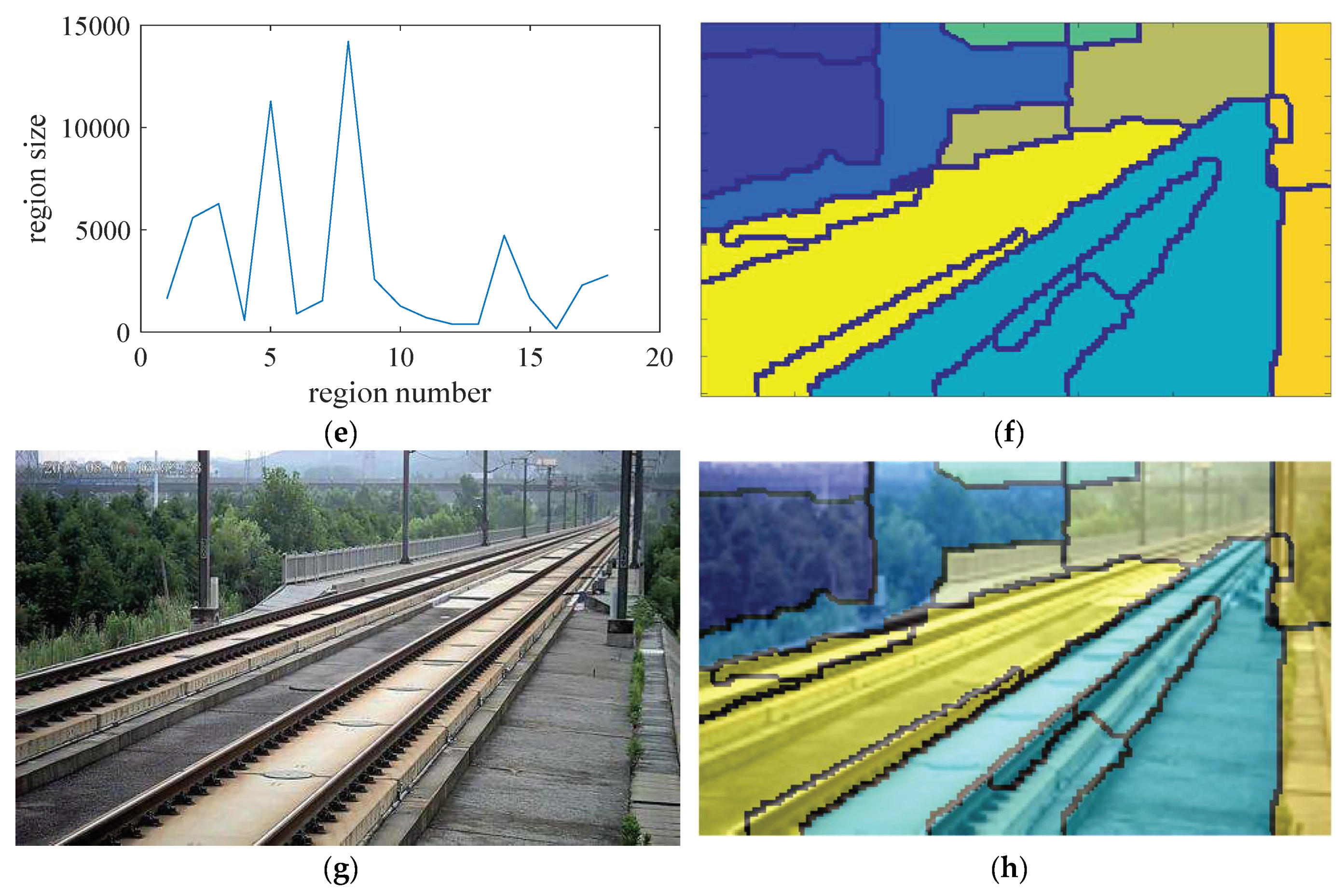
- The statistical distribution of region size is shown in Figure 7e, where , and is the serial number of the regions. Choose the smallest region along its boundary line and find the neighbor region which shares the weakest boundary with it. Then combine them into a new region. As shown in Figure 7d, regions in number 1, 2, 3, and 4 are combined as one new region in Figure 7f;
- Repeat Step 4 to reduce N until the area of the smallest region is larger than a threshold S, which is used to limit the minimum area of the remained regions;
- Compare the final N with another threshold Q to limit the minimum quantity of the remained regions. If , select the second minimum level weight and go back to Step 2;
4. Local Area Recognition in Railway Scene
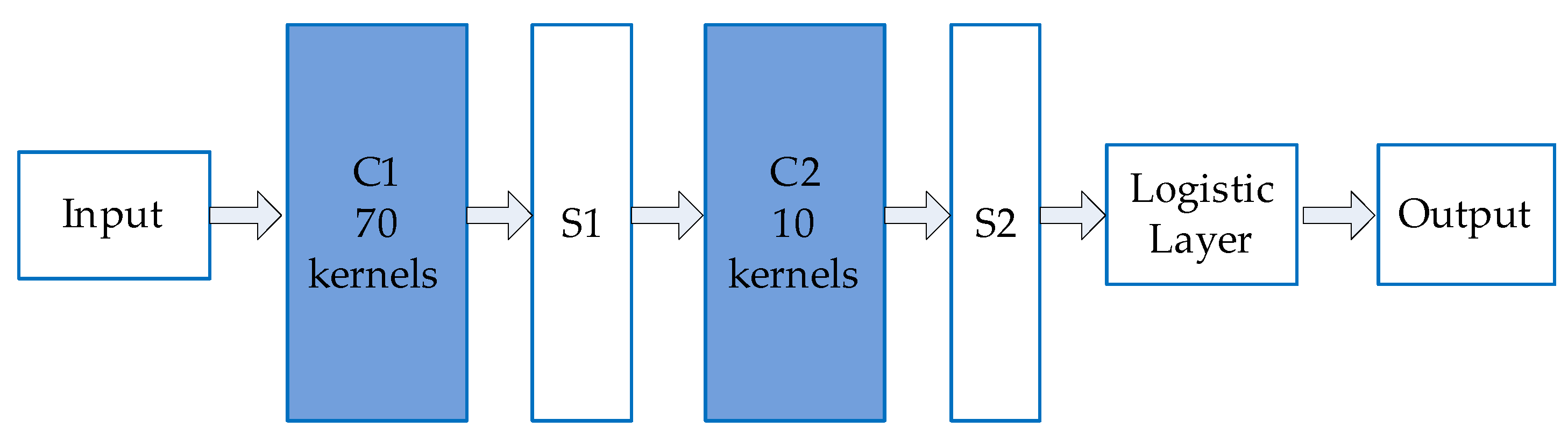
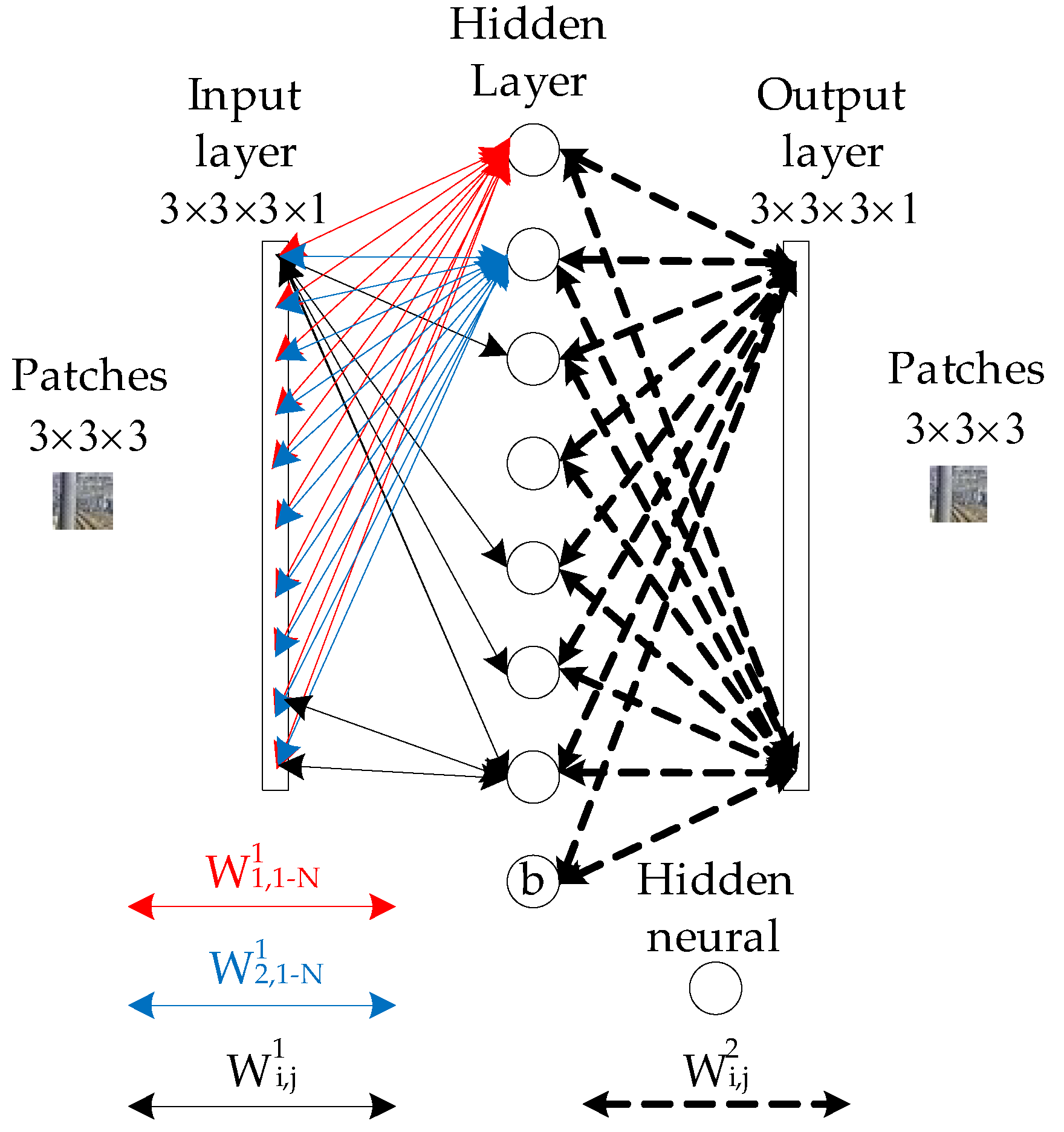
4.1. Structure of Simplified CNN
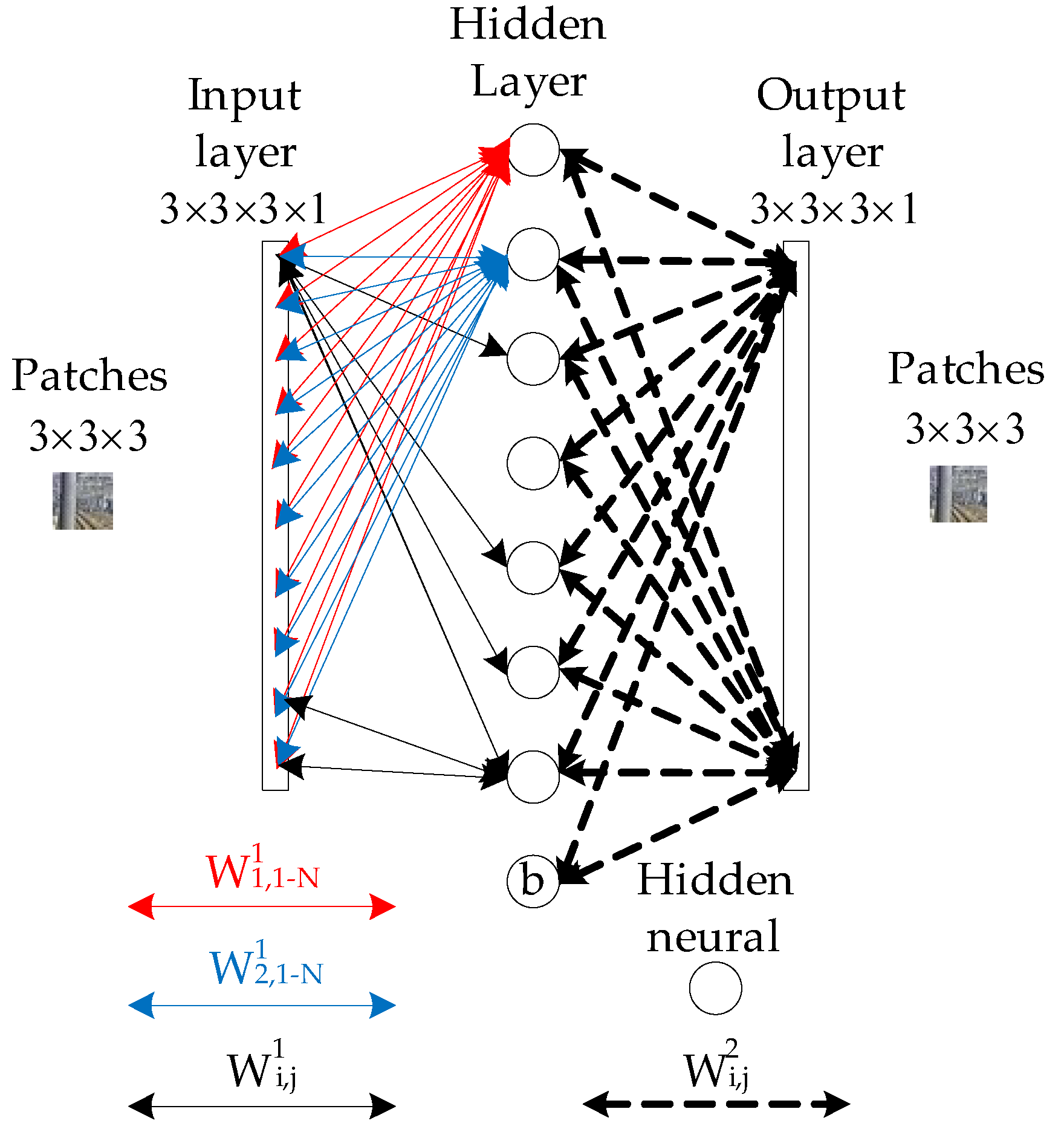
4.2. Optimization of the Simplified CNN
4.3. Performance of the Simplified CNN
5. Experiments and Results
5.1. Railway Scene Dataset
5.2. Modification of the Workflow for the Case of Small Track Portion
5.3. Metrics
5.4. Performance of the Proposed Segmentation Algorithm
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Y.; Yu, Z.; Zhu, L.; Guo, B. Fast feature extraction algorithm for high-speed railway clearance intruding objects based on CNN. J. Sci. Instrum. 2017, 38, 1267–1275. [Google Scholar]
- Hou, G.; Yu, Z. Research on flexible protection technology of high speed railways. J. Railw. Stand. Des. 2006, 11, 16–18. [Google Scholar]
- Cao, D.; Fang, H.; Wang, F.; Zhu, H.; Sun, M. A fiber bragg-grating-based miniature sensor for the fast detection of soil moisture profiles in highway slopes and subgrades. Sensors 2018, 18, 4431. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y. Application study of fiber bragg-grating technology in disaster prevention of high-speed railway. J. Railw. Signal. Commun. 2009, 45, 48–50. [Google Scholar]
- Oh, S.; Kim, G.; Lee, H. A monitoring system with ubiquitous sensors for passenger safety in railway platform. In Proceedings of the 7th International Conference on Power Electronics, Daegu, Korea, 22–26 October 2007; pp. 289–294. [Google Scholar]
- Wang, Y.; Shi, H.; Zhu, L.; Guo, B. Research of surveillance system for intruding the existing railway lines clearance during Beijing-Shanghai high speed railway construction. In Proceedings of the 3rd International Symposium on Test Automation and Instrumentation, Xiamen, China, 22–25 May 2010; pp. 218–223. [Google Scholar]
- Luy, M.; Cam, E.; Ulamis, F.; Uzun, I.; Akin, S.I. Initial results of testing a multilayer laser scanner in a collision avoidance system for light rail vehicles. Appl. Sci. 2018, 8, 475. [Google Scholar] [CrossRef]
- Guo, B.; Yu, Z.; Zhang, N.; Zhu, L.; Gao, C. 3D point cloud segmentation, classification and recognition algorithm of railway scene. Chin. J. Sci. Instrum. 2017, 38, 2103–2111. [Google Scholar]
- Zhan, D.; Jing, D.; Wu, M.; Zhang, D.; Yu, L.; Chen, T. An accurate and efficient vision measurement approach for railway catenary geometry parameters. IEEE Trans. Instrum. Meas. 2018, 67, 2841–2853. [Google Scholar] [CrossRef]
- Guo, B.; Zhu, L.; Shi, H. Intrusion detection algorithm for railway clearance with rapid DBSCAN clustering. J. Sci. Instrum. 2012, 33, 241–247. [Google Scholar]
- Guo, B.; Yang, L.; Shi, H.; Wang, Y.; Xu, X. High-speed railway clearance intrusion detection algorithm with fast background subtraction. J. Sci. Instrum. 2016, 37, 1371–1378. [Google Scholar]
- Shi, H.; Chai, H.; Wang, Y. Study on railway embedded detection algorithm for railway intrusion based on object recognition and tracking. J. China Railw. Soc. 2015, 37, 58–65. [Google Scholar]
- Vazquez, J.; Mazo, M.; Lazaro, J.L.; Luna, C.A.; Urena, J.; Garcia, J.J.; Hierrezuelo, L. Detection of moving objects in railway using vision. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 872–875. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunck, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Arbeláez, P. Boundary extraction in natural images using ultrametric contour maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006; p. 182. [Google Scholar]
- Verbeek, J.; Triggs, B. Region classification with Markov field aspect models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Ladický, L.; Russell, C.; Kohli, P.; Torr, P. Associative hierarchical CRFs for object class image segmentation. In Proceedings of the 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 739–746. [Google Scholar]
- Arbeláez, P.; Pont-Tuset, J.; Barron, J.; Marques, F.; Malik, J. Multiscale combinatorial grouping. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 328–335. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. In Neural Information Processing Systems; Morgan-Kaufmann: San Francisco, CA, USA, 1990; pp. 396–404. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the 9th International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 1, pp. 10–17. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Zhu, Y.; Luo, K.; Ma, C.; Liu, Q.; Jin, B. Superpixel segmentation based synthetic classifications with clear boundary information for a legged robot. Sensors 2018, 18, 2808. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Chen, Y.; Zhang, S. Traffic sign recognition based on pyramid histogram fusion descriptor and HIK-SVM. J. Transp. Syst. Eng. Inf. Technol. 2017, 17, 220–226. [Google Scholar]
- Fang, Z.; Duan, J.; Zheng, B. Traffic signs recognition and tracking based on feature color and SNCC algorithm. J. Transp. Syst. Eng. Inf. Technol. 2014, 14, 47–52. [Google Scholar]
- Liu, K.; Ying, Z.; Cui, Y. SAR image target recognition based on unsupervised K-means feature and data augmentation. J. Signal Process. 2017, 33, 452–458. [Google Scholar]
- Zhang, X.; Fan, J.; Xu, J.; Shi, X. Image super-resolution algorithm via K-means clustering and support vector data description. J. Image Graph. 2016, 21, 135–144. [Google Scholar]
- Ma, G.; Tian, Y.; Li, X. Application of K-means clustering algorithm in color image segmentation of grouper in seawater background. J. Comput. Appl. Softw. 2016, 33, 192–195. [Google Scholar]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Pont-Tuset, J.; Arbeláez, P.; Barron, J.; Marques, F.; Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 128–140. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. arXiv, 2013; arXiv:1301.3572. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D Images for object detection and segmentation. In Proceedings of the 13th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; Volume 8695, pp. 345–360. [Google Scholar]
- Petrelli, A.; Pau, D.; Di Stefano, L. Analysis of compact features for RGB-D visual research. In Proceedings of the 18th International Conference on Image Analysis & Processing, Genoa, Italy, 7–11 September 2015; Volume 9280, pp. 14–24. [Google Scholar]
- Canny, J.F. A computation approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 769–798. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel Size | Kernel Quantity | Calculation Time (s) | Accuracy | |
|---|---|---|---|---|
| C1 | C2 | |||
| 3 × 3 | 50 | 10 | 0.00372 | 72.25% |
| 70 | 10 | 0.00495 | 73% | |
| 100 | 10 | 0.00689 | 75% | |
| 5 × 5 | 100 | 10 | 0.0125 | 76% |
| 7 × 7 | 100 | 10 | 0.0217 | 76.5% |
| Kernel Size | Kernel Quantity | Accuracy | |
|---|---|---|---|
| C1 | C2 | ||
| 3 × 3 | 50 | 10 | 98% |
| 70 | 10 | 98.5 | |
| 100 | 10 | 98.5% | |
| 5 × 5 | 100 | 10 | 98.75% |
| 7 × 7 | 100 | 10 | 99.25% |
| Partial-Scanning Workflow | Complete-Processing Workflow | ||||
|---|---|---|---|---|---|
| Scan Time (s) | Proportion of Track Area | Segmentation and Classification Time (s) | Total (s) | Time (s) | |
| 1 | 0.297 | 41.7% | 1.042 | 1.339 | 2.5 |
| 2 | 0.297 | 25% | 0.625 | 0.922 | 2.5 |
| 3 | 0.297 | 75% | 1.875 | 2.172 | 2.5 |
| 4 | 0.297 | 40% | 1 | 1.927 | 2.5 |
| 5 | 0.297 | 30% | 0.75 | 1.047 | 2.5 |
| Algorithm | Mean IU | Mean PA | Mean EP | Time (s) | |
|---|---|---|---|---|---|
| MCG | 72.05% | 79.94% | 10.63% | 7 | |
| FCN | 89.83% | 91.26% | 16.20% | 41 | |
| Our Algorithm | Four optimal Gaussian kernels | 81.94% | 95.90% | 18.17% | 0.9–2.8 |
| Eight regular Gaussian kernels | 85.23% | 93.85% | 17.56% | 1.1–4.4 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhu, L.; Yu, Z.; Guo, B. An Adaptive Track Segmentation Algorithm for a Railway Intrusion Detection System. Sensors 2019, 19, 2594. https://doi.org/10.3390/s19112594
Wang Y, Zhu L, Yu Z, Guo B. An Adaptive Track Segmentation Algorithm for a Railway Intrusion Detection System. Sensors. 2019; 19(11):2594. https://doi.org/10.3390/s19112594
Chicago/Turabian StyleWang, Yang, Liqiang Zhu, Zujun Yu, and Baoqing Guo. 2019. "An Adaptive Track Segmentation Algorithm for a Railway Intrusion Detection System" Sensors 19, no. 11: 2594. https://doi.org/10.3390/s19112594
APA StyleWang, Y., Zhu, L., Yu, Z., & Guo, B. (2019). An Adaptive Track Segmentation Algorithm for a Railway Intrusion Detection System. Sensors, 19(11), 2594. https://doi.org/10.3390/s19112594