Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving


 ,
,  ,
,  ,
,
Abstract
:1. Introduction
- We propose a new light-weight network for semantic segmentation. Basically, the DeconvNet architecture is downsampled to half the original size which performs better for the off-road autonomous driving domain;
- We use the TL technique to segment the Freiburg Forest dataset. During this, the light-weight network is initialized with the trained weights from the corresponding layers in the Deconvnet architecture;
- We study the effect of using various synthetic datasets as an intermediate domain to segment the real-world dataset in detail.
2. Background and Related Work
2.1. Background
2.1.1. Convolutional Neural Networks (CNN)
2.1.2. Transfer Learning
2.2. Related Work
3. Proposed Methods
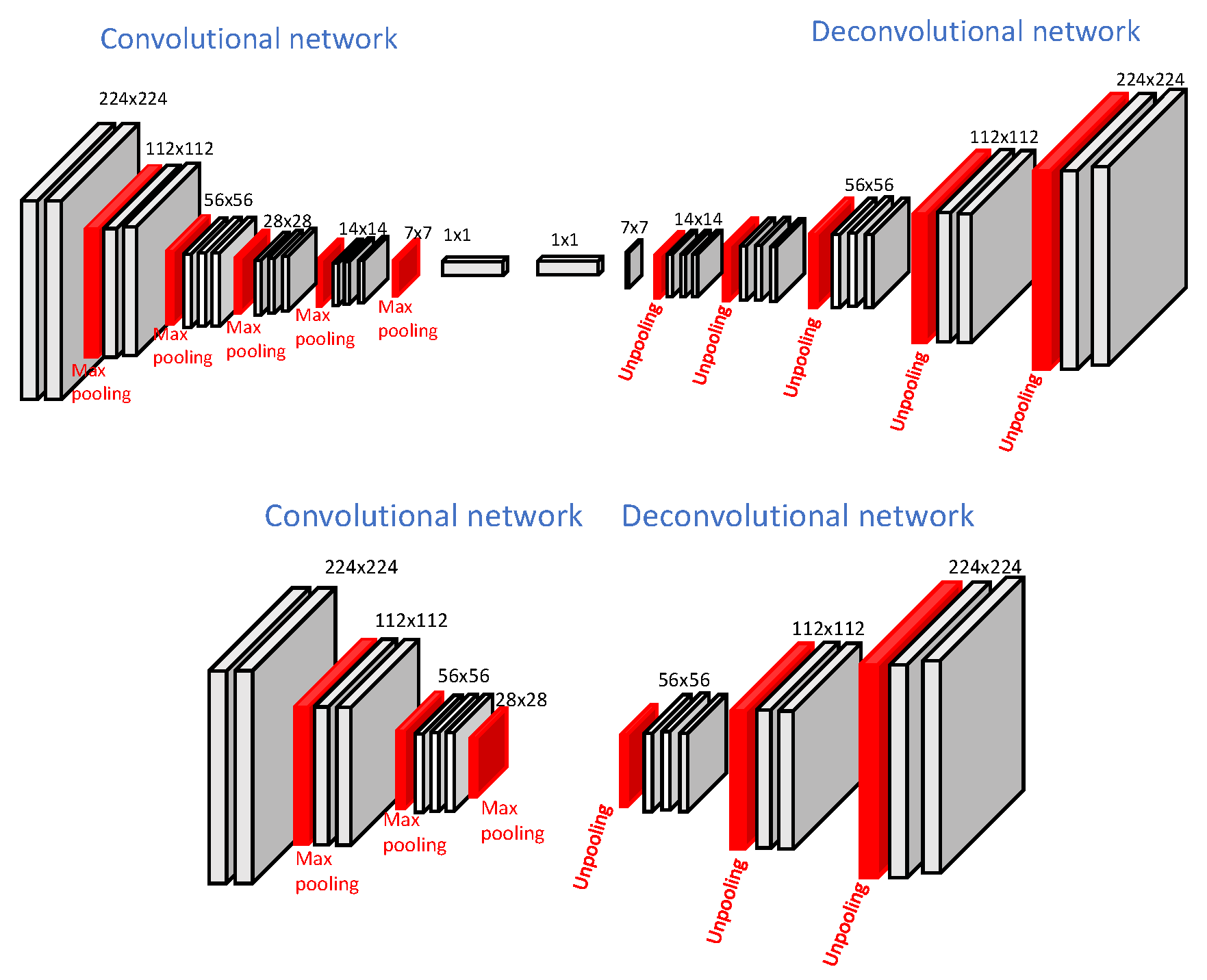
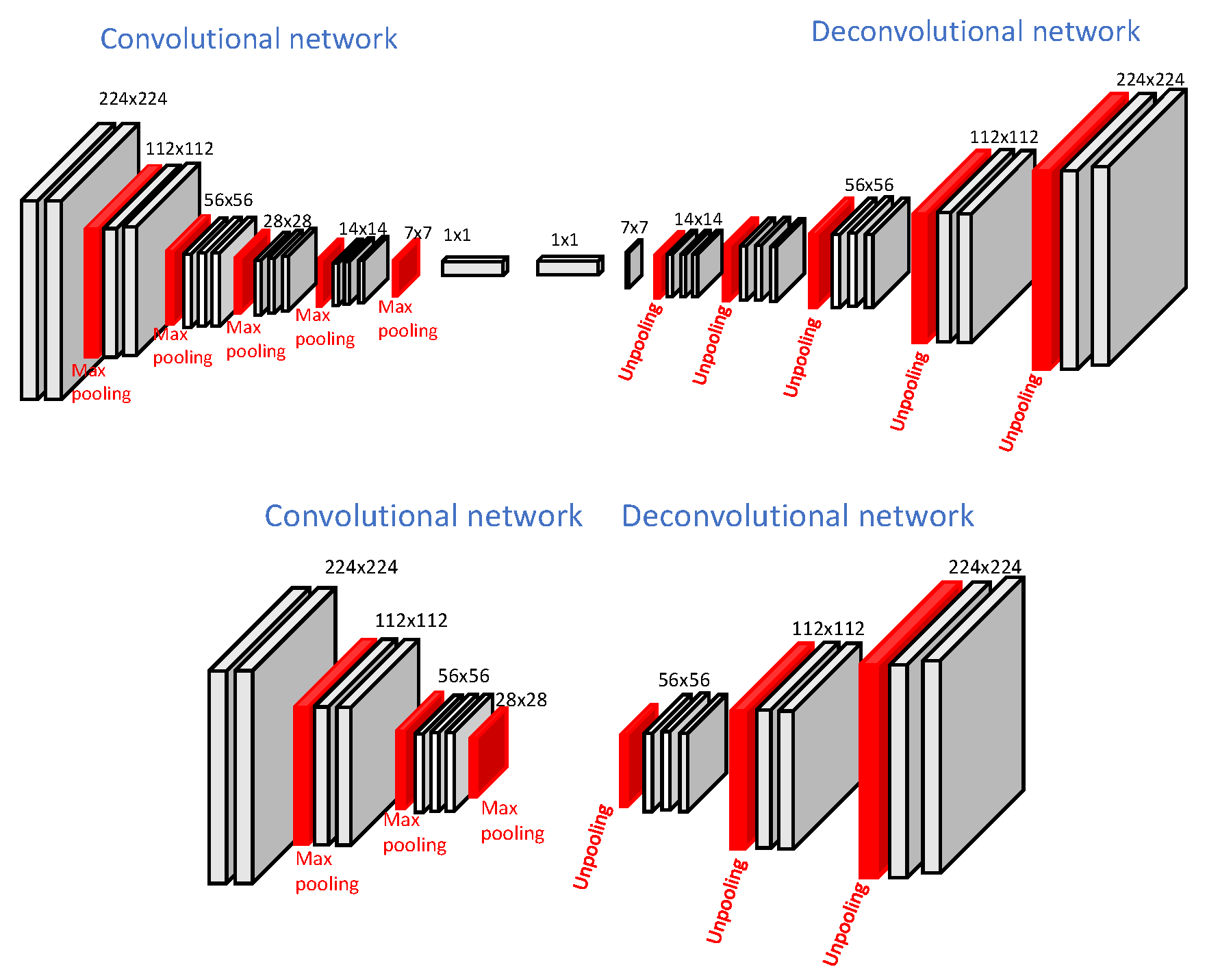
3.1. Segmentation Network Structure
3.1.1. Computational Complexity
3.1.2. Frame Rate
3.2. Training
4. Experiments and Results
4.1. Dataset Description
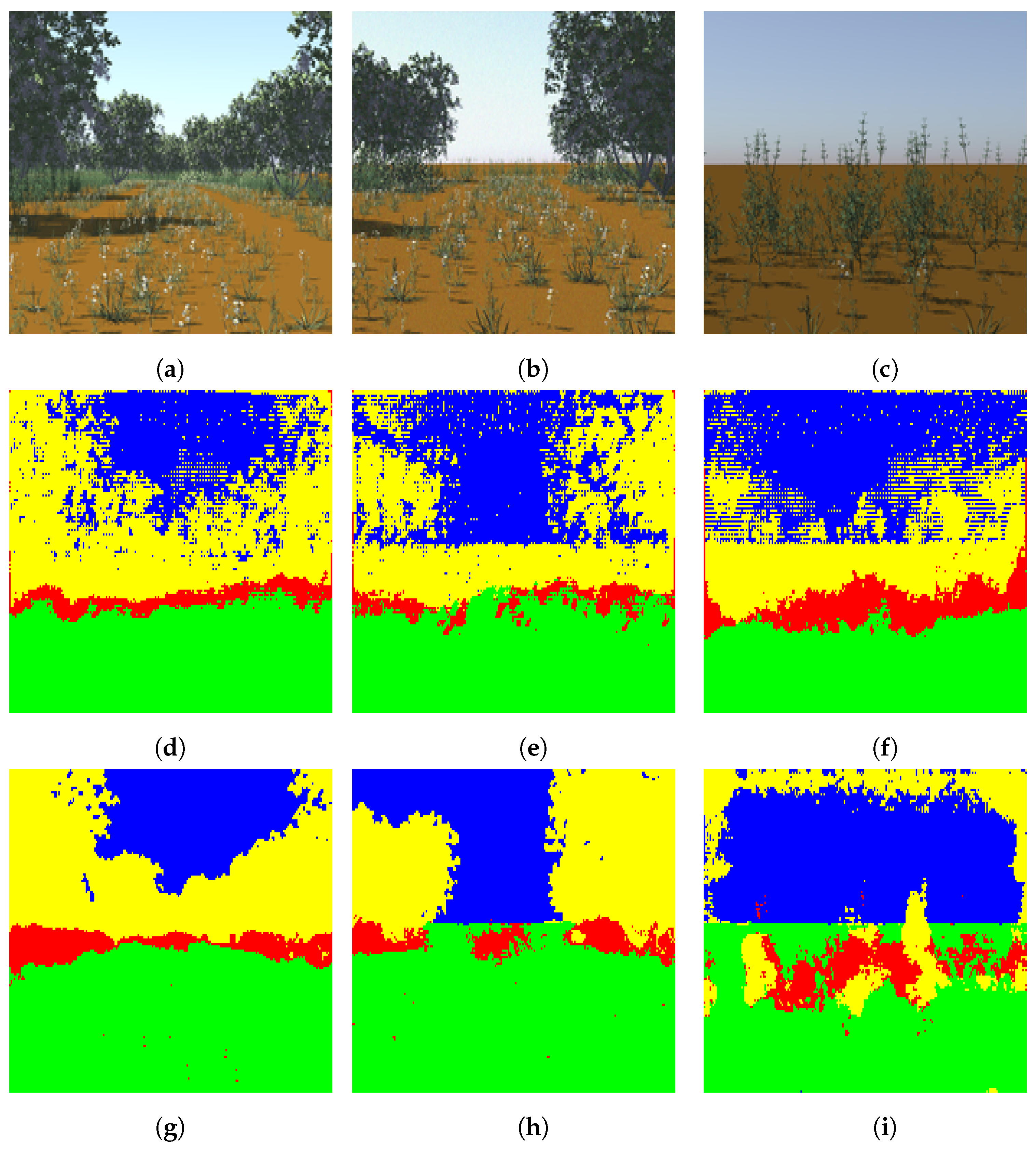
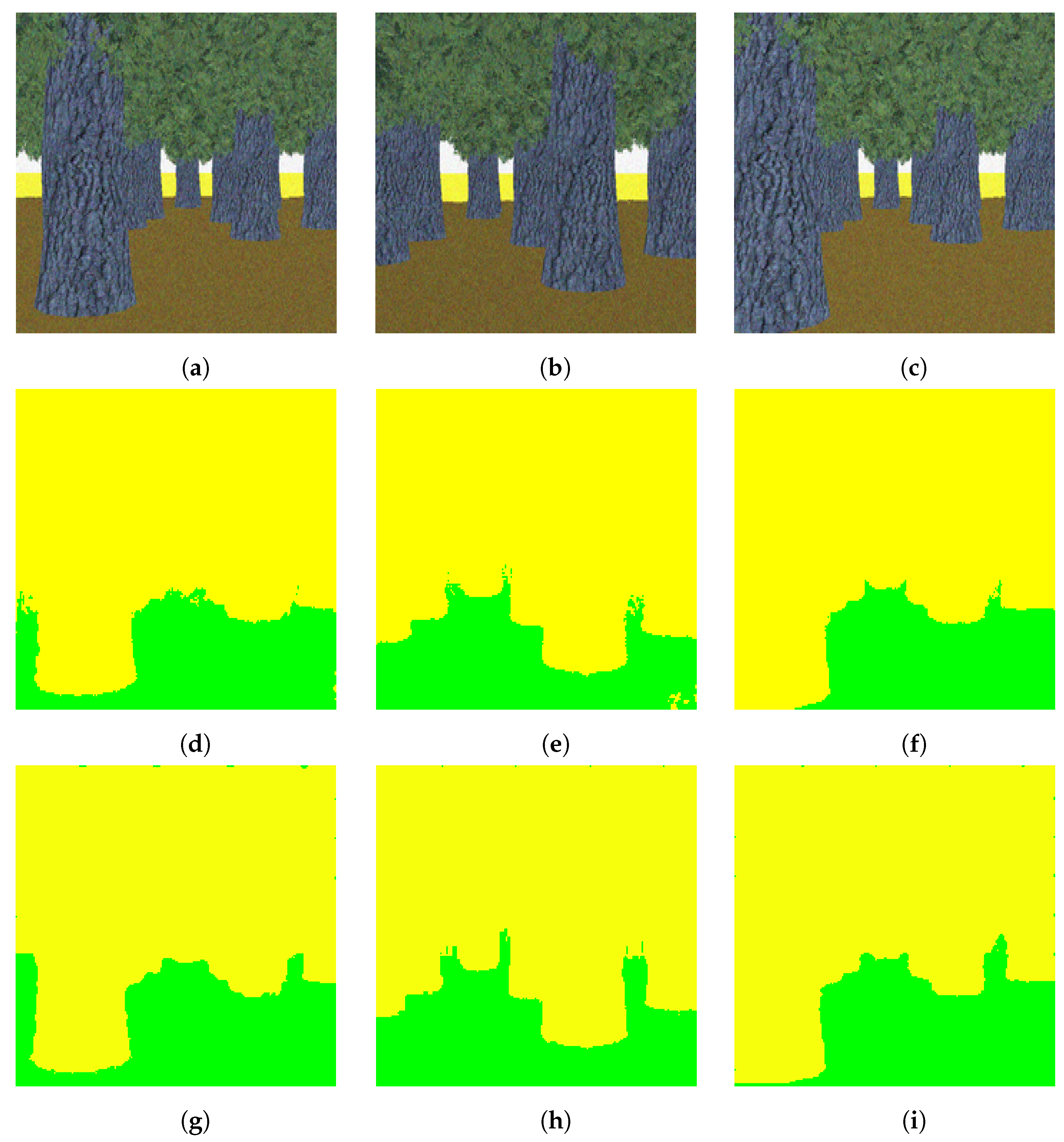
4.1.1. The Synthetic Dataset
The Two-Class Synthetic Dataset
The Four-Class High-Definition Dataset
The Four-Class Random Synthetic Dataset
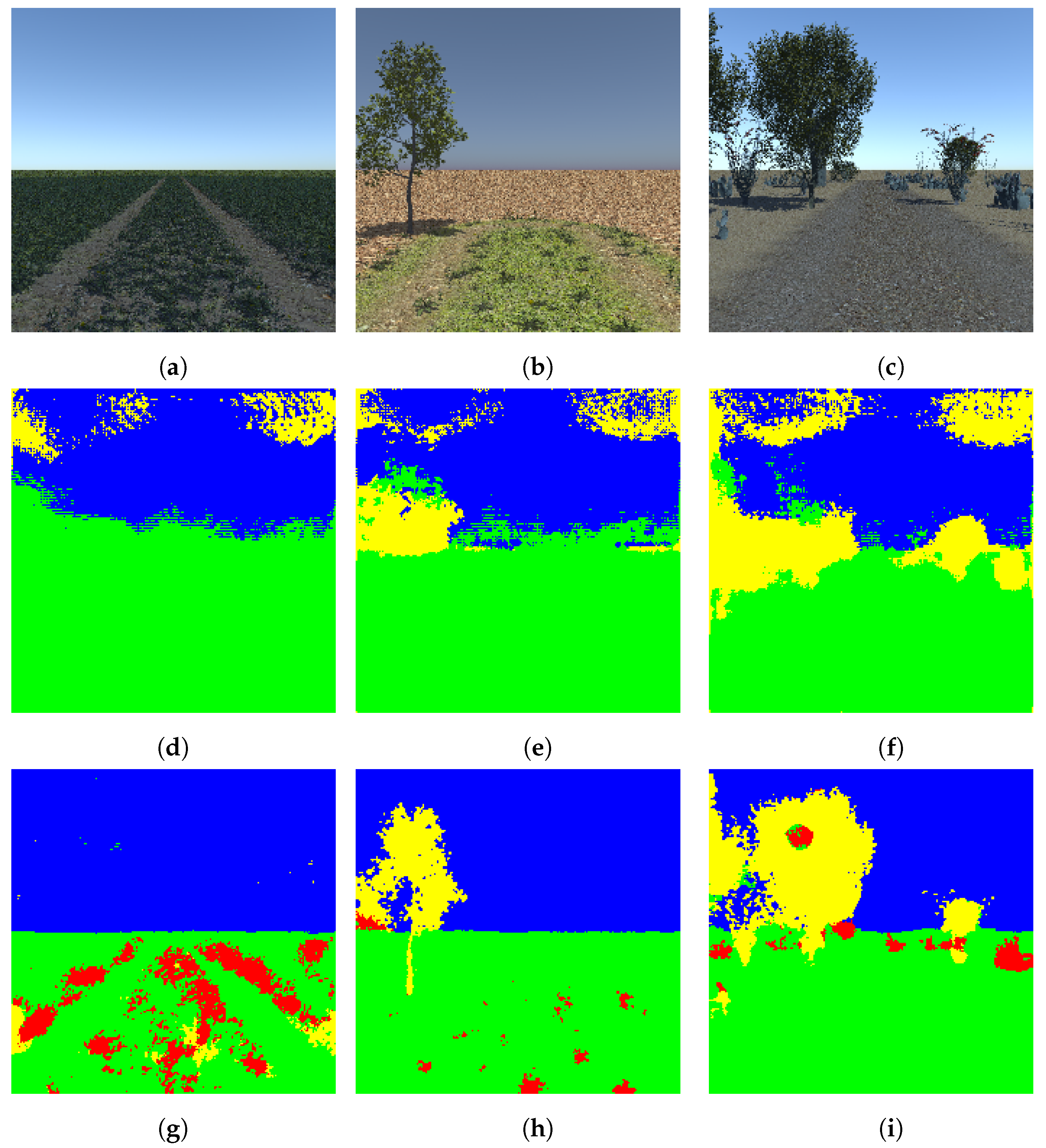
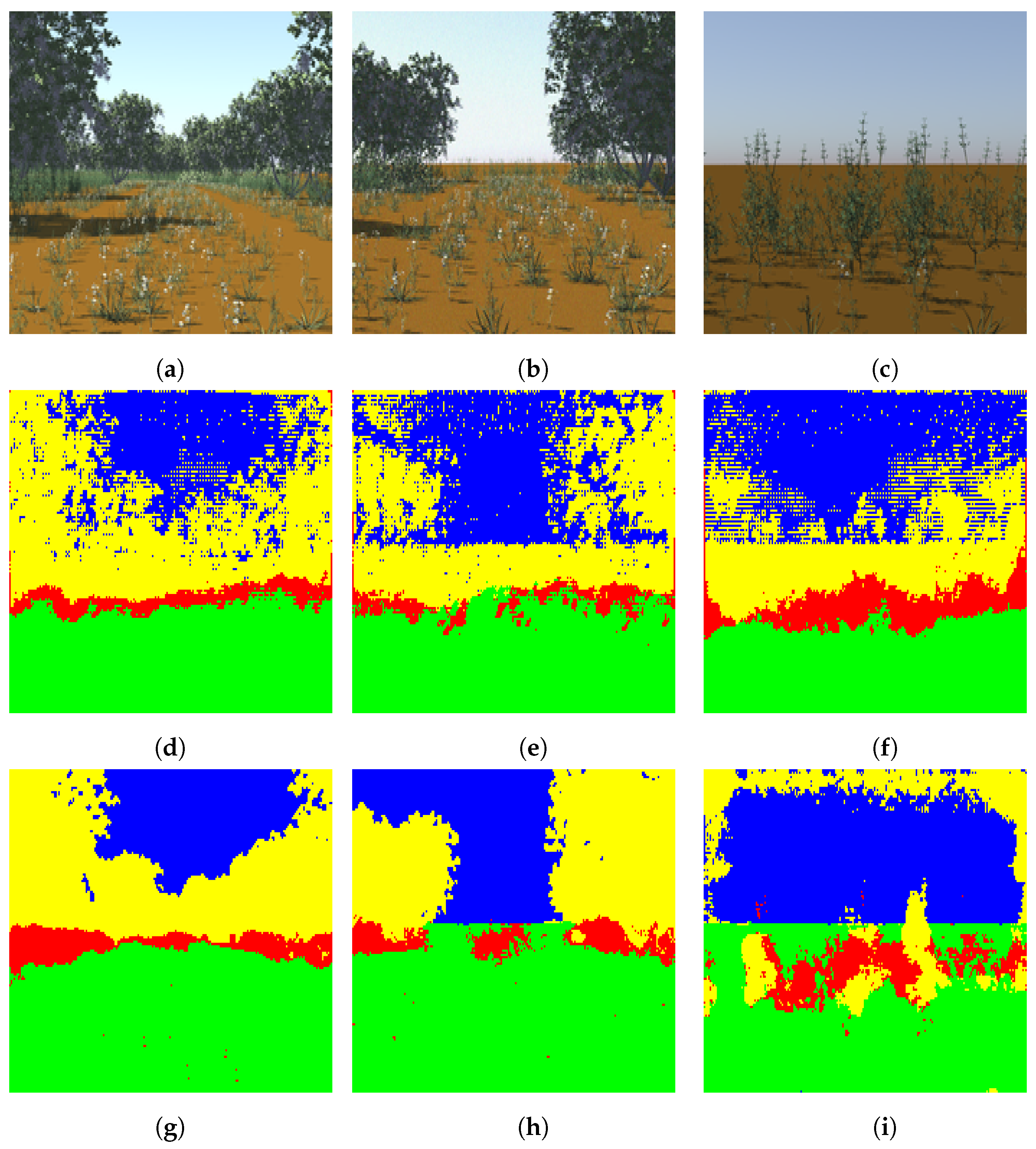
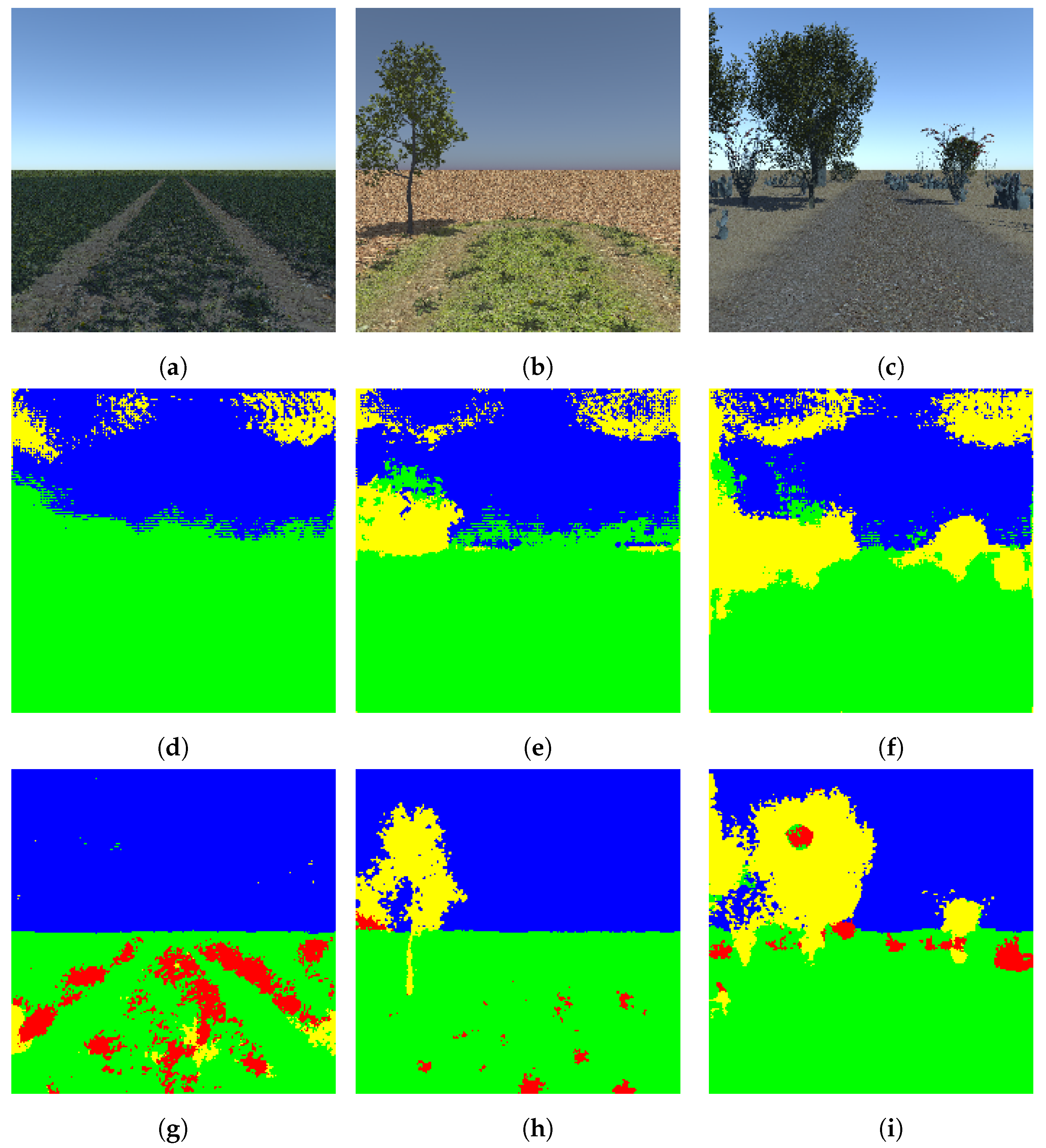
4.1.2. The Real-World Dataset
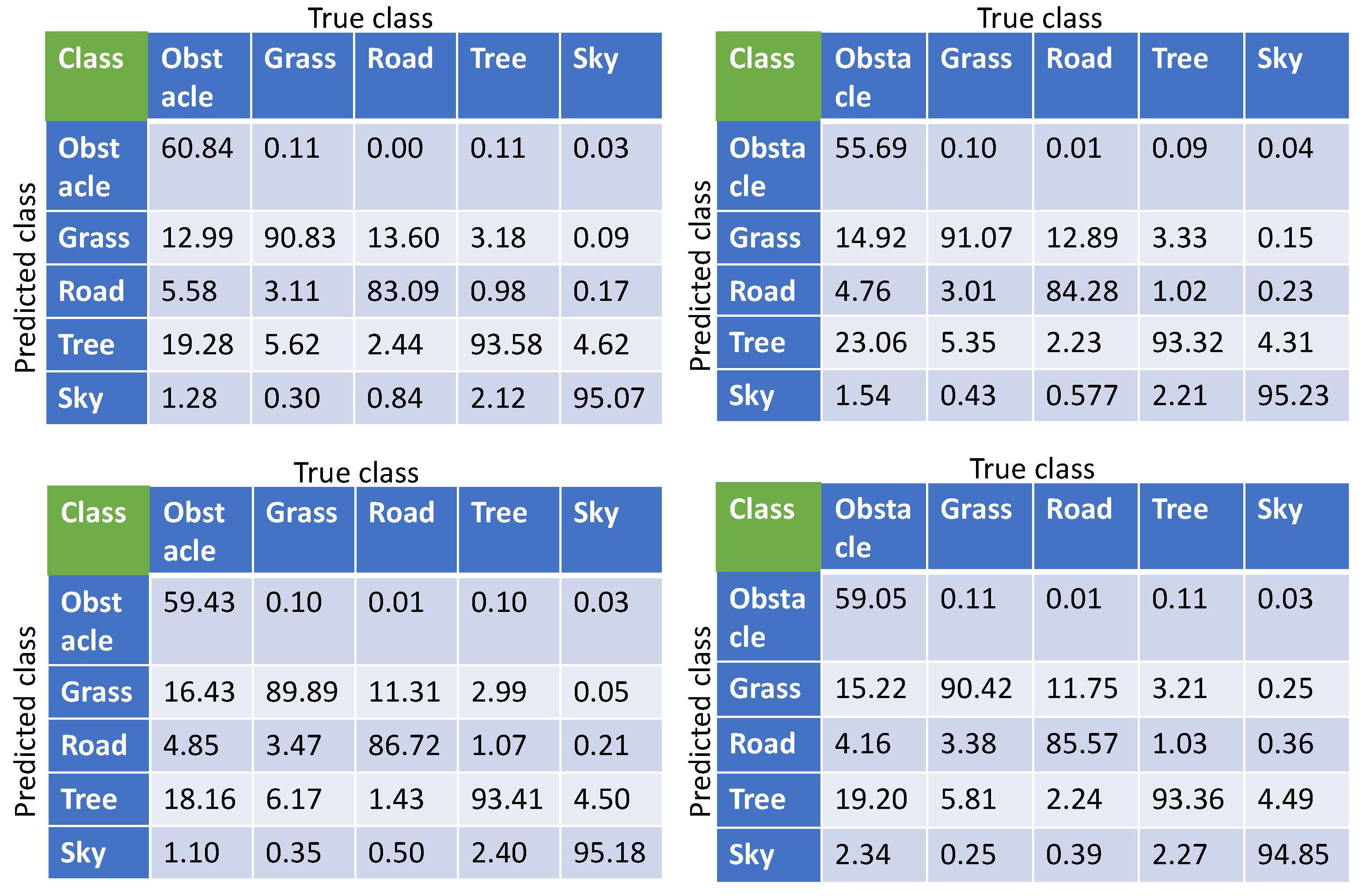
4.2. Segmentation of the Real-World Dataset with Transfer Learning
4.3. Utilizing the Synthetic Dataset
4.3.1. The Two-Class Synthetic Dataset
4.3.2. The Four-Class High-Definition Dataset
4.3.3. The Four-class random synthetic dataset
5. Result Analysis and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the NIPS’12 the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lin, K.; Gong, L.; Huang, Y.; Liu, C.; Pan, J. Deep learning-based segmentation and quantification of cucumber Powdery Mildew using convolutional neural network. Front. Plant Sci. 2019, 10, 155. [Google Scholar] [CrossRef] [PubMed]
- Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. In Proceedings of the NIPS’12 the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 2843–2851. [Google Scholar]
- Kolařík, M.; Burget, R.; Uher, V.; Říha, K.; Dutta, M.K. Optimized High Resolution 3D Dense-U-Net Network for Brain and Spine Segmentation. Appl. Sci. 2019, 9, 404. [Google Scholar] [CrossRef]
- Liu, Y.; Ren, Q.; Geng, J.; Ding, M.; Li, J. Efficient Patch-Wise Semantic Segmentation for Large-Scale Remote Sensing Images. Sensors 2018, 18, 3232. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Gao, L.; Zhang, B.; Yang, F.; Liao, W. High-Resolution Aerial Imagery Semantic Labeling with Dense Pyramid Network. Sensors 2018, 18, 3774. [Google Scholar] [CrossRef] [PubMed]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A Novel Object-Based Deep Learning Framework for Semantic Segmentation of Very High-Resolution Remote Sensing Data: Comparison with Convolutional and Fully Convolutional Networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 297–312. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 3320–3328. [Google Scholar]
- Van Opbroek, A.; Ikram, M.A.; Vernooij, M.W.; de Bruijne, M. Supervised image segmentation across scanner protocols: A transfer learning approach. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Nice, France, 1 October 2012; pp. 160–167. [Google Scholar]
- Van Opbroek, A.; Ikram, M.A.; Vernooij, M.W.; De Bruijne, M. Transfer learning improves supervised image segmentation across imaging protocols. IEEE Trans. Med. Imaging 2015, 34, 1018–1030. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Wei, L.; Runge, L.; Xiaolei, L. Traffic sign detection and recognition via transfer learning. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 5884–5887. [Google Scholar]
- Ying, W.; Zhang, Y.; Huang, J.; Yang, Q. Transfer learning via learning to transfer. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5072–5081. [Google Scholar]
- Xiao, H.; Wei, Y.; Liu, Y.; Zhang, M.; Feng, J. Transferable Semi-supervised Semantic Segmentation. arXiv 2017, arXiv:1711.06828. [Google Scholar]
- Hong, S.; Oh, J.; Lee, H.; Han, B. Learning transferrable knowledge for semantic segmentation with deep convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3204–3212. [Google Scholar]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble Knowledge Transfer for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1499–1508. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the UTLW’11 the 2011 International Conference on Unsupervised and Transfer Learning Workshop, Washington, DC, USA, 2 July 2011; pp. 17–36. [Google Scholar]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Edinburgh, Scotland, 27 June 2012; pp. 37–49. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MI, USA, 2016; Volume 1. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Maturana, D.; Chou, P.W.; Uenoyama, M.; Scherer, S. Real-time semantic mapping for autonomous off-road navigation. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 335–350. [Google Scholar]
- Adhikari, S.P.; Yang, C.; Slot, K.; Kim, H. Accurate Natural Trail Detection Using a Combination of a Deep Neural Network and Dynamic Programming. Sensors 2018, 18, 178. [Google Scholar] [CrossRef] [PubMed]
- Holder, C.J.; Breckon, T.P.; Wei, X. From on-road to off: transfer learning within a deep convolutional neural network for segmentation and classification of off-road scenes. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 149–162. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Valada, A.; Oliveira, G.; Brox, T.; Burgard, W. Deep Multispectral Semantic Scene Understanding of Forested Environments using Multimodal Fusion. In Proceedings of the 2016 International Symposium on Experimental Robotics (ISER 2016), Tokyo, Japan, 3–6 October 2016. [Google Scholar]
- Hudson, C.R.; Goodin, C.; Doude, M.; Carruth, D.W. Analysis of Dual LIDAR Placement for Off-Road Autonomy Using MAVS. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Kosice, Slovakia, 23–25 August 2018; pp. 137–142. [Google Scholar]
- Goodin, C.; Sharma, S.; Doude, M.; Carruth, D.; Dabbiru, L.; Hudson, C. Training of Neural Networks with Automated Labeling of Simulated Sensor Data; SAE Technical Paper; Society of Automotive Engineers: Troy, MI, USA, 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer’s Name | Kernel Size | Stride | Pad | Output Size |
|---|---|---|---|---|
| input | - | - | - | |
| conv1-1 | 1 | 1 | ||
| conv1-2 | 1 | 1 | ||
| pool1 | 2 | 0 | ||
| conv2-1 | 1 | 1 | ||
| conv2-2 | 1 | 1 | ||
| pool2 | 2 | 0 | ||
| conv3-1 | 1 | 1 | ||
| conv3-2 | 1 | 1 | ||
| conv3-3 | 1 | 1 | ||
| pool3 | 2 | 0 | ||
| unpool3 | 2 | 0 | ||
| deconv3-1 | 1 | 1 | ||
| deconv3-2 | 1 | 1 | ||
| deconv3-3 | 1 | 1 | ||
| unpool2 | 2 | 0 | ||
| deconv2-1 | 1 | 1 | ||
| deconv2-2 | 1 | 1 | ||
| unpool1 | 2 | 0 | ||
| deconv1-1 | 1 | 1 | ||
| deconv1-2 | 1 | 1 | ||
| output | 1 | 1 |
| Network | Complexity | Ratio |
|---|---|---|
| DeconvNet | O (1.56) | |
| Light-weight |
| Data | Method | DeconvNet | Light-Weight |
|---|---|---|---|
| Synthetic | TL on two-class | 97.62 (%) | 99.15 (%) |
| TL on four-class high-definition | 65.61 (%) | 75.71 (%) | |
| TL on four-class random | 73.23 (%) | 91.00 (%) |
| Data | Method | DeconvNet | Light-Weight |
|---|---|---|---|
| Freiburg | W/O synthetic data | 73.65(%) | 94.43(%) |
| After using two-class synthetic | 66.62(%) | 94.06(%) | |
| After using four-class high-definition | 68.7(%) | 94.59(%) | |
| After using four-class random synthetic | 68.14(%) | 93.89(%) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, S.; Ball, J.E.; Tang, B.; Carruth, D.W.; Doude, M.; Islam, M.A. Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving. Sensors 2019, 19, 2577. https://doi.org/10.3390/s19112577
Sharma S, Ball JE, Tang B, Carruth DW, Doude M, Islam MA. Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving. Sensors. 2019; 19(11):2577. https://doi.org/10.3390/s19112577
Chicago/Turabian StyleSharma, Suvash, John E. Ball, Bo Tang, Daniel W. Carruth, Matthew Doude, and Muhammad Aminul Islam. 2019. "Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving" Sensors 19, no. 11: 2577. https://doi.org/10.3390/s19112577
APA StyleSharma, S., Ball, J. E., Tang, B., Carruth, D. W., Doude, M., & Islam, M. A. (2019). Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving. Sensors, 19(11), 2577. https://doi.org/10.3390/s19112577