An Recognition–Verification Mechanism for Real-Time Chinese Sign Language Recognition Based on Multi-Information Fusion

Abstract
1. Introduction
2. Online Sign Language Recognition
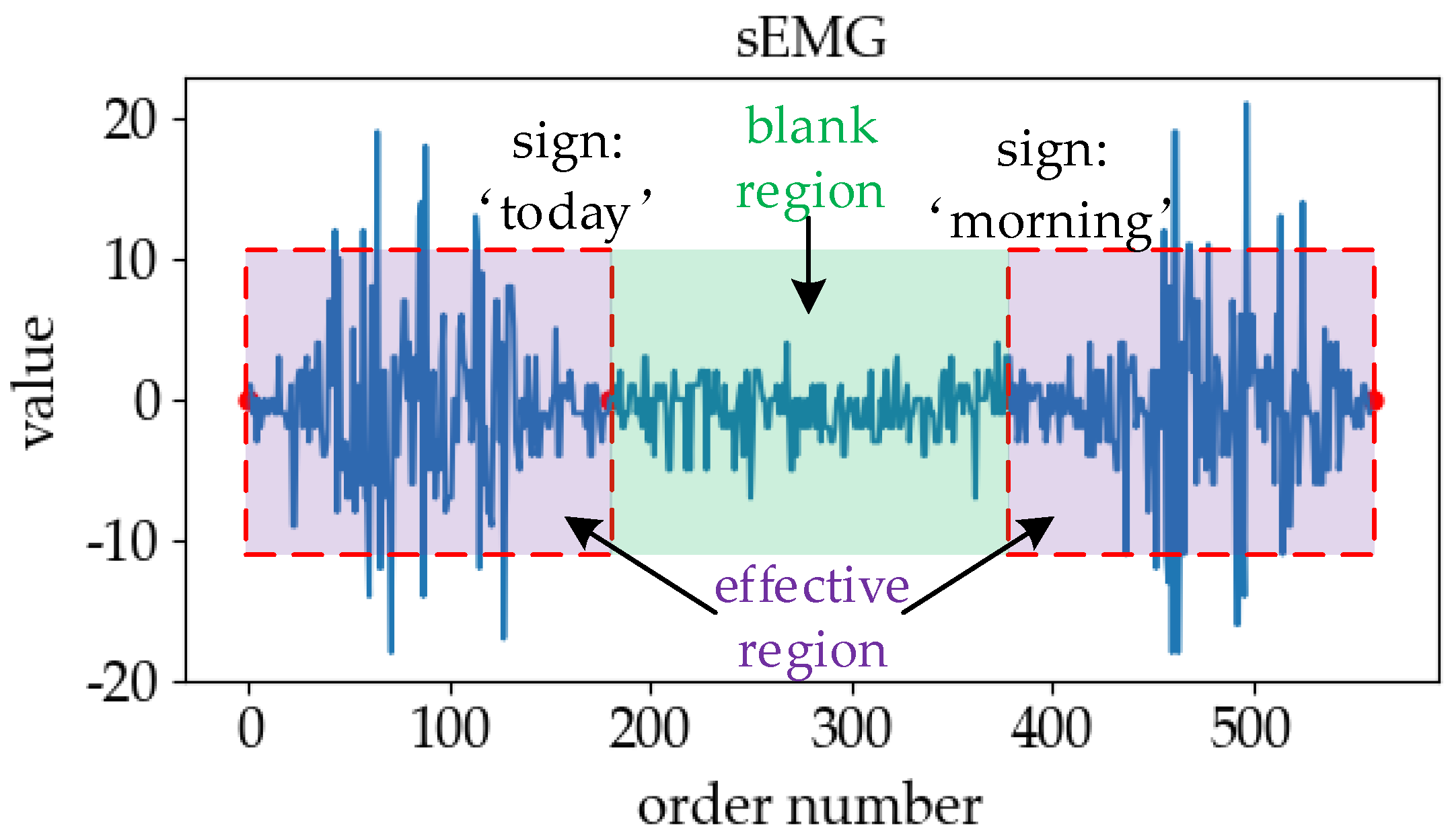
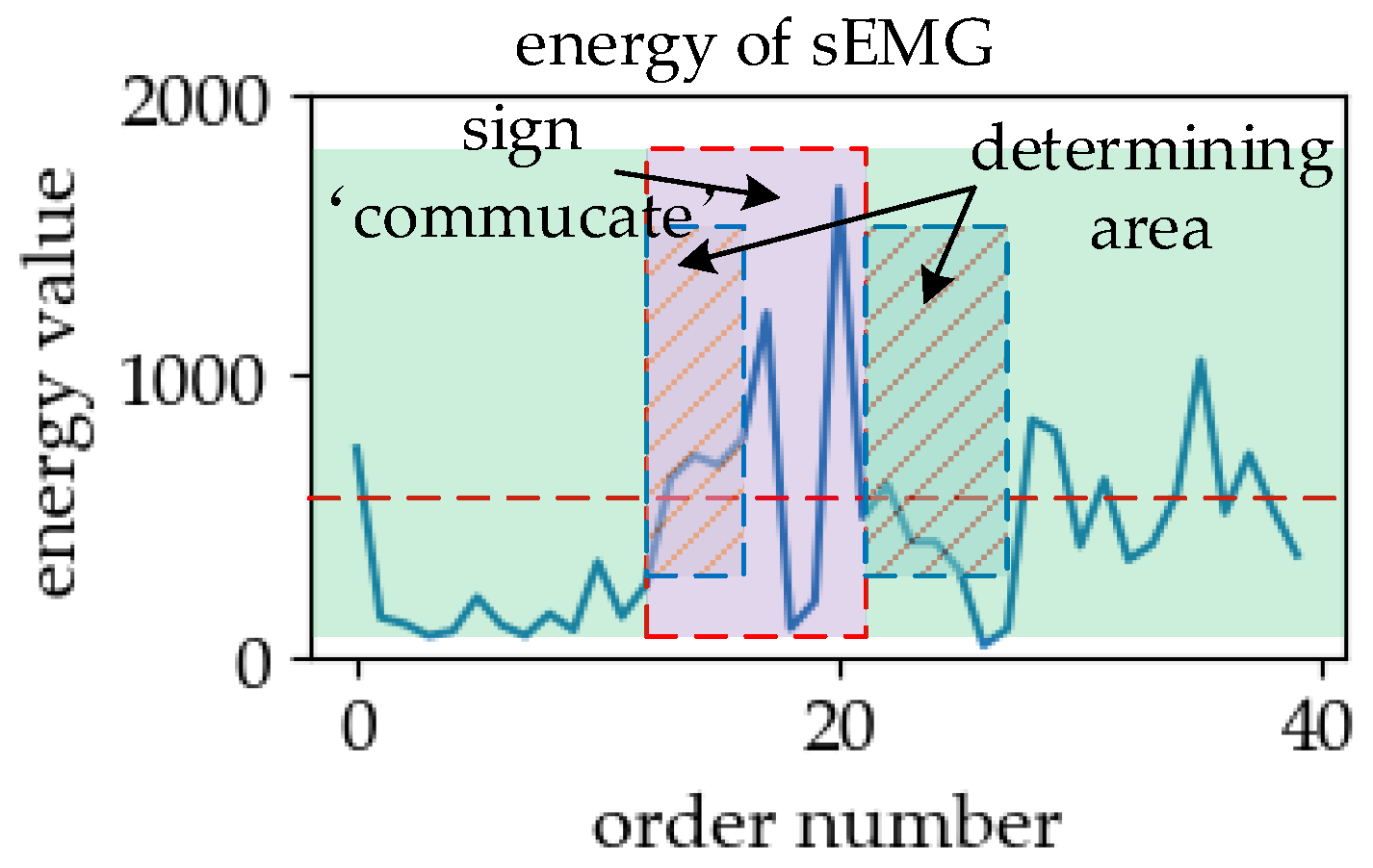
2.1. Analysis of Online Sign Language Recognition
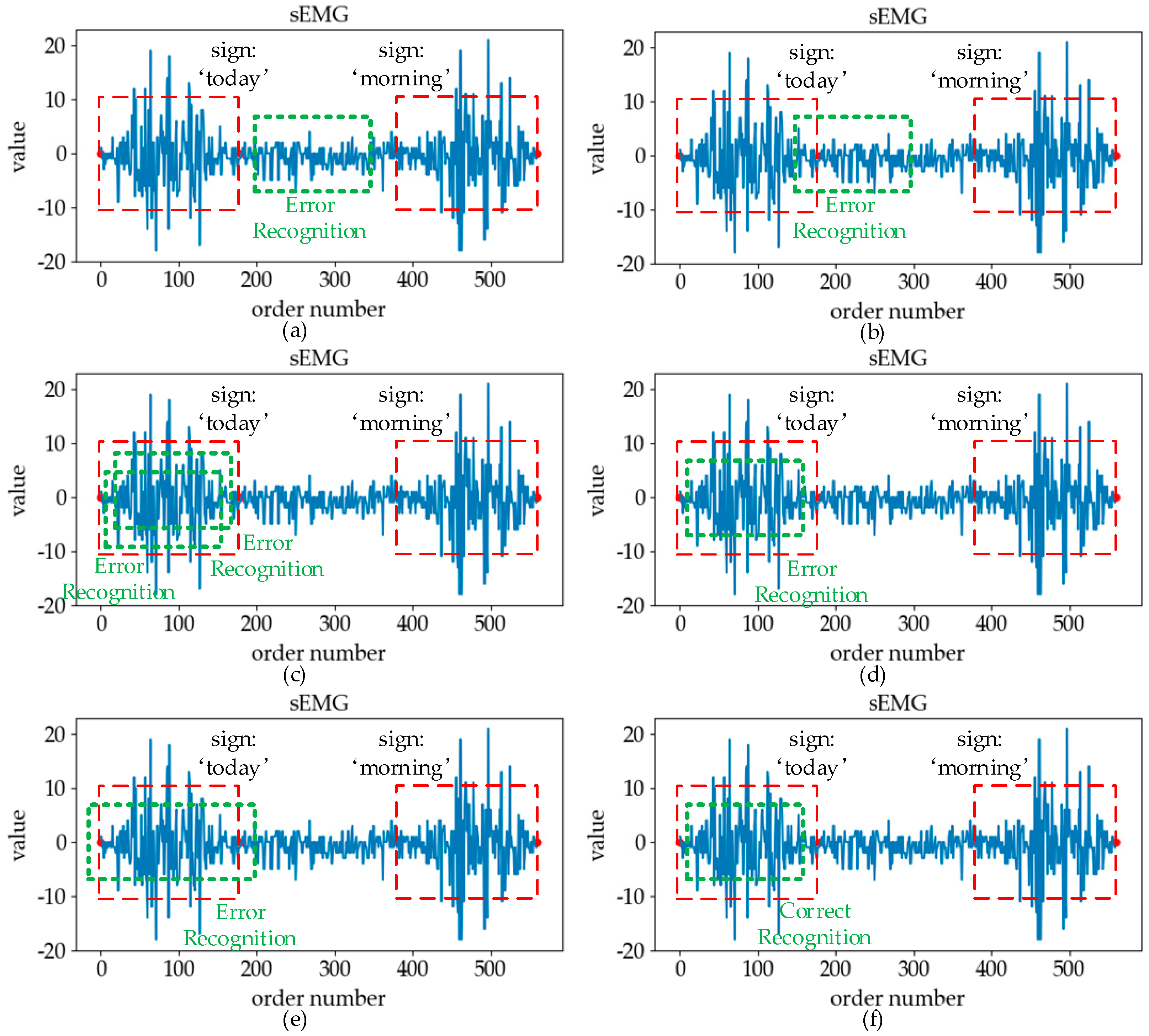
- Insert: the misrecognition that the data segment in the blank region is identified as an exact category of sign language.
- Misalignment: the misrecognition of the data segment combining the adjacent zone and part of the effective region data into a certain type of sign language.
- Repeat: the misrecognition that the same effective region is correctly recognized multiple times.
- Substitute: the misrecognition of the data segment of a certain type of sign language in the effective region into another type.
- Delete: the misrecognition that the entire effective region is recognized as the blank region.
2.2. Traditional Segmentation–Recognition Mechanism
3. Database
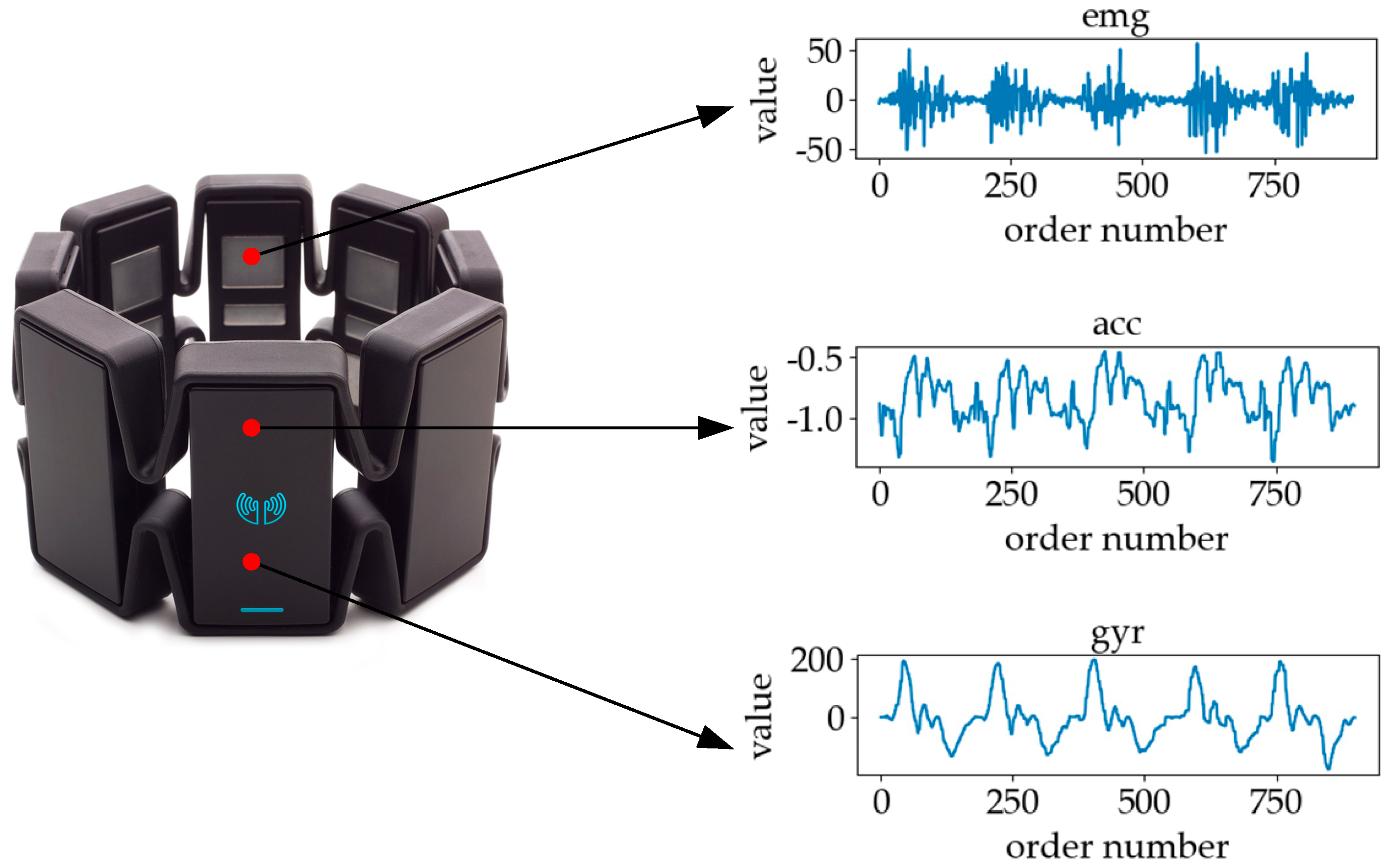
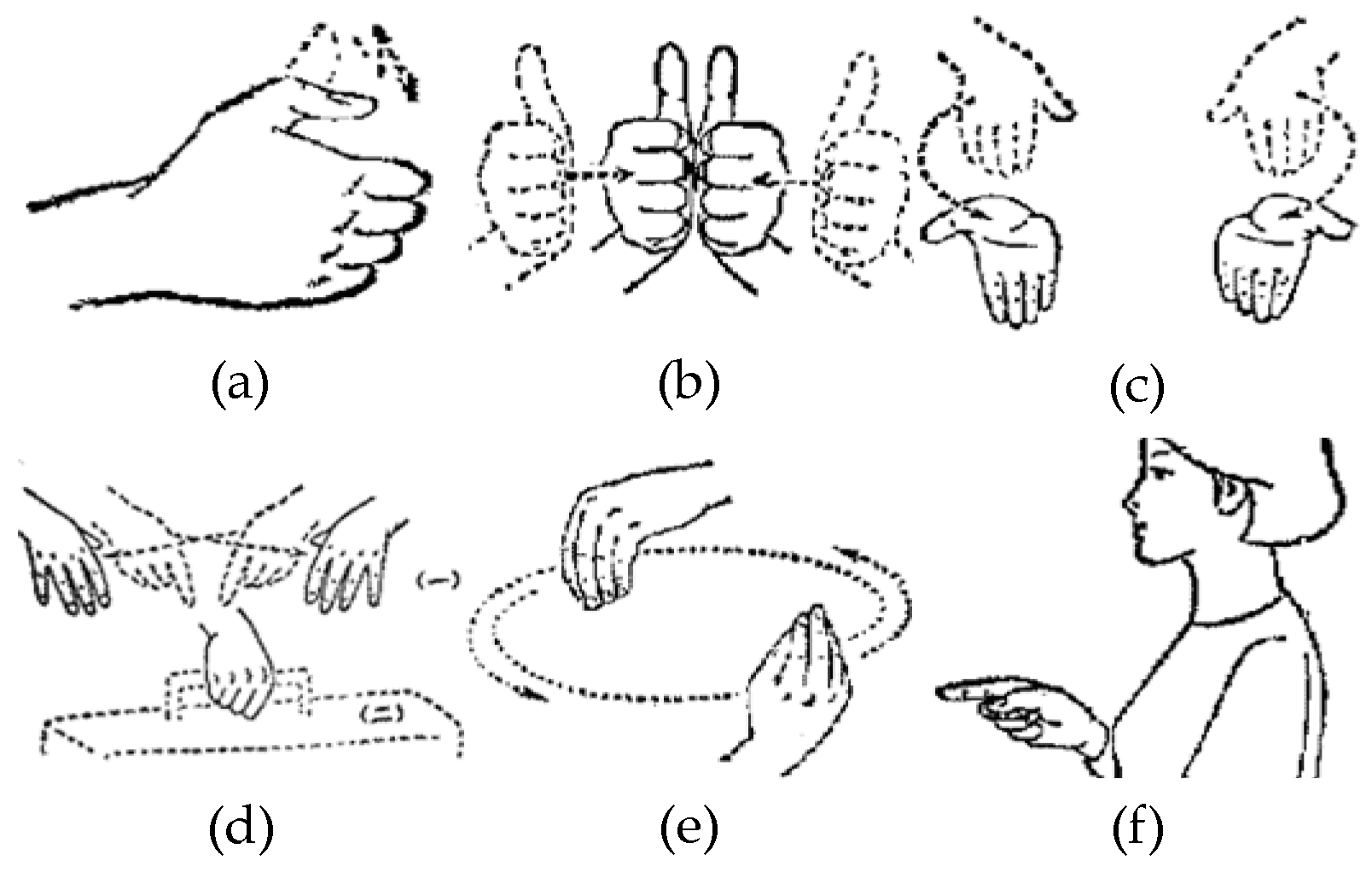
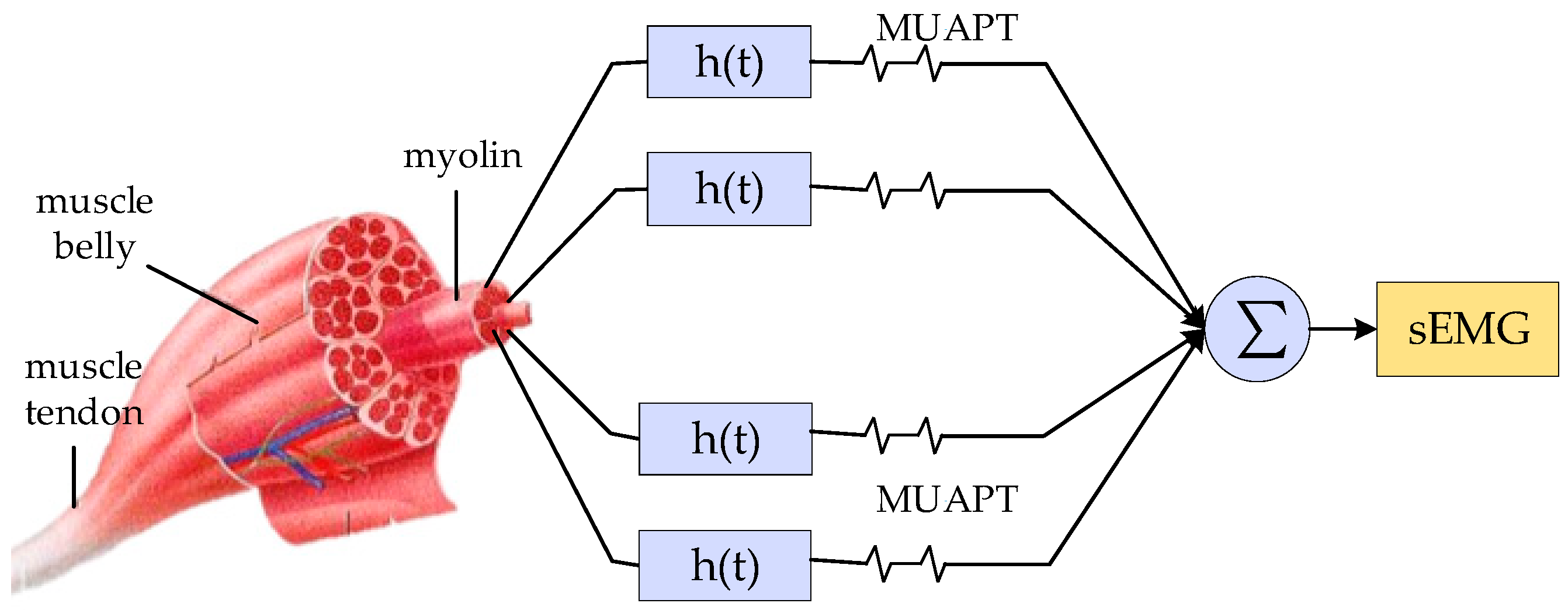
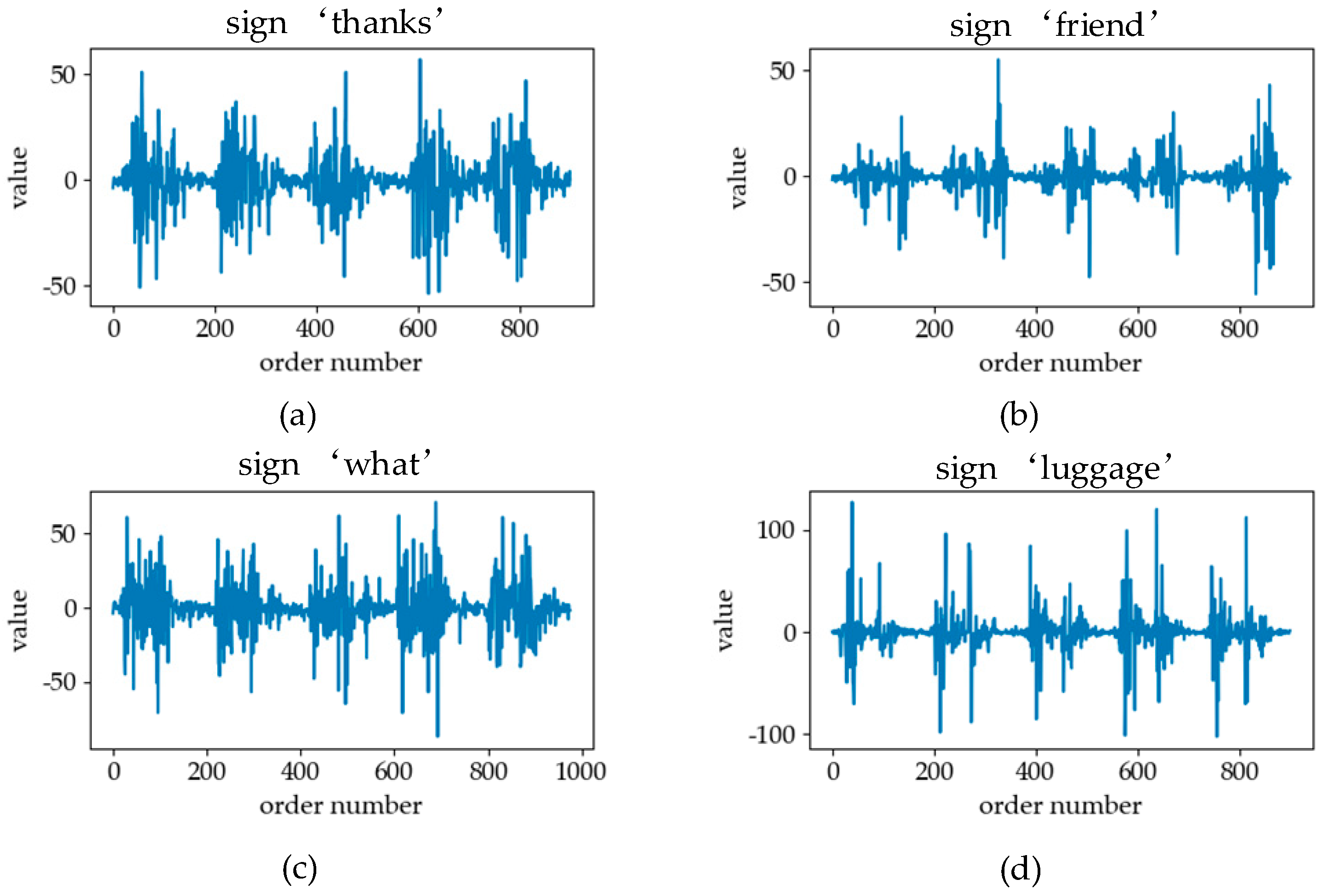
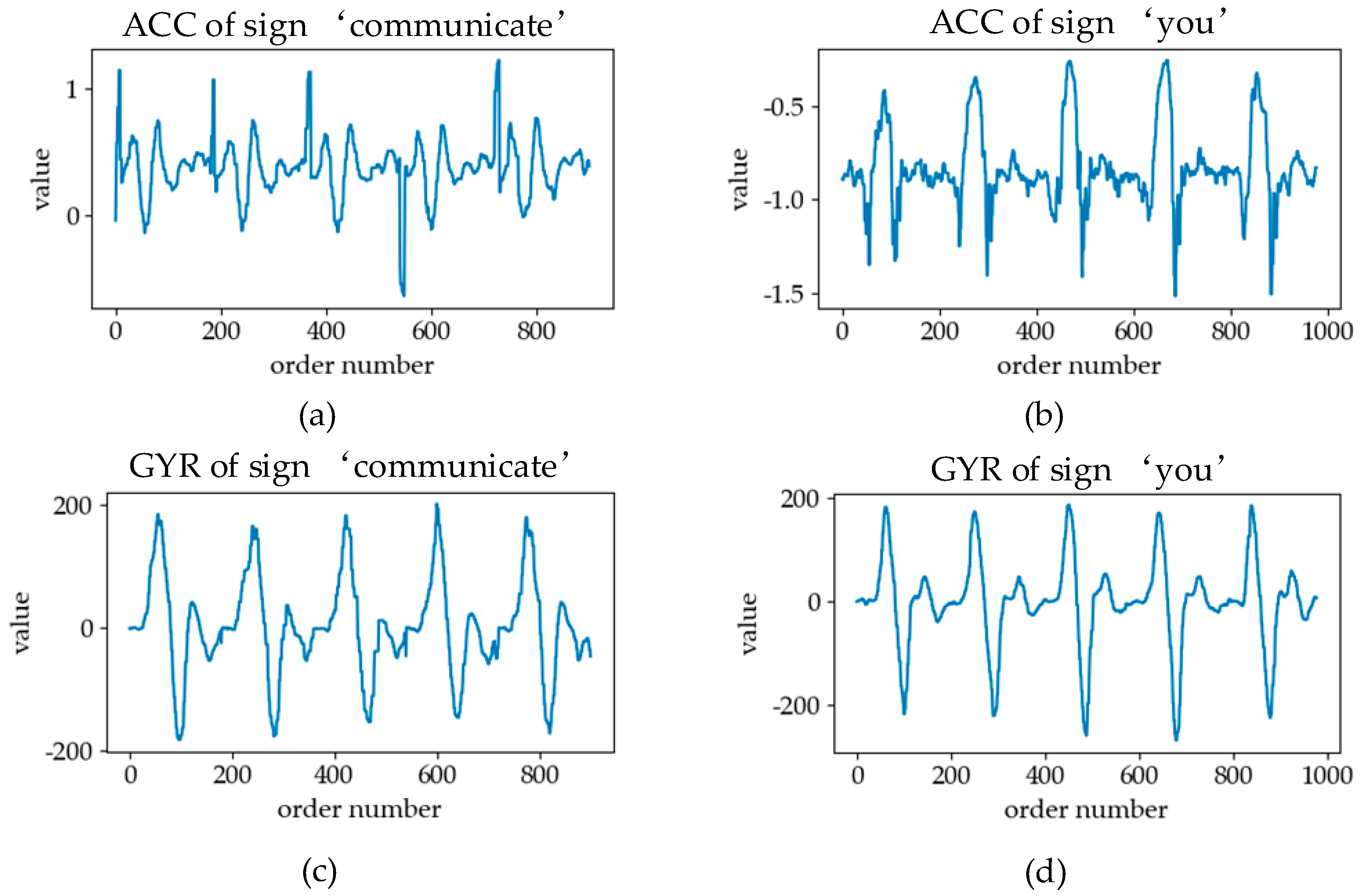
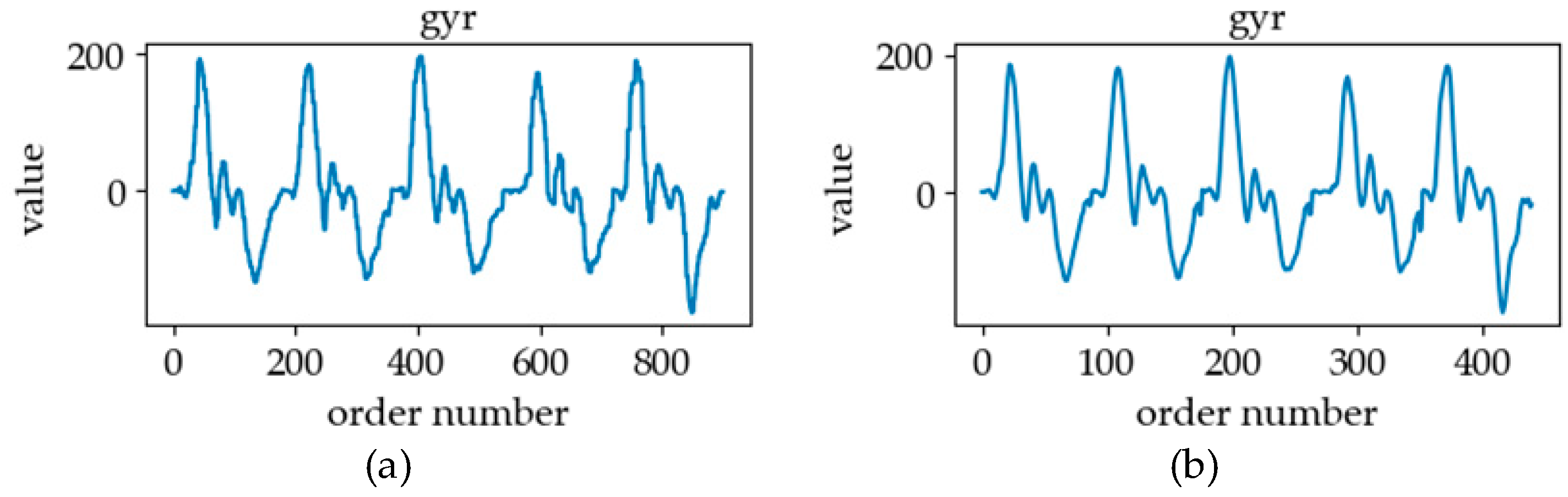
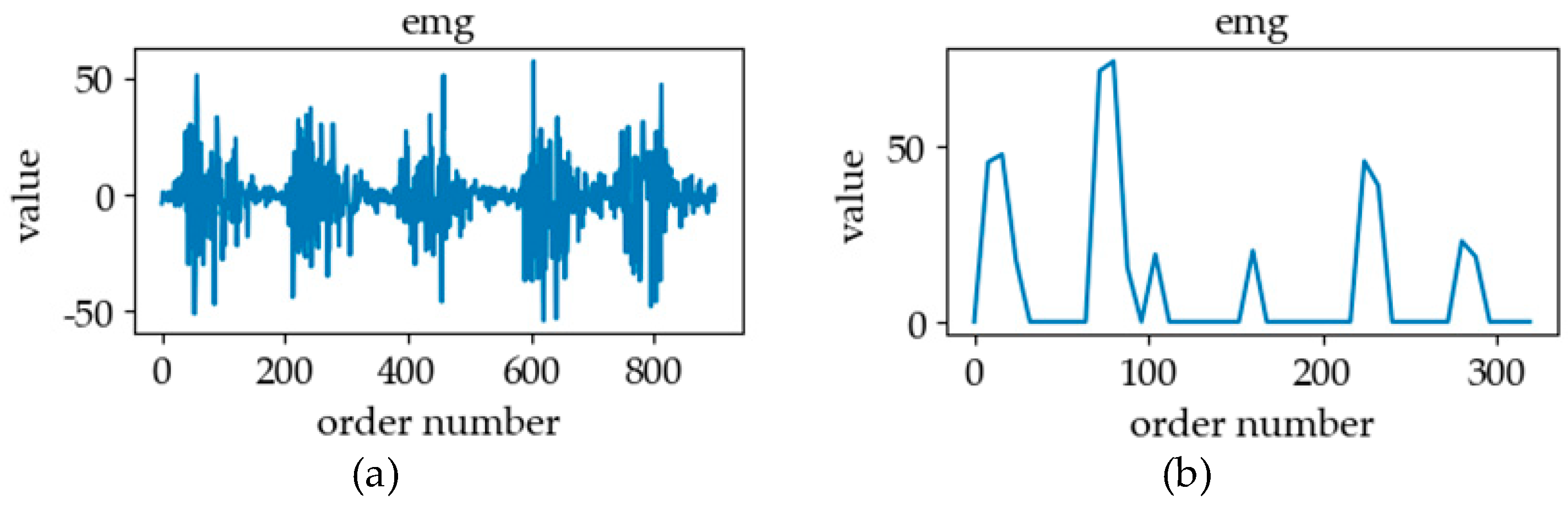
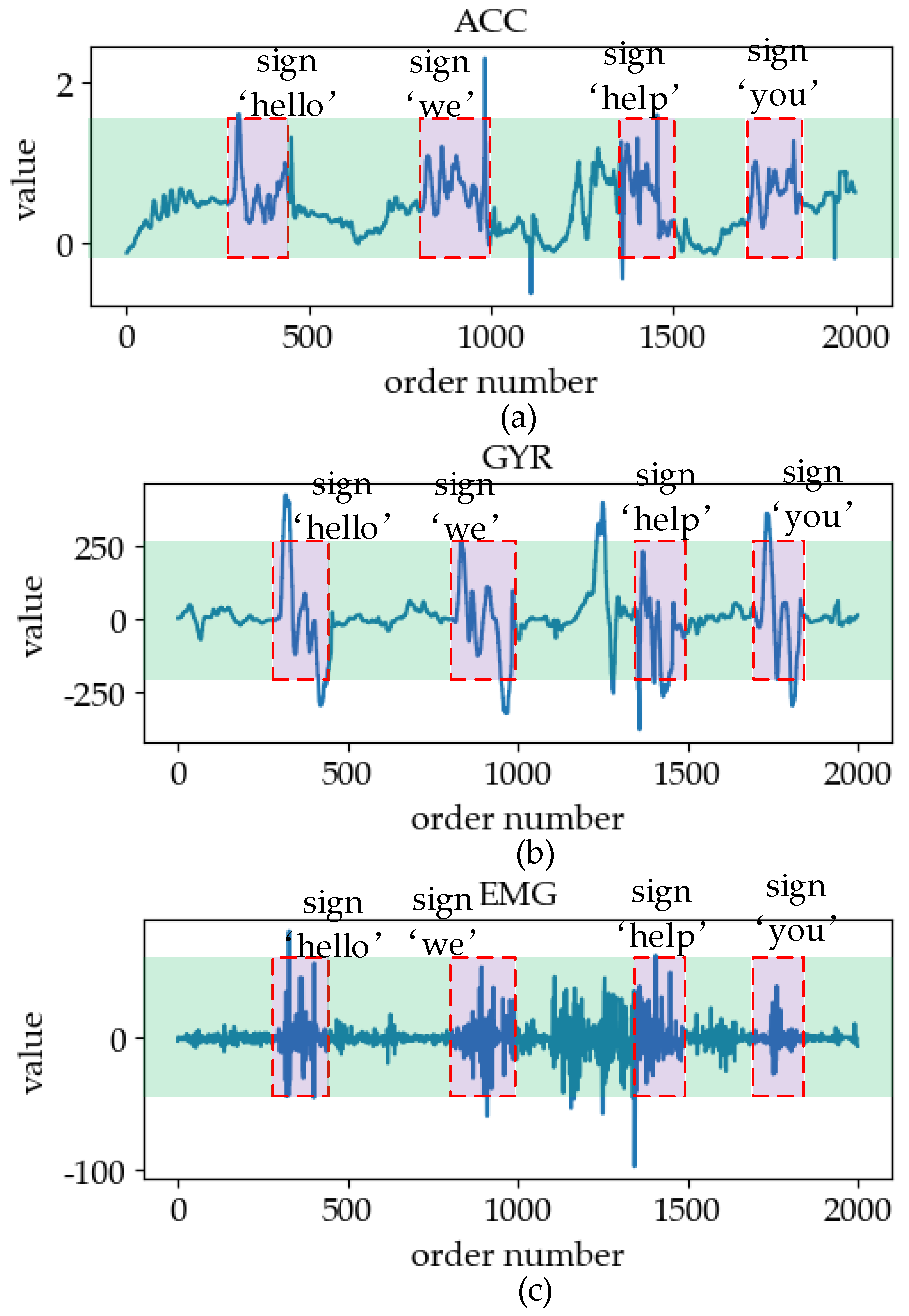
3.1. Sign Language Signals
3.2. Sign Language Database
4. Method
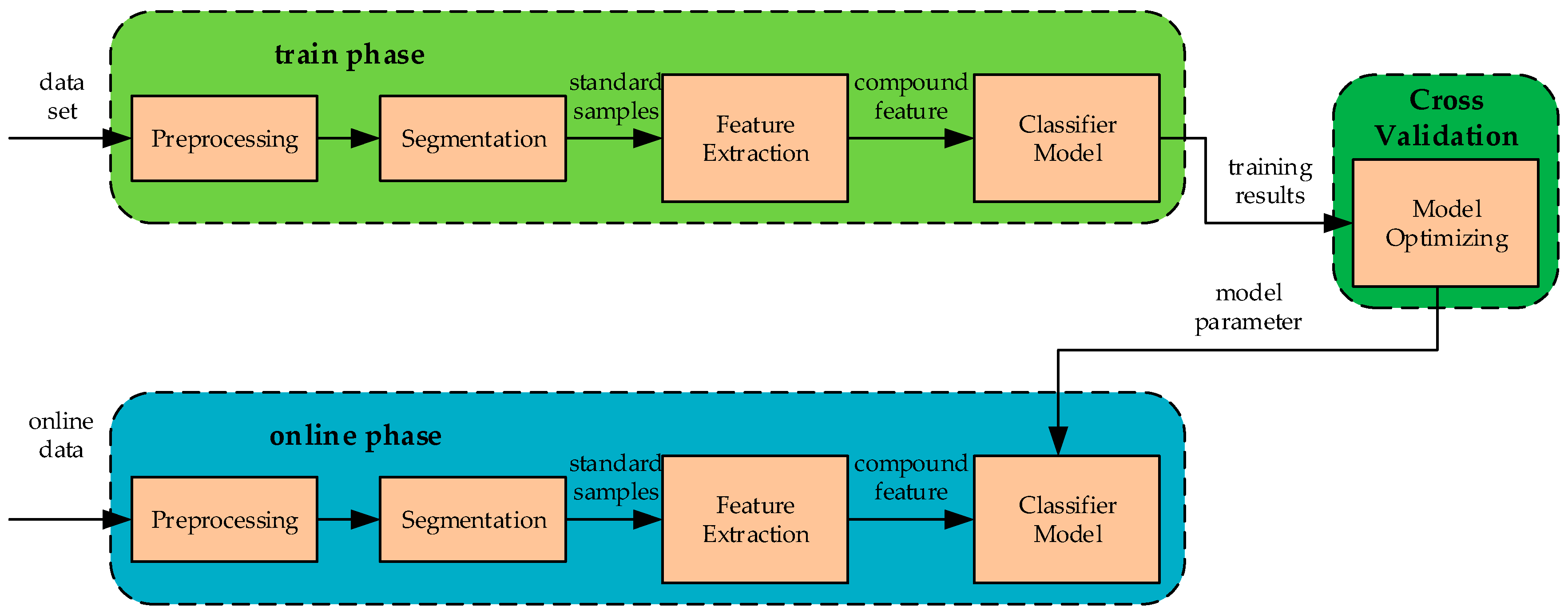
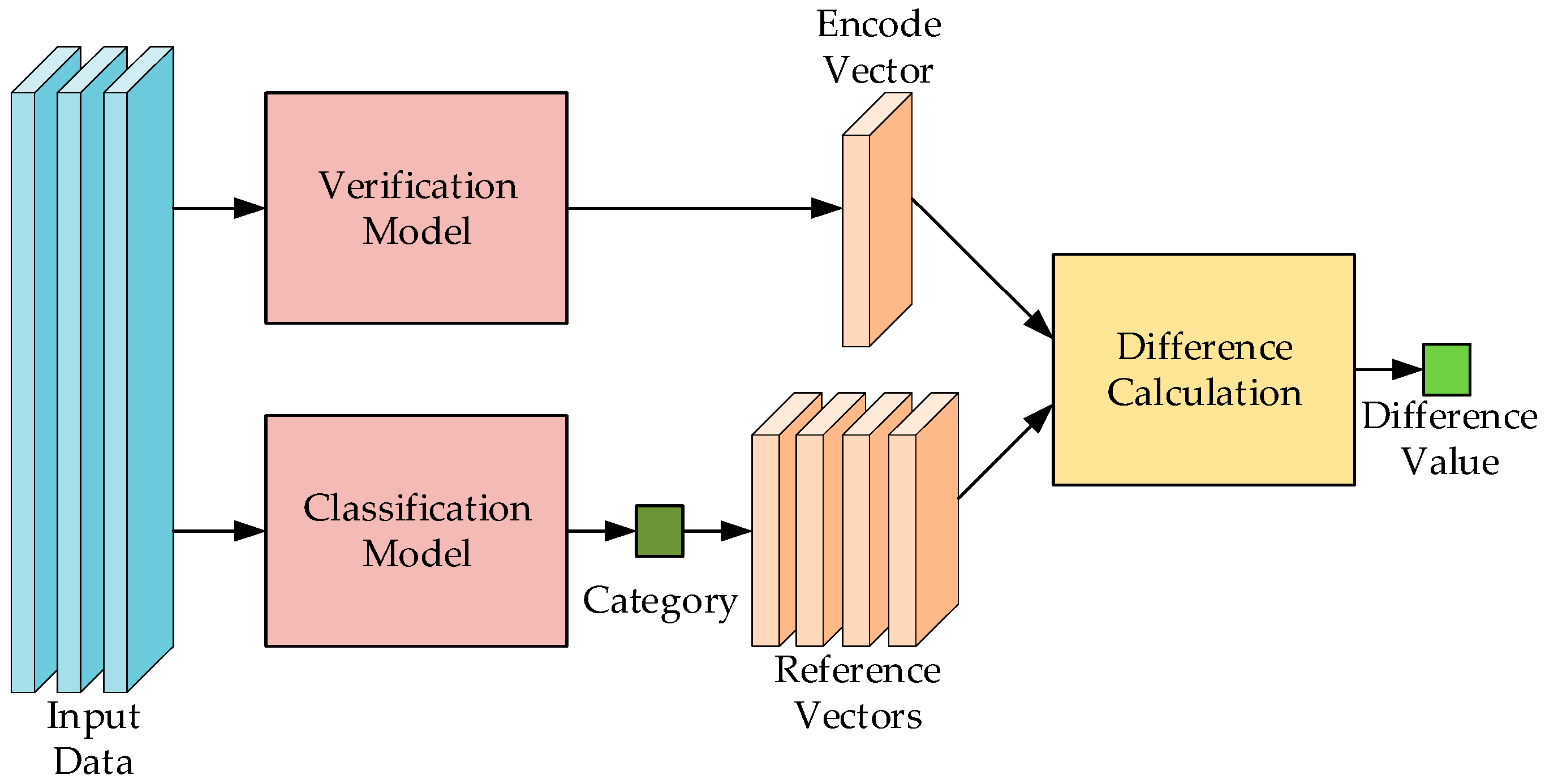
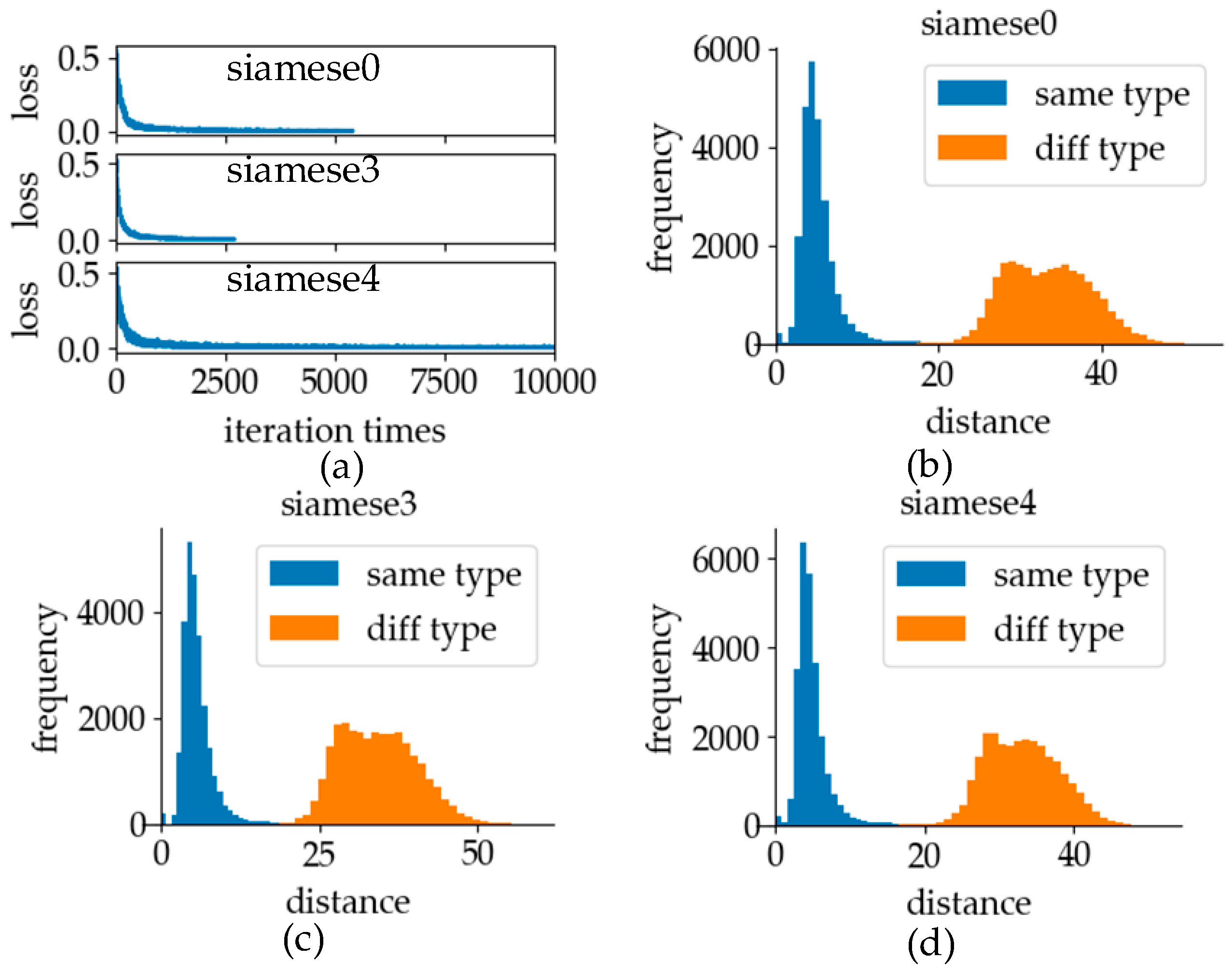
4.1. Recognition–Verification Mechanism
4.2. Data Pre-Processing
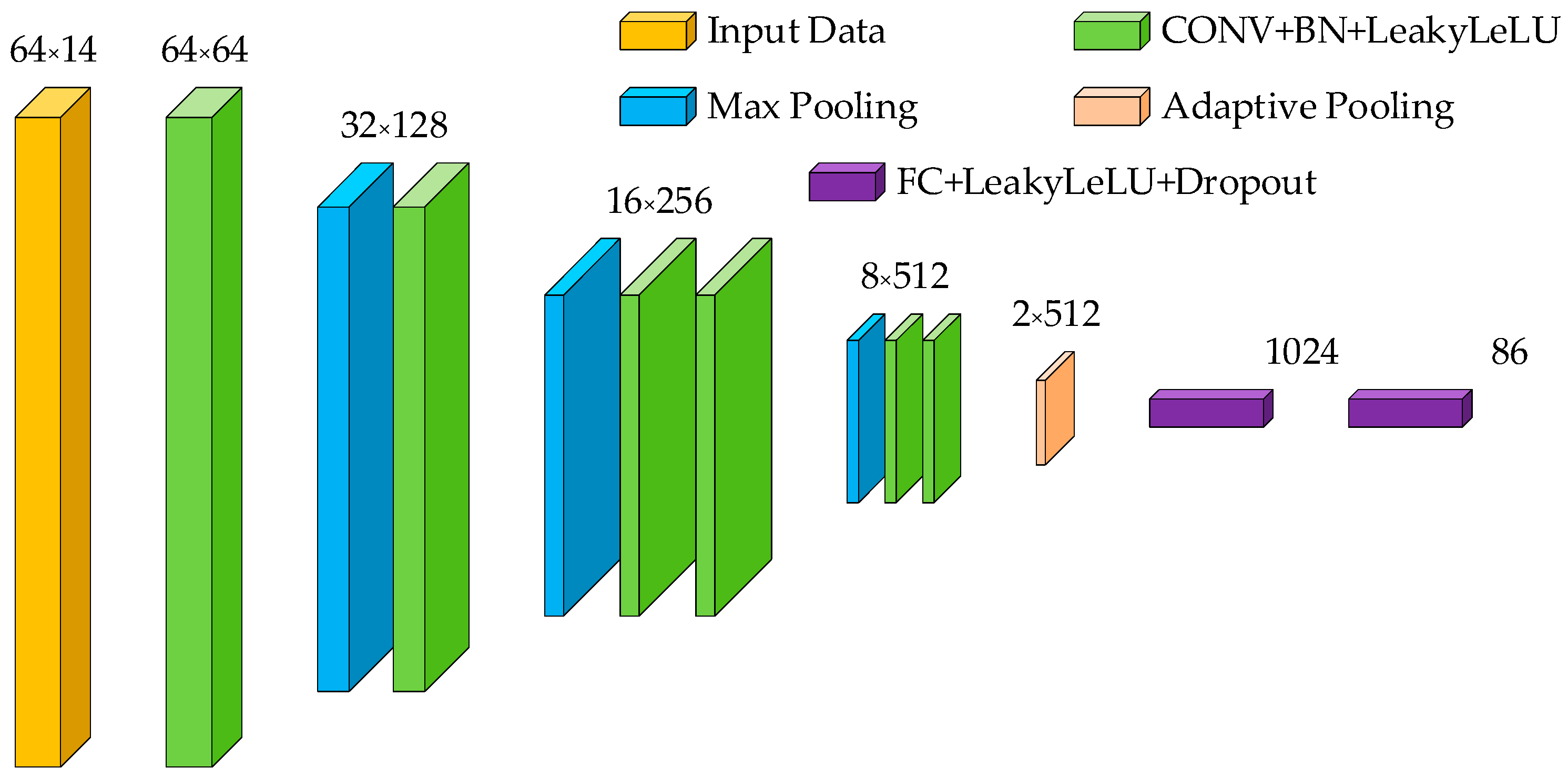
4.3. Classification Model
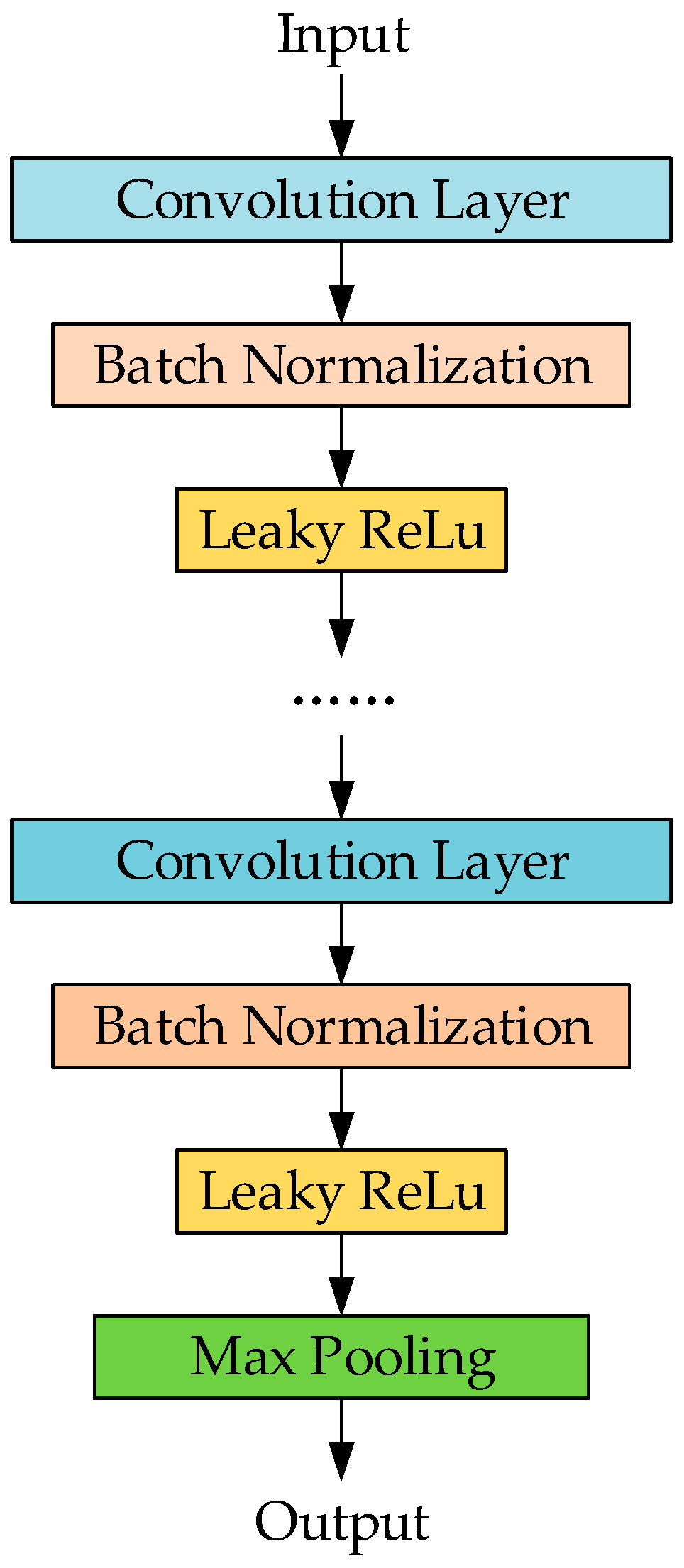
4.3.1. 1D Convolutional Neural Network
4.3.2. Classification Model
4.3.3. Training
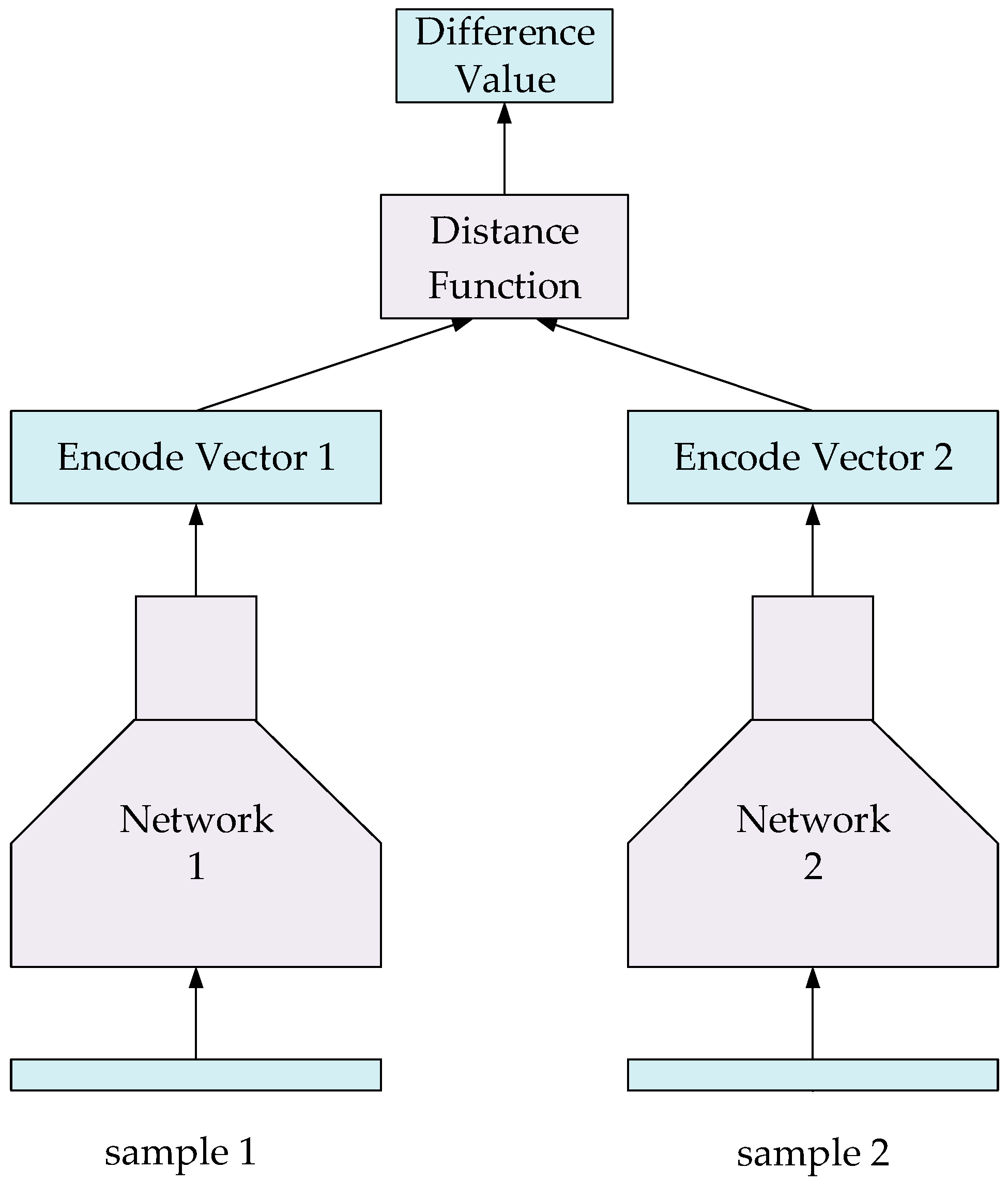
4.4. Verification Model
4.4.1. Verification Model for Sign Language Recognition
4.4.2. Training Method
4.4.3. Operation Stage
5. Experiments
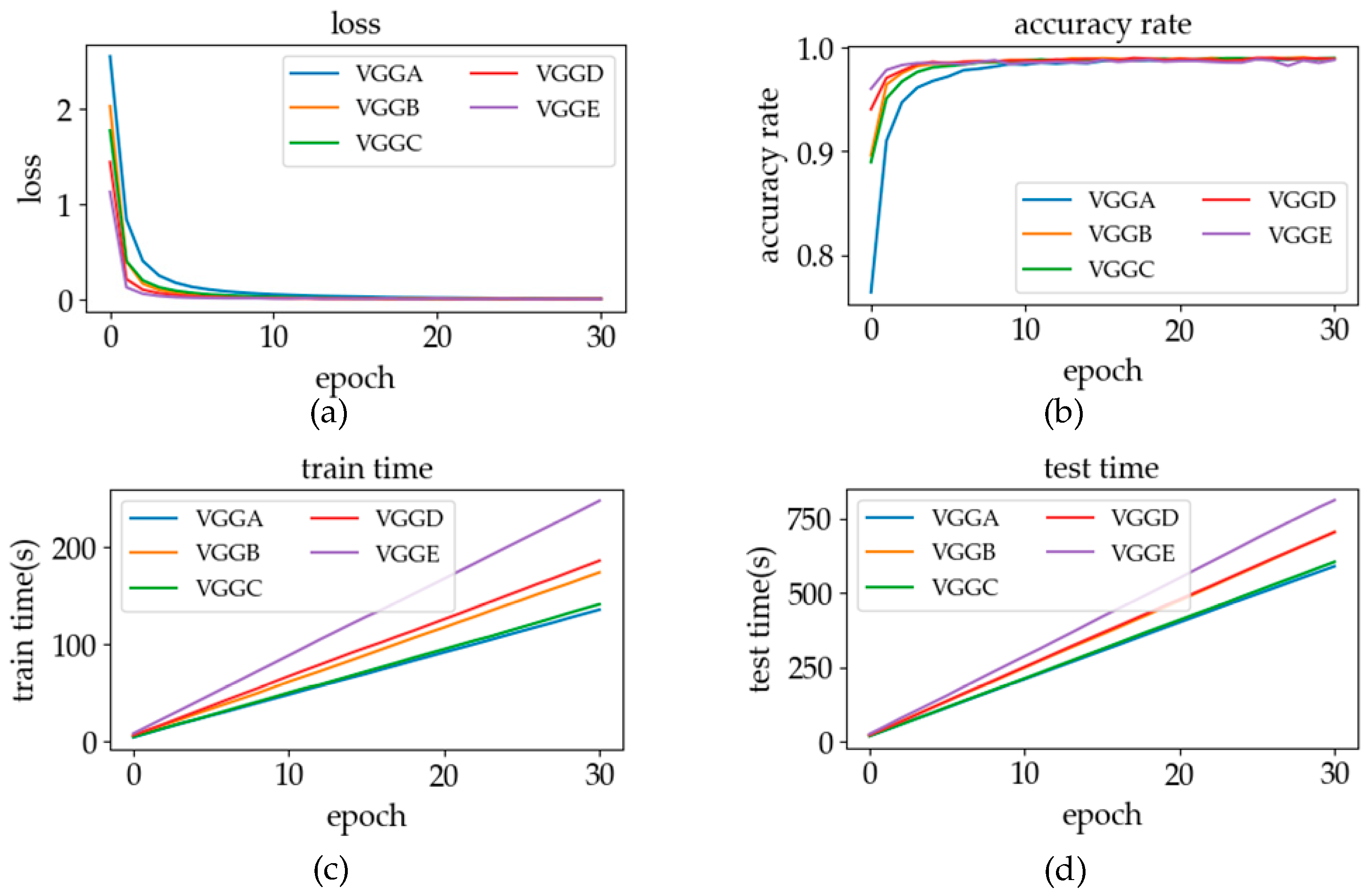
5.1. The Optimization of the Classification Model
5.1.1. The Layers of the Network
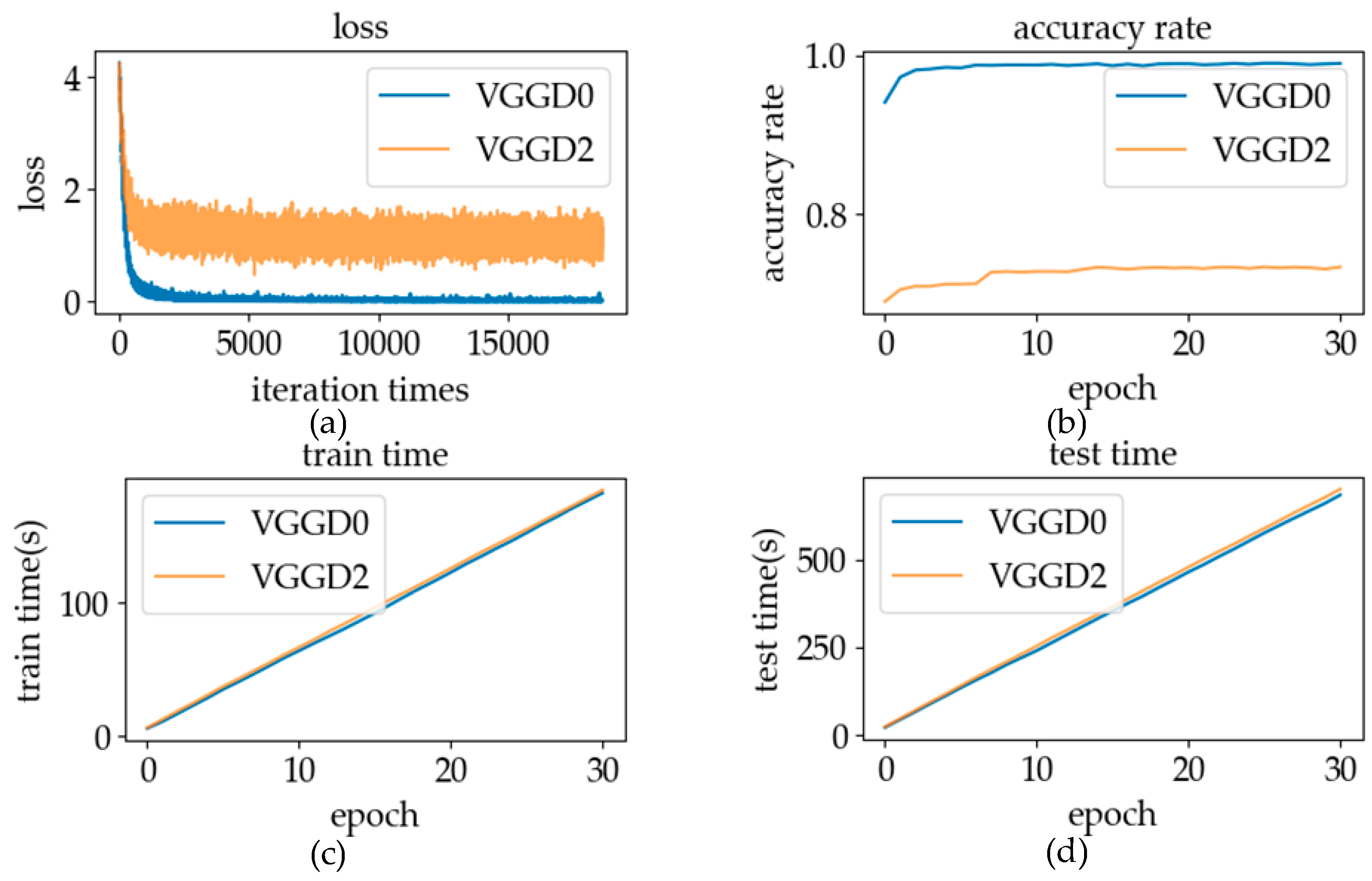
5.1.2. Adaptive Pooling Layer
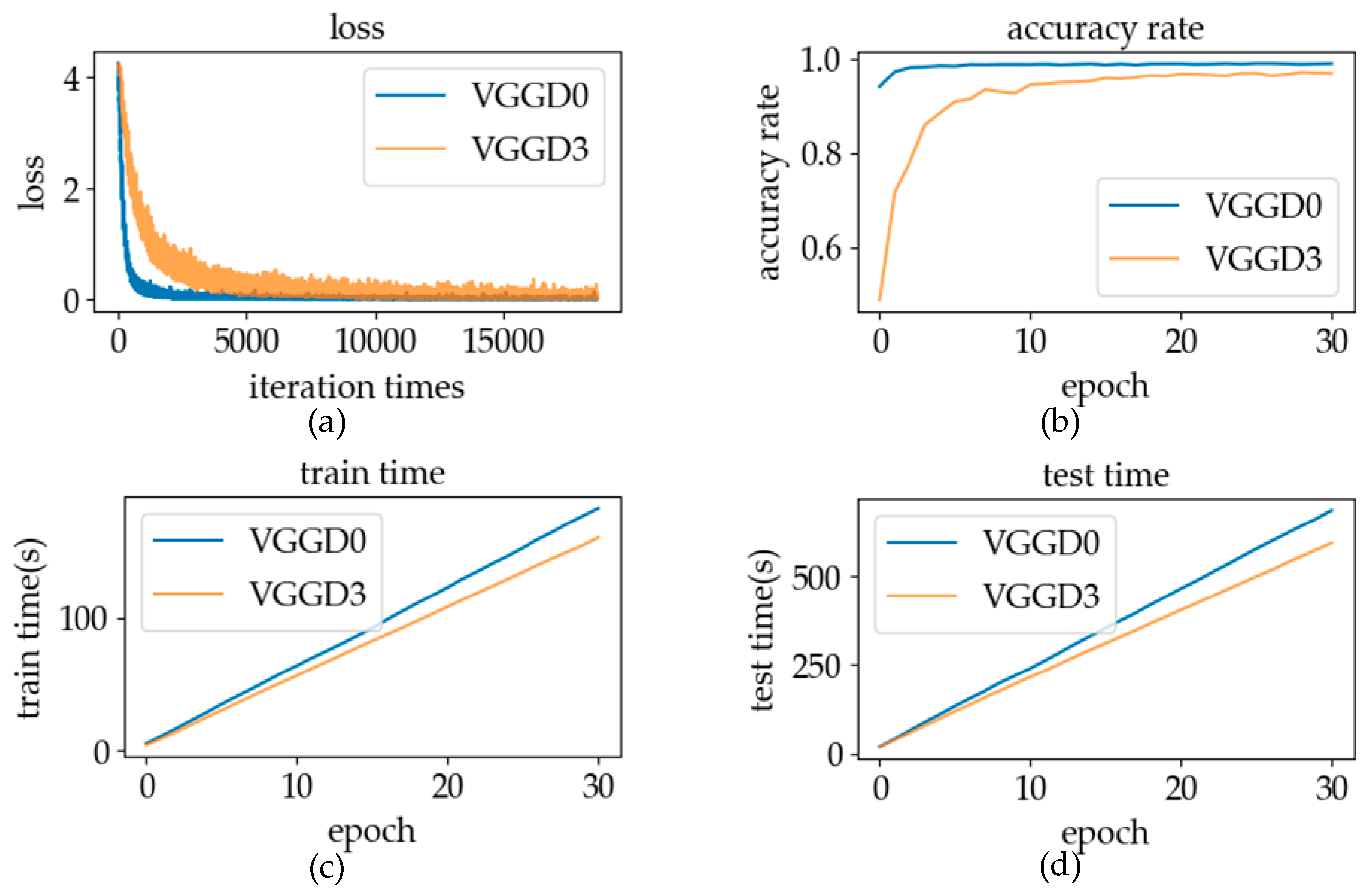
5.1.3. The Activation Function
5.1.4. Batch Normalization
- The layer of BN can alleviate the internal covariate shift, improve the stability in the network training process, and make it possible to use a large learning rate in the network training process, so as to accelerate the training of neural network.
- The problem of gradient explosion and disappearance can be alleviated to a certain extent, thus making it possible to train the deep network.
- Since the input of the hidden layer is processed in a standardized way, BN can make the network training process less affected by parameter initialization.
5.2. The Optimization of the Verification Model
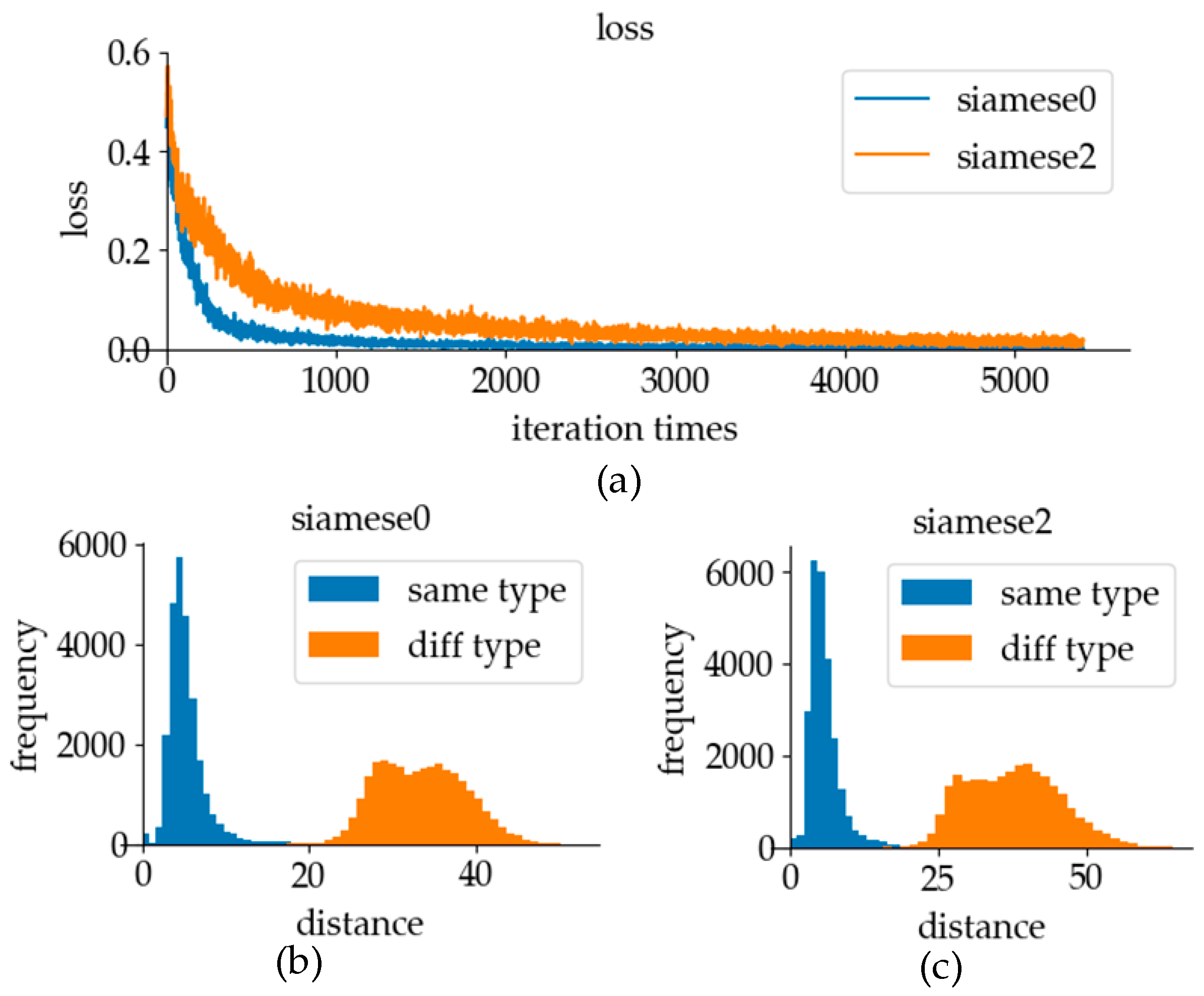
5.2.1. Loss Function
5.2.2. Model Initialization
5.2.3. Batch Size
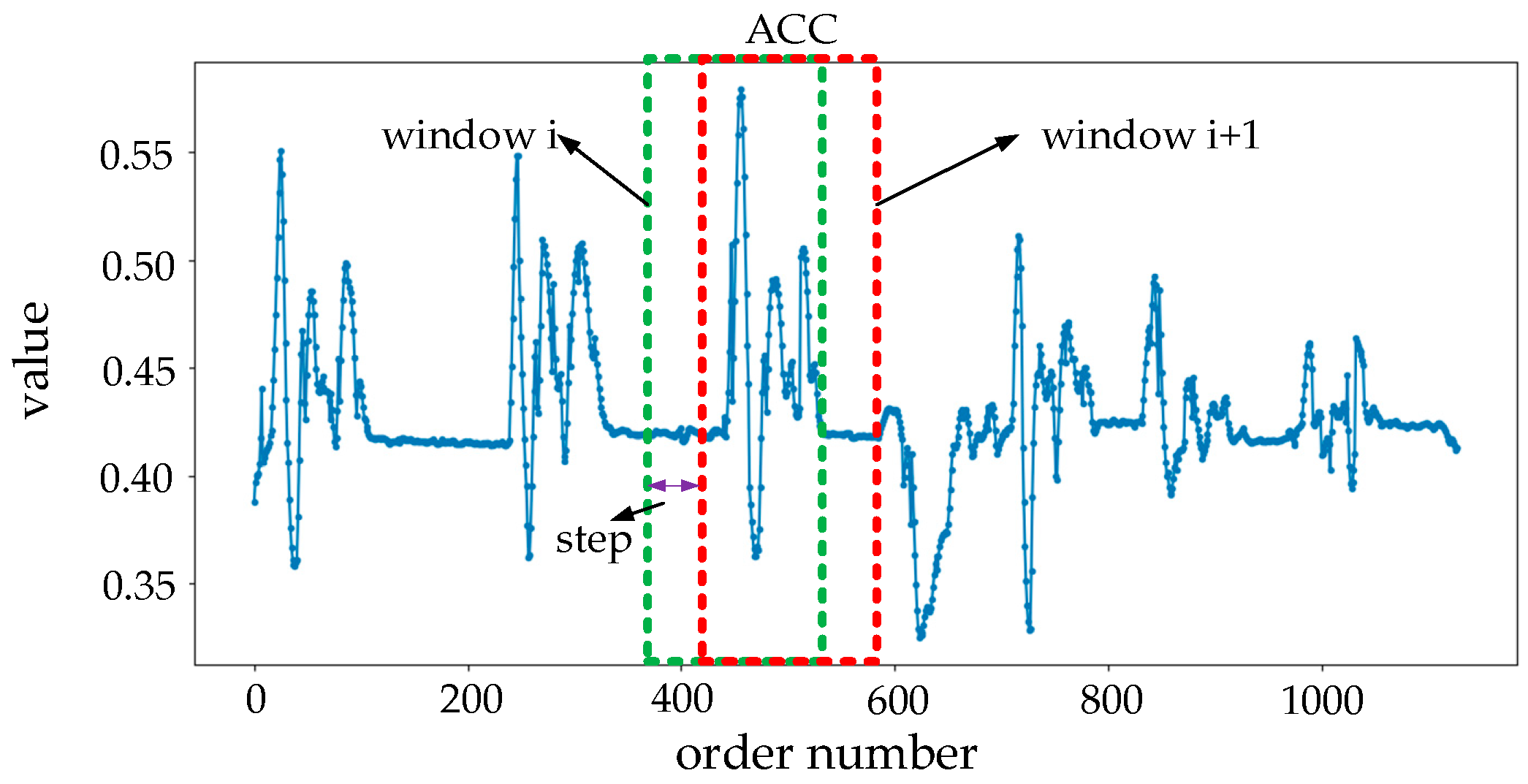
5.3. Online Sign Language Recognition
5.3.1. Online Dataset
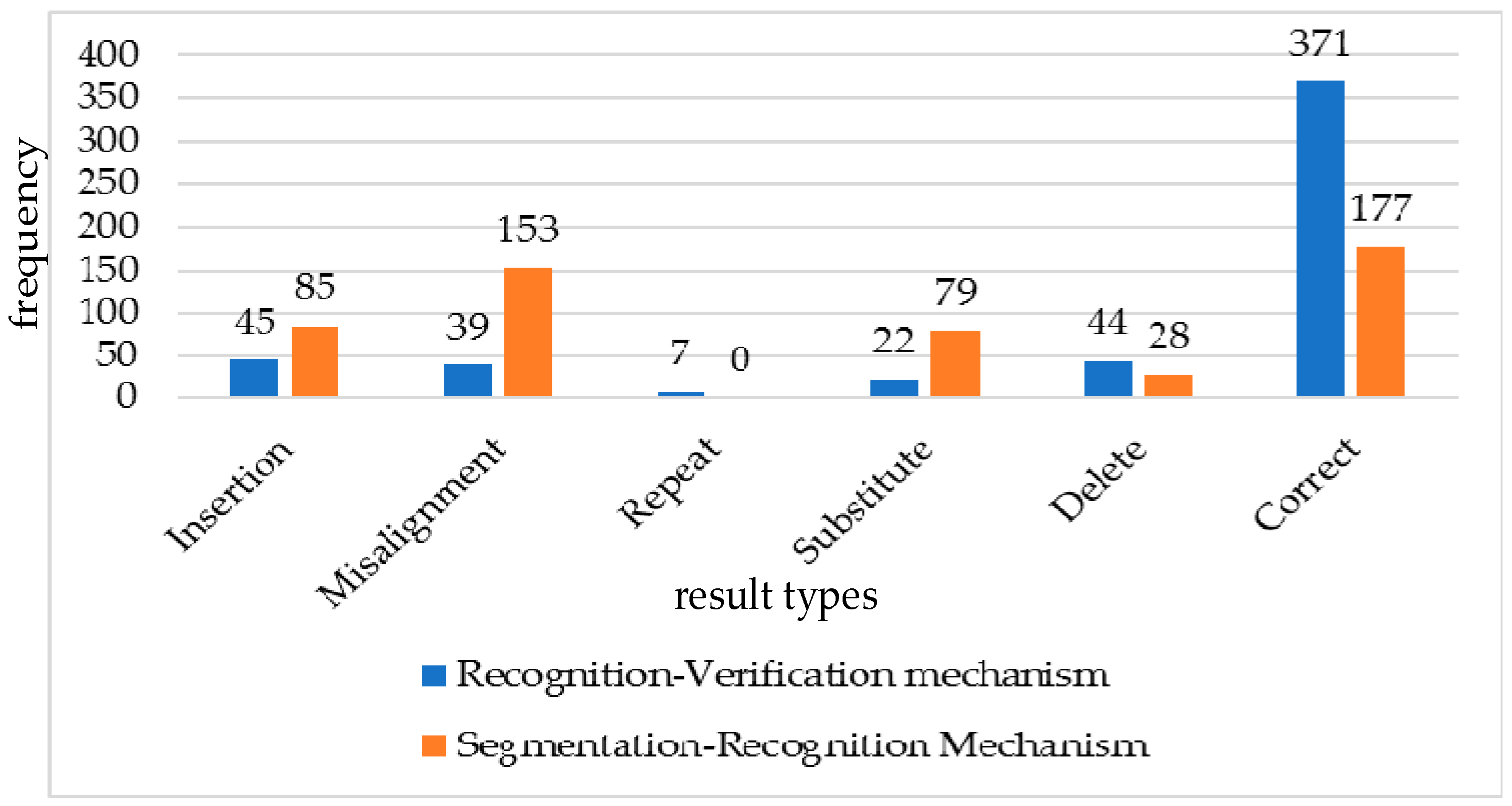
5.3.2. Recognition–Verification Mechanism in Online Recognition
5.3.3. Segmentation–Recognition Mechanism in Online Recognition
6. Results
6.1. Classification Model
6.1.1. The Layers of Network
6.1.2. Adaptive Average Pooling Layer
6.1.3. The Activation Function
6.1.4. Batch Normalization
6.2. Verification Model
6.2.1. Loss Function
6.2.2. Model Initialization
6.2.3. Batch Size
6.3. Online Sign Language Recognition
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Wei, S.; Chen, X.; Yang, X.; Cao, S.; Zhang, X. A Component-Based Vocabulary-Extensible Sign Language Gesture Recognition Framework. Sensors 2016, 16, 556. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Chen, X.; Liu, A.; Peng, H. A Novel Phonology- and Radical-Coded Chinese Sign Language Recognition Framework Using Accelerometer and Surface Electromyography Sensors. Sensors 2015, 15, 23303–23324. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Chen, X.; Cao, X.; Wei, S.; Zhang, X. Chinese Sign Language Recognition Based on An Optimized Tree-structure Framework. IEEE J. Biomed. Health Inform. 2017, 21, 994–1004. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Chen, X.; Li, Q.; Zhang, X.; Zhou, P. A Hand Gesture Recognition Framework and Wearable Gesture-Based Interaction Prototype for Mobile Devices. IEEE Trans. Hum. Mach. Syst. 2014, 44, 293–299. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H. Video-based Sign Language Recognition without Temporal Segmentation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 2257–2264. [Google Scholar]
- Quivira, F.; Koike-Akino, T.; Wang, Y.; Erdogmus, D. Translating sEMG Signals to Continuous Hand Poses using Recurrent Neural Networks. In Proceedings of the IEEE Conference on Biomedical and Health Informatics (BHI), Las Vegas, NV, USA, 9 April 2018; pp. 166–169. [Google Scholar]
- Li, C.; Ren, J.; Huang, H.; Wang, B.; Zhu, Y.; Hu, H. PCA and deep learning based myoelectric grasping control of a prosthetic hand. Biomed. Eng. Online 2018, 17, 107–204. [Google Scholar] [CrossRef]
- Ding, I.; Lin, R.; Lin, Z. Service robot system with integration of wearable myo armband for specialized hand gesture human–computer interfaces for people with disabilities with mobility problems. Comput. Electr. Eng. 2018, 69, 815–827. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X.; Zhang, X.; Wang, Z. A Sign-Component-Based Framework for Chinese Sign Language Recognition Using Accelerometer and sEMG Data. IEEE Trans Biomed Eng. 2012, 59, 2695–2704. [Google Scholar] [PubMed]
- Zhang, X.; Chen, X.; Wang, W.H.; Yang, J.; Lantz, V.; Wang, K. Hand gesture recognition and virtual game control based on 3D accelerometer and EMG sensors. In Proceedings of the 2009 International Conference on Intelligent User Interfaces, Sanibel Island, FL, USA, 8–11 February 2009; pp. 401–405. [Google Scholar]
- Li, H.; Greenspan, M. Model-based segmentation and recognition of dynamic gestures in continuous video streams. Pattern Recognit. 2011, 44, 1614–1628. [Google Scholar] [CrossRef]
- Tang, J.; Cheng, H.; Zhao, Y.; Guo, H. Structured Dynamic Time Warping for Continuous Hand Trajectory Gesture Recognition. Pattern Recognit. 2018, 80, 21–31. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. Recurrent Convolutional Neural Networks for Continuous Sign Language Recognition by Staged Optimization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1610–1618. [Google Scholar]
- Camgoz, N.; Hadfield, S.; Koller, O.; Bowden, R. SubUNets: End-to-End Hand Shape and Continuous Sign Language Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2075–3084. [Google Scholar]
- Fang, B.; Sun, F.; Liu, H.; Liu, C. 3D human gesture capturing and recognition by the IMMU-based data glove. Neurocomputing 2018, 277, 198–207. [Google Scholar] [CrossRef]
- Galka, J.; Masior, M.; Zaborski, M.; Barczewska, K. Inertial Motion Sensing Glove for Sign Language Gesture Acquisition and Recognition. IEEE Sens. J. 2016, 16, 6310–6316. [Google Scholar] [CrossRef]
- Luo, X.; Wu, X.; Chen, L.; Zhao, Y.; Zhang, L.; Li, G.; Hou, W. Synergistic Myoelectrical Activities of Forearm Muscles Improving Robust Recognition of Multi-Fingered Gestures. Sensors 2019, 19, 640. [Google Scholar] [CrossRef]
- Teak-Wei, C.; Boon-Giin, L. American Sign Language Recognition Using Leap Motion Controller with Machine Learning Approach. Sensors 2018, 18, 3554. [Google Scholar]
- Su, R.; Chen, X.; Cao, S.; Zhang, X. Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors. Sensors 2016, 16, 100. [Google Scholar] [CrossRef] [PubMed]
- Madushanka, A.; Senevirathne, R.; Wijesekara, L.; Arunatilake, S. Framework for Sinhala Sign Language recognition and translation using a wearable armband. In Proceedings of the 2016 Sixteenth International Conference on Advances in ICT for Emerging Regions (ICTer), Negombo, Sri Lanka, 1–3 September 2016; pp. 49–57. [Google Scholar]
- Gu, Y.; Yang, D.; Huang, Q.; Yang, W.; Liu, H. Robust EMG pattern recognition in the presence of confounding factors: Features, classifiers and adaptive learning. Expert Syst. Appl. 2018, 96, 208–217. [Google Scholar] [CrossRef]
- Chowdhury, R.; Reaz, M.; Ali, M.; Bakar, A.; Chellappan, K.; Chang, T. Surface Electromyography Signal Processing and Classification Techniques. Sensors 2013, 13, 12431–12466. [Google Scholar] [CrossRef] [PubMed]
- Reaz, I.; Hussain, M.S.; Mohd-Yasin, F. Techniques of EMG signal analysis: Detection, processing, classification and applications. Biol. Proced. Online 2006, 8, 11–35. [Google Scholar] [CrossRef] [PubMed]
- Chu, J.; Moon, I.; Lee, Y.; Kim, S.; Mun, M. A Supervised Feature-Projection-Based Real-Time EMG Pattern Recognition for Multifunction Myoelectric Hand Control. IEEE/ASME Trans. Mechatron. 2007, 12, 282–290. [Google Scholar] [CrossRef]
- Baddar, W.; Kim, D.; Ro, Y. Learning Features Robust to Image Variations with Siamese Networks for Facial Expression Recognition. In Proceedings of the International Conference on Multimedia Modeling, Reykjavik, Iceland, 4–6 January 2017; pp. 189–200. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Kar, A.; Rai, N.; Sikka, K.; Sharma, G. AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5699–5708. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Zhang, X.; Zou, Y.; Shi, W. Dilated convolution neural network with LeakyReLU for environmental sound classification. In Proceedings of the International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017; pp. 1–5. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hadsell, R.; Chopra, S.; Lecun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 1–8. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Keskar, N.; Mudigere, D.; Nocedal, J.; Mikhail, S.; Ping, T. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Wu, J.; Sun, L.; Jafari, R. A Wearable System for Recognizing American Sign Language in Real-Time Using IMU and Surface EMG Sensors. IEEE J. Biomed. Health Inform. 2016, 20, 1285–1290. [Google Scholar] [CrossRef] [PubMed]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sign Language Categories | ||||||||
|---|---|---|---|---|---|---|---|---|
| friend | today | think | luggage | how | good | doctor | afternoon | one |
| hello | egg | me | ok | where | support | lighter | morning | dusk |
| sky | home | airport | consign | find | we | fever | yesterday | say |
| evening | return | who | take off | why | Shenyang | teacher | communicate | ask |
| happy | go | toilet | time | ID card | help | like | how to go | do |
| noon | late | refund | miss | terminal | China | listen | not found | [] |
| thanks | meat | ticket | change | watch | Liaoning | come | tomorrow | |
| sorry | contact | worry | flight | key | world | love | confiscate | |
| it’s ok | you | how | delay | knife | Beijing | want | everybody | |
| eat | what | question | excuse | cigarette | charge | drink | (early) morning | |
| VGGA | VGGB | VGGC | VGGD | VGGE |
|---|---|---|---|---|
| Conv3-64 | Conv3-64 | Conv3-64 | Conv3-64 | Conv3-64 |
| MaxPooling | ||||
| Conv3-128 | Conv3-128 | Conv3-128 | Conv3-128 | Conv3-128 |
| MaxPooling | ||||
| Conv3-256 | Conv3-256 | Conv3-256 | Conv3-256 | Conv3-256 |
| Conv3-256 | Conv3-256 | Conv3-256 | Conv3-256 | |
| MaxPooling | ||||
| Conv3-256 | Conv3-512 | Conv3-512 | Conv3-512 | |
| Conv3-256 | Conv3-512 | Conv3-512 | ||
| MaxPooling | ||||
| Conv3-512 | ||||
| Conv3-512 | ||||
| MaxPooling | ||||
| APL | ||||
| FC-86 | ||||
| Model | Loss = 0.5 | Loss = 0.1 | Loss = 0.05 | Loss = 0.01 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| e | AR | t | e | AR | t | e | AR | t | e | AR | t | |
| VGGA | 3 | 94.72 | 13.41 | 8 | 97.96 | 35.05 | 12 | 98.55 | 52.56 | 0 | 0 | 0 |
| VGGB | 2 | 96.44 | 11.27 | 5 | 98.41 | 28.03 | 7 | 98.55 | 38.8 | 17 | 98.92 | 94.89 |
| VGGC | 2 | 95.11 | 9.05 | 5 | 98.09 | 22.43 | 8 | 98.56 | 36.28 | 20 | 98.92 | 90.54 |
| VGGD | 2 | 97.07 | 12.08 | 4 | 98.4 | 24.18 | 5 | 98.63 | 30.29 | 14 | 98.83 | 84.98 |
| VGGE | 2 | 97.85 | 16.05 | 3 | 98.31 | 24.05 | 4 | 98.51 | 31.98 | 11 | 98.54 | 88.45 |
| Sign Language Thresholds | ||||||||
|---|---|---|---|---|---|---|---|---|
| 14.90 | 14.38 | 16.17 | 14.06 | 14.53 | 14.87 | 17.55 | 16.33 | 16.35 |
| 15.23 | 14.58 | 14.42 | 15.06 | 15.42 | 14.38 | 14.83 | 14.93 | 17.26 |
| 16.11 | 14.92 | 15.27 | 15.77 | 16.56 | 14.58 | 16.38 | 14.82 | 15.14 |
| 19.03 | 17.28 | 14.62 | 15.25 | 17.24 | 15.23 | 14.27 | 16.46 | 14.12 |
| 16.47 | 14.23 | 15.30 | 16.17 | 15.29 | 13.49 | 15.63 | 17.26 | 16.37 |
| 14.67 | 17.93 | 16.88 | 15.19 | 12.99 | 15.16 | 13.22 | 14.62 | 21.99 |
| 16.33 | 15.39 | 15.98 | 13.60 | 19.03 | 15.29 | 16.15 | 15.76 | |
| 16.59 | 14.64 | 14.98 | 15.10 | 14.18 | 15.29 | 15.38 | 16.45 | |
| 14.73 | 14.76 | 16.01 | 14.99 | 14.99 | 15.72 | 14.53 | 14.89 | |
| 14.96 | 14.26 | 14.72 | 16.32 | 13.76 | 14.58 | 15.76 | 15.34 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Zhao, S.; Zhou, X.; Li, C.; Li, M.; Zeng, Z. An Recognition–Verification Mechanism for Real-Time Chinese Sign Language Recognition Based on Multi-Information Fusion. Sensors 2019, 19, 2495. https://doi.org/10.3390/s19112495
Wang F, Zhao S, Zhou X, Li C, Li M, Zeng Z. An Recognition–Verification Mechanism for Real-Time Chinese Sign Language Recognition Based on Multi-Information Fusion. Sensors. 2019; 19(11):2495. https://doi.org/10.3390/s19112495
Chicago/Turabian StyleWang, Fei, Shusen Zhao, Xingqun Zhou, Chen Li, Mingyao Li, and Zhen Zeng. 2019. "An Recognition–Verification Mechanism for Real-Time Chinese Sign Language Recognition Based on Multi-Information Fusion" Sensors 19, no. 11: 2495. https://doi.org/10.3390/s19112495
APA StyleWang, F., Zhao, S., Zhou, X., Li, C., Li, M., & Zeng, Z. (2019). An Recognition–Verification Mechanism for Real-Time Chinese Sign Language Recognition Based on Multi-Information Fusion. Sensors, 19(11), 2495. https://doi.org/10.3390/s19112495