A Lighted Deep Convolutional Neural Network Based Fault Diagnosis of Rotating Machinery

Abstract
:1. Introduction
2. Theoretical Basis
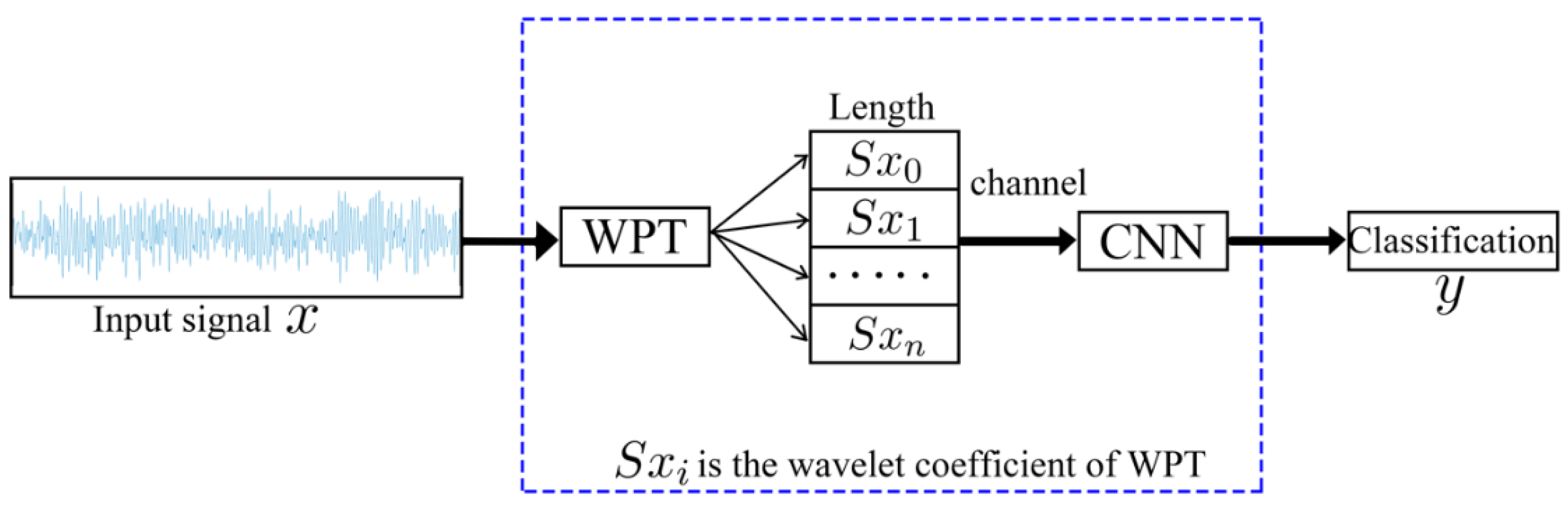
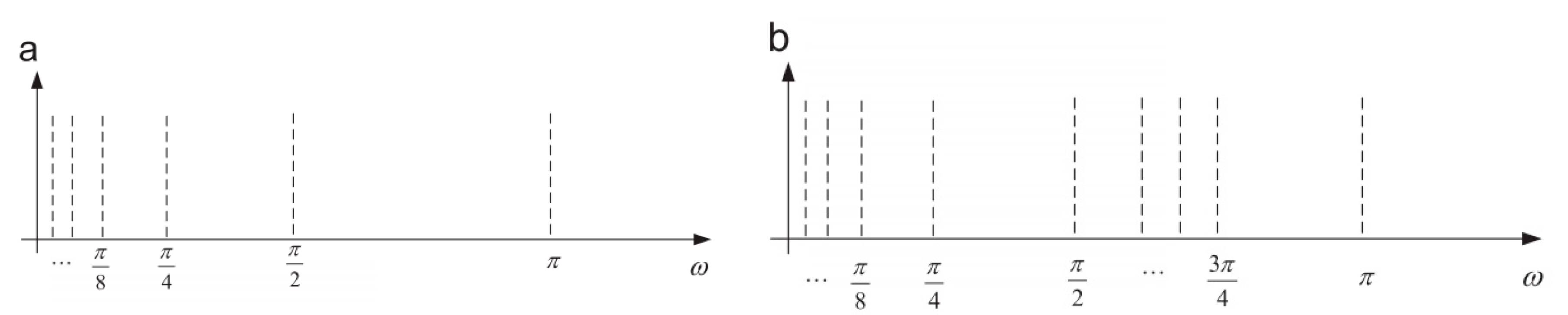
2.1. Wavelet Packet Transform (WPT)
2.2. Deep Convolutional Networks (DCNs)
2.3. One-by-One Convolutions
3. Lightweight CNN Structure Design
3.1. DCNN Design
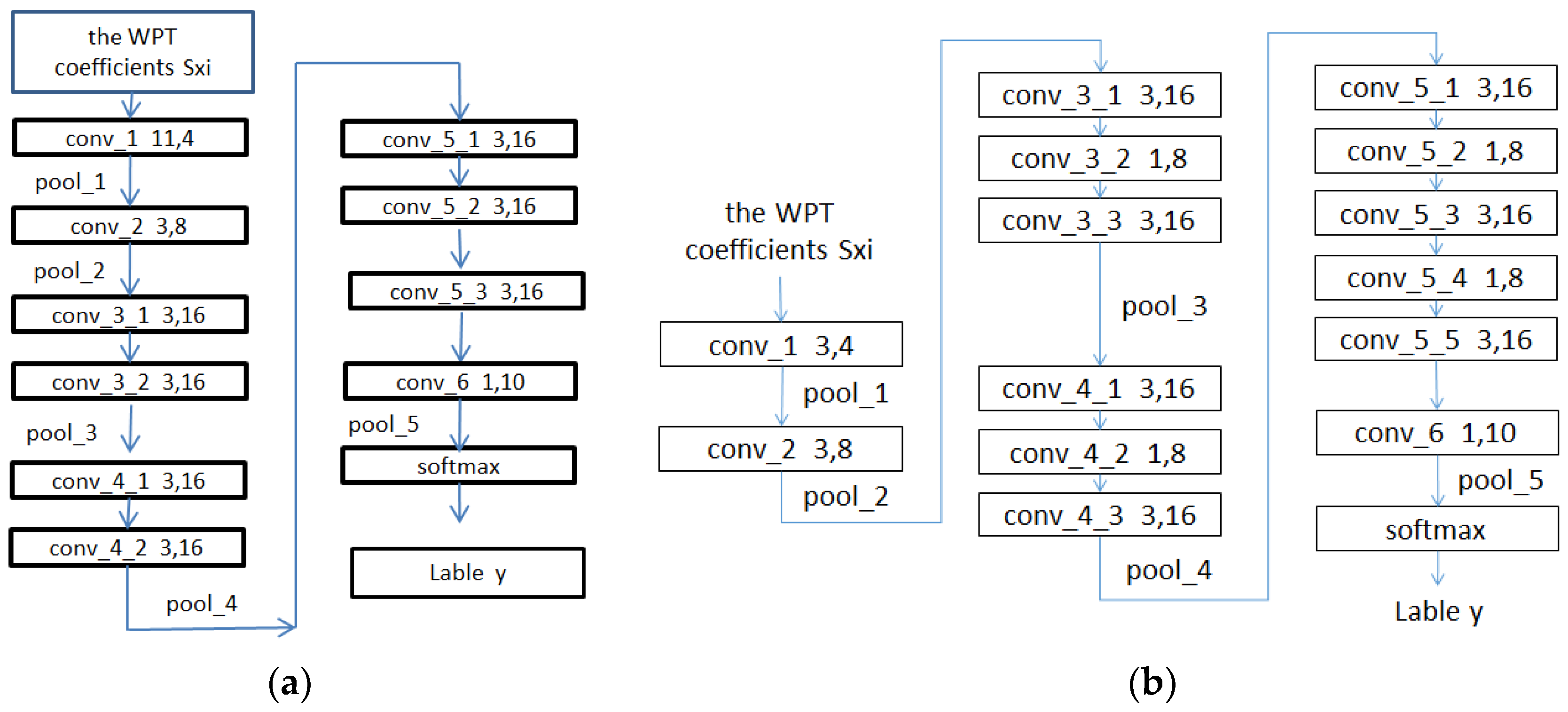
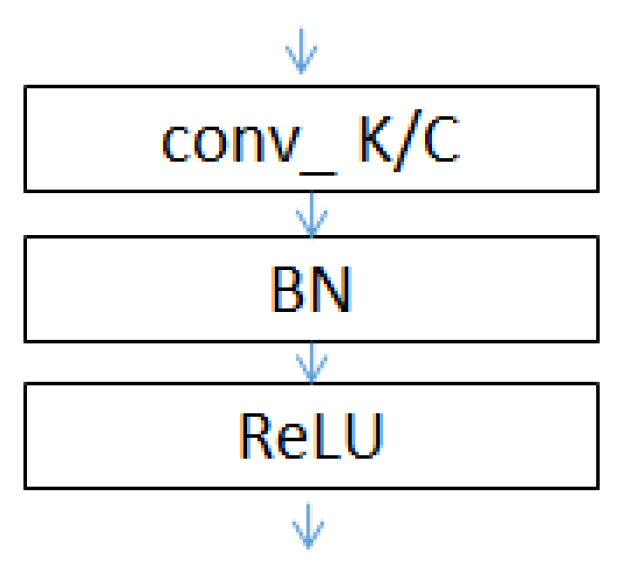
- The conv_1 to conv_5 convolutional layers of the network include convolution operations, rectified linear unit (ReLU) activation functions and BN (as shown in Figure 6). The use of the ReLU activation functions and BN can increase the rate of convergence and prevent a gradient explosion and vanishing problems. Maximum pooling is used in the poo1_1 to pool_4 pooling layers to allow the features that pass through the pooling layers to be translation invariant, thereby removing some noise while reducing the dimensionality of the features.
- The lengths of the conv_1 to conv_5 convolutional layers of the network are set to 11, 3, 3, 3 and 3, respectively, using the smoothing function of the convolution kernel. The length of the conv_1 layer is set to 11 to suppress noise.
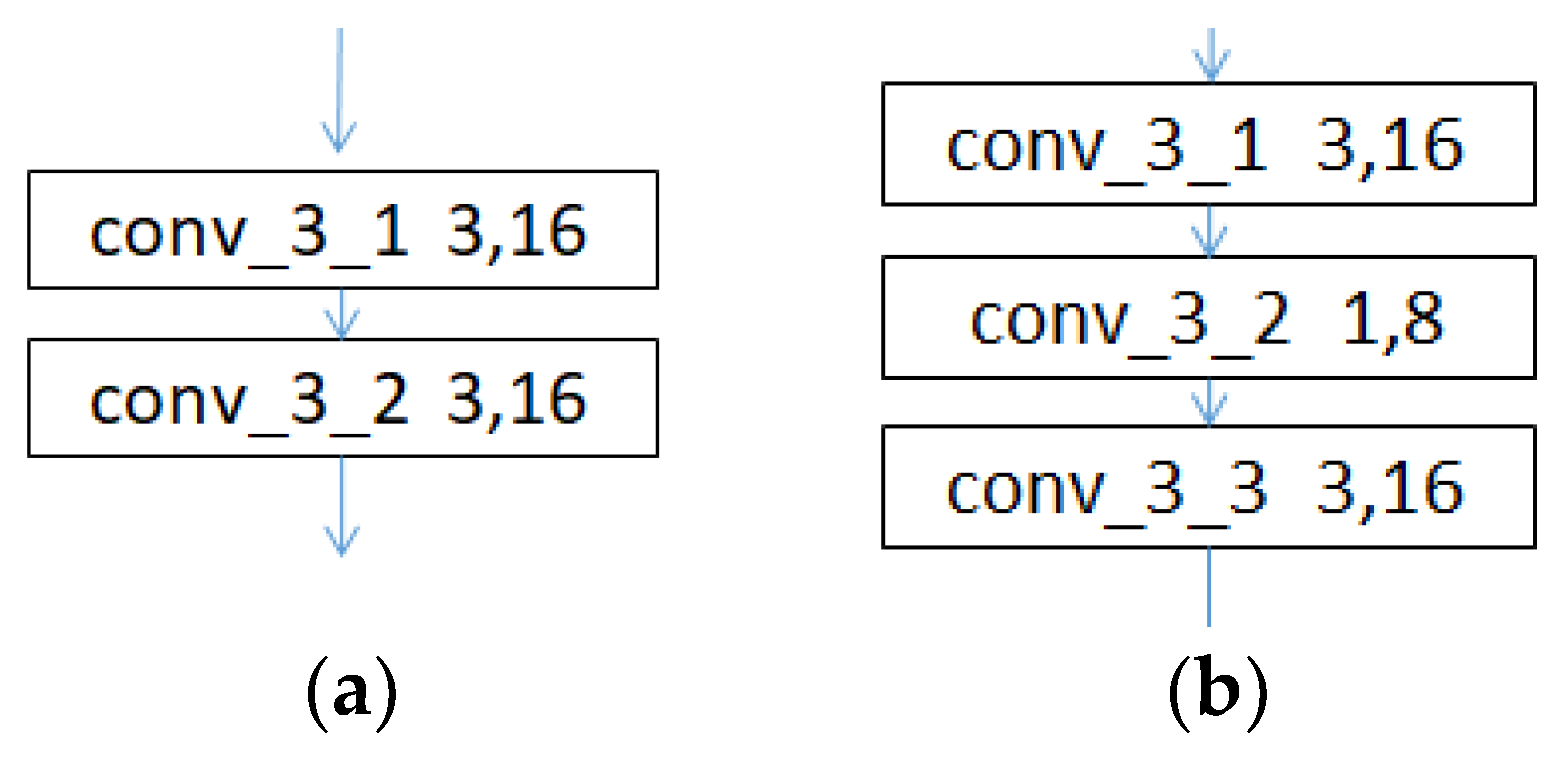
- An alternating cascade of convolutional layers with kernel sizes of 3 × 3 and 1 × 1 is used in the conv_3 to conv_5 convolutional blocks to reduce the dimensionality while increasing the depth of the network, thereby reducing the number of training parameters and realizing a lightweight model. This method has been proven effective elsewhere [29].
- In the second half of the network, the conv_6 and pool_6 layers are used to substitute for a commonly used fully connected layer to reduce the risk of overfitting caused by a fully connected layer while reducing the number of network parameters. A linear activation function is used in the conv_6 convolutional layer because a linear mapping is required to map the number of channels of the input feature to the same value of the classification. Other activation functions are not able to achieve this and may even slow down the convergence of the network. Global average pooling is used in the pool_5 pooling layer to allow the feature map input into each channel to correspond to each output feature, thereby improving the consistency between the feature maps and output types. The stability of the pooling process is also enhanced by the summation of the spatial information.
3.2. Performance Analysis of Network Parameters
4. Experiment and Analysis
4.1. Experimental Data
4.1.1. Introduction of the Dataset
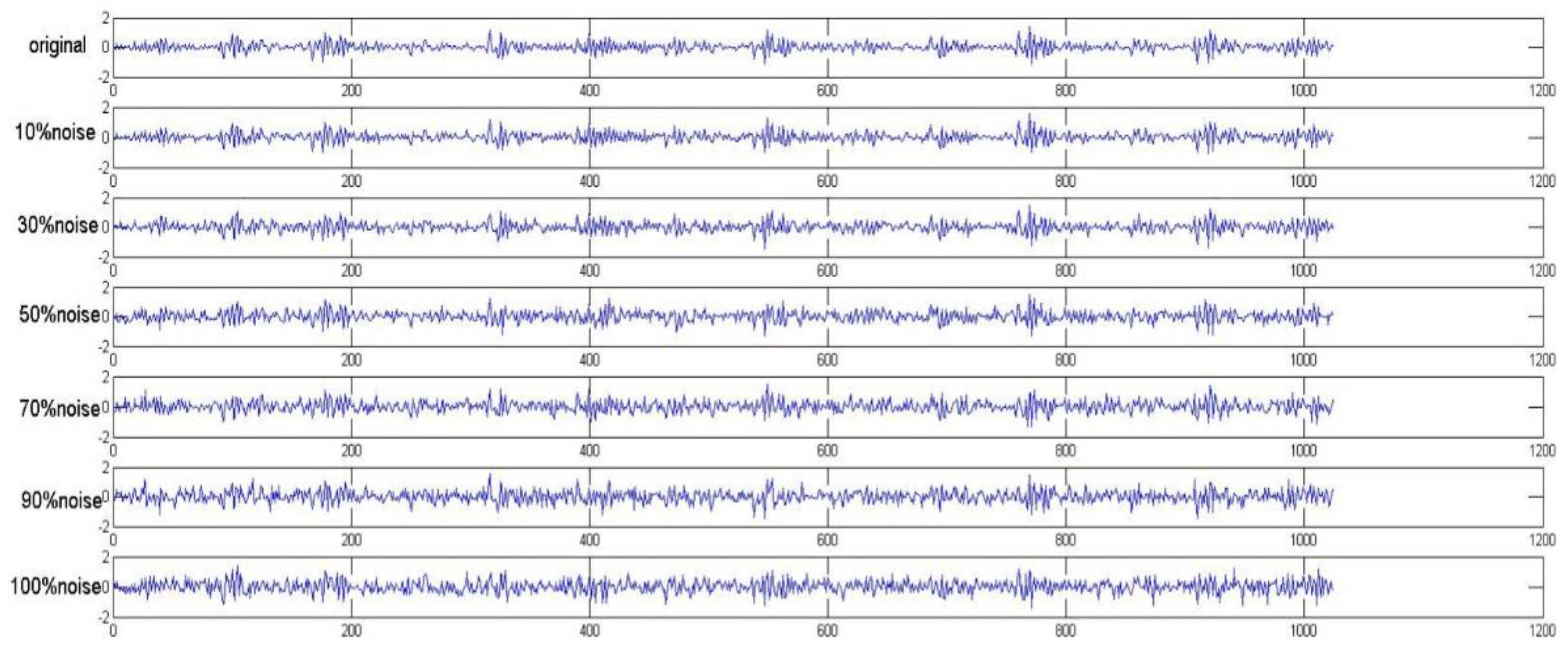
4.1.2. Data Preparation
4.1.3. Experimental Description
4.2. Experiment and Analysis
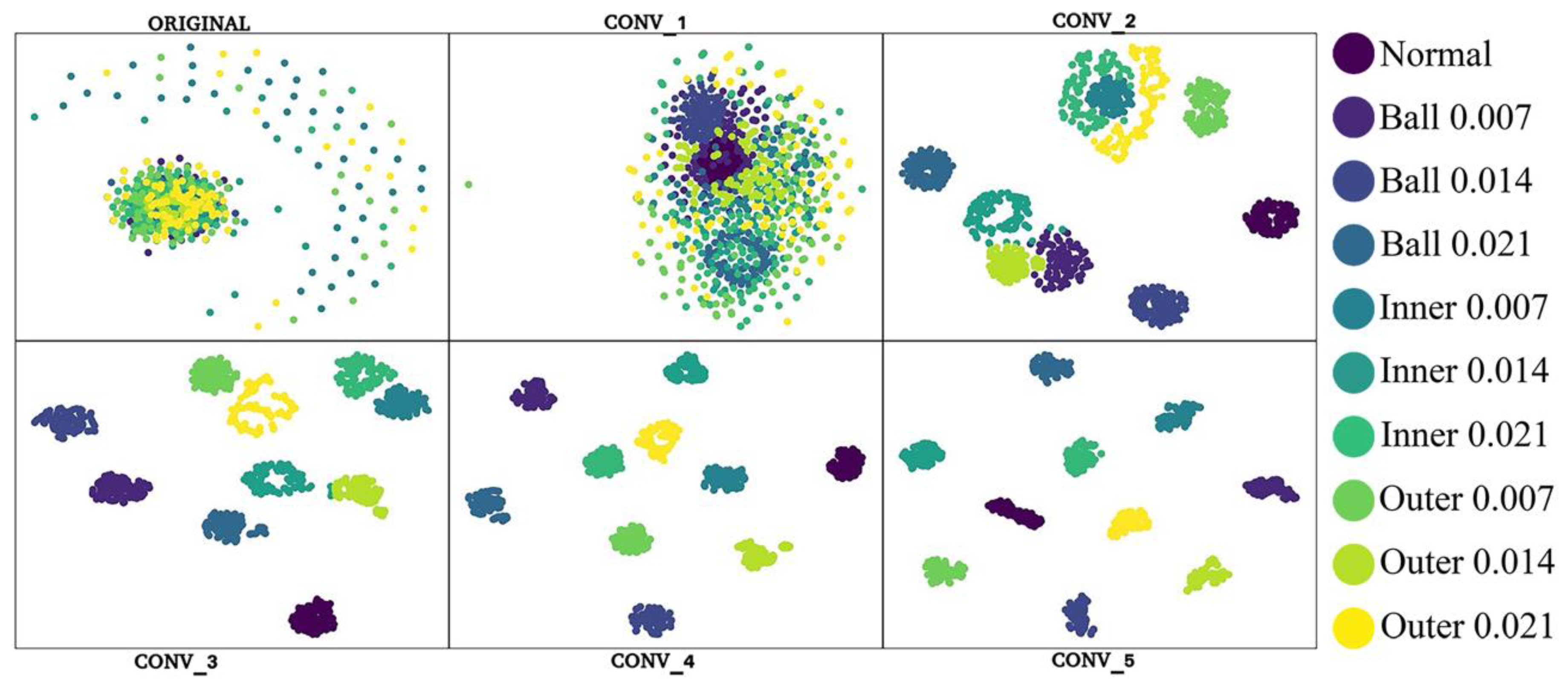
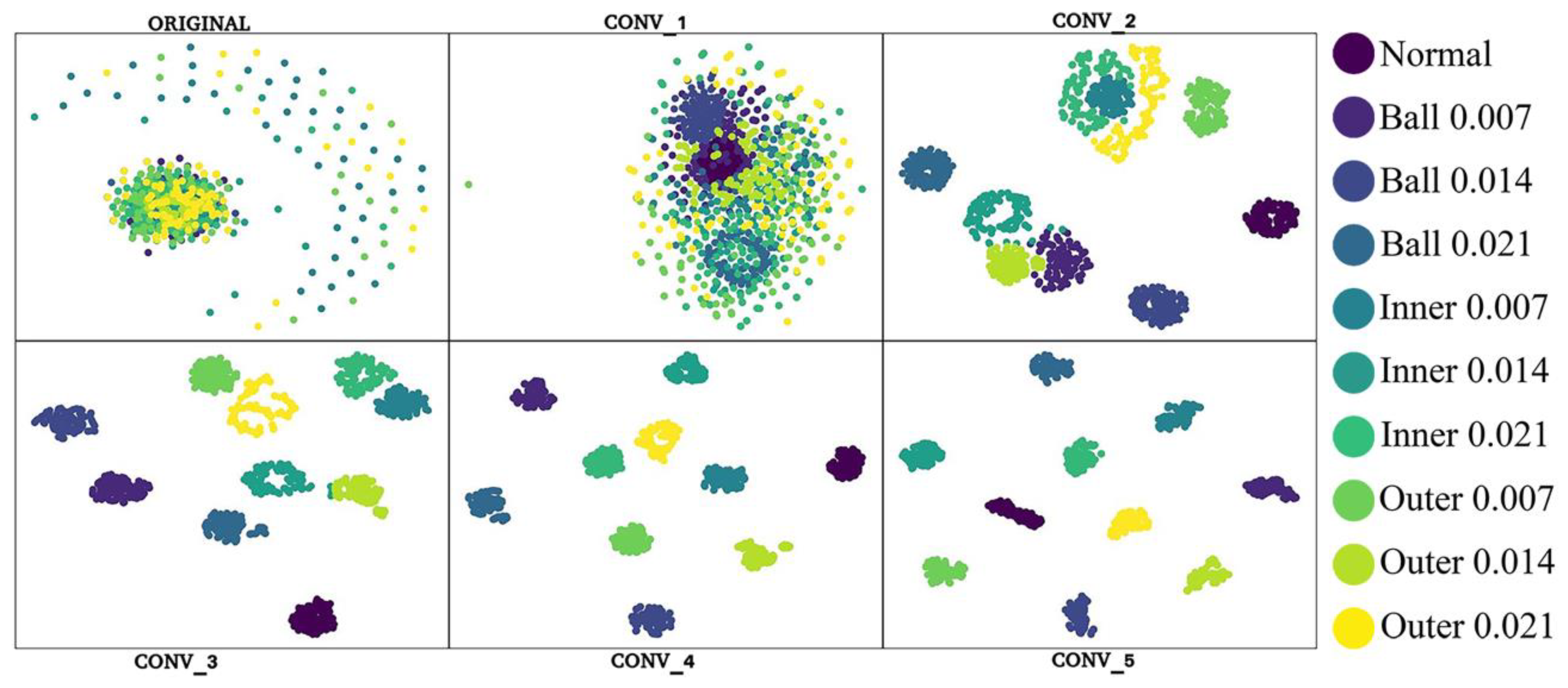
4.3. Visualization of the Network Learning Process
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, R.N.; Yang, B.Y.; Zio, E.; Chen, X.F. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Yan, R.Q.; Gao, R.X.; Chen, X.F. Wavelets for fault diagnosis of rotary machines: A review with applications. Signal Process. 2014, 96, 1–15. [Google Scholar] [CrossRef]
- Chen, J.L.; Li, Z.P.; Pan, J.; Chen, G.G.; Zi, Y.Y.; Yuan, J.; Chen, B.Q.; He, Z.J. Wavelet transform based on inner product in fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2016, 70, 1–35. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Shao, H.D.; Jiang, H.K.; Zhang, H.Z.; Duan, W.J.; Liang, T.C.; Wu, S.P. Rolling bearing fault feature learning using improved convolutional deep belief network with compressed sensing. Mech. Syst. Signal Process. 2018, 100, 743–765. [Google Scholar] [CrossRef]
- Adamczak, S.; Stępień, K.; Wrzochal, M. Comparative study of measurement systems used to evaluate vibrations of rolling bearings. Procedia Eng. 2017, 192, 971–975. [Google Scholar] [CrossRef]
- Lei, Y.G.; Lin, J.; Zuo, M.J.; He, Z.J. Condition monitoring and fault diagnosis of planetary gearboxes: A review. Measurement 2014, 48, 292–305. [Google Scholar] [CrossRef]
- Rojas, A.; Nandi, A.K. Practical scheme for fast detection and classification of rolling-element bearing faults using support vector machines. Mech. Syst. Signal Process. 2006, 20, 1523–1536. [Google Scholar] [CrossRef]
- Xia, H.; He, Y.G.; Wu, J. Fault-dictionary diagnostic method in frequency domain for nonlinear networks based on Volterra series and backward propagation neural networks (BPNN). J. Hunan Univ. Nat. Sci. 2004, 31, 41–43. [Google Scholar]
- Lei, Y.G.; He, Z.J.; Zi, Y.Y. Application of an intelligent classification method to mechanical fault diagnosis. Expert Syst. Appl. 2009, 36, 9941–9948. [Google Scholar] [CrossRef]
- Gangsar, P.; Tiwari, R. Multifault Diagnosis of induction motor at intermediate operating conditions using wavelet packet transform and support vector machine. J. Dyn. Syst-T. ASME 2018, 140, 081014-1-8. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Shao, H.D.; Jiang, H.K.; Wang, F.A.; Zhao, H.W. An enhancement deep feature fusion method for rotating machinery fault diagnosis. Knowl. Based Syst. 2017, 119, 200–220. [Google Scholar] [CrossRef]
- Rosa, E.D.L.; Yu, W. Randomized algorithms for nonlinear system identification with deep learning modification. Inf. Sci. 2016, 364–365, 197–212. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.G.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar] [CrossRef]
- Li, C.; Sanchez, R.V.; Zurita, G.; Cerrada, M.; Cabrera, D.; Vásquez, R.E. Gearbox fault diagnosis based on deep random forest fusion of acoustic and vibratory signals. Mech. Syst. Signal Process. 2016, 76–77, 283–293. [Google Scholar] [CrossRef]
- Gan, M.; Wang, C.; Zhu, C.A. Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings. Mech. Syst. Signal Process. 2016, 72–73, 92–104. [Google Scholar] [CrossRef]
- Sun, C.; Ma, M.; Zhao, Z.B.; Chen, X.F. Sparse deep stacking network for fault diagnosis of motor. IEEE Trans. Ind. Inform. 2018, 14, 3261–3270. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.Q.; Wang, J.J.; Mao, K.Z. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef] [PubMed]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-time motor fault detection by 1-D convolutional neural networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Zhuang, Z.L.; Qin, W. Intelligent fault diagnosis of rolling bearing using one-dimensional multi-scale deep convolutional neural network based health state classification. In Proceedings of the IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018. [Google Scholar]
- Zhang, W.; Li, C.H.; Peng, G.L.; Chen, Y.H.; Zhang, Z.J. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.Y.; Gao, L.; Zhang, Y.Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A novel fault diagnosis method for rotating machinery based on a convolutional neural network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef]
- Liu, R.N.; Meng, G.T.; Yang, B.Y.; Sun, C.; Chen, X.F. Dislocated time series convolutional neural architecture: An intelligent fault diagnosis approach for electric machine. IEEE Trans. Ind. Inf. 2017, 13, 1310–1320. [Google Scholar] [CrossRef]
- Zhao, M.H.; Kang, M.; Tang, B.P.; Pecht, M. Deep residual networks with dynamically weighted wavelet coefficients for fault diagnosis of planetary gearboxes. IEEE Trans. Ind. Electron. 2018, 65, 4290–4300. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Yu, W. A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Sun, Z.; Chang, C.C. Structural damage assessment based on wavelet packet transform. J. Struct. Eng. 2002, 128, 1354–1361. [Google Scholar] [CrossRef]
- Stępień, K.; Makieła, W. An analysis of deviations of cylindrical surfaces with the use of wavelet transform. Metrol. Meas. Syst. 2013, 20, 139–150. [Google Scholar] [CrossRef]
- Dibal, P.Y.; Onwuka, E.N.; Agajo, J.; Alenoghena, C.O. Enhanced discrete wavelet packet sub-band frequency edge detection using Hilbert transform. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 3880–3882. [Google Scholar] [CrossRef]
- Zong, X.F.; Men, A.D.; Yang, B. Rate-distortion optimal wavelet packet transform for low bit rate video coding. In Proceedings of the IEEE International Workshop on Imaging Systems and Techniques, Shenzhen, China, 11–12 May 2009; pp. 359–363. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Review: Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. PAMI. Available online: https://arxiv.org/abs/1709.01507 (accessed on 5 December 2018).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Data Sets. Available online: http://csegroups.case.edu/bearingdatacenter/pages/download-data-file (accessed on 23 February 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Memory Requirement | Computational Complexity |
|---|---|---|
| [28] | 72.35 KB | 1.40 × 106 |
| [23] | 203.80 KB | 6.81 × 107 |
| [24] | 258.52 KB | 4.69 × 106 |
| [25] | 367.814 KB | 2.00 × 108 |
| [27] | 565.16 KB | 8.08 × 107 |
| [15] | 2696.54 KB | 1.37 × 106 |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | Model 7 | |
|---|---|---|---|---|---|---|---|
| K/C | K/C | K/C | K/C | K/C | K/C | K/C | |
| conv_1 | 11 × 1/4 | 11 × 1/4 | 11 × 1/4 | 11 × 1/4 | 11 × 1/8 | 11 × 1/16 | 11 × 1/32 |
| conv_2 | 3 × 1/8 | 3 × 1/8 | 3 × 1/8 | 3 × 1/8 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 |
| conv_3_1 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 |
| conv_3_2 | / | 1 × 1/8 | 1 × 1/8 | 1 × 1/8 | 1 × 1/16 | 1 × 1/32 | 1 × 1/64 |
| conv_3_3 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 |
| conv_4_1 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 | 3 × 1/256 |
| conv_4_2 | / | 1 × 1/8 | 1 × 1/16 | 1 × 1/16 | 1 × 1/32 | 1 × 1/64 | 1 × 1/128 |
| conv_4_3 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 | 3 × 1/256 |
| conv_5_1 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 | 3 × 1/256 | 3 × 1/512 |
| conv_5_2 | / | 1 × 1/8 | 1 × 1/16 | 1 × 1/32 | 1 × 1/64 | 1 × 1/128 | 1 × 1/246 |
| conv_5_3 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 | 3 × 1/256 | 3 × 1/512 |
| conv_5_4 | / | 1 × 1/8 | 1 × 1/16 | 1 × 1/32 | 1 × 1/64 | 1 × 1/128 | 1 × 1/256 |
| conv_5_5 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | 3 × 1/64 | 3 × 1/128 | 3 × 1/256 | 3 × 1/512 |
| conv_6 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 |
| The number of parameters | 23.77 KB | 19.90 KB | 56.93 KB | 142.68 KB | 557.07 KB | 2201.10 KB | 8750.16 KB |
| The computation of the floating numbers | 1.77 × 105 | 1.61 × 105 | 2.66 × 105 | 4.41 × 105 | 1.57 × 106 | 5.92 × 106 | 2.29 × 107 |
| Note | Uncompressed 4 channels | Compressed 4 channels | Compressed 4 channels | Compressed 4 channels | Compressed 8 channels | Compressed 16 channels | Compressed 32 channels |
| The maximum number of channels is 16 | The maximum number of channels is 16 | The maximum number of channels is 32 | The maximum number of channels is 64 | The maximum number of channels is 128 | The maximum number of channels is 256 | The maximum number of channels is 512 |
| Method | Number of Parameters | Computation of Floating Number | Input Length Specification |
|---|---|---|---|
| WPT-CNN | 19.90 KB | 1.61 × 105 | 64 × 1 × 16 |
| Reference [28] | 72.35 KB | 1.40 × 106 | 32 × 32 × 1 |
| Reference [23] | 203.80 KB | 6.81 × 107 | 400 × 1 × 1 |
| Reference [24] | 258.52 KB | 4.69 × 106 | 1024 × 1 × 1 |
| Reference [27] | 565.16 KB | 8.08 × 107 | 512 × 10 × 1 |
| Reference [25] | 367.814 KB | 2.00 × 108 | 128 × 128 × 1 |
| Reference [15] | 2696.54 KB | 1.37 × 106 | 1024 × 1 × 1 |
| Resnet-50 | 80,849.75 KB | 2.04 × 109 | 1024 × 1 × 1 |
| Resnet-18 | 14,325.75 KB | 3.35 × 108 | 1024 × 1 × 1 |
| VGG-16 | 78,544.75 KB | 9.24 × 108 | 1024 × 1 × 1 |
| 1D-LeNet5 | 1349 KB | 1.27 × 106 | 1024 × 1 × 1 |
| Hardware Environment | Software Environment | |
|---|---|---|
| CPU | Intel Core i7-8700k, 3.7 GHz, six-core twelve threads | Ubuntu 16.04 system TensorFlow 1.10 framework and Python programming language |
| GPU | NVIDIA 1080Ti 11G | |
| Memory | 32 GB | |
| Storage | 2 TB | |
| Datasets | Load (HP) | Training Samples | Test Samples | Fault Types | Flaw Size (Inches) | Models |
|---|---|---|---|---|---|---|
| A/B/C/D | 0/1/2/3 | 800/800/800/800 | 100/100/100/100 | normal | 0 | 1 |
| 800/800/800/800 | 100/100/100/100 | ball | 0.007 | 2 | ||
| 800/800/800/800 | 100/100/100/100 | ball | 0.014 | 3 | ||
| 800/800/800/800 | 100/100/100/100 | ball | 0.021 | 4 | ||
| 800/800/800/800 | 100/100/100/100 | inner_race | 0.007 | 5 | ||
| 800/800/800/800 | 100/100/100/100 | inner_race | 0.014 | 6 | ||
| 800/800/800/800 | 100/100/100/100 | inner_race | 0.021 | 7 | ||
| 800/800/800/800 | 100/100/100/100 | outer_race | 0.007 | 8 | ||
| 800/800/800/800 | 100/100/100/100 | outer_race | 0.014 | 9 | ||
| 800/800/800/800 | 100/100/100/100 | outer_race | 0.021 | 10 |
| Validation Sets | Title 2 | 0% | 10% | 30% | 50% | 70% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|
| Time domain | 100 | 100 | 94.48 | 90.49 | 85.79 | 81.62 | 77.87 | 76.88 |
| ±0.17 | ±0.57 | ±0.72 | ±1.15 | ±1.48 | ±0.88 | |||
| WPT3 | 100 | 100 | 96.80 | 93.4 | 90.77 | 88.56 | 86.62 | 85.74 |
| ±0.31 | 3±0.33 | ±0.33 | ±0.92 | ±0.71 | ±0.73 | |||
| WPT4 | 100 | 100 | 98.18 | 97.26 | 95.83 | 94.55 | 93.07 | 92.11 |
| ±0.25 | ±0.37 | ±0.38 | ±0.47 | ±0.89 | ±0.63 | |||
| WPT5 | 100 | 99.4 | 96.69 | 95.78 | 94.30 | 92.66 | 90.40 | 90.16 |
| ±0.26 | ±0.33 | ±0.49 | ±0.76 | ±0.69 | ±0.99 | |||
| WPT6 | 100 | 97.2 | 96.02 | 94.03 | 91.49 | 89.01 | 86.43 | 85.83 |
| ±0.34 | ±0.60 | ±0.84 | ±0.72 | ±1.10 | ±0.72 |
| Convolution Kernels | Validation Sets | 0% | 10% | 30% | 50% | 70% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|
| 3 | 100 | 100 | 98.18 | 97.26 | 95.83 | 94.55 | 93.07 | 92.11 |
| ±0.25 | ±0.37 | ±0.38 | ±0.47 | ±0.89 | ±0.63 | |||
| 5 | 100 | 100 | 99.02 | 97.94 | 96.76 | 95.29 | 93.54 | 92.85 |
| ±0.19 | ±0.32 | ±0.57 | ±0.39 | ±0.76 | ±0.42 | |||
| 7 | 100 | 99.9 | 99.73 | 99.11 | 98.44 | 96.98 | 95.31 | 95.03 |
| ±0.18 | ±0.34 | ±0.41 | ±0.43 | ±0.54 | ±0.87 | |||
| 9 | 100 | 100 | 96.66 | 96.06 | 94.88 | 94.12 | 93.16 | 92.61 |
| ±0.22 | ±0.39 | ±0.59 | ±0.51 | ±0.29 | ±0.92 | |||
| 11 | 100 | 100 | 99.33 | 99.02 | 98.63 | 97.71 | 96.57 | 96.35 |
| ±0.12 | ±0.26 | ±0.24 | ±0.45 | ±0.43 | ±0.52 | |||
| 13 | 100 | 100 | 99.06 | 98.57 | 97.57 | 96.70 | 95.74 | 95.04 |
| ±0.17 | ±0.34 | ±0.37 | ±0.52 | ±0.33 | ±0.45 | |||
| 15 | 100 | 100 | 99.50 | 99.08 | 98.38 | 97.49 | 96.35 | 96.24 |
| ±0.17 | ±0.30 | ±0.21 | ±0.52 | ±0.57 | ±0.57 | |||
| 23 | 100 | 100 | 98.11 | 97.29 | 96.13 | 95.11 | 94.38 | 93.89 |
| ±0.33 | ±0.27 | ±0.50 | ±0.53 | ±0.45 | ±0.59 | |||
| 31 | 100 | 99.9 | 99.03 | 98.28 | 97.30 | 96.47 | 95.52 | 94.70 |
| ±0.14 | ±0.29 | ±0.41 | ±0.42 | ±0.55 | ±0.48 |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | Model 7 | ||
|---|---|---|---|---|---|---|---|---|
| Noise resistance | 0% | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 10% | 99.76 | 99.33 | 99.71 | 99.40 | 99.99 | 99.97 | 100.0 | |
| ±0.07 | ±0.12 | ±0.12 | ±0.18 | ±0.03 | ±0.05 | ±0.00 | ||
| 30% | 99.19 | 99.02 | 98.78 | 99.28 | 99.81 | 99.71 | 99.91 | |
| ±0.27 | ±0.26 | ±0.25 | ±0.27 | ±0.14 | ±0.14 | ±0.09 | ||
| 50% | 98.37 | 98.63 | 97.79 | 97.01 | 98.25 | 99.09 | 99.52 | |
| ±0.45 | ±0.24 | ±0.31 | ±0.60 | ±0.41 | ±0.34 | ±0.18 | ||
| 70% | 97.57 | 97.71 | 96.55 | 95.85 | 97.25 | 98.61 | 98.87 | |
| ±0.32 | ±0.45 | ±0.37 | ±0.37 | ±0.47 | ±0.29 | ±0.24 | ||
| 90% | 96.41 | 96.57 | 95.18 | 94.36 | 96.75 | 97.64 | 98.11 | |
| ±0.58 | ±0.43 | ±0.53 | ±0.84 | ±0.46 | ±0.40 | ±0.40 | ||
| 100% | 96.11 | 96.35 | 95.09 | 94.53 | 96.75 | 97.38 | 97.65 | |
| ±0.44 | ±0.52 | ±0.54 | ±0.42 | ±0.46 | ±0.20 | ±0.32 | ||
| Transfer-learning ability | AB | 98.8 | 100 | 99.9 | 100 | 98.4 | 99.2 | 99.4 |
| AC | 99.1 | 100 | 100 | 99.9 | 99.6 | 99.8 | 97.3 | |
| AD | 99.3 | 99.9 | 99.5 | 99.9 | 98.7 | 99.7 | 99.2 | |
| Number of parameters | 23.77 KB | 19.90 KB | 56.93 KB | 142.68 KB | 557.07 KB | 2201.10 KB | 8750.16 KB | |
| The computation of floating numbers | 1.77 × 105 | 1.61 × 105 | 2.66 × 105 | 4.41 × 105 | 1.57 × 106 | 5.92 × 106 | 2.29 × 107 | |
| 3 Layers | 4 Layers | 5 Layers | 6 Layers | |
|---|---|---|---|---|
| conv_1 | 11 × 1/4 | 11 × 1/4 | 11 × 1/4 | 11 × 1/4 |
| conv_2 | 3 × 1/8 | 3 × 1/8 | 3 × 1/8 | 3 × 1/8 |
| conv_3_1 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 |
| conv_3_2 | 1 × 1/8 | 1 × 1/8 | 1 × 1/8 | 1 × 1/8 |
| conv_3_3 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 | 3 × 1/16 |
| conv_4_1 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | |
| conv_4_2 | 1 × 1/8 | 1 × 1/8 | 1 × 1/16 | |
| conv_4_3 | 3 × 1/16 | 3 × 1/16 | 3 × 1/32 | |
| conv_5_1 | 3 × 1/16 | 3 × 1/16 | ||
| conv_5_2 | 1 × 1/8 | 1 × 1/8 | ||
| conv_5_3 | 3 × 1/16 | 3 × 1/16 | ||
| conv_5_4 | 1 × 1/8 | 1 × 1/8 | ||
| conv_5_5 | 3 × 1/16 | 3 × 1/16 | ||
| conv_6_1 | 3 × 1/16 | |||
| conv_6_2 | 1 × 1/8 | |||
| conv_6_3 | 3 × 1/16 | |||
| conv_6_4 | 1 × 1/8 | |||
| conv_6_5 | 3 × 1/16 | |||
| conv_6 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 | 1 × 1/10 |
| Layers | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|
| Validation sets | 100 | 100 | 100 | 100 | |
| Normal | 100 | 100 | 100 | 100 | |
| Transfer-learning ability | AB | 90.9 | 99.70 | 100 | 99.6 |
| AC | 93.5 | 99.40 | 100 | 99.8 | |
| AD | 91.5 | 98.90 | 99.8 | 99.6 | |
| Noise resistance | 10% | 99.11 ± 0.40 | 99.72 ± 0.10 | 99.33 ± 0.12 | 98.95 ± 0.17 |
| 30% | 97.05 ± 0.40 | 99.32 ± 0.26 | 99.02 ± 0.26 | 98.32 ± 0.32 | |
| 50% | 94.33 ± 0.60 | 98.69 ± 0.25 | 98.63 ± 0.24 | 97.29 ± 0.58 | |
| 70% | 91.87 ± 0.74 | 97.49 ± 0.36 | 97.71 ± 0.45 | 95.69 ± 0.43 | |
| 90% | 89.35 ± 0.95 | 96.61 ± 0.67 | 96.57 ± 0.43 | 94.42 ± 0.51 | |
| 100% | 87.94 ± 0.96 | 95.88 ± 0.59 | 96.35 ± 0.52 | 93.97 ± 0.55 | |
| Number of parameters | 7.49 KB | 12.65 KB | 19.90 KB | 27.15 KB | |
| The computation of floating number | 1.26 × 105 | 1.47 × 105 | 1.61 × 105 | 1.75 × 105 | |
| 0% | 10% | 30% | 50% | 70% | 90% | 100% | |
|---|---|---|---|---|---|---|---|
| AB | 100 | 99.54 ± 0.25 | 98.82 ± 0.24 | 97.71 ± 0.47 | 96.96 ± 0.50 | 96.12 ± 0.57 | 95.53 ± 0.51 |
| AC | 100 | 99.42 ± 0.14 | 98.78 ± 0.25 | 98.21 ± 0.32 | 97.38 ± 0.45 | 96.64 ± 0.44 | 95.94 ± 0.38 |
| AD | 99.8 | 97.21 ± 0.21 | 96.35 ± 0.43 | 95.63 ± 0.46 | 94.64 ± 0.63 | 93.16 ± 0.47 | 93.28 ± 0.88 |
| BA | 98.9 | 97.07 ± 0.33 | 96.16 ± 0.43 | 94.42 ± 0.48 | 93.13 ± 0.51 | 91.79 ± 1.00 | 90.34 ± 0.73 |
| BC | 100 | 99.47 ± 0.15 | 99.44 ± 0.15 | 99.19 ± 0.18 | 98.54 ± 0.29 | 98.11 ± 0.42 | 97.65 ± 0.42 |
| BD | 99.9 | 98.15 ± 0.22 | 97.78 ± 0.36 | 97.23 ± 0.20 | 96.66 ± 0.30 | 95.64 ± 0.32 | 95.52 ± 0.61 |
| CA | 93.4 | 92.81 ± 0.31 | 91.40 ± 0.38 | 89.99 ± 0.62 | 88.59 ± 0.82 | 86.93 ± 0.80 | 86.31 ± 0.53 |
| CB | 98.7 | 97.27 ± 0.17 | 96.87 ± 0.34 | 96.54 ± 0.40 | 95.86 ± 0.39 | 95.44 ± 0.62 | 94.88 ± 0.27 |
| CD | 100 | 99.87 ± 0.13 | 99.50 ± 0.13 | 99.01 ± 0.27 | 98.48 ± 0.36 | 97.58 ± 0.52 | 97.23 ± 0.42 |
| DA | 95.3 | 91.84 ± 0.32 | 90.45 ± 0.54 | 89.18 ± 0.56 | 88.41 ± 0.58 | 86.90 ± 0.60 | 86.33 ± 0.76 |
| DB | 98.4 | 97.98 ± 0.14 | 97.59 ± 0.33 | 97.31 ± 0.22 | 96.73 ± 0.48 | 95.99 ± 0.39 | 95.90 ± 0.51 |
| DC | 100 | 99.72 ± 0.04 | 99.66 ± 0.15 | 98.97 ± 0.17 | 99.05 ± 0.14 | 98.19 ± 0.32 | 97.88 ± 0.29 |
| Validation Sets | 0% | 10% | 30% | 50% | 70% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|
| WPT-CNN | 100 | 100 | 99.33 | 99.02 | 98.63 | 97.71 | 96.57 | 96.35 |
| ±0.12 | ±0.26 | ±0.24 | ±0.45 | ±0.43 | ±0.52 | |||
| Reference [28] | 100 | 100 | 99.85 | 98.33 | 95.60 | 91.95 | 88.02 | 85.94 |
| ±0.08 | ±0.27 | ±0.44 | ±0.52 | ±0.55 | ±1.13 | |||
| Reference [24] | 100 | 99.70 | 99.53 | 98.24 | 94.51 | 90.72 | 86.69 | 85.35 |
| ±0.18 | ±0.26 | ±0.61 | ±0.51 | ±0.54 | ±0.45 | |||
| Reference [23] | 100 | 100 | 80.13 | 71.61 | 64.50 | 59.88 | 57.01 | 55.83 |
| ±0.19 | ±0.27 | ±0.44 | ±0.37 | ±0.40 | ±0.37 | |||
| Reference [26] | 100 | 100 | 88.10 | 66.28 | 55.24 | 48.38 | 43.89 | 42.02 |
| ±0.87 | ±0.58 | ±1.20 | ±0.90 | ±1.03 | ±0.98 | |||
| Reference [27] | 100 | 99.90 | 97.46 | 85.14 | 70.59 | 58.57 | 50.96 | 48.38 |
| ±0.52 | ±0.80 | ±0.75 | ±1.03 | ±0.47 | ±0.73 | |||
| Reference [19] | 100 | 99.80 | 99.15 | 98.01 | 96.36 | 94.03 | 91.79 | 90.74 |
| ±0.20 | ±0.50 | ±0.31 | ±0.69 | ±0.86 | ±0.64 | |||
| Reference [15] | 99.1 | 97.50 | 95.54 | 93.88 | 92.86 | 90.81 | 88.90 | 87.49 |
| ±0.25 | ±0.50 | ±0.38 | ±0.66 | ±1.03 | ±0.92 | |||
| Reference [11] | 93.6 | 88.30 | 88.08 | 85.38 | 76.66 | 64.03 | 46.81 | 38.47 |
| ±0.33 | 0.77 | ±0.88 | ±0.75 | ±1.37 | ±0.95 |
| AB | AC | AD | BA | BC | BD | CA | CB | CD | DA | DB | DC | AVG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WPT-CNN | 100 | 100 | 99.8 | 98.9 | 100 | 99.9 | 93.4 | 98.7 | 100 | 95.3 | 98.4 | 100 | 98.70 |
| Reference [28] | 98.4 | 99.9 | 98.2 | 99.8 | 100 | 98.9 | 96.0 | 98.3 | 99.3 | 90.4 | 93.8 | 100 | 97.75 |
| Reference [24] | 99.5 | 99.9 | 96.9 | 99.5 | 100 | 98.2 | 96.8 | 98.4 | 99.0 | 97.1 | 97.1 | 99.1 | 98.46 |
| Reference [23] | 99.9 | 98.9 | 89.8 | 99.9 | 99.9 | 97.9 | 98.6 | 99.4 | 99.8 | 81.3 | 85.0 | 94.2 | 95.40 |
| Reference [26] | 89.3 | 84.5 | 73.0 | 83.6 | 98.0 | 91.5 | 85.1 | 96.9 | 95.9 | 78.0 | 88.0 | 95.3 | 88.26 |
| Reference [27] | 98.7 | 98.3 | 81.7 | 98.7 | 99.9 | 98.5 | 93.2 | 97.7 | 97.4 | 89.4 | 92.0 | 94.9 | 95.03 |
| Reference [19] | 71.1 | 74.8 | 72.6 | 87.6 | 87.4 | 76.6 | 77.5 | 88.0 | 79.5 | 77.7 | 78.9 | 86.7 | 79.87 |
| Reference [15] | 33.7 | 44.6 | 43.6 | 43.3 | 42.0 | 51.5 | 48.4 | 47.7 | 48.3 | 42.8 | 46.3 | 41.8 | 44.50 |
| Reference [11] | 40.4 | 40.3 | 39.3 | 40.5 | 55.3 | 59.8 | 41.2 | 56.3 | 57.1 | 36.9 | 56.1 | 52.6 | 47.98 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; Cai, W.; Liu, W.; Shang, Z.; Liu, G. A Lighted Deep Convolutional Neural Network Based Fault Diagnosis of Rotating Machinery. Sensors 2019, 19, 2381. https://doi.org/10.3390/s19102381
Ma S, Cai W, Liu W, Shang Z, Liu G. A Lighted Deep Convolutional Neural Network Based Fault Diagnosis of Rotating Machinery. Sensors. 2019; 19(10):2381. https://doi.org/10.3390/s19102381
Chicago/Turabian StyleMa, Shangjun, Wei Cai, Wenkai Liu, Zhaowei Shang, and Geng Liu. 2019. "A Lighted Deep Convolutional Neural Network Based Fault Diagnosis of Rotating Machinery" Sensors 19, no. 10: 2381. https://doi.org/10.3390/s19102381
APA StyleMa, S., Cai, W., Liu, W., Shang, Z., & Liu, G. (2019). A Lighted Deep Convolutional Neural Network Based Fault Diagnosis of Rotating Machinery. Sensors, 19(10), 2381. https://doi.org/10.3390/s19102381