ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison



Abstract
1. Introduction
- Universal (present for all individuals)
- Stability over time
- Easy to measure/acquire
- Low sensitivity to other physiological factors (e.g., stress, fatigue)
- Unique for each person
- Fraud resistance (difficult to fake)
- Continuous nature (always available to measure)
- Liveness indication (present only from live humans)
2. Biometric System Architecture
3. Experimental Methodology
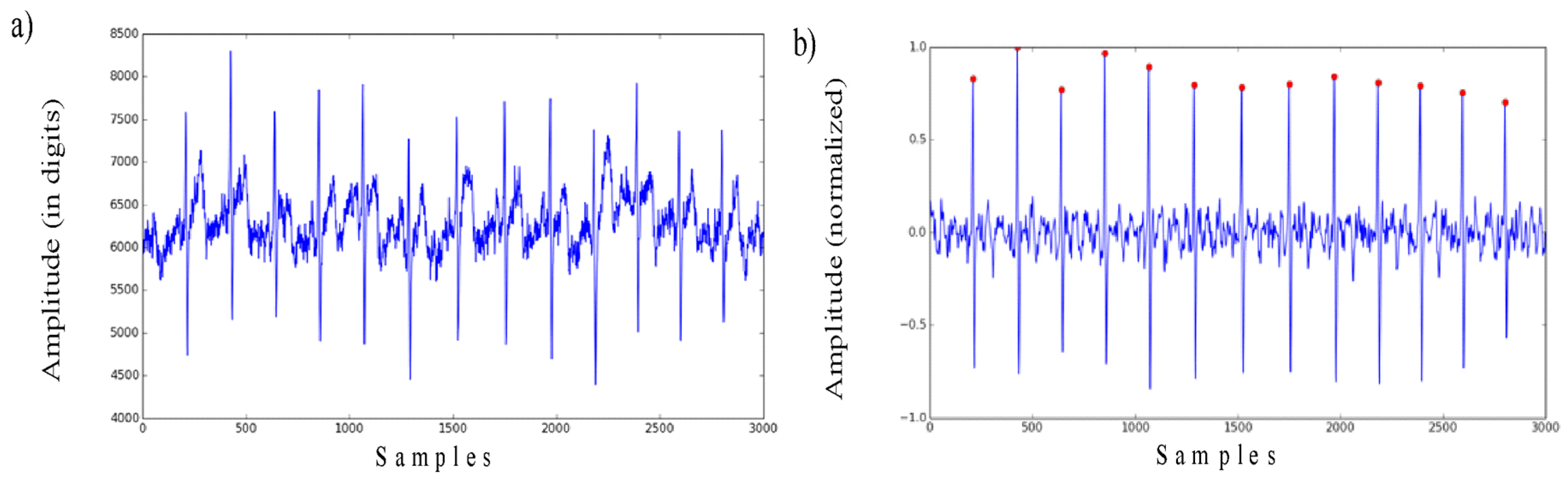
- First, different datasets from different sources (both self-collected and publicly available on the Internet) should be included into the study. It is expected that these datasets should have different origins and internal structures. The main parameters that should be taken into consideration are the number of users, total number of records, mean, minimum and maximum number of records per user, records length, etc. There are two constraints related to the dataset selection. The first one is that the dataset should contain records coming only from healthy people with a normal rhythm [16]. The second constraint assumes that the data should be recorded from the same scheme of electrode placement on the patient’s body, called the lead in cardiology. The reason for this is that the ECG waveform strongly varies when measured from different parts of the body.
- Second, the records classification should be performed through the use of different algorithms. In our experiments, we expect to use just one single heartbeat (the waveform between the onset of neighboring p-waves) for human identification. Thus, no sequential algorithm will be analysed here, only simple supervised machine learning techniques that map a multidimensional input vector (samples of an ECG heartbeat) onto a specified output vector (number of users). A comparison of various algorithms is required for two main reasons: first, to get some basic intuition on how some complex non-linear algorithms will behave, when compared to simpler linear algorithms while processing this kind of data; and second, to ensure that there is no bias in the different datasets. This means that the algorithms should demonstrate a similar behaviour on different datasets.
- Third, one of the most important stages while designing machine learning based experiments is to select the most appropriate metrics. In our case, since all datasets are relatively balanced, we decided to choose an identification accuracy (error rate) to estimate the algorithms’ performance.
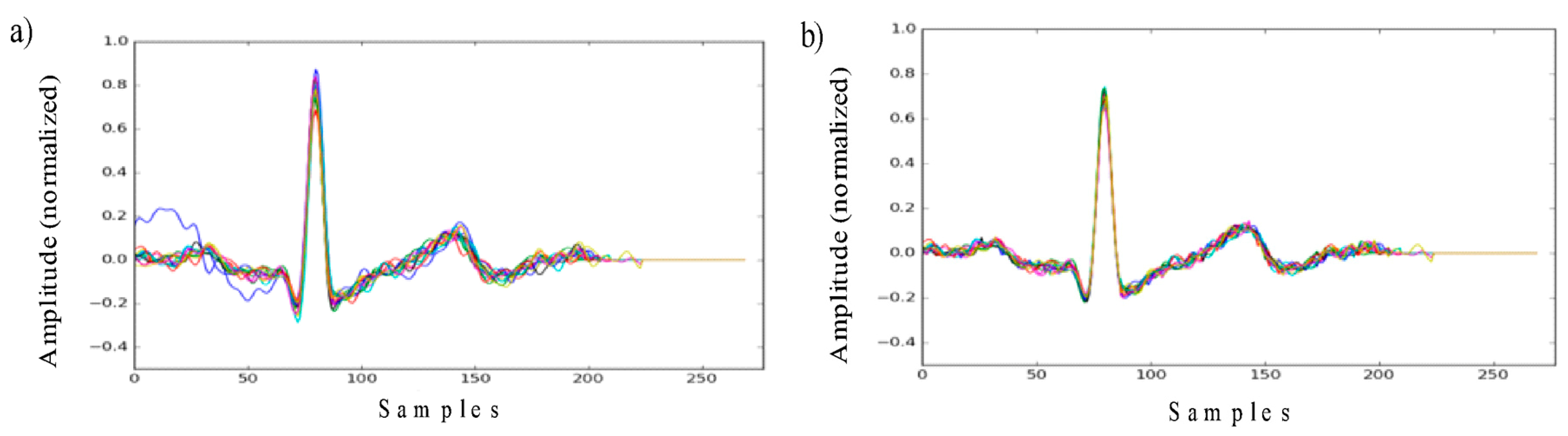
- Finally, it is also proposed to have two-alternative data pre-processing algorithms in place. The first one is described in the section above. It means filtering, normalization and outlier correction. Another one proposes the use of a dimensionality reduction on the top. This trick is commonly used in machine learning and might help to improve the overall classification performance. In our case, it was decided to use PCA, as this is one of the simplest, most commonly used and efficient compression algorithms.
4. Datasets Description
4.1. Lviv Biometric Dataset (LBDS)
4.2. Physionet ECG-ID
4.3. Physionet QT-Database
4.4. Physionet MIT-BIH Normal Sinus Rhythm
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ECG | Electrocardiogram |
| ADC | Analog to Digital Converter |
| MCU/PC | Microcontroller Unit/Personal Computer |
| PCA | Principle Component Analysis |
| LBDS | Lviv Biometric Dataset |
| SVM | Support Vector Machine |
| LDA | Linear Discriminant Analysis |
| KNN | K Nearest Neighbor |
| MLP | Multilayer Perceptron |
References
- Jain, A.; Flynn, P.; Ross, A.A. Handbook of Biometrics; Springer: New York, NY, USA, 2008; ISBN 978-0-387-71041-9. [Google Scholar]
- Kindt, E.J. Privacy and Data Protection Issues of Biometric Applications: A Comparative Legal Analysis; Springer: Dordrecht, The Netherlands, 2013; ISBN 978-94-007-7522-0. [Google Scholar]
- Fratini, A.; Sansone, M.; Bifulco, P.; Cesarel, M. Individual identification via electrocardiogram analysis. Biomed. Eng. Online 2015, 14, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Kaur, G.; Singh, D.; Kaur, S. Electrocardiogram (ECG) as a Biometric Characteristic: A Review. Int. J. Emerging Res. Manage. Technol. 2015, 4, 202–206. [Google Scholar]
- Lee, W.; Kim, S.; Kim, D. Individual Biometric Identification Using Multi-Cycle Electrocardiographic Waveform Patterns. Sensors 2018, 18, 1005. [Google Scholar] [CrossRef]
- Pal, A.; Singh, Y.N. ECG Biometric Recognition. In Mathematics and Computing, Proceedings of the 4th International Conference Communications in Computer and Information Science (ICMC 2018), Varanasi, India, 9–11 January 2018; Ghosh, D., Giri, D., Mohapatra, R.N., Savas, E., Sakurai, K., Singh, L.P., Eds.; Springer: Singapore, 2018; Volume 834, pp. 61–73. [Google Scholar] [CrossRef]
- Matos, A.C.; Lourenc, A.; Nascimento, J. Embedded system for individual recognition based on ECG Biometrics. In Proceedings of the Conference on Electronics, Telecommunications and Computers (CETC), Lisbon, Portugal, 5–6 December 2013; pp. 265–272. [Google Scholar] [CrossRef][Green Version]
- Wieclaw, L.; Khoma, Y.; Falat, P.; Sabodashko, D.; Herasymenko, V. Biometric Identification from Raw ECG Signal Using Deep Learning Techniques. In Proceedings of the 9th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Bucharest, Romania, 21–23 September 2017; pp. 129–133. [Google Scholar]
- Cheng, Y.; Ye, Y.; Hou, M.; He, W.; Li, Y.; Deng, X. A Fast and Robust Non-Sparse Signal Recovery Algorithm for Wearable ECG Telemonitoring Using ADMM-Based Block Sparse Bayesian Learning. Sensors 2018, 18, 2021. [Google Scholar] [CrossRef] [PubMed]
- Mawi Band: Stress and Heart Health Monitor Verification. Available online: https://mawi.band/ (accessed on 9 December 2018).
- SoftServe Biolock. Smart Identity Verification. Available online: https://demo.softserveinc.com/biolock/ (accessed on 9 December 2018).
- Bassiouni, M.; Khalefa, W.; El-Dahshan, E.S.A.; Salem, A.B.M. A study on the Intelligent Techniques of the ECG-based Biometric Systems. In Proceedings of the International Conference on Communications and Computers (CC 2015) and the International Conference on Circuits, Systems and Signal Processing (CSSP 2015), Agios Nikolaos, Crete, Greece, 17–19 October 2015. [Google Scholar]
- Pinto, J.R.; Cardoso, J.S.; Lourenço, A.; Carreiras, C. Towards a Continuous Biometric System Based on ECG Signals Acquired on the Steering Wheel. Sensors 2017, 17, 2228. [Google Scholar] [CrossRef] [PubMed]
- e-Health Sensor Platform V2.0 for Arduino and Raspberry Pi. Available online: https://www.cooking-hacks.com/documentation/tutorials/ehealth-biometric-sensor-platform-arduino-raspberry-pi-medical (accessed on 9 December 2018).
- Khoma, V.; Pelc, M.; Khoma, Y.; Sabodashko, D. Outlier Correction in ECG-Based Human Identification. In Biomedical Engineering and Neuroscience, Proceedings of the 3rd International Scientific Conference on Brain-Computer Interfaces (BCI 2018), Opole, Poland, 13–14 March 2018, Advances in Intelligent Systems and Computing; Hunek, W., Paszkiel, S., Eds.; Springer: Cham, Switzerland, 2018; Volume 720, pp. 11–22. [Google Scholar]
- Gertsch, M. The ECG: A Two-Step Approach to Diagnosis, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 19–21. [Google Scholar] [CrossRef]
- Lviv Biometric Data Set. Available online: https://github.com/YuriyKhoma/Lviv-Biometric-Data-Set/ (accessed on 9 December 2018).
- The ECG-ID Database. Available online: https://physionet.org/physiobank/database/ecgiddb/ (accessed on 9 December 2018).
- The Physionet License Terms. Available online: https://physionet.org/faq.shtml#license/ (accessed on 14 May 2019).
- The QT Database. Available online: https://physionet.org/physiobank/database/qtdb/ (accessed on 9 December 2018).
- Laguna, P.; Mark, R.G.; Goldberger, A.L.; Moody, G.B. A Database for Evaluation of Algorithms for Measurement of QT and Other Waveform Intervals in the ECG. Comput. Cardiol. 1997, 24, 673–676. [Google Scholar]
- The MIT-BIH Normal Sinus Rhythm Database. Available online: https://physionet.org/physiobank/database/nsrdb/ (accessed on 9 December 2018).
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Pattern Recognition and Machine Learning; Jordan, M., Kleinberg, J., Scholkopf, B., Eds.; Springer: Singapore, 2006. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Parameter | LBDS | ECG-ID | QT | Normal Sinus Rhythm |
|---|---|---|---|---|
| Lead | modified I-lead (from the fingers of the right and left hand) | I-lead | I-lead | I-lead |
| Number of users | 53 | 90 | 22 | 18 |
| Total number of records | 545 | 310 | 22 | 18 |
| Records per user | from 3 to 15 | from 1 to 22 | 1 | 1 |
| Sampling rate | 277 Hz | 500 Hz | 250 Hz | 125 Hz |
| Average record time | ~10 seconds | 20 seconds | 15 minutes | ~10:20 hours (from 8:00 to 13:50 hours) |
| Physionet ECG-ID | LBDS | Physionet QT | MIT-BIH Normal Sinus Rhythm | |
|---|---|---|---|---|
| Logistic Regression | 0.8286 | 0.9417 | 0.8809 | 0.7492 |
| SVM classifier | 0.8817 | 0.9599 | 0.9174 | 0.7707 |
| LDA classifier | 0.9328 | 0.9831 | 0.9659 | 0.9017 |
| KNN classifier | 0.8903 | 0.9746 | 0.9686 | 0.7967 |
| Naive Bayes | 0.7003 | 0.9587 | 0.9034 | 0.6607 |
| Random Forest | 0.8362 | 0.9546 | 0.9278 | 0.8192 |
| xgboost classifier | 0.7352 | 0.9126 | 0.9191 | 0.8591 |
| MLP (1 hidden layer) | 0.8933 | 0.9711 | 0.9162 | 0.8925 |
| MLP (2 hidden layer) | 0.8976 | 0.9464 | 0.9478 | 0.8744 |
| MLP (3 hidden layer) | 0.8406 | 0.92373 | 0.9294 | 0.8808 |
| PCA + Logistic Regression | 0.8286 | 0.9383 | 0.8465 | 0.7335 |
| PCA + SVM classifier | 0.8865 | 0.9593 | 0.8832 | 0.7472 |
| PCA + LDA classifier | 0.9536 | 0.9833 | 0.9481 | 0.8798 |
| PCA + KNN classifier | 0.8913 | 0.9758 | 0.9675 | 0.7957 |
| PCA + Naive Bayes | 0.6211 | 0.9511 | 0.8915 | 0.6681 |
| PCA + Random Forest | 0.7782 | 0.9199 | 0.8947 | 0.7418 |
| PCA + xgboost classifier | 0.6723 | 0.8911 | 0.9460 | 0.7305 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pelc, M.; Khoma, Y.; Khoma, V. ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison. Sensors 2019, 19, 2350. https://doi.org/10.3390/s19102350
Pelc M, Khoma Y, Khoma V. ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison. Sensors. 2019; 19(10):2350. https://doi.org/10.3390/s19102350
Chicago/Turabian StylePelc, Mariusz, Yuriy Khoma, and Volodymyr Khoma. 2019. "ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison" Sensors 19, no. 10: 2350. https://doi.org/10.3390/s19102350
APA StylePelc, M., Khoma, Y., & Khoma, V. (2019). ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison. Sensors, 19(10), 2350. https://doi.org/10.3390/s19102350